COCO Integration#
With support from the team behind the COCO dataset, we’ve made it easy to download, visualize, and evaluate on the COCO dataset natively in FiftyOne!
Note
Check out this tutorial to see how you can use FiftyOne to evaluate a model on COCO.
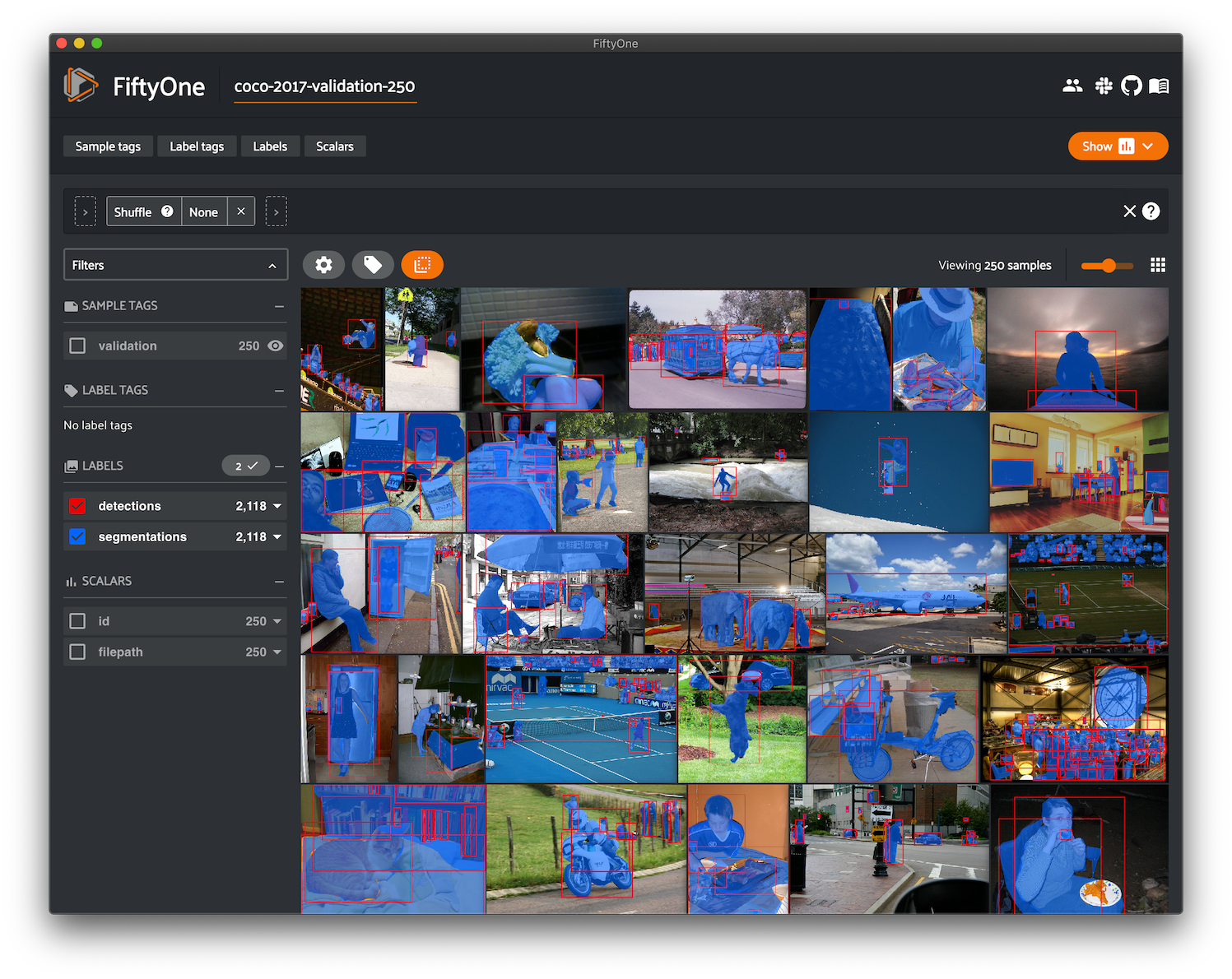
Loading the COCO dataset#
The FiftyOne Dataset Zoo provides support for loading both the COCO-2014 and COCO-2017 datasets.
Like all other zoo datasets, you can use
load_zoo_dataset() to download
and load a COCO split into FiftyOne:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4# Download and load the validation split of COCO-2017
5dataset = foz.load_zoo_dataset("coco-2017", split="validation")
6
7session = fo.launch_app(dataset)
Note
FiftyOne supports loading annotations for the detection task, including bounding boxes and segmentations.
By default, only the bounding boxes are loaded, but you can customize which
label types are loaded via the optional label_types argument (see below
for details).
Note
We will soon support loading labels for the keypoints, captions, and panoptic segmentation tasks as well. Stay tuned!
In addition, FiftyOne provides parameters that can be used to efficiently download specific subsets of the COCO dataset, allowing you to quickly explore different slices of the dataset without downloading the entire split.
When performing partial downloads, FiftyOne will use existing downloaded data first if possible before resorting to downloading additional data from the web.
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4#
5# Load 50 random samples from the validation split
6#
7# Only the required images will be downloaded (if necessary).
8# By default, only detections are loaded
9#
10
11dataset = foz.load_zoo_dataset(
12 "coco-2017",
13 split="validation",
14 max_samples=50,
15 shuffle=True,
16)
17
18session = fo.launch_app(dataset)
19
20#
21# Load segmentations for 25 samples from the validation split that
22# contain cats and dogs
23#
24# Images that contain all `classes` will be prioritized first, followed
25# by images that contain at least one of the required `classes`. If
26# there are not enough images matching `classes` in the split to meet
27# `max_samples`, only the available images will be loaded.
28#
29# Images will only be downloaded if necessary
30#
31
32dataset = foz.load_zoo_dataset(
33 "coco-2017",
34 split="validation",
35 label_types=["segmentations"],
36 classes=["cat", "dog"],
37 max_samples=25,
38)
39
40session.dataset = dataset
The following parameters are available to configure partial downloads of both
COCO-2014 and COCO-2017 by passing them to
load_zoo_dataset():
split (None) and splits (None): a string or list of strings, respectively, specifying the splits to load. Supported values are
("train", "test", "validation"). If neither is provided, all available splits are loadedlabel_types (None): a label type or list of label types to load. Supported values are
("detections", "segmentations"). By default, only detections are loadedclasses (None): a string or list of strings specifying required classes to load. If provided, only samples containing at least one instance of a specified class will be loaded
image_ids (None): a list of specific image IDs to load. The IDs can be specified either as
<split>/<image-id>strings or<image-id>ints or strings. Alternatively, you can provide the path to a TXT (newline-separated), JSON, or CSV file containing the list of image IDs to load in either of the first two formatsinclude_id (False): whether to include the COCO ID of each sample in the loaded labels
include_license (False): whether to include the COCO license of each sample in the loaded labels, if available. The supported values are:
"False"(default): don’t load the licenseTrue/"name": store the string license name"id": store the integer license ID"url": store the license URL
only_matching (False): whether to only load labels that match the
classesorattrsrequirements that you provide (True), or to load all labels for samples that match the requirements (False)num_workers (None): the number of processes to use when downloading individual images. By default,
multiprocessing.cpu_count()is usedshuffle (False): whether to randomly shuffle the order in which samples are chosen for partial downloads
seed (None): a random seed to use when shuffling
max_samples (None): a maximum number of samples to load per split. If
label_typesand/orclassesare also specified, first priority will be given to samples that contain all of the specified label types and/or classes, followed by samples that contain at least one of the specified labels types or classes. The actual number of samples loaded may be less than this maximum value if the dataset does not contain sufficient samples matching your requirements
Note
See
COCO2017Dataset and
COCODetectionDatasetImporter
for complete descriptions of the optional keyword arguments that you can
pass to load_zoo_dataset().
Loading COCO-formatted data#
In addition to loading the COCO datasets themselves, FiftyOne also makes it easy to load your own datasets and model predictions stored in COCO format.
The example code below demonstrates this workflow. First, we generate a JSON file containing COCO-formatted labels to work with:
1import os
2
3import fiftyone as fo
4import fiftyone.zoo as foz
5
6dataset = foz.load_zoo_dataset("quickstart")
7
8# The directory in which the dataset's images are stored
9IMAGES_DIR = os.path.dirname(dataset.first().filepath)
10
11# Export some labels in COCO format
12dataset.take(5, seed=51).export(
13 dataset_type=fo.types.COCODetectionDataset,
14 label_field="ground_truth",
15 labels_path="/tmp/coco.json",
16)
Note
When exporting instance segmentations, FiftyOne converts masks to polygons
using an approximation algorithm controlled by the tolerance parameter
(in pixels). Lower values preserve more points at the cost of larger file
sizes. Use tolerance=0 for a lossless export:
dataset.take(5, seed=51).export(
dataset_type=fo.types.COCODetectionDataset,
label_field="ground_truth",
labels_path="/tmp/coco.json",
tolerance=0, # lossless: preserves all segmentation points
)
The default value is tolerance=2, which reduces the number of polygon
vertices while keeping a small approximation error. Typical values are 1 to 3 pixels.
See also
See
COCODetectionDatasetExporter
for complete descriptions of all export parameters.
Now we have a /tmp/coco.json file on disk containing COCO labels
corresponding to the images in IMAGES_DIR:
python -m json.tool /tmp/coco.json
{
"info": {...},
"licenses": [],
"categories": [
{
"id": 1,
"name": "airplane",
"supercategory": null
},
...
],
"images": [
{
"id": 1,
"file_name": "003486.jpg",
"height": 427,
"width": 640,
"license": null,
"coco_url": null
},
...
],
"annotations": [
{
"id": 1,
"image_id": 1,
"category_id": 1,
"bbox": [
34.34,
147.46,
492.69,
192.36
],
"area": 94773.8484,
"iscrowd": 0
},
...
]
}
We can now use
Dataset.from_dir() to load the
COCO-formatted labels into a new FiftyOne
dataset:
1# Load COCO formatted dataset
2coco_dataset = fo.Dataset.from_dir(
3 dataset_type=fo.types.COCODetectionDataset,
4 data_path=IMAGES_DIR,
5 labels_path="/tmp/coco.json",
6 include_id=True,
7)
8
9# COCO categories are also imported
10print(coco_dataset.info["categories"])
11# [{'id': 1, 'name': 'airplane', 'supercategory': None}, ...]
12
13print(coco_dataset)
Name: 2021.06.28.15.14.38
Media type: image
Num samples: 5
Persistent: False
Tags: []
Sample fields:
id: fiftyone.core.fields.ObjectIdField
filepath: fiftyone.core.fields.StringField
tags: fiftyone.core.fields.ListField(fiftyone.core.fields.StringField)
metadata: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.metadata.ImageMetadata)
created_at: fiftyone.core.fields.DateTimeField
last_modified_at: fiftyone.core.fields.DateTimeField
detections: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Detections)
coco_id: fiftyone.core.fields.IntField
In the above call to
Dataset.from_dir(), we provide
the data_path and labels_path parameters to specify the
location of the source images and their COCO labels, respectively, and we set
include_id=True so that the COCO ID for each image from our JSON labels
will be added to each imported sample.
Note
See
COCODetectionDatasetImporter
for complete descriptions of the optional keyword arguments that you can
pass to Dataset.from_dir().
If your workflow generates model predictions in COCO format, you can use the
add_coco_labels() utility method
to add them to your dataset as follows:
1import fiftyone.utils.coco as fouc
2
3#
4# Mock COCO predictions, where:
5# - `image_id` corresponds to the `coco_id` field of `coco_dataset`
6# - `category_id` corresponds to `coco_dataset.info["categories"]`
7#
8predictions = [
9 {"image_id": 1, "category_id": 2, "bbox": [258, 41, 348, 243], "score": 0.87},
10 {"image_id": 2, "category_id": 4, "bbox": [61, 22, 504, 609], "score": 0.95},
11]
12categories = coco_dataset.info["categories"]
13
14# Add COCO predictions to `predictions` field of dataset
15fouc.add_coco_labels(coco_dataset, "predictions", predictions, categories)
16
17# Verify that predictions were added to two images
18print(coco_dataset.count("predictions")) # 2
COCO-style evaluation#
By default,
evaluate_detections()
will use COCO-style evaluation to
analyze predictions.
You can also explicitly request that COCO-style evaluation be used by setting
the method parameter to "coco".
See this page for more information about using FiftyOne to analyze object detection models.
Note
FiftyOne’s implementation of COCO-style evaluation matches the reference implementation available via pycocotools.
Overview#
When running COCO-style evaluation using
evaluate_detections():
Predicted and ground truth objects are matched using a specified IoU threshold (default = 0.50). This threshold can be customized via the
iouparameterBy default, only objects with the same
labelwill be matched. Classwise matching can be disabled via theclasswiseparameterGround truth objects can have an
iscrowdattribute that indicates whether the annotation contains a crowd of objects. Multiple predictions can be matched to crowd ground truth objects. The name of this attribute can be customized by passing the optionaliscrowdattribute ofCOCOEvaluationConfigtoevaluate_detections()
When you specify an eval_key parameter, a number of helpful fields will be
populated on each sample and its predicted/ground truth objects:
True positive (TP), false positive (FP), and false negative (FN) counts for each sample are saved in top-level fields of each sample:
TP: sample.<eval_key>_tp FP: sample.<eval_key>_fp FN: sample.<eval_key>_fn
The fields listed below are populated on each individual object instance; these fields tabulate the TP/FP/FN status of the object, the ID of the matching object (if any), and the matching IoU:
TP/FP/FN: object.<eval_key> ID: object.<eval_key>_id IoU: object.<eval_key>_iou
Note
See COCOEvaluationConfig for complete descriptions of the optional
keyword arguments that you can pass to
evaluate_detections()
when running COCO-style evaluation.
Example evaluation#
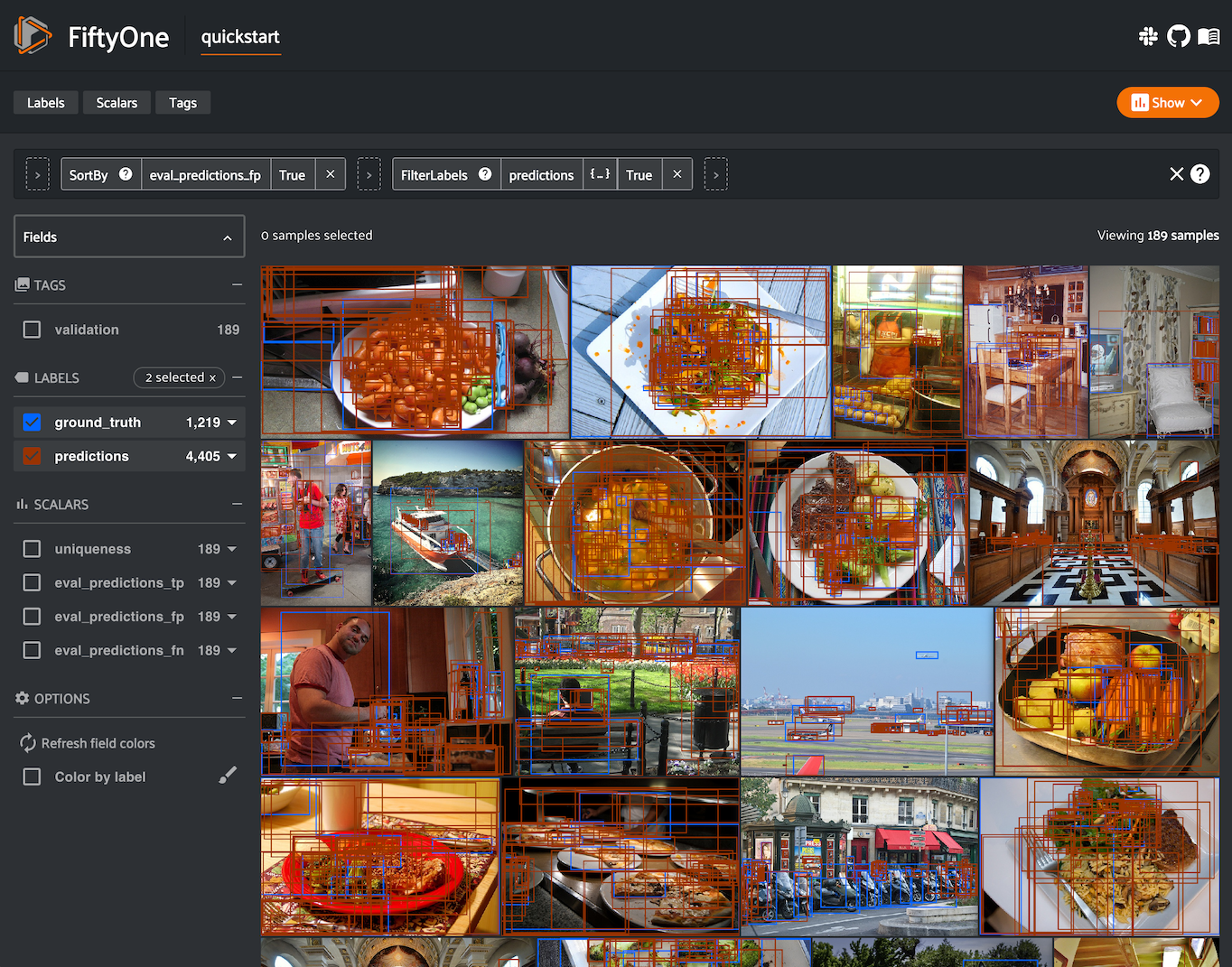
The example below demonstrates COCO-style detection evaluation on the quickstart dataset from the Dataset Zoo:
1import fiftyone as fo
2import fiftyone.zoo as foz
3from fiftyone import ViewField as F
4
5dataset = foz.load_zoo_dataset("quickstart")
6print(dataset)
7
8# Evaluate the objects in the `predictions` field with respect to the
9# objects in the `ground_truth` field
10results = dataset.evaluate_detections(
11 "predictions",
12 gt_field="ground_truth",
13 method="coco",
14 eval_key="eval",
15)
16
17# Get the 10 most common classes in the dataset
18counts = dataset.count_values("ground_truth.detections.label")
19classes = sorted(counts, key=counts.get, reverse=True)[:10]
20
21# Print a classification report for the top-10 classes
22results.print_report(classes=classes)
23
24# Print some statistics about the total TP/FP/FN counts
25print("TP: %d" % dataset.sum("eval_tp"))
26print("FP: %d" % dataset.sum("eval_fp"))
27print("FN: %d" % dataset.sum("eval_fn"))
28
29# Create a view that has samples with the most false positives first, and
30# only includes false positive boxes in the `predictions` field
31view = (
32 dataset
33 .sort_by("eval_fp", reverse=True)
34 .filter_labels("predictions", F("eval") == "fp")
35)
36
37# Visualize results in the App
38session = fo.launch_app(view=view)
precision recall f1-score support
person 0.45 0.74 0.56 783
kite 0.55 0.72 0.62 156
car 0.12 0.54 0.20 61
bird 0.63 0.67 0.65 126
carrot 0.06 0.49 0.11 47
boat 0.05 0.24 0.08 37
surfboard 0.10 0.43 0.17 30
airplane 0.29 0.67 0.40 24
traffic light 0.22 0.54 0.31 24
bench 0.10 0.30 0.15 23
micro avg 0.32 0.68 0.43 1311
macro avg 0.26 0.54 0.32 1311
weighted avg 0.42 0.68 0.50 1311
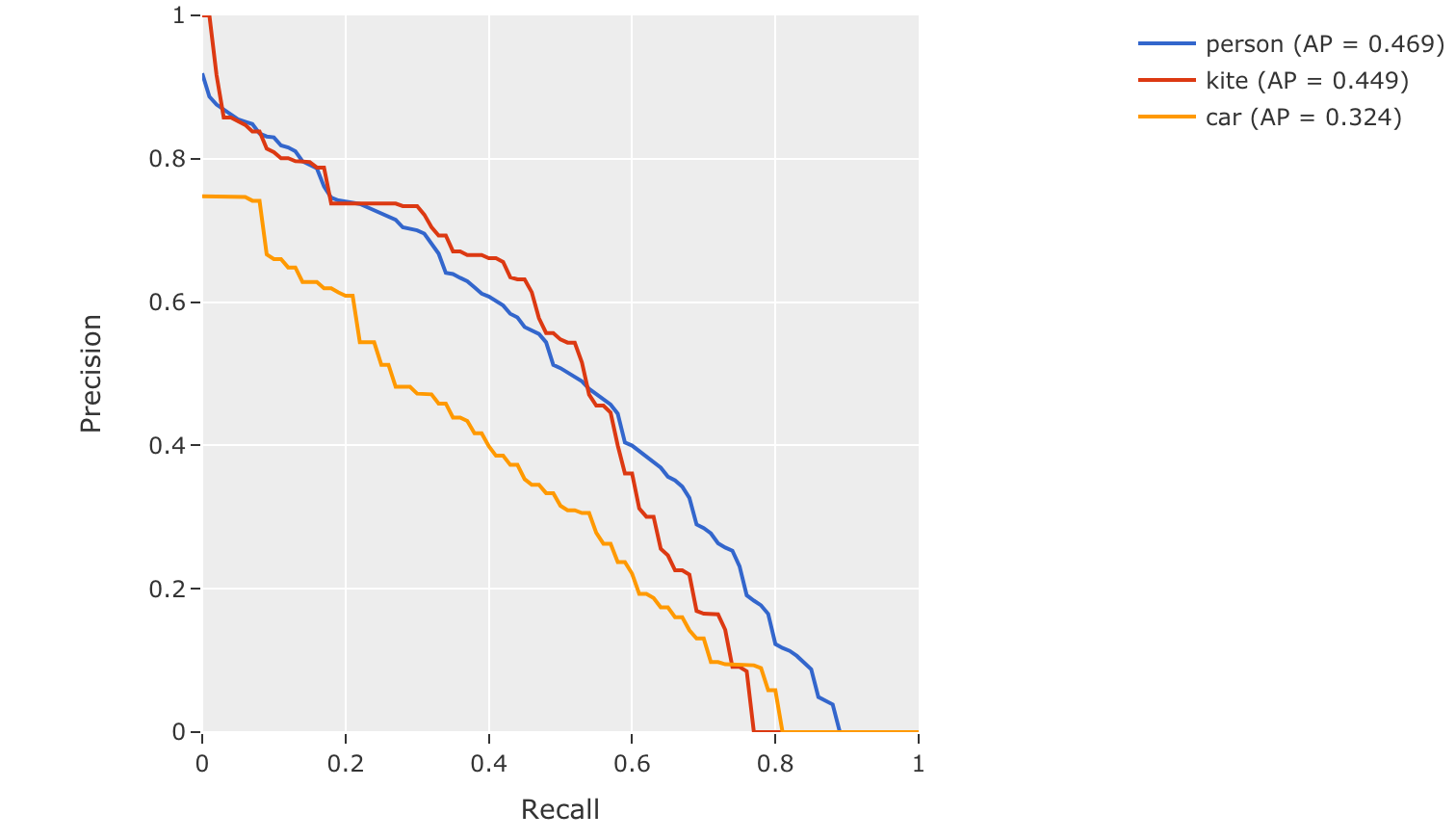
mAP and PR curves#
You can compute mean average precision (mAP), mean average recall (mAR), and
precision-recall (PR) curves for your predictions by passing the
compute_mAP=True flag to
evaluate_detections():
Note
All mAP and mAR calculations are performed according to the COCO evaluation protocol.
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5print(dataset)
6
7# Performs an IoU sweep so that mAP, mAR, and PR curves can be computed
8results = dataset.evaluate_detections(
9 "predictions",
10 gt_field="ground_truth",
11 method="coco",
12 compute_mAP=True,
13)
14
15print(results.mAP())
16# 0.3957
17
18print(results.mAR())
19# 0.5210
20
21plot = results.plot_pr_curves(classes=["person", "kite", "car"])
22plot.show()
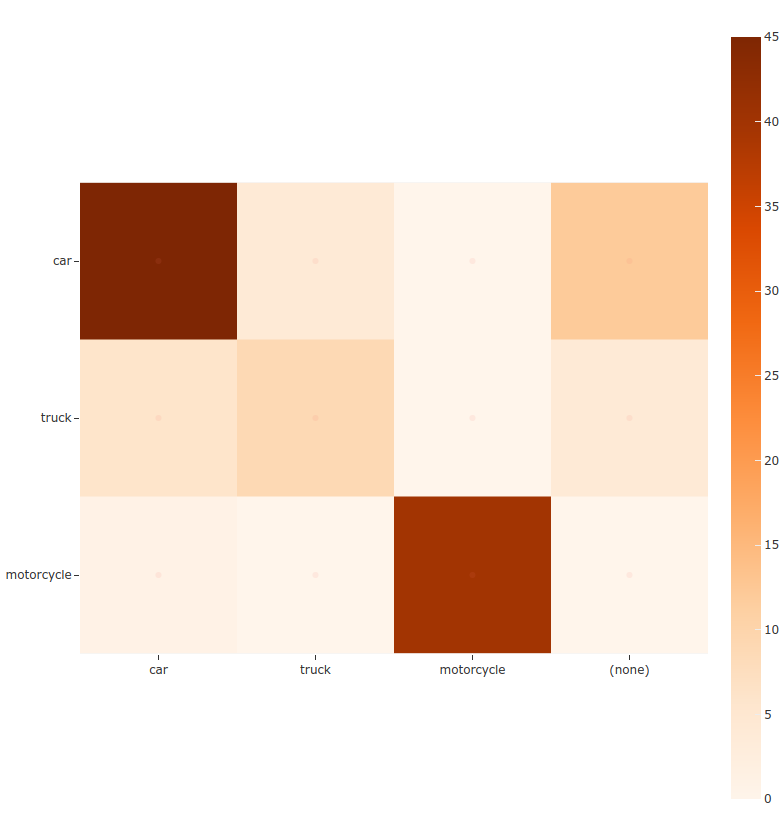
Confusion matrices#
You can also easily generate confusion matrices for the results of COCO-style evaluations.
In order for the confusion matrix to capture anything other than false
positive/negative counts, you will likely want to set the
classwise parameter
to False during evaluation so that predicted objects can be matched with
ground truth objects of different classes.
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5
6# Perform evaluation, allowing objects to be matched between classes
7results = dataset.evaluate_detections(
8 "predictions",
9 gt_field="ground_truth",
10 method="coco",
11 classwise=False,
12)
13
14# Generate a confusion matrix for the specified classes
15plot = results.plot_confusion_matrix(classes=["car", "truck", "motorcycle"])
16plot.show()
Note
Did you know? Confusion matrices can be
attached to your Session object and dynamically explored using FiftyOne’s
interactive plotting features!
mAP protocol#
The COCO evaluation protocol is a popular evaluation protocol used by many works in the computer vision community.
COCO-style mAP is derived from VOC-style evaluation with the addition of a crowd attribute and an IoU sweep.
The steps to compute COCO-style mAP are detailed below.
Preprocessing
Filter ground truth and predicted objects by class (unless
classwise=False)Sort predicted objects by confidence score so high confidence objects are matched first. Only the top 100 predictions are factored into evaluation (configurable with
max_preds)Sort ground truth objects so
iscrowdobjects are matched lastCompute IoU between every ground truth and predicted object within the same class (and between classes if
classwise=False) in each imageIoU between predictions and crowd objects is calculated as the intersection of both boxes divided by the area of the prediction only. A prediction fully inside the crowd box has an IoU of 1
Matching
Once IoUs have been computed, predictions and ground truth objects are matched to compute true positives, false positives, and false negatives:
For each class, start with the highest confidence prediction, match it to the ground truth object that it overlaps with the highest IoU. A prediction only matches if the IoU is above the specified
iouthresholdIf a prediction matched to a non-crowd object, it will not match to a crowd even if the IoU is higher
Multiple predictions can match to the same crowd ground truth object, each counting as a true positive
If a prediction maximally overlaps with a ground truth object that has already been matched (by a higher confidence prediction), the prediction is matched with the next highest IoU ground truth object
(Only relevant if
classwise=False) predictions can only match to crowds if they are of the same class
Computing mAP
Compute matches for 10 IoU thresholds from 0.5 to 0.95 in increments of 0.05
The next 6 steps are computed separately for each class and IoU threshold:
Construct a boolean array of true positives and false positives, sorted (via mergesort) by confidence
Compute the cumulative sum of the true positive and false positive array
Compute precision by elementwise dividing the TP-FP-sum array by the total number of predictions up to that point
Compute recall by elementwise dividing TP-FP-sum array by the number of ground truth objects for the class
Ensure that precision is a non-increasing array
Interpolate precision values so that they can be plotted with an array of 101 evenly spaced recall values
For every class that contains at least one ground truth object, compute the average precision (AP) by averaging the precision values over all 10 IoU thresholds. Then compute mAP by averaging the per-class AP values over all classes