|
|
|
|
Clustering and Labeling with Embeddings#
In this notebook, we will explore how to use embeddings to cluster and assign labels to dataset samples. This technique is valuable when dealing with unlabeled datasets or when refining existing labels.
Learning Objectives:#
Understand clustering techniques and their role in dataset labeling.
Compute embeddings and cluster dataset samples.
Use FiftyOne Plugin for clustering MVTec dataset
Use FiftyOne for visualization and dataset management.
Why Use Clustering for Labeling?#
Labeling datasets manually is expensive and time-consuming. Clustering helps by automatically grouping similar samples based on embeddings. This method is useful for:
Unsupervised Learning: Automatically discovering patterns in unlabeled data.
Dataset Cleanup: Detecting mislabeled samples.
Efficient Annotation: Pre-labeling groups for human annotators.
Common clustering techniques include:
K-Means (partition-based clustering)
DBSCAN (density-based clustering)
Hierarchical Clustering (tree-based grouping)
Relevant Documentation:
[ ]:
!pip install fiftyone huggingface_hub gdown umap-learn torch torchvision scikit-learn
Select a GPU Runtime if possible, install the requirements, restart the session, and verify the device information.
[ ]:
import torch
def get_device():
"""Get the appropriate device for model inference."""
if torch.cuda.is_available():
return "cuda"
elif hasattr(torch.backends, "mps") and torch.backends.mps.is_available():
return "mps"
return "cpu"
DEVICE = get_device()
print(f"Using device: {DEVICE}")
Requirement step: Remove Category Labels (Keep Only Defects)#
Since category labels in your dataset are stored as category.label, you can remove them like is showing in the following cell. This removes all category.label fields from the dataset while keeping defect.label.
[ ]:
import gdown
url = "https://drive.google.com/uc?id=1nAuFIyl2kM-TQXduSJ9Fe_ZEIVog4tth"
gdown.download(url, output="mvtec_ad.zip", quiet=False)
!unzip mvtec_ad.zip
import fiftyone as fo
dataset_name = "MVTec_AD_nc"
# Check if the dataset exists
if dataset_name in fo.list_datasets():
print(f"Dataset '{dataset_name}' exists. Loading...")
dataset = fo.load_dataset(dataset_name)
else:
print(f"Dataset '{dataset_name}' does not exist. Creating a new one...")
dataset_ = fo.Dataset.from_dir(
dataset_dir="/content/mvtec-ad",
dataset_type=fo.types.FiftyOneDataset
)
dataset = dataset_.clone(dataset_name, persistent=True)
# Iterate over samples and remove category labels
for sample in dataset:
sample["category"] = None # Remove category classification
sample.save()
print("✅ All category labels removed. Only defect labels remain.")
print(dataset)
print(dataset.last())
[ ]:
# Compute embeddings for MVTec AD using CLIP
import fiftyone as fo
import fiftyone.brain as fob
import fiftyone.zoo.models as fozm
import fiftyone.utils.huggingface as fouh # Hugging Face integration
# List all datasets
datasets = fo.list_datasets()
# Print datasets
print(datasets)
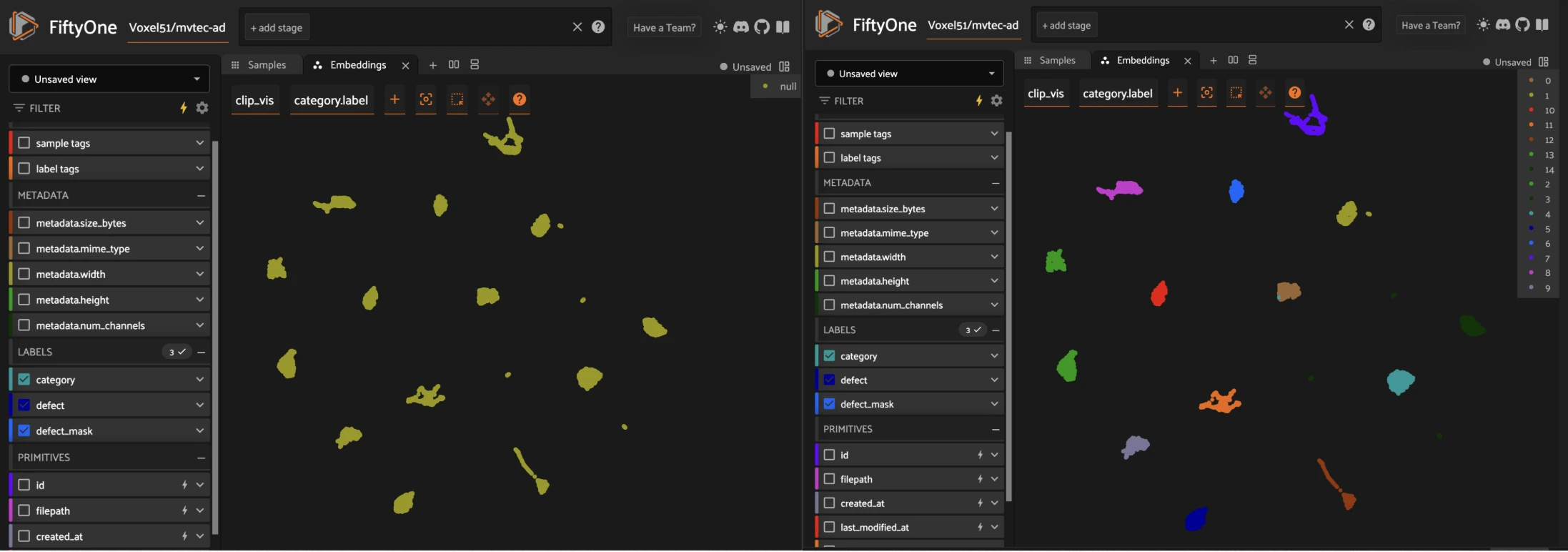
Generating Embeddings#
Before clustering, we must generate embeddings that capture meaningful feature representations. FiftyOne provides multiple ways to obtain embeddings:
Using pre-trained models from FiftyOne’s Model Zoo (e.g., CLIP, ResNet).
Extracting embeddings from custom models (e.g., OpenAI, Anomalib, or self-trained networks).
[ ]:
import fiftyone.zoo as foz
model = foz.load_zoo_model("open-clip-vit-base32-torch")
# Compute embeddings
fob.compute_visualization(dataset, model=model, embeddings=...)
Relevant Documentation: Computing Embeddings in FiftyOne
[ ]:
import fiftyone.brain as fob
import fiftyone.zoo.models as fozm
# Load a pretrained model (e.g., CLIP)
model = fozm.load_zoo_model("clip-vit-base32-torch")
fob.compute_visualization(
dataset,
model=model,
embeddings="mvtec_emb_nc",
brain_key="mvtec_embeddings_nc",
method="umap", # Change to "tsne" for t-SNE
num_dims=2 # Reduce to 2D
)
print("✅ Embeddings computed.")
[ ]:
dataset.reload()
print(dataset)
print(dataset.last())
[ ]:
session = fo.launch_app(dataset, port=5153, auto=False)
print(session.url)
Clustering Dataset Samples with a FiftyOne Plugin#
Once we have embeddings, we can cluster dataset samples based on similarity. the theory around that is not complex but it could take some time for running and testing what do you want to do. For Example for clustering samples by similarity you maybe need to use the following code:
Example using K-Means Clustering:
from sklearn.cluster import KMeans
num_clusters = 5
kmeans = KMeans(n_clusters=num_clusters, random_state=42)
cluster_labels = kmeans.fit_predict(embeddings)
After clustering, we can assign labels to our dataset:
import fiftyone as fo
# Assign clustering results to FiftyOne dataset
for sample, label in zip(dataset, cluster_labels):
sample["cluster"] = int(label) # Store as an integer field
sample.save()
But, What if I tell you you don’t need to write a code for doing that#
FiftyOne provides an extensible plugin system that allows users to enhance their workflows with additional functionalities, such as dataset visualization, embeddings analysis, and automated clustering. A FiftyOne Plugin is a modular component that extends the capabilities of the FiftyOne UI or backend. These plugins can be used for various tasks, including visualization, dataset processing, and machine learning model integration.
Clustering Plugin in FiftyOne#
One powerful plugin available in FiftyOne is the Clustering Plugin, which allows users to group similar samples together based on embeddings. This is useful for tasks like:
Understanding patterns in your dataset
Identifying redundant or mislabeled data
Grouping anomalies or outliers
Relevant Documentation:
Install the Clustering Plugin#
You can see how FiftyOne App allows you to cluster your dataset using a variety of algorithms: K-Means, Birch, Agglomerative, HDBSCAN. It also serves as a proof of concept for adding new “types” of runs to FiftyOne!!!
You will also need to have scikit-learn installed:
[ ]:
!fiftyone plugins download https://github.com/jacobmarks/clustering-plugin
!pip install -U scikit-learn
[ ]:
session = fo.launch_app(dataset, port=5153, auto=False)
print(session.url)
[ ]:
dataset.reload()
print(dataset)
print(dataset.last())
Try experimenting with different clustering methods (e.g., HDBSCAN, Birch clustering) and evaluate their impact on labeling quality! 🚀