Note
This is a community plugin, an external project maintained by its respective author. Community plugins are not part of FiftyOne core and may change independently. Please review each plugin’s documentation and license before use.
EgoExOR: An Ego-Exo-Centric Operating Room Dataset for Surgical Activity Understanding#
Authors: Ege Özsoy, Arda Mamur, Felix Tristram, Chantal Pellegrini, Magdalena Wysocki, Benjamin Busam, Nassir Navab
News#
18 February 2026: EgoExOR-HQ — A new enriched version of the dataset is now available on TUM/EgoExOR (Hugging Face). This release adds:
High-quality images (1344×1344 instead of 336×336)
Raw depth images (instead of pre-merged point clouds)
Per-device audios
15 May 2025: EgoExOR — Initial release. Dataset, scene graph generation code, benchmarks, and pretrained model available on Hugging Face. Includes 94 minutes of multimodal surgical data (egocentric + exocentric), scene graph annotations (36 entities, 22 relations), and baseline model for surgical activity understanding.
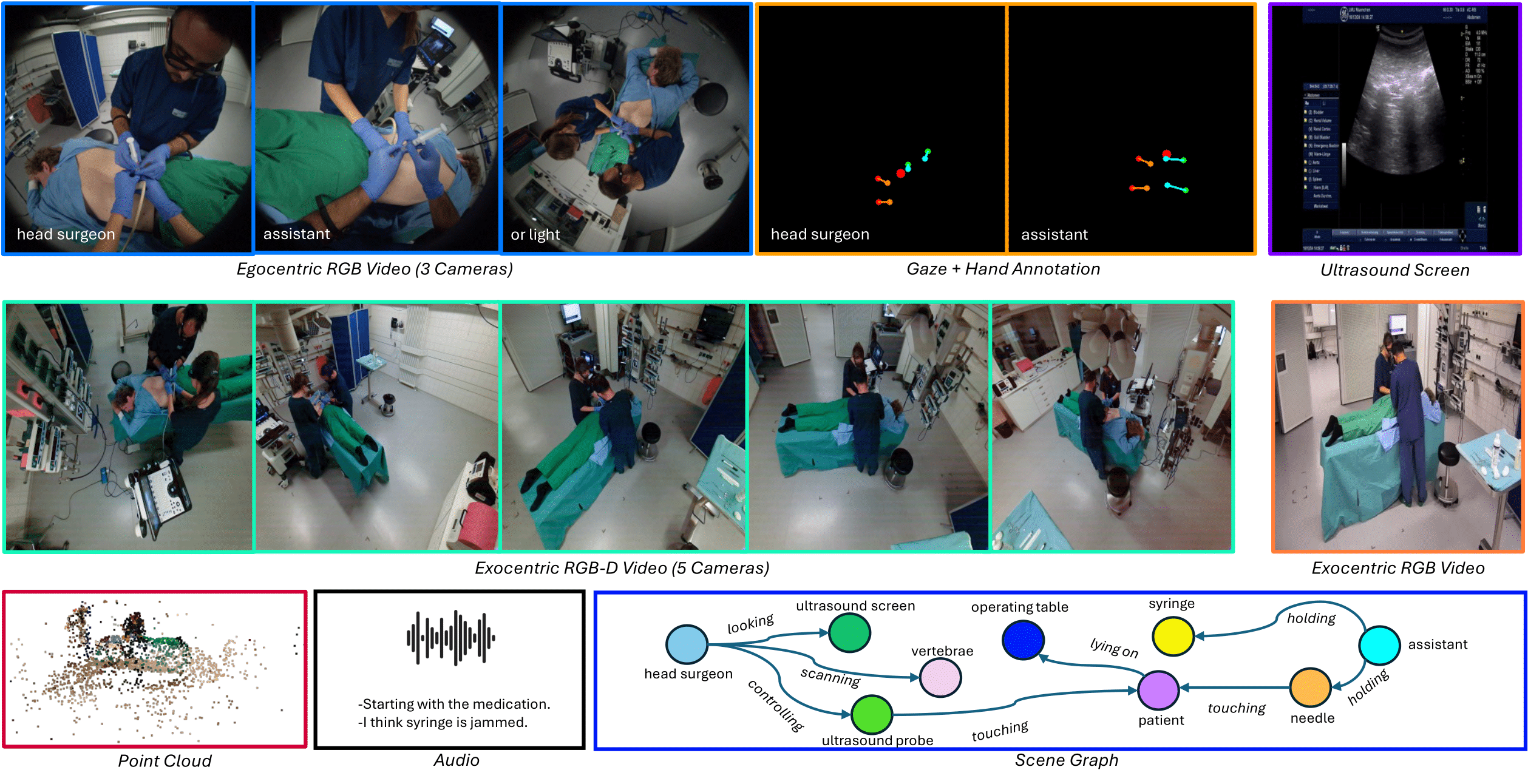
Operating rooms (ORs) demand precise coordination among surgeons, nurses, and equipment in a fast-paced, occlusion-heavy environment, necessitating advanced perception models to enhance safety and efficiency. Existing datasets either provide partial egocentric views or sparse exocentric multi-view context, but do not explore the comprehensive combination of both. We introduce EgoExOR, the first OR dataset and accompanying benchmark to fuse first-person and third-person perspectives. Spanning 94 minutes (84,553 frames at 15 FPS) of two emulated spine procedures—Ultrasound-Guided Needle Insertion and Minimally Invasive Spine Surgery—EgoExOR integrates egocentric data (RGB, gaze, hand tracking, audio) from wearable glasses, exocentric RGB and depth from RGB-D cameras, and ultrasound imagery. Its detailed scene graph annotations, covering 36 entities and 22 relations (568,235 triplets), enable robust modeling of clinical interactions, supporting tasks like action recognition and human-centric perception. This new dataset and benchmark set a new foundation for OR perception, offering a rich, multimodal resource for next-generation clinical perception.
Installation#
Environment Setup:
Install dependencies:
pip install -r requirements.txt
You may need to comment out
rerun-sdkand install it manually with conda-forge (known issue).Install LLaVA and extras:
cd scene_graph_generation/LLaVA && pip install -e . pip install flash-attn --no-build-isolation pip install spconv-cu117 # match your CUDA version pip install numpy==1.26.4 # if needed conda install pytorch-scatter -c pyg # or follow https://github.com/rusty1s/pytorch_scatter
Prepare the Data and Models#
Download the dataset — Follow
data/README.mdMerge HDF5 files
python -m data.utils.merge_h5 \ --data_dir /path/to/dataset/root_dir/ \ --input_files miss_1.h5 miss_2.h5 miss_3.h5 miss_4.h5 ultrasound_1.h5 ultrasound_2.h5 ultrasound_3.h5 ultrasound_4.h5 ultrasound_5_14.h5 ultrasound_5_58.h5 \ --splits_file splits.h5 \ --output_file egoexor.h5
Generate training JSON (for training)
python -m scene_graph_prediction.llava_helpers.generate_dataset_format_for_llava \ --hdf5_path "egoexor.h5" --dataset_name egoexor
Adjust parameters (e.g.
N_PEM) inegoexor.json.
Train#
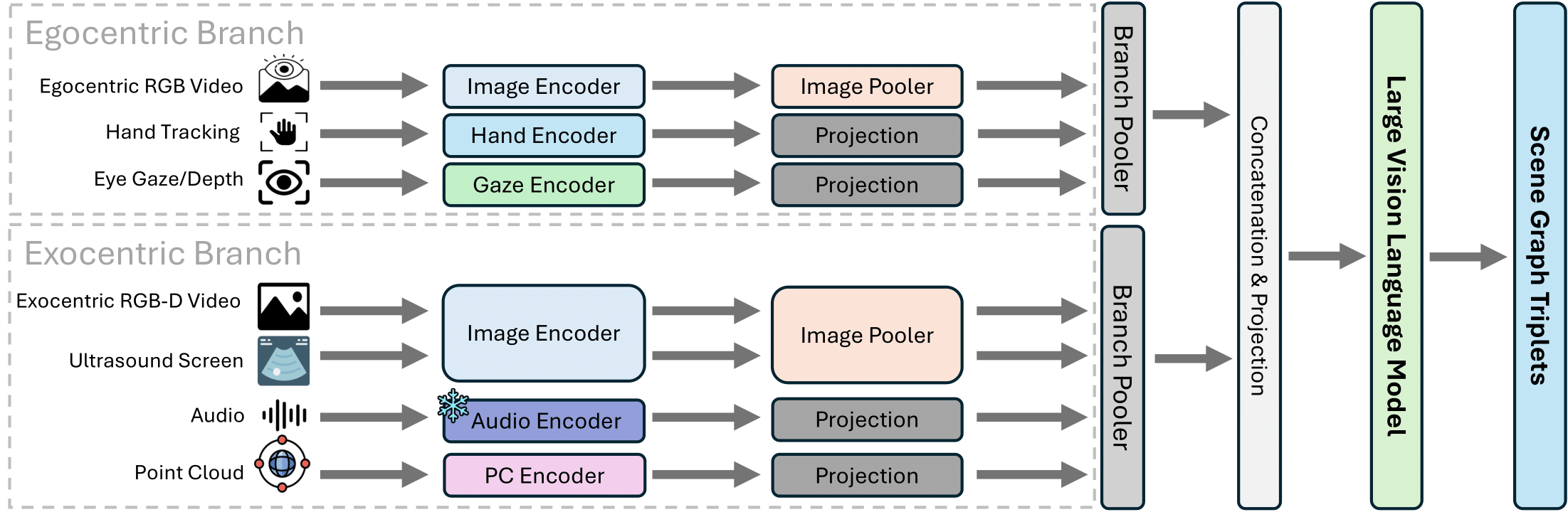
Scene Graph Generation Model — Our baseline uses two distinct branches: the egocentric branch processes first-person RGB, hand pose, and gaze; the exocentric branch handles third-person RGB-D, ultrasound, audio, and point clouds. This section builds on MM-OR and LLaVA.
Train (from LLaVA folder):
python -m llava.train.train_mem \ --lora_enable True \ --bits 4 \ --lora_r 128 \ --lora_alpha 256 \ --mm_projector_lr 2e-5 \ --model_name_or_path liuhaotian/llava-v1.5-7b \ --version v1 \ --dataset_name egoexor \ --data_path ../data/llava_samples/train_4perm_Falsetemp_Falsetempaug_EgoExOR_drophistory0.5.json \ --hdf5_path /path/to/egoexor.h5/ \ --token_weight_path ../data/llava_samples/train_token_freqs_7b_4perm_EgoExOR.json \ --vision_tower openai/clip-vit-large-patch14-336 \ --mm_projector_type mlp2x_gelu \ --mm_vision_select_layer -2 \ --mm_use_im_start_end False \ --mm_use_im_patch_token False \ --image_aspect_ratio pad \ --group_by_modality_length True \ --bf16 True \ --output_dir ./checkpoints/llava-v1.5-7b-task-lora_hybridor_qlora_4perm_EgoExOR \ --num_train_epochs 1 \ --per_device_train_batch_size 2 \ --per_device_eval_batch_size 2 \ --gradient_accumulation_steps 8 \ --evaluation_strategy "no" \ --save_strategy "steps" \ --save_steps 1 \ --learning_rate 2e-5 \ --max_grad_norm 0.1 \ --weight_decay 0. \ --warmup_ratio 0.03 \ --lr_scheduler_type "cosine" \ --logging_steps 1 \ --tf32 True \ --model_max_length 2048 \ --gradient_checkpointing True \ --dataloader_num_workers 4 \ --lazy_preprocess True \ --report_to wandb \ --run_name llava-v1.5-7b-task-lora_hybridor_qlora_4perm_EgoExOR \ --mv_type "learned" \ --unfreeze_n_vision_tower_layers 12 \ --multimodal_drop_prop 0.50 \ --do_augment False
Evaluate#
Pretrained model: EgoExOR on Hugging Face
Setup:
Download and unzip the model from the link above.
Download the test sample JSON from the model repository.
Adjust
data_dirandhdf5_pathinegoexor.json.
Run:
python -m scene_graph_prediction.main \
--config "egoexor.json" \
--model_path "path/to/model" \
--data_path "path/to/data_samples" \
--benchmark_on "egoexor" \
--mode "infer"
License#
Released under the Apache 2.0 License. Free for academic and commercial use with attribution.
Citation#
@inproceedings{NEURIPS2025_5e3ffa2c,
author = {\"{O}zsoy, Ege and Mamur, Arda and Tristram, Felix and Pellegrini, Chantal and Wysocki, Magdalena and Busam, Benjamin and Navab, Nassir},
booktitle = {Advances in Neural Information Processing Systems},
editor = {D. Belgrave and C. Zhang and H. Lin and R. Pascanu and P. Koniusz and M. Ghassemi and N. Chen},
pages = {},
publisher = {Curran Associates, Inc.},
title = {EgoExOR: An Ego-Exo-Centric Operating Room Dataset for Surgical Activity Understanding},
url = {https://proceedings.neurips.cc/paper_files/paper/2025/file/5e3ffa2c53dce23986ca0f8d1d2bbc7e-Paper-Datasets_and_Benchmarks_Track.pdf},
volume = {38},
year = {2025}
}