Using FiftyOne Datasets#
After a Dataset has been loaded or created, FiftyOne provides powerful
functionality to inspect, search, and modify it from a Dataset-wide down to
a Sample level.
The following sections provide details of how to use various aspects of a
FiftyOne Dataset.
Datasets#
Instantiating a Dataset object creates a new dataset.
1import fiftyone as fo
2
3dataset1 = fo.Dataset("my_first_dataset")
4dataset2 = fo.Dataset("my_second_dataset")
5dataset3 = fo.Dataset() # generates a default unique name
Check to see what datasets exist at any time via list_datasets():
1print(fo.list_datasets())
2# ['my_first_dataset', 'my_second_dataset', '2020.08.04.12.36.29']
Load a dataset using
load_dataset().
Dataset objects are singletons. Cool!
1_dataset2 = fo.load_dataset("my_second_dataset")
2_dataset2 is dataset2 # True
If you try to load a dataset via Dataset(...) or create a new dataset via
load_dataset() you’re going to
have a bad time:
1_dataset2 = fo.Dataset("my_second_dataset")
2# Dataset 'my_second_dataset' already exists; use `fiftyone.load_dataset()`
3# to load an existing dataset
4
5dataset4 = fo.load_dataset("my_fourth_dataset")
6# DoesNotExistError: Dataset 'my_fourth_dataset' not found
Dataset media type#
The media type of a dataset is determined by the
media type of the Sample objects that it contains.
The media_type property of a
dataset is set based on the first sample added to it:
1import fiftyone as fo
2
3dataset = fo.Dataset()
4
5print(dataset.media_type)
6# None
7
8sample = fo.Sample(filepath="/path/to/image.png")
9dataset.add_sample(sample)
10
11print(dataset.media_type)
12# "image"
Note that datasets are homogeneous; they must contain samples of the same media type (except for grouped datasets):
1sample = fo.Sample(filepath="/path/to/video.mp4")
2dataset.add_sample(sample)
3# MediaTypeError: Sample media type 'video' does not match dataset media type 'image'
The following media types are available:
Media type |
Description |
|---|---|
|
Datasets that contain images |
|
Datasets that contain videos |
|
Datasets that contain 3D scenes |
|
Datasets that contain point clouds |
|
Datasets that contain grouped data slices |
|
Fallback value for datasets that contain samples that are not one of the natively available media types |
custom † |
Datasets that contain samples with a custom media type will inherit that type |
Note
† FiftyOne Enterprise users must upgrade their
deployment to 2.8.0+ in order to use unknown or “custom” media types.
Dataset persistence#
By default, datasets are non-persistent. Non-persistent datasets are deleted from the database each time the database is shut down. Note that FiftyOne does not store the raw data in datasets directly (only the labels), so your source files on disk are untouched.
To make a dataset persistent, set its
persistent property to
True:
1# Make the dataset persistent
2dataset1.persistent = True
Without closing your current Python shell, open a new shell and run:
1import fiftyone as fo
2
3# Verify that both persistent and non-persistent datasets still exist
4print(fo.list_datasets())
5# ['my_first_dataset', 'my_second_dataset', '2020.08.04.12.36.29']
All three datasets are still available, since the database connection has not been terminated.
However, if you exit all processes with fiftyone imported, then open a new
shell and run the command again:
1import fiftyone as fo
2
3# Verify that non-persistent datasets have been deleted
4print(fo.list_datasets())
5# ['my_first_dataset']
you’ll see that the my_second_dataset and 2020.08.04.12.36.29 datasets have
been deleted because they were not persistent.
Dataset version#
The version of the fiftyone package for which a dataset is formatted is
stored in the version property
of the dataset.
If you upgrade your fiftyone package and then load a dataset that was created
with an older version of the package, it will be automatically migrated to the
new package version (if necessary) the first time you load it.
Dataset stats#
You can use the stats() method on
a dataset to obtain information about the size of the dataset on disk,
including its metadata in the database and optionally the size of the physical
media on disk:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5
6fo.pprint(dataset.stats(include_media=True))
{
'samples_count': 200,
'samples_bytes': 1290762,
'samples_size': '1.2MB',
'media_bytes': 24412374,
'media_size': '23.3MB',
'total_bytes': 25703136,
'total_size': '24.5MB',
}
You can also invoke
stats() on a
dataset view to retrieve stats for a specific subset of
the dataset:
1view = dataset[:10].select_fields("ground_truth")
2
3fo.pprint(view.stats(include_media=True))
{
'samples_count': 10,
'samples_bytes': 10141,
'samples_size': '9.9KB',
'media_bytes': 1726296,
'media_size': '1.6MB',
'total_bytes': 1736437,
'total_size': '1.7MB',
}
Storing info#
All Dataset instances have an
info property, which contains a
dictionary that you can use to store any JSON-serializable information you wish
about your dataset.
Datasets can also store more specific types of ancillary information such as class lists and mask targets.
1import fiftyone as fo
2
3dataset = fo.Dataset()
4
5# Store a class list in the dataset's info
6dataset.info = {
7 "dataset_source": "https://...",
8 "author": "...",
9}
10
11# Edit existing info
12dataset.info["owner"] = "..."
13dataset.save() # must save after edits
Note
You must call
dataset.save() after updating
the dataset’s info property
in-place to save the changes to the database.
Dataset App config#
All Dataset instances have an
app_config property that
contains a DatasetAppConfig that you can use to store dataset-specific
settings that customize how the dataset is visualized in the
FiftyOne App.
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5session = fo.launch_app(dataset)
6
7# View the dataset's current App config
8print(dataset.app_config)
Multiple media fields#
You can declare multiple media fields on a dataset and configure which field is used by various components of the App by default:
1import fiftyone.utils.image as foui
2
3# Generate some thumbnail images
4foui.transform_images(
5 dataset,
6 size=(-1, 32),
7 output_field="thumbnail_path",
8 output_dir="/tmp/thumbnails",
9)
10
11# Configure when to use each field
12dataset.app_config.media_fields = ["filepath", "thumbnail_path"]
13dataset.app_config.grid_media_field = "thumbnail_path"
14dataset.save() # must save after edits
15
16session.refresh()
You can set media_fallback=True if you want the App to fallback to the
filepath field if an alternate media field is missing for a particular
sample in the grid and/or modal:
1# Fallback to `filepath` if an alternate media field is missing
2dataset.app_config.media_fallback = True
3dataset.save()
Custom color scheme#
You can store a custom color scheme on a dataset that should be used by default whenever the dataset is loaded in the App:
1dataset.evaluate_detections(
2 "predictions", gt_field="ground_truth", eval_key="eval"
3)
4
5# Store a custom color scheme
6dataset.app_config.color_scheme = fo.ColorScheme(
7 color_pool=["#ff0000", "#00ff00", "#0000ff", "pink", "yellowgreen"],
8 color_by="value",
9 fields=[
10 {
11 "path": "ground_truth",
12 "colorByAttribute": "eval",
13 "valueColors": [
14 {"value": "fn", "color": "#0000ff"}, # false negatives: blue
15 {"value": "tp", "color": "#00ff00"}, # true positives: green
16 ]
17 },
18 {
19 "path": "predictions",
20 "colorByAttribute": "eval",
21 "valueColors": [
22 {"value": "fp", "color": "#ff0000"}, # false positives: red
23 {"value": "tp", "color": "#00ff00"}, # true positives: green
24 ]
25 }
26 ]
27)
28dataset.save() # must save after edits
29
30# Setting `color_scheme` to None forces the dataset's default color scheme
31# to be loaded
32session.color_scheme = None
Note
Refer to the ColorScheme class for documentation of the available
customization options.
Note
Did you know? You can also configure color schemes directly in the App!
Active fields#
You can configure the default state of the sidebar’s checkboxes:
1# By default all label fields excluding Heatmap and Segmentation are active
2active_fields = fo.DatasetAppConfig.default_active_fields(dataset)
3
4# Add filepath and id fields
5active_fields.paths.extend(["id", "filepath"])
6
7# Active fields can be inverted setting exclude to True
8# active_fields.exclude = True
9
10# Modify the dataset's App config
11dataset.app_config.active_fields = active_fields
12dataset.save() # must save after edits
13
14session.refresh()
Disable frame filtering#
Filtering by frame-level fields of video datasets in the App’s grid view can be expensive when the dataset is large.
You can disable frame filtering for a video dataset as follows:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart-video")
5
6dataset.app_config.disable_frame_filtering = True
7dataset.save() # must save after edits
8
9session = fo.launch_app(dataset)
Note
Did you know? You can also globally disable frame filtering for all video datasets via your App config.
Resetting a dataset’s App config#
You can conveniently reset any property of a dataset’s App config by setting it
to None:
1# Reset the dataset's color scheme
2dataset.app_config.color_scheme = None
3dataset.save() # must save after edits
4
5print(dataset.app_config)
6
7session.refresh()
or you can reset the entire App config by setting the
app_config property to
None:
1# Reset App config
2dataset.app_config = None
3print(dataset.app_config)
4
5session = fo.launch_app(dataset)
Note
Check out this section for more information about customizing the behavior of the App.
Storing class lists#
All Dataset instances have
classes and
default_classes
properties that you can use to store the lists of possible classes for your
annotations/models.
The classes property is a
dictionary mapping field names to class lists for a single Label field of the
dataset.
If all Label fields in your dataset have the same semantics, you can store a
single class list in the store a single target dictionary in the
default_classes
property of your dataset.
You can also pass your class lists to methods such as
evaluate_classifications(),
evaluate_detections(),
and export() that
require knowledge of the possible classes in a dataset or field(s).
1import fiftyone as fo
2
3dataset = fo.Dataset()
4
5# Set default classes
6dataset.default_classes = ["cat", "dog"]
7
8# Edit the default classes
9dataset.default_classes.append("other")
10dataset.save() # must save after edits
11
12# Set classes for the `ground_truth` and `predictions` fields
13dataset.classes = {
14 "ground_truth": ["cat", "dog"],
15 "predictions": ["cat", "dog", "other"],
16}
17
18# Edit a field's classes
19dataset.classes["ground_truth"].append("other")
20dataset.save() # must save after edits
Note
You must call
dataset.save() after updating
the dataset’s classes and
default_classes
properties in-place to save the changes to the database.
Storing mask targets#
All Dataset instances have
mask_targets and
default_mask_targets
properties that you can use to store label strings for the pixel values of
Segmentation field masks.
The mask_targets property
is a dictionary mapping field names to target dicts, each of which is a
dictionary defining the mapping between pixel values (2D masks) or RGB hex
strings (3D masks) and label strings for the Segmentation masks in the
specified field of the dataset.
If all Segmentation fields in your dataset have the same semantics, you can
store a single target dictionary in the
default_mask_targets
property of your dataset.
When you load datasets with Segmentation fields in the App that have
corresponding mask targets, the label strings will appear in the App’s tooltip
when you hover over pixels.
You can also pass your mask targets to methods such as
evaluate_segmentations()
and export() that
require knowledge of the mask targets for a dataset or field(s).
If you are working with 2D segmentation masks, specify target keys as integers:
1import fiftyone as fo
2
3dataset = fo.Dataset()
4
5# Set default mask targets
6dataset.default_mask_targets = {1: "cat", 2: "dog"}
7
8# Edit the default mask targets
9dataset.default_mask_targets[255] = "other"
10dataset.save() # must save after edits
11
12# Set mask targets for the `ground_truth` and `predictions` fields
13dataset.mask_targets = {
14 "ground_truth": {1: "cat", 2: "dog"},
15 "predictions": {1: "cat", 2: "dog", 255: "other"},
16}
17
18# Edit an existing mask target
19dataset.mask_targets["ground_truth"][255] = "other"
20dataset.save() # must save after edits
If you are working with RGB segmentation masks, specify target keys as RGB hex strings:
1import fiftyone as fo
2
3dataset = fo.Dataset()
4
5# Set default mask targets
6dataset.default_mask_targets = {"#499CEF": "cat", "#6D04FF": "dog"}
7
8# Edit the default mask targets
9dataset.default_mask_targets["#FF6D04"] = "person"
10dataset.save() # must save after edits
11
12# Set mask targets for the `ground_truth` and `predictions` fields
13dataset.mask_targets = {
14 "ground_truth": {"#499CEF": "cat", "#6D04FF": "dog"},
15 "predictions": {
16 "#499CEF": "cat", "#6D04FF": "dog", "#FF6D04": "person"
17 },
18}
19
20# Edit an existing mask target
21dataset.mask_targets["ground_truth"]["#FF6D04"] = "person"
22dataset.save() # must save after edits
Note
You must call
dataset.save() after updating
the dataset’s
mask_targets and
default_mask_targets
properties in-place to save the changes to the database.
Storing keypoint skeletons#
All Dataset instances have
skeletons and
default_skeleton
properties that you can use to store keypoint skeletons for Keypoint field(s)
of a dataset.
The skeletons property is a
dictionary mapping field names to KeypointSkeleton instances, each of which
defines the keypoint label strings and edge connectivity for the Keypoint
instances in the specified field of the dataset.
If all Keypoint fields in your dataset have the same semantics, you can store
a single KeypointSkeleton in the
default_skeleton
property of your dataset.
When you load datasets with Keypoint fields in the App that have
corresponding skeletons, the skeletons will automatically be rendered and label
strings will appear in the App’s tooltip when you hover over the keypoints.
Keypoint skeletons can be associated with Keypoint or Keypoints fields
whose points attributes all
contain a fixed number of semantically ordered points.
The edges argument
contains lists of integer indexes that define the connectivity of the points in
the skeleton, and the optional
labels argument
defines the label strings for each node in the skeleton.
For example, the skeleton below is defined by edges between the following nodes:
left hand <-> left shoulder <-> right shoulder <-> right hand
left eye <-> right eye <-> mouth
1import fiftyone as fo
2
3dataset = fo.Dataset()
4
5# Set keypoint skeleton for the `ground_truth` field
6dataset.skeletons = {
7 "ground_truth": fo.KeypointSkeleton(
8 labels=[
9 "left hand" "left shoulder", "right shoulder", "right hand",
10 "left eye", "right eye", "mouth",
11 ],
12 edges=[[0, 1, 2, 3], [4, 5, 6]],
13 )
14}
15
16# Edit an existing skeleton
17dataset.skeletons["ground_truth"].labels[-1] = "lips"
18dataset.save() # must save after edits
Note
When using keypoint skeletons, each Keypoint instance’s
points list must always
respect the indexing defined by the field’s KeypointSkeleton.
If a particular keypoint is occluded or missing for an object, use
[float("nan"), float("nan")] in its
points list.
Note
You must call
dataset.save() after updating
the dataset’s
skeletons and
default_skeleton
properties in-place to save the changes to the database.
Storing camera calibration#
All Dataset instances have
camera_intrinsics and
static_transforms
properties that you can use to store camera calibration parameters for
multi-sensor datasets.
The camera_intrinsics
property is a dictionary mapping sensor/camera names to CameraIntrinsics
instances that define the internal parameters of each camera:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart-groups")
5
6# Store intrinsics for a stereo camera setup (1080p parameters)
7dataset.camera_intrinsics = {
8 "left": fo.PinholeCameraIntrinsics(fx=1100, fy=1100, cx=960, cy=540),
9 "right": fo.PinholeCameraIntrinsics(fx=1100, fy=1100, cx=960, cy=540),
10}
11dataset.save()
The static_transforms
property is a dictionary mapping frame pairs to StaticTransform instances
that define the 6-DOF rigid transformations between coordinate frames. Keys
should be formatted as "source_frame::target_frame" or simply
"source_frame" (which implies "world" as the target):
1import fiftyone as fo
2
3# Store sensor mounting positions relative to the vehicle center ("ego")
4dataset.static_transforms = {
5 # Left camera: 1.5m forward, 0.5m left, 1.2m up
6 "left::ego": fo.StaticTransform(
7 translation=[1.5, 0.5, 1.2],
8 quaternion=[0, 0, 0, 1],
9 source_frame="left",
10 target_frame="ego",
11 ),
12 # Right camera: 1.5m forward, 0.5m right, 1.2m up
13 "right::ego": fo.StaticTransform(
14 translation=[1.5, -0.5, 1.2],
15 quaternion=[0, 0, 0, 1],
16 source_frame="right",
17 target_frame="ego",
18 ),
19 # Lidar: centered, 2.0m up (roof-mounted)
20 "lidar::ego": fo.StaticTransform(
21 translation=[0.0, 0.0, 2.0],
22 quaternion=[0, 0, 0, 1],
23 source_frame="lidar",
24 target_frame="ego",
25 ),
26}
27dataset.save()
Note
See this section for more information about creating and using camera intrinsics and extrinsics.
Note
You must call
dataset.save() after updating
the dataset’s
camera_intrinsics
and
static_transforms
properties in-place to save the changes to the database.
Deleting a dataset#
Delete a dataset explicitly via
Dataset.delete(). Once a dataset
is deleted, any existing reference in memory will be in a volatile state.
Dataset.name and
Dataset.deleted will still be valid
attributes, but calling any other attribute or method will raise a
DoesNotExistError.
1dataset = fo.load_dataset("my_first_dataset")
2dataset.delete()
3
4print(fo.list_datasets())
5# []
6
7print(dataset.name)
8# my_first_dataset
9
10print(dataset.deleted)
11# True
12
13print(dataset.persistent)
14# DoesNotExistError: Dataset 'my_first_dataset' is deleted
Samples#
An individual Sample is always initialized with a filepath to the
corresponding data on disk.
1# An image sample
2sample = fo.Sample(filepath="/path/to/image.png")
3
4# A video sample
5another_sample = fo.Sample(filepath="/path/to/video.mp4")
Note
Creating a new Sample does not load the source data into memory. Source
data is read only as needed by the App.
Adding samples to a dataset#
A Sample can easily be added to an existing Dataset:
1dataset = fo.Dataset("example_dataset")
2dataset.add_sample(sample)
When a sample is added to a dataset, the relevant attributes of the Sample
are automatically updated:
1print(sample.in_dataset)
2# True
3
4print(sample.dataset_name)
5# example_dataset
Every sample in a dataset is given a unique ID when it is added:
1print(sample.id)
2# 5ee0ebd72ceafe13e7741c42
Multiple samples can be efficiently added to a dataset in batches:
1print(len(dataset))
2# 1
3
4dataset.add_samples(
5 [
6 fo.Sample(filepath="/path/to/image1.jpg"),
7 fo.Sample(filepath="/path/to/image2.jpg"),
8 fo.Sample(filepath="/path/to/image3.jpg"),
9 ]
10)
11
12print(len(dataset))
13# 4
Accessing samples in a dataset#
FiftyOne provides multiple ways to access a Sample in a Dataset.
You can iterate over the samples in a dataset:
1for sample in dataset:
2 print(sample)
Use first() and
last() to retrieve the first and
last samples in a dataset, respectively:
1first_sample = dataset.first()
2last_sample = dataset.last()
Samples can be accessed directly from datasets by their IDs or their filepaths.
Sample objects are singletons, so the same Sample instance is returned
whenever accessing the sample from the Dataset:
1same_sample = dataset[sample.id]
2print(same_sample is sample)
3# True
4
5also_same_sample = dataset[sample.filepath]
6print(also_same_sample is sample)
7# True
You can use dataset views to perform more sophisticated operations on samples like searching, filtering, sorting, and slicing.
Note
Accessing a sample by its integer index in a Dataset is not allowed. The
best practice is to lookup individual samples by ID or filepath, or use
array slicing to extract a range of samples, and iterate over samples in a
view.
dataset[0]
# KeyError: Accessing dataset samples by numeric index is not supported.
# Use sample IDs, filepaths, slices, boolean arrays, or a boolean ViewExpression instead
Deleting samples from a dataset#
Samples can be removed from a Dataset through their ID, either one at a time
or in batches via
delete_samples():
1dataset.delete_samples(sample_id)
2
3# equivalent to above
4del dataset[sample_id]
5
6dataset.delete_samples([sample_id1, sample_id2])
Samples can also be removed from a Dataset by passing Sample instance(s)
or DatasetView instances:
1# Remove a random sample
2sample = dataset.take(1).first()
3dataset.delete_samples(sample)
4
5# Remove 10 random samples
6view = dataset.take(10)
7dataset.delete_samples(view)
If a Sample object in memory is deleted from a dataset, it will revert to
a Sample that has not been added to a Dataset:
1print(sample.in_dataset)
2# False
3
4print(sample.dataset_name)
5# None
6
7print(sample.id)
8# None
The last_deletion_at
property of a Dataset tracks the datetime that a sample was last deleted
from the dataset:
1print(dataset.last_deletion_at)
2# datetime.datetime(2025, 5, 4, 21, 0, 52, 942511)
Fields#
A Field is an attribute of a Sample that stores information about the
sample.
Fields can be dynamically created, modified, and deleted from samples on a
per-sample basis. When a new Field is assigned to a Sample in a Dataset,
it is automatically added to the dataset’s schema and thus accessible on all
other samples in the dataset.
If a field exists on a dataset but has not been set on a particular sample, its
value will be None.
Default sample fields#
By default, all Sample instances have the following fields:
Field |
Type |
Default |
Description |
|---|---|---|---|
|
string |
|
The ID of the sample in its parent dataset, which
is generated automatically when the sample is
added to a dataset, or |
|
string |
REQUIRED |
The path to the source data on disk. Must be provided at sample creation time |
|
string |
N/A |
The media type of the sample. Computed
automatically from the provided |
|
list |
|
A list of string tags for the sample |
|
|
Type-specific metadata about the source data |
|
|
datetime |
|
The datetime that the sample was added to its
parent dataset, which is generated automatically,
or |
|
datetime |
|
The datetime that the sample was last modified,
which is updated automatically, or |
Note
The created_at and last_modified_at fields are
read-only and are automatically populated/updated
when you add samples to datasets and modify them, respectively.
1import fiftyone as fo
2
3sample = fo.Sample(filepath="/path/to/image.png")
4
5print(sample)
<Sample: {
'id': None,
'media_type': 'image',
'filepath': '/path/to/image.png',
'tags': [],
'metadata': None,
'created_at': None,
'last_modified_at': None,
}>
Accessing fields of a sample#
The names of available fields can be checked on any individual Sample:
1sample.field_names
2# ('id', 'filepath', 'tags', 'metadata', 'created_at', 'last_modified_at')
The value of a Field for a given Sample can be accessed either by either
attribute or item access:
1sample.filepath
2sample["filepath"] # equivalent
Field schemas#
You can use
get_field_schema() to
retrieve detailed information about the schema of the samples in a dataset:
1dataset = fo.Dataset("a_dataset")
2dataset.add_sample(sample)
3
4dataset.get_field_schema()
OrderedDict([
('id', <fiftyone.core.fields.ObjectIdField at 0x7fbaa862b358>),
('filepath', <fiftyone.core.fields.StringField at 0x11c77ae10>),
('tags', <fiftyone.core.fields.ListField at 0x11c790828>),
('metadata', <fiftyone.core.fields.EmbeddedDocumentField at 0x11c7907b8>),
('created_at', <fiftyone.core.fields.DateTimeField at 0x7fea48361af0>),
('last_modified_at', <fiftyone.core.fields.DateTimeField at 0x7fea48361b20>)]),
])
You can also view helpful information about a dataset, including its schema, by printing it:
1print(dataset)
Name: a_dataset
Media type: image
Num samples: 1
Persistent: False
Tags: []
Sample fields:
id: fiftyone.core.fields.ObjectIdField
filepath: fiftyone.core.fields.StringField
tags: fiftyone.core.fields.ListField(fiftyone.core.fields.StringField)
metadata: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.metadata.ImageMetadata)
created_at: fiftyone.core.fields.DateTimeField
last_modified_at: fiftyone.core.fields.DateTimeField
Note
Did you know? You can store metadata such as descriptions on your dataset’s fields!
Adding fields to a sample#
New fields can be added to a Sample using item assignment:
1sample["integer_field"] = 51
2sample.save()
If the Sample belongs to a Dataset, the dataset’s schema will automatically
be updated to reflect the new field:
1print(dataset)
Name: a_dataset
Media type: image
Num samples: 1
Persistent: False
Tags: []
Sample fields:
id: fiftyone.core.fields.ObjectIdField
filepath: fiftyone.core.fields.StringField
tags: fiftyone.core.fields.ListField(fiftyone.core.fields.StringField)
metadata: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.metadata.ImageMetadata)
created_at: fiftyone.core.fields.DateTimeField
last_modified_at: fiftyone.core.fields.DateTimeField
integer_field: fiftyone.core.fields.IntField
A Field can be any primitive type, such as bool, int, float, str,
date, datetime, list, dict, or more complex data structures
like label types:
1sample["animal"] = fo.Classification(label="alligator")
2sample.save()
Whenever a new field is added to a sample in a dataset, the field is available
on every other sample in the dataset with the value None.
Fields must have the same type (or None) across all samples in the dataset.
Setting a field to an inappropriate type raises an error:
1sample2.integer_field = "a string"
2sample2.save()
3# ValidationError: a string could not be converted to int
Note
You must call sample.save() in
order to persist changes to the database when editing samples that are in
datasets.
Adding fields to a dataset#
You can also use
add_sample_field() to
declare new sample fields directly on datasets without explicitly populating
any values on its samples:
1import fiftyone as fo
2
3sample = fo.Sample(
4 filepath="image.jpg",
5 ground_truth=fo.Classification(label="cat"),
6)
7
8dataset = fo.Dataset()
9dataset.add_sample(sample)
10
11# Declare new primitive fields
12dataset.add_sample_field("scene_id", fo.StringField)
13dataset.add_sample_field("quality", fo.FloatField)
14
15# Declare untyped list fields
16dataset.add_sample_field("more_tags", fo.ListField)
17dataset.add_sample_field("info", fo.ListField)
18
19# Declare a typed list field
20dataset.add_sample_field("also_tags", fo.ListField, subfield=fo.StringField)
21
22# Declare a new Label field
23dataset.add_sample_field(
24 "predictions",
25 fo.EmbeddedDocumentField,
26 embedded_doc_type=fo.Classification,
27)
28
29print(dataset.get_field_schema())
{
'id': <fiftyone.core.fields.ObjectIdField object at 0x7f9280803910>,
'filepath': <fiftyone.core.fields.StringField object at 0x7f92d273e0d0>,
'tags': <fiftyone.core.fields.ListField object at 0x7f92d2654f70>,
'metadata': <fiftyone.core.fields.EmbeddedDocumentField object at 0x7f9280803d90>,
'created_at': <fiftyone.core.fields.DateTimeField object at 0x7fea48361af0>,
'last_modified_at': <fiftyone.core.fields.DateTimeField object at 0x7fea48361b20>,
'ground_truth': <fiftyone.core.fields.EmbeddedDocumentField object at 0x7f92d2605190>,
'scene_id': <fiftyone.core.fields.StringField object at 0x7f9280803490>,
'quality': <fiftyone.core.fields.FloatField object at 0x7f92d2605bb0>,
'more_tags': <fiftyone.core.fields.ListField object at 0x7f92d08e4550>,
'info': <fiftyone.core.fields.ListField object at 0x7f92d264f9a0>,
'also_tags': <fiftyone.core.fields.ListField object at 0x7f92d264ff70>,
'predictions': <fiftyone.core.fields.EmbeddedDocumentField object at 0x7f92d2605640>,
}
Whenever a new field is added to a dataset, the field is immediately available
on all samples in the dataset with the value None:
1print(sample)
<Sample: {
'id': '642d8848f291652133df8d3a',
'media_type': 'image',
'filepath': '/Users/Brian/dev/fiftyone/image.jpg',
'tags': [],
'metadata': None,
'created_at': datetime.datetime(2024, 7, 22, 5, 0, 25, 372399),
'last_modified_at': datetime.datetime(2024, 7, 22, 5, 0, 25, 372399),
'ground_truth': <Classification: {
'id': '642d8848f291652133df8d38',
'tags': [],
'label': 'cat',
'confidence': None,
'logits': None,
}>,
'scene_id': None,
'quality': None,
'more_tags': None,
'info': None,
'also_tags': None,
'predictions': None,
}>
You can also declare nested fields on existing embedded documents using dot notation:
1# Declare a new attribute on a `Classification` field
2dataset.add_sample_field("predictions.breed", fo.StringField)
Note
See this section for more options for dynamically expanding the schema of nested lists and embedded documents.
You can use get_field() to
retrieve a Field instance by its name or embedded.field.name. And, if the
field contains an embedded document, you can call
get_field_schema()
to recursively inspect its nested fields:
1field = dataset.get_field("predictions")
2print(field.document_type)
3# <class 'fiftyone.core.labels.Classification'>
4
5print(set(field.get_field_schema().keys()))
6# {'logits', 'confidence', 'breed', 'tags', 'label', 'id'}
7
8# Directly retrieve a nested field
9field = dataset.get_field("predictions.breed")
10print(type(field))
11# <class 'fiftyone.core.fields.StringField'>
If your dataset contains a ListField with no value type declared, you can add
the type later by appending [] to the field path:
1field = dataset.get_field("more_tags")
2print(field.field) # None
3
4# Declare the subfield types of an existing untyped list field
5dataset.add_sample_field("more_tags[]", fo.StringField)
6
7field = dataset.get_field("more_tags")
8print(field.field) # StringField
9
10# List fields can also contain embedded documents
11dataset.add_sample_field(
12 "info[]",
13 fo.EmbeddedDocumentField,
14 embedded_doc_type=fo.DynamicEmbeddedDocument,
15)
16
17field = dataset.get_field("info")
18print(field.field) # EmbeddedDocumentField
19print(field.field.document_type) # DynamicEmbeddedDocument
Note
Declaring the value type of list fields is required if you want to filter by the list’s values in the App.
Editing sample fields#
You can make any edits you wish to the fields of an existing Sample:
1sample = fo.Sample(
2 filepath="/path/to/image.jpg",
3 ground_truth=fo.Detections(
4 detections=[
5 fo.Detection(label="CAT", bounding_box=[0.1, 0.1, 0.4, 0.4]),
6 fo.Detection(label="dog", bounding_box=[0.5, 0.5, 0.4, 0.4]),
7 ]
8 )
9)
10
11detections = sample.ground_truth.detections
12
13# Edit an existing detection
14detections[0].label = "cat"
15
16# Add a new detection
17new_detection = fo.Detection(label="animals", bounding_box=[0, 0, 1, 1])
18detections.append(new_detection)
19
20print(sample)
21
22sample.save() # if the sample is in a dataset
Note
You must call sample.save() in
order to persist changes to the database when editing samples that are in
datasets.
A common workflow is to iterate over a dataset or view and edit each sample:
1for sample in dataset:
2 sample["new_field"] = ...
3 sample.save()
The iter_samples() method
is an equivalent way to iterate over a dataset that provides a
progress=True option that prints a progress bar tracking the status of the
iteration:
1# Prints a progress bar tracking the status of the iteration
2for sample in dataset.iter_samples(progress=True):
3 sample["new_field"] = ...
4 sample.save()
The iter_samples() method
also provides an autosave=True option that causes all changes to samples
emitted by the iterator to be automatically saved using efficient batch
updates:
1# Automatically saves sample edits in efficient batches
2for sample in dataset.iter_samples(autosave=True):
3 sample["new_field"] = ...
Using autosave=True can significantly improve performance when editing
large datasets. See this section for more information
on batch update patterns.
Removing fields from a sample#
A field can be deleted from a Sample using del:
1del sample["integer_field"]
If the Sample is not yet in a dataset, deleting a field will remove it from
the sample. If the Sample is in a dataset, the field’s value will be None.
Fields can also be deleted at the Dataset level, in which case they are
removed from every Sample in the dataset:
1dataset.delete_sample_field("integer_field")
2
3sample.integer_field
4# AttributeError: Sample has no field 'integer_field'
Storing field metadata#
You can store metadata such as descriptions and other info on the fields of your dataset.
One approach is to manually declare the field with
add_sample_field()
with the appropriate metadata provided:
1import fiftyone as fo
2
3dataset = fo.Dataset()
4dataset.add_sample_field(
5 "int_field", fo.IntField, description="An integer field"
6)
7
8field = dataset.get_field("int_field")
9print(field.description) # An integer field
You can also use
get_field() to
retrieve a field and update it’s metadata at any time:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5dataset.add_dynamic_sample_fields()
6
7field = dataset.get_field("ground_truth")
8field.description = "Ground truth annotations"
9field.info = {"url": "https://fiftyone.ai"}
10field.save() # must save after edits
11
12field = dataset.get_field("ground_truth.detections.area")
13field.description = "Area of the box, in pixels^2"
14field.info = {"url": "https://fiftyone.ai"}
15field.save() # must save after edits
16
17dataset.reload()
18
19field = dataset.get_field("ground_truth")
20print(field.description) # Ground truth annotations
21print(field.info) # {'url': 'https://fiftyone.ai'}
22
23field = dataset.get_field("ground_truth.detections.area")
24print(field.description) # Area of the box, in pixels^2
25print(field.info) # {'url': 'https://fiftyone.ai'}
Note
You must call
field.save() after updating
a fields’s description
and info attributes in-place to
save the changes to the database.
Note
Did you know? You can view field metadata directly in the App by hovering over fields or attributes in the sidebar!
Read-only fields#
Certain default sample fields like created_at
and last_modified_at are read-only and thus cannot be manually edited:
1from datetime import datetime
2import fiftyone as fo
3
4sample = fo.Sample(filepath="/path/to/image.jpg")
5
6dataset = fo.Dataset()
7dataset.add_sample(sample)
8
9sample.created_at = datetime.utcnow()
10# ValueError: Cannot edit read-only field 'created_at'
11
12sample.last_modified_at = datetime.utcnow()
13# ValueError: Cannot edit read-only field 'last_modified_at'
You can also manually mark additional fields or embedded fields as read-only at any time:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5
6# Declare a new read-only field
7dataset.add_sample_field("uuid", fo.StringField, read_only=True)
8
9# Mark 'filepath' as read-only
10field = dataset.get_field("filepath")
11field.read_only = True
12field.save() # must save after edits
13
14# Mark a nested field as read-only
15field = dataset.get_field("ground_truth.detections.label")
16field.read_only = True
17field.save() # must save after edits
18
19sample = dataset.first()
20
21sample.filepath = "no.jpg"
22# ValueError: Cannot edit read-only field 'filepath'
23
24sample.ground_truth.detections[0].label = "no"
25sample.save()
26# ValueError: Cannot edit read-only field 'ground_truth.detections.label'
Note
You must call
field.save() after updating
a fields’s read_only
attributes in-place to save the changes to the database.
Note that read-only fields do not interfere with the ability to add/delete samples from datasets:
1sample = fo.Sample(filepath="/path/to/image.jpg", uuid="1234")
2dataset.add_sample(sample)
3
4dataset.delete_samples(sample)
Any fields that you’ve manually marked as read-only may be reverted to editable at any time:
1sample = dataset.first()
2
3# Revert 'filepath' to editable
4field = dataset.get_field("filepath")
5field.read_only = False
6field.save() # must save after edits
7
8# Revert nested field to editable
9field = dataset.get_field("ground_truth.detections.label")
10field.read_only = False
11field.save() # must save after edits
12
13sample.filepath = "yes.jpg"
14sample.ground_truth.detections[0].label = "yes"
15sample.save()
Summary fields#
Summary fields allow you to efficiently perform queries on large datasets where directly querying the underlying field is prohibitively slow due to the number of objects/frames in the field.
For example, suppose you’re working on a
video dataset with frame-level objects, and you’re
interested in finding videos that contain specific classes of interest, eg
person, in at least one frame:
1import fiftyone as fo
2import fiftyone.zoo as foz
3from fiftyone import ViewField as F
4
5dataset = foz.load_zoo_dataset("quickstart-video")
6dataset.set_field("frames.detections.detections.confidence", F.rand()).save()
7
8session = fo.launch_app(dataset)
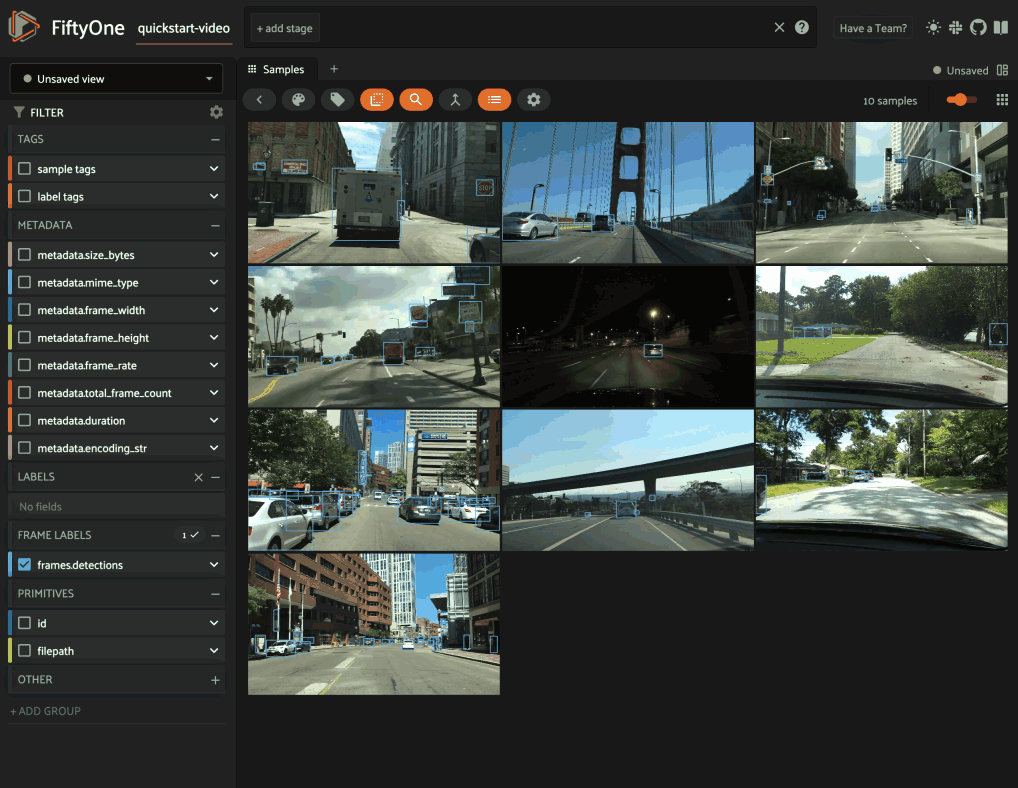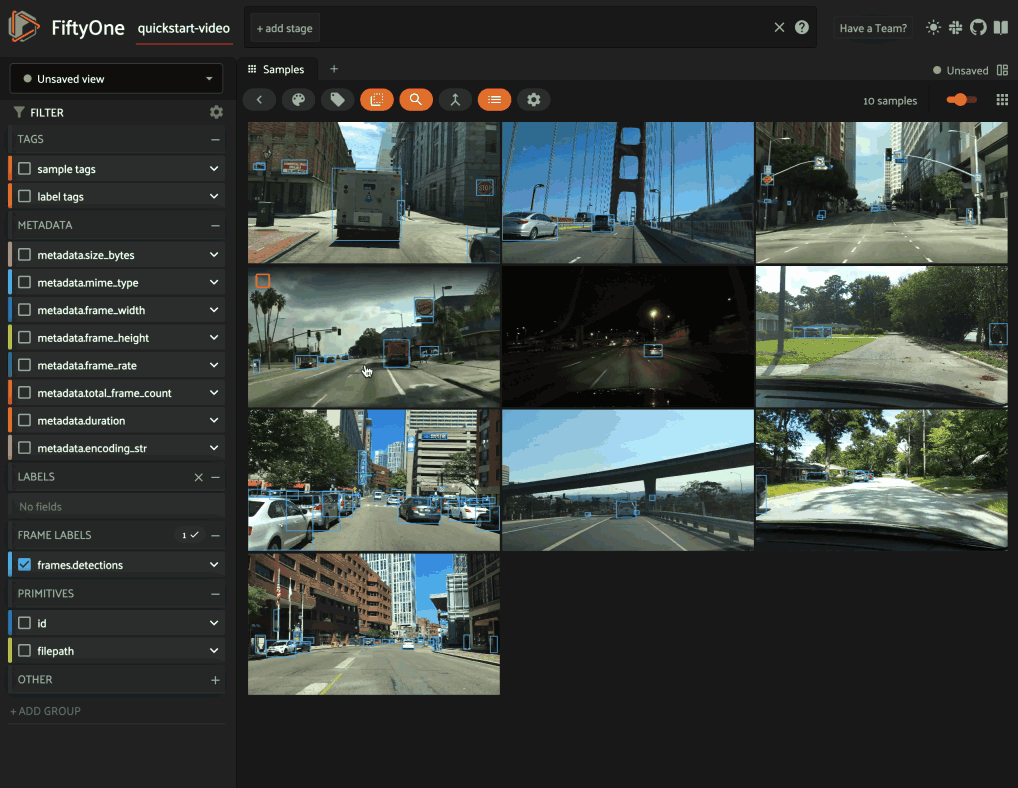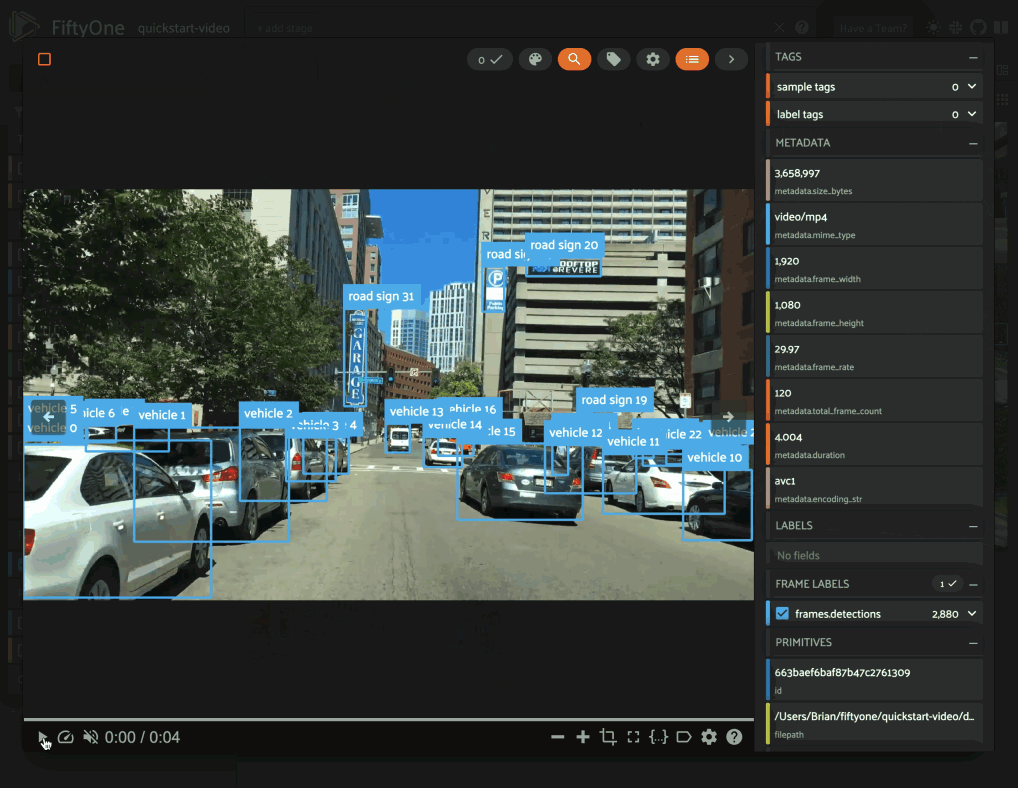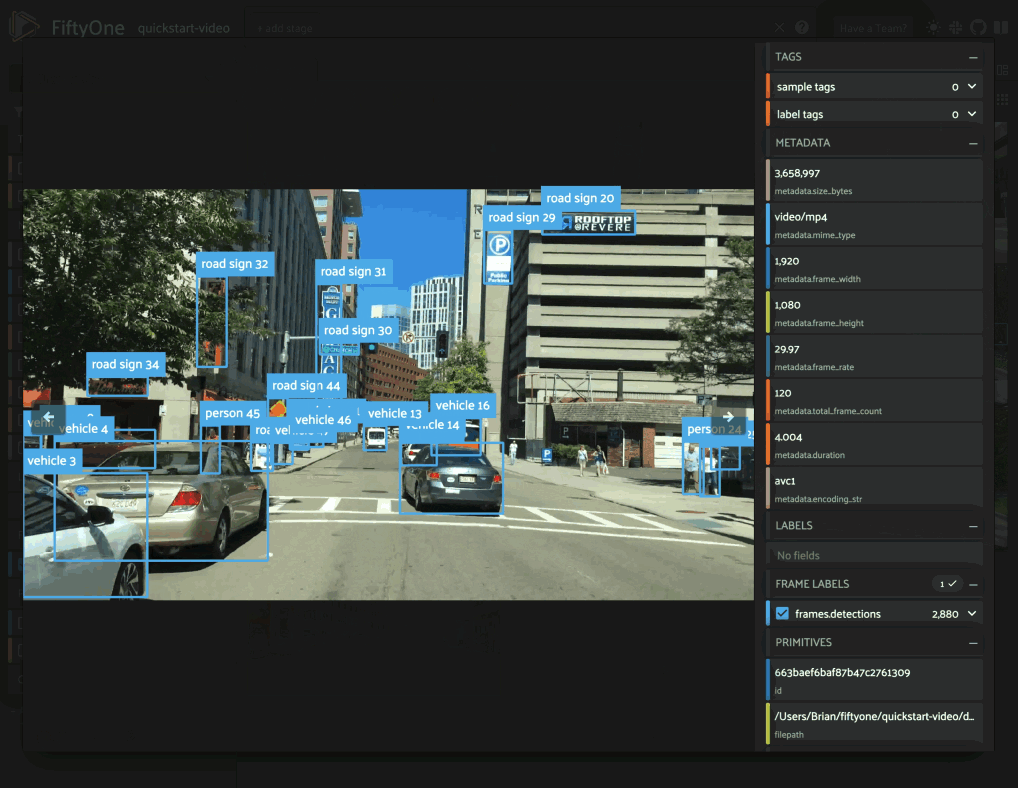
One approach is to directly query the frame-level field (frames.detections
in this case) in the App’s sidebar. However, when the dataset is large, such
queries are inefficient, as they cannot unlock
query performance and thus require
full collection scans over all frames to retrieve the relevant samples.
A more efficient approach is to first use
create_summary_field()
to summarize the relevant input field path(s):
1# Generate a summary field for object labels
2field_name = dataset.create_summary_field("frames.detections.detections.label")
3
4# The name of the summary field that was created
5print(field_name)
6# 'frames_detections_label'
7
8# Generate a summary field for [min, max] confidences
9dataset.create_summary_field("frames.detections.detections.confidence")
Summary fields can be generated for sample-level and frame-level fields, and the input fields can be either categorical or numeric:
When the input field is categorical (string or boolean), the summary field of each sample is populated with the list of unique values observed in the field (across all frames for video samples):
1sample = dataset.first()
2print(sample.frames_detections_label)
3# ['vehicle', 'road sign', 'person']
You can also pass include_counts=True to include counts for each
unique value in the summary field:
1# Generate a summary field for object labels and counts
2dataset.create_summary_field(
3 "frames.detections.detections.label",
4 field_name="frames_detections_label2",
5 include_counts=True,
6)
7
8sample = dataset.first()
9print(sample.frames_detections_label2)
10"""
11[
12 <DynamicEmbeddedDocument: {'label': 'road sign', 'count': 198}>,
13 <DynamicEmbeddedDocument: {'label': 'vehicle', 'count': 175}>,
14 <DynamicEmbeddedDocument: {'label': 'person', 'count': 120}>,
15]
16"""
When the input field is numeric (int, float, date, or datetime), the
summary field of each sample is populated with the [min, max] range
of the values observed in the field (across all frames for video
samples):
1sample = dataset.first()
2print(sample.frames_detections_confidence)
3# <DynamicEmbeddedDocument: {'min': 0.01, 'max': 0.99}>
You can also pass the group_by parameter to specify an attribute to
group by to generate per-attribute [min, max] ranges:
1# Generate a summary field for per-label [min, max] confidences
2dataset.create_summary_field(
3 "frames.detections.detections.confidence",
4 field_name="frames_detections_confidence2",
5 group_by="label",
6)
7
8sample = dataset.first()
9print(sample.frames_detections_confidence2)
10"""
11[
12 <DynamicEmbeddedDocument: {'label': 'vehicle', 'min': 0.00, 'max': 0.98}>,
13 <DynamicEmbeddedDocument: {'label': 'person', 'min': 0.02, 'max': 0.97}>,
14 <DynamicEmbeddedDocument: {'label': 'road sign', 'min': 0.01, 'max': 0.99}>,
15]
16"""
As the above examples illustrate, summary fields allow you to encode various types of information at the sample-level that you can directly query to find samples that contain specific values.
Moreover, summary fields are indexed by default and the App can natively leverage these indexes to provide performant filtering:
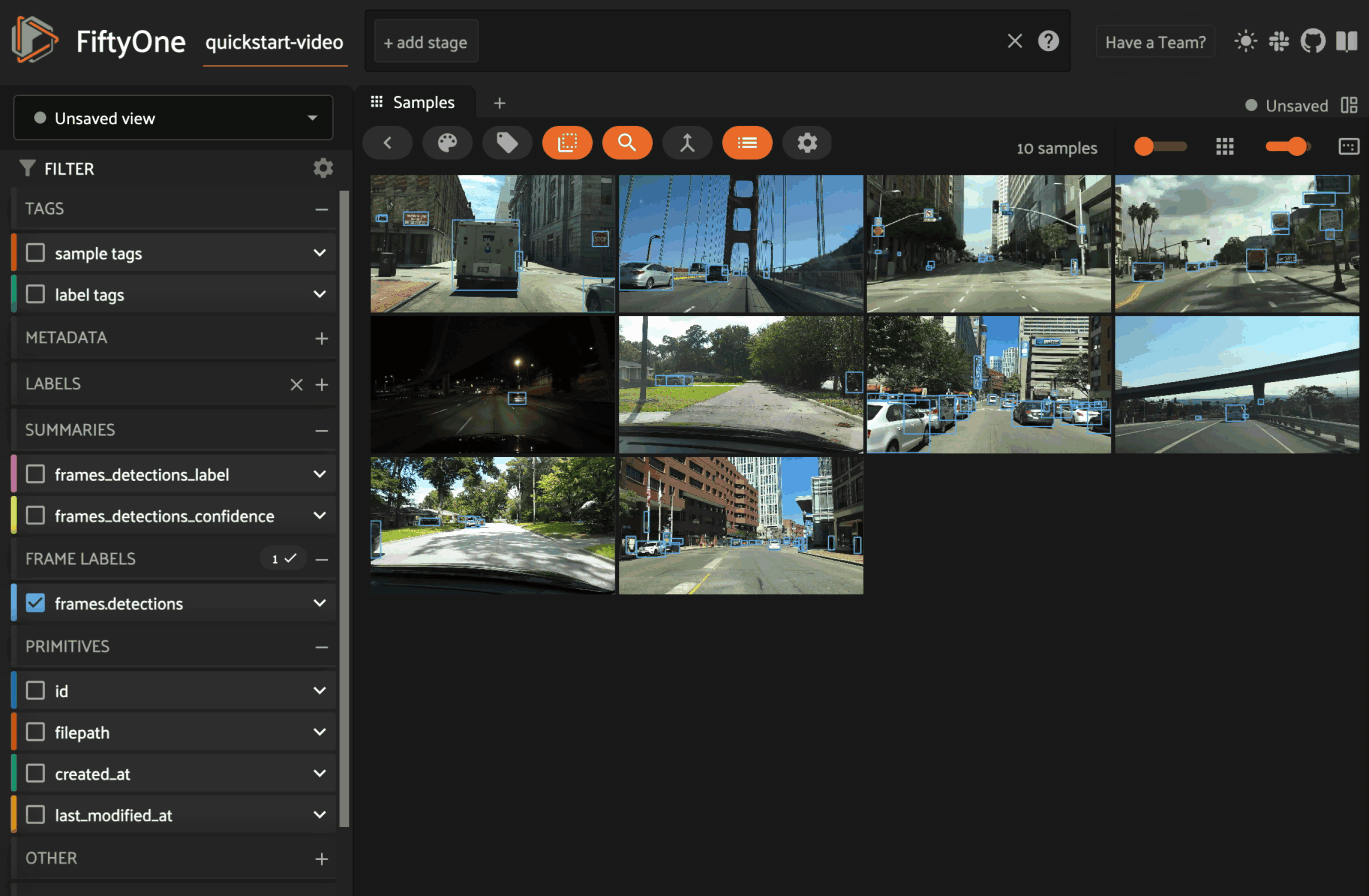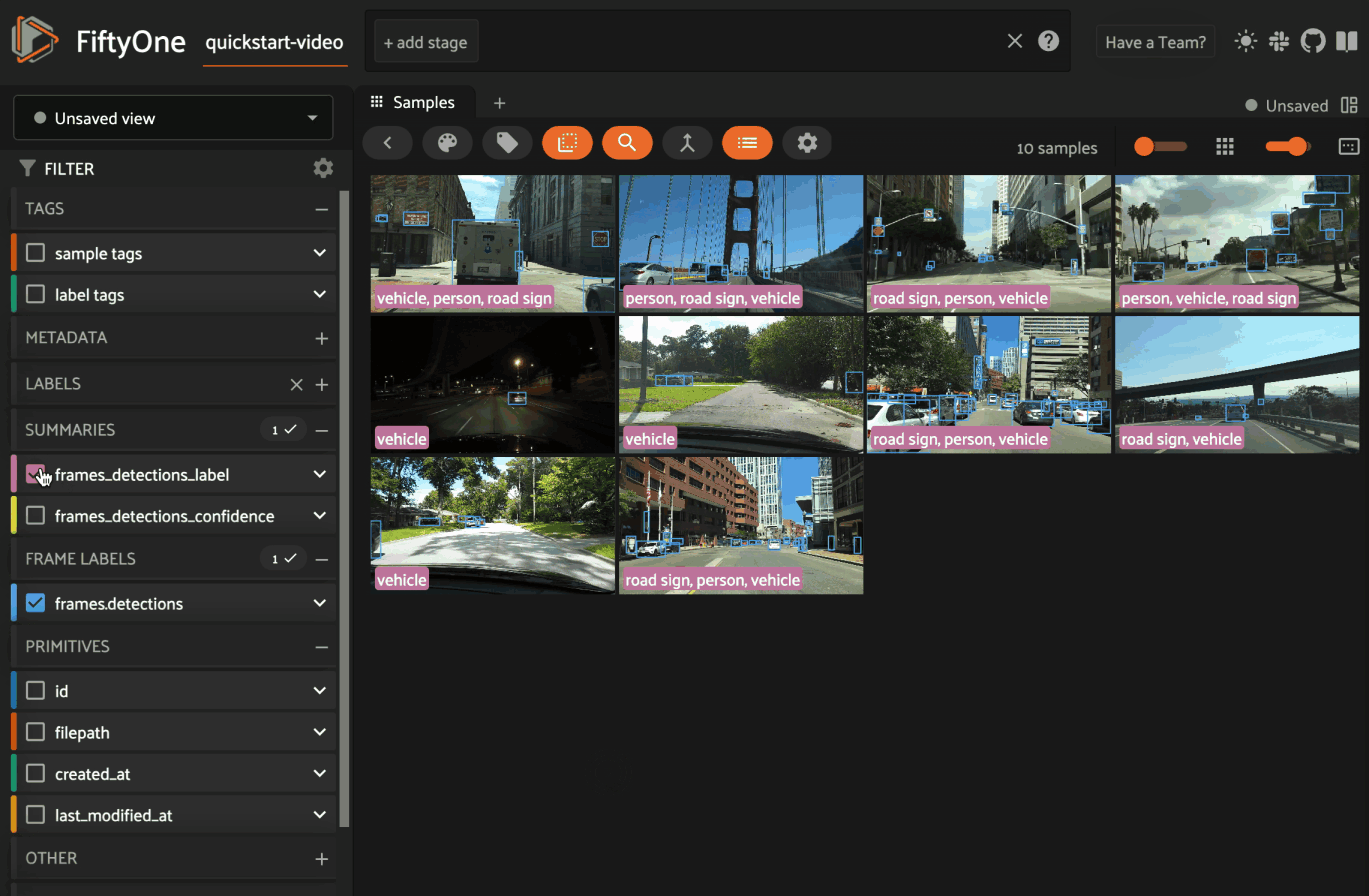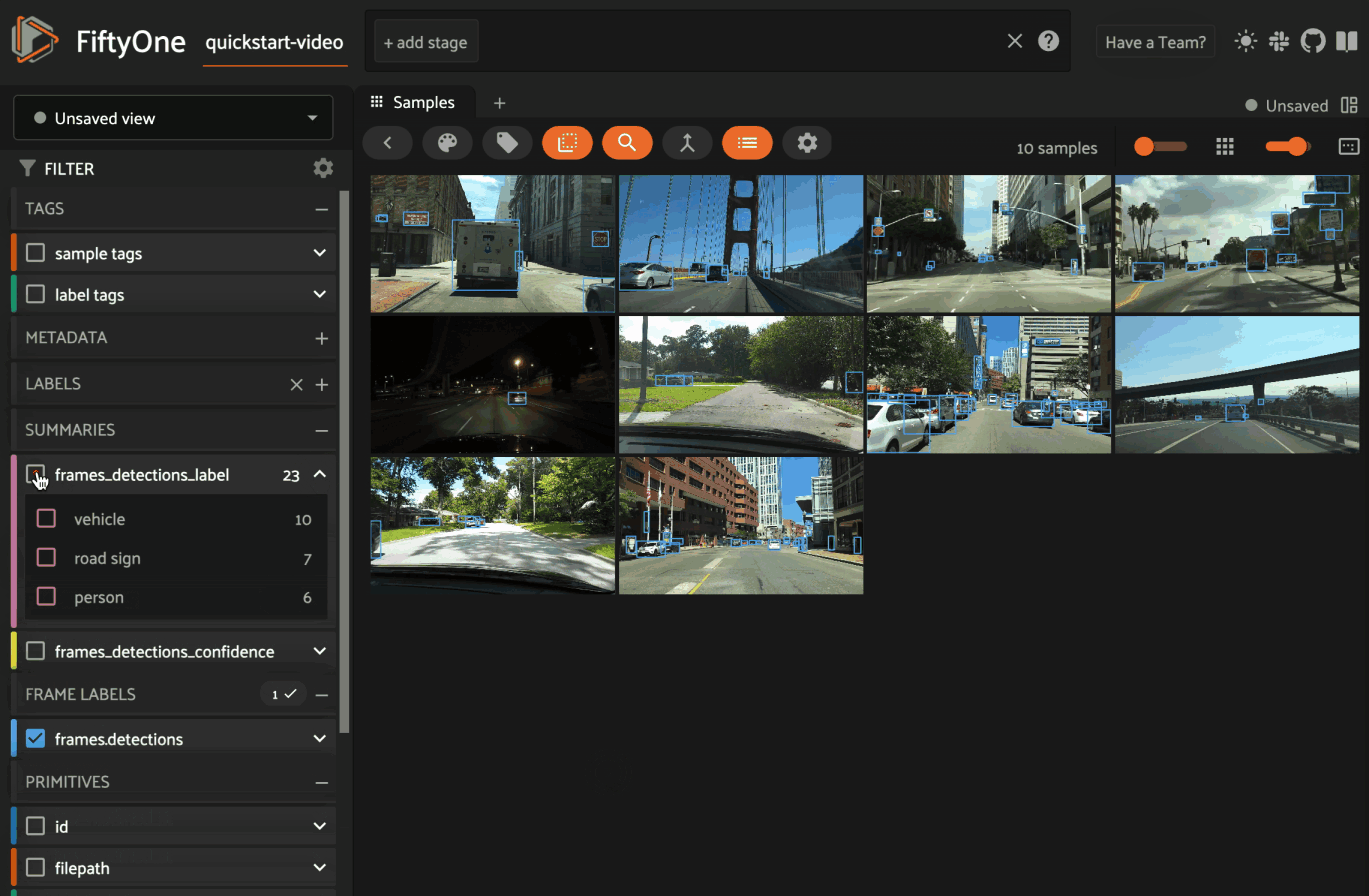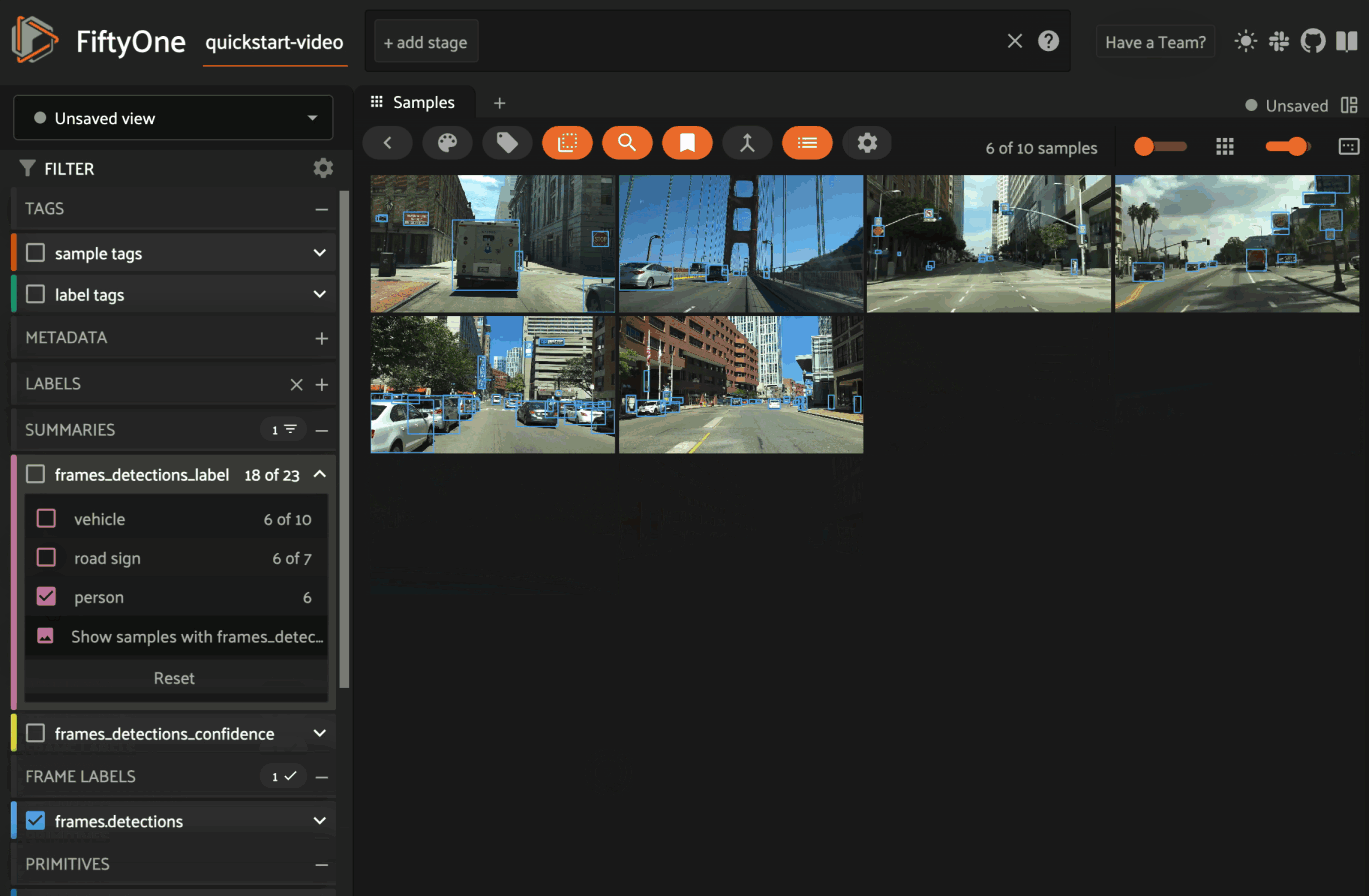
Note
Summary fields are automatically added to a summaries
sidebar group in the App for
easy access and organization.
They are also read-only by default, as they are implicitly derived from the contents of their source field and are not intended to be directly modified.
You can use
list_summary_fields()
to list the names of the summary fields on your dataset:
1print(dataset.list_summary_fields())
2# ['frames_detections_label', 'frames_detections_confidence', ...]
Since a summary field is derived from the contents of another field, it must be
updated whenever there have been modifications to its source field. You can use
check_summary_fields()
to check for summary fields that may need to be updated:
1# Newly created summary fields don't needed updating
2print(dataset.check_summary_fields())
3# []
4
5# Modify the dataset
6label_upper = F("label").upper()
7dataset.set_field("frames.detections.detections.label", label_upper).save()
8
9# Summary fields now (may) need updating
10print(dataset.check_summary_fields())
11# ['frames_detections_label', 'frames_detections_confidence', ...]
Note
Note that inclusion in
check_summary_fields()
is only a heuristic, as any sample modifications may not have affected
the summary’s source field.
Use update_summary_field()
to regenerate a summary field based on the current values of its source field:
1dataset.update_summary_field("frames_detections_label")
Finally, use
delete_summary_field()
or delete_summary_fields()
to delete existing summary field(s) that you no longer need:
1dataset.delete_summary_field("frames_detections_label")
Media type#
When a Sample is created, its media type is inferred from the filepath to
the source media and available via the media_type attribute of the sample,
which is read-only.
Optionally, the media_type keyword argument can be provided to the Sample
constructor to provide an explicit media type.
If media_type is not provided explicitly, it is inferred from the
MIME type of the file on disk,
as per the table below:
MIME type/extension |
|
Description |
|---|---|---|
|
|
Image sample |
|
|
Video sample |
|
|
3D sample |
|
|
Point cloud sample |
other |
|
Generic sample |
Note
The filepath of a sample can be changed after the sample is created, but
the new filepath must have the same media type. In other words,
media_type is immutable.
Note
When creating new 3D datasets from direct 3D asset files such as .glb,
.pcd, or .ply, pass media_type="3d" explicitly.
Metadata#
All Sample instances have a metadata field, which can optionally be
populated with a Metadata instance that stores data type-specific metadata
about the raw data in the sample. The FiftyOne App and
the FiftyOne Brain will use this provided metadata in
some workflows when it is available.
For image samples, the ImageMetadata class is used to store
information about images, including their
size_bytes,
mime_type,
width,
height, and
num_channels.
You can populate the metadata field of an existing dataset by calling
Dataset.compute_metadata():
1import fiftyone.zoo as foz
2
3dataset = foz.load_zoo_dataset("quickstart")
4
5# Populate metadata fields (if necessary)
6dataset.compute_metadata()
7
8print(dataset.first())
Alternatively, FiftyOne provides a
ImageMetadata.build_for()
factory method that you can use to compute the metadata for your images
when constructing Sample instances:
1image_path = "/path/to/image.png"
2
3metadata = fo.ImageMetadata.build_for(image_path)
4
5sample = fo.Sample(filepath=image_path, metadata=metadata)
6
7print(sample)
<Sample: {
'id': None,
'media_type': 'image',
'filepath': '/path/to/image.png',
'tags': [],
'metadata': <ImageMetadata: {
'size_bytes': 544559,
'mime_type': 'image/png',
'width': 698,
'height': 664,
'num_channels': 3,
}>,
'created_at': None,
'last_modified_at': None,
}>
For video samples, the VideoMetadata class is used to store
information about videos, including their
size_bytes,
mime_type,
frame_width,
frame_height,
frame_rate,
total_frame_count,
duration, and
encoding_str.
You can populate the metadata field of an existing dataset by calling
Dataset.compute_metadata():
1import fiftyone.zoo as foz
2
3dataset = foz.load_zoo_dataset("quickstart-video")
4
5# Populate metadata fields (if necessary)
6dataset.compute_metadata()
7
8print(dataset.first())
Alternatively, FiftyOne provides a
VideoMetadata.build_for()
factory method that you can use to compute the metadata for your videos
when constructing Sample instances:
1video_path = "/path/to/video.mp4"
2
3metadata = fo.VideoMetadata.build_for(video_path)
4
5sample = fo.Sample(filepath=video_path, metadata=metadata)
6
7print(sample)
<Sample: {
'id': None,
'media_type': 'video',
'filepath': '/Users/Brian/Desktop/people.mp4',
'tags': [],
'metadata': <VideoMetadata: {
'size_bytes': 2038250,
'mime_type': 'video/mp4',
'frame_width': 1920,
'frame_height': 1080,
'frame_rate': 29.97002997002997,
'total_frame_count': 68,
'duration': 2.268933,
'encoding_str': 'avc1',
}>,
'created_at': None,
'last_modified_at': None,
'frames': <Frames: 0>,
}>
Dates and datetimes#
Builtin datetime fields#
Datasets and samples have various builtin datetime fields that are automatically updated when certain events occur.
The
Dataset.last_loaded_at
property tracks the datetime that the dataset was last loaded:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5
6print(dataset.last_loaded_at)
7# 2025-05-04 21:00:45.559520
The
Dataset.last_modified_at
property tracks the datetime that dataset-level metadata was last modified,
including:
when properties such as
name,persistent,tags,description,info, andapp_configare editedwhen fields are added or deleted from the dataset’s schema
when group slices are added or deleted from the dataset’s schema
when saved views or workspaces are added, edited, or deleted
when annotation, brain, evaluation, or custom runs are added, edited, or deleted
1last_modified_at1 = dataset.last_modified_at
2
3dataset.name = "still-quickstart"
4
5last_modified_at2 = dataset.last_modified_at
6assert last_modified_at2 > last_modified_at1
7
8dataset.app_config.sidebar_groups = ...
9dataset.save()
10
11last_modified_at3 = dataset.last_modified_at
12assert last_modified_at3 > last_modified_at2
13
14dataset.add_sample_field("foo", fo.StringField)
15
16last_modified_at4 = dataset.last_modified_at
17assert last_modified_at4 > last_modified_at3
Note
The
Dataset.last_modified_at
property is not updated when samples are added, edited, or deleted from
a dataset.
Use the methods described below to ascertain this information.
All samples have a builtin last_modified_at field that automatically tracks
the datetime that each sample was last modified:
1sample = dataset.first()
2last_modified_at1 = sample.last_modified_at
3
4sample.foo = "bar"
5sample.save()
6
7last_modified_at2 = sample.last_modified_at
8assert last_modified_at2 > last_modified_at1
The last_modified_at field is indexed by default, which means you can
efficiently check when a dataset’s samples were last modified via
max():
1last_modified_at1 = dataset.max("last_modified_at")
2
3dataset.add_samples(...)
4
5last_modified_at2 = dataset.max("last_modified_at")
6assert last_modified_at2 > last_modified_at1
7
8dataset.set_field("foo", "spam").save()
9
10last_modified_at3 = dataset.max("last_modified_at")
11assert last_modified_at3 > last_modified_at2
The
Dataset.last_deletion_at
property tracks the datetime that a sample was last deleted
from the dataset:
1last_deletion_at1 = dataset.last_deletion_at
2
3dataset.delete_samples(...)
4
5last_deletion_a2 = dataset.last_deletion_at
6assert last_deletion_a2 > last_deletion_at1
Video datasets
The frames of video datasets also have a builtin
last_modified_at field that automatically tracks the datetime that each
frame was last modified:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart-video")
5
6sample = dataset.first()
7frame = sample.frames.first()
8last_modified_at1 = frame.last_modified_at
9
10frame["foo"] = "bar"
11frame.save()
12
13last_modified_at2 = frame.last_modified_at
14assert last_modified_at2 > last_modified_at1
The last_modified_at frame field is indexed by default, which means you can
efficiently check when a dataset’s frames were last modified via
max():
1last_modified_at1 = dataset.max("frames.last_modified_at")
2
3dataset.add_samples(...)
4
5last_modified_at2 = dataset.max("frames.last_modified_at")
6assert last_modified_at2 > last_modified_at1
7
8dataset.set_field("frames.foo", "spam").save()
9
10last_modified_at3 = dataset.max("last_modified_at")
11assert last_modified_at3 > last_modified_at2
When frames are deleted from a dataset, the last_modified_at field of the
parent samples are automatically updated:
1sample = dataset.first()
2last_modified_at1 = sample.last_modified_at
3
4del sample.frames[1]
5sample.save()
6
7last_modified_at2 = sample.last_modified_at
8assert last_modified_at2 > last_modified_at1
Custom datetime fields#
You can store date information in FiftyOne datasets by populating fields with
date or datetime values:
1from datetime import date, datetime
2import fiftyone as fo
3
4dataset = fo.Dataset()
5dataset.add_samples(
6 [
7 fo.Sample(
8 filepath="image1.png",
9 acquisition_time=datetime(2021, 8, 24, 21, 18, 7),
10 acquisition_date=date(2021, 8, 24),
11 ),
12 fo.Sample(
13 filepath="image2.png",
14 acquisition_time=datetime.utcnow(),
15 acquisition_date=date.today(),
16 ),
17 ]
18)
19
20print(dataset)
21print(dataset.head())
Note
Did you know? You can create dataset views with date-based queries!
Internally, FiftyOne stores all dates as UTC timestamps, but you can provide
any valid datetime object when setting a DateTimeField of a sample,
including timezone-aware datetimes, which are internally converted to UTC
format for safekeeping.
1# A datetime in your local timezone
2now = datetime.utcnow().astimezone()
3
4sample = fo.Sample(filepath="image.png", acquisition_time=now)
5
6dataset = fo.Dataset()
7dataset.add_sample(sample)
8
9# Samples are singletons, so we reload so `sample` will contain values as
10# loaded from the database
11dataset.reload()
12
13sample.acquisition_time.tzinfo # None
By default, when you access a datetime field of a sample in a dataset, it is
retrieved as a naive datetime instance expressed in UTC format.
However, if you prefer, you can
configure FiftyOne to load datetime fields as
timezone-aware datetime instances in a timezone of your choice.
Warning
FiftyOne assumes that all datetime instances with no explicit timezone
are stored in UTC format.
Therefore, never use datetime.datetime.now() when populating a datetime
field of a FiftyOne dataset! Instead, use datetime.datetime.utcnow().
Labels#
The Label class hierarchy is used to store semantic information about ground
truth or predicted labels in a sample.
Although such information can be stored in custom sample fields
(e.g, in a DictField), it is recommended that you store label information in
Label instances so that the FiftyOne App and the
FiftyOne Brain can visualize and compute on your
labels.
Note
All Label instances are dynamic! You can add custom fields to your
labels to store custom information:
# Provide some default fields
label = fo.Classification(label="cat", confidence=0.98)
# Add custom fields
label["int"] = 5
label["float"] = 51.0
label["list"] = [1, 2, 3]
label["bool"] = True
label["dict"] = {"key": ["list", "of", "values"]}
You can also declare dynamic attributes on your dataset’s schema, which allows you to enforce type constraints, filter by these custom attributes in the App, and more.
FiftyOne provides a dedicated Label subclass for many common tasks. The
subsections below describe them.
Regression#
The Regression class represents a numeric regression value for an image. The
value itself is stored in the
value attribute of the
Regression object. This may be a ground truth value or a model prediction.
The optional
confidence attribute can
be used to store a score associated with the model prediction and can be
visualized in the App or used, for example, when
evaluating regressions.
1import fiftyone as fo
2
3sample = fo.Sample(filepath="/path/to/image.png")
4
5sample["ground_truth"] = fo.Regression(value=51.0)
6sample["prediction"] = fo.Classification(value=42.0, confidence=0.9)
7
8print(sample)
<Sample: {
'id': None,
'media_type': 'image',
'filepath': '/path/to/image.png',
'tags': [],
'metadata': None,
'created_at': None,
'last_modified_at': None,
'ground_truth': <Regression: {
'id': '616c4bef36297ec40a26d112',
'tags': [],
'value': 51.0,
'confidence': None,
}>,
'prediction': <Classification: {
'id': '616c4bef36297ec40a26d113',
'tags': [],
'label': None,
'confidence': 0.9,
'logits': None,
'value': 42.0,
}>,
}>
Classification#
The Classification class represents a classification label for an image. The
label itself is stored in the
label attribute of the
Classification object. This may be a ground truth label or a model
prediction.
The optional
confidence and
logits attributes may be
used to store metadata about the model prediction. These additional fields can
be visualized in the App or used by Brain methods, e.g., when
computing label mistakes.
1import fiftyone as fo
2
3sample = fo.Sample(filepath="/path/to/image.png")
4
5sample["ground_truth"] = fo.Classification(label="sunny")
6sample["prediction"] = fo.Classification(label="sunny", confidence=0.9)
7
8print(sample)
<Sample: {
'id': None,
'media_type': 'image',
'filepath': '/path/to/image.png',
'tags': [],
'metadata': None,
'created_at': None,
'last_modified_at': None,
'ground_truth': <Classification: {
'id': '5f8708db2018186b6ef66821',
'label': 'sunny',
'confidence': None,
'logits': None,
}>,
'prediction': <Classification: {
'id': '5f8708db2018186b6ef66822',
'label': 'sunny',
'confidence': 0.9,
'logits': None,
}>,
}>
Note
Did you know? You can store class lists for your models on your datasets.
Multilabel classification#
The Classifications class represents a list of classification labels for an
image. The typical use case is to represent multilabel annotations/predictions
for an image, where multiple labels from a model may apply to a given image.
The labels are stored in a
classifications
attribute of the object, which contains a list of Classification instances.
Metadata about individual labels can be stored in the Classification
instances as usual; additionally, you can optionally store logits for the
overarching model (if applicable) in the
logits attribute of the
Classifications object.
1import fiftyone as fo
2
3sample = fo.Sample(filepath="/path/to/image.png")
4
5sample["ground_truth"] = fo.Classifications(
6 classifications=[
7 fo.Classification(label="animal"),
8 fo.Classification(label="cat"),
9 fo.Classification(label="tabby"),
10 ]
11)
12sample["prediction"] = fo.Classifications(
13 classifications=[
14 fo.Classification(label="animal", confidence=0.99),
15 fo.Classification(label="cat", confidence=0.98),
16 fo.Classification(label="tabby", confidence=0.72),
17 ]
18)
19
20print(sample)
<Sample: {
'id': None,
'media_type': 'image',
'filepath': '/path/to/image.png',
'tags': [],
'metadata': None,
'created_at': None,
'last_modified_at': None,
'ground_truth': <Classifications: {
'classifications': [
<Classification: {
'id': '5f8708f62018186b6ef66823',
'label': 'animal',
'confidence': None,
'logits': None,
}>,
<Classification: {
'id': '5f8708f62018186b6ef66824',
'label': 'cat',
'confidence': None,
'logits': None,
}>,
<Classification: {
'id': '5f8708f62018186b6ef66825',
'label': 'tabby',
'confidence': None,
'logits': None,
}>,
],
'logits': None,
}>,
'prediction': <Classifications: {
'classifications': [
<Classification: {
'id': '5f8708f62018186b6ef66826',
'label': 'animal',
'confidence': 0.99,
'logits': None,
}>,
<Classification: {
'id': '5f8708f62018186b6ef66827',
'label': 'cat',
'confidence': 0.98,
'logits': None,
}>,
<Classification: {
'id': '5f8708f62018186b6ef66828',
'label': 'tabby',
'confidence': 0.72,
'logits': None,
}>,
],
'logits': None,
}>,
}>
Note
Did you know? You can store class lists for your models on your datasets.
Object detection#
The Detections class represents a list of object detections in an image. The
detections are stored in the
detections attribute of
the Detections object.
Each individual object detection is represented by a Detection object. The
string label of the object should be stored in the
label attribute, and the
bounding box for the object should be stored in the
bounding_box attribute.
Note
FiftyOne stores box coordinates as floats in [0, 1] relative to the
dimensions of the image. Bounding boxes are represented by a length-4 list
in the format:
[<top-left-x>, <top-left-y>, <width>, <height>]
Note
Did you know? FiftyOne also supports 3D detections!
In the case of model predictions, an optional confidence score for each
detection can be stored in the
confidence attribute.
1import fiftyone as fo
2
3sample = fo.Sample(filepath="/path/to/image.png")
4
5sample["ground_truth"] = fo.Detections(
6 detections=[fo.Detection(label="cat", bounding_box=[0.5, 0.5, 0.4, 0.3])]
7)
8sample["prediction"] = fo.Detections(
9 detections=[
10 fo.Detection(
11 label="cat",
12 bounding_box=[0.480, 0.513, 0.397, 0.288],
13 confidence=0.96,
14 ),
15 ]
16)
17
18print(sample)
<Sample: {
'id': None,
'media_type': 'image',
'filepath': '/path/to/image.png',
'tags': [],
'metadata': None,
'created_at': None,
'last_modified_at': None,
'ground_truth': <Detections: {
'detections': [
<Detection: {
'id': '5f8709172018186b6ef66829',
'attributes': {},
'label': 'cat',
'bounding_box': [0.5, 0.5, 0.4, 0.3],
'mask': None,
'confidence': None,
'index': None,
}>,
],
}>,
'prediction': <Detections: {
'detections': [
<Detection: {
'id': '5f8709172018186b6ef6682a',
'attributes': {},
'label': 'cat',
'bounding_box': [0.48, 0.513, 0.397, 0.288],
'mask': None,
'confidence': 0.96,
'index': None,
}>,
],
}>,
}>
Note
Did you know? You can store class lists for your models on your datasets.
Like all Label types, you can also add custom attributes to your detections
by dynamically adding new fields to each Detection instance:
1import fiftyone as fo
2
3detection = fo.Detection(
4 label="cat",
5 bounding_box=[0.5, 0.5, 0.4, 0.3],
6 age=51, # custom attribute
7 mood="salty", # custom attribute
8)
9
10print(detection)
<Detection: {
'id': '60f7458c467d81f41c200551',
'attributes': {},
'tags': [],
'label': 'cat',
'bounding_box': [0.5, 0.5, 0.4, 0.3],
'mask': None,
'confidence': None,
'index': None,
'age': 51,
'mood': 'salty',
}>
Note
Did you know? You can view custom attributes in the App tooltip by hovering over the objects.
Instance segmentations#
Object detections stored in Detections may also have instance segmentation
masks.
These masks can be stored in one of two ways: either directly in the database
via the mask attribute, or on
disk referenced by the
mask_path attribute.
Masks stored directly in the database must be 2D numpy arrays
containing either booleans or 0/1 integers that encode the extent of the
instance mask within the
bounding_box of the
object.
For masks stored on disk, the
mask_path attribute should
contain the file path to the mask image. We recommend storing masks as
single-channel PNG images, where a pixel value of 0 indicates the
background (rendered as transparent in the App), and any other
value indicates the object.
Masks can be of any size; they are stretched as necessary to fill the object’s bounding box when visualizing in the App.
1import numpy as np
2from PIL import Image
3
4import fiftyone as fo
5
6# Example instance mask
7mask = ((np.random.randn(32, 32) > 0) * 255).astype(np.uint8)
8mask_path = "/path/to/mask.png"
9Image.fromarray(mask).save(mask_path)
10
11sample = fo.Sample(filepath="/path/to/image.png")
12
13sample["prediction"] = fo.Detections(
14 detections=[
15 fo.Detection(
16 label="cat",
17 bounding_box=[0.480, 0.513, 0.397, 0.288],
18 mask_path=mask_path,
19 confidence=0.96,
20 ),
21 ]
22)
23
24print(sample)
<Sample: {
'id': None,
'media_type': 'image',
'filepath': '/path/to/image.png',
'tags': [],
'metadata': None,
'created_at': None,
'last_modified_at': None,
'prediction': <Detections: {
'detections': [
<Detection: {
'id': '5f8709282018186b6ef6682b',
'attributes': {},
'tags': [],
'label': 'cat',
'bounding_box': [0.48, 0.513, 0.397, 0.288],
'mask': None,
'mask_path': '/path/to/mask.png',
'confidence': 0.96,
'index': None,
}>,
],
}>,
}>
Like all Label types, you can also add custom attributes to your instance
segmentations by dynamically adding new fields to each Detection instance:
1import numpy as np
2import fiftyone as fo
3
4detection = fo.Detection(
5 label="cat",
6 bounding_box=[0.5, 0.5, 0.4, 0.3],
7 mask_path="/path/to/mask.png",
8 age=51, # custom attribute
9 mood="salty", # custom attribute
10)
11
12print(detection)
<Detection: {
'id': '60f74568467d81f41c200550',
'attributes': {},
'tags': [],
'label': 'cat',
'bounding_box': [0.5, 0.5, 0.4, 0.3],
'mask_path': '/path/to/mask.png',
'confidence': None,
'index': None,
'age': 51,
'mood': 'salty',
}>
Note
Did you know? You can view custom attributes in the App tooltip by hovering over the objects.
Polylines and polygons#
The Polylines class represents a list of
polylines or
polygons in an image. The polylines
are stored in the
polylines attribute of the
Polylines object.
Each individual polyline is represented by a Polyline object, which
represents a set of one or more semantically related shapes in an image. The
points attribute contains a
list of lists of (x, y) coordinates defining the vertices of each shape
in the polyline. If the polyline represents a closed curve, you can set the
closed attribute to True to
indicate that a line segment should be drawn from the last vertex to the first
vertex of each shape in the polyline. If the shapes should be filled when
rendering them, you can set the
filled attribute to True.
Polylines can also have string labels, which are stored in their
label attribute.
Note
FiftyOne stores vertex coordinates as floats in [0, 1] relative to the
dimensions of the image.
Note
Did you know? FiftyOne also supports 3D polylines!
1import fiftyone as fo
2
3sample = fo.Sample(filepath="/path/to/image.png")
4
5# A simple polyline
6polyline1 = fo.Polyline(
7 points=[[(0.3, 0.3), (0.7, 0.3), (0.7, 0.3)]],
8 closed=False,
9 filled=False,
10)
11
12# A closed, filled polygon with a label
13polyline2 = fo.Polyline(
14 label="triangle",
15 points=[[(0.1, 0.1), (0.3, 0.1), (0.3, 0.3)]],
16 closed=True,
17 filled=True,
18)
19
20sample["polylines"] = fo.Polylines(polylines=[polyline1, polyline2])
21
22print(sample)
<Sample: {
'id': None,
'media_type': 'image',
'filepath': '/path/to/image.png',
'tags': [],
'metadata': None,
'created_at': None,
'last_modified_at': None,
'polylines': <Polylines: {
'polylines': [
<Polyline: {
'id': '5f87094e2018186b6ef6682e',
'attributes': {},
'label': None,
'points': [[(0.3, 0.3), (0.7, 0.3), (0.7, 0.3)]],
'index': None,
'closed': False,
'filled': False,
}>,
<Polyline: {
'id': '5f87094e2018186b6ef6682f',
'attributes': {},
'label': 'triangle',
'points': [[(0.1, 0.1), (0.3, 0.1), (0.3, 0.3)]],
'index': None,
'closed': True,
'filled': True,
}>,
],
}>,
}>
Like all Label types, you can also add custom attributes to your polylines by
dynamically adding new fields to each Polyline instance:
1import fiftyone as fo
2
3polyline = fo.Polyline(
4 label="triangle",
5 points=[[(0.1, 0.1), (0.3, 0.1), (0.3, 0.3)]],
6 closed=True,
7 filled=True,
8 kind="right", # custom attribute
9)
10
11print(polyline)
<Polyline: {
'id': '60f746b4467d81f41c200555',
'attributes': {},
'tags': [],
'label': 'triangle',
'points': [[(0.1, 0.1), (0.3, 0.1), (0.3, 0.3)]],
'confidence': None,
'index': None,
'closed': True,
'filled': True,
'kind': 'right',
}>
Note
Did you know? You can view custom attributes in the App tooltip by hovering over the objects.
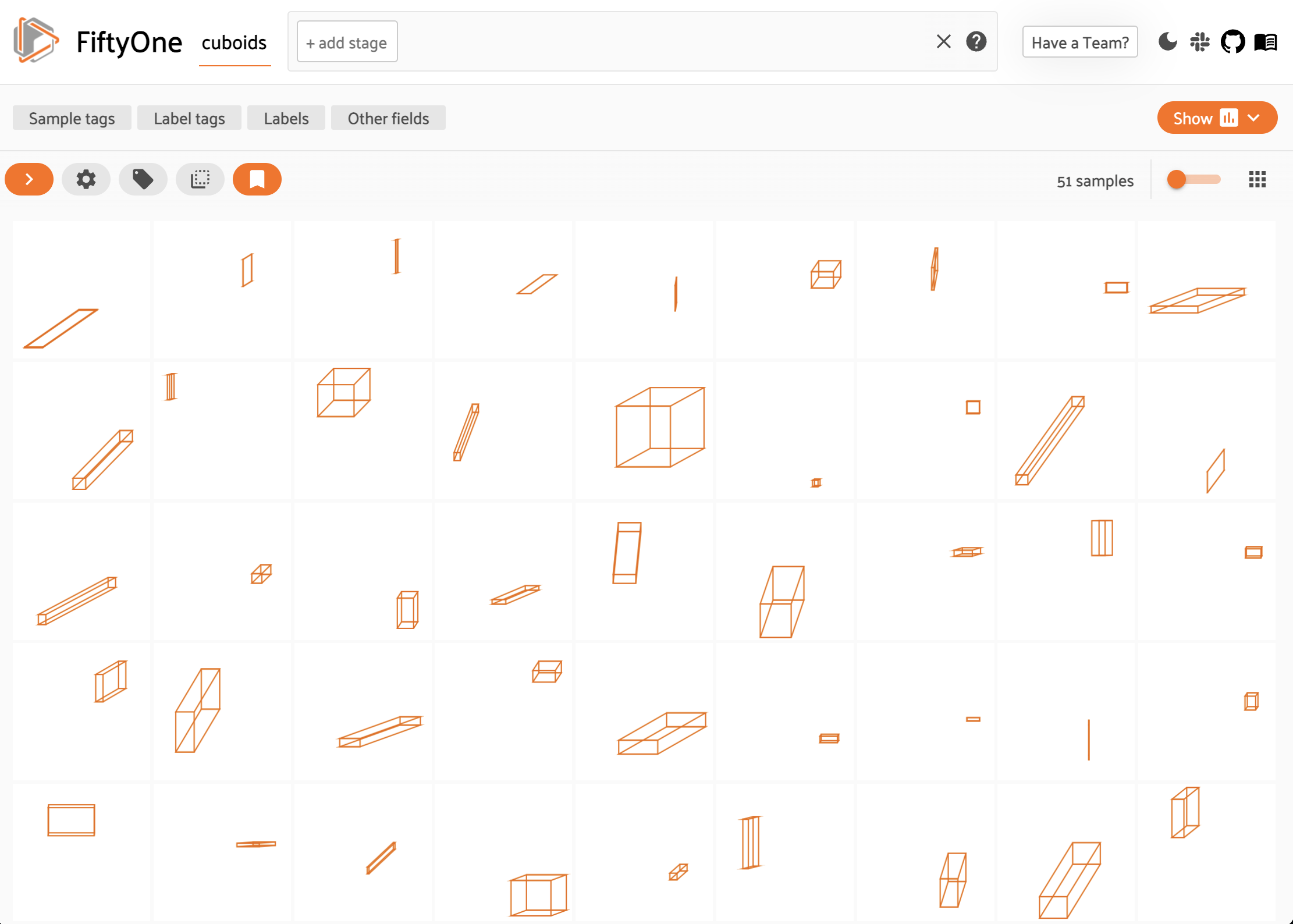
Cuboids#
You can store and visualize cuboids in FiftyOne using the
Polyline.from_cuboid()
method.
The method accepts a list of 8 (x, y) points describing the vertices of the
cuboid in the format depicted below:
7--------6
/| /|
/ | / |
3--------2 |
| 4-----|--5
| / | /
|/ |/
0--------1
Note
FiftyOne stores vertex coordinates as floats in [0, 1] relative to the
dimensions of the image.
1import cv2
2import numpy as np
3import fiftyone as fo
4
5def random_cuboid(frame_size):
6 width, height = frame_size
7 x0, y0 = np.array([width, height]) * ([0, 0.2] + 0.8 * np.random.rand(2))
8 dx, dy = (min(0.8 * width - x0, y0 - 0.2 * height)) * np.random.rand(2)
9 x1, y1 = x0 + dx, y0 - dy
10 w, h = (min(width - x1, y1)) * np.random.rand(2)
11 front = [(x0, y0), (x0 + w, y0), (x0 + w, y0 - h), (x0, y0 - h)]
12 back = [(x1, y1), (x1 + w, y1), (x1 + w, y1 - h), (x1, y1 - h)]
13 vertices = front + back
14 return fo.Polyline.from_cuboid(
15 vertices, frame_size=frame_size, label="cuboid"
16 )
17
18frame_size = (256, 128)
19
20filepath = "/tmp/image.png"
21size = (frame_size[1], frame_size[0], 3)
22cv2.imwrite(filepath, np.full(size, 255, dtype=np.uint8))
23
24dataset = fo.Dataset("cuboids")
25dataset.add_samples(
26 [
27 fo.Sample(filepath=filepath, cuboid=random_cuboid(frame_size))
28 for _ in range(51)]
29)
30
31session = fo.launch_app(dataset)
Like all Label types, you can also add custom attributes to your cuboids by
dynamically adding new fields to each Polyline instance:
1polyline = fo.Polyline.from_cuboid(
2 vertics, frame_size=frame_size,
3 label="vehicle",
4 filled=True,
5 type="sedan", # custom attribute
6)
Note
Did you know? You can view custom attributes in the App tooltip by hovering over the objects.
Rotated bounding boxes#
You can store and visualize rotated bounding boxes in FiftyOne using the
Polyline.from_rotated_box()
method, which accepts rotated boxes described by their center coordinates,
width/height, and counter-clockwise rotation, in radians.
Note
FiftyOne stores vertex coordinates as floats in [0, 1] relative to the
dimensions of the image.
1import cv2
2import numpy as np
3import fiftyone as fo
4
5def random_rotated_box(frame_size):
6 width, height = frame_size
7 xc, yc = np.array([width, height]) * (0.2 + 0.6 * np.random.rand(2))
8 w, h = 1.5 * (min(xc, yc, width - xc, height - yc)) * np.random.rand(2)
9 theta = 2 * np.pi * np.random.rand()
10 return fo.Polyline.from_rotated_box(
11 xc, yc, w, h, theta, frame_size=frame_size, label="box"
12 )
13
14frame_size = (256, 128)
15
16filepath = "/tmp/image.png"
17size = (frame_size[1], frame_size[0], 3)
18cv2.imwrite(filepath, np.full(size, 255, dtype=np.uint8))
19
20dataset = fo.Dataset("rotated-boxes")
21dataset.add_samples(
22 [
23 fo.Sample(filepath=filepath, box=random_rotated_box(frame_size))
24 for _ in range(51)
25 ]
26)
27
28session = fo.launch_app(dataset)
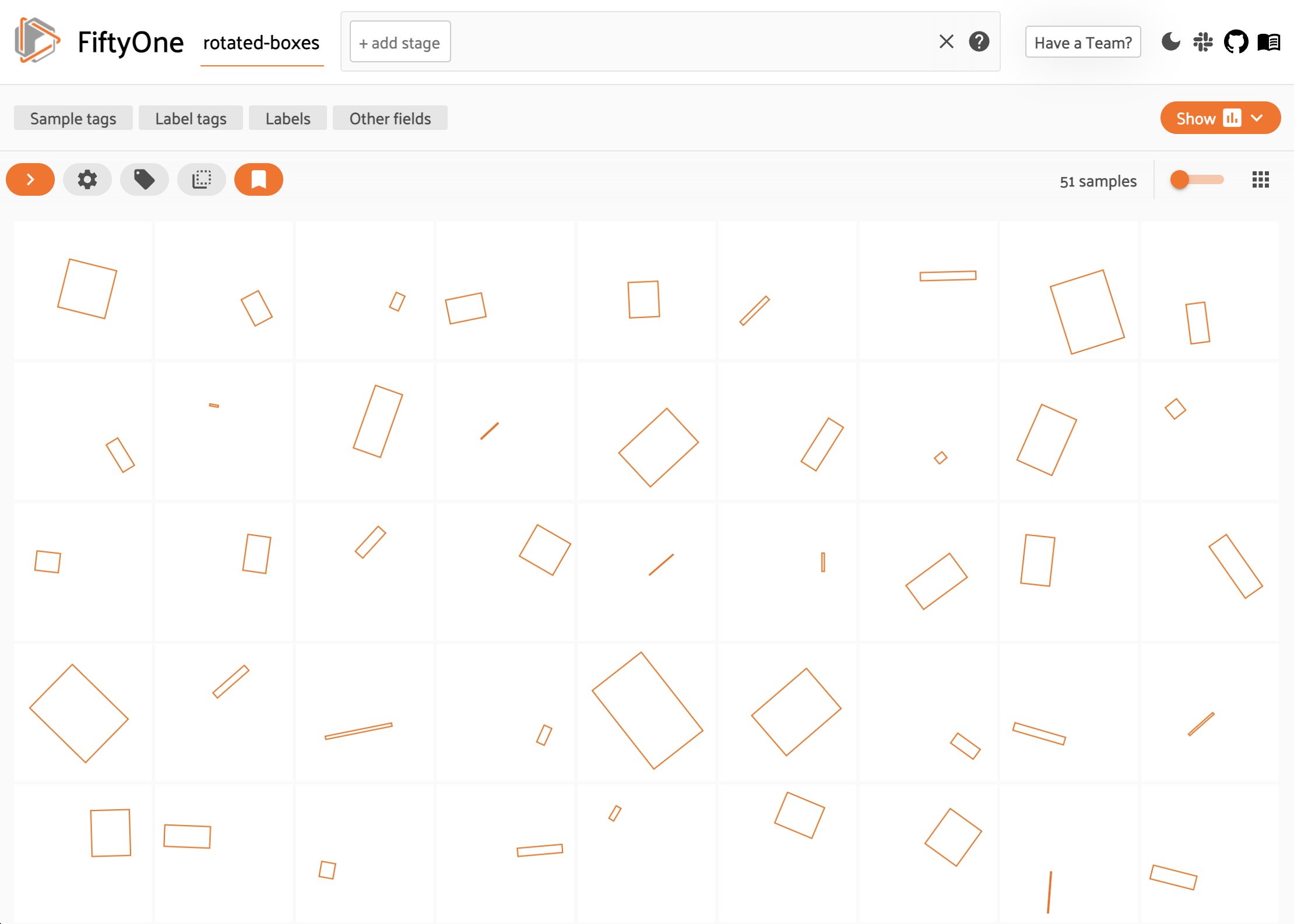
Like all Label types, you can also add custom attributes to your rotated
bounding boxes by dynamically adding new fields to each Polyline instance:
1polyline = fo.Polyline.from_rotated_box(
2 xc, yc, width, height, theta, frame_size=frame_size,
3 label="cat",
4 mood="surly", # custom attribute
5)
Note
Did you know? You can view custom attributes in the App tooltip by hovering over the objects.
Keypoints#
The Keypoints class represents a collection of keypoint groups in an image.
The keypoint groups are stored in the
keypoints attribute of the
Keypoints object. Each element of this list is a Keypoint object whose
points attribute contains a
list of (x, y) coordinates defining a group of semantically related
keypoints in the image.
For example, if you are working with a person model that outputs 18 keypoints
(left eye, right eye, nose, etc.) per person, then each Keypoint
instance would represent one person, and a Keypoints instance would represent
the list of people in the image.
Note
FiftyOne stores keypoint coordinates as floats in [0, 1] relative to the
dimensions of the image.
Each Keypoint object can have a string label, which is stored in its
label attribute, and it can
optionally have a list of per-point confidences in [0, 1] in its
confidence attribute:
1import fiftyone as fo
2
3sample = fo.Sample(filepath="/path/to/image.png")
4
5sample["keypoints"] = fo.Keypoints(
6 keypoints=[
7 fo.Keypoint(
8 label="square",
9 points=[(0.3, 0.3), (0.7, 0.3), (0.7, 0.7), (0.3, 0.7)],
10 confidence=[0.6, 0.7, 0.8, 0.9],
11 )
12 ]
13)
14
15print(sample)
<Sample: {
'id': None,
'media_type': 'image',
'filepath': '/path/to/image.png',
'tags': [],
'metadata': None,
'created_at': None,
'last_modified_at': None,
'keypoints': <Keypoints: {
'keypoints': [
<Keypoint: {
'id': '5f8709702018186b6ef66831',
'attributes': {},
'label': 'square',
'points': [(0.3, 0.3), (0.7, 0.3), (0.7, 0.7), (0.3, 0.7)],
'confidence': [0.6, 0.7, 0.8, 0.9],
'index': None,
}>,
],
}>,
}>
Like all Label types, you can also add custom attributes to your keypoints by
dynamically adding new fields to each Keypoint instance. As a special case,
if you add a custom list attribute to a Keypoint instance whose length
matches the number of points, these values will be interpreted as per-point
attributes and rendered as such in the App:
1import fiftyone as fo
2
3keypoint = fo.Keypoint(
4 label="rectangle",
5 kind="square", # custom object attribute
6 points=[(0.3, 0.3), (0.7, 0.3), (0.7, 0.7), (0.3, 0.7)],
7 confidence=[0.6, 0.7, 0.8, 0.9],
8 occluded=[False, False, True, False], # custom per-point attributes
9)
10
11print(keypoint)
<Keypoint: {
'id': '60f74723467d81f41c200556',
'attributes': {},
'tags': [],
'label': 'rectangle',
'points': [(0.3, 0.3), (0.7, 0.3), (0.7, 0.7), (0.3, 0.7)],
'confidence': [0.6, 0.7, 0.8, 0.9],
'index': None,
'kind': 'square',
'occluded': [False, False, True, False],
}>
If your keypoints have semantic meanings, you can store keypoint skeletons on your dataset to encode the meanings.
If you are working with keypoint skeletons and a particular point is missing or not visible for an instance, use nan values for its coordinates:
1keypoint = fo.Keypoint(
2 label="rectangle",
3 points=[
4 (0.3, 0.3),
5 (float("nan"), float("nan")), # use nan to encode missing points
6 (0.7, 0.7),
7 (0.3, 0.7),
8 ],
9)
Note
Did you know? When you view datasets with keypoint skeletons in the App, label strings and edges will be drawn when you visualize the keypoint fields.
Semantic segmentation#
The Segmentation class represents a semantic segmentation mask for an image
with integer values encoding the semantic labels for each pixel in the image.
The mask can either be stored on disk and referenced via the
mask_path attribute or
stored directly in the database via the
mask attribute.
Note
It is recommended to store segmentations on disk and reference them via the
mask_path attribute,
for efficiency.
Note that mask_path
must contain the absolute path to the mask on disk in order to use the
dataset from different current working directories in the future.
Segmentation masks can be stored in either of these formats:
2D 8-bit or 16-bit images or numpy arrays
3D 8-bit RGB images or numpy arrays
Segmentation masks can have any size; they are stretched as necessary to fit the image’s extent when visualizing in the App.
1import cv2
2import numpy as np
3
4import fiftyone as fo
5
6# Example segmentation mask
7mask_path = "/tmp/segmentation.png"
8mask = np.random.randint(10, size=(128, 128), dtype=np.uint8)
9cv2.imwrite(mask_path, mask)
10
11sample = fo.Sample(filepath="/path/to/image.png")
12sample["segmentation1"] = fo.Segmentation(mask_path=mask_path)
13sample["segmentation2"] = fo.Segmentation(mask=mask)
14
15print(sample)
<Sample: {
'id': None,
'media_type': 'image',
'filepath': '/path/to/image.png',
'tags': [],
'metadata': None,
'created_at': None,
'last_modified_at': None,
'segmentation1': <Segmentation: {
'id': '6371d72425de9907b93b2a6b',
'tags': [],
'mask': None,
'mask_path': '/tmp/segmentation.png',
}>,
'segmentation2': <Segmentation: {
'id': '6371d72425de9907b93b2a6c',
'tags': [],
'mask': array([[8, 5, 5, ..., 9, 8, 5],
[0, 7, 8, ..., 3, 4, 4],
[5, 0, 2, ..., 0, 3, 4],
...,
[4, 4, 4, ..., 3, 6, 6],
[0, 9, 8, ..., 8, 0, 8],
[0, 6, 8, ..., 2, 9, 1]], dtype=uint8),
'mask_path': None,
}>,
}>
When you load datasets with Segmentation fields containing 2D masks in the
App, each pixel value is rendered as a different color (if possible) from the
App’s color pool. When you view RGB segmentation masks in the App, the mask
colors are always used.
Note
Did you know? You can store semantic labels for your segmentation fields on your dataset. Then, when you view the dataset in the App, label strings will appear in the App’s tooltip when you hover over pixels.
Note
The pixel value 0 and RGB value #000000 are reserved “background”
classes that are always rendered as invisible in the App.
If mask targets are provided, all observed values not present in the targets are also rendered as invisible in the App.
Heatmaps#
The Heatmap class represents a continuous-valued heatmap for an image.
The map can either be stored on disk and referenced via the
map_path attribute or stored
directly in the database via the map
attribute. When using the
map_path attribute, heatmaps
may be 8-bit or 16-bit grayscale images. When using the
map attribute, heatmaps should be 2D
numpy arrays. By default, the map values are assumed to be in [0, 1] for
floating point arrays and [0, 255] for integer-valued arrays, but you can
specify a custom [min, max] range for a map by setting its optional
range attribute.
Heatmaps can have any size; they are stretched as necessary to fit the image’s extent when visualizing in the App.
Note
It is recommended to store heatmaps on disk and reference them via the
map_path attribute, for
efficiency.
Note that map_path
must contain the absolute path to the map on disk in order to use the
dataset from different current working directories in the future.
1import cv2
2import numpy as np
3
4import fiftyone as fo
5
6# Example heatmap
7map_path = "/tmp/heatmap.png"
8map = np.random.randint(256, size=(128, 128), dtype=np.uint8)
9cv2.imwrite(map_path, map)
10
11sample = fo.Sample(filepath="/path/to/image.png")
12sample["heatmap1"] = fo.Heatmap(map_path=map_path)
13sample["heatmap2"] = fo.Heatmap(map=map)
14
15print(sample)
<Sample: {
'id': None,
'media_type': 'image',
'filepath': '/path/to/image.png',
'tags': [],
'metadata': None,
'created_at': None,
'last_modified_at': None,
'heatmap1': <Heatmap: {
'id': '6371d9e425de9907b93b2a6f',
'tags': [],
'map': None,
'map_path': '/tmp/heatmap.png',
'range': None,
}>,
'heatmap2': <Heatmap: {
'id': '6371d9e425de9907b93b2a70',
'tags': [],
'map': array([[179, 249, 119, ..., 94, 213, 68],
[190, 202, 209, ..., 162, 16, 39],
[252, 251, 181, ..., 221, 118, 231],
...,
[ 12, 91, 201, ..., 14, 95, 88],
[164, 118, 171, ..., 21, 170, 5],
[232, 156, 218, ..., 224, 97, 65]], dtype=uint8),
'map_path': None,
'range': None,
}>,
}>
When visualizing heatmaps in the App, when the App is
in color-by-field mode, heatmaps are rendered in their field’s color with
opacity proportional to the magnitude of the heatmap’s values. For example, for
a heatmap whose range is
[-10, 10], pixels with the value +9 will be rendered with 90% opacity, and
pixels with the value -3 will be rendered with 30% opacity.
When the App is in color-by-value mode, heatmaps are rendered using the
colormap defined by the colorscale of your
App config, which can be:
The string name of any colorscale recognized by Plotly
A manually-defined colorscale like the following:
[ [0.000, "rgb(165,0,38)"], [0.111, "rgb(215,48,39)"], [0.222, "rgb(244,109,67)"], [0.333, "rgb(253,174,97)"], [0.444, "rgb(254,224,144)"], [0.555, "rgb(224,243,248)"], [0.666, "rgb(171,217,233)"], [0.777, "rgb(116,173,209)"], [0.888, "rgb(69,117,180)"], [1.000, "rgb(49,54,149)"], ]
The example code below demonstrates the possibilities that heatmaps provide by overlaying random gaussian kernels with positive or negative sign on an image dataset and configuring the App’s colorscale in various ways on-the-fly:
1import os
2import numpy as np
3import fiftyone as fo
4import fiftyone.zoo as foz
5
6def random_kernel(metadata):
7 h = metadata.height // 2
8 w = metadata.width // 2
9 sign = np.sign(np.random.randn())
10 x, y = np.meshgrid(np.linspace(-1, 1, w), np.linspace(-1, 1, h))
11 x0, y0 = np.random.random(2) - 0.5
12 kernel = sign * np.exp(-np.sqrt((x - x0) ** 2 + (y - y0) ** 2))
13 return fo.Heatmap(map=kernel, range=[-1, 1])
14
15dataset = foz.load_zoo_dataset("quickstart").select_fields().clone()
16dataset.compute_metadata()
17
18for sample in dataset:
19 heatmap = random_kernel(sample.metadata)
20
21 # Convert to on-disk
22 map_path = os.path.join("/tmp/heatmaps", os.path.basename(sample.filepath))
23 heatmap.export_map(map_path, update=True)
24
25 sample["heatmap"] = heatmap
26 sample.save()
27
28session = fo.launch_app(dataset)
1# Select `Settings -> Color by value` in the App
2# Heatmaps will now be rendered using your default colorscale (printed below)
3print(session.config.colorscale)
1# Switch to a different named colorscale
2session.config.colorscale = "RdBu"
3session.refresh()
1# Switch to a custom colorscale
2session.config.colorscale = [
3 [0.00, "rgb(166,206,227)"],
4 [0.25, "rgb(31,120,180)"],
5 [0.45, "rgb(178,223,138)"],
6 [0.65, "rgb(51,160,44)"],
7 [0.85, "rgb(251,154,153)"],
8 [1.00, "rgb(227,26,28)"],
9]
10session.refresh()
Temporal detection#
The TemporalDetection class represents an event occurring during a specified
range of frames in a video.
The label attribute
stores the detection label, and the
support attribute
stores the [first, last] frame range of the detection in the video.
The optional
confidence
attribute can be used to store a model prediction score, and you can add
custom attributes as well, which can be visualized in the
App.
1import fiftyone as fo
2
3sample = fo.Sample(filepath="/path/to/video.mp4")
4sample["events"] = fo.TemporalDetection(label="meeting", support=[10, 20])
5
6print(sample)
<Sample: {
'id': None,
'media_type': 'video',
'filepath': '/path/to/video.mp4',
'tags': [],
'metadata': None,
'created_at': None,
'last_modified_at': None,
'events': <TemporalDetection: {
'id': '61321c8ea36cb17df655f44f',
'tags': [],
'label': 'meeting',
'support': [10, 20],
'confidence': None,
}>,
'frames': <Frames: 0>,
}>
If your temporal detection data is represented as timestamps in seconds, you
can use the
from_timestamps()
factory method to perform the necessary conversion to frames automatically
based on the sample’s video metadata:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4# Download a video to work with
5dataset = foz.load_zoo_dataset("quickstart-video", max_samples=1)
6filepath = dataset.first().filepath
7
8sample = fo.Sample(filepath=filepath)
9sample.compute_metadata()
10
11sample["events"] = fo.TemporalDetection.from_timestamps(
12 [1, 2], label="meeting", sample=sample
13)
14
15print(sample)
<Sample: {
'id': None,
'media_type': 'video',
'filepath': '~/fiftyone/quickstart-video/data/Ulcb3AjxM5g_053-1.mp4',
'tags': [],
'metadata': <VideoMetadata: {
'size_bytes': 1758809,
'mime_type': 'video/mp4',
'frame_width': 1920,
'frame_height': 1080,
'frame_rate': 29.97002997002997,
'total_frame_count': 120,
'duration': 4.004,
'encoding_str': 'avc1',
}>,
'created_at': None,
'last_modified_at': None,
'events': <TemporalDetection: {
'id': '61321e498d5f587970b29183',
'tags': [],
'label': 'meeting',
'support': [31, 60],
'confidence': None,
}>,
'frames': <Frames: 0>,
}>
The TemporalDetections class holds a list of temporal detections for a
sample:
1import fiftyone as fo
2
3sample = fo.Sample(filepath="/path/to/video.mp4")
4sample["events"] = fo.TemporalDetections(
5 detections=[
6 fo.TemporalDetection(label="meeting", support=[10, 20]),
7 fo.TemporalDetection(label="party", support=[30, 60]),
8 ]
9)
10
11print(sample)
<Sample: {
'id': None,
'media_type': 'video',
'filepath': '/path/to/video.mp4',
'tags': [],
'metadata': None,
'created_at': None,
'last_modified_at': None,
'events': <TemporalDetections: {
'detections': [
<TemporalDetection: {
'id': '61321ed78d5f587970b29184',
'tags': [],
'label': 'meeting',
'support': [10, 20],
'confidence': None,
}>,
<TemporalDetection: {
'id': '61321ed78d5f587970b29185',
'tags': [],
'label': 'party',
'support': [30, 60],
'confidence': None,
}>,
],
}>,
'frames': <Frames: 0>,
}>
Note
Did you know? You can store class lists for your models on your datasets.
3D detections#
The App’s 3D visualizer supports rendering 3D object
detections represented as Detection instances with their label, location,
dimensions, and rotation attributes populated as shown below:
1import fiftyone as fo
2
3# Object label
4label = "vehicle"
5
6# Object center `[x, y, z]` in scene coordinates
7location = [0.47, 1.49, 69.44]
8
9# Object dimensions `[x, y, z]` in scene units
10dimensions = [2.85, 2.63, 12.34]
11
12# Object rotation `[x, y, z]` around its center, in `[-pi, pi]`
13rotation = [0, -1.56, 0]
14
15# A 3D object detection
16detection = fo.Detection(
17 label=label,
18 location=location,
19 dimensions=dimensions,
20 rotation=rotation,
21)
Note
Did you know? You can view custom attributes in the App tooltip by hovering over the objects.
3D polylines#
The App’s 3D visualizer supports rendering 3D
polylines represented as Polyline instances with their label and points3d
attributes populated as shown below:
1import fiftyone as fo
2
3# Object label
4label = "lane"
5
6# A list of lists of `[x, y, z]` points in scene coordinates describing
7# the vertices of each shape in the polyline
8points3d = [[[-5, -99, -2], [-8, 99, -2]], [[4, -99, -2], [1, 99, -2]]]
9
10# A set of semantically related 3D polylines
11polyline = fo.Polyline(label=label, points3d=points3d)
Note
Did you know? You can view custom attributes in the App tooltip by hovering over the objects.
Geolocation#
The GeoLocation class can store single pieces of location data in its
properties:
point: a[longitude, latitude]pointline: a line of longitude and latitude coordinates stored in the following format:[[lon1, lat1], [lon2, lat2], ...]
polygon: a polygon of longitude and latitude coordinates stored in the format below, where the first element describes the boundary of the polygon and any remaining entries describe holes:[ [[lon1, lat1], [lon2, lat2], ...], [[lon1, lat1], [lon2, lat2], ...], ... ]
Note
All geolocation coordinates are stored in [longitude, latitude]
format.
If you have multiple geometries of each type that you wish to store on a single
sample, then you can use the GeoLocations class and its appropriate
properties to do so.
1import fiftyone as fo
2
3sample = fo.Sample(filepath="/path/to/image.png")
4
5sample["location"] = fo.GeoLocation(
6 point=[-73.9855, 40.7580],
7 polygon=[
8 [
9 [-73.949701, 40.834487],
10 [-73.896611, 40.815076],
11 [-73.998083, 40.696534],
12 [-74.031751, 40.715273],
13 [-73.949701, 40.834487],
14 ]
15 ],
16)
17
18print(sample)
<Sample: {
'id': None,
'media_type': 'image',
'filepath': '/path/to/image.png',
'tags': [],
'metadata': None,
'created_at': None,
'last_modified_at': None,
'location': <GeoLocation: {
'id': '60481f3936dc48428091e926',
'tags': [],
'point': [-73.9855, 40.758],
'line': None,
'polygon': [
[
[-73.949701, 40.834487],
[-73.896611, 40.815076],
[-73.998083, 40.696534],
[-74.031751, 40.715273],
[-73.949701, 40.834487],
],
],
}>,
}>
Note
Did you know? You can create location-based views that filter your data by their location!
All location data is stored in GeoJSON format in the database. You can easily retrieve the raw GeoJSON data for a slice of your dataset using the values() aggregation:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart-geo")
5
6values = dataset.take(5).values("location.point", _raw=True)
7print(values)
[{'type': 'Point', 'coordinates': [-73.9592175465766, 40.71052995514191]},
{'type': 'Point', 'coordinates': [-73.97748118760413, 40.74660360881843]},
{'type': 'Point', 'coordinates': [-73.9508690871987, 40.766631164626]},
{'type': 'Point', 'coordinates': [-73.96569416502996, 40.75449283200206]},
{'type': 'Point', 'coordinates': [-73.97397106211423, 40.67925541341504]}]
Label attributes#
The Detection, Polyline, and Keypoint label types have an optional
attributes field that you
can use to store custom attributes on the object.
The attributes field is a
dictionary mapping attribute names to Attribute instances, which contain the
value of the attribute and any
associated metadata.
Warning
The attributes field
will be removed in an upcoming release.
Instead, add custom attributes directly to your
Label objects:
detection = fo.Detection(label="cat", bounding_box=[0.1, 0.1, 0.8, 0.8])
detection["custom_attribute"] = 51
# Equivalent
detection = fo.Detection(
label="cat",
bounding_box=[0.1, 0.1, 0.8, 0.8],
custom_attribute=51,
)
There are Attribute subclasses for various types of attributes you may want
to store. Use the appropriate subclass when possible so that FiftyOne knows the
schema of the attributes that you’re storing.
Attribute class |
Value type |
Description |
|---|---|---|
|
A boolean attribute |
|
|
A categorical attribute |
|
|
A numeric attribute |
|
|
A list attribute |
|
arbitrary |
A generic attribute of any type |
1import fiftyone as fo
2
3sample = fo.Sample(filepath="/path/to/image.png")
4
5sample["ground_truth"] = fo.Detections(
6 detections=[
7 fo.Detection(
8 label="cat",
9 bounding_box=[0.5, 0.5, 0.4, 0.3],
10 attributes={
11 "age": fo.NumericAttribute(value=51),
12 "mood": fo.CategoricalAttribute(value="salty"),
13 },
14 ),
15 ]
16)
17sample["prediction"] = fo.Detections(
18 detections=[
19 fo.Detection(
20 label="cat",
21 bounding_box=[0.480, 0.513, 0.397, 0.288],
22 confidence=0.96,
23 attributes={
24 "age": fo.NumericAttribute(value=51),
25 "mood": fo.CategoricalAttribute(
26 value="surly", confidence=0.95
27 ),
28 },
29 ),
30 ]
31)
32
33print(sample)
<Sample: {
'id': None,
'media_type': 'image',
'filepath': '/path/to/image.png',
'tags': [],
'metadata': None,
'created_at': None,
'last_modified_at': None,
'ground_truth': <Detections: {
'detections': [
<Detection: {
'id': '60f738e7467d81f41c20054c',
'attributes': {
'age': <NumericAttribute: {'value': 51}>,
'mood': <CategoricalAttribute: {
'value': 'salty', 'confidence': None, 'logits': None
}>,
},
'tags': [],
'label': 'cat',
'bounding_box': [0.5, 0.5, 0.4, 0.3],
'mask': None,
'confidence': None,
'index': None,
}>,
],
}>,
'prediction': <Detections: {
'detections': [
<Detection: {
'id': '60f738e7467d81f41c20054d',
'attributes': {
'age': <NumericAttribute: {'value': 51}>,
'mood': <CategoricalAttribute: {
'value': 'surly', 'confidence': 0.95, 'logits': None
}>,
},
'tags': [],
'label': 'cat',
'bounding_box': [0.48, 0.513, 0.397, 0.288],
'mask': None,
'confidence': 0.96,
'index': None,
}>,
],
}>,
}>
Note
Did you know? You can view attribute values in the App tooltip by hovering over the objects.
Converting label types#
FiftyOne provides a number of utility methods to convert between different representations of certain label types, such as converting between instance segmentations, semantic segmentations, and polylines.
Let’s load some instance segmentations from the COCO dataset to see this in action:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset(
5 "coco-2017",
6 split="validation",
7 label_types=["segmentations"],
8 classes=["cat", "dog"],
9 label_field="instances",
10 max_samples=25,
11 only_matching=True,
12)
13
14sample = dataset.first()
15detections = sample["instances"]
For example, you can use
Detections.to_polylines()
to convert instance segmentations to polylines:
1# Convert `Detections` to `Polylines`
2polylines = detections.to_polylines(tolerance=2)
3print(polylines)
Or you can use
Detections.to_segmentation()
to convert instance segmentations to semantic segmentation masks:
1metadata = fo.ImageMetadata.build_for(sample.filepath)
2
3# Convert `Detections` to `Segmentation`
4segmentation = detections.to_segmentation(
5 frame_size=(metadata.width, metadata.height),
6 mask_targets={1: "cat", 2: "dog"},
7)
8
9# Export the segmentation to disk
10segmentation.export_mask("/tmp/mask.png", update=True)
11
12print(segmentation)
Methods such as
Segmentation.to_detections()
and Segmentation.to_polylines()
also exist to transform semantic segmentations back into individual shapes.
In addition, the fiftyone.utils.labels module contains a variety of
utility methods for converting entire collections’ labels between common
formats:
1import fiftyone.utils.labels as foul
2
3# Convert instance segmentations to semantic segmentations stored on disk
4foul.objects_to_segmentations(
5 dataset,
6 "instances",
7 "segmentations",
8 output_dir="/tmp/segmentations",
9 mask_targets={1: "cat", 2: "dog"},
10)
11
12# Convert instance segmentations to polylines format
13foul.instances_to_polylines(dataset, "instances", "polylines", tolerance=2)
14
15# Convert semantic segmentations to instance segmentations
16foul.segmentations_to_detections(
17 dataset,
18 "segmentations",
19 "instances2",
20 mask_targets={1: "cat", 2: "dog"},
21 mask_types="thing", # give each connected region a separate instance
22)
23
24print(dataset)
Name: coco-2017-validation-25
Media type: image
Num samples: 25
Persistent: False
Tags: []
Sample fields:
id: fiftyone.core.fields.ObjectIdField
filepath: fiftyone.core.fields.StringField
tags: fiftyone.core.fields.ListField(fiftyone.core.fields.StringField)
metadata: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.metadata.ImageMetadata)
created_at: fiftyone.core.fields.DateTimeField
last_modified_at: fiftyone.core.fields.DateTimeField
instances: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Detections)
segmentations: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Segmentation)
polylines: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Polylines)
instances2: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Detections)
Note that, if your goal is to export the labels to disk, FiftyOne can
automatically coerce the labels into the correct
format based on the type of the label_field and the dataset_type that you
specify for the export without explicitly storing the transformed labels as a
new field on your dataset:
1# Export the instance segmentations in the `instances` field as semantic
2# segmentation images on disk
3dataset.export(
4 label_field="instances",
5 dataset_type=fo.types.ImageSegmentationDirectory,
6 labels_path="/tmp/masks",
7 mask_targets={1: "cat", 2: "dog"},
8)
Projecting 3D detections to 2D#
FiftyOne provides functionality through
detections_3d_to_cuboids_2d
to project 3D object detections into 2D images as polylines. This functionality
is specific to grouped datasets with multiple modalities such as images and
point clouds.
The 3D detections (in_field) should be stored in a field of type
Detection with the necessary attributes such as
location, dimensions, and rotation populated. You need to provide
the following additional information for the projections:
Coordinate transformation data used to convert 3D bounding boxes from the point cloud coordinate system into the camera coordinate system.
Represented as a dictionary mapping the key field (defaults to sample id) of the spatial slice to a list of transformation tuples.
Each transformation is a
(translation, rotation)tuple, where:translation: a 3-element vector (list[float]ornp.ndarray) specifying the translation in 3D spacerotation: a 3x3 rotation matrix (list[float]ornp.ndarray) specifying the orientation
[Optional] Forward flags indicating whether to apply the corresponding transformation in the forward direction (from point cloud to camera) or in the inverse direction (from camera to point cloud).
Represented as a dictionary mapping the key field (defaults to sample id) of the spatial slice to a list of boolean flags. The length of the list must match the number of transformations for the sample.
If not provided, all transformations are assumed to be applied in the forward direction.
Camera model used to account for camera intrinsics and lens distortion during 3D-to-2D projection.
Specified via the
camera_modelargument, which accepts a projection function with the signature:projection_function(points3d: np.ndarray, camera_params: dict) -> np.ndarray
points3d: an(N, 3)NumPy array of 3D points to be projectedcamera_params: a dictionary of camera parameters required by the projection function
FiftyOne provides a pinhole camera model via the
utils3d.pinhole_projectorfunction, which is used by default if no camera model is specified.Note
For the pinhole camera model, the following orientation is assumed: - x axis points to the right in the image plane - y axis points down in the image plane - z axis points forward from the camera
To use the pinhole camera model, you must ensure that your 3D boxes are oriented in the same way, likely by applying an additional rotation transformation.
Camera parameter data to project the 3D boxes onto the 2D image plane.
Represented as a dictionary mapping key field of the camera slice to dicts with the keys required by the camera model you are using.
For example, for the default pinhole camera model, the dictionary should contain the key
intrinsics, which is a 3x3np.ndarraycamera intrinsics matrix of the form:[[fx, 0, cx], [ 0, fy, cy], [ 0, 0, 1]]
The example code below demonstrates how to perform this projection using FiftyOne:
1import fiftyone as fo
2from fiftyone.utils.labels import detections_3d_to_cuboids_2d
3import numpy as np
4
5dataset = fo.load_dataset("your_grouped_dataset")
6
7# Example transformation: Assume that for all samples, the same
8# transformation is applied. A 90 degree rotation around the x axis to align
9# the point cloud and camera coordinate systems with 0 translation
10dataset.group_slice = "spatial_slice"
11rotation = np.array([[1, 0, 0],
12 [0, 0, -1],
13 [0, 1, 0]])
14translation = np.array([0, 0, 0])
15
16# Example camera parameters: Assume that for all samples, the same camera
17# intrinsics are used. Note that camera_params has to use camera slice fields
18# as keys
19intrinsics = np.array([[1000, 0, 512],
20 [0, 1000, 384],
21 [0, 0, 1]])
22
23transformations = {}
24camera_params = {}
25for group in dataset.iter_groups():
26 lidar_sample = group["spatial_slice"]
27 transformations[lidar_sample.id] = [(translation, rotation)]
28 camera_sample = group["camera_slice"]
29 camera_params[camera_sample.id] = {
30 "intrinsics": intrinsics
31 }
32
33# Assuming a grouped dataset with image and point cloud modalities
34# - image slice named "camera_slice"
35# - point cloud slice named "spatial_slice"
36# - 3D detections stored in the "detections_3d" field
37# The projected 2D cuboids will be stored in the "cuboids_2d" field
38
39detections_3d_to_cuboids_2d(
40 dataset,
41 spatial_slice_name="spatial_slice",
42 camera_slice_name="camera_slice",
43 in_field="detections_3d",
44 out_field="cuboids_2d",
45 transformations=transformations,
46 camera_params=camera_params,
47)
Dynamic attributes#
Any field(s) of your FiftyOne datasets that contain DynamicEmbeddedDocument
values can have arbitrary custom attributes added to their instances.
For example, all Label classes and Metadata classes are dynamic, so you can add custom attributes to them as follows:
1# Provide some default attributes
2label = fo.Classification(label="cat", confidence=0.98)
3
4# Add custom attributes
5label["int"] = 5
6label["float"] = 51.0
7label["list"] = [1, 2, 3]
8label["bool"] = True
9label["dict"] = {"key": ["list", "of", "values"]}
By default, dynamic attributes are not included in a dataset’s schema, which means that these attributes may contain arbitrary heterogeneous values across the dataset’s samples.
However, FiftyOne provides methods that you can use to formally declare custom dynamic attributes, which allows you to enforce type constraints, filter by these custom attributes in the App, and more.
You can use
get_dynamic_field_schema()
to detect the names and type(s) of any undeclared dynamic embedded document
attributes on a dataset:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5
6print(dataset.get_dynamic_field_schema())
{
'ground_truth.detections.iscrowd': <fiftyone.core.fields.FloatField>,
'ground_truth.detections.area': <fiftyone.core.fields.FloatField>,
}
You can then use
add_sample_field() to
declare a specific dynamic embedded document attribute:
1dataset.add_sample_field("ground_truth.detections.iscrowd", fo.FloatField)
or you can use the
add_dynamic_sample_fields()
method to declare all dynamic embedded document attribute(s) that contain
values of a single type:
1dataset.add_dynamic_sample_fields()
Note
Pass the add_mixed=True option to
add_dynamic_sample_fields()
if you wish to declare all dynamic attributes that contain mixed values
using a generic Field type.
You can provide the optional flat=True option to
get_field_schema() to
retrieve a flattened version of a dataset’s schema that includes all embedded
document attributes as top-level keys:
1print(dataset.get_field_schema(flat=True))
{
'id': <fiftyone.core.fields.ObjectIdField>,
'filepath': <fiftyone.core.fields.StringField>,
'tags': <fiftyone.core.fields.ListField>,
'metadata': <fiftyone.core.fields.EmbeddedDocumentField>,
'metadata.size_bytes': <fiftyone.core.fields.IntField>,
'metadata.mime_type': <fiftyone.core.fields.StringField>,
'metadata.width': <fiftyone.core.fields.IntField>,
'metadata.height': <fiftyone.core.fields.IntField>,
'metadata.num_channels': <fiftyone.core.fields.IntField>,
'created_at': <fiftyone.core.fields.DateTimeField object at 0x7fea584bc730>,
'last_modified_at': <fiftyone.core.fields.DateTimeField object at 0x7fea584bc280>,
'ground_truth': <fiftyone.core.fields.EmbeddedDocumentField>,
'ground_truth.detections': <fiftyone.core.fields.ListField>,
'ground_truth.detections.id': <fiftyone.core.fields.ObjectIdField>,
'ground_truth.detections.tags': <fiftyone.core.fields.ListField>,
...
'ground_truth.detections.iscrowd': <fiftyone.core.fields.FloatField>,
'ground_truth.detections.area': <fiftyone.core.fields.FloatField>,
...
}
By default, dynamic attributes are not declared on a dataset’s schema when samples are added to it:
1import fiftyone as fo
2
3sample = fo.Sample(
4 filepath="/path/to/image.jpg",
5 ground_truth=fo.Detections(
6 detections=[
7 fo.Detection(
8 label="cat",
9 bounding_box=[0.1, 0.1, 0.4, 0.4],
10 mood="surly",
11 ),
12 fo.Detection(
13 label="dog",
14 bounding_box=[0.5, 0.5, 0.4, 0.4],
15 mood="happy",
16 )
17 ]
18 )
19)
20
21dataset = fo.Dataset()
22dataset.add_sample(sample)
23
24schema = dataset.get_field_schema(flat=True)
25
26assert "ground_truth.detections.mood" not in schema
However, methods such as
add_sample(),
add_samples(),
add_dir(),
from_dir(), and
merge_samples()
provide an optional dynamic=True option that you can provide to automatically
declare any dynamic embedded document attributes encountered while importing
data:
1dataset = fo.Dataset()
2
3dataset.add_sample(sample, dynamic=True)
4schema = dataset.get_field_schema(flat=True)
5
6assert "ground_truth.detections.mood" in schema
Note that, when declaring dynamic attributes on non-empty datasets, you must
ensure that the attribute’s type is consistent with any existing values in that
field, e.g., by first running
get_dynamic_field_schema()
to check the existing type(s). Methods like
add_sample_field()
and
add_samples(..., dynamic=True)
do not validate newly declared field’s types against existing field values:
1import fiftyone as fo
2
3sample1 = fo.Sample(
4 filepath="/path/to/image1.jpg",
5 ground_truth=fo.Classification(
6 label="cat",
7 mood="surly",
8 age="bad-value",
9 ),
10)
11
12sample2 = fo.Sample(
13 filepath="/path/to/image2.jpg",
14 ground_truth=fo.Classification(
15 label="dog",
16 mood="happy",
17 age=5,
18 ),
19)
20
21dataset = fo.Dataset()
22
23dataset.add_sample(sample1)
24
25# Either of these are problematic
26dataset.add_sample(sample2, dynamic=True)
27dataset.add_sample_field("ground_truth.age", fo.IntField)
28
29sample1.reload() # ValidationError: bad-value could not be converted to int
If you declare a dynamic attribute with a type that is not compatible with
existing values in that field, you will need to remove that field from the
dataset’s schema using
remove_dynamic_sample_field()
in order for the dataset to be usable again:
1# Removes dynamic field from dataset's schema without deleting the values
2dataset.remove_dynamic_sample_field("ground_truth.age")
You can use
select_fields()
and
exclude_fields()
to create views that select/exclude specific dynamic
attributes from your dataset and its schema:
1dataset.add_sample_field("ground_truth.age", fo.Field)
2sample = dataset.first()
3
4assert "ground_truth.age" in dataset.get_field_schema(flat=True)
5assert sample.ground_truth.has_field("age")
6
7# Omits the `age` attribute from the `ground_truth` field
8view = dataset.exclude_fields("ground_truth.age")
9sample = view.first()
10
11assert "ground_truth.age" not in view.get_field_schema(flat=True)
12assert not sample.ground_truth.has_field("age")
13
14# Only include `mood` (and default) attributes of the `ground_truth` field
15view = dataset.select_fields("ground_truth.mood")
16sample = view.first()
17
18assert "ground_truth.age" not in view.get_field_schema(flat=True)
19assert not sample.ground_truth.has_field("age")
Custom embedded documents#
If you work with collections of related fields that you would like to organize
under a single top-level field, you can achieve this by defining and using
custom EmbeddedDocument and DynamicEmbeddedDocument classes to populate
your datasets.
Using custom embedded document classes enables you to access your data using the same object-oriented interface enjoyed by FiftyOne’s builtin label types.
The EmbeddedDocument class represents a fixed collection of fields with
predefined types and optional default values, while the
DynamicEmbeddedDocument class supports predefined fields but also allows
users to populate arbitrary custom fields at runtime, like FiftyOne’s
builtin label types.
Defining custom documents on-the-fly#
The simplest way to define custom embedded documents on your datasets is to
declare empty DynamicEmbeddedDocument field(s) and then incrementally
populate new dynamic attributes as needed.
To illustrate, let’s start by defining an empty embedded document field:
1import fiftyone as fo
2
3dataset = fo.Dataset()
4
5# Define an empty embedded document field
6dataset.add_sample_field(
7 "camera_info",
8 fo.EmbeddedDocumentField,
9 embedded_doc_type=fo.DynamicEmbeddedDocument,
10)
From here, there are a variety of ways to add new embedded attributes to the field.
You can explicitly declare new fields using
add_sample_field():
1# Declare a new `camera_id` attribute
2dataset.add_sample_field("camera_info.camera_id", fo.StringField)
3
4assert "camera_info.camera_id" in dataset.get_field_schema(flat=True)
or you can implicitly declare new fields using
add_samples() with the
dynamic=True flag:
1# Includes a new `quality` attribute
2sample1 = fo.Sample(
3 filepath="/path/to/image1.jpg",
4 camera_info=fo.DynamicEmbeddedDocument(
5 camera_id="123456789",
6 quality=51.0,
7 ),
8)
9
10sample2 = fo.Sample(
11 filepath="/path/to/image2.jpg",
12 camera_info=fo.DynamicEmbeddedDocument(camera_id="123456789"),
13)
14
15# Automatically declares new dynamic attributes as they are encountered
16dataset.add_samples([sample1, sample2], dynamic=True)
17
18assert "camera_info.quality" in dataset.get_field_schema(flat=True)
or you can implicitly declare new fields using
set_values()
with the dynamic=True flag:
1# Populate a new `description` attribute on each sample in the dataset
2dataset.set_values("camera_info.description", ["foo", "bar"], dynamic=True)
3
4assert "camera_info.description" in dataset.get_field_schema(flat=True)
Defining custom documents in modules#
You can also define custom embedded document classes in Python modules and
packages that you maintain, using the appropriate types from the
fiftyone.core.fields module to declare your fields and their types,
defaults, etc.
The benefit of this approach over the on-the-fly definition from the previous
section is that you can provide extra metadata such as whether fields are
required or should have default values if they are not explicitly set
during creation.
Warning
In order to work with datasets containing custom embedded documents defined
using this approach, you must configure your module_path in
all environments where you intend to work with the datasets that use
these classes, not just the environment where you create the dataset.
To avoid this requirement, consider defining custom documents on-the-fly instead.
For example, suppose you add the following embedded document classes to a
foo.bar module:
1from datetime import datetime
2
3import fiftyone as fo
4
5class CameraInfo(fo.EmbeddedDocument):
6 camera_id = fo.StringField(required=True)
7 quality = fo.FloatField()
8 description = fo.StringField()
9
10class LabelMetadata(fo.DynamicEmbeddedDocument):
11 created_at = fo.DateTimeField(default=datetime.utcnow)
12 model_name = fo.StringField()
and then foo.bar to FiftyOne’s module_path config setting (see
this page for more ways to register this):
export FIFTYONE_MODULE_PATH=foo.bar
# Verify module path
fiftyone config
You’re now free to use your custom embedded document classes as you please, whether this be top-level sample fields or nested fields:
1import fiftyone as fo
2import foo.bar as fb
3
4sample = fo.Sample(
5 filepath="/path/to/image.png",
6 camera_info=fb.CameraInfo(
7 camera_id="123456789",
8 quality=99.0,
9 ),
10 weather=fo.Classification(
11 label="sunny",
12 confidence=0.95,
13 metadata=fb.LabelMetadata(
14 model_name="resnet50",
15 description="A dynamic field",
16 )
17 ),
18)
19
20dataset = fo.Dataset()
21dataset.add_sample(sample)
22
23dataset.name = "test"
24dataset.persistent = True
As long as foo.bar is on your module_path, this dataset can be loaded in
future sessions and manipulated as usual:
1import fiftyone as fo
2
3dataset = fo.load_dataset("test")
4print(dataset.first())
<Sample: {
'id': '6217b696d181786cff360740',
'media_type': 'image',
'filepath': '/path/to/image.png',
'tags': [],
'metadata': None,
'created_at': datetime.datetime(2024, 7, 22, 5, 16, 10, 701907),
'last_modified_at': datetime.datetime(2024, 7, 22, 5, 16, 10, 701907),
'camera_info': <CameraInfo: {
'camera_id': '123456789',
'quality': 99.0,
'description': None,
}>,
'weather': <Classification: {
'id': '6217b696d181786cff36073e',
'tags': [],
'label': 'sunny',
'confidence': 0.95,
'logits': None,
'metadata': <LabelMetadata: {
'created_at': datetime.datetime(2022, 2, 24, 16, 47, 18, 10000),
'model_name': 'resnet50',
'description': 'A dynamic field',
}>,
}>,
}>
Image datasets#
Any Sample whose filepath is a file with MIME type image/* is recognized
as a image sample, and datasets composed of image samples have media type
image:
1import fiftyone as fo
2
3sample = fo.Sample(filepath="/path/to/image.png")
4
5dataset = fo.Dataset()
6dataset.add_sample(sample)
7
8print(dataset.media_type) # image
9print(sample)
<Sample: {
'id': '6655ca275e20e244f2c8fe31',
'media_type': 'image',
'filepath': '/path/to/image.png',
'tags': [],
'metadata': None,
'created_at': datetime.datetime(2024, 7, 22, 5, 15, 8, 122038),
'last_modified_at': datetime.datetime(2024, 7, 22, 5, 15, 8, 122038),
}>
Example image dataset#
To get started exploring image datasets, try loading the quickstart dataset from the zoo:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5
6print(dataset.count("ground_truth.detections")) # 1232
7print(dataset.count("predictions.detections")) # 5620
8print(dataset.count_values("ground_truth.detections.label"))
9# {'dog': 15, 'airplane': 24, 'dining table': 15, 'hot dog': 5, ...}
10
11session = fo.launch_app(dataset)
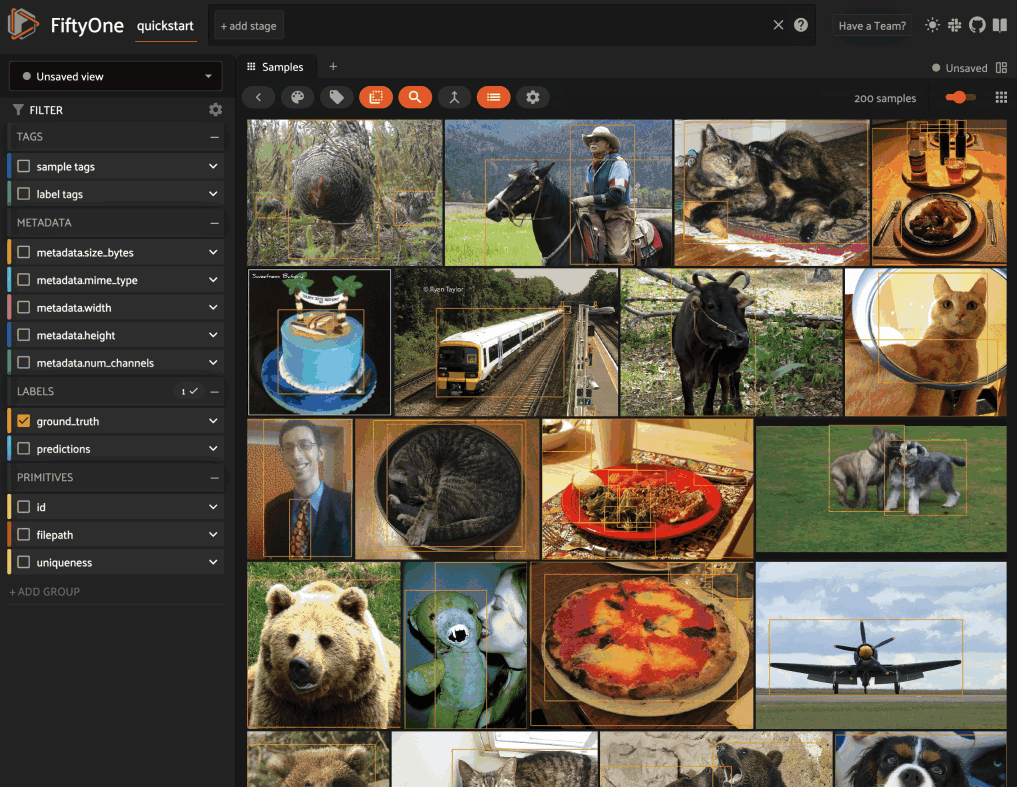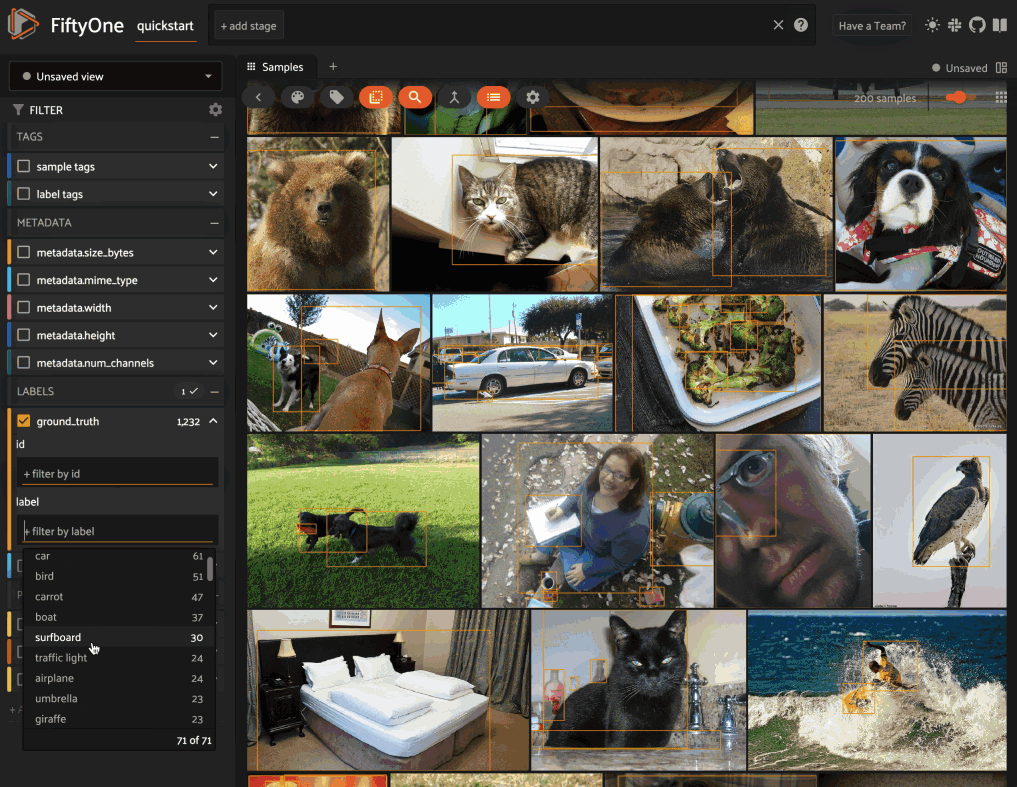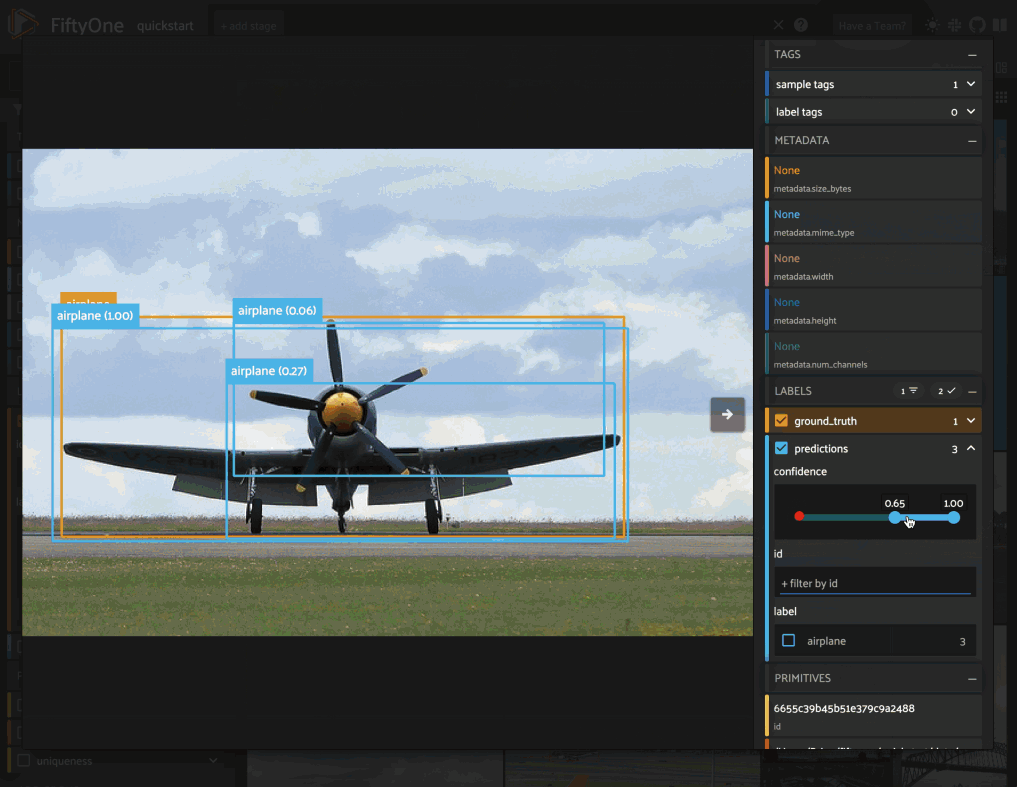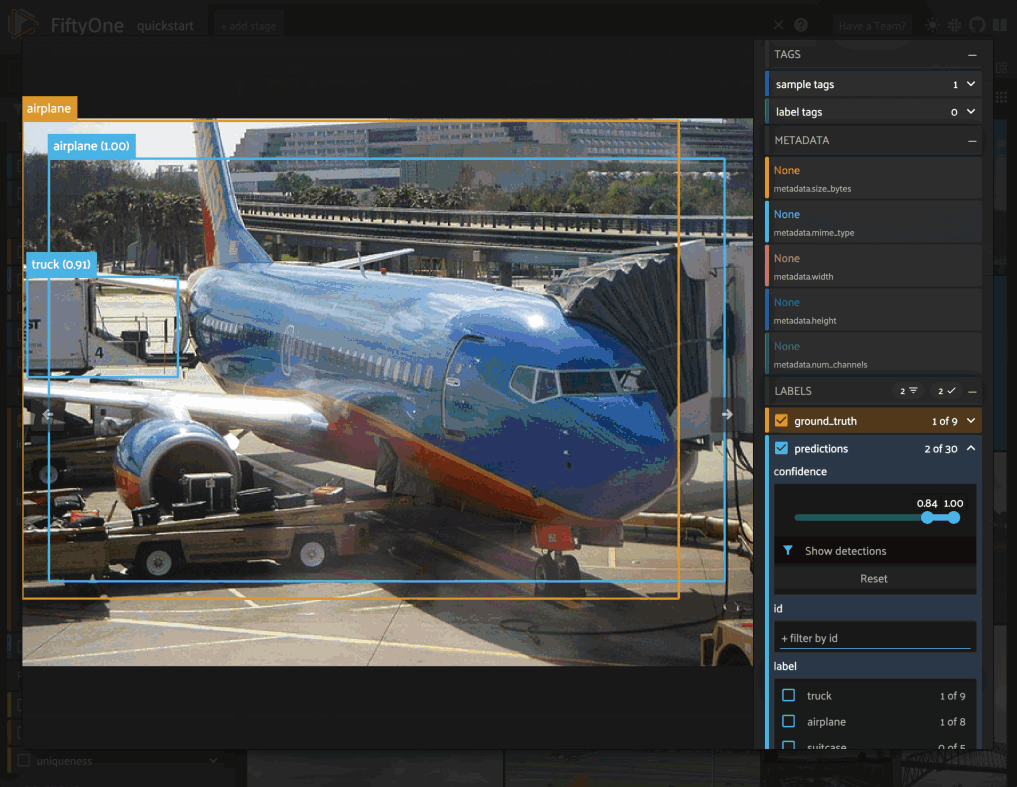
Video datasets#
Any Sample whose filepath is a file with MIME type video/* is recognized
as a video sample, and datasets composed of video samples have media type
video:
1import fiftyone as fo
2
3sample = fo.Sample(filepath="/path/to/video.mp4")
4
5dataset = fo.Dataset()
6dataset.add_sample(sample)
7
8print(dataset.media_type) # video
9print(sample)
<Sample: {
'id': '6403ccef0a3af5bc780b5a10',
'media_type': 'video',
'filepath': '/path/to/video.mp4',
'tags': [],
'metadata': None,
'created_at': datetime.datetime(2024, 7, 22, 5, 3, 17, 229263),
'last_modified_at': datetime.datetime(2024, 7, 22, 5, 3, 17, 229263),
'frames': <Frames: 0>,
}>
All video samples have a reserved frames attribute in which you can store
frame-level labels and other custom annotations for the video. The frames
attribute is a dictionary whose keys are frame numbers and whose values are
Frame instances that hold all of the Label instances and other
primitive-type fields for the frame.
Note
FiftyOne uses 1-based indexing for video frame numbers.
You can add, modify, and delete labels of any type as well as primitive fields such as integers, strings, and booleans using the same dynamic attribute syntax that you use to interact with samples:
1frame = fo.Frame(
2 quality=97.12,
3 weather=fo.Classification(label="sunny"),
4 objects=fo.Detections(
5 detections=[
6 fo.Detection(label="cat", bounding_box=[0.1, 0.1, 0.2, 0.2]),
7 fo.Detection(label="dog", bounding_box=[0.7, 0.7, 0.2, 0.2]),
8 ]
9 )
10)
11
12# Add labels to the first frame of the video
13sample.frames[1] = frame
14sample.save()
Note
You must call sample.save() in
order to persist changes to the database when editing video samples and/or
their frames that are in datasets.
<Sample: {
'id': '6403ccef0a3af5bc780b5a10',
'media_type': 'video',
'filepath': '/path/to/video.mp4',
'tags': [],
'metadata': None,
'created_at': datetime.datetime(2024, 7, 22, 5, 3, 17, 229263),
'last_modified_at': datetime.datetime(2024, 7, 22, 5, 3, 17, 229263),
'frames': <Frames: 1>, <-- `frames` now contains 1 frame of labels
}>
Note
The frames attribute of video samples behaves like a defaultdict; a new
Frame will be created if the frame number does not exist when you access
it.
You can iterate over the frames in a video sample using the expected syntax:
1for frame_number, frame in sample.frames.items():
2 print(frame)
<Frame: {
'id': '6403cd972a54cee076f88bd2',
'frame_number': 1,
'created_at': datetime.datetime(2024, 7, 22, 5, 3, 40, 839000),
'last_modified_at': datetime.datetime(2024, 7, 22, 5, 3, 40, 839000),
'quality': 97.12,
'weather': <Classification: {
'id': '609078d54653b0094e9baa52',
'tags': [],
'label': 'sunny',
'confidence': None,
'logits': None,
}>,
'objects': <Detections: {
'detections': [
<Detection: {
'id': '609078d54653b0094e9baa53',
'attributes': {},
'tags': [],
'label': 'cat',
'bounding_box': [0.1, 0.1, 0.2, 0.2],
'mask': None,
'confidence': None,
'index': None,
}>,
<Detection: {
'id': '609078d54653b0094e9baa54',
'attributes': {},
'tags': [],
'label': 'dog',
'bounding_box': [0.7, 0.7, 0.2, 0.2],
'mask': None,
'confidence': None,
'index': None,
}>,
],
}>,
}>
Notice that the dataset’s summary indicates that the dataset has media type
video and includes the schema of any frame fields you add:
1print(dataset)
Name: 2021.05.03.18.30.20
Media type: video
Num samples: 1
Persistent: False
Tags: []
Sample fields:
id: fiftyone.core.fields.ObjectIdField
filepath: fiftyone.core.fields.StringField
tags: fiftyone.core.fields.ListField(fiftyone.core.fields.StringField)
metadata: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.metadata.VideoMetadata)
created_at: fiftyone.core.fields.DateTimeField
last_modified_at: fiftyone.core.fields.DateTimeField
Frame fields:
id: fiftyone.core.fields.ObjectIdField
frame_number: fiftyone.core.fields.FrameNumberField
created_at: fiftyone.core.fields.DateTimeField
last_modified_at: fiftyone.core.fields.DateTimeField
quality: fiftyone.core.fields.FloatField
weather: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Classification)
objects: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Detections)
You can retrieve detailed information about the schema of the frames of a
video Dataset using
dataset.get_frame_field_schema().
The samples in video datasets can be accessed
like usual, and the sample’s frame
labels can be modified by updating the frames attribute of a Sample:
1sample = dataset.first()
2for frame_number, frame in sample.frames.items():
3 frame["frame_str"] = str(frame_number)
4 del frame["weather"]
5 del frame["objects"]
6
7sample.save()
8
9print(sample.frames[1])
<Frame: {
'id': '6403cd972a54cee076f88bd2',
'frame_number': 1,
'created_at': datetime.datetime(2024, 7, 22, 5, 3, 40, 839000),
'last_modified_at': datetime.datetime(2024, 7, 22, 5, 4, 49, 430051),
'quality': 97.12,
'weather': None,
'objects': None,
'frame_str': '1',
}>
Note
You must call sample.save() in
order to persist changes to the database when editing video samples and/or
their frames that are in datasets.
See this page for more information about building labeled video samples.
Example video dataset#
To get started exploring video datasets, try loading the quickstart-video dataset from the zoo:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart-video")
5
6print(dataset.count("frames")) # 1279
7print(dataset.count("frames.detections.detections")) # 11345
8print(dataset.count_values("frames.detections.detections.label"))
9# {'vehicle': 7511, 'road sign': 2726, 'person': 1108}
10
11session = fo.launch_app(dataset)
Linking labels across frames#
When working with video datasets, you may want to represent the fact that multiple frame-level labels correspond to the same logical object moving through the video.
You can achieve this linking by assigning the same Instance to the
instance attribute of the relevant Detection, Keypoint, or Polyline
objects across the frames of a Sample:
1import fiftyone as fo
2
3sample = fo.Sample(filepath="/path/to/video.mp4")
4
5# Create instance representing a logical object
6person_instance = fo.Instance()
7
8# Add labels for the person in frame 1
9sample.frames[1]["objects"] = fo.Detections(
10 detections=[
11 fo.Detection(
12 label="person",
13 bounding_box=[0.1, 0.1, 0.2, 0.2],
14 instance=person_instance, # link this detection
15 )
16 ]
17)
18
19# Add labels for the same person in frame 2
20sample.frames[2]["objects"] = fo.Detections(
21 detections=[
22 fo.Detection(
23 label="person",
24 bounding_box=[0.12, 0.11, 0.2, 0.2],
25 instance=person_instance, # link this detection
26 )
27 ]
28)
Note
Linking labels in this way enables helpful interactions in the FiftyOne App. See this section for more details.
3D datasets#
3D datasets have media_type="3d" and can be created from supported 3D asset
files directly, or from .fo3d scene files.
Direct assets are the simplest choice when a sample is a single mesh or point cloud:
1import fiftyone as fo
2
3samples = [
4 fo.Sample(filepath="/path/to/model.glb", media_type="3d"),
5 fo.Sample(filepath="/path/to/point-cloud.pcd", media_type="3d"),
6 fo.Sample(filepath="/path/to/mesh.ply", media_type="3d"),
7]
8
9dataset = fo.Dataset()
10dataset.add_samples(samples)
11
12print(dataset.media_type) # 3d
Features such as
camera intrinsics and extrinsics, camera
frustum rendering, and 3D annotation are
available whether your sample points directly to a
supported 3D asset or to an .fo3d scene.
Wrap assets in .fo3d when you need advanced scene customization such as
lights, camera configuration, transformations, materials, shapes, or multiple
assets in one scene. An FO3D file encapsulates a 3D scene constructed using the
Scene class, which provides methods
to add, remove, and manipulate 3D objects in the scene. A scene is
internally represented as a n-ary tree of 3D objects, where each
object is a node in the tree. A 3D object is either a
3D mesh, point cloud,
or a 3D shape geometry.
A scene may be explicitly initialized with additional attributes, such as
camera,
lights, and
background. By default, a
scene is created with neutral lighting, and a perspective camera whose
up is set to Y axis in a right-handed coordinate system.
After a scene is constructed, it should be written to the disk using the
scene.write() method, which
serializes the scene into an FO3D file.
1import fiftyone as fo
2
3scene = fo.Scene()
4scene.camera = fo.PerspectiveCamera(up="Z")
5
6mesh = fo.GltfMesh("mesh", "mesh.glb")
7mesh.rotation = fo.Euler(90, 0, 0, degrees=True)
8
9sphere1 = fo.SphereGeometry("sphere1", radius=2.0)
10sphere1.position = [-1, 0, 0]
11sphere1.default_material.color = "red"
12
13sphere2 = fo.SphereGeometry("sphere2", radius=2.0)
14sphere2.position = [1, 0, 0]
15sphere2.default_material.color = "blue"
16
17scene.add(mesh, sphere1, sphere2)
18
19scene.write("/path/to/scene.fo3d")
20
21sample = fo.Sample(filepath="/path/to/scene.fo3d")
22
23dataset = fo.Dataset()
24dataset.add_sample(sample)
25
26print(dataset.media_type) # 3d
To modify an existing scene, load it via
Scene.from_fo3d(), perform any
necessary updates, and then re-write it to disk:
1import fiftyone as fo
2
3scene = fo.Scene.from_fo3d("/path/to/scene.fo3d")
4
5for node in scene.traverse():
6 if isinstance(node, fo.SphereGeometry):
7 node.visible = False
8
9scene.write("/path/to/scene.fo3d")
3D meshes#
A 3D mesh is a collection of vertices, edges, and faces that define the shape
of a 3D object. Whereas some mesh formats store only the geometry of the mesh,
others also store the material properties and textures of the mesh. If a
mesh file contains material properties and textures, FiftyOne will
automatically load and display them. You may also
assign default material for your meshes by setting the
default_material
attribute of the mesh. In the absence of any material information,
meshes are assigned a
MeshStandardMaterial
with reasonable defaults that can also be dynamically configured from the app.
Please refer to material_3d for more
details.
FiftyOne currently supports
GLTF,
OBJ,
PLY,
STL, and
FBX 7.x+ mesh formats.
Note
We recommend the GLTF format for
3D meshes where possible, as it is the most compact, efficient, and
web-friendly format for storing and transmitting 3D models.
1import fiftyone as fo
2
3scene = fo.Scene()
4
5mesh1 = fo.GltfMesh("mesh1", "mesh.glb")
6mesh1.rotation = fo.Euler(90, 0, 0, degrees=True)
7
8mesh2 = fo.ObjMesh("mesh2", "mesh.obj")
9mesh3 = fo.PlyMesh("mesh3", "mesh.ply")
10mesh4 = fo.StlMesh("mesh4", "mesh.stl")
11mesh5 = fo.FbxMesh("mesh5", "mesh.fbx")
12
13scene.add(mesh1, mesh2, mesh3, mesh4, mesh5)
14
15scene.write("/path/to/scene.fo3d")
3D point clouds#
FiftyOne supports the PCD point cloud format. A code snippet to create a PCD object that can be added to a FiftyOne 3D scene is shown below:
1import fiftyone as fo
2
3pcd = fo.PointCloud("my-pcd", "point-cloud.pcd")
4pcd.default_material.shading_mode = "custom"
5pcd.default_material.custom_color = "red"
6pcd.default_material.point_size = 2
7
8scene = fo.Scene()
9scene.add(pcd)
10
11scene.write("/path/to/scene.fo3d")
You can customize the appearance of a point cloud by setting the
default_material attribute of the point cloud object, or dynamically from
the app. Please refer to the
PointCloudMaterial
class for more details.
Note
If your scene contains multiple point clouds, you can control which point
cloud is included in
orthographic projections by
initializing it with flag_for_projection=True.
Here’s how a typical PCD file is structured:
1import numpy as np
2import open3d as o3d
3
4points = np.array([(x1, y1, z1), (x2, y2, z2), ...])
5colors = np.array([(r1, g1, b1), (r2, g2, b2), ...])
6
7pcd = o3d.geometry.PointCloud()
8pcd.points = o3d.utility.Vector3dVector(points)
9pcd.colors = o3d.utility.Vector3dVector(colors)
10
11o3d.io.write_point_cloud("/path/to/point-cloud.pcd", pcd)
Note
When working with modalities such as LIDAR, intensity data is assumed to be
encoded in the r channel of the rgb field of the
PCD files.
When coloring by intensity in the App, the intensity values are automatically scaled to use the full dynamic range of the colorscale.
3D shapes#
FiftyOne provides a set of primitive 3D shape geometries that can be added to a 3D scene. The following 3D shape geometries are supported:
Box:
BoxGeometrySphere:
SphereGeometryCylinder:
CylinderGeometryPlane:
PlaneGeometry
Similar to meshes and point clouds, shapes can be manipulated by setting their
position, rotation, and scale. Their appearance can be customized either by
setting the default_material attribute of the shape object, or dynamically
from the app.
1import fiftyone as fo
2
3scene = fo.Scene()
4
5box = fo.BoxGeometry("box", width=0.5, height=0.5, depth=0.5)
6box.position = [0, 0, 1]
7box.default_material.color = "red"
8
9sphere = fo.SphereGeometry("sphere", radius=2.0)
10sphere.position = [-1, 0, 0]
11sphere.default_material.color = "blue"
12
13cylinder = fo.CylinderGeometry("cylinder", radius_top=0.5, height=1)
14cylinder.position = [0, 1, 0]
15
16plane = fo.PlaneGeometry("plane", width=2, height=2)
17plane.rotation = fo.Euler(90, 0, 0, degrees=True)
18
19scene.add(box, sphere, cylinder, plane)
20
21scene.write("/path/to/scene.fo3d")
3D annotations#
3D samples may contain any type and number of custom fields, including 3D detections and 3D polylines, which are natively visualizable by the App’s 3D visualizer.
Because 3D annotations are stored in dedicated fields of datasets rather than being embedded in FO3D files, they can be queried and filtered via dataset views and in the App just like other primitive/label fields.
1import fiftyone as fo
2
3scene = fo.Scene()
4scene.add(fo.GltfMesh("mesh", "mesh.gltf"))
5scene.write("/path/to/scene.fo3d")
6
7detection = fo.Detection(
8 label="vehicle",
9 location=[0.47, 1.49, 69.44],
10 dimensions=[2.85, 2.63, 12.34],
11 rotation=[0, -1.56, 0],
12)
13
14sample = fo.Sample(
15 filepath="/path/to/scene.fo3d",
16 ground_truth=fo.Detections(detections=[detection]),
17)
Orthographic projection images#
In order to visualize 3D datasets in the App’s grid view, you can use
compute_orthographic_projection_images()
to generate orthographic projection images of each scene:
1import fiftyone as fo
2import fiftyone.utils.utils3d as fou3d
3import fiftyone.zoo as foz
4
5# Load an example 3D dataset
6dataset = foz.load_zoo_dataset("quickstart-3d")
7
8# This dataset already has orthographic projections populated, but let's
9# recompute them to demonstrate the idea
10fou3d.compute_orthographic_projection_images(
11 dataset,
12 (-1, 512), # (width, height) of each image; -1 means aspect-preserving
13 bounds=((-50, -50, -50), (50, 50, 50)),
14 projection_normal=(0, -1, 0),
15 output_dir="/tmp/quickstart-3d-proj",
16 shading_mode="height",
17)
18
19session = fo.launch_app(dataset)
Note that the method also supports grouped datasets that contain 3D slice(s):
1import fiftyone as fo
2import fiftyone.utils.utils3d as fou3d
3import fiftyone.zoo as foz
4
5# Load an example group dataset that contains a 3D slice
6dataset = foz.load_zoo_dataset("quickstart-groups")
7
8# Populate orthographic projections
9fou3d.compute_orthographic_projection_images(dataset, (-1, 512), "/tmp/proj")
10
11dataset.group_slice = "pcd"
12session = fo.launch_app(dataset)
Note
Orthographic projection images currently only include point clouds, not meshes or 3D shapes.
If a scene contains multiple point clouds, you can
control which point cloud to project by initializing it with
flag_for_projection=True.
The above method populates an OrthographicProjectionMetadata field on each
sample that contains the path to its projection image and other necessary
information to properly
visualize it in the App.
Refer to the
compute_orthographic_projection_images()
documentation for available parameters to customize the projections.
Note
Did you know? You can use the inbuilt projection capabilities in FiftyOne to visualize 3D bounding boxes of 3D slices in grouped datasets on 2D images.
Example 3D datasets#
To get started exploring 3D datasets, try loading the quickstart-3d dataset from the zoo:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart-3d")
5
6print(dataset.count_values("ground_truth.label"))
7# {'bottle': 5, 'stairs': 5, 'keyboard': 5, 'car': 5, ...}
8
9session = fo.launch_app(dataset)
Also check out the quickstart-groups dataset, which contains a point cloud slice:
1import fiftyone as fo
2import fiftyone.utils.utils3d as fou3d
3import fiftyone.zoo as foz
4
5dataset = foz.load_zoo_dataset("quickstart-groups")
6
7# Populate orthographic projections
8fou3d.compute_orthographic_projection_images(dataset, (-1, 512), "/tmp/proj")
9
10print(dataset.count("ground_truth.detections")) # 1100
11print(dataset.count_values("ground_truth.detections.label"))
12# {'Pedestrian': 133, 'Car': 774, ...}
13
14dataset.group_slice = "pcd"
15session = fo.launch_app(dataset)
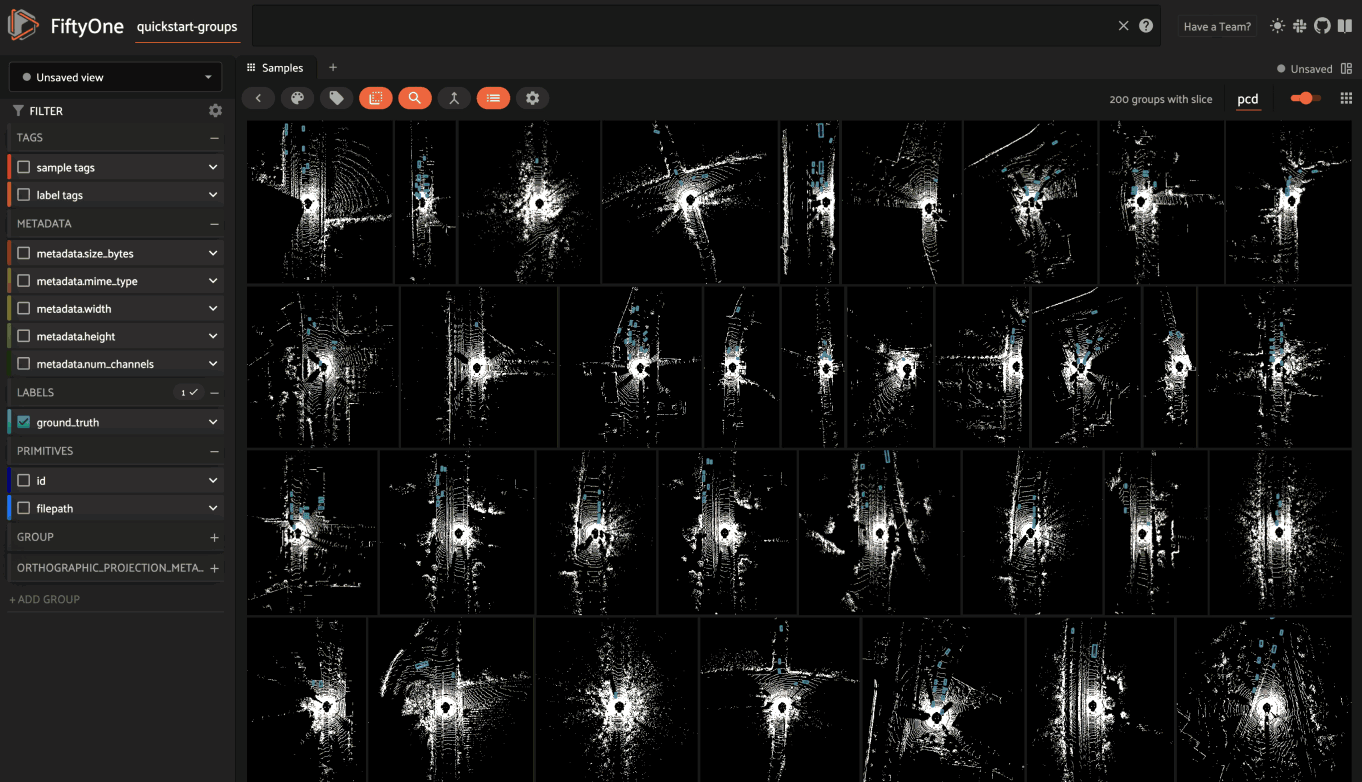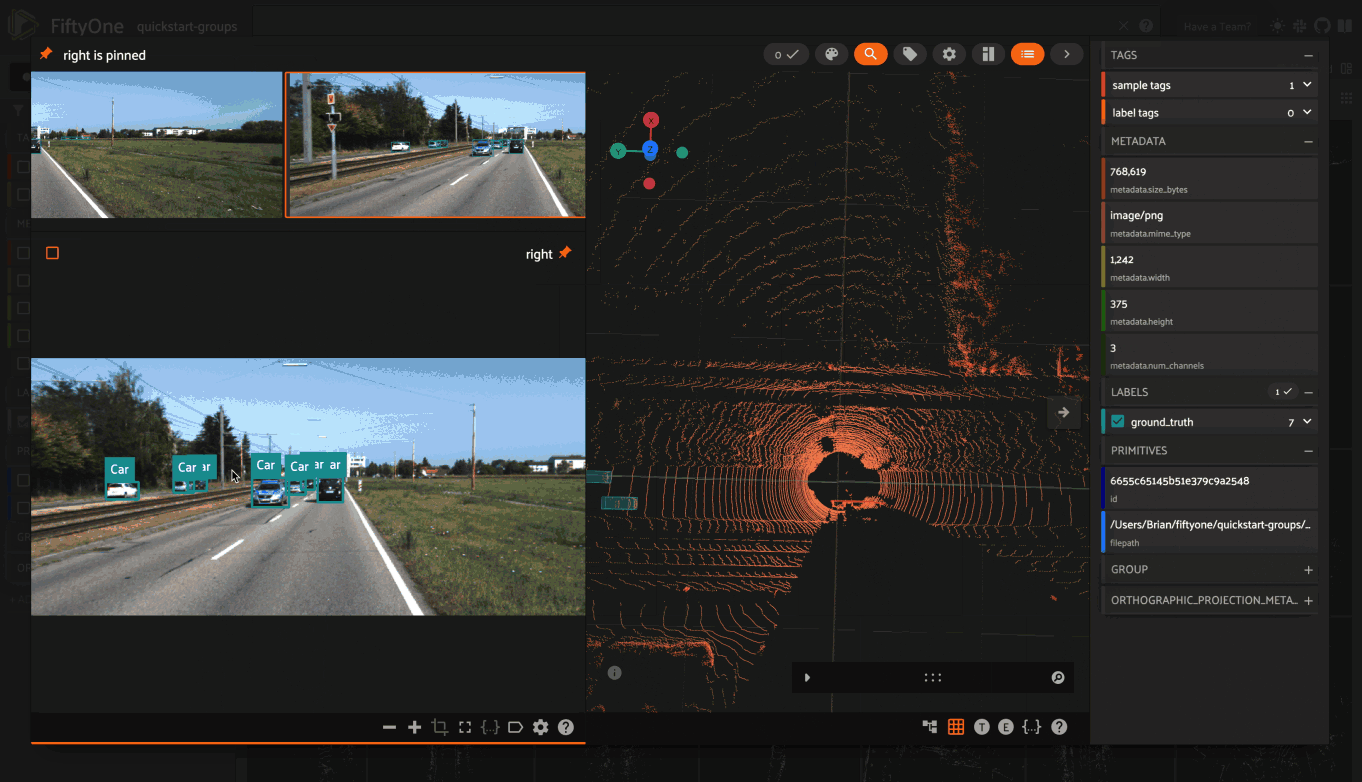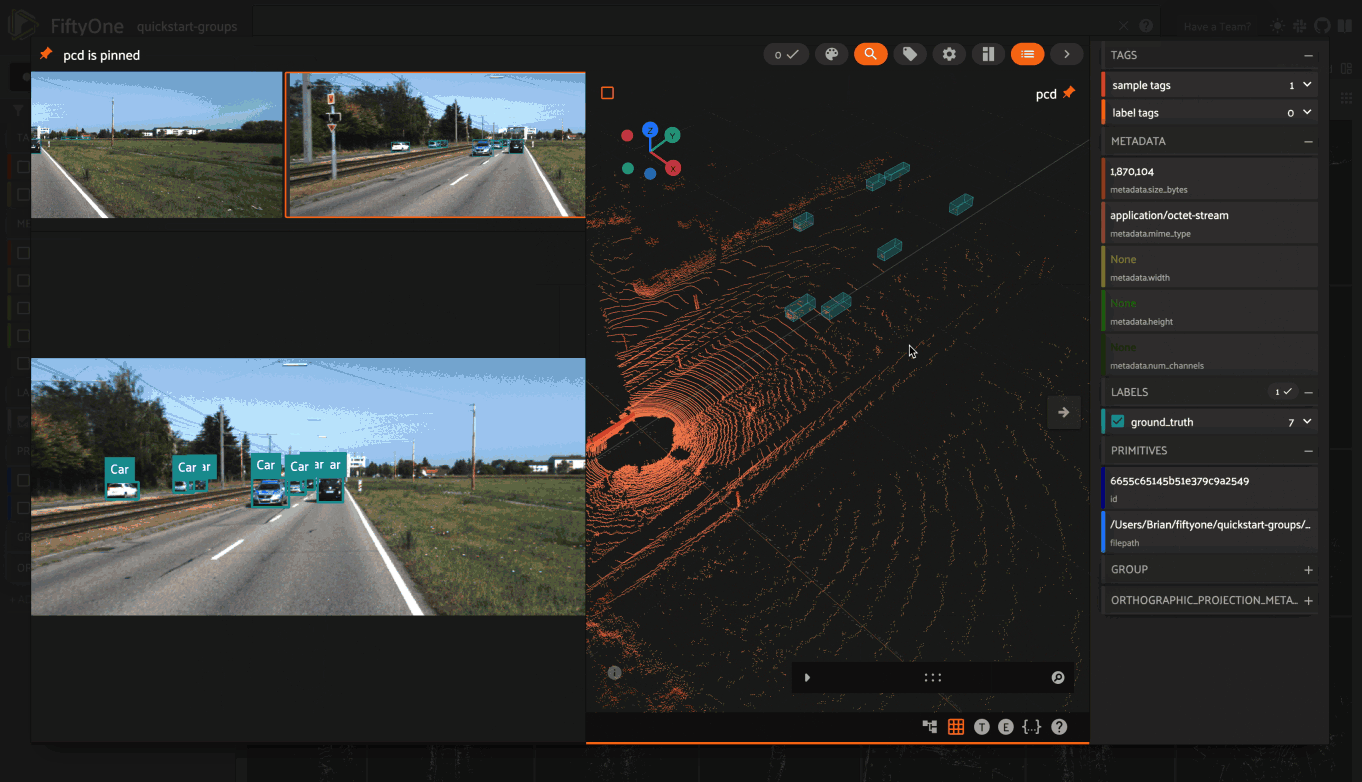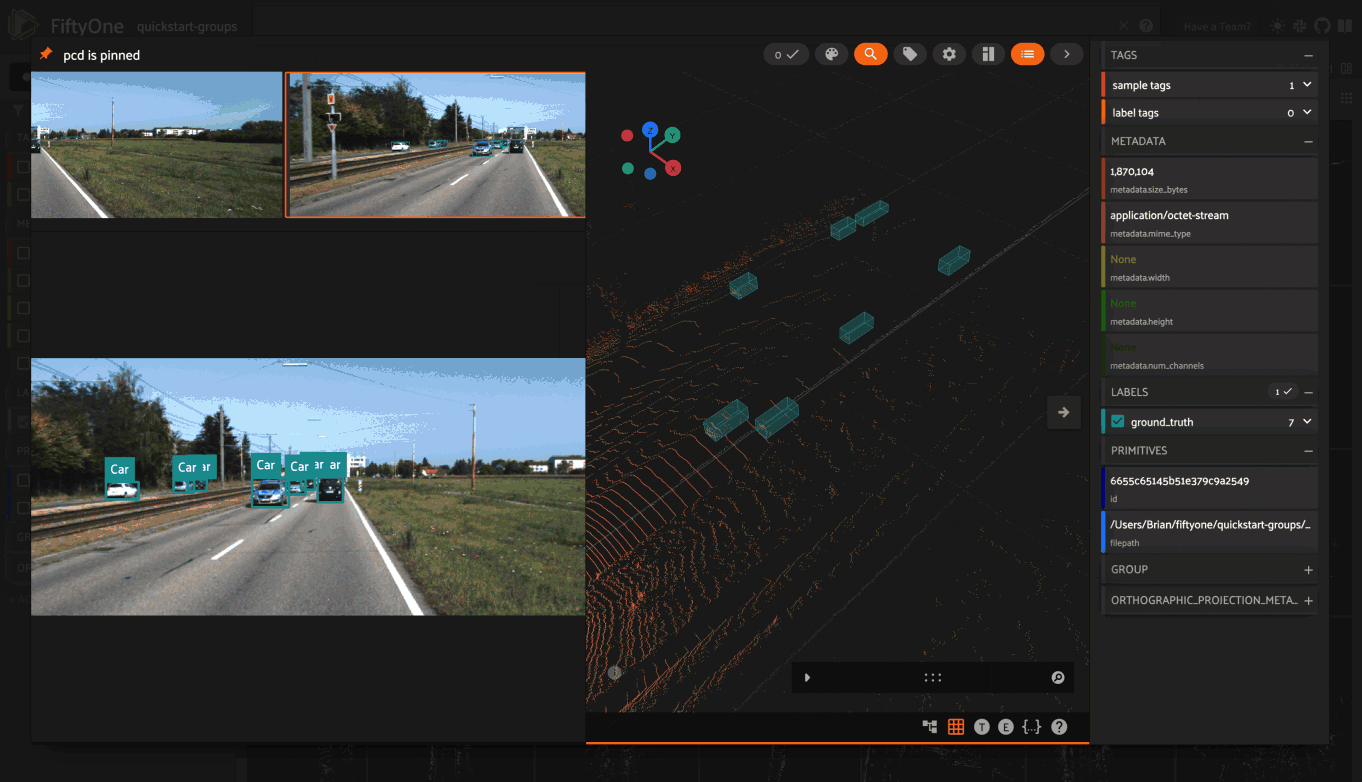
Point cloud datasets#
Warning
The point-cloud media type has been deprecated in favor of the
3D media type.
While we’ll keep supporting the point-cloud media type for backward
compatibility, we recommend using the 3d media type for new datasets.
To use a PCD file as a 3D sample in a new dataset, create it with
media_type="3d" explicitly.
Any Sample whose filepath is a
PCD file
with extension .pcd is recognized as a point cloud sample, and datasets
composed of point cloud samples have media type point-cloud:
1import fiftyone as fo
2
3sample = fo.Sample(filepath="/path/to/point-cloud.pcd")
4
5dataset = fo.Dataset()
6dataset.add_sample(sample)
7
8print(dataset.media_type) # point-cloud
9print(sample)
<Sample: {
'id': '6403ce64c8957c42bc8f9e67',
'media_type': 'point-cloud',
'filepath': '/path/to/point-cloud.pcd',
'tags': [],
'metadata': None,
'created_at': datetime.datetime(2024, 7, 22, 5, 16, 10, 701907),
'last_modified_at': datetime.datetime(2024, 7, 22, 5, 16, 10, 701907),
}>
Point cloud samples may contain any type and number of custom fields, including 3D detections and 3D polylines, which are natively visualizable by the App’s 3D visualizer.
Camera intrinsics and extrinsics#
FiftyOne provides support for storing and working with camera intrinsic and extrinsic parameters, which are essential for 3D computer vision tasks such as multi-sensor fusion, depth estimation, and 3D reconstruction.
Note
See storing camera calibration for information about storing intrinsics and extrinsics at the dataset level.
Camera intrinsics#
Camera intrinsics describe the internal parameters of a camera, including focal
length, principal point, and lens distortion. FiftyOne provides several
CameraIntrinsics subclasses for different camera models:
PinholeCameraIntrinsics: Simple pinhole camera model with no distortionOpenCVCameraIntrinsics: Brown-Conrady distortion model with radial and tangential coefficients (up to 8 parameters)OpenCVFisheyeCameraIntrinsics: Fisheye equidistant projection model
1import fiftyone as fo
2
3# Create OpenCV camera intrinsics with distortion
4intrinsics = fo.OpenCVCameraIntrinsics(
5 fx=1000.0, # focal length x (pixels)
6 fy=1000.0, # focal length y (pixels)
7 cx=960.0, # principal point x
8 cy=540.0, # principal point y
9 k1=-0.1, # radial distortion coefficient
10 k2=0.05, # radial distortion coefficient
11 p1=0.001, # tangential distortion coefficient
12 p2=-0.001, # tangential distortion coefficient
13)
14
15# Access the 3x3 intrinsic matrix
16K = intrinsics.intrinsic_matrix
17
18# Create intrinsics from a matrix
19import numpy as np
20
21K = np.array([
22 [1200.0, 0.0, 640.0],
23 [0.0, 1200.0, 480.0],
24 [0.0, 0.0, 1.0]
25])
26intrinsics = fo.PinholeCameraIntrinsics.from_matrix(K)
Sensor extrinsics#
The StaticTransform class represents a 6-DOF rigid transformation between
coordinate frames, defined by a translation vector and a rotation quaternion.
1import fiftyone as fo
2
3# Create a camera-to-ego transformation
4extrinsics = fo.StaticTransform(
5 translation=[1.5, 0.0, 1.2], # [tx, ty, tz]
6 quaternion=[0.0, 0.0, 0.0, 1.0], # [qx, qy, qz, qw] (scalar-last)
7 source_frame="camera_front",
8 target_frame="ego",
9)
10
11# Access the 4x4 transformation matrix
12T = extrinsics.transform_matrix
13
14# Get the 3x3 rotation matrix
15R = extrinsics.rotation_matrix
16
17# Compute the inverse transformation (ego -> camera_front)
18inv_extrinsics = extrinsics.inverse()
19
20# Compose transformations (A->B composed with B->C = A->C)
21camera_to_world = camera_to_ego.compose(ego_to_world)
You can also create extrinsics from a transformation matrix:
1import numpy as np
2import fiftyone as fo
3
4# 4x4 homogeneous transformation matrix
5T = np.eye(4)
6T[:3, 3] = [1.0, 2.0, 3.0] # translation
7
8extrinsics = fo.StaticTransform.from_matrix(
9 T,
10 source_frame="camera",
11 target_frame="world",
12)
Note
For low-level transformation utilities such as quaternion math, coordinate
system conversions (OpenCV, OpenGL, ROS, etc.), and matrix operations, see
the fiftyone.utils.transforms module.
Resolving calibration#
When working with samples, you can resolve camera calibration parameters using
the resolve_intrinsics()
and resolve_transformation()
methods. These methods implement a resolution chain that checks multiple
sources in order of precedence.
For intrinsics, the resolution order is:
Sample-level
CameraIntrinsicsfield (inline value)Sample-level
CameraIntrinsicsReffield (reference to dataset-level)Group slice name lookup in
dataset.camera_intrinsics(for grouped datasets)
For extrinsics, use the source_frame and target_frame parameters to
specify the desired transformation. The chain_via parameter enables
composing transformations through intermediate frames (e.g., camera → ego →
world).
Resolution precedence for extrinsics is:
Direct
source_frame -> target_framematchIf provided, explicit
chain_viapath onlyIf
chain_viais omitted andtarget_frame="world", automatic chaining through up to two intermediate frames
Automatic chaining only applies when a unique forward path exists. If no valid
path exists, or more than one valid path exists, no automatic chain is chosen
and resolution returns None. When deterministic path selection matters,
provide chain_via explicitly.
Note
For grouped datasets, the group slice name plays an important role in resolution:
Intrinsics: When resolving intrinsics, if no sample-level value is found, the current
dataset.group_slicename is used to look up the intrinsics indataset.camera_intrinsicsExtrinsics: When
source_frameis not specified, it is automatically inferred from the group slice name
This means you can store calibration keyed by slice name (e.g., "left",
"right") and resolution will automatically find the correct parameters
for the current slice.
The following example demonstrates a typical autonomous vehicle workflow with static sensor calibration stored at the dataset level and dynamic ego pose stored at the sample level:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart-groups")
5
6# Store static intrinsics (1080p parameters)
7dataset.camera_intrinsics = {
8 "left": fo.PinholeCameraIntrinsics(fx=1100, fy=1100, cx=960, cy=540),
9 "right": fo.PinholeCameraIntrinsics(fx=1100, fy=1100, cx=960, cy=540),
10}
11
12# Store static sensor mounting positions relative to vehicle center ("ego")
13dataset.static_transforms = {
14 "left::ego": fo.StaticTransform(
15 translation=[1.5, 0.5, 1.2],
16 quaternion=[0, 0, 0, 1],
17 source_frame="left",
18 target_frame="ego",
19 ),
20 "right::ego": fo.StaticTransform(
21 translation=[1.5, -0.5, 1.2],
22 quaternion=[0, 0, 0, 1],
23 source_frame="right",
24 target_frame="ego",
25 ),
26}
27dataset.save()
28
29# Focus on the left camera
30dataset.group_slice = "left"
31sample = dataset.first()
32
33# Store dynamic ego pose at sample level (vehicle location in the world)
34sample["ego_pose"] = fo.StaticTransform(
35 translation=[100.0, 50.0, 0.0],
36 quaternion=[0, 0, 0, 1],
37 source_frame="ego",
38 target_frame="world",
39)
40sample.save()
41
42# Resolve intrinsics (infers "left" from dataset.group_slice)
43intrinsics = dataset.resolve_intrinsics(sample)
44
45# Resolve full transform chain: left camera -> ego -> world
46extrinsics = dataset.resolve_transformation(
47 sample,
48 source_frame="left",
49 target_frame="world",
50 chain_via=["ego"],
51)
3D projection#
The CameraProjector class provides utilities for projecting points between 3D
world coordinates and 2D image coordinates.
1import fiftyone as fo
2
3# Using intrinsics and extrinsics resolved from the previous example
4projector = fo.CameraProjector(intrinsics, extrinsics)
5
6# Project a world point onto the image
7# A stop sign at world coordinates (110, 52, 2):
8# 10m in front of car, 2m left, 2m high
9world_point = [[110.0, 52.0, 2.0]]
10pixel = projector.project(world_point)
11
12print(pixel) # [[x, y]] image coordinates
You can also unproject 2D points back to 3D if you have depth information:
1import numpy as np
2import fiftyone as fo
3
4# Unproject pixel coordinates to 3D using known depth
5pixels = np.array([[960.0, 540.0]]) # image center
6depths = np.array([10.0]) # 10 meters away
7
8points_3d = projector.unproject(pixels, depths)
Generic datasets#
Any Sample whose filepath does not infer a known media type will be
assigned a media type of unknown. Adding these samples to a Dataset will
result in a generic dataset with a media type of unknown.
1import fiftyone as fo
2
3sample = fo.Sample(filepath="/path/to/file.json")
4
5dataset = fo.Dataset()
6dataset.add_sample(sample)
7
8print(dataset.media_type) # unknown
9print(sample)
<Sample: {
'id': '8414ce63c3410c42bc8f6a94',
'media_type': 'unknown',
'filepath': '/path/to/file.json',
'tags': [],
'metadata': None,
'created_at': datetime.datetime(2025, 3, 1, 2, 33, 11, 414002),
'last_modified_at': datetime.datetime(2025, 3, 1, 2, 33, 11, 414002),
}>
Custom datasets#
When a Sample is created, a custom value can be provided as the media_type
keyword argument. Adding the sample to a Dataset will result in a dataset
with media_type inherited from the sample. Custom media types can be used
to extend functionality for sample types that are not natively supported.
For App support in the grid or the modal, pair custom media types with custom sample renderers. This plugin feature lets you provide domain-specific rendering for custom media types whose samples may not be handled by FiftyOne’s built-in media renderers.
1import fiftyone as fo
2
3sample = fo.Sample(filepath="/path/to/file.aac", media_type="audio")
4
5dataset = fo.Dataset()
6dataset.add_sample(sample)
7
8print(dataset.media_type) # audio
9print(sample)
<Sample: {
'id': '6641fe61a3991e67aa1e5f49',
'media_type': 'audio',
'filepath': '/path/to/file.aac',
'tags': [],
'metadata': None,
'created_at': datetime.datetime(2025, 3, 1, 2, 34, 31, 776414),
'last_modified_at': datetime.datetime(2025, 3, 1, 2, 34, 31, 776414),
}>
DatasetViews#
Previous sections have demonstrated how to add and interact with Dataset
components like samples, fields, and labels. The true power of FiftyOne lies in
the ability to search, sort, filter, and explore the contents of a Dataset.
Behind this power is the DatasetView. Whenever an operation
like match() or
sort_by() is applied to a
dataset, a DatasetView is returned. As the name implies, a DatasetView
is a view into the data in your Dataset that was produced by a series of
operations that manipulated your data in different ways.
A DatasetView is composed of SampleView objects for a subset of the samples
in your dataset. For example, a view may contain only samples with a given tag,
or samples whose labels meet a certain criteria.
In turn, each SampleView represents a view into the content of the underlying
Sample in the dataset. For example, a SampleView may represent the contents
of a sample with Detections below a specified threshold filtered out.
1import fiftyone as fo
2import fiftyone.zoo as foz
3from fiftyone import ViewField as F
4
5dataset = foz.load_zoo_dataset("quickstart")
6dataset.compute_metadata()
7
8# Create a view containing the 5 samples from the validation split whose
9# images are >= 48 KB that have the most predictions with confidence > 0.9
10complex_view = (
11 dataset
12 .match_tags("validation")
13 .match(F("metadata.size_bytes") >= 48 * 1024) # >= 48 KB
14 .filter_labels("predictions", F("confidence") > 0.9)
15 .sort_by(F("predictions.detections").length(), reverse=True)
16 .limit(5)
17)
18
19# Check to see how many predictions there are in each matching sample
20print(complex_view.values(F("predictions.detections").length()))
21# [29, 20, 17, 15, 15]
Merging datasets#
The Dataset class provides a powerful
merge_samples() method
that you can use to merge the contents of another Dataset or DatasetView
into an existing dataset.
By default, samples with the same absolute filepath are merged, and top-level
fields from the provided samples are merged in, overwriting any existing values
for those fields, with the exception of list fields (e.g.,
tags) and label list fields (e.g.,
Detections), in which case the elements of the lists
themselves are merged. In the case of label list fields, labels with the same
id in both collections are updated rather than duplicated.
The merge_samples()
method can be configured in numerous ways, including:
Which field to use as a merge key, or an arbitrary function defining the merge key
Whether existing samples should be modified or skipped
Whether new samples should be added or omitted
Whether new fields can be added to the dataset schema
Whether list fields should be treated as ordinary fields and merged as a whole rather than merging their elements
Whether to merge only specific fields, or all but certain fields
Mapping input fields to different field names of this dataset
For example, the following snippet demonstrates merging a new field into an existing dataset:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset1 = foz.load_zoo_dataset("quickstart")
5
6# Create a dataset containing only ground truth objects
7dataset2 = dataset1.select_fields("ground_truth").clone()
8
9# Create a view containing only the predictions
10predictions_view = dataset1.select_fields("predictions")
11
12# Merge the predictions
13dataset2.merge_samples(predictions_view)
14
15print(dataset1.count("ground_truth.detections")) # 1232
16print(dataset2.count("ground_truth.detections")) # 1232
17
18print(dataset1.count("predictions.detections")) # 5620
19print(dataset2.count("predictions.detections")) # 5620
Note that the argument to
merge_samples() can be a
DatasetView, which means that you can perform possibly-complex
transformations to the source dataset to select the
desired content to merge.
Consider the following variation of the above snippet, which demonstrates a
workflow where Detections from another dataset are merged into a dataset with
existing Detections in the same field:
1from fiftyone import ViewField as F
2
3# Create a new dataset that only contains predictions with confidence >= 0.9
4dataset3 = (
5 dataset1
6 .select_fields("predictions")
7 .filter_labels("predictions", F("confidence") > 0.9)
8).clone()
9
10# Create a view that contains only the remaining predictions
11low_conf_view = dataset1.filter_labels("predictions", F("confidence") < 0.9)
12
13# Merge the low confidence predictions back in
14dataset3.merge_samples(low_conf_view, fields="predictions")
15
16print(dataset1.count("predictions.detections")) # 5620
17print(dataset3.count("predictions.detections")) # 5620
Finally, the example below demonstrates the use of a custom merge key to define which samples to merge:
1import os
2
3# Create a dataset with 100 samples of ground truth labels
4dataset4 = dataset1[50:150].select_fields("ground_truth").clone()
5
6# Create a view with 50 overlapping samples of predictions
7predictions_view = dataset1[:100].select_fields("predictions")
8
9# Merge predictions into dataset, using base filename as merge key and
10# never inserting new samples
11dataset4.merge_samples(
12 predictions_view,
13 key_fcn=lambda sample: os.path.basename(sample.filepath),
14 insert_new=False,
15)
16
17print(len(dataset4)) # 100
18print(len(dataset4.exists("predictions"))) # 50
Note
Did you know? You can use
merge_dir() to directly
merge the contents of a dataset on disk into an existing FiftyOne
dataset without first loading it into a
temporary dataset and then using
merge_samples() to
perform the merge.
Cloning datasets#
You can use clone() to create a
copy of a dataset:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5
6dataset2 = dataset.clone()
7dataset2.add_sample_field("new_field", fo.StringField)
8
9# The source dataset is unaffected
10assert "new_field" not in dataset.get_field_schema()
Dataset clones contain deep copies of all samples and dataset-level metadata such as runs, saved views, and workspaces from the source dataset. The source media files, however, are not copied.
Note
Did you know? You can also clone specific subsets of your datasets.
By default, cloned datasets also retain all
custom indexes that you’ve created on
the source collection, but you can control this by passing the optional
include_indexes parameter to
clone():
1dataset.create_index("ground_truth.detections.label")
2
3# Do not retain custom indexes on the cloned dataset
4dataset2 = dataset.clone(include_indexes=False)
5
6# Only include specific custom indexes
7dataset2 = dataset.clone(include_indexes=["ground_truth.detections.label"])
Batch updates#
You are always free to perform any necessary modifications to a Dataset by
iterating over it via a Python loop and explicitly
performing the edits that you require.
However, the Dataset class provides a number of methods that allow you to
efficiently perform various common batch actions to your entire dataset.
Cloning, renaming, clearing, and deleting fields#
You can use the
clone_sample_field(),
rename_sample_field(),
clear_sample_field(),
and
delete_sample_field()
methods to efficiently perform common actions on the sample fields of a
Dataset:
1import fiftyone as fo
2import fiftyone.zoo as foz
3from fiftyone import ViewField as F
4
5dataset = foz.load_zoo_dataset("quickstart")
6
7# Clone an existing field
8dataset.clone_sample_field("predictions", "also_predictions")
9print("also_predictions" in dataset.get_field_schema()) # True
10
11# Rename a field
12dataset.rename_sample_field("also_predictions", "still_predictions")
13print("still_predictions" in dataset.get_field_schema()) # True
14
15# Clear a field (sets all values to None)
16dataset.clear_sample_field("still_predictions")
17print(dataset.count_values("still_predictions")) # {None: 200}
18
19# Delete a field
20dataset.delete_sample_field("still_predictions")
You can also use dot notation to manipulate the fields or subfields of embedded documents in your dataset:
1sample = dataset.first()
2
3# Clone an existing embedded field
4dataset.clone_sample_field(
5 "predictions.detections.label",
6 "predictions.detections.also_label",
7)
8print(sample.predictions.detections[0]["also_label"]) # "bird"
9
10# Rename an embedded field
11dataset.rename_sample_field(
12 "predictions.detections.also_label",
13 "predictions.detections.still_label",
14)
15print(sample.predictions.detections[0]["still_label"]) # "bird"
16
17# Clear an embedded field (sets all values to None)
18dataset.clear_sample_field("predictions.detections.still_label")
19print(sample.predictions.detections[0]["still_label"]) # None
20
21# Delete an embedded field
22dataset.delete_sample_field("predictions.detections.still_label")
Save contexts#
You are always free to perform arbitrary edits to a Dataset by iterating over
its contents and editing the samples directly:
1import random
2
3import fiftyone as fo
4import fiftyone.zoo as foz
5from fiftyone import ViewField as F
6
7dataset = foz.load_zoo_dataset("quickstart")
8
9# Populate a new field on each sample in the dataset
10for sample in dataset:
11 sample["random"] = random.random()
12 sample.save()
13
14print(dataset.count("random")) # 200
15print(dataset.bounds("random")) # (0.0007, 0.9987)
However, the above pattern can be inefficient for large datasets because each
sample.save() call makes a new
connection to the database.
The iter_samples() method
provides an autosave=True option that causes all changes to samples
emitted by the iterator to be automatically saved using an efficient batch
update strategy:
1# Automatically saves sample edits in efficient batches
2for sample in dataset.select_fields().iter_samples(autosave=True):
3 sample["random"] = random.random()
Note
As the above snippet shows, you should also optimize your iteration by selecting only the required fields.
You can configure the default batching strategy that is used via your
FiftyOne config, or you can configure the
batching strategy on a per-method call basis by passing the optional
batch_size and batching_strategy arguments to
iter_samples().
You can also use the
save_context()
method to perform batched edits using the pattern below:
1# Use a context to save sample edits in efficient batches
2with dataset.save_context() as context:
3 for sample in dataset.select_fields():
4 sample["random"] = random.random()
5 context.save(sample)
The benefit of the above approach versus passing autosave=True to
iter_samples() is that
context.save() allows you
to be explicit about which samples you are editing, which avoids unnecessary
computations if your loop only edits certain samples.
Updating samples#
The
update_samples()
method provides an efficient interface for applying a function to each sample
in a collection and saving the sample edits:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("cifar10", split="train")
5view = dataset.select_fields("ground_truth")
6
7def update_fcn(sample):
8 sample.ground_truth.label = sample.ground_truth.label.upper()
9
10view.update_samples(update_fcn)
11print(dataset.count_values("ground_truth.label"))
12# {'DEER': 5000, 'HORSE': 5000, 'AIRPLANE': 5000, ..., 'DOG': 5000}
Note
As the above snippet shows, you should optimize your iteration by selecting only the required fields.
By default,
update_samples()
leverages a multiprocessing pool to parallelize the work across a number of
workers, resulting in significant performance improvements over the equivalent
iter_samples(autosave=True)
syntax:
1for sample in view.iter_samples(autosave=True, progress=True):
2 update_fcn(sample)
Keep the following points in mind while using
update_samples():
The samples are not processed in any particular order
Your
update_fcnshould not modify global state or variables defined outside of the function
You can configure the number of workers that
update_samples()
uses in a variety of ways:
Configure the default number of workers used by all
update_samples()calls by setting thedefault_process_pool_workersvalue in your FiftyOne configManually configure the number of workers for a particular
update_samples()call by passing thenum_workersparameterIf neither of the above settings are applied,
update_samples()will userecommend_process_pool_workers()to choose a number of worker processes, unless the method is called in a daemon process (subprocess), in which case no workers are used
Note
You can set default_process_pool_workers<=1 or num_workers<=1 to
disable the use of multiprocessing pools in
update_samples().
By default,
update_samples()
evenly distributes samples to all workers in a single batch per worker.
However, you can pass the batch_size parameter to customize the number of
samples sent to each worker at a time:
1view.update_samples(update_fcn, batch_size=50, num_workers=4)
You can also pass progress="workers" to
update_samples()
to render progress bar(s) for each worker:
1view.update_samples(update_fcn, num_workers=16, progress="workers")
Batch 01/16: 100%|█████████████████████████████████████████████████| 3125/3125 [899.01it/s]
Batch 02/16: 100%|█████████████████████████████████████████████████| 3125/3125 [894.90it/s]
Batch 03/16: 100%|█████████████████████████████████████████████████| 3125/3125 [900.14it/s]
Batch 04/16: 100%|█████████████████████████████████████████████████| 3125/3125 [895.61it/s]
Batch 05/16: 100%|█████████████████████████████████████████████████| 3125/3125 [903.09it/s]
Batch 06/16: 100%|█████████████████████████████████████████████████| 3125/3125 [895.33it/s]
Batch 07/16: 100%|█████████████████████████████████████████████████| 3125/3125 [893.26it/s]
Batch 08/16: 100%|█████████████████████████████████████████████████| 3125/3125 [889.17it/s]
Batch 09/16: 100%|█████████████████████████████████████████████████| 3125/3125 [888.16it/s]
Batch 10/16: 100%|█████████████████████████████████████████████████| 3125/3125 [893.69it/s]
Batch 11/16: 100%|█████████████████████████████████████████████████| 3125/3125 [896.80it/s]
Batch 12/16: 100%|█████████████████████████████████████████████████| 3125/3125 [903.28it/s]
Batch 13/16: 100%|█████████████████████████████████████████████████| 3125/3125 [893.63it/s]
Batch 14/16: 100%|█████████████████████████████████████████████████| 3125/3125 [891.26it/s]
Batch 15/16: 100%|█████████████████████████████████████████████████| 3125/3125 [905.06it/s]
Batch 16/16: 100%|█████████████████████████████████████████████████| 3125/3125 [911.72it/s]
Map operations#
The
map_samples()
method provides a powerful and efficient interface for iterating over samples,
applying a function to each sample, and returning the results as a generator.
1from collections import Counter
2
3import fiftyone as fo
4import fiftyone.zoo as foz
5
6dataset = foz.load_zoo_dataset("cifar10", split="train")
7view = dataset.select_fields("ground_truth")
8
9def map_fcn(sample):
10 return sample.ground_truth.label.upper()
11
12counter = Counter()
13for _, label in view.map_samples(map_fcn):
14 counter[label] += 1
15
16print(dict(counter))
17# {'DEER': 5000, 'HORSE': 5000, 'AIRPLANE': 5000, ..., 'DOG': 5000}
Note
As the above snippet shows, you should optimize your iteration by selecting only the required fields.
By default,
map_samples()
leverages a multiprocessing pool to parallelize the work across a number of
workers, resulting in significant performance improvements over the equivalent
iter_samples() syntax:
1counter = Counter()
2for sample in view.iter_samples(progress=True):
3 label = map_fcn(sample)
4 counter[label] += 1
Keep the following points in mind while using
map_samples():
The samples are not processed in any particular order
Your
map_fcnshould not modify global state or variables defined outside of the functionIf your
map_fcnmodifies samples in-place, you must passsave=Trueto save these edits
Note
Your map_fcn cannot return Sample objects directly. If you are
tempted to do this, then chances are good that you can express the
operation more efficiently and idiomatically via
dataset views.
You can configure the number of workers that
map_samples()
uses in a variety of ways:
Configure the default number of workers used by all
map_samples()calls by setting thedefault_process_pool_workersvalue in your FiftyOne configManually configure the number of workers for a particular
map_samples()call by passing thenum_workersparameterIf neither of the above settings are applied,
map_samples()will userecommend_process_pool_workers()to choose a number of worker processes, unless the method is called in a daemon process (subprocess), in which case no workers are used
Note
You can set default_process_pool_workers<=1 or num_workers<=1 to
disable the use of multiprocessing pools in
map_samples().
By default,
map_samples()
evenly distributes samples to all workers in a single shard per worker.
However, you can pass the batch_size parameter to customize the number of
samples sent to each worker at a time:
1counter = Counter()
2for _, label in view.map_samples(map_fcn, batch_size=50, num_workers=4):
3 counter[label] += 1
You can also pass progress="workers" to
map_samples()
to render progress bar(s) for each worker:
1counter = Counter()
2for _, label in view.map_samples(map_fcn, num_workers=16, progress="workers"):
3 counter[label] += 1
Batch 01/16: 100%|█████████████████████████████████████████████████| 3125/3125 [899.01it/s]
Batch 02/16: 100%|█████████████████████████████████████████████████| 3125/3125 [894.90it/s]
Batch 03/16: 100%|█████████████████████████████████████████████████| 3125/3125 [900.14it/s]
Batch 04/16: 100%|█████████████████████████████████████████████████| 3125/3125 [895.61it/s]
Batch 05/16: 100%|█████████████████████████████████████████████████| 3125/3125 [903.09it/s]
Batch 06/16: 100%|█████████████████████████████████████████████████| 3125/3125 [895.33it/s]
Batch 07/16: 100%|█████████████████████████████████████████████████| 3125/3125 [893.26it/s]
Batch 08/16: 100%|█████████████████████████████████████████████████| 3125/3125 [889.17it/s]
Batch 09/16: 100%|█████████████████████████████████████████████████| 3125/3125 [888.16it/s]
Batch 10/16: 100%|█████████████████████████████████████████████████| 3125/3125 [893.69it/s]
Batch 11/16: 100%|█████████████████████████████████████████████████| 3125/3125 [896.80it/s]
Batch 12/16: 100%|█████████████████████████████████████████████████| 3125/3125 [903.28it/s]
Batch 13/16: 100%|█████████████████████████████████████████████████| 3125/3125 [893.63it/s]
Batch 14/16: 100%|█████████████████████████████████████████████████| 3125/3125 [891.26it/s]
Batch 15/16: 100%|█████████████████████████████████████████████████| 3125/3125 [905.06it/s]
Batch 16/16: 100%|█████████████████████████████████████████████████| 3125/3125 [911.72it/s]
Setting values#
Another strategy for performing efficient batch edits is to use
set_values() to
set a field (or embedded field) on each sample in the dataset in a single
batch operation:
1import random
2
3import fiftyone as fo
4import fiftyone.zoo as foz
5from fiftyone import ViewField as F
6
7dataset = foz.load_zoo_dataset("quickstart")
8
9# Two ways to populate a `random` field on each sample in the dataset
10
11# Dict syntax (recommended): provide a dict mapping sample IDs to values
12values = {id: random.random() for id in dataset.values("id")}
13dataset.set_values("random", values, key_field="id")
14
15print(dataset.bounds("random"))
16# (0.0028, 0.9925)
17
18# List syntax: provide one value for each sample in the dataset
19values = [random.random() for _ in range(len(dataset))]
20dataset.set_values("random", values)
21
22print(dataset.bounds("random"))
23# (0.0055, 0.9996)
When applicable, using
set_values()
is more efficient than performing the equivalent operation via an explicit
iteration over the Dataset because it avoids the need to read Sample
instances into memory and sequentially save them.
As demonstrated above, you can use
set_values()
in two ways:
Dict syntax (recommended): provide values as a dict whose keys specify the
key_fieldvalues of the samples whose field you want to set to the corresponding valuesList syntax: provide values as a list, one for each sample in the collection on which you are invoking this method
Note
The most performant strategy for setting large numbers of field values is
to use the dict syntax with key_field="id" when setting sample fields
and key_field="frames.id" when setting frame fields. All other syntaxes
internally convert to these IDs before ultimately performing the updates.
You can also use
set_values() to
optimize more complex operations, such as editing attributes of specific
object detections in a nested list.
Consider the following loop, which adds a tag to all low confidence predictions in a field:
1# Add a tag to all low confidence predictions in the dataset
2for sample in dataset:
3 for detection in sample["predictions"].detections:
4 if detection.confidence < 0.06:
5 detection.tags.append("low_confidence")
6
7 sample.save()
8
9print(dataset.count_label_tags())
10# {'low_confidence': 447}
An equivalent but more efficient approach is to use
values() to
extract the slice of data you wish to modify and then use
set_values() to
save the updated data in a single batch operation:
1# Remove the tags we added in the previous variation
2dataset.untag_labels("low_confidence")
3
4# Load the tags for all low confidence detections
5view = dataset.filter_labels("predictions", F("confidence") < 0.06)
6tags = view.values("predictions.detections.tags")
7
8# Add the 'low_confidence' tag to each detection's tags list
9for sample_tags in tags:
10 for detection_tags in sample_tags:
11 detection_tags.append("low_confidence")
12
13# Save the updated tags
14view.set_values("predictions.detections.tags", tags)
15
16print(dataset.count_label_tags())
17# {'low_confidence': 447}
You can also use
set_values() to
perform batch updates to frame-level fields:
1import random
2
3import fiftyone as fo
4import fiftyone.zoo as foz
5
6dataset = foz.load_zoo_dataset("quickstart-video")
7
8# Dict syntax (recommended): provide a dict mapping frame IDs to values
9frame_ids = dataset.values("frames.id", unwind=True)
10values = {id: random.random() for id in frame_ids}
11
12dataset.set_values("frames.random", values, key_field="frames.id")
13print(dataset.bounds("frames.random"))
14# (0.00013, 0.9993)
15
16# List syntax: provide lists of lists of values, each list containing a
17# value for each frame in that sample of the dataset
18values = []
19for sample in dataset:
20 values.append([random.random() for _ in sample.frames])
21
22dataset.set_values("frames.random", values)
23print(dataset.bounds("frames.random"))
24# (0.00055, 0.9995)
Setting label values#
Often when working with Label fields, the edits you want to make may be
naturally represented as a mapping between label IDs and corresponding
attribute values to set on each Label instance. In such cases, you can use
set_label_values()
to efficiently perform the updates:
1import fiftyone as fo
2import fiftyone.zoo as foz
3from fiftyone import ViewField as F
4
5dataset = foz.load_zoo_dataset("quickstart")
6
7# Grab some labels
8view = dataset.limit(5).filter_labels("predictions", F("confidence") > 0.5)
9
10# Two ways to populate a `random` attribute on each label
11
12# List syntax (recommended): provide sample IDs and label IDs
13values = []
14for sid, lids in zip(*view.values(["id", "predictions.detections.id"])):
15 for lid in lids:
16 values.append({"sample_id": sid, "label_id": lid, "value": True})
17
18dataset.set_label_values("predictions.detections.random", values)
19
20print(dataset.count_values("predictions.detections.random"))
21# {True: 25, None: 5595}
22
23# Dict syntax: provide only label IDs
24label_ids = view.values("predictions.detections.id", unwind=True)
25values = {_id: True for _id in label_ids}
26dataset.set_label_values("predictions.detections.random", values)
27
28print(dataset.count_values("predictions.detections.random"))
29# {True: 25, None: 5595}
As demonstrated above, you can use
set_label_values()
in two ways:
List syntax (recommended): provide a list of dicts of the form
{"sample_id": sample_id, "label_id": label_id, "value": value}specifying the sample IDs and label IDs of each label you want to editDict syntax: provide a dict mapping label IDs to values
Note
set_label_values()
is most efficient when you use the list syntax for values that includes
the sample/frame ID of each label that you are modifying.