|
|
|
|
DINOv3 visual search#
1. Install Required Libraries#
We start by installing FiftyOne and the Hugging Face transformers library. This will allow us to load the DINOv3 model from Hugging Face and use FiftyOne’s dataset visualization and analysis features.
Note: We install transformers directly from the development branch to ensure compatibility with the latest DINOv3 features.
Since the DINOv3 functionality is not yet available in the stable transformers release, we install it from the development branch. See the FiftyOne + Hugging Face integration guide for more details on using experimental model versions.
[ ]:
!pip install --upgrade pip
!pip install git+https://github.com/huggingface/transformers
!pip install -q huggingface_hub
!pip install fiftyone
2. Log in to Hugging Face#
We authenticate with Hugging Face to retrieve the latest model weights. You must have access to the model you want to load. See Hugging Face authentication docs for details.
[ ]:
from huggingface_hub import notebook_login
notebook_login()
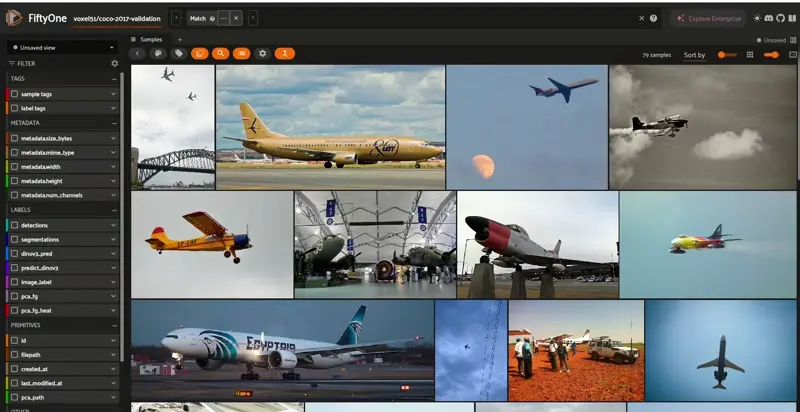
Load a quick start dataset#
To explore more dataset option visit the docs Dataset Zoo or load your own dataset
[ ]:
import fiftyone as fo
import fiftyone.zoo as foz
# You can load your own dataset
dataset = foz.load_zoo_dataset(
"https://github.com/voxel51/coco-2017",
split="validation",
)
You can load any of the model available in Hugging Face https://huggingface.co/collections/facebook/dinov3-68924841bd6b561778e31009
Thanks to the integration of Hugging Face in Fiftyone we are able to perform multiple tasks with the model, explore more here Integration HuggingFace
Working with DINOv3 Embeddings in FiftyOne#
In this example, we focus on using DINOv3 embeddings for visual search and similarity-based exploration in FiftyOne.
Workflow#
- Compute embeddingsWe run each image through the DINOv3 model and extract either:
The class token embedding (for global representation), or
The patch token embeddings (for more granular, region-level similarity).
Learn more: Computing embeddings in FiftyOne.
- Visualize embeddingsWe project the embeddings into 2D space using dimensionality reduction (e.g., t-SNE or UMAP) so we can see clusters of visually similar images.
FiftyOne makes this interactive through its Embeddings Visualization in the App.
- Compute similarity searchUsing FiftyOne’s similarity search tools, we select a query image (in this example, the first image in the dataset, but you can choose any).
The system finds and ranks the most visually similar images based on embedding distance.
- Sort by similarityWe display the results sorted from most to least similar, making it easy to:
Detect near-duplicates.
Explore visual clusters.
Identify outliers in the dataset.
[51]:
import transformers
import fiftyone.utils.transformers as fouhft
transformers_model = transformers.AutoModel.from_pretrained("facebook/dinov3-vitl16-pretrain-lvd1689m")
model_config = fouhft.FiftyOneTransformerConfig(
{
"model": transformers_model,
"name_or_path":"facebook/dinov3-vitl16-pretrain-lvd1689m",
}
)
model = fouhft.FiftyOneTransformer(model_config)
[52]:
dataset.compute_embeddings(model, embeddings_field="embeddings_dinov3")
100% |███████████████| 5000/5000 [5.1m elapsed, 0s remaining, 16.3 samples/s]
INFO:eta.core.utils: 100% |███████████████| 5000/5000 [5.1m elapsed, 0s remaining, 16.3 samples/s]
[54]:
dataset
[54]:
Name: voxel51/coco-2017-validation
Media type: image
Num samples: 5000
Persistent: False
Tags: []
Sample fields:
id: fiftyone.core.fields.ObjectIdField
filepath: fiftyone.core.fields.StringField
tags: fiftyone.core.fields.ListField(fiftyone.core.fields.StringField)
metadata: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.metadata.ImageMetadata)
created_at: fiftyone.core.fields.DateTimeField
last_modified_at: fiftyone.core.fields.DateTimeField
detections: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Detections)
segmentations: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Detections)
embeddings_dinov3: fiftyone.core.fields.VectorField
[55]:
import fiftyone.brain as fob
viz = fob.compute_visualization(
dataset,
embeddings="embeddings_dinov3",
brain_key="dino_dense_umap"
)
Generating visualization...
INFO:fiftyone.brain.visualization:Generating visualization...
UMAP( verbose=True)
Fri Aug 15 20:04:17 2025 Construct fuzzy simplicial set
Fri Aug 15 20:04:17 2025 Finding Nearest Neighbors
Fri Aug 15 20:04:17 2025 Building RP forest with 9 trees
Fri Aug 15 20:04:23 2025 NN descent for 12 iterations
1 / 12
2 / 12
3 / 12
4 / 12
5 / 12
Stopping threshold met -- exiting after 5 iterations
Fri Aug 15 20:04:39 2025 Finished Nearest Neighbor Search
Fri Aug 15 20:04:39 2025 Construct embedding
completed 0 / 500 epochs
completed 50 / 500 epochs
completed 100 / 500 epochs
completed 150 / 500 epochs
completed 200 / 500 epochs
completed 250 / 500 epochs
completed 300 / 500 epochs
completed 350 / 500 epochs
completed 400 / 500 epochs
completed 450 / 500 epochs
Fri Aug 15 20:04:44 2025 Finished embedding
[57]:
session = fo.launch_app(dataset, port=5151)
[57]:
print(session.url)
https://5151-gpu-t4-s-85ayl83jjz0q-a.us-west4-1.prod.colab.dev?polling=true
[58]:
idx = fob.compute_similarity(
dataset,
embeddings="embeddings_dinov3",
metric="cosine",
brain_key="dino_sim",
)
[59]:
query_id = dataset.first().id
view = dataset.sort_by_similarity(query_id, k=20)
[115]:
session.view = view
Classification Tasks with DINOv3#
In this example, we use the DINOv3 model to perform an image classification task by integrating its embeddings with a Logistic Regression (linear) classifier.
Workflow#
- Extract embeddingsWe feed each image through the DINOv3 model and extract the class token embedding.
The class token acts as a compact representation of the entire image.
More on embeddings: FiftyOne embeddings guide.
- Train a linear classifierUsing the extracted embeddings as input features and the ground truth labels from our dataset, we train a Logistic Regression (linear) classifier to predict image classes.
Linear classifiers are effective for high-dimensional feature spaces like DINOv3 embeddings.
- Run inferenceWe pass unseen images through the same pipeline to generate embeddings and predict their class labels using the trained SVM.
- Evaluate results in FiftyOneWe visualize and analyze the model predictions in FiftyOne, using:
Classification evaluation to compute metrics like accuracy, precision, and recall.
Confusion matrix to see where the model is making mistakes.
Get id, path, embeddinds and classes to create a classifier
[95]:
from collections import Counter
from sklearn.preprocessing import normalize
from sklearn.linear_model import LogisticRegression
import numpy as np
ids = dataset.values("id")
paths = dataset.values("filepath")
embs = dataset.values("embeddings_dinov3")
det_lists = dataset.values("detections.detections.label")
img_labels = [Counter(L).most_common(1)[0][0] if L else None for L in det_lists]
dataset.set_values(
"image_label",
[fo.Classification(label=l) if l is not None else None for l in img_labels],
)
[96]:
mask = [(x is not None) and (y is not None) for x, y in zip(embs, img_labels)]
X = normalize(np.stack([x for x,m in zip(embs,mask) if m], axis=0))
y = [lab for lab,m in zip(img_labels,mask) if m]
[97]:
# 3) Train a tiny linear head
clf = LogisticRegression(max_iter=2000, class_weight="balanced", n_jobs=-1).fit(X, y)
[ ]:
# --- inference on ALL samples using embeddings only ---
for sample in dataset.iter_samples(autosave=True, progress=True):
v = sample["embeddings_dinov3"]
if v is None:
continue
X = normalize(np.asarray(v, dtype=np.float32).reshape(1, -1))
p = clf.predict_proba(X)[0]
k = int(np.argmax(p))
sample["predict_dinov3"] = fo.Classification(
label=str(clf.classes_[k]),
confidence=float(p[k]),
)
100% |███████████████| 5000/5000 [1.2m elapsed, 0s remaining, 93.4 samples/s]
INFO:eta.core.utils: 100% |███████████████| 5000/5000 [1.2m elapsed, 0s remaining, 93.4 samples/s]
Evaluate the results of the classification
[99]:
results = dataset.evaluate_classifications(
"predict_dinov3", gt_field="image_label", method="simple", eval_key="dino_simple"
)
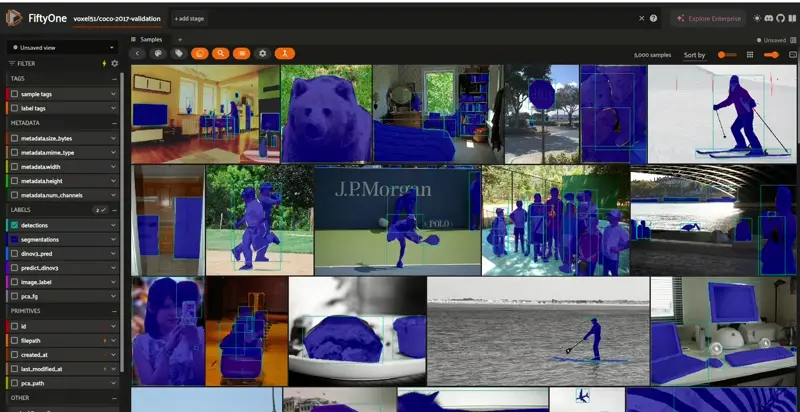
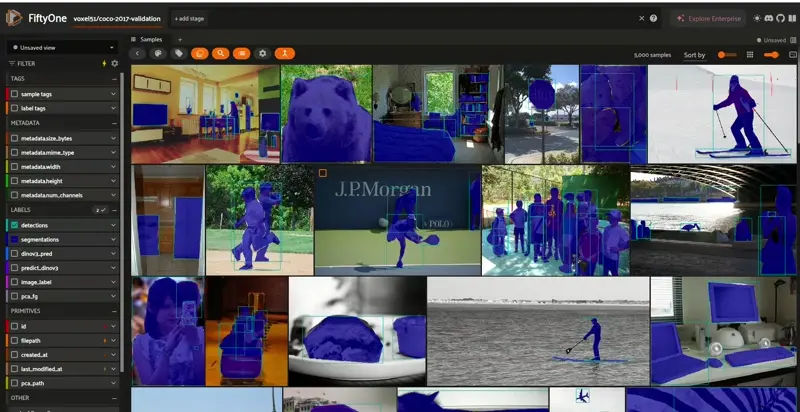
PCA/CLS Foreground Segmentation with DINOv3#
This step builds a foreground mask per image straight from DINOv3’s internal features, no training required. It’s useful to:
Quickly highlight the main subject (saliency-ish) to reduce background bias
Improve visual search by focusing on foreground regions
Speed up data curation (find images with weak/strong foreground, spot occlusions)
Generate lightweight pseudo-labels that you can review in the FiftyOne App
What we compute (high level)#
ViT models (DINOv3 ViT): for each image patch, compute the cosine similarity to the CLS token. Patches more aligned with CLS are treated as foreground.
ConvNeXt-style models: compute the cosine similarity of each spatial feature to the global average feature vector.
We then normalize → optionally smooth → threshold the similarity map:
Min–max scale to
[0, 1]Optional average pooling in patch space to denoise
Threshold to get a binary mask (foreground/background)
Finally, we upsample to the original image size and write the results into the dataset:
A binary segmentation field (
fo.Segmentation)Optionally, a soft heatmap field (
fo.Heatmap) with values in[0, 1]
These overlays render natively in the FiftyOne App.
[117]:
import numpy as np
from PIL import Image, ImageOps
import torch
import torch.nn.functional as F
import fiftyone as fo
from fiftyone import Segmentation, Heatmap
from transformers import AutoImageProcessor, AutoModel
def build_pca_fg_masks(
dataset: fo.Dataset,
model_id: str = "facebook/dinov3-vits16-pretrain-lvd1689m",
field: str = "pca_fg", # Segmentation field (binary 0/1)
heatmap_field: str | None = None, # optional: store soft map (0..1) as fo.Heatmap
thresh: float = 0.5, # FG threshold after smoothing
smooth_k: int = 3, # avg-pool kernel in patch space (0/1 to disable)
device: str | None = None,
):
"""
Compute a DINOv3 PCA/CLS-style foreground mask for every sample and write to dataset.
- ViT: cosine(sim) to CLS over patch tokens
- ConvNeXt: cosine(sim) to global-avg feature over feature map
- Masks are overlaid natively in the FiftyOne App.
"""
device = device or ("cuda" if torch.cuda.is_available() else "cpu")
processor = AutoImageProcessor.from_pretrained(model_id)
model = AutoModel.from_pretrained(model_id).to(device).eval()
# --- schema (once) ---
if not dataset.has_field(field):
dataset.add_sample_field(field, fo.EmbeddedDocumentField, embedded_doc_type=fo.Segmentation)
if heatmap_field and not dataset.has_field(heatmap_field):
dataset.add_sample_field(heatmap_field, fo.EmbeddedDocumentField, embedded_doc_type=fo.Heatmap)
# mask targets (older APIs use property, not a setter)
mt = dict(dataset.mask_targets or {})
mt[field] = {0: "background", 1: "foreground"}
dataset.mask_targets = mt
dataset.save()
@torch.inference_mode()
def _fg_mask(path: str) -> tuple[np.ndarray, np.ndarray]:
"""Returns (mask_uint8_HxW, soft_fg01_HxW_float32)."""
img = ImageOps.exif_transpose(Image.open(path).convert("RGB"))
W0, H0 = img.size
bf = processor(images=img, return_tensors="pt").to(device)
last = model(**bf).last_hidden_state # ViT: [B,1+R+P,D] | ConvNeXt: [B,C,H,W]
# ---- ViT path ----
if last.ndim == 3:
hs = last[0].float() # [1+R+P,D]
num_reg = getattr(model.config, "num_register_tokens", 0)
patch = getattr(model.config, "patch_size", 16)
patches = hs[1 + num_reg :, :] # [P,D]
_, _, Hc, Wc = bf["pixel_values"].shape
gh, gw = Hc // patch, Wc // patch
cls = hs[0:1, :]
sims = (F.normalize(patches, dim=1) @ F.normalize(cls, dim=1).T).squeeze(1) # [P]
fg = sims.detach().cpu().view(gh, gw) # CPU [gh,gw]
# ---- ConvNeXt path ----
else:
fm = last[0].float() # [C,H,W]
C, gh, gw = fm.shape
grid = F.normalize(fm.permute(1, 2, 0).reshape(-1, C), dim=1) # [H*W,C]
gvec = F.normalize(fm.mean(dim=(1, 2), keepdim=True).squeeze().unsqueeze(0), dim=1) # [1,C]
fg = (grid @ gvec.T).detach().cpu().reshape(gh, gw) # CPU [gh,gw]
# min-max → [0,1]
fg01 = (fg - fg.min()) / (fg.max() - fg.min() + 1e-8)
# optional smoothing in patch space
if smooth_k and smooth_k > 1:
fg01 = F.avg_pool2d(fg01.unsqueeze(0).unsqueeze(0), smooth_k, 1, smooth_k // 2).squeeze()
# threshold → binary mask on patch grid
mask_small = (fg01 > thresh).to(torch.uint8).numpy() # [gh,gw] {0,1}
# upsample both to original size
mask_full = Image.fromarray(mask_small * 255).resize((W0, H0), Image.NEAREST)
soft_full = Image.fromarray((fg01.numpy() * 255).astype(np.uint8)).resize((W0, H0), Image.BILINEAR)
mask = (np.array(mask_full) > 127).astype(np.uint8) # HxW {0,1}
soft = np.array(soft_full).astype(np.float32) / 255.0 # HxW [0,1]
return mask, soft
# --- process all samples ---
skipped = 0
for s in dataset.iter_samples(autosave=True, progress=True):
try:
m, soft = _fg_mask(s.filepath)
s[field] = Segmentation(mask=m)
if heatmap_field:
# Heatmap expects a 2D float array in [0,1]; the App colors it
s[heatmap_field] = Heatmap(map=soft)
except Exception:
s[field] = None
if heatmap_field:
s[heatmap_field] = None
skipped += 1
print(f"✓ wrote masks to '{field}'" + (f" and heatmaps to '{heatmap_field}'" if heatmap_field else "") + f". skipped: {skipped}")
[118]:
build_pca_fg_masks(dataset, field="pca_fg", heatmap_field="pca_fg_heat", thresh=0.5, smooth_k=3)
100% |███████████████| 5000/5000 [6.1m elapsed, 0s remaining, 18.1 samples/s]
INFO:eta.core.utils: 100% |███████████████| 5000/5000 [6.1m elapsed, 0s remaining, 18.1 samples/s]
✓ wrote masks to 'pca_fg' and heatmaps to 'pca_fg_heat'. skipped: 0