|
|
|
|
Google Gemini Vision in FiftyOne#
The rapid advancement of multimodal AI models has opened new possibilities for computer vision workflows. Google’s Gemini Vision models combine powerful visual understanding with natural language processing, enabling sophisticated image analysis, generation, and manipulation tasks.
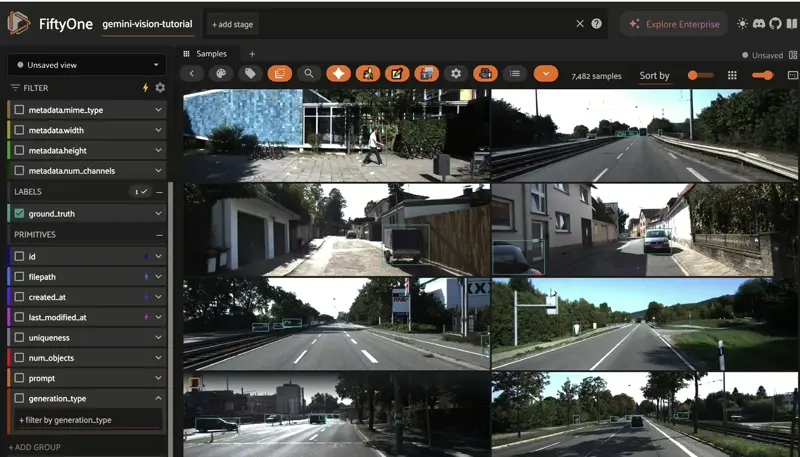
The Gemini Vision Plugin for FiftyOne brings these capabilities directly into your data-centric workflows, allowing you to leverage Gemini’s vision-language models for dataset analysis, augmentation, and quality improvement.
In this tutorial, we’ll demonstrate how to use the Gemini Vision Plugin with FiftyOne to analyze a real-world autonomous driving dataset, identify dataset issues, and use Gemini’s generative capabilities to improve data quality.
Specifically, this walkthrough covers:
Installing and configuring the Gemini Vision Plugin for FiftyOne
Loading the KITTI autonomous driving dataset
Analyzing dataset quality and identifying biases using FiftyOne Brain
Using Gemini Vision to query and understand images
Detecting missing classes and annotation gaps
Generating new training images with text-to-image
Editing existing images to address dataset gaps
Transferring styles between images
Analyzing video content with Gemini’s video understanding capabilities
So, what’s the takeaway?
By combining FiftyOne’s dataset analysis capabilities with Gemini Vision’s multimodal AI features, you can build a powerful workflow for understanding, improving, and augmenting your computer vision datasets.
What is Google Gemini Vision?#
Google Gemini is a family of multimodal AI models developed by Google DeepMind. Gemini Vision extends these models’ capabilities to understand and generate visual content:
Multimodal Understanding: Process both images and text together for deep contextual understanding
1M Token Context Window: Analyze large amounts of visual and textual data in a single request (with Gemini 3.0)
Image Generation: Create new images from text descriptions
Image Editing: Modify existing images based on natural language instructions
Video Understanding: Analyze and query video content with temporal awareness
Adjustable Reasoning: Control the depth of analysis with configurable thinking levels
The Gemini Vision Plugin makes these capabilities accessible directly within your FiftyOne workflows, enabling seamless integration of generative AI into your data preparation pipelines.
Setup#
To get started, you need to install FiftyOne and the Gemini Vision Plugin:
[ ]:
!pip install fiftyone
[ ]:
!fiftyone plugins download https://github.com/AdonaiVera/gemini-vision-plugin
Configure Gemini API Access#
To use the Gemini Vision Plugin, you’ll need a Google Cloud account with the Gemini API enabled.
Important: The Gemini API requires billing to be enabled on your Google Cloud account. You can get started at Google AI Studio.
Once you have your API key, set it as an environment variable:
[3]:
import os
# Set your Gemini API key
os.environ["GEMINI_API_KEY"] = "YOUR_GEMINI_API_KEY"
Now import FiftyOne and related modules:
[ ]:
import fiftyone as fo
import fiftyone.zoo as foz
import fiftyone.brain as fob
from fiftyone import ViewField as F
import fiftyone.operators as foo
from fiftyone.utils.huggingface import load_from_hub
Exploring Gemini Vision Capabilities with FiftyOne#
In this first part of the tutorial, we explore multiple Gemini Vision capabilities integrated with FiftyOne, showing how multimodal models can help you understand, enrich, and debug your datasets.
We’ll walk through several real-world use cases, starting from simple dataset understanding and moving toward more advanced tasks like OCR, spatial reasoning, and video understanding.
1. Asking Questions About Your Dataset (Visual Q&A)#
We start with the simplest and often most powerful use case: asking questions about your dataset.
Using the FiftyOne quickstart, we load a dataset and begin asking natural language questions such as:
What objects appear most frequently?
Are there any anomalies or unusual samples?
What is happening in this image or scene?
This is a great first step to quickly understand what’s inside your database, validate assumptions, and spot potential issues before training or evaluation.
This approach is especially useful when working with large or unfamiliar datasets.
[ ]:
dataset = foz.load_zoo_dataset("quickstart")
session = fo.launch_app(dataset, auto=False)
2. OCR: Extracting Text and Adding It to Your Dataset#
Next, we move into OCR (Optical Character Recognition).
Here, Gemini Vision is used to dynamically extract structured information from documents such as invoices, receipts, or forms. For example:
Invoice numbers
Dates
Total amounts
Vendor names
We then map this extracted information back into the dataset using bounding boxes, so the detected text becomes a first-class citizen in FiftyOne—searchable, filterable, and visualizable.
This enables workflows like:
Auditing documents
Validating annotations
Building downstream analytics pipelines
In this example, we load a receipts dataset directly from Hugging Face (Voxel51/consolidated_receipt_dataset) to show how quickly you can enrich real-world document data with OCR annotations inside FiftyOne.
You can access more than 100 datasets already available in FiftyOne format—explore the full dataset ecosystem here: https://docs.voxel51.com/dataset_zoo/index.html
[ ]:
# Load the dataset
dataset = load_from_hub("Voxel51/consolidated_receipt_dataset")
session = fo.launch_app(dataset, auto=False)
3. Spatial Understanding with Keypoints and References#
In this section, we explore spatial understanding.
The idea here is not just to recognize what is in an image, but where things are and how they relate to each other. Gemini Vision can point to specific regions or objects, and we can visualize these results using FiftyOne keypoints and spatial annotations.
Examples include:
Pointing to specific components in an image
Highlighting regions of interest
Visualizing relationships between objects
For this example, we use the ALOHA Pen Uncap dataset from Hugging Face, which contains real-world robot manipulation demonstrations captured from an egocentric perspective. The dataset is designed for studying fine-grained manipulation, action understanding, and spatial reasoning in robotics:
[ ]:
dataset = load_from_hub("Voxel51/aloha_pen_uncap", max_samples=100)
session = fo.launch_app(dataset, auto=False)
4. Video Understanding: Events, Timing, and Context#
Finally, we extend these ideas to video understanding.
Instead of analyzing a single image, we process full videos to:
Understand what is happening over time
Detect key events
Extract timestamps and temporal segments
Answer questions about sequences and actions
This is particularly useful for applications like surveillance, sports analysis, robotics, or long-form video datasets.
[ ]:
dataset = foz.load_zoo_dataset("quickstart-video")
session = fo.launch_app(dataset, auto=False)
Why This Matters#
By combining Gemini Vision’s multimodal reasoning with FiftyOne’s dataset management and visualization, you can:
Explore datasets faster
Add rich semantic metadata
Debug data issues visually
Build more interpretable AI systems
Next, let’s put this into practice. We’ll walk through a hands-on driving example, starting with dataset exploration and then using Gemini to analyze, enrich, and improve the quality of the dataset, step by step.
Load the KITTI Dataset#
For this tutorial, we’ll use the KITTI Dataset, a large-scale diverse driving dataset containing 7,481 annotated images, and the test split contains 7,518 unlabeled images, across various weather conditions, times of day, and scenes.
KITTI is perfect for demonstrating Gemini Vision’s capabilities because:
It contains diverse real-world scenarios
It has complex multi-object scenes
It’s used for autonomous driving research, where dataset quality is critical
It may contain annotation biases and gaps that we can identify and address
Downloading the dataset for the first time can take around 30 minutes, and for this tutorial, we’ll use a subset of the training split.
[ ]:
dataset = foz.load_zoo_dataset(
"kitti",
dataset_name = "gemini-vision-tutorial",
split="train",
persistent=True,
max_samples=100,
)
Let’s visualize the dataset in the FiftyOne App:
[ ]:
session = fo.launch_app(dataset)
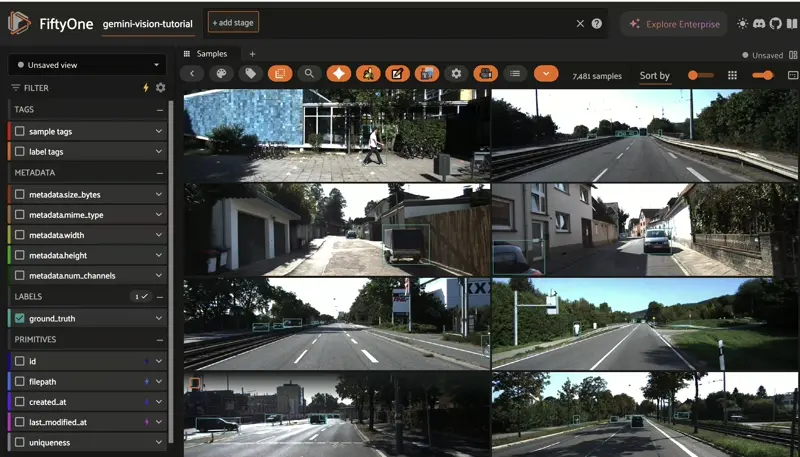
Analyzing Dataset Quality with FiftyOne Brain#
Before we start using Gemini Vision, let’s analyze our dataset to understand its characteristics and identify potential issues. FiftyOne Brain provides powerful capabilities for dataset analysis.
Identifying Class Imbalance and Bias#
First, let’s examine the distribution of object classes in our dataset to identify any biases or underrepresented categories. You can also explore these insights with the Dashboard plugin, which lets you build custom dashboards to visualize key statistics about your dataset.
[4]:
# Count the distribution of object classes in detections
class_counts = dataset.count_values("ground_truth.detections.label")
# Display class distribution
print("Object Class Distribution:")
print("=" * 50)
for cls, count in sorted(class_counts.items(), key=lambda x: x[1], reverse=True):
print(f"{cls}: {count}")
Object Class Distribution:
==================================================
Car: 28742
DontCare: 11295
Pedestrian: 4487
Van: 2914
Cyclist: 1627
Truck: 1094
Misc: 973
Tram: 511
Person_sitting: 222
Computing Dataset Uniqueness#
Next, let’s use FiftyOne Brain to identify unique and potentially redundant samples in our dataset:
[ ]:
# Compute uniqueness scores
fob.compute_uniqueness(dataset)
# Sort by uniqueness to see most and least unique samples
unique_view = dataset.sort_by("uniqueness", reverse=True)
print(f"Most unique samples (uniqueness > 0.9): {len(dataset.match(F('uniqueness') > 0.9))}")
print(f"Potentially redundant samples (uniqueness < 0.3): {len(dataset.match(F('uniqueness') < 0.3))}")
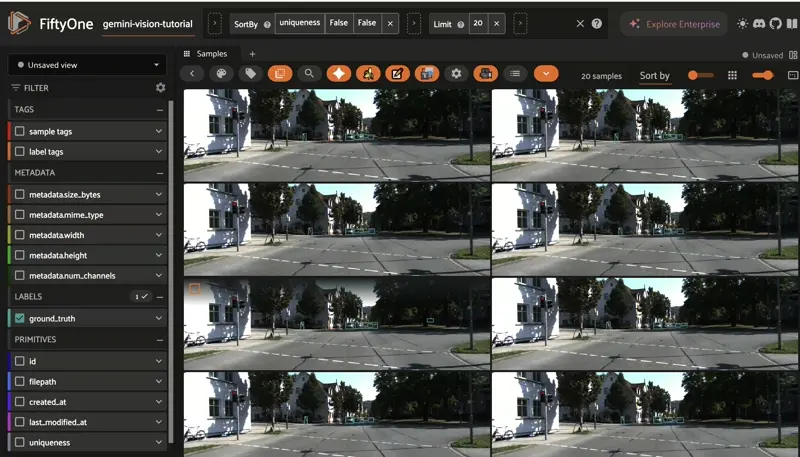
Detecting Near-Duplicate Images#
Duplicate or near-duplicate images can inflate evaluation metrics and waste training time. Let’s find them:
[ ]:
# Detect near-duplicate images
results = fob.compute_similarity(
dataset,
model="clip-vit-base32-torch",
brain_key="img_sim"
)
# Find potential duplicates
dup_view = dataset.sort_by("uniqueness").limit(20)
session.view = dup_view
Visualizing Dataset Embeddings#
Let’s compute embeddings and visualize the dataset structure to identify clusters and potential gaps:
[ ]:
!pip install umap-learn
[ ]:
# Compute visualization with embeddings
results = fob.compute_visualization(
dataset,
model="clip-vit-base32-torch",
brain_key="img_viz",
method="umap"
)
# Launch app to view the embeddings visualization
session = fo.launch_app(dataset)
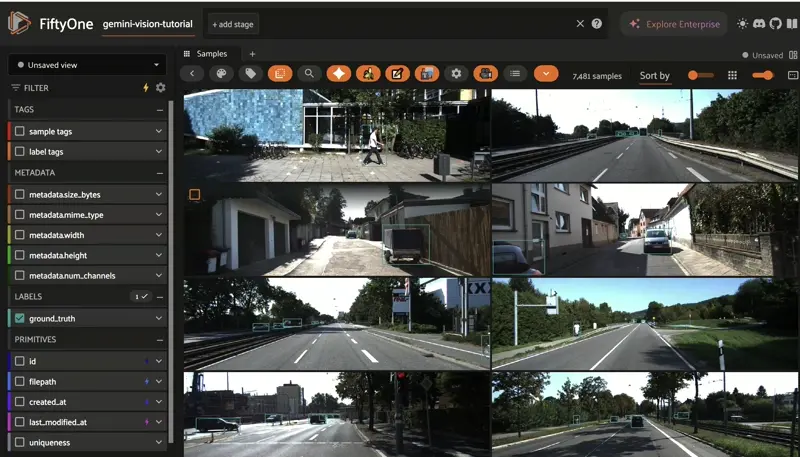
The embeddings plot in the FiftyOne App reveals clustering patterns in the data. Isolated samples or sparse regions may indicate underrepresented scenarios that need more data.
Using Gemini Vision for Image Understanding#
Now let’s use the Gemini Vision Plugin to query and understand images in our dataset. The plugin provides several operators that can be accessed through the FiftyOne App or programmatically.
Querying Images with Natural Language#
Let’s select a few samples and use Gemini to analyze them. First, we’ll select some samples with specific objects:
[ ]:
# Select samples with cars
car_view = dataset.filter_labels("ground_truth", F("label") == "Car").take(5)
# View in the app
session.view = car_view
 |
|
Now, you can use the Gemini Vision Plugin operators from the FiftyOne App:
Select one or more samples in the App
Press the backtick key (`) to open the operator browser
Search for “query_gemini_vision” or “Query Gemini Vision”
Enter your query, for example:
“Describe the weather and lighting conditions in this image”
“What time of day does this appear to be?”
“Are there any pedestrians or cyclists visible?”
“Describe potential safety hazards in this driving scene”
The plugin will use Gemini Vision to analyze the image and return a text response, which you can save to a custom field in your dataset.
Identifying Missing Annotations#
One powerful use case for Gemini Vision is identifying objects that may be missing from annotations. Let’s use it to audit our annotations:
[ ]:
# Select a sample to analyze
sample = dataset.first()
# Get the list of currently annotated classes
annotated_classes = [det.label for det in sample.ground_truth.detections]
print(f"Currently annotated classes: {set(annotated_classes)}")
print("\nUse the Gemini Vision Query operator in the App to ask:")
print("'List all objects visible in this image, especially those that might be relevant for autonomous driving.'")
print("\nCompare Gemini's response with the annotations to find missing objects.")
view = dataset.select([sample.id])
session = fo.launch_app(view)
Analyzing Difficult or Ambiguous Cases#
Let’s identify samples with many objects that might be challenging to annotate:
[ ]:
# Find samples with many objects
dataset.compute_metadata()
# Count detections per sample
for sample in dataset:
if sample.ground_truth:
sample["num_objects"] = len(sample.ground_truth.detections)
else:
sample["num_objects"] = 0
sample.save()
# View samples with the most objects
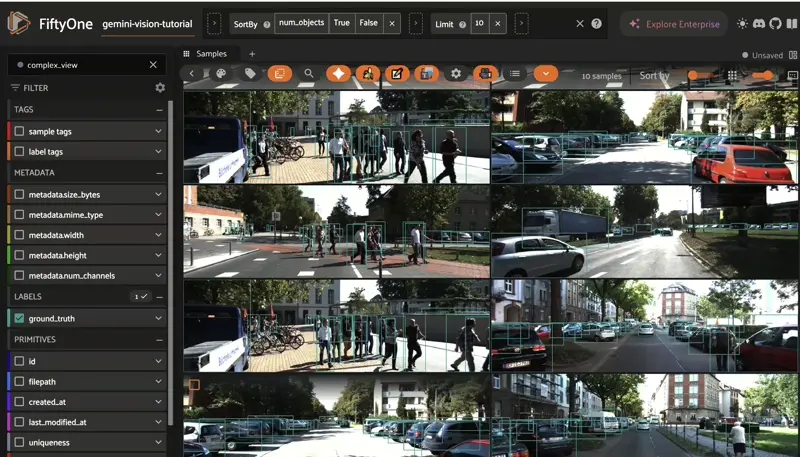
complex_view = dataset.sort_by("num_objects", reverse=True).limit(10)
session.view = complex_view
print("These complex scenes are good candidates for Gemini Vision analysis to:")
print("- Verify annotation completeness")
print("- Identify occlusions and difficult objects")
print("- Understand scene context and relationships between objects")

Detecting Missing Classes and Coverage Gaps#
Based on our class distribution analysis, we may have identified underrepresented object classes. Let’s systematically find which classes are missing or underrepresented:
[24]:
# Get all classes present in the dataset
class_counts = dataset.count_values("ground_truth.detections.label")
all_classes = sorted(class_counts.keys())
# Define a threshold for rare classes
threshold = 5 # Consider classes with fewer than 5 instances as rare
# Identify rare classes
rare_classes = []
for cls, count in class_counts.items():
if count < threshold:
rare_classes.append((cls, count))
print(f"Total classes in dataset: {len(all_classes)}")
print(f"\nRare classes (< {threshold} instances):")
for cls, count in sorted(rare_classes, key=lambda x: x[1]):
print(f" - {cls}: {count} instances")
print("\nMost common classes:")
for cls, count in sorted(class_counts.items(), key=lambda x: x[1], reverse=True)[:5]:
print(f" - {cls}: {count} instances")
Total classes in dataset: 9
Rare classes (< 5 instances):
Most common classes:
- Car: 28742 instances
- DontCare: 11295 instances
- Pedestrian: 4487 instances
- Van: 2914 instances
- Cyclist: 1627 instances
Identifying Scenario Coverage Gaps#
Beyond object classes, we should also consider scenario diversity. Let’s use Gemini Vision to categorize our images by scenario characteristics:
[25]:
# Sample a subset for scenario analysis
analysis_view = dataset.take(50)
print("Use the Gemini Vision Query operator to categorize these samples by:")
print("\n1. Weather conditions:")
print(" Query: 'What are the weather conditions? Classify as: clear, rainy, foggy, snowy, or cloudy.'")
print("\n2. Time of day:")
print(" Query: 'What time of day is this? Classify as: dawn, day, dusk, or night.'")
print("\n3. Scene type:")
print(" Query: 'What type of driving environment is this? Classify as: highway, urban, residential, or rural.'")
print("\nSave responses to custom fields like 'gemini_weather', 'gemini_time', 'gemini_scene'")
print("Then use FiftyOne's count_values() to identify underrepresented scenarios.")
Use the Gemini Vision Query operator to categorize these samples by:
1. Weather conditions:
Query: 'What are the weather conditions? Classify as: clear, rainy, foggy, snowy, or cloudy.'
2. Time of day:
Query: 'What time of day is this? Classify as: dawn, day, dusk, or night.'
3. Scene type:
Query: 'What type of driving environment is this? Classify as: highway, urban, residential, or rural.'
Save responses to custom fields like 'gemini_weather', 'gemini_time', 'gemini_scene'
Then use FiftyOne's count_values() to identify underrepresented scenarios.
Addressing Dataset Gaps with Image Generation#
Now that we’ve identified missing classes and underrepresented scenarios, let’s use Gemini’s text-to-image generation capabilities to create synthetic training data.
Generating Images for Missing Classes#
The Gemini Vision Plugin includes a text-to-image generation operator. You can use it from the FiftyOne App:
Open the operator browser (backtick key)
Search for “generate_image” or “Generate Image”
Enter prompts for missing or rare classes:
Example prompts for autonomous driving scenarios:
[27]:
# Example: Define prompts for missing scenarios programmatically
generation_prompts = {
"fire_hydrant": "A city street scene with a fire hydrant in the foreground, cars parked on the side, shot from a dashboard camera perspective",
"motorcycle": "A motorcyclist riding on a highway during sunset, viewed from a car's perspective",
"cyclist_rain": "A residential street with a cyclist and a stop sign, rainy weather, dashboard camera view",
"night_traffic": "A busy urban intersection at night with traffic lights, pedestrians crossing, and various vehicles",
"foggy_highway": "A foggy morning highway scene with trucks and cars, limited visibility"
}
print("Use these prompts with the Gemini Generate Image operator:")
for name, prompt in generation_prompts.items():
print(f"\n{name}:")
print(f" {prompt}")
Use these prompts with the Gemini Generate Image operator:
fire_hydrant:
A city street scene with a fire hydrant in the foreground, cars parked on the side, shot from a dashboard camera perspective
motorcycle:
A motorcyclist riding on a highway during sunset, viewed from a car's perspective
cyclist_rain:
A residential street with a cyclist and a stop sign, rainy weather, dashboard camera view
night_traffic:
A busy urban intersection at night with traffic lights, pedestrians crossing, and various vehicles
foggy_highway:
A foggy morning highway scene with trucks and cars, limited visibility
Editing Images to Augment Dataset Diversity#
In addition to generating new images, Gemini Vision can edit existing images based on natural language instructions. This is useful for creating variations and augmenting dataset diversity.
Using the Image Editing Operator#
To edit images with Gemini Vision:
Select a single sample in the FiftyOne App
Open the operator browser (backtick key)
Search for “edit_image” or “Edit Image”
Enter editing instructions
Example editing prompts: The edited image will be saved with the original prompt preserved in metadata.
[ ]:
# Select samples with clear weather for editing
clear_weather_view = dataset.take(10)
session.view = clear_weather_view
print("Selected samples for editing. Use the Edit Image operator with prompts like:")
print(" - 'Change the weather to rainy, add rain and wet roads'")
print(" - 'Make it nighttime with street lights illuminated'")
print(" - 'Add fog to reduce visibility'")
print("\nThis creates weather and lighting variations to improve model robustness.")
Transferring Styles Between Images#
Gemini Vision can combine multiple images to create new scenes or transfer styles. This is useful for:
Transferring weather conditions from one image to another
Combining objects from different scenes
Creating composite training examples
Using Multi-Image Composition#
To use multi-image composition:
Select 2-3 samples in the FiftyOne App
Open the operator browser
Search for “compose_images” or “Multi-Image Composition”
Enter composition instructions
Example composition prompts:
[30]:
# This example shows the concept - actual execution is done through the App
print("Multi-Image Composition Workflow:")
print("\n1. Find an image with desired weather/lighting conditions")
print("2. Find an image with desired scene/object composition")
print("3. Select both images")
print("4. Use Multi-Image Composition operator to combine them")
print("\nExample: Transfer nighttime lighting to a daytime scene,")
print("creating a diverse set of lighting conditions for training.")
Multi-Image Composition Workflow:
1. Find an image with desired weather/lighting conditions
2. Find an image with desired scene/object composition
3. Select both images
4. Use Multi-Image Composition operator to combine them
Example: Transfer nighttime lighting to a daytime scene,
creating a diverse set of lighting conditions for training.
Video Understanding with Gemini Vision#
Gemini Vision also supports video understanding, allowing you to analyze temporal sequences and extract insights from video data. This is particularly relevant for autonomous driving where temporal context matters.
Loading Video Data#
Let’s load a video dataset to demonstrate Gemini’s video understanding capabilities:
[ ]:
# Load the quickstart-video dataset
video_dataset = foz.load_zoo_dataset(
"quickstart-video",
max_samples=5
)
video_dataset.name = "gemini-vision-video"
video_dataset.persistent = True
# Launch app to view videos
session = fo.launch_app(video_dataset)
Querying Video Content#
The Gemini Vision Plugin includes a video understanding operator with multiple modes:
Describe: Get a detailed description of the video content
Segment: Identify temporal segments with different characteristics
Extract: Extract specific information (objects, actions, events)
Question: Ask specific questions about the video content
To use video understanding:
Select a video sample in the FiftyOne App
Open the operator browser
Search for “analyze_video” or “Video Understanding”
Select the mode and enter your query
Example video queries:
[32]:
# Example queries for video analysis
video_queries = [
{
"mode": "describe",
"query": "Provide a detailed description of this driving video including weather, traffic conditions, and notable events"
},
{
"mode": "extract",
"query": "List all vehicle types that appear in this video with their approximate timestamps"
},
{
"mode": "question",
"query": "Are there any potentially dangerous situations in this driving video?"
},
{
"mode": "segment",
"query": "Segment this video by traffic density (low, medium, high)"
}
]
print("Video Understanding Queries:")
for i, q in enumerate(video_queries, 1):
print(f"\n{i}. Mode: {q['mode']}")
print(f" Query: {q['query']}")
Video Understanding Queries:
1. Mode: describe
Query: Provide a detailed description of this driving video including weather, traffic conditions, and notable events
2. Mode: extract
Query: List all vehicle types that appear in this video with their approximate timestamps
3. Mode: question
Query: Are there any potentially dangerous situations in this driving video?
4. Mode: segment
Query: Segment this video by traffic density (low, medium, high)
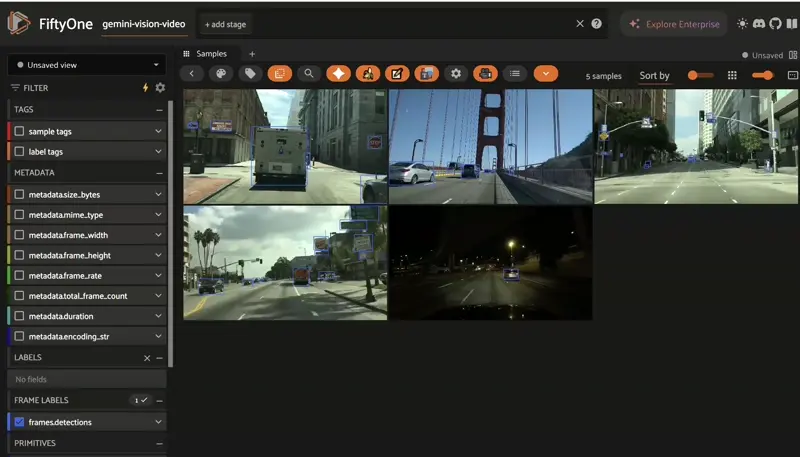
Now it’s your turn, keep exploring Gemini Vision to pull more insights from the video. You can try things like analyzing temporal patterns, extracting temporal annotations, and more.
Analyzing Temporal Patterns#
Video understanding allows you to identify temporal patterns that aren’t visible in individual frames:
[33]:
print("Temporal Analysis Use Cases:")
print("\n1. Lane Changes:")
print(" Query: 'Identify all lane change maneuvers and their timestamps'")
print("\n2. Traffic Signal Compliance:")
print(" Query: 'Does the vehicle stop at all red lights? Provide timestamps.'")
print("\n3. Pedestrian Interactions:")
print(" Query: 'Identify all moments when pedestrians cross the road'")
print("\n4. Weather Changes:")
print(" Query: 'Does the weather change during this video? If so, when?'")
print("\n5. Scene Transitions:")
print(" Query: 'Segment this video by scene type (highway, urban, residential)'")
Temporal Analysis Use Cases:
1. Lane Changes:
Query: 'Identify all lane change maneuvers and their timestamps'
2. Traffic Signal Compliance:
Query: 'Does the vehicle stop at all red lights? Provide timestamps.'
3. Pedestrian Interactions:
Query: 'Identify all moments when pedestrians cross the road'
4. Weather Changes:
Query: 'Does the weather change during this video? If so, when?'
5. Scene Transitions:
Query: 'Segment this video by scene type (highway, urban, residential)'
Extracting Temporal Annotations#
The responses from video understanding can be used to create temporal annotations in FiftyOne:
[34]:
# Example: After using Gemini to segment a video, you can create frame-level tags
# This is a conceptual example - actual implementation would parse Gemini's response
print("Workflow for creating temporal annotations from Gemini responses:")
print("\n1. Use Video Understanding operator to segment video")
print("2. Gemini returns timestamps for each segment")
print("3. Convert timestamps to frame numbers")
print("4. Tag frames with segment characteristics")
print("\nExample: Tag frames as 'high_traffic', 'medium_traffic', 'low_traffic'")
print("based on Gemini's temporal segmentation")
Workflow for creating temporal annotations from Gemini responses:
1. Use Video Understanding operator to segment video
2. Gemini returns timestamps for each segment
3. Convert timestamps to frame numbers
4. Tag frames with segment characteristics
Example: Tag frames as 'high_traffic', 'medium_traffic', 'low_traffic'
based on Gemini's temporal segmentation
Pipeline: Scale Image Editing with Gemini#
Scale your dataset by applying multiple edit prompts to images programmatically. The pipeline uses the image_editing operator and stores metadata (generation_type, prompt) on each generated sample for easy filtering and visualization.
[ ]:
# Edit prompts to apply
prompts = ["Add rain", "Make it night time", "Add fog"]
# Select samples (exclude already-generated ones)
original_samples = dataset.match(~F("generation_type").exists())
# Number of examples to process
num_examples = 3
# Run pipeline
async def run_pipeline():
for sample in original_samples.limit(num_examples):
for prompt in prompts:
print(f"Processing: {sample.filename} - '{prompt}'...")
try:
result = await foo.execute_operator(
"@adonaivera/gemini_vision/image_editing",
ctx={
"dataset": dataset,
"selected": [sample.id],
},
params={
"prompt": prompt,
"model": "gemini-3-pro-image-preview",
"use_original_size": True,
},
)
print(f" ✓ Done: {prompt} in {sample.filename}")
except Exception as e:
print(f" ✗ Error processing {prompt} in {sample.filename}: {e}")
# Run the async pipeline
await run_pipeline()
[ ]:
# View results - filter by generation_type field added by operator
session = fo.launch_app(dataset, auto=False)
session.view = dataset.match(F("generation_type") == "image_editing")
You’ve successfully scaled your dataset using Gemini’s image editing capabilities. Each generated image is stored with metadata (generation_type, prompt, source_file) for easy filtering and traceability.
Summary#
In this tutorial, we’ve demonstrated how the Gemini Vision Plugin extends FiftyOne’s capabilities with powerful multimodal AI features:
Dataset Analysis:
Used FiftyOne Brain to identify class imbalances, duplicates, and coverage gaps
Leveraged Gemini Vision to audit annotations and identify missing labels
Classified images by scenario characteristics (weather, time, scene type)
Dataset Enhancement:
Generated synthetic images for underrepresented classes and scenarios
Edited existing images to create weather and lighting variations
Transferred styles between images to augment dataset diversity
Video Understanding:
Analyzed temporal patterns in driving videos
Extracted event timestamps and segmented videos by characteristics
Queried video content with natural language
By combining FiftyOne’s data-centric workflows with Gemini Vision’s multimodal AI capabilities, you can build higher-quality, more diverse datasets that lead to more robust computer vision models.
For more information: