|
|
|
|
Integrating Cosmos Transfer 2.5 for Data Scarcity#
Description of the Integration#
This tutorial demonstrates how to integrate NVIDIA Cosmos Transfer 2.5, a state-of-the-art world foundation model (WFM) for Physical AI, with FiftyOne, an open-source tool for visual dataset exploration and model evaluation. The integration enables you to seamlessly curate, visualize, and process multimodal datasets (RGB, depth, segmentation, edge maps, etc.) through Cosmos Transfer’s multi-control generation capabilities, all within the FiftyOne ecosystem.
By combining Cosmos’s autoregressive world generation with FiftyOne’s dataset management and visualization tools, this workflow bridges simulation and real-world analysis. It helps developers explore augmented data, evaluate generation quality, and build robust datasets for robotics, autonomous vehicles, video analytics AI agents, and other kind of solutions we will showcase in this tutorial.
So, what’s the takeaway?#
With this integration, you can:
Streamline data curation and augmentation pipelines using Cosmos-Transfer and FiftyOne.
Automate control map generation and inference on large video datasets.
Visualize and compare original and generated outputs side-by-side in FiftyOne.
Prepare your datasets for physical AI research and real-world deployment.
Setup#
1. Install FiftyOne#
You’ll need Python 3.9+ and other libraries to work with FiftyOne Brain.
pip install fiftyone umap-learn
2. Install Cosmos Transfer 2.5 and Dependencies#
Clone the Cosmos Transfer 2.5 repository and install it in editable mode and follow the Cosmos Transfer 2.5 Setup Guide for environment configuration and model weight downloads.
System requirements#
NVIDIA GPUs with Ampere architecture (RTX 30 Series, A100) or newer
NVIDIA driver >=570.124.06 compatible with CUDA 12.8.1
Linux x86-64
glibc>=2.35 (e.g Ubuntu >=22.04)
Python 3.10
Installation#
After you have your machine ready, follow these instructions
Ensure the following dependencies are met:
PyTorch ≥ 2.5
TorchVision
CUDA 12+ (Blackwell optimized)
FFmpeg (for video conversion)
Gradio (for optional interface)
EasyIO (for multi-storage backend)
json5, pyrefly, and torch-compile (for tokenizer optimization)
Load Your Dataset into FiftyOne#
For this tutorial, we’ll use a subset of the BioTrove dataset, which include samples of moths in multiple scenarios but the majority of them not in the real environments.
[ ]:
import fiftyone as fo
import fiftyone.utils.huggingface as fouh
# Your source dataset (images)
dataset_src = fouh.load_from_hub(
"pjramg/moth_biotrove",
persistent=True,
overwrite=True, # set to False if you don't want to re-download
max_samples=2,
)
print(dataset_src.name, dataset_src.media_type, len(dataset_src))
[ ]:
import os
# Get the filepath of the first sample
first_sample = dataset_src.first()
sample_filepath = first_sample.filepath
# Extract the directory where the dataset is stored
dataset_directory = os.path.dirname(sample_filepath)
print(f"Dataset directory: {dataset_directory}")
Create a grouped dataset#
For educational purposes we will create a slice per step in our Cosmos-Transfer integration.
[ ]:
import fiftyone as fo
dataset_grp_name = "moth_biotrove_grouped"
if fo.dataset_exists(dataset_grp_name):
fo.delete_dataset(dataset_grp_name)
# Create dataset WITHOUT media_type
dataset_grp = fo.Dataset(dataset_grp_name)
# Add a group field with a default slice
dataset_grp.persistent = True
dataset_grp
Check Dataset Format and Add Videos#
In this example, the FiftyOne dataset is downloaded from the HuggingFace Hub into the local FiftyOne directory, typically located at:
~/fiftyone/huggingface/hub/<username>/<dataset_name>/
Each sample image will be converted into a 1-second video with the same filename.
Convert Images to Videos (Python Version)#
Instead of using a shell loop, we programmatically:
Locate the directory where FiftyOne stores the downloaded dataset media.
Create a new
videos/directory next to the images.Walk through every image in the dataset.
Convert each JPG into a 1-second MP4 video using FFmpeg.
This method works consistently across environments and avoids issues with shell globbing or missing directories.
Below is the Python code used in this notebook:
[ ]:
import os
import subprocess
from pathlib import Path
# 1) Where your dataset images live
images_root = Path(dataset_directory)
# 2) Create videos folder in the same parent directory as the data folder
videos_root = images_root.parent / "videos"
videos_root.mkdir(parents=True, exist_ok=True)
print(f"Images root: {images_root.resolve()}")
print(f"Videos root: {videos_root.resolve()}")
# 3) Walk all subdirectories under images_root
for dirpath, _dirnames, filenames in os.walk(images_root):
jpgs = sorted([f for f in filenames if f.lower().endswith(".jpg")])
if not jpgs:
# No JPGs in this folder, skip
continue
dirpath = Path(dirpath)
# Process each image individually
for jpg_file in jpgs:
input_image = dirpath / jpg_file
# Get the image name without extension
image_name = Path(jpg_file).stem
# Create output video with same name as image
output_video = videos_root / f"{image_name}.mp4"
cmd = [
"ffmpeg",
"-y",
"-loop", "1", # Loop the single image
"-i", str(input_image),
"-t", "1", # Duration of 1 second
"-vf", "pad=ceil(iw/2)*2:ceil(ih/2)*2", # Pad to even dimensions
"-c:v", "libx264",
"-pix_fmt", "yuv420p",
str(output_video),
]
print(f"\nProcessing image: {jpg_file}")
print(f"Output video: {output_video}")
try:
subprocess.run(cmd, check=True, capture_output=True, text=True)
print(f"✓ Created: {output_video}")
except subprocess.CalledProcessError as e:
print(f"✗ Error processing {jpg_file}:")
print(f"stderr: {e.stderr}")
continue
print("\nDone!")
[ ]:
from pathlib import Path
import fiftyone as fo
# Where the MP4s were written by your FFmpeg loop
VIDEO_ROOT = videos_root
def guess_video_path(image_path: str) -> str | None:
"""
Given an image path, try to infer the matching MP4 path.
Strategy:
- Take the image filename stem
- Expect an MP4 named <stem>.mp4 under VIDEO_ROOT
"""
p = Path(image_path)
image_stem = p.stem # filename without extension
candidate = VIDEO_ROOT / f"{image_stem}.mp4"
return str(candidate) if candidate.exists() else None
# Add slice to the grouped dataset
dataset_grp.add_group_field("group", default="image")
# Optional: copy over selected label fields from the source sample to the new grouped sample
# Exclude system fields
exclude = {"id", "filepath", "group", "tags", "metadata"}
schema = dataset_src.get_field_schema()
# Build grouped samples
samples_to_add = []
for s in dataset_src.iter_samples(progress=True):
video_fp = guess_video_path(s.filepath)
# Always create the group anchor
g = fo.Group()
# --- IMAGE SLICE ---
img_sample = fo.Sample(
filepath=s.filepath,
group=g.element("image"),
tags=list(s.tags) if s.tags else None,
metadata=s.metadata,
)
# copy user fields
for field in schema:
if field not in exclude and hasattr(s, field):
img_sample[field] = getattr(s, field)
samples_to_add.append(img_sample)
# --- VIDEO SLICE (optional if present) ---
if video_fp is not None:
vid_sample = fo.Sample(
filepath=video_fp,
group=g.element("video"),
tags=list(s.tags) if s.tags else None,
)
samples_to_add.append(vid_sample)
dataset_grp.add_samples(samples_to_add)
print(dataset_grp.name, dataset_grp.media_type, len(dataset_grp))
Full Python Batch Pipeline#
Cosmos-Transfer 2.5 + FiftyOne Integration#
The pipeline automates the complete process of dataset augmentation and model inference:
Collect input videos from the assets directory or a custom list file.
Generate Canny edge videos using OpenCV to serve as control maps for Cosmos-Transfer 2.5.
Write JSON spec files defining prompts, guidance, and control paths for each video.
Run Cosmos-Transfer inference by invoking the official examples/inference.py script through subprocess, leveraging your current Python environment.
Extract the final frame from each output video to create a static “output last” thumbnail image.
Attach all derived data—edge videos, generated outputs, and last-frame thumbnails—as new slices (edge, output, output_last) in your existing grouped FiftyOne dataset.
Once complete, you can open the dataset in the FiftyOne App to visually compare the original images, control maps, generated videos, and last-frame outputs side-by-side. This all-in-Python workflow provides a fully reproducible, GPU-accelerated, and data-centric way to evaluate Cosmos-Transfer 2.5 results directly within your notebook environment.
Configuration Variables#
images_root: Path to the original dataset images downloaded from Hugging Facebase_dir: Parent directory containing all pipeline data (images_root.parent)ASSETS_DIR: Directory containing input videos for processingOUT_DIR: Directory where Cosmos inference results are savedSPECS_DIR: Directory for JSON specification files used by CosmosEDGE_DIR: Directory for Canny edge detection control videosLAST_FRAMES_DIR: Directory for extracted last frames from output videosMAX_VIDS: Maximum number of videos to process (default: 100)COSMOS_DIR: Root directory of the Cosmos repositoryINFER_SCRIPT: Path to the Cosmos inference script
Inference Parameters#
MOTH_PROMPT: Detailed prompt describing the desired output styleNEG_PROMPT: Negative prompt to avoid unwanted artifactsGUIDANCE: Guidance scale for inference (default: 7)RESOLUTION: Output resolution (default: “720”)NUM_STEPS: Number of inference steps (default: 38)
FiftyOne Integration#
GROUPED_DATASET_NAME: Name of the FiftyOne grouped dataset to update with new slices
This configuration ensures all pipeline outputs are organized in a consistent structure alongside your original Hugging Face dataset, making it easy to manage and integrate with FiftyOne’s grouped dataset functionality.
[ ]:
# --- Python-only batch pipeline: Cosmos-Transfer2.5 + FiftyOne ---
import os
import sys
import json
import subprocess
from pathlib import Path
from typing import List, Optional
from datetime import datetime
import cv2
import fiftyone as fo
# Set the environment variable for PyTorch in case of memory issues
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"
# -------------------- CONFIG --------------------
# Get the dataset directory from your earlier code
images_root = Path(dataset_directory) # This is ~/fiftyone/huggingface/hub/<username>/<dataset_name>/data
base_dir = images_root.parent # This is ~/fiftyone/huggingface/hub/<username>/<dataset_name>
#Setup where the COSMOS-TRANSFER2.5 REPO folder is
os.environ["COSMOS_DIR"] = "/path/to/cosmos-transfer2.5/folder"
# Set all directories relative to the base directory
ASSETS_DIR = base_dir / "videos" # Where your input videos are
OUT_DIR = base_dir / "cosmos_result" # Where inference outputs go
SPECS_DIR = base_dir / "specs" # JSON specs
EDGE_DIR = base_dir / "edge" # Edge control videos
LAST_FRAMES_DIR = base_dir / "last_frame" # Last frames extracted from outputs
LIST_FILE = Path(os.environ.get("LIST_FILE", str(ASSETS_DIR / "video_list.txt")))
MAX_VIDS = int(os.environ.get("MAX_VIDS", "100"))
COSMOS_DIR = Path(os.environ.get("COSMOS_DIR", "."))
INFER_SCRIPT = COSMOS_DIR / "examples" / "inference.py"
GROUPED_DATASET_NAME = "moth_biotrove_grouped"
print(f"Base directory: {base_dir}")
print(f"Videos directory: {ASSETS_DIR}")
print(f"Output directory: {OUT_DIR}")
print(f"Edge directory: {EDGE_DIR}")
print(f"Last frames directory: {LAST_FRAMES_DIR}")
# Prompts / inference params
MOTH_PROMPT = os.environ.get("MOTH_PROMPT", """
The video depicts a realistic outdoor scene captured during daytime in a natural environment.
A single moth is the primary subject, sharply focused, with crisp wing edges, fine scale texture, and natural coloration.
The background consists of softly blurred green leaves and sunlit foliage, replacing the original scene.
Lighting is natural and diffused, as if under mild sunlight or partial shade, producing realistic contrast, soft shadows, and gentle highlights on the moth and nearby leaves.
The overall tone is photographic and lifelike, with balanced exposure and true-to-life colors.
Fine details such as subtle motion blur, tiny airborne particles, and depth of field contribute to a high-quality, authentic nature documentary aesthetic.
Avoid stylization; the output should appear like a professional macro wildlife recording captured in natural daylight.
""").strip()
NEG_PROMPT = os.environ.get(
"NEG_PROMPT",
"blurry, motion blur, defocus, low-detail, oversmoothed, painterly, cartoon, glow, haze, "
"halos, banding, ghosting, soft edges, unrealistic lighting, watercolor, low contrast"
)
GUIDANCE = int(os.environ.get("GUIDANCE", "7"))
RESOLUTION = os.environ.get("RESOLUTION", "720")
NUM_STEPS = int(os.environ.get("NUM_STEPS", "38"))
# -------------------- UTILITIES --------------------
def list_videos(assets_dir: Path, list_file: Path, max_vids: int) -> List[Path]:
"""Collect input .mp4 videos, respecting an optional list file."""
vids: List[Path] = []
if list_file.exists():
with list_file.open() as f:
for line in f:
name = line.strip()
if not name:
continue
vids.append((assets_dir / name).with_suffix(".mp4") if not name.endswith(".mp4") else assets_dir / name)
else:
vids = sorted(assets_dir.glob("*.mp4"))
if max_vids > 0:
vids = vids[:max_vids]
return vids
def ensure_dirs():
SPECS_DIR.mkdir(parents=True, exist_ok=True)
EDGE_DIR.mkdir(parents=True, exist_ok=True)
OUT_DIR.mkdir(parents=True, exist_ok=True)
def write_spec_json(spec_path: Path, video_abs: Path, edge_abs: Path, name: str):
obj = {
"name": name,
"prompt": MOTH_PROMPT,
"negative_prompt": NEG_PROMPT,
"video_path": str(video_abs),
"guidance": GUIDANCE,
"resolution": RESOLUTION,
"num_steps": NUM_STEPS,
"edge": {
"control_weight": 1.0,
"control_path": str(edge_abs),
},
}
spec_path.parent.mkdir(parents=True, exist_ok=True)
spec_path.write_text(json.dumps(obj, indent=2))
def make_edge_video(input_video: Path, output_video: Path) -> bool:
"""Generate Canny edge control video (grayscale) for an input video."""
cap = cv2.VideoCapture(str(input_video))
if not cap.isOpened():
print(f"[ERROR] Cannot open video: {input_video}")
return False
fps = cap.get(cv2.CAP_PROP_FPS) or 24
w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
out = cv2.VideoWriter(str(output_video), fourcc, fps, (w, h), isColor=False)
ok = True
while True:
ret, frame = cap.read()
if not ret:
break
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray, 80, 180)
out.write(edges)
cap.release()
out.release()
if not output_video.exists():
print(f"[ERROR] Edge video not created: {output_video}")
ok = False
return ok
def run_cosmos_inference(spec_json: Path, out_dir: Path) -> bool:
"""Call the Cosmos inference script via the current Python interpreter."""
if not INFER_SCRIPT.exists():
print(f"[ERROR] inference script not found: {INFER_SCRIPT}")
return False
cmd = [sys.executable, str(INFER_SCRIPT), "-i", str(spec_json), "-o", str(out_dir)]
try:
subprocess.run(cmd, check=True)
return True
except subprocess.CalledProcessError as e:
print(f"[ERROR] inference failed ({spec_json.name}): {e}")
return False
def extract_last_frame(video_path: Path, dst_dir: Path) -> Optional[Path]:
"""Extract last frame as PNG from a video."""
dst_dir.mkdir(parents=True, exist_ok=True)
cap = cv2.VideoCapture(str(video_path))
if not cap.isOpened():
print(f"[warn] cannot open {video_path}")
return None
total = int(cap.get(cv2.CAP_PROP_FRAME_COUNT) or 0)
out_png = dst_dir / f"{video_path.stem}_last.png"
if total > 0:
cap.set(cv2.CAP_PROP_POS_FRAMES, max(total - 1, 0))
ret, frame = cap.read()
if not ret or frame is None:
cap.set(cv2.CAP_PROP_POS_FRAMES, max(total - 2, 0))
ret, frame = cap.read()
cap.release()
if not ret or frame is None:
print(f"[warn] could not read last frame for {video_path}")
return None
cv2.imwrite(str(out_png), frame)
return out_png
# Fallback for weird metadata
last = None
while True:
ret, frame = cap.read()
if not ret:
break
last = frame
cap.release()
if last is None:
return None
cv2.imwrite(str(out_png), last)
return out_png
def base_key(path: Path) -> str:
"""Derive a key shared across slices; here we use filename stem."""
return path.stem
# -------------------- PIPELINE --------------------
ensure_dirs()
videos = list_videos(ASSETS_DIR, LIST_FILE, MAX_VIDS)
print(f"[info] found {len(videos)} videos under {ASSETS_DIR}")
ok = fail = 0
for idx, v in enumerate(videos, 1):
if not v.exists():
print(f"[warn] missing: {v}")
fail += 1
continue
name = base_key(v)
edge_mp4 = EDGE_DIR / f"{name}_edge.mp4"
spec_json = SPECS_DIR / f"{name}.json"
print(f"[{idx}/{len(videos)}] Edge gen: {name}")
if not make_edge_video(v, edge_mp4):
fail += 1
continue
write_spec_json(spec_json, v.resolve(), edge_mp4.resolve(), name)
print(f"[{idx}/{len(videos)}] Inference: {name}")
if run_cosmos_inference(spec_json, OUT_DIR):
ok += 1
else:
fail += 1
print(f"Done. Success: {ok} Failed: {fail}")
print(f"Specs: {SPECS_DIR}")
print(f"Edges: {EDGE_DIR}")
print(f"Outputs: {OUT_DIR}")
FiftyOne Integration: Adding Cosmos Pipeline Results to Grouped Dataset#
This cell integrates the Cosmos-Transfer2.5 pipeline outputs into your existing FiftyOne grouped dataset, adding three new slices for each processed video.
Process Overview#
Load Existing Grouped Dataset
Loads the grouped dataset created earlier (containing
imageandvideoslices)Raises an error if the dataset doesn’t exist
Index Groups by Image Keys
Iterates through all samples in the
imagesliceCreates a mapping from filename stems to their corresponding group objects
This enables matching Cosmos outputs back to their original groups
Add New Slices to Groups
For each Cosmos output video, the following slices are added to the matching group:
edge: Canny edge detection video used as control inputoutput: Cosmos-generated output videooutput_last: Last frame extracted from the output video (as an image)
Error Handling
Tracks unmatched outputs (videos without corresponding groups)
Warns about missing edge videos or failed frame extractions
Reports summary statistics
Dataset Finalization
Adds all new samples to the dataset in batch
Reloads the dataset to ensure changes are reflected
Displays final group slices and media types
Launch FiftyOne App
Opens the FiftyOne App for interactive visualization
Displays the URL for accessing the App
Expected Group Structure#
After this cell completes, each group will contain up to 5 slices:
image: Original image from Hugging Face datasetvideo: Video created from the imageedge: Last frame of Canny edge detection videooutput: Cosmos-generated output videooutput_last: Last frame of the Cosmos output (image)
This grouped structure allows synchronized visualization and comparison of all related data in the FiftyOne App.
[ ]:
# -------------------- FIFTYONE INTEGRATION --------------------
import fiftyone as fo
from pathlib import Path
def base_key(path: Path) -> str:
return path.stem
if fo.dataset_exists(GROUPED_DATASET_NAME):
dataset_grp = fo.load_dataset(GROUPED_DATASET_NAME)
else:
raise RuntimeError(
f"Grouped dataset '{GROUPED_DATASET_NAME}' not found. "
"Create it earlier (image/video slices) before running this cell."
)
# --- Index groups by the IMAGE slice ---
image_groups = {}
for s in dataset_grp.match({"group.name": "image"}).iter_samples(progress=True):
image_groups[base_key(Path(s.filepath))] = s.group
new_slices = []
# Folder where last-frame PNGs will go
edge_last_dir = OUT_DIR / "edge_last_frames"
output_last_dir = OUT_DIR / "output_last_frames"
edge_last_dir.mkdir(parents=True, exist_ok=True)
output_last_dir.mkdir(parents=True, exist_ok=True)
# Loop over ALL outputs (*.mp4) but skip *_control_edge.mp4
for out_vid in sorted(OUT_DIR.glob("*.mp4")):
stem = out_vid.stem
if stem.endswith("_control_edge"):
continue
key = stem
grp = image_groups.get(key)
if grp is None:
print(f"[warn] No matching group found for output: {key}")
continue
# --- 1. Edge last frame slice ---
cosmos_edge_fp = OUT_DIR / f"{key}_control_edge.mp4"
if cosmos_edge_fp.exists():
edge_png = extract_last_frame(cosmos_edge_fp, edge_last_dir)
if edge_png and edge_png.exists():
new_slices.append(
fo.Sample(
filepath=str(edge_png),
group=grp.element("edge"),
)
)
else:
print(f"[warn] Could not extract last frame for edge: {cosmos_edge_fp}")
else:
print(f"[warn] Cosmos edge video not found: {cosmos_edge_fp}")
# --- 2. Output video slice ---
new_slices.append(
fo.Sample(
filepath=str(out_vid),
group=grp.element("output"),
)
)
# --- 3. Output last frame slice ---
output_png = extract_last_frame(out_vid, output_last_dir)
if output_png and output_png.exists():
new_slices.append(
fo.Sample(
filepath=str(output_png),
group=grp.element("output_last"),
)
)
else:
print(f"[warn] Could not extract last frame for output: {out_vid}")
# --- Add slices to dataset ---
if new_slices:
dataset_grp.add_samples(new_slices)
print(f"[OK] Added {len(new_slices)} new slices (edge_last/output/output_last)")
print(f"[info] Group slices now: {dataset_grp.group_slices}")
print(f"[info] Group media types: {dataset_grp.group_media_types}")
else:
print("[warn] No new slices were added")
dataset_grp.reload()
print(f"\n[info] Final dataset summary:")
print(f" Total samples: {len(dataset_grp)}")
print(f" Available group slices: {dataset_grp.group_slices}")
session = fo.launch_app(dataset_grp, port=5151, auto=False)
print(f"[info] FiftyOne App launched at: {session.url}")
Adding Slice Identifier Field to Grouped Dataset#
This cell adds a slice_name field to the grouped dataset to identify which group slice each sample belongs to. This is useful for filtering, visualization, and analysis based on slice origin.
[ ]:
# Add a field to store the slice name
dataset_grp.add_sample_field("slice_name", fo.StringField)
# Iterate through each slice and set the slice_name field
for slice_name in ["image", "output_last"]:
# Get samples from this slice
slice_view = dataset_grp.select_group_slices(slice_name)
# Set the slice_name field for all samples in this slice
for sample in slice_view:
sample["slice_name"] = slice_name
sample.save()
Computing Embeddings and Similarity Index for image and output_last Slices in FiftyOne#
This cell demonstrates how to compute embeddings and build a similarity index for both image and output_last slices in a grouped dataset using the CLIP model from the FiftyOne Model Zoo.
Workflow
Select multiple slices: Create a flattened view containing samples from both
imageandoutput_lastslices usingselect_group_slices(["image", "output_last"]).Load the model: Retrieve the
clip-vit-base32-torchmodel from the FiftyOne Model Zoo, which can generate embeddings for images.Compute embeddings: Use the model to generate embeddings for all samples in the flattened view and store them in a field called
embeddings.Build a similarity index: Use FiftyOne Brain’s
compute_similarity()to index the embeddings and enable similarity search or ranking directly in the FiftyOne App under the brain keykey_sim.”
[ ]:
import fiftyone.zoo as foz
import fiftyone.brain as fob
# Select the two slices you need (e.g., "image" and "output_last")
flattened_view = dataset_grp.select_group_slices(["image", "output_last"])
# Load a model and compute embeddings
model = foz.load_zoo_model("clip-vit-base32-torch")
flattened_view.compute_embeddings(model, embeddings_field="embeddings")
# Create similarity index for crops
fob.compute_similarity(
flattened_view,
model="clip-vit-base32-torch",
embeddings="embeddings",
brain_key="key_sim",
)
print("[INFO] output_last_view embeddings computed successfully!")
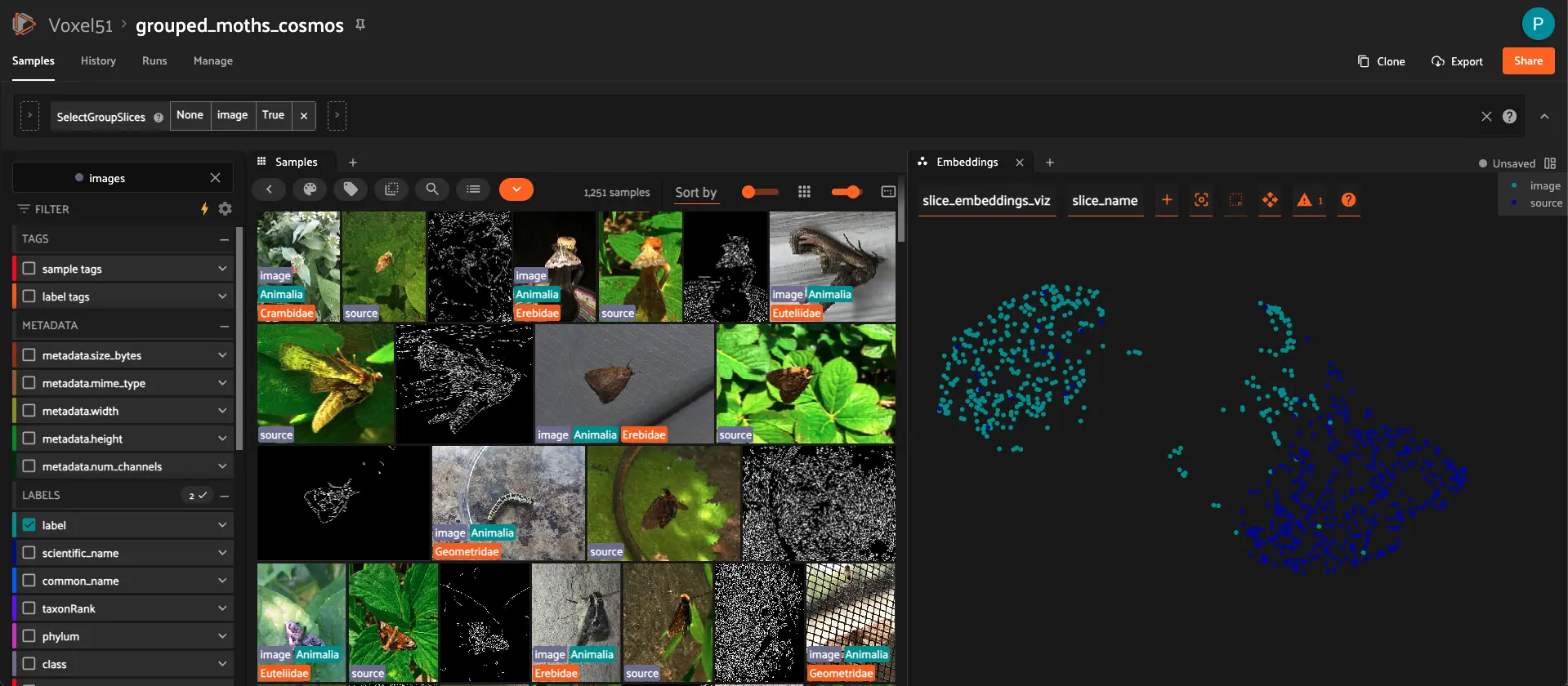
Visualizing Embeddings for image and output_last Slices in FiftyOne#
This cell creates an interactive 2D visualization of the embeddings computed for both ``image`` and ``output_last`` slices using dimensionality reduction.
What it does
Use existing embeddings: Works with the embeddings already computed and stored in the
"embeddings"field on theflattened_view(containing bothimageandoutput_lastslices).Apply dimensionality reduction: Uses UMAP to reduce the high-dimensional embeddings to 2D for visualization. You can also use
"tsne"or"pca"as alternatives.Store results: Saves the visualization under the brain key
"slice_embeddings_viz"for access in the FiftyOne App.Explore: Open the FiftyOne App’s Embeddings panel to interactively explore clusters, filter by the
slice_namefield to distinguish betweenimageandoutput_lastsamples, and select points of interest.
Tip: Color the visualization by slice_name to see how the two slices compare in the embedding space: ```python plot = results.visualize(labels=”slice_name”) plot.show()
[ ]:
import fiftyone.brain as fob
# Compute visualization using the embeddings you already computed
results = fob.compute_visualization(
flattened_view,
embeddings="embeddings", # The field where your embeddings are stored
method="umap", # You can also use "tsne" or "pca"
brain_key="slice_embeddings_viz",
num_dims=2,
verbose=True
)
[ ]:
session = fo.launch_app(flattened_view, port=5151, auto=False)
Summary#
In this tutorial, we built a complete integration pipeline between Cosmos-Transfer 2.5 and FiftyOne, entirely within a Python notebook.
You learned how to:
Set up and install both Cosmos-Transfer 2.5 and FiftyOne, ensuring all required dependencies (PyTorch, CUDA, OpenCV) are ready for GPU-accelerated inference.
Load and prepare datasets (such as the BioTrove subset) from Hugging Face, convert images to video format when needed, and organize everything into grouped datasets in FiftyOne for multimodal exploration.
Generate control maps automatically using Canny edge detection to guide Cosmos-Transfer’s multi-ControlNet inference process.
Run Cosmos-Transfer inference in pure Python, without shell scripts, by dynamically creating JSON spec files and invoking the model through
subprocess.Extract the last frame from each output video to create a static visualization slice for comparison and analysis.
Explore results in FiftyOne, side-by-side, across slices (
image,video,edge,output,output_last) to visualize model performance, quality, and domain alignment.
This end-to-end workflow demonstrates how to connect synthetic data generation and real-world evaluation into a single reproducible, data-centric loop—helping you accelerate experimentation, debug model behavior, and evaluate Physical AI systems across robotics, autonomous driving, and environmental perception tasks.
Would you like to know more about a easy integration between Cosmos-Transfer and FiftyOne?#
You can run this in your side using all the magic of Open-Source, if you want to move this to the next level. I encourage you to book a demo and see all the capabilities with this integration. Visit: Physical AI Workbench