|
|
|
|
Speed Up FiftyOneTorchDataset with Vectorize Mode#
This recipe shows how to eliminate database query overhead during training by enabling vectorize mode in FiftyOneTorchDataset. With vectorize=True, all required fields are preloaded into memory before training begins, removing per-sample database lookups from the hot path. Specifically, it covers:
Enabling vectorize mode with
vectorize=Trueand a GetItem subclassUnderstanding how vectorize mode changes the input to your
__call__methodWriting a GetItem that works with preloaded field dicts for efficient training
API references: FiftyOneTorchDataset · GetItem
Setup#
If you haven’t already, install FiftyOne:
[ ]:
!pip install fiftyone
In this tutorial, we’ll use PyTorch for working with tensors and inspecting sample data. To follow along, you’ll need to install torch and torchvision, if necessary:
[ ]:
!pip install torch torchvision
Import Libraries#
[ ]:
import fiftyone as fo
import fiftyone.zoo as foz
from fiftyone.utils.torch import FiftyOneTorchDataset
import urllib.request
This recipe requires a helper file, utils.py, which contains reusable functions for building get_item methods, creating dataloaders, and setting up models. The following cell downloads it into your working directory so it can be imported directly.
[ ]:
url = "https://cdn.voxel51.com/tutorials_torch_dataset_examples/notebook_the_cache_field_names_argument/utils.py"
urllib.request.urlretrieve(url, "utils.py")
[ ]:
import utils
[ ]:
import torch
from torch.utils.data import DataLoader
import numpy as np
import torchvision.transforms.v2 as transforms
from torchvision import tv_tensors
import matplotlib.pyplot as plt
import matplotlib.patches as plt_patches
from PIL import Image
from utils import SimpleGetItem
[ ]:
torch.multiprocessing.set_start_method("forkserver")
torch.multiprocessing.set_forkserver_preload(["torch", "fiftyone"])
Vectorize Mode#
By default, FiftyOneTorchDataset queries the backing MongoDB database on every __getitem__ call. For large training runs this per-sample overhead adds up quickly.
Passing vectorize=True to .to_torch() switches to vectorize mode: all fields declared in your GetItem are serialized into memory up front, so sample retrieval during training is a simple dict lookup with no database I/O. This delivers a significant speedup when data loading is the bottleneck.
# Wrap your function with SimpleGetItem to declare which fields to preload
get_item_wrapper = SimpleGetItem(my_get_item_fn, ["id", "filepath", "my_field"])
# vectorize=True preloads all declared fields into memory before training begins
torch_dataset = view.to_torch(get_item_wrapper, vectorize=True)
Note: With
vectorize=True, all fields you declare in your GetItem are preloaded into memory before training begins — no additional configuration is needed beyond the field list you already provide.
Load Dataset#
[ ]:
dataset = foz.load_zoo_dataset("quickstart")
[ ]:
# make sure it's persistent
print(dataset.persistent)
# if it's not, set this to True
if not dataset.persistent:
dataset.persistent = True
[ ]:
some_interesting_view = dataset.take(100)
Writing a GetItem for Vectorize Mode#
In vectorize mode, your GetItem.__call__ receives a dict of preloaded field values rather than a live fiftyone.core.sample.Sample. The keys match the field names you declared in your GetItem. Here’s an example that loads detections from the quickstart dataset:
[ ]:
augmentations = transforms.Compose([
transforms.CenterCrop(512),
transforms.ClampBoundingBoxes(),
])
def get_item_cached(sample_dict):
image = Image.open(sample_dict["filepath"])
og_wh = np.array([image.width, image.height])
image = tv_tensors.Image(image)
detections = sample_dict["ground_truth.detections.bounding_box"] or []
detections_tensor = (
torch.tensor(detections)
if len(detections) > 0
else torch.zeros((0, 4))
)
res = {
"box": tv_tensors.BoundingBoxes(
detections_tensor * torch.tensor([*og_wh, *og_wh]),
format=tv_tensors.BoundingBoxFormat("XYWH"),
canvas_size=image.shape[-2:],
),
"label": sample_dict["ground_truth.detections.label"],
"id": sample_dict["id"],
}
image, res = augmentations(image, res)
return image, res
[ ]:
# Declare all fields your get_item accesses
fields_of_interest = [
"id",
"filepath",
"ground_truth.detections.bounding_box",
"ground_truth.detections.label",
]
# Wrap with SimpleGetItem to specify field names, then enable vectorize mode
get_item_wrapper = SimpleGetItem(get_item_cached, fields_of_interest)
torch_dataset = some_interesting_view.to_torch(get_item_wrapper, vectorize=True)
Visualizing the result#
Run the cell below a few times to inspect different samples from the dataset:
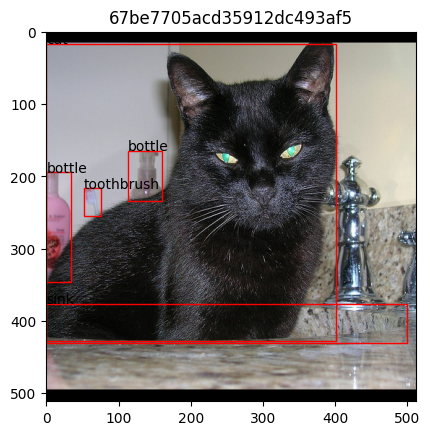
[21]:
# run this a couple of times to look through samples in the dataset
random_index = np.random.randint(0, len(torch_dataset))
image, res = torch_dataset[random_index]
plt.title(res["id"])
plt.imshow(image.permute(1, 2, 0).numpy())
axes = plt.gca()
for b, l in zip(res["box"], res["label"]):
rect = plt_patches.Rectangle(
(b[0], b[1]), b[2], b[3], linewidth=1, edgecolor="r", facecolor="none"
)
axes.add_patch(rect)
axes.annotate(l, rect.get_xy())
plt.show()
The dataset works with a standard DataLoader for use in a training loop:
[ ]:
# utils.get_item_cached_quickstart is the same get_item_cached as above
fields_of_interest = [
"id",
"filepath",
"ground_truth.detections.bounding_box",
"ground_truth.detections.label",
]
get_item_wrapper = SimpleGetItem(utils.get_item_cached_quickstart, fields_of_interest)
torch_dataset = some_interesting_view.to_torch(get_item_wrapper, vectorize=True)
dataloader = utils.create_dataloader_simple(torch_dataset)
[ ]:
ids_seen = utils.ids_in_dataloader(dataloader)
[ ]:
# confirm we have seen each sample once
from collections import Counter
ids_with_counts = Counter(ids_seen)
assert set(ids_with_counts.keys()) == set(some_interesting_view.values("id"))
assert np.all(np.array(list(ids_with_counts.values())) == 1)
[ ]:
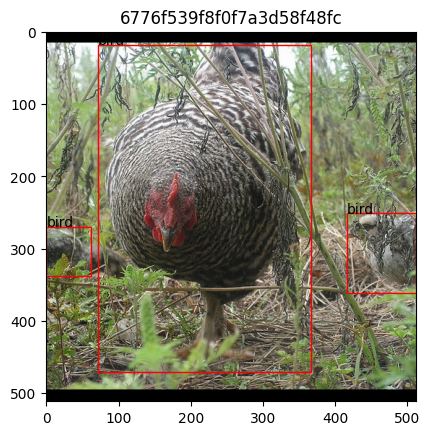
# visualizing results, run this a couple of times to see different batches
iterator = iter(dataloader)
[ ]:
image, res = next(iterator)
fig, axes = plt.subplots(1, len(image), figsize=(4 * len(image), 3))
for i, img in enumerate(image):
axes[i].set_title(res[i]["id"])
axes[i].imshow(img.permute(1, 2, 0).numpy())
for b, l in zip(res[i]["box"], res[i]["label"]):
rect = plt_patches.Rectangle(
(b[0], b[1]), b[2], b[3], linewidth=1, edgecolor="r", facecolor="none"
)
axes[i].add_patch(rect)
axes[i].annotate(l, rect.get_xy())
plt.show()