Note
This is a community plugin, an external project maintained by its respective author. Community plugins are not part of FiftyOne core and may change independently. Please review each plugin’s documentation and license before use.
ColPali v1.3 for FiftyOne#
Integration of ColPali v1.3 (merged) as a FiftyOne Zoo Model for visual document retrieval.
Overview#
ColPali is a Vision Language Model based on PaliGemma-3B that generates ColBERT-style multi-vector representations for efficient document retrieval. This integration adapts ColPali for use with FiftyOne’s embedding and similarity infrastructure.
Deviations from Native Implementation#
The Challenge#
ColPali natively produces variable-length multi-vector embeddings:
Images:
(1031 vectors, 128 dims)per documentQueries:
(19 vectors, 128 dims)per text query
These variable-length embeddings are incompatible with FiftyOne’s standard similarity infrastructure, which requires fixed-dimension vectors.
Our Solution: Two-Stage Compression#
Stage 1: Token Pooling (Intelligent Compression)#
We use ColPali’s built-in HierarchicalTokenPooler with pool_factor=3:
Images:
(1031, 128)→(~344, 128)Queries:
(19, 128)→(~6, 128)Performance: Retains ~97.8% of native ColPali accuracy
Benefit: Removes redundant patches (e.g., white backgrounds)
Stage 2: Final Pooling (FiftyOne Compatibility)#
After token pooling, we apply a final pooling operation to produce fixed-dimension embeddings:
Strategy |
Output |
Best For |
|---|---|---|
|
|
Holistic document matching, layout understanding |
|
|
Specific content/keyword matching |
Both strategies produce embeddings compatible with FiftyOne’s similarity search.
Installation#
# Install FiftyOne and ColPali dependencies
pip install fiftyone colpali-engine transformers torch huggingface-hub
Quick Start#
Register the Zoo Model#
import fiftyone.zoo as foz
# Register this repository as a remote zoo model source
foz.register_zoo_model_source(
"https://github.com/harpreetsahota204/colpali_v1_3",
overwrite=True
)
Load Dataset#
import fiftyone as fo
from fiftyone.utils.huggingface import load_from_hub
# Load document dataset from Hugging Face
dataset = load_from_hub(
"Voxel51/document-haystack-10pages",
overwrite=True
)
Basic Workflow#
import fiftyone.zoo as foz
import fiftyone.brain as fob
# Load ColPali model with desired pooling strategy
model = foz.load_zoo_model(
"vidore/colpali-v1.3-merged",
pooling_strategy="max", # or "mean" (default)
pool_factor=3 # Compression factor
)
# Compute embeddings for all documents
dataset.compute_embeddings(
model=model,
embeddings_field="copali_embeddings",
)
# Check embedding dimensions
print(dataset.first()['copali_embeddings'].shape) # Should be (128,)
# Build similarity index
text_img_index = fob.compute_similarity(
dataset,
model="vidore/colpali-v1.3-merged",
embeddings_field="copali_embeddings",
brain_key="copali_sim",
model_kwargs={
"pooling_strategy": "max",
"pool_factor": 3,
}
)
# Sort by similarity to text query
text_sim = text_img_index.sort_by_similarity(
["AIG Documents", "UPS Documents", "The secret currency is Euro", "The secret office supply is a stapler"]
k=3
)
# Launch FiftyOne App
session = fo.launch_app(dataset, auto=False)
Zero-shot classification#
classes = dataset.distinct("document_name.label")
model.classes = classes
model.text_prompt = "A document from "
dataset.apply_model(
model,
label_field="document_name_predictions"
)
Advanced Embedding Workflows#
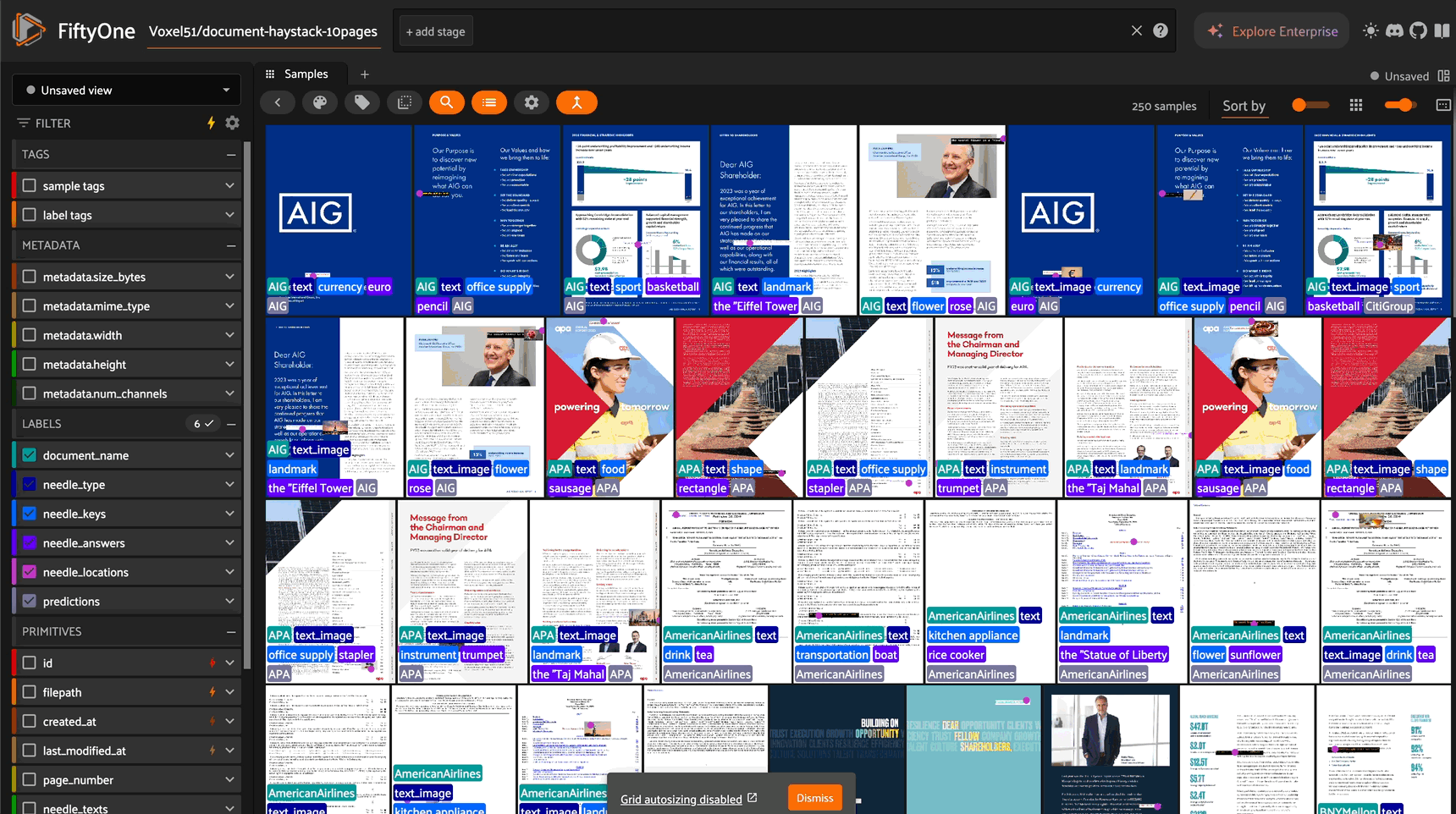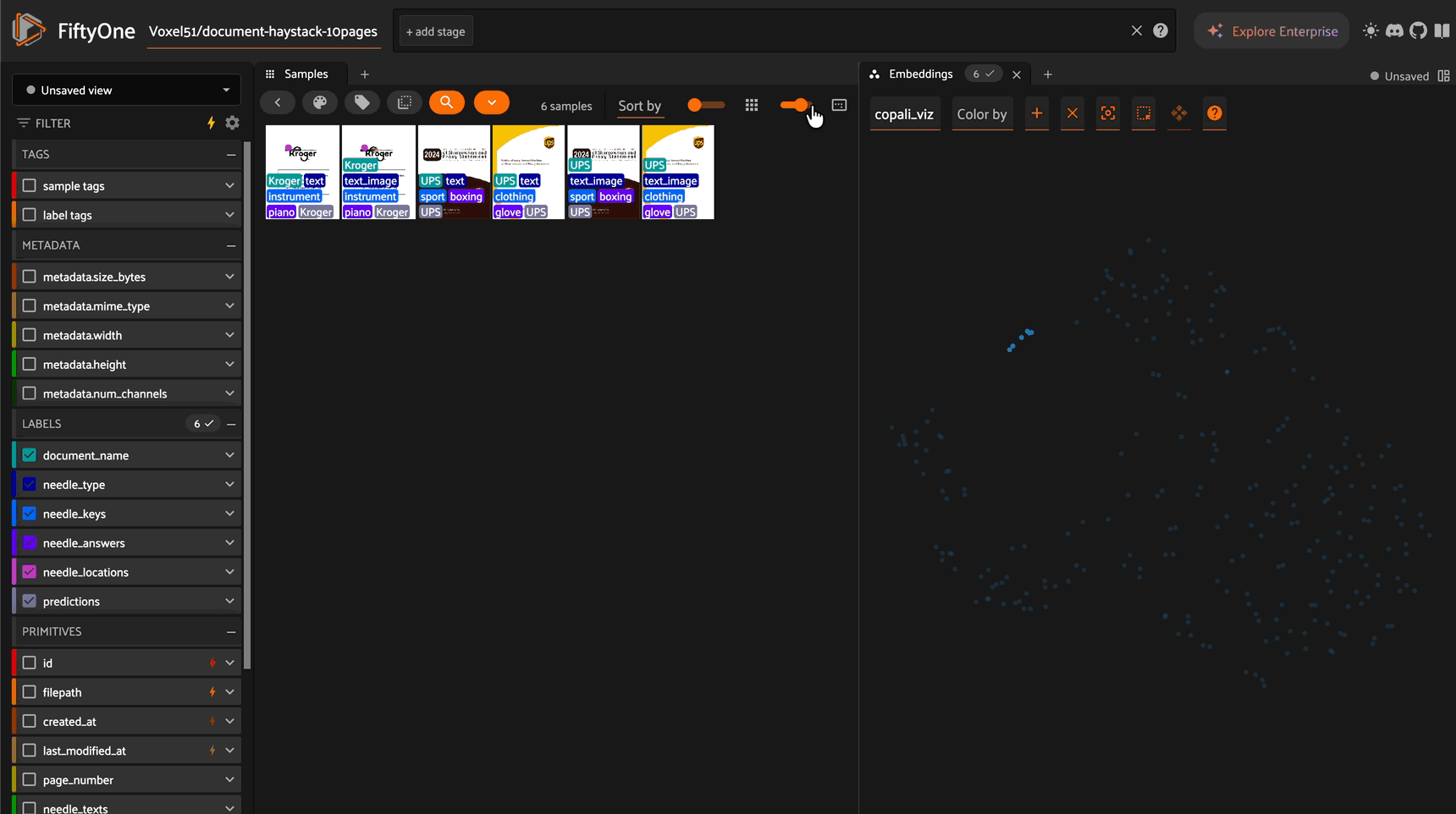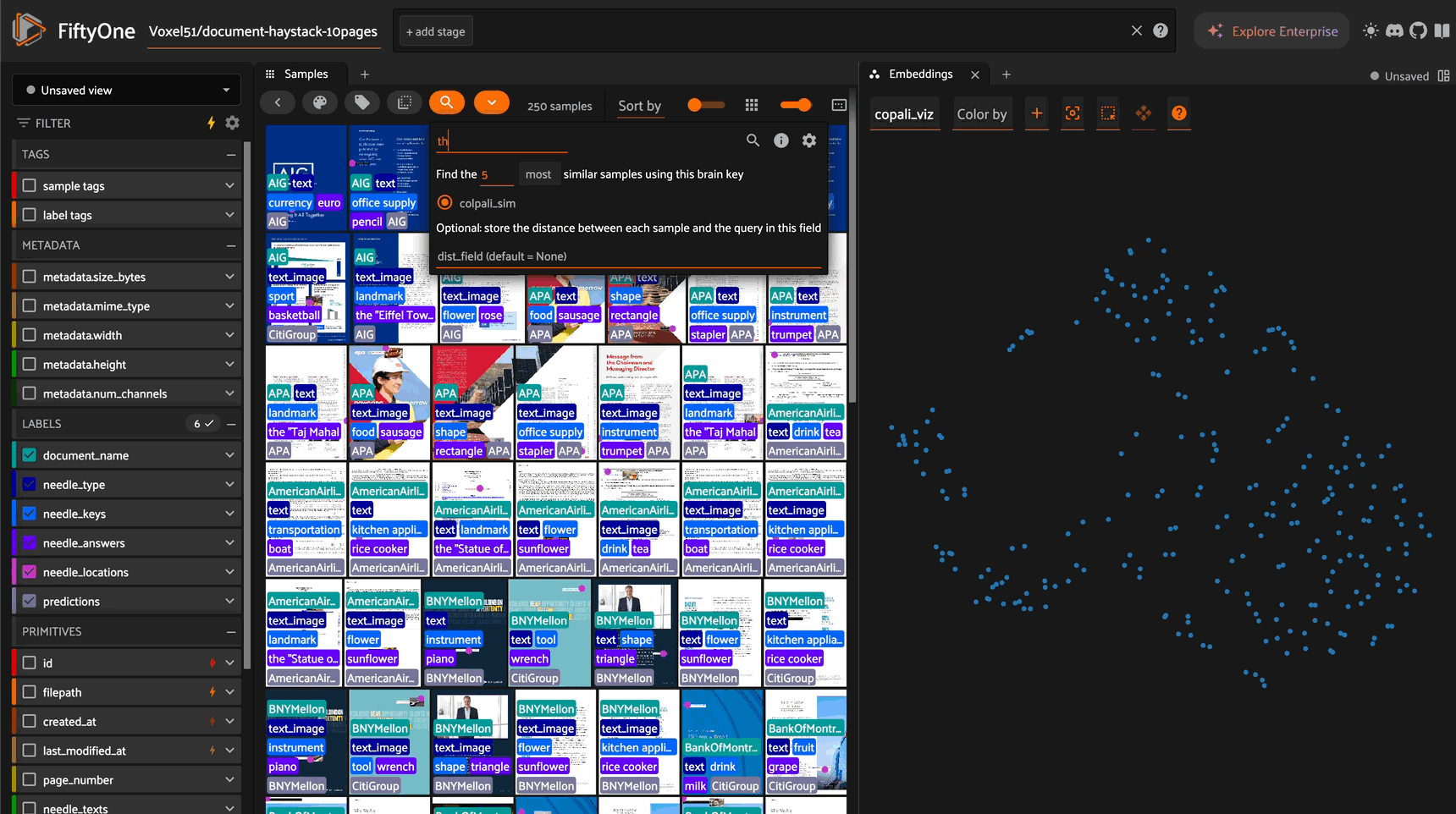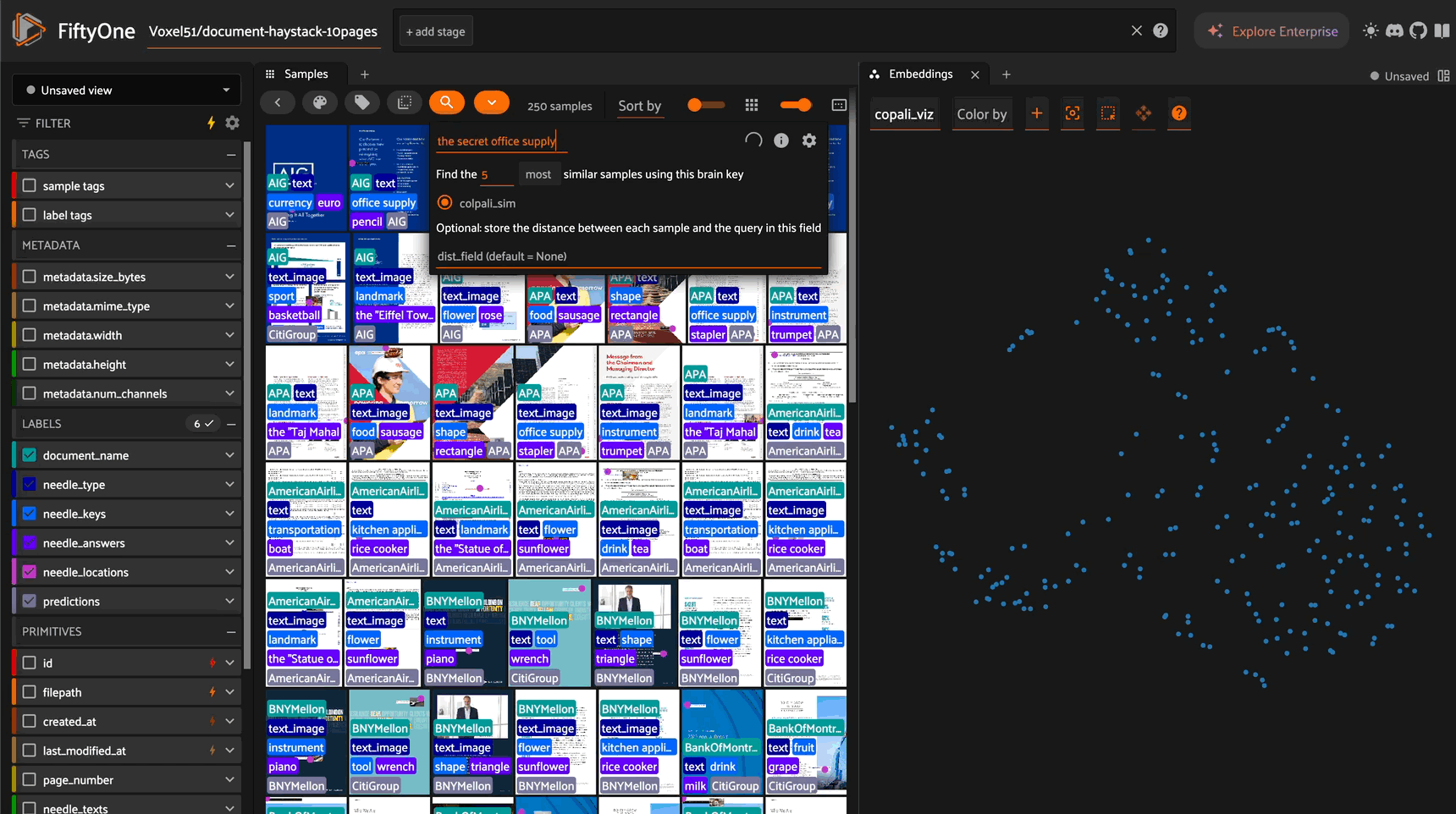
Embedding Visualization with UMAP#
Create 2D visualizations of your document embeddings:
import fiftyone.brain as fob
# First compute embeddings
dataset.compute_embeddings(
model=model,
embeddings_field="colpali_embeddings"
)
# Create UMAP visualization
results = fob.compute_visualization(
dataset,
method="umap", # Also supports "tsne", "pca"
brain_key="colpali_viz",
embeddings="colpali_embeddings"
)
# Explore in the App
session = fo.launch_app(dataset)
Similarity Search#
Build powerful similarity search with ColPali embeddings:
import fiftyone.brain as fob
# Build similarity index
results = fob.compute_similarity(
dataset,
backend="sklearn", # Fast sklearn backend
brain_key="colpali_sim",
embeddings="colpali_embeddings"
)
# Find similar images
sample_id = dataset.first().id
similar_samples = dataset.sort_by_similarity(
sample_id,
brain_key="colpali_sim",
k=10 # Top 10 most similar
)
# View results
session = fo.launch_app(similar_samples)
Dataset Representativeness#
Score how representative each sample is of your dataset:
import fiftyone.brain as fob
# Compute representativeness scores
fob.compute_representativeness(
dataset,
representativeness_field="colpali_represent",
method="cluster-center",
embeddings="colpali_embeddings"
)
# Find most representative samples
representative_view = dataset.sort_by("colpali_represent", reverse=True)
Duplicate Detection#
Find and remove near-duplicate documents:
import fiftyone.brain as fob
# Detect duplicates using embeddings
results = fob.compute_uniqueness(
dataset,
embeddings="colpali_embeddings"
)
# Filter to most unique samples
unique_view = dataset.sort_by("uniqueness", reverse=True)
Advanced: Custom Analysis Pipeline#
Combine multiple ColPali outputs for comprehensive analysis:
# Global embeddings for similarity
embedding_model = foz.load_zoo_model("nv_labs/c-colpali_v3-h")
dataset.compute_embeddings(embedding_model, "colpali_embeddings")
# Build similarity index
import fiftyone.brain as fob
fob.compute_similarity(dataset, embeddings="colpali_embeddings", brain_key="colpali_sim")
# Comprehensive analysis
session = fo.launch_app(dataset)
Technical Details#
FiftyOne Integration Architecture#
Raw embeddings → Token pooling (factor=3) → Final pooling (mean/max) → Fixed (128,)
Retrieval Pipeline:
dataset.compute_embeddings(model, embeddings_field="embeddings")
> embed_images(): Applies token + final pooling
> Returns (128,) compressed vectors
> Stores in FiftyOne for similarity search
Both pipelines produce consistent, fixed-dimension embeddings compatible with FiftyOne’s infrastructure.
Key Implementation Notes#
raw_inputs=True: ColPaliProcessor handles all preprocessing, so FiftyOne’s default transforms are disabledImage Format Conversion: FiftyOne may pass images as PIL, numpy arrays, or tensors; we convert all to PIL for ColPaliProcessor compatibility
Compression: Uses token-pooled and final-pooled embeddings
Fixed Dimensions: After compression, all embeddings are 128-dimensional and compatible with all FiftyOne brain methods
Single-Vector Scoring: Uses
score_single_vector()after embeddings are compressed to fixed dimensions
Configuration Options#
Pooling Strategy#
# Mean pooling (default) - holistic document matching
model = foz.load_zoo_model(
"vidore/colpali-v1.3-merged",
pooling_strategy="mean"
)
# Max pooling - specific content/keyword matching
model = foz.load_zoo_model(
"vidore/colpali-v1.3-merged",
pooling_strategy="max"
)
Pool Factor#
# More aggressive compression (faster, less accurate)
model = foz.load_zoo_model(
"vidore/colpali-v1.3-merged",
pool_factor=5
)
Resources#
Original Repository: illuin-tech/colpali
Model Weights: vidore/colpali-v1.3-merged
Paper: ColPali: Efficient Document Retrieval with Vision Language Models
Citation#
If you use ColPali in your research, please cite:
@misc{faysse2024colpaliefficientdocumentretrieval,
title={ColPali: Efficient Document Retrieval with Vision Language Models},
author={Manuel Faysse and Hugues Sibille and Tony Wu and Bilel Omrani and Gautier Viaud and Céline Hudelot and Pierre Colombo},
year={2024},
eprint={2407.01449},
archivePrefix={arXiv},
primaryClass={cs.IR},
url={https://arxiv.org/abs/2407.01449},
}
License#
Model Weights: Gemma License
Integration Code: Apache 2.0 License (see LICENSE)
Files#
zoo.py: ColPali model implementation with token pooling__init__.py: Package initializationmanifest.json: Zoo model metadata
Requirements#
See manifest.json for complete dependencies:
colpali-engine(includes HierarchicalTokenPooler)transformerstorch/torchvisionhuggingface-hubfiftyone