|
|
|
|
Exploring Video Analytics with TwelveLabs and FiftyOne#
Welcome to this hands-on workshop where we will learn how to load and explore datasets using FiftyOne. This notebook will guide you through programmatic interaction via the FiftyOne SDK and visualization using the FiftyOne App.
Learning Objectives:#
Load video datasets into FiftyOne.
Use Plugins to connect external API to the FiftyOne’s workflow .
Calculate video embeddings using TwelveLabs.
Visualize clip embeddings in FiftyOne, curate and filter your datasets.
In this example, we use dataset loading from directory and a Kaggle dataset.
Download, extract and add the dataset in the root folder of this repo. I have called it “Video Dataset for Safe and Unsafe Behaviours”
[ ]:
import os
os.environ["TL_API_KEY"] = "your_twelve_labs_api_key"
os.environ["FIFTYONE_ALLOW_LEGACY_ORCHESTRATORS"] = "true"
[ ]:
import fiftyone as fo
import twelvelabs
import os
# Check if API key is set for TwelveLabs
api_key = os.getenv("TL_API_KEY")
if api_key:
print("TwelveLabs API key found.")
else:
print("TwelveLabs API key is missing.")
[ ]:
import os
import fiftyone as fo
import fiftyone.types as fot
import pandas as pd
import re
# Define the path to your dataset and dataset name
dataset_path = os.getenv("VIDEO_DATASET_PATH", "path/to/your/video/dataset") # Set environment variable or replace with your dataset path
dataset_name = os.getenv("FIFTYONE_DATASET_NAME", "my_video_dataset") # Set environment variable or replace with your dataset name
# Check if the dataset already exists
if fo.dataset_exists(dataset_name):
# Delete the existing dataset
fo.delete_dataset(dataset_name)
# Create a FiftyOne dataset
dataset = fo.Dataset(dataset_name)
[ ]:
print(dataset)
[ ]:
import fiftyone as fo
import os
from fiftyone.core.labels import Classification
# Define the path to your dataset (set via environment variable or replace with your dataset path)
dataset_path = os.getenv("VIDEO_DATASET_PATH", "path/to/your/video/dataset")
[ ]:
# Add the label field as a Classification label
dataset.add_sample_field(
"label",
fo.EmbeddedDocumentField,
embedded_doc_type=Classification,
)
# Iterate over the train and test directories
for split in ['train', 'test']:
split_dir = os.path.join(dataset_path, split)
for label_folder in os.listdir(split_dir):
folder_path = os.path.join(split_dir, label_folder)
if os.path.isdir(folder_path):
for video_file in os.listdir(folder_path):
video_path = os.path.join(folder_path, video_file)
if video_path.endswith(('.mp4', '.avi', '.mov')):
sample = fo.Sample(filepath=video_path)
# Assign the label using the Classification type
sample["label"] = Classification(label=label_folder) # Label as Classification type
# Add the tag to the sample based on the split (train/test)
sample.tags = [split]
dataset.add_sample(sample)
[ ]:
session = fo.launch_app(dataset, auto=False, port= 5151)
[ ]:
from collections import defaultdict
import fiftyone as fo
# Create a function to select 5 videos per label (train and test)
def select_5_videos_per_label(dataset, split):
# Dictionary to store videos per label
label_videos = defaultdict(list)
# Filter dataset by split (train or test)
if split == "train":
split_view = dataset.match_tags("train")
elif split == "test":
split_view = dataset.match_tags("test")
else:
raise ValueError("Invalid split. Choose 'train' or 'test'.")
# Iterate through the samples and group them by label
for sample in split_view:
# Access the label correctly since it's a TemporalDetection type
label = sample["label"].label # Get the label text from the TemporalDetection field
label_videos[label].append(sample)
# Create a list to hold the selected samples (5 per label)
selected_samples = []
# Select only 5 videos per label (ensure you have exactly 5 videos per label)
for label, videos in label_videos.items():
selected_samples.extend(videos[:5]) # Select the first 5 videos for each label
# Ensure we have only 40 videos total (5 videos per 8 labels)
selected_samples = selected_samples[:40] # Limit to 40 videos in total
# Create a filtered view with the selected samples
selected_view = dataset.select([sample.id for sample in selected_samples])
return selected_view
# Assuming you already have a dataset loaded
# dataset = fo.load_dataset("video_dataset") # Replace with your actual dataset name
# Select 5 videos per label for the train and test datasets
train_selected_view = select_5_videos_per_label(dataset, "train")
test_selected_view = select_5_videos_per_label(dataset, "test")
# Optionally launch the FiftyOne app to visualize the selected data
# session = fo.launch_app(train_selected_view, port=5153, auto=False)
[ ]:
dataset.persistent=True
[ ]:
# Set export directory
export_dir = "./Safe_Unsafe_Train"
# Export in FiftyOne format
train_selected_view.export(
export_dir=export_dir,
dataset_type=fo.types.FiftyOneDataset,
overwrite=True,
)
[ ]:
from fiftyone.utils.huggingface import push_to_hub
push_to_hub(train_selected_view, export_dir)
[ ]:
# Set export directory (make this generic)
export_dir = "./exported_test_dataset"
# Export in FiftyOne format
test_selected_view.export(
export_dir=export_dir,
dataset_type=fo.types.FiftyOneDataset,
overwrite=True,
)
# Check if the dataset already exists
if fo.dataset_exists("FIFTYONE_DATASET_NAME"):
fo.delete_dataset("FIFTYONE_DATASET_NAME")
dataset_test = test_selected_view.clone("FIFTYONE_DATASET_NAME")
[ ]:
print(dataset_test)
[ ]:
from fiftyone.utils.huggingface import push_to_hub
push_to_hub(train_selected_view, export_dir)
[ ]:
!fiftyone plugins download https://github.com/danielgural/semantic_video_search
[ ]:
# Optionally launch the FiftyOne app to visualize the selected data
session = fo.launch_app(train_selected_view, port=5152, auto=False)
[ ]:
# Run this in your terminal
# export TL_API_KEY="your_twelvelabs_api_key"
# export FIFTYONE_ALLOW_LEGACY_ORCHESTRATORS="true"
# !fiftyone delegated launch
[ ]:
import fiftyone.utils.video as fouv
import fiftyone.brain as fob
def create_clip_dataset(
dataset: fo.Dataset,
clip_field: str,
new_dataset_name: str = "clips",
overwrite: bool = True,
viz: bool = False,
sim: bool = False,
) -> fo.Dataset:
clips = []
clip_view = dataset.to_clips(clip_field)
clip_dataset = fo.Dataset(name=new_dataset_name,overwrite=overwrite)
i = 0
last_file = ""
samples = []
for clip in clip_view:
out_path = clip.filepath.split(".")[0] + f"_{i}.mp4"
fpath = clip.filepath
fouv.extract_clip(fpath, output_path=out_path, support=clip.support)
clip.filepath = out_path
samples.append(clip)
clip.filepath = fpath
if clip.filepath == last_file:
i += 1
else:
i = 0
last_file = clip.filepath
clip_dataset.add_samples(samples)
clip_dataset.add_sample_field("Twelve Labs Marengo-retrieval-27 Embeddings", fo.VectorField)
clip_dataset.set_field("Twelve Labs Marengo-retrieval-27 Embeddings", clip_view.values("Twelve Labs Marengo-retrieval-27.embedding"))
return clip_dataset
[ ]:
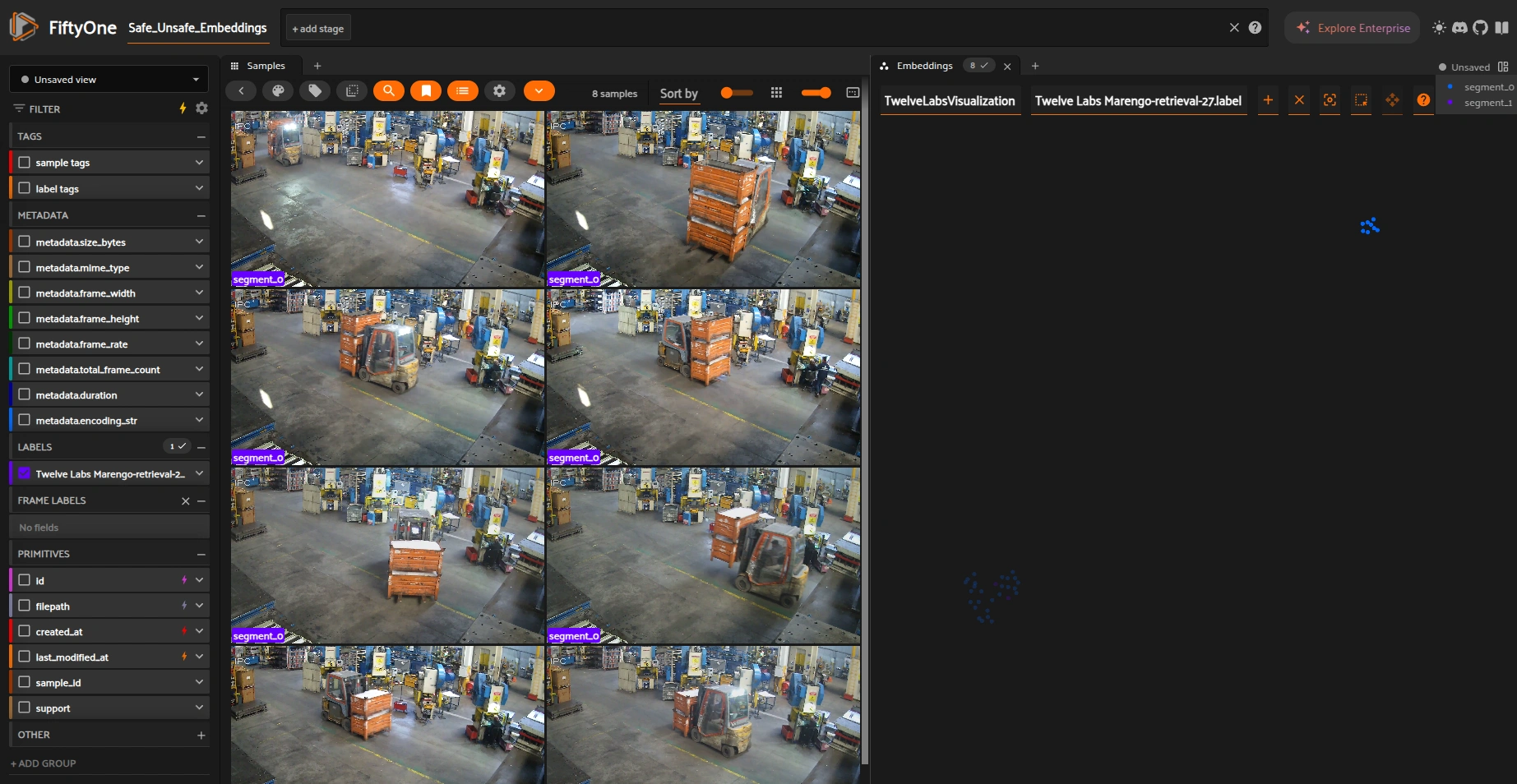
clip_dataset = create_clip_dataset(dataset_test, "Twelve Labs Marengo-retrieval-27", overwrite=True)
[ ]:
# Need this to grab embeddings
clip_view = dataset_test.to_clips("Twelve Labs Marengo-retrieval-27")