Note
This is a Hugging Face dataset. For large datasets, ensure huggingface_hub>=1.1.3 to avoid rate limits. Learn more in the Hugging Face integration docs.
Dataset Card for IndoorSceneRecognition#
The database contains 67 Indoor categories, and a total of 15620 images. The number of images varies across categories, but there are at least 100 images per category. All images are in jpg format.
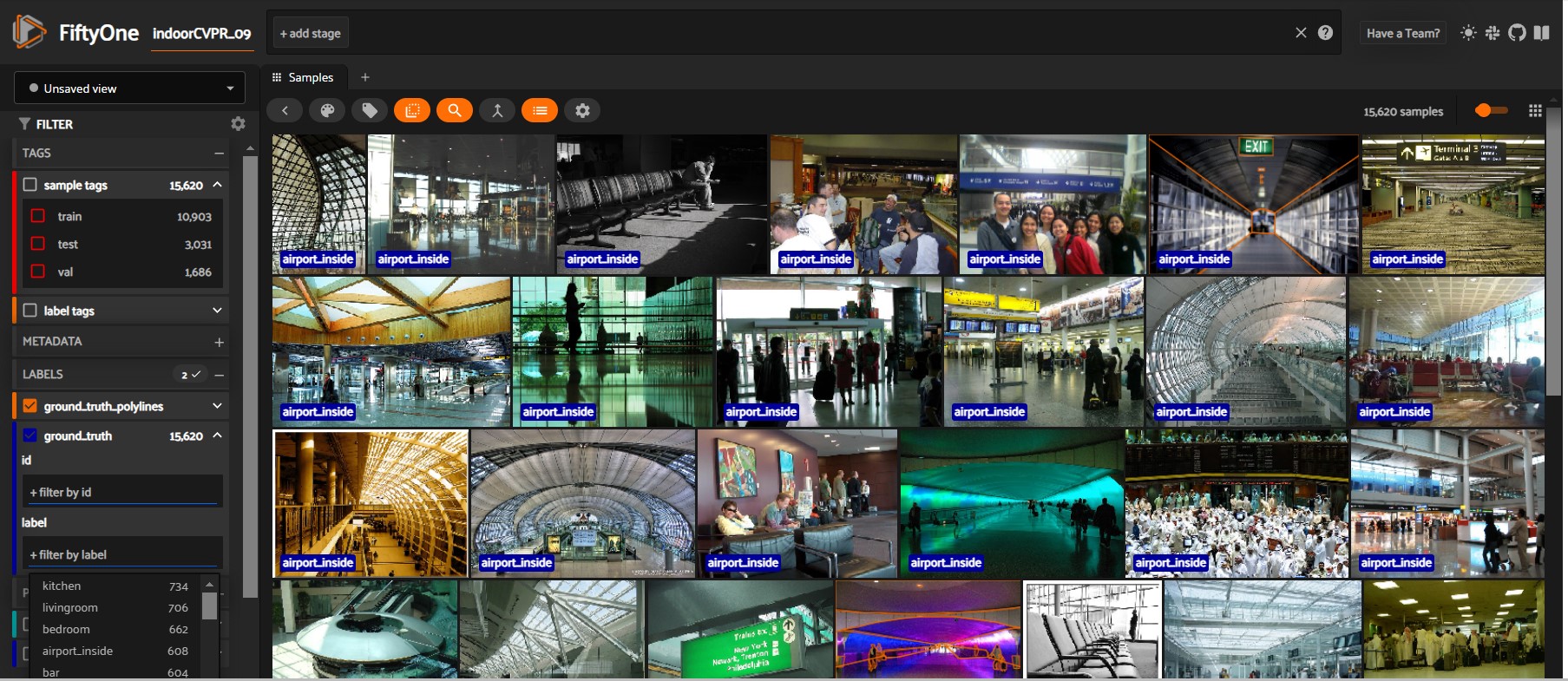
This is a FiftyOne dataset with 15620 samples.
Installation#
If you haven’t already, install FiftyOne:
pip install -U fiftyone
Usage#
import fiftyone as fo
import fiftyone.utils.huggingface as fouh
# Load the dataset
# Note: other available arguments include 'max_samples', etc
dataset = fouh.load_from_hub("Voxel51/IndoorSceneRecognition")
# Launch the App
session = fo.launch_app(dataset)
Dataset Details#
Dataset Description#
Curated by: A. Quattoni, A. Torralba, Aude Oliva
Funded by: National Science Foundation Career award (IIS 0747120)
Language(s) (NLP): en
License: mit
Dataset Sources#
Paper : https://ieeexplore.ieee.org/document/5206537
Homepage: https://web.mit.edu/torralba/www/indoor.html
Uses#
categorizing indoor scenes and segmentation of the objects in a scene
Dataset Structure#
Name: IndoorSceneRecognition
Media type: image
Num samples: 15620
Persistent: False
Tags: []
Sample fields:
id: fiftyone.core.fields.ObjectIdField
filepath: fiftyone.core.fields.StringField
tags: fiftyone.core.fields.ListField(fiftyone.core.fields.StringField)
metadata: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.metadata.ImageMetadata)
ground_truth: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Classification)
ground_truth_polylines: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Polylines)
The dataset has 3 splits: “train”, “val”, and “test”. Samples are tagged with their split.
Dataset Creation#
Curation Rationale#
The authors of the paper A. Quattoni and A.Torralba wanted to propose a prototype based model that can exploit local and global discriminative information in a indoor scene recognition problem. To test out the approach, with the help of Aude Oliva, they created a dataset of 67 indoor scenes categories covering a wide range of domains.
Annotation process#
A subset of the images are segmented and annotated with the objects that they contain. The annotations are in LabelMe format
Citation#
BibTeX:
@INPROCEEDINGS{5206537,
author={Quattoni, Ariadna and Torralba, Antonio},
booktitle={2009 IEEE Conference on Computer Vision and Pattern Recognition},
title={Recognizing indoor scenes},
year={2009},
volume={},
number={},
pages={413-420},
keywords={Layout},
doi={10.1109/CVPR.2009.5206537}}