|
|
|
|
Getting Started with Manufacturing Datasets#
Welcome to this hands-on workshop where we will learn how to load and explore datasets using FiftyOne. This notebook will guide you through programmatic interaction via the FiftyOne SDK and visualization using the FiftyOne App.
Learning Objectives:#
Load datasets into FiftyOne from different sources.
Understand the structure and metadata of datasets.
Use FiftyOne’s querying and filtering capabilities.
Interactively explore datasets in the FiftyOne App.
In this example, we use Hugging Face Hub for dataset loading, but you are encouraged to explore other sources like local files, cloud storage, or custom dataset loaders.
In this notebook, we covered:#
Loading datasets from Hugging Face Hub (extendable to other sources).
Exploring dataset structure and metadata.
Applying filtering and querying techniques to analyze data.
Utilizing the FiftyOne App for interactive visualization.
Clone dataset views and export your Data in FiftyOne Format
Requirements and FiftyOne Installation#
First thing you need to do is create a Python environment in your system, if you are not familiar with that please take a look of this ReadmeFile, where we will explain how to create the environment. After that be sure you activate the created environment and install FiftyOne there.
Install FiftyOne#
[ ]:
!pip install fiftyone huggingface_hub gdown
Select a GPU Runtime if possible, install the requirements, restart the session, and verify the device information.
[ ]:
import torch
def get_device():
"""Get the appropriate device for model inference."""
if torch.cuda.is_available():
return "cuda"
elif hasattr(torch.backends, "mps") and torch.backends.mps.is_available():
return "mps"
return "cpu"
DEVICE = get_device()
print(f"Using device: {DEVICE}")
Loading a Dataset into FiftyOne#
FiftyOne provides multiple ways to import datasets, including:
Hugging Face Hub (as demonstrated here)
Local files (images, videos, or annotations in JSON, COCO, PASCAL VOC, etc.)
Cloud storage (AWS S3, Google Drive, etc.) - Just for FiftyOne Enterprise
To load a dataset, we specify the source and format, ensuring FiftyOne properly indexes the data.
Relevant Documentation: Dataset Importing in FiftyOne
We are using MVTec AD Dataset from Voxel51 Hugging Face Hub. The difference between the original resource and the Voxel51’s one is the data structure, while in the first one we have a tree directory with category,in the second one we have an unstructure dataset with metadata such as categories.label, and defect.label.
[ ]:
import fiftyone as fo # base library and app
import fiftyone.utils.huggingface as fouh # Hugging Face integration
dataset_name = "MVTec_AD"
# Check if the dataset exists
if dataset_name in fo.list_datasets():
print(f"Dataset '{dataset_name}' exists. Loading...")
dataset = fo.load_dataset(dataset_name)
else:
print(f"Dataset '{dataset_name}' does not exist. Creating a new one...")
# Clone the dataset with a new name and make it persistent
dataset_ = fouh.load_from_hub("Voxel51/mvtec-ad", persistent=True, overwrite=True)
dataset = dataset_.clone("MVTec_AD")
Alternative - For Colab users#
If you find any issues downloading the dataset from Hugging Face, please uncomment and use the following code cell.
[ ]:
import gdown
url = "https://drive.google.com/uc?id=1nAuFIyl2kM-TQXduSJ9Fe_ZEIVog4tth"
gdown.download(url, output="mvtec_ad.zip", quiet=False)
!unzip mvtec_ad.zip
import fiftyone as fo
dataset_name = "MVTec_AD"
# Check if the dataset exists
if dataset_name in fo.list_datasets():
print(f"Dataset '{dataset_name}' exists. Loading...")
dataset = fo.load_dataset(dataset_name)
else:
print(f"Dataset '{dataset_name}' does not exist. Creating a new one...")
dataset_ = fo.Dataset.from_dir(
dataset_dir="/content/mvtec-ad",
dataset_type=fo.types.FiftyOneDataset
)
dataset = dataset_.clone("MVTec_AD")
Exploring the Dataset#
Once the dataset is loaded, we can inspect its structure using FiftyOne’s SDK. We will explore:
The number of samples in the dataset.
Available metadata and labels.
How images/videos are structured.
Relevant Documentation: Inspecting Datasets in FiftyOne You can also call the first Sample of the Dataset to see what the Fields looks like:
[ ]:
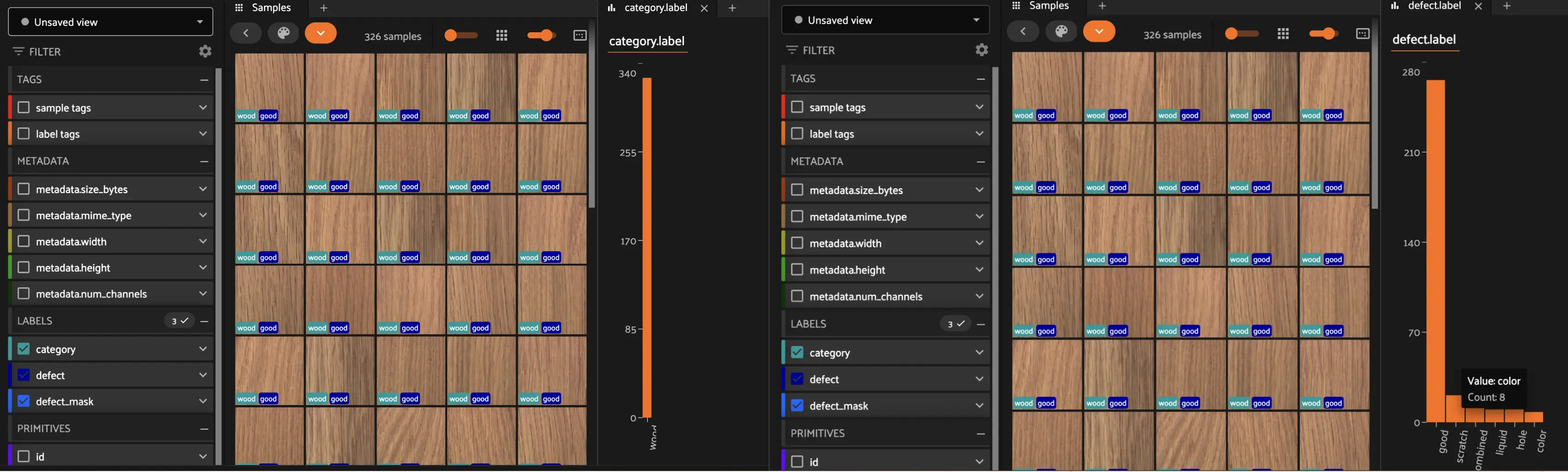
print(dataset)
print(dataset.first()) # Inspect the first or last sample
[ ]:
session = fo.launch_app(dataset, auto=False)
print(session.url)
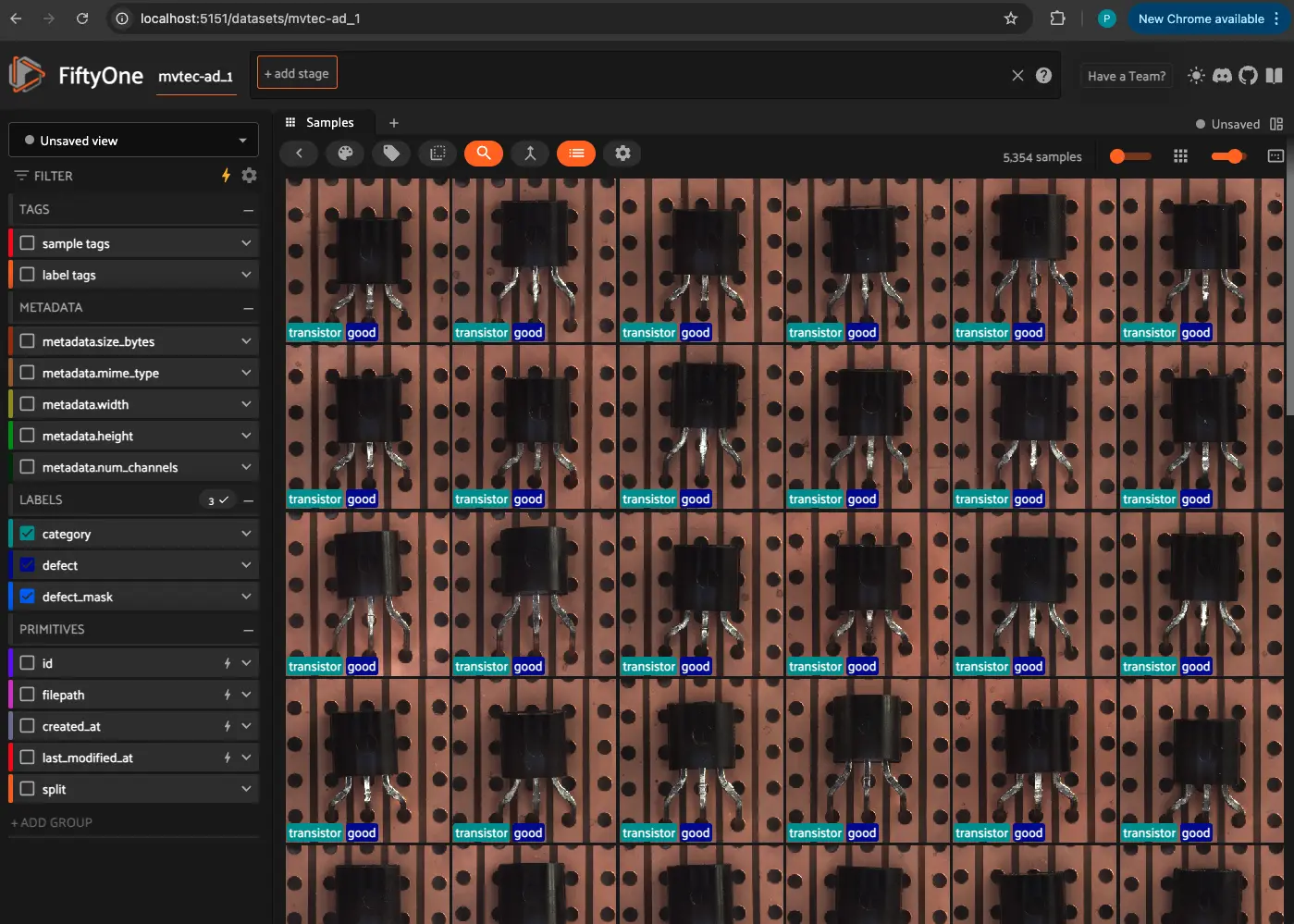
Querying and Filtering#
FiftyOne provides a powerful querying engine to filter and analyze datasets efficiently. We can apply filters to:
Retrieve specific labels (e.g., all images with “cat” labels).
Apply confidence thresholds to object detections.
Filter data based on metadata (e.g., image size, timestamp).
Relevant Documentation: Dataset views, Querying Samples, Common filters
Examples:#
Show all images containing a particular class.
Retrieve samples with object detection confidence above a threshold.
Filter out low-quality images based on metadata.
[ ]:
import fiftyone.core.expressions as foe
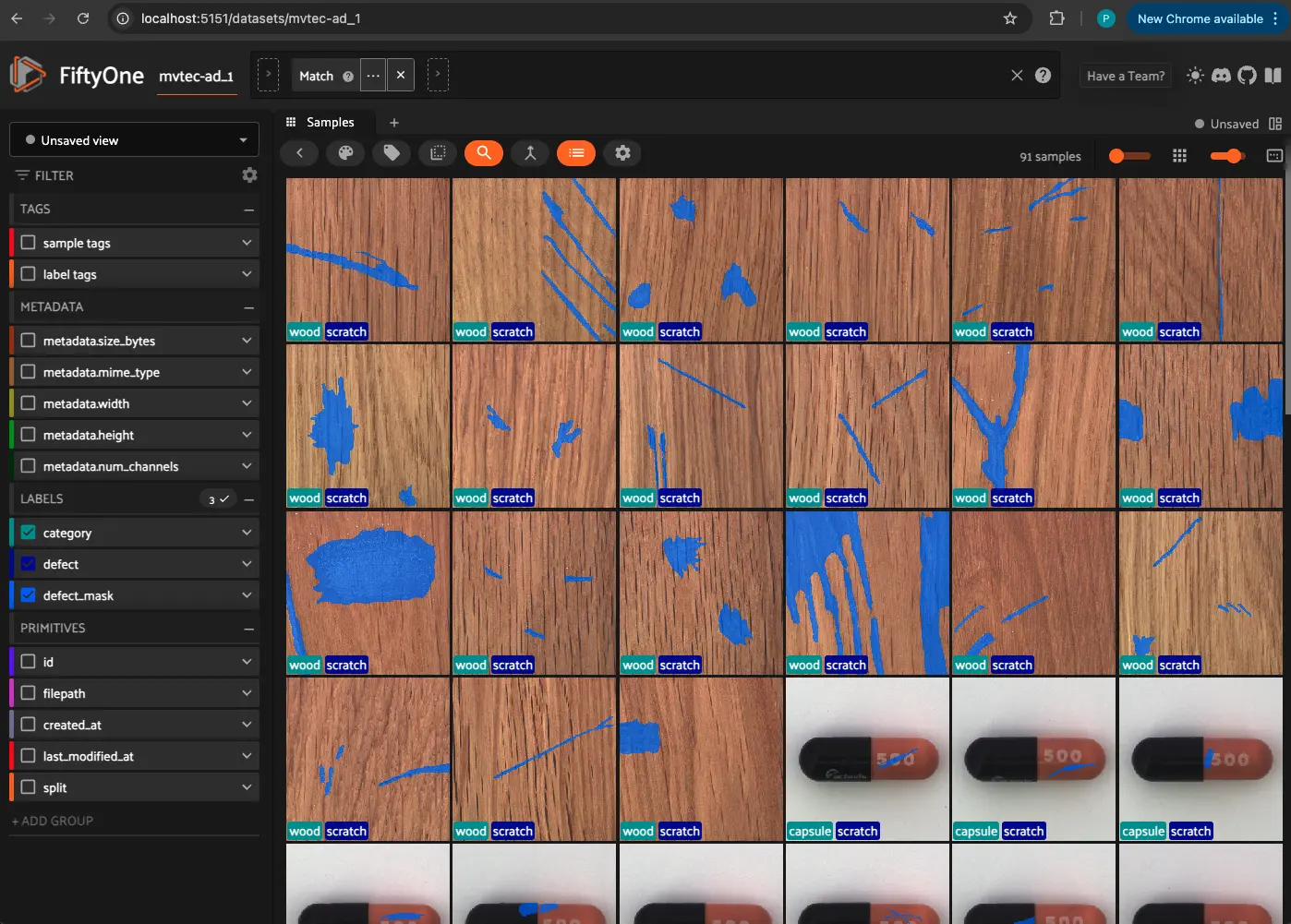
# Query images where the defect is labeled as "scratch"
view = dataset.match(foe.ViewField("defect.label") == "scratch")
print(view)
# Launch FiftyOne App with the filtered dataset
session = fo.launch_app(view, port=5151, auto=False)
print(session.url)
[ ]:
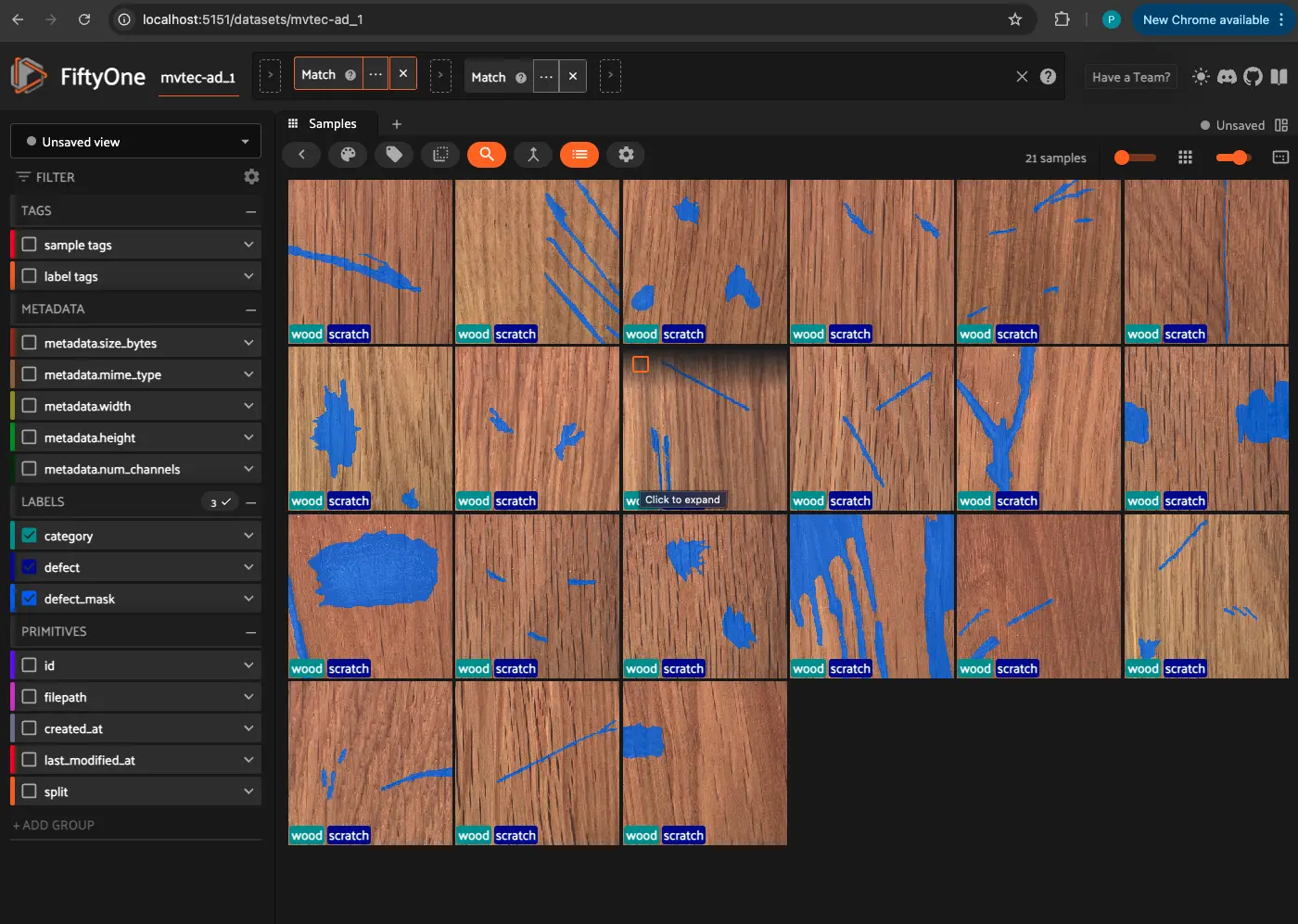
filter = view.match(foe.ViewField("category.label") == "wood")
session.view = filter
print(filter)
[ ]:
# Launch FiftyOne App with the filtered dataset
session = fo.launch_app(filter, port=5151, auto=False)
print(session.url)
Interactive Exploration with the FiftyOne App#
The FiftyOne App allows users to interactively browse, filter, and analyze datasets. This visual interface is an essential tool for understanding dataset composition and refining data exploration workflows.
Key features of the FiftyOne App:
Interactive filtering of images/videos.
Object detection visualization.
Dataset statistics and metadata overview.
Relevant Documentation: Using the FiftyOne App
Intereacting with Plugins to understand the dataset#
FiftyOne provides a powerful plugin framework that allows for extending and customizing the functionality of the tool to suit your specific needs. In this case we will use the @voxel51/dashboard plugin, a plugin that enables users to construct custom dashboards that display statistics of interest about the current dataset (and beyond)
[ ]:
#!fiftyone plugins download https://github.com/voxel51/fiftyone-plugins --plugin-names @voxel51/dashboard
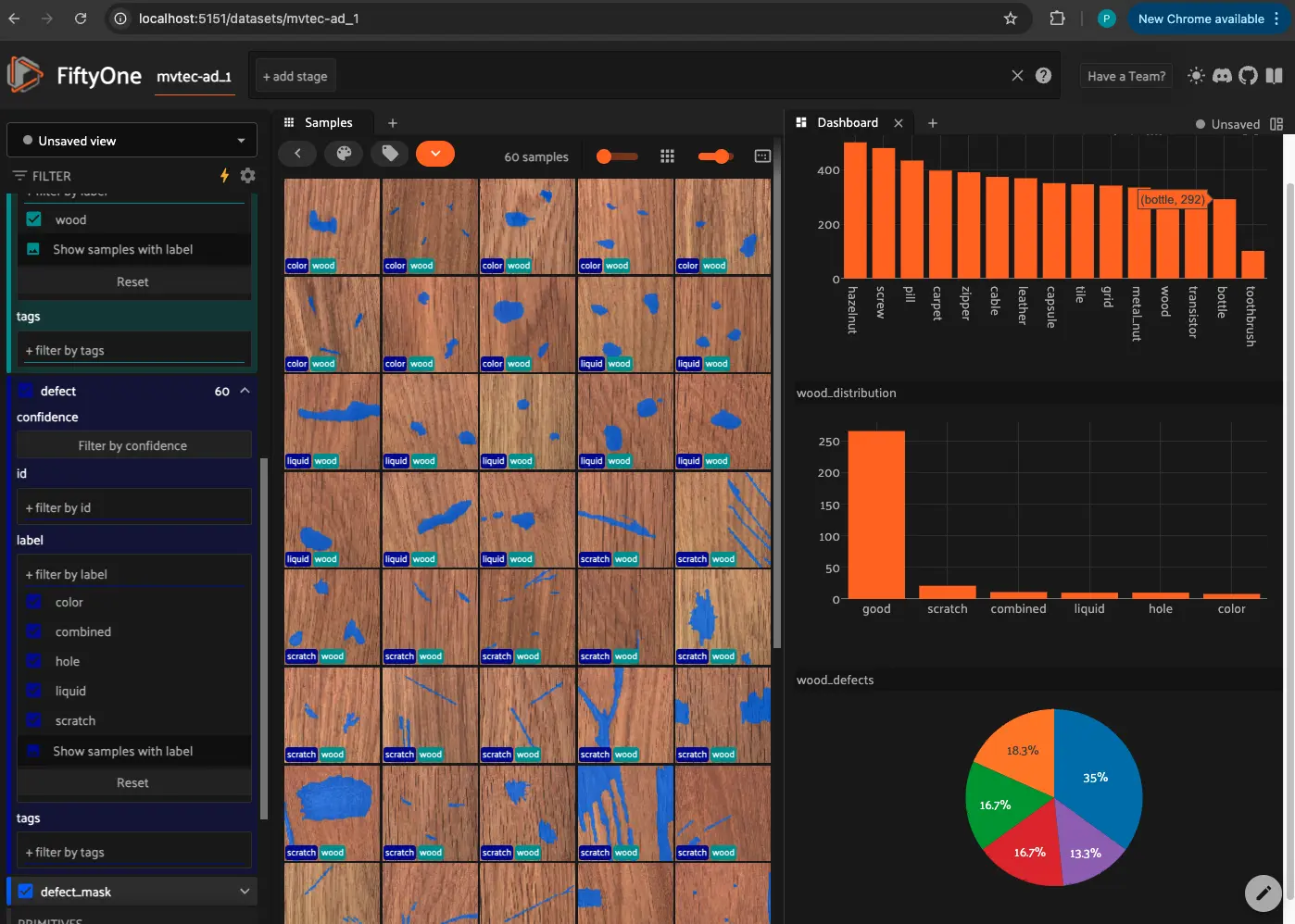
New dataset#
Creates a new dataset containing a copy of the contents of the view.
[ ]:
new_dataset= view.clone()
print(new_dataset)
Exporting Dataset to FiftyOneDataset#
FiftyOne supports various dataset formats. In this notebook, we’ve worked with a custom dataset from Hugging Face Hub. Now, we export it into a FiftyOne-compatible dataset to leverage additional capabilities.
For more details on the dataset types supported by FiftyOne, refer to this documentation
[ ]:
export_dir = "MVTec_scratch"
new_dataset.export(
export_dir=export_dir,
dataset_type=fo.types.FiftyOneDataset,
)
Next Steps:#
Try modifying the dataset loading parameters, apply different filters, and explore the FiftyOne App’s visualization features! 🚀