|
|
|
|
Exploring the Dataset Zoo#
This experience introduces you to the core components of the FiftyOne Zoo:
The Dataset Zoo for accessing and exploring public datasets
The Model Zoo for running pre-trained models on your data
Creating your own remotely-sourced datasets for reuse and collaboration
Whether you’re a researcher, engineer, or educator, these tools help streamline your computer vision workflows in FiftyOne.
💡 Make sure to run
pip install fiftyone torch torchvisionbefore starting.
[ ]:
!pip install fiftyone
!pip install torch torchvision
FiftyOne Zoo: A Hub for Datasets and Models#
FiftyOne Zoo provides easy access to a vast collection of pre-built datasets and pre-trained models. This notebook will guide you through exploring and using these resources.
Key Components:#
Dataset Zoo: Offers a wide range of computer vision datasets, ready for immediate use.
Model Zoo: Provides pre-trained models for various tasks, enabling quick experimentation and deployment.
Let’s dive in!
[1]:
import fiftyone as fo
import fiftyone.zoo as foz
Dataset Zoo#
Exploring the Dataset Zoo#
The Dataset Zoo simplifies the process of loading and working with popular datasets.
Listing Available Datasets#
[2]:
print("Available Datasets:")
for dataset_name in foz.list_zoo_datasets():
print(f"- {dataset_name}")
Available Datasets:
- activitynet-100
- activitynet-200
- bdd100k
- caltech101
- caltech256
- cifar10
- cifar100
- cityscapes
- coco-2014
- coco-2017
- fashion-mnist
- fiw
- hmdb51
- imagenet-2012
- imagenet-sample
- kinetics-400
- kinetics-600
- kinetics-700
- kinetics-700-2020
- kitti
- kitti-multiview
- lfw
- mnist
- open-images-v6
- open-images-v7
- places
- quickstart
- quickstart-3d
- quickstart-geo
- quickstart-groups
- quickstart-video
- sama-coco
- ucf101
- voc-2007
- voc-2012
Loading a Dataset (Example: MNIST)#
[ ]:
dataset = foz.load_zoo_dataset("mnist")
print(dataset)
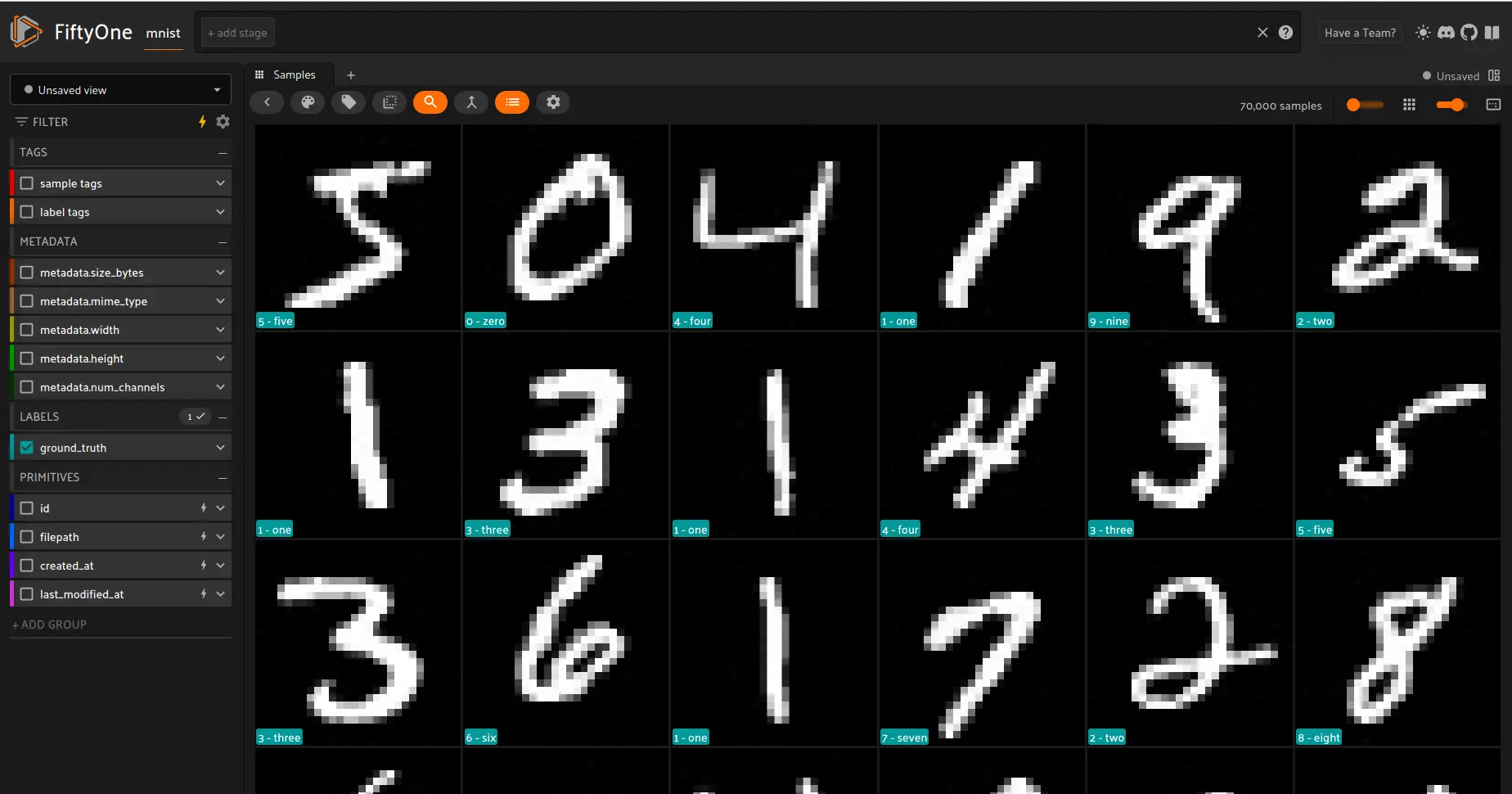
Visualizing the Dataset#
[ ]:
session = fo.launch_app(dataset)
Session launched. Run `session.show()` to open the App in a cell output.
Welcome to
███████╗██╗███████╗████████╗██╗ ██╗ ██████╗ ███╗ ██╗███████╗
██╔════╝██║██╔════╝╚══██╔══╝╚██╗ ██╔╝██╔═══██╗████╗ ██║██╔════╝
█████╗ ██║█████╗ ██║ ╚████╔╝ ██║ ██║██╔██╗ ██║█████╗
██╔══╝ ██║██╔══╝ ██║ ╚██╔╝ ██║ ██║██║╚██╗██║██╔══╝
██║ ██║██║ ██║ ██║ ╚██████╔╝██║ ╚████║███████╗
╚═╝ ╚═╝╚═╝ ╚═╝ ╚═╝ ╚═════╝ ╚═╝ ╚═══╝╚══════╝ v1.3.1
If you're finding FiftyOne helpful, here's how you can get involved:
|
| ⭐⭐⭐ Give the project a star on GitHub ⭐⭐⭐
| https://github.com/voxel51/fiftyone
|
| 🚀🚀🚀 Join the FiftyOne Discord community 🚀🚀🚀
| https://community.voxel51.com/
|
Loading a Specific Split (Example: COCO)#
[ ]:
try:
coco_train = foz.load_zoo_dataset("coco-2017", split="train")
print(coco_train)
except:
print("coco-2017 dataset is not available, please install it if needed.")
Downloading and Loading a Dataset with Specific Splits and Downsampling (Example: open-images-v6)#
[ ]:
try:
dataset = foz.load_zoo_dataset(
"open-images-v6",
splits=["train", "validation"],
label_types=["detections", "segmentations"],
classes=["Car", "Person"],
max_samples=50,
)
print(dataset)
except:
print("open-images-v6 dataset is not available, please install it if needed.")
Working with Dataset Metadata#
[ ]:
try:
metadata = foz.get_zoo_dataset_info("coco-2017")
print(metadata)
except:
print("coco-2017 metadata is not available, please install it if needed.")
Example: Loading a Remote Image Dataset#
With fiftyOne you can work/create zoo datasets whose download/preparation methods are hosted via GitHub repositories or public URLs
[24]:
dataset = foz.load_zoo_dataset(
"https://github.com/voxel51/coco-2017",
split="validation",
)
session = fo.launch_app(dataset, port=5152, auto=False)
Downloading https://github.com/voxel51/coco-2017...
33.7Kb [1.4ms elapsed, ? remaining, 350.4Mb/s]
Downloading split 'validation' to '/home/paula/fiftyone/voxel51/coco-2017/validation' if necessary
Downloading annotations to '/home/paula/fiftyone/voxel51/coco-2017/tmp-download/annotations_trainval2017.zip'
100% |██████| 1.9Gb/1.9Gb [1.4m elapsed, 0s remaining, 20.7Mb/s]
Extracting annotations to '/home/paula/fiftyone/voxel51/coco-2017/raw/instances_val2017.json'
Downloading images to '/home/paula/fiftyone/voxel51/coco-2017/tmp-download/val2017.zip'
20% |█-----| 1.2Gb/6.1Gb [1.0m elapsed, 4.0m remaining, 22.8Mb/s]
Other loading examples with remote datasets#
Load 50 random samples from the validation split
Only the required images will be downloaded (if necessary). By default, only detections are loaded
[ ]:
dataset = foz.load_zoo_dataset(
"https://github.com/voxel51/coco-2017",
split="validation",
max_samples=50,
shuffle=True,
)
session = fo.launch_app(dataset, port=5152, auto=False)
Load segmentations for 25 samples from the validation split that contain cats and dogs
Images that contain all classes will be prioritized first, followed by images that contain at least one of the required classes. If there are not enough images matching classes in the split to meet max_samples, only the available images will be loaded. Images will only be downloaded if necessary
[ ]:
dataset = foz.load_zoo_dataset(
"https://github.com/voxel51/coco-2017",
split="validation",
label_types=["segmentations"],
classes=["cat", "dog"],
max_samples=25,
)
session = fo.launch_app(dataset, port=5152, auto=False)
Download the entire validation split and load both detections and segmentations.
Subsequent partial loads of the validation split will never require downloading any images.
[ ]:
dataset = foz.load_zoo_dataset(
"https://github.com/voxel51/coco-2017",
split="validation",
label_types=["detections", "segmentations"],
)
session = fo.launch_app(dataset, port=5152, auto=False)