|
|
|
|
Evaluating a Classifier with FiftyOne#
This notebook demonstrates an end-to-end example of fine-tuning a classification model using fastai on a Kaggle dataset and using FiftyOne to evaluate it and understand the strengths and weaknesses of both the model and the underlying ground truth annotations.
Specifically, we’ll cover:
Downloading the dataset via the Kaggle API
Loading the dataset into FiftyOne
Indexing the dataset by uniqueness using FiftyOne’s uniqueness method to identify interesting visual characteristics
Fine-tuning a model on the dataset using fastai
Evaluating the fine-tuned model using FiftyOne
Exporting the FiftyOne dataset for offline analysis
So, what’s the takeaway?
The loss function of your model training loop alone doesn’t give you the full picture of a model. In practice, the limiting factor on your model’s performance is often data quality issues that FiftyOne can help you address. In this notebook, we’ll cover:
Viewing the most unique incorrect samples using FiftyOne’s uniqueness method
Viewing the hardest incorrect predictions using FiftyOne’s hardness method
Identifying ground truth mistakes using FiftyOne’s mistakenness method
Running the workflow presented here on your ML projects will help you to understand the current failure modes (edge cases) of your model and how to fix them, including:
Identifying scenarios that require additional training samples in order to boost your model’s performance
Deciding whether your ground truth annotations have errors/weaknesses that need to be corrected before any subsequent model training will be profitable
Setup#
If you haven’t already, install FiftyOne:
[ ]:
!pip install fiftyone
We’ll also need torch and torchvision installed:
[1]:
!pip install torch torchvision
Download dataset#
Let’s start by downloading the Malaria Cell Images Dataset from Kaggle using the Kaggle API:
[ ]:
!pip install --upgrade kaggle
[4]:
%%bash
# You can create an account for free and get an API token as follows:
# kaggle.com > account > API > Create new API token
export KAGGLE_USERNAME=XXXXXXXXXXXXXXXX
export KAGGLE_KEY=XXXXXXXXXXXXXXXX
kaggle datasets download -d iarunava/cell-images-for-detecting-malaria
Downloading cell-images-for-detecting-malaria.zip
100%|██████████| 675M/675M [00:23<00:00, 30.7MB/s]
[5]:
%%bash
unzip -q cell-images-for-detecting-malaria.zip
rm -rf cell_images/cell_images
rm cell_images/Parasitized/Thumbs.db
rm cell_images/Uninfected/Thumbs.db
rm cell-images-for-detecting-malaria.zip
The unzipped dataset consists of a cell_images/ folder with two subdirectories—Uninfected and Parasitized—that each contain 13782 example images of the respective class of this binary classification task:
[6]:
%%bash
ls -lah cell_images/Uninfected | head
ls -lah cell_images/Parasitized | head
printf "\nClass counts\n"
ls -lah cell_images/Uninfected | wc -l
ls -lah cell_images/Parasitized | wc -l
total 354848
drwxr-xr-x 13781 voxel51 staff 431K Feb 18 08:56 .
drwxr-xr-x 4 voxel51 staff 128B Feb 18 08:56 ..
-rw-r--r-- 1 voxel51 staff 11K Oct 14 2019 C100P61ThinF_IMG_20150918_144104_cell_128.png
-rw-r--r-- 1 voxel51 staff 11K Oct 14 2019 C100P61ThinF_IMG_20150918_144104_cell_131.png
-rw-r--r-- 1 voxel51 staff 9.7K Oct 14 2019 C100P61ThinF_IMG_20150918_144104_cell_144.png
-rw-r--r-- 1 voxel51 staff 5.8K Oct 14 2019 C100P61ThinF_IMG_20150918_144104_cell_21.png
-rw-r--r-- 1 voxel51 staff 9.4K Oct 14 2019 C100P61ThinF_IMG_20150918_144104_cell_25.png
-rw-r--r-- 1 voxel51 staff 7.5K Oct 14 2019 C100P61ThinF_IMG_20150918_144104_cell_34.png
-rw-r--r-- 1 voxel51 staff 10K Oct 14 2019 C100P61ThinF_IMG_20150918_144104_cell_48.png
total 404008
drwxr-xr-x 13781 voxel51 staff 431K Feb 18 08:56 .
drwxr-xr-x 4 voxel51 staff 128B Feb 18 08:56 ..
-rw-r--r-- 1 voxel51 staff 14K Oct 14 2019 C100P61ThinF_IMG_20150918_144104_cell_162.png
-rw-r--r-- 1 voxel51 staff 18K Oct 14 2019 C100P61ThinF_IMG_20150918_144104_cell_163.png
-rw-r--r-- 1 voxel51 staff 13K Oct 14 2019 C100P61ThinF_IMG_20150918_144104_cell_164.png
-rw-r--r-- 1 voxel51 staff 13K Oct 14 2019 C100P61ThinF_IMG_20150918_144104_cell_165.png
-rw-r--r-- 1 voxel51 staff 11K Oct 14 2019 C100P61ThinF_IMG_20150918_144104_cell_166.png
-rw-r--r-- 1 voxel51 staff 14K Oct 14 2019 C100P61ThinF_IMG_20150918_144104_cell_167.png
-rw-r--r-- 1 voxel51 staff 11K Oct 14 2019 C100P61ThinF_IMG_20150918_144104_cell_168.png
Class counts
13782
13782
Load dataset into FiftyOne#
Let’s load the dataset into FiftyOne and explore it!
[ ]:
import os
import fiftyone as fo
DATASET_DIR = os.path.join(os.getcwd(),"cell_images/")
Create FiftyOne dataset#
FiftyOne provides builtin support for loading datasets in dozens of common formats with a single line of code:
[ ]:
# Create FiftyOne dataset
dataset = fo.Dataset.from_dir(
DATASET_DIR,
fo.types.ImageClassificationDirectoryTree,
name="malaria-cell-images",
)
dataset.persistent = True
print(dataset)
100% |███| 27558/27558 [35.8s elapsed, 0s remaining, 765.8 samples/s]
Name: malaria-cell-images
Media type: image
Num samples: 27558
Persistent: True
Info: {'classes': ['Parasitized', 'Uninfected']}
Tags: []
Sample fields:
filepath: fiftyone.core.fields.StringField
tags: fiftyone.core.fields.ListField(fiftyone.core.fields.StringField)
metadata: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.metadata.Metadata)
ground_truth: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Classification)
(Future use) Load an existing FiftyOne dataset#
Now that the data is loaded into FiftyOne, you can easily work with the same dataset in a future session on the same machine by loading it by name:
[ ]:
# Load existing dataset
dataset = fo.load_dataset("malaria-cell-images")
print(dataset)
Index the dataset by visual uniqueness#
Let’s start by indexing the dataset by visual uniqueness using FiftyOne’s image uniqueness method.
This method adds a scalar uniqueness field to each sample that measures the relative visual uniqueness of each sample compared to the other samples in the dataset.
[ ]:
import fiftyone.brain as fob
fob.compute_uniqueness(dataset)
Loading uniqueness model...
Downloading model from Google Drive ID '1SIO9XreK0w1ja4EuhBWcR10CnWxCOsom'...
100% |████| 100.6Mb/100.6Mb [135.7ms elapsed, 0s remaining, 741.3Mb/s]
Preparing data...
Generating embeddings...
100% |███| 27558/27558 [39.6s elapsed, 0s remaining, 618.6 samples/s]
Computing uniqueness...
Saving results...
100% |███| 27558/27558 [42.9s elapsed, 0s remaining, 681.0 samples/s]
Uniqueness computation complete
Visualize dataset in the App#
Now let’s launch the FiftyOne App and use it to interactively explore the dataset.
For example, try using the view bar to sort the samples so that we can view the most visually unique samples in the dataset:
[2]:
# Most of the MOST UNIQUE samples are parasitized
session = fo.launch_app(dataset)

Now let’s add a Limit(500) stage in the view bar and open the Labels tab to view some statistics about the 500 most unique samples in the dataset.
Notice that a vast majority of the most visually unique samples in the dataset are Parasitized, which makes sense because these are the infected, abnormal cells.
[6]:
session.show()

Conversely, if we use the view bar to show the 500 least visually unique samples, we find that 499 of them are Uninfected!
[7]:
# All of the LEAST UNIQUE samples are uninfected
session.show()

[8]:
session.show()

Training a model#
Now that we have some basic intuition about the dataset, let’s train a model!
In this example, we’ll use fastai to fine-tune a pre-trained model on our dataset in just a few lines of code and a few minutes of GPU time.
[ ]:
!pip install --upgrade fastai
[ ]:
import numpy as np
from fastai.data.all import *
from fastai.vision.data import *
from fastai.vision.all import *
The code sample below loads the dataset into a fastai data loader:
[ ]:
# Load dataset into fastai
path = Path(DATASET_DIR)
splitter = RandomSplitter(valid_pct=0.2)
item_tfms = [Resize(224)]
batch_tfms = [
*aug_transforms(flip_vert=True, max_zoom=1.2, max_warp=0),
Normalize.from_stats(*imagenet_stats),
]
data_block = DataBlock(
blocks=[ImageBlock, CategoryBlock],
get_items=get_image_files,
get_y=parent_label,
splitter=splitter,
item_tfms=item_tfms,
batch_tfms=batch_tfms,
)
data = data_block.dataloaders(path, bs=64)
data.show_batch()
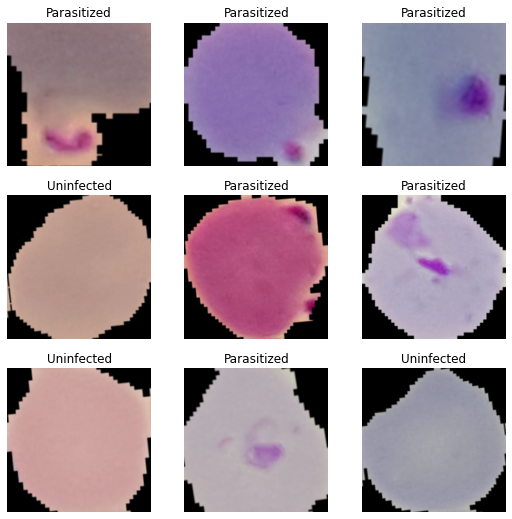
Now let’s load a pre-trained xresnet34 model:
[ ]:
# Load a pre-trained model
learner = cnn_learner(data, xresnet34, metrics=[accuracy]).to_fp16()
and fine-tune it for 15 epochs on our dataset:
[ ]:
# Fine-tune model on our dataset
learner.fine_tune(15)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.346846 | 0.330612 | 0.878606 | 01:27 |
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.242244 | 0.199095 | 0.928325 | 01:43 |
| 1 | 0.215641 | 0.166363 | 0.943205 | 01:42 |
| 2 | 0.196613 | 0.149990 | 0.946834 | 01:43 |
| 3 | 0.185642 | 0.135028 | 0.952822 | 01:42 |
| 4 | 0.156264 | 0.128932 | 0.953366 | 01:43 |
| 5 | 0.157303 | 0.127865 | 0.955181 | 01:42 |
| 6 | 0.153651 | 0.117362 | 0.957177 | 01:42 |
| 7 | 0.150719 | 0.120508 | 0.956088 | 01:42 |
| 8 | 0.137772 | 0.114590 | 0.955181 | 01:42 |
| 9 | 0.131181 | 0.113628 | 0.956632 | 01:42 |
| 10 | 0.130191 | 0.107792 | 0.961894 | 01:42 |
| 11 | 0.132632 | 0.111199 | 0.959898 | 01:42 |
| 12 | 0.119349 | 0.106245 | 0.962257 | 01:43 |
| 13 | 0.125340 | 0.106004 | 0.961169 | 01:42 |
| 14 | 0.121119 | 0.106404 | 0.962257 | 01:42 |
In this case, we reached 96.2% validation accuracy in about 25 minutes!
Let’s preview some sample predictions using fastai:
[ ]:
learner.show_results()
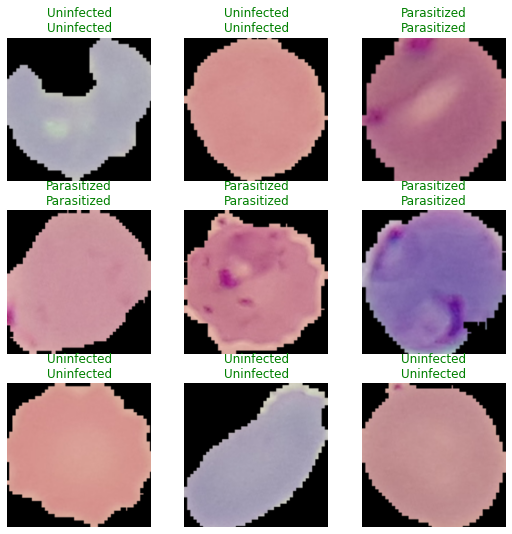
Save model checkpoint#
Let’s save a checkpoint of our model so we can load it later.
[ ]:
# Save model checkpoint
learner.save("xresnet34-malaria")
Path('models/xresnet34-malaria.pth')
If you’re working in a Colab notebook and would like to download your model, you can do so as follows:
[ ]:
# (Colab only) Download model to your machine
from google.colab import files
files.download("models/xresnet34-malaria.pth")
(Future use) Load saved model#
Run this block if you would like to load a model that your previously trained and exported as a checkpoint.
For Colab users, run this first block to upload the checkpoint from your local machine:
[ ]:
# (Colab only) Upload model from your machine
from google.colab import files
uploaded = files.upload()
for filename in uploaded.keys():
print("Uploaded '%s'" % filename)
fastai expects the model to be in a models/ directory, so let’s move it:
[ ]:
%%bash
mkdir -p models/
mv xresnet34-malaria.pth models/
Now we can load the saved model:
[ ]:
# Loads `models/xresnet34-malaria.pth` generated by `.save()`
learner = cnn_learner(data, xresnet34, metrics=[accuracy]).to_fp16()
learner.load("xresnet34-malaria")
Evaluating model with FiftyOne#
While 96% accuracy sounds great, aggregate evaluation metrics are not enough to get a full understanding of the performance of a model and what needs to be done to further improve it.
Add predictions to FiftyOne dataset#
Let’s add our model’s predictions to our FiftyOne dataset so we can evaluate it in more detail:
[ ]:
from fiftyone import ViewField as F
def do_inference(learner, dl, dataset, classes, tag):
# Perform inference
preds, _ = learner.get_preds(ds_idx=dl.split_idx)
preds = preds.numpy()
# Save predictions to FiftyOne dataset
with fo.ProgressBar() as pb:
for filepath, scores in zip(pb(dl.items), preds):
sample = dataset[str(filepath)]
target = np.argmax(scores)
sample.tags = [tag]
sample["predictions"] = fo.Classification(
label=classes[target],
confidence=scores[target],
logits=np.log(scores),
)
sample.save()
classes = list(data.vocab)
# Run inference on train split
do_inference(learner, data.train, dataset, classes, "train")
# Run inference on validation split
do_inference(learner, data.valid, dataset, classes, "validation")
100% |███| 22047/22047 [1.1m elapsed, 0s remaining, 324.2 samples/s]
The predictions are stored in a predictions field of our dataset:
[ ]:
print(dataset)
Name: malaria-cell-images
Media type: image
Num samples: 27558
Persistent: True
Info: {'classes': ['Parasitized', 'Uninfected']}
Tags: ['train', 'validation']
Sample fields:
filepath: fiftyone.core.fields.StringField
tags: fiftyone.core.fields.ListField(fiftyone.core.fields.StringField)
metadata: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.metadata.Metadata)
ground_truth: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Classification)
uniqueness: fiftyone.core.fields.FloatField
predictions: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Classification)
We’ve added predictions for both the train split:
[ ]:
print(dataset.match_tags("train").first())
<SampleView: {
'id': '601acd101a0300d4addd48cd',
'media_type': 'image',
'filepath': '/content/cell_images/Parasitized/C100P61ThinF_IMG_20150918_144104_cell_162.png',
'tags': BaseList(['train']),
'metadata': None,
'ground_truth': <Classification: {
'id': '601acd101a0300d4addd48cc',
'label': 'Parasitized',
'confidence': None,
'logits': None,
}>,
'uniqueness': 0.43538014682836707,
'predictions': <Classification: {
'id': '601ae8711a0300d4ade1dc03',
'label': 'Parasitized',
'confidence': 0.9984512329101562,
'logits': array([-1.5499677e-03, -6.4702997e+00], dtype=float32),
}>,
}>
and the validation split:
[ ]:
print(dataset.match_tags("validation").first())
<SampleView: {
'id': '601acd101a0300d4addd48e5',
'media_type': 'image',
'filepath': '/content/cell_images/Parasitized/C100P61ThinF_IMG_20150918_144104_cell_170.png',
'tags': BaseList(['validation']),
'metadata': None,
'ground_truth': <Classification: {
'id': '601acd101a0300d4addd48e4',
'label': 'Parasitized',
'confidence': None,
'logits': None,
}>,
'uniqueness': 0.31238555314371125,
'predictions': <Classification: {
'id': '601ae69b1a0300d4ade1901f',
'label': 'Parasitized',
'confidence': 0.9914804697036743,
'logits': array([-0.00855603, -4.765392 ], dtype=float32),
}>,
}>
Running the evaluation#
FiftyOne provides a powerful evaluation API for evaluating various types of models at the aggregate and sample-level.
In this case, we’ll use the binary classification functionality to analyze our model:
[9]:
# Evaluate the predictions in the `predictions` field with respect to the
# labels in the `ground_truth` field
results = dataset.evaluate_classifications(
"predictions",
gt_field="ground_truth",
eval_key="eval",
method="binary",
classes=["Uninfected", "Parasitized"],
)
The method returned a results object that provides a number of convenient methods for analyzing our predictions.
Viewing aggregate metrics#
Let’s start by printing a classification report:
[6]:
results.print_report()
precision recall f1-score support
Uninfected 0.95 0.98 0.96 13779
Parasitized 0.98 0.95 0.96 13779
accuracy 0.96 27558
macro avg 0.96 0.96 0.96 27558
weighted avg 0.96 0.96 0.96 27558
Now, how about a confusion matrix:
[7]:
plot = results.plot_confusion_matrix()
plot.show()
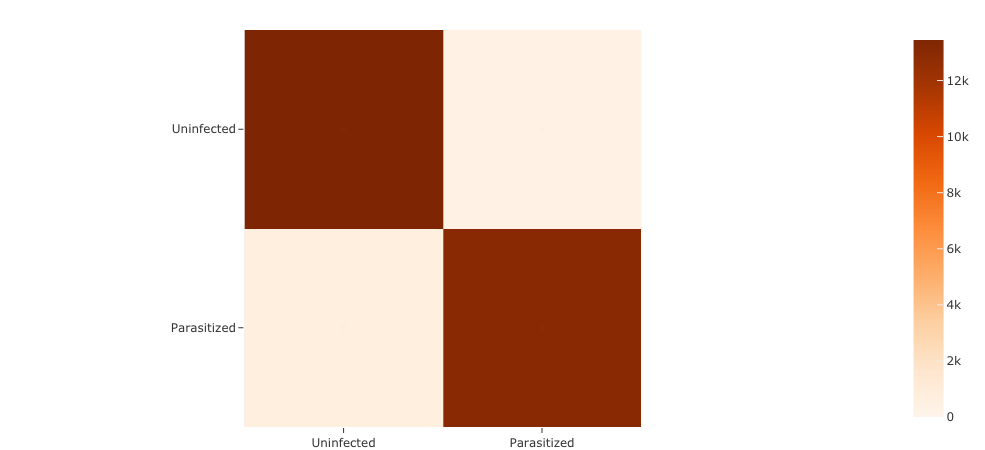
[8]:
plot.freeze() # replaces interactive plot with static image
and finally a precision-recall curve:
[9]:
plot = results.plot_pr_curve()
plot.show()
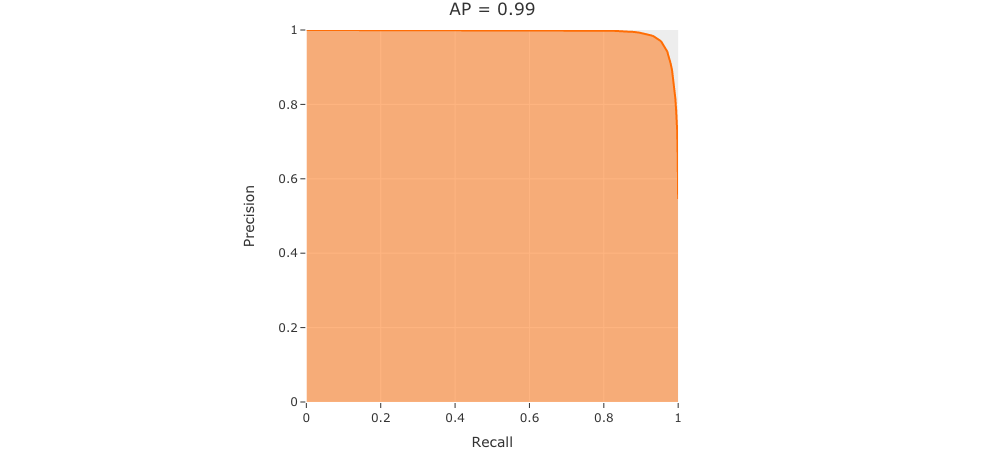
[10]:
plot.freeze() # replaces interactive plot with static image
The evaluation method also populated a new eval field on our samples that records whether each prediction is a true positive (TP), false positive (FP), false negative (FN), or true negative (TN).
In a few minutes, we’ll use this field to interactively explore each type of prediction visually in the App. But for now, let’s check the distribution of these labels:
[10]:
print(dataset.count_values("eval"))
{'FN': 708, 'FP': 334, 'TN': 13445, 'TP': 13071}
Visualizing the most unique predictions#
Now that we have a sense for the aggregate performance of our model, let’s dive into sample-level analysis by loading a dataset view in the App that shows the correctly predicted samples from the validation split, sorted in descending order by the visual uniqueness that we previously computed and stored in the uniqueness field of the dataset:
[21]:
# Show most unique CORRECT predictions on validation split
session.view = (
dataset
.match_tags("validation")
.match(F("predictions.label") == F("ground_truth.label"))
.sort_by("uniqueness", reverse=True)
)

Now, things get more interesting when we update our view to show the most visually unique INCORRECT predictions from the validation split.
Note that some of these ground truth labels look questionable; it seems that some of our our ground truth annotations may need to be updated. We’ll investigate this more later.
[22]:
# Show most unique INCORRECT predictions on validation split
session.view = (
dataset
.match_tags("validation")
.match(F("predictions.label") != F("ground_truth.label"))
.sort_by("uniqueness", reverse=True)
)

Compute sample hardness with FiftyOne#
During training, it is useful to identify samples that are more difficult for a model to learn so that training can be more focused around these hard samples.
Let’s use FiftyOne’s hardness method to index our dataset by the hardness of our predictions in the predictions field.
This method populates a scalar hardness field on each of our samples.
[ ]:
import fiftyone.brain as fob
fob.compute_hardness(dataset, "predictions")
Computing hardness...
100% |███| 27558/27558 [1.2m elapsed, 0s remaining, 374.5 samples/s]
Hardness computation complete
Now let’s use our hardness measure to view the HARDEST FALSE POSITIVE samples in the validation split of our dataset.
These are the failure modes of our current model, and this is where we need to dedicate our human time to understand what’s going on.
Here are some important questions to ask yourself:
Are any of the ground truth annotations on these samples incorrect? If so, then correcting them will make the biggest positive impact on the ability of our model to separate these two classes
Are these predictions actually false positives? If so, then adding more examples that are visually similar to these to your training dataset will also improve your model
[23]:
# Show the HARDEST FALSE POSITIVES on validation split
session.view = (
dataset
.match_tags("validation")
.match(F("eval") == "FP")
.sort_by("hardness", reverse=True)
)

Viewing the HARDEST FALSE NEGATIVE samples from the validation split also gives insights into what fools our model into wrongly believing that a sample is uninfected.
Or, are the ground truth annotations incorrect? The same questions from the previous section apply. Finding mistakes in your ground truth data is equally as important as identifying the true failure modes of your model.
[16]:
# Show the HARDEST FALSE NEGATIVES on validation split
session.view = (
dataset
.match_tags("validation")
.match(F("eval") == "FN")
.sort_by("hardness", reverse=True)
)

Finding ground truth mistakes using FiftyOne#
Even well-known datasets can have significant ground truth mistakes.
Fortunately, FiftyOne provides a mistakenness method that can automatically identify the potential ground truth mistakes in your dataset.
The cell below runs the mistakenness method using the predictions in the predictions field of the dataset as a point of reference to find the most likely mistakes in the ground_truth annotations:
[ ]:
import fiftyone.brain as fob
fob.compute_mistakenness(dataset, "predictions", label_field="ground_truth")
Computing mistakenness...
100% |███| 27558/27558 [1.3m elapsed, 0s remaining, 341.9 samples/s]
Mistakenness computation complete
We can easily update our view in the App to show, for example, the most likely annotation mistakes in the train split of our dataset. In the cell below, we have only selected the eval field in the App so that we see the samples together with their TP/FP/FN/TN evaluation labels.
I’m not a medical imaging expert, but to my untrained eye, the examples below suggest two concrete opportunities for improvement to our training dataset:
Many of the false negatives below seem to be true negatives. These ground truth annotations likely need another annotation pass to correct for errors
Many of the remaining false negatives seem to be cases where the infection is near the boundary of the cell images. Augmenting the training dataset with more
Parasitizedexamples of this kind would likely improve the performance of our model!
[18]:
# Show the most likely ANNOTATION MISTAKES on the train split
session.view = (
dataset
.match_tags("train")
.sort_by("mistakenness", reverse=True)
)

[26]:
session.freeze()
Export incorrect samples for further analysis#
Now that we’ve identified some potential sources of annotation error, we can easily extract some aggregate analyses of the incorrect predictions:
[19]:
# Print stats about errors
train_fp = dataset.match_tags("train").match(F("eval") == "FP")
train_fn = dataset.match_tags("train").match(F("eval") == "FN")
valid_fp = dataset.match_tags("validation").match(F("eval") == "FP")
valid_fn = dataset.match_tags("validation").match(F("eval") == "FN")
print("Train FP: %d" % train_fp.count())
print("Train FN: %d" % train_fn.count())
print("Validation FP: %d" % valid_fp.count())
print("Validation FN: %d" % valid_fn.count())
Train FP: 273
Train FN: 580
Validation FP: 61
Validation FN: 128
The code sample below generates a JSON export of the 1042 samples in the dataset where the model generated false positive or false negative predictions:
This JSON file includes the filepaths for the raw images, so this file can be easily forwarded to your annotation team/vendor to complete a re-annotation pass.
[ ]:
# Export FP and FN samples to JSON
ERRORS_JSON_PATH = "errors.json"
errors = (
dataset
.match(F("eval").is_in(["FP", "FN"]))
.set_field("ground_truth.logits", None)
.set_field("predictions.logits", None)
)
errors.write_json(ERRORS_JSON_PATH, rel_dir=DATASET_DIR)
100% |█████| 1042/1042 [952.0ms elapsed, 0s remaining, 1.1K samples/s]
If you’re working in a Colab notebook, you can download the errors JSON file to your machine as follows:
[ ]:
# (Colab only) Download errors to your machine
from google.colab import files
files.download(ERRORS_JSON_PATH)
Summary#
In this notebook, we covered loading a dataset into FiftyOne, fine-tuning a fastai model on it, and analyzing the failure modes of the model using FiftyOne.
So, what’s the takeaway?
The loss function of your training loop doesn’t tell the whole story of your model; it’s critical to study the failure modes of your model so you can take the right actions to improve them.
In this notebook, we covered two types of actions:
Finding potential annotation mistakes and exporting the problem samples for review/reannotation
Identifying scenarios that require additional training samples
In upcoming tutorials, we’ll cover how FiftyOne can enable you to automate both of these actions. Stay tuned!
Appendix A: Dataset export#
FiftyOne provides native support for exporting datasets in dozens of common formats.
If you’re working in a notebook, you may want to export the entire dataset, including the additional analysis fields such as the uniqueness, hardness, mistakenness, and eval fields that we added in this tutorial. FiftyOne provides two simple options for this:
Option 1: export without images#
One option is to export only the labels (no raw images) in JSON format:
[ ]:
# Export dataset in JSON format (no images)
JSON_PATH = "malaria-cell-images.json"
dataset.write_json(JSON_PATH, rel_dir=DATASET_DIR)
100% |███| 27558/27558 [39.7s elapsed, 0s remaining, 694.6 samples/s]
[ ]:
# (Colab only) Download dataset to your machine
from google.colab import files
files.download(JSON_PATH)
Option 2: export with images#
Alternatively, you can export the entire dataset (labels + images) as an archive:
[ ]:
# Export entire dataset
import eta.core.utils as etau
EXPORT_ZIP = "malaria-cell-images.zip"
dataset.export(EXPORT_ZIP, dataset_type=fo.types.FiftyOneDataset)
[ ]:
# (Colab only) Download dataset to your machine
from google.colab import files
files.download(EXPORT_ZIP)
You can load an exported FiftyOne dataset back into FiftyOne in one line of code.
Option 1: loading an export without images#
If you exported only the labels (no raw images) in JSON format, you can reload the dataset into any environment that contains the raw images as follows:
[ ]:
# (Colab only) Upload dataset from your machine
from google.colab import files
uploaded = files.upload()
for filename in uploaded.keys():
print("Uploaded '%s'" % filename)
[ ]:
# Load JSON export with images already gathered separately
import fiftyone as fo
JSON_PATH = "malaria-cell-images.json"
DATASET_DIR = "cell_images/"
dataset = fo.Dataset.from_json(JSON_PATH, rel_dir=DATASET_DIR)
print(dataset)
100% |███| 27558/27558 [1.1m elapsed, 0s remaining, 379.0 samples/s]
Name: malaria-cell-images_i5rigy
Media type: image
Num samples: 27558
Persistent: False
Info: {'classes': ['Parasitized', 'Uninfected']}
Tags: ['train', 'validation']
Sample fields:
filepath: fiftyone.core.fields.StringField
tags: fiftyone.core.fields.ListField(fiftyone.core.fields.StringField)
metadata: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.metadata.Metadata)
ground_truth: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Classification)
uniqueness: fiftyone.core.fields.FloatField
predictions: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Classification)
eval: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Classification)
hardness: fiftyone.core.fields.FloatField
mistakenness: fiftyone.core.fields.FloatField
Option 2: loading an export with images#
If you exported the entire dataset (images + labels) then you can reload the dataset in another session as follows:
[ ]:
# (Colab only) Upload dataset from your machine
from google.colab import files
uploaded = files.upload()
for filename in uploaded.keys():
print("Uploaded '%s'" % filename)
[ ]:
!unzip malaria-cell-images.zip
[ ]:
# Load dataset into FiftyOne
import fiftyone as fo
DATASET_DIR = "malaria-cell-images"
dataset = fo.Dataset.from_dir(DATASET_DIR, fo.types.FiftyOneDataset)
print(dataset)
Appendix B: fastai export#
Export a model#
Exporting a fastai model as an encapsulated pickle file is also easy:
[ ]:
# Export your model as a standalone `pkl` file
learner.export("models/xresnet34-malaria.pkl")
[ ]:
# (Colab only) Download model to your machine
from google.colab import files
files.download("models/xresnet34-malaria.pkl")
Loading an exported model#
Run the code block below if you’d like to load an existing fastai model and run inference on new data with it in colab:
[ ]:
# (Colab only) Upload model from your machine
from google.colab import files
uploaded = files.upload()
for filename in uploaded.keys():
print("Uploaded '%s'" % filename)
[ ]:
%%bash
mkdir -p models/
mv xresnet34-malaria.pkl models/
[ ]:
# Load exported model
learner = load_learner("models/xresnet34-malaria.pkl")
[ ]:
# Perform test inference
#IMAGE_PATH = "cell_images/Uninfected/C145P106ThinF_IMG_20151016_154844_cell_62.png"
IMAGE_PATH = "cell_images/Parasitized/C100P61ThinF_IMG_20150918_144104_cell_162.png"
print(learner.predict(IMAGE_PATH))
('Parasitized', tensor(0), tensor([0.9980, 0.0020]))