Note
This is a community plugin, an external project maintained by its respective author. Community plugins are not part of FiftyOne core and may change independently. Please review each plugin’s documentation and license before use.
BiModernVBert for FiftyOne#
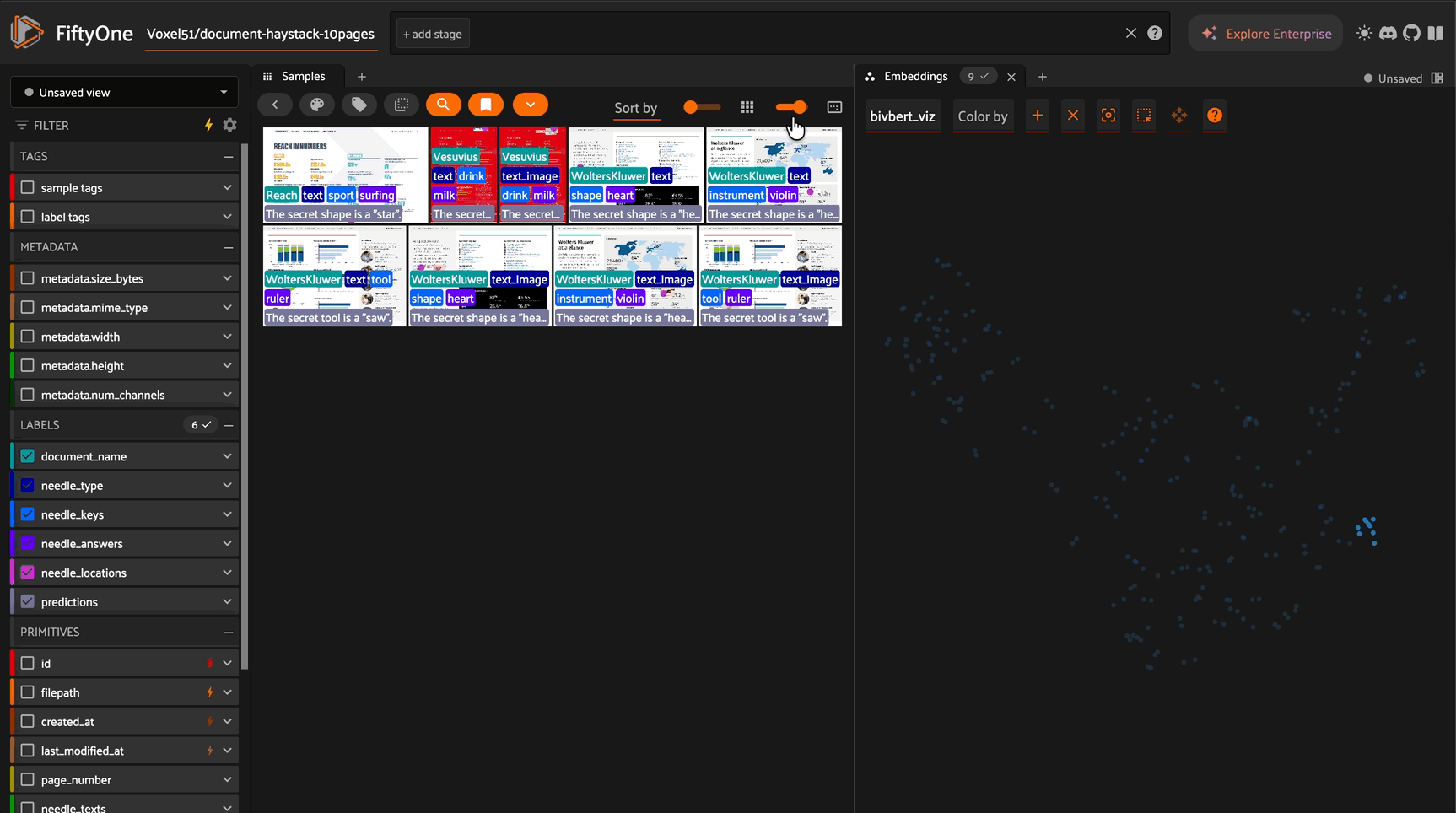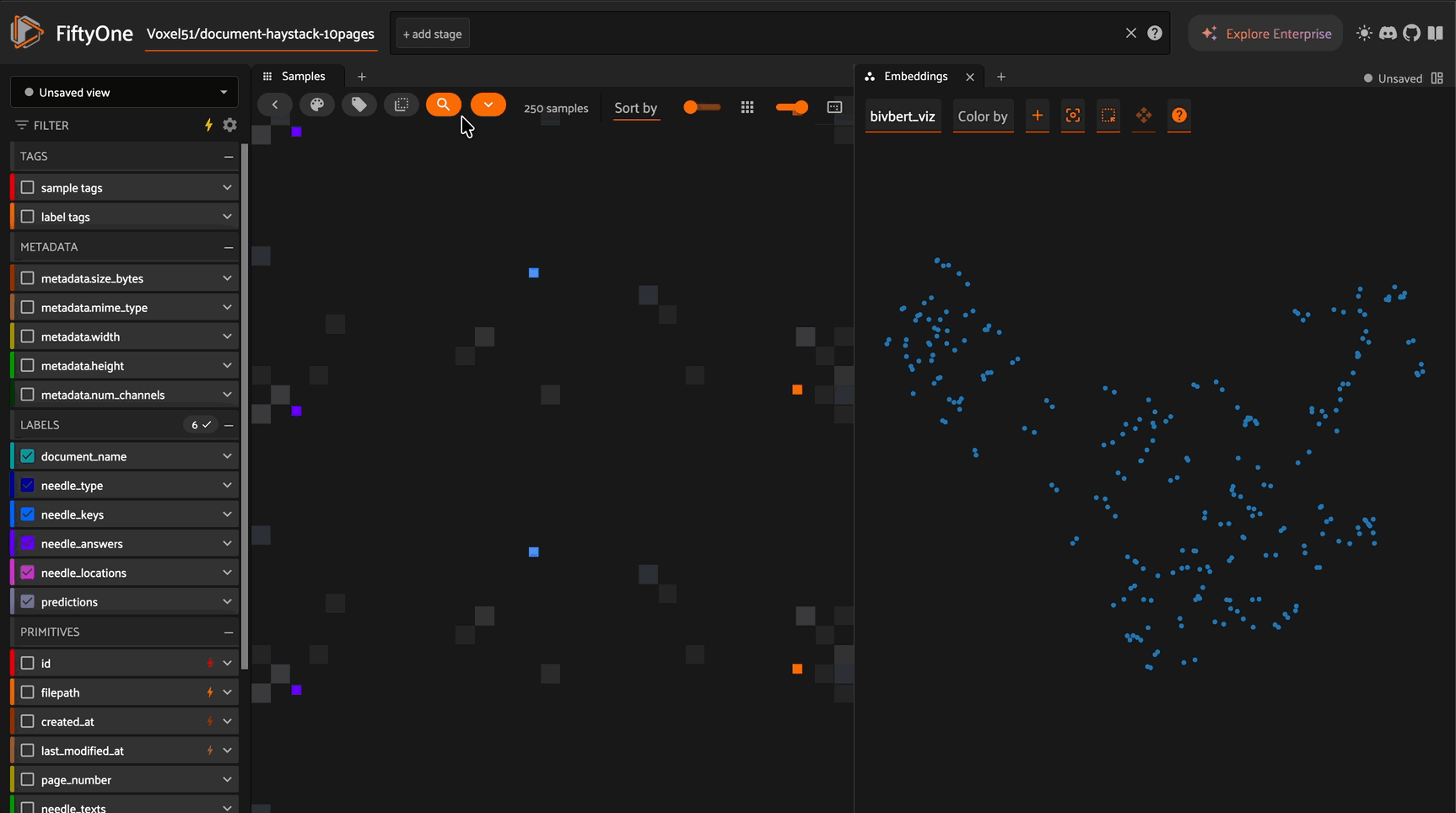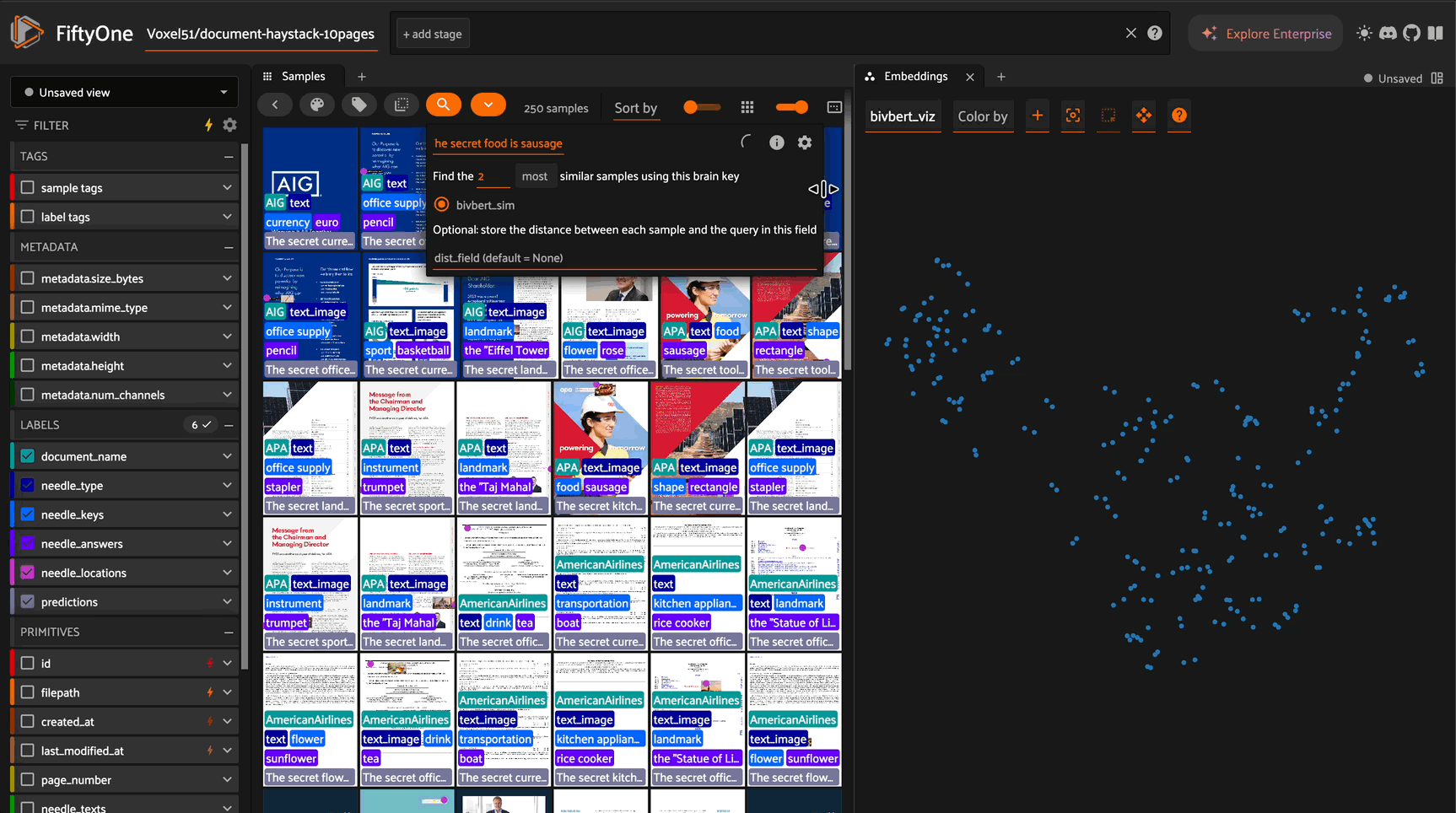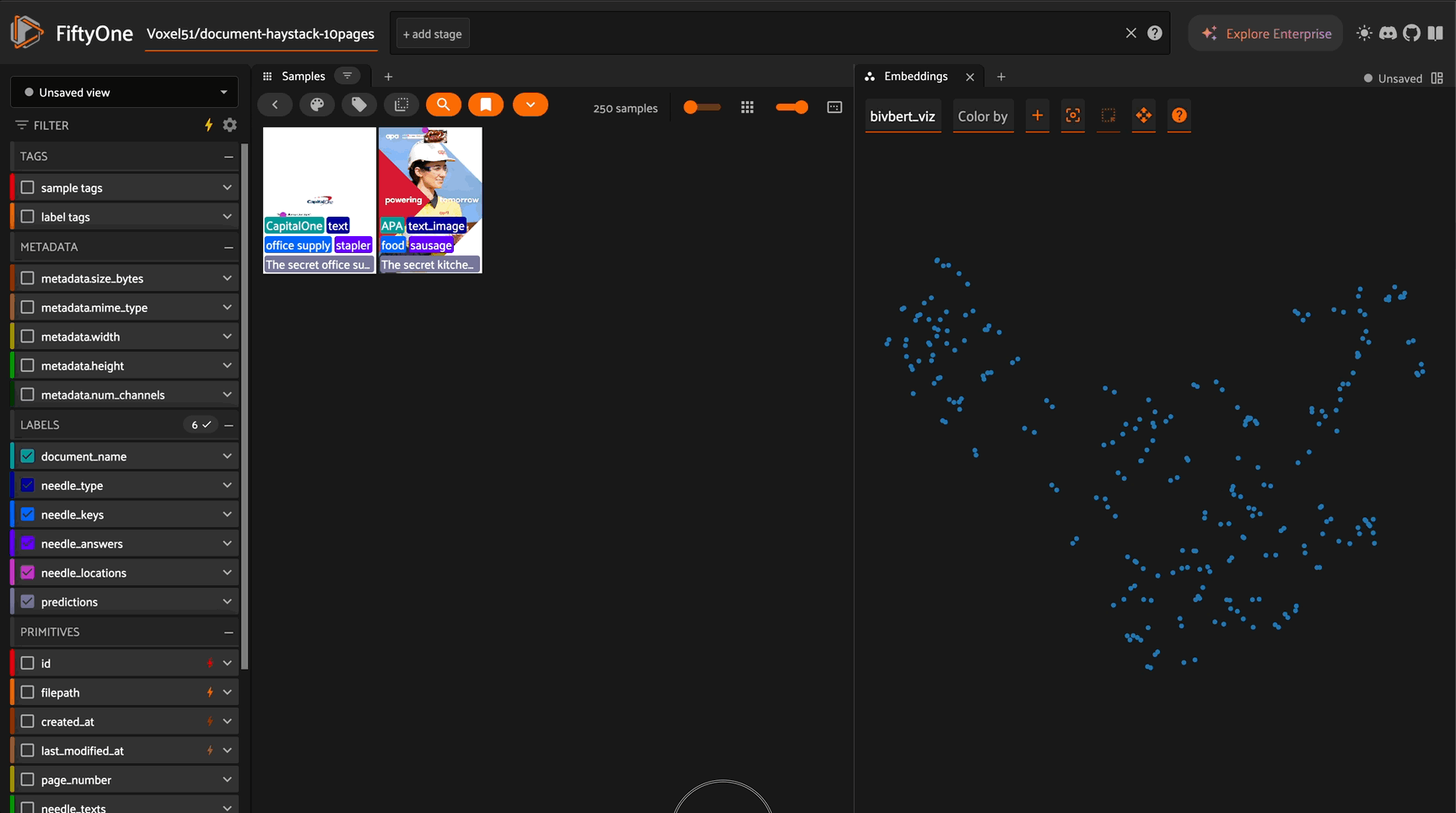
BiModernVBert is a vision-language model built on the ModernVBert architecture that generates embeddings for both images and text in a shared 768-dimensional vector space. Unlike multi-vector models (ColPali, Jina v4), BiModernVBert uses single-vector embeddings with simple cosine similarity, making it efficient for large-scale document retrieval while maintaining strong performance.
Key Features#
Single-Vector Embeddings: 768-dimensional vectors for both images and text
Normalized Embeddings: L2-normalized, ready for efficient cosine similarity
Simple Architecture: No multi-vector complexity or pooling required
Efficient Retrieval: Fast similarity search with single vectors
Zero-Shot Classification: Use text prompts to classify images without training
Document Understanding: Optimized for visual document analysis
Built-in Scoring: Uses processor’s efficient cosine similarity implementation
How It Works#
Retrieval Pipeline:
dataset.compute_embeddings(model, embeddings_field="embeddings")
> embed_images()
> processor.process_images(imgs)
> model(**inputs)
> Returns (batch, 768) normalized embeddings
> Stores in FiftyOne for cosine similarity search
Classification Pipeline:
dataset.apply_model(model, label_field="predictions")
> _predict_all()
> Get image embeddings (batch, 768)
> Get text embeddings for classes (num_classes, 768)
> processor.score(text_embs, image_embs) # Cosine similarity
> Returns classification logits
> Output processor → Classification labels
Installation#
Note: This model requires the colpali-engine package which provides the BiModernVBert implementation.
# Install FiftyOne and BiModernVBert dependencies
pip install fiftyone torch transformers pillow
pip install git+https://github.com/illuin-tech/colpali.git@vbert#egg=colpali-engine
Quick Start#
Load Dataset#
import fiftyone as fo
from fiftyone.utils.huggingface import load_from_hub
# Load document dataset from Hugging Face
dataset = load_from_hub(
"Voxel51/document-haystack-10pages",
overwrite=True,
max_samples=250 # Optional: subset for testing
)
Register the Zoo Model#
import fiftyone.zoo as foz
# Register this repository as a remote zoo model source
foz.register_zoo_model_source(
"https://github.com/harpreetsahota204/bimodernvbert",
overwrite=True
)
Basic Workflow#
import fiftyone.zoo as foz
import fiftyone.brain as fob
# Load BiModernVBert model
model = foz.load_zoo_model("ModernVBERT/bimodernvbert")
# Compute embeddings for all documents
dataset.compute_embeddings(
model=model,
embeddings_field="bimodernvbert_embeddings"
)
# Check embedding dimensions
print(dataset.first()['bimodernvbert_embeddings'].shape) # (768,)
# Build similarity index
text_img_index = fob.compute_similarity(
dataset,
model="ModernVBERT/bimodernvbert",
embeddings_field="bimodernvbert_embeddings",
brain_key="bimodernvbert_sim"
)
# Query for specific content
results = text_img_index.sort_by_similarity(
"invoice from 2024",
k=10 # Top 10 results
)
# Launch FiftyOne App
session = fo.launch_app(results, auto=False)
Advanced Embedding Workflows#
Embedding Visualization with UMAP#
Create 2D visualizations of your document embeddings:
import fiftyone.brain as fob
# First compute embeddings
dataset.compute_embeddings(
model=model,
embeddings_field="bimodernvbert_embeddings"
)
# Create UMAP visualization
results = fob.compute_visualization(
dataset,
method="umap", # Also supports "tsne", "pca"
brain_key="bimodernvbert_viz",
embeddings="bimodernvbert_embeddings",
num_dims=2
)
# Explore in the App
session = fo.launch_app(dataset)
Dataset Representativeness#
Score how representative each sample is of your dataset:
import fiftyone.brain as fob
# Compute representativeness scores
fob.compute_representativeness(
dataset,
representativeness_field="bimodernvbert_represent",
method="cluster-center",
embeddings="bimodernvbert_embeddings"
)
# Find most representative samples
representative_view = dataset.sort_by("bimodernvbert_represent", reverse=True)
Duplicate Detection#
Find and remove near-duplicate documents:
import fiftyone.brain as fob
# Detect duplicates using embeddings
results = fob.compute_uniqueness(
dataset,
embeddings="bimodernvbert_embeddings"
)
# Filter to most unique samples
unique_view = dataset.sort_by("uniqueness", reverse=True)
Zero-Shot Classification#
BiModernVBert supports zero-shot classification using cosine similarity between image and text embeddings:
import fiftyone.zoo as foz
# Load model with classes for classification
model = foz.load_zoo_model(
"ModernVBERT/bimodernvbert",
classes=["invoice", "receipt", "form", "contract", "other"],
text_prompt="This document is a"
)
# Apply model for zero-shot classification
dataset.apply_model(
model,
label_field="document_type_predictions"
)
# View predictions
print(dataset.first()['document_type_predictions'])
session = fo.launch_app(dataset)
Dynamic Classification with Multiple Tasks#
import fiftyone.zoo as foz
# Load model once
model = foz.load_zoo_model("ModernVBERT/bimodernvbert")
# Task 1: Classify document types
model.classes = ["invoice", "receipt", "form", "contract"]
model.text_prompt = "This is a"
dataset.apply_model(model, label_field="doc_type")
# Task 2: Classify importance (reuse same model!)
model.classes = ["high_priority", "medium_priority", "low_priority"]
model.text_prompt = "The priority level is"
dataset.apply_model(model, label_field="priority")
# Task 3: Classify language
model.classes = ["english", "spanish", "french", "german", "chinese"]
model.text_prompt = "The document language is"
dataset.apply_model(model, label_field="language")
Resources#
Model Hub: ModernVBERT/bimodernvbert
ColPali Engine: colpali-engine
FiftyOne Docs: docs.voxel51.com
Base Architecture: ModernVBert
Citation#
If you use BiModernVBert in your research, please cite:
@misc{teiletche2025modernvbertsmallervisualdocument,
title={ModernVBERT: Towards Smaller Visual Document Retrievers},
author={Paul Teiletche and Quentin Macé and Max Conti and Antonio Loison and Gautier Viaud and Pierre Colombo and Manuel Faysse},
year={2025},
eprint={2510.01149},
archivePrefix={arXiv},
primaryClass={cs.IR},
url={https://arxiv.org/abs/2510.01149},
}
License#
Model: MIT
Integration Code: Apache 2.0 (see LICENSE)
Contributing#
Found a bug or have a feature request? Please open an issue on GitHub!
Acknowledgments#
ModernVBERT Team for the excellent BiModernVBert model
ColPali Engine for the model implementation and processor
Voxel51 for the FiftyOne framework and brain module architecture
HuggingFace for model hosting