|
|
|
|
Loading a Segmentation Dataset#
In this first step, we will explore how to load segmentation datasets into FiftyOne. Segmentation datasets may be of two types: semantic segmentation (pixel-wise class labels) and instance segmentation (individual object masks).
FiftyOne makes it easy to load both types using its Dataset Zoo or from custom formats like COCO or FiftyOne format. Let’s start by loading a common format instance segmentation dataset.
Loading a Common Format Segmentation Dataset#
Segmentation datasets are often provided in standard formats such as COCO, VOC, YOLO, KITTI, and FiftyOne format. FiftyOne supports direct ingestion of these datasets with just a few lines of code.
Make sure your dataset follows the folder structure and file naming conventions required by the specific format (e.g., COCO JSON annotations or class mask folders for semantic segmentation).
[ ]:
!pip install fiftyone huggingface_hub
[ ]:
import fiftyone as fo
# Create the dataset
name = "my-dataset"
dataset_dir = "/path/to/segmentation-dataset"
# Create the dataset
dataset = fo.Dataset.from_dir(
dataset_dir=dataset_dir,
dataset_type=fo.types.COCODetectionDataset, # Change with your type
name=name,
)
# View summary info about the dataset
print(dataset)
# Print the first few samples in the dataset
print(dataset.head())
Check out the docs for each format to find optional parameters you can pass for things like train/test split, subfolders, or label paths, check more in the User Guide of Using Datasets
FiftyOne with a Coffee-Beans Dataset#
We will walk through how to use FiftyOne to build better segmentation datasets and models.
Load your own dataset into FiftyOne. For this example, we use a Coffee-Beans Dataset in COCO format.
Use FiftyOne in a notebook
Explore your segmentation dataset using views and the FiftyOne App
Note: To load the dataset locally, visit the Coffee-Beans Dataset page on Hugging Face, download the files, and then load them using the following command.
[ ]:
!git clone https://huggingface.co/datasets/pjramg/colombian_coffee
If you only see small pointer files instead of the actual images, it means Git LFS wasn’t used. In that case, use Git LFS to pull the full dataset.
[ ]:
!sudo apt install git-lfs
!git lfs install
[ ]:
import fiftyone as fo
dataset = fo.Dataset.from_dir(
dataset_type=fo.types.COCODetectionDataset,
dataset_dir="./colombian_coffee",
data_path="images/default",
labels_path="annotations/instances_default.json",
label_types="segmentations",
label_field="categories",
name="coffee",
include_id=True,
overwrite=True
)
# View summary info about the dataset
print(dataset)
# Print the first few samples in the dataset
print(dataset.head())
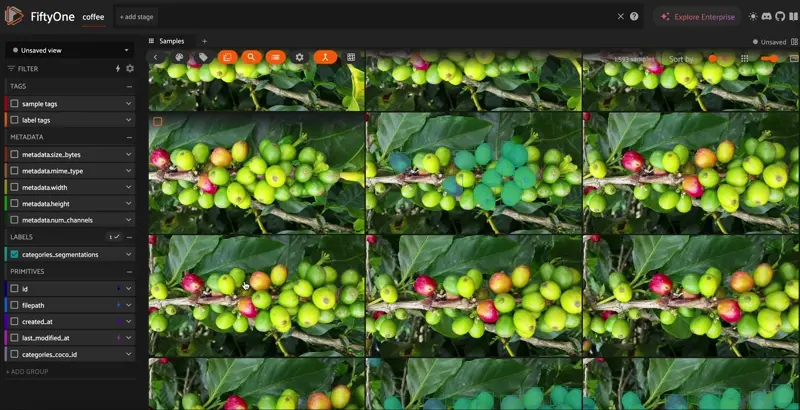
We can see our images have loaded in the App, but no segmentation masks are shown yet. Next, we’ll ensure annotations are properly loaded.
[ ]:
session = fo.launch_app(dataset)
Using the App#
With the FiftyOne App, you can visualize your samples and their segmentation masks in an interactive UI. Double-click any sample to enter the expanded view, where you can study individual samples with overlayed masks.
The view bar lets you filter and search your dataset to analyze specific classes or objects.
You can seamlessly move between Python and the App. For example, create a filtered view using the Shuffle() and Limit() stages in Python or directly in the App UI.
Once your annotations are loaded correctly, you can confirm that your segmentation masks (not detections!) are present and visualized correctly. 🎉
[ ]:
session.show()