|
|
|
|
Data Loading with FiftyOneTorchDataset#
This recipe demonstrates how to load samples from a FiftyOne dataset into PyTorch using FiftyOneTorchDataset and custom GetItem definitions. This is useful when you want to train or evaluate models in Torch while flexibly choosing which fields (such as filepaths, labels, or detections) to include. Specifically, it covers:
Loading an example dataset from the Dataset Zoo
Defining custom GetItem classes to map dataset fields into Torch-ready formats
Creating a FiftyOneTorchDataset and using it with a PyTorch
DataLoaderRetrieving custom batches of samples for training and visualization
API references: FiftyOneTorchDataset · GetItem
Setup#
If you haven’t already, install FiftyOne:
[ ]:
!pip install fiftyone
In this tutorial, we’ll use PyTorch for working with tensors and inspecting sample data. To follow along, you’ll need to install torch and torchvision, if necessary:
[ ]:
!pip install torch torchvision
Import Libraries#
[ ]:
import torch
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from PIL import Image
[ ]:
import fiftyone as fo
import fiftyone.zoo as foz
from fiftyone.utils.torch import GetItem, FiftyOneTorchDataset
Load Dataset#
[ ]:
# Load a dataset
dataset = foz.load_zoo_dataset("quickstart")
# make sure its persistent
dataset.persistent = True
GetItem#
A GetItem defines how each sample is transformed into model input. It declares which fields it needs via required_keys, and implements the transformation in __call__.
[ ]:
# define a GetItem
class FilepathGetItem(GetItem):
# required_keys lists the keys that this GetItem will use
# they don't have to be specific to your field schema
# they are simply names assigned for expected fields
# we can later map a specific dataset's field names to the keys expected by a GetItem
# here we only need the filepath of the sample
@property
def required_keys(self):
return ["filepath"]
# __call__ implements the transformation from a sample dict to model input
# sample_dict is a dictionary with the keys listed in required_keys
# and the corresponding values from the sample
def __call__(self, sample_dict):
return sample_dict["filepath"]
[ ]:
# when instantiating a GetItem, we can pass a field_mapping dictionary
# to map the expected keys to specific fields in the dataset
# by default, keys are mapped to fields of the same name
# but we can override this with field_mapping
dummy_sample_dict = {
"filepath": "/path/to/image.jpg"
}
# without a field mapping, the key "filepath" maps to the field "filepath"
get_item = FilepathGetItem()
print(get_item(dummy_sample_dict)) # prints: /path/to/image.jpg
FiftyOneTorchDataset#
Pass any GetItem to .to_torch() on a dataset or view to get a FiftyOneTorchDataset — a standard torch.utils.data.Dataset compatible with any DataLoader.
[ ]:
torch_dataset = dataset.to_torch(FilepathGetItem())
[ ]:
torch_dataset[0] # prints the filepath of the first sample in the dataset
[ ]:
# notice that torch_dataset is a standard PyTorch Dataset
print(isinstance(torch_dataset, torch.utils.data.Dataset)) # prints: True
[ ]:
# you can use it in a DataLoader as normal
dataloader = torch.utils.data.DataLoader(
torch_dataset,
batch_size=8,
worker_init_fn=FiftyOneTorchDataset.worker_init
)
[ ]:
for i, batch in enumerate(dataloader):
print(f"Batch {i}: {batch}")
if i >= 2:
break
Field Mapping#
The field_mapping argument on GetItem connects the keys declared in required_keys to actual field names in your dataset. This lets you reuse the same GetItem across datasets that use different field names.
[ ]:
class DetectionGetItem(GetItem):
@property
def required_keys(self):
return ["filepath", "detections_field"]
def __call__(self, sample_dict):
return {
"filepath" : sample_dict["filepath"],
"labels" : [det.label for det in sample_dict["detections_field"].detections],
"boxes" : [det.bounding_box for det in sample_dict["detections_field"].detections]
}
[ ]:
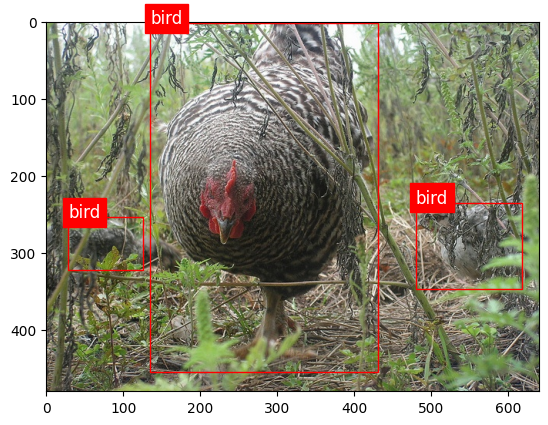
def plot_boxes(d):
img = Image.open(d["filepath"])
w, h = img.size
fig, ax = plt.subplots(1)
ax.imshow(img)
for label, box in zip(d["labels"], d["boxes"]):
x, y, bw, bh = box
rect = patches.Rectangle((x * w, y * h), bw * w, bh * h, linewidth=1, edgecolor="r", facecolor="none")
ax.add_patch(rect)
ax.text(x * w, y * h, label, color="white", fontsize=12, backgroundcolor="red")
plt.show()
[ ]:
# this dataset will use the "ground_truth" field for the "detections_field" key
gt_dataset = dataset.to_torch(
DetectionGetItem(field_mapping={"detections_field": "ground_truth"})
)
# meanwhile, this dataset will use the "predictions" field for the "detections_field" key
pred_dataset = dataset.to_torch(
DetectionGetItem(field_mapping={"detections_field": "predictions"})
)
[44]:
plot_boxes(gt_dataset[0])
[45]:
plot_boxes(pred_dataset[0])

[ ]:
# again we can use these datasets in DataLoaders as normal
# here we have to use a collate function because the number of detections
# per image can vary, so we can't simply stack them into a tensor
def detection_collate(batch):
filepaths = [item["filepath"] for item in batch]
labels = [item["labels"] for item in batch]
boxes = [item["boxes"] for item in batch]
return {
"filepaths": filepaths,
"labels": labels,
"boxes": boxes
}
gt_dataloader = torch.utils.data.DataLoader(
gt_dataset,
batch_size=4,
worker_init_fn=FiftyOneTorchDataset.worker_init,
collate_fn=detection_collate
)
[ ]:
for batch in gt_dataloader:
print(batch["filepaths"])
print(batch["labels"])
print(batch["boxes"])
break
With this, you can load batches of samples directly from any FiftyOne dataset or view using PyTorch, while customizing exactly which fields are retrieved via GetItem.