FiftyOne#
Start building with FiftyOne
Get Started#
What are you working on?
Explore all getting started guides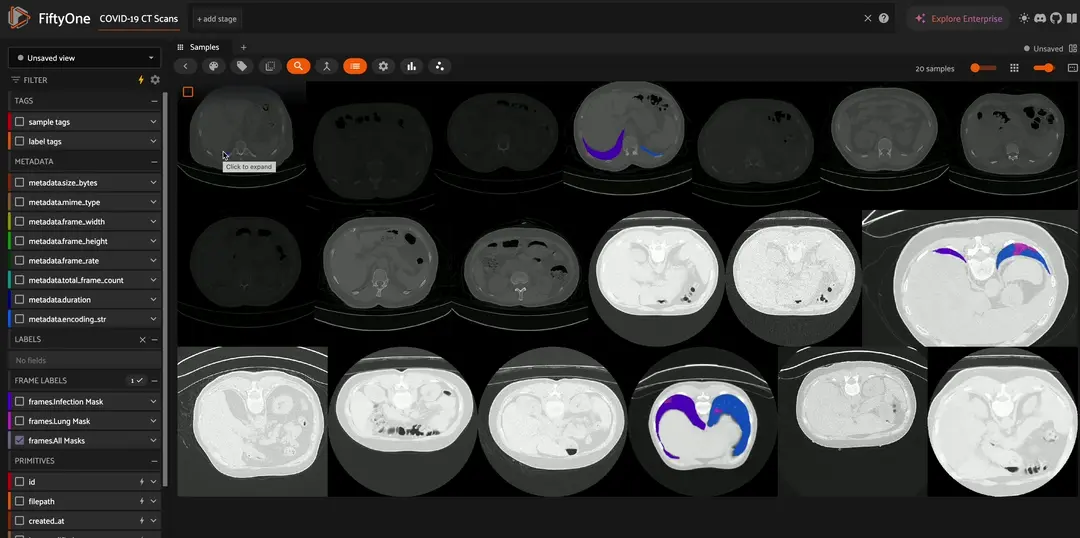
Capabilities#
Explore FiftyOne's key features
Everything you need to build, evaluate, and ship better computer vision models.
Visualize
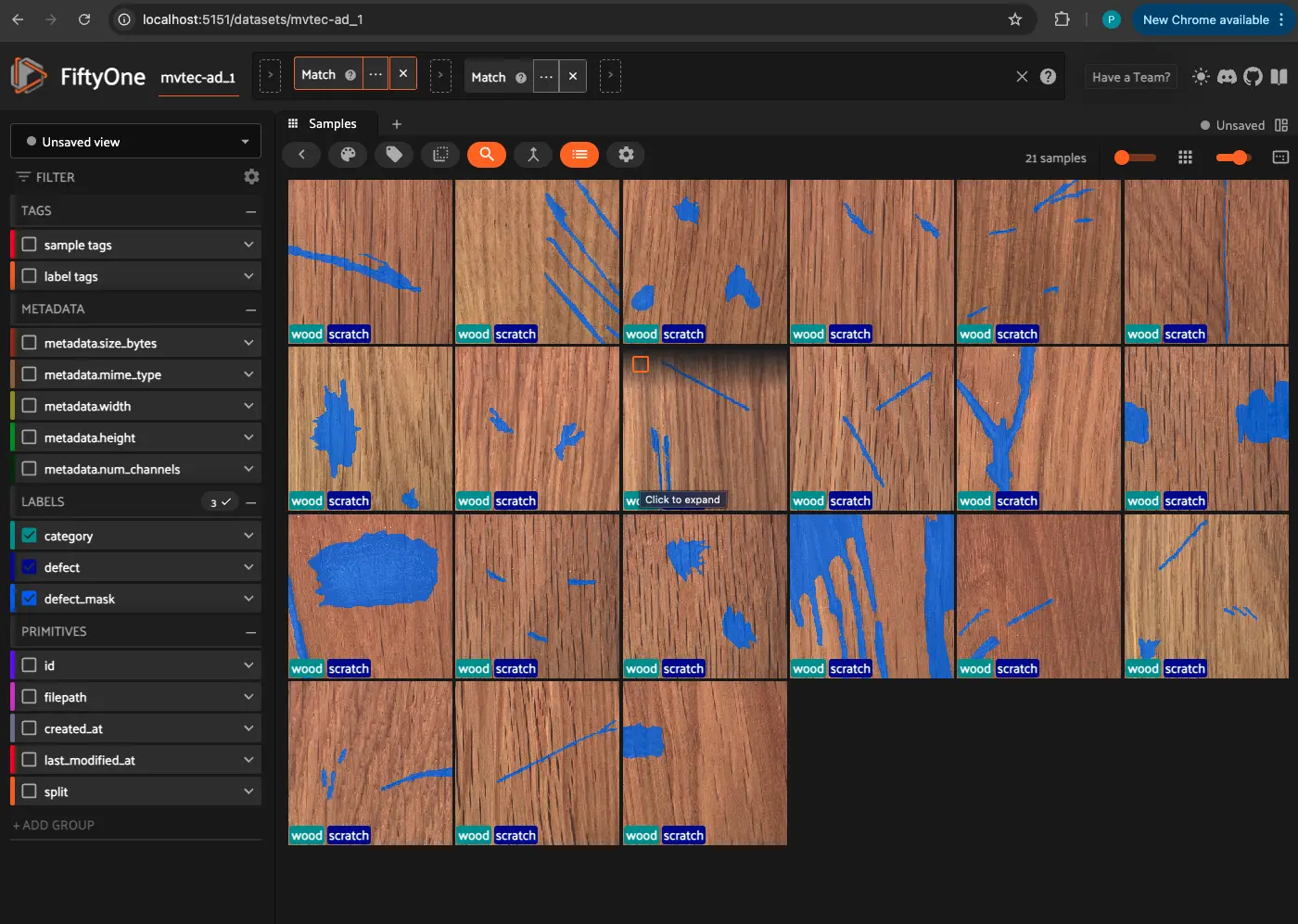
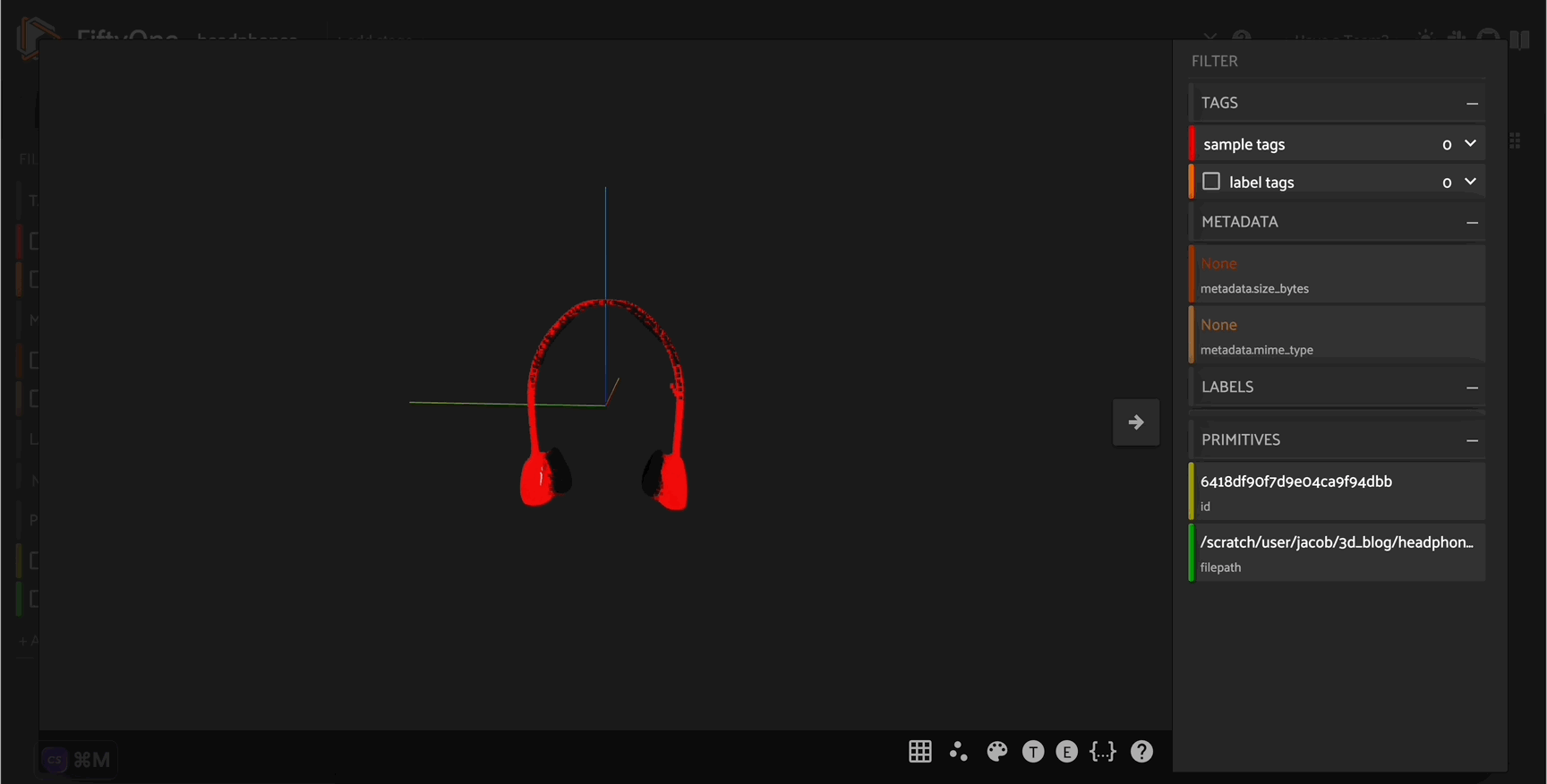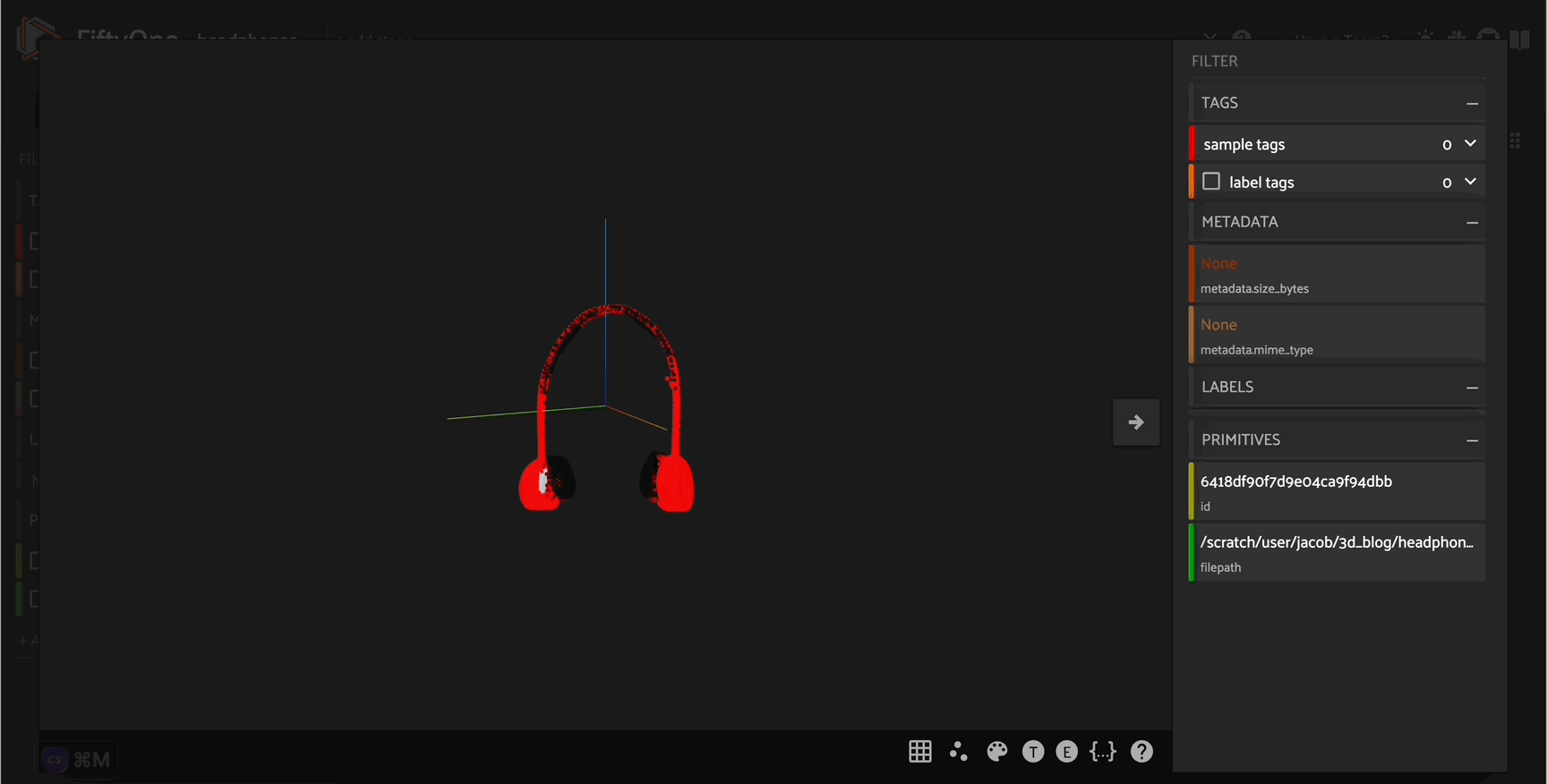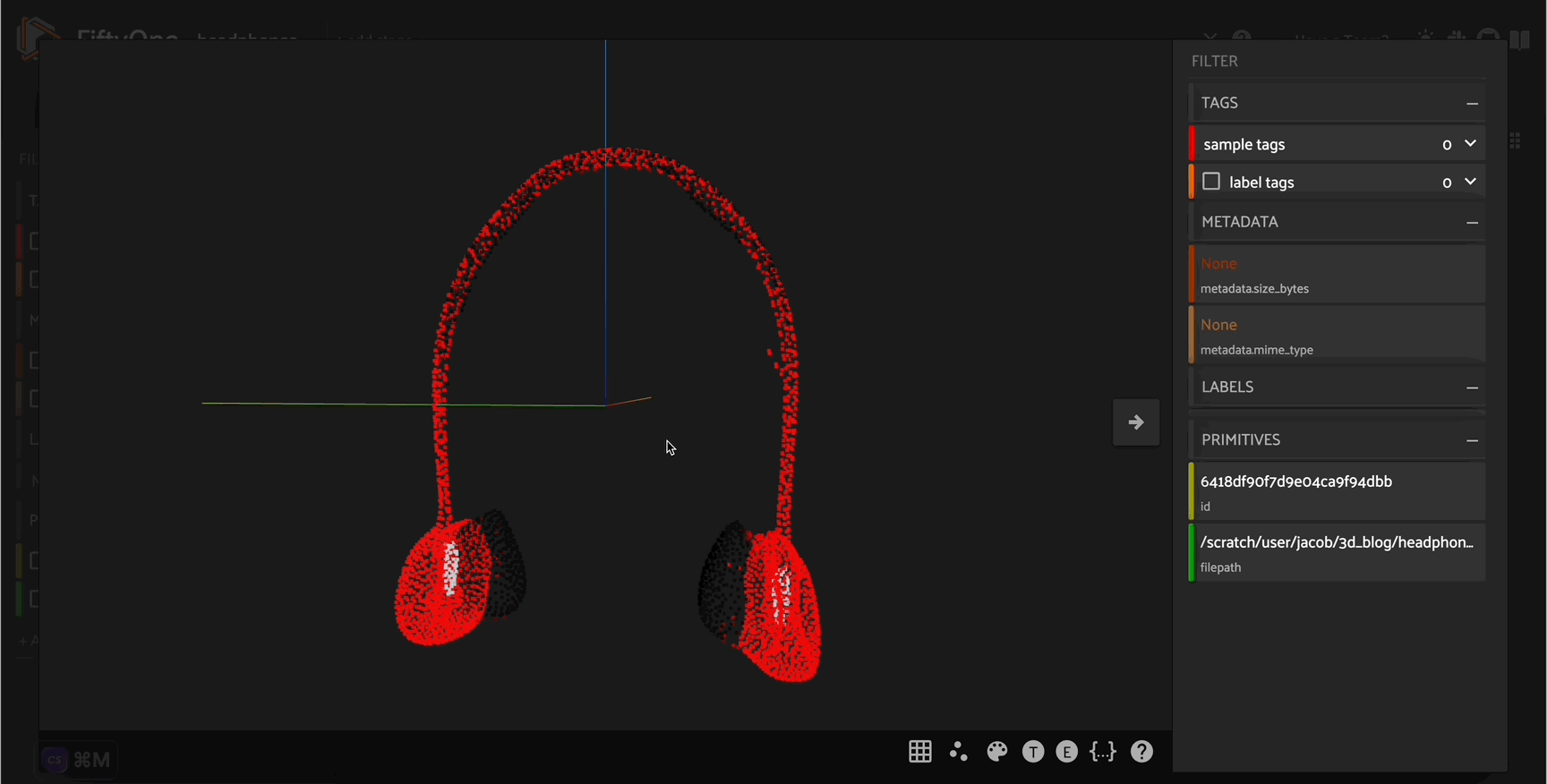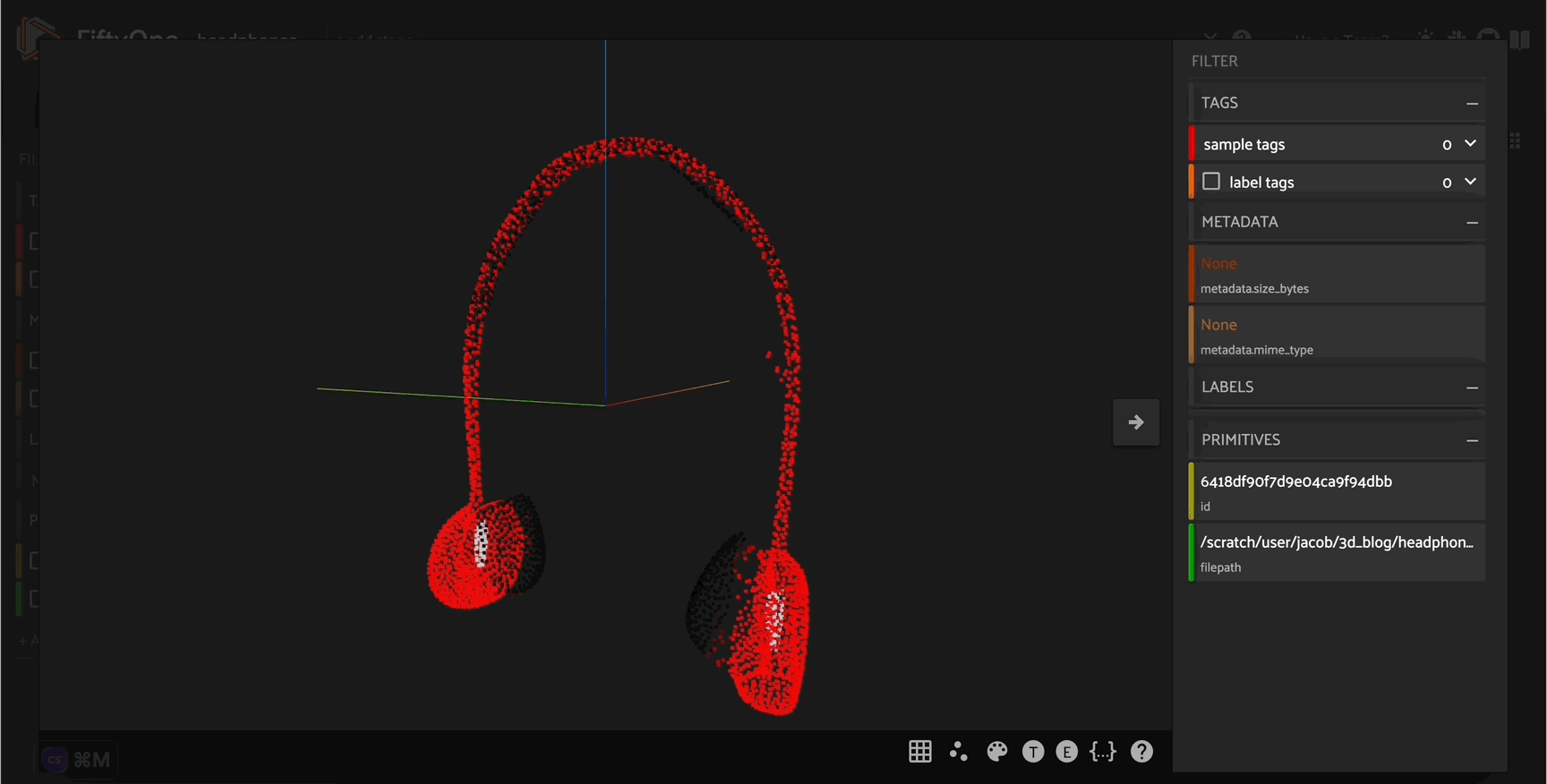
Explore your data in the FiftyOne App. Browse images, videos, and 3D data side-by-side with labels, metadata, and model predictions — all in one interactive view.
Explore the App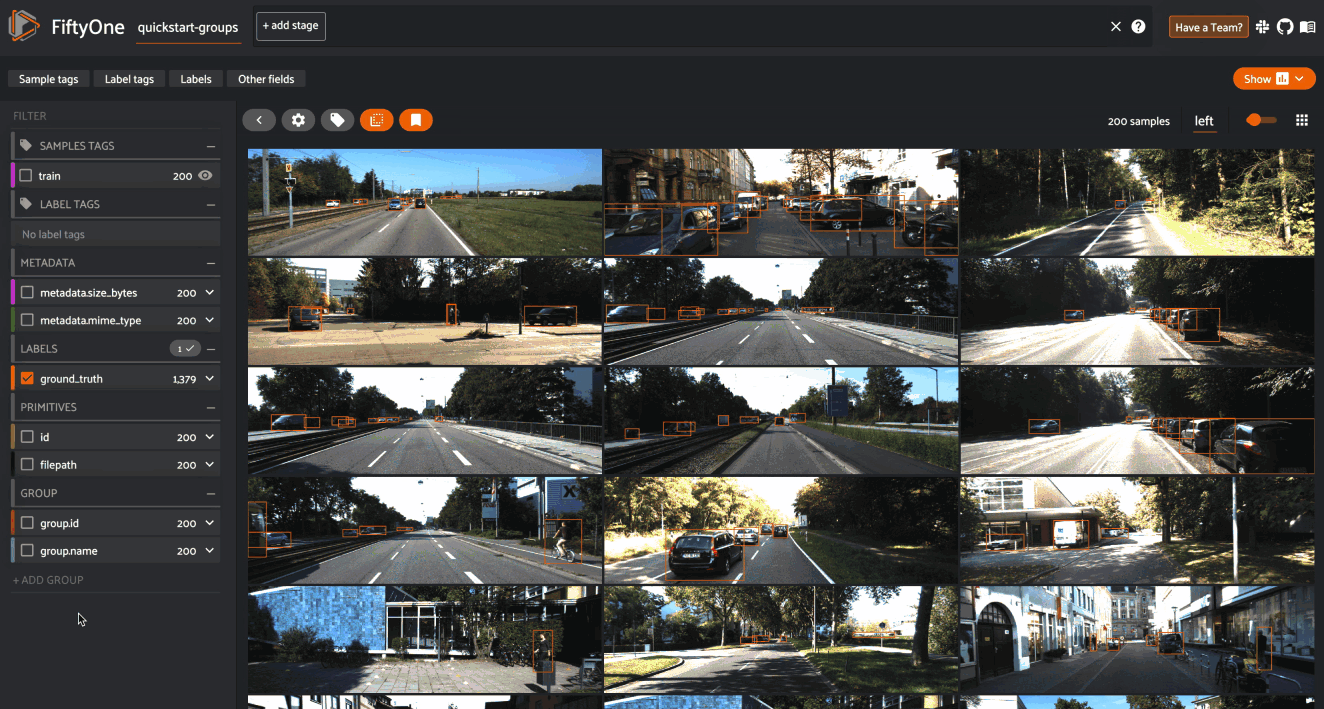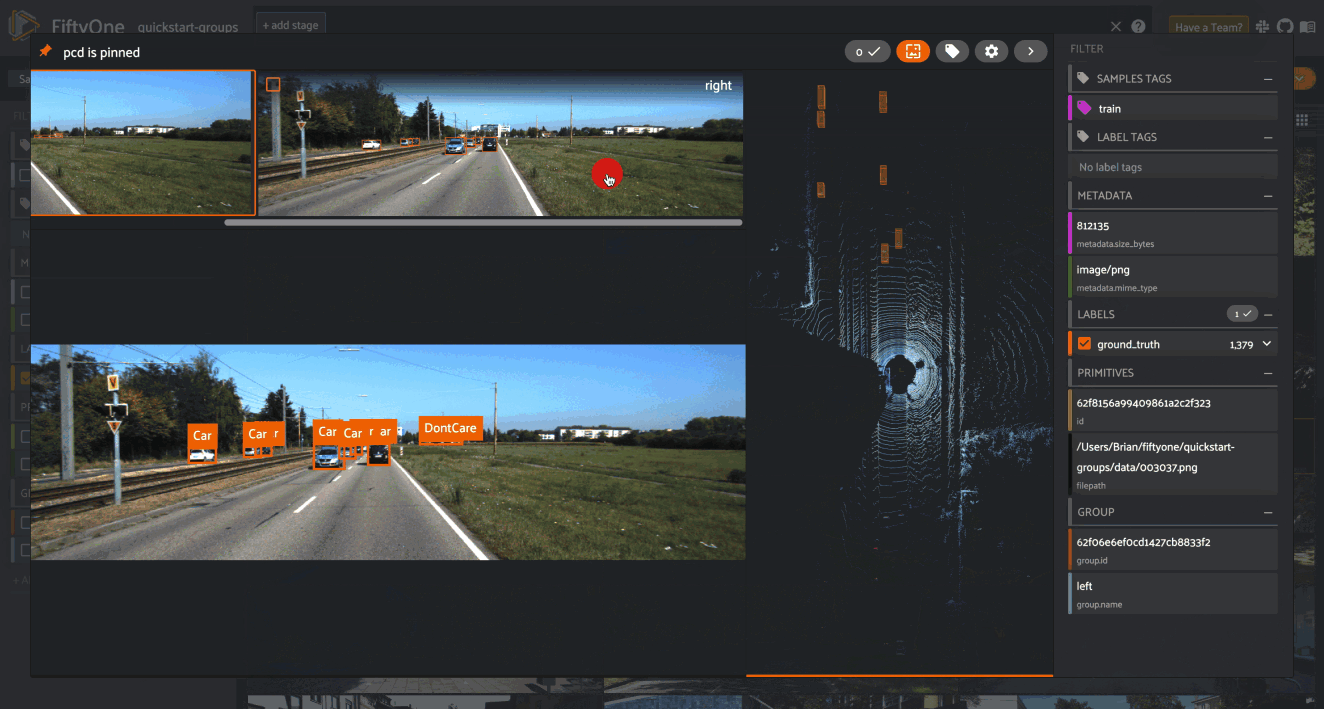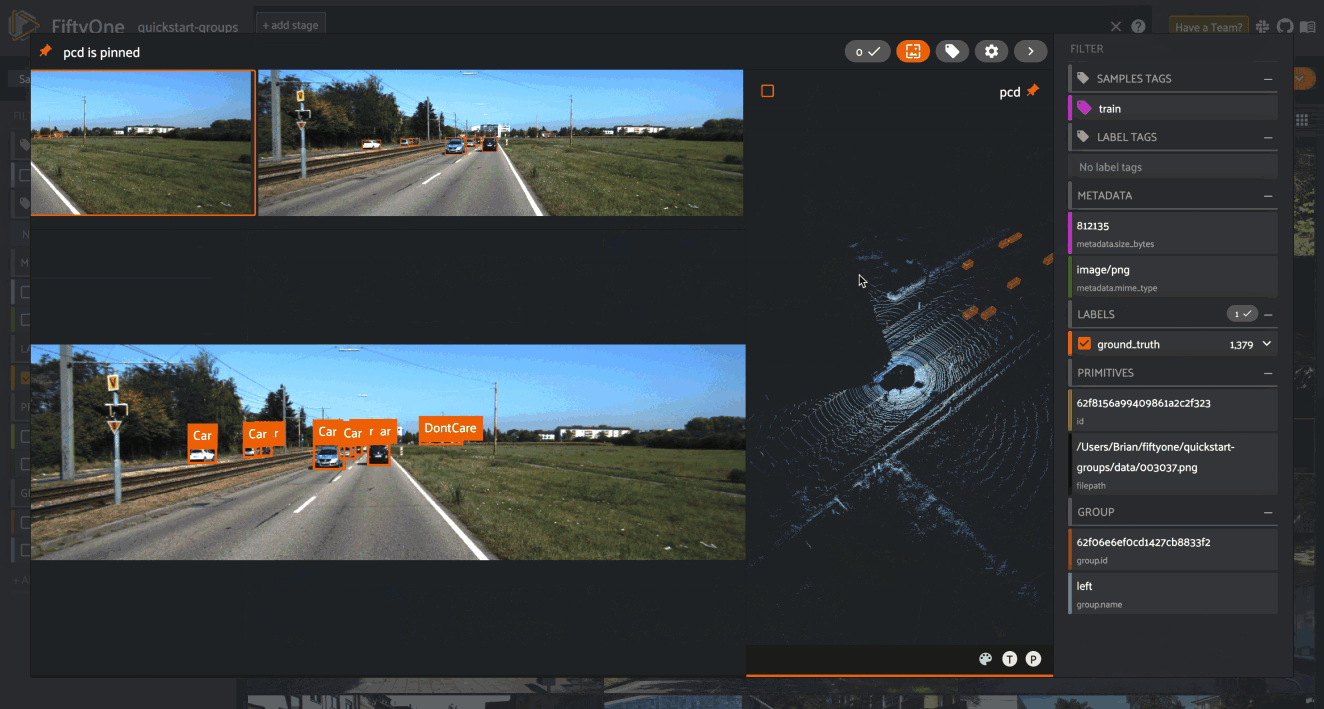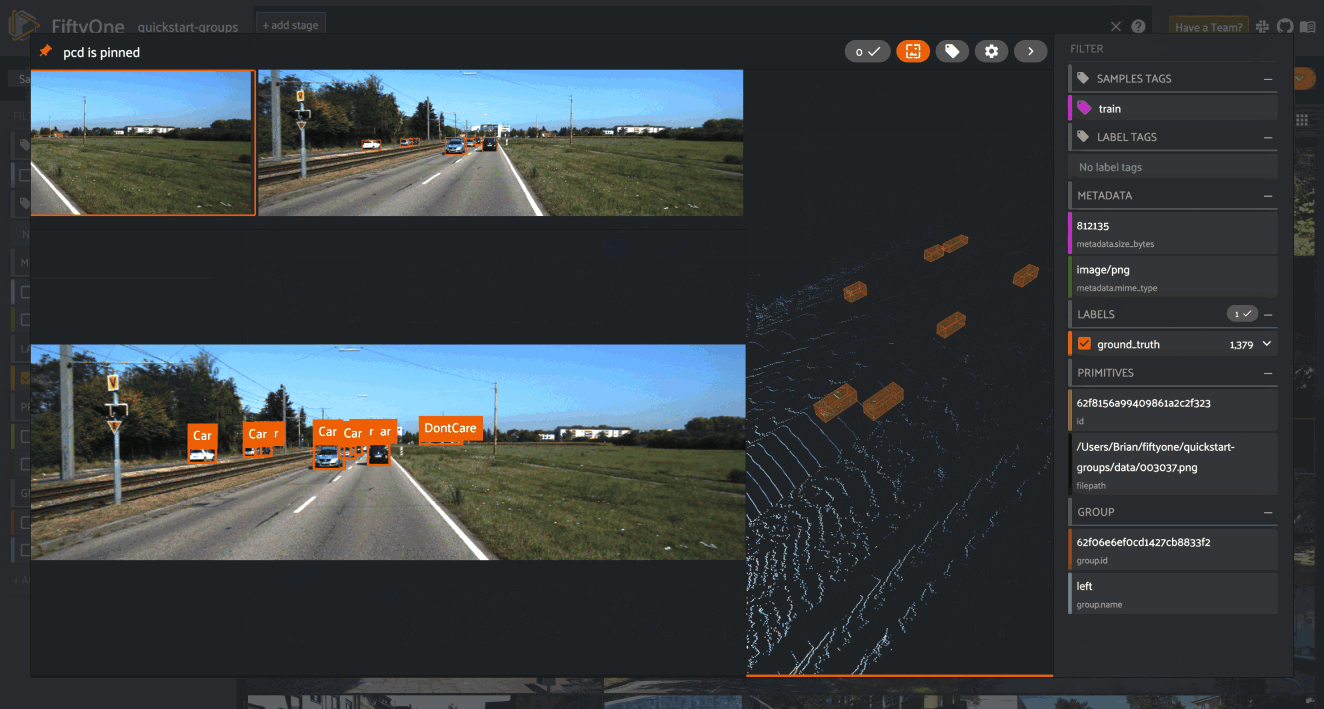
Curate
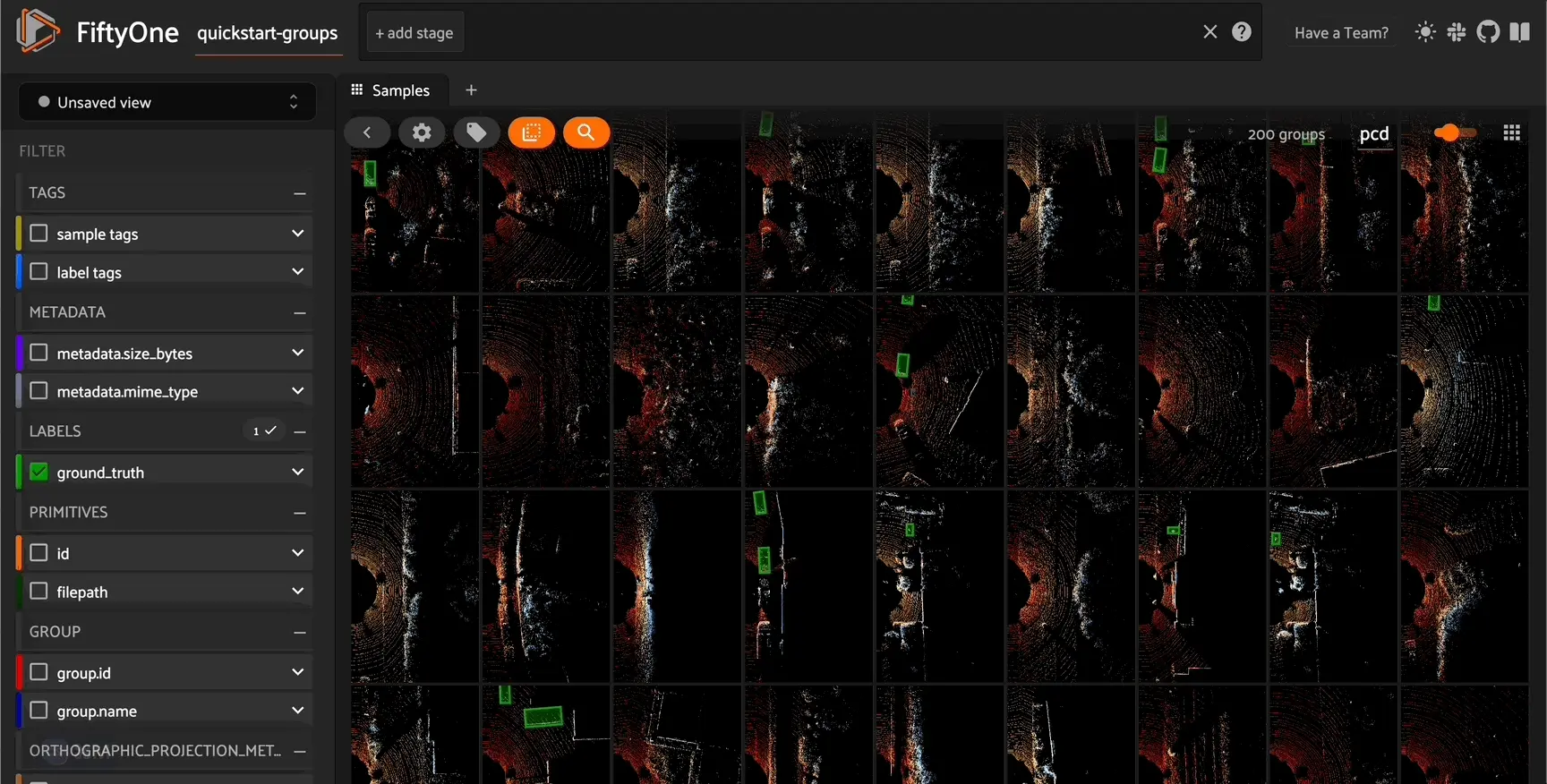
Reveal hidden structure in your data with embedding visualizations. Mine hard samples, find near-duplicates, and recommend the best data for annotation.
Get embeddings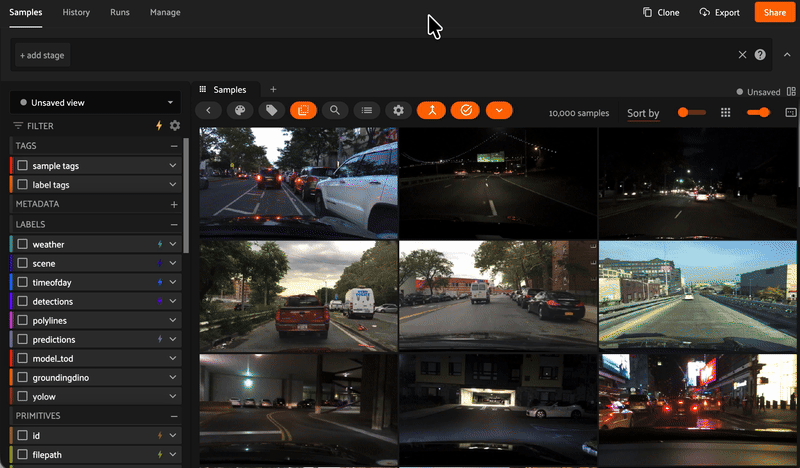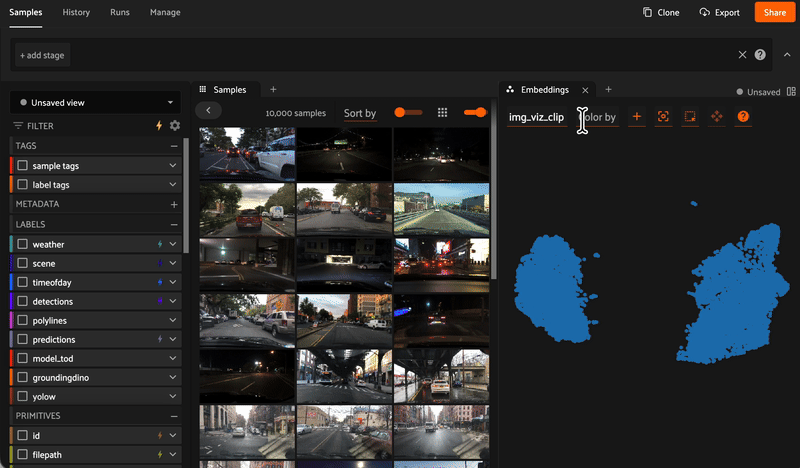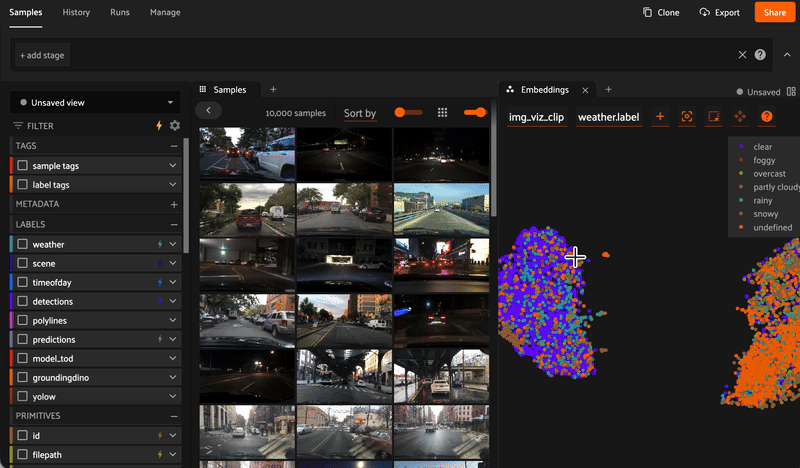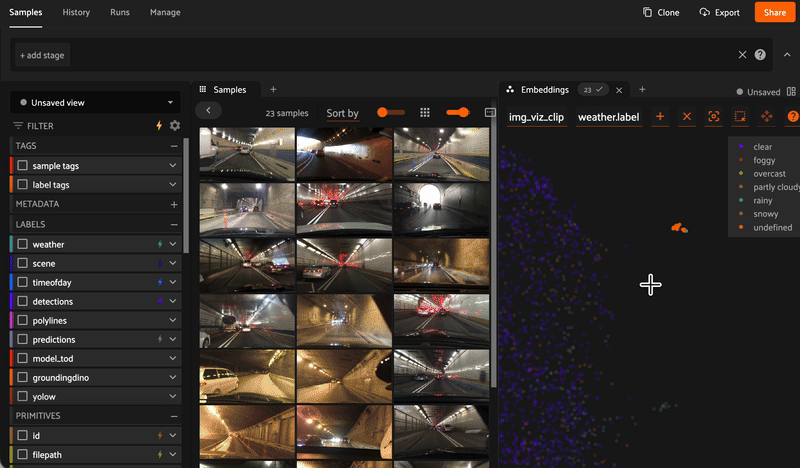
Annotate
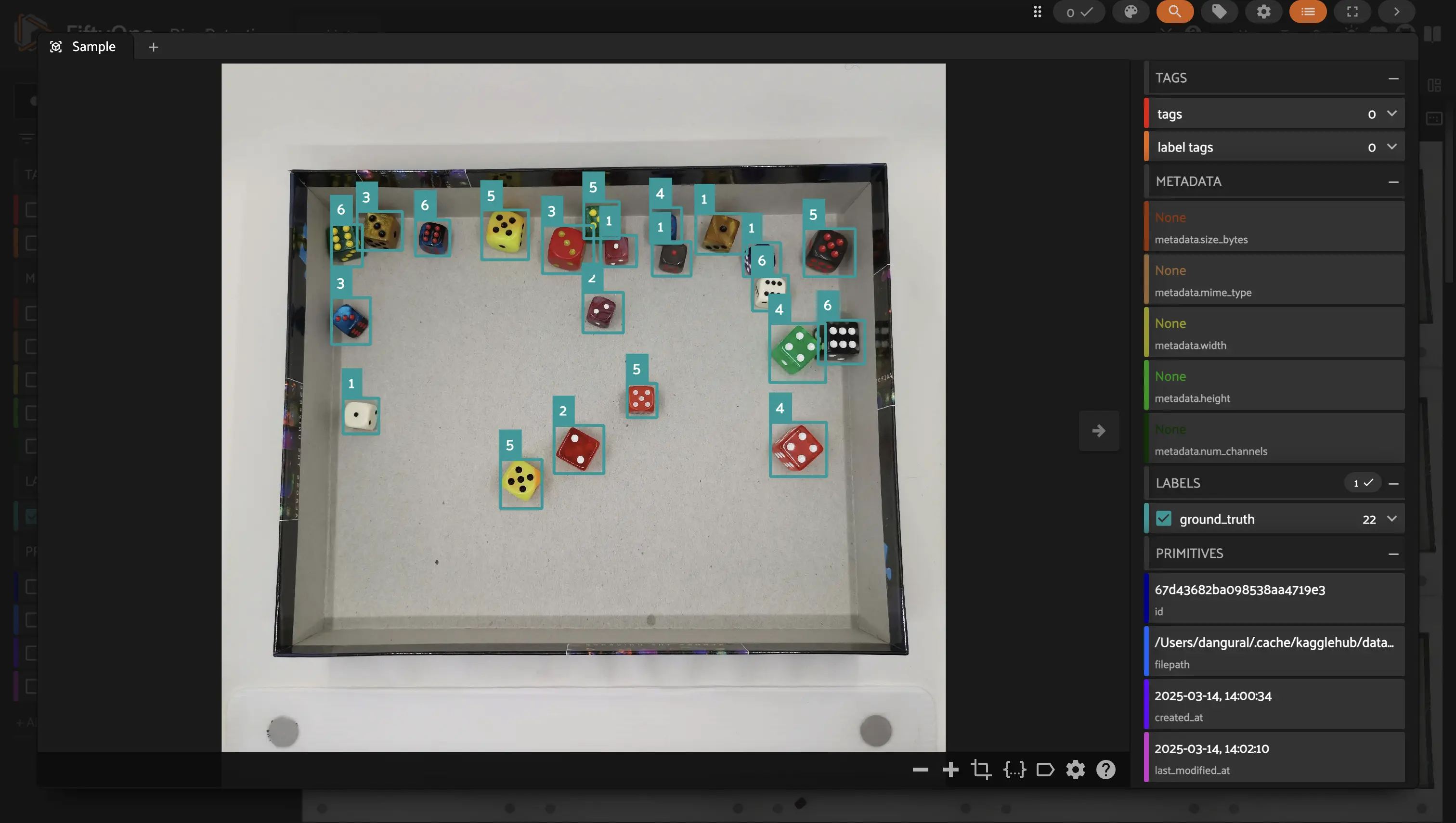
Annotation mistakes create an artificial ceiling on model performance. Use FiftyOne to automatically identify possible label mistakes and correct them in-app.
Annotate your data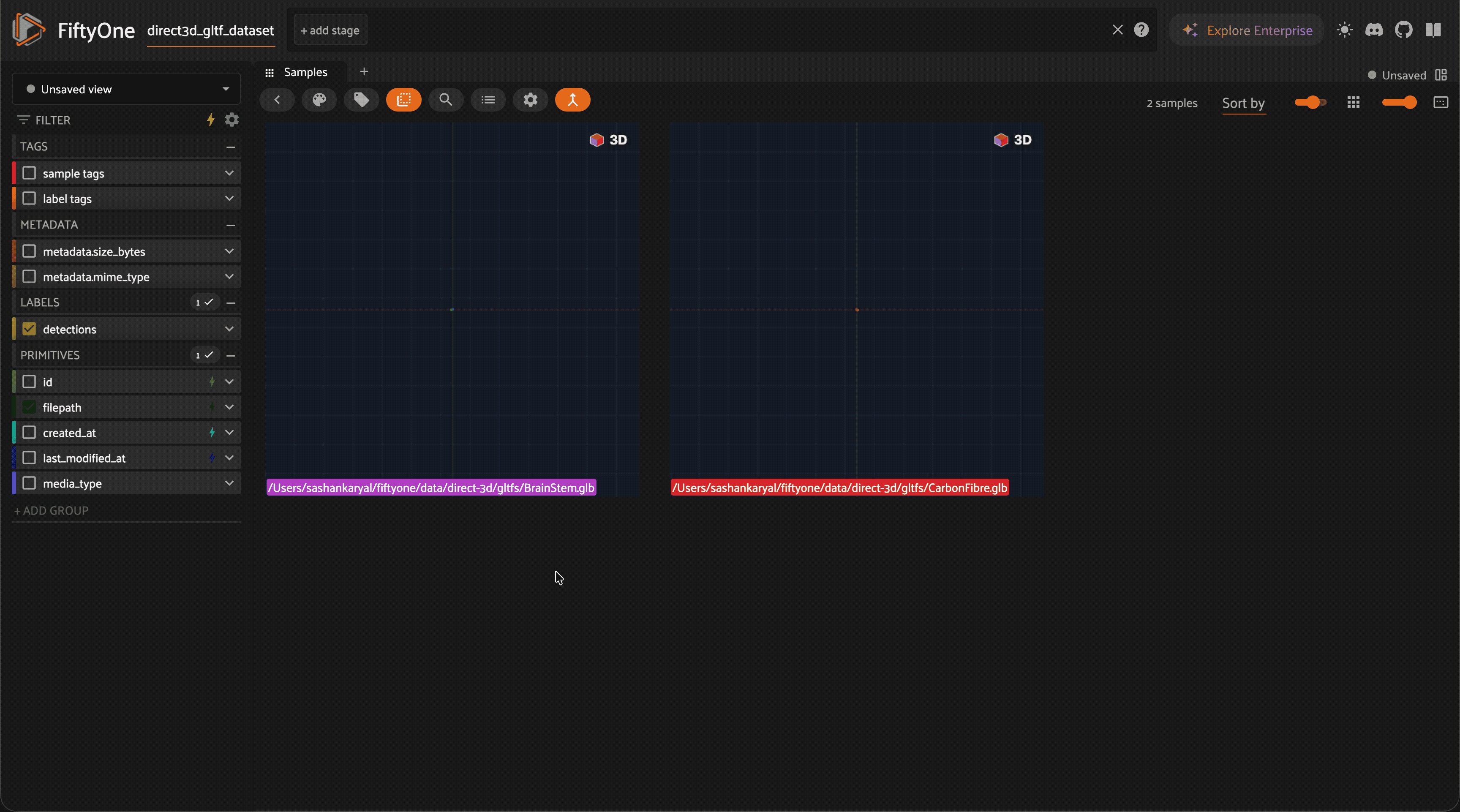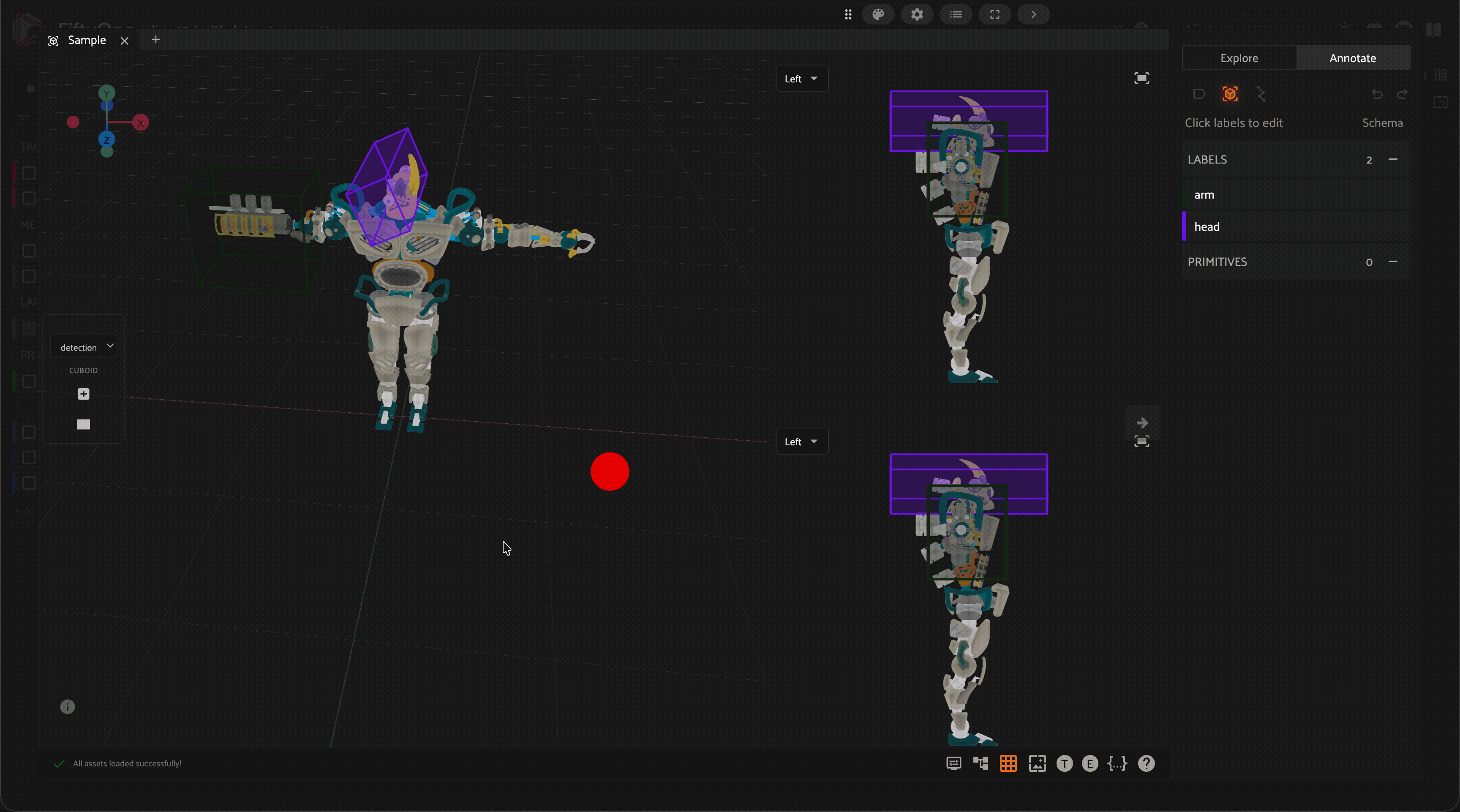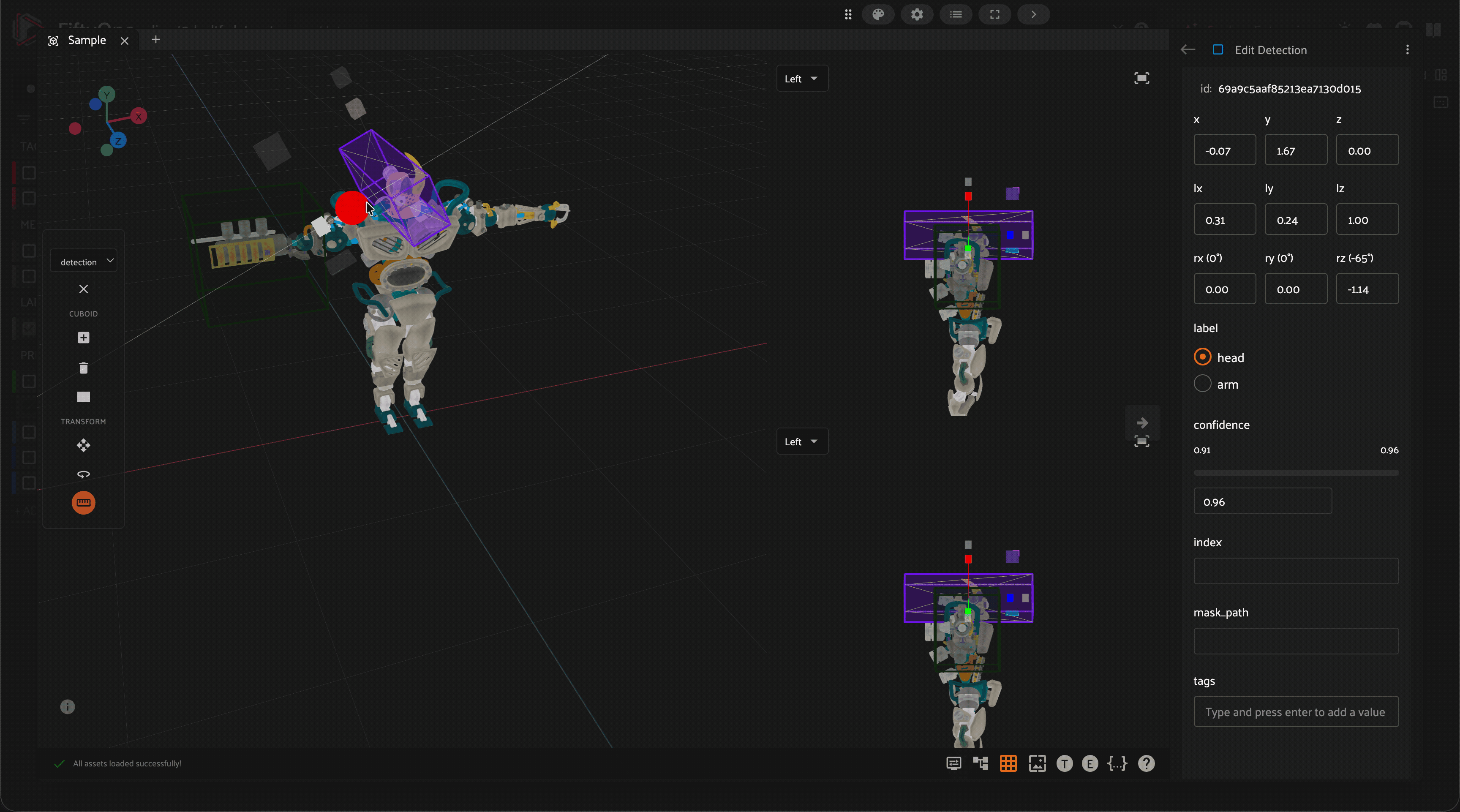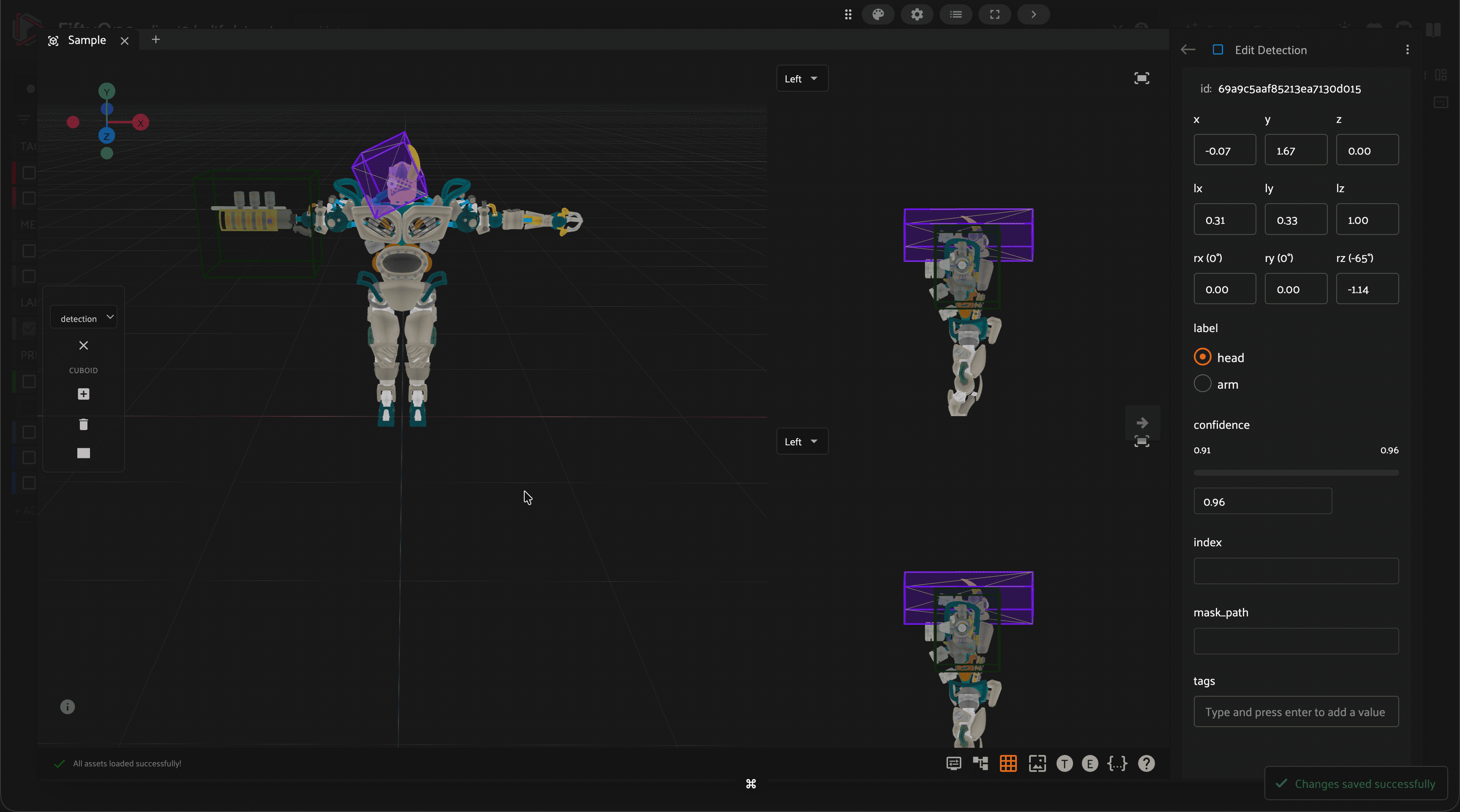
Evaluate
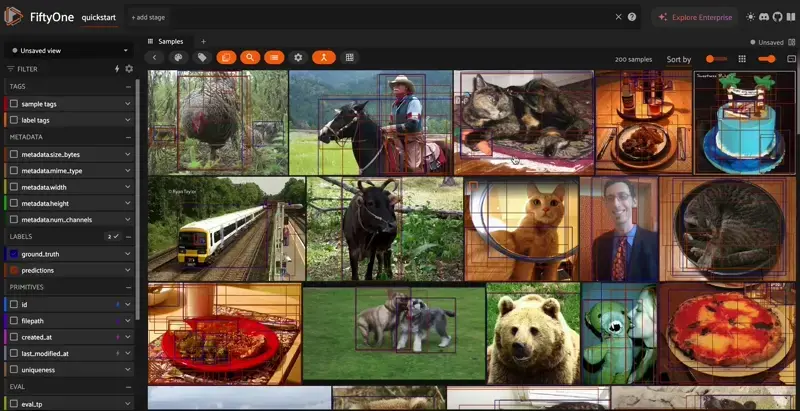
Aggregate metrics alone don't give you the full picture. FiftyOne makes it easy to see where your models succeed and fail so you can iterate faster.
Evaluate models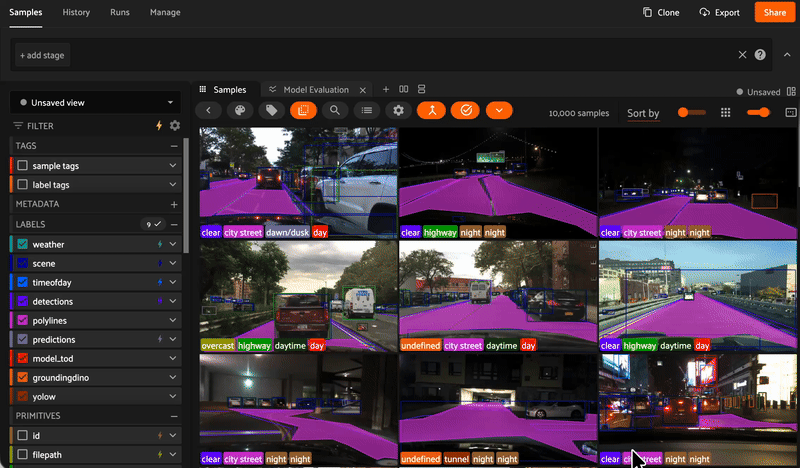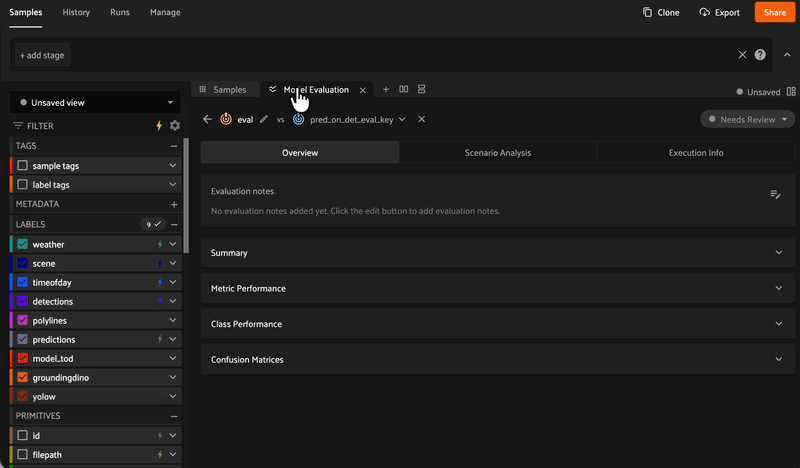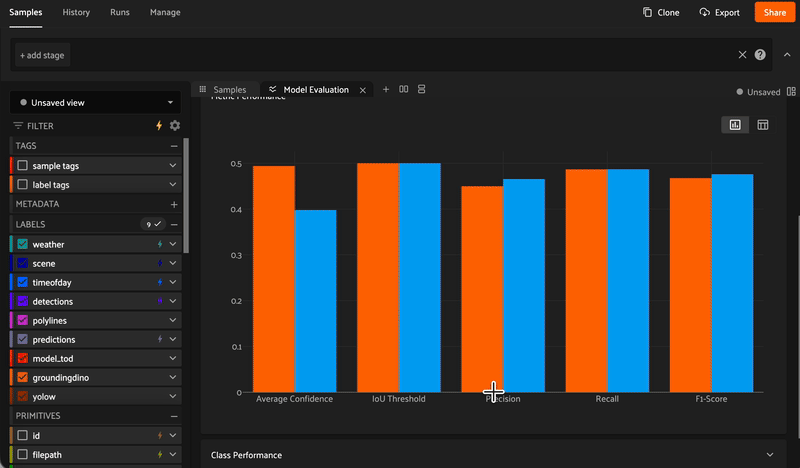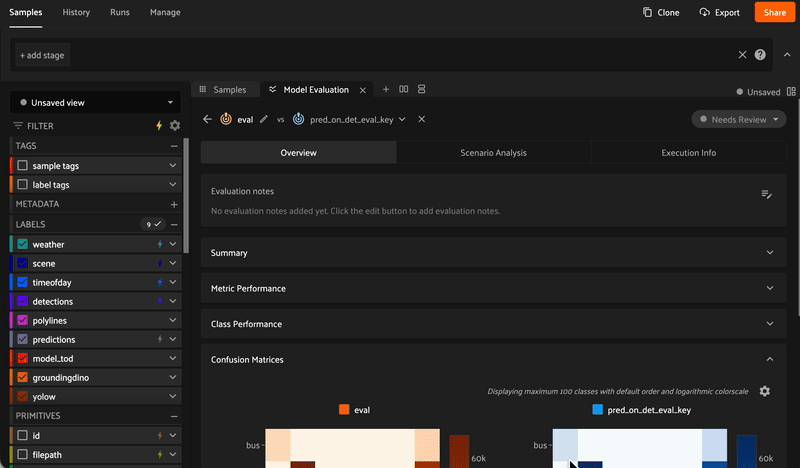
Integrations#
Works with your favorite tools
FiftyOne integrates natively with your favorite tools. Click on a logo to learn how.
View all integrations
































Community#
Need support?
If you run into any issues with FiftyOne or have any burning questions, feel free to connect with us