|
|
|
|
Understanding and Using Embeddings#
Welcome to this hands-on workshop where we will explore embeddings and their importance in Visual AI. Embeddings play a crucial role in image search, clustering, anomaly detection, and representation learning. In this notebook, we will learn how to generate, visualize, and explore embeddings using FiftyOne.
Learning Objectives:#
Understand what embeddings are and why they matter in Visual AI.
Learn how to compute and store embeddings in FiftyOne.
Use embeddings for similarity search and visualization.
Leverage FiftyOne’s interactive tools to explore embeddings.
What Are Embeddings?#
Embeddings are vector representations of data (images, videos, text, etc.) that capture meaningful characteristics. For images, embeddings store compressed feature representations learned by deep learning models. These features enable tasks such as:
Similarity Search: Find images that are visually similar.
Clustering: Group images with shared characteristics.
Anomaly Detection: Identify outliers in datasets.
Transfer Learning: Use learned embeddings to improve other AI tasks.
Further Reading:#
Generating Embeddings in FiftyOne#
FiftyOne provides seamless integration for embedding computation. You can extract embeddings using pre-trained deep learning models (such as CLIP, ResNet, or custom models) and store them in FiftyOne datasets.
How It Works:#
Load a dataset in FiftyOne.
Extract embeddings from a model.
Store and visualize embeddings.
Relevant Documentation: Computing and Storing Embeddings
Note: You must install the umap-learn>=0.5 package in order to use UMAP-based visualization. This is recommended, as UMAP is awesome! If you do not wish to install UMAP, try method='tsne' instead
[ ]:
!pip install fiftyone huggingface_hub gdown umap-learn torch torchvision
Select a GPU Runtime if possible, install the requirements, restart the session, and verify the device information.
[ ]:
import torch
def get_device():
"""Get the appropriate device for model inference."""
if torch.cuda.is_available():
return "cuda"
elif hasattr(torch.backends, "mps") and torch.backends.mps.is_available():
return "mps"
return "cpu"
DEVICE = get_device()
print(f"Using device: {DEVICE}")
Download dataset from source#
[ ]:
import fiftyone as fo # base library and app
import fiftyone.utils.huggingface as fouh # Hugging Face integration
dataset_name = "MVTec_AD"
# Check if the dataset exists
if dataset_name in fo.list_datasets():
print(f"Dataset '{dataset_name}' exists. Loading...")
dataset = fo.load_dataset(dataset_name)
else:
print(f"Dataset '{dataset_name}' does not exist. Creating a new one...")
# Clone the dataset with a new name and make it persistent
dataset_ = fouh.load_from_hub("Voxel51/mvtec-ad", persistent=True, overwrite=True)
dataset = dataset_.clone("MVTec_AD")
dataset_emb = fo.load_dataset("MVTec_AD_emb")
We can download the file from Google Drive using gdown
Let’s get started by importing the FiftyOne library, and the utils we need for a COCO format dataset, depending of the dataset format you should change that option. Supported Formats
[ ]:
import gdown
url = "https://drive.google.com/uc?id=1nAuFIyl2kM-TQXduSJ9Fe_ZEIVog4tth"
gdown.download(url, output="mvtec_ad.zip", quiet=False)
!unzip mvtec_ad.zip
import fiftyone as fo
dataset_name = "MVTec_AD"
# Check if the dataset exists
if dataset_name in fo.list_datasets():
print(f"Dataset '{dataset_name}' exists. Loading...")
dataset_emb = fo.load_dataset(dataset_name)
else:
print(f"Dataset '{dataset_name}' does not exist. Creating a new one...")
dataset_ = fo.Dataset.from_dir(
dataset_dir="/content/mvtec-ad",
dataset_type=fo.types.FiftyOneDataset
)
dataset_emb = dataset_.clone("MVTec_AD")
[ ]:
print(dataset_emb)
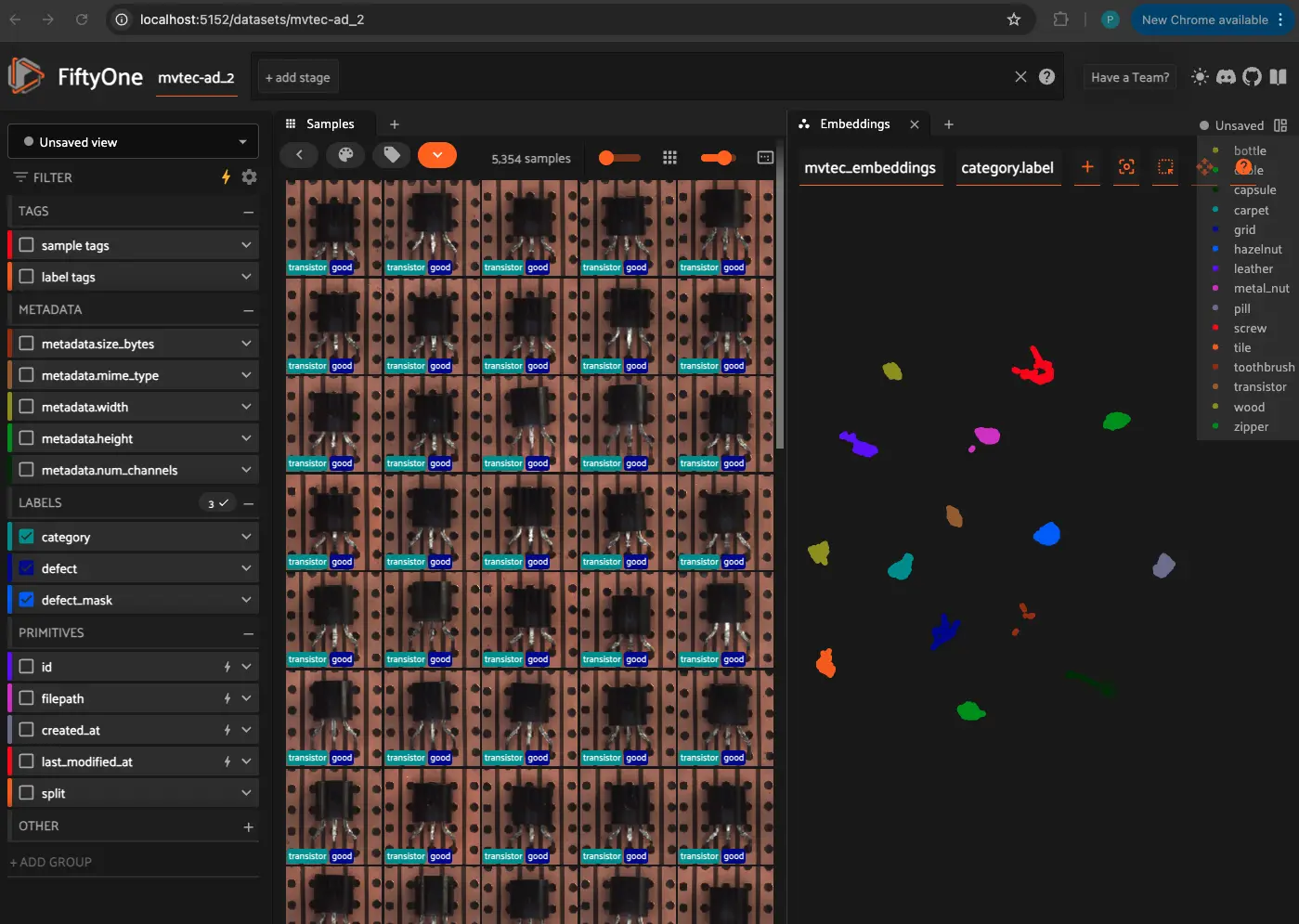
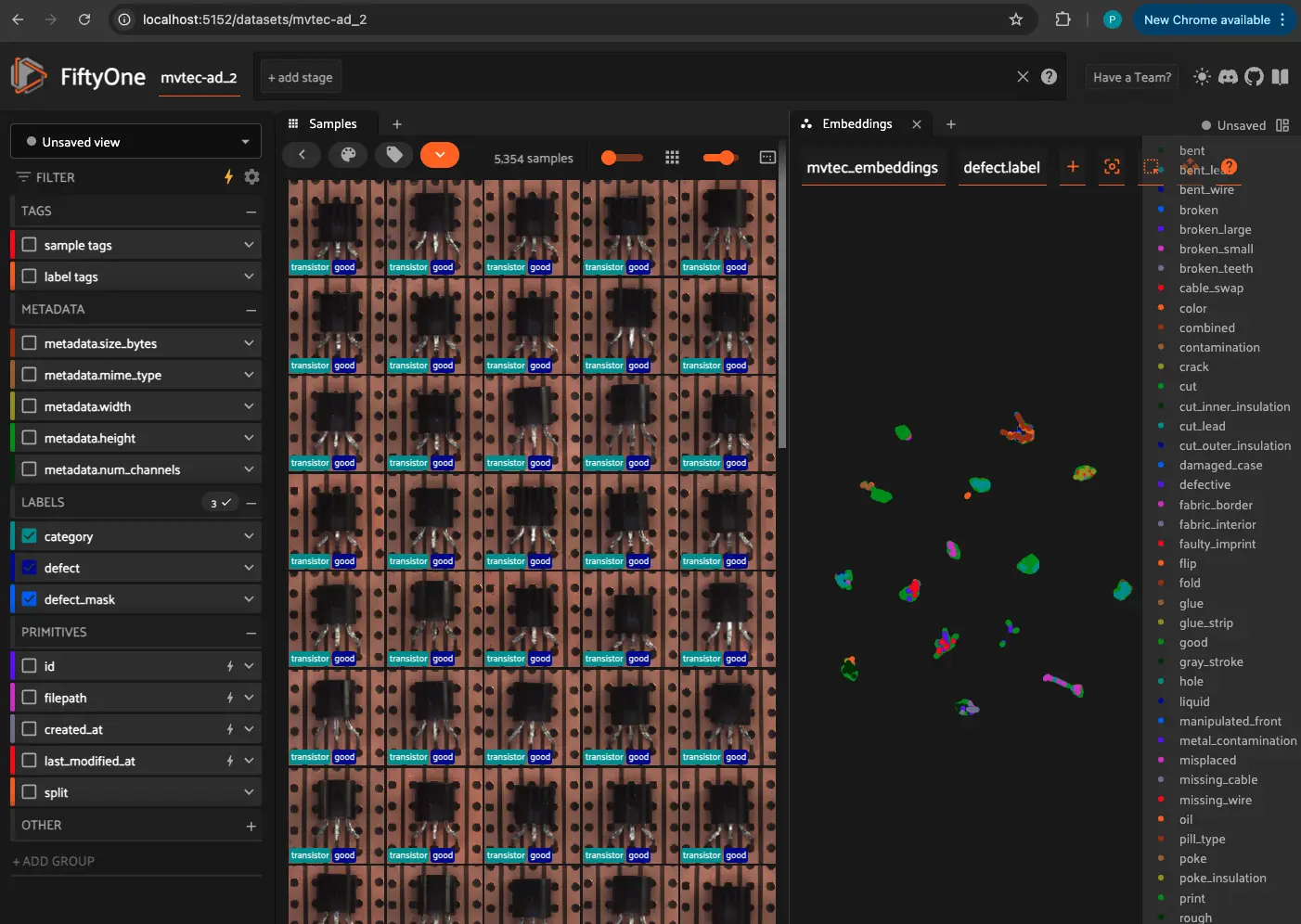
Exploring and Visualizing Embeddings#
Once embeddings are generated, we can visualize them using dimensionality reduction techniques like:
t-SNE (t-Distributed Stochastic Neighbor Embedding)
UMAP (Uniform Manifold Approximation and Projection)
These methods reduce the high-dimensional feature space into 2D/3D representations for interactive visualization.
Relevant Documentation: Visualizing Embeddings in FiftyOne, Dimensionality Reduction
Note: Be patient, it will take about 5-10 minutes to compute the embeddings.
[ ]:
# Compute embeddings for MVTec AD using CLIP
import fiftyone.brain as fob
import fiftyone.zoo.models as fozm
# Load a pre-trained model (e.g., CLIP)
model = fozm.load_zoo_model("clip-vit-base32-torch")
fob.compute_visualization(
dataset_emb,
model=model,
embeddings="mvtec_emb",
brain_key="mvtec_embeddings",
method="umap", # Change to "tsne" for t-SNE
num_dims=2 # Reduce to 2D
)
[ ]:
dataset_emb.reload()
print(dataset_emb)
print(dataset_emb.last())
Performing Similarity Search with Embeddings#
With embeddings, we can search for visually similar images by computing the nearest neighbors in the embedding space. FiftyOne provides built-in tools to perform similarity search efficiently.
Relevant Documentation: Performing Similarity Search
[ ]:
session = fo.launch_app(dataset_emb, port=5152, auto=False)
print(session.url)
Next Steps:#
Try using different models for embedding extraction, explore clustering techniques, and test similarity search with your own datasets! 🚀