ActivityNet Integration#
With FiftyOne, you can easily download, visualize, and evaluate on the ActivityNet dataset!
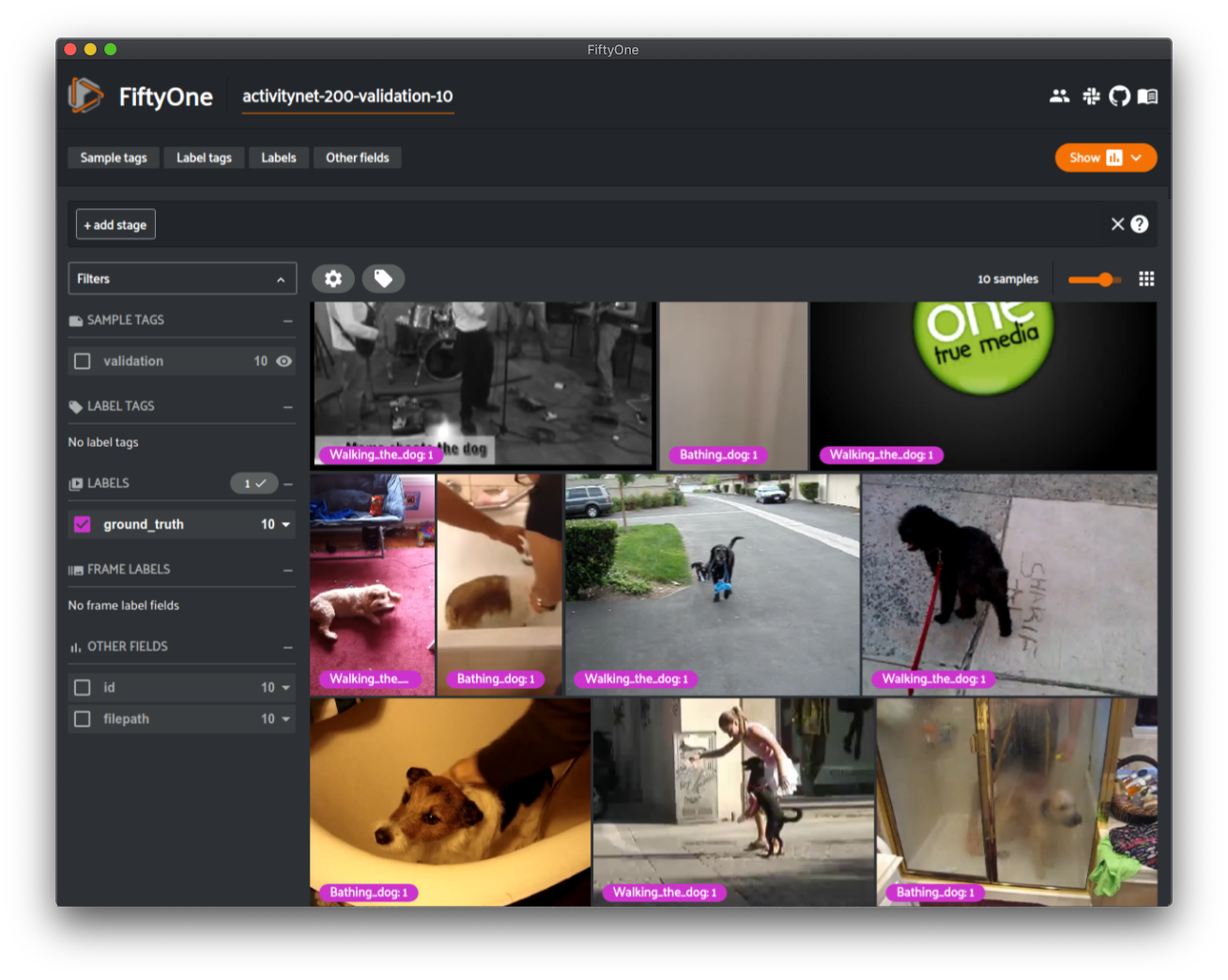
Loading the ActivityNet dataset#
The FiftyOne Dataset Zoo provides support for loading both the ActivityNet 100 and ActivityNet 200 datasets.
Like all other zoo datasets, you can use
load_zoo_dataset() to download
and load an ActivityNet split into FiftyOne:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4# Download and load 10 samples from the validation split of ActivityNet 200
5dataset = foz.load_zoo_dataset(
6 "activitynet-200",
7 split="validation",
8 max_samples=10,
9)
10
11session = fo.launch_app(dataset)
Note
ActivityNet 200 is a superset of ActivityNet 100 so we have made sure to only store one copy of every video on disk. Videos in the ActivityNet 100 zoo directory are used directly by ActivityNet 200.
Partial Downloads#
In addition, FiftyOne provides parameters that can be used to efficiently download specific subsets of the ActivityNet dataset, allowing you to quickly explore different slices of the dataset without downloading the entire split.
When performing partial downloads, FiftyOne will use existing downloaded data first if possible before resorting to downloading additional data from YouTube.
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4#
5# Load 10 random samples from the validation split
6#
7# Only the required videos will be downloaded (if necessary).
8#
9
10dataset = foz.load_zoo_dataset(
11 "activitynet-200",
12 split="validation",
13 max_samples=10,
14 shuffle=True,
15)
16
17session = fo.launch_app(dataset)
18
19#
20# Load 10 samples from the validation split that
21# contain the actions "Bathing dog" and "Walking the dog"
22# with a maximum duration of 20 seconds
23#
24# Videos that contain all ``classes`` will be prioritized first, followed
25# by videos that contain at least one of the required ``classes``. If
26# there are not enough videos matching ``classes`` in the split to meet
27# ``max_samples``, only the available videos will be loaded.
28#
29# Videos will only be downloaded if necessary
30#
31
32dataset = foz.load_zoo_dataset(
33 "activitynet-200",
34 split="validation",
35 classes=["Bathing dog", "Walking the dog"],
36 max_samples=10,
37 max_duration=20,
38)
39
40session.dataset = dataset
The following parameters are available to configure partial downloads of both
ActivityNet 100 and ActivityNet 200 by passing them to
load_zoo_dataset():
split (None) and splits (None): a string or list of strings, respectively, specifying the splits to load. Supported values are
("train", "test", "validation"). If none are provided, all available splits are loadedsource_dir (None): the directory containing the manually downloaded ActivityNet files used to avoid downloading videos from YouTube
classes (None): a string or list of strings specifying required classes to load. If provided, only samples containing at least one instance of a specified class will be loaded
max_duration (None): only videos with a duration in seconds that is less than or equal to the
max_durationwill be downloaded. By default, all videos are downloadedcopy_files (True): whether to move (False) or create copies (True) of the source files when populating
dataset_dir. This is only applicable when asource_diris providednum_workers (None): the number of processes to use when downloading individual videos. By default,
multiprocessing.cpu_count()is usedshuffle (False): whether to randomly shuffle the order in which samples are chosen for partial downloads
seed (None): a random seed to use when shuffling
max_samples (None): a maximum number of samples to load per split. If
classesare also specified, only up to the number of samples that contain at least one specified class will be loaded. By default, all matching samples are loaded
Full Split Downloads#
Many videos have been removed from YouTube since the creation of ActivityNet. As a result, you must first download the official source files from the ActivityNet maintainers in order to load a full split into FiftyOne.
To download the source files, you must fill out this form.
After downloading the source files, they can be loaded into FiftyOne like so:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4source_dir = "/path/to/dir-with-activitynet-files"
5
6# Load the entire ActivityNet 200 dataset into FiftyOne
7dataset = foz.load_zoo_dataset("activitynet-200", source_dir=source_dir)
8
9session = fo.launch_app(dataset)
where source_dir contains the source files in the following format:
source_dir/
missing_files.zip
missing_files_v1-2_test.zip
missing_files_v1-3_test.zip
v1-2_test.tar.gz
v1-2_train.tar.gz
v1-2_val.tar.gz
v1-3_test.tar.gz
v1-3_train_val.tar.gz
If you have already decompressed the archives, that is okay too:
source_dir/
missing_files/
v_<id>.<ext>
...
missing_files_v1-2_test/
v_<id>.<ext>
...
missing_files_v_1-3_test/
v_<id>.<ext>
...
v1-2/
train/
v_<id>.<ext>
...
val/
...
test/
...
v1-3/
train_val/
v_<id>.<ext>
...
test/
...
If you are only interested in loading specific splits into FiftyOne, the files for the other splits do not need to be present.
Note
When load_zoo_dataset()
is called with the source_dir parameter, the contents are copied (or
moved, if copy_files=False) into the zoo dataset’s backing directory.
Therefore, future use of the loaded dataset or future calls to
load_zoo_dataset()
will not require the source_dir parameter.
ActivityNet-style evaluation#
The evaluate_detections()
method provides builtin support for running
ActivityNet-style evaluation.
ActivityNet-style evaluation is the default method when evaluating
TemporalDetections labels, but you can also explicitly request it by setting
the method parameter to "activitynet".
Note
FiftyOne’s implementation of ActivityNet-style evaluation matches the reference implementation available via the ActivityNet API.
Overview#
When running ActivityNet-style evaluation using
evaluate_detections():
Predicted and ground truth segments are matched using a specified IoU threshold (default = 0.50). This threshold can be customized via the
iouparameterBy default, only segments with the same
labelwill be matched. Classwise matching can be disabled by passingclasswise=FalsemAP is computed by averaging over the same range of IoU values used by COCO
When you specify an eval_key parameter, a number of helpful fields will be
populated on each sample and its predicted/ground truth segments:
True positive (TP), false positive (FP), and false negative (FN) counts for each sample are saved in top-level fields of each sample:
TP: sample.<eval_key>_tp FP: sample.<eval_key>_fp FN: sample.<eval_key>_fn
The fields listed below are populated on each individual temporal detection segment; these fields tabulate the TP/FP/FN status of the segment, the ID of the matching segment (if any), and the matching IoU:
TP/FP/FN: segment.<eval_key> ID: segment.<eval_key>_id IoU: segment.<eval_key>_iou
Note
See ActivityNetEvaluationConfig for complete descriptions of the optional
keyword arguments that you can pass to
evaluate_detections()
when running ActivityNet-style evaluation.
Example evaluation#
The example below demonstrates ActivityNet-style temporal detection evaluation on the ActivityNet 200 dataset:
1import random
2
3import fiftyone as fo
4import fiftyone.zoo as foz
5from fiftyone import ViewField as F
6
7# Load subset of ActivityNet 200
8classes = ["Bathing dog", "Walking the dog"]
9dataset = foz.load_zoo_dataset(
10 "activitynet-200",
11 split="validation",
12 classes=classes,
13 max_samples=10,
14)
15print(dataset)
16
17# Generate some fake predictions for this example
18random.seed(51)
19dataset.clone_sample_field("ground_truth", "predictions")
20for sample in dataset:
21 for det in sample.predictions.detections:
22 det.support[0] += random.randint(-10,10)
23 det.support[1] += random.randint(-10,10)
24 det.support[0] = max(det.support[0], 1)
25 det.support[1] = max(det.support[1], det.support[0] + 1)
26 det.confidence = random.random()
27 det.label = random.choice(classes)
28
29 sample.save()
30
31# Evaluate the segments in the `predictions` field with respect to the
32# segments in the `ground_truth` field
33results = dataset.evaluate_detections(
34 "predictions",
35 gt_field="ground_truth",
36 eval_key="eval",
37)
38
39# Print a classification report for the classes
40results.print_report(classes=classes)
41
42# Print some statistics about the total TP/FP/FN counts
43print("TP: %d" % dataset.sum("eval_tp"))
44print("FP: %d" % dataset.sum("eval_fp"))
45print("FN: %d" % dataset.sum("eval_fn"))
46
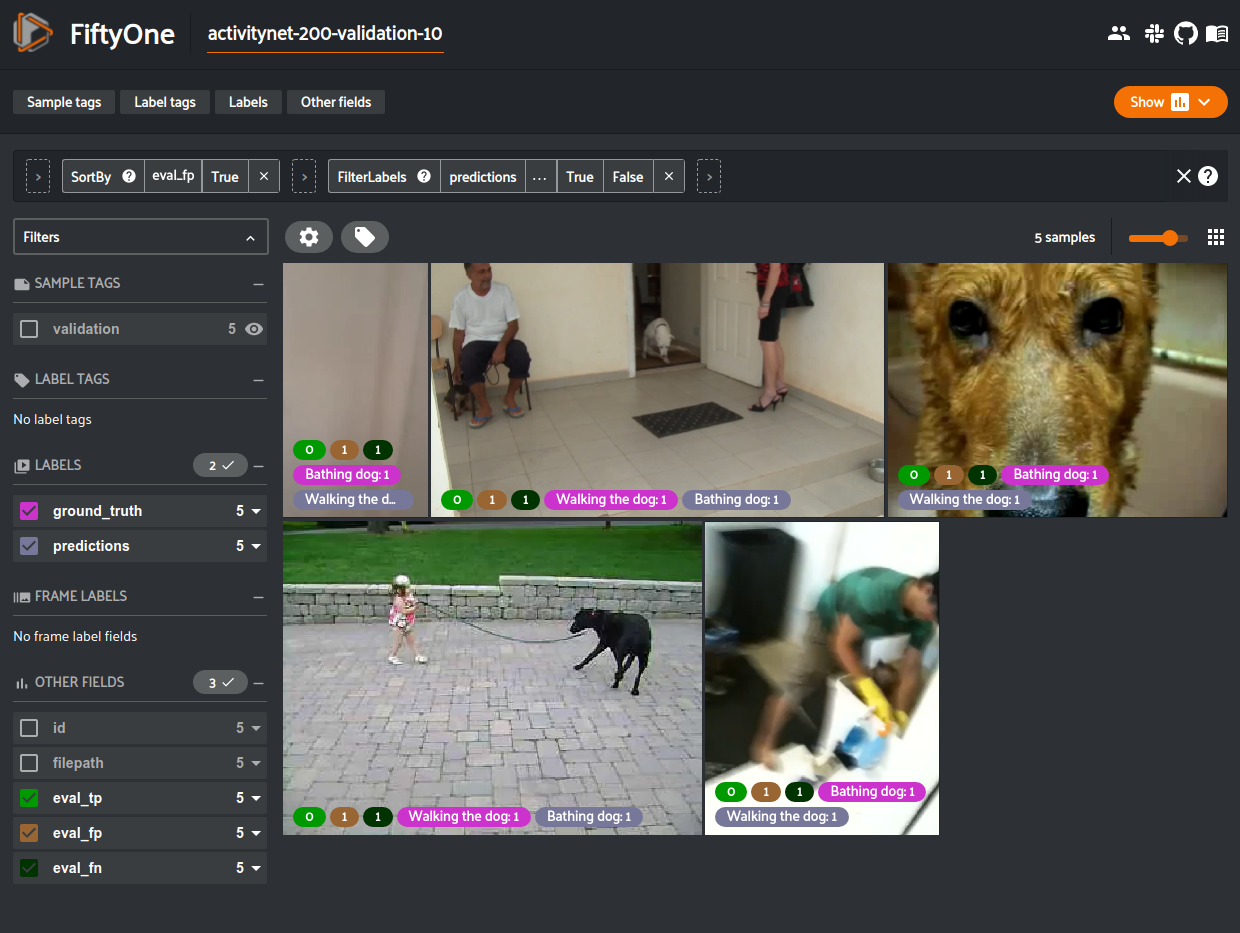
47# Create a view that has samples with the most false positives first, and
48# only includes false positive segments in the `predictions` field
49view = (
50 dataset
51 .sort_by("eval_fp", reverse=True)
52 .filter_labels("predictions", F("eval") == "fp")
53)
54
55# Visualize results in the App
56session = fo.launch_app(view=view)
precision recall f1-score support
Bathing dog 0.50 0.40 0.44 5
Walking the dog 0.50 0.60 0.55 5
micro avg 0.50 0.50 0.50 10
macro avg 0.50 0.50 0.49 10
weighted avg 0.50 0.50 0.49 10
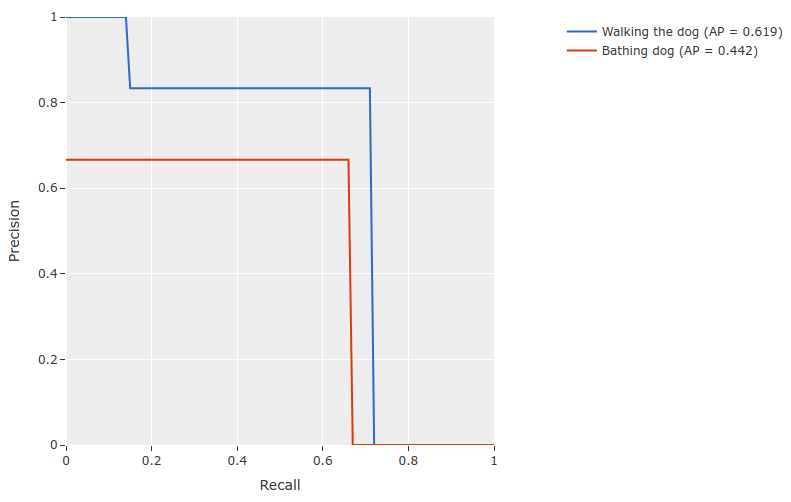
mAP and PR curves#
You can compute mean average precision (mAP) and precision-recall (PR) curves
for your segments by passing the compute_mAP=True flag to
evaluate_detections():
Note
All mAP calculations are performed according to the ActivityNet evaluation protocol.
1import random
2
3import fiftyone as fo
4import fiftyone.zoo as foz
5
6# Load subset of ActivityNet 200
7classes = ["Bathing dog", "Walking the dog"]
8dataset = foz.load_zoo_dataset(
9 "activitynet-200",
10 split="validation",
11 classes=classes,
12 max_samples=10,
13)
14print(dataset)
15
16# Generate some fake predictions for this example
17random.seed(51)
18dataset.clone_sample_field("ground_truth", "predictions")
19for sample in dataset:
20 for det in sample.predictions.detections:
21 det.support[0] += random.randint(-10,10)
22 det.support[1] += random.randint(-10,10)
23 det.support[0] = max(det.support[0], 1)
24 det.support[1] = max(det.support[1], det.support[0] + 1)
25 det.confidence = random.random()
26 det.label = random.choice(classes)
27
28 sample.save()
29
30# Performs an IoU sweep so that mAP and PR curves can be computed
31results = dataset.evaluate_detections(
32 "predictions",
33 gt_field="ground_truth",
34 eval_key="eval",
35 compute_mAP=True,
36)
37
38print(results.mAP())
39# 0.367
40
41plot = results.plot_pr_curves(classes=classes)
42plot.show()
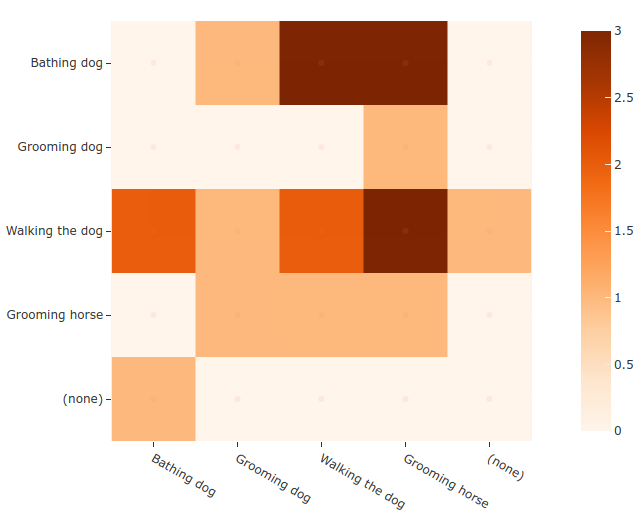
Confusion matrices#
You can also easily generate confusion matrices for the results of ActivityNet-style evaluations.
In order for the confusion matrix to capture anything other than false
positive/negative counts, you will likely want to set the
classwise
parameter to False during evaluation so that predicted segments can be
matched with ground truth segments of different classes.
1import random
2
3import fiftyone as fo
4import fiftyone.zoo as foz
5
6# Load subset of ActivityNet 200
7classes = ["Bathing dog", "Grooming dog", "Grooming horse", "Walking the dog"]
8dataset = foz.load_zoo_dataset(
9 "activitynet-200",
10 split="validation",
11 classes=classes,
12 max_samples=20,
13)
14print(dataset)
15
16# Generate some fake predictions for this example
17random.seed(51)
18dataset.clone_sample_field("ground_truth", "predictions")
19for sample in dataset:
20 for det in sample.predictions.detections:
21 det.support[0] += random.randint(-10,10)
22 det.support[1] += random.randint(-10,10)
23 det.support[0] = max(det.support[0], 1)
24 det.support[1] = max(det.support[1], det.support[0] + 1)
25 det.confidence = random.random()
26 det.label = random.choice(classes)
27
28 sample.save()
29
30# Perform evaluation, allowing objects to be matched between classes
31results = dataset.evaluate_detections(
32 "predictions", gt_field="ground_truth", classwise=False
33)
34
35# Generate a confusion matrix for the specified classes
36plot = results.plot_confusion_matrix(classes=classes)
37plot.show()
Note
Did you know? Confusion matrices can be
attached to your Session object and dynamically explored using FiftyOne’s
interactive plotting features!
ActivityNet Challenge#
Since FiftyOne’s implementation of ActivityNet-style evaluation matches the reference implementation from the ActivityNet API used in the ActivityNet challenges. you can use it to compute the official mAP for your model while also enjoying the benefits of working in the FiftyOne ecosystem, including using views to manipulate your dataset and visually exploring your model’s predictions in the FiftyOne App!
The example snippet below loads the ActivityNet 200 dataset and runs the official ActivityNet evaluation protocol on some mock model predictions:
1import random
2
3import fiftyone as fo
4import fiftyone.zoo as foz
5
6# Load subset of ActivityNet 200
7classes = ["Bathing dog", "Walking the dog"]
8dataset = foz.load_zoo_dataset(
9 "activitynet-200",
10 split="validation",
11 classes=classes,
12 max_samples=10,
13)
14
15# Generate some fake predictions for this example
16random.seed(51)
17dataset.clone_sample_field("ground_truth", "predictions")
18for sample in dataset:
19 for det in sample.predictions.detections:
20 det.support[0] += random.randint(-10,10)
21 det.support[1] += random.randint(-10,10)
22 det.support[0] = max(det.support[0], 1)
23 det.support[1] = max(det.support[1], det.support[0] + 1)
24 det.confidence = random.random()
25 det.label = random.choice(classes)
26
27 sample.save()
28
29# Evaluate predictions via the official ActivityNet protocol
30results = dataset.evaluate_detections(
31 "predictions",
32 gt_field="ground_truth",
33 compute_mAP=True,
34)
35
36# The official mAP for the results
37print(results.mAP())
Note
Check out this recipe to learn how to add your model’s predictions to a FiftyOne Dataset.
mAP protocol#
The ActivityNet mAP protocol is similar to COCO-style mAP, with the primary difference being a different IoU computation using temporal segments, a lack of crowds, and the way interpolation of precision values is handled.
The steps to compute ActivityNet-style mAP are detailed below.
Preprocessing
Filter ground truth and predicted segments by class (unless
classwise=False)Sort predicted segments by confidence score so high confidence segments are matched first
Compute IoU between every ground truth and predicted segment within the same class (and between classes if
classwise=False) in each video
Matching
Once IoUs have been computed, predictions and ground truth segments are matched to compute true positives, false positives, and false negatives:
For each class, start with the highest confidence prediction, match it to the ground truth segment that it overlaps with the highest IoU. A prediction only matches if the IoU is above the specified
iouthresholdIf a prediction maximally overlaps with a ground truth segment that has already been matched (by a higher confidence prediction), the prediction is matched with the next highest IoU ground truth segment
Computing mAP
Compute matches for 10 IoU thresholds from 0.5 to 0.95 in increments of 0.05
The next 6 steps are computed separately for each class and IoU threshold:
Construct a boolean array of true positives and false positives, sorted by confidence
Compute the cumulative sum of the true positive and false positive array
Compute precision by elementwise dividing the TP-FP-sum array by the total number of predictions up to that point
Compute recall by elementwise dividing TP-FP-sum array by the number of ground truth segments for the class
Ensure that precision is a non-increasing array
(Unlike COCO) DO NOT interpolate precision values onto an 101 evenly spaced recall values. In FiftyOne, this step is performed anyway with the results stored separately for the purpose of plotting PR curves. It is not factored into mAP calculation
For every class that contains at least one ground truth segment, compute the average precision (AP) by averaging the precision values over all 10 IoU thresholds. Then compute mAP by averaging the per-class AP values over all classes