Data Lens#
Data Lens is a feature built into the FiftyOne Enterprise App that allows you to use FiftyOne to explore and import samples from external data sources.
Whether your data resides in a database like PostgreSQL or a data lake like Databricks or BigQuery, Data Lens provides a way to search your data sources, visualize sample data, and import into FiftyOne for further analysis.
How it works#
- Define your search experience
Tailor the interactions with your data source to exactly what you need. Data Lens provides a flexible framework which allows for extensive customization, allowing you to hone in on the questions that are most critical to your workflow. See Integrating with Data Lens to learn more.
- Connect your data source
Provide configuration to Data Lens to connect to your data source. Once connected, you can start searching for samples directly from FiftyOne. See Connecting a data source to learn more.
- Interact with your data
View your samples using Data Lens’ rich preview capabilities. Refine your search criteria to find samples of interest, then import your samples into a FiftyOne dataset for further analysis. See Exploring samples to learn more.
Connecting a data source#
A data source represents anywhere that you store your data outside of FiftyOne. This could be a local SQL database, a hosted data lake, or an internal data platform. To connect to your data source, you’ll first implement a simple operator which FiftyOne can use to communicate with your data source.
Once your operator is defined, you can navigate to the “Data sources” tab by clicking on the tab header or by clicking on “Connect to a data source” from the “Home” tab.
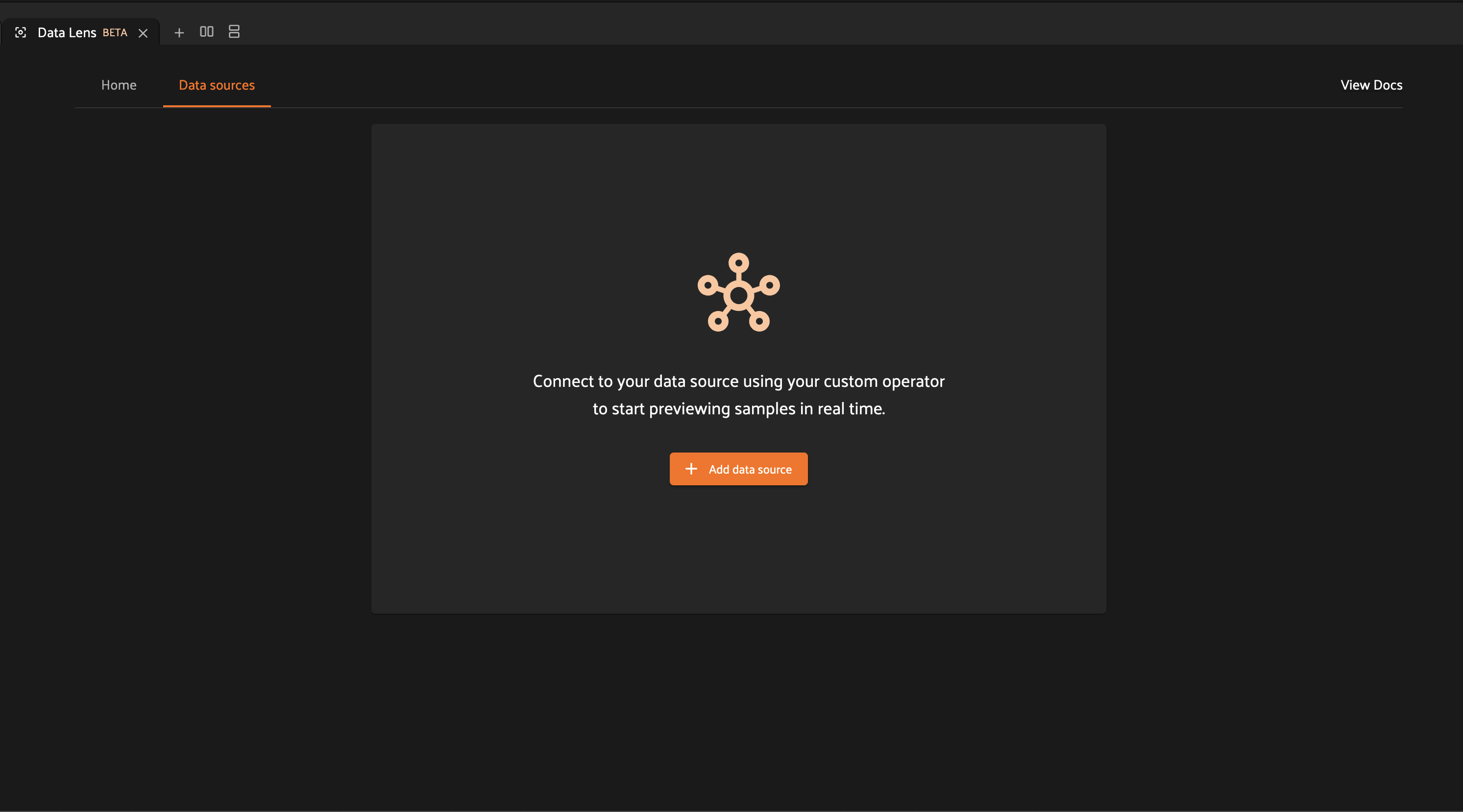
Add a new data source by clicking on “Add data source”.
Enter a useful name for your data source and provide the URI for your operator.
The URI should have the format <your-plugin-name>/<your-operator-name>.
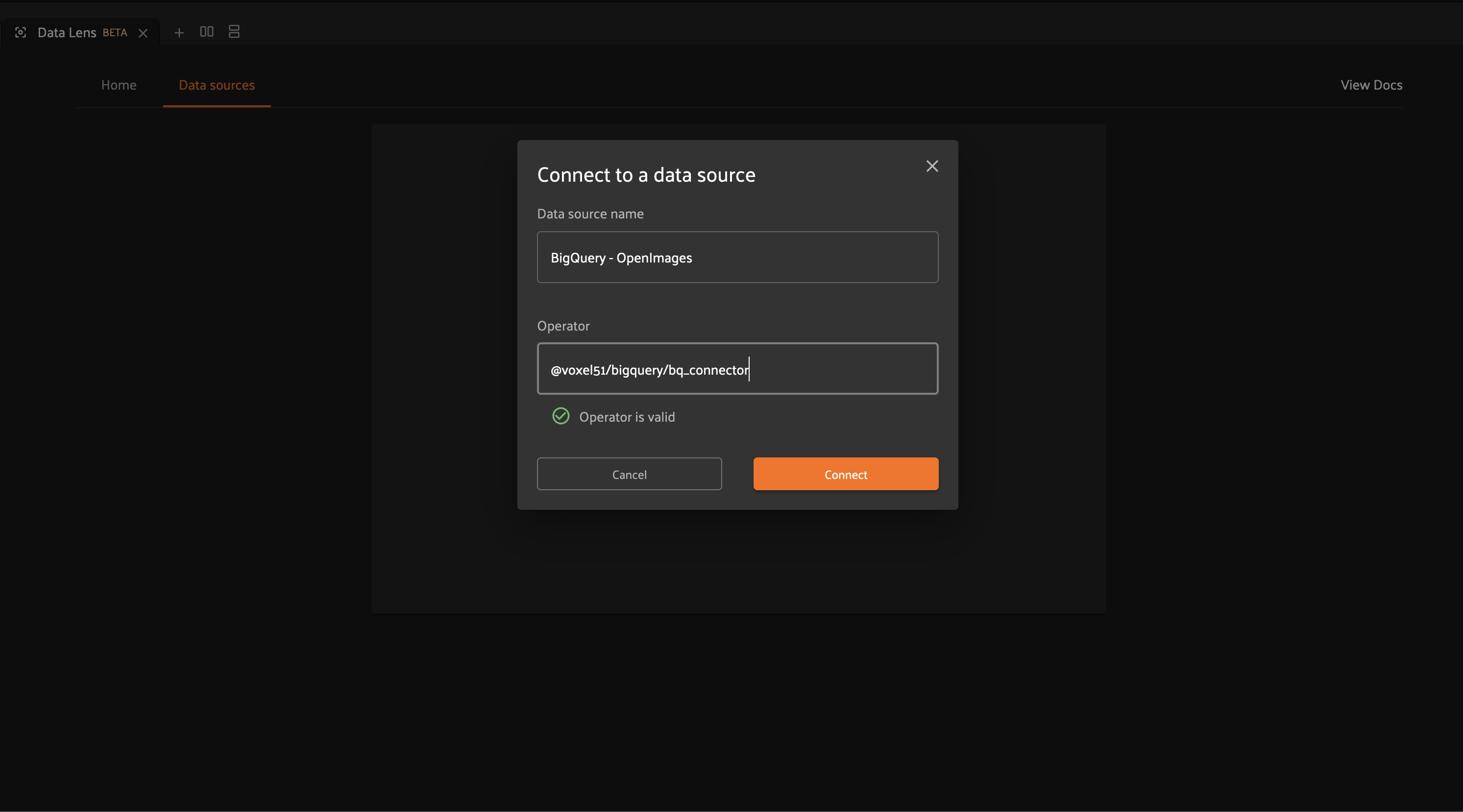
Click “Connect” once you’re finished to save your configuration.
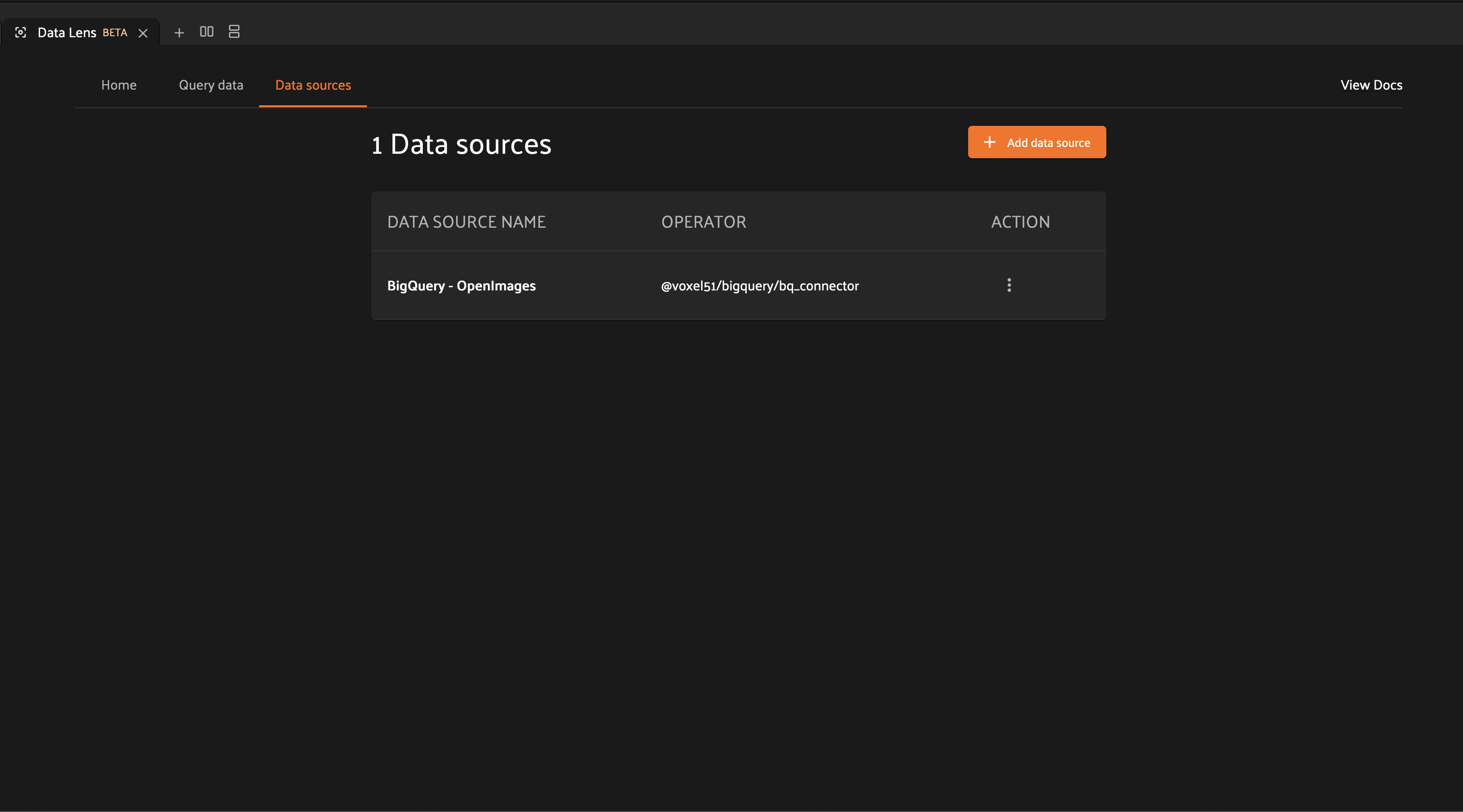
If you need to update your Data Lens configuration, simply click the action menu icon and select “Edit”. Similarly, you can delete a Data Lens configuration by clicking the action menu icon and selecting “Delete”.
That’s it. Now you’re ready to explore your data source. You can head over to the “Query data” tab and start interacting with your data.
Note
Don’t have a Data Lens operator yet? When you’re ready to get started, you can follow our detailed integration guide.
Exploring samples#
Once you’ve connected to a data source, you can open the “Query data” tab to start working with your data.
In this tab, you can select from your connected data sources using the “Select a data source” dropdown.
Below this dropdown, you can parameterize your search using the available query parameters. These parameters are unique to each connected data source, allowing you to tailor your search experience to exactly what you need. Selecting a new data source will automatically update the query parameters to match those expected by your data source.
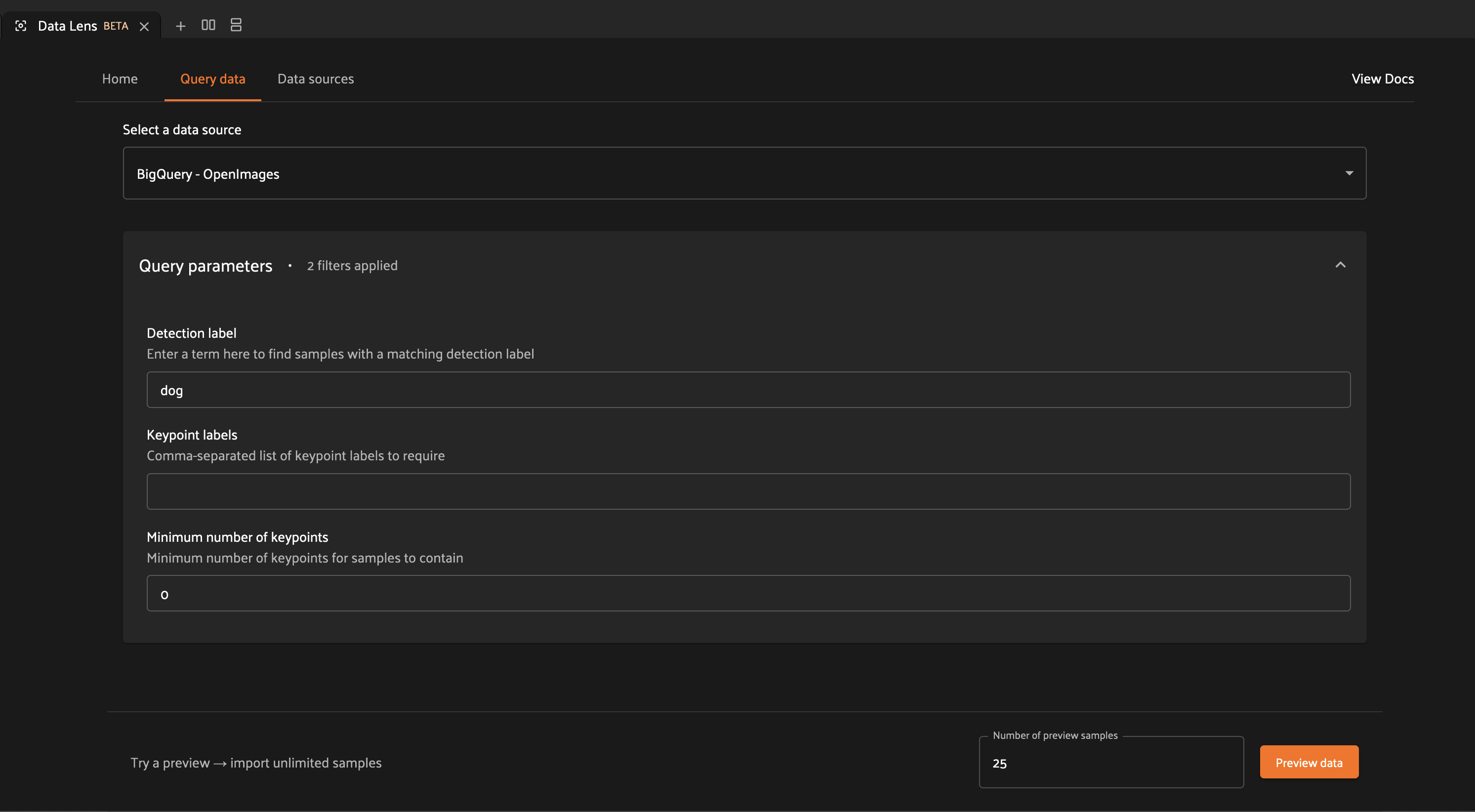
After you enter your query parameters, you can click the “Preview data” button at the bottom of the page to fetch samples which match your query parameters. These samples will be displayed in the preview panel, along with any features associated with the sample like labels or bounding boxes.
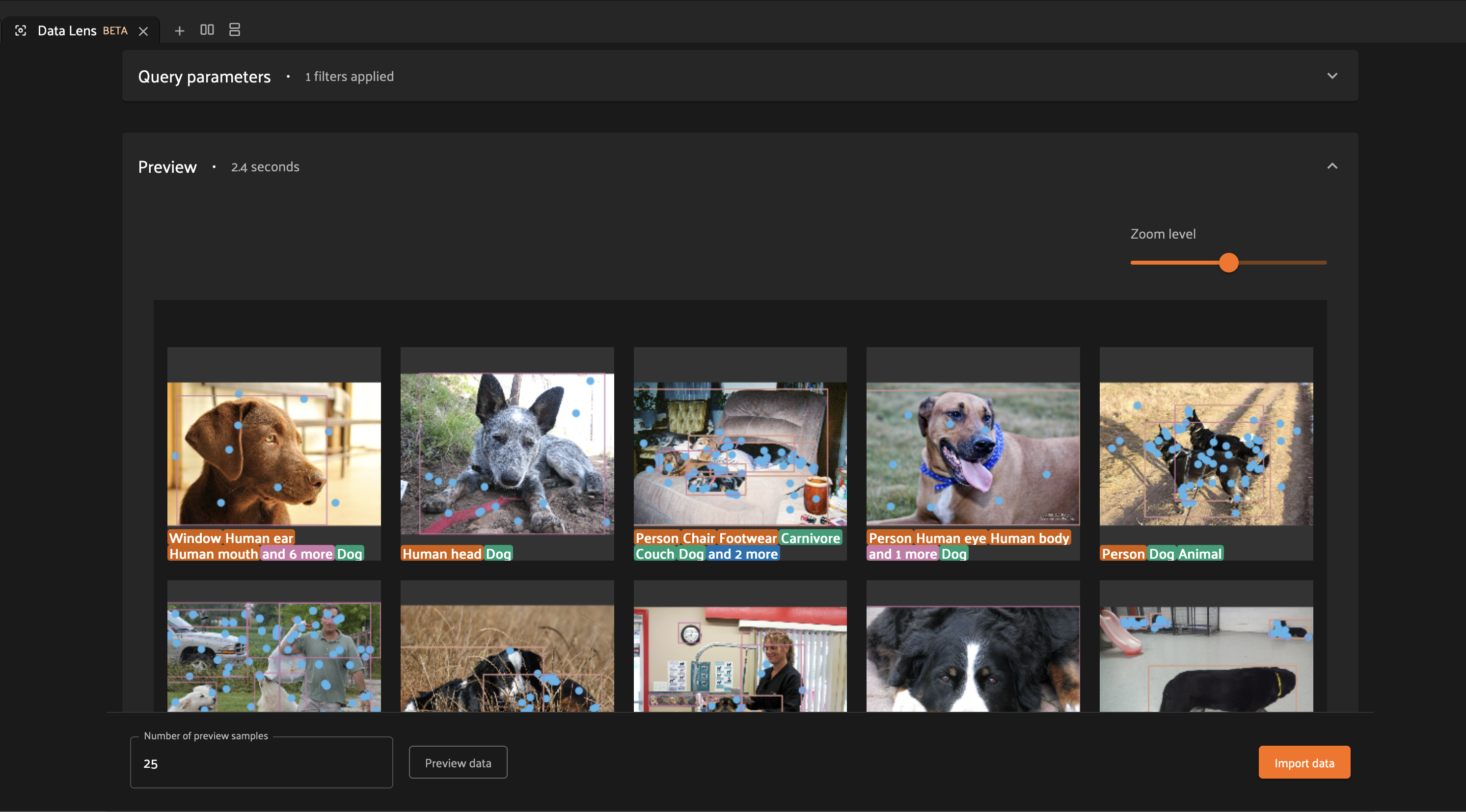
You can use the zoom slider to control the size of the samples, and you can modify the number of preview samples shown by changing the “Number of preview samples” input value and clicking “Preview data” again.
If you want to change your search, simply reopen the query parameters panel and modify your inputs. Clicking “Preview data” will fetch new samples matching the current query parameters.
If you want to import your samples into FiftyOne for further analysis, you can import your samples to a dataset.
Importing samples to FiftyOne#
After generating a preview in Data Lens, you can click on the “Import data” button to open the import dialog.
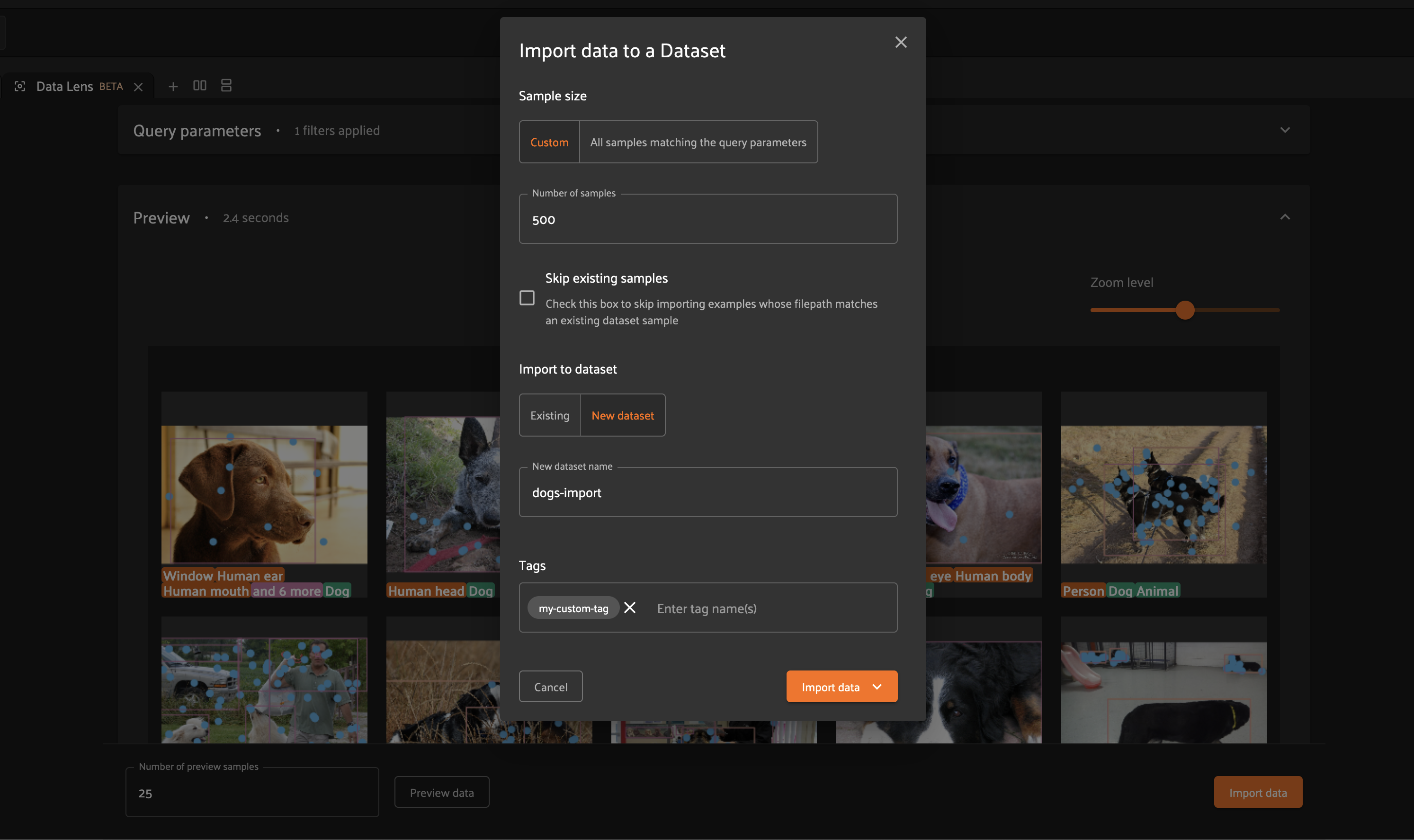
Imports can be limited to a specific number of samples, or you can import all samples matching your query parameters.
The “Skip existing samples” checkbox allows you to configure the behavior for
merging samples into a dataset. If checked, samples with a filepath which is
already present in the dataset will be skipped. If left unchecked, all samples
will be added to the dataset.
Note
If you elect to skip existing samples, this will also deduplicate samples within the data being imported.
After configuring the size/behavior of your import, select a destination dataset for the samples. This can be an existing dataset, or you can choose to create a new dataset.
You can optionally specify tags to append to the tags field of each imported
sample.
When you click import, you will have the option to either execute immediately or to schedule this import for asynchronous execution.
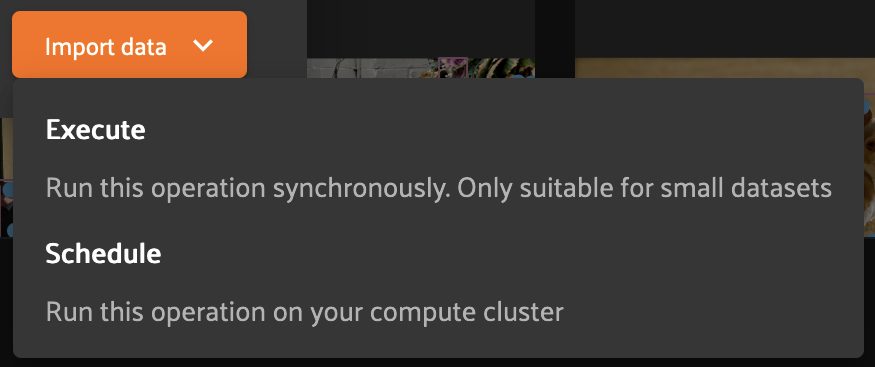
If you are importing a small number of samples, then immediate execution may be appropriate. However, for most cases it is recommended to schedule the import, as this will result in more consistent and performant execution.
Note
Scheduled imports use the delegated operations framework to execute asynchronously on your connected compute cluster!
After selecting your execution preference, you will be able to monitor the status of your import through the information provided by the import panel.
In the case of immediate execution, you will be presented with an option to view your samples once the import is complete. Clicking on this button will open your destination dataset containing your imported samples.
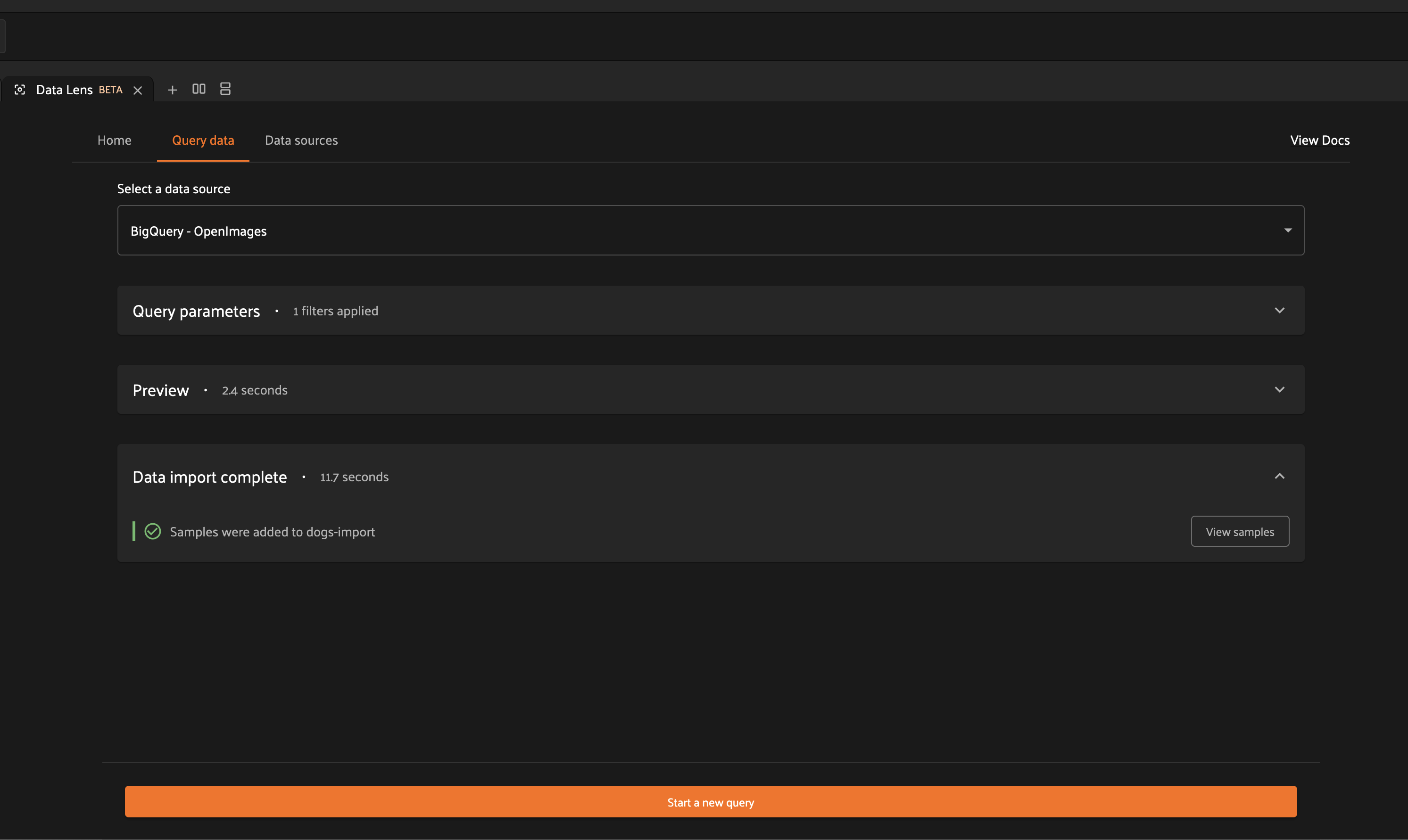
In the case of scheduled execution, you will be presented with an option to visit the Runs page.
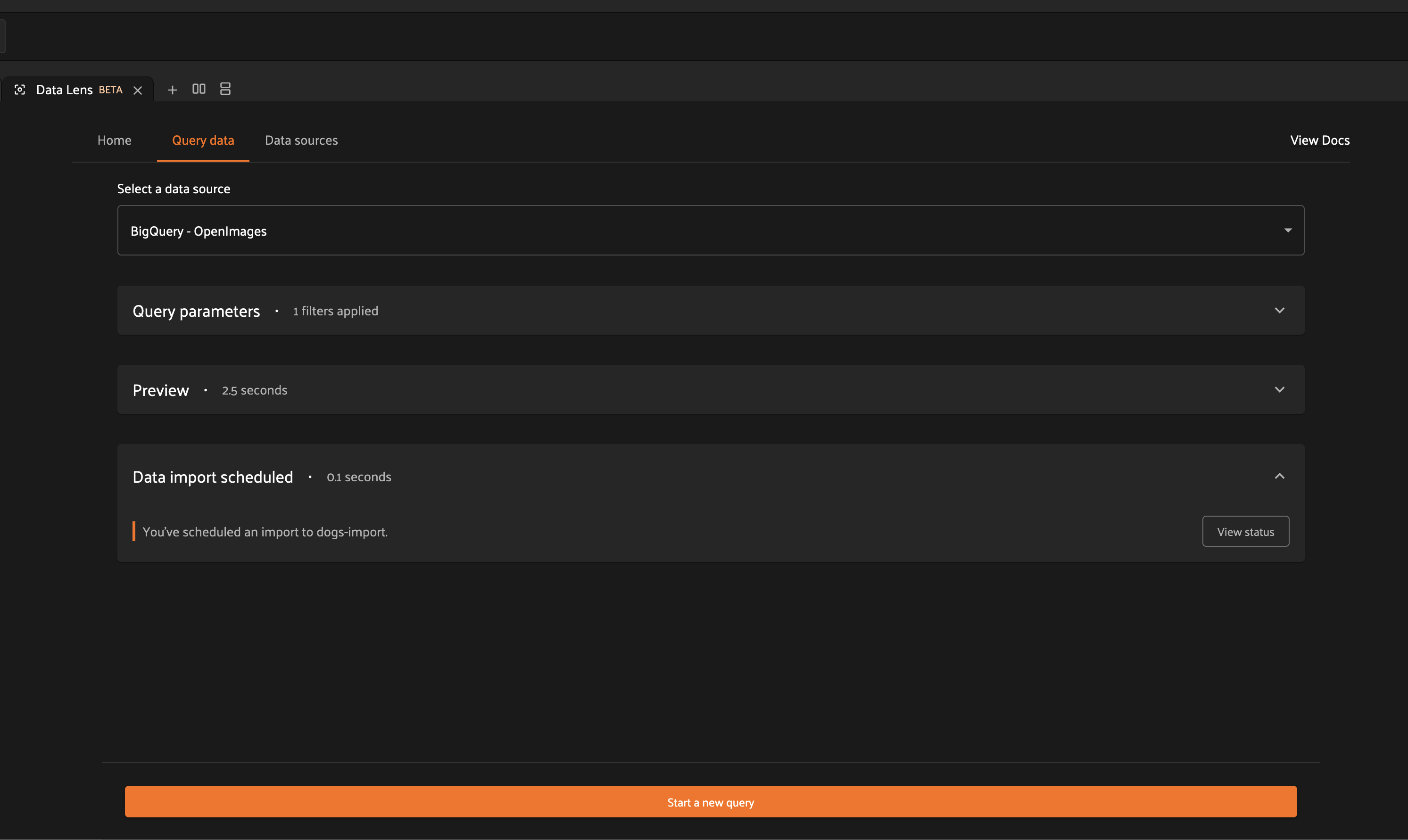
From the Runs page, you can track the status of your import.

Once your samples are imported, you will be able to leverage the full capabilities of FiftyOne to analyze and curate your data, and you can continue to use Data Lens to augment your datasets.
Integrating with Data Lens#
Data Lens makes use of FiftyOne’s powerful plugins framework to allow you to tailor your experience to meet the needs of your data. As part of the plugin framework, you are able to create custom operators, which are self-contained Python classes that provide custom functionality to FiftyOne.
Data Lens defines an operator interface which makes it easy to connect to your data sources. We’ll walk through an example of creating your first Data Lens operator.
Setting up your operator#
To assist with Data Lens integration, we can use the
DataLensOperator
base class provided with the Enterprise SDK. This base class handles the
implementation for the operator’s execute() method, and defines a single
abstract method that we’ll implement.
1# my_plugin/__init__.py
2from typing import Generator
3
4import fiftyone.operators as foo
5from fiftyone.operators.data_lens import (
6 DataLensOperator,
7 DataLensSearchRequest,
8 DataLensSearchResponse
9)
10
11
12class MyCustomDataLensOperator(DataLensOperator):
13 """Custom operator which integrates with Data Lens."""
14
15 @property
16 def config(self) -> foo.OperatorConfig:
17 return foo.OperatorConfig(
18 name="my_custom_data_lens_operator",
19 label="My custom Data Lens operator",
20 unlisted=True,
21 execute_as_generator=True,
22 )
23
24 def handle_lens_search_request(
25 self,
26 request: DataLensSearchRequest,
27 ctx: foo.ExecutionContext
28 ) -> Generator[DataLensSearchResponse, None, None]
29 # We'll implement our logic here
30 pass
Let’s take a look at what we have so far.
1class MyCustomDataLensOperator(DataLensOperator):
Our operator extends the
DataLensOperator
provided by the Enterprise SDK. This base class defines the abstract
handle_lens_search_request()
method, which we will need to implement.
1@property
2def config(self) -> foo.OperatorConfig:
3 return foo.OperatorConfig(
4 # This is the name of your operator. FiftyOne will canonically
5 # refer to your operator as <your-plugin>/<your-operator>.
6 name="my_custom_data_lens_operator",
7
8 # This is a human-friendly label for your operator.
9 label="My custom Data Lens operator",
10
11 # Setting unlisted to True prevents your operator from appearing
12 # in lists of general-purpose operators, as this operator is not
13 # intended to be directly executed.
14 unlisted=True,
15
16 # For compatibility with the DataLensOperator base class, we
17 # instruct FiftyOne to execute our operator as a generator.
18 execute_as_generator=True,
19 )
The config property
is part of the standard operator interface and
provides configuration options for your operator.
1def handle_lens_search_request(
2 self,
3 request: DataLensSearchRequest,
4 ctx: foo.ExecutionContext
5) -> Generator[DataLensSearchResponse, None, None]
6 pass
The
handle_lens_search_request()
method provides us with two arguments: a
DataLensSearchRequest
instance, and the current operator execution context.
The
DataLensSearchRequest
is generated by the Data Lens framework and provides information about the
Data Lens user’s query. The request object has
the following properties:
request.search_params: a dict containing the search parameters provided by the Data Lens user.request.batch_size: a number indicating the maximum number of samples to return in a single batch.request.max_results: a number indicating the maximum number of samples to return across all batches.
Note
The Data Lens framework will automatically truncate responses to adhere
to request.max_results. Any sample data beyond this limit will be
discarded.
The ctx argument provides access to a
range of useful capabilities which you can
leverage in your operator, including things like
providing secrets to your operator.
Using these inputs, we are expected to return a generator which yields
DataLensSearchResponse
objects. To start, we’ll create some synthetic data to better understand the
interaction between Data Lens and our operator. We’ll look at a
more realistic example later on.
Note
Why a generator? Generators provide a convenient approach for long-lived, lazy-fetching connections that are common in databases and data lakes. While Data Lens does support operators which do not execute as generators, we recommend using a generator for ease of integration.
Generating search responses#
To adhere to the Data Lens interface, we need to yield
DataLensSearchResponse
objects from our operator. A
DataLensSearchResponse
is comprised of the following fields:
response.result_count: a number indicating the number of samples being returned in this response.response.query_result: a list of dicts containing serializedSampledata, e.g. obtained viato_dict().
Note
Data Lens expects sample data to adhere to the
Sample format, which is easy to
achieve by using the FiftyOne SDK to create your sample data, as shown
below.
To see how Data Lens works, let’s yield a response with a single synthetic sample.
1def handle_lens_search_request(
2 self,
3 request: DataLensSearchRequest,
4 ctx: foo.ExecutionContext
5) -> Generator[DataLensSearchResponse, None, None]
6 # We'll use a placeholder image for our synthetic data
7 image_url = "https://placehold.co/150x150"
8
9 # Create a sample using the SDK
10 synthetic_sample = fo.Sample(filepath=image_url)
11
12 # Convert our samples to dicts
13 samples = [synthetic_sample.to_dict()]
14
15 # We'll ignore any inputs for now and yield a single response
16 yield DataLensSearchResponse(
17 result_count=len(samples),
18 query_result=samples
19 )
Let’s see what this looks like in Data Lens.
After adding the operator as a data source, we can navigate to the “Query data” tab to interact with the operator. When we click the preview button, the Data Lens framework invokes our operator to retrieve sample data. Our operator yields a single sample, and we see that sample shown in the preview.
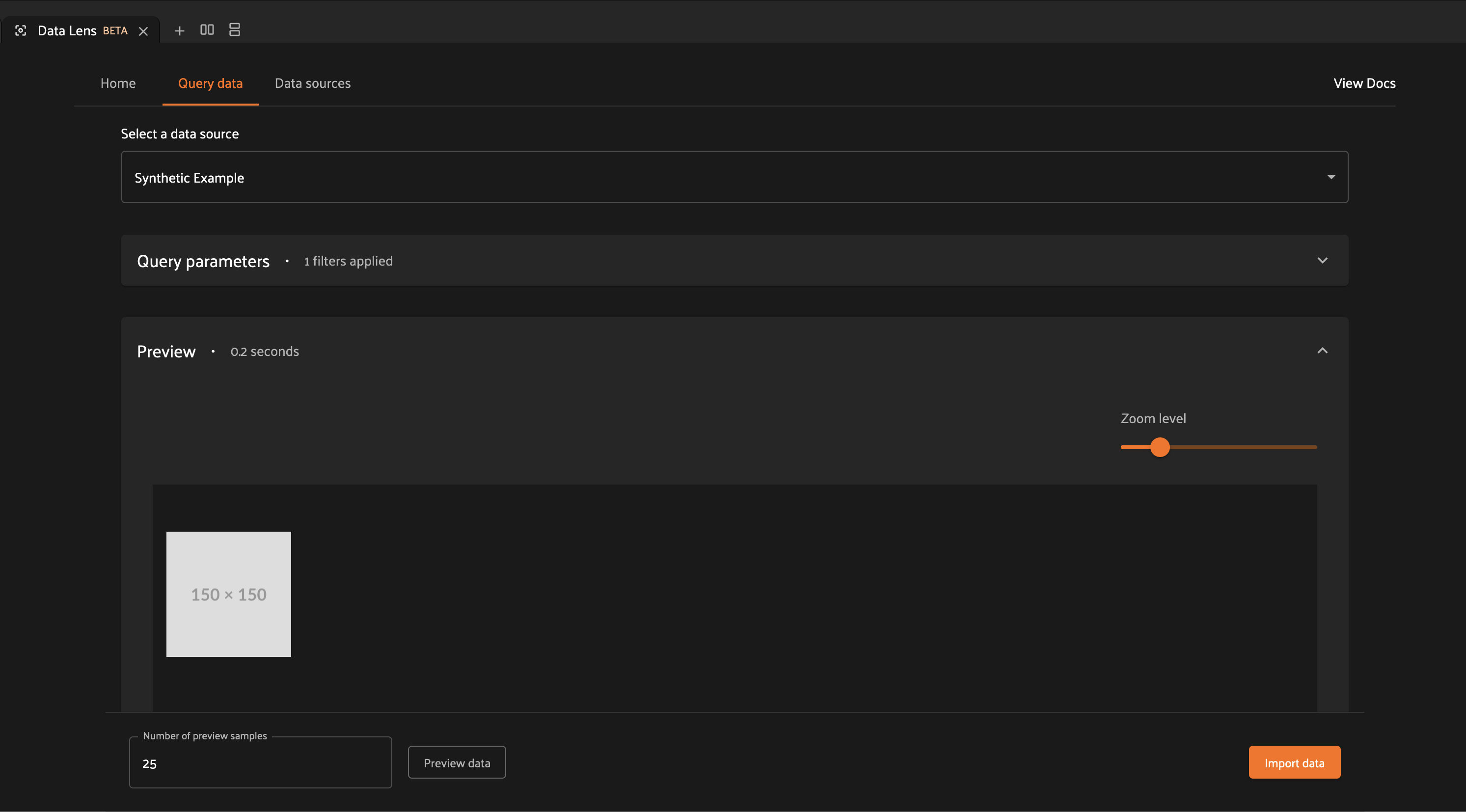
Let’s modify our operator to incorporate the request.batch_size property.
1def handle_lens_search_request(
2 self,
3 request: DataLensSearchRequest,
4 ctx: foo.ExecutionContext
5) -> Generator[DataLensSearchResponse, None, None]
6 samples = []
7
8 # Generate number of samples equal to request.batch_size
9 for i in range(request.batch_size):
10 samples.append(
11 fo.Sample(
12 # We'll modify our synthetic data to include the
13 # sample's index as the image text.
14 filepath=f"https://placehold.co/150x150?text={i + 1}"
15 ).to_dict()
16 )
17
18 # Still yielding a single response
19 yield DataLensSearchResponse(
20 result_count=len(samples),
21 query_result=samples
22 )
Now if we re-run our preview, we see that we get a number of samples equal to the “Number of preview samples” input.
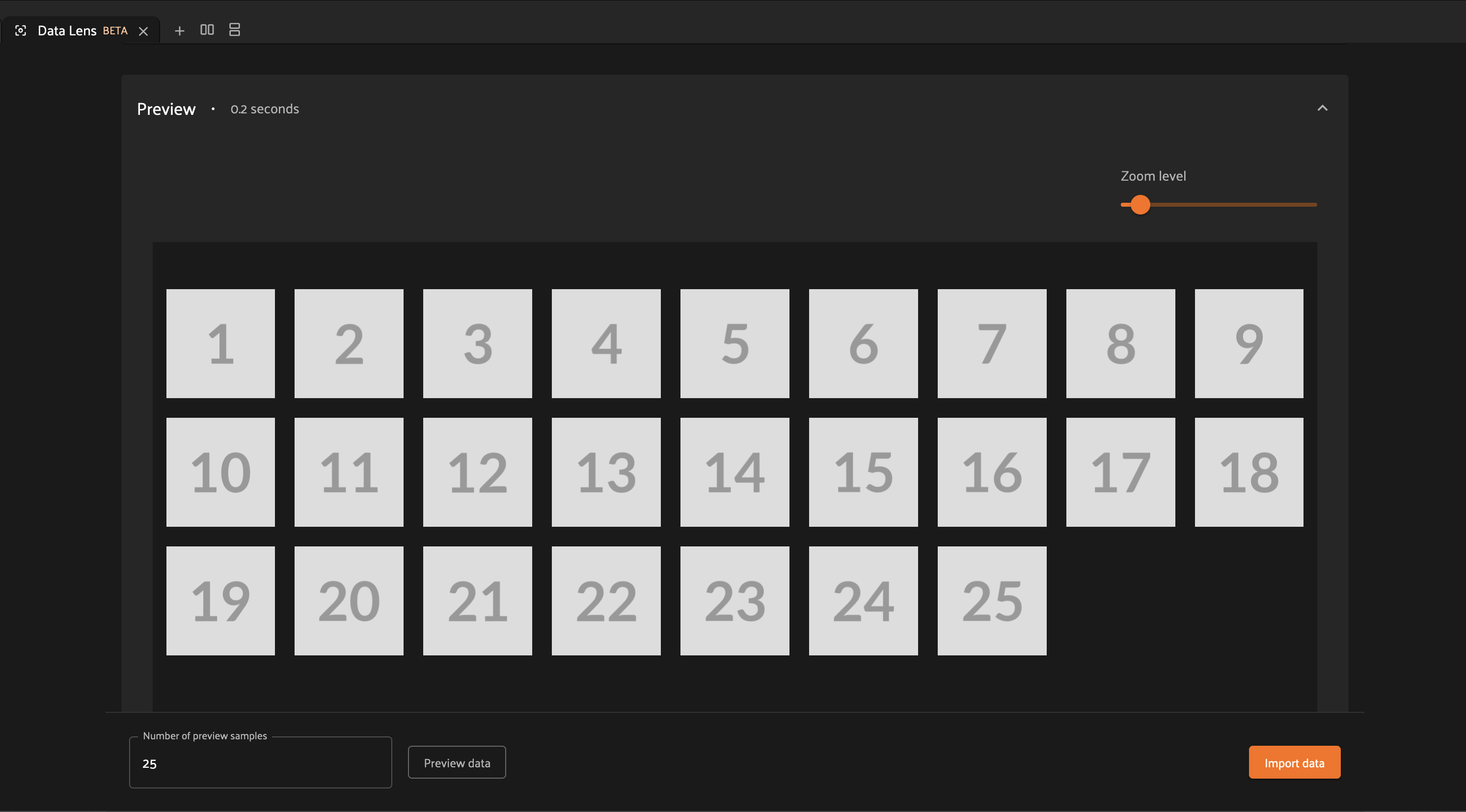
If we modify that number and regenerate the preview, we can see that the number of samples remains in sync. For preview functionality, Data Lens fetches sample data in a single batch, so we can expect these values to be the same.
Working with user-provided data#
Let’s now look at how Data Lens users are able to interact with our operator. Data Lens is designed to enable users to quickly explore samples of interest, and a key component is providing users a way to control the behavior of our operator.
To achieve this, we simply need to define the possible inputs to our operator
in the
resolve_input()
method.
1def resolve_input(self):
2 # We define our inputs as an object.
3 # We'll add specific fields to this object which represent a single input.
4 inputs = types.Object()
5
6 # Add a string field named "sample_text"
7 inputs.str("sample_text", label="Sample text", description="Text to render in samples")
8
9 return types.Property(inputs)
Note
For more information on operator inputs, see the plugin documentation.
With this method implemented, Data Lens will construct a form allowing users to define any or all of these inputs.
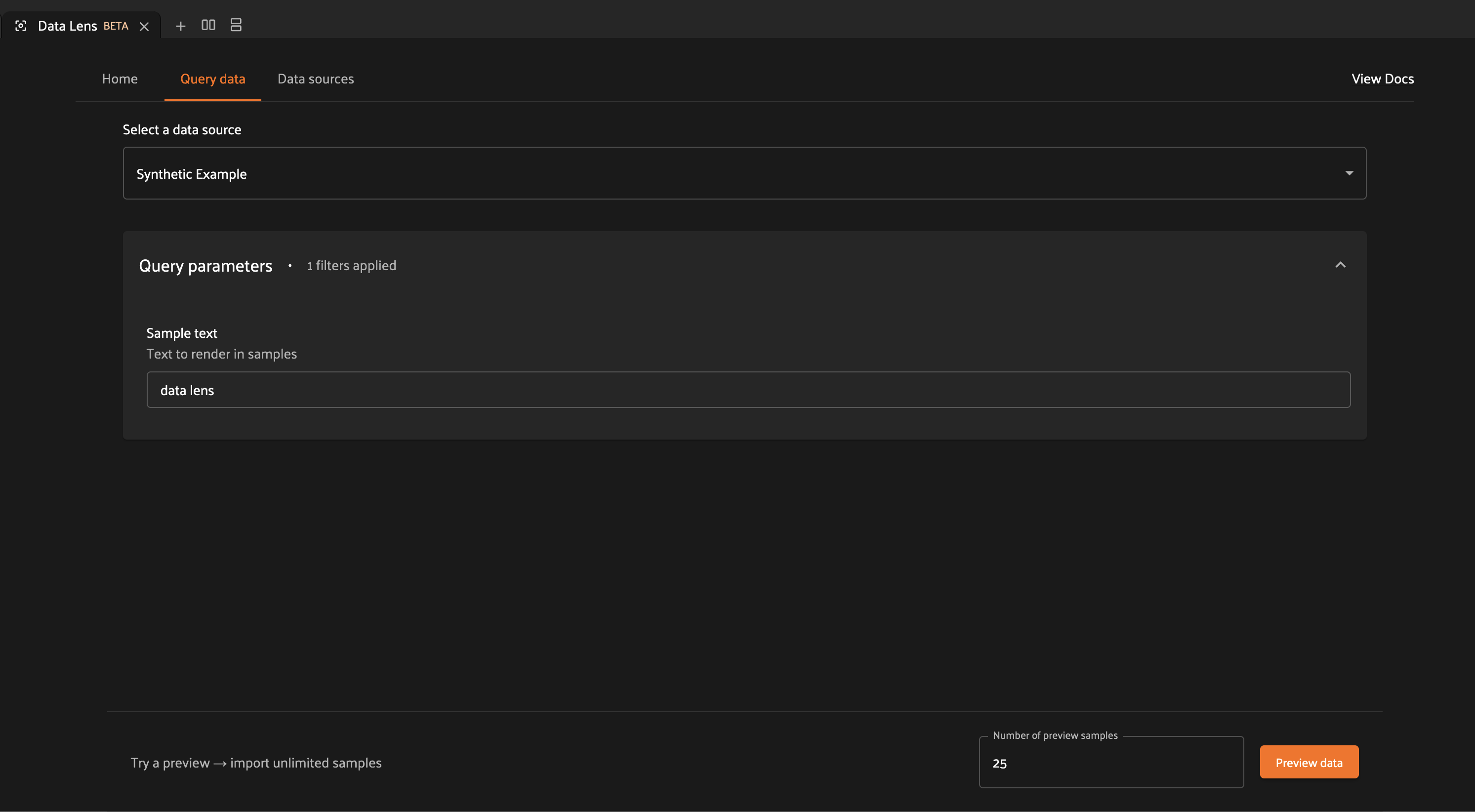
We can then use this data to change the behavior of our operator. Let’s add
logic to integrate sample_text into our operator.
1def handle_lens_search_request(
2 self,
3 request: DataLensSearchRequest,
4 ctx: foo.ExecutionContext
5) -> Generator[DataLensSearchResponse, None, None]
6 # Retrieve our "sample_text" input from request.search_params.
7 # These parameter names should match those used in resolve_input().
8 sample_text = request.search_params.get("sample_text", "")
9
10 samples = []
11
12 # Create a sample for each character in our input text
13 for char in sample_text:
14 samples.append(
15 fo.Sample(
16 filepath=f"https://placehold.co/150x150?text={char}"
17 ).to_dict()
18 )
19
20 # Yield batches when we have enough samples
21 if len(samples) == request.batch_size:
22 yield DataLensSearchResponse(
23 result_count=len(samples),
24 query_result=samples
25 )
26
27 # Reset our batch
28 samples = []
29
30 # We've generated all our samples, but might be in the middle of a batch
31 if len(samples) > 0:
32 yield DataLensSearchResponse(
33 result_count=len(samples),
34 query_result=samples
35 )
36
37 # Now we're done :)
Now when we run our preview, we can see that the text we provide as input is reflected in the samples returned by our operator. Modifying the text and regenerating the preview yields the expected result.
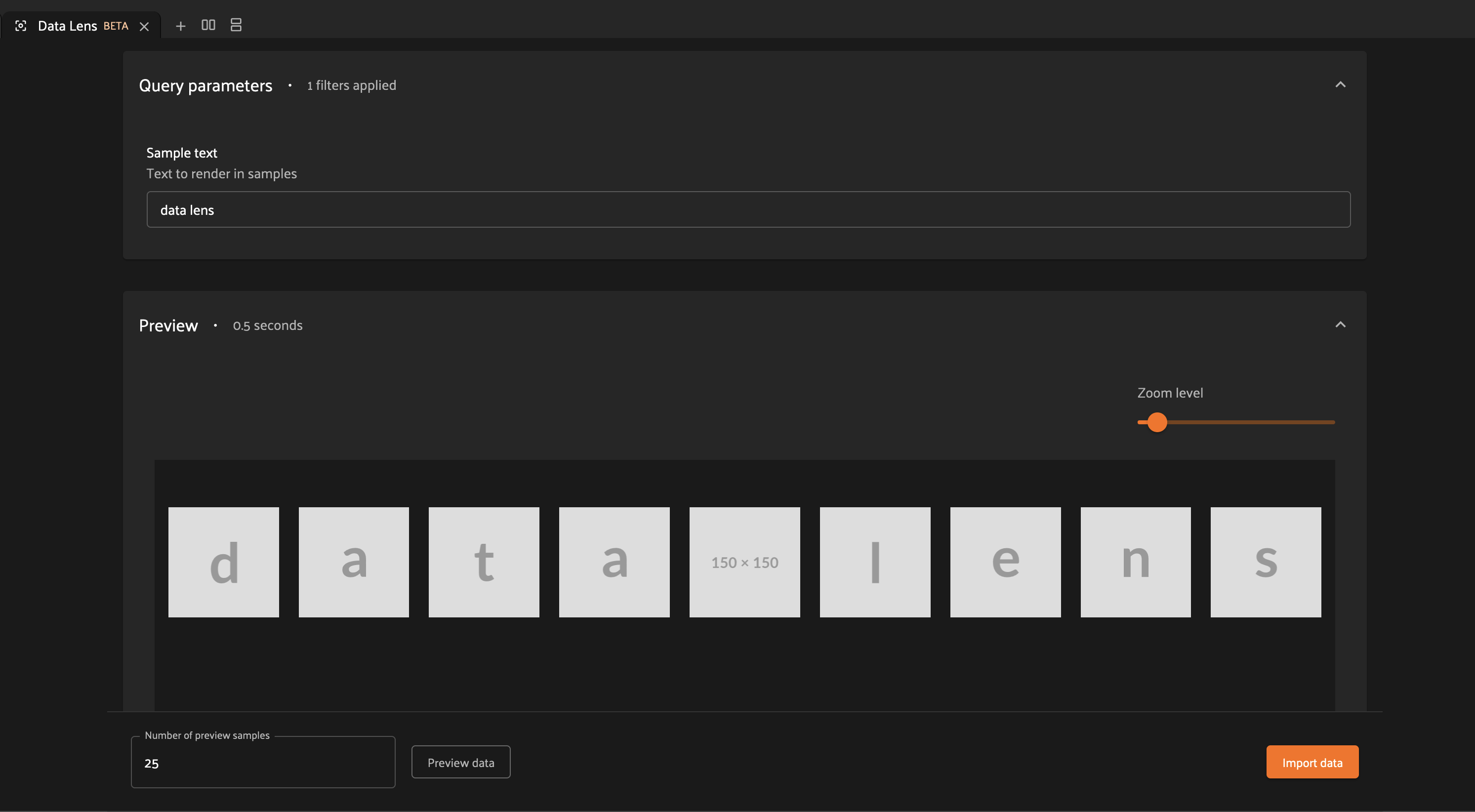
There are a couple things to note about the changes we made here.
Inputs can be specified with
required=True, in which case Data Lens will ensure that the user provides a value for that input. If an input is not explicitly required, then we should be sure to handle the case where it is not present.In most real scenarios, our operator will be processing more samples than fit in a single batch. (This is even true here, where there is no upper bound on our input length). As such, our operator should respect the
request.batch_sizeparameter and yield batches of samples as they are available.
Note
This example is meant to illustrate how users can interact with our operator. For a more realistic view into how inputs can tailor our search experience, see our example integration with Databricks.
Differences in preview and import#
While the examples here are focused on preview functionality, the Data Lens
framework invokes your operator in the same way to achieve both preview and
import functionality. The request.batch_size and request.max_results
parameters can be used to optimize your data retrieval, but preview and import
should otherwise be treated as functionally equivalent.
Example data source connectors#
This section provides example Data Lens connectors for various popular data sources.
Databricks#
Below is an example of a Data Lens connector for Databricks. This example uses a schema consistent with the Berkeley DeepDrive dataset format.
1import json
2import time
3from typing import Generator
4
5import fiftyone as fo
6from databricks.sdk import WorkspaceClient
7from databricks.sdk.service.sql import (
8 StatementResponse, StatementState, StatementParameterListItem
9)
10from fiftyone import operators as foo
11from fiftyone.operators import types
12from fiftyone.operators.data_lens import (
13 DataLensOperator, DataLensSearchRequest, DataLensSearchResponse
14)
15
16class DatabricksConnector(DataLensOperator):
17 """Data Lens operator which retrieves samples from Databricks."""
18
19 @property
20 def config(self) -> foo.OperatorConfig:
21 return foo.OperatorConfig(
22 name="databricks_connector",
23 label="Databricks Connector",
24 unlisted=True,
25 execute_as_generator=True,
26 )
27
28 def resolve_input(self, ctx: foo.ExecutionContext):
29 inputs = types.Object()
30
31 # Times of day
32 inputs.bool(
33 "daytime",
34 label="Day",
35 description="Show daytime samples",
36 default=True,
37 )
38 inputs.bool(
39 "night",
40 label="Night",
41 description="Show night samples",
42 default=True,
43 )
44 inputs.bool(
45 "dawn/dusk",
46 label="Dawn / Dusk",
47 description="Show dawn/dusk samples",
48 default=True,
49 )
50
51 # Weather
52 inputs.bool(
53 "clear",
54 label="Clear weather",
55 description="Show samples with clear weather",
56 default=True,
57 )
58 inputs.bool(
59 "rainy",
60 label="Rainy weather",
61 description="Show samples with rainy weather",
62 default=True,
63 )
64
65 # Detection label
66 inputs.str(
67 "detection_label",
68 label="Detection label",
69 description="Filter samples by detection label",
70 )
71
72 return types.Property(inputs)
73
74 def handle_lens_search_request(
75 self,
76 request: DataLensSearchRequest,
77 ctx: foo.ExecutionContext
78 ) -> Generator[DataLensSearchResponse, None, None]:
79 handler = DatabricksHandler()
80 for response in handler.handle_request(request, ctx):
81 yield response
82
83
84class DatabricksHandler:
85 """Handler for interacting with Databricks tables."""
86
87 def __init__(self):
88 self.client = None
89 self.warehouse_id = None
90
91 def handle_request(
92 self,
93 request: DataLensSearchRequest,
94 ctx: foo.ExecutionContext
95 ) -> Generator[DataLensSearchResponse, None, None]:
96
97 # Initialize the client
98 self._init_client(ctx)
99
100 # Iterate over samples
101 sample_buffer = []
102 for sample in self._iter_data(request):
103 sample_buffer.append(self._transform_sample(sample))
104
105 # Yield batches of data as they are available
106 if len(sample_buffer) == request.batch_size:
107 yield DataLensSearchResponse(
108 result_count=len(sample_buffer),
109 query_result=sample_buffer,
110 )
111
112 sample_buffer = []
113
114 # Yield final batch if it's non-empty
115 if len(sample_buffer) > 0:
116 yield DataLensSearchResponse(
117 result_count=len(sample_buffer),
118 query_result=sample_buffer,
119 )
120
121 # No more samples.
122
123 def _init_client(self, ctx: foo.ExecutionContext):
124 """Prepare the Databricks client for query execution."""
125
126 # Initialize the Databricks client using credentials provided via `ctx.secret`
127 self.client = WorkspaceClient(
128 host=ctx.secret("DATABRICKS_HOST"),
129 account_id=ctx.secret("DATABRICKS_ACCOUNT_ID"),
130 client_id=ctx.secret("DATABRICKS_CLIENT_ID"),
131 client_secret=ctx.secret("DATABRICKS_CLIENT_SECRET"),
132 )
133
134 # Start a SQL warehouse instance to execute our query
135 self.warehouse_id = self._start_warehouse()
136 if self.warehouse_id is None:
137 raise ValueError("No available warehouse")
138
139 def _start_warehouse(self) -> str:
140 """Start a SQL warehouse and return its ID."""
141
142 last_warehouse_id = None
143
144 # If any warehouses are already running, use the first available
145 for warehouse in self.client.warehouses.list():
146 last_warehouse_id = warehouse.id
147 if warehouse.health.status is not None:
148 return warehouse.id
149
150 # Otherwise, manually start the last available warehouse
151 if last_warehouse_id is not None:
152 self.client.warehouses.start(last_warehouse_id)
153
154 return last_warehouse_id
155
156 def _iter_data(self, request: DataLensSearchRequest) -> Generator[dict, None, None]:
157 """Iterate over sample data retrieved from Databricks."""
158
159 # Filter samples based on selected times of day
160 enabled_times_of_day = tuple([
161 f'"{tod}"'
162 for tod in ["daytime", "night", "dawn/dusk"]
163 if request.search_params.get(tod, False)
164 ])
165
166 # Filter samples based on selected weather
167 enabled_weather = tuple([
168 f'"{weather}"'
169 for weather in ["clear", "rainy"]
170 if request.search_params.get(weather, False)
171 ])
172
173 # Build Databricks query
174 query = f"""
175 SELECT * FROM datasets.bdd.det_train samples
176 WHERE
177 samples.attributes.timeofday IN ({", ".join(enabled_times_of_day)})
178 AND samples.attributes.weather IN ({", ".join(enabled_weather)})
179 """
180
181 query_parameters = []
182
183 # Filter samples based on detection label if provided
184 if request.search_params.get("detection_label") not in (None, ""):
185 query += f"""
186 AND samples.name IN (
187 SELECT DISTINCT(labels.name)
188 FROM datasets.bdd.det_train_labels labels
189 WHERE labels.category = :detection_label
190 )
191 """
192
193 query_parameters.append(
194 StatementParameterListItem(
195 "detection_label",
196 value=request.search_params.get("detection_label")
197 )
198 )
199
200 # Execute query asynchronously;
201 # we'll get a statement_id that we can use to poll for results
202 statement_response = self.client.statement_execution.execute_statement(
203 query,
204 self.warehouse_id,
205 catalog="datasets",
206 parameters=query_parameters,
207 row_limit=request.max_results,
208 wait_timeout="0s"
209 )
210
211 # Poll on our statement until it's no longer in an active state
212 while (
213 statement_response.status.state in
214 (StatementState.PENDING, StatementState.RUNNING)
215 ):
216 statement_response = self.client.statement_execution.get_statement(
217 statement_response.statement_id
218 )
219
220 time.sleep(2.5)
221
222 # Process the first batch of data
223 json_result = self._response_to_dicts(statement_response)
224
225 for element in json_result:
226 yield element
227
228 # Databricks paginates samples using "chunks"; iterate over chunks until next is None
229 while statement_response.result.next_chunk_index is not None:
230 statement_response = self.client.statement_execution.get_statement_result_chunk_n(
231 statement_response.statement_id,
232 statement_response.result.next_chunk_index
233 )
234
235 # Process the next batch of data
236 json_result = self._response_to_dicts(statement_response)
237
238 for element in json_result:
239 yield element
240
241 def _transform_sample(self, sample: dict) -> dict:
242 """Transform a dict of raw Databricks data into a FiftyOne Sample dict."""
243
244 return fo.Sample(
245 filepath=f"cloud://bucket/{sample.get('name')}",
246 detections=self._build_detections(sample),
247 ).to_dict()
248
249 def _build_detections(self, sample: dict) -> fo.Detections:
250 # Images are a known, static size
251 image_width = 1280
252 image_height = 720
253
254 # Extract detection labels and pre-process bounding boxes
255 labels_list = json.loads(sample["labels"])
256 for label_data in labels_list:
257 if "box2d" in label_data:
258 label_data["box2d"] = {
259 k: float(v)
260 for k, v in label_data["box2d"].items()
261 }
262
263 return fo.Detections(
264 detections=[
265 fo.Detection(
266 label=label_data["category"],
267 # FiftyOne expects bounding boxes to be of the form
268 # [x, y, width, height]
269 # where values are normalized to the image's dimensions.
270 #
271 # Our source data is of the form
272 # {x1, y1, x2, y2}
273 # where values are in absolute pixels.
274 bounding_box=[
275 label_data["box2d"]["x1"] / image_width,
276 label_data["box2d"]["y1"] / image_height,
277 (label_data["box2d"]["x2"] - label_data["box2d"]["x1"]) / image_width,
278 (label_data["box2d"]["y2"] - label_data["box2d"]["y1"]) / image_height
279 ]
280 )
281 for label_data in labels_list
282 if "box2d" in label_data
283 ]
284 )
285
286 def _response_to_dicts(self, response: StatementResponse) -> list[dict]:
287 # Check for response errors before processing
288 self._check_for_error(response)
289
290 # Extract column names from response
291 columns = response.manifest.schema.columns
292 column_names = [column.name for column in columns]
293
294 # Extract data from response
295 data = response.result.data_array or []
296
297 # Each element in data is a list of raw column values.
298 # Remap ([col1, col2, ..., colN], [val1, val2, ..., valN]) tuples
299 # to {col1: val1, col2: val2, ..., colN: valN} dicts
300 return [
301 {
302 key: value
303 for key, value in zip(column_names, datum)
304 }
305 for datum in data
306 ]
307
308 def _check_for_error(self, response: StatementResponse):
309 if response is None:
310 raise ValueError("received null response from databricks")
311
312 if response.status is not None:
313 if response.status.error is not None:
314 raise ValueError("databricks error: ({0}) {1}".format(
315 response.status.error.error_code,
316 response.status.error.message
317 ))
318
319 if response.status.state in (
320 StatementState.CLOSED,
321 StatementState.FAILED,
322 StatementState.CANCELED,
323 ):
324 raise ValueError(
325 f"databricks error: response state = {response.status.state}"
326 )
Google BigQuery#
Below is an example of a Data Lens connector for BigQuery:
1import fiftyone.operators as foo
2import fiftyone.operators.types as types
3from fiftyone.operators.data_lens import (
4 DataLensOperator,
5 DataLensSearchRequest,
6 DataLensSearchResponse
7)
8
9from google.cloud import bigquery
10
11
12class BigQueryConnector(DataLensOperator):
13 @property
14 def config(self):
15 return foo.OperatorConfig(
16 name="bq_connector",
17 label="BigQuery Connector",
18 unlisted=True,
19 execute_as_generator=True,
20 )
21
22 def resolve_input(self, ctx):
23 inputs = types.Object()
24
25 # We'll enable searching on detection labels
26 inputs.str(
27 "detection_label",
28 label="Detection label",
29 description="Enter a label to find samples with a matching detection",
30 required=True,
31 )
32
33 return types.Property(inputs)
34
35 def handle_lens_search_request(
36 self,
37 request: DataLensSearchRequest,
38 ctx: foo.ExecutionContext,
39 ) -> Generator[DataLensSearchResponse, None, None]:
40 handler = BigQueryHandler()
41 for batch in handler.handle_request(request, ctx):
42 yield batch
43
44
45class BigQueryHandler:
46 def handle_request(
47 self,
48 request: DataLensSearchRequest,
49 ctx: foo.ExecutionContext,
50 ) -> Generator[DataLensSearchResponse, None, None]:
51 # Create our client.
52 # If needed, we can use secrets from `ctx.secrets` to provide credentials
53 # or other secure configuration required to interact with our data source.
54 client = bigquery.Client()
55
56 try:
57 # Retrieve our Data Lens search parameters
58 detection_label = request.search_params.get("detection_label", "")
59
60 # Construct our query
61 query = """
62 SELECT
63 media_path, tags, detections, keypoints
64 FROM `my_dataset.samples_json`,
65 UNNEST(JSON_QUERY_ARRAY(detections)) as detection
66 WHERE JSON_VALUE(detection.label) = @detection_label
67 """
68
69 # Submit our query to BigQuery
70 job_config = bigquery.QueryJobConfig(
71 query_parameters=[
72 bigquery.ScalarQueryParameter(
73 "detection_label",
74 "STRING",
75 detection_label
76 )
77 ]
78 )
79 query_job = client.query(query, job_config=job_config)
80
81 # Wait for results
82 rows = query_job.result(
83 # BigQuery will handle pagination automatically, but
84 # we can optimize its behavior by synchronizing with
85 # the parameters provided by Data Lens
86 page_size=request.batch_size,
87 max_results=request.max_results
88 )
89
90 samples = []
91
92 # Iterate over data from BigQuery
93 for row in rows:
94
95 # Transform sample data from BigQuery format to FiftyOne
96 samples.append(self.convert_to_sample(row))
97
98 # Yield next batch when we have enough samples
99 if len(samples) == request.batch_size:
100 yield DataLensSearchResponse(
101 result_count=len(samples),
102 query_result=samples
103 )
104
105 # Reset our batch
106 samples = []
107
108 # We've run out of rows, but might have a partial batch
109 if len(samples) > 0:
110 yield DataLensSearchResponse(
111 result_count=len(samples),
112 query_result=samples
113 )
114
115 # Our generator is now exhausted
116
117 finally:
118 # Clean up our client on exit
119 client.close()
Let’s take a look at a few parts in detail.
1# Create our client
2client = bigquery.Client()
In practice, you’ll likely need to use secrets to securely provide credentials to connect to your data source.
1# Retrieve our Data Lens search parameters
2detection_label = request.search_params.get("detection_label", "")
3
4# Construct our query
5query = """
6 SELECT
7 media_path, tags, detections, keypoints
8 FROM `my_dataset.samples_json`,
9 UNNEST(JSON_QUERY_ARRAY(detections)) as detection
10 WHERE JSON_VALUE(detection.label) = @detection_label
11 """
Here we’re using our user-provided input parameters to tailor our query to only the samples of interest. This logic can be as simple or complex as needed to match our use case.
1# Wait for results
2rows = query_job.result(
3 # BigQuery will handle pagination automatically, but
4 # we can optimize its behavior by synchronizing with
5 # the parameters provided by Data Lens
6 page_size=request.batch_size,
7 max_results=request.max_results
8)
Here we’re using request.batch_size and request.max_results to help
BigQuery align its performance with our use case. In cases where
request.max_results is smaller than our universe of samples (such as during
preview or small imports), we can prevent fetching more data than we need,
improving both query performance and operational cost.
1# Transform sample data from BigQuery format to FiftyOne
2samples.append(self.convert_to_sample(row))
Here we are converting our sample data from its storage format to a FiftyOne
Sample. This is where we’ll add features
to our samples, such as labels.
As we can see from this example, we can make our Data Lens search experience as powerful as it needs to be. We can leverage internal libraries and services, hosted solutions, and tooling that meets the specific needs of our data. We can expose flexible but precise controls to users to allow them to find exactly the data that’s needed.
Snippet: Dynamic user inputs#
As the volume and complexity of your data grows, you may want to expose many options to Data Lens users, but doing so all at once can be overwhelming for the user. In this example, we’ll look at how we can use dynamic operators to conditionally expose configuration options to Data Lens users.
1class MyOperator(DataLensOperator):
2 @property
3 def config(self) -> foo.OperatorConfig:
4 return OperatorConfig(
5 name="my_operator",
6 label="My operator",
7 dynamic=True,
8 )
By setting dynamic=True in our operator config, our operator will be able to
customize the options shown to a Data Lens user based on the current state.
Let’s use this to optionally show an “advanced options” section in our query
parameters.
1def resolve_input(self, ctx: foo.ExecutionContext):
2 inputs = types.Object()
3
4 inputs.str("some_param", label="Parameter value")
5 inputs.str("other_param", label="Other value")
6
7 inputs.bool("show_advanced", label="Show advanced options", default=False)
8
9 # Since this is a dynamic operator,
10 # we can use `ctx.params` to conditionally show options
11 if ctx.params.get("show_advanced") is True:
12 # In this example, we'll optionally show configuration which allows a user
13 # to remap selected sample fields to another name.
14 # This could be used to enable users to import samples into datasets with
15 # varying schemas.
16 remappable_fields = ("field_a", "field_b")
17 for field_name in remappable_fields:
18 inputs.str(f"{field_name}_remap", label=f"Remap {field_name} to another name")
19
20 return types.Property(inputs)
Our operator’s resolve_input method will be called each time ctx.params
changes, which allows us to create an experience that is tailored to the Data
Lens user’s behavior. In this example, we’re optionally displaying advanced
configuration that allows a user to remap sample fields. Applying this
remapping might look something like this.
1def _remap_sample_fields(self, sample: dict, request: DataLensSearchRequest):
2 remappable_fields = ("field_a", "field_b")
3 for field_name in remappable_fields:
4 remapped_field_name = request.search_params.get(f"{field_name}_remap")
5 if remapped_field_name not in (None, ""):
6 sample[remapped_field_name] = sample[field_name]
7 del sample[field_name]
Of course, dynamic operators can be used for much more than this. Search experiences can be broadened or narrowed to allow for both breadth and depth within your connected data sources.
As an example, suppose a user is searching for detections of “traffic light” in an autonomous driving dataset. A dynamic operator can be used to expose additional search options that are specific to traffic lights, such as being able to select samples with only red, yellow, or green lights. In this way, dynamic operators provide a simple mechanism for developing intuitive and context-sensitive search experiences for Data Lens users.