Ultralytics Integration#
FiftyOne integrates natively with Ultralytics, so you can load, fine-tune, and run inference with your favorite Ultralytics models on your FiftyOne datasets with just a few lines of code!
Setup#
To get started with Ultralytics, just install the following packages:
pip install "ultralytics>=8.1.0" "torch>=1.8"
Inference#
The examples below show how to run inference with various Ultralytics models on the following sample dataset:
1# Suppress Ultralytics logging
2import os; os.environ["YOLO_VERBOSE"] = "False"
3
4import fiftyone as fo
5import fiftyone.zoo as foz
6import fiftyone.utils.ultralytics as fou
7
8from ultralytics import YOLO
9
10# Load an example dataset
11dataset = foz.load_zoo_dataset("quickstart", max_samples=25)
12dataset.select_fields().keep_fields()
Image classification#
You can directly pass Ultralytics YOLO classification models to
apply_model():
1# YOLOv8
2model = YOLO("yolov8n-cls.pt")
3# model = YOLO("yolov8s-cls.pt")
4# model = YOLO("yolov8m-cls.pt")
5# model = YOLO("yolov8l-cls.pt")
6# model = YOLO("yolov8x-cls.pt")
7
8dataset.apply_model(model, label_field="classif")
9
10session = fo.launch_app(dataset)
Object detection#
You can directly pass Ultralytics YOLO or RTDETR detection models to
apply_model():
1# YOLOv8
2model = YOLO("yolov8s.pt")
3# model = YOLO("yolov8m.pt")
4# model = YOLO("yolov8l.pt")
5# model = YOLO("yolov8x.pt")
6
7# YOLOv5
8# model = YOLO("yolov5s.pt")
9# model = YOLO("yolov5m.pt")
10# model = YOLO("yolov5l.pt")
11# model = YOLO("yolov5x.pt")
12
13# YOLOv9
14# model = YOLO("yolov9c.pt")
15# model = YOLO("yolov9e.pt")
16
17# YOLOv10
18# model = YOLO("yolov10n.pt)
19# model = YOLO("yolov10s.pt)
20# model = YOLO("yolov10m.pt)
21# model = YOLO("yolov10l.pt)
22# model = YOLO("yolov10x.pt)
23
24# YOLOv11
25# model = YOLO("yolo11n.pt)
26# model = YOLO("yolo11s.pt)
27# model = YOLO("yolo11m.pt)
28# model = YOLO("yolo11l.pt)
29# model = YOLO("yolo11x.pt)
30
31# RTDETR
32# model = YOLO("rtdetr-l.pt")
33# model = YOLO("rtdetr-x.pt")
34
35dataset.apply_model(model, label_field="boxes")
36
37session = fo.launch_app(dataset)
Alternatively, you can use the
to_detections() utility to
manually convert Ultralytics predictions to
FiftyOne format:
1for sample in dataset.iter_samples(progress=True):
2 result = model(sample.filepath)[0]
3 sample["boxes"] = fou.to_detections(result)
4 sample.save()
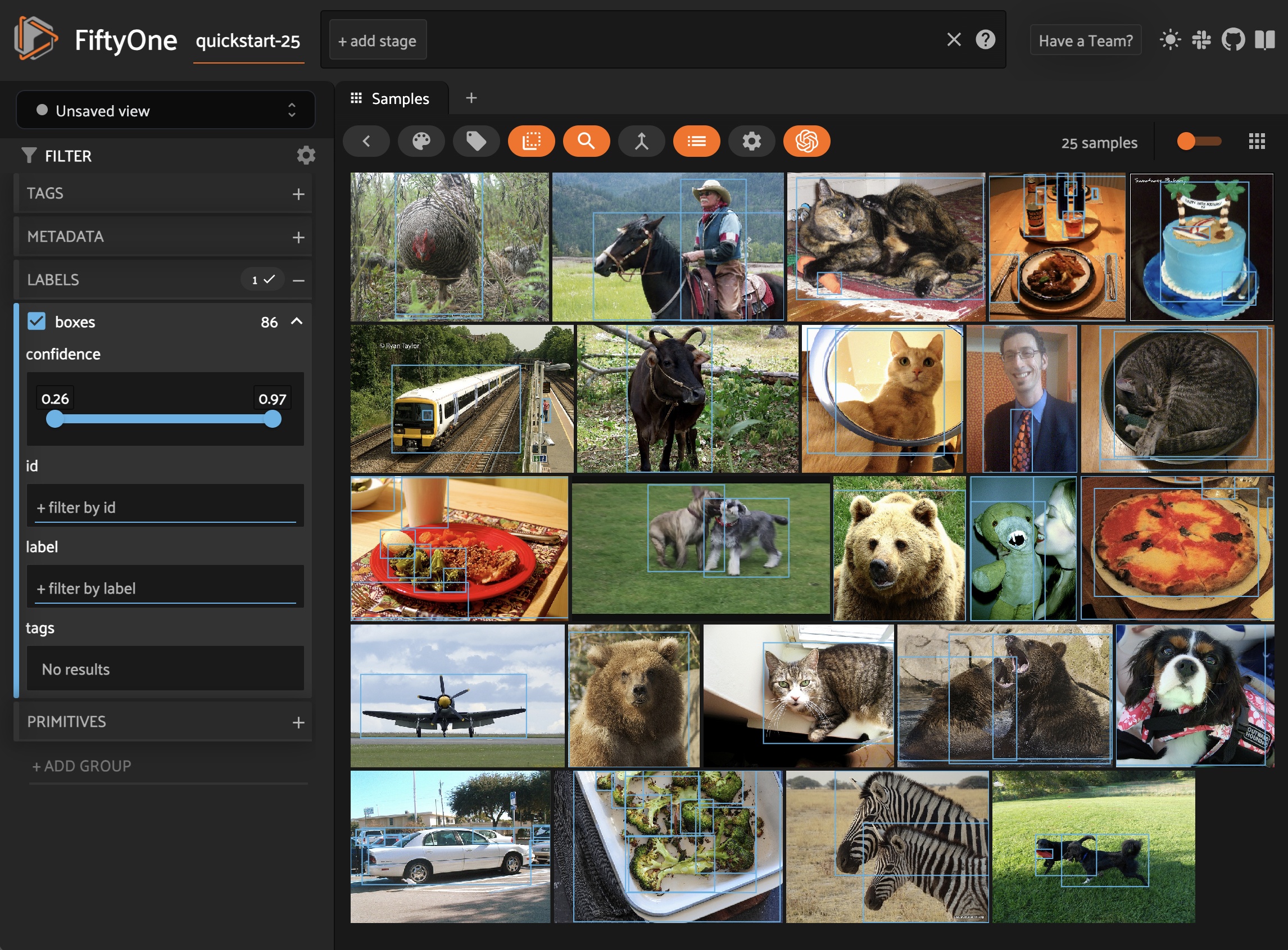
You can also load any of these models directly from the FiftyOne Model Zoo:
1model_name = "yolov5l-coco-torch"
2# model_name = "yolov8m-coco-torch"
3# model_name = "yolov9e-coco-torch"
4# model_name = "yolov10s-coco-torch"
5# model_name = "yolo11x-coco-torch"
6# model_name = "rtdetr-l-coco-torch"
7
8model = foz.load_zoo_model(model_name)
9
10dataset.apply_model(model, label_field="boxes", confidence_thresh=0.5)
11
12session = fo.launch_app(dataset)
You can use list_zoo_models() to see all
available YOLO models that are compatible with Ultralytics or SuperGradients:
1print(foz.list_zoo_models(tags="yolo"))
In general, YOLO model names will contain “yolov”, followed by the version number, then the model size (“n”, “s”, “m”, “l”, or “x”), and an indicator of the label classes (“coco” for MS COCO or “world” for open-world), followed by “torch”.
Instance segmentation#
You can directly pass Ultralytics YOLO segmentation models to
apply_model():
1model = YOLO("yolov8s-seg.pt")
2# model = YOLO("yolov8m-seg.pt")
3# model = YOLO("yolov8l-seg.pt")
4# model = YOLO("yolov8x-seg.pt")
5
6# model = YOLO("yolo11s-seg.pt")
7# model = YOLO("yolo11m-seg.pt")
8# model = YOLO("yolo11l-seg.pt")
9# model = YOLO("yolo11x-seg.pt")
10
11dataset.apply_model(model, label_field="instances")
12
13session = fo.launch_app(dataset)
Alternatively, you can use the
to_instances() and
to_polylines() utilities to
manually convert Ultralytics predictions into the desired
FiftyOne format:
1for sample in dataset.iter_samples(progress=True):
2 result = model(sample.filepath)[0]
3 sample["detections"] = fou.to_detections(result)
4 sample["instances"] = fou.to_instances(result)
5 sample["polylines"] = fou.to_polylines(result)
6 sample.save()
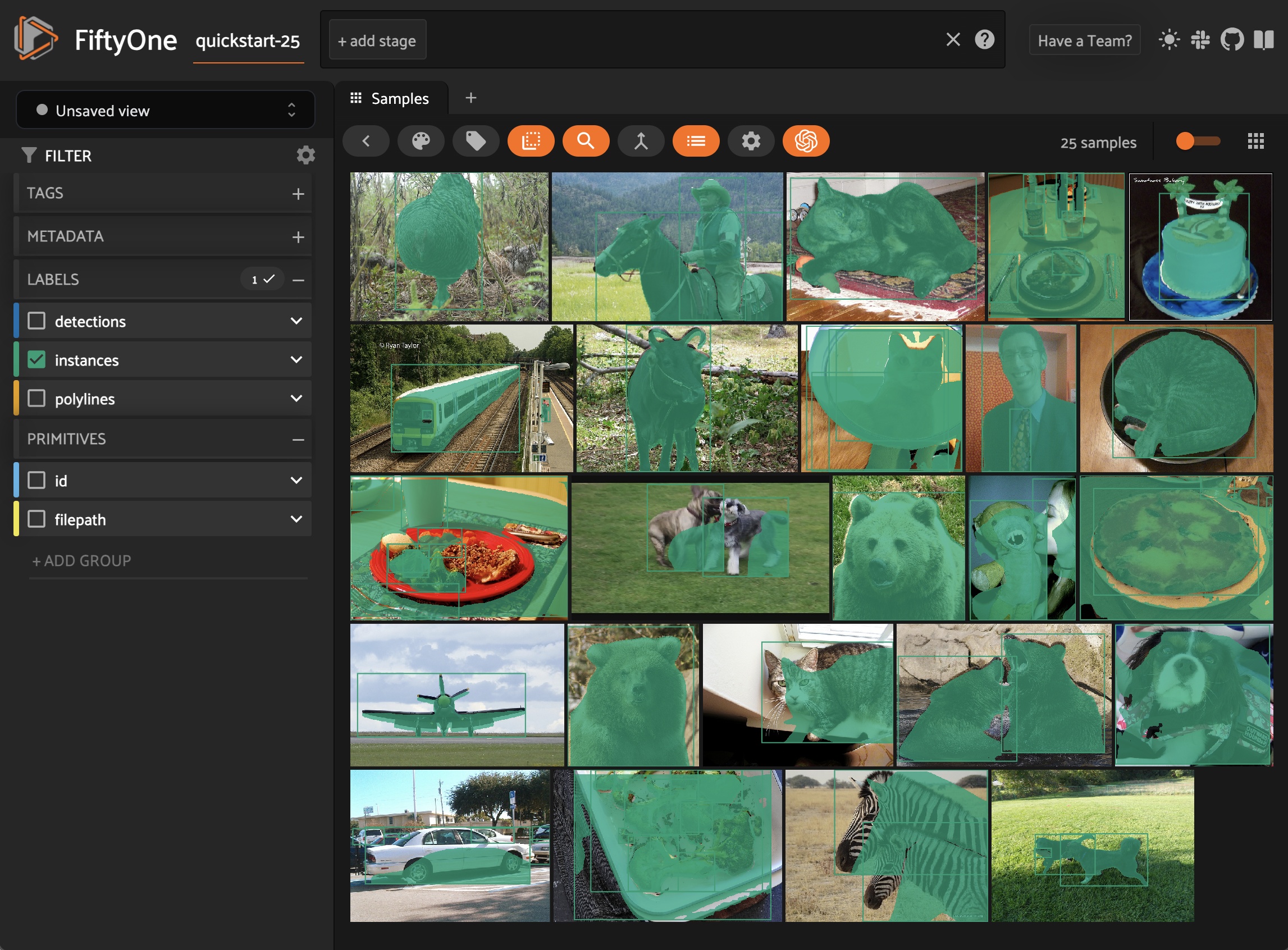
You can also load YOLOv8, YOLOv9, and YOLO11 segmentation models from the FiftyOne Model Zoo:
1model_name = "yolov8n-seg-coco-torch"
2# model_name = "yolov8s-seg-coco-torch"
3# model_name = "yolov8m-seg-coco-torch"
4# model_name = "yolov8l-seg-coco-torch"
5# model_name = "yolov8x-seg-coco-torch"
6
7# model_name = "yolov9c-seg-coco-torch"
8# model_name = "yolov9e-seg-coco-torch"
9
10# model_name = "yolo11n-seg-coco-torch"
11# model_name = "yolo11s-seg-coco-torch"
12# model_name = "yolo11m-seg-coco-torch"
13# model_name = "yolo11l-seg-coco-torch"
14# model_name = "yolo11x-seg-coco-torch"
15
16model = foz.load_zoo_model(model_name)
17
18dataset.apply_model(model, label_field="yolo_seg")
19
20session = fo.launch_app(dataset)
Keypoints#
You can directly pass Ultralytics YOLO pose models to
apply_model():
1model = YOLO("yolov8s-pose.pt")
2# model = YOLO("yolov8m-pose.pt")
3# model = YOLO("yolov8l-pose.pt")
4# model = YOLO("yolov8x-pose.pt")
5
6dataset.apply_model(model, label_field="keypoints")
7
8# Store the COCO-pose keypoint skeleton so the App can render it
9dataset.default_skeleton = fo.KeypointSkeleton(
10 labels=[
11 "nose", "left eye", "right eye", "left ear", "right ear",
12 "left shoulder", "right shoulder", "left elbow", "right elbow",
13 "left wrist", "right wrist", "left hip", "right hip",
14 "left knee", "right knee", "left ankle", "right ankle",
15 ],
16 edges=[
17 [11, 5, 3, 1, 0, 2, 4, 6, 12],
18 [9, 7, 5, 6, 8, 10],
19 [15, 13, 11, 12, 14, 16],
20 ],
21)
22
23session = fo.launch_app(dataset)
Alternatively, you can use the
to_keypoints() utility to
manually convert Ultralytics predictions to FiftyOne format:
1for sample in dataset.iter_samples(progress=True):
2 result = model(sample.filepath)[0]
3 sample["keypoints"] = fou.to_keypoints(result)
4 sample.save()
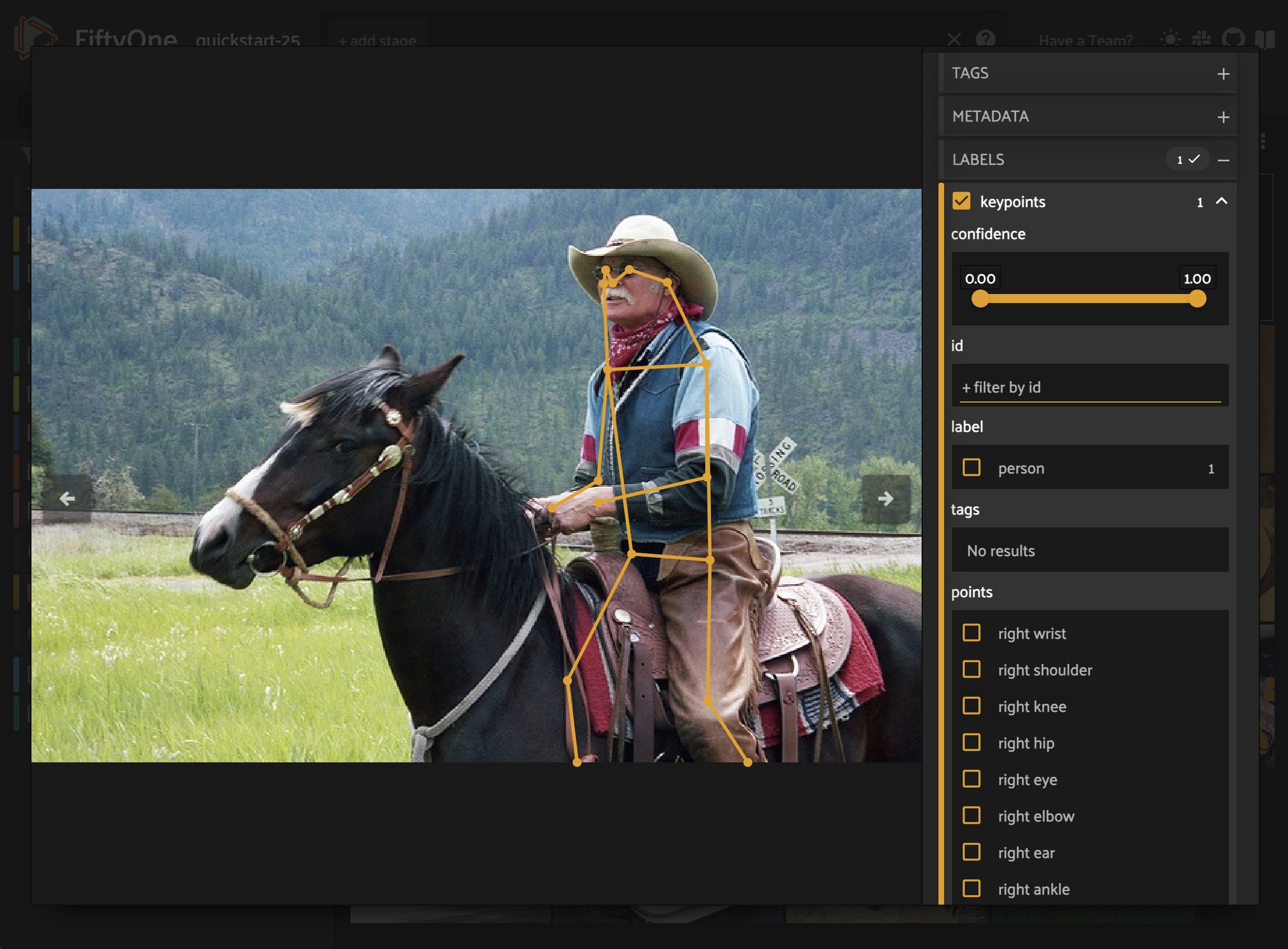
Oriented bounding boxes#
You can directly pass Ultralytics YOLO oriented bounding box models to
apply_model():
1model = YOLO("yolov8n-obb.pt")
2# model = YOLO("yolov8s-obb.pt")
3# model = YOLO("yolov8m-obb.pt")
4# model = YOLO("yolov8l-obb.pt")
5# model = YOLO("yolov8x-obb.pt")
6
7dataset.apply_model(model, label_field="oriented_boxes")
8
9session = fo.launch_app(dataset)
You can also load YOLOv8 oriented bounding box models from the FiftyOne Model Zoo:
1model_name = "yolov8n-obb-dotav1-torch"
2# model_name = "yolov8s-obb-dotav1-torch"
3# model_name = "yolov8m-obb-dotav1-torch"
4# model_name = "yolov8l-obb-dotav1-torch"
5# model_name = "yolov8x-obb-dotav1-torch"
6
7model = foz.load_zoo_model(model_name)
8
9dataset.apply_model(model, label_field="oriented_boxes")
10
11session = fo.launch_app(dataset)
Note
The oriented bounding box models are trained on the DOTA dataset, which consists of drone images with oriented bounding boxes. The models are trained to predict on bird’s eye view images, so applying them to regular images may not yield good results.
Open vocabulary detection#
FiftyOne’s Ultralytics integration also supports real-time open vocabulary object detection via YOLO World.
The usage syntax is the same as for regular object detection, with the caveat that you can set the classes that the model should detect:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4from ultralytics import YOLO
5
6# Load dataset
7dataset = foz.load_zoo_dataset(
8 "voc-2007", split="validation", max_samples=100
9)
10dataset.select_fields().keep_fields()
11
12# Load model
13model = YOLO("yolov8l-world.pt")
14# model = YOLO("yolov8s-world.pt")
15# model = YOLO("yolov8m-world.pt")
16# model = YOLO("yolov8x-world.pt")
17
18# Set open vocabulary classes
19model.set_classes(
20 ["plant", "window", "keyboard", "human baby", "computer monitor"]
21)
22
23label_field = "yolo_world_detections"
24
25# Apply model
26dataset.apply_model(model, label_field=label_field)
27
28# Visualize the detection patches
29patches = dataset.to_patches(label_field)
30session = fo.launch_app(patches)
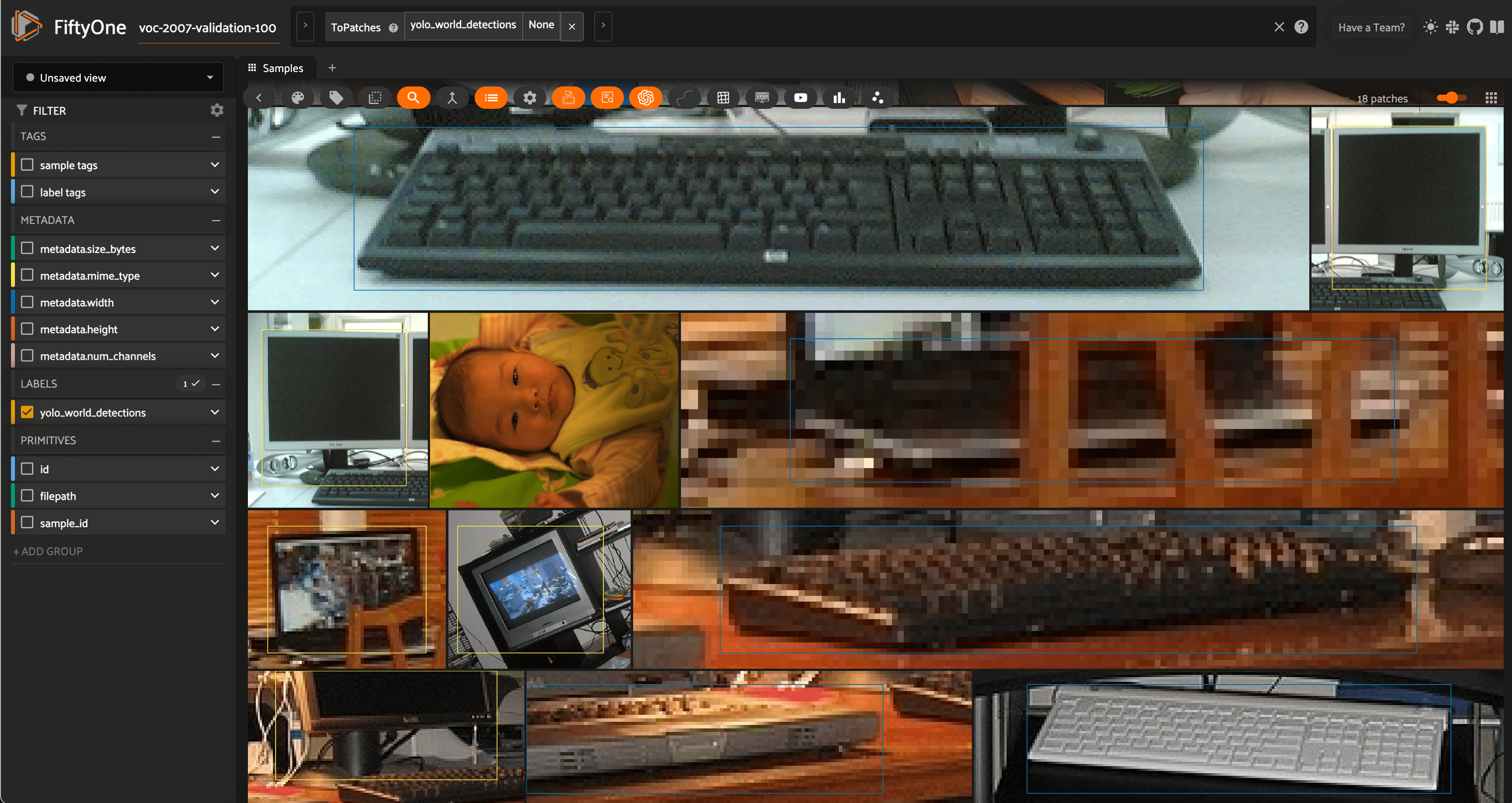
You can also load these open-vocabulary models from the FiftyOne Model Zoo, optionally specifying the classes that the model should detect:
1model_name = "yolov8l-world-torch"
2# model_name = "yolov8m-world-torch"
3# model_name = "yolov8x-world-torch"
4
5model = foz.load_zoo_model(
6 model_name,
7 classes=["plant", "window", "keyboard", "human baby", "computer monitor"],
8)
9
10dataset.apply_model(model, label_field="yolo_world_detections")
11
12session = fo.launch_app(dataset)
Open vocabulary segmentation#
FiftyOne’s Ultralytics integration also supports real-time open vocabulary instance segmentation via YOLOE.
The usage syntax is the same as for regular instance segmentation, with the caveat that you can set the classes that the model should segment:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4from ultralytics import YOLO
5
6# Load dataset
7dataset = foz.load_zoo_dataset(
8 "voc-2007", split="validation", max_samples=100
9)
10dataset.select_fields().keep_fields()
11
12# Load model
13model = YOLO("yoloe-11s-seg.pt")
14# model = YOLO("yoloe-11m-seg.pt")
15# model = YOLO("yoloe-11l-seg.pt")
16
17# model = YOLO("yoloe-v8s-seg.pt")
18# model = YOLO("yoloe-v8m-seg.pt")
19# model = YOLO("yoloe-v8l-seg.pt")
20
21# Set open vocabulary classes
22classes = ["plant", "window", "keyboard", "human baby", "computer monitor"]
23model.set_classes(classes, model.get_text_pe(classes))
24
25label_field = "yoloe_segmentations"
26
27# Apply model
28dataset.apply_model(model, label_field=label_field)
You can also load these open-vocabulary models from the FiftyOne Model Zoo, optionally specifying the classes that the model should detect:
1model_name = "yoloe11s-seg-torch"
2# model_name = "yoloe11m-seg-torch"
3# model_name = "yoloe11l-seg-torch"
4
5# model_name = "yoloev8s-seg-torch"
6# model_name = "yoloev8m-seg-torch"
7# model_name = "yoloev8l-seg-torch"
8
9model = foz.load_zoo_model(
10 model_name,
11 classes=["plant", "window", "keyboard", "human baby", "computer monitor"],
12)
13
14dataset.apply_model(model, label_field="yoloe_segmentations")
15
16session = fo.launch_app(dataset)
Note
While Ultralytics YOLOE models support text and visual prompts, YOLOE in FiftyOne currently only supports text prompts.
Batch inference#
When using
apply_model(),
you can request batch inference by passing the optional batch_size parameter:
1dataset.apply_model(model, label_field="predictions", batch_size=16)
The manual inference loops can be also executed using batch inference via the pattern below:
1from fiftyone.core.utils import iter_batches
2
3filepaths = dataset.values("filepath")
4batch_size = 16
5
6predictions = []
7for paths in iter_batches(filepaths, batch_size):
8 results = model(paths)
9 predictions.extend(fou.to_detections(results))
10
11dataset.set_values("predictions", predictions)
You can also provide overrides to the underlying Ultralytics model by passing
them as kwargs to
load_zoo_model():
1# Use rectangular resizing with a batch size of 1
2model = foz.load_zoo_model(model_name, overrides={"rect": True})
3dataset.apply_model(model, label_field="predictions", batch_size=1)
Note
See this section for more information about performing batch updates to your FiftyOne datasets.
Training#
You can use FiftyOne’s builtin YOLOv5 exporter to export your FiftyOne datasets for use with Ultralytics models.
For example, the code below prepares a random subset of the Open Images v7 dataset for fine-tuning:
1import fiftyone as fo
2import fiftyone.utils.ultralytics as fou
3import fiftyone.zoo as foz
4
5# The path to export the dataset
6EXPORT_DIR = "/tmp/oiv7-yolo"
7
8# Prepare train split
9
10train = foz.load_zoo_dataset(
11 "open-images-v7",
12 split="train",
13 label_types=["detections"],
14 max_samples=100,
15)
16
17# YOLO format requires a common classes list
18classes = train.default_classes
19
20train.export(
21 export_dir=EXPORT_DIR,
22 dataset_type=fo.types.YOLOv5Dataset,
23 label_field="ground_truth",
24 split="train",
25 classes=classes,
26)
27
28# Prepare validation split
29
30validation = foz.load_zoo_dataset(
31 "open-images-v7",
32 split="validation",
33 label_types=["detections"],
34 max_samples=10,
35)
36
37validation.export(
38 export_dir=EXPORT_DIR,
39 dataset_type=fo.types.YOLOv5Dataset,
40 label_field="ground_truth",
41 split="val", # Ultralytics uses 'val'
42 classes=classes,
43)
From here, training an Ultralytics model is as simple as passing the path to the dataset YAML file:
1from ultralytics import YOLO
2
3# The path to the `dataset.yaml` file we created above
4YAML_FILE = "/tmp/oiv7-yolo/dataset.yaml"
5
6# Load a model
7model = YOLO("yolov8s.pt") # load a pretrained model
8# model = YOLO("yolov8s.yaml") # build a model from scratch
9
10# Train the model
11model.train(data=YAML_FILE, epochs=3)
12
13# Evaluate model on the validation set
14metrics = model.val()
15
16# Export the model
17path = model.export(format="onnx")