Note
This is a community plugin, an external project maintained by its respective author. Community plugins are not part of FiftyOne core and may change independently. Please review each plugin’s documentation and license before use.
LightOnOCR-2 FiftyOne Integration#
![]()
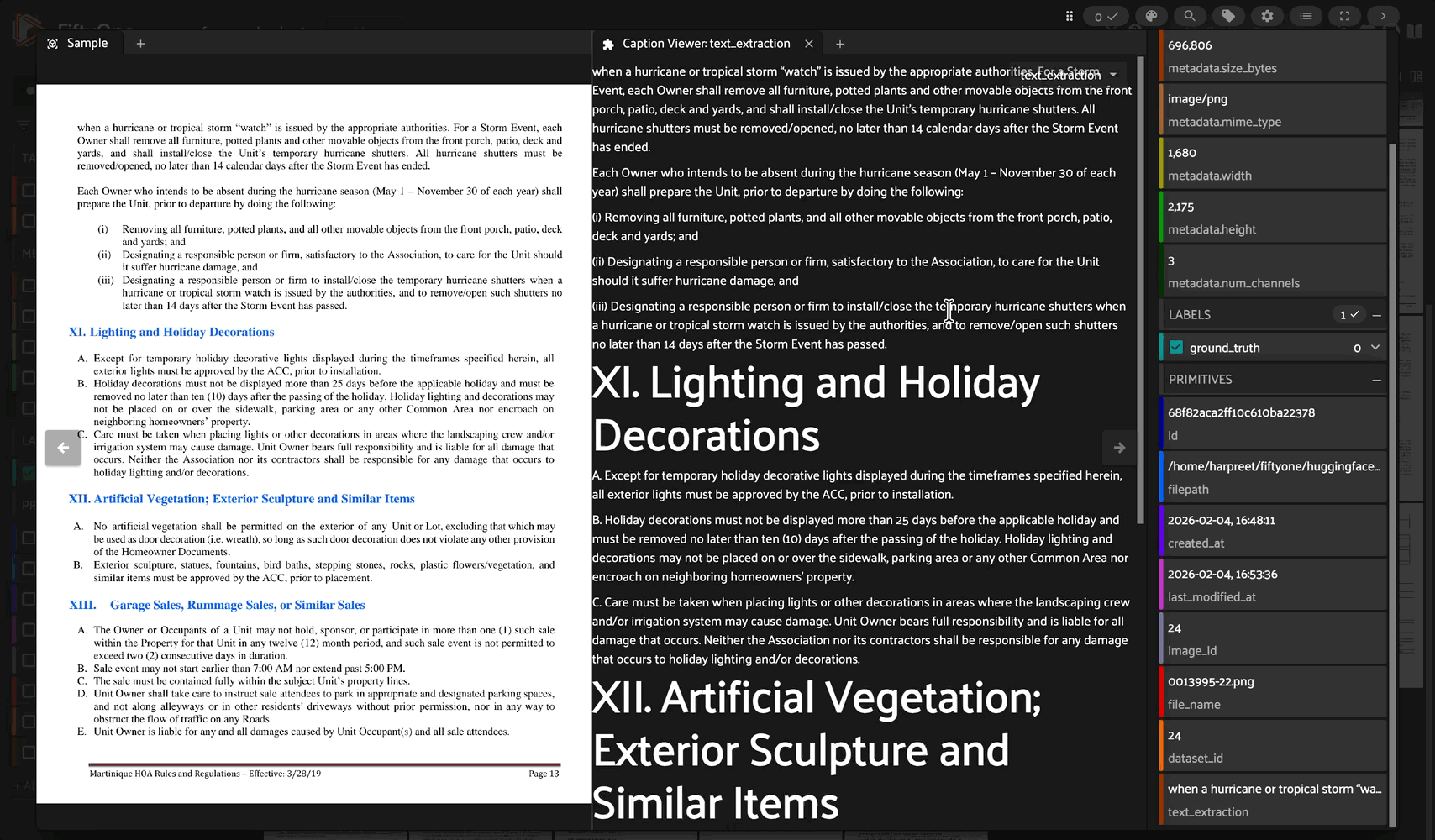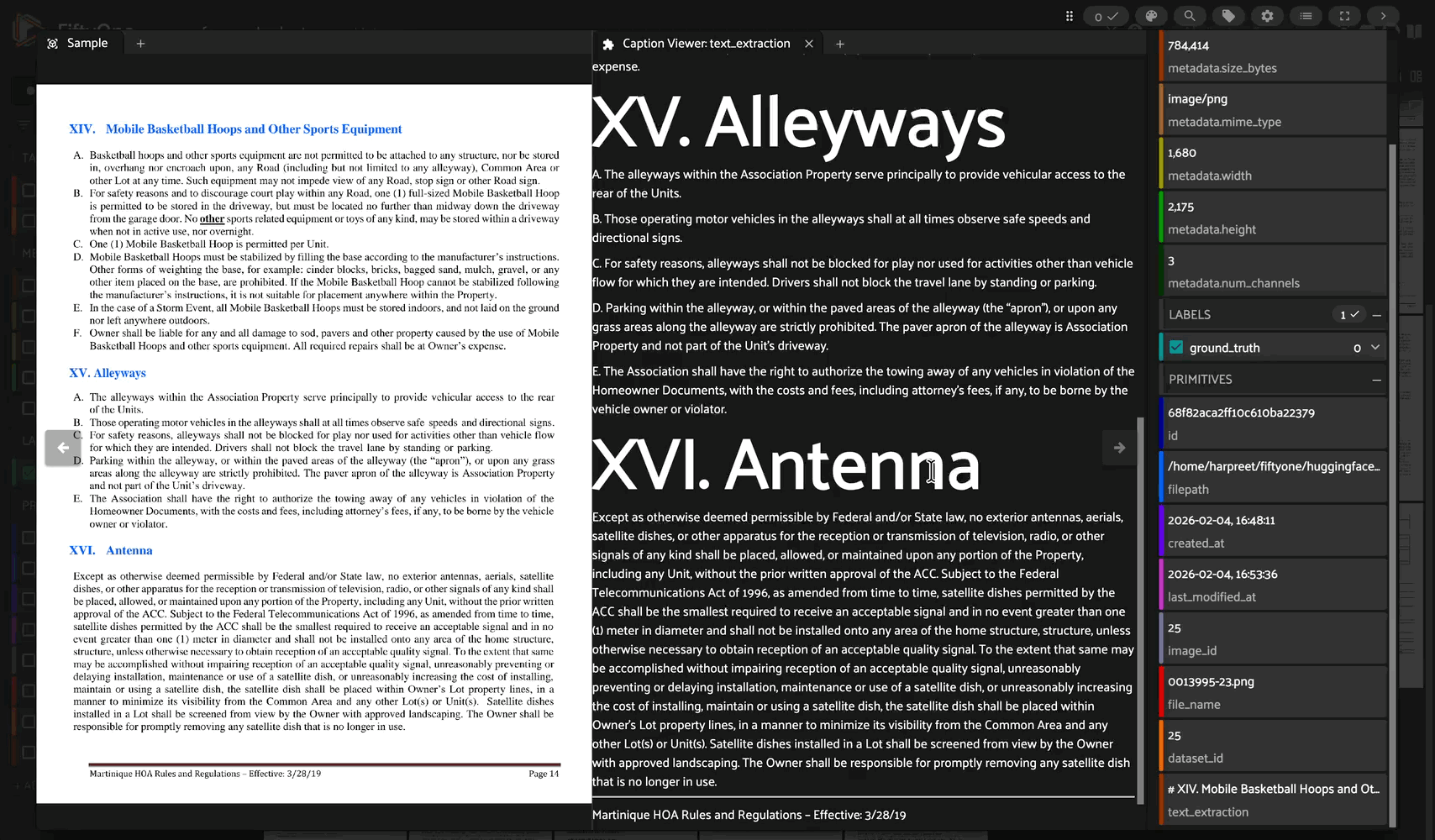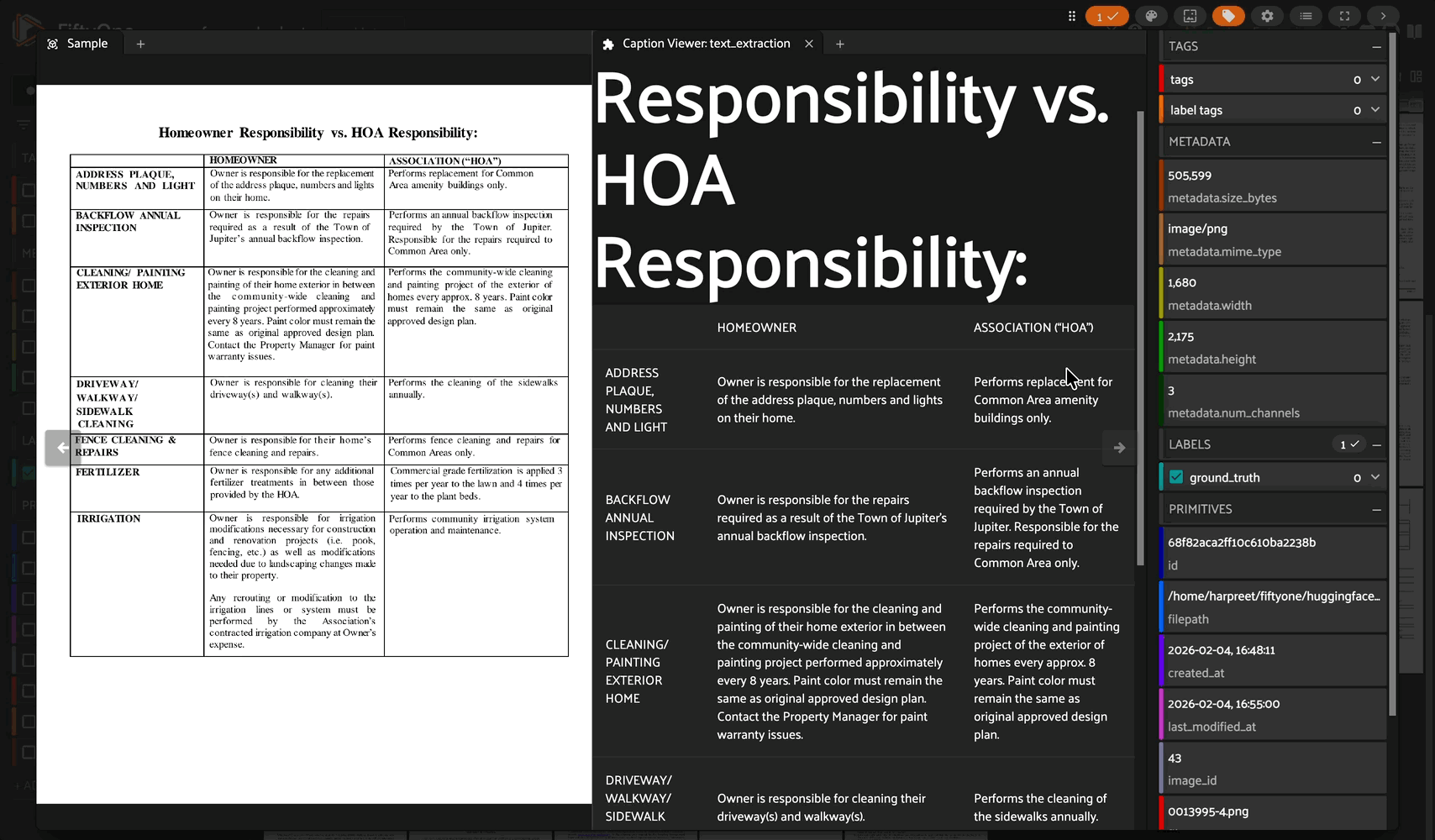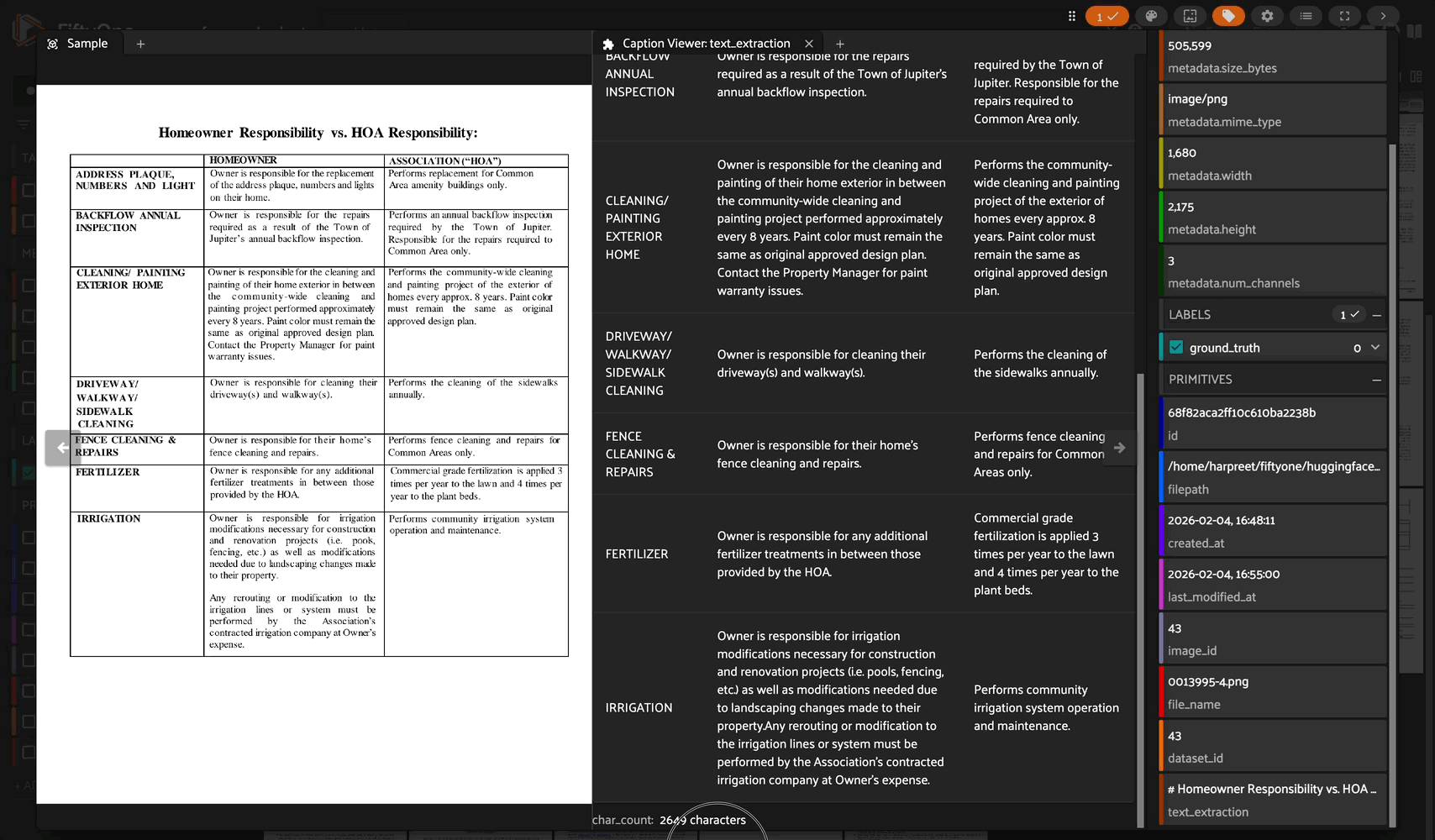
A FiftyOne integration for LightOnOCR-2-1B, a state-of-the-art 1B-parameter end-to-end multilingual vision-language model for document OCR.
About LightOnOCR-2#
LightOnOCR-2-1B is a compact, end-to-end multilingual VLM that converts document images (PDFs, scans, photos) into clean, naturally ordered text without brittle multi-stage OCR pipelines.
Key Features#
State-of-the-Art Performance: Achieves the highest score on OlmOCR-Bench while being 9× smaller than prior best-performing models
End-to-End Architecture: Single unified model - fully differentiable and easy to optimize without fragile multi-stage pipelines
Multilingual Support: Strong coverage of European languages with emphasis on French and scientific documents
Complex Layout Handling: Excels at tables, forms, receipts, scientific notation, and multi-column layouts
High Resolution: Trained at 1540px maximum longest edge for improved legibility of small text and dense mathematical notation
Fast Inference: 5.71 pages/sec on H100 - substantially higher throughput than larger models
Model Variants#
Model |
Description |
|---|---|
|
Best OCR model (RLVR-optimized) |
Installation#
pip install fiftyone transformers torch pillow
Optional: Install the Caption Viewer plugin for better text visualization:
fiftyone plugins download https://github.com/harpreetsahota204/caption_viewer
Quick Start#
Register and Load the Model#
import fiftyone as fo
import fiftyone.zoo as foz
# Register the model source
foz.register_zoo_model_source(
"https://github.com/harpreetsahota204/LightOnOCR-2",
overwrite=True
)
# Load the model
model = foz.load_zoo_model("lightonai/LightOnOCR-2-1B")
Apply to a Dataset#
# Load or create your dataset
dataset = fo.Dataset.from_images_dir("/path/to/documents")
# Apply OCR extraction
dataset.apply_model(
model,
label_field="ocr_text",
batch_size=8,
num_workers=2
)
# Launch the FiftyOne App to visualize results
session = fo.launch_app(dataset)
View Results#
# Get the first sample
sample = dataset.first()
# Print extracted text
print(sample.ocr_text)
Configuration Options#
The model accepts several configuration parameters:
model = foz.load_zoo_model(
"lightonai/LightOnOCR-2-1B",
max_new_tokens=4096, # Maximum tokens to generate (default: 4096)
prompt=None, # Optional custom prompt (default: None)
batch_size=8 # Batch size for inference (default: 8)
)
Parameters#
Parameter |
Default |
Description |
|---|---|---|
|
|
Maximum number of tokens to generate per image |
|
|
Optional text prompt to guide extraction |
|
|
Batch size for efficient inference |
Apply Model Parameters#
dataset.apply_model(
model,
label_field="ocr_text", # Field name to store results
batch_size=8, # Images per inference batch
num_workers=4, # Parallel data loading workers
skip_failures=False # Whether to skip failed samples
)
Using the Caption Viewer Plugin#
For the best viewing experience of extracted text in the FiftyOne App:
Click on any sample to open the modal view
Click the
+button to add a panelSelect “Caption Viewer” from the panel list
In the panel menu (), select
ocr_text(or your label field)
The Caption Viewer automatically:
Renders line breaks properly
Converts HTML tables to markdown
Pretty-prints JSON content
Shows character counts
Best Use Cases#
LightOnOCR-2-1B excels at:
Scientific PDFs: Dense typography, accurate LaTeX math transcription
Scanned Documents: Moderately degraded, noisy, or rotated scans
European Languages: Strong Latin script support (especially French)
Complex Layouts: Multi-column documents, tables, forms
Limitations#
Non-Latin scripts (CJK, Arabic) may have degraded fidelity
Handwritten text transcription is inconsistent
Primarily optimized for printed/typeset documents
Links#
Paper: arXiv:2601.14251
FiftyOne: github.com/voxel51/fiftyone
License#
Model: Apache 2.0
This Integration: Apache 2.0
Citation#
@article{taghadouini2026lightonocr,
title={LightOnOCR: A 1B End-to-End Multilingual Vision-Language Model for State-of-the-Art OCR},
author={Taghadouini, Said and Cavaill{\`e}s, Adrien and Aubertin, Baptiste},
journal={arXiv preprint arXiv:2601.14251},
year={2026}
}