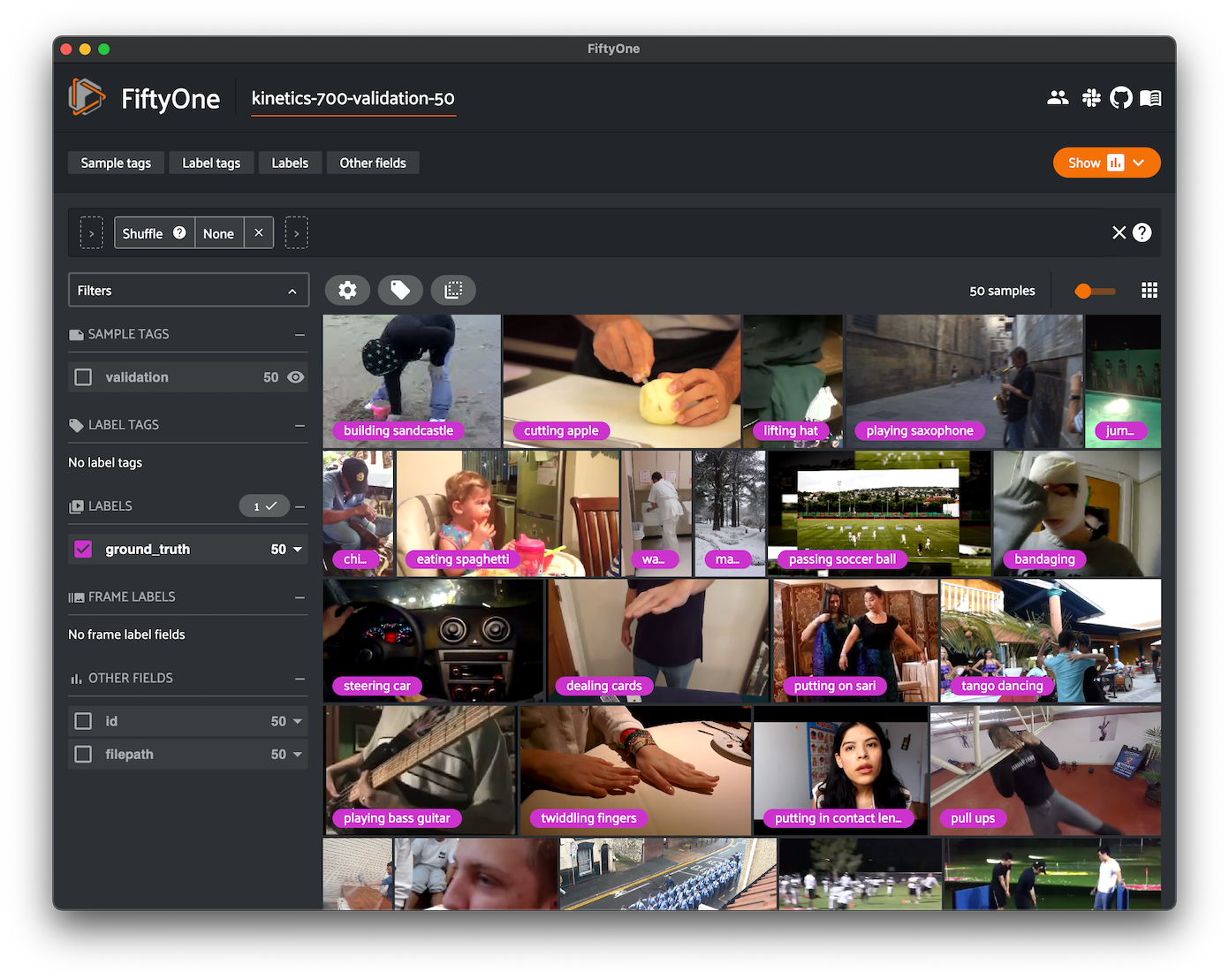
Kinetics 700-2020#
Kinetics is a collection of large-scale, high-quality datasets of URL links of up to 650,000 video clips that cover 400/600/700 human action classes, depending on the dataset version. The videos include human-object interactions such as playing instruments, as well as human-human interactions such as shaking hands and hugging. Each action class has at least 400/600/700 video clips. Each clip is human annotated with a single action class and lasts around 10 seconds.
This version contains videos and action classifications for the 700 class version of the dataset that was updated with new videos in 2020. This dataset is a superset of Kinetics 700.
Details
Dataset name:
kinetics-700-2020Dataset source: https://deepmind.com/research/open-source/kinetics
Dataset size: 710 GB
Tags:
video, classification, action-recognitionSupported splits:
train, test, validationZooDataset class:
Kinetics7002020Dataset
Original split stats:
Train split: 542,352 videos
Test split: 67,433 videos
Validation split: 34,125 videos
CVDF split stats:
Train split: 534,073 videos
Test split: 64,260 videos
Validation split: 33,914 videos
Dataset size
Train split: 603 GB
Test split: 59 GB
Validation split: 48 GB
Partial downloads
Kinetics is a massive dataset, so FiftyOne provides parameters that can be used to efficiently download specific subsets of the dataset to suit your needs. When new subsets are specified, FiftyOne will use existing downloaded data first if possible before resorting to downloading additional data from the web.
Kinetics videos were originally only accessible from YouTube. Over time, some videos have become unavailable so the CVDF have hosted the Kinetics dataset on AWS.
If you are partially downloading the dataset through FiftyOne, the specific videos of interest will be downloaded from YouTube, if necessary. However, when you load an entire split, the CVDF-provided files will be downloaded from AWS.
The following parameters are available to configure a partial download of
Kinetics by passing them to
load_zoo_dataset():
split (None) and splits (None): a string or list of strings, respectively, specifying the splits to load. Supported values are
("train", "test", "validation"). If neither is provided, all available splits are loadedclasses (None): a string or list of strings specifying required classes to load. If provided, only samples containing at least one instance of a specified class will be loaded
num_workers (None): the number of processes to use when downloading individual videos. By default,
multiprocessing.cpu_count()is usedshuffle (False): whether to randomly shuffle the order in which samples are chosen for partial downloads
seed (None): a random seed to use when shuffling
max_samples (None): a maximum number of samples to load per split. If
classesare also specified, only up to the number of samples that contain at least one specified class will be loaded. By default, all matching samples are loaded
Example usage
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4#
5# Load 10 random samples from the validation split
6#
7# Only the required videos will be downloaded (if necessary).
8#
9
10dataset = foz.load_zoo_dataset(
11 "kinetics-700-2020",
12 split="validation",
13 max_samples=10,
14 shuffle=True,
15)
16
17session = fo.launch_app(dataset)
18
19#
20# Load 10 samples from the validation split that
21# contain the actions "springboard diving" and "surfing water"
22#
23# Videos that contain all `classes` will be prioritized first, followed
24# by videos that contain at least one of the required `classes`. If
25# there are not enough videos matching `classes` in the split to meet
26# `max_samples`, only the available videos will be loaded.
27#
28# Videos will only be downloaded if necessary
29#
30# Subsequent partial loads of the validation split will never require
31# downloading any videos
32#
33
34dataset = foz.load_zoo_dataset(
35 "kinetics-700-2020",
36 split="validation",
37 classes=["springboard diving", "surfing water"],
38 max_samples=10,
39)
40
41session.dataset = dataset
#
# Load 10 random samples from the validation split
#
# Only the required videos will be downloaded (if necessary).
#
fiftyone zoo datasets load kinetics-700-2020 \
--split validation \
--kwargs max_samples=10
fiftyone app launch kinetics-700-2020-validation-10
#
# Download the entire validation split
#
# Subsequent partial loads of the validation split will never require
# downloading any videos
#
fiftyone zoo datasets load kinetics-700-2020 --split validation
fiftyone app launch kinetics-700-2020-validation
Note
In order to work with video datasets, you’ll need to have ffmpeg installed.