Hugging Face Integration#
FiftyOne integrates natively with Hugging Face’s Transformers library, so you can load, fine-tune, and run inference with your favorite Transformers models on your FiftyOne datasets with just a few lines of code!
FiftyOne also integrates with the Hugging Face Hub, so you can push datasets to and load datasets from the Hub with ease.
Transformers Library#
Setup#
To get started with
Transformers, just install the
transformers package:
pip install -U transformers
Inference#
All
Transformers models
that support image classification, object detection, semantic segmentation, or
monocular depth estimation tasks can be passed directly to your FiftyOne dataset’s
apply_model()
method.
The examples below show how to run inference with various Transformers models on the following sample dataset:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart", max_samples=25)
5dataset.select_fields().keep_fields()
Image classification#
You can pass transformers classification models directly to FiftyOne
dataset’s
apply_model()
method:
1# BeiT
2from transformers import BeitForImageClassification
3model = BeitForImageClassification.from_pretrained(
4 "microsoft/beit-base-patch16-224"
5)
6
7# DeiT
8from transformers import DeiTForImageClassification
9model = DeiTForImageClassification.from_pretrained(
10 "facebook/deit-base-distilled-patch16-224"
11)
12
13# DINOv2
14from transformers import Dinov2ForImageClassification
15model = Dinov2ForImageClassification.from_pretrained(
16 "facebook/dinov2-small-imagenet1k-1-layer"
17)
18
19# MobileNetV2
20from transformers import MobileNetV2ForImageClassification
21model = MobileNetV2ForImageClassification.from_pretrained(
22 "google/mobilenet_v2_1.0_224"
23)
24
25# Swin Transformer
26from transformers import SwinForImageClassification
27model = SwinForImageClassification.from_pretrained(
28 "microsoft/swin-tiny-patch4-window7-224"
29)
30
31# ViT
32from transformers import ViTForImageClassification
33model = ViTForImageClassification.from_pretrained(
34 "google/vit-base-patch16-224"
35)
36
37# ViT-Hybrid
38from transformers import ViTHybridForImageClassification
39model = ViTHybridForImageClassification.from_pretrained(
40 "google/vit-hybrid-base-bit-384"
41)
42
43# Any auto model
44from transformers import AutoModelForImageClassification
45model = AutoModelForImageClassification.from_pretrained(
46 "facebook/levit-128S"
47)
1dataset.apply_model(model, label_field="classif_predictions")
2
3session = fo.launch_app(dataset)
Alternatively, you can manually run inference with the transformers model and
then use the
to_classification()
utility to convert the predictions to FiftyOne format:
1from PIL import Image
2import torch
3import fiftyone.utils.transformers as fout
4
5from transformers import ViTHybridForImageClassification, AutoProcessor
6transformers_model = ViTHybridForImageClassification.from_pretrained(
7 "google/vit-hybrid-base-bit-384"
8)
9processor = AutoProcessor.from_pretrained("google/vit-hybrid-base-bit-384")
10id2label = transformers_model.config.id2label
11
12for sample in dataset.iter_samples(progress=True):
13 image = Image.open(sample.filepath)
14 inputs = processor(image, return_tensors="pt")
15 with torch.no_grad():
16 result = transformers_model(**inputs)
17
18 sample["classif_predictions"] = fout.to_classification(result, id2label)
19 sample.save()
Finally, you can load transformers models directly from the
FiftyOne Model Zoo!
To load a transformers classification model from the zoo, specify
"classification-transformer-torch" as the first argument, and pass in the
model’s name or path as a keyword argument:
1import fiftyone.zoo as foz
2
3model = foz.load_zoo_model(
4 "classification-transformer-torch",
5 name_or_path="facebook/levit-128S", # HF model name or path
6)
7
8dataset.apply_model(model, label_field="levit")
9
10session = fo.launch_app(dataset)
Object detection#
You can pass transformers detection models directly to your FiftyOne
dataset’s
apply_model()
method:
1# DETA
2from transformers import DetaForObjectDetection
3model = DetaForObjectDetection.from_pretrained(
4 "jozhang97/deta-swin-large"
5)
6
7# DETR
8from transformers import DetrForObjectDetection
9model = DetrForObjectDetection.from_pretrained(
10 "facebook/detr-resnet-50"
11)
12
13# DeformableDETR
14from transformers import DeformableDetrForObjectDetection
15model = DeformableDetrForObjectDetection.from_pretrained(
16 "SenseTime/deformable-detr"
17)
18
19# Table Transformer
20from transformers import TableTransformerForObjectDetection
21model = TableTransformerForObjectDetection.from_pretrained(
22 "microsoft/table-transformer-detection"
23)
24
25# YOLOS
26from transformers import YolosForObjectDetection
27model = YolosForObjectDetection.from_pretrained(
28 "hustvl/yolos-tiny"
29)
30
31# Any auto model
32from transformers import AutoModelForObjectDetection
33model = AutoModelForObjectDetection.from_pretrained(
34 "microsoft/conditional-detr-resnet-50"
35)
1dataset.apply_model(model, label_field="det_predictions")
2
3session = fo.launch_app(dataset)
Alternatively, you can manually run inference with the transformers model and
then use the
to_detections() utility to
convert the predictions to FiftyOne format:
from PIL import Image
import torch
import fiftyone.utils.transformers as fout
from transformers import AutoModelForObjectDetection, AutoProcessor
transformers_model = AutoModelForObjectDetection.from_pretrained(
"microsoft/conditional-detr-resnet-50"
)
processor = AutoProcessor.from_pretrained(
"microsoft/conditional-detr-resnet-50"
)
id2label = transformers_model.config.id2label
for sample in dataset.iter_samples(progress=True):
image = Image.open(sample.filepath)
inputs = processor(image, return_tensors="pt")
with torch.no_grad():
outputs = transformers_model(**inputs)
target_sizes = torch.tensor([image.size[::-1]])
result = processor.post_process_object_detection(
outputs, target_sizes=target_sizes
)
sample["det_predictions"] = fout.to_detections(
result, id2label, [image.size]
)
sample.save()
Finally, you can load transformers models directly from the
FiftyOne Model Zoo!
To load a transformers detection model from the zoo, specify
"detection-transformer-torch" as the first argument, and pass in the model’s
name or path as a keyword argument:
1import fiftyone.zoo as foz
2
3model = foz.load_zoo_model(
4 "detection-transformer-torch",
5 name_or_path="facebook/detr-resnet-50", # HF model name or path
6)
7
8dataset.apply_model(model, label_field="detr")
9
10session = fo.launch_app(dataset)
Semantic segmentation#
You can pass a transformers semantic segmentation model directly to your
FiftyOne dataset’s
apply_model()
method:
1# Mask2Former
2from transformers import Mask2FormerForUniversalSegmentation
3model = Mask2FormerForUniversalSegmentation.from_pretrained(
4 "facebook/mask2former-swin-small-coco-instance"
5)
6
7# Mask2Former
8from transformers import MaskFormerForInstanceSegmentation
9model = MaskFormerForInstanceSegmentation.from_pretrained(
10 "facebook/maskformer-swin-base-ade"
11)
12
13# Segformer
14from transformers import SegformerForSemanticSegmentation
15model = SegformerForSemanticSegmentation.from_pretrained(
16 "nvidia/segformer-b0-finetuned-ade-512-512"
17)
18
19# Any auto model
20from transformers import AutoModelForSemanticSegmentation
21model = AutoModelForSemanticSegmentation.from_pretrained(
22 "Intel/dpt-large-ade"
23)
1dataset.apply_model(model, label_field="seg_predictions")
2dataset.default_mask_targets = model.config.id2label
3
4session = fo.launch_app(dataset)
Alternatively, you can manually run inference with the transformers model and
then use the
to_segmentation() utility
to convert the predictions to FiftyOne format:
from PIL import Image
import fiftyone.utils.transformers as fout
from transformers import AutoModelForSemanticSegmentation, AutoProcessor
transformers_model = AutoModelForSemanticSegmentation.from_pretrained(
"Intel/dpt-large-ade"
)
processor = AutoProcessor.from_pretrained("Intel/dpt-large-ade")
for sample in dataset.iter_samples(progress=True):
image = Image.open(sample.filepath)
inputs = processor(image, return_tensors="pt")
target_size = [image.size[::-1]]
with torch.no_grad():
output = transformers_model(**inputs)
result = processor.post_process_semantic_segmentation(
output, target_sizes=target_size
)
sample["seg_predictions"] = fout.to_segmentation(result)
sample.save()
Finally, you can load transformers models directly from the
FiftyOne Model Zoo!
To load a transformers semantic segmentation model from the zoo, specify
"segmentation-transformer-torch" as the first argument, and pass in the
model’s name or path as a keyword argument:
1import fiftyone.zoo as foz
2
3model = foz.load_zoo_model(
4 "segmentation-transformer-torch",
5 name_or_path="nvidia/segformer-b0-finetuned-ade-512-512",
6)
7
8dataset.apply_model(model, label_field="segformer")
9
10session = fo.launch_app(dataset)
Monocular depth estimation#
You can pass a transformers monocular depth estimation model directly to your
FiftyOne dataset’s apply_model()
method:
1# DPT
2from transformers import DPTForDepthEstimation
3model = DPTForDepthEstimation.from_pretrained("Intel/dpt-large")
4
5# GLPN
6from transformers import GLPNForDepthEstimation
7model = GLPNForDepthEstimation.from_pretrained("vinvino02/glpn-kitti")
8
9# Depth Anything
10from transformers import AutoModelForDepthEstimation
11model = AutoModelForDepthEstimation.from_pretrained("LiheYoung/depth-anything-small-hf")
12
13# Depth Anything-V2
14from transformers import AutoModelForDepthEstimation
15model = AutoModelForDepthEstimation.from_pretrained("depth-anything/Depth-Anything-V2-Small-hf")
1dataset.apply_model(model, label_field="depth_predictions")
2
3session = fo.launch_app(dataset)
Alternatively, you can load transformers depth estimation models directly from
the FiftyOne Model Zoo!
To load a transformers depth estimation model from the zoo, specify
"depth-estimation-transformer-torch" as the first argument, and pass in the
model’s name or path as a keyword argument:
1import fiftyone.zoo as foz
2
3model = foz.load_zoo_model(
4 "depth-estimation-transformer-torch",
5 name_or_path="Intel/dpt-hybrid-midas",
6)
7
8dataset.apply_model(model, label_field="dpt_hybrid_midas")
9
10session = fo.launch_app(dataset)
Zero-shot classification#
Zero-shot image classification models from transformers can be loaded
directly from the FiftyOne Model Zoo!
To load a transformers zero-shot classification model from the zoo, specify
"zero-shot-classification-transformer-torch" as the first argument, and pass
in the model’s name or path as a keyword argument:
1import fiftyone.zoo as foz
2
3model = foz.load_zoo_model(
4 "zero-shot-classification-transformer-torch",
5 name_or_path="BAAI/AltCLIP", # HF model name or path
6 classes=["cat", "dog", "bird", "fish", "turtle"], # optional
7)
Once loaded, you can pass the model directly to your FiftyOne dataset’s
apply_model()
method:
1dataset.apply_model(model, label_field="altclip")
2
3session = fo.launch_app(dataset)
You can also generate embeddings for the samples in your dataset with zero shot models as follows:
1import fiftyone.zoo as foz
2
3model = foz.load_zoo_model(
4 "zero-shot-classification-transformer-torch",
5 name_or_path="BAAI/AltCLIP", # HF model name or path
6)
7
8dataset.compute_embeddings(model, embeddings_field="altclip_embeddings")
9
10session = fo.launch_app(dataset)
You can also change the label classes of zero shot models any time by setting
the classes attribute of the model:
1model.classes = ["cat", "dog", "bird", "fish", "turtle"]
2
3dataset.apply_model(model, label_field="altclip")
4
5session = fo.launch_app(dataset)
The
convert_transformers_model()
utility also allows you to manually convert a zero-shot transformers model to
FiftyOne format:
1import fiftyone.utils.transformers as fout
2
3from transformers import CLIPSegModel
4transformers_model = CLIPSegModel.from_pretrained(
5 "CIDAS/clipseg-rd64-refined"
6)
7
8model = fout.convert_transformers_model(
9 transformers_model,
10 task="image-classification", # or "semantic-segmentation"
11)
Note
Some zero-shot models are compatible with multiple tasks, so it is recommended that you specify the task type when converting the model.
Zero-shot object detection#
Zero-shot object detection models from transformers can be loaded directly
from the FiftyOne Model Zoo!
To load a transformers zero-shot object detection model from the zoo, specify
"zero-shot-detection-transformer-torch" as the first argument, and pass
in the model’s name or path as a keyword argument. You can optionally pass in a
list of label classes as a keyword argument classes:
1import fiftyone.zoo as foz
2
3model = foz.load_zoo_model(
4 "zero-shot-detection-transformer-torch",
5 name_or_path="google/owlvit-base-patch32", # HF model name or path
6 classes=["cat", "dog", "bird", "fish", "turtle"], # optional
7)
The
convert_transformers_model()
utility also allows you to manually convert a zero-shot transformers model to
FiftyOne format:
1import fiftyone.utils.transformers as fout
2
3from transformers import OwlViTForObjectDetection
4transformers_model = OwlViTForObjectDetection.from_pretrained(
5 "google/owlvit-base-patch32"
6)
7
8model = fout.convert_transformers_model(
9 transformers_model,
10 task="object-detection",
11)
Note
Some zero-shot models are compatible with multiple tasks, so it is recommended that you specify the task type when converting the model.
As of transformers>=4.40.0 and fiftyone>=0.24.0, you can also use
Grounding DINO
models for zero-shot object detection:
1import fiftyone.zoo as foz
2
3model = foz.load_zoo_model(
4 "zero-shot-detection-transformer-torch",
5 name_or_path="IDEA-Research/grounding-dino-tiny",
6 classes=["cat"],
7)
8
9dataset.apply_model(model, label_field="cats", confidence_thresh=0.2)
Note
The confidence_thresh parameter is optional and can be used to filter out
predictions with confidence scores below the specified threshold. You may
need to adjust this value based on the model and dataset you are working.
Also note that whereas OwlViT models accept multiple classes, Grounding DINO
models only accept a single class.
Batch inference#
When using
apply_model(),
you can request batch inference by passing the optional batch_size parameter:
1dataset.apply_model(model, label_field="det_predictions", batch_size=16)
The manual inference loops can be also executed using batch inference via the pattern below:
1from fiftyone.core.utils import iter_batches
2import fiftyone.utils.transformers as fout
3
4# Load a detection model and its corresponding processor
5from transformers import YolosForObjectDetection, AutoProcessor
6transformers_model = YolosForObjectDetection.from_pretrained(
7 "hustvl/yolos-tiny"
8)
9processor = AutoProcessor.from_pretrained("hustvl/yolos-tiny")
10id2label = transformers_model.config.id2label
11
12filepaths = dataset.values("filepath")
13batch_size = 16
14
15predictions = []
16for paths in iter_batches(filepaths, batch_size):
17 images = [Image.open(p) for p in paths]
18 image_sizes = [i.size for i in images]
19 target_sizes = torch.tensor([image.size[::-1] for image in images])
20 inputs = processor(images, return_tensors="pt")
21 with torch.no_grad():
22 outputs = transformers_model(**inputs)
23
24 results = processor.post_process_object_detection(
25 outputs, target_sizes=target_sizes
26 )
27 predictions.extend(fout.to_detections(results, id2label, image_sizes))
28
29dataset.set_values("det_predictions", predictions)
Note
See this section for more information about performing batch updates to your FiftyOne datasets.
Embeddings#
Any transformers model that supports image classification or object detection
tasks — zero-shot or otherwise — can be used to compute embeddings for your
samples.
Note
For zero-shot models, FiftyOne will use the transformers model’s
get_image_features() method to extract embeddings.
For non-zero-shot models, regardless of whether you use a classification,
detection, or base model, FiftyOne will extract embeddings from the
last_hidden_state of the model’s base encoder.
Image embeddings#
To compute embeddings for images, you can pass the transformers model
directly to your FiftyOne dataset’s
compute_embeddings()
method:
1# Embeddings from base model
2from transformers import BeitModel
3model = BeitModel.from_pretrained(
4 "microsoft/beit-base-patch16-224-pt22k"
5)
6
7# Embeddings from classification model
8from transformers import BeitForImageClassification
9model = BeitForImageClassification.from_pretrained(
10 "microsoft/beit-base-patch16-224"
11)
12
13# Embeddings from detection model
14from transformers import DetaForObjectDetection
15model = DetaForObjectDetection.from_pretrained(
16 "jozhang97/deta-swin-large-o365"
17)
18
19# Embeddings from zero-shot classification model
20from transformers import AltCLIPModel
21model = AltCLIPModel.from_pretrained(
22 "BAAI/AltCLIP"
23)
24
25# Embeddings from zero-shot detection model
26from transformers import OwlViTForObjectDetection
27model = OwlViTForObjectDetection.from_pretrained(
28 "google/owlvit-base-patch32"
29)
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart", max_samples=25)
5dataset.select_fields().keep_fields()
6
7dataset.compute_embeddings(model, embeddings_field="embeddings")
Alternatively, you can use the
convert_transformers_model()
utility to convert a transformers model to FiftyOne format, which allows you
to check the model’s
has_embeddings property to
see if the model can be used to generate embeddings:
1import numpy as np
2from PIL import Image
3import fiftyone.utils.transformers as fout
4
5from transformers import BeitModel
6transformers_model = BeitModel.from_pretrained(
7 "microsoft/beit-base-patch16-224-pt22k"
8)
9
10model = fout.convert_transformers_model(transformers_model)
11print(model.has_embeddings) # True
12
13# Embed an image directly
14image = Image.open(dataset.first().filepath)
15embedding = model.embed(np.array(image))
Text embeddings#
Zero-shot image classification and object detection models from transformers
can also be used to compute embeddings for text:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart", max_samples=25)
5dataset.select_fields().keep_fields()
6
7model = foz.load_zoo_model(
8 "zero-shot-classification-transformer-torch",
9 name_or_path="BAAI/AltCLIP",
10)
11
12embedding = model.embed_prompt("a photo of a dog")
You can check whether a model supports text embeddings by checking the
can_embed_prompts
property:
1import fiftyone.zoo as foz
2
3# A zero-shot model that supports text embeddings
4model = foz.load_zoo_model(
5 "zero-shot-classification-transformer-torch",
6 name_or_path="BAAI/AltCLIP",
7)
8print(model.can_embed_prompts) # True
9
10# A classification model that does not support text embeddings
11model = foz.load_zoo_model(
12 "classification-transformer-torch",
13 name_or_path="microsoft/beit-base-patch16-224",
14)
15print(model.can_embed_prompts) # False
Batch embeddings#
You can request batch inference by passing the optional batch_size parameter
to
compute_embeddings():
1dataset.compute_embeddings(model, embeddings_field="embeddings", batch_size=16)
Patch embeddings#
You can compute embeddings for image patches by passing transformers models
directly to your FiftyOne dataset’s
compute_patch_embeddings()
method:
1import fiftyone as fo
2import fiftyone.zoo as foz
3import fiftyone.utils.transformers as fout
4
5dataset = foz.load_zoo_dataset("quickstart", max_samples=25)
6
7from transformers import BeitModel
8model = BeitModel.from_pretrained(
9 "microsoft/beit-base-patch16-224-pt22k"
10)
11
12dataset.compute_patch_embeddings(
13 model,
14 patches_field="ground_truth",
15 embeddings_field="embeddings",
16)
Brain methods#
Because transformers models can be used to compute embeddings, they can be
passed to Brain methods like
compute_similarity() and
compute_visualization():
1import fiftyone as fo
2import fiftyone.brain as fob
3import fiftyone.zoo as foz
4
5dataset = foz.load_zoo_dataset("quickstart", max_samples=25)
6
7# Classification model
8from transformers import BeitModel
9transformers_model = BeitModel.from_pretrained(
10 "microsoft/beit-base-patch16-224-pt22k"
11)
12
13# Detection model
14from transformers import DetaForObjectDetection
15transformers_model = DetaForObjectDetection.from_pretrained(
16 "jozhang97/deta-swin-large"
17)
18
19# Zero-shot classification model
20from transformers import AutoModelForImageClassification
21transformers_model = AutoModelForImageClassification.from_pretrained(
22 "BAAI/AltCLIP"
23)
24
25# Zero-shot detection model
26from transformers import OwlViTForObjectDetection
27transformers_model = OwlViTForObjectDetection.from_pretrained(
28 "google/owlvit-base-patch32"
29)
1# Option 1: directly pass `transformers` model
2fob.compute_similarity(dataset, model=transformers_model, brain_key="sim1")
3fob.compute_visualization(dataset, model=transformers_model, brain_key="vis1")
1# Option 2: pass pre-computed embeddings
2dataset.compute_embeddings(transformers_model, embeddings_field="embeddings")
3
4fob.compute_similarity(dataset, embeddings="embeddings", brain_key="sim2")
5fob.compute_visualization(dataset, embeddings="embeddings", brain_key="vis2")
Because transformers zero-shot models can be used to embed text, they can
also be used to construct similarity indexes on your datasets which support
natural language queries.
To use this functionality, you must pass the model by name into the brain
method, along with any necessary keyword arguments that must be passed to
load_zoo_model() to load the correct
model:
1import fiftyone as fo
2import fiftyone.brain as fob
3import fiftyone.zoo as foz
4
5dataset = foz.load_zoo_dataset("quickstart", max_samples=25)
6
7fob.compute_similarity(
8 dataset,
9 brain_key="zero_shot_sim",
10 model="zero-shot-classification-transformer-torch",
11 name_or_path="BAAI/AltCLIP",
12)
13
14view = dataset.sort_by_similarity("A photo of a dog", k=25)
15
16session = fo.launch_app(view)
Hugging Face Hub#
FiftyOne integrates with the Hugging Face Hub to allow you to push datasets to and load datasets from the Hub with ease. This integration simplifies the process of sharing datasets with the machine learning and computer vision community, and allows you to easily access and work with many of the most popular vision and multimodal datasets available!
Setup#
To push datasets to and load datasets from the Hugging Face Hub, you will need the Hugging Face Hub Python client, which you can install via PyPI:
pip install "huggingface_hub>=0.20.0"
To push a dataset to the Hub, and in some cases, to access a dataset on the hub, you will need to have a Hugging Face Hub account.
Hugging Face handles authentication via tokens, which you can obtain by logging into your account and navigating to the Access Tokens section of your profile. At the bottom of this page, you can create a new token with write or read access to the Hub. Once you have your token, you can set it as an environment variable:
export HF_TOKEN="<your-token-here>"
Pushing datasets to the Hub#
If you are working with a dataset in FiftyOne and you want to quickly share it
with others, you can do so via the
push_to_hub()
function, which takes two positional arguments:
the FiftyOne sample collection (a
DatasetorDatasetView)the
repo_name, which will be combined with your Hugging Face username or organization name to construct therepo_idwhere the sample collection will be uploaded.
As you will see, this simple function allows you to push datasets and filtered views containing images, videos, point clouds, and other multimodal data to the Hugging Face Hub, providing you with incredible flexibility in the process.
Basic usage#
The basic recipe for pushing a FiftyOne dataset to the Hub is just two lines of code. As a starting point, let’s use the example Quickstart dataset dataset from the FiftyOne Dataset Zoo:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
To push the dataset to the Hugging Face Hub, all you need to do is call
push_to_hub() with the dataset
and the desired repo_name:
1from fiftyone.utils.huggingface import push_to_hub
2
3push_to_hub(dataset, "my-quickstart-dataset")
When you run this code, a few things happen:
The dataset and its media files are exported to a temporary directory and uploaded to the specified Hugging Face repo.
A
fiftyone.ymlconfig file for the dataset is generated and uploaded to the repo, which contains all of the necessary information so that the dataset can be loaded withload_from_hub().A Hugging Face Dataset Card for the dataset is auto-generated, providing tags, metadata, license info, and a code snippet illustrating how to load the dataset from the hub.
Your dataset will be available on the Hub at the following URL:
https://huggingface.co/datasets/<your-username-or-org-name>/my-quickstart-dataset
Pushing a DatasetView to the Hub works in exactly the same way. For example,
if you want to push a filtered view of the quickstart dataset containing only
predictions with high confidence, you can do so by creating the view as usual,
and then passing that in to
push_to_hub():
1from fiftyone.utils.huggingface import push_to_hub
2
3# Create view with high confidence predictions
4view = dataset.filter_labels("predictions", F("confidence") > 0.95)
5
6# Push view to the Hub as a new dataset
7push_to_hub(view, "my-quickstart-high-conf")
When you do so, note that the view is exported as a new dataset, and other details from the original dataset are not included.
FiftyOne is a visual toolkit, so when you push a dataset to the Hub, you can
optionally include a preview (image, gif, or video) of the dataset, that will be
displayed on the dataset page. To do this, you can pass the preview_path
argument to push_to_hub(), with
either a relative or absolute path to the preview file on your local machine:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4from fiftyone.utils.huggingface import push_to_hub
5
6dataset = foz.load_zoo_dataset("quickstart")
7
8session = fo.launch_app(dataset)
9
10# Screenshot and save the preview image to a file...
11
12push_to_hub(
13 dataset,
14 "my-quickstart-with-preview",
15 preview_path="/path/to/preview.jpg"
16)
The preview file will be uploaded to the Hub along with the dataset, and will be displayed on the dataset card!
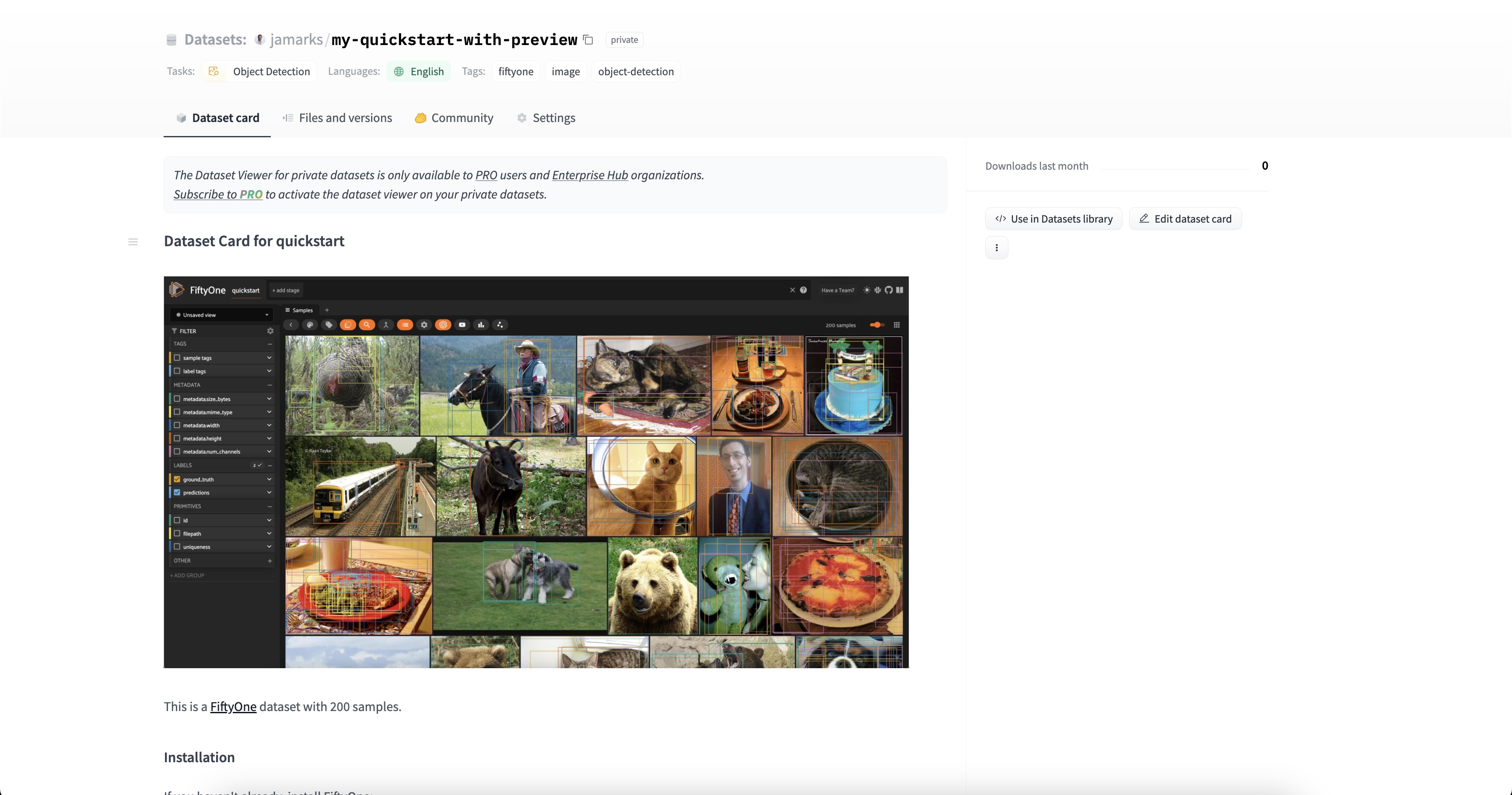
Pushing large datasets#
Large datasets with many samples require a bit more care when pushing to the
Hub. Hugging Face limits the number of files that can be uploaded in a single
directory to 10000, so if your dataset contains more than 10000 samples, the
data will need to be split into multiple directories. FiftyOne handles this
automatically when pushing large datasets to the Hub, but you can manually
configure the number of samples per directory by passing the chunk_size
argument to push_to_hub():
1from fiftyone.utils.huggingface import push_to_hub
2
3# Limit to 100 images per directory
4push_to_hub(dataset, "my-large-dataset", chunk_size=100)
Note
The chunk_size argument is currently only supported when exporting in
FiftyOneDataset format (the default).
Advanced usage#
The push_to_hub() function
provides a number of optional arguments that allow you to customize how your
dataset is pushed to the Hub, including whether the dataset is public or private,
what license it is released under, and more.
FiftyOne’s push_to_hub()
function supports the Hugging Face Hub API arguments private and exist_ok.
private (bool): Whether the dataset should be private. If
True, the dataset will be private and only accessible to you. IfFalse, the dataset will be public and accessible to anyone with the link. Defaults toFalse.- exist_ok (bool): Whether to overwrite an existing dataset with the same
repo_name. IfTrue, the existing dataset will be overwritten. IfFalse, an error will be raised if a dataset with the samerepo_namealready exists. Defaults toFalse.
For example, to push a dataset to the Hub as private, you can do the following:
1from fiftyone.utils.huggingface import push_to_hub
2
3push_to_hub(dataset, "my-private-dataset", private=True)
You can also specify the tags, license, and description of the dataset,
all of which will propagate to the fiftyone.yml config file and the Hugging
Face Dataset Card. For example, to push a video action recognition dataset with
an MIT license and a description, you can do the following:
1import fiftyone as fo
2import fiftyone.zoo as foz
3from fiftyone.utils.huggingface import push_to_hub
4
5dataset = foz.load_zoo_dataset("quickstart-video")
6
7push_to_hub(
8 dataset,
9 "my-action-recognition-dataset",
10 tags=["video", "action-recognition"],
11 license="mit",
12 description="A dataset of videos for action recognition tasks",
13)
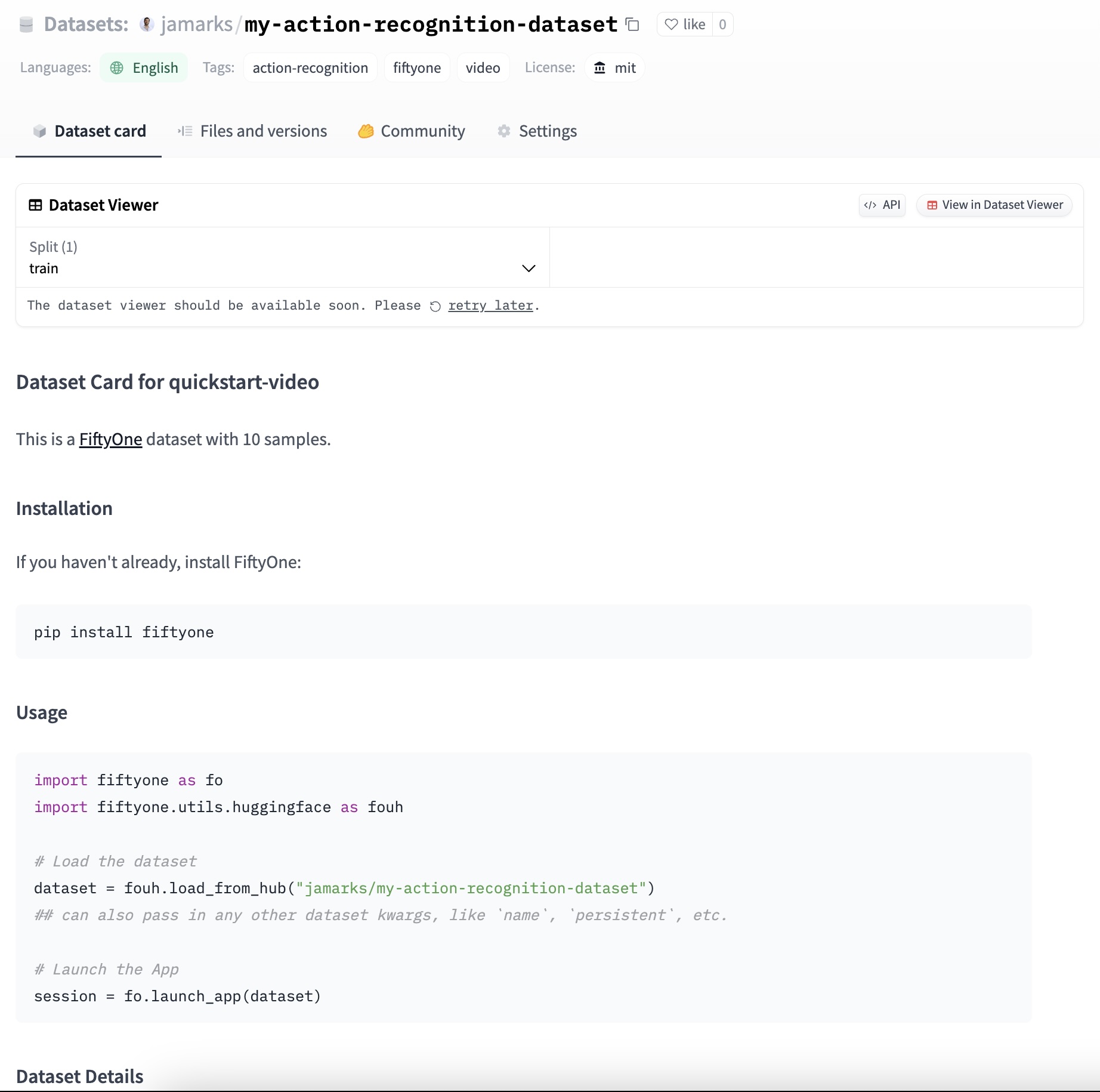
The pushed dataset will be available on the Hub and the dataset page will look like this:
Note
The tags argument can be a string or a list of strings. The tag fiftyone
is automatically added to all datasets pushed with FiftyOne, communicating
that the dataset was created with FiftyOne and can be loaded with the
load_from_hub() function.
The license is specified as a string. For a list of supported licenses, see the Hugging Face Hub documentation.
The description argument can be used for whatever you like. When the dataset
is loaded from the Hub, this description will be accessible via the dataset’s
description property.
Additionally, you can specify the “format” of the uploaded dataset. By default, the format is the standard FiftyOneDataset format, but you can also specify the data is uploaded in any of these common formats. For example, to push the quickstart dataset in COCO format, with a Creative Commons Attribution 4.0 license, you can do the following:
1import fiftyone as fo
2import fiftyone.zoo as foz
3from fiftyone.utils.huggingface import push_to_hub
4import fiftyone.types as fot
5
6dataset = foz.load_zoo_dataset("quickstart")
7dataset_type = fot.dataset_types.COCODetectionDataset
8
9push_to_hub(
10 dataset,
11 "quickstart-coco",
12 dataset_type=dataset_type,
13 license="cc-by-4.0",
14 label_fields="*", # convert all label fields, not just ground truth
15)
Note
The label_fields argument is used to specify which label fields to convert
to the specified dataset type. By default when using some dataset formats,
only the ground_truth label field is converted. If you want to convert all
label fields, you can set label_fields="*". If you want to convert specific
label fields, you can pass a list of field names.
Additionally, you can specify the minimum version of FiftyOne required to load
the dataset by passing the min_fiftyone_version argument. This is useful when
the dataset utilizes features that are only available in versions above a certain
release. For example, to specify that the dataset requires fiftyone>=0.23.0:
1import fiftyone as fo
2import fiftyone.zoo as foz
3from fiftyone.utils.huggingface import push_to_hub
4
5dataset = foz.load_zoo_dataset("quickstart")
6
7push_to_hub(
8 dataset,
9 "quickstart-min-version",
10 min_fiftyone_version="0.23.0",
11)
Loading datasets from the Hub#
To load a dataset from the Hugging Face Hub, you can use the
load_from_hub() function.
Note
If you encounter HTTP 429 (Too Many Requests) errors when downloading
large datasets, upgrade to huggingface_hub>=1.1.3:
pip install --upgrade "huggingface_hub>=1.1.3"
This version includes a fix for redundant API calls that caused rate limiting. For more details, see the Hugging Face Hub rate limits and release notes.
This function supports loading datasets in any of the common formats supported by FiftyOne, as well as image-based datasets stored via Parquet files, as is common with datasets from the datasets library which have been uploaded to the Hugging Face Hub. Below, we will walk through all of the ways you can load datasets from the Hub.
In its simplest usage, the
load_from_hub() function
only requires the repo_id of the dataset you want to load. For example, to
load the private dataset that we
pushed to the Hub earlier, you can do the following:
1from fiftyone.utils.huggingface import load_from_hub
2
3dataset = load_from_hub("<username-or-org>/my-private-dataset")
Note
As long as you have an environment variable HF_TOKEN set with your Hugging
Face token (with read access), you can load private or gated datasets that you have
access to from the Hub.
Loading datasets from repo configs#
When you push a dataset to the Hub using
push_to_hub(), a fiftyone.yml
config file is generated and uploaded to the repo. This file contains all of the
information necessary to load the dataset from the Hugging Face Hub. More
generally, any repo on the Hugging Face Hub that contains a fiftyone.yml or
fiftyone.yaml file (assuming the file is correctly formatted) can be loaded
using the load_from_hub()
function by passing the repo_id of the dataset, without needing to specify any
additional arguments.
For example, to load the quickstart dataset that we pushed to the Hub earlier,
1from fiftyone.utils.huggingface import load_from_hub
2
3dataset = load_from_hub("<username>/my-quickstart-dataset")
where <username> is your Hugging Face username or organization name.
Loading datasets from local configs#
If the repo was uploaded to the Hugging Face Hub via FiftyOne’s
push_to_hub() function, then
the fiftyone.yml config file will be generated and uploaded to the repo.
However, some common datasets like
mnist were uploaded to the Hub
using the datasets library and do not contain a fiftyone.yml or
fiftyone.yaml file. If you know how the dataset is structured, you can load
the dataset by passing the path to a local yaml config file that describes the
dataset via the config_file keyword argument.
For example, to load the mnist dataset from the Hub, you might have a local
yaml config file like this:
format: ParquetFilesDataset
classification_fields: label
To load the dataset from the Hub, you can pass the repo_id of the dataset and
the path to the local yaml config file:
1from fiftyone.utils.huggingface import load_from_hub
2
3dataset = load_from_hub(
4 "ylecun/mnist",
5 config_file="/path/to/mnist.yml",
6)
For a comprehensive list of the supported fields in the yaml config file, see Supported config fields.
Loading datasets with config kwargs#
In addition to loading datasets from repo configs and local configs, you can
also load datasets from the Hub by passing the necessary config arguments
directly to load_from_hub().
This is useful when you want to load a dataset from the Hub that does not have
a fiftyone.yml or fiftyone.yaml file, and the structure of the dataset is
simple enough that you can specify the necessary arguments directly.
For example, to load the mnist dataset from the Hub, you can pass the format
and classification_fields arguments directly:
1from fiftyone.utils.huggingface import load_from_hub
2
3dataset = load_from_hub(
4 "ylecun/mnist",
5 format="ParquetFilesDataset",
6 classification_fields="label",
7)
This will tell FiftyOne that the data is stored in Parquet files, and that the
label field should be treated as a classification field, to be converted into
a Classification label field in the dataset.
Supported config fields#
Whether you are loading a dataset from a repo config, a local config file, or passing the config arguments directly, you can specify a number of fields.
Broadly speaking, these fields fall into three categories: format specification, media field specification, and label field specification.
Let’s look at these categories in more detail:
Format specification:
format (str): The format of the dataset. This can be any of the common formats supported by FiftyOne — just pass the name of the format as a string. For example, to load a dataset in the COCO format, you can pass
format="COCODetectionDataset". To specify that the dataset is stored in Parquet files, you can passformat="ParquetFilesDataset"(or simplyformat="parquet"for short). This is the only required field.name (str): The name of the FiftyOne
Datasetto be created. If therepo_idis cumbersome, this can be used to specify a simpler default name. For example, for this sheep dataset rather than using therepo_idkeremberke/aerial-sheep-object-detection, you can specifyname="sheep-detection".subsets (str or list): The subset or subsets of the Hugging Face dataset that are compatible with this config, and are available to be loaded. In Hugging Face, the “dataset” in a repo can contain multiple “subsets”, which may or may not have the same schema. Take the Street View House Numbers dataset for example. This dataset has two subsets:
"cropped_digits"and"full_numbers". Thecropped_digitssubset contains classification labels, while thefull_numberssubset contains detection labels. A single config would not be able to specify the schema for both subsets, so you can specify the subset you want to load (or if you are the dataset author, which subset you want to allow people to load in this way) with thesubsetsfield. For example, to load thecropped_digitssubset of the SVHN dataset, you can passsubsets="cropped_digits". Note that this is not a required field, and by default all subsets are loaded. Also note that subsets are distinct from splits in the dataset, which are handled by thesplitsfield (see below).splits (str or list): The split or splits of the Hugging Face dataset that are compatible with this config, and are available to be loaded. As is standard for machine learning, many datasets are split into training, validation, and test sets. The specific names of these splits may vary from dataset to dataset, but
load_from_hub()identifies the names of all splits and by default, will assume that all of these splits are to be loaded. If you only want to load a specific split or splits, you can specify them with thesplitsfield. For example, to load the training split of the CIFAR10 dataset, you can passsplits="train". If you want to load multiple splits, you can pass them as a list, e.g.,splits=["train", "test"]. Note that this is not a required field, and by default all splits are loaded.
Media field specification:
While not all Parquet datasets contain media fields, all FiftyOne Sample objects
must be connected to at least one media file. The following fields can be used
to configure the media fields in the Hugging Face dataset that should be converted
to FiftyOne media fields:
filepath (str): In FiftyOne,
filepathis a default field that is used to store the path to the primary media file for each sample in the dataset. For Hugging Face parquet datasets, primary media fields for image datasets are typically stored in theimagecolumns, so this is where FiftyOne’sload_from_hub()looks by default. If the primary media field is stored in a different column, you can specify the column name with the keyfilepath. For example, the COYO-700M dataset has the primary media field referenced in theurlcolumn. Specifyingfilepath="url"will tell FiftyOne to look in theurlcolumn for the primary media file path. Images will be downloaded from the corresponding URLs and saved to disk.thumbnail_path (str): The field containing the path to a thumbnail image for each sample in the dataset, if such a field exists. If a
thumbnail_pathis specified, this media file will be shown in the sample grid in the FiftyOne App. This can be useful for quickly visualizing the dataset when the primary media field contains large (e.g., high-resolution) images. For more information on thumbnail images, see this section.additional_media_fields (dict): If each sample has multiple associated media files that you may want to visualize in the FiftyOne App, you can specify these non-default media fields in the
additional_media_fieldsdictionary, where the keys are the column names in the Hugging Face dataset and the values are the names of the fields in the FiftyOneDatasetthat will store the paths. Note that this is not the same as grouped datasets.
Label field specification:
FiftyOne’s Hugging Face Hub integration currently supports converting labels of
type Classification, Detections, and Segmentation from Hugging Face
Parquet datasets to FiftyOne label fields. The following fields can be used to
specify the label fields in the Hugging Face dataset that should be converted to
FiftyOne label fields:
classification_fields (str or list): The column or columns in the Hugging Face dataset that should be converted to FiftyOne
Classificationlabel fields. contain classification labels. For example, if the dataset contains alabelfield that contains classification labels, you can specifyclassification_fields="label". If the dataset contains multiple classification fields, you can specify them as a list, e.g.,classification_fields=["label1", "label2"]. This is not a required field, and if the dataset does not contain classification labels, you can omit it.detection_fields (str or list): The column or columns in the Hugging Face dataset that should be converted to FiftyOne
Detectionslabel fields. If the dataset contains detection labels, you can specify the column name or names here. For example, if the dataset contains adetectionsfield that contains detection labels, you can specifydetection_fields="detections". If the dataset contains multiple detection fields, you can specify them as a list, e.g.,detection_fields=["detections1", "detections2"]. This is not a required field, and if the dataset does not contain detection labels, you can omit it.mask_fields (str or list): The column or columns in the Hugging Face dataset that should be converted to FiftyOne
Segmentationlabel fields. The column in the Hugging Face dataset must contain an image or the URL for an image that can be used as a segmentation mask. If necessary, the images will be downloaded and saved to disk. If the dataset contains mask labels, you can specify the column name or names here. For example, if the dataset contains amasksfield that contains mask labels, you can specifymask_fields="masks". This is not a required field, and if the dataset does not contain mask labels, you can omit it.
Configuring the download process#
When loading datasets from the Hugging Face Hub, FiftyOne will download the
all of the data specified by the repo_id and the config. If no splits or
subsets are listed in the config, this means that all samples across all splits
and subsets will be downloaded. This can be a time-consuming process, especially
for large datasets, and sometimes you may only want to download a fixed number
of samples to get started exploring the dataset.
FiftyOne’s load_from_hub()
function supports a variety of arguments that allow you to control the download
process, from the maximum number of samples to be downloaded to the batch size
to use when making requests to the Datasets Server. Here are the supported
arguments:
max_samples (int): The number of samples to download from the dataset. If not specified, all samples will be downloaded.
batch_size (int): The batch size to use when making requests to the Datasets Server. Defaults to 100, which is the max batch size allowed by the Datasets Server.
num_workers (int): The number of worker to use when downloading media files. If not specified, the number of workers will be resolved by looking at your FiftyOne Config.
splits (str or list): The split or splits of the Hugging Face dataset that you want to download. This overrides the
splitsfield in the config.subsets (str or list): The subset or subsets of the Hugging Face dataset that you want to download. This overrides the
subsetsfield in the config.overwrite (bool): Whether to overwrite existing an existing dataset with the same name. If
True, the existing dataset will be overwritten. IfFalse, an error will be raised if a dataset with the same name already exists. Defaults toFalse.persistent (bool): Whether to persist the dataset to the underlying database after it is loaded. If
True, the dataset will be available for loading in future FiftyOne sessions by passing the dataset’s name into FiftyOne’sload_dataset()function. Defaults toFalse.revision (str): The revision (specified by a commit hash to the Hugging Face repo) of the dataset to load. If not specified, the latest revision will be loaded.
Basic examples#
Okay, so load_from_hub() is
very powerful, and can be used in a ton of ways. All of this flexibility
can be a bit overwhelming, so let’s walk through a few examples to show you how
easy it is in practice to load datasets from the Hugging Face Hub.
Note
To make these downloads as fast as possible, we recommend setting the
max_samples argument to a reasonable number, like 1000, to get a feel for
the dataset. If you like what you see, you can always download more samples!
Classification Datasets
Let’s start by loading the
MNIST dataset into FiftyOne. All you
need to do is pass the repo_id of the dataset — in this case "ylecun/mnist" — to
load_from_hub(), specify the
format as "parquet", and specify the classification_fields as "label":
1from fiftyone.utils.huggingface import load_from_hub
2
3dataset = load_from_hub(
4 "ylecun/mnist",
5 format="parquet",
6 classification_fields="label",
7 max_samples=1000,
8)
9
10session = fo.launch_app(dataset)
The same exact syntax works for the CIFAR-10
and FashionMNIST datasets,
which are also available on the Hub. In fact, you can load any of the following
classification datasets from the Hub using the same syntax, just by changing the
repo_id:
CIFAR-10 (use
"uoft-cs/cifar10")ImageNet (use
"ILSVRC/imagenet-1k")FashionMNIST (use
"zalando-datasets/fashion_mnist")Tiny ImageNet (use
"zh-plus/tiny-imagenet")Food-101 (use
"ethz/food101")Dog Food (use
"sasha/dog-food")ImageNet-Sketch (use
"songweig/imagenet_sketch")Oxford Flowers (use
"nelorth/oxford-flowers")Cats vs. Dogs (use
"microsoft/cats_vs_dogs")ObjectNet-1.0 (use
"timm/objectnet")
A very similar syntax can be used to load classification datasets that contain
multiple classification fields, such as
CIFAR-100 and the
WikiArt dataset. For example,
to load the CIFAR-100 dataset, you can specify the classification_fields as
["coarse_label", "fine_label"]:
1from fiftyone.utils.huggingface import load_from_hub
2
3dataset = load_from_hub(
4 "uoft-cs/cifar100",
5 format="parquet",
6 classification_fields=["coarse_label", "fine_label"],
7 max_samples=1000,
8)
9
10session = fo.launch_app(dataset)
To load the WikiArt dataset,
you can specify the classification_fields as ["artist", "genre", "style"]:
1from fiftyone.utils.huggingface import load_from_hub
2
3dataset = load_from_hub(
4 "huggan/wikiart",
5 format="parquet",
6 classification_fields=["artist", "genre", "style"],
7 max_samples=1000,
8)
9
10session = fo.launch_app(dataset)
As touched upon earlier, you can also load a classification subset of a
dataset. For example, to load the cropped_digits subset of the
Street View House Numbers dataset:
1from fiftyone.utils.huggingface import load_from_hub
2
3dataset = load_from_hub(
4 "ufldl-stanford/svhn",
5 format="parquet",
6 classification_fields="label",
7 subsets="cropped_digits",
8 max_samples=1000,
9)
10
11session = fo.launch_app(dataset)
Detection Datasets
Loading detection datasets from the Hub is just as easy. For example, to load
the MS COCO
dataset, you can specify the detection_fields as "objects", which is the
standard column name for detection features in Hugging Face datasets:
1from fiftyone.utils.huggingface import load_from_hub
2
3dataset = load_from_hub(
4 "detection-datasets/coco",
5 format="parquet",
6 detection_fields="objects",
7 max_samples=1000,
8)
9
10session = fo.launch_app(dataset)
The same syntax works for many other popular detection datasets on the Hub, including:
CPPE - 5 (use
"rishitdagli/cppe-5")WIDER FACE (use
"CUHK-CSE/wider_face")License Plate Object Detection (use
"keremberke/license-plate-object-detection")Aerial Sheep Object Detection (use
"keremberke/aerial-sheep-object-detection")
Some detection datasets have their detections stored under a column with a
different name. For example, the full_numbers subset of the
Street View House Numbers dataset
stores its detections under the column digits. To load this subset, you can
specify the detection_fields as "digits":
1from fiftyone.utils.huggingface import load_from_hub
2
3dataset = load_from_hub(
4 "ufldl-stanford/svhn",
5 format="parquet",
6 detection_fields="digits",
7 subsets="full_numbers",
8 max_samples=1000,
9)
10
11session = fo.launch_app(dataset)
Note
Not all detection datasets on the Hub are stored in a format that is currently supported by FiftyOne. For instance, the Fashionpedia dataset has detections stored in Pascal VOC format, which is not the standard Hugging Face format.
Segmentation Datasets
Loading segmentation datasets from the Hub is also a breeze. For example, to
load the “instance_segmentation” subset from
SceneParse150, all you
need to do is specify the mask_fields as "annotation":
1from fiftyone.utils.huggingface import load_from_hub
2
3dataset = load_from_hub(
4 "zhoubolei/scene_parse150",
5 format="parquet",
6 subsets="instance_segmentation",
7 mask_fields="annotation",
8 max_samples=1000,
9)
10
11session = fo.launch_app(dataset)
Many other segmentation datasets on the Hub can be loaded in the same way, such as ADE 20K Tiny:
1from fiftyone.utils.huggingface import load_from_hub
2
3dataset = load_from_hub(
4 "nateraw/ade20k-tiny",
5 format="parquet",
6 mask_fields="label",
7)
8
9# only 20 samples in the dataset
10
11session = fo.launch_app(dataset)
In other cases, because there are now multiple image columns — one for the
sample image and one for the mask — the naming convention for the dataset might
be different, and you may need to explicitly specify the filepath. For
example, to load the
Sidewalk Semantic
dataset:
1from fiftyone.utils.huggingface import load_from_hub
2
3# Note: you need access to the dataset to load it!
4
5dataset = load_from_hub(
6 "segments/sidewalk-semantic",
7 format="parquet",
8 filepath="pixel_values",
9 mask_fields="label",
10 max_samples=1000,
11)
12
13session = fo.launch_app(dataset)
Note
Once you have the dataset loaded into FiftyOne, you may want to set the dataset’s mask targets to specify the names of the classes represented in the segmentation masks.
Unlabelled Image Datasets
Some datasets on the Hub contain images and metadata in the form of features, but do not explicitly contain classification, detection, or segmentation labels. This is common for text-to-image tasks, as well as captioning and visual question answering tasks. These datasets can also be converted and loaded into FiftyOne! Once the dataset is loaded into FiftyOne, you can process the data and generate labels for whatever tasks you are interested in.
Let’s look at a few examples:
For DiffusionDB, you can load the dataset as follows:
1from fiftyone.utils.huggingface import load_from_hub
2
3dataset = load_from_hub(
4 "poloclub/diffusiondb",
5 format="parquet",
6 max_samples=1000,
7)
8
9session = fo.launch_app(dataset)
Here are some other popular datasets on the Hub that can be loaded following the same syntax:
Nouns: (use
"m1guelpf/nouns")New Yorker Caption Contest: (use
"jmhessel/newyorker_caption_contest")Captcha Dataset: (use
"project-sloth/captcha-images")MathVista: (use
"AI4Math/MathVista")TextVQA: (use
"textvqa")VQA-RAD: (use
"flaviagiammarino/vqa-rad")ScienceQA: (use
"derek-thomas/ScienceQA")PathVQA: (use
"flaviagiammarino/path-vqa")
Many other popular datasets on the Hub can be loaded in the same way, with slight
modifications to filepath or other arguments as needed. Here are a few examples:
For COYO-700M, we just
need to specify the filepath as "url":
1from fiftyone.utils.huggingface import load_from_hub
2
3dataset = load_from_hub(
4 "kakaobrain/coyo-700m",
5 format="parquet",
6 filepath="url",
7 max_samples=1000,
8)
9
10session = fo.launch_app(dataset)
For RedCaps, we instead use
"image_url" as the filepath:
1from fiftyone.utils.huggingface import load_from_hub
2
3dataset = load_from_hub(
4 "kdexd/red_caps",
5 format="parquet",
6 filepath="image_url",
7 max_samples=1000,
8)
9
10session = fo.launch_app(dataset)
For MMMU
(A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for
Expert AGI), we use "image_1" as the filepath:
1from fiftyone.utils.huggingface import load_from_hub
2
3dataset = load_from_hub(
4 "MMMU/MMMU",
5 format="parquet",
6 filepath="image_1",
7 max_samples=1000,
8)
9
10session = fo.launch_app(dataset)
Advanced examples#
The load_from_hub() function
also allows us to load datasets in much more complex formats, as well as with
more advanced configurations. Let’s walk through a few examples to show you how
to leverage the full power of FiftyOne’s Hugging Face Hub integration.
Loading Datasets from Revisions
When you load a dataset from the Hugging Face Hub, you are loading the latest
revision of the dataset. However, you can also load a specific revision of the
dataset by specifying the revision argument. For example, to load the last
revision of DiffusionDB before NSFW scores were added, you can specify this via:
1from fiftyone.utils.huggingface import load_from_hub
2
3dataset = load_from_hub(
4 "poloclub/diffusiondb",
5 format="parquet",
6 subset="2m_random_1k", ## just one of the subsets
7 max_samples=1000,
8 revision="5fa48ba66a44822d82d024d195fbe918e6c42ca6",
9)
10
11session = fo.launch_app(dataset)
Loading Datasets with Multiple Media Fields
Some datasets on the Hub contain multiple media fields for each sample. Take
MagicBrush for example, which
contains a "source_img" and a "target_img" for each sample, in addition
to a segmentation mask denoting the area of the source image to be modified. To
load this dataset, you can specify the filepath as "source_img" and the
target image via additional_media_fields. Because this is getting a bit more
complex, we’ll create a local yaml config file to specify the dataset format:
format: ParquetFilesDataset
name: magicbrush
filepath: source_img
additional_media_fields:
target_img: target_img
mask_fields: mask_img
Now, you can load the dataset using the local yaml config file:
1from fiftyone.utils.huggingface import load_from_hub
2
3dataset = load_from_hub(
4 "osunlp/MagicBrush",
5 config_file="/path/to/magicbrush.yml",
6 max_samples=1000,
7)
8
9session = fo.launch_app(dataset)
Customizing the Download Process
When loading datasets from the Hub, you can customize the download process by
specifying the batch_size, num_workers, and overwrite arguments. For
example, to download the full_numbers subset of the Street View House Numbers dataset with a batch size of 50 and 4
workers, you can do the following:
1from fiftyone.utils.huggingface import load_from_hub
2
3dataset = load_from_hub(
4 "ufldl-stanford/svhn",
5 format="parquet",
6 detection_fields="digits",
7 subsets="full_numbers",
8 max_samples=1000,
9 batch_size=50,
10 num_workers=4,
11)
12
13session = fo.launch_app(dataset)
Loading Private or Gated Datasets
Like public datasets, you can also load private or gated datasets from the Hub,
as long as you have the necessary permissions. If your Hugging Face token is
set as an environment variable HF_TOKEN, this is as simple as specifying the
repo_id of the dataset. If you don’t have your token set, or you need to use
a specific token for a specific dataset, you can specify the token argument.
You can do so following this recipe:
1from fiftyone.utils.huggingface import load_from_hub
2
3dataset = load_from_hub(
4 "my-private-dataset-repo-id",
5 token="<my-secret-token>",
6 ...
7)
8
9session = fo.launch_app(dataset)