Note
This is a community plugin, an external project maintained by its respective author. Community plugins are not part of FiftyOne core and may change independently. Please review each plugin’s documentation and license before use.
fo-vllm#
FiftyOne plugin for VLM inference via vLLM. One operator, any model, any numerous tasks.
Installation#
fiftyone plugins download https://github.com/Burhan-Q/fiftyone-vllm
Or install locally:
fiftyone plugins create /path/to/fiftyone-vllm
Reference vLLM
The compose.yml Docker Compose file is included as a reference for launching a local online vLLM server. Uses latest vLLM tag, was tested originally with vllm==0.16.0 tag.
Demo (Detect)#
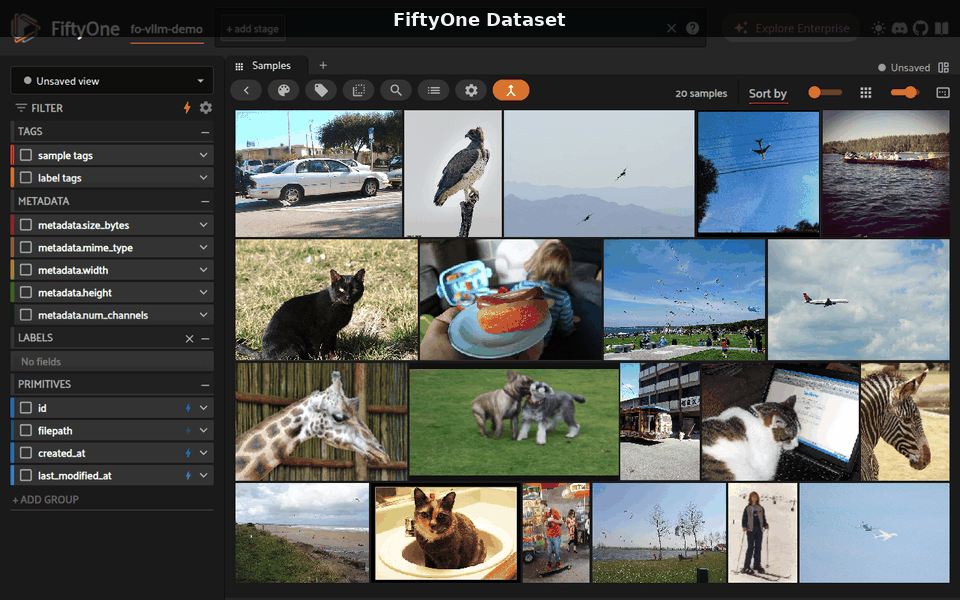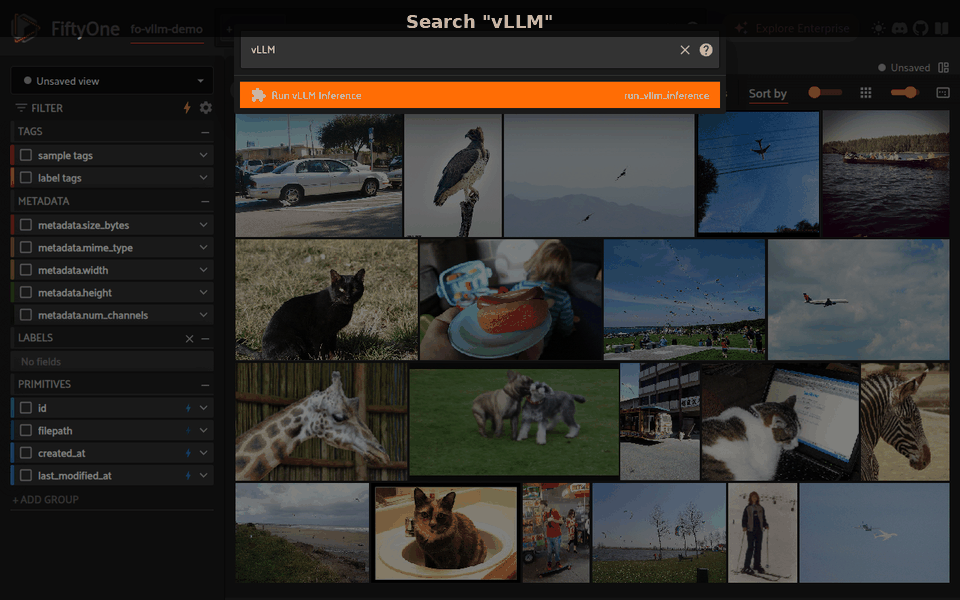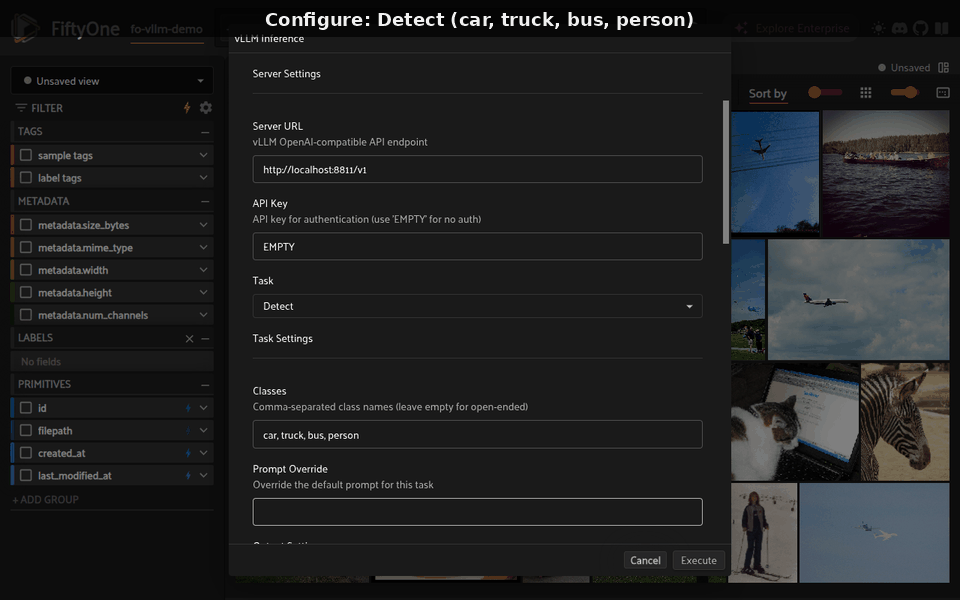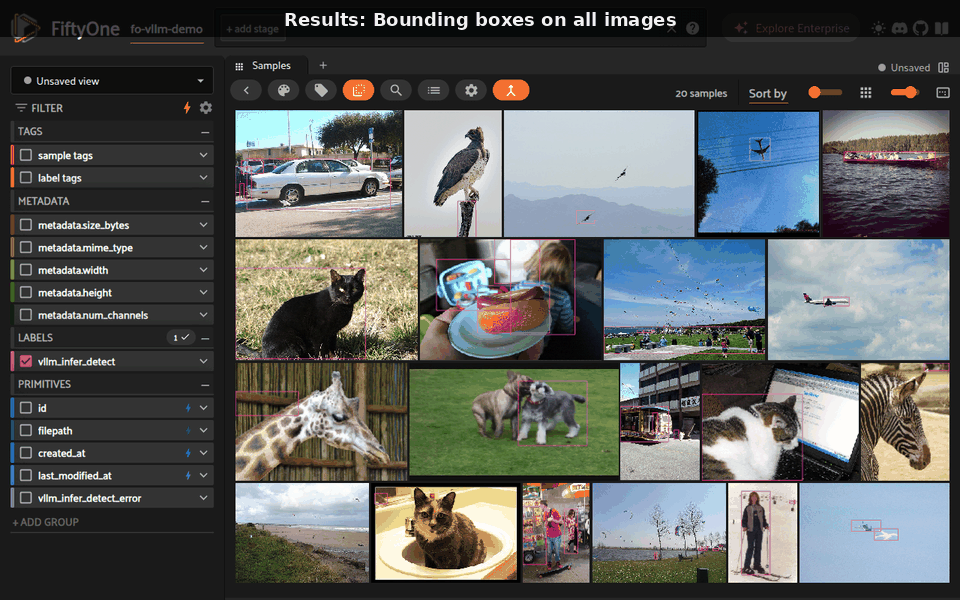
Tasks#
Task |
FiftyOne Type |
Structured Output |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
All responses are constrained via vLLM structured output — no free-text parsing. |
Usage#
FiftyOne App#
Open the operator browser (` shortcut), search Run vLLM Inference, and fill in the form.
Python SDK#
import fiftyone as fo
import fiftyone.operators as foo
dataset = fo.load_dataset("my-images")
# Caption
foo.execute_operator(
"@Burhan-Q/fo-vllm/run_vllm_inference",
params={
"model": "Qwen/Qwen2.5-VL-7B-Instruct",
"base_url": "http://localhost:8000/v1", # usually will be a remote deployment
"task": "caption",
},
dataset_name=dataset.name,
)
print(dataset.first().vllm_infer_caption.label)
# Classify (with class constraint)
foo.execute_operator(
"@Burhan-Q/fo-vllm/run_vllm_inference",
params={
"model": "Qwen/Qwen2.5-VL-7B-Instruct",
"base_url": "http://localhost:8000/v1",
"task": "classify",
"classes": "indoor, outdoor, aerial",
},
dataset_name=dataset.name,
)
# Detect (with optional class constraint)
foo.execute_operator(
"@Burhan-Q/fo-vllm/run_vllm_inference",
params={
"model": "Qwen/Qwen2.5-VL-7B-Instruct",
"base_url": "http://localhost:8000/v1",
"task": "detect",
"classes": "car, truck, bus",
},
dataset_name=dataset.name,
)
# VQA
foo.execute_operator(
"@Burhan-Q/fo-vllm/run_vllm_inference",
params={
"model": "Qwen/Qwen2.5-VL-7B-Instruct",
"base_url": "http://localhost:8000/v1",
"task": "vqa",
"question": "How many people are in this image?",
},
dataset_name=dataset.name,
)
Other tasks (tag, ocr) follow the same pattern. Use prompt_override to replace any task’s default prompt, or system_prompt for custom system instructions.
Additional options#
foo.execute_operator(
"@Burhan-Q/fo-vllm/run_vllm_inference",
params={
"model": "Qwen/Qwen2.5-VL-7B-Instruct",
"base_url": "http://localhost:8000/v1",
"task": "caption",
"log_metadata": True, # attach model_name, prompt, infer_cfg to each label
"overwrite_last": True, # overwrite previous result instead of creating new field
},
dataset_name=dataset.name,
)
Output fields#
Results are stored as vllm_infer_{task_default} (e.g., vllm_infer_caption, vllm_infer_detections). Subsequent runs auto-increment the suffix unless overwrite_last is enabled.
Per-sample errors go to {field_name}_error.
Configuration#
Server#
Parameter |
Default |
Description |
|---|---|---|
|
(required) |
HuggingFace model ID served by vLLM |
|
|
vLLM OpenAI-compatible endpoint |
|
|
API key |
Also configurable via FiftyOne secrets: FIFTYONE_VLLM_BASE_URL, FIFTYONE_VLLM_API_KEY.
All settings persist across sessions (global + per-dataset). Use “Paste JSON config” mode to import/export configurations.
Advanced#
Parameter |
Default |
Description |
|---|---|---|
|
task-specific |
0.0 for deterministic tasks, 0.2 for generative |
|
512 |
Max tokens per response |
|
1.0 |
Nucleus sampling |
|
8 |
Samples per batch |
|
16 |
Parallel requests to vLLM |
|
4 |
Threads for image encoding |
|
|
|
|
|
Detection coordinates: |
|
|
Detection box format: |
Compatible models#
Any multi-modal VLM that vLLM can serve, see the vLLM docs for supported models. Tested: Qwen2.5-VL & Gemma3.
Requirements#
Python >= 3.11, FiftyOne >= 1.13.2
openai >= 1.0,pillow >= 9.0vLLM >= 0.16 (server-side)
No GPU dependencies on the client.