Note
This is a community plugin, an external project maintained by its respective author. Community plugins are not part of FiftyOne core and may change independently. Please review each plugin’s documentation and license before use.
SigLIP2 for FiftyOne#
This repository provides a FiftyOne integration for Google’s SigLIP2 embedding models, enabling powerful text-image similarity search capabilities in your FiftyOne datasets.
Overview#
SigLIP2 models create a shared embedding space for both images and text, allowing for:
Image-to-text similarity search
Text-to-image similarity search
Zero-shot image classification
Multimodal embeddings
This integration makes it easy to leverage these capabilities directly within your FiftyOne workflows.
Model Variants#
SigLIP2 comes in multiple variants with different tradeoffs
Model Type |
Parameters |
Image-Text Retrieval Performance |
NaFlex Variant |
|---|---|---|---|
Base (B) |
86M |
Shows significant improvements, particularly due to distillation techniques. Smaller models in the family. |
Available |
Large (L) |
303M |
Exhibits strong retrieval performance, consistently outperforming SigLIP and other baselines [analysis based on Table 1]. |
|
So400m |
400M |
Generally achieves higher retrieval performance compared to Base and Large models [analysis based on Table 1]. Also performs well as a vision encoder for VLMs. |
Available |
Giant (g) |
1B |
Achieves the highest reported retrieval performance among the SigLIP 2 variants [analysis based on Table 1]. |
N/A |
Key takeaways:
SigLIP 2 models come in four sizes, with increasing parameter counts generally leading to improved performance.
For image-text retrieval, larger models like So400m and Giant tend to perform better.
NaFlex variants, which support multiple resolutions and preserve native aspect ratios, are available for at least the Base, Large, and So400m sizes. These can be particularly beneficial for aspect-sensitive tasks like document understanding.
All SigLIP 2 models are multilingual vision-language encoders.
The So400m models offer a strong balance of performance and computational efficiency compared to the largest models.
Choosing the Right Variant#
For general photos/natural images: Standard fixed-resolution models (e.g.,
siglip2-so400m-patch16-384)For document-like, OCR, or screen images: NaFlex variants (e.g.,
siglip2-so400m-patch16-naflex)For speed-critical applications: Base models (e.g.,
siglip2-base-patch16-256)For highest accuracy: Giant models (e.g.,
siglip2-g-patch16-384)
Usage#
Installation#
Register and download the model from this repository:
import fiftyone.zoo as foz
# Register this custom model source
foz.register_zoo_model_source("https://github.com/harpreetsahota204/siglip2")
# Download your preferred SigLIP2 variant
foz.download_zoo_model(
"https://github.com/harpreetsahota204/siglip2",
model_name="google/siglip2-so400m-patch16-naflex",
)
Loading the Model#
import fiftyone.zoo as foz
model = foz.load_zoo_model(
"google/siglip2-so400m-patch16-naflex"
)
Computing Image Embeddings#
dataset.compute_embeddings(
model=model,
embeddings_field="siglip2_embeddings",
)
Visualizing Embeddings#
import fiftyone.brain as fob
results = fob.compute_visualization(
dataset,
embeddings="siglip2_embeddings",
method="umap",
brain_key="siglip2_viz",
num_dims=2,
)
# View in the App
session = fo.launch_app(dataset)
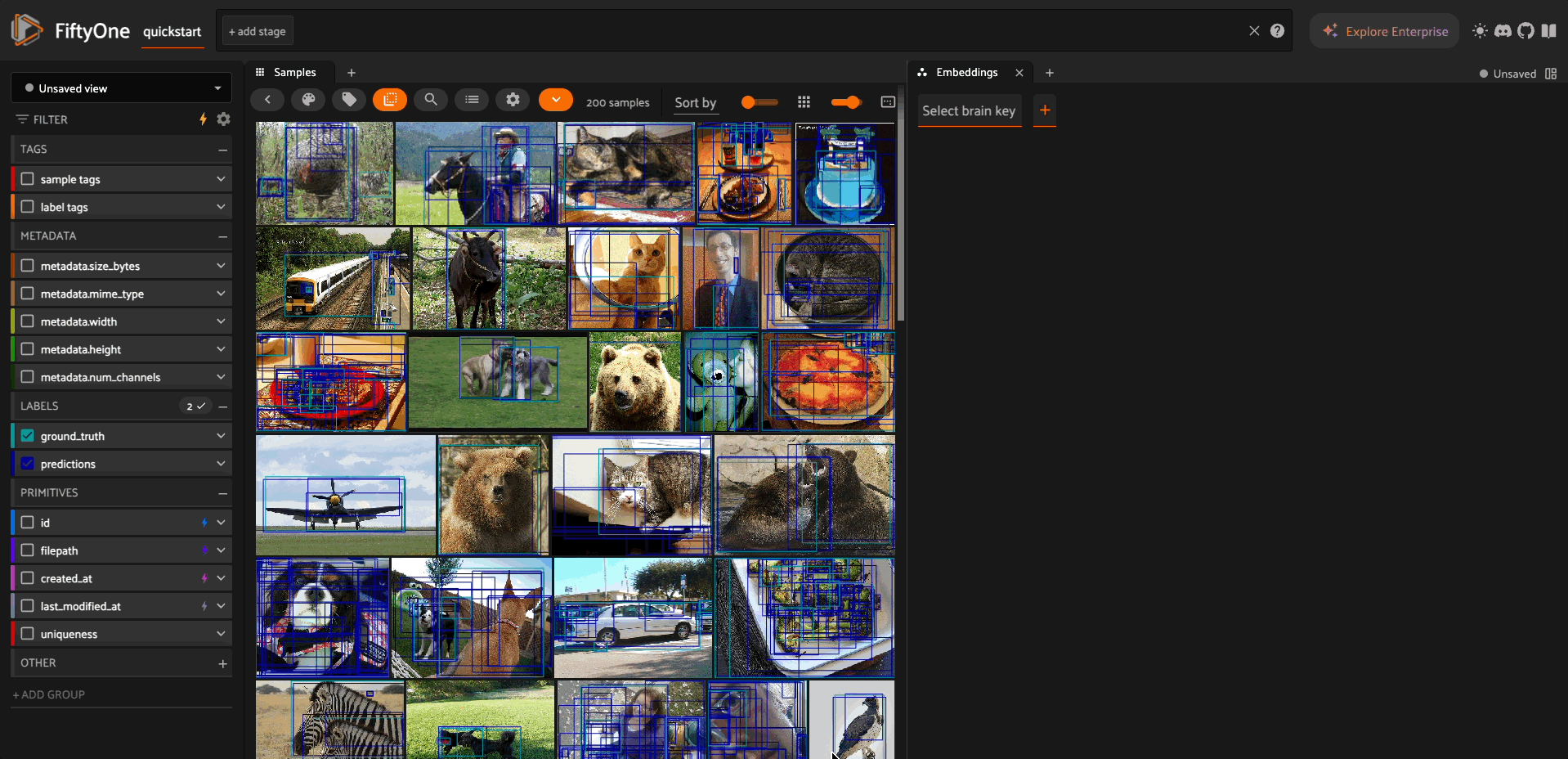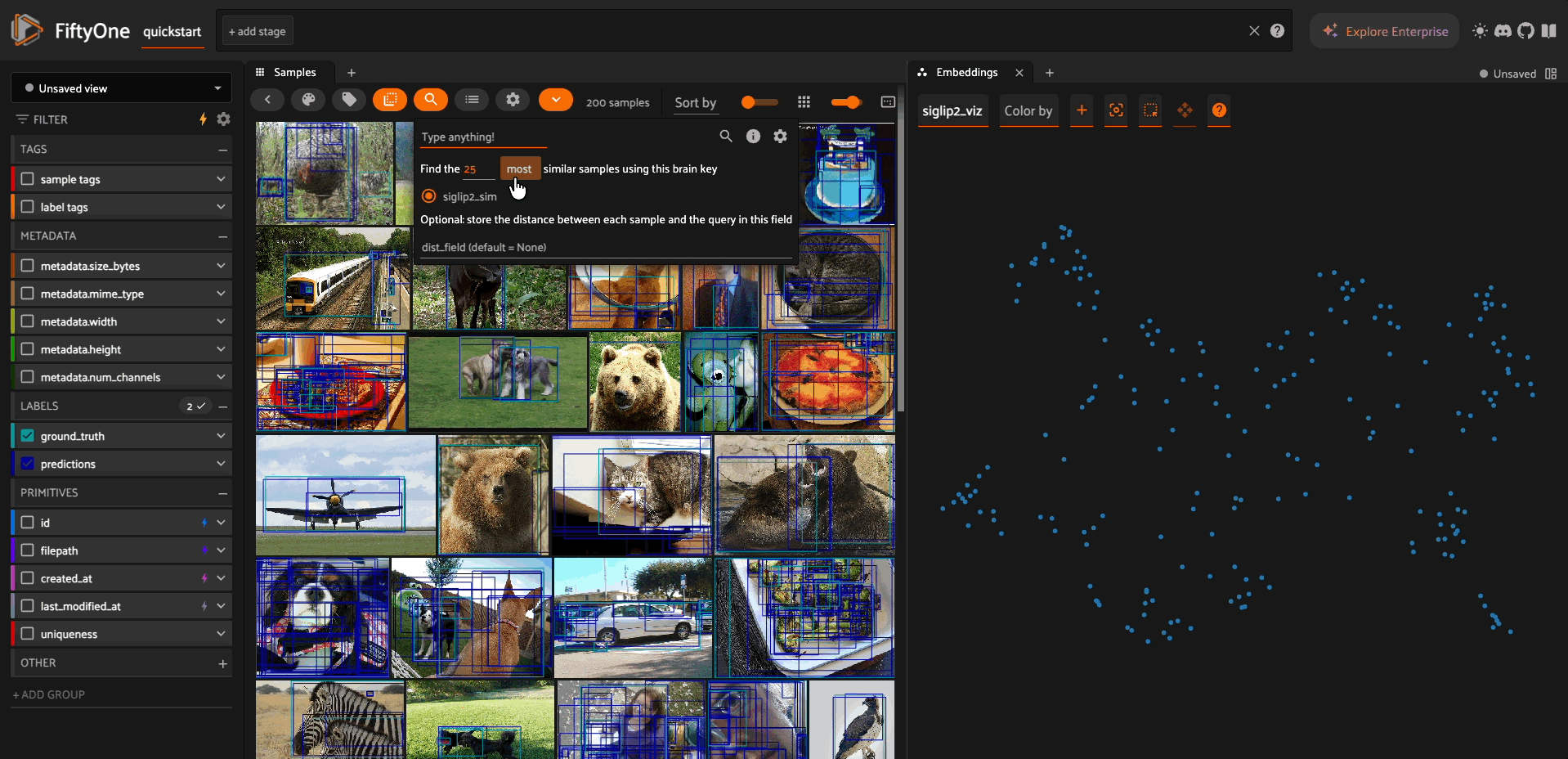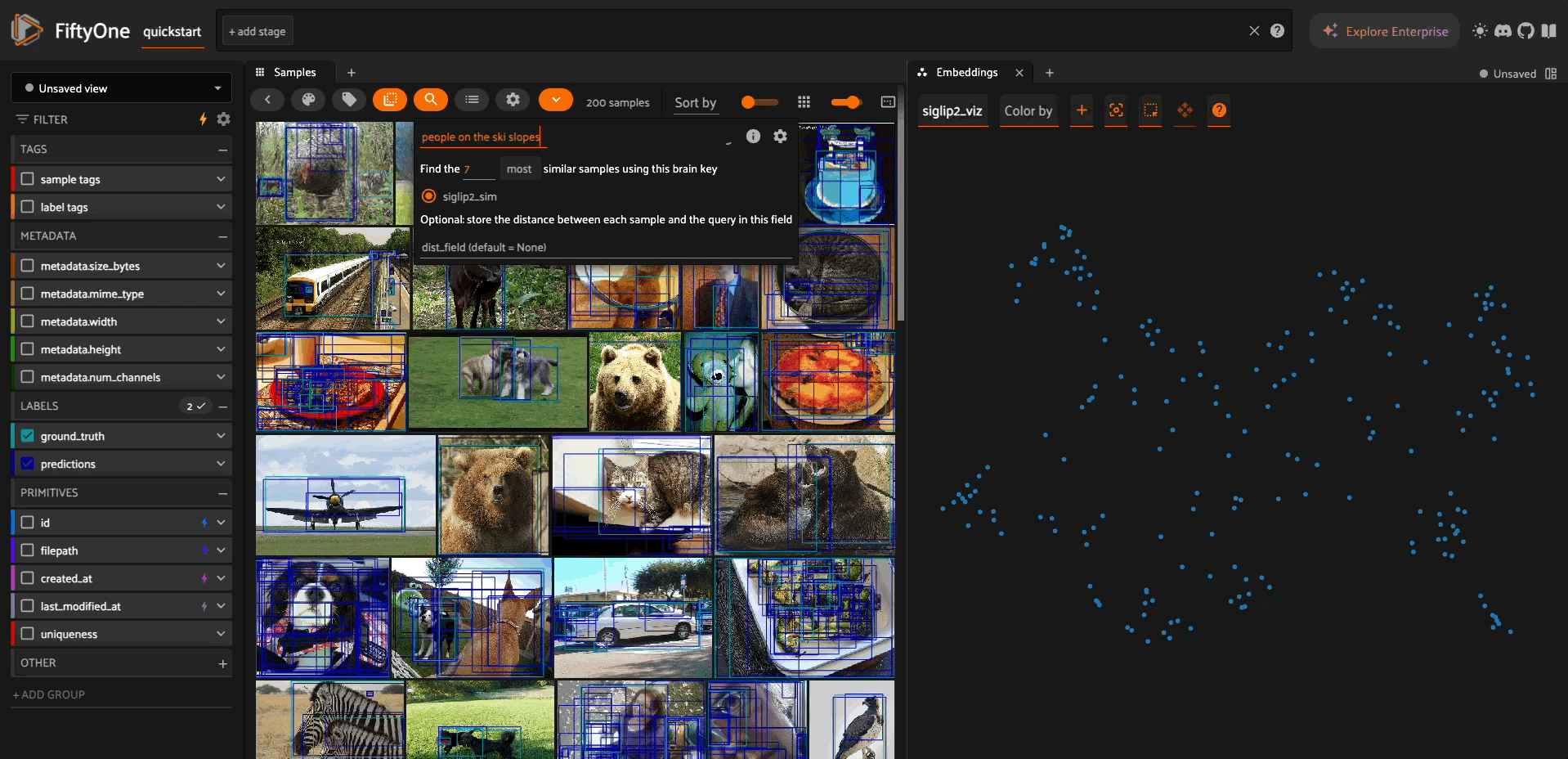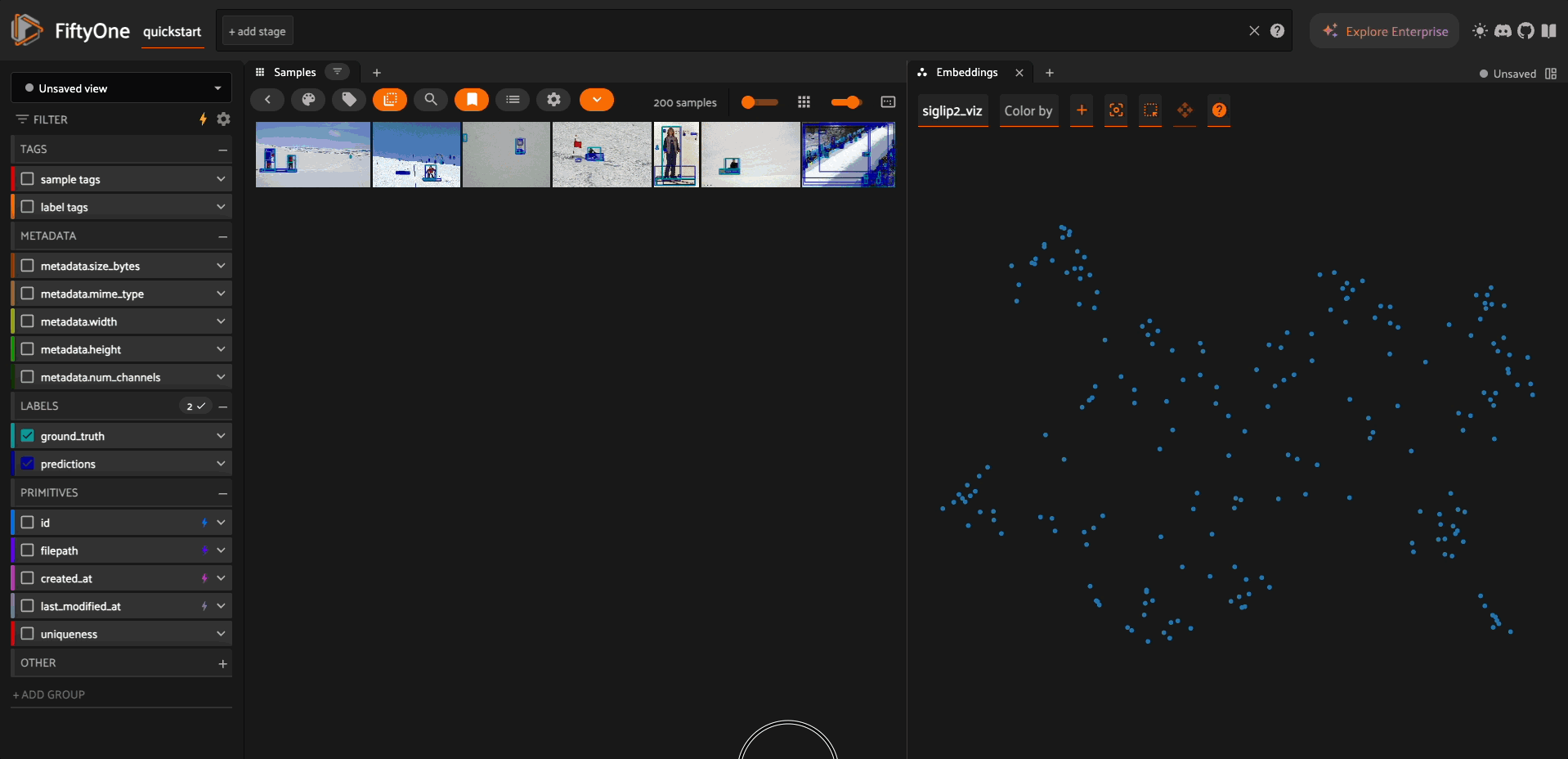
Text-Image Similarity Search#
import fiftyone.brain as fob
# Build a similarity index
text_img_index = fob.compute_similarity(
dataset,
model=model,
brain_key="siglip2_similarity",
)
# Search by text query
similar_images = text_img_index.sort_by_similarity("a dog playing in the snow")
# View results
session = fo.launch_app(similar_images)
Performance Notes#
Text-image similarity performance depends on the model variant used
SigLIP2 models excel at multilingual retrieval without specific training
Higher resolutions generally improve retrieval accuracy but increase processing time
NaFlex variants work particularly well for document images where aspect ratio matters
License#
This model is released with Apache-2.0 license. Refer to the official GitHub repository for licensing details.
Citation#
@article{tschannen2025siglip,
title={SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features},
author={Tschannen, Michael and Gritsenko, Alexey and Wang, Xiao and Naeem, Muhammad Ferjad and Alabdulmohsin, Ibrahim and Parthasarathy, Nikhil and Evans, Talfan and Beyer, Lucas and Xia, Ye and Mustafa, Basil and H\'enaff, Olivier and Harmsen, Jeremiah and Steiner, Andreas and Zhai, Xiaohua},
year={2025},
journal={arXiv preprint arXiv:2502.14786}
}
}