|
|
|
|
Finding Detection Mistakes with FiftyOne#
Annotations mistakes create an artificial ceiling on the performance of your models. However, finding these mistakes by hand is at least as arduous as the original annotation work! Enter FiftyOne.
In this tutorial, we explore how FiftyOne can be used to help you find mistakes in your object detection annotations. To detect mistakes in classification datasets, check out this tutorial.
We’ll cover the following concepts:
Loading your existing dataset into FiftyOne
Adding model predictions to your dataset
Computing insights into your dataset relating to possible label mistakes
Visualizing mistakes in the FiftyOne App
So, what’s the takeaway?
FiftyOne can help you find and correct label mistakes in your datasets, enabling you to curate higher quality datasets and, ultimately, train better models!
Setup#
If you haven’t already, install FiftyOne:
[ ]:
!pip install fiftyone
In order to compute mistakenness, your dataset needs to have two detections fields, one with your ground truth annotations and one with your model predictions.
In this example, we’ll load the quickstart dataset from the FiftyOne Dataset Zoo, which has ground truth annotations and predictions from a PyTorch Faster-RCNN model for a few samples from the COCO dataset.
[3]:
import fiftyone as fo
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset("quickstart")
Dataset already downloaded
Loading 'quickstart'
100% |█████████████████| 200/200 [2.0s elapsed, 0s remaining, 99.8 samples/s]
Dataset 'quickstart' created
[4]:
print(dataset)
Name: quickstart
Media type: image
Num samples: 200
Persistent: False
Tags: []
Sample fields:
id: fiftyone.core.fields.ObjectIdField
filepath: fiftyone.core.fields.StringField
tags: fiftyone.core.fields.ListField(fiftyone.core.fields.StringField)
metadata: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.metadata.ImageMetadata)
ground_truth: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Detections)
uniqueness: fiftyone.core.fields.FloatField
predictions: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Detections)
[5]:
# Print a sample ground truth detection
sample = dataset.first()
print(sample.predictions.detections[0])
<Detection: {
'id': '5f452c60ef00e6374aad9394',
'attributes': {},
'tags': [],
'label': 'bird',
'bounding_box': [
0.22192673683166503,
0.06093006531397502,
0.4808845520019531,
0.8937615712483724,
],
'mask': None,
'confidence': 0.9750854969024658,
'index': None,
}>
Let’s start by visualizing the dataset in the FiftyOne App:
[ ]:
# Open the dataset in the App
session = fo.launch_app(dataset)
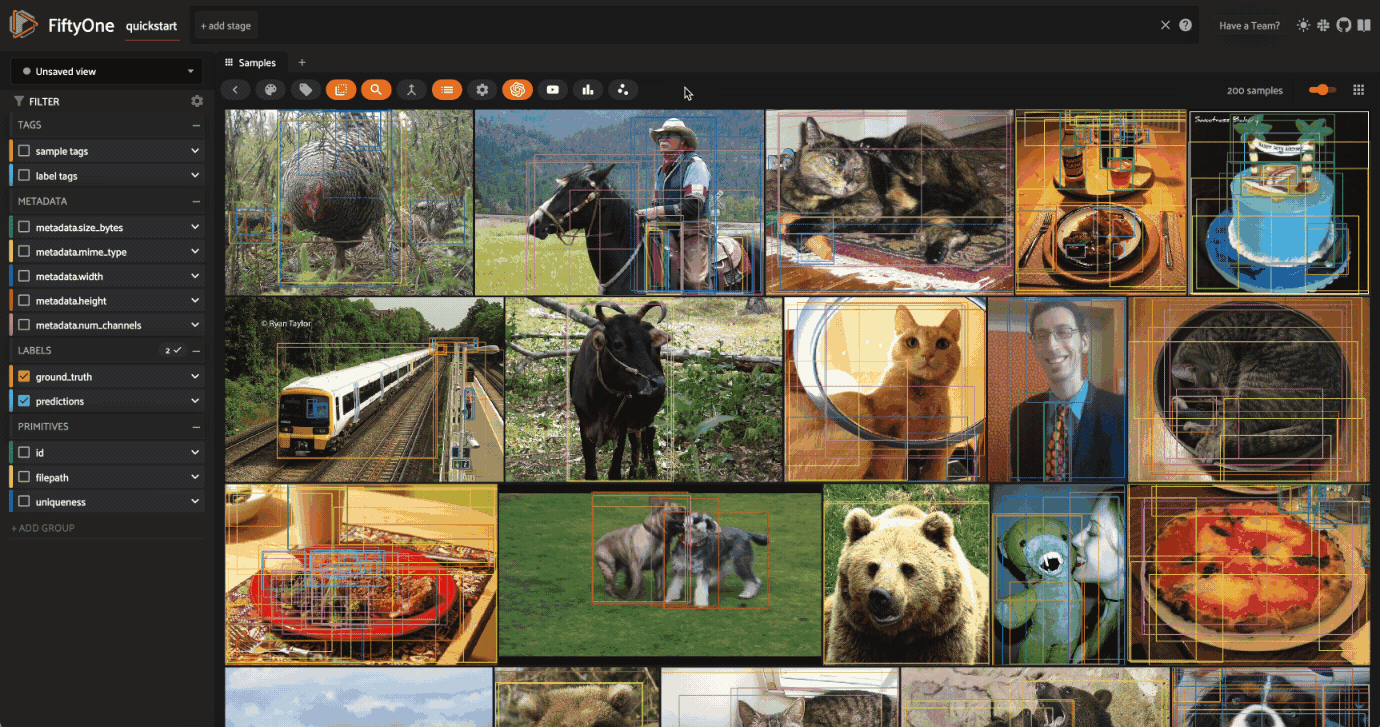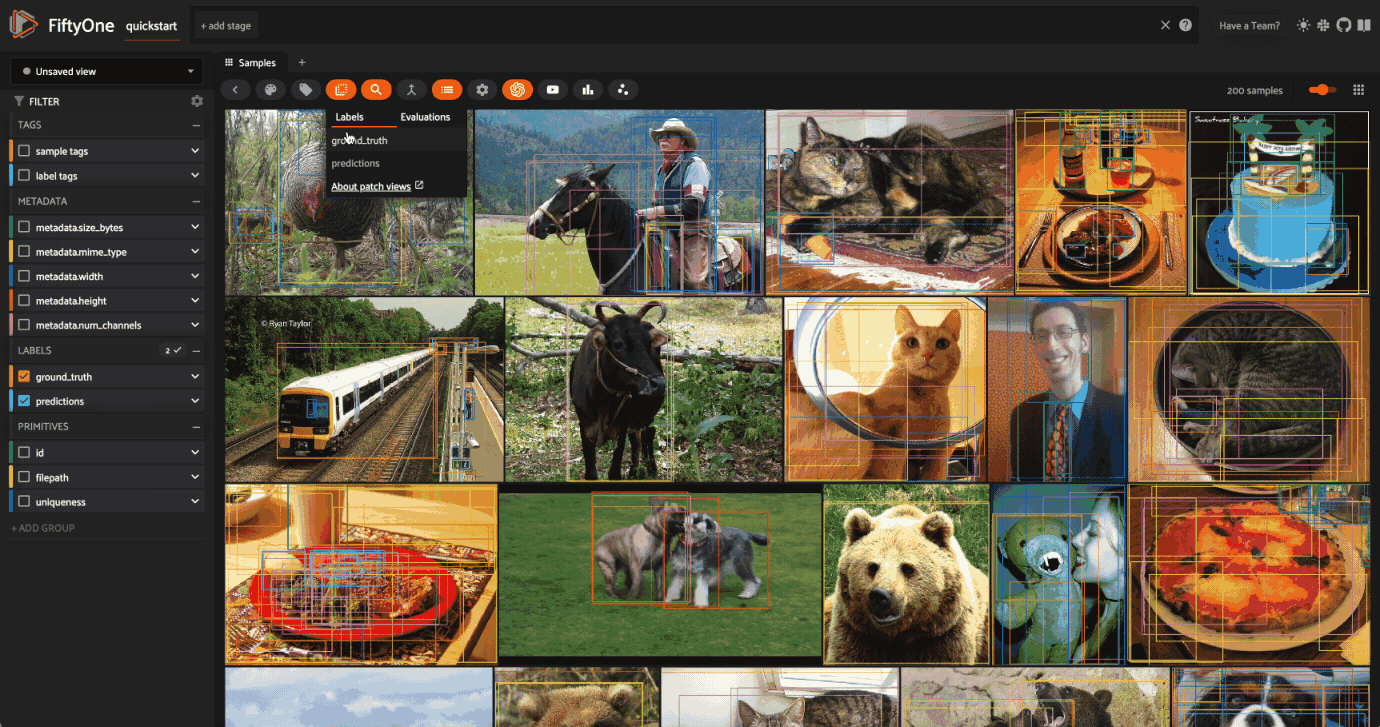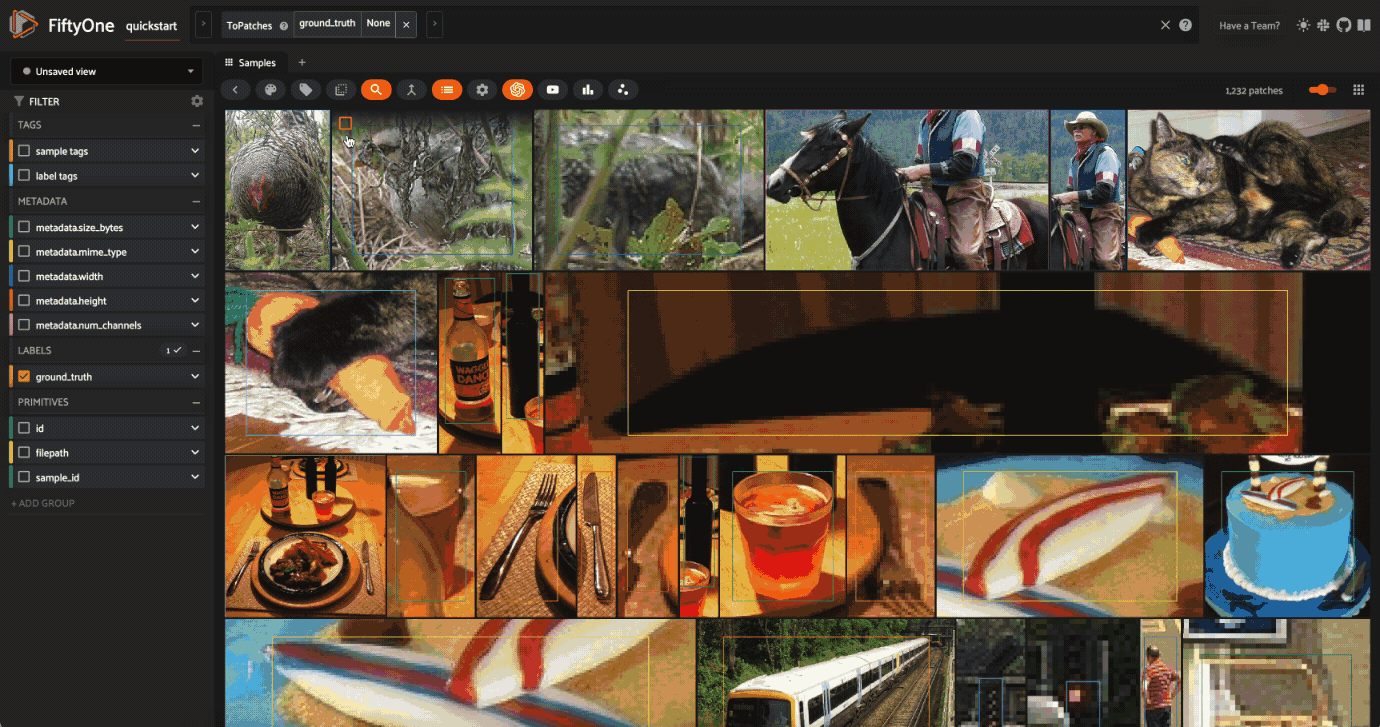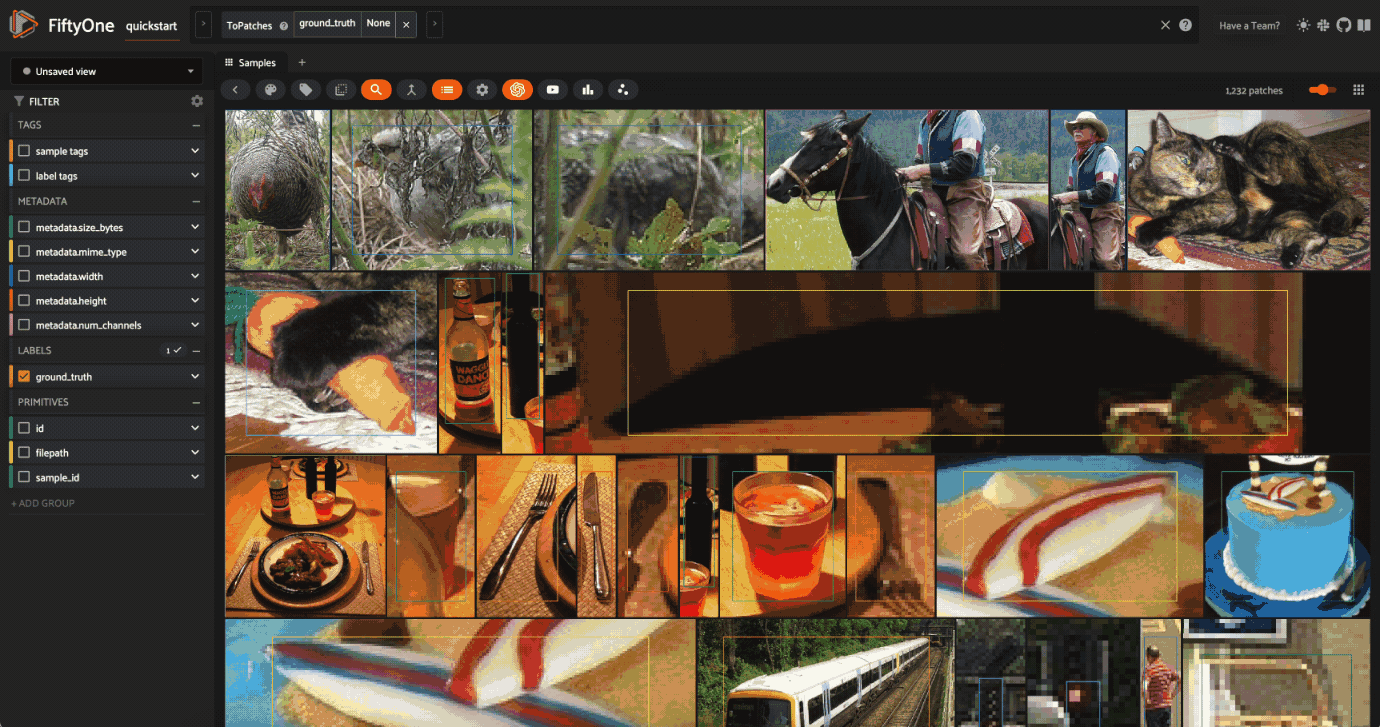
When working with FiftyOne datasets that contain a field with Detections, you can create a patches view both through Python and directly in the FiftyOne App to view each detection as a separate sample.
[8]:
patches_view = dataset.to_patches("ground_truth")
print(patches_view)
Dataset: quickstart
Media type: image
Num patches: 1232
Patch fields:
id: fiftyone.core.fields.ObjectIdField
sample_id: fiftyone.core.fields.ObjectIdField
filepath: fiftyone.core.fields.StringField
tags: fiftyone.core.fields.ListField(fiftyone.core.fields.StringField)
metadata: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.metadata.ImageMetadata)
ground_truth: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Detection)
View stages:
1. ToPatches(field='ground_truth', config=None)
Let’s open the App and click the patches button, then select ground_truth to create the same view that we created above.
[ ]:
session = fo.launch_app(dataset)
Compute mistakenness#
Now we’re ready to assess the mistakenness of the ground truth detections.
We can do so by running the compute_mistakenness() method from the FiftyOne Brain:
[15]:
import fiftyone.brain as fob
# Compute mistakenness of annotations in `ground_truth` field using
# predictions from `predictions` field as point of reference
fob.compute_mistakenness(dataset, "predictions", label_field="ground_truth")
Evaluating detections...
100% |█████████████████| 200/200 [13.8s elapsed, 0s remaining, 9.9 samples/s]
Computing mistakenness...
100% |█████████████████| 200/200 [2.6s elapsed, 0s remaining, 52.2 samples/s]
Mistakenness computation complete
The above method populates a number of fields on the samples of our dataset as well as the ground truth and predicted objects:
New ground truth object attributes (in ground_truth field):
mistakenness(float): A measure of the likelihood that a ground truth object’s label is incorrectmistakenness_loc: A measure of the likelihood that a ground truth object’s localization (bounding box) is inaccuratepossible_spurious: Ground truth objects that were not matched with a predicted object and are deemed to be likely spurious annotations will have this attribute set to True
New predicted object attributes (in predictions field):
possible_missing: If a highly confident prediction with no matching ground truth object is encountered, this attribute is set to True to indicate that it is a likely missing ground truth annotation
Sample-level fields:
mistakenness: The maximum mistakenness of the ground truth objects in each samplepossible_spurious: The number of possible spurious ground truth objects in each samplepossible_missing: The number of possible missing ground truth objects in each sample
Analyzing the results#
Let’s use FiftyOne to investigate the results.
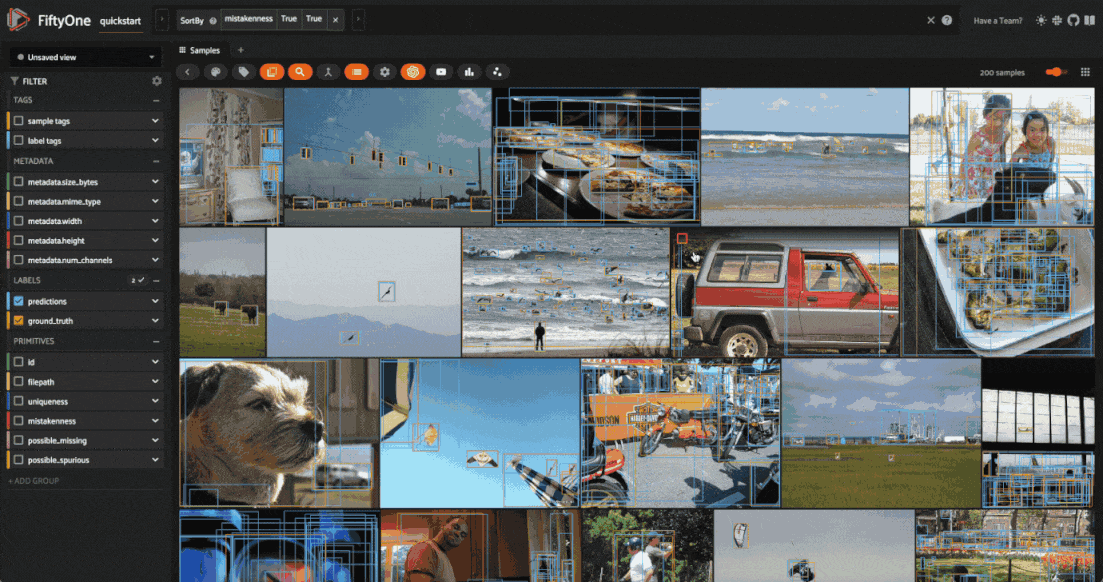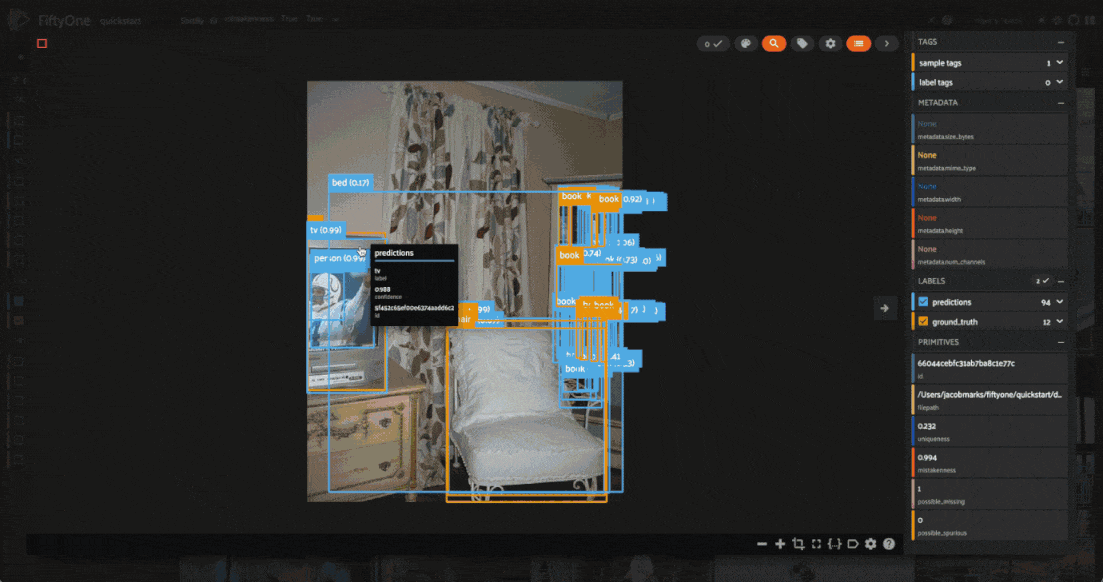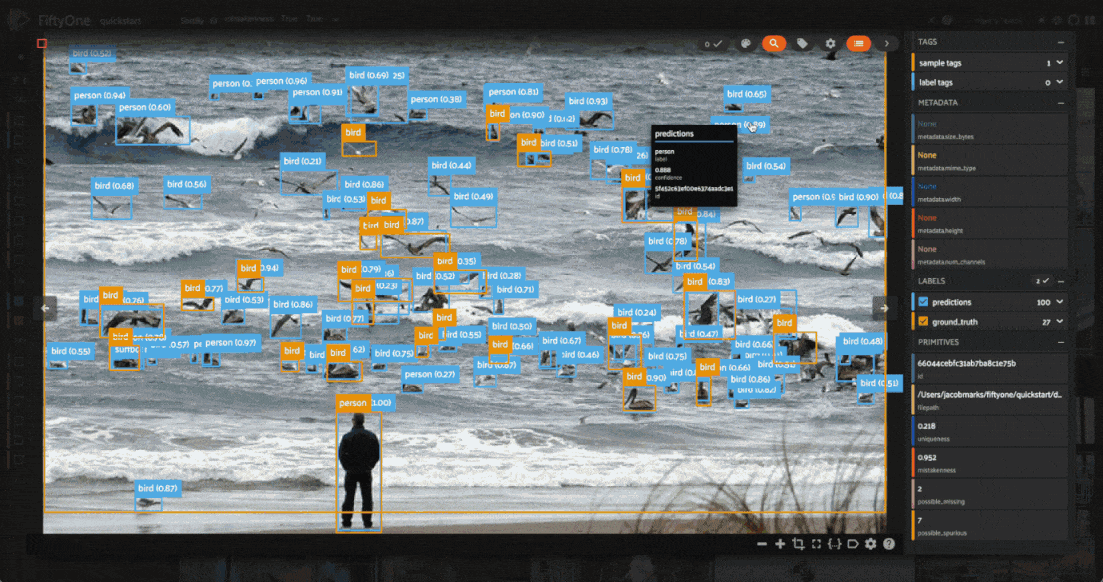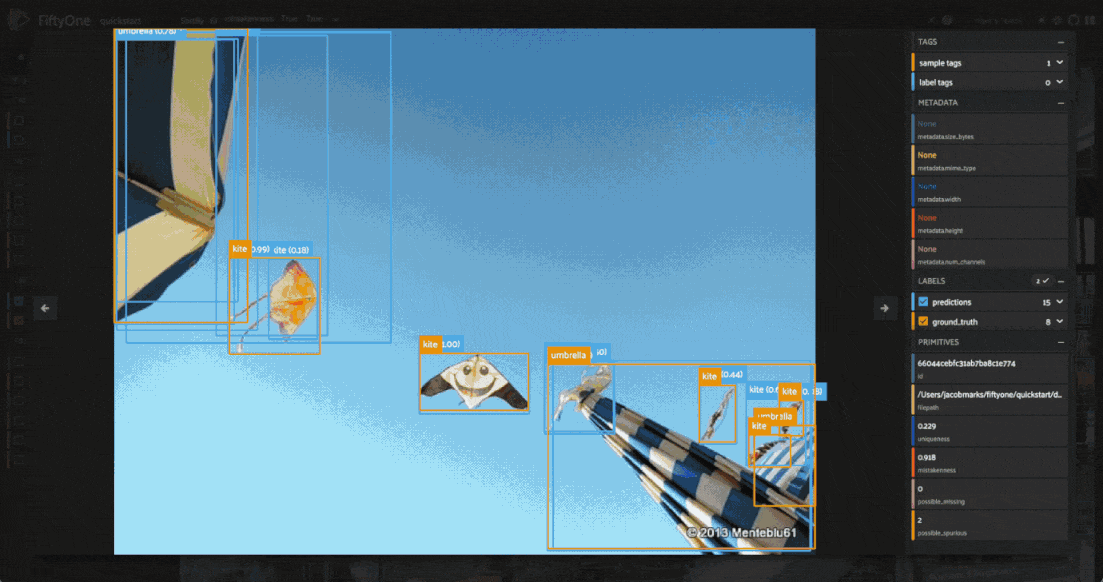
First, let’s show the samples with the most likely annotation mistakes:
[20]:
from fiftyone import ViewField as F
# Sort by likelihood of mistake (most likely first)
mistake_view = dataset.sort_by("mistakenness", reverse=True)
# Print some information about the view
print(mistake_view)
Dataset: quickstart
Media type: image
Num samples: 200
Sample fields:
id: fiftyone.core.fields.ObjectIdField
filepath: fiftyone.core.fields.StringField
tags: fiftyone.core.fields.ListField(fiftyone.core.fields.StringField)
metadata: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.metadata.ImageMetadata)
ground_truth: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Detections)
uniqueness: fiftyone.core.fields.FloatField
predictions: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Detections)
mistakenness: fiftyone.core.fields.FloatField
possible_missing: fiftyone.core.fields.IntField
possible_spurious: fiftyone.core.fields.IntField
View stages:
1. SortBy(field_or_expr='mistakenness', reverse=True, create_index=True)
[7]:
# Inspect some samples and detections
# This is the first detection of the first sample
print(mistake_view.first().ground_truth.detections[0])
<Detection: {
'id': '5f452487ef00e6374aad2744',
'attributes': BaseDict({}),
'tags': BaseList([]),
'label': 'tv',
'bounding_box': BaseList([
0.002746666666666667,
0.36082,
0.24466666666666667,
0.3732,
]),
'mask': None,
'confidence': None,
'index': None,
'area': 16273.3536,
'iscrowd': 0.0,
'mistakenness': 0.005771428346633911,
'mistakenness_loc': 0.16955941131917984,
}>
Let’s use the App to visually inspect the results:
[ ]:
# Show the samples we processed in rank order by the mistakenness
session.view = mistake_view
Another useful query is to find all objects that have a high mistakenness, lets say > 0.95:
[ ]:
from fiftyone import ViewField as F
session.view = dataset.filter_labels("ground_truth", F("mistakenness") > 0.95)
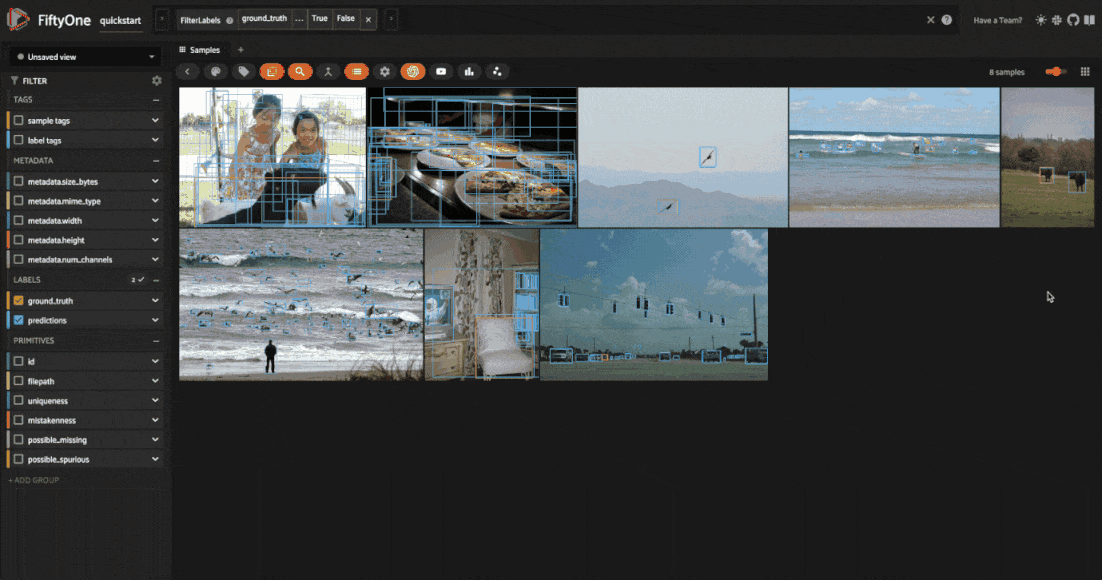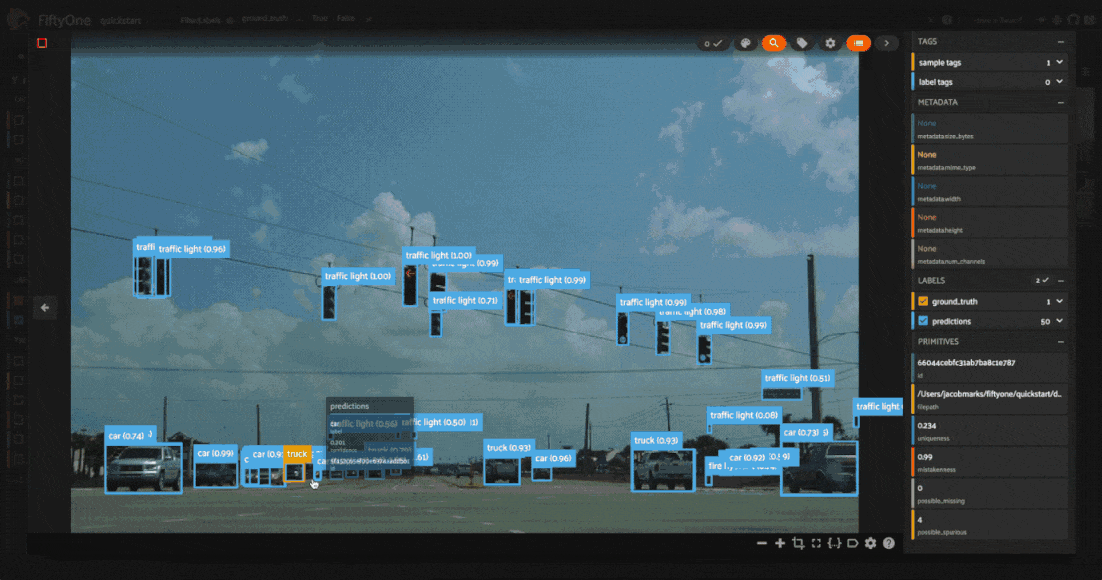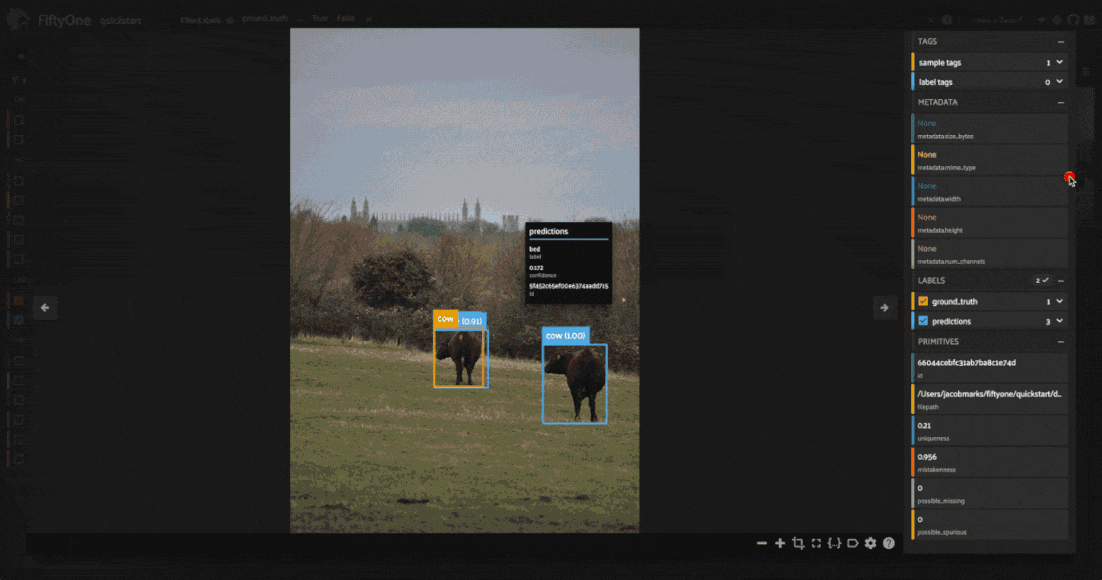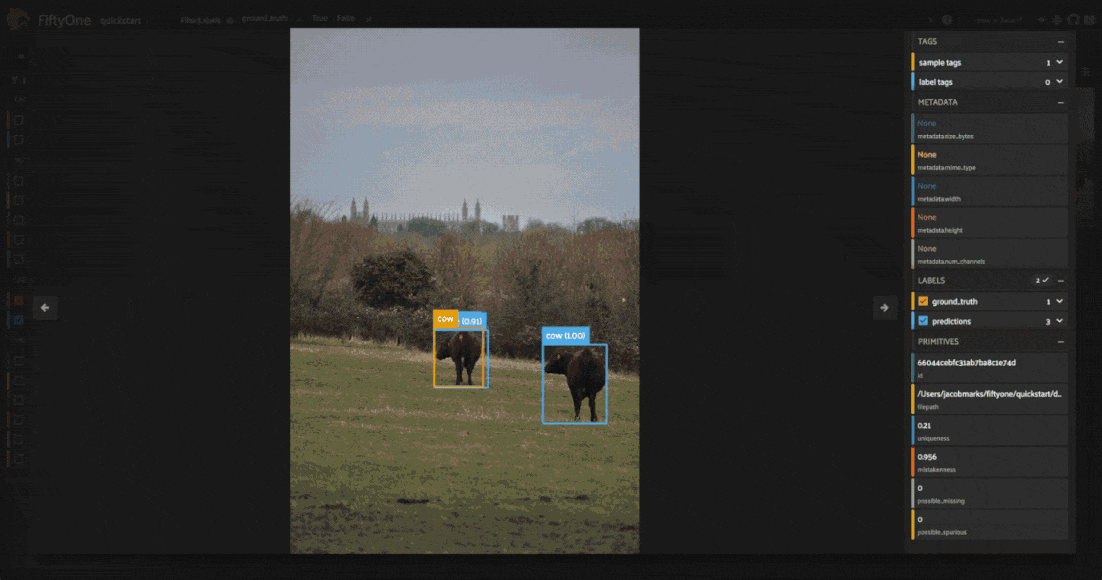
Looking through the results, we can see that many of these images have a bunch of predictions which actually look like they are correct, but no ground truth annotations. This is a common mistake in object detection datasets, where the annotator may have missed some objects in the image. On the other hand, there are some detections which are mislabeled, like the cow in the fifth image above which is predicted to be a horse.
We can use a similar workflow to look at objects that may be localized poorly:
[ ]:
session.view = dataset.filter_labels("ground_truth", F("mistakenness_loc") > 0.85)
In some of these examples, like the image of people on the beach, there is not necessarily highly mistaken localization, there are just a bunch of small, relatively overlapping objects. In other examples, such as the handbag in the second instance and the skis in the third instance, the localization is clearly off.
The possible_missing field can also be useful to sort by to find instances of incorrect annotations.
Similarly, possible_spurious can be used to find objects that the model detected that may have been missed by annotators.
[ ]:
session.view = dataset.match(F("possible_missing") > 0)
An example that showed up from this search is shown above. There is an apple that was not annotated that the model detected.
Tagging and resolution#
Any label or collection of labels can be tagged at any time in the sample grid or expanded sample view. In the expanded sample view, individual samples can be selected by clicking on them in the media player. We can, for example, tag this apple prediction as missing and any other predictions without an associated ground truth detection.
Labels with specific tags can then be selected with select_labels() stage and sent off to assist in improving the annotations with your annotation provided of choice. FiftyOne currently offers integrations for both Labelbox and Scale.
[14]:
# A dataset can be filtered to only contain labels with certain tags
# Helpful for isolating labels with issues and sending off to an annotation provider
missing_ground_truth = dataset.select_labels(tags="missing")
REMEMBER: Since you are using model predictions to guide the mistakenness process, the better your model, the more accurate the mistakenness suggestions. Additionally, using logits of confidence scores will also provide better results.
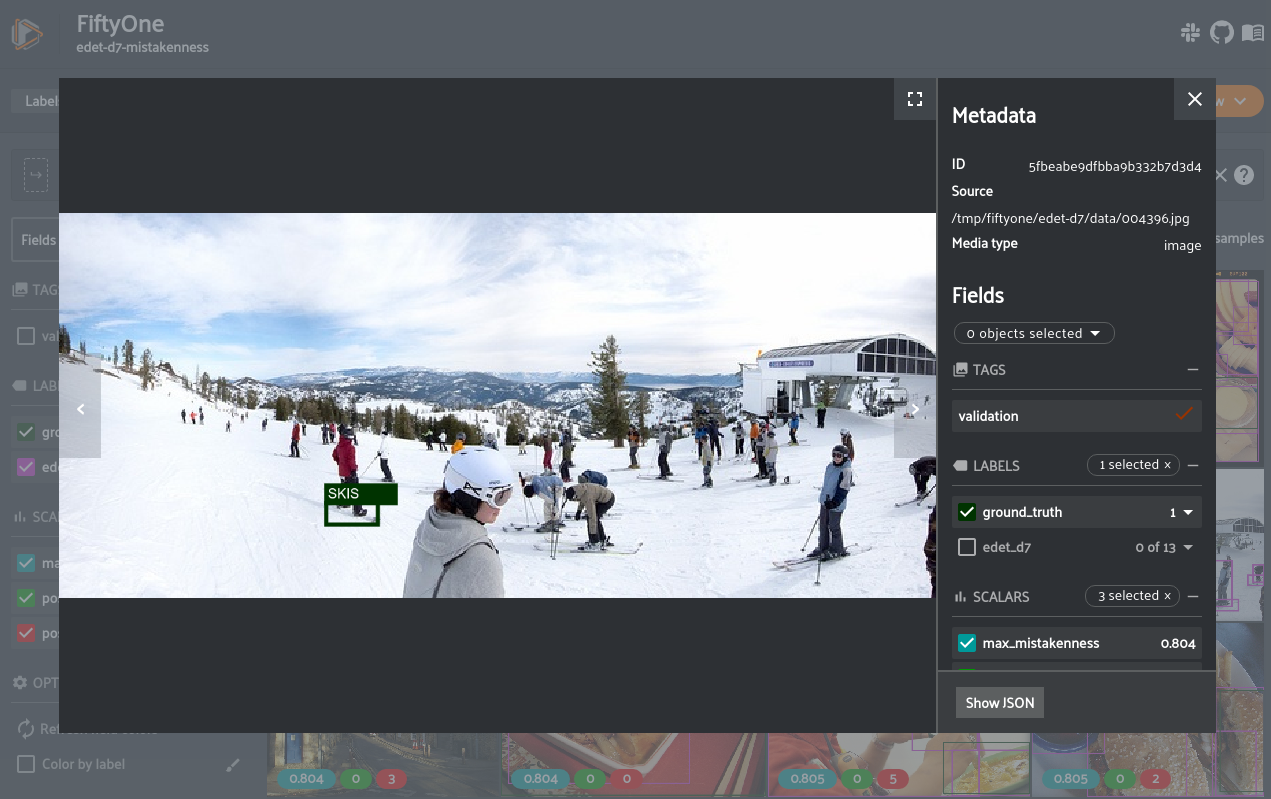
We used Faster-RCNN in this example which is quite a few years old. Using EfficientDet D7 provided much better results. For example, it was easily able to find this snowboard labeled as skis:
[13]:
session.freeze() # screenshot the active App for sharing