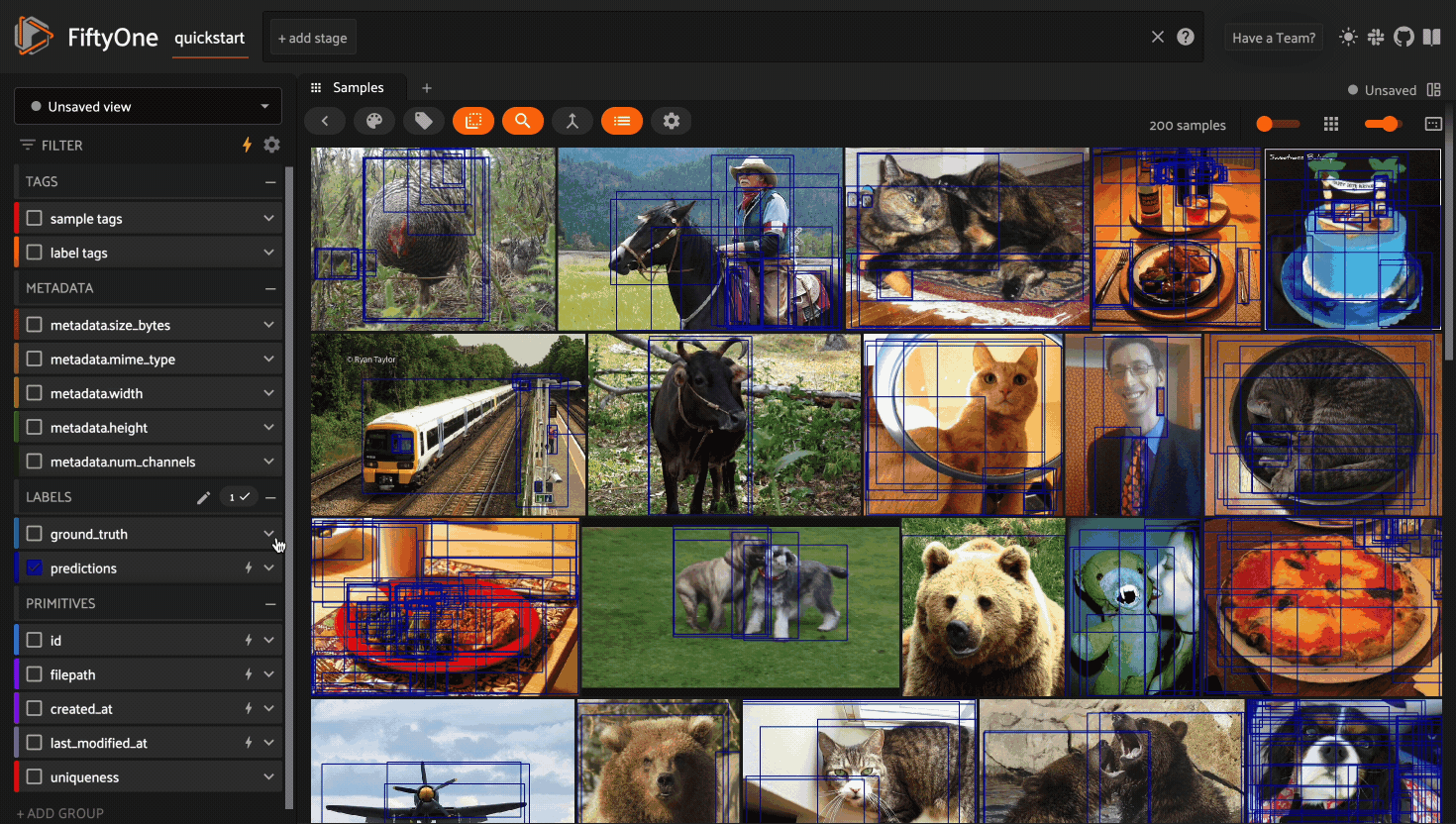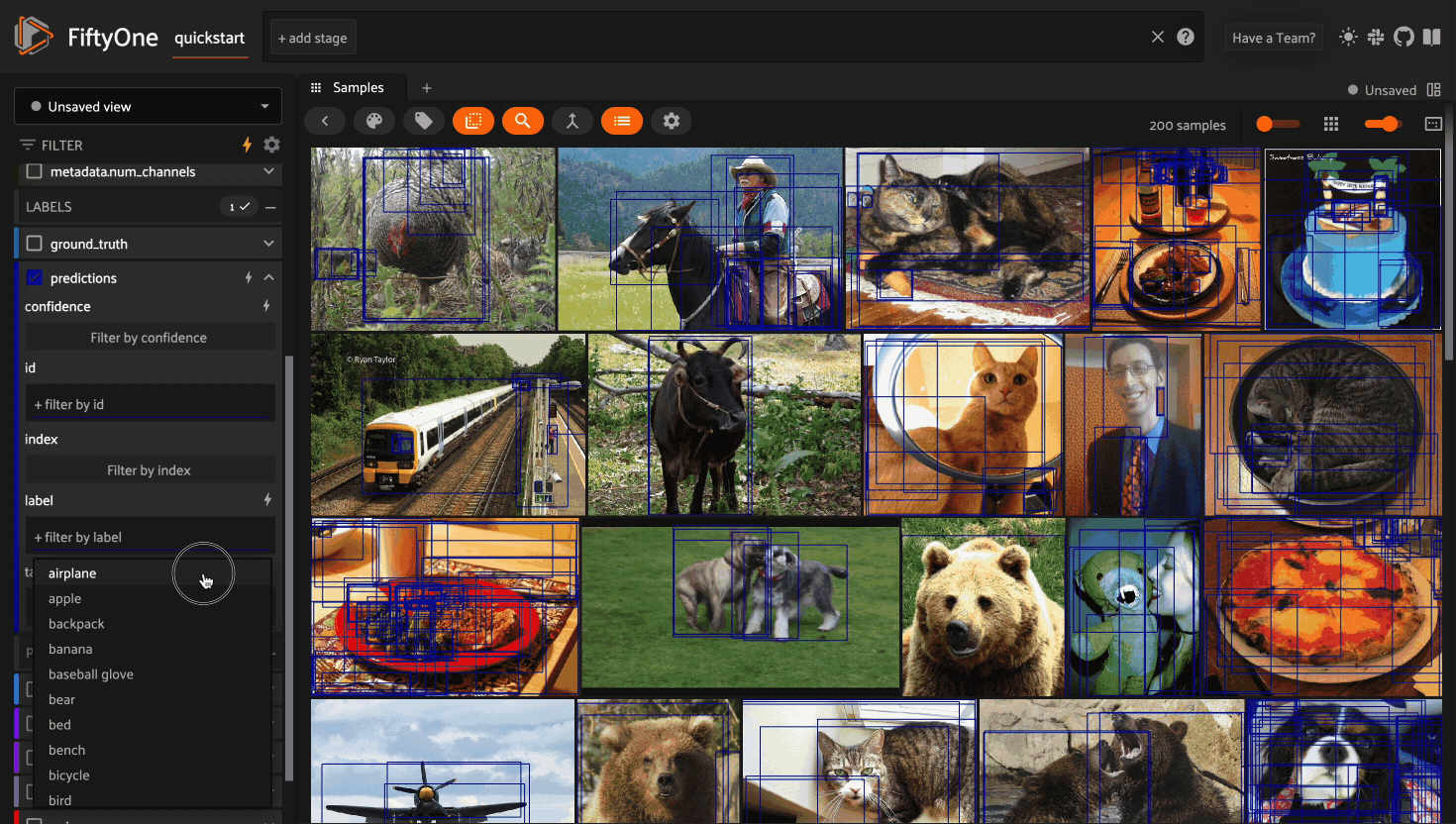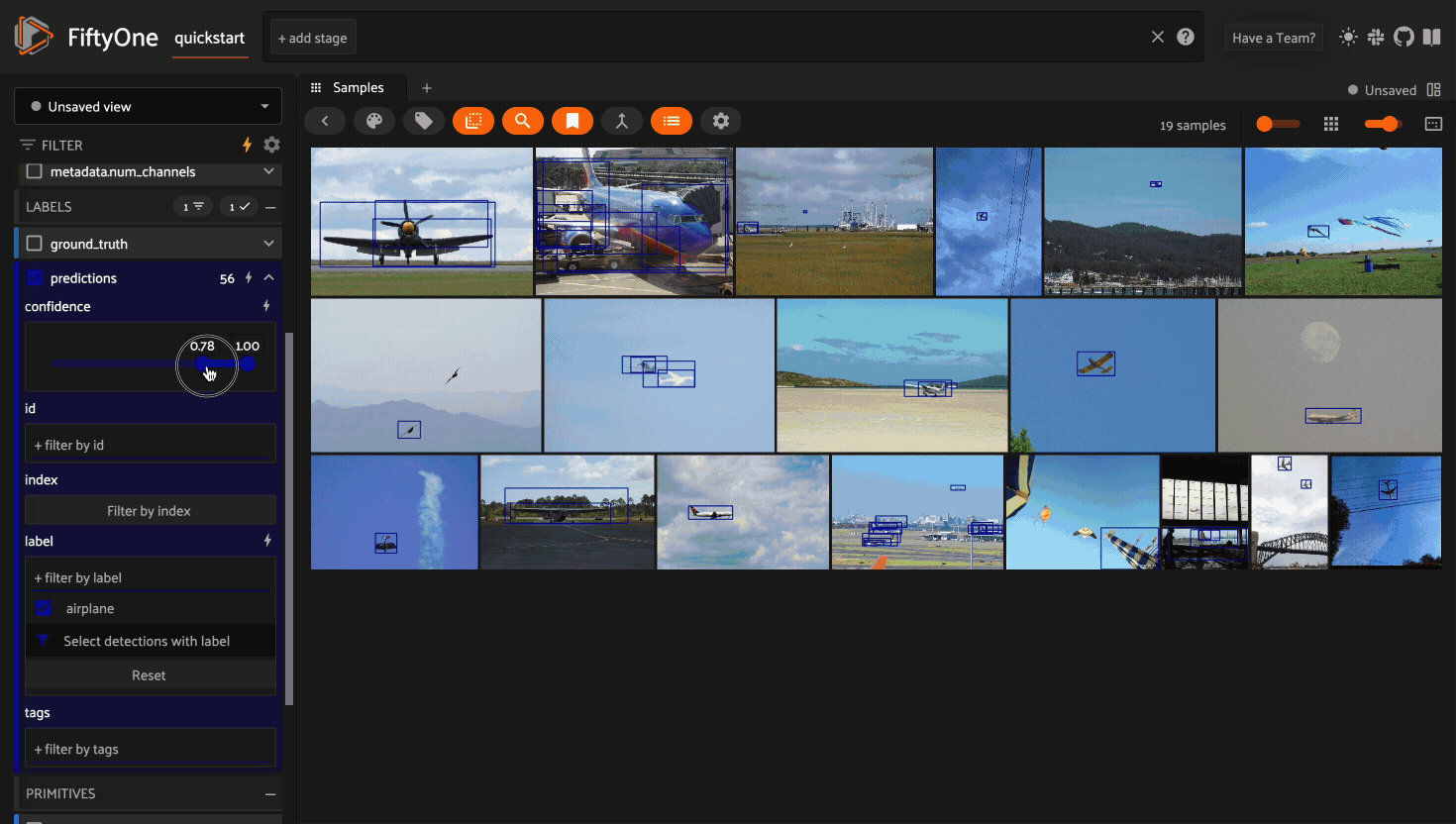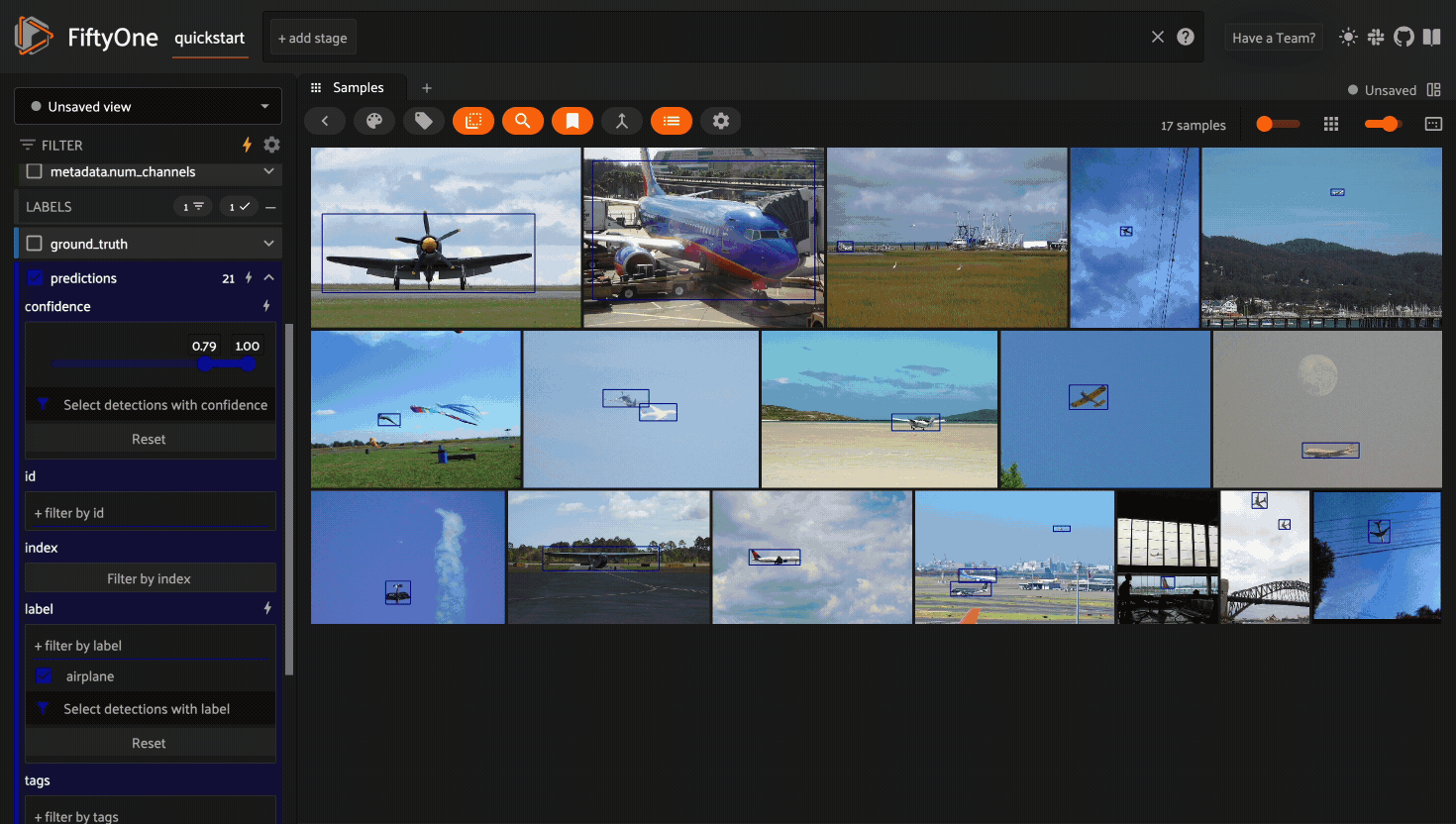
Using the FiftyOne App#
The FiftyOne App is a powerful graphical user interface that enables you to visualize, browse, and interact directly with your datasets.
Note
Did you know? You can use FiftyOne’s plugin framework to customize and extend the behavior of the App!
App environments#
The FiftyOne App can be used in any environment that you’re working in, from a local IPython shell, to a remote machine or cloud instance, to a Jupyter or Colab notebook. Check out the environments guide for best practices when working in each environment.
Sessions#
The basic FiftyOne workflow is to open a Python shell and load a Dataset.
From there you can launch the FiftyOne App and interact with it
programmatically via a session.
Creating a session#
You can launch an instance of the App by calling
launch_app(). This method returns a
Session instance, which you can subsequently use to interact programmatically
with the App!
1import fiftyone as fo
2
3session = fo.launch_app()
App sessions are highly flexible. For example, you can launch launch multiple App instances and connect multiple App instances to the same dataset.
By default, when you’re working in a non-notebook context, the App will be opened in a new tab of your web browser. See this FAQ for supported browsers.
Note
fo.launch_app() will launch the
App asynchronously and return control to your Python process. The App will
then remain connected until the process exits.
Therefore, if you are using the App in a script, you should use
session.wait() to block
execution until you close it manually:
# Launch the App
session = fo.launch_app(...)
# (Perform any additional operations here)
# Blocks execution until the App is closed
session.wait()
# Or block execution indefinitely with a negative wait value
# session.wait(-1)
Note
When working inside a Docker container, FiftyOne should automatically
detect and appropriately configure networking. However, if you are unable
to load the App in your browser, you many need to manually
set the App address to 0.0.0.0:
session = fo.launch_app(..., address="0.0.0.0")
See this page for more information about working with FiftyOne inside Docker.
Note
If you are a Windows user launching the App from a script, you should use the pattern below to avoid multiprocessing issues, since the App is served via a separate process:
import fiftyone as fo
dataset = fo.load_dataset(...)
if __name__ == "__main__":
# Ensures that the App processes are safely launched on Windows
session = fo.launch_app(dataset)
session.wait()
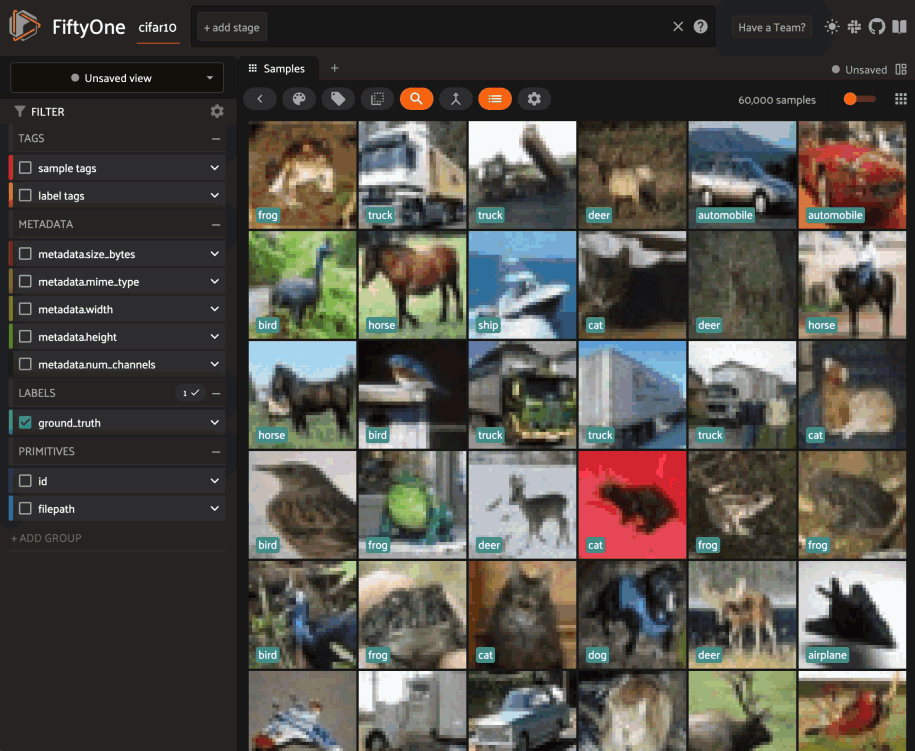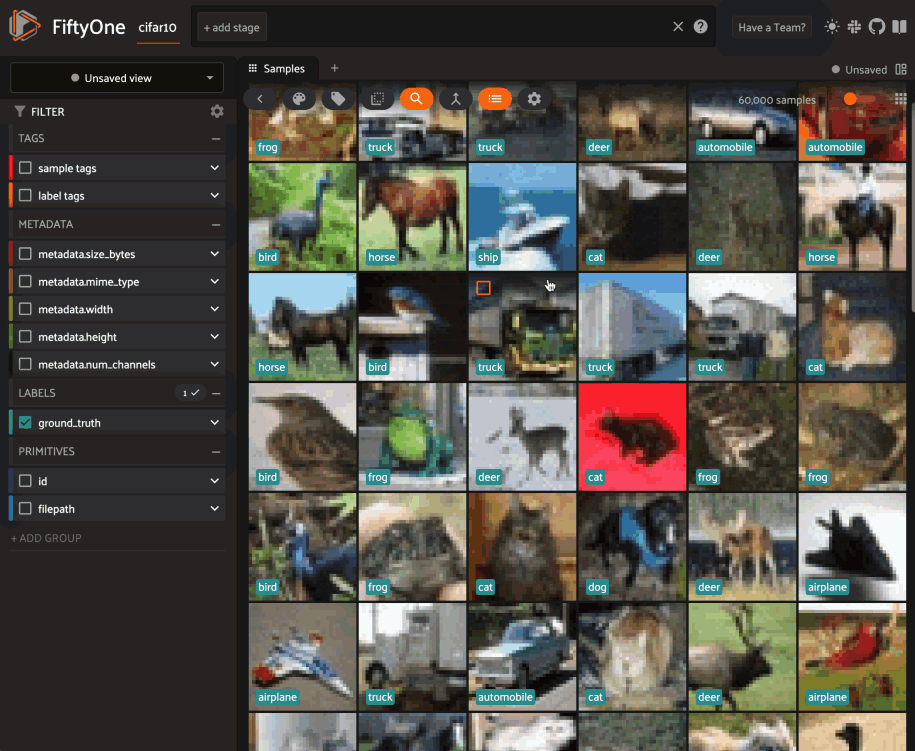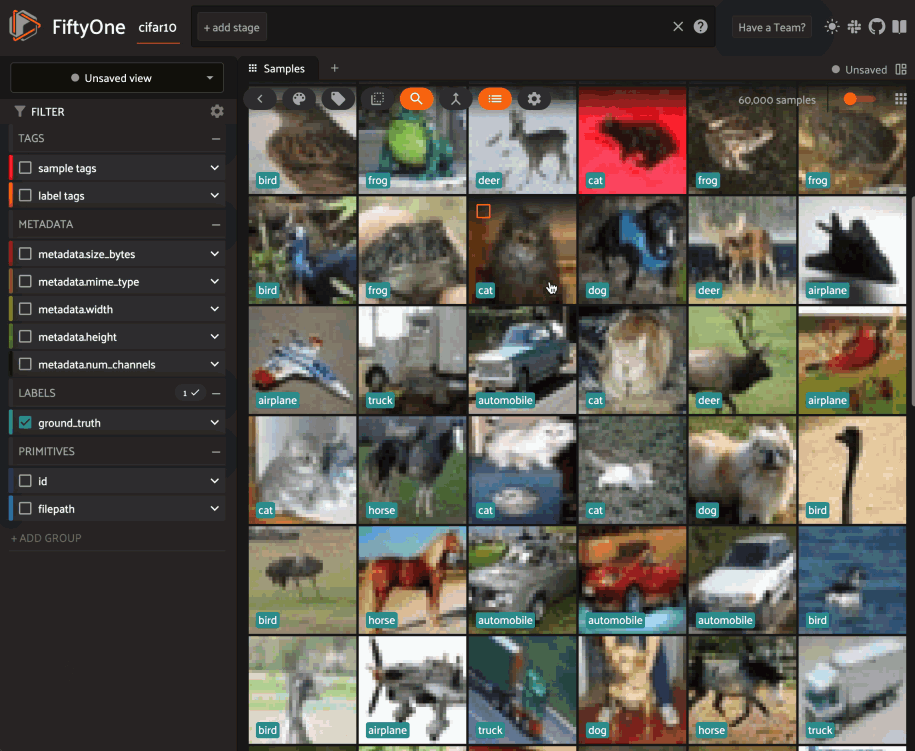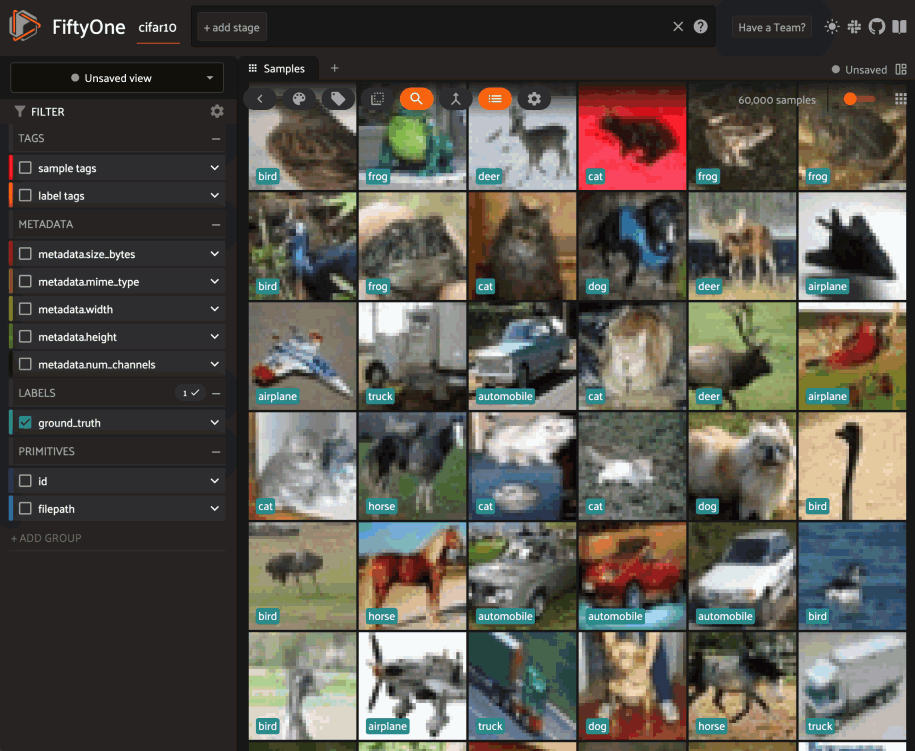
Updating a session’s dataset#
Sessions can be updated to show a new Dataset by updating the
Session.dataset property of the
session object:
1import fiftyone.zoo as foz
2
3dataset = foz.load_zoo_dataset("cifar10")
4
5# View the dataset in the App
6session.dataset = dataset
Updating a session’s view#
You can also show a specific view into the current dataset
in the App by setting the
Session.view property of the
session.
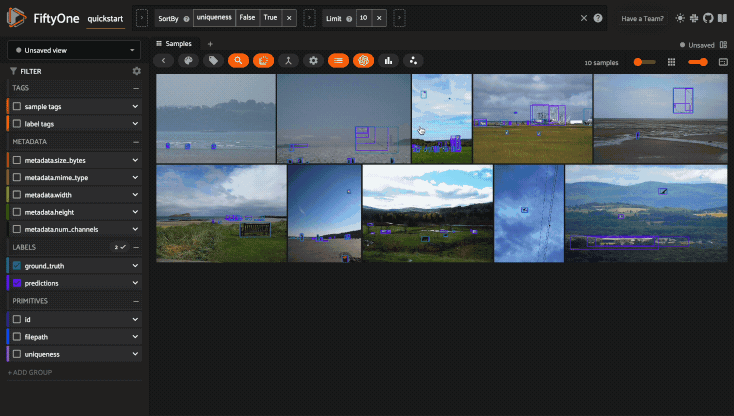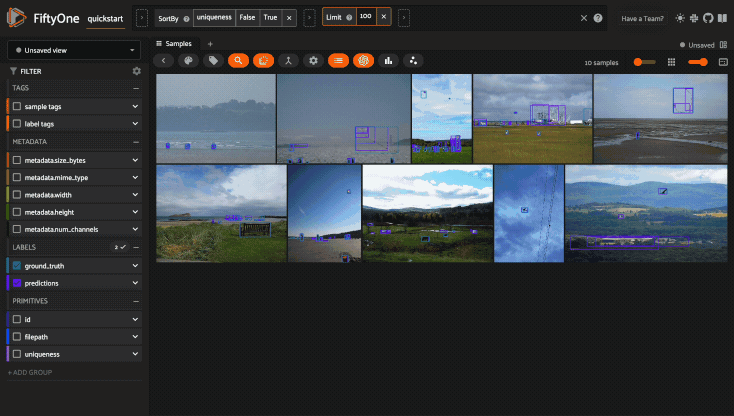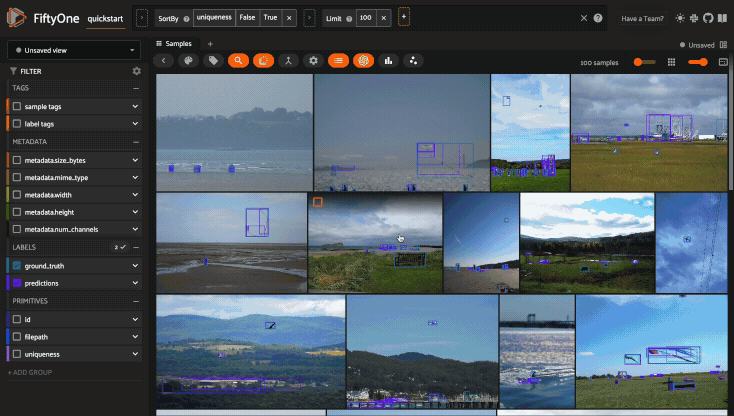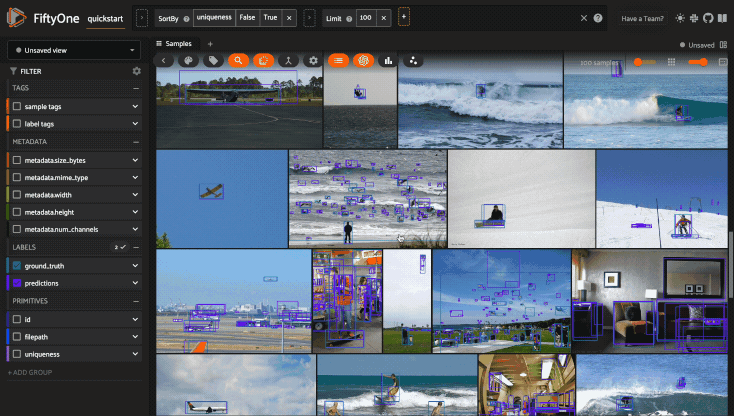
For example, the command below loads a DatasetView in the App that shows the
first 10 samples in the dataset sorted by their uniqueness field:
1session.view = dataset.sort_by("uniqueness").limit(10)
Loading a sample or group#
You can immediately load a specific sample
in the modal when launching a new Session by
providing its ID via the sample_id parameter:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5sample_id = dataset.last().id
6
7session = fo.launch_app(dataset, sample_id=sample_id)
You can also programmatically load a sample in the modal on an existing session
by setting its
session.sample_id property:
1sample_id = dataset.take(1).first().id
2
3session.sample_id = sample_id
Note
Did you know? You can link directly to a sample by copy + pasting the App’s URL into your browser search bar!
Similarly, for group datasets, you can immediately load a
specific group in the modal when launching a new Session by providing its ID
via the group_id parameter:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart-groups")
5group_id = dataset.last().group.id
6
7session = fo.launch_app(dataset, group_id=group_id)
You can also programmatically load a group in the modal on an existing session
by setting its
session.group_id property:
1group_id = dataset.take(1).first().group.id
2
3session.group_id = group_id
Note
Did you know? You can link directly to a group by copy + pasting the App’s URL into your browser search bar!
Remote sessions#
If your data is stored on a remote machine, you can forward a session from the remote machine to your local machine and seamlessly browse your remote dataset from you web browser.
Check out the environments page for more information on possible configurations of local/remote/cloud data and App access.
Remote machine#
On the remote machine, you can load a Dataset and launch a remote session
using either the Python library or the CLI.
Load a Dataset and call
launch_app() with the
remote=True argument.
1# On remote machine
2
3import fiftyone as fo
4
5dataset = fo.load_dataset("<dataset-name>")
6
7session = fo.launch_app(dataset, remote=True) # optional: port=XXXX
You can use the optional port parameter to choose the port of your
remote machine on which to serve the App. The default is 5151, which
can also be customized via the default_app_port parameter of your
FiftyOne config.
You can also provide the optional address parameter to restrict the
hostnames/IP addresses that can connect to your remote session. See
this page for more information.
Note that you can manipulate the session object on the remote machine as
usual to programmatically interact with the App instance that you’ll
connect to locally next.
Run the fiftyone app launch command in a terminal:
# On remote machine
fiftyone app launch <dataset-name> --remote # optional: --port XXXX
You can use the optional --port flag to choose the port of your
remote machine on which to serve the App. The default is 5151, which
can also be customized via the default_app_port parameter of your
FiftyOne config.
Local machine#
On the local machine, you can access an App instance connected to the remote session by either manually configuring port forwarding or via the FiftyOne CLI:
Open a new terminal window on your local machine and execute the following command to setup port forwarding to connect to your remote session:
# On local machine
ssh -N -L 5151:127.0.0.1:XXXX [<username>@]<hostname>
Leave this process running and open http://localhost:5151 in your browser to access the App.
In the above, [<username>@]<hostname> specifies the remote machine to
connect to, XXXX refers to the port that you chose when you launched the
session on your remote machine (the default is 5151), and 5151 specifies
the local port to use to connect to the App (and can be customized).
If you have FiftyOne installed on your local machine, you can use the CLI to automatically configure port forwarding and open the App in your browser as follows:
# On local machine
fiftyone app connect --destination [<username>@]<hostname>
If you choose a custom port XXXX on the remote machine, add a
--port XXXX flag to the above command.
If you would like to use a custom local port to serve the App, add a
--local-port YYYY flag to the above command.
Note
Remote sessions are highly flexible. For example, you can connect to multiple remote sessions and run multiple remote sessions from one machine.
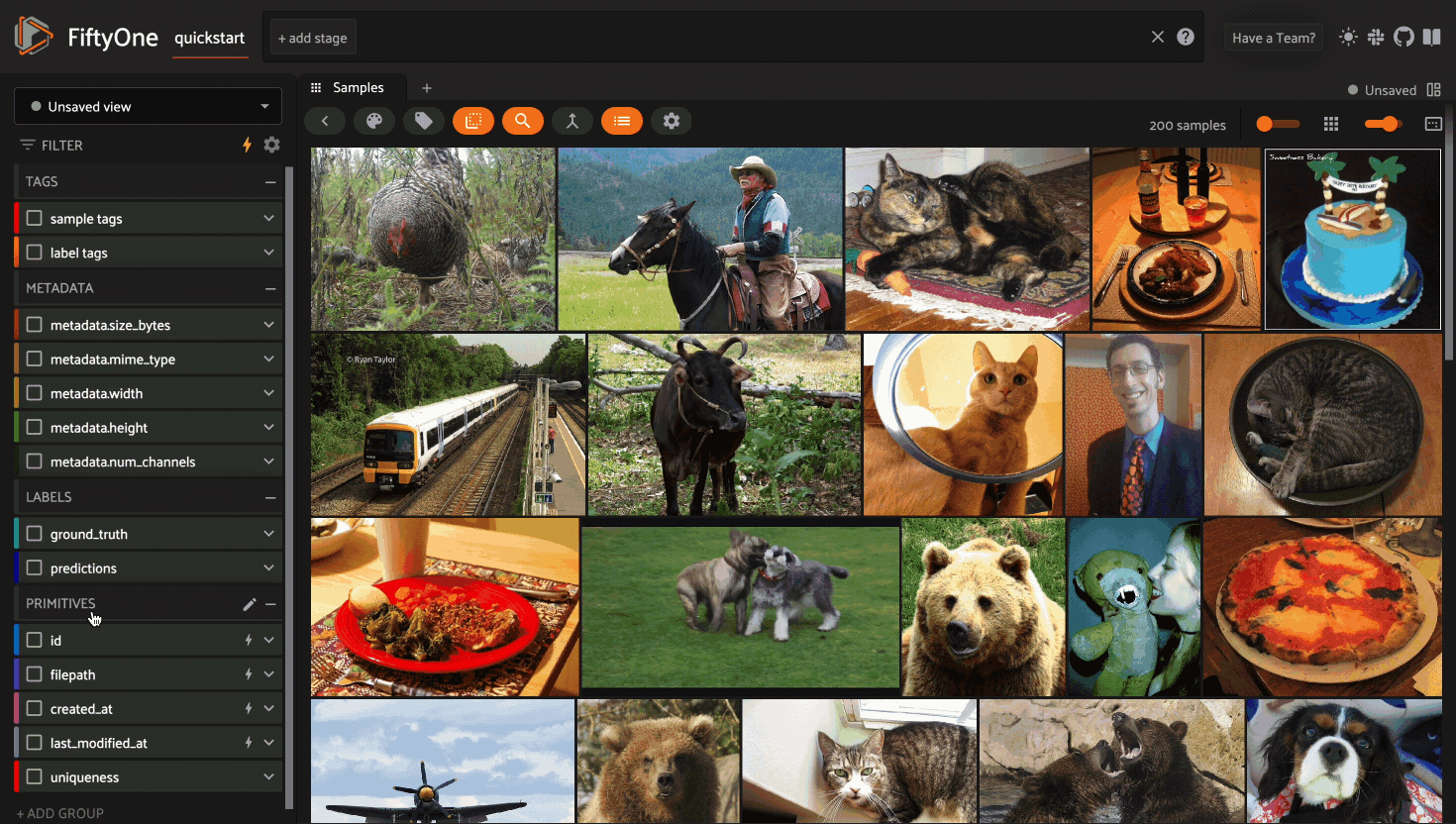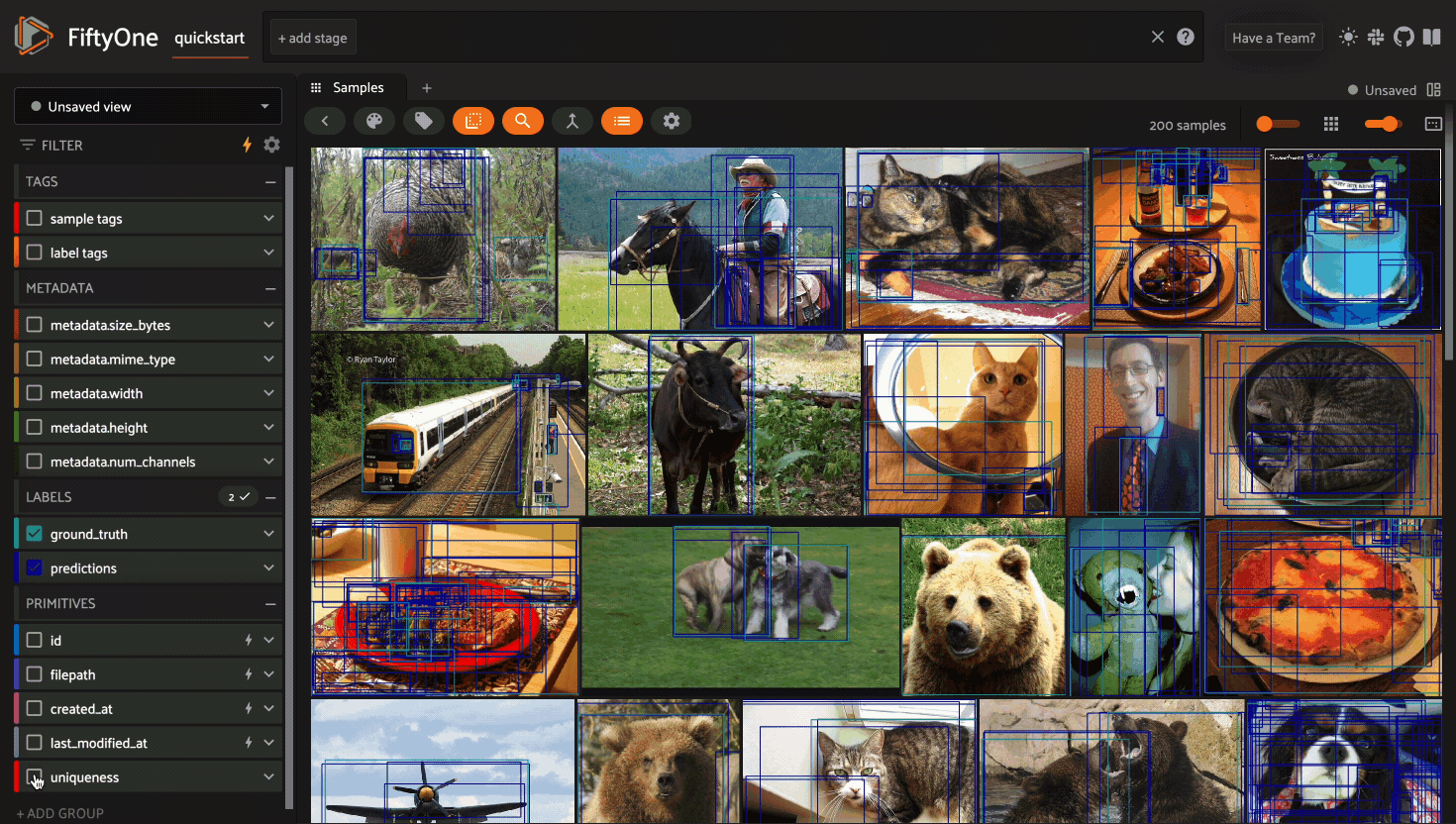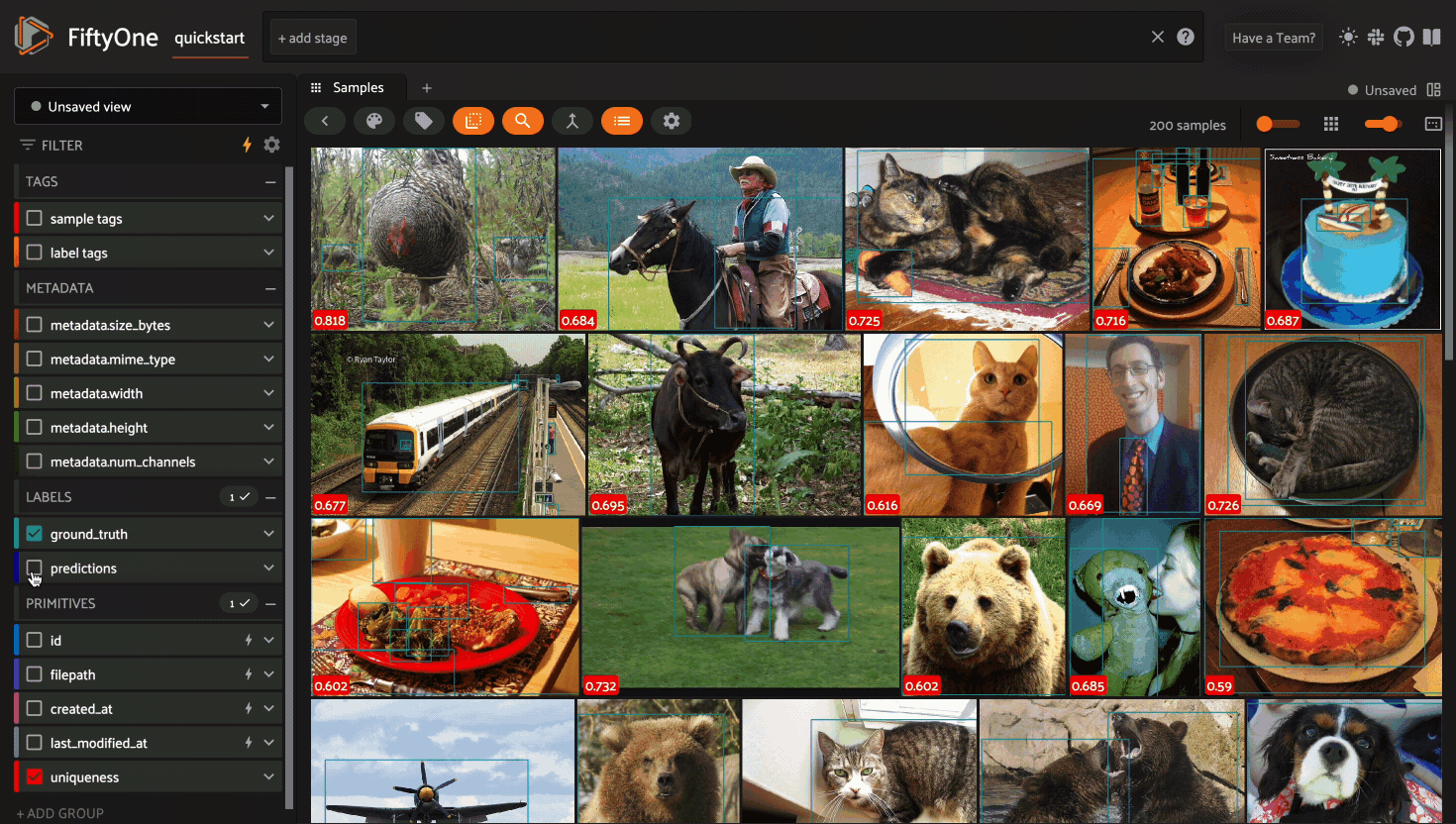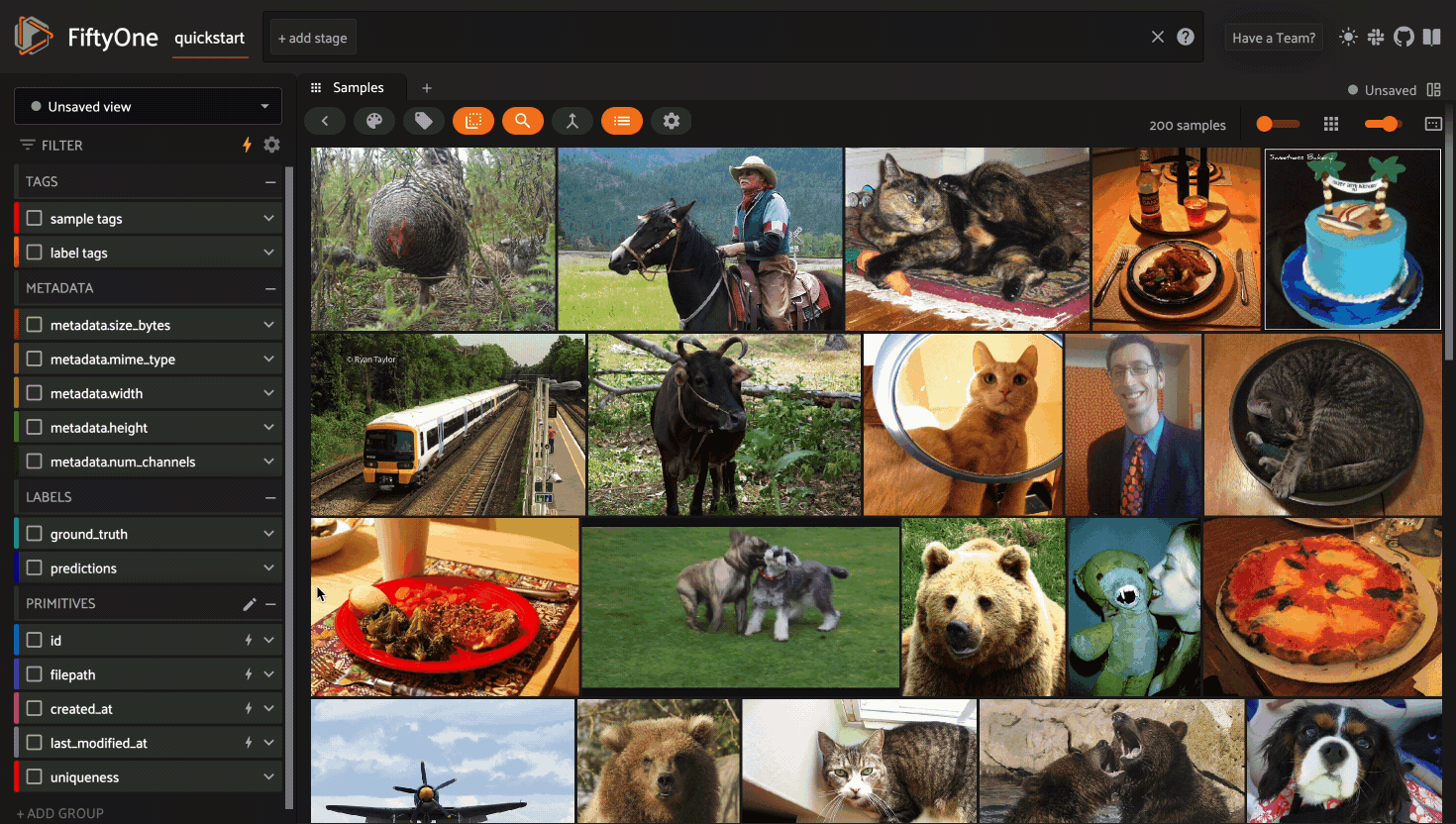
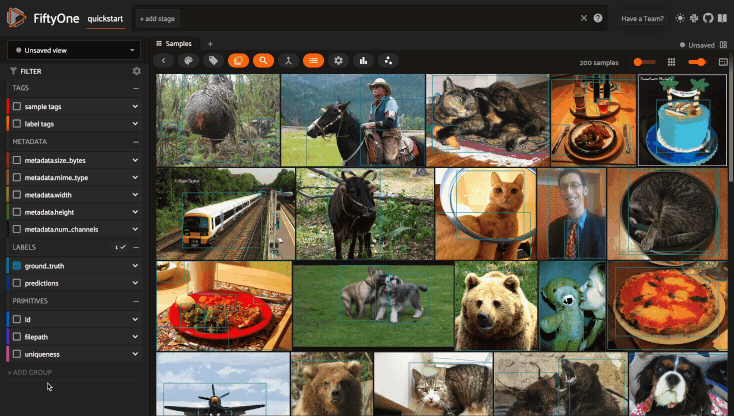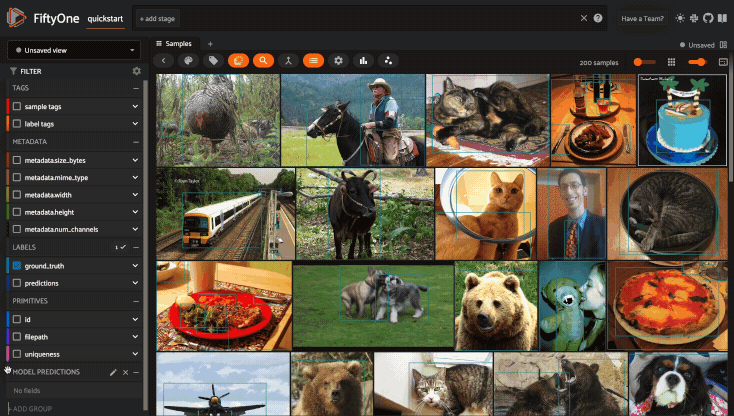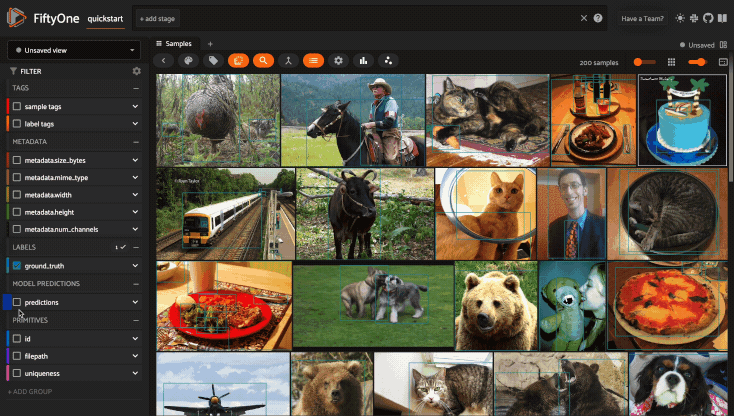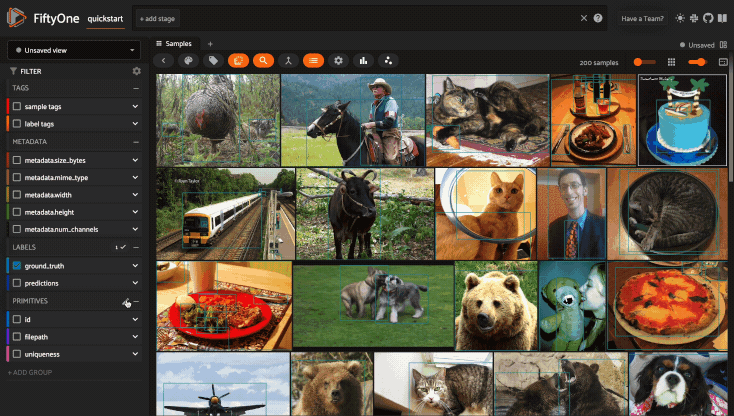
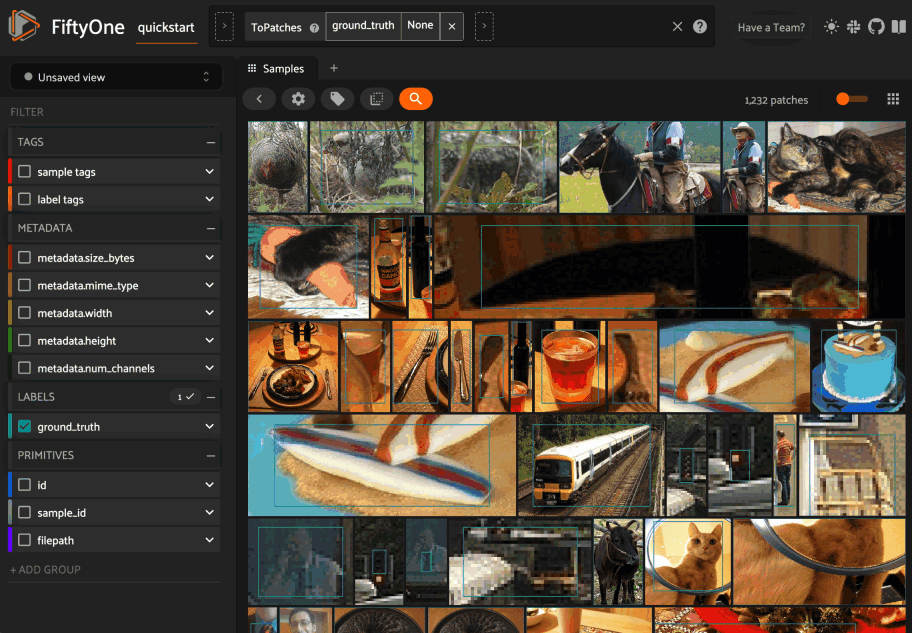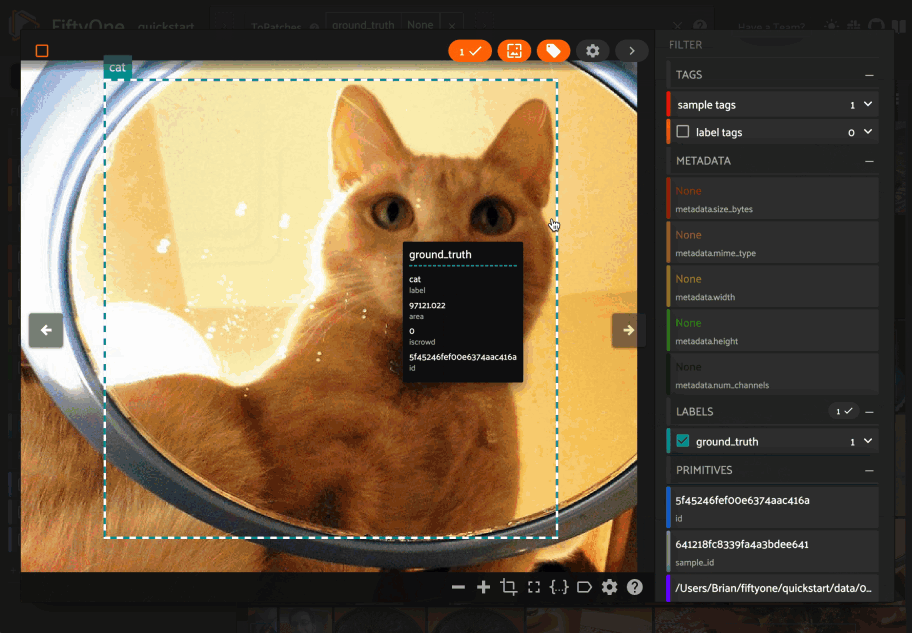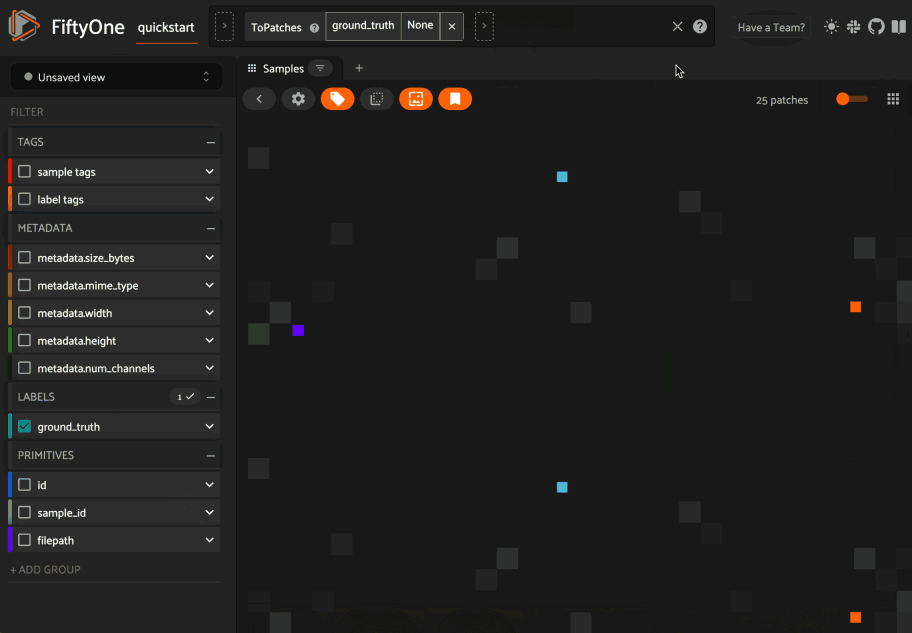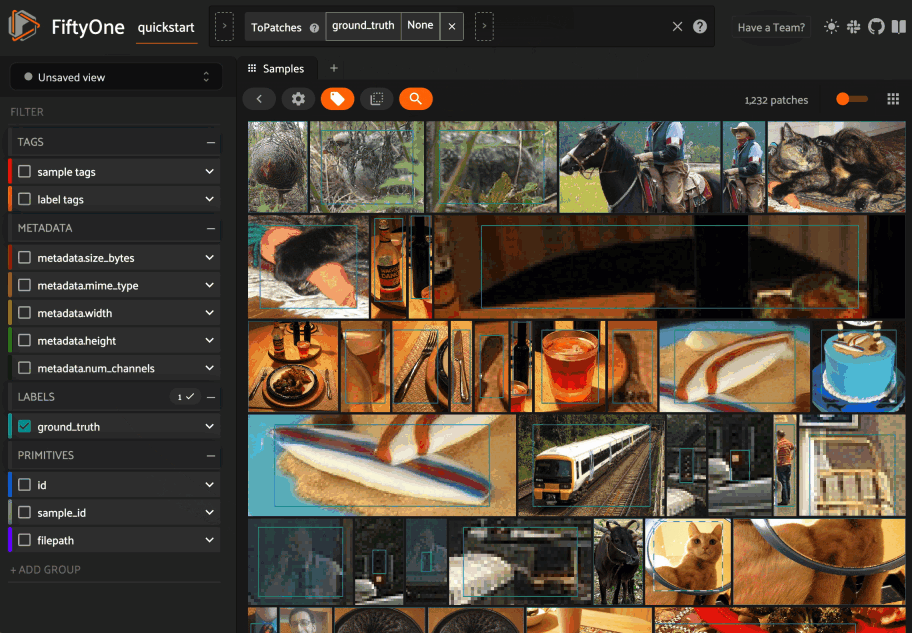
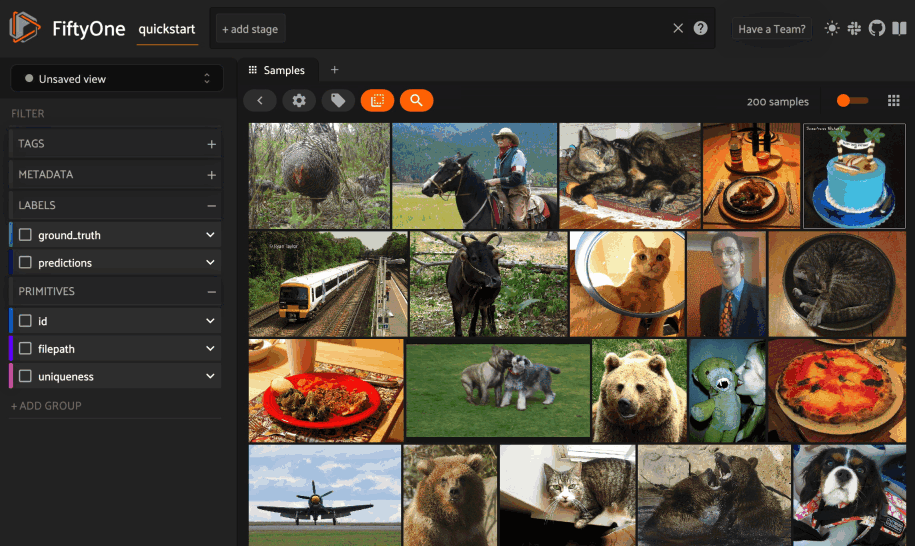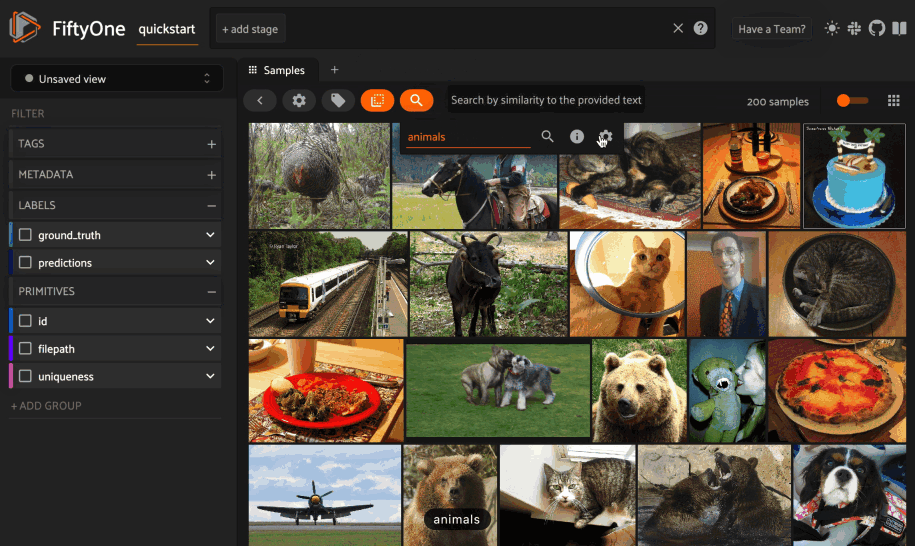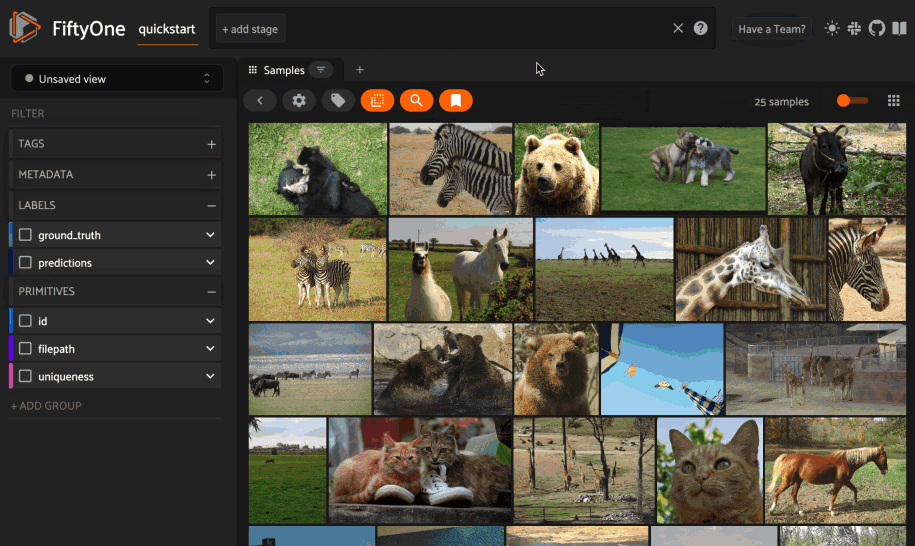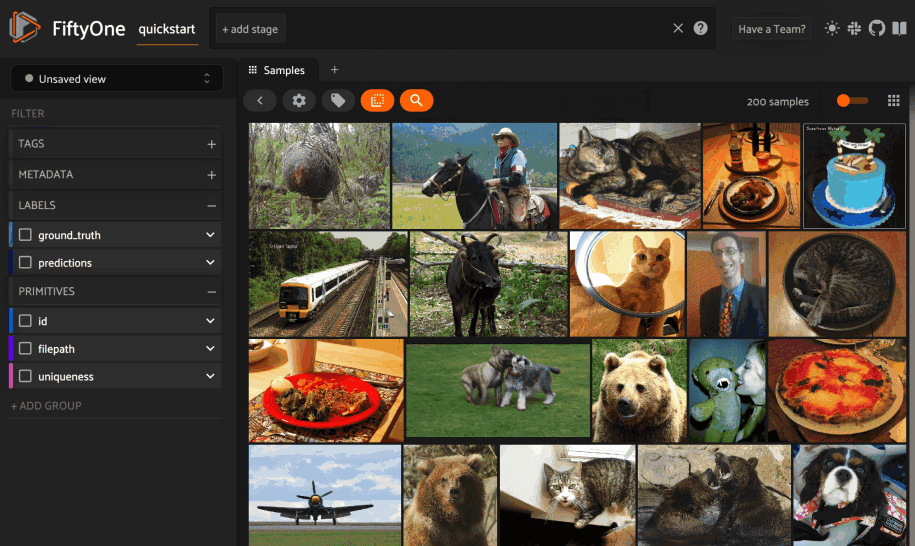
Using the sidebar#
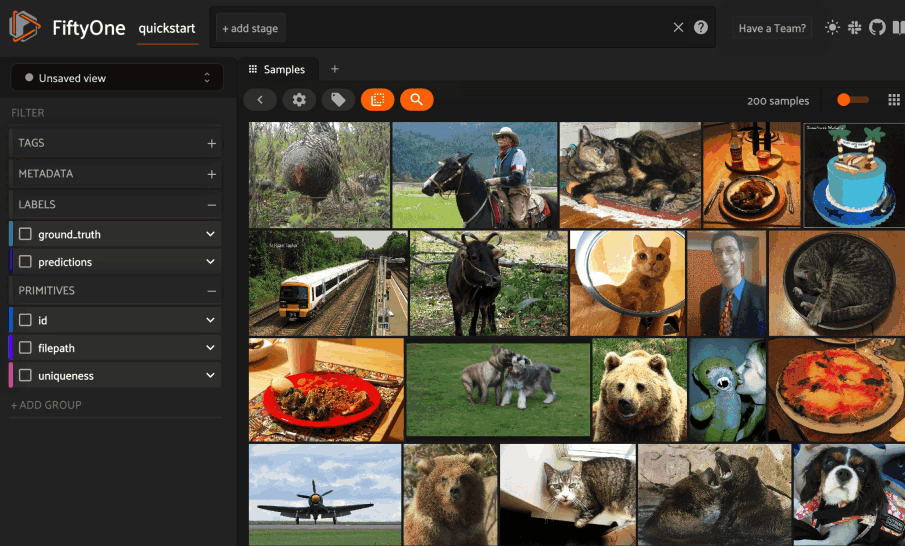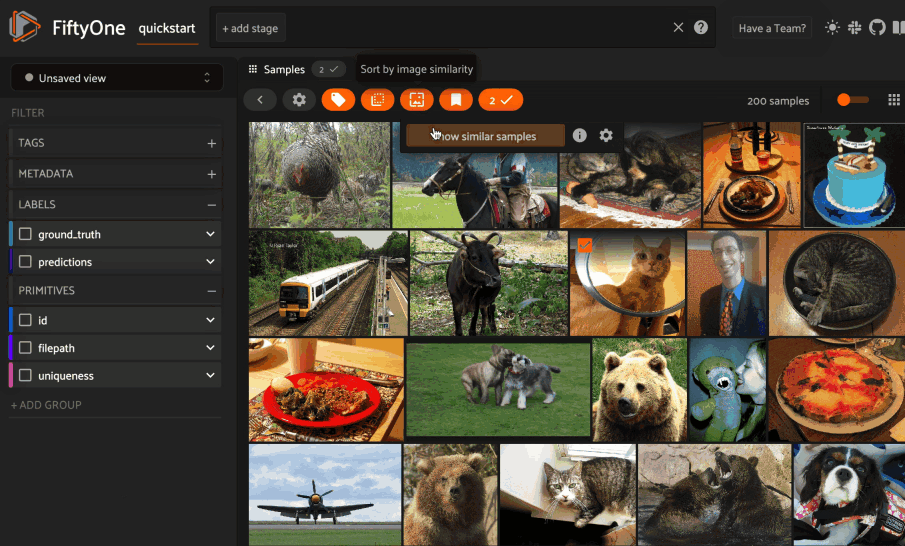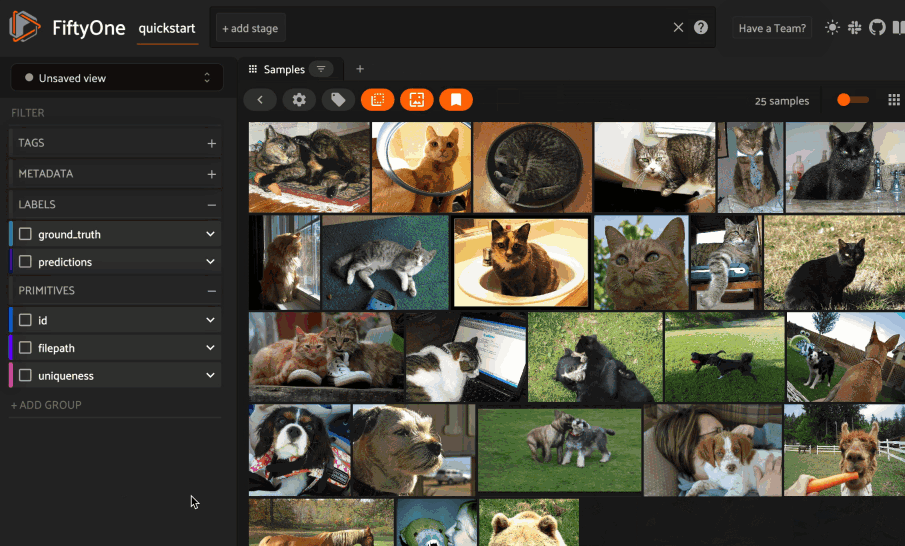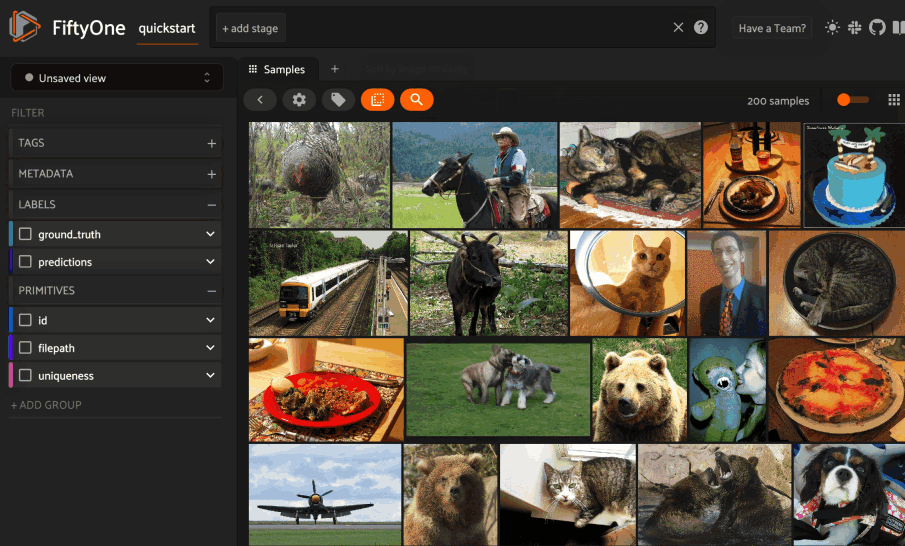
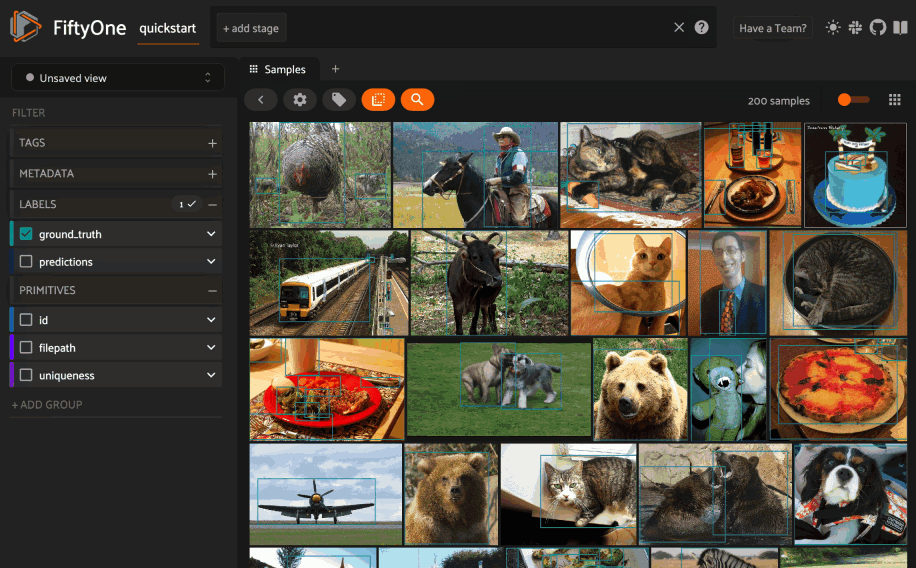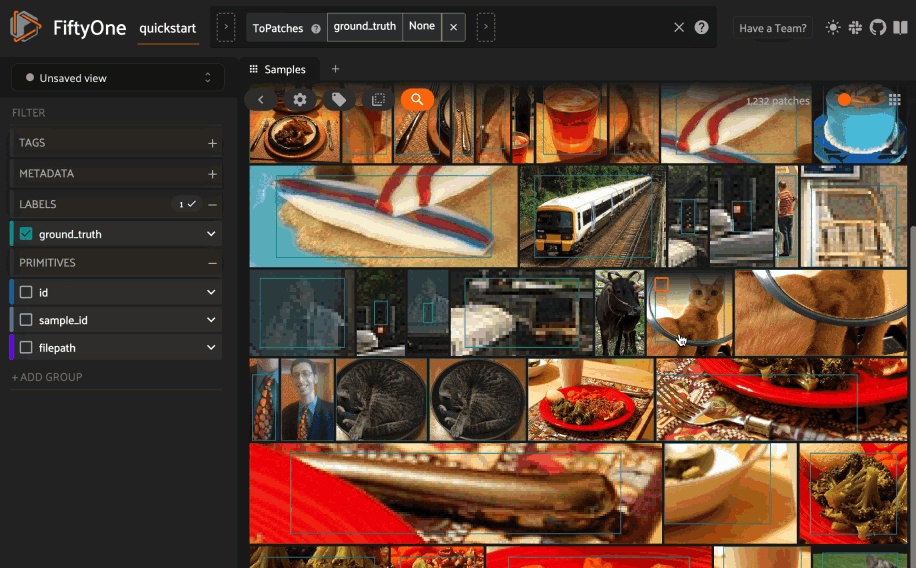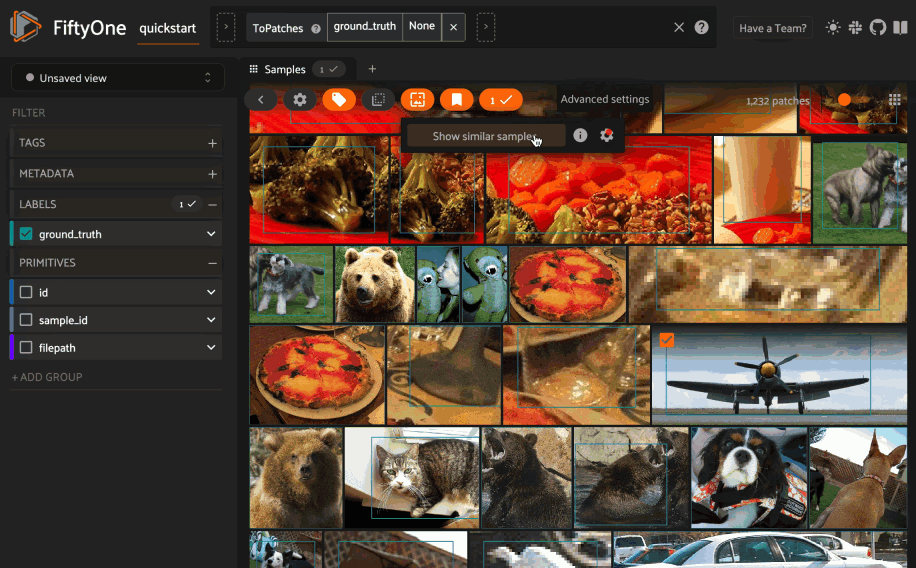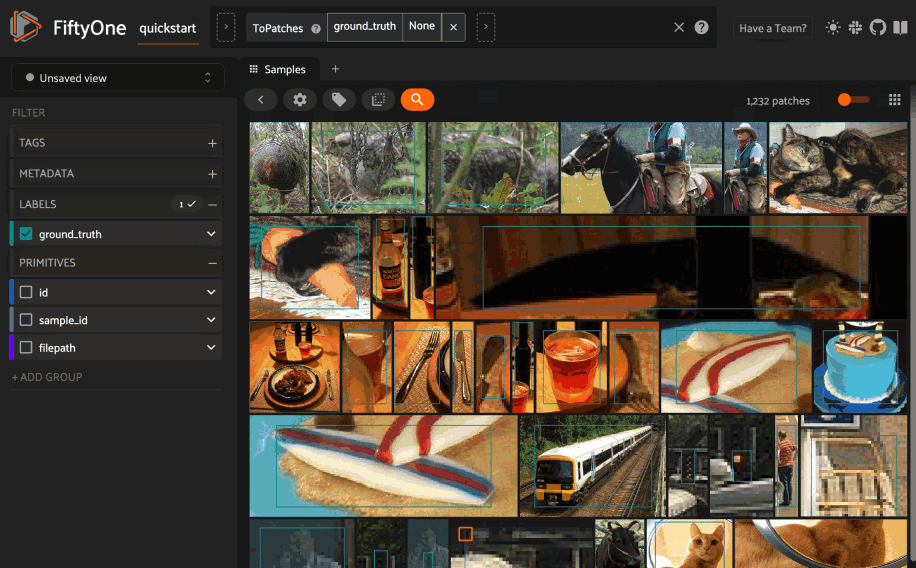
Any labels, tags, and scalar fields can be overlaid on the samples in the App by toggling the corresponding checkboxes in the App’s sidebar:
By default, only label fields (excluding heatmaps and
semantic segmentations) are visible by default,
but you can programmatically define a dataset’s a default configuration for
these checkboxes by setting the
active_fields property
of the dataset’s App config:
1# By default all label fields excluding Heatmap and Segmentation are active
2active_fields = fo.DatasetAppConfig.default_active_fields(dataset)
3
4# Add filepath and id fields
5active_fields.paths.extend(["id", "filepath"])
6
7# Active fields can be inverted setting exclude to True
8# active_fields.exclude = True
9
10# Modify the dataset's App config
11dataset.app_config.active_fields = active_fields
12dataset.save() # must save after edits
13
14session = fo.launch_app(dataset)
You can conveniently reset the active fields to their default state by setting
active_fields to None:
1# Reset active fields
2dataset.app_config.active_fields = None
3dataset.save() # must save after edits
4
5session = fo.launch_app(dataset)
If you have stored metadata on your fields, then you can view this information in the App by hovering over field or attribute names in the App’s sidebar:
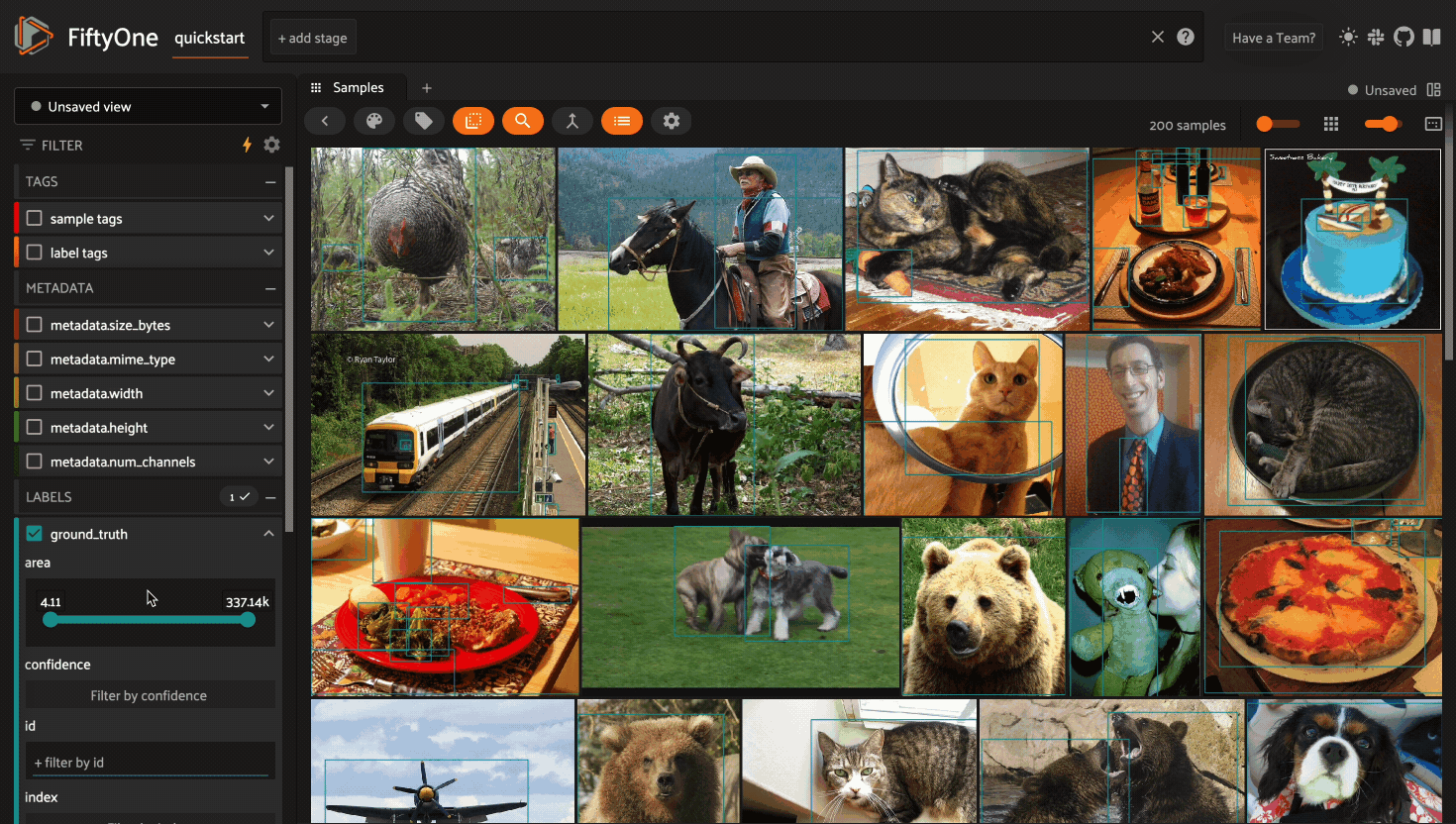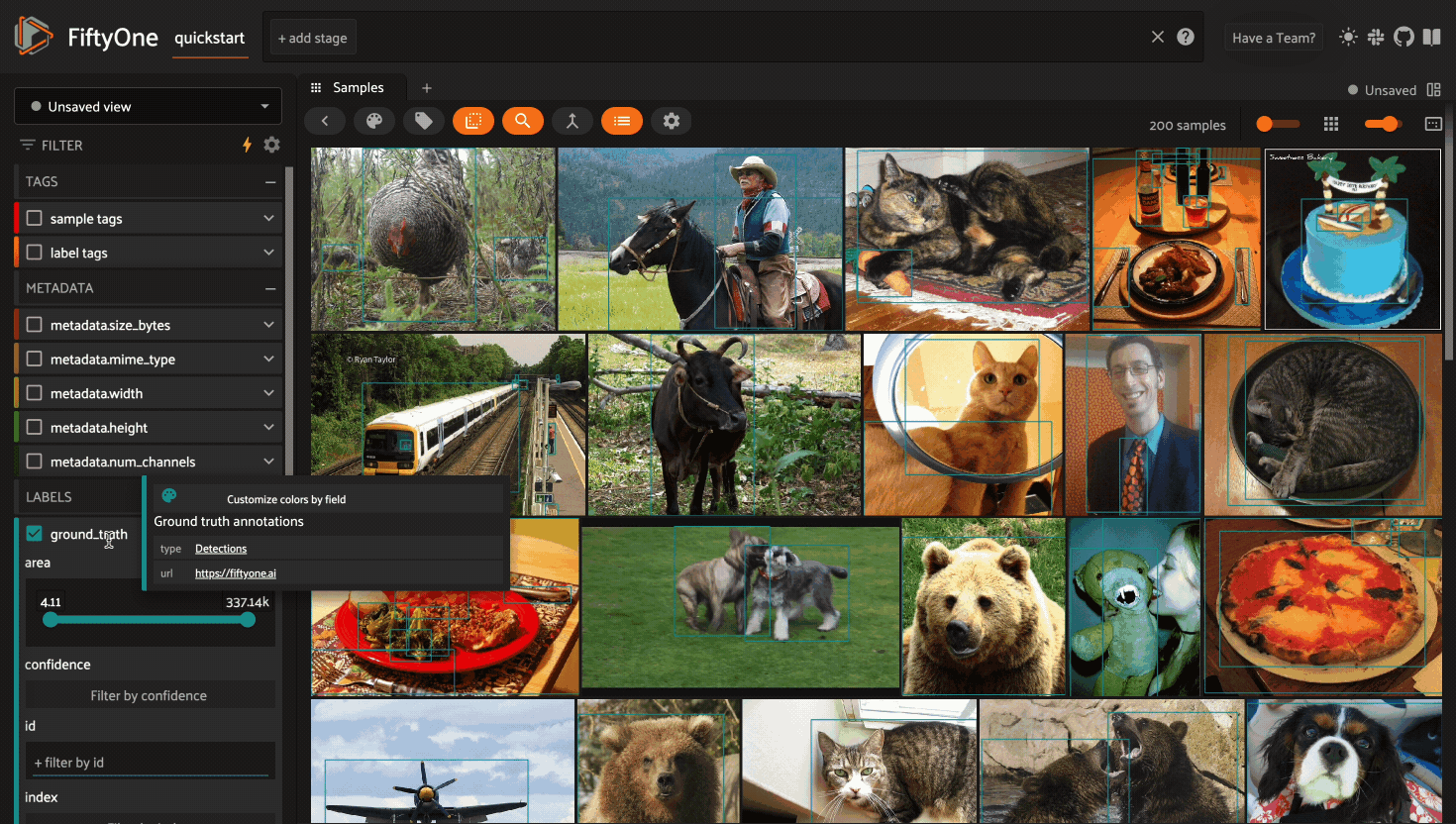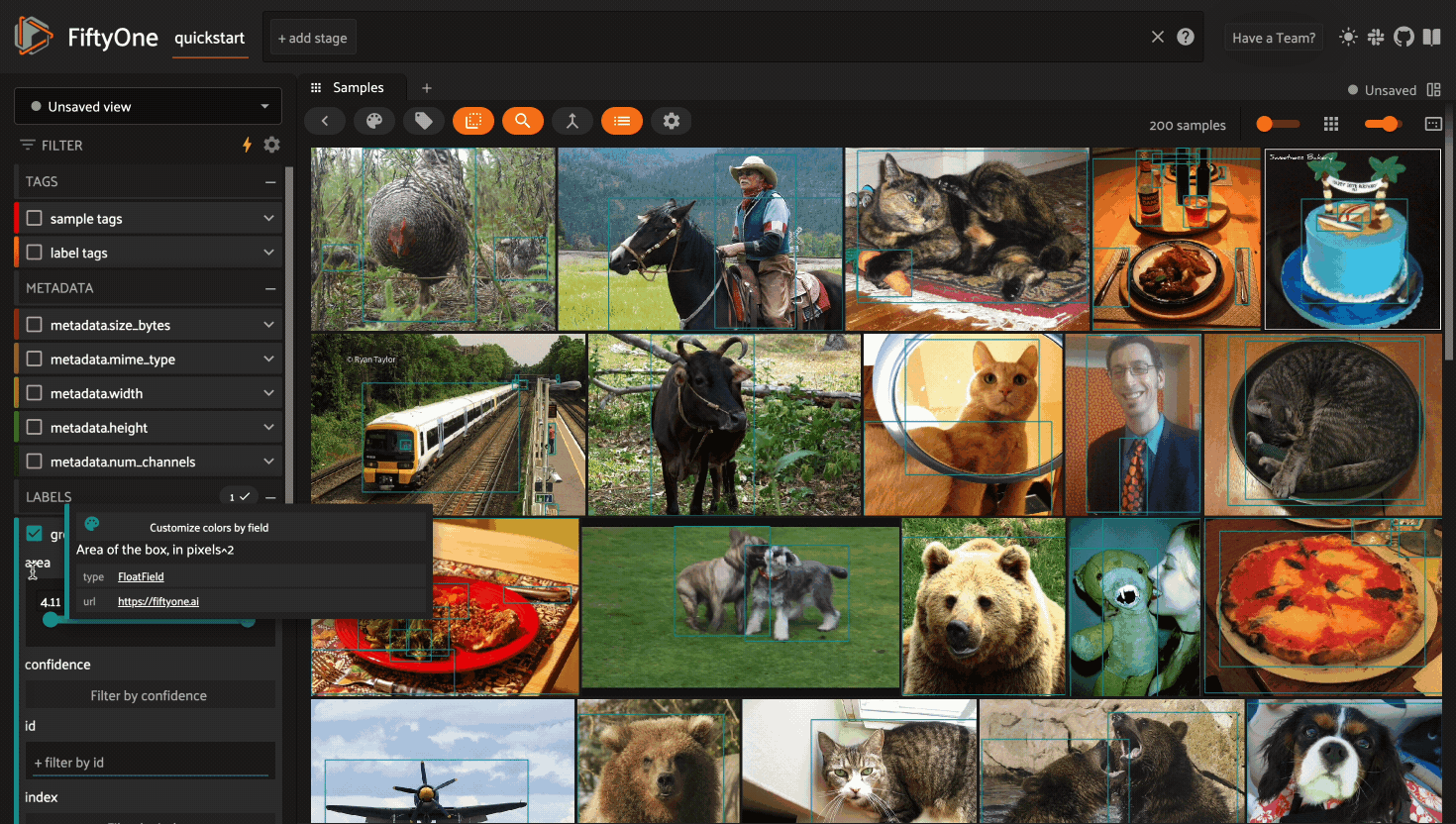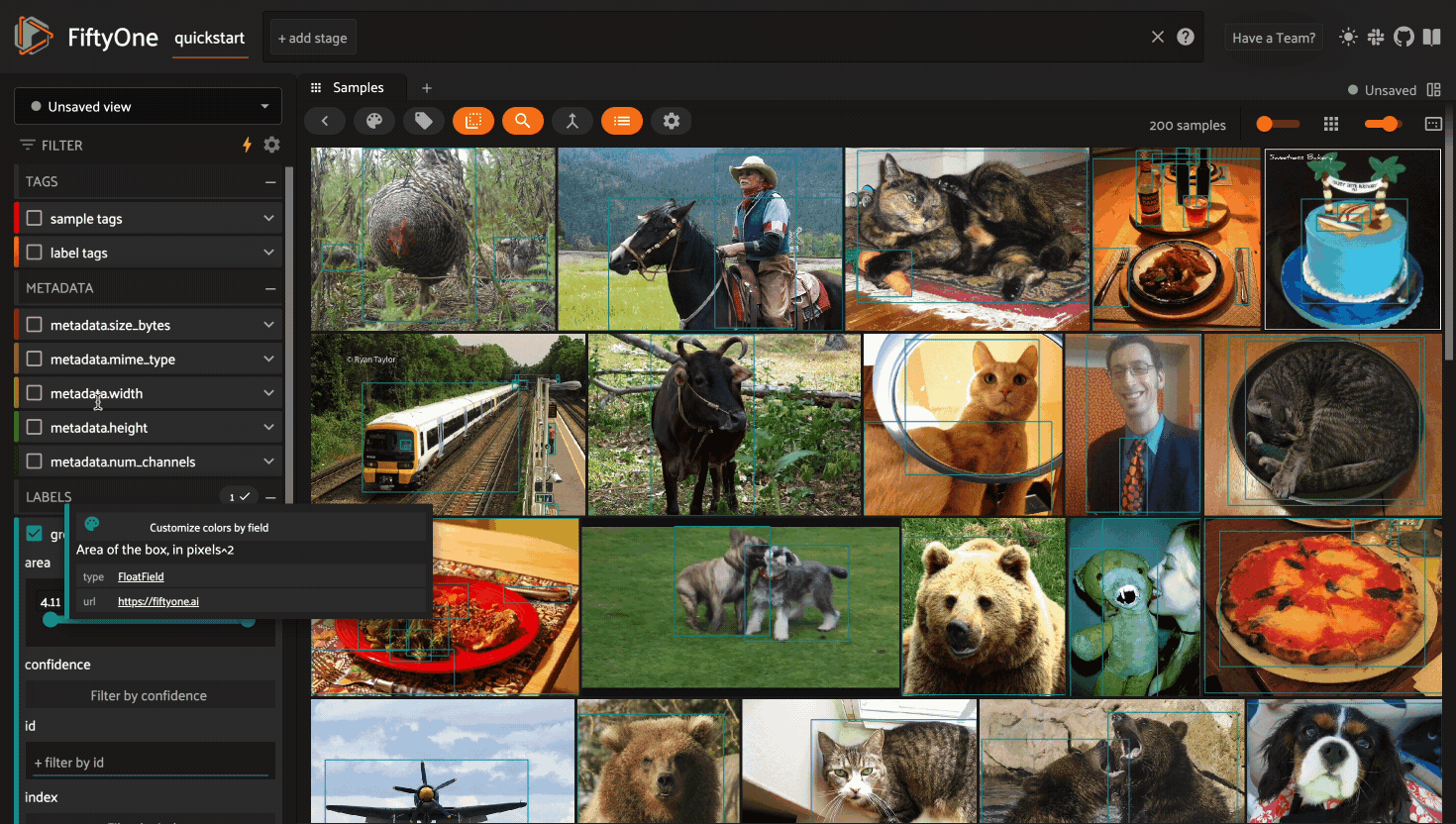
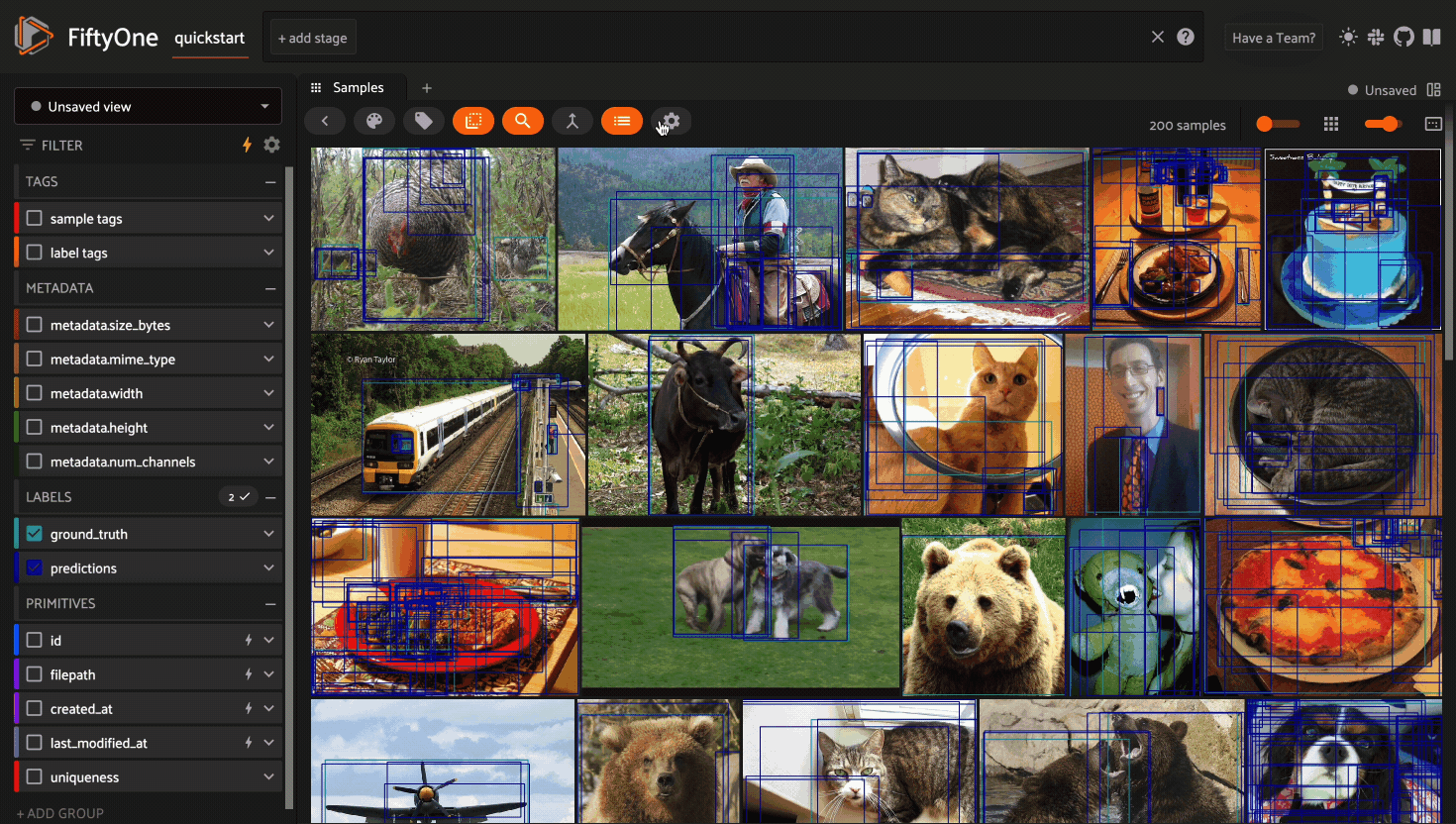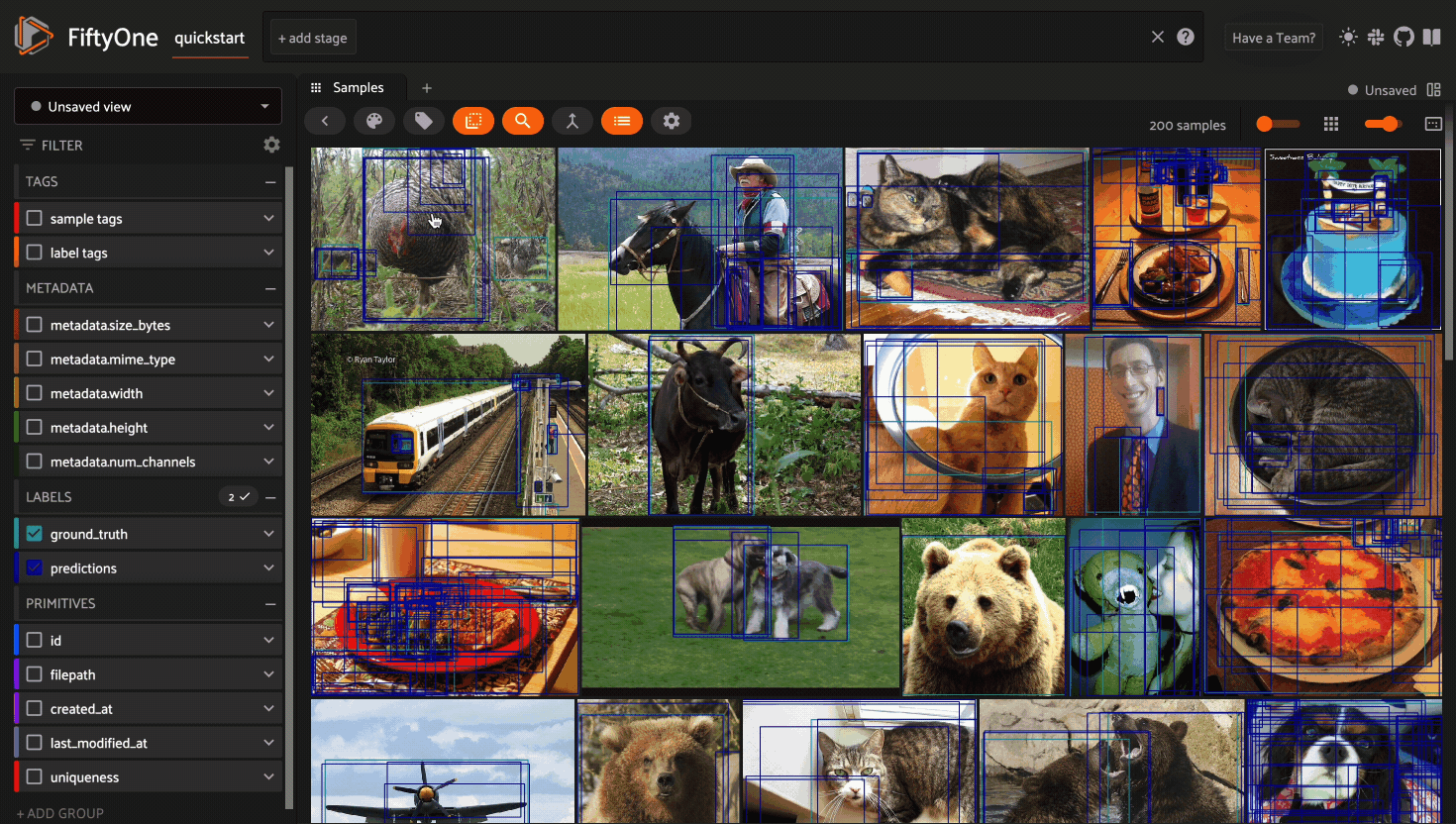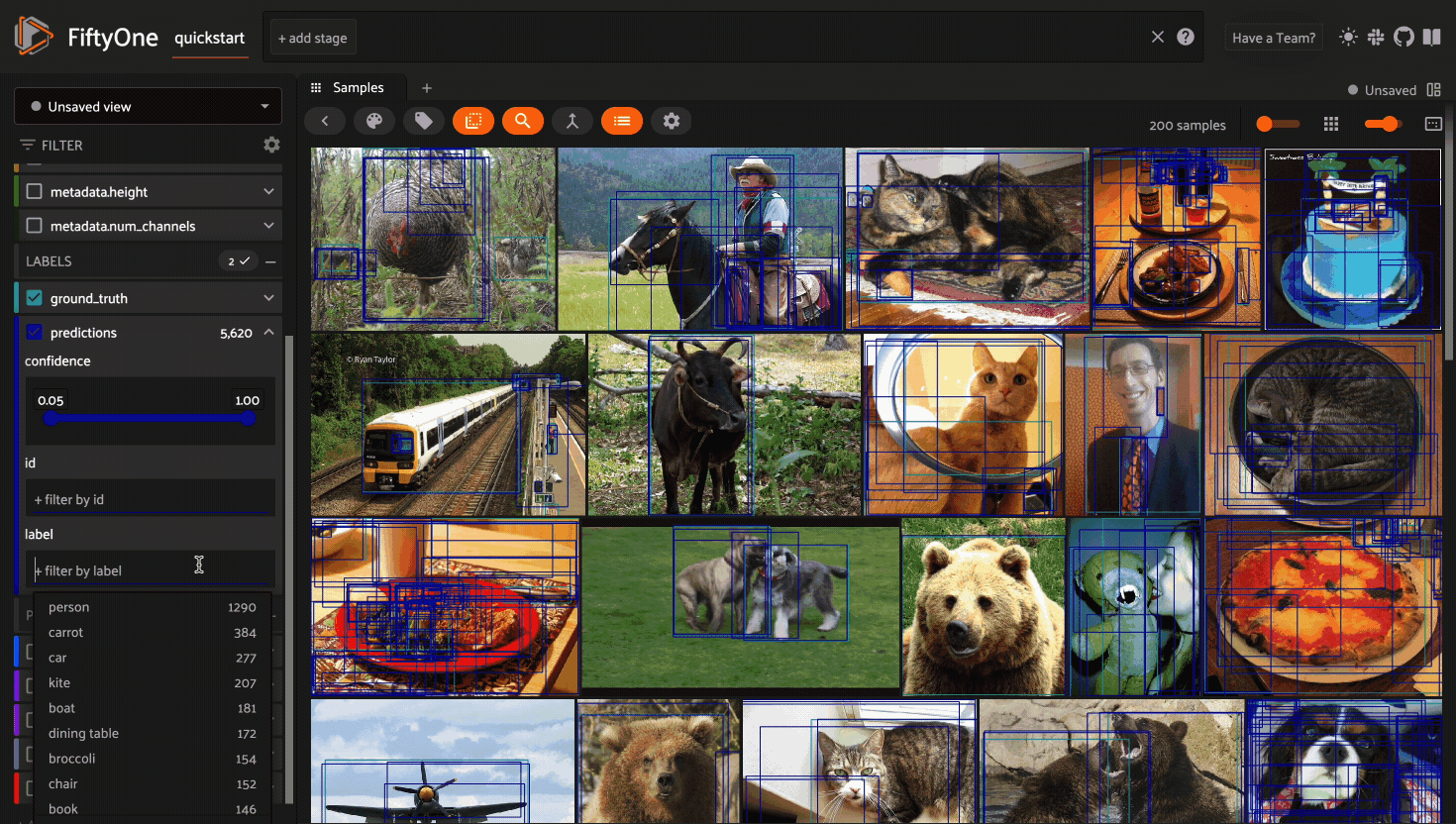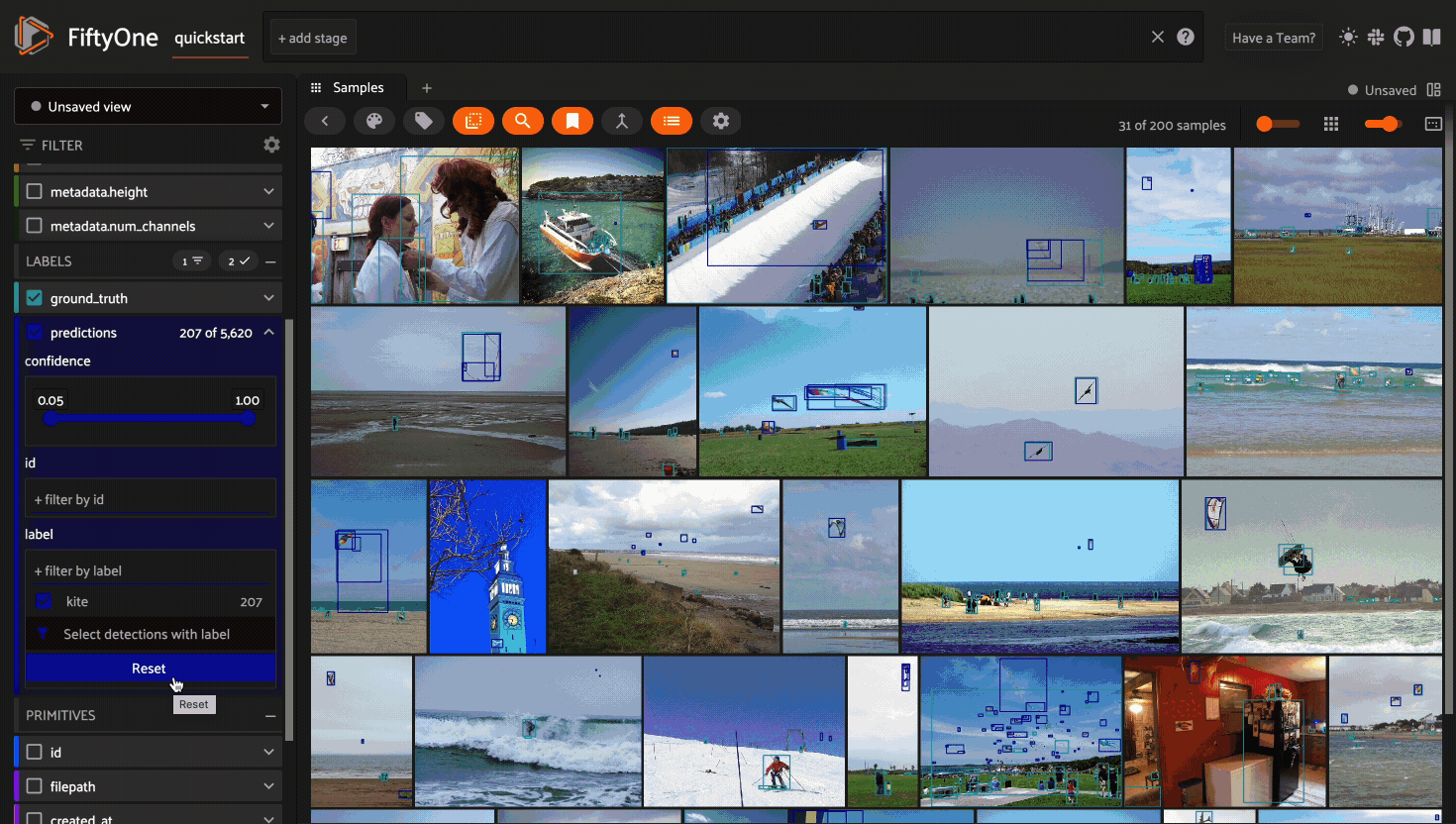
Filtering sample fields#
The App provides UI elements in both grid view and expanded sample view that you can use to filter your dataset. To view the available filter options for a field, click the caret icon to the right of the field’s name.
Whenever you modify a filter element, the App will automatically update to show only those samples and/or labels that match the filter.
Note
Did you know? When you declare custom attributes on your dataset’s schema, they will automatically become filterable in the App!
Note
Did you know? When you have applied filter(s) in the App, a bookmark icon appears in the top-left corner of the sample grid. Click this button to convert your filters to an equivalent set of stage(s) in the view bar!
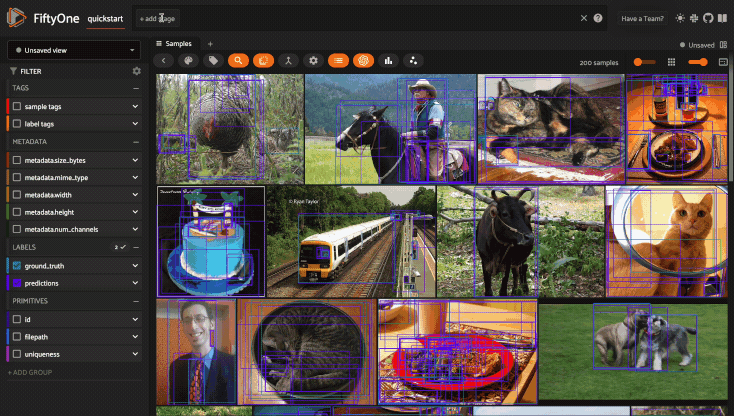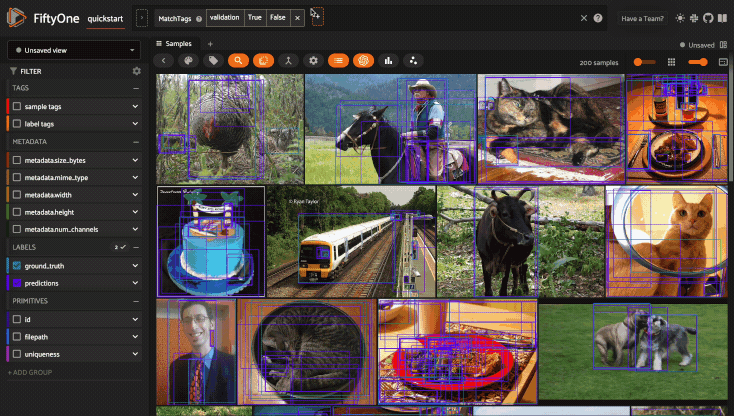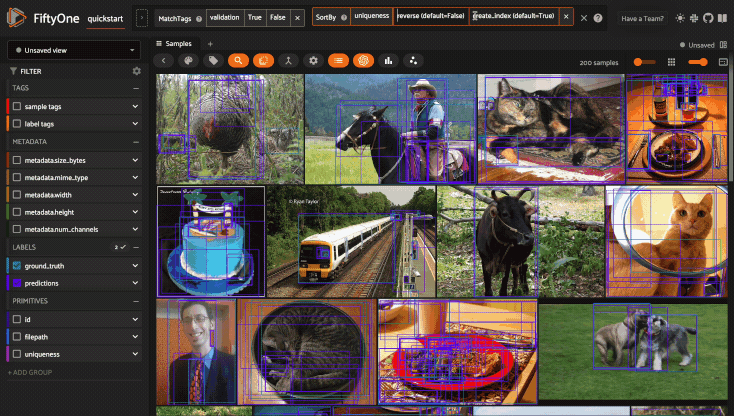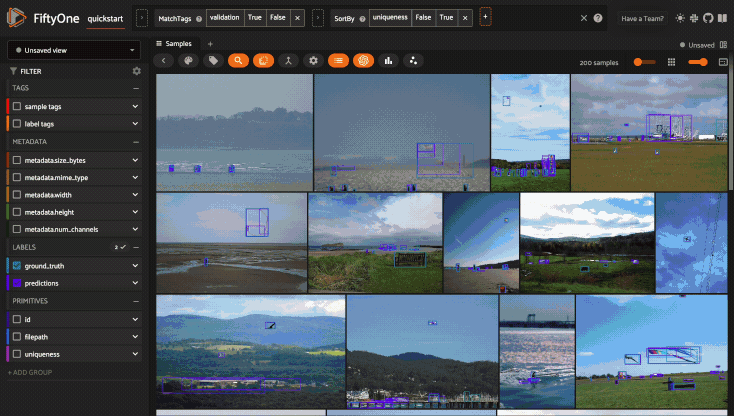
Sorting in the grid#
You can sort the samples in the grid by selecting a numeric or datetime field
from the Sort by dropdown in the upper right corner of the Samples panel.
Note
When Query Performance is enabled, only fields that are indexed can be sorted on.
Managing grid memory usage#
When scrolling through the grid, a certain number samples are cached by the App to improve the navigation experience. The number of samples is thresholded by a size estimate in megabytes. The default grid cache size is 1/8 of your device’s memory and only accounts for samples that are not currently visible on your screen.
When autosizing is enabled, the cache size also serves as the threshold for visible items on screen. By default, autosizing is enabled for all datasets and will zoom in on page load or during scrolling, if necessary. When disabled, the setting is persisted to your browser’s storage with respect to the dataset.
Autosizing is particularly useful for high-resolution images and video and
dense array data from large Detection and Segmentation masks and Heatmap
maps. To disable autosizing, toggle the setting in the settings cog or simply
zoom back out with the slider setting.
Optimizing Query Performance#
The App’s sidebar is optimized to leverage database indexes whenever possible.
Fields that are indexed are indicated by lightning bolt icons next to their field/attribute names:
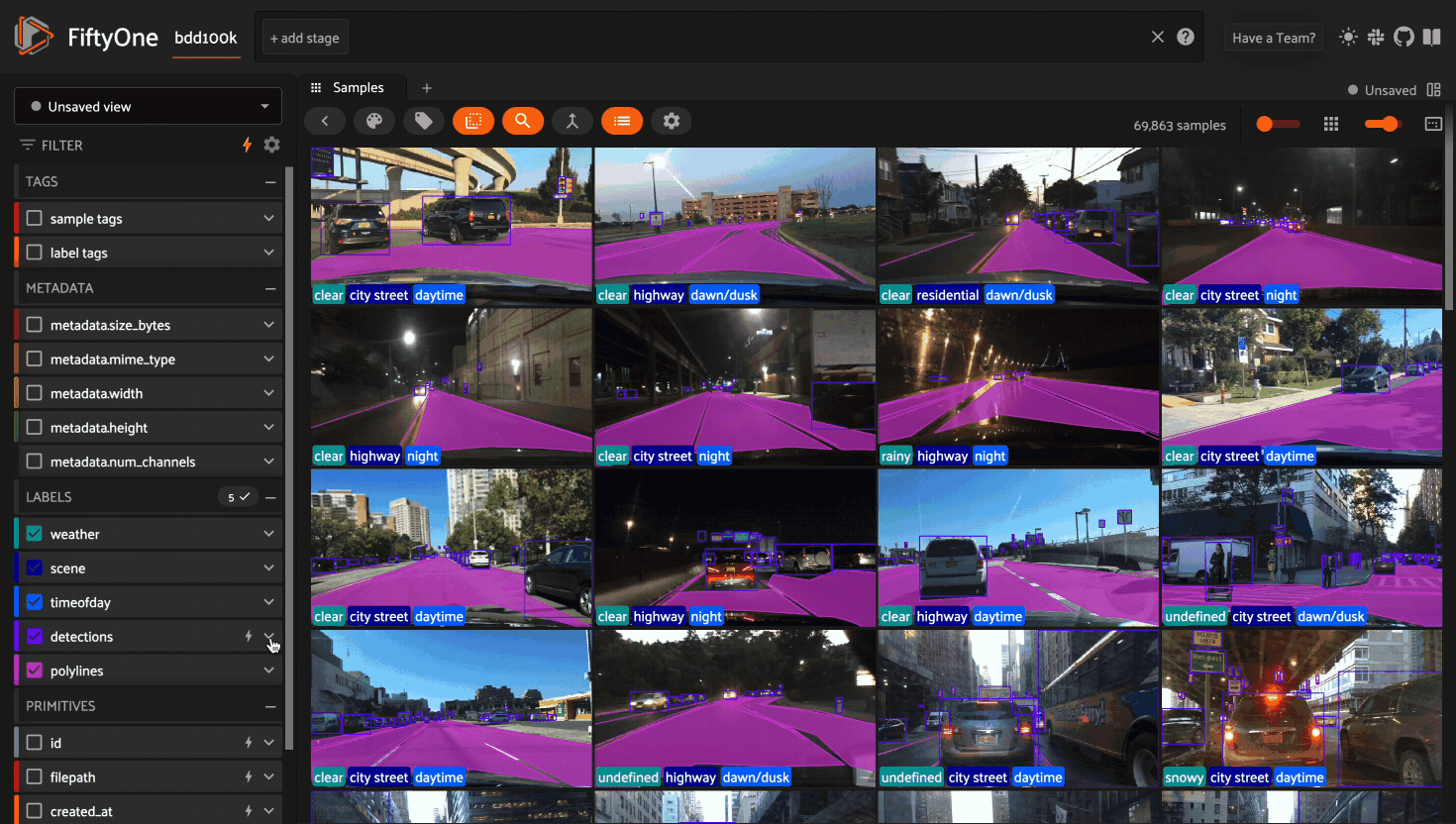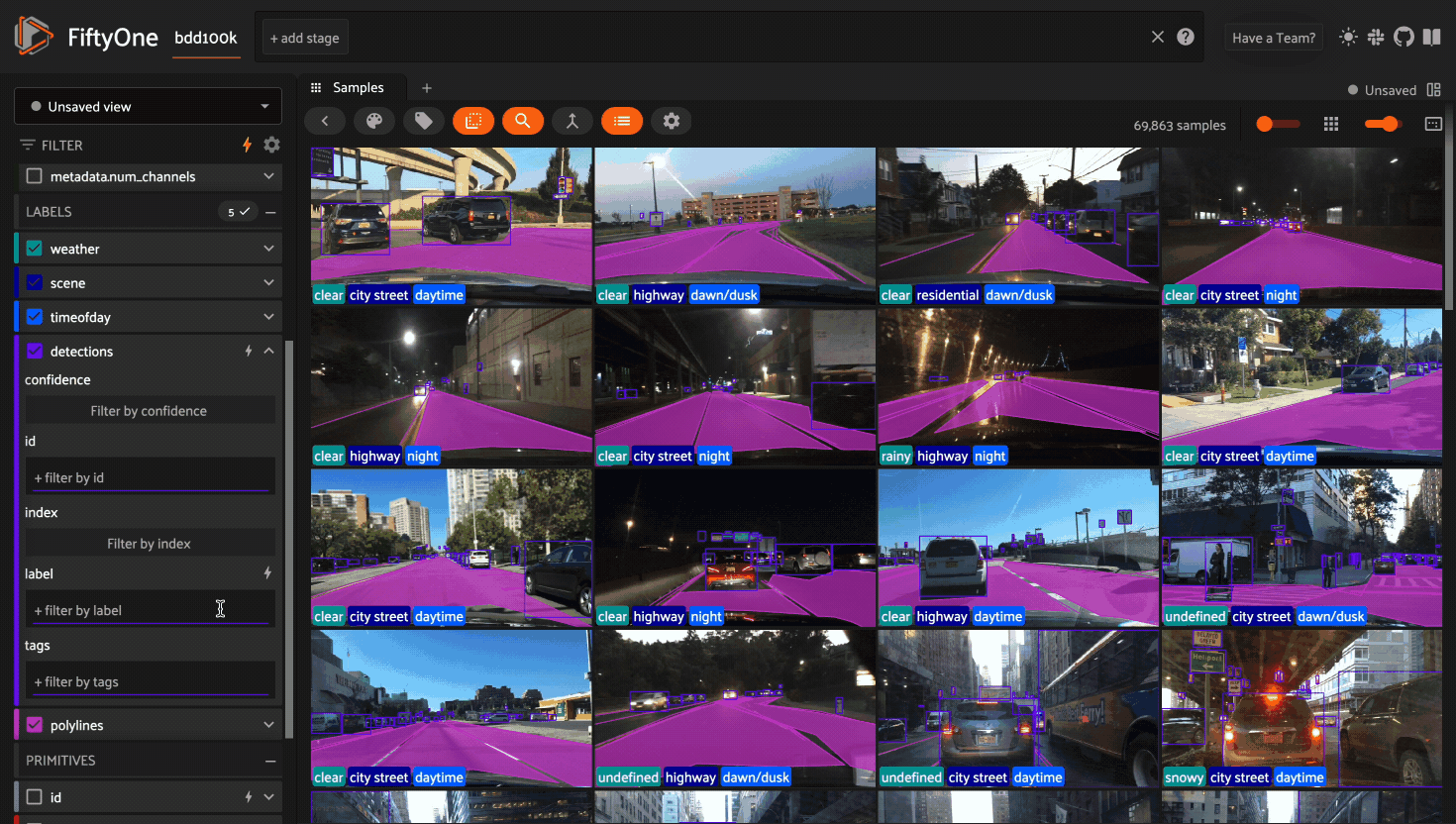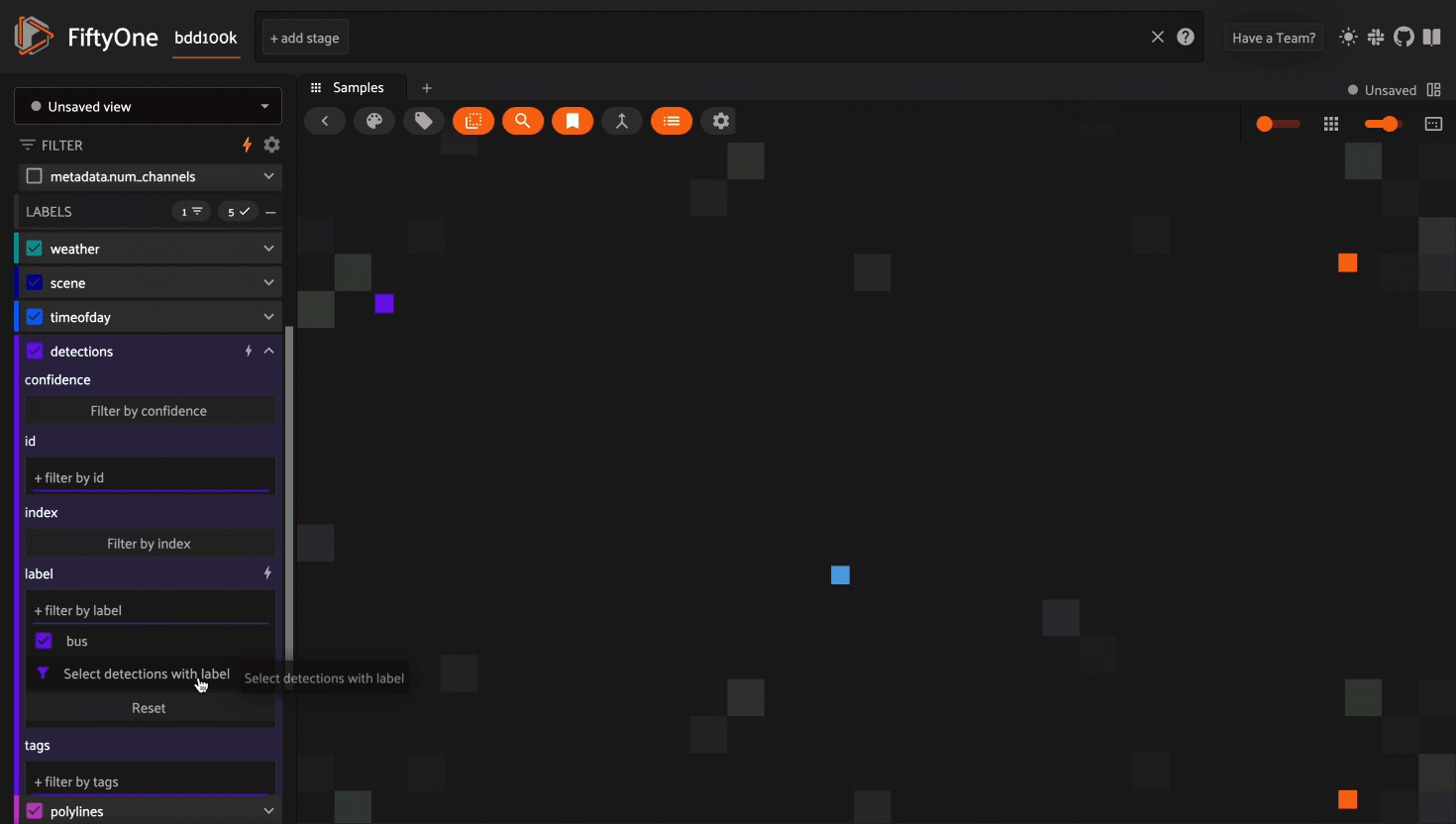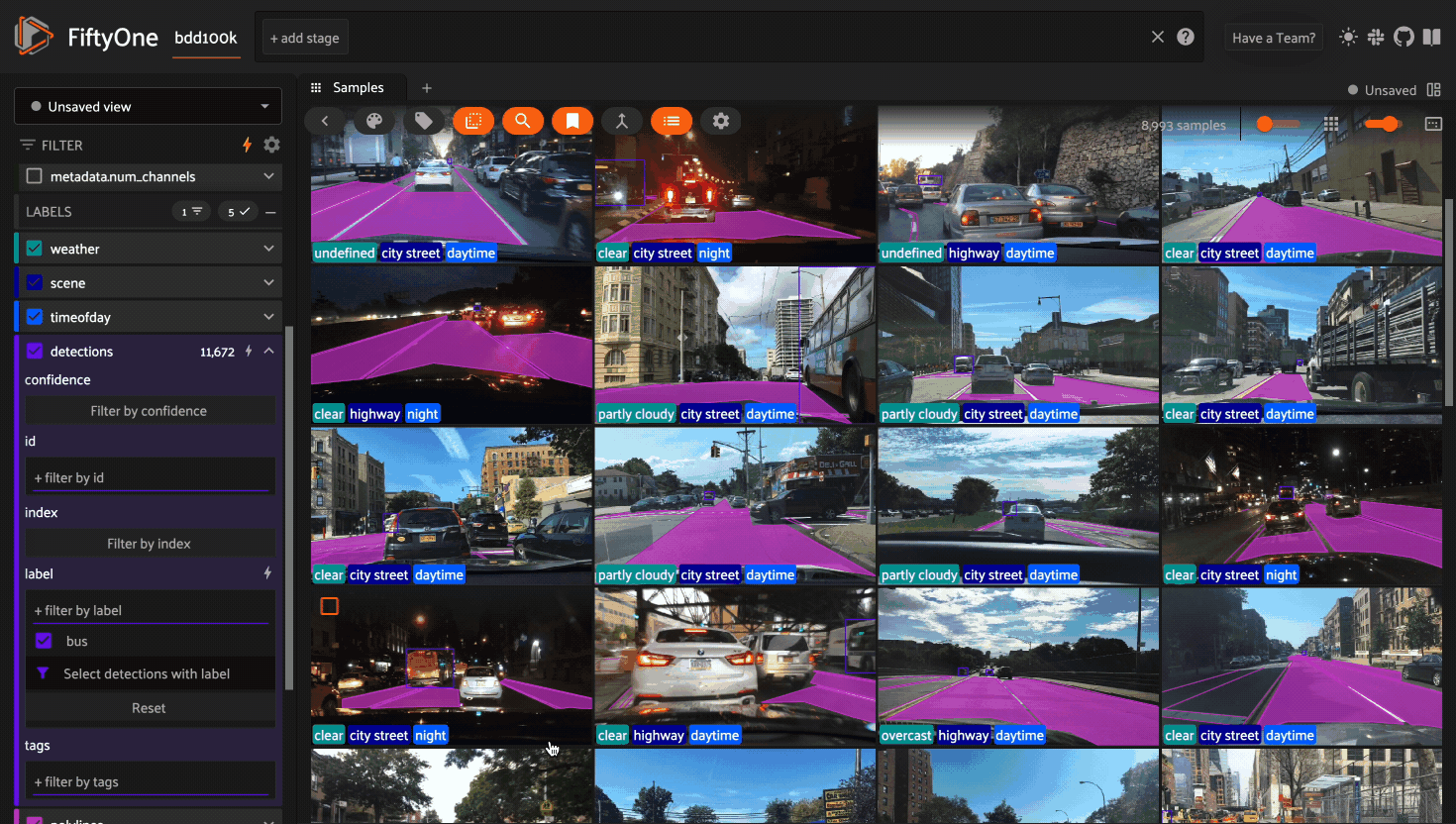
The above GIF shows query performance in action on the train split of the
BDD100K dataset with an index on the
detections.detections.label field:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4# The path to the source files that you manually downloaded
5source_dir = "/path/to/dir-with-bdd100k-files"
6
7dataset = foz.load_zoo_dataset(
8 "bdd100k",
9 split="train",
10 source_dir=source_dir,
11)
12
13dataset.create_index("detections.detections.label")
14
15session = fo.launch_app(dataset)
Note
When filtering by multiple fields, queries will be more efficient when your first filter is on an indexed field.
The SDK provides a number of useful utilities for managing indexes on your datasets:
list_indexes()- list all existing indexescreate_index()- create a new indexdrop_index()- drop an existing indexget_index_information()- get information about the existing indexes
Note
Did you know? With FiftyOne Enterprise you can manage indexes natively in the App via the Query Performance panel.
In general, we recommend indexing only the specific fields that you wish to perform initial filters on:
1import fiftyone as fo
2
3dataset = fo.Dataset()
4
5# Index specific top-level fields
6dataset.create_index("camera_id")
7dataset.create_index("recorded_at")
8dataset.create_index("annotated_at")
9dataset.create_index("annotated_by")
10
11# Index specific embedded document fields
12dataset.create_index("ground_truth.detections.label")
13dataset.create_index("ground_truth.detections.confidence")
14
15# Note: it is faster to declare indexes before adding samples
16dataset.add_samples(...)
17
18session = fo.launch_app(dataset)
Note
Filtering by frame fields of video datasets is not directly optimizable by creating indexes. Instead, use summary fields to efficiently query frame-level information on large video datasets.
Frame filtering in the App’s grid view can be disabled by setting
disable_frame_filtering=True in your
App config.
For grouped datasets, you should create a
compound index for each
field you wish to filter by that includes the field itself and ends with the
group slice name. This ensures grid results and counts are performant when
filtering by that field and matching on the active slice:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart-groups")
5
6# Index a specific field
7dataset.create_index("ground_truth.detections.label")
8dataset.create_index([("ground_truth.detections.label", 1), ("group.name", 1)])
9
10session = fo.launch_app(dataset)
For datasets with a small number of fields, you can index all fields by adding a single global wildcard index:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5dataset.create_index("$**")
6
7session = fo.launch_app(dataset)
Warning
For large datasets with many fields, global wildcard indexes may require a substantial amount of RAM and query performance may be degraded compared to selectively indexing a smaller number of fields.
You can also wildcard index all attributes of a specific embedded document field:
1# Wildcard index for all attributes of ground truth detections
2dataset.create_index("ground_truth.detections.$**")
Note
Numeric field filters are not supported by wildcard indexes.
Compound indexes#
With the right indexes configured, the App can support efficient filtering of massive datasets in complex scenarios.
In the simplest case, a single index allows efficient subset creation. If the number of samples matching the initial filter is small enough, you can then refine your search results with additional filters on unindexed fields as necessary.
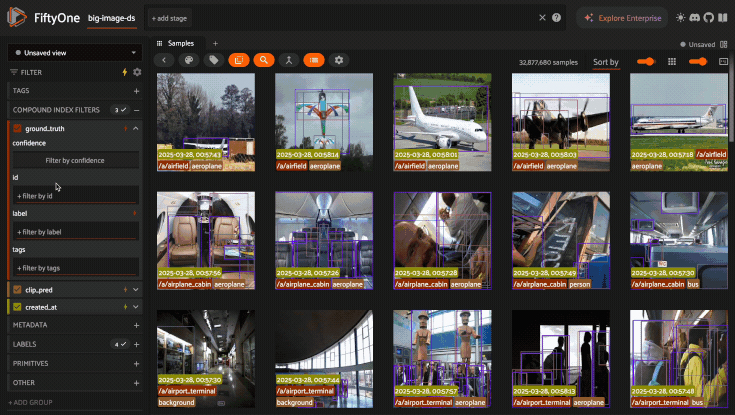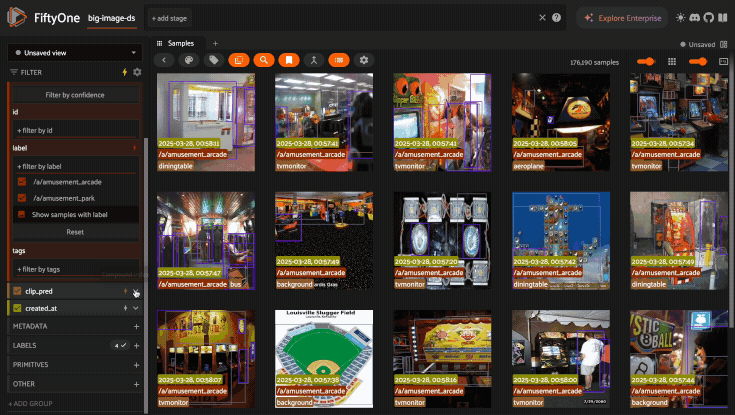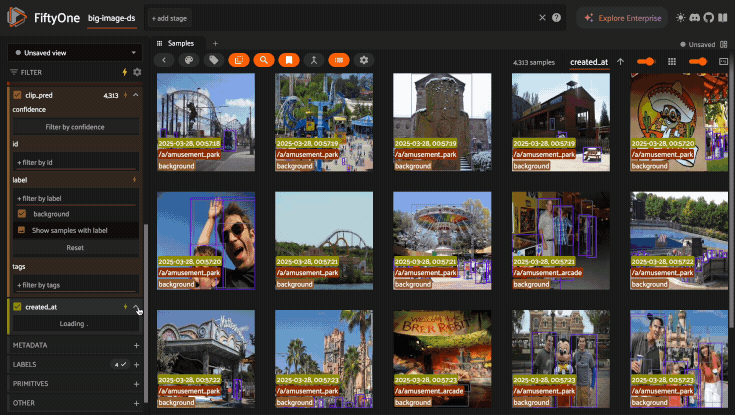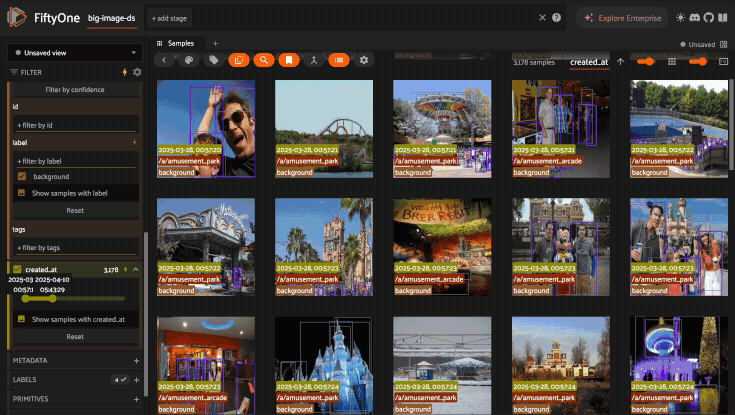
Compound indexes are useful in situations where you need to perform multiple filters to obtain a sufficiently small working set. Consider the following example:
1import fiftyone as fo
2
3dataset = fo.load_dataset("big-image-ds")
4
5dataset.create_index(
6 [("ground_truth.label", 1), ("clip_pred.label", 1), ("created_at", 1)]
7)
With this compound index created, we can efficiently perform the following multi-stage filtering + sorting operation on a 30M sample dataset.
Filter by
ground_truth.labelThen filter by
clip_pred.labelThen filter and sort by
created_at
The GIF below demonstrates this flow in action:
Note
As filters are applied, fields that are covered by a compound index have their lightning bolt highlighted in solid orange to indicate that filtering by these fields will be performant even if the current number of matching results is large.
Compound indexes can require significant database memory, but they are a powerful tool to support efficient exploration of massive datasets.
Query performant view stages#
In addition to the full dataset, Query Performance remains active (lightning bolts visible in the sidebar) when you add the view stages listed below to your view.
For ExcludeFields and
SelectFields, index performance
applies to all fields still present in the schema.
SelectGroupSlices is query
performant. Expect optimal performance when all slices are included in the
flattened view.
The GroupBy stage is a query performant
stage when order_by and order_by_key values are provided and a compound
index exists on the group_by and order_by fields with a unique
constraint and at least one index exists that begins with the order_by
field. Query performant fields then exist when they follow the order_by in
a compound index.
1import fiftyone as fo
2
3dataset = fo.load_dataset("frames-as-video")
4dataset.create_index([("video", 1), ("frame_number", 1)], unique=True)
5
6# create query performant fields for filtering and sorting
7dataset.create_index([("frame_number", 1), ("created_at", 1)])
8dataset.create_index([("frame_number", 1), ("last_modified_at", 1)])
9
10# create the "video" view and save it
11videos = dataset.group_by(
12 "video",
13 order_by="frame_number",
14 order_by_key=1,
15 create_index=False
16)
17dataset.save_view("videos", videos)
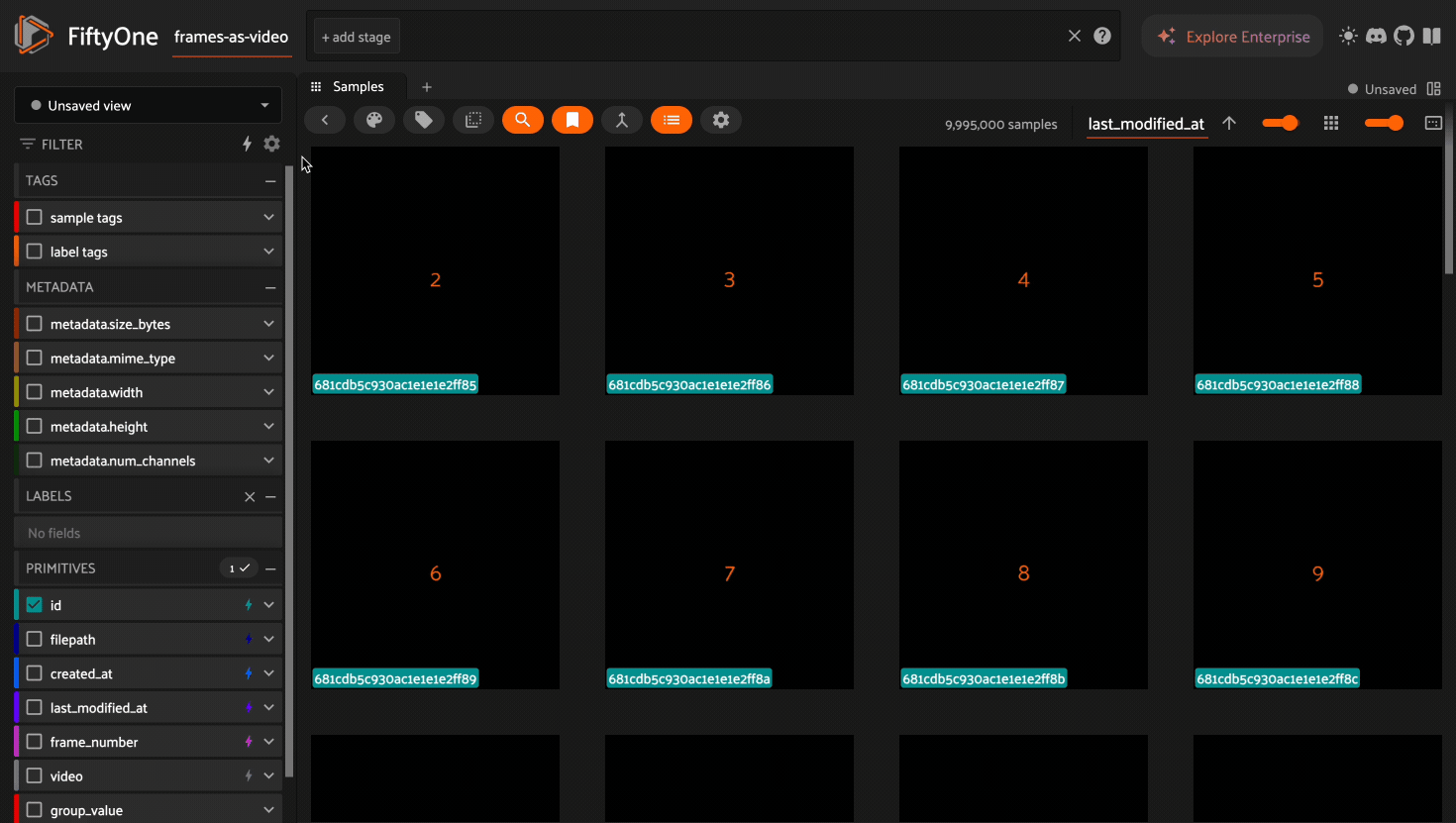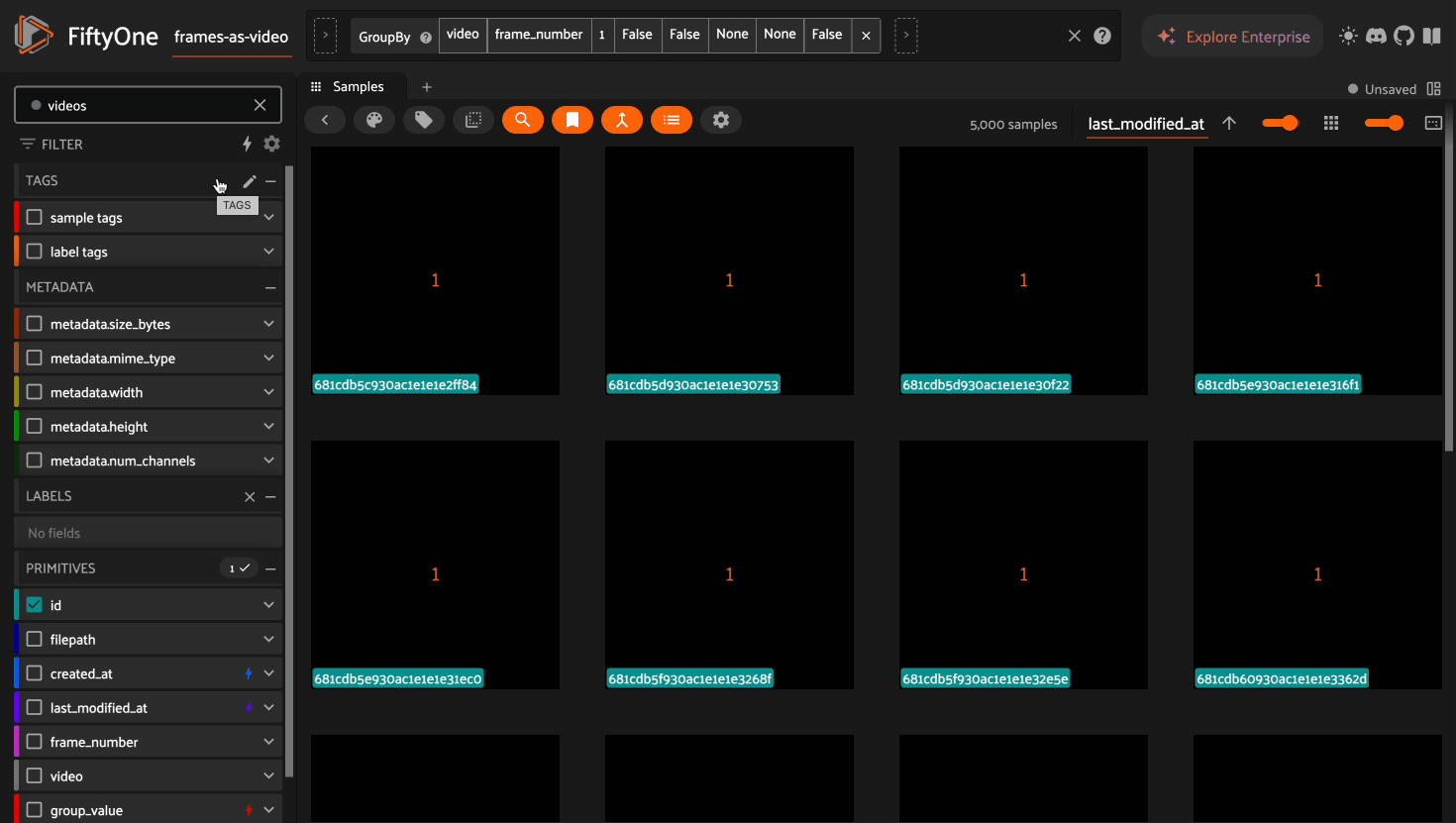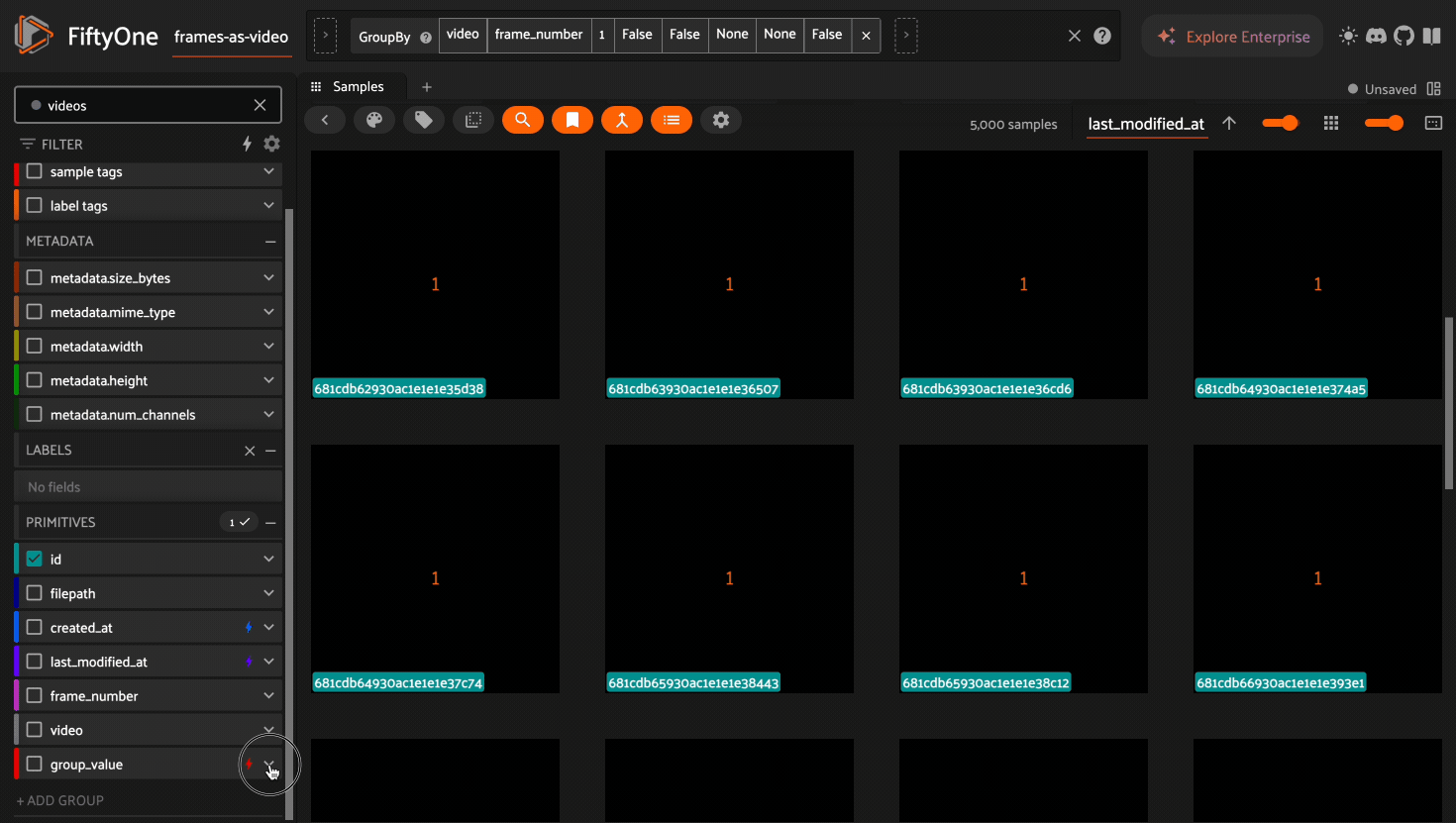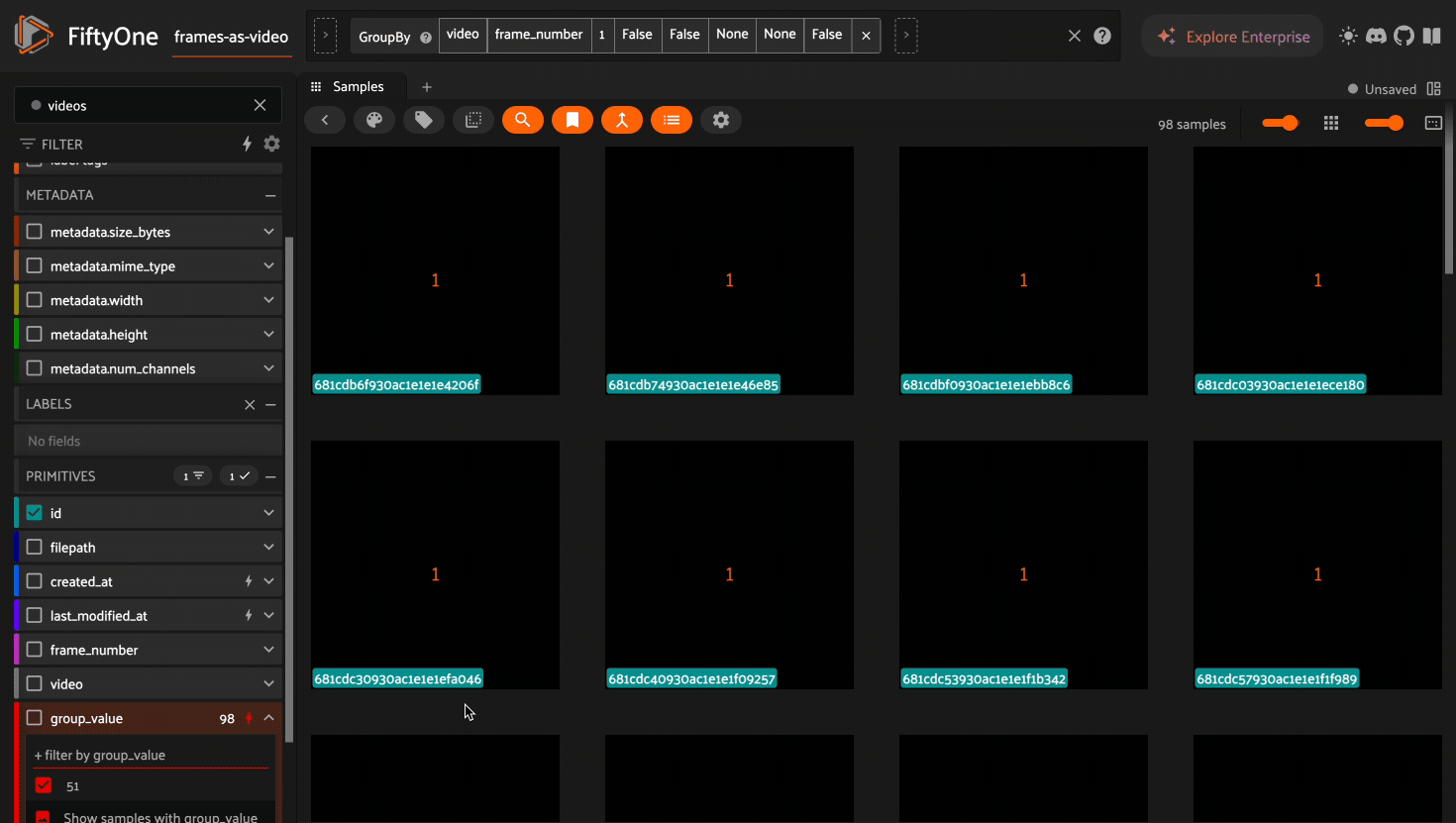
Sidebar filters in the grid now match on the order_by_key sample for each
group, i.e. where frame_number is 1 in the above example. Group level
metadata is stored on the key sample to efficiently filter on large datasets.
1import fiftyone as fo
2import random
3
4dataset = fo.load_dataset("frames-as-video")
5videos = dataset.load_saved_view("videos")
6
7dataset.create_index([("frame_number", 1), ("group_value", 1)])
8
9# store group level values on the key samples
10for poster_sample in videos.iter_samples(autosave=True):
11 poster_sample["group_value"] = str(random.randint(0, 51))
Unindexed sidebar results#
When Query Performance is enabled, dropdowns and sliders in the sidebar will automatically leverage indexes whenever possible to show the full set/range of values.
If an index is not available, a limited number of samples are scanned to populate dropdowns and sliders, which ensures that the sidebar responds rapidly to your inputs.
Note
By default, a maximum of 10,000 samples are scanned for unindexed fields, but you can customize this via the settings menu (cog icon) above the grid.
As shown in the GIF below, if a sidebar facet leverages a partial scan, you’ll see an indication of this along with a suggestion to create an index if you require full search results for a particular field:
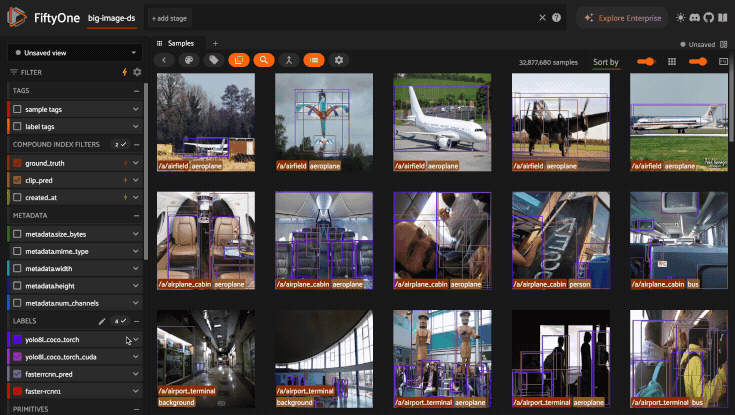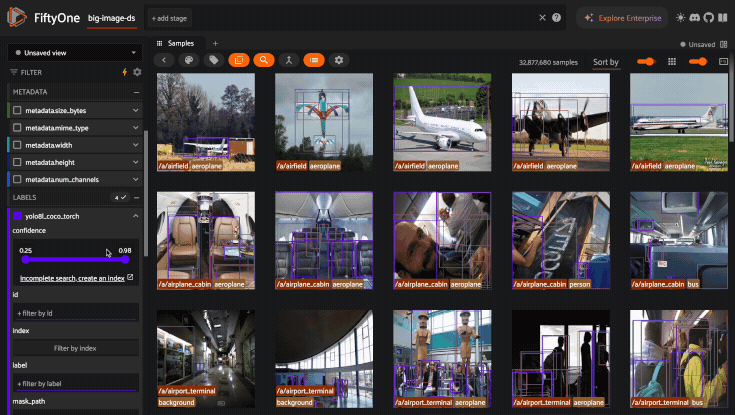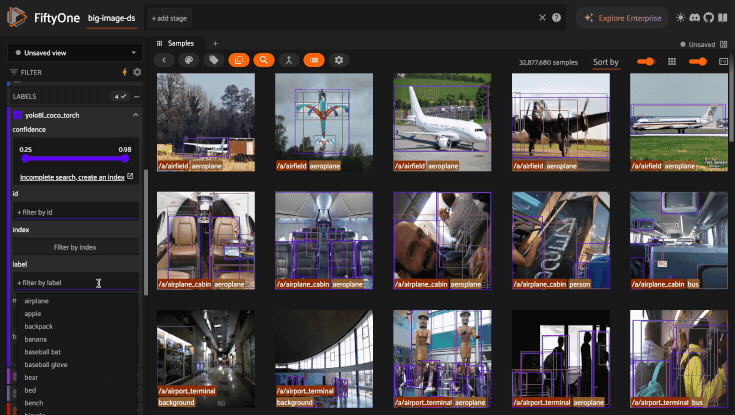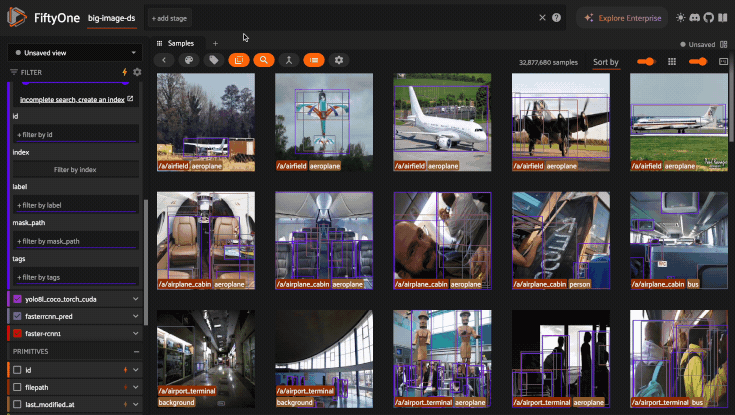
For example, you can enable full search results in the GIF above by creating the following indexes:
1import fiftyone as fo
2
3dataset = fo.load_dataset("big-image-ds")
4
5dataset.create_index("yolo8l_coco_torch.detections.confidence")
6dataset.create_index("yolo8l_coco_torch.detections.label")
Note
The sidebar can leverage indexes for a field if it has a single index or if there is a compound index whose first field matches.
For example, a ("created_at", "ground_truth.label") compound index
provides indexed sidebar results for the created_at field.
Disabling Query Performance#
Query Performance is enabled by default for all datasets. This is generally the recommended setting for all large datasets to ensure that queries are performant.
However, in certain circumstances you may prefer to disable Query Performance, which enables the App’s sidebar to show additional information such as label/value counts that are useful but more expensive to compute.
You can disable Query Performance for a particular dataset for its lifetime (in your current browser) via the gear icon in the Samples panel’s actions row:
You can also disable Query Performance by default for all datasets by setting
default_query_performance=False in your
App config.
Sidebar groups#
You can customize the layout of the App’s sidebar by creating/renaming/deleting groups and dragging fields between groups directly in the App:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5session = fo.launch_app(dataset)
Note
Any changes you make to a dataset’s sidebar groups in the App are saved on the dataset and will persist between sessions.
You can also programmatically modify a dataset’s sidebar groups by editing the
sidebar_groups property
of the dataset’s App config:
1# Get the default sidebar groups for the dataset
2sidebar_groups = fo.DatasetAppConfig.default_sidebar_groups(dataset)
3
4# Collapse the `metadata` section by default
5print(sidebar_groups[2].name) # metadata
6sidebar_groups[2].expanded = False
7
8# Add a new group
9sidebar_groups.append(fo.SidebarGroupDocument(name="new"))
10
11# Modify the dataset's App config
12dataset.app_config.sidebar_groups = sidebar_groups
13dataset.save() # must save after edits
14
15session = fo.launch_app(dataset)
You can conveniently reset the sidebar groups to their default state by setting
sidebar_groups to None:
1# Reset sidebar groups
2dataset.app_config.sidebar_groups = None
3dataset.save() # must save after edits
4
5session = fo.launch_app(dataset)
Note
If a dataset has fields that do not appear in the dataset’s
sidebar_groups
property, these fields will be dynamically assigned to default groups in
the App at runtime.
Using the view bar#
The view bar makes all of the powerful searching, sorting, and filtering operations provided by dataset views available directly in the App.
Note
Any changes to the current view that you make in the view bar are
automatically reflected in the DatasetView exposed by the
Session.view property of the
App’s session object.
Grouping samples#
You can use the group action in the App’s menu to dynamically group your samples by a field of your choice:
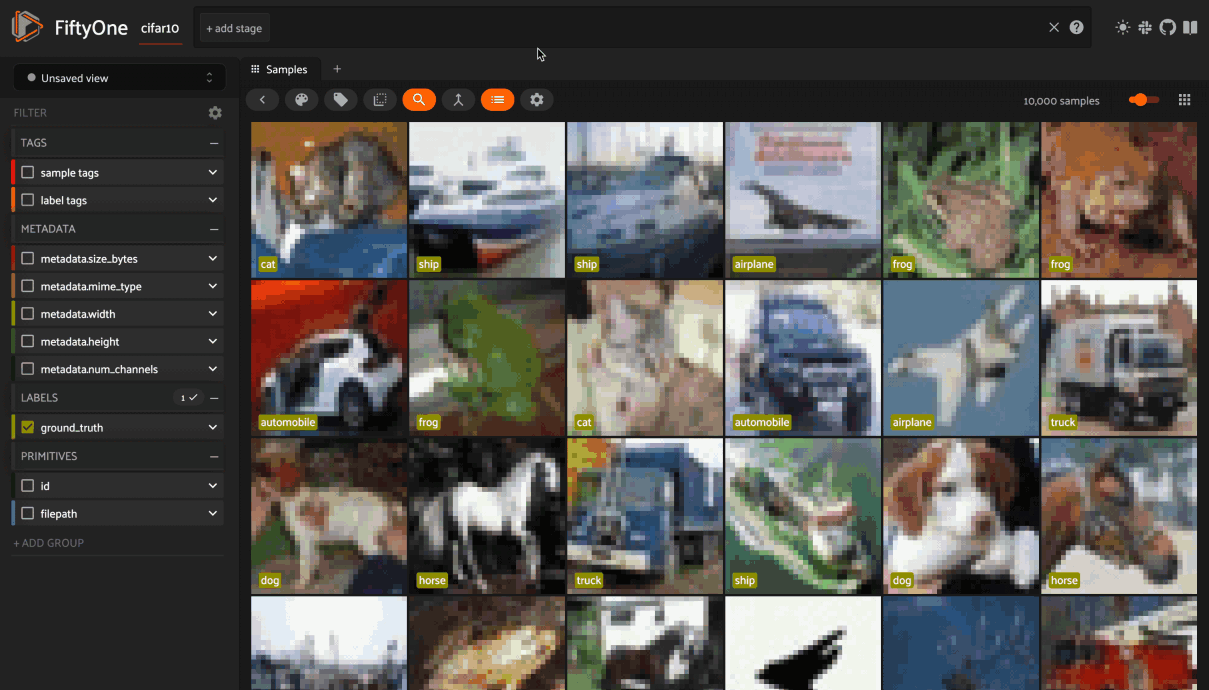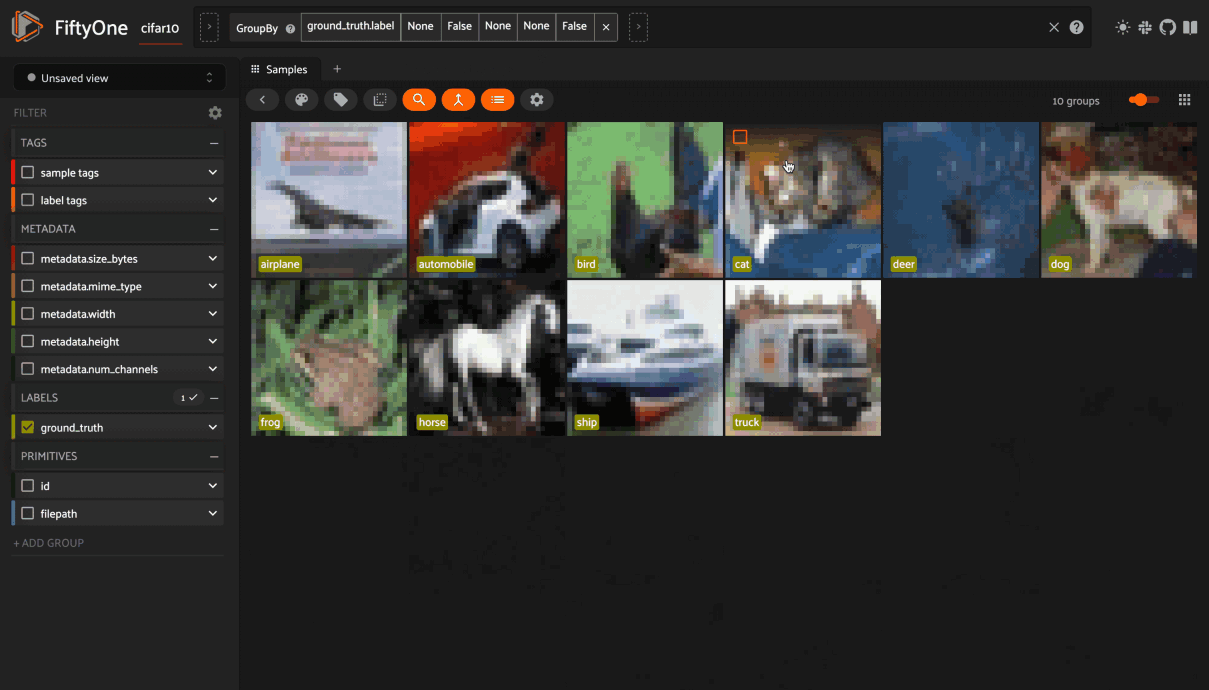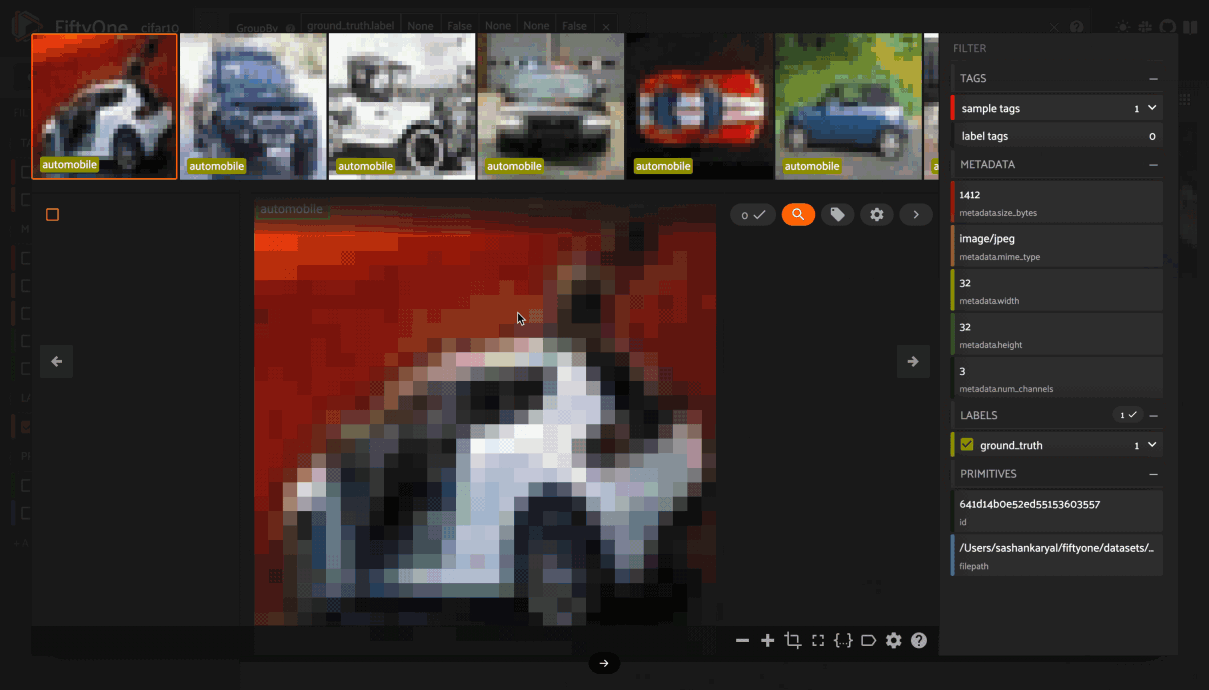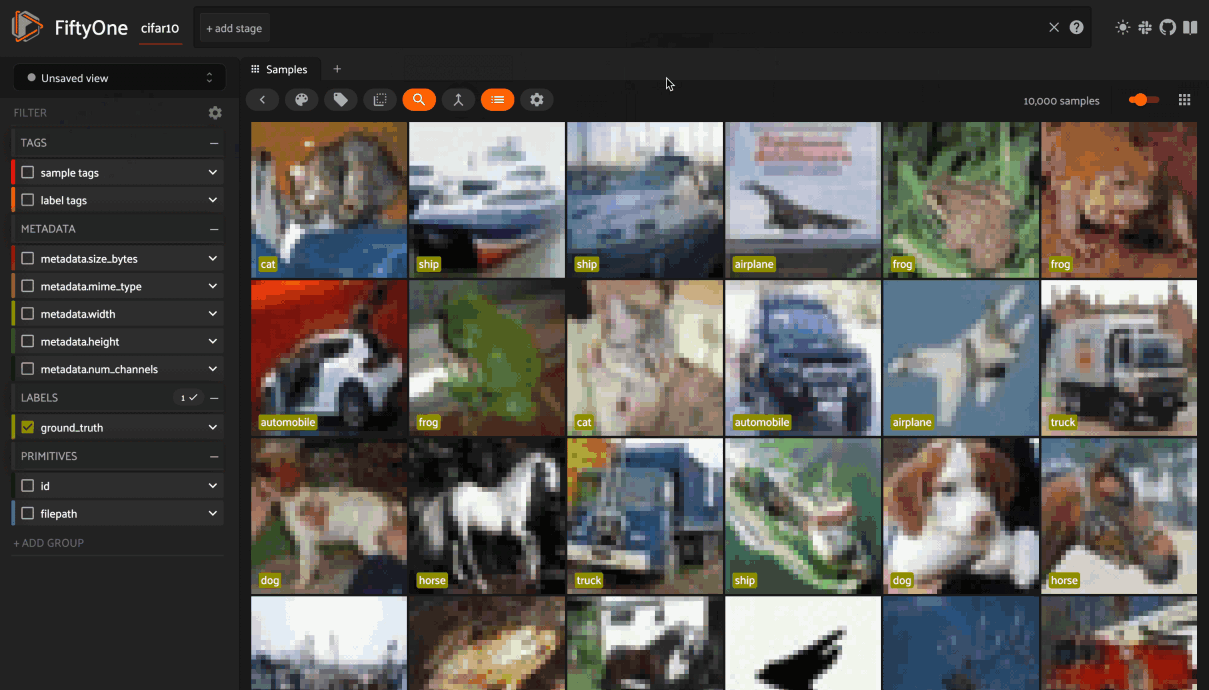
In this mode, the App’s grid shows the first sample from each group, and you can click on a sample to view all elements of the group in the modal.
You may navigate through the elements of the group either sequentially using the carousel, or randomly using the pagination UI at the bottom of the modal.
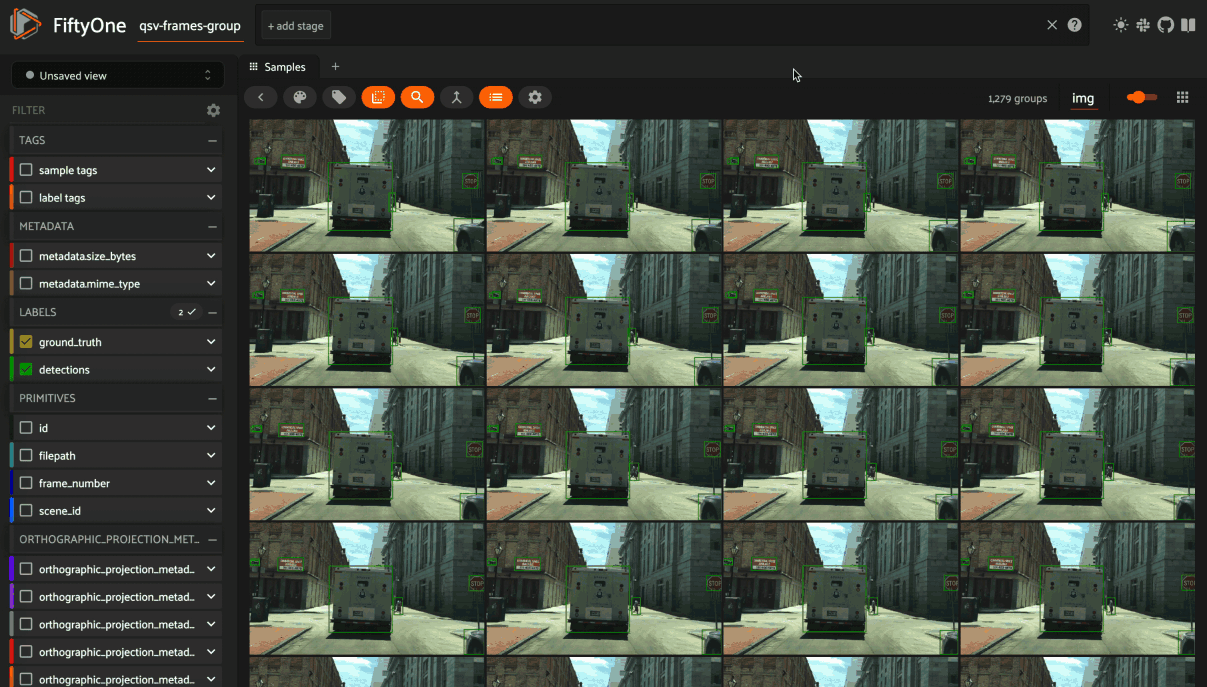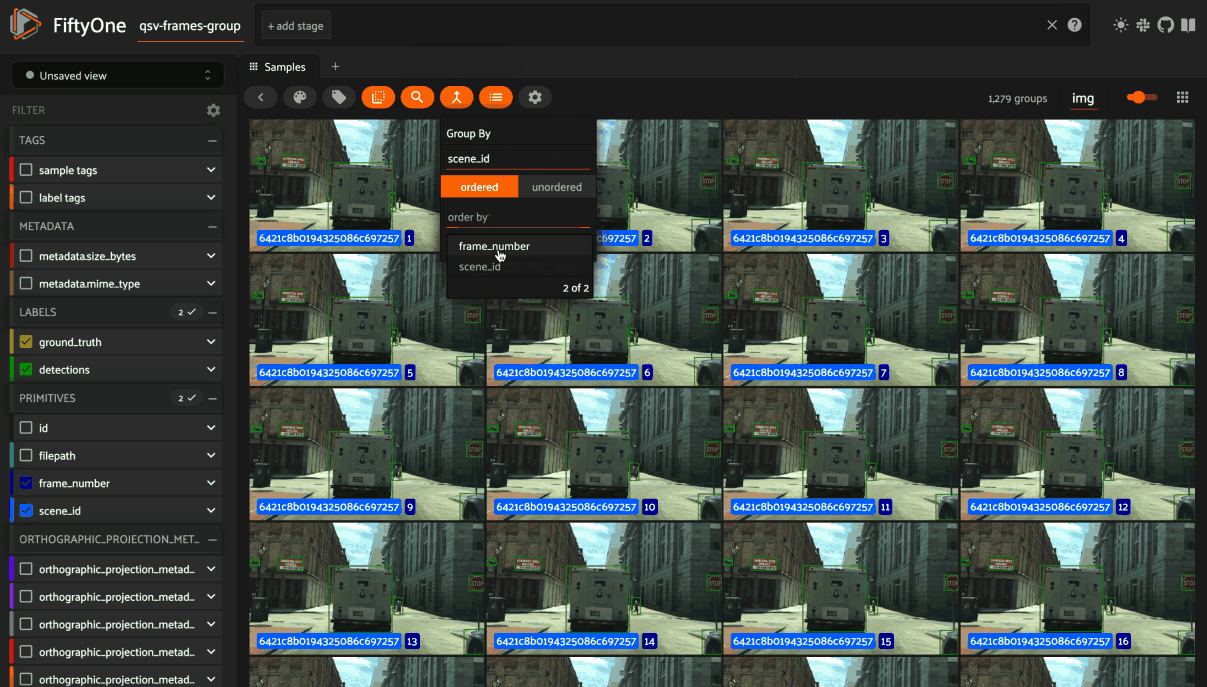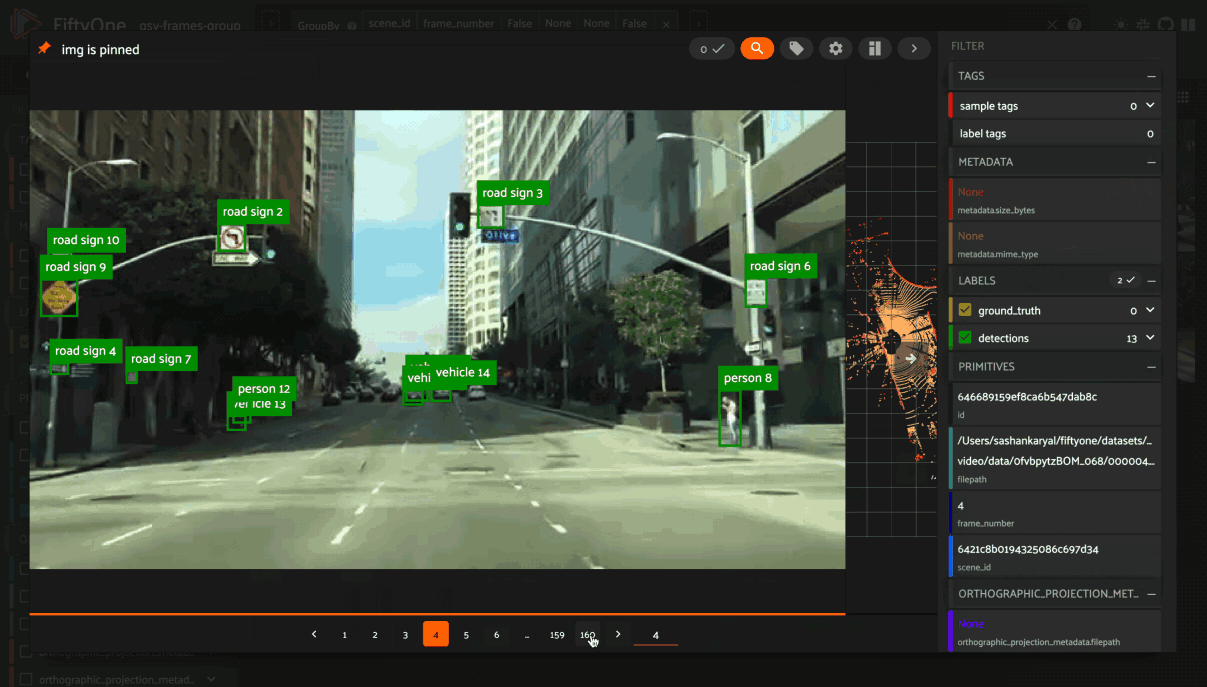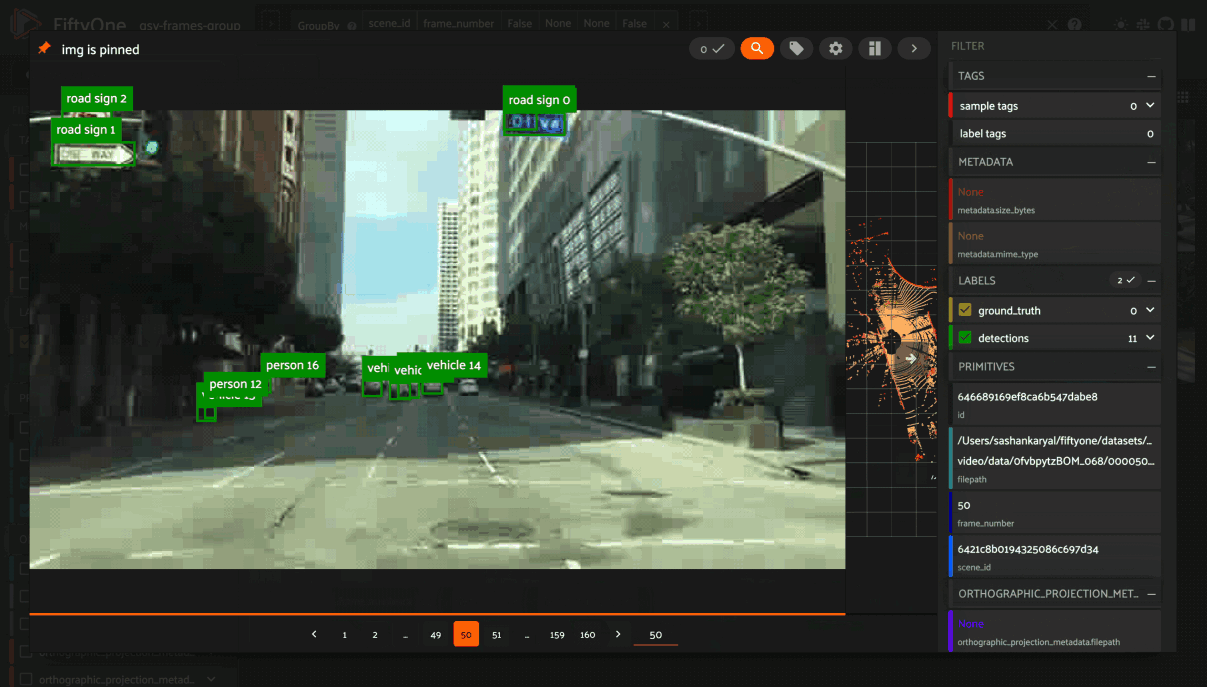
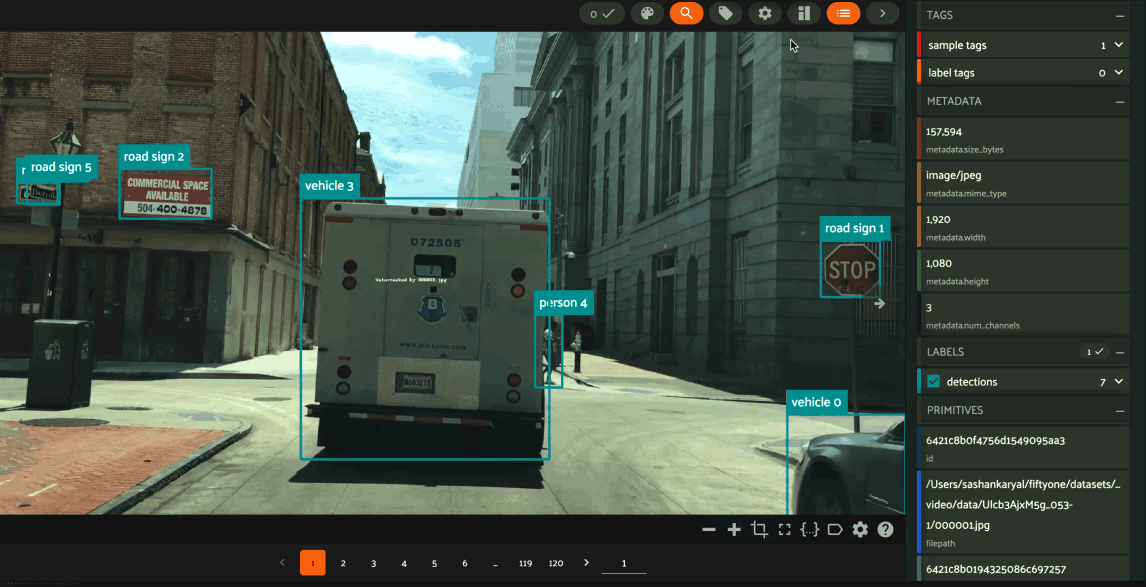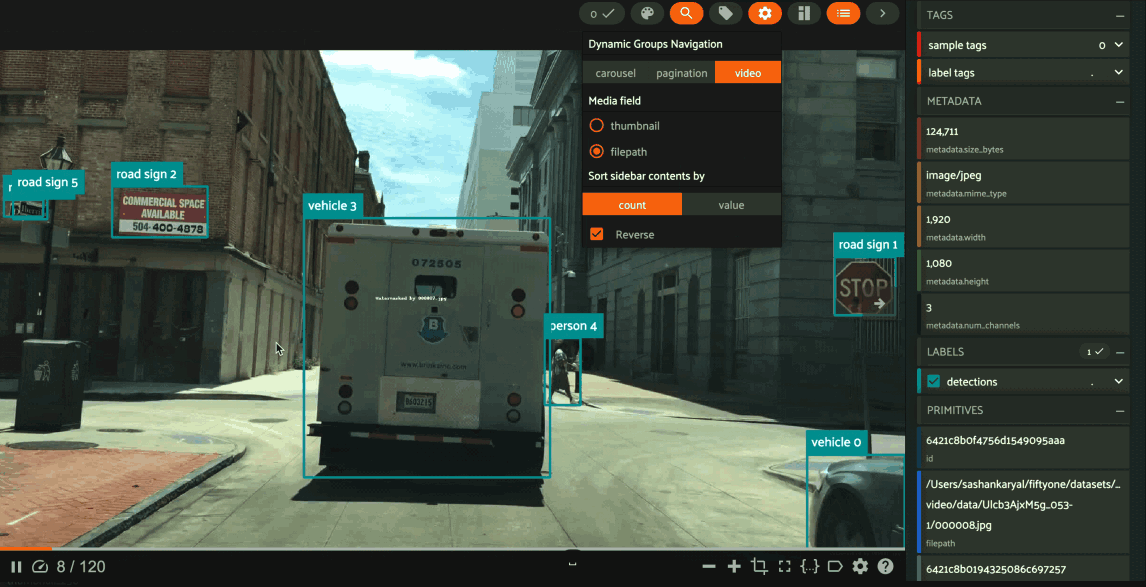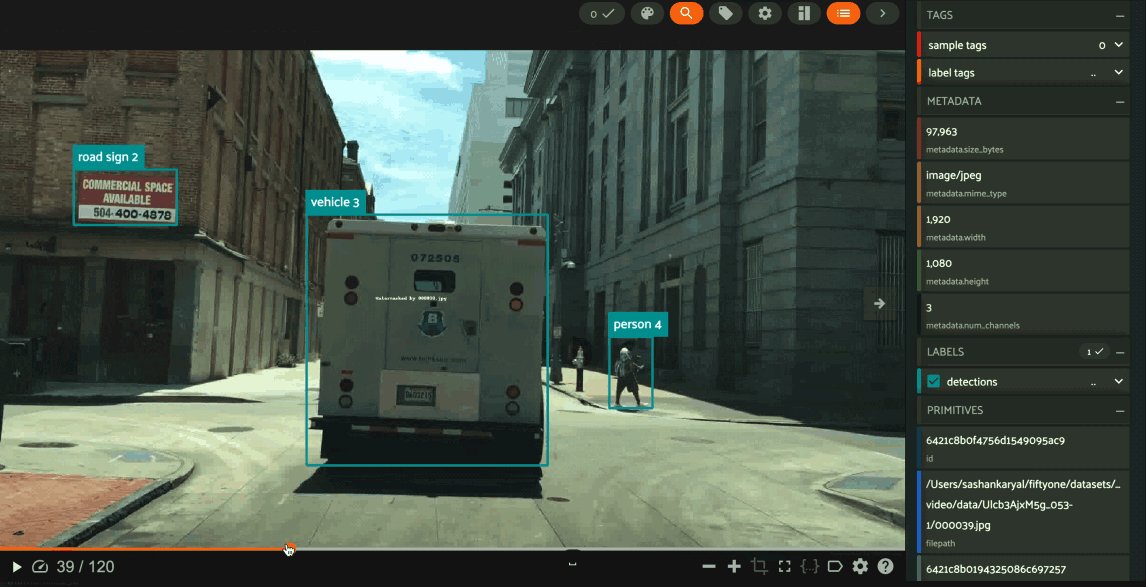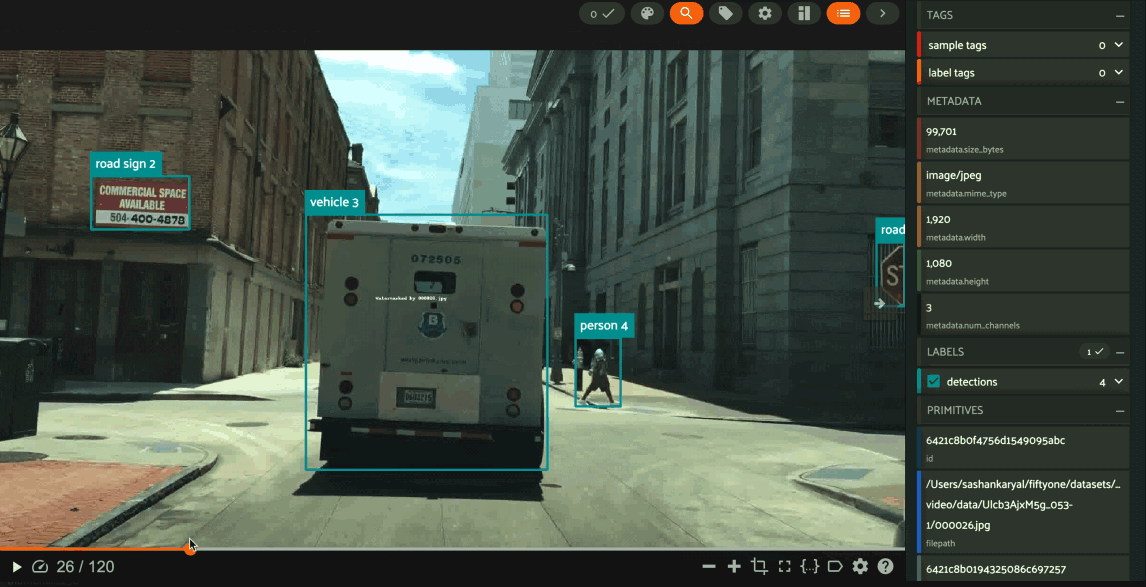
When viewing ordered groups, you have an additional option to render the elements of the group as a video.
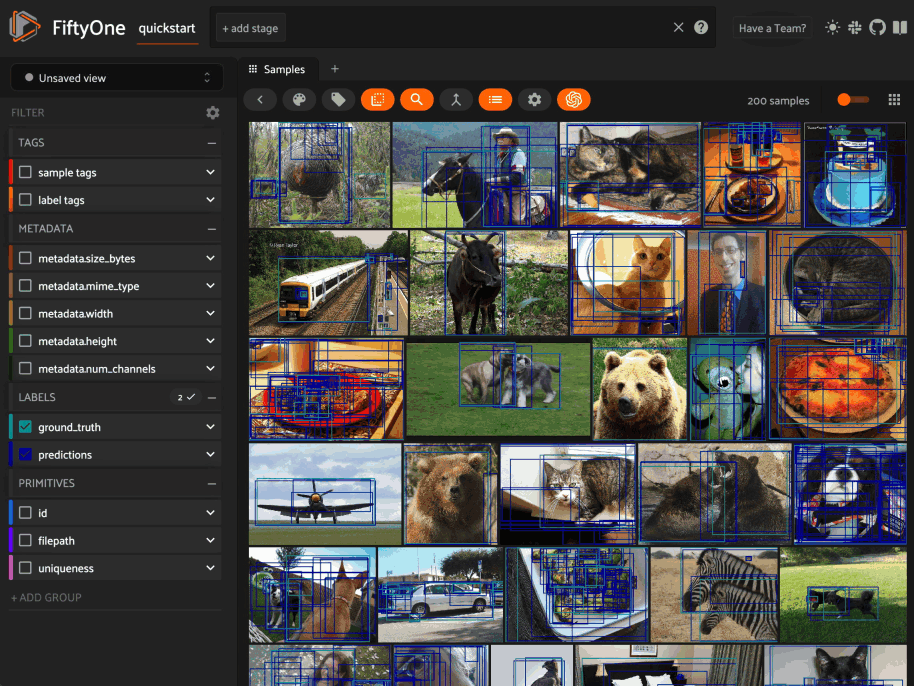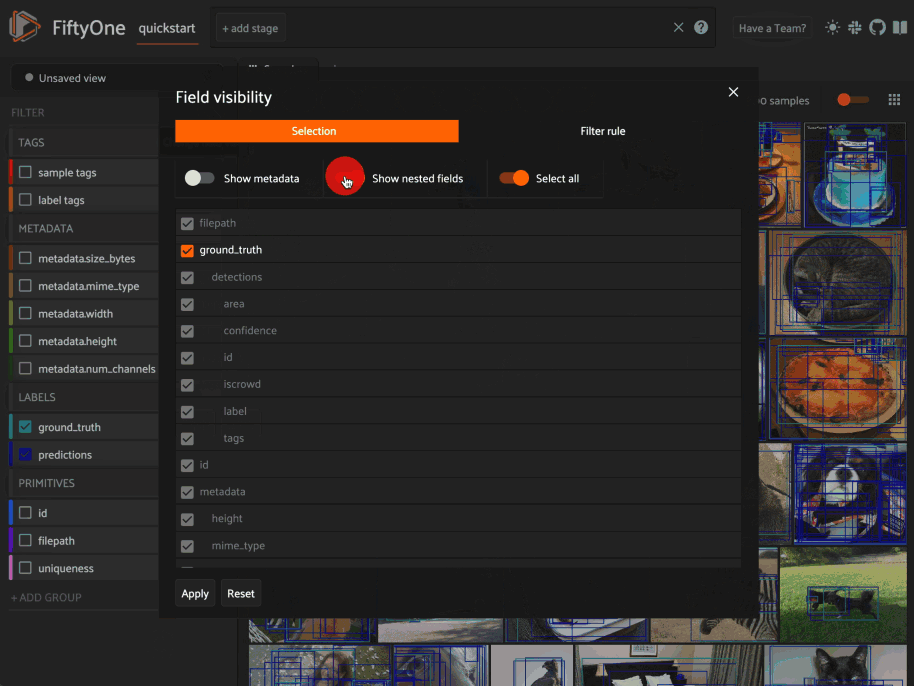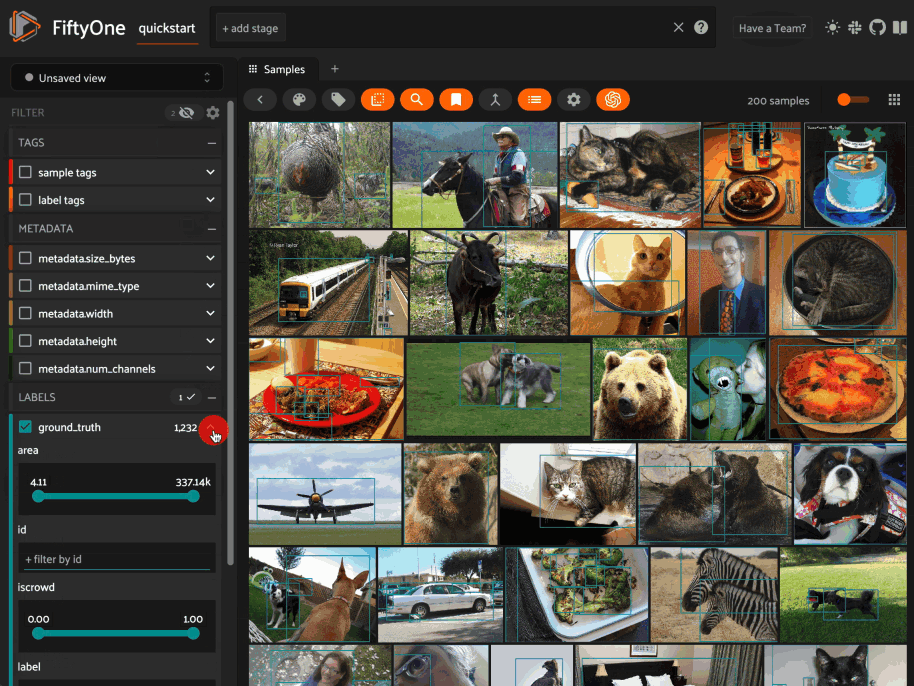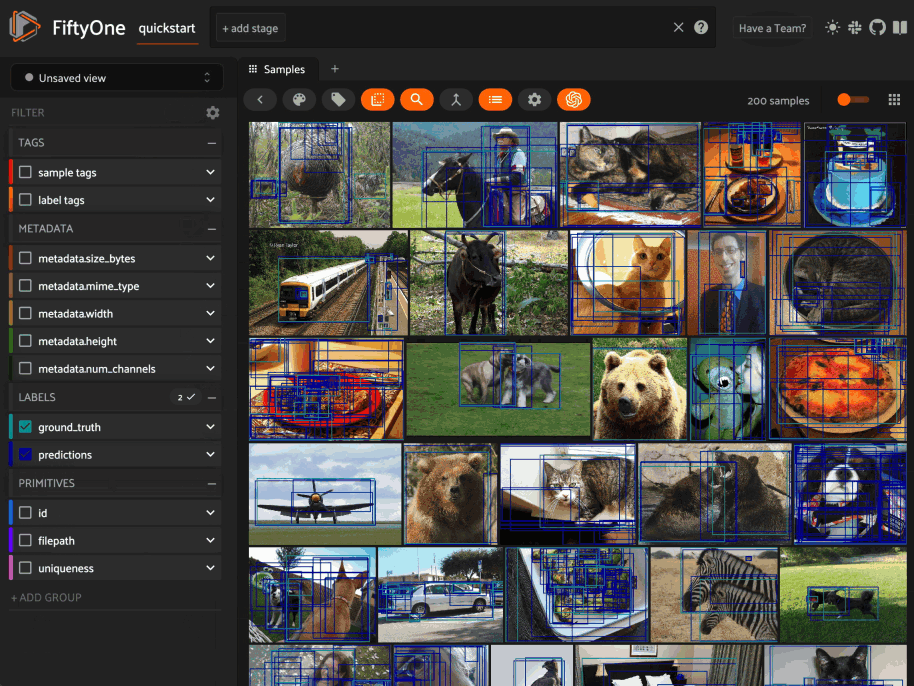
Field visibility#
You can configure which fields of your dataset appear in the App’s sidebar by clicking the settings icon in the upper right of the sidebar to open the Field visibility modal.
Consider the following example:
1import fiftyone as fo
2import fiftyone.zoo as foz
3from datetime import datetime
4
5dataset = foz.load_zoo_dataset("quickstart")
6dataset.add_dynamic_sample_fields()
7
8field = dataset.get_field("ground_truth")
9field.description = "Ground truth annotations"
10field.info = {"creator": "alice", "created_at": datetime.utcnow()}
11field.save()
12
13field = dataset.get_field("predictions")
14field.description = "YOLOv8 predictions"
15field.info = {"owner": "bob", "created_at": datetime.utcnow()}
16field.save()
17
18session = fo.launch_app(dataset)
Manual selection#
You can use the Selection tab to manually select which fields to display.
By default, only top-level fields are available for selection, but if you want
fine-grained control you can opt to include nested fields
(eg dynamic attributes of your label fields) in the
selection list as well.
Note
You cannot exclude default fields/attributes from your dataset’s schema, so these rows are always disabled in the Field visibility UI.
Click Apply to reload the App with only the specified fields in the sidebar.
When you do so, a filter icon will appear to the left of the settings icon in
the sidebar indicating how many fields are currently excluded. You can reset
your selection by clicking this icon or reopening the modal and pressing the
Reset button at the bottom.
Note
If your dataset has many fields and you frequently work with different subsets of them, you can persist/reload field selections by saving views.
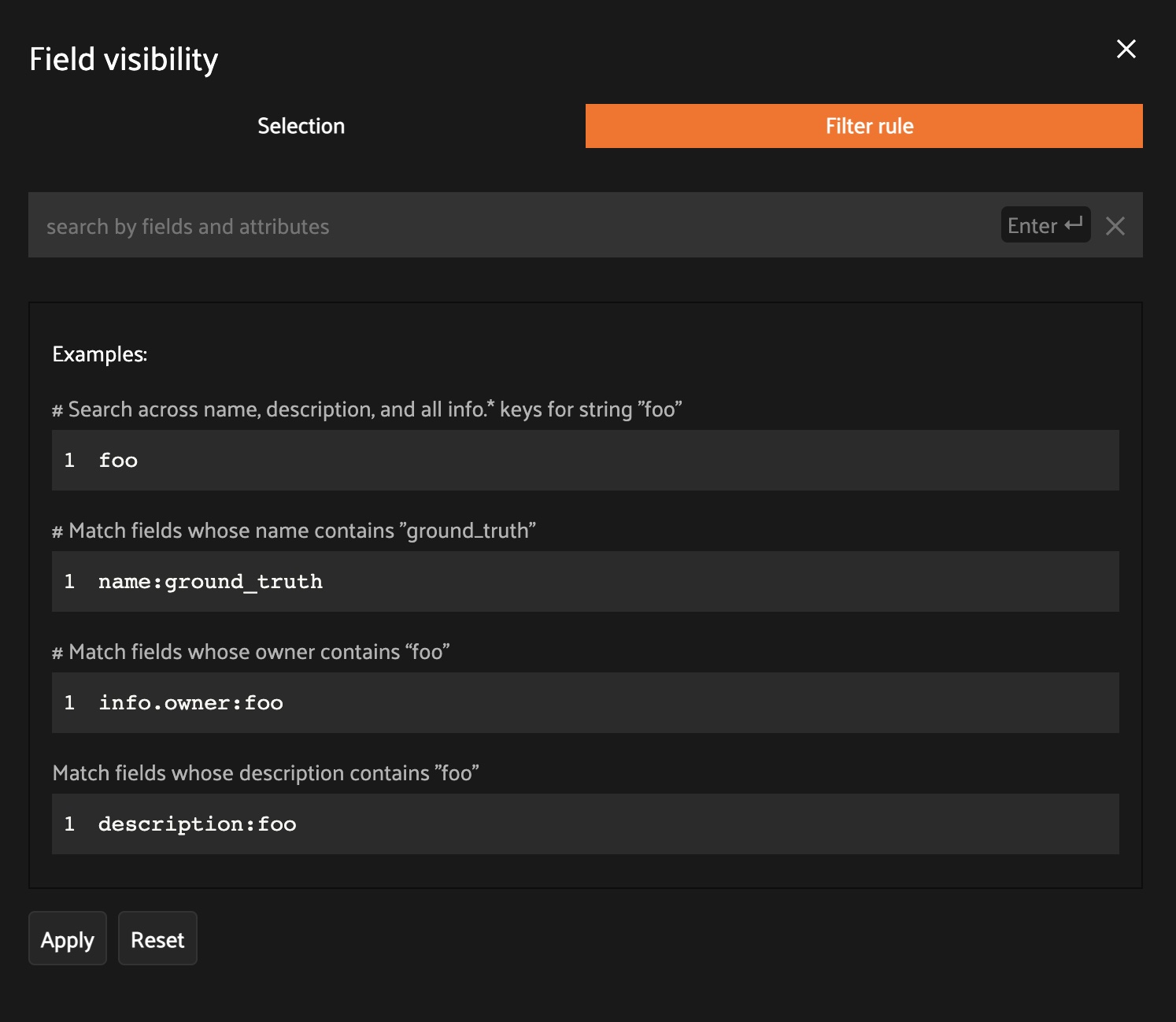
Filter rules#
Alternatively, you can use the Filter rule tab to define a rule that is
dynamically applied to the dataset’s
field metadata each time the App loads to
determine which fields to include in the sidebar.
Note
Filter rules are dynamic. If you save a view that contains a filter rule, the matching fields may increase or decrease over time as you modify the dataset’s schema.
Filter rules provide a simple syntax with different options for matching fields:
Note
All filter rules are implemented as substring matches against the stringified contents of the relevant field metadata.
Color schemes#
You can configure the color scheme used by the App to render content by clicking on the color palette icon above the sample grid.
Consider the following example:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5dataset.evaluate_detections(
6 "predictions", gt_field="ground_truth", eval_key="eval"
7)
8
9session = fo.launch_app(dataset)
Color schemes in the App#
The GIF below demonstrates how to:
Configure a custom color pool from which to draw colors for otherwise unspecified fields/values
Configure the colors assigned to specific fields in color by
fieldmodeConfigure the colors used to render specific annotations based on their attributes in color by
valuemodeSave the customized color scheme as the default for the dataset
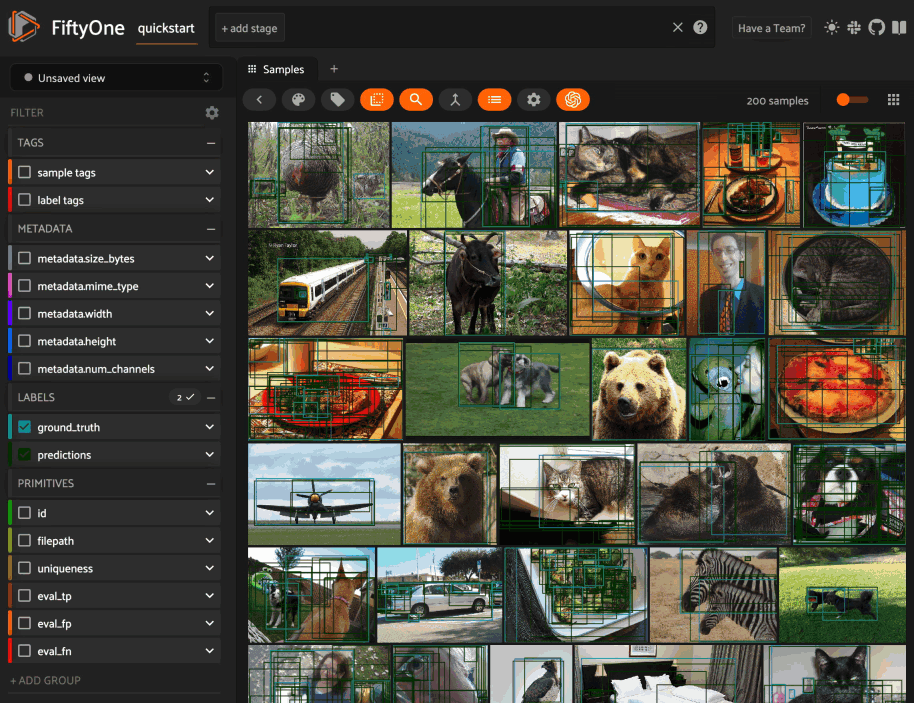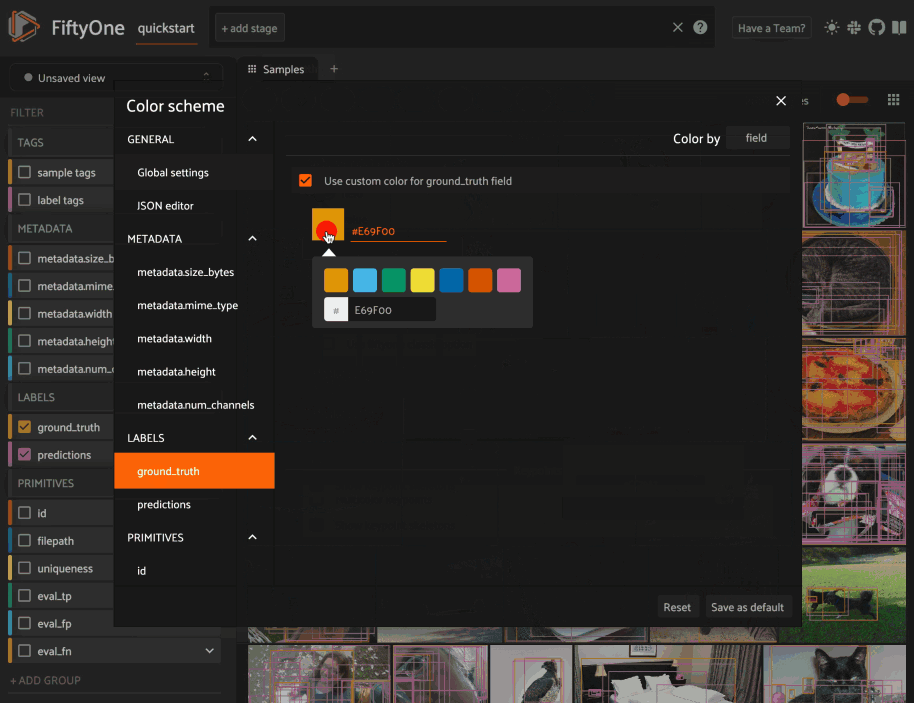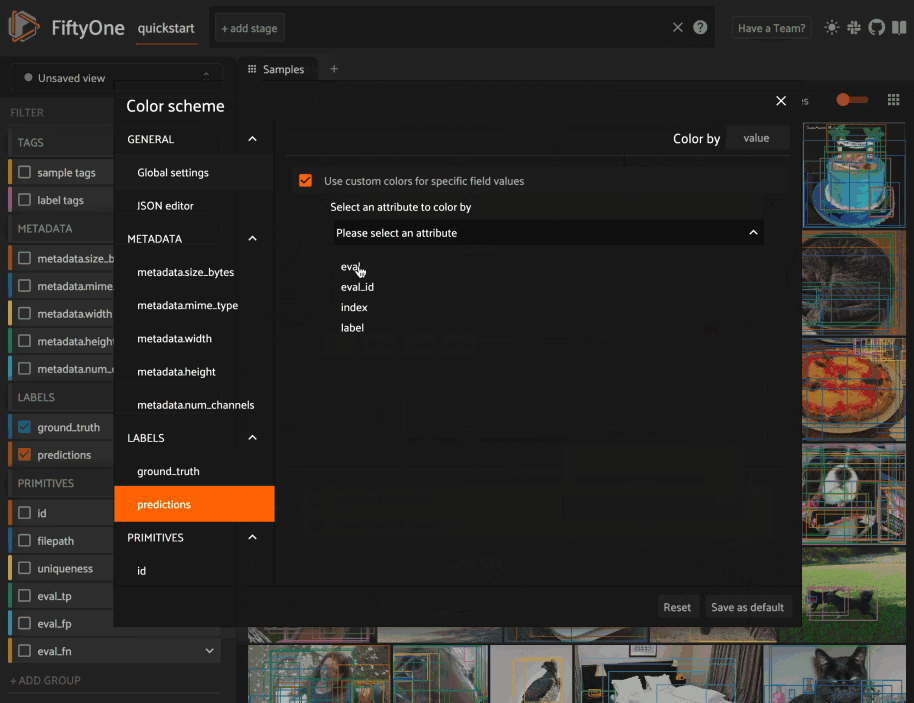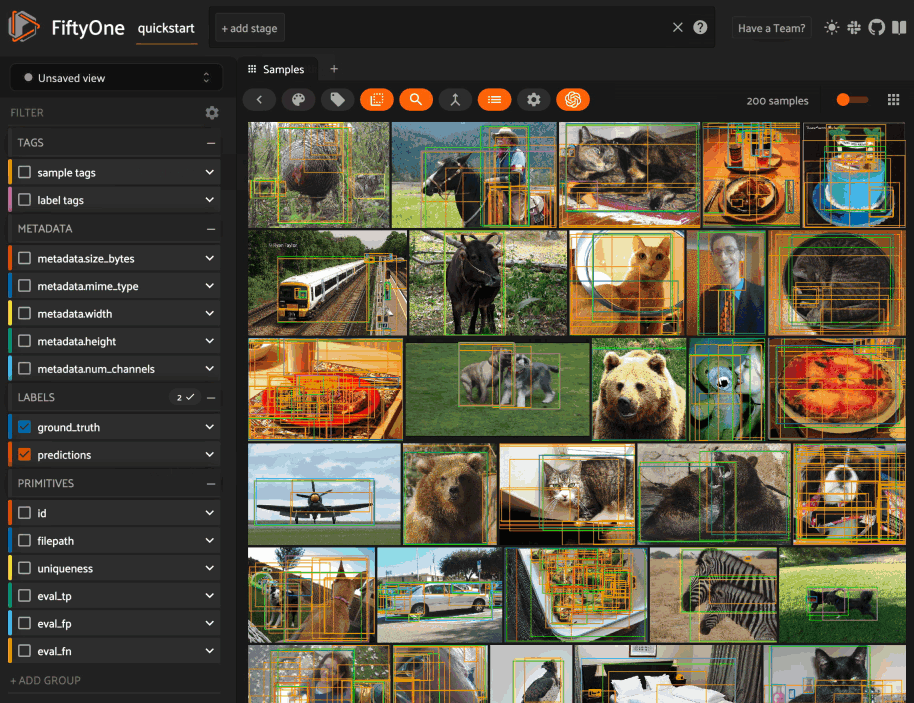
Note
Any customizations you make only apply to the current dataset. Each time you load a new dataset, the color scheme will revert to that dataset’s default color scheme (if any) or else the global default color scheme.
To persist a color scheme, you can press Save as default to save the
color scheme as the dataset’s default scheme, copy it via the modal’s JSON
viewer, or access it programmatically via
session.color_scheme
as described below.
The following table describes the available color scheme customization options in detail:
Tab |
Element |
Description |
|---|---|---|
Global settings |
Color annotations by |
Whether to color the annotations in the grid/modal based on
the |
Global settings |
Color pool |
A pool of colors from which colors are randomly assigned for otherwise unspecified fields/values |
Global settings |
Label Opacity |
Color opacity of annotations |
Global settings |
Multicolor keypoints |
Whether to independently coloy keypoint points by their index |
Global settings |
Show keypoints skeletons |
Whether to show keypoint skeletons, if available |
Global settings |
Default mask targets colors |
If the MaskTargetsField is defined with integer keys, the dataset can assign a default color based on the integer keys |
Global settings |
Default colorscale |
The default colorscale to use when rendering heatmaps |
JSON editor |
A JSON representation of the current color scheme that you can directly edit or copy + paste |
|
All |
|
Reset the current color scheme to the dataset’s default (if any) or else the global default scheme |
All |
|
Save the current color scheme as the default for the current dataset. Note that this scheme can be viewed and/or modified in Python |
All |
|
Deletes the current dataset’s default color scheme |
|
Use custom colors for |
Allows you to specify a custom color to use whenever
rendering any content from that field in the grid/modal
when the App is in color by |
|
Use custom colors for specific field values |
Allows you to specify custom colors to use to render
annotations in this field based on the individual values
that it takes. In the case of embedded document fields,you
must also specify an attribute of each object. For example,
color all
|
Color schemes in Python#
You can also programmatically configure a session’s color scheme by creating
ColorScheme instances in Python:
1# Create a custom color scheme
2fo.ColorScheme(
3 color_pool=["#ff0000", "#00ff00", "#0000ff", "pink", "yellowgreen"],
4 fields=[
5 {
6 "path": "ground_truth",
7 "colorByAttribute": "eval",
8 "valueColors": [
9 # false negatives: blue
10 {"value": "fn", "color": "#0000ff"},
11 # true positives: green
12 {"value": "tp", "color": "#00ff00"},
13 ]
14 },
15 {
16 "path": "predictions",
17 "colorByAttribute": "eval",
18 "valueColors": [
19 # false positives: red
20 {"value": "fp", "color": "#ff0000"},
21 # true positives: green
22 {"value": "tp", "color": "#00ff00"},
23 ]
24 },
25 {
26 "path": "segmentations",
27 "maskTargetsColors": [
28 # 12: red
29 {"intTarget": 12, "color": "#ff0000"},
30 # 15: green
31 {"intTarget": 15, "color": "#00ff00"},
32 ]
33 }
34 ],
35 color_by="value",
36 opacity=0.5,
37 default_colorscale= {"name": "rdbu", "list": None},
38 colorscales=[
39 {
40 # field definition overrides the default_colorscale
41 "path": "heatmap_2",
42 # if name is defined, it will override the list
43 "name": None,
44 "list": [
45 {"value": 0.0, "color": "rgb(0,255,255)"},
46 {"value": 0.5, "color": "rgb(255,0,0)"},
47 {"value": 1.0, "color": "rgb(0,0,255)"},
48 ],
49 }
50 ],
51)
Note
Refer to the ColorScheme class for documentation of the available
customization options.
You can launch the App with a custom color scheme by passing the optional
color_scheme parameter to
launch_app():
1# Launch App with a custom color scheme
2session = fo.launch_app(dataset, color_scheme=color_scheme)
Once the App is launched, you can retrieve your current color scheme at any
time via the
session.color_scheme
property:
1print(session.color_scheme)
You can also dynamically edit your current color scheme by modifying it:
1# Change the session's current color scheme
2session.color_scheme = fo.ColorScheme(...)
3
4# Edit the existing color scheme in-place
5session.color_scheme.color_pool = [...]
6session.refresh()
Note
Did you know? You can also configure default color schemes for individual datasets via Python!
Saving views#
You can use the menu in the upper-left of the App to record the current state of the App’s view bar and filters sidebar as a saved view into your dataset:
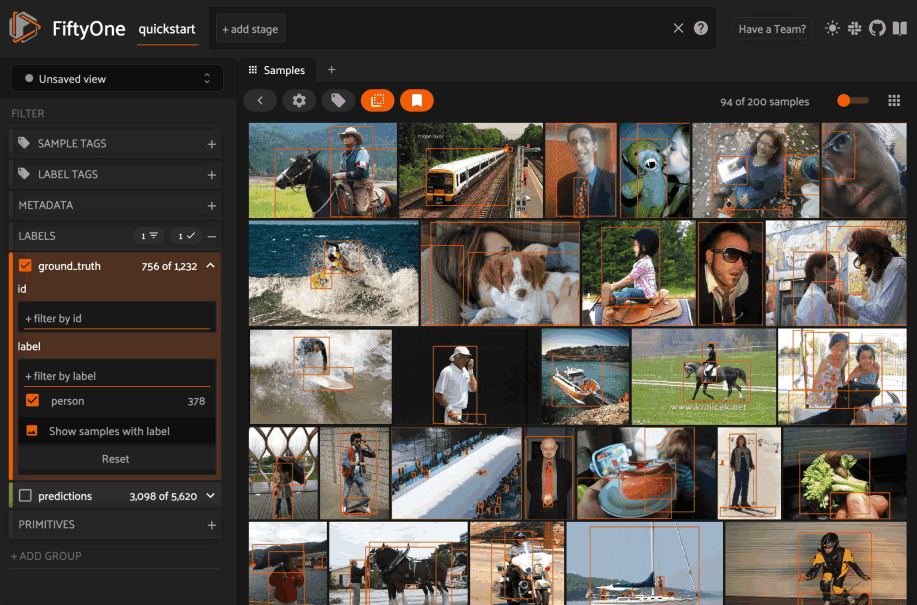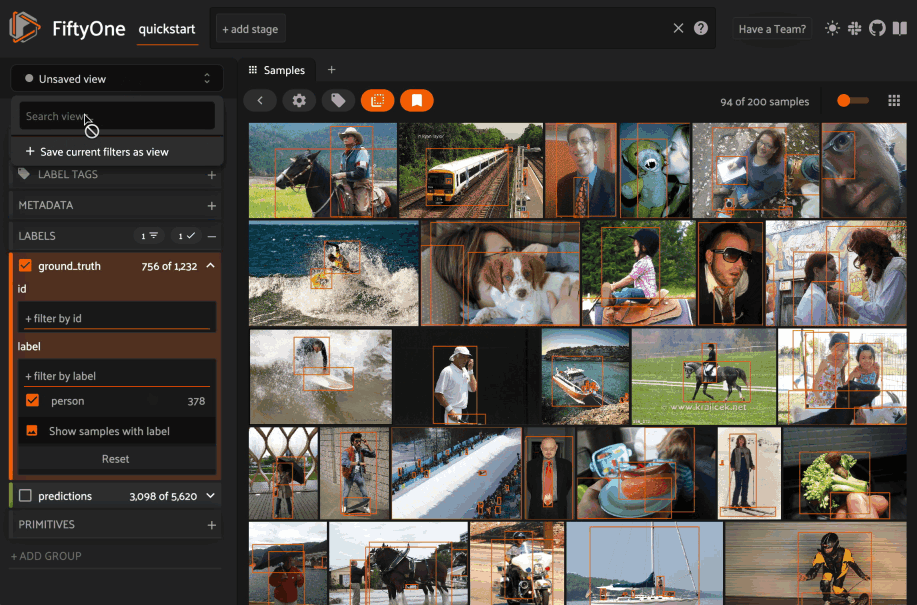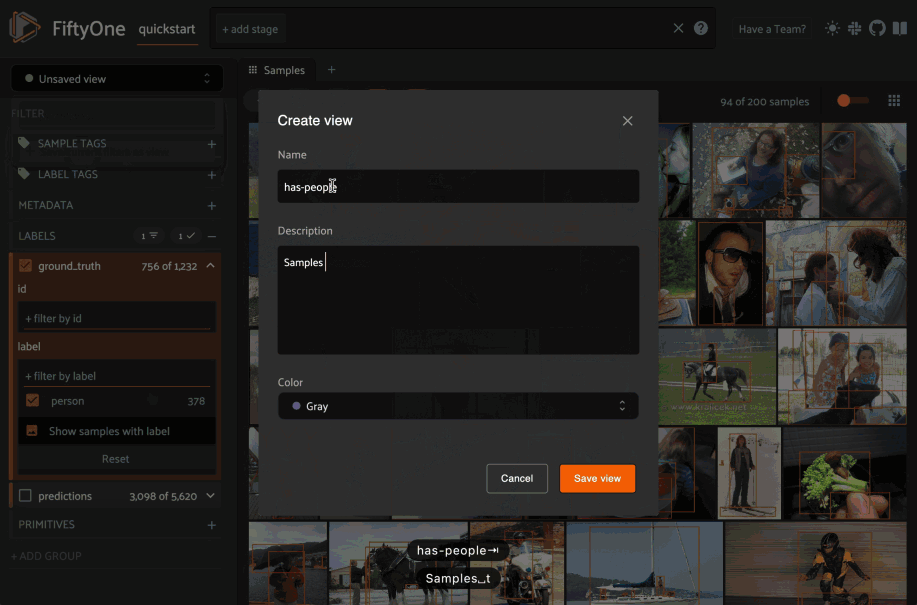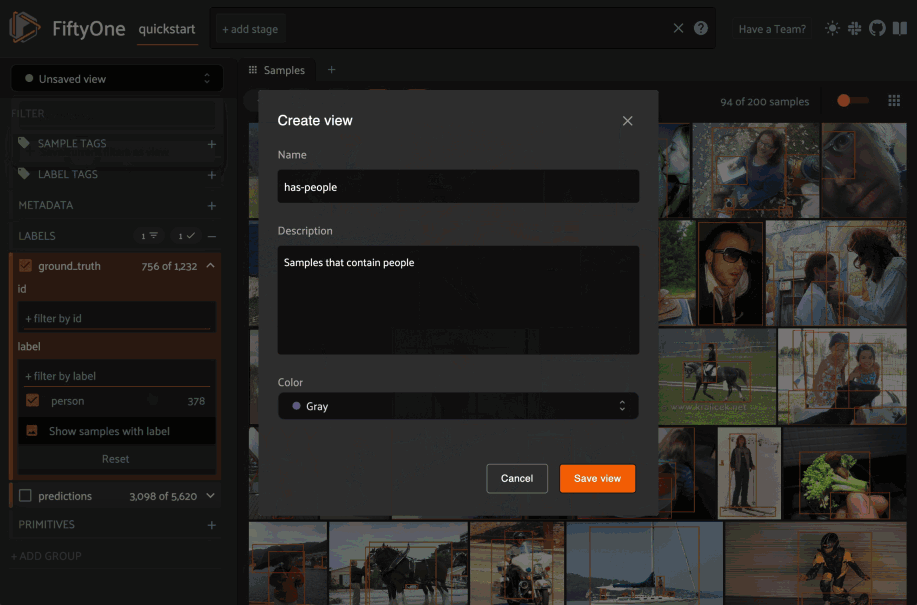
Saved views are persisted on your dataset under a name of your choice so that you can quickly load them in a future session via this UI.
Saved views are a convenient way to record semantically relevant subsets of a dataset, such as:
Samples in a particular state, eg with certain tag(s)
A subset of a dataset that was used for a task, eg training a model
Samples that contain content of interest, eg object types or image characteristics
Note
Saved views only store the rule(s) used to extract content from the underlying dataset, not the actual content itself. Saving views is cheap. Don’t worry about storage space!
Keep in mind, though, that the contents of a saved view may change as the underlying dataset is modified. For example, if a save view contains samples with a certain tag, the view’s contents will change as you add/remove this tag from samples.
You can load a saved view at any time by selecting it from the saved view menu:
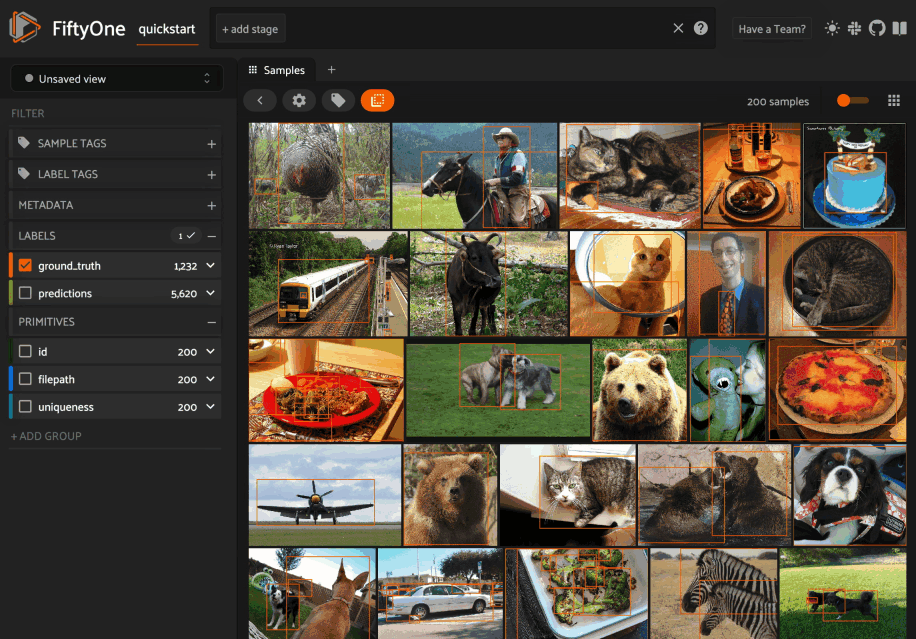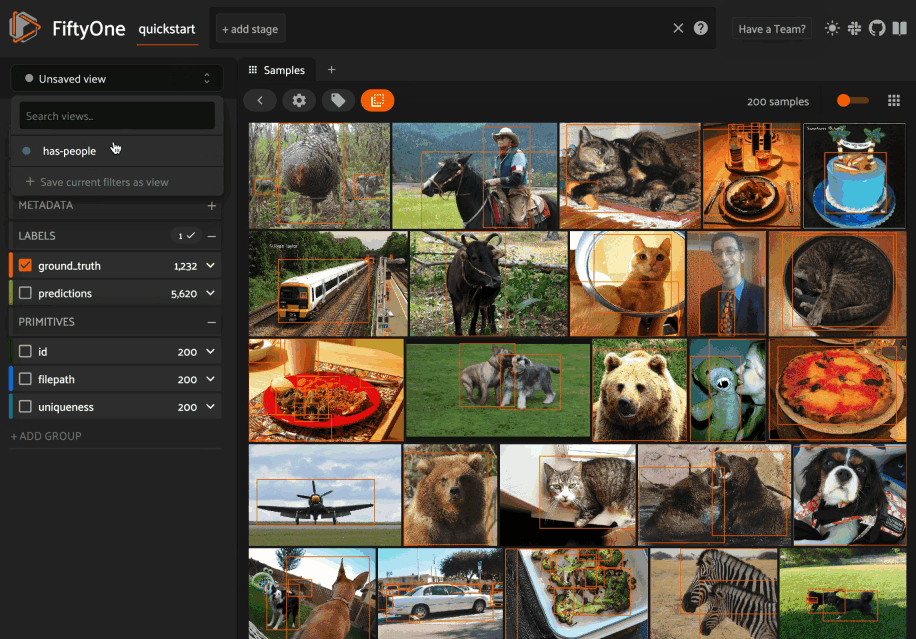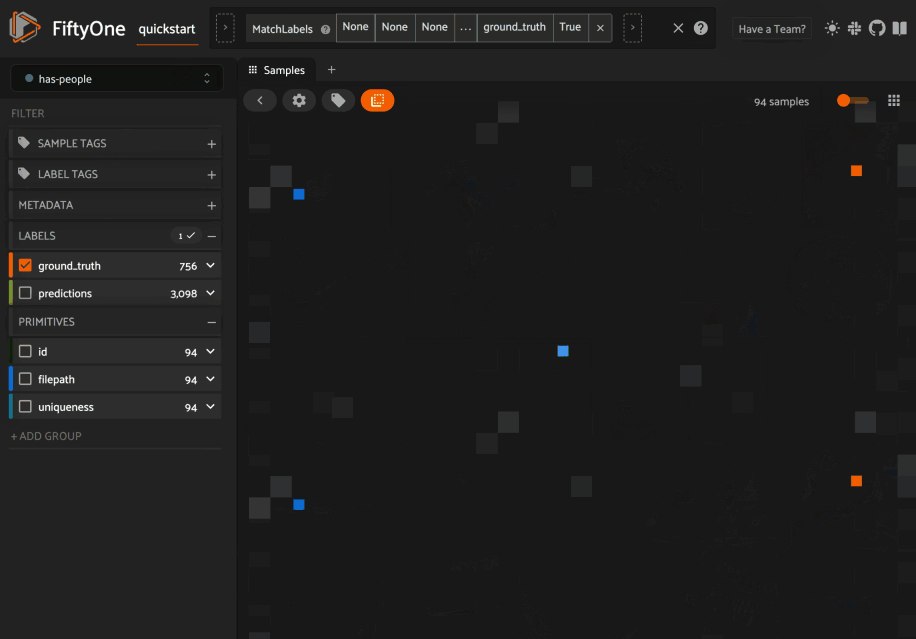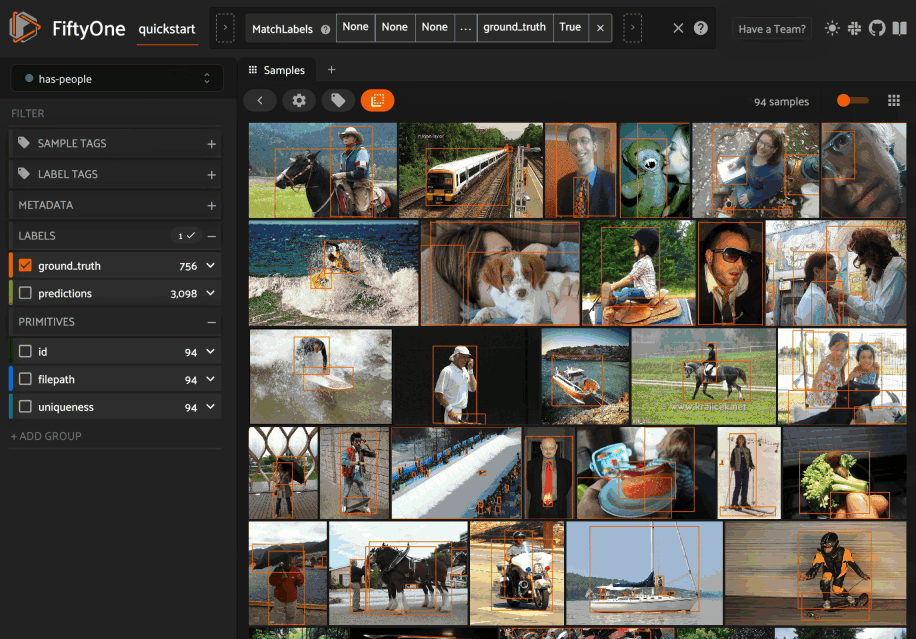
You can also edit or delete saved views by clicking on their pencil icon:
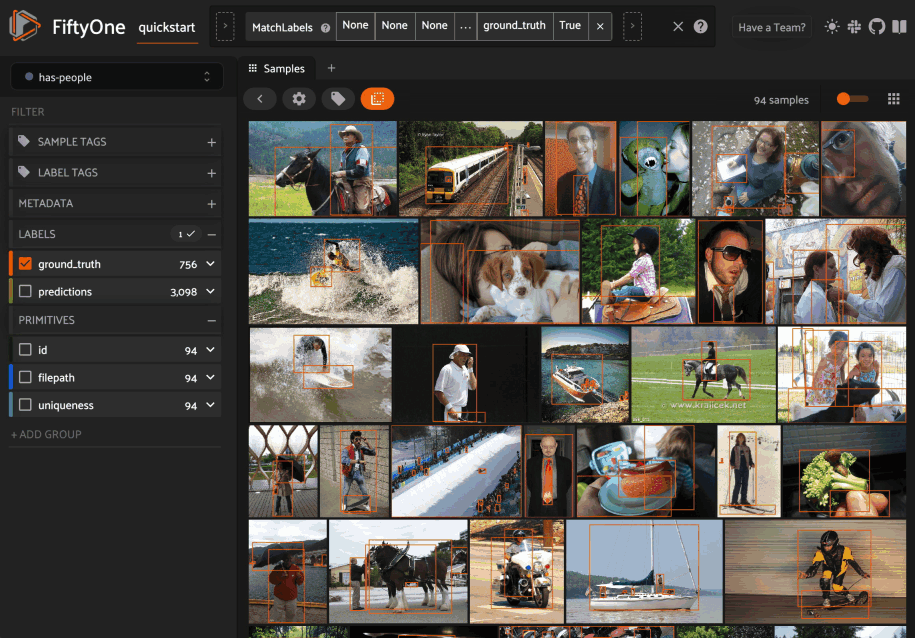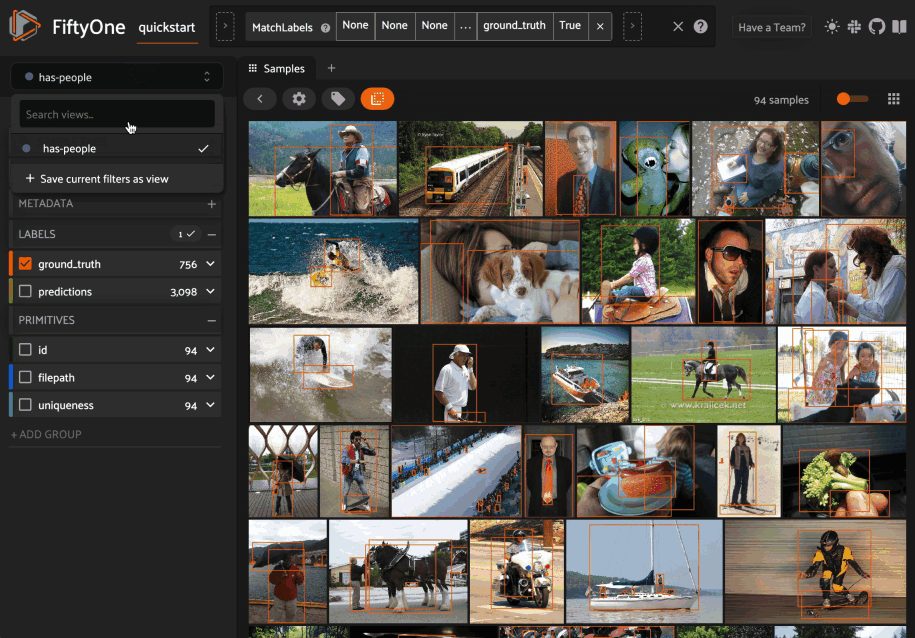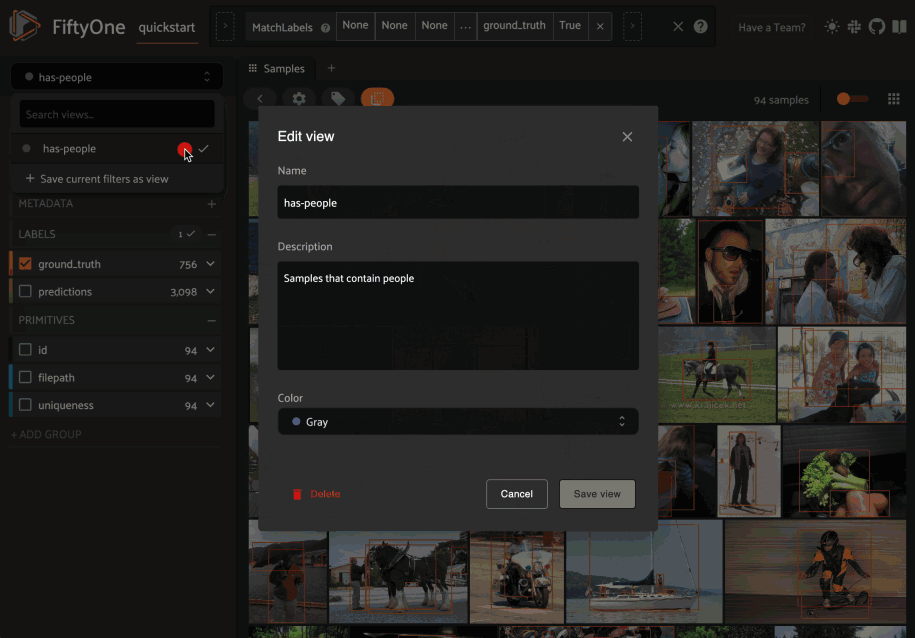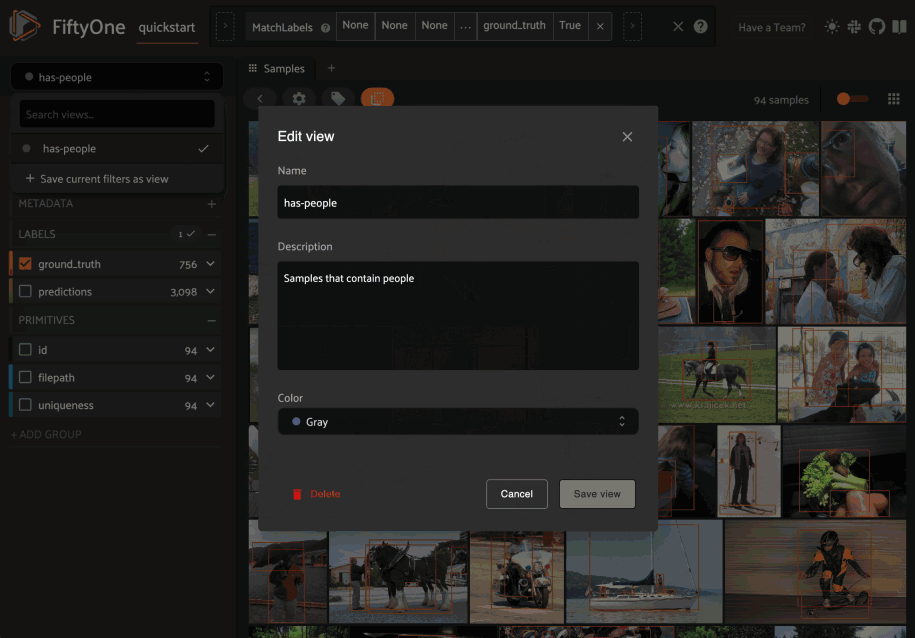
Note
Did you know? You can also programmatically create, modify, and delete saved views via Python!
Viewing a sample#
Click a sample to open an expanded view of the sample. This modal also
contains information about the fields of the Sample and allows you to access
the raw JSON description of the sample.
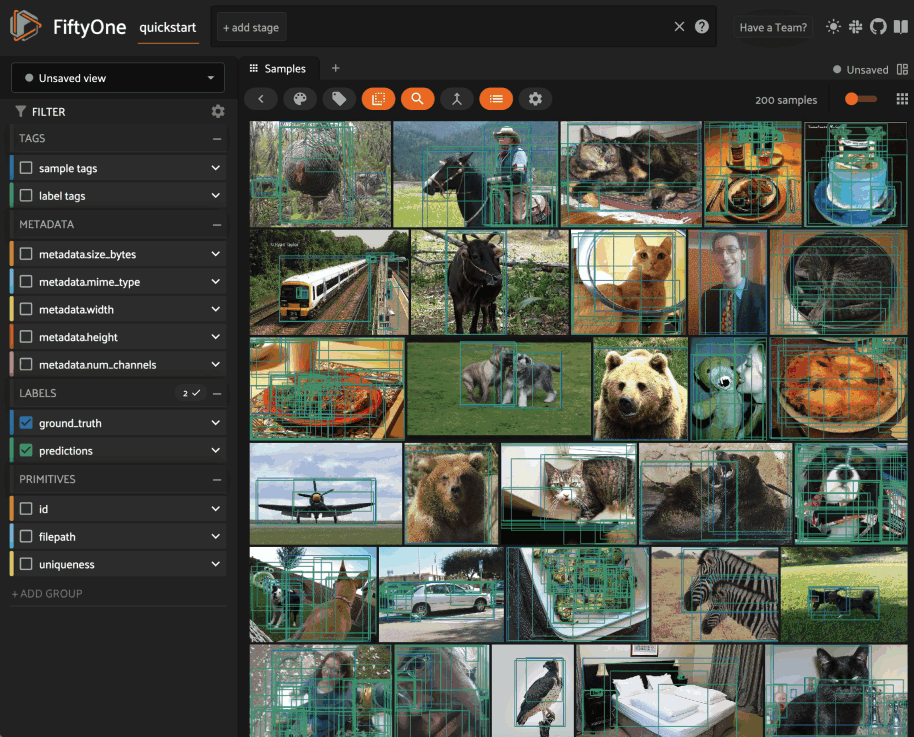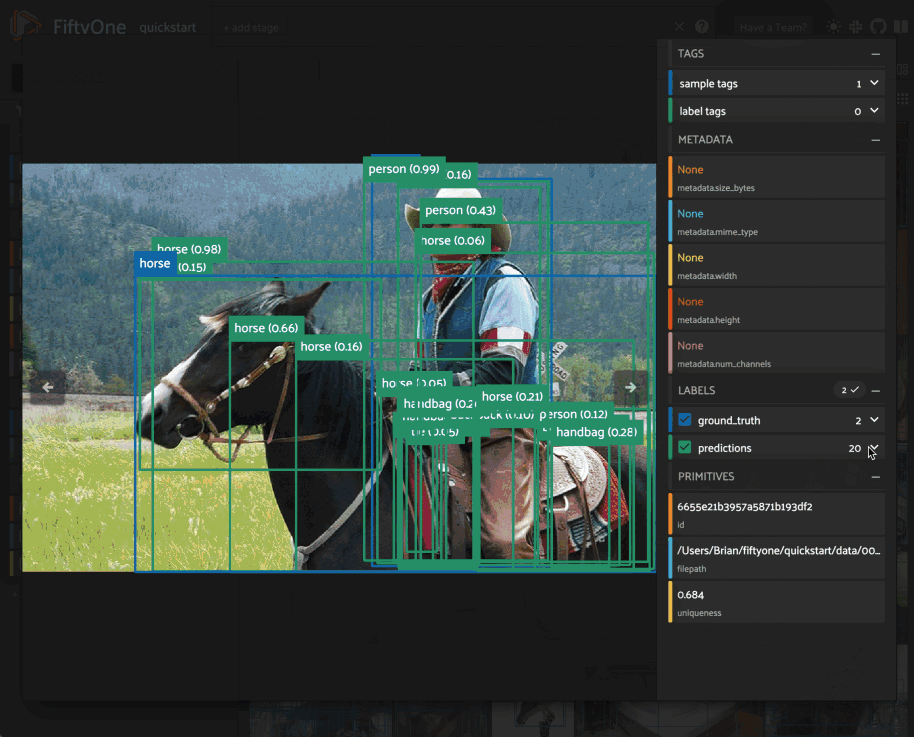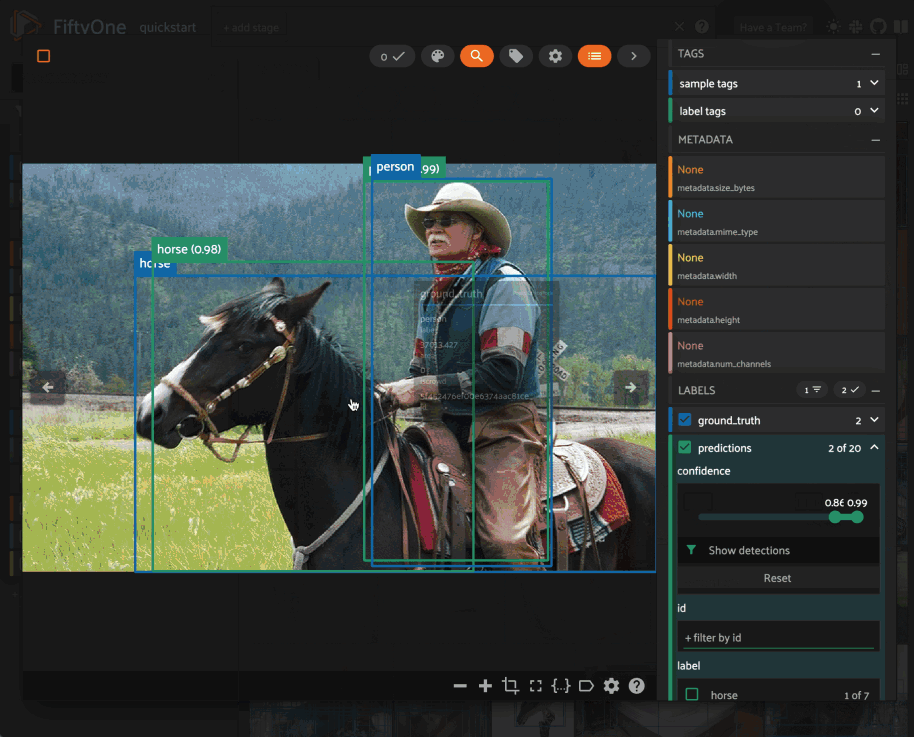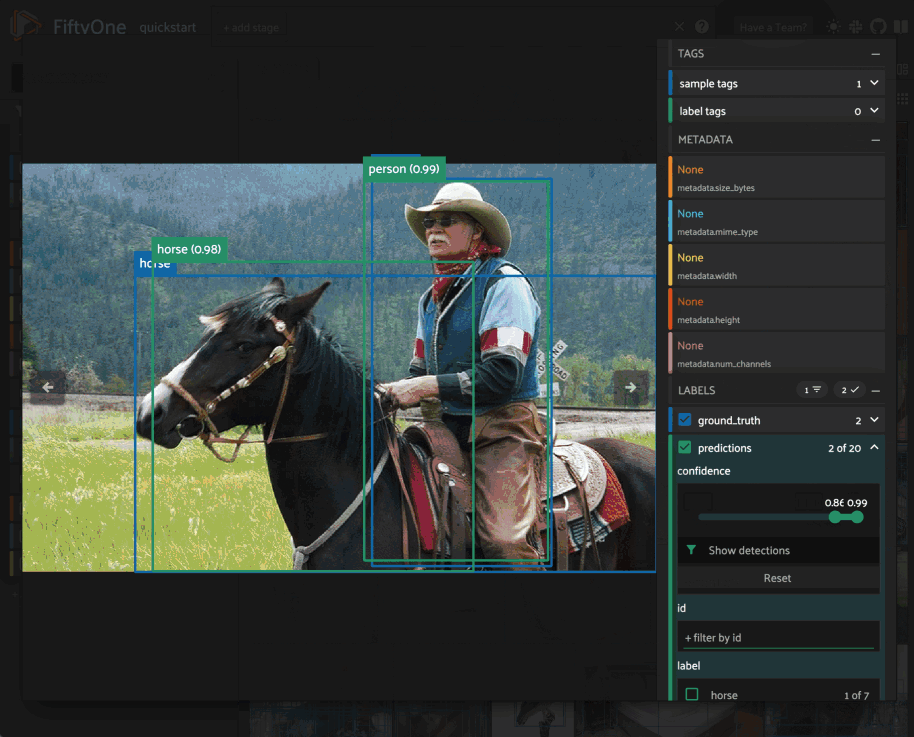
If your labels contain many dynamic attributes, you
may find it helpful to configure which attributes are shown in the tooltip.
To do so, press ctrl while hovering over a label to lock the tooltip
in-place and then use the show/hide buttons to customize the display.
Note
Tooltip customizations are persisted in your browser’s local storage on a per-dataset and per-field basis.

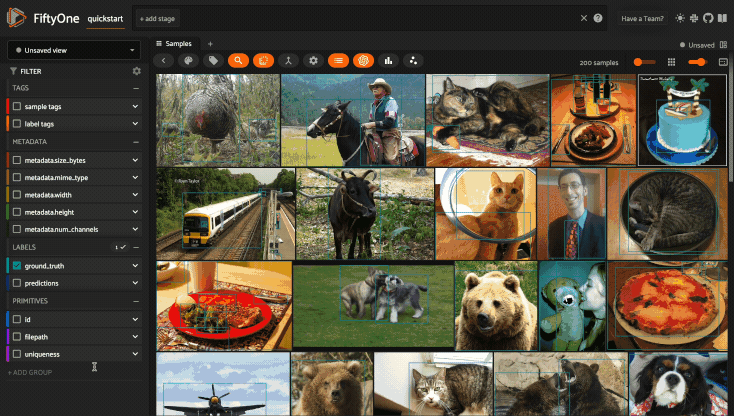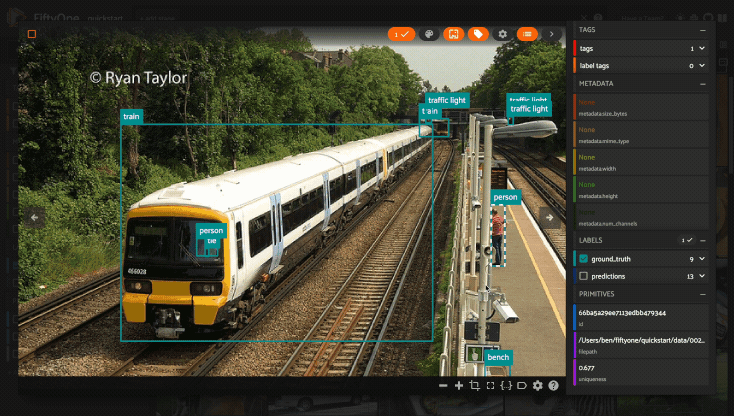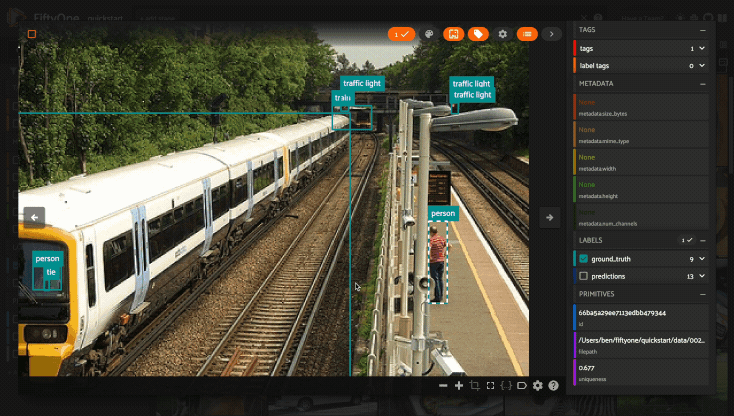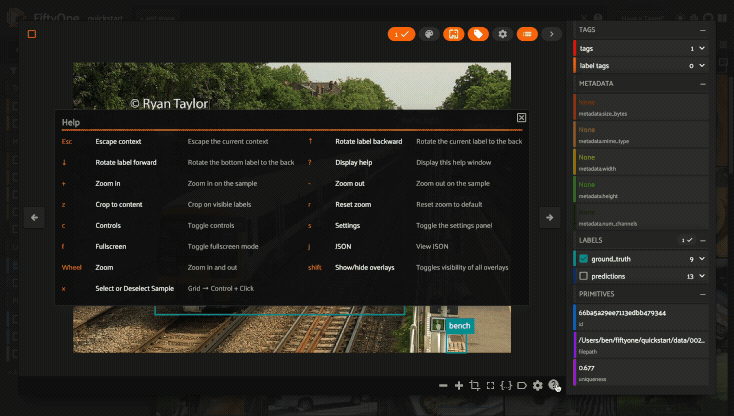
Using the image visualizer#
The image visualizer allows you to interactively visualize images along with their associated labels. When you hover over an image in the visualizer, a head-up display (HUD) appears with a control bar providing various options.
For example, you can zoom in/out and pan around an image by scrolling and
click-dragging with your mouse or trackpad. You can also zoom tightly into the
currently visible (or selected) labels by clicking on the Crop icon in the
controls HUD or using the z keyboard shortcut. Press ESC to reset your
view.
When multiple labels are overlaid on top of each other, the up and down arrows offer a convenient way to rotate the z-order of the labels that your cursor is hovering over, so every label and it’s tooltip can be viewed.
The settings icon in the controls HUD contains a variety of options for customizing the rendering of your labels, including whether to show object labels, confidences, or the tooltip. The default settings for these parameters can be configured via the App config.
Keyboard shortcuts are available for almost every action. Click the ? icon
in the controls HUD or use the ? keyboard shortcut to display the list of
available actions and their associated hotkeys.
Note
When working in Jupyter/Colab notebooks, you can hold
down the SHIFT key when zoom-scrolling or using the arrow keys to
navigate between samples/labels to restrict your inputs to the App and thus
prevent them from also affecting your browser window.
Using the video visualizer#
The video visualizer offers all of the same functionality as the image visualizer, as well as some convenient actions and shortcuts for navigating through a video and its labels.
There are a variety of additional video-specific keyboard shortcuts. For
example, you can press the spacebar to play/pause the video, and you can press
0, 1, …, 9 to seek to the 0%, 10%, …, 90% timestamp in the video.
When the video is paused, you can use < and > to navigate frame-by-frame
through the video.
Click the ? icon in the controls HUD or use the ? keyboard shortcut to
display the list of available actions and their associated hotkeys.
All of the same options in the image settings are available in the video settings menu in the controls HUD, as well as additional options like whether to show frame numbers rather than timestamp in the HUD. The default settings for all such parameters can be configured via the App config.
Playback rate and volume are also available in the video controls HUD. Clicking on one of the icons resets the setting to the default. And when hovering, a slider appears to adjust the setting manually.
Note
Did you know? The video visualizer streams frame data on-demand, which means that playback begins as soon as possible and even heavyweight label types like segmentations are supported!
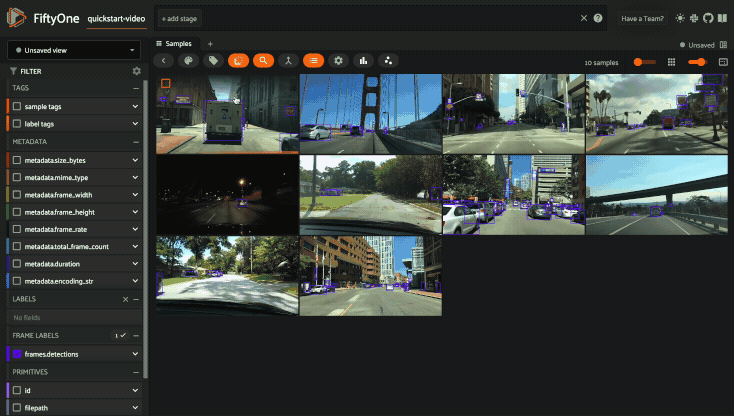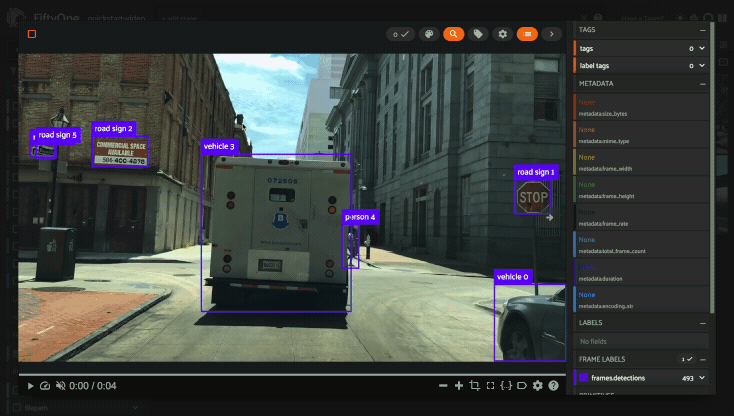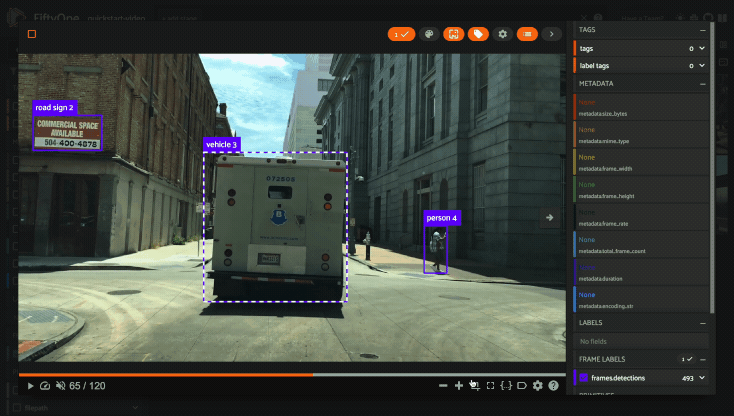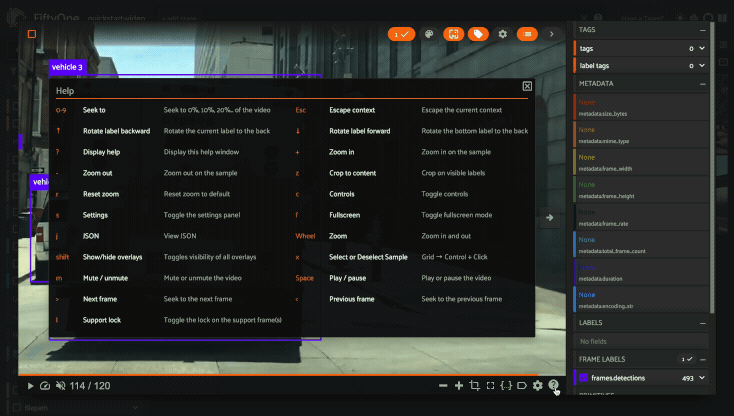
Note
When working in Jupyter/Colab notebooks, you can hold
down the SHIFT key when zoom-scrolling or using the arrow keys to
navigate between samples/labels to restrict your inputs to the App and thus
prevent them from also affecting your browser window.
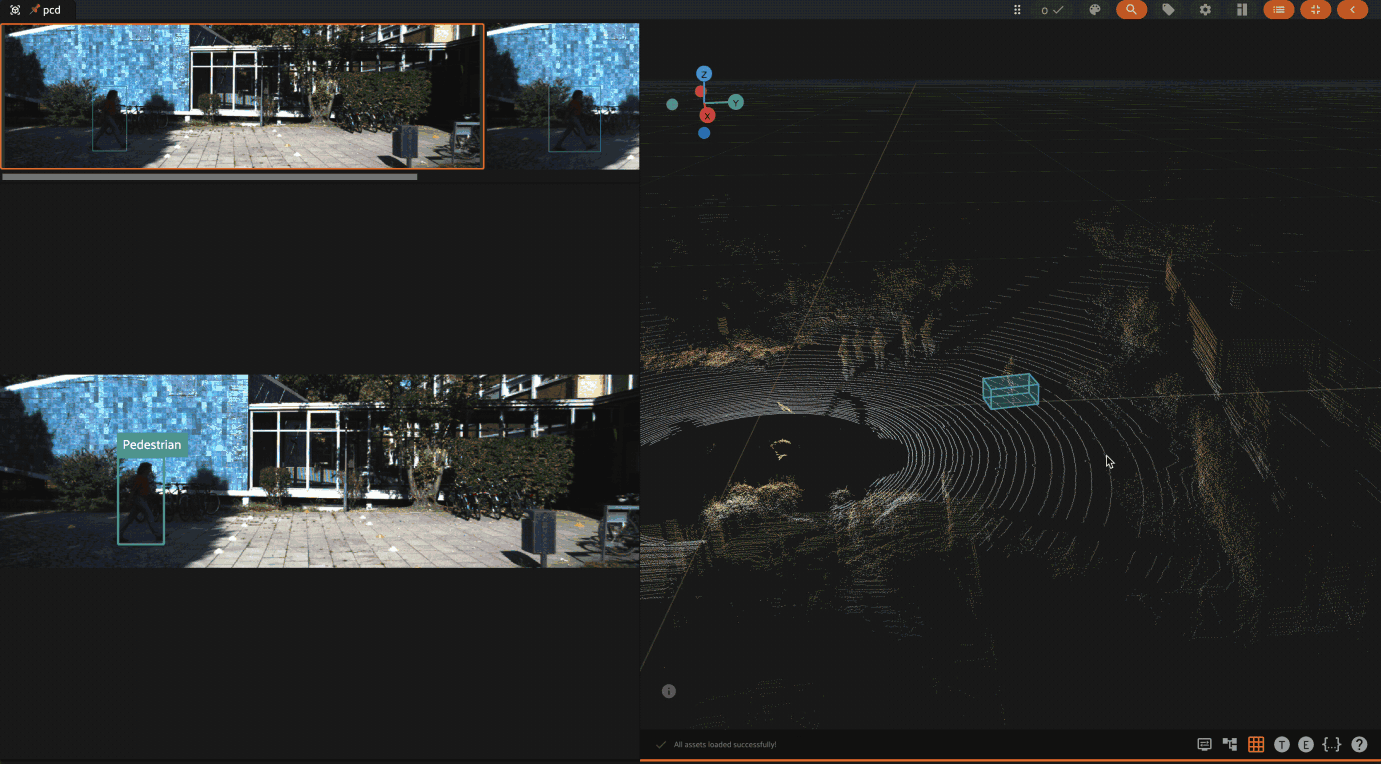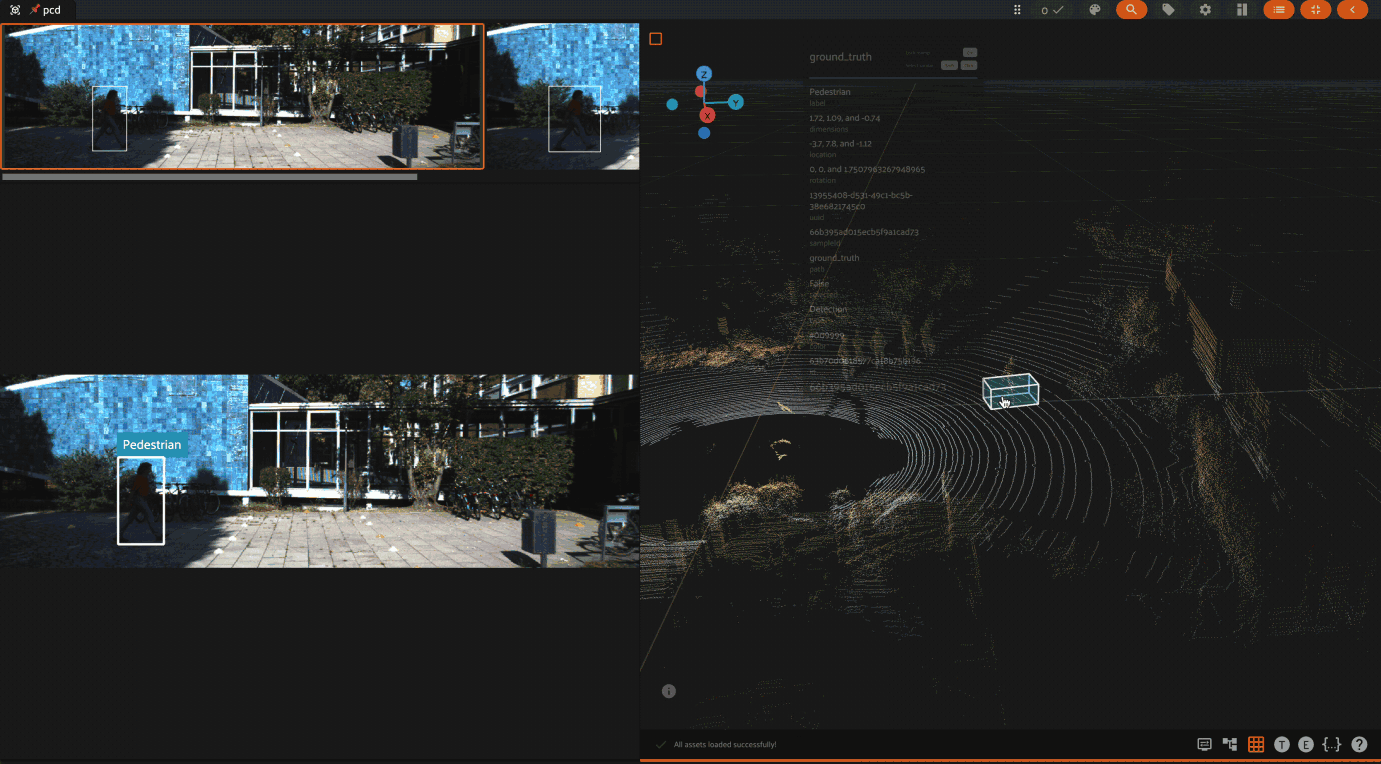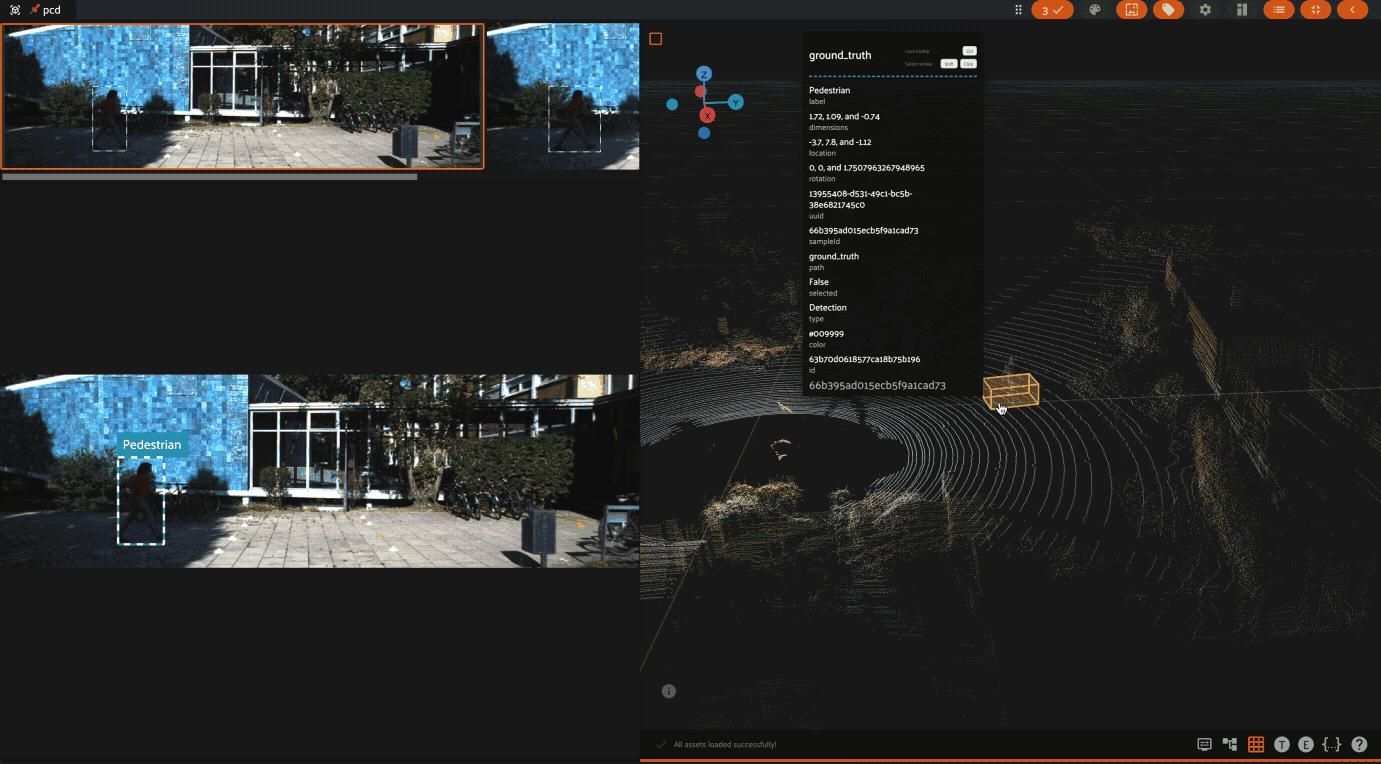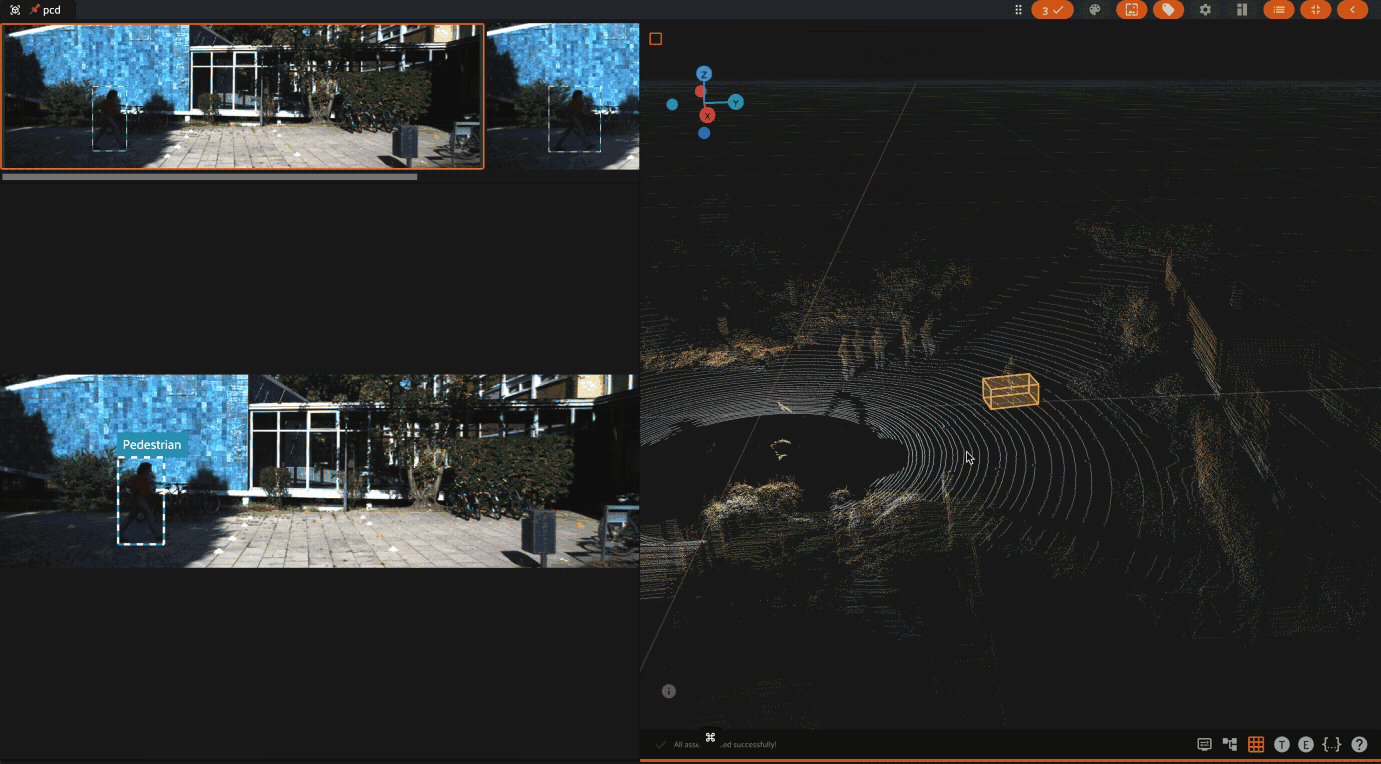
Using the 3D visualizer#
The 3D visualizer allows you to interactively visualize 3D samples or point cloud samples along with any associated 3D detections and 3D polylines:
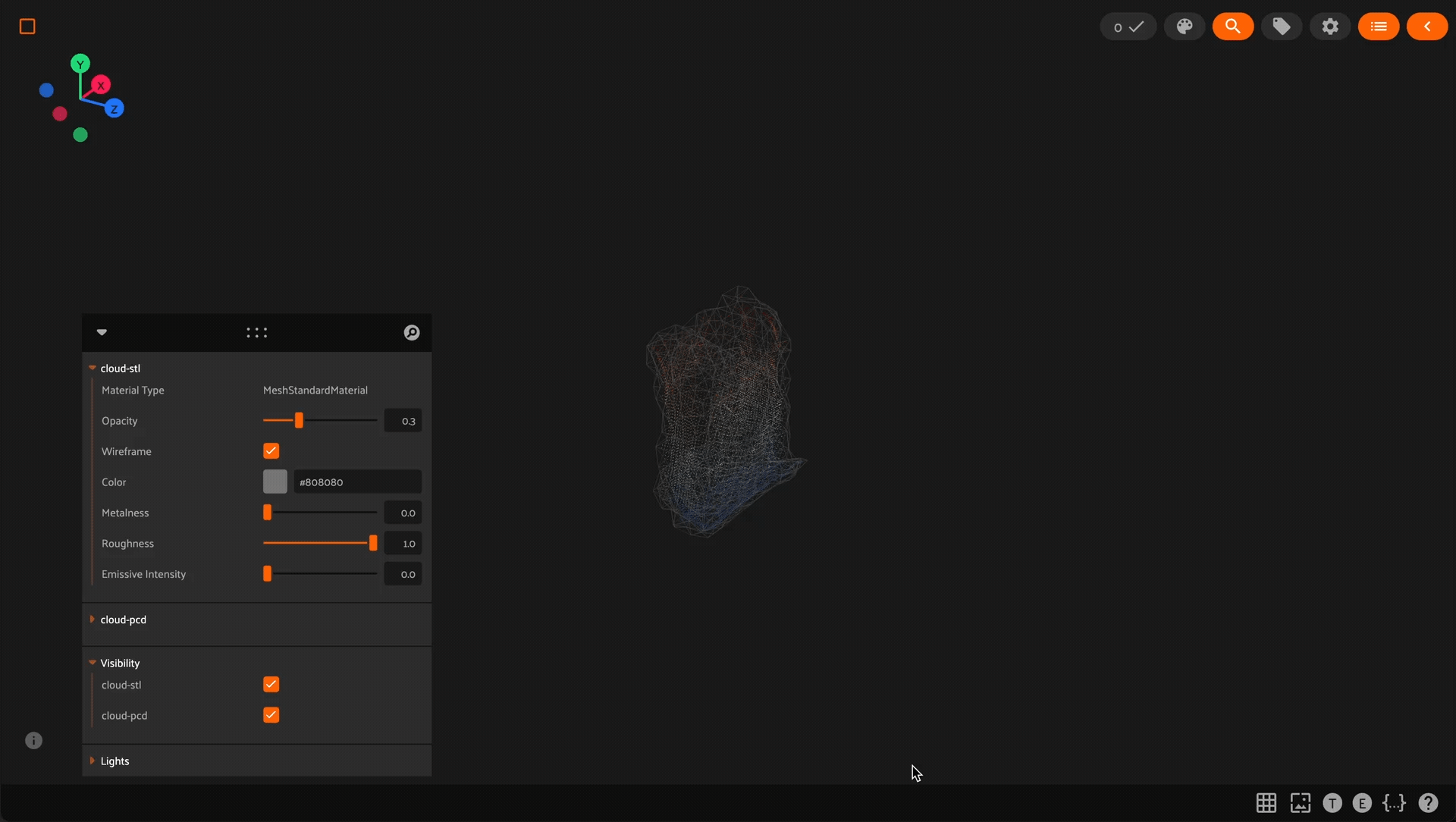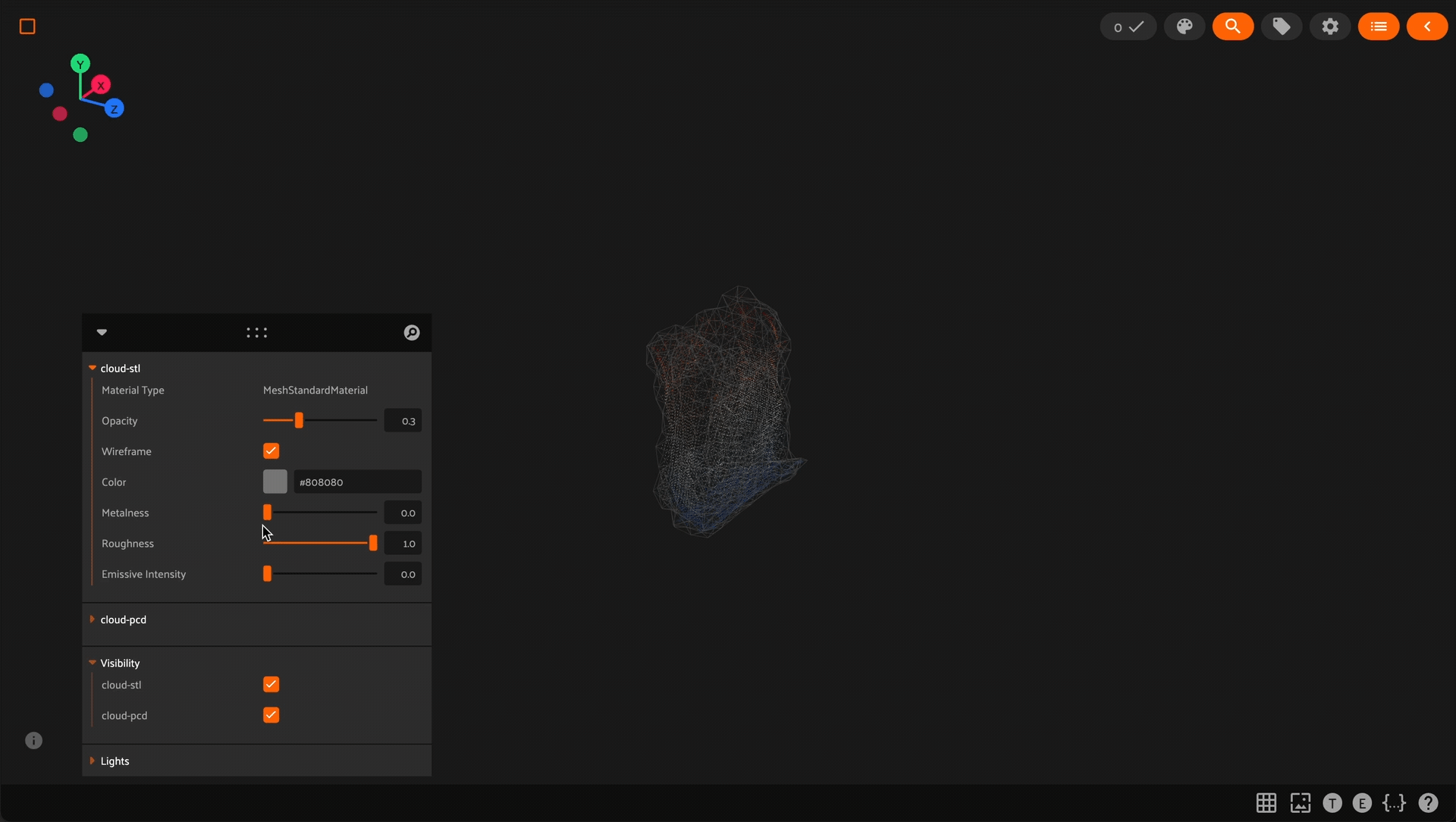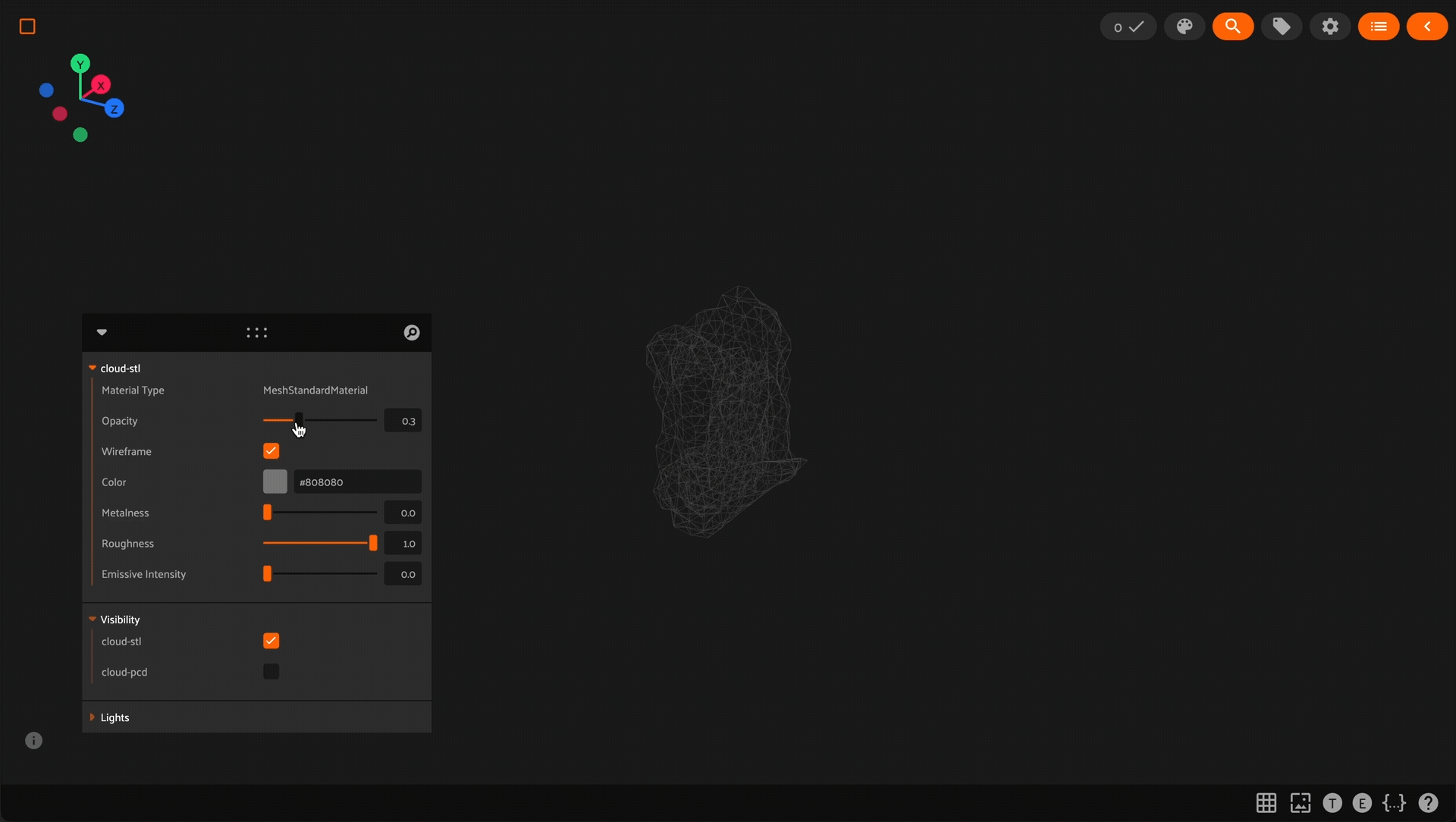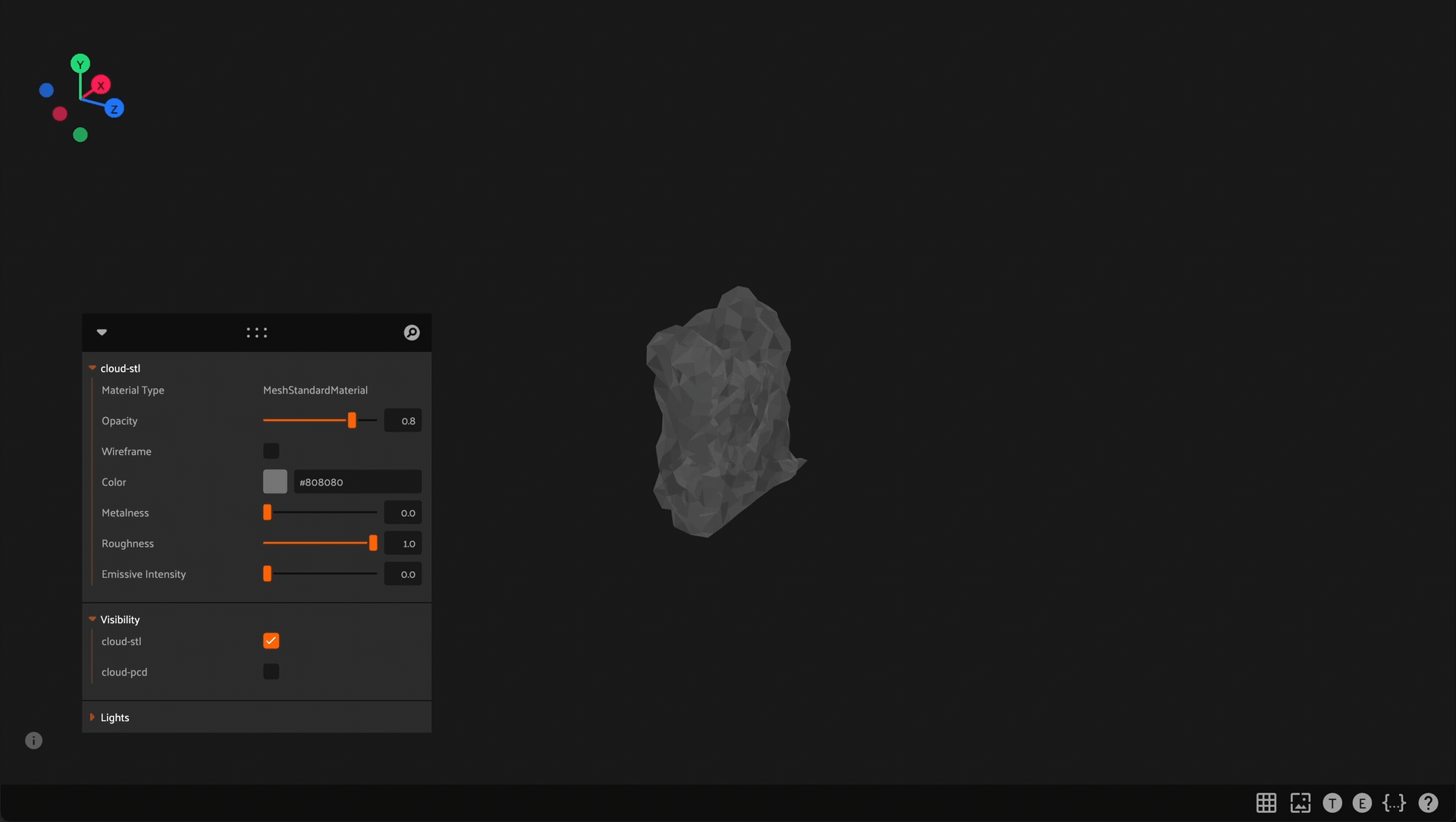
The table below summarizes the mouse/keyboard controls that the 3D visualizer supports:
Input |
Action |
Description |
|---|---|---|
Wheel |
Zoom |
Zoom in and out |
Drag |
Rotate |
Rotate the camera |
Shift + drag |
Translate |
Translate the camera |
B |
Background |
Toggle background on/off |
F |
Fullscreen |
Toggle fullscreen |
G |
Grid |
Toggle the grid on/off |
T |
Top-down |
Reset camera to top-down view |
E |
Ego-view |
Reset the camera to ego view |
R |
Render |
Toggle render preferences |
ESC |
Escape context |
Escape the current context |
A variety of context-specific options are available in a draggable panel in the 3D visualizer that let you configure lights, as well as material and visibility of the 3D objects in the scene.
In addition, the HUD at the bottom of the 3D visualizer provides the following controls:
Click the grid icon to toggle the grid on/off
Click the
Tto reset the camera to top-down viewClick the
Eto reset the camera to ego-view
For point clouds, when coloring by intensity, the color of each point is
computed by mapping the r channel of the rgb field of the
PCD file
onto a fixed colormap, which is scaled so that the full colormap is matched to
the observed dynamic range of r values for each sample.
Similarly, when coloring by height, the z value of each point is mapped to
the full colormap using the same strategy.
Dynamic point cloud coloring#
FiftyOne supports dynamic coloring of point clouds based on any attribute in your PCD file. This allows you to visualize and analyze point cloud data in powerful ways, such as:
Working with semantic segmentation data where different classes need distinct colors
Analyzing LIDAR data where you want to visualize intensity values to identify reflective surfaces
Inspecting custom attributes like confidence scores or prediction errors
Comparing multiple attributes by quickly switching between different color schemes
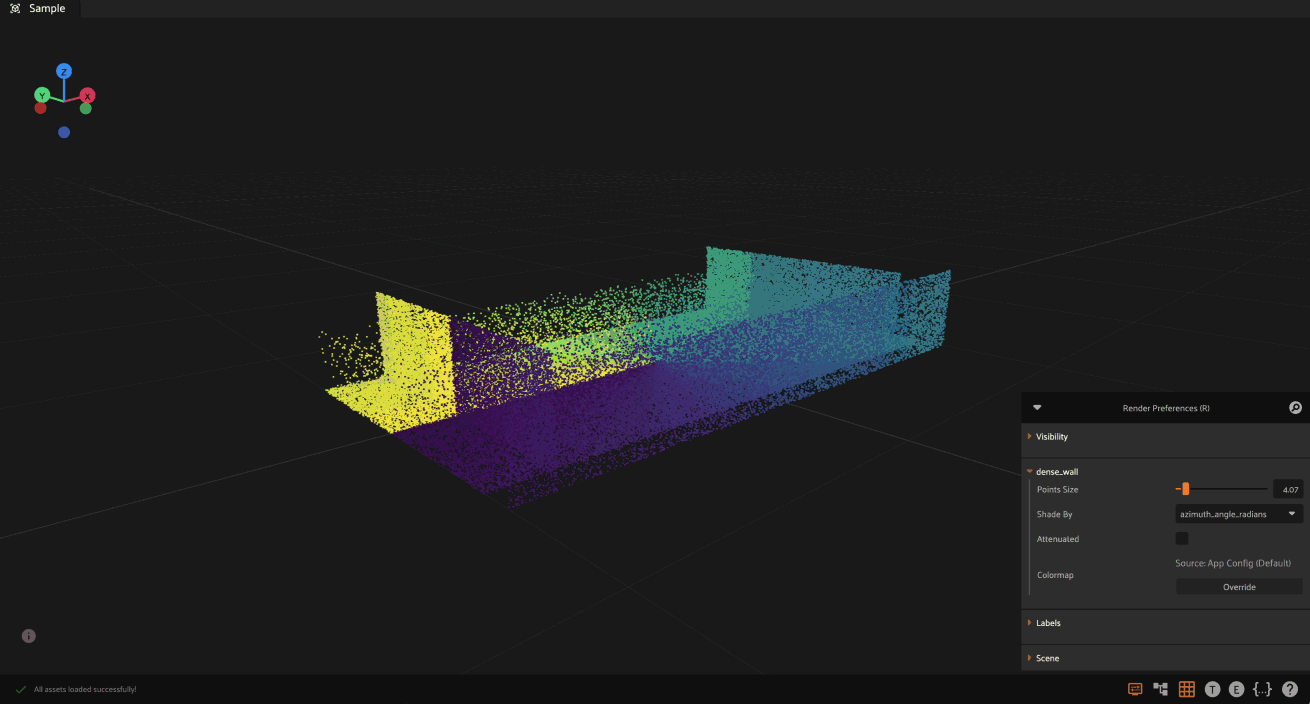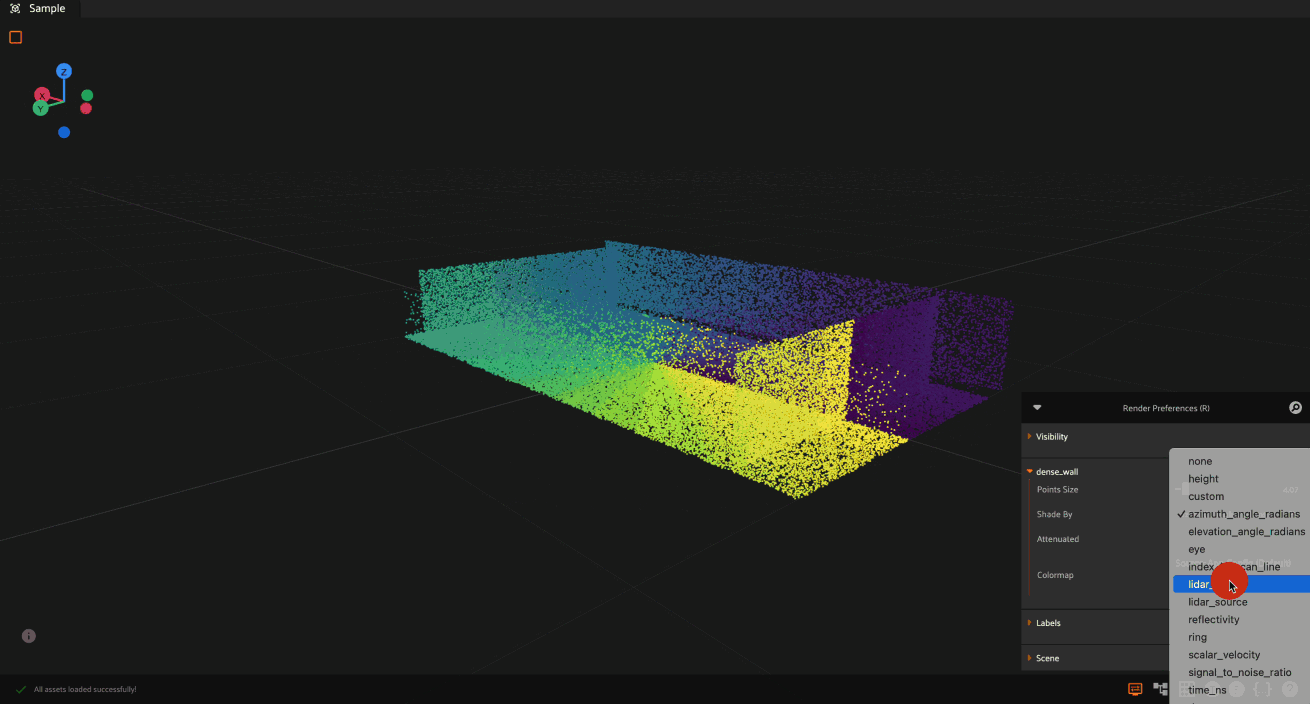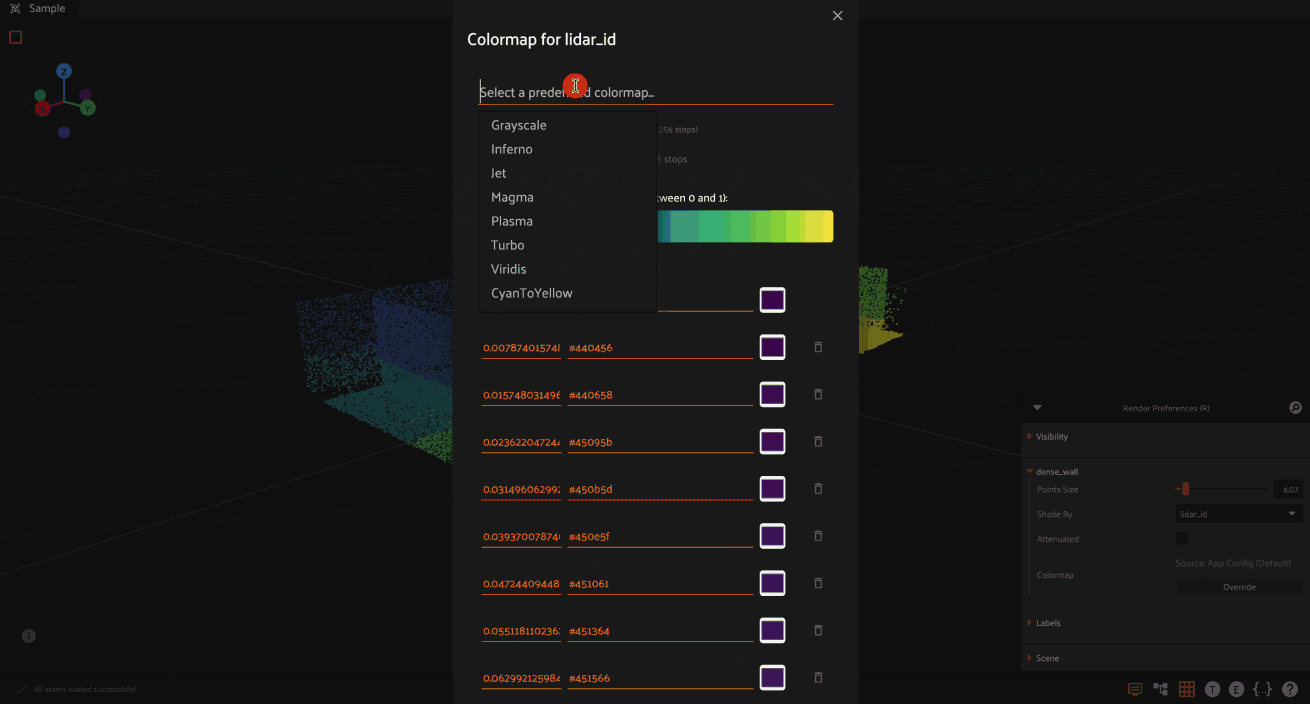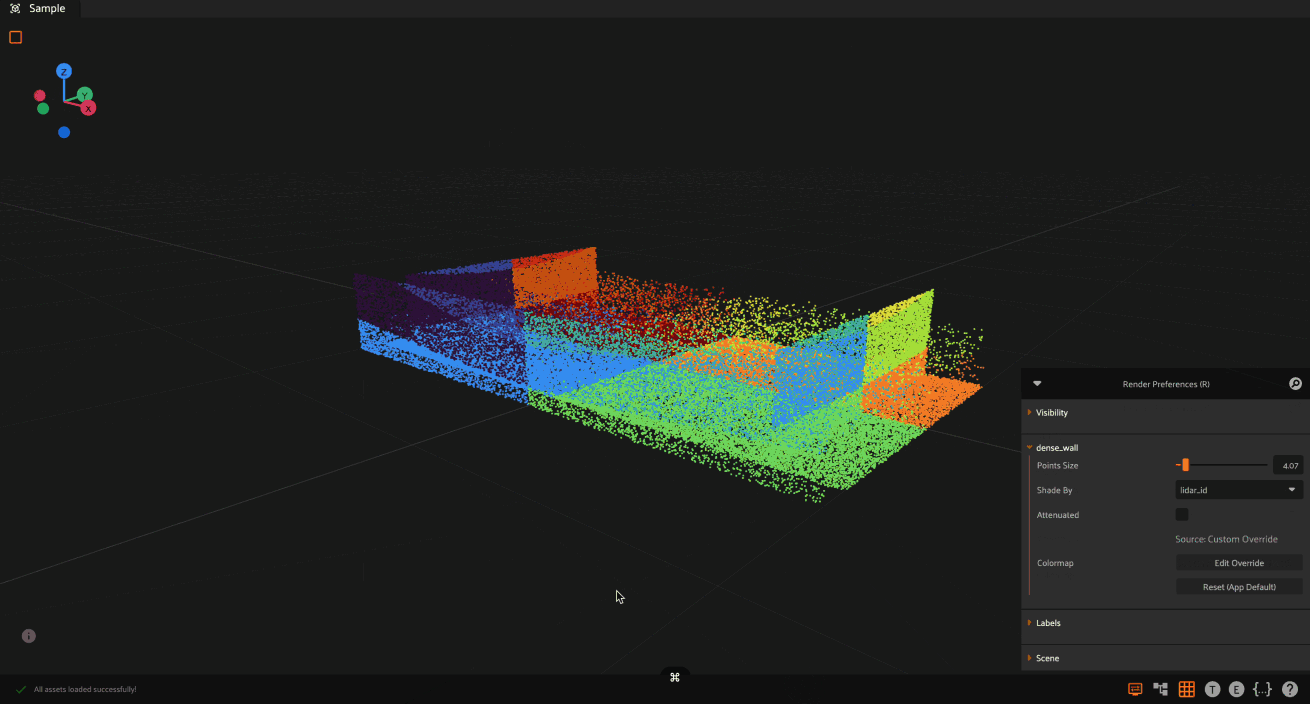
To use dynamic coloring:
Press
Ror click the render preferences icon in the 3D visualizer menuSelect the attribute to color by from the “Shade by” dropdown
Optionally, override the colormap from the available options by clicking the “Override” button
Colormap selection follows this precedence order:
Colormap from browser storage (if previously overridden)
Colormap defined in the
colorscalesproperty of the dataset’s App config for the specific attributeColormap defined in the
default_colorscaleproperty of the dataset’s App configDefault colormap (red-to-blue gradient)
You can override the colormap for any attribute by clicking the “Override”
button in the render preferences panel. This will open a new UI where you can:
Add or remove color stops
Preview the gradient
Reset to the app config or default colormap
Note
Colormap overrides are persisted in your browser’s local storage, so they will be remembered across sessions.
You can define default colormaps for point cloud attributes of a dataset by
configuring them in the dataset’s App config.
You must use the prefix ::fo3d::pcd:: followed by the attribute name in the
path field. For example, to define a colormap for the lidar_id attribute,
the path should be ::fo3d::pcd::lidar_id:
1import fiftyone as fo
2
3dataset = fo.load_dataset(...)
4
5# Configure colormaps for point cloud attributes
6dataset.app_config.color_scheme = fo.ColorScheme(
7 colorscales=[
8 {
9 "path": "::fo3d::pcd::lidar_id",
10 "name": "viridis", # use a named colormap
11 },
12 {
13 "path": "::fo3d::pcd::intensity",
14 "list": [ # or define a custom colormap
15 {"value": 0, "color": "rgb(0, 0, 255)"},
16 {"value": 1, "color": "rgb(0, 255, 255)"},
17 ],
18 },
19 ],
20 default_colorscale={"name": "jet"}, # default for other attributes
21)
22dataset.save()
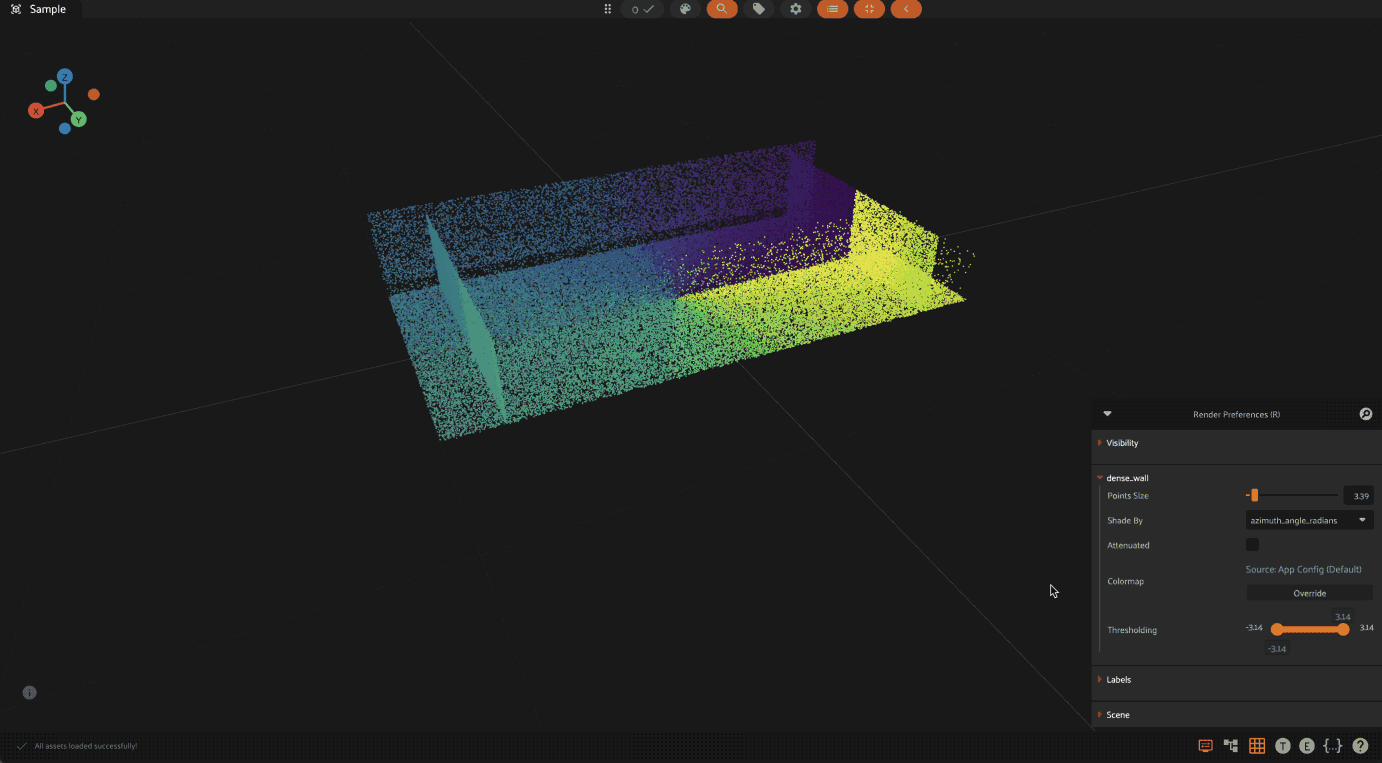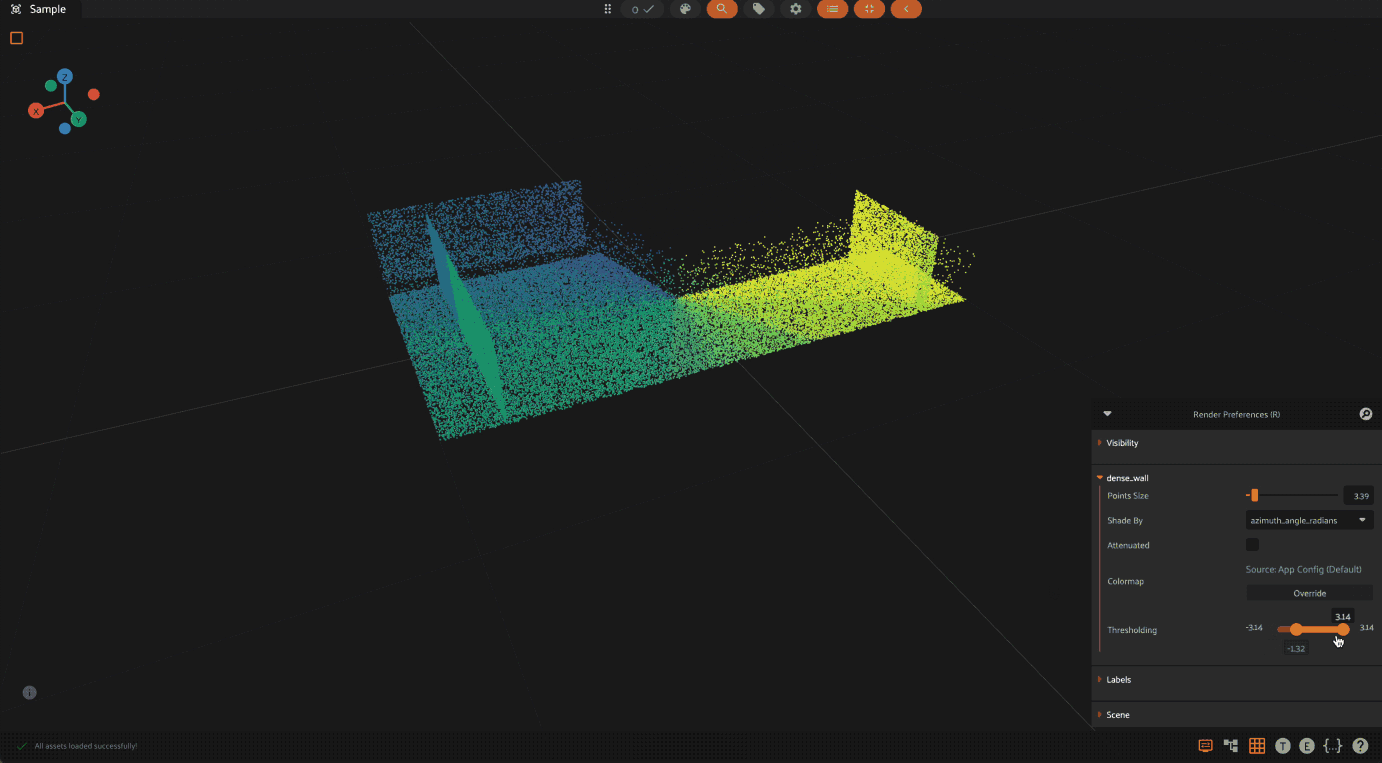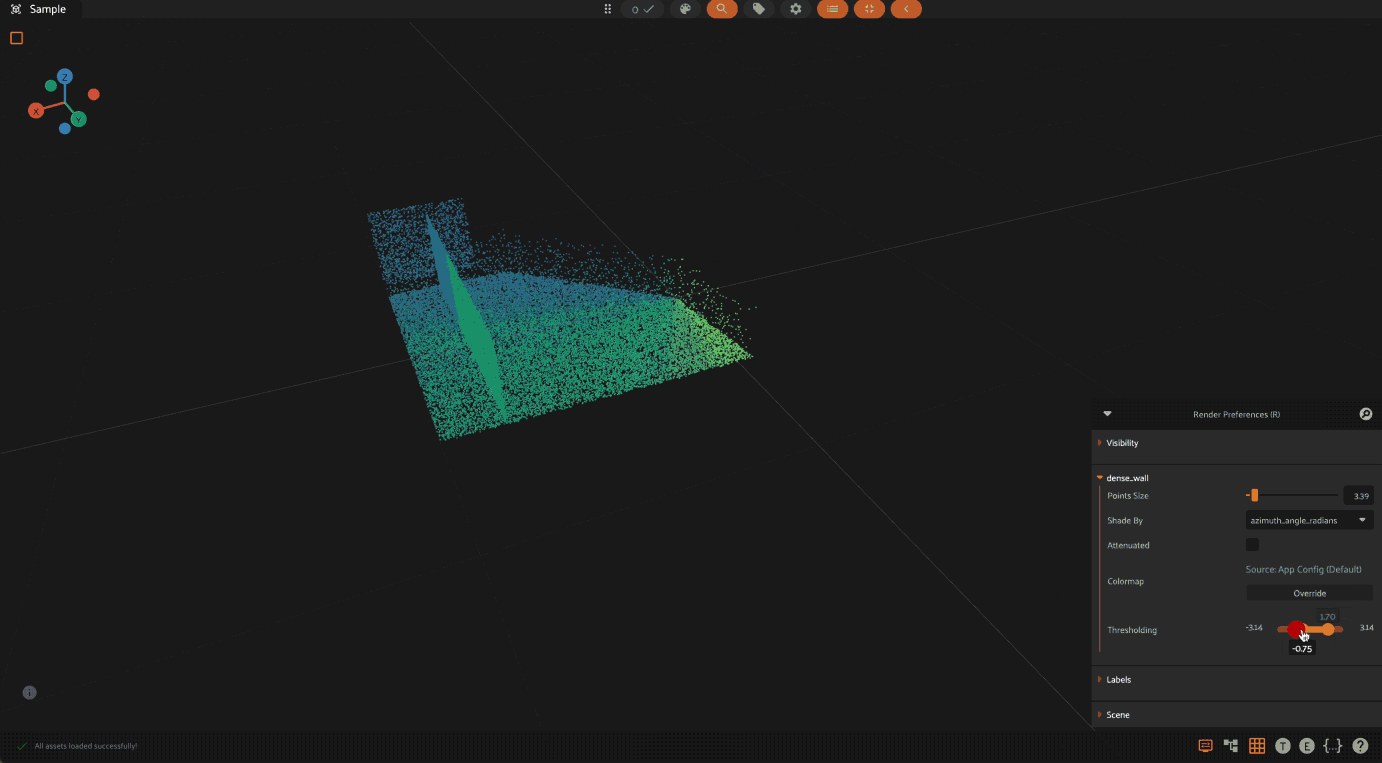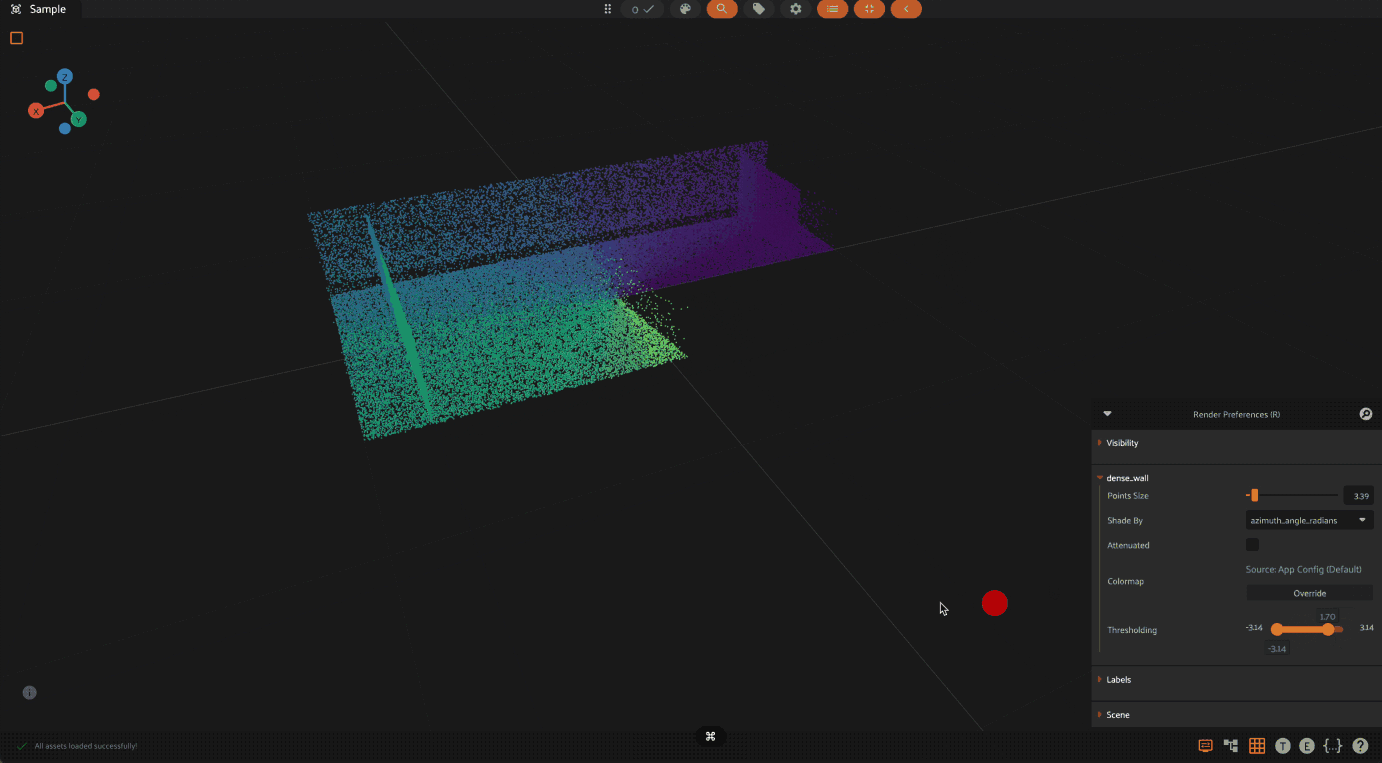
When visualizing point clouds with dynamic attributes, you can apply thresholding to focus on specific value ranges. This is particularly useful for:
Filtering out noise or outliers in your data
Isolating points of interest based on their attribute values
Analyzing specific ranges of values in your point cloud
To use thresholding:
Press
Ror click the render preferences icon in the 3D visualizer menuSelect the attribute to color by from the “Shade by” dropdown
Use the threshold slider that appears below the colormap controls
Adjust the minimum and maximum values to show only points within that range
The threshold slider shows the full range of values for the selected attribute,
and points outside the selected range will be hidden from view.
Note
Thresholding is available for all numeric attributes except height and RGB values. The threshold range is automatically adjusted based on the data type of the attribute (integer or float).
Viewing 3D samples in the grid#
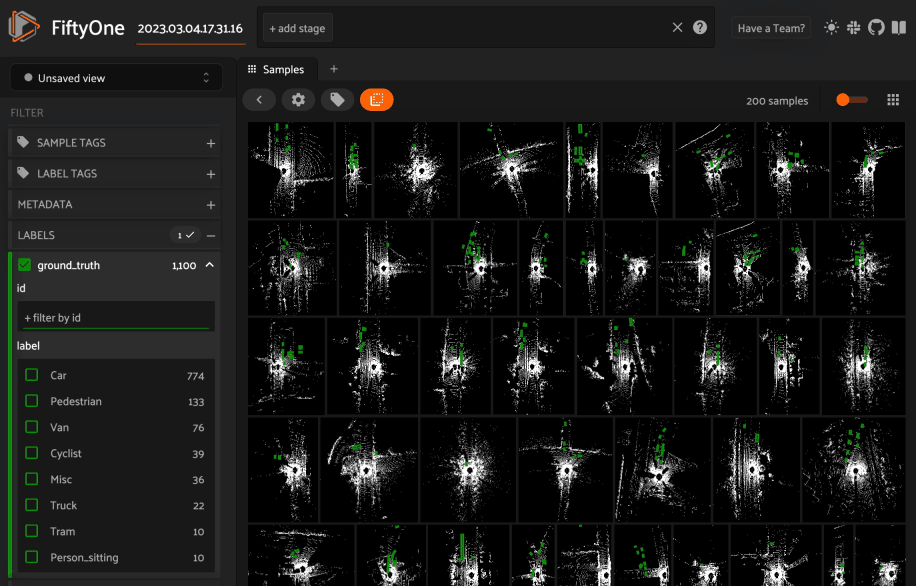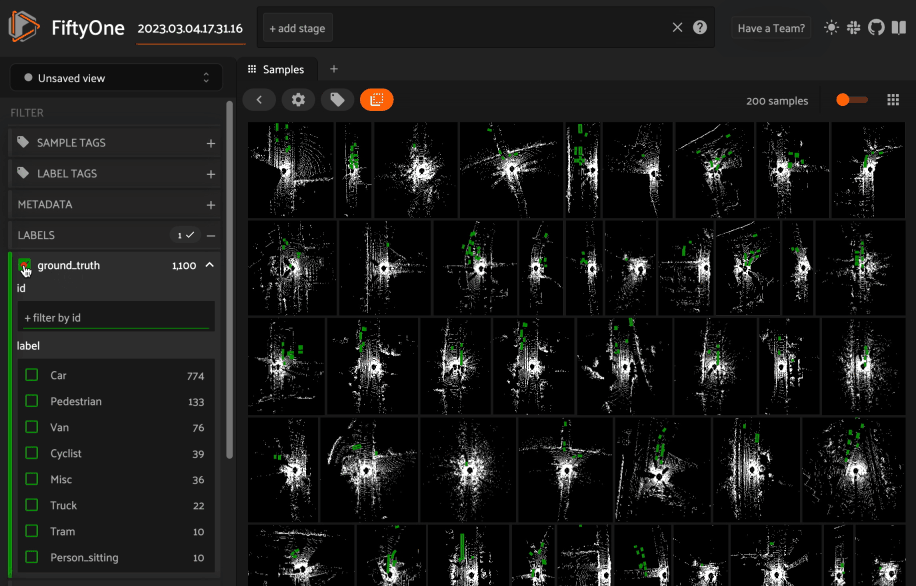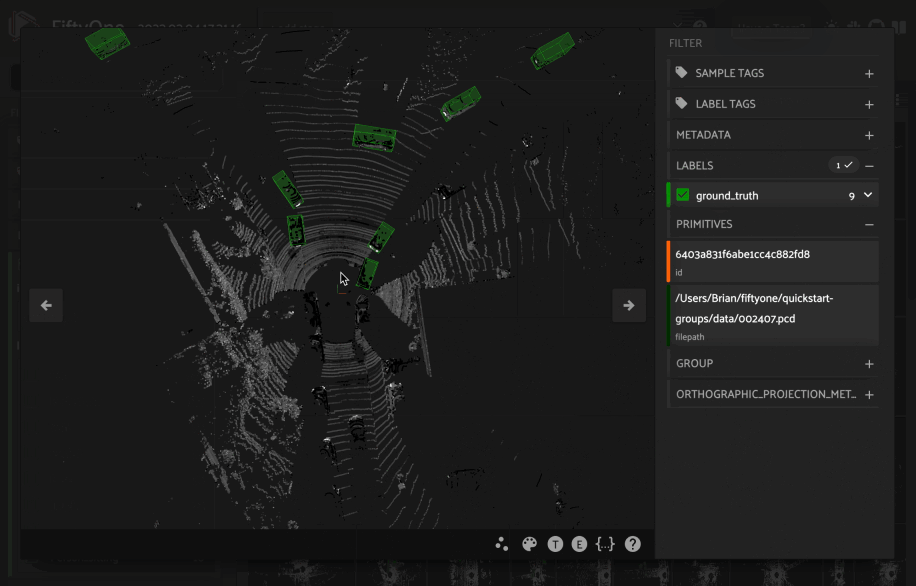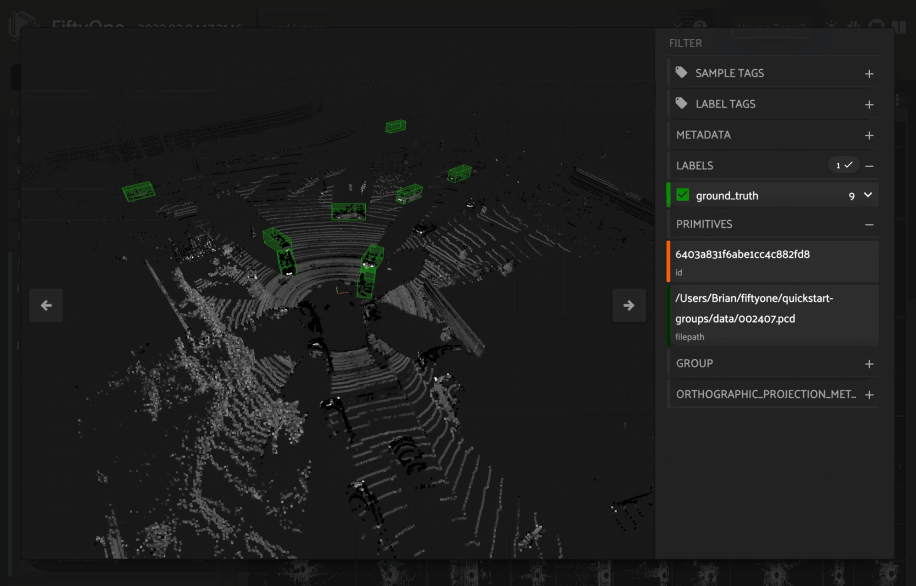
When you load 3D collections in the App, any 3D detections and 3D polylines fields will be visualized in the grid using an orthographic projection (onto the xy plane by default).
In addition, if you have populated orthographic projection images on your dataset, the projection images will be rendered for each sample in the grid:
1import fiftyone as fo
2import fiftyone.utils.utils3d as fou3d
3import fiftyone.zoo as foz
4
5# Load an example 3D dataset
6dataset = (
7 foz.load_zoo_dataset("quickstart-groups")
8 .select_group_slices("pcd")
9 .clone()
10)
11
12# Populate orthographic projections
13fou3d.compute_orthographic_projection_images(dataset, (-1, 512), "/tmp/proj")
14
15session = fo.launch_app(dataset)
Configuring the 3D visualizer#
The 3D visualizer can be configured by including any subset of the settings
shown below under the plugins.3d key of your
App config:
// The default values are shown below
{
"plugins": {
"3d": {
// Whether to show the 3D visualizer
"enabled": true,
// The initial camera position in the 3D scene
"defaultCameraPosition": {"x": 0, "y": 0, "z": 0},
// The default up direction for the scene
"defaultUp": [0, 0, 1],
"pointCloud": {
// Don't render points below this z value
"minZ": null
}
}
}
}
You can also store dataset-specific plugin settings by storing any subset of the above values on a dataset’s App config:
1# Configure the 3D visualizer for a dataset's PCD/Label data
2dataset.app_config.plugins["3d"] = {
3 "defaultCameraPosition": {"x": 0, "y": 0, "z": 100},
4}
5dataset.save()
Note
Dataset-specific plugin settings will override any settings from your global App config.
Annotating a sample NEW#
When visualizing images or 3D samples in the expanded view, you can click the “Annotate” tab located in the right sidebar to access FiftyOne’s in-App annotation features.
FiftyOne’s in-App annotation features extend the existing data visualization UI,
allowing you to edit metadata on a sample-by-sample basis directly within the
App. The label types currently supported are: Classification, Detections,
Polylines, and |Cuboids|. You can also edit non-label primitive fields,
as well.
To perform in-App annotation, your dataset requires an Annotation Schema. Fields are not automatically included and must be explicitly added through the Schema Manager, which you can access in the “Annotate” tab of the visualizer. You can also create new fields on your dataset via the Schema Manager, as well.
Note
In FiftyOne Enterprise, only users with Can manage dataset access can access the Schema Manager.
For more information on FiftyOne’s in-App annotation features, visit this User Guide!
Linking labels#
FiftyOne provides a mechanism to link related labels together, such as the same object instance observed across multiple frames of a video or across different slices of a grouped dataset.
This linking is achieved by assigning the same Instance to the instance
attribute of the relevant Detection, Keypoint, or Polyline objects:
1import fiftyone as fo
2
3# Create instance representing a logical object
4person_instance = fo.Instance()
5
6detection1 = fo.Detection(
7 label="person",
8 bounding_box=[0.1, 0.1, 0.2, 0.2],
9 instance=person_instance, # link this detection
10)
11
12detection2 = fo.Detection(
13 label="person",
14 bounding_box=[0.12, 0.11, 0.2, 0.2],
15 instance=person_instance, # link this detection
16)
When labels are linked via their instance attribute, the App provides
enhanced visualizations and interactions:
Visual linking (on hover): when you hover over a label that is part of an instance group, all other labels belonging to the same instance (across frames or group slices) will be highlighted with a white border
Bulk selection (shift + click): when you hold the
shiftkey and click on a label that is part of an instance group, you will select or deselect all labels belonging to that same instance in bulk. This is particularly useful for tasks like reviewing or tagging all occurrences of a specific object instance quickly
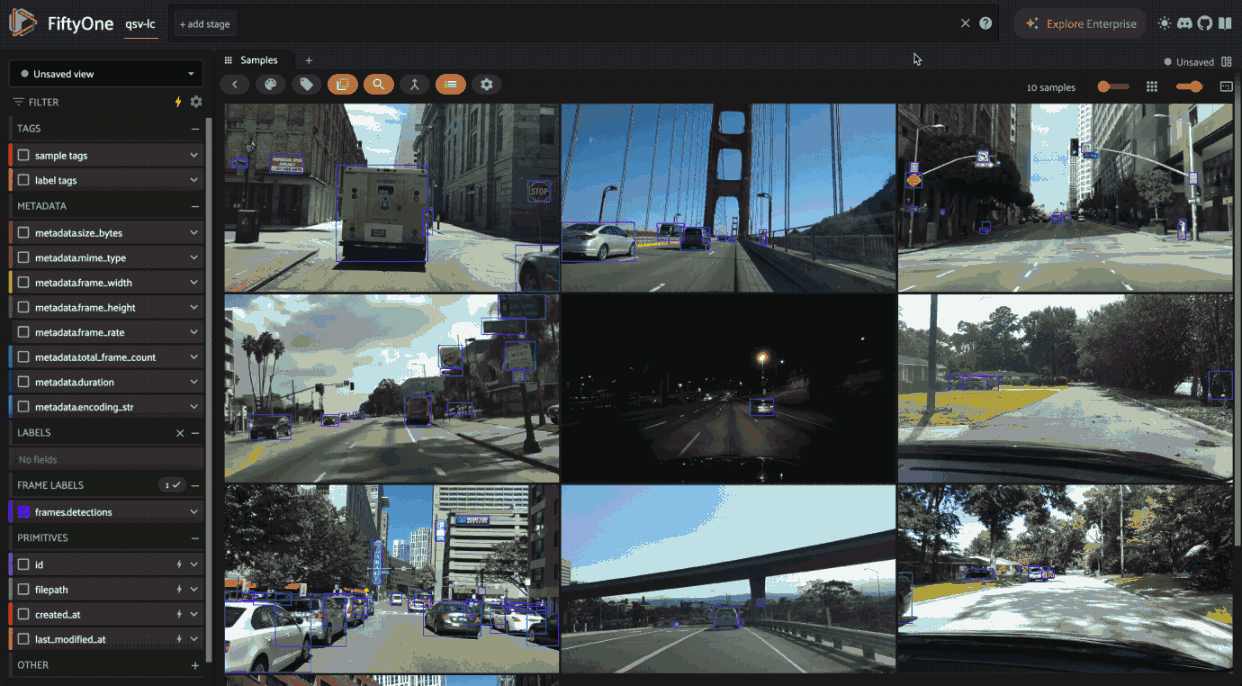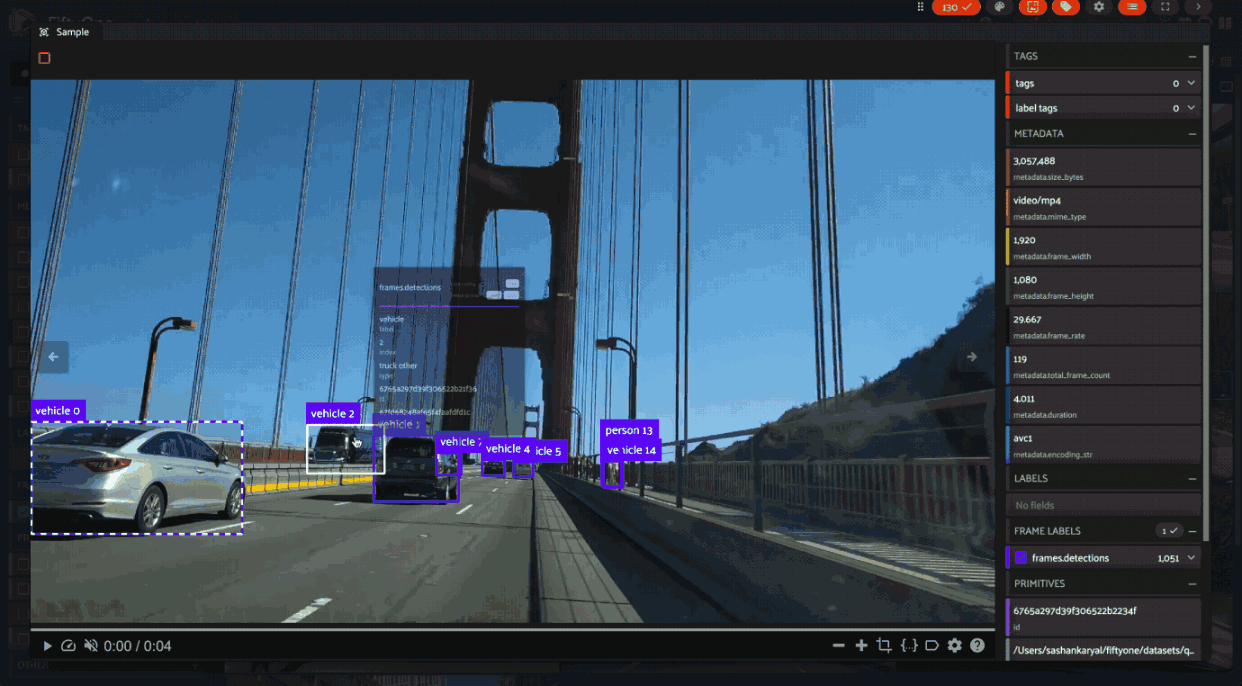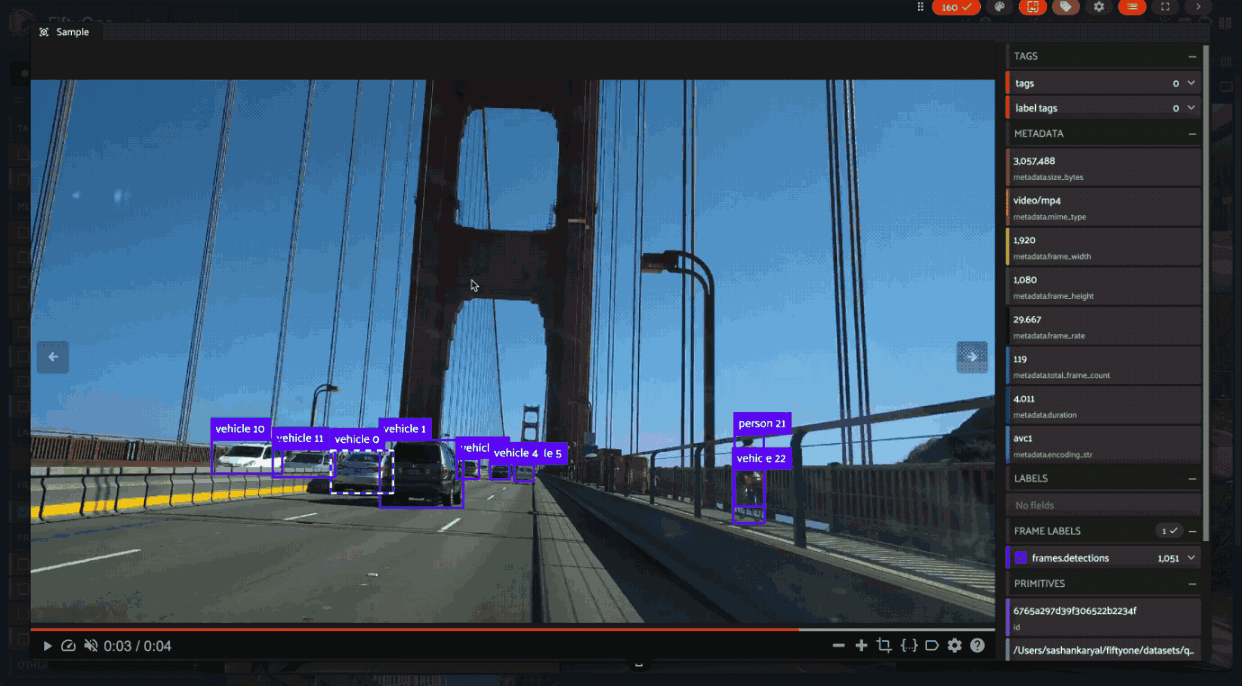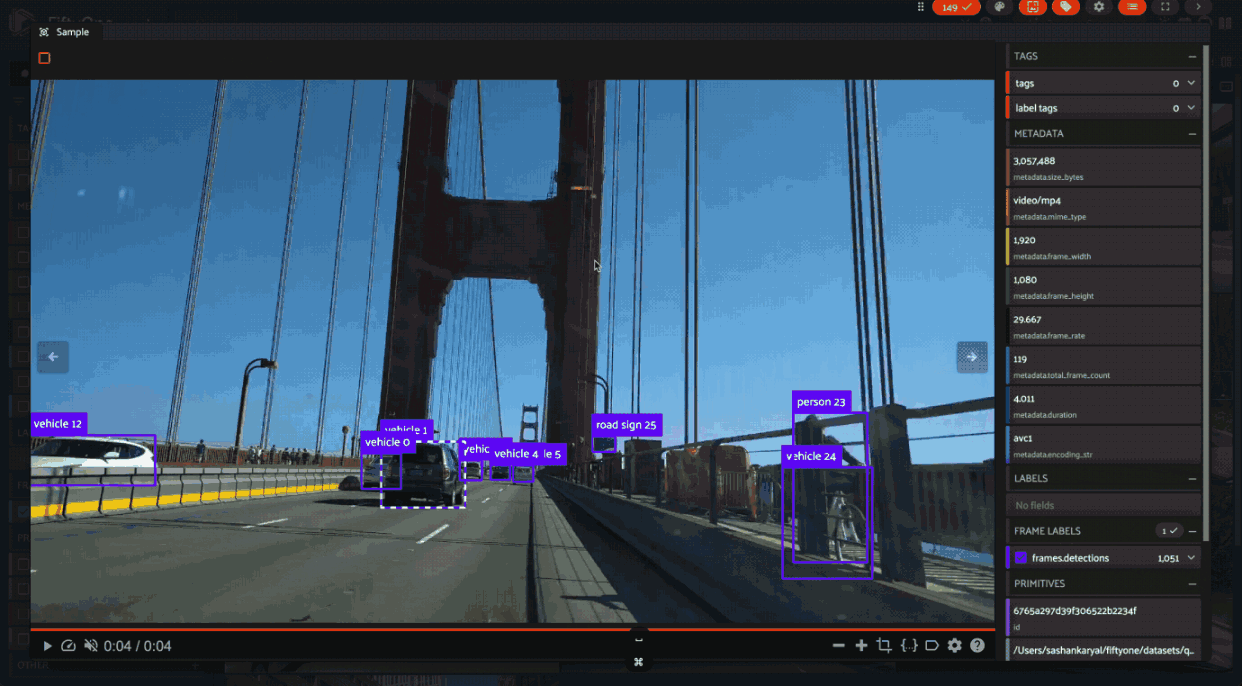
Video datasets#
In video datasets, label correspondence helps track objects over time.
Hovering over a detection in one frame can highlight the same detected object in other frames. Shift-clicking allows for selecting/deselecting all instances of that object throughout the relevant frames of the video:
Grouped datasets#
In grouped datasets, label correspondence links the same object viewed from different perspectives (group slices).
Hovering over an object in one camera view can highlight its corresponding occurrences in other camera views within the same group. Shift-clicking enables bulk selection/deselection of these corresponding objects across the group slices:
Spaces#
Spaces provide a customizable framework for organizing interactive Panels of information within the App.
FiftyOne natively includes the following Panels:
Samples panel: the media grid that loads by default when you launch the App
Embeddings panel: a canvas for working with embeddings visualizations
Model Evaluation panel: interactively analyze and visualize your model’s performance
Map panel: visualizes the geolocation data of datasets that have a
GeoLocationfieldHistograms panel: a dashboard of histograms for the fields of your dataset
Note
You can also configure custom Panels via plugins!
Configuring spaces in the App#
Consider the following example dataset:
1import fiftyone as fo
2import fiftyone.brain as fob
3import fiftyone.zoo as foz
4
5dataset = foz.load_zoo_dataset("quickstart")
6fob.compute_visualization(dataset, brain_key="img_viz")
7
8session = fo.launch_app(dataset)
You can configure spaces visually in the App in a variety of ways described below.
Click the + icon in any Space to add a new Panel:
When you have multiple Panels open in a Space, you can use the divider buttons to split the Space either horizontally or vertically:
You can rearrange Panels at any time by dragging their tabs between Spaces, or
close Panels by clicking their x icon:
Configuring spaces in Python#
You can also programmatically configure your Space layout and the states of the
individual Panels via the Space and Panel classes in Python, as shown
below:
1samples_panel = fo.Panel(type="Samples", pinned=True)
2
3histograms_panel = fo.Panel(
4 type="Histograms",
5 state=dict(plot="Labels"),
6)
7
8embeddings_panel = fo.Panel(
9 type="Embeddings",
10 state=dict(brainResult="img_viz", colorByField="metadata.size_bytes"),
11)
12
13spaces = fo.Space(
14 children=[
15 fo.Space(
16 children=[
17 fo.Space(children=[samples_panel]),
18 fo.Space(children=[histograms_panel]),
19 ],
20 orientation="horizontal",
21 ),
22 fo.Space(children=[embeddings_panel]),
23 ],
24 orientation="vertical",
25)
The children property of each
Space describes what the Space contains, which can be either:
A list of
Spaceinstances. In this case, the Space contains a nested list of Spaces, arranged either horizontally or vertically, as per theorientationproperty of the parent SpaceA list of
Panelinstances describing the Panels that should be available as tabs within the Space
Set a Panel’s pinned property to
True if you do not want a Panel’s tab to have a close icon x in the App.
Each Panel also has a state dict
that can be used to configure the specific state of the Panel to load. Refer to
the sections below for each Panel’s available state.
You can launch the App with an initial spaces layout by passing the optional
spaces parameter to
launch_app():
1# Launch the App with an initial Spaces layout
2session = fo.launch_app(dataset, spaces=spaces)
Once the App is launched, you can retrieve your current layout at any time via
the session.spaces property:
1print(session.spaces)
You can also programmatically configure the App’s current layout by setting
session.spaces to any valid
Space instance:
1# Change the session's current Spaces layout
2session.spaces = spaces
Note
Inspecting session.spaces of
a session whose Spaces layout you’ve configured in the App is a convenient
way to discover the available state options for each Panel type!
You can reset your spaces to their default state by setting
session.spaces to None:
1# Reset spaces layout in the App
2session.spaces = None
Saving workspaces#
If you find yourself frequently using/recreating a certain spaces layout, you can save it as a workspace with a name of your choice and then load it later via the App or programmatically!
Saving workspaces in the App#
Continuing from the example above, once you’ve configured a spaces layout of interest, click the “Unsaved workspace” icon in the upper right corner to open the workspaces menu and save your current workspace with a name and optional description/color of your choice:
Note
Saved workspaces include all aspects of your current spaces layout, including panel types, layouts, sizes, and even the current state of each panel!
You can load saved workspaces at any time later via this same menu:
You can also edit the details of an existing saved workspace at any time by clicking on its pencil icon in the workspace menu:

Note
If you want to modify the layout of an existing saved workspace, you must delete the existing workspace and then re-save it under the same name after modifying the layout in the App.
Saving workspaces in Python#
You can also programmatically create and manage saved workspaces!
Use save_workspace()
to create a new saved workspace with a name of your choice:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5
6samples_panel = fo.Panel(type="Samples", pinned=True)
7
8histograms_panel = fo.Panel(
9 type="Histograms",
10 state=dict(plot="Labels"),
11)
12
13embeddings_panel = fo.Panel(
14 type="Embeddings",
15 state=dict(brainResult="img_viz", colorByField="metadata.size_bytes"),
16)
17
18workspace = fo.Space(
19 children=[
20 fo.Space(
21 children=[
22 fo.Space(children=[samples_panel]),
23 fo.Space(children=[histograms_panel]),
24 ],
25 orientation="horizontal",
26 ),
27 fo.Space(children=[embeddings_panel]),
28 ],
29 orientation="vertical",
30)
31
32dataset.save_workspace(
33 "my-workspace",
34 workspace,
35 description="Samples, embeddings, histograms, oh my!",
36 color="#FF6D04",
37)
Note
Pro tip! You can save your current spaces layout in the App via
session.spaces:
workspace = session.spaces
dataset.save_workspace("my-workspace", workspace, ...)
Then in a future session you can load the workspace by name with
load_workspace():
1import fiftyone as fo
2
3dataset = fo.load_dataset("quickstart")
4
5# Retrieve a saved workspace and launch app with it
6workspace = dataset.load_workspace("my-workspace")
7session = fo.launch_app(dataset, spaces=workspace)
8
9# Or, load a workspace on an existing session
10session.spaces = workspace
Saved workspaces have certain editable metadata such as a name, description,
and color that you can view via
get_workspace_info()
and update via
update_workspace_info():
1# Get a saved workspace's editable info
2print(dataset.get_workspace_info("my-workspace"))
3
4# Update the workspace's name and add a description
5info = dict(
6 name="still-my-workspace",
7 description="Samples, embeddings, histograms, oh my oh my!!",
8)
9dataset.update_workspace_info("my-workspace", info)
10
11# Verify that the info has been updated
12print(dataset.get_workspace_info("still-my-workspace"))
13# {
14# 'name': 'still-my-workspace',
15# 'description': 'Samples, embeddings, histograms, oh my oh my!!',
16# 'color': None
17# }
You can also use
list_workspaces(),
has_workspace(),
and
delete_workspace()
to manage your saved workspaces.
Samples panel#
By default, when you launch the App, your spaces layout will contain a single space with the Samples panel active:
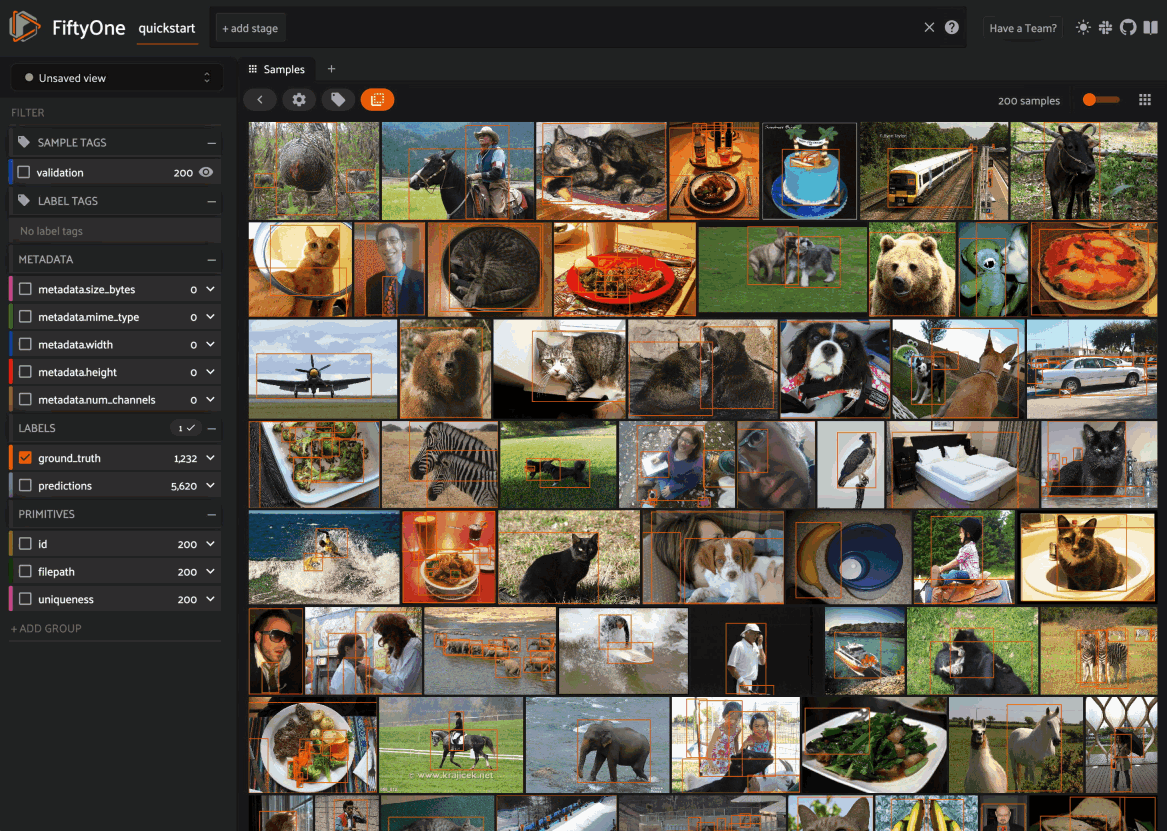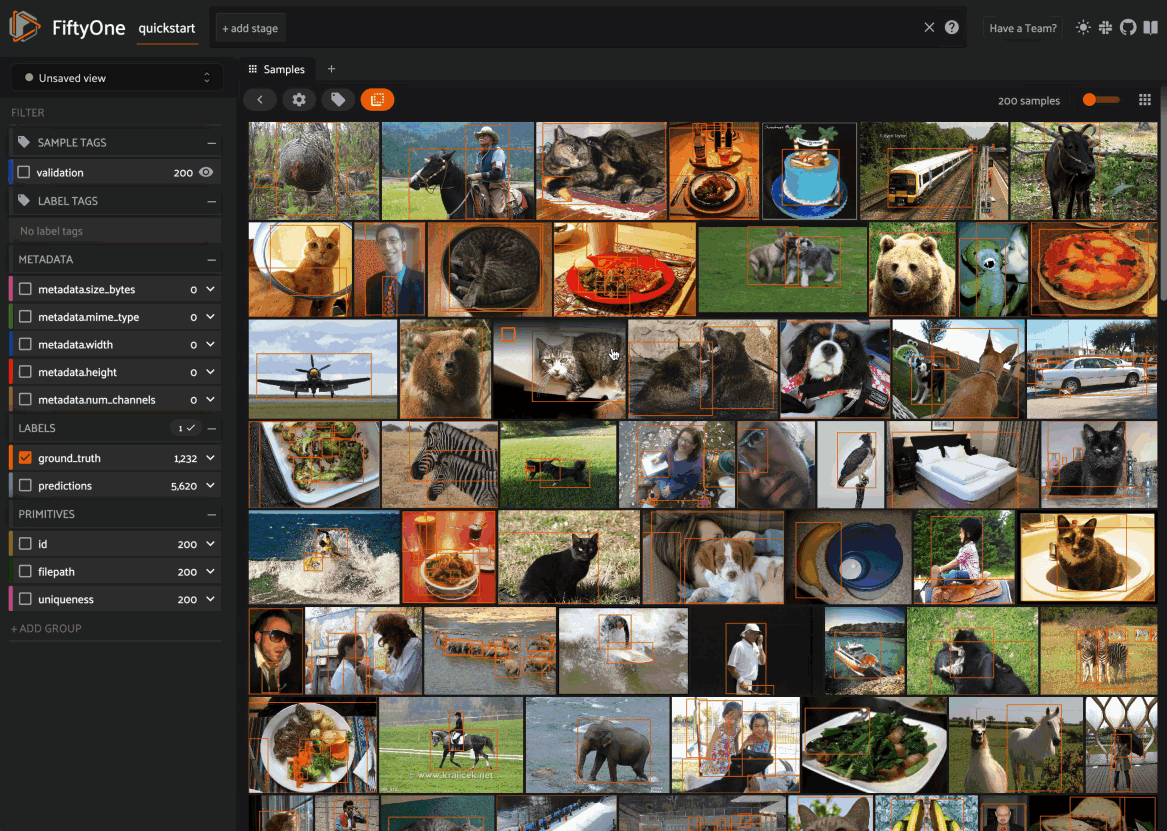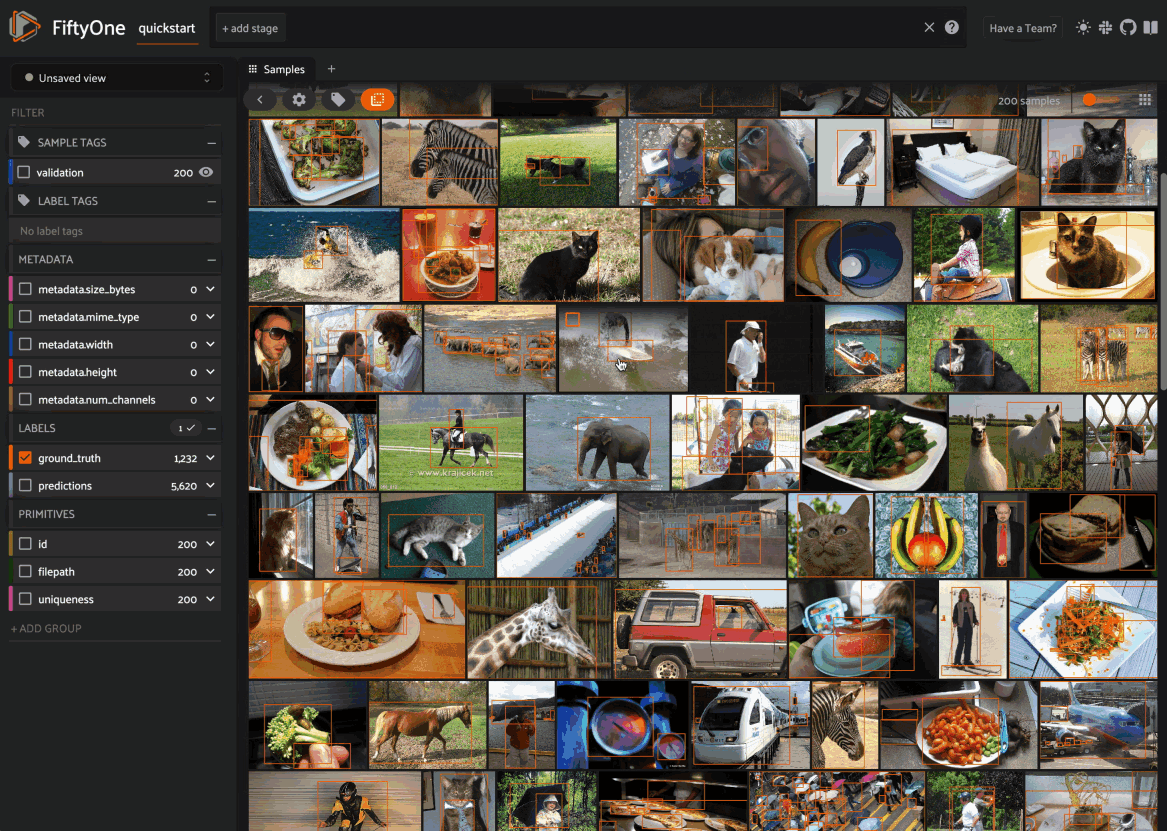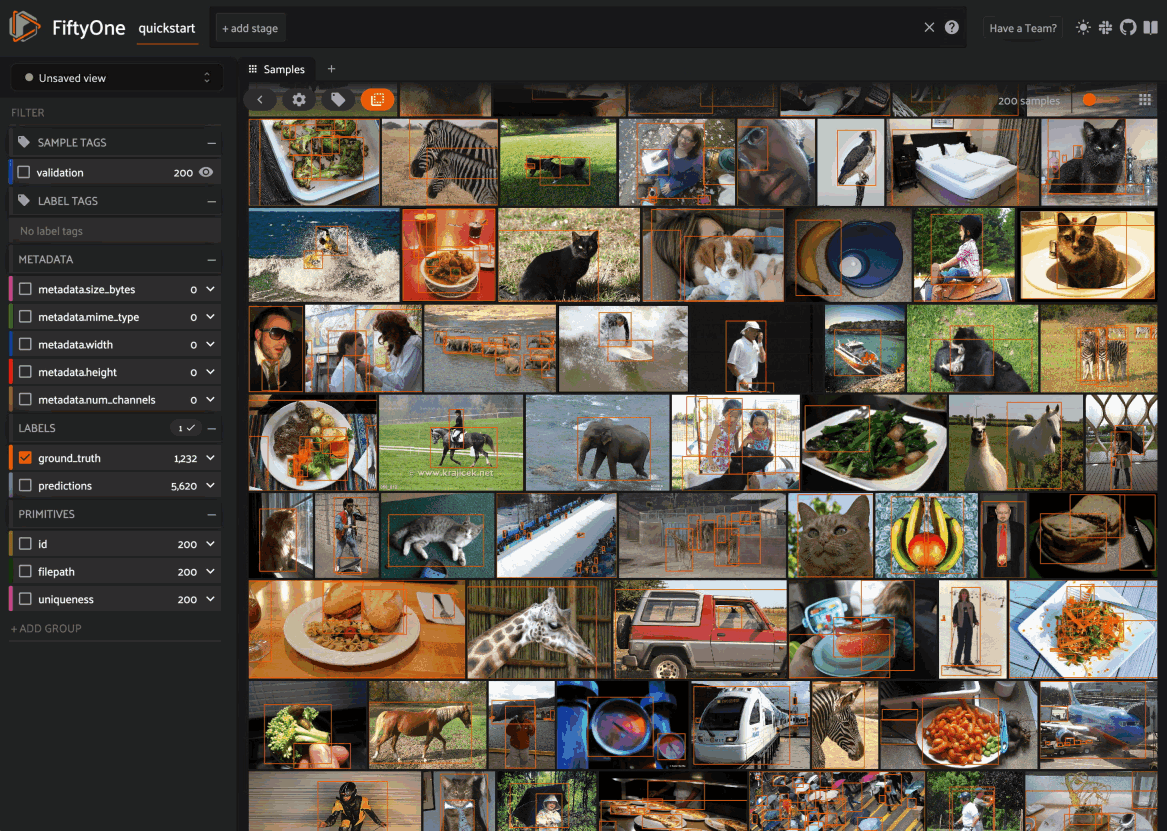
When configuring spaces in Python, you can create a Samples panel as follows:
1samples_panel = fo.Panel(type="Samples")
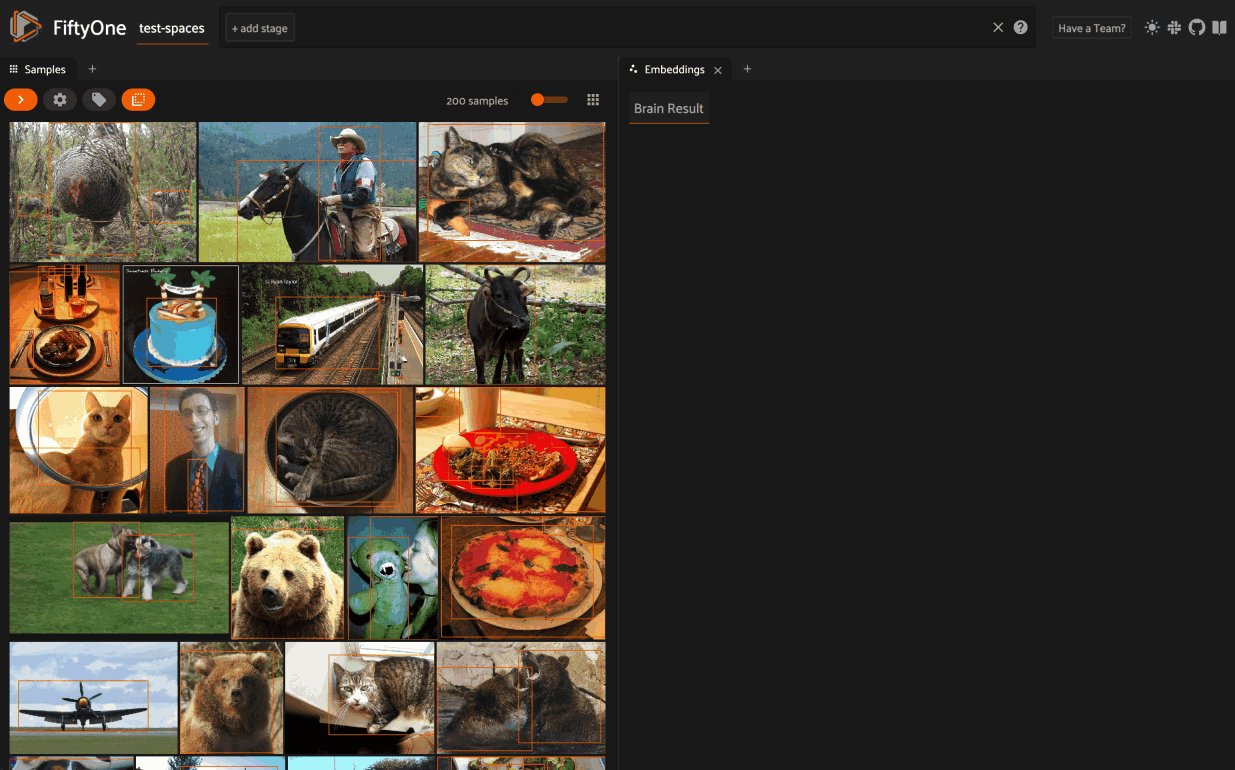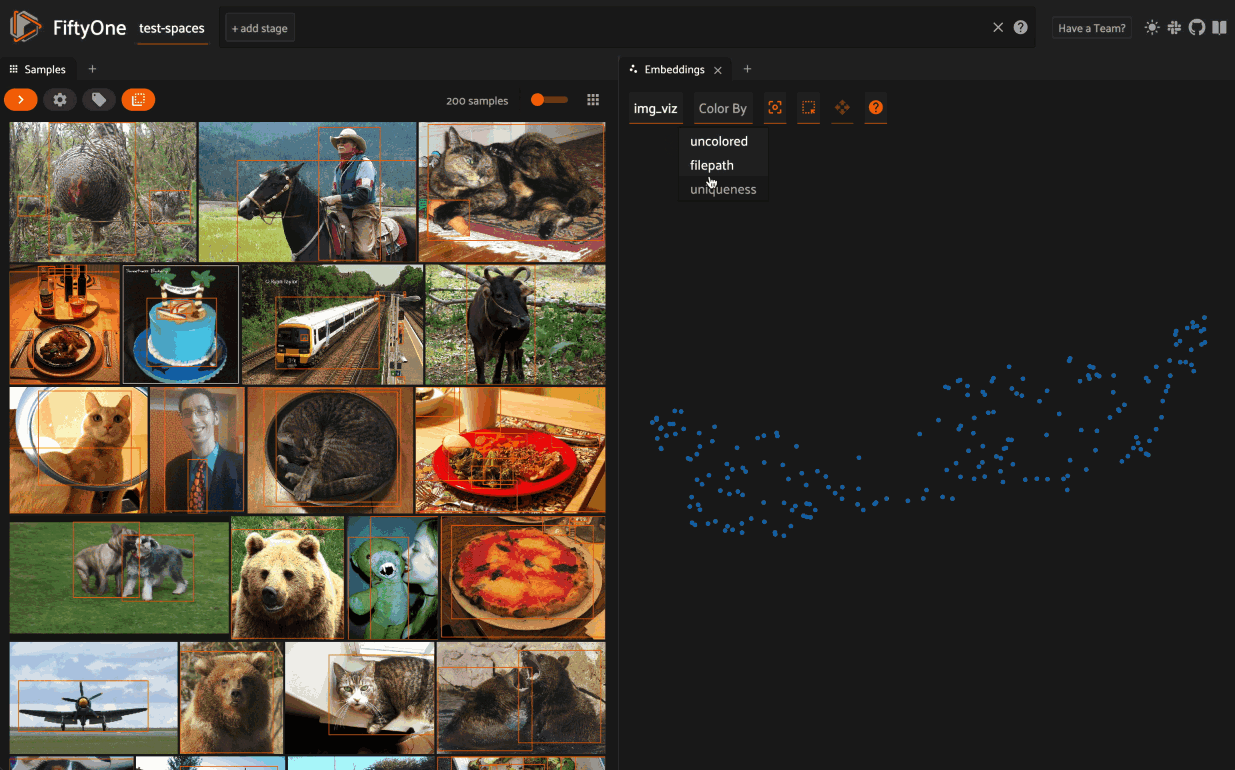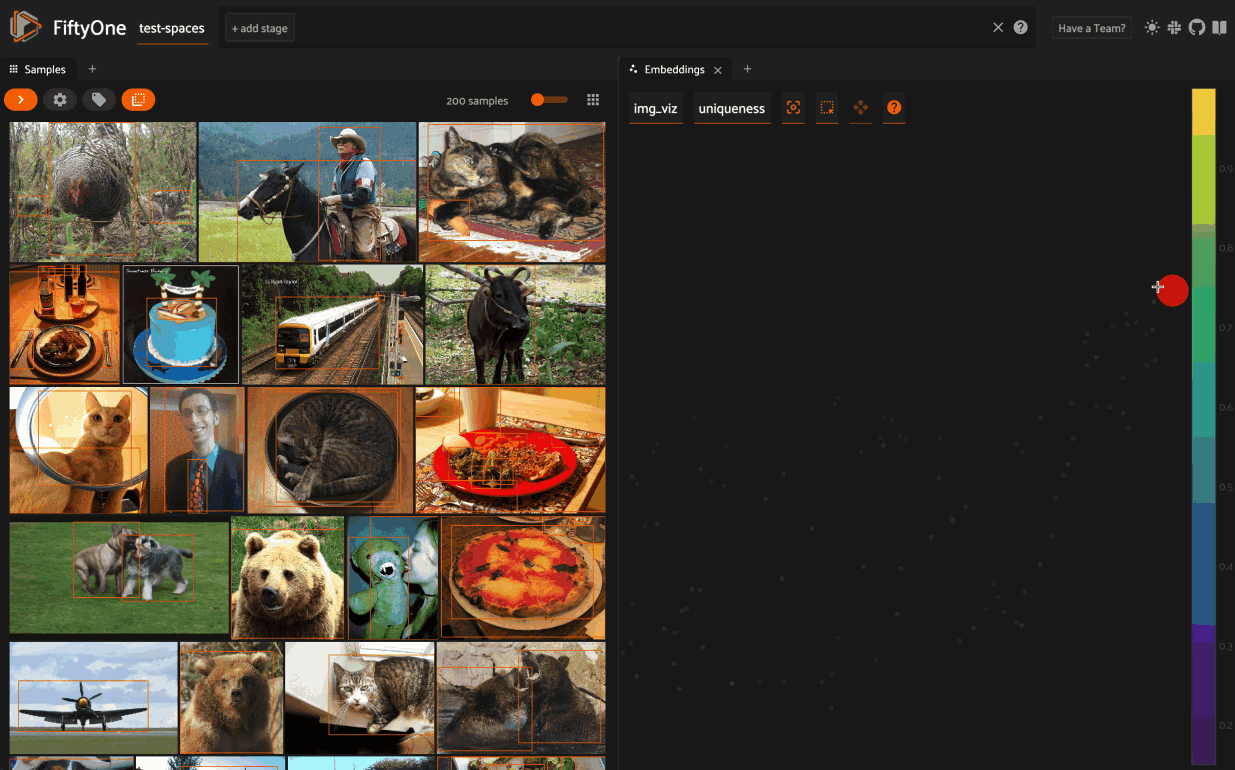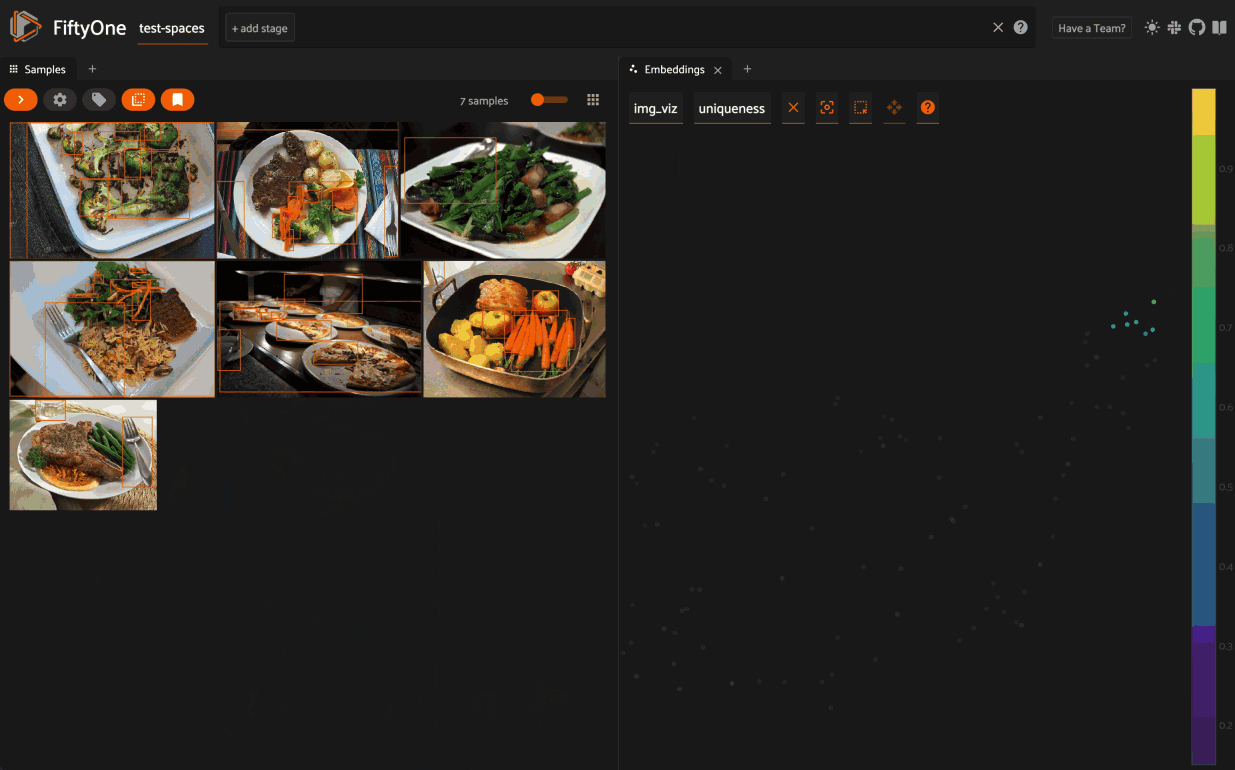
Embeddings panel#
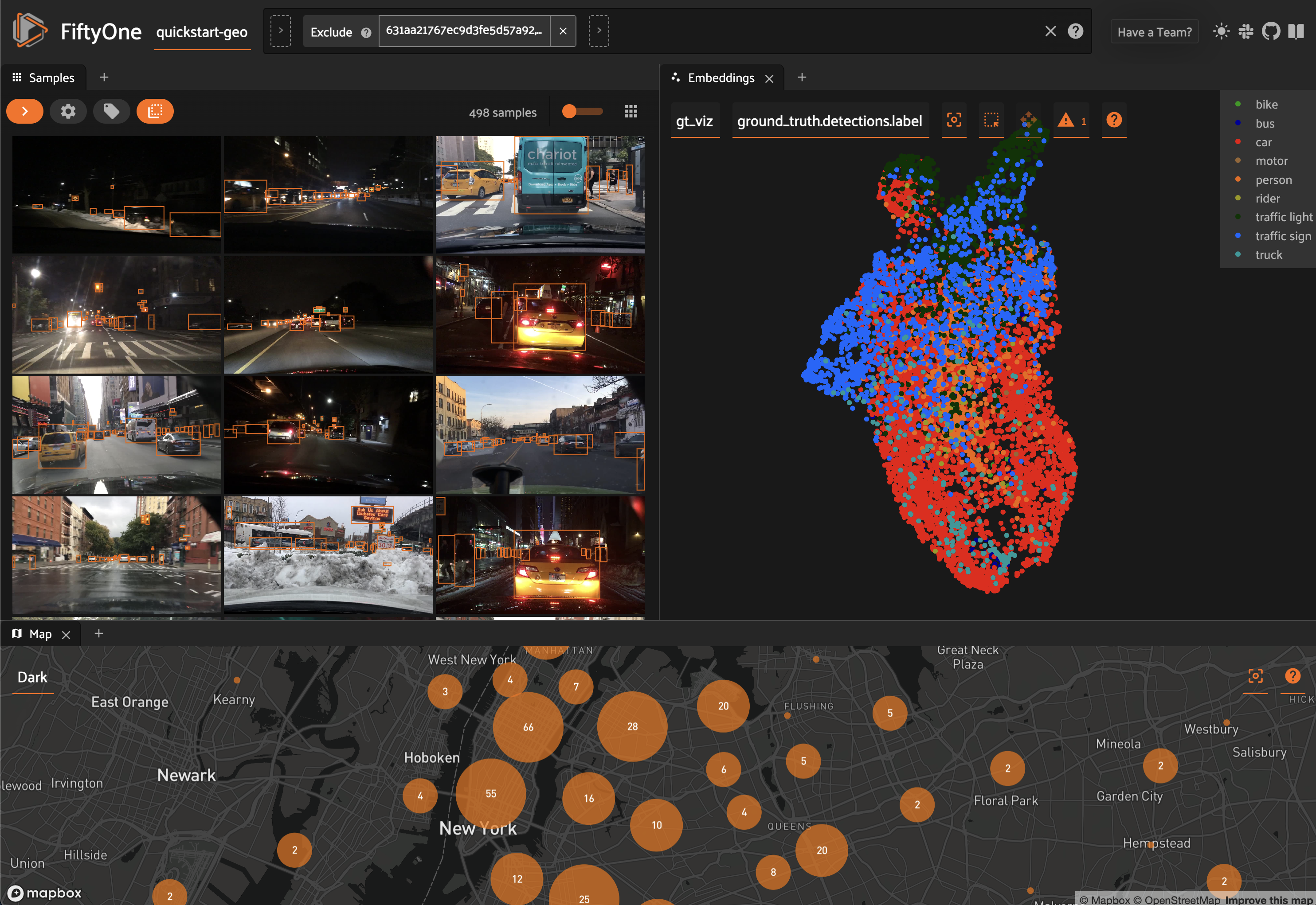
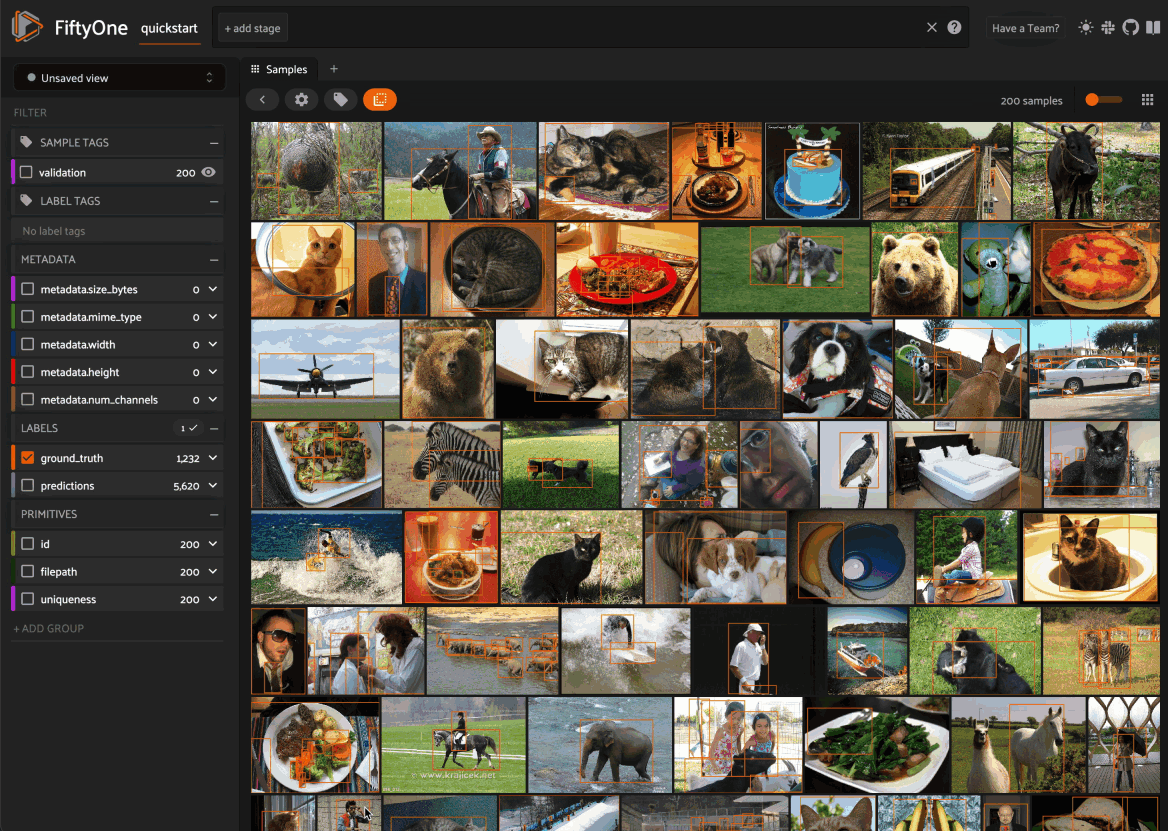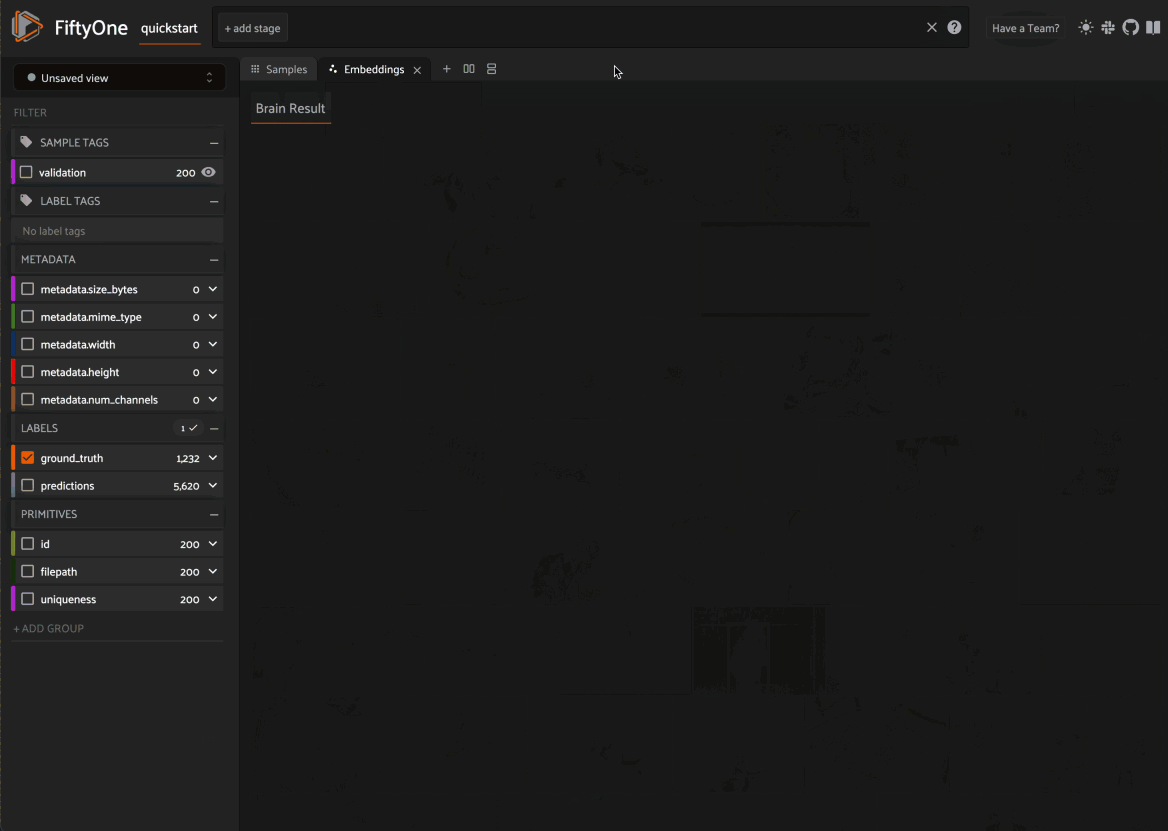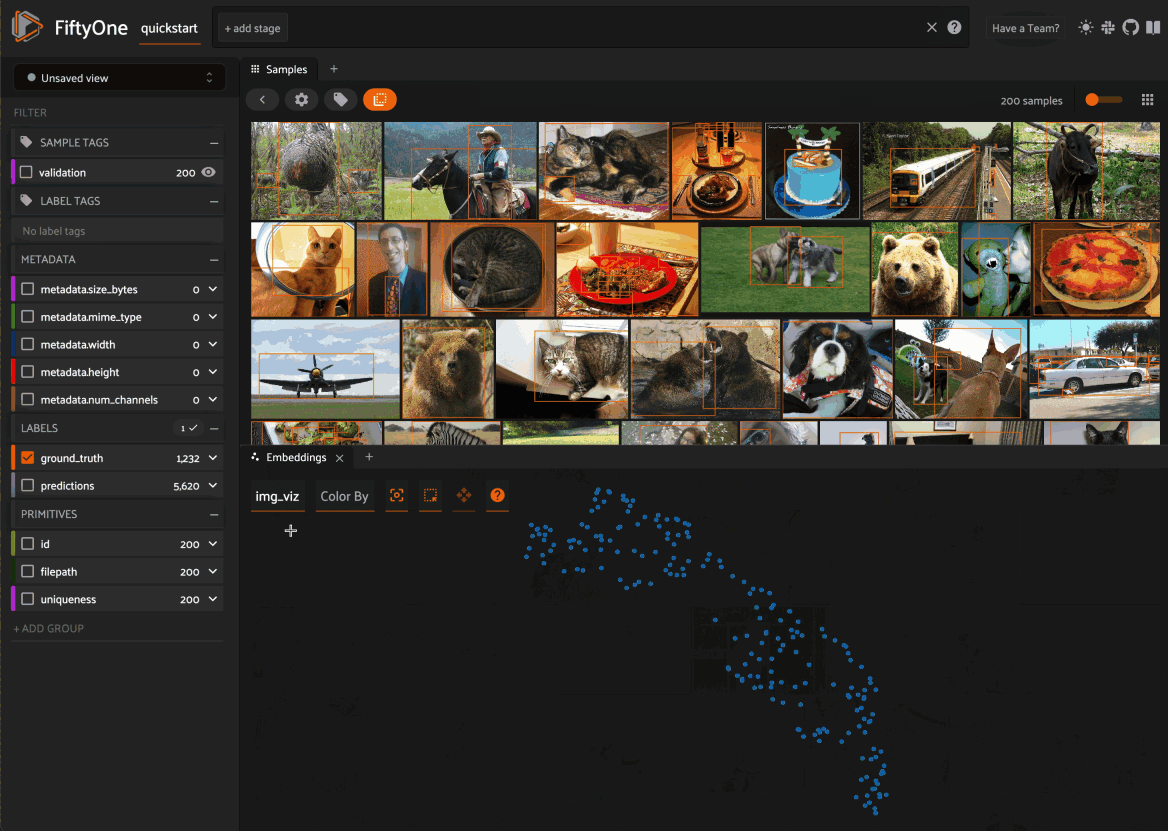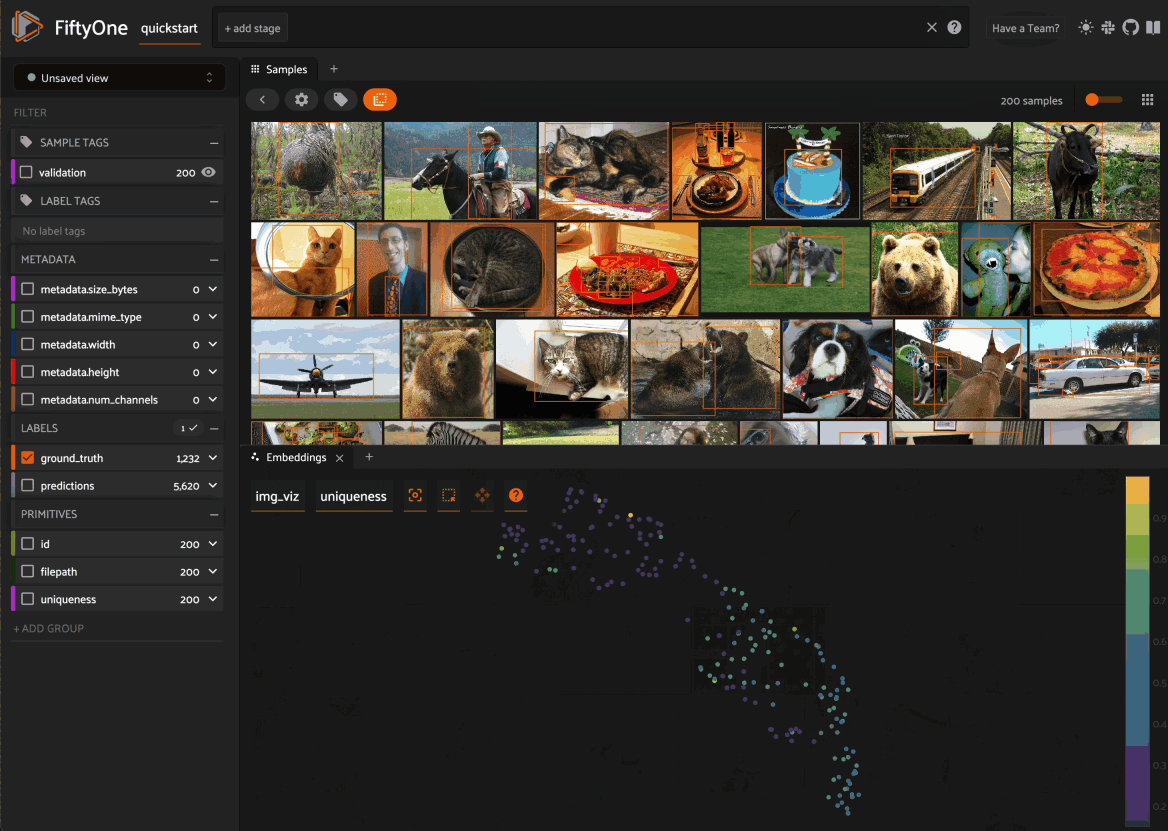
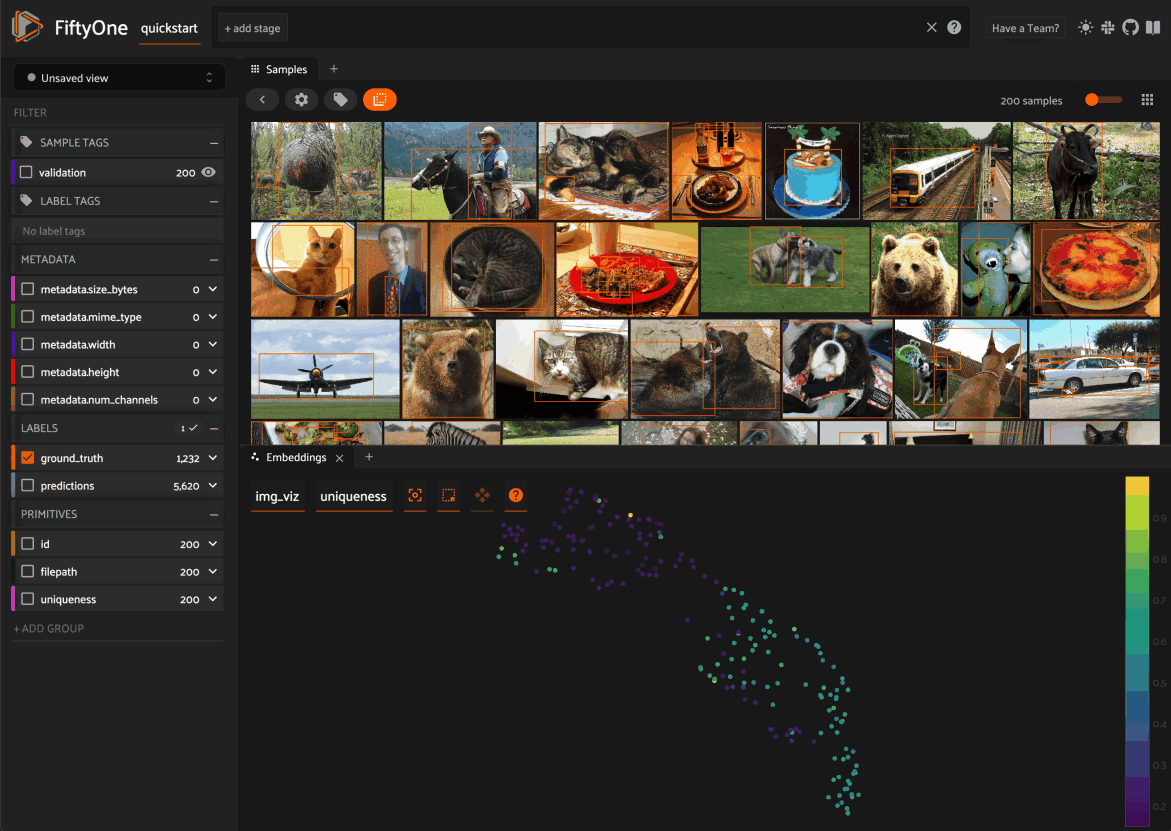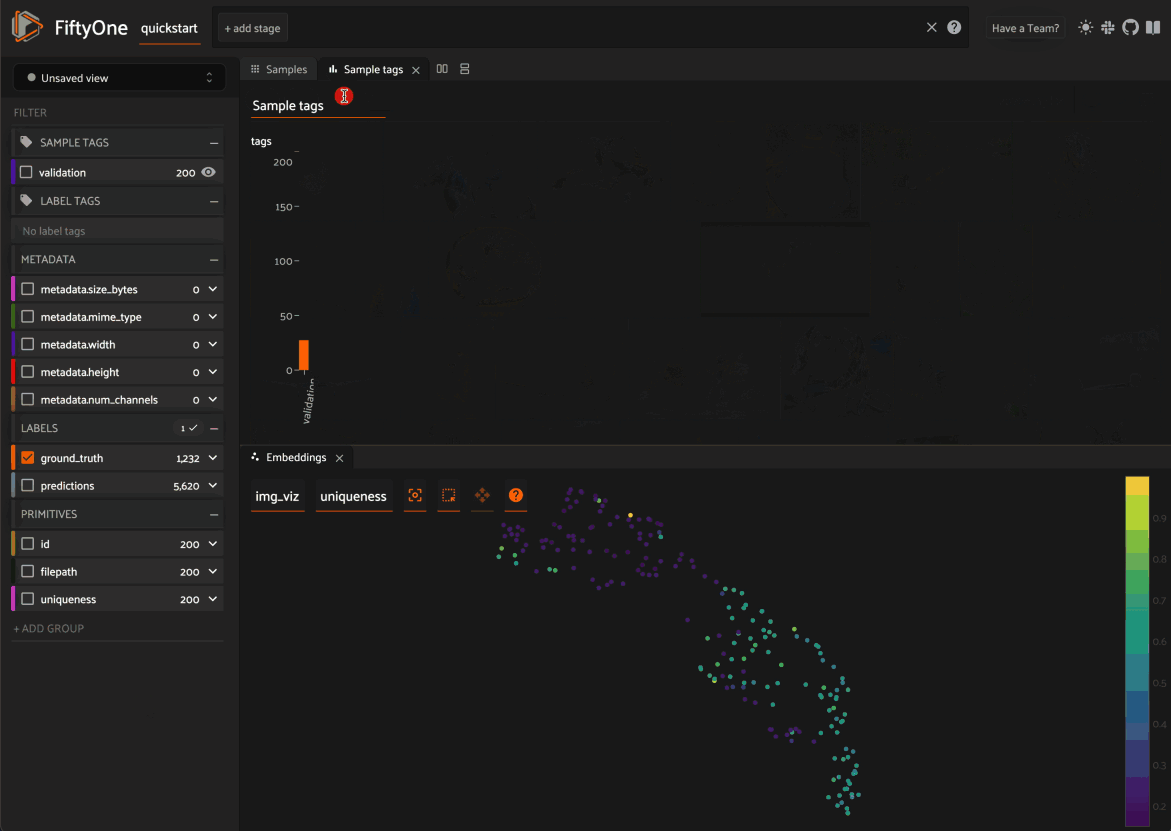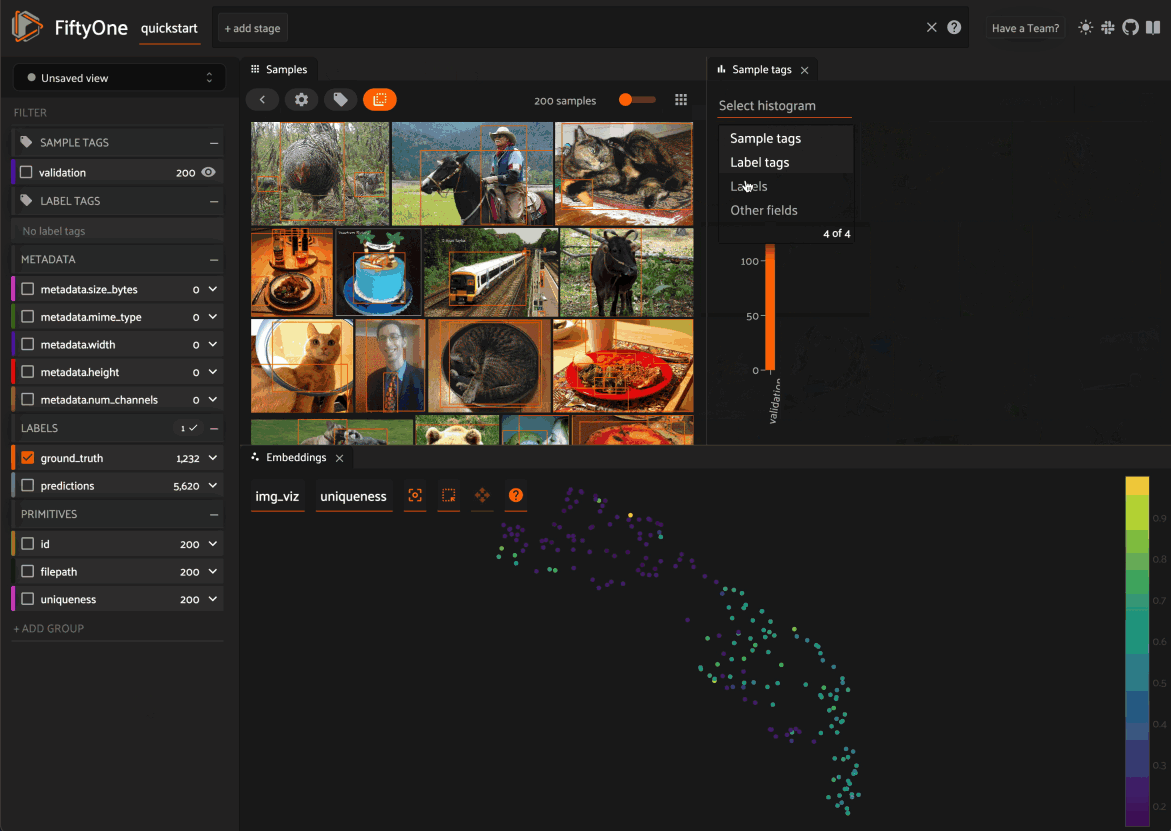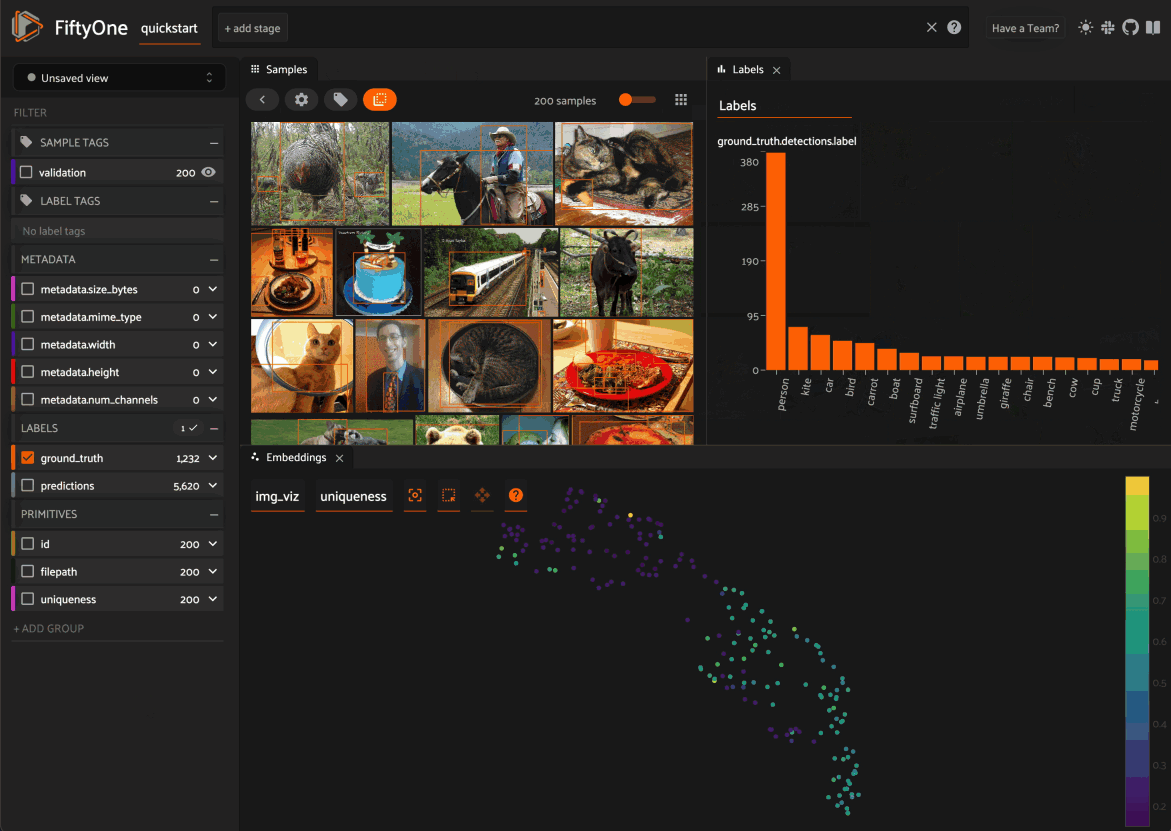
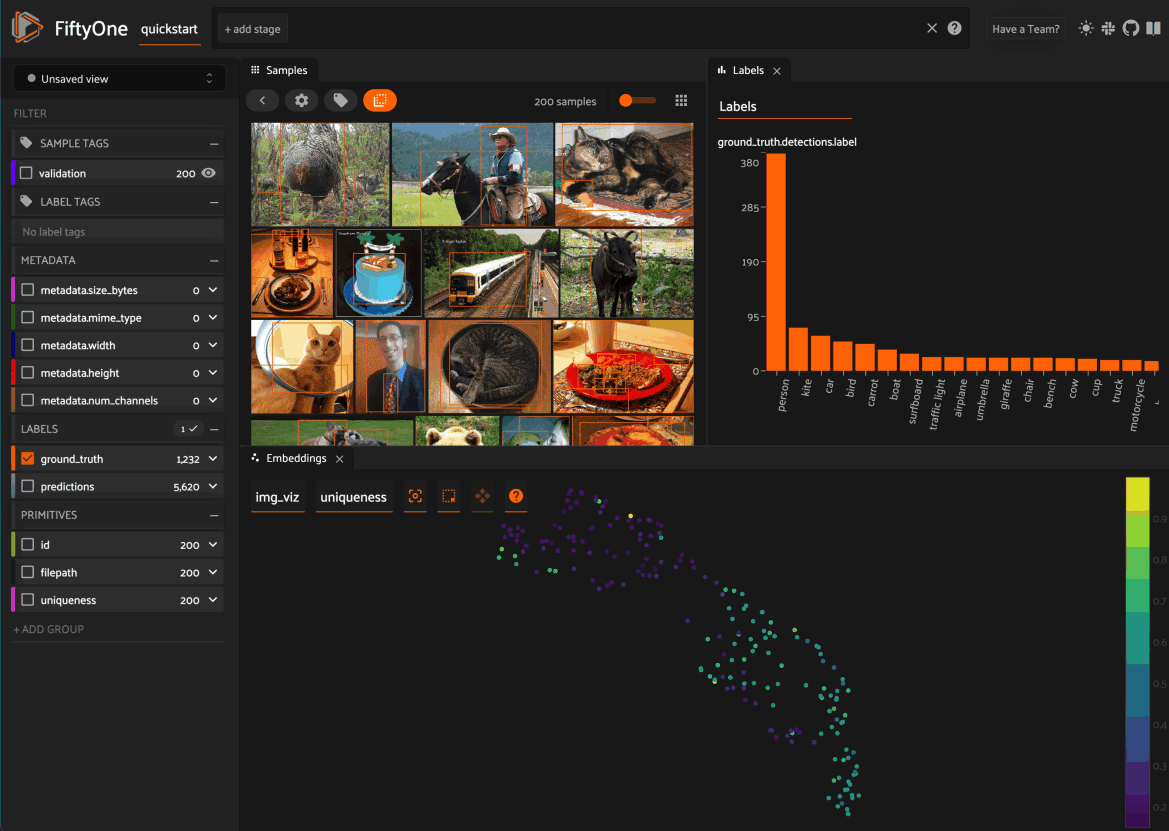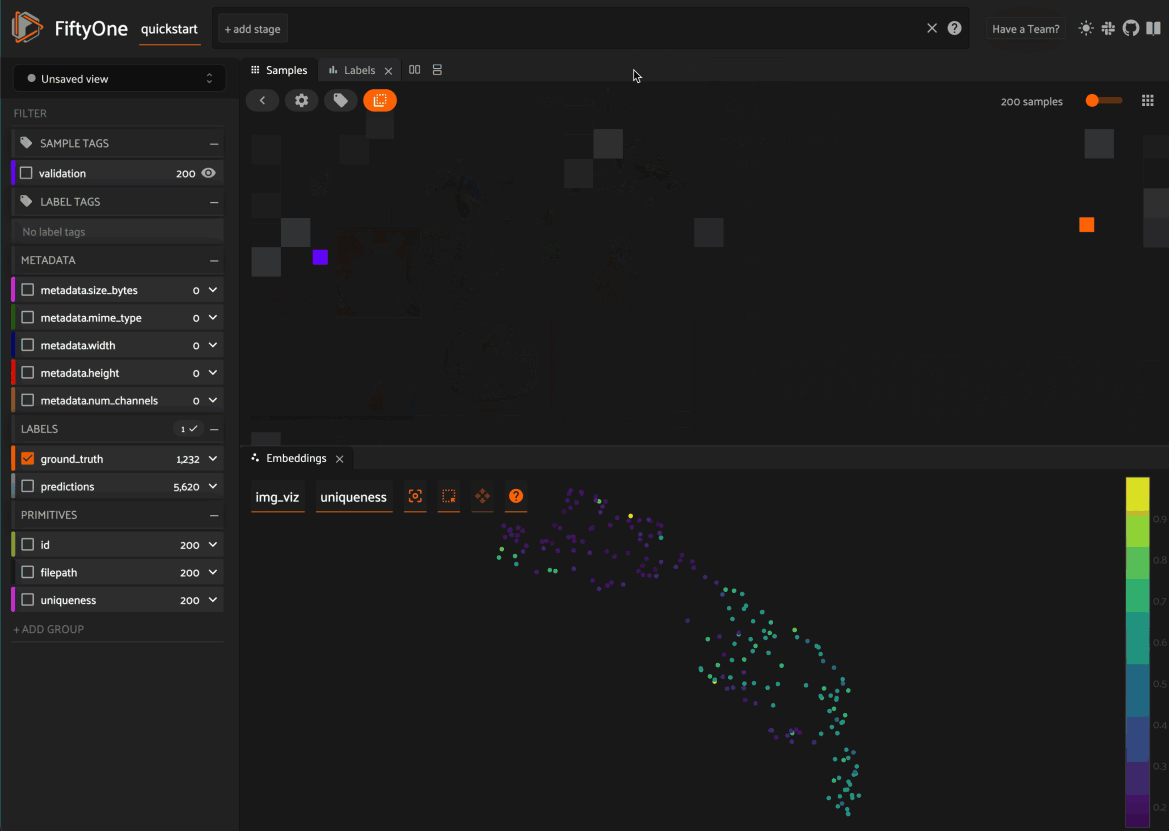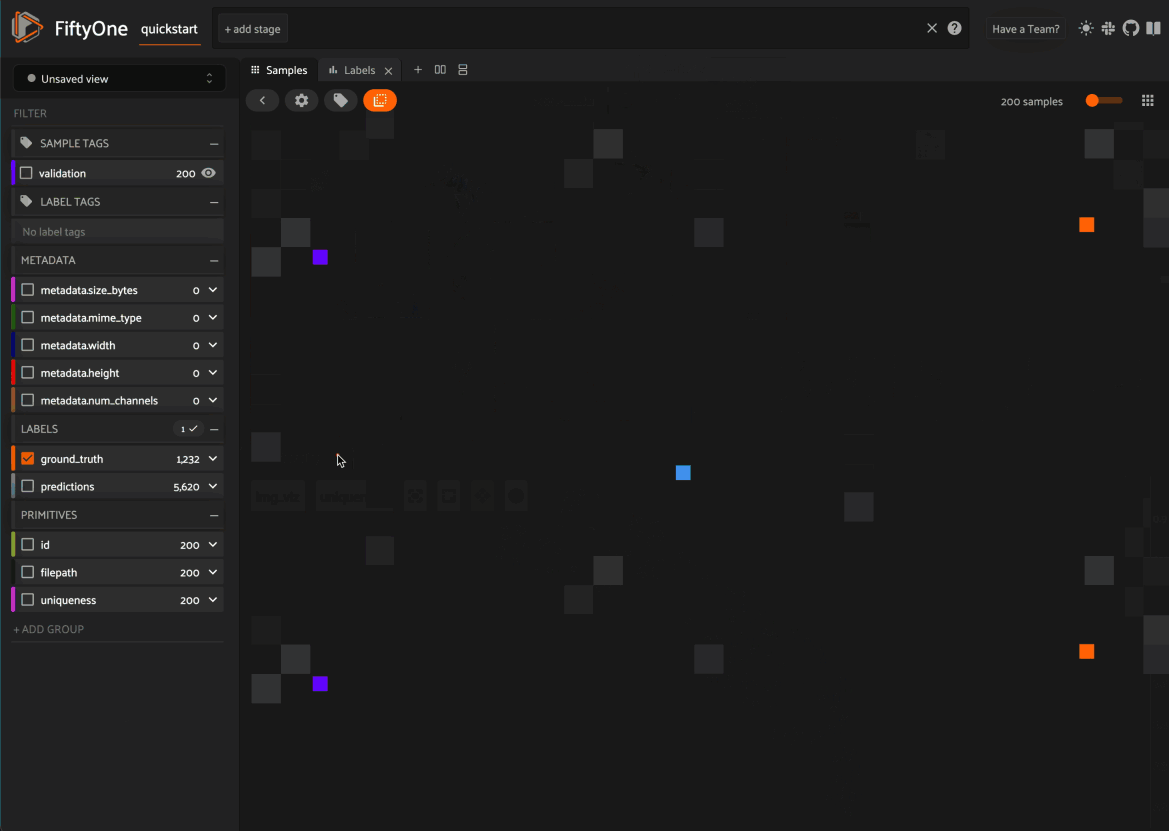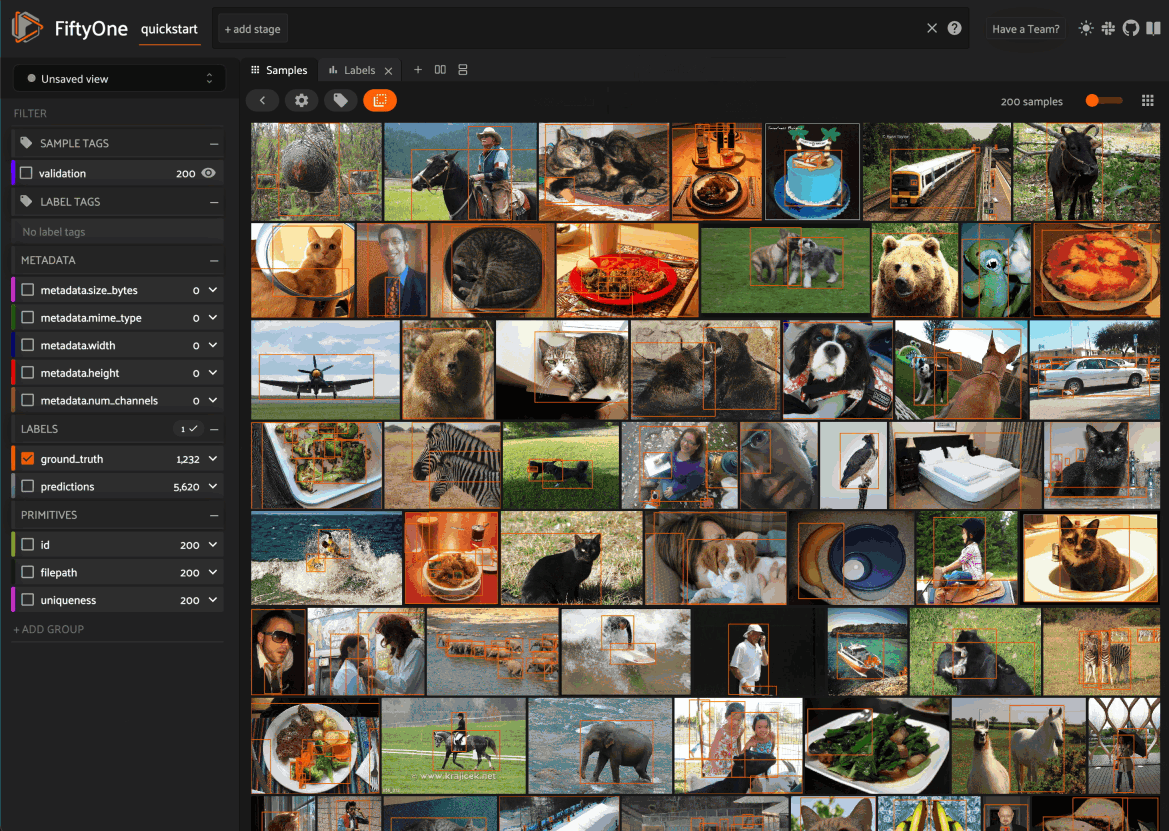
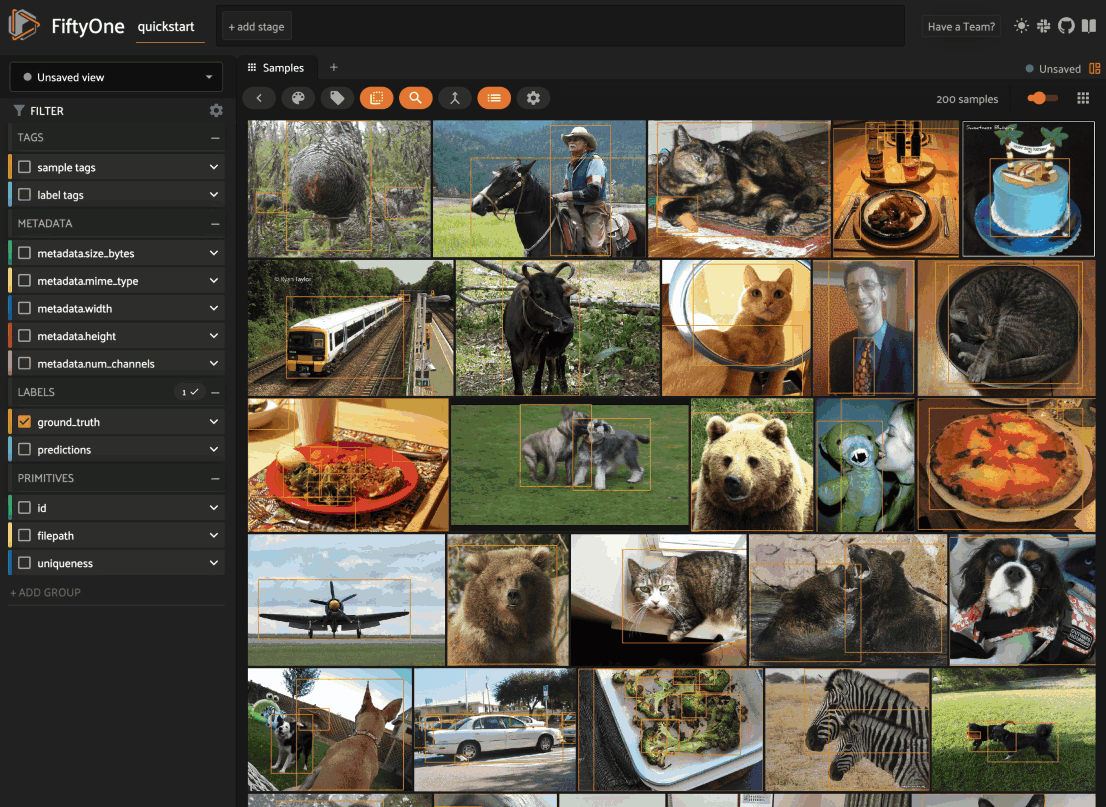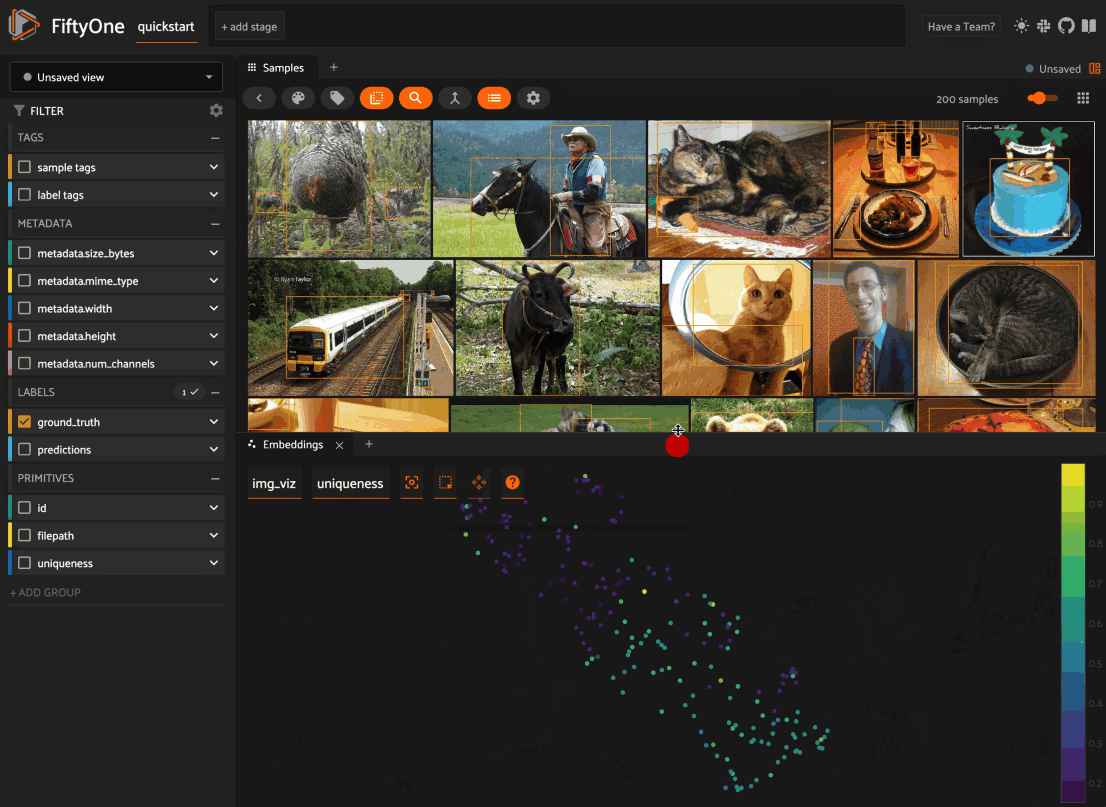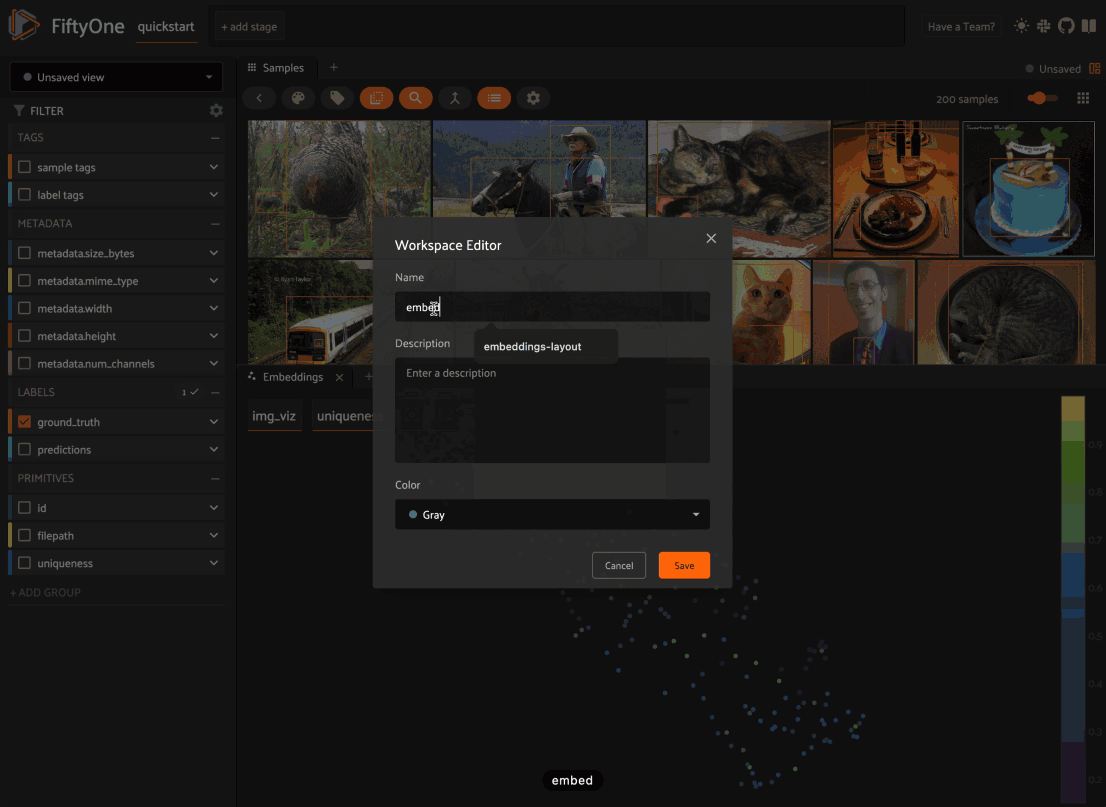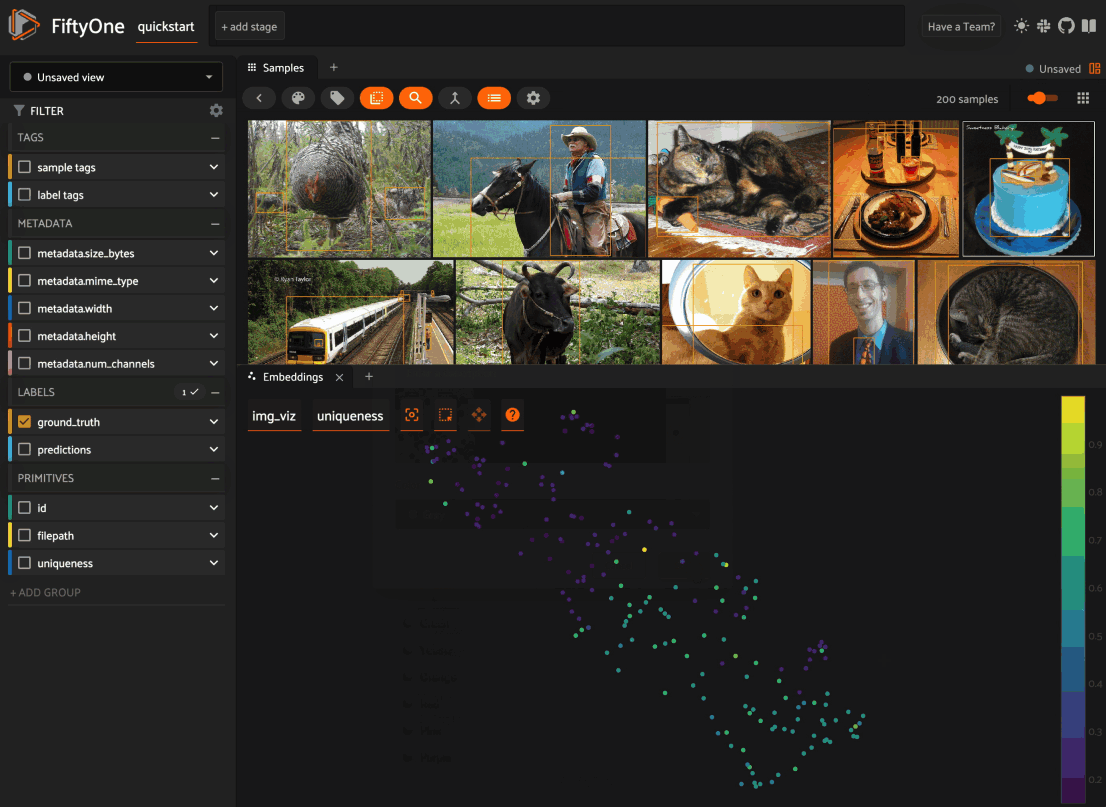
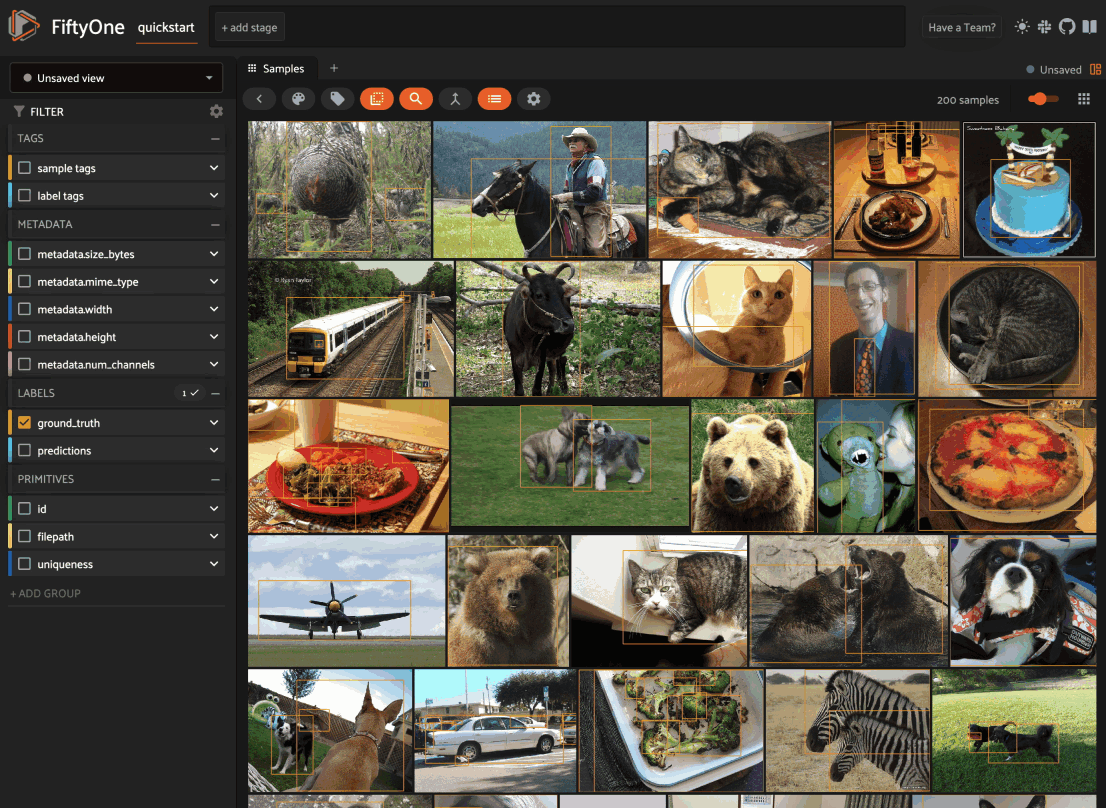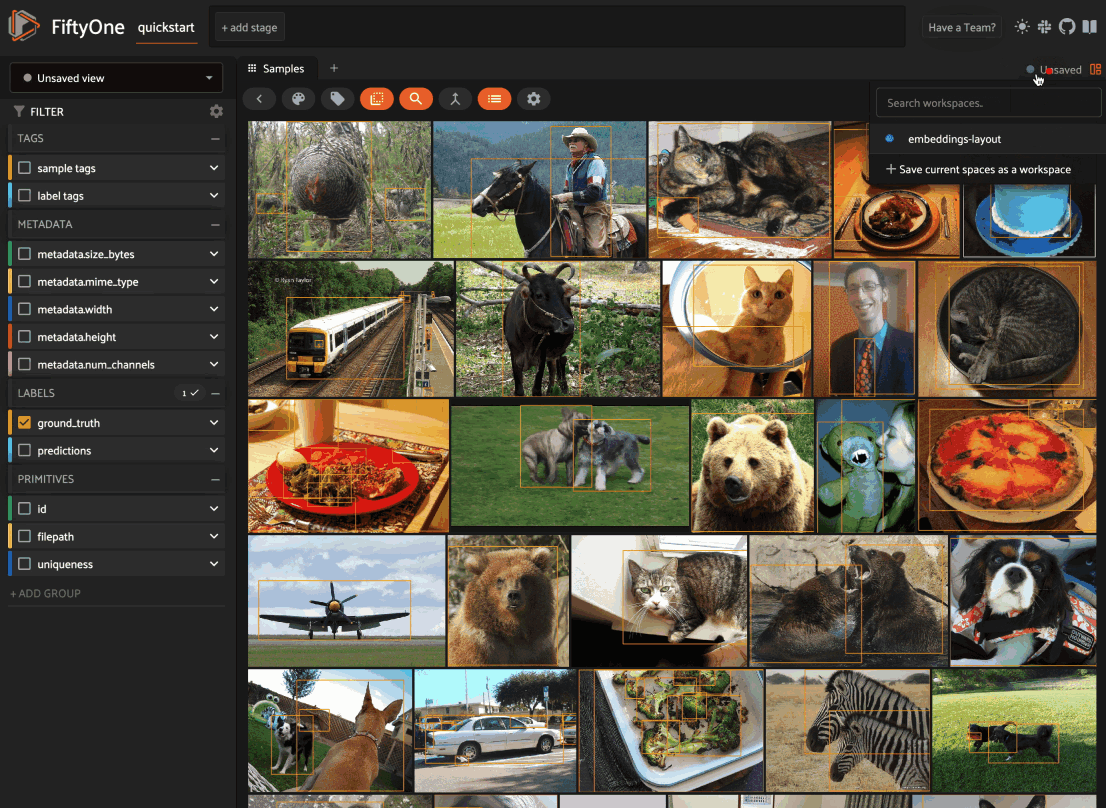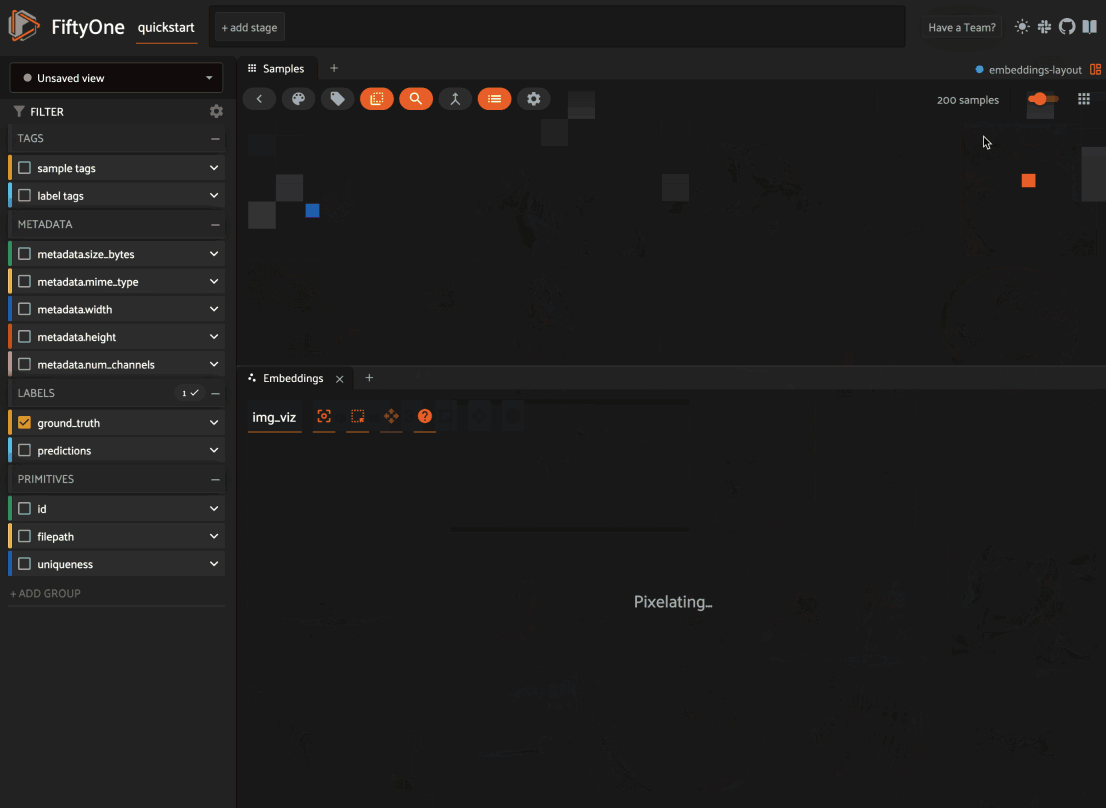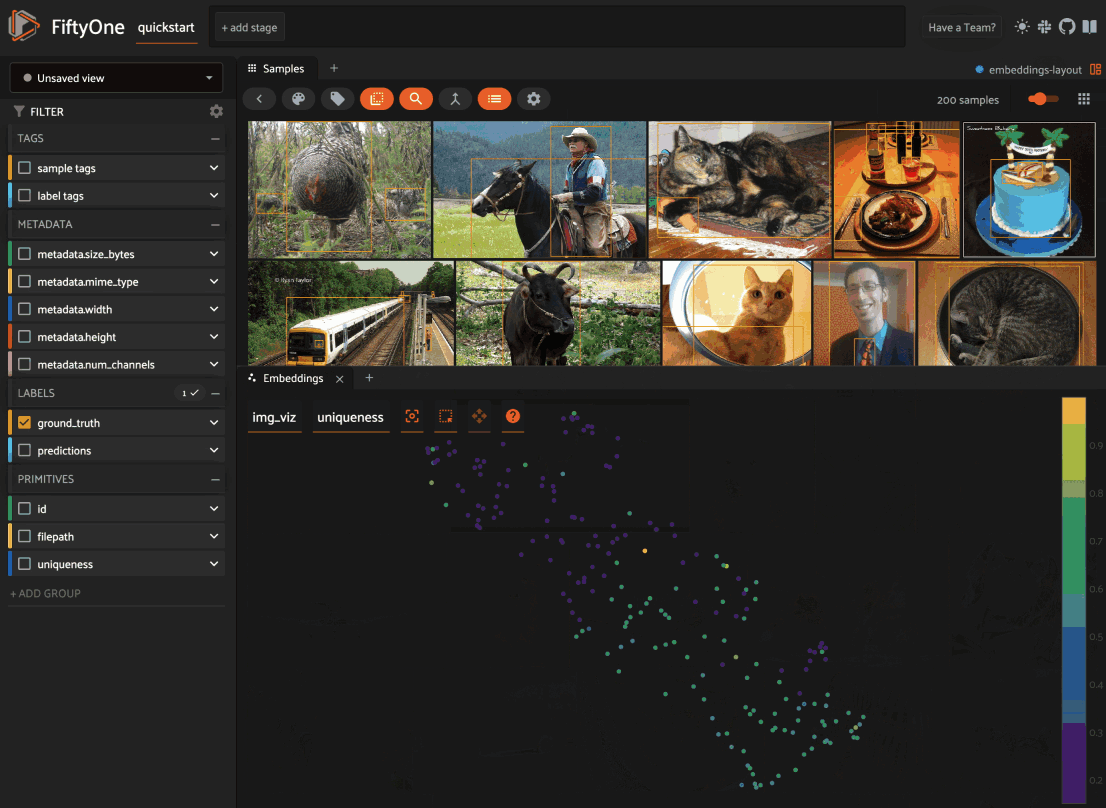
When you load a dataset in the App that contains an embeddings visualization, you can open the Embeddings panel to visualize and interactively explore a scatterplot of the embeddings in the App:
1import fiftyone as fo
2import fiftyone.brain as fob
3import fiftyone.zoo as foz
4
5dataset = foz.load_zoo_dataset("quickstart")
6
7# Image embeddings
8fob.compute_visualization(dataset, brain_key="img_viz")
9
10# Object patch embeddings
11fob.compute_visualization(
12 dataset, patches_field="ground_truth", brain_key="gt_viz"
13)
14
15session = fo.launch_app(dataset)
Use the two menus in the upper-left corner of the Panel to configure your plot:
Brain key: the brain key associated with the
compute_visualization()run to displayColor by: an optional sample field (or label attribute, for patches embeddings) to color the points by
From there you can lasso points in the plot to show only the corresponding samples/patches in the Samples panel:
Note
Did you know? With FiftyOne Enterprise you can generate embeddings visualizations natively from the App in the background while you work.
The embeddings UI also provides a number of additional controls:
Press the
panicon in the menu (or typeg) to switch to pan mode, in which you can click and drag to change your current field of viewPress the
lassoicon (or types) to switch back to lasso modePress the
locateicon to reset the plot’s viewport to a tight crop of the current view’s embeddingsPress the
xicon (or double click anywhere in the plot) to clear the current selection
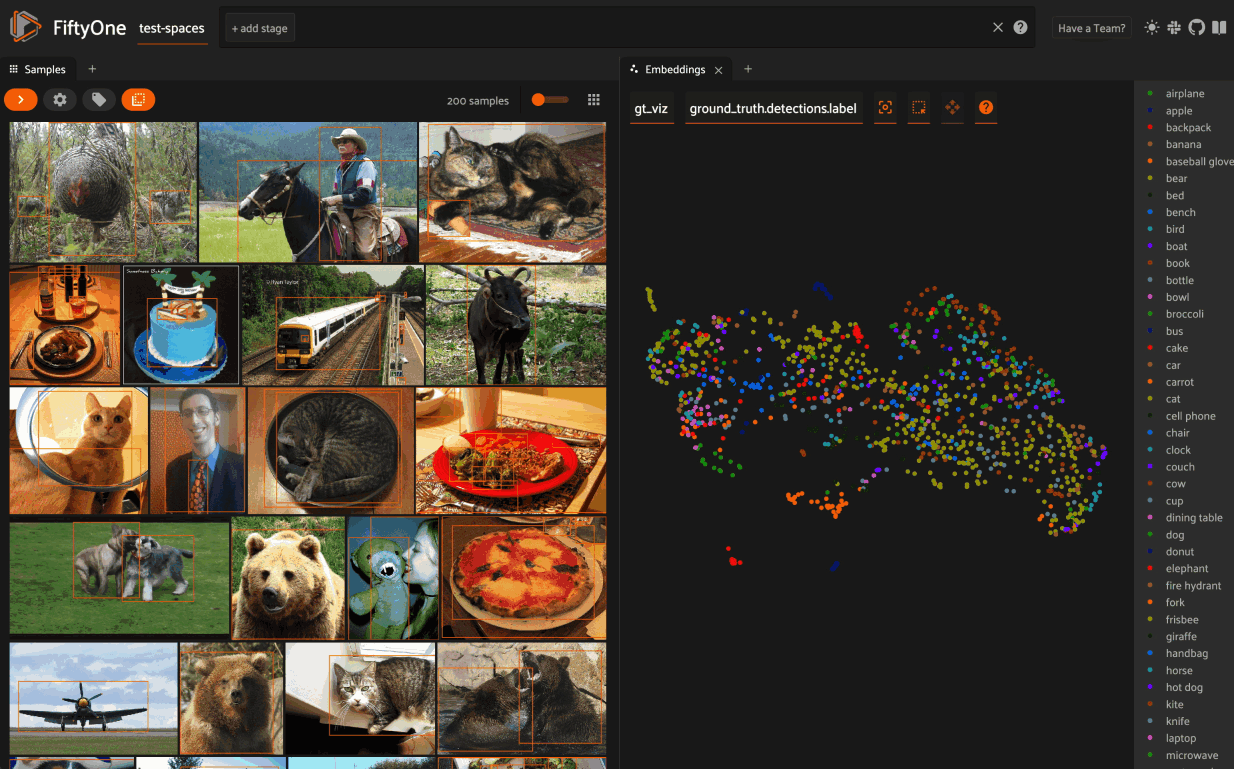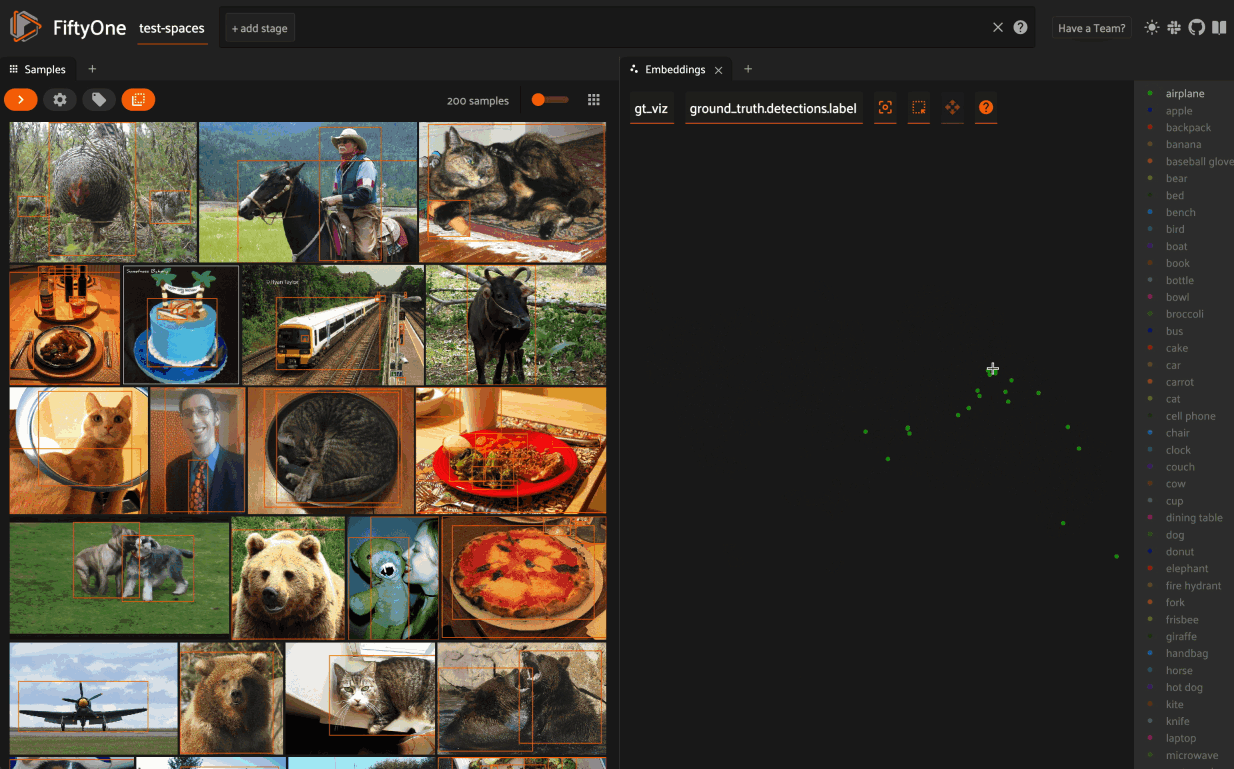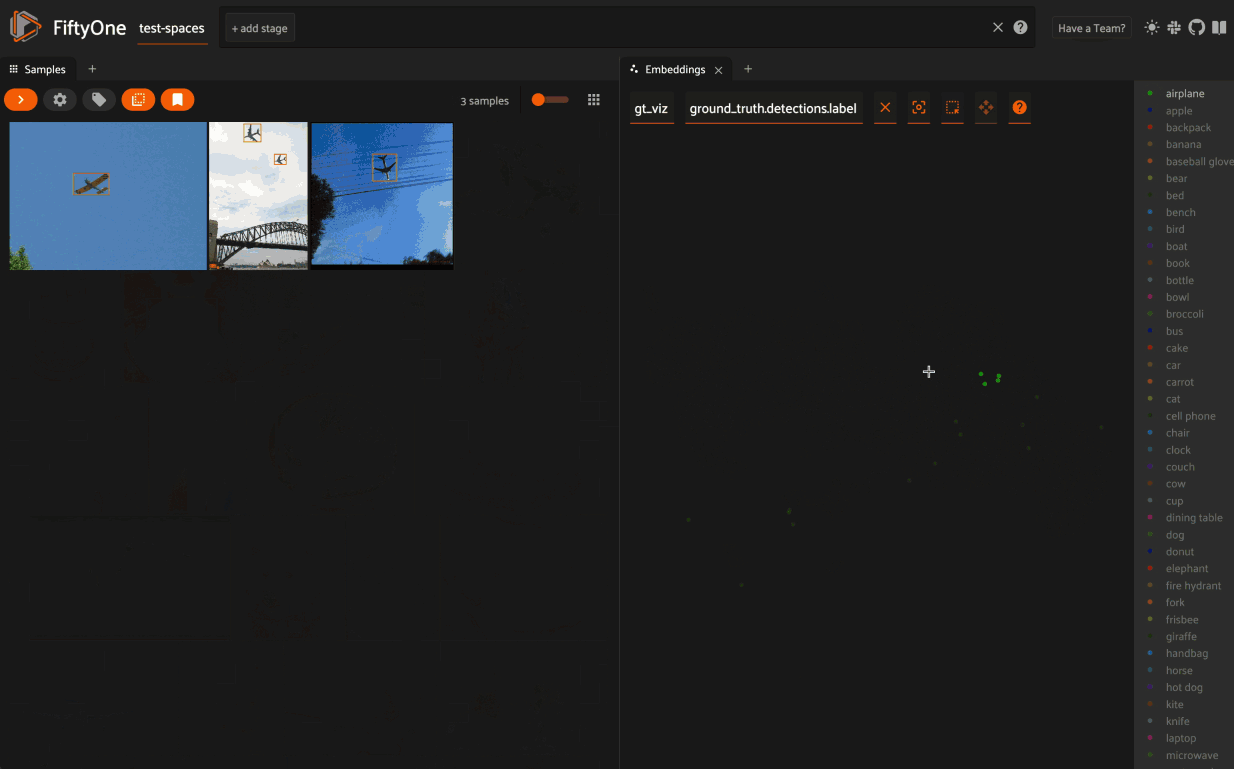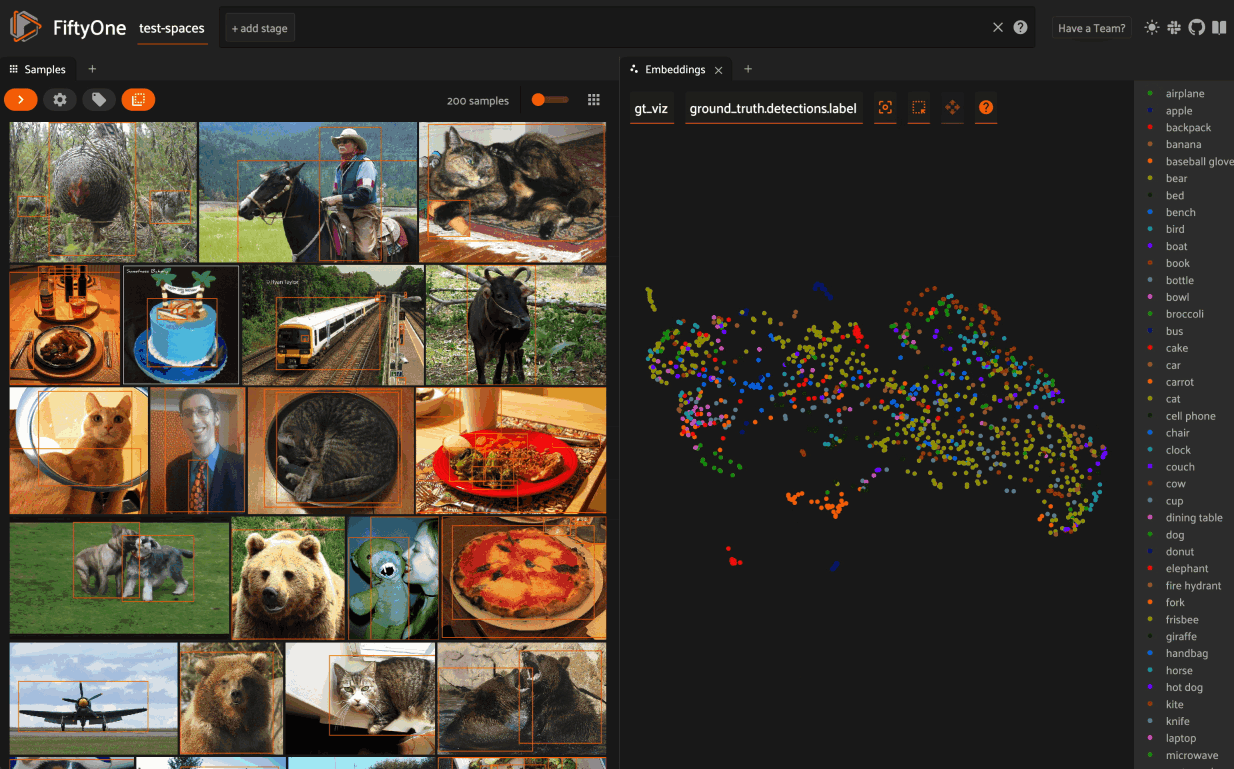
When coloring points by categorical fields (strings and integers) with fewer than 100 unique classes, you can also use the legend to toggle the visibility of each class of points:
Single click on a legend trace to show/hide that class in the plot
Double click on a legend trace to show/hide all other classes in the plot
When configuring spaces in Python, you can define an Embeddings panel as follows:
1embeddings_panel = fo.Panel(
2 type="Embeddings",
3 state=dict(brainResult="img_viz", colorByField="uniqueness"),
4)
The Embeddings panel supports the following state parameters:
brainResult: the brain key associated with the
compute_visualization()run to displaycolorByField: an optional sample field (or label attribute, for patches embeddings) to color the points by
Similarity Search panel NEW#
When you load a dataset in the App that has one or more similarity indexes, you can open the Similarity Search panel to create, manage, and revisit similarity searches on the dataset.
To get started, compute a similarity index on your dataset using
compute_similarity():
1import fiftyone as fo
2import fiftyone.brain as fob
3import fiftyone.zoo as foz
4
5dataset = foz.load_zoo_dataset("quickstart")
6
7# Index images by similarity using the default sklearn backend
8# with a cosine distance metric
9fob.compute_similarity(
10 dataset,
11 model="clip-vit-base32-torch",
12 backend="sklearn",
13 metric="cosine",
14 brain_key="img_sim",
15)
16
17session = fo.launch_app(dataset)
Once the dataset is indexed, you can open the Similarity Search panel from the similarity popover’s settings button, or from the App’s panels menu.
Note
Refer to the Brain guide for more information on supported backends (sklearn, Qdrant, Pinecone, MongoDB, etc.), distance metrics, and using custom or precomputed embeddings.
Home page#
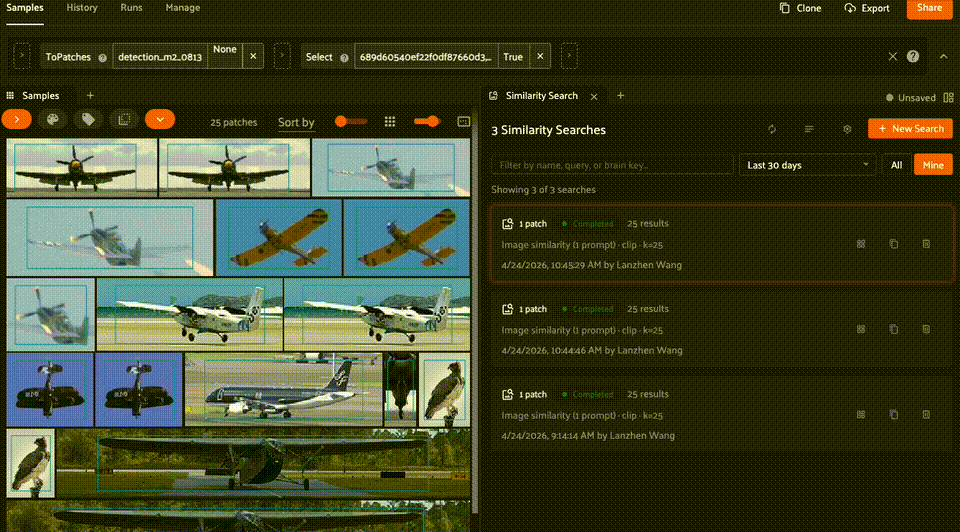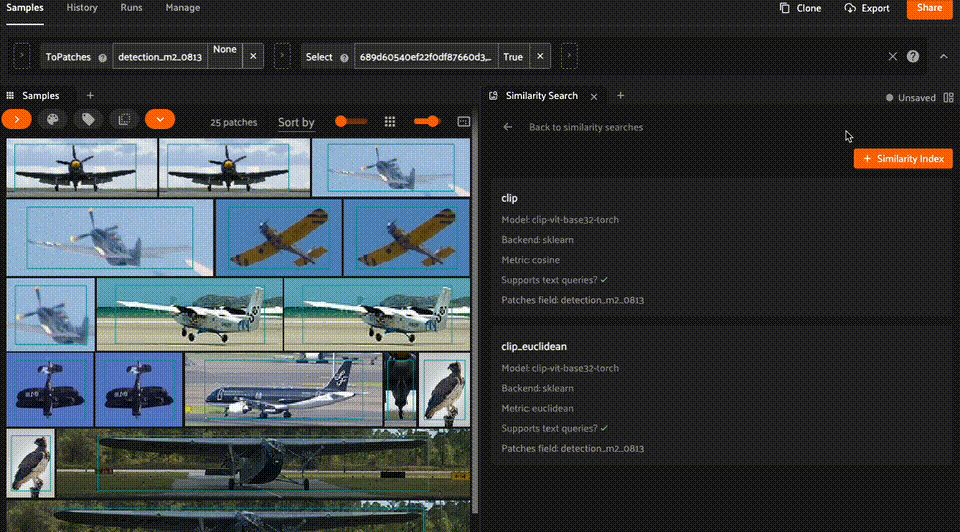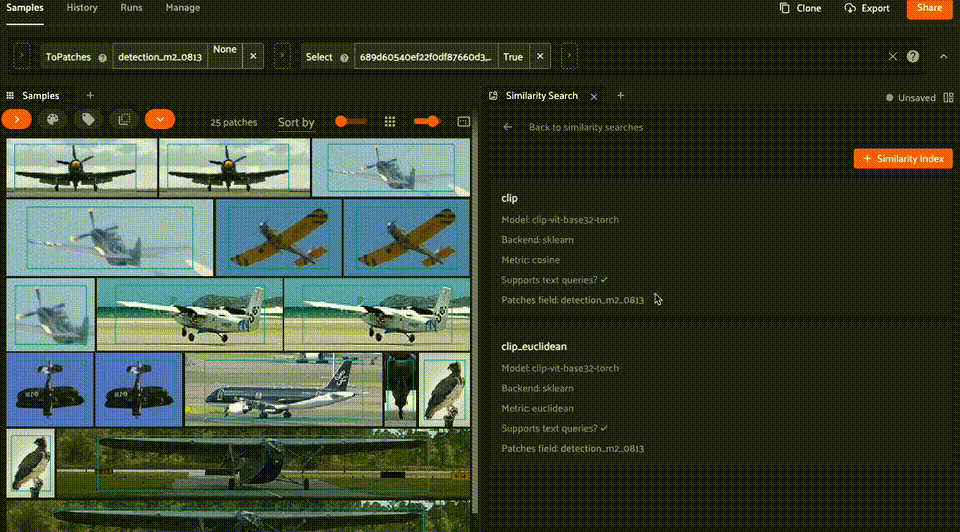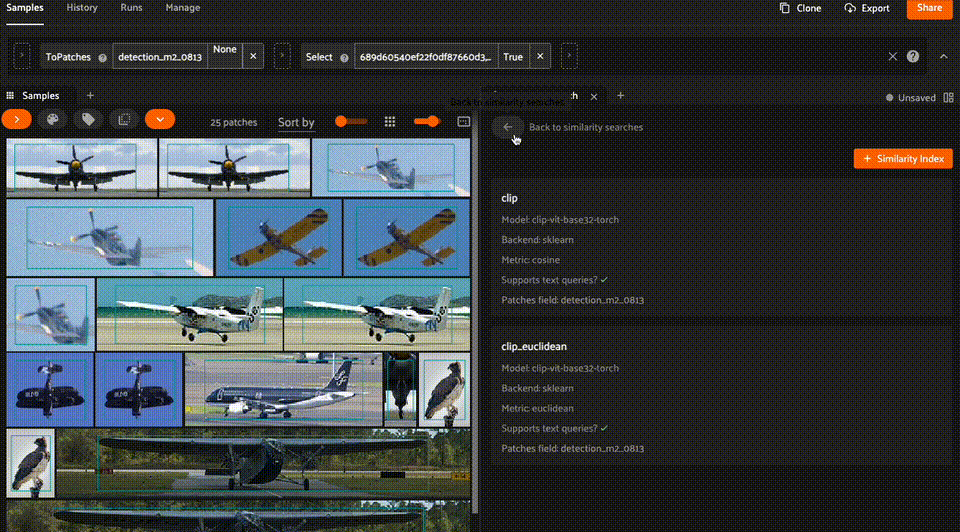
The panel’s home page displays a list of all past similarity search runs. Click any completed run to apply its results to the current view.
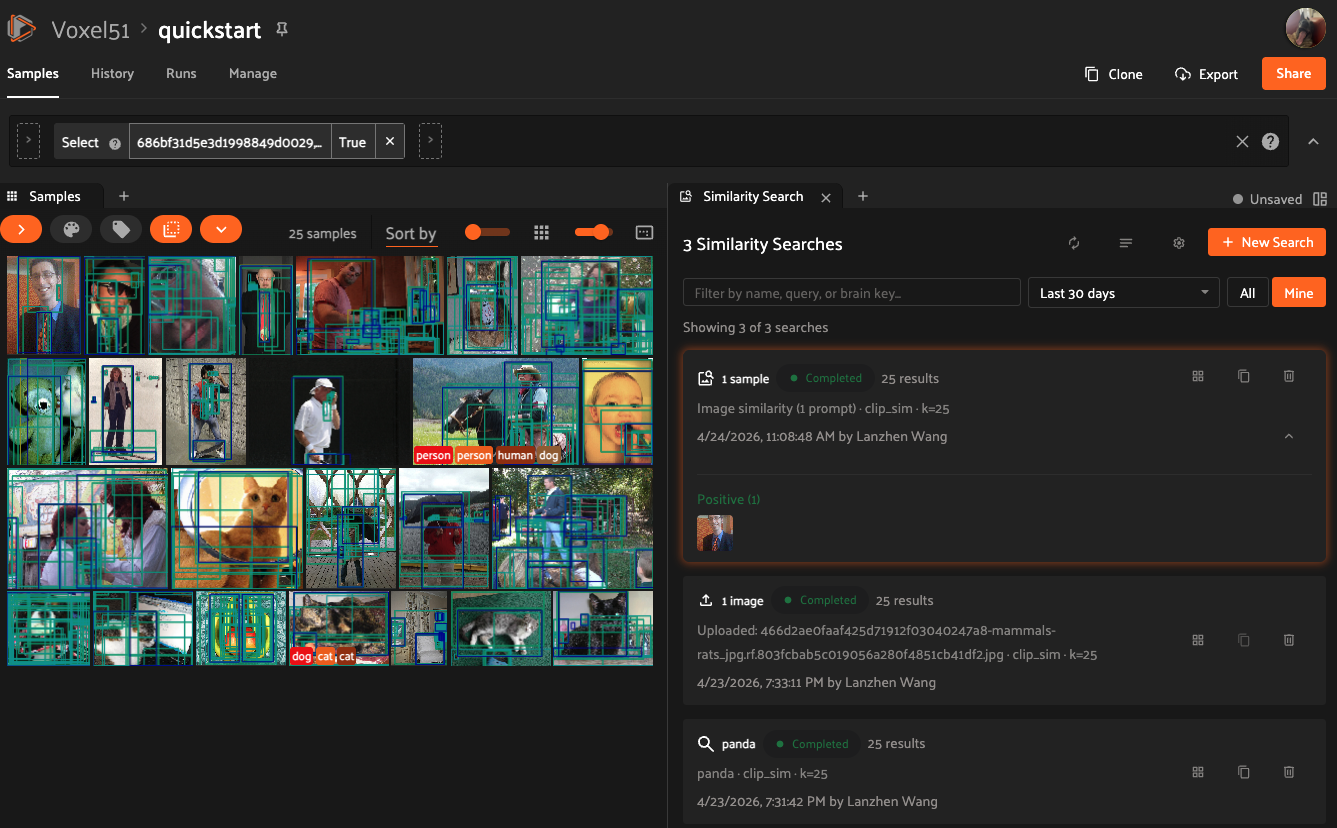
You can filter the run list by:
Date range: Today, Last 7 days, Last 30 days, or Older
Search text: filter by query content or run name
Owner: show all runs or only your own (Enterprise only, for users with Can manage dataset access)
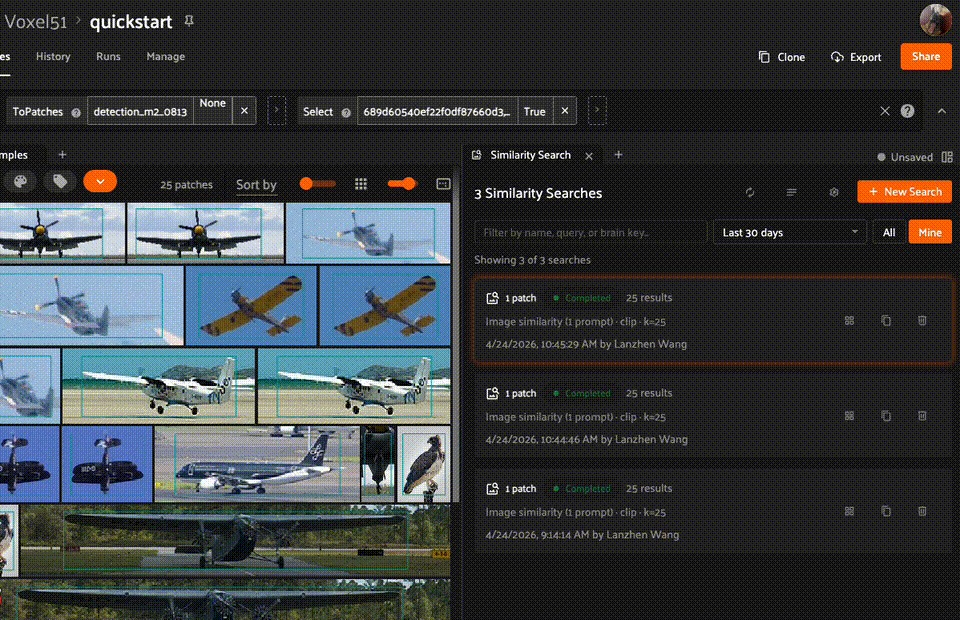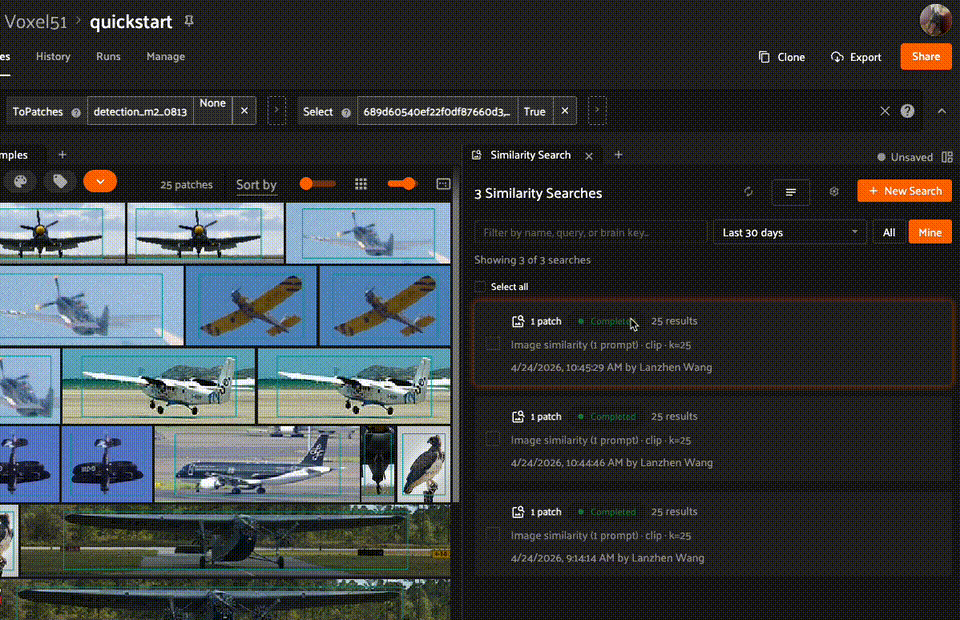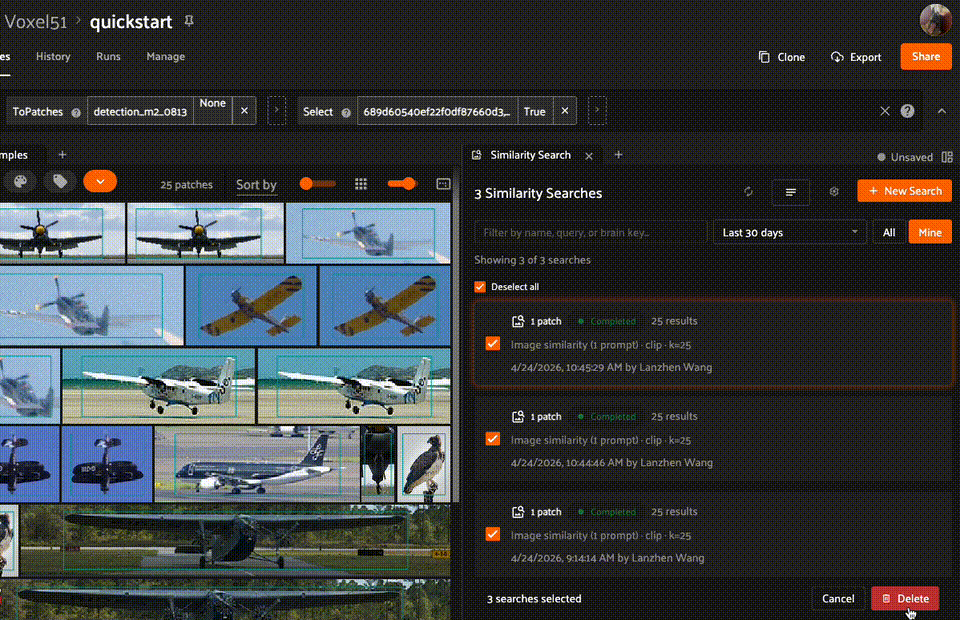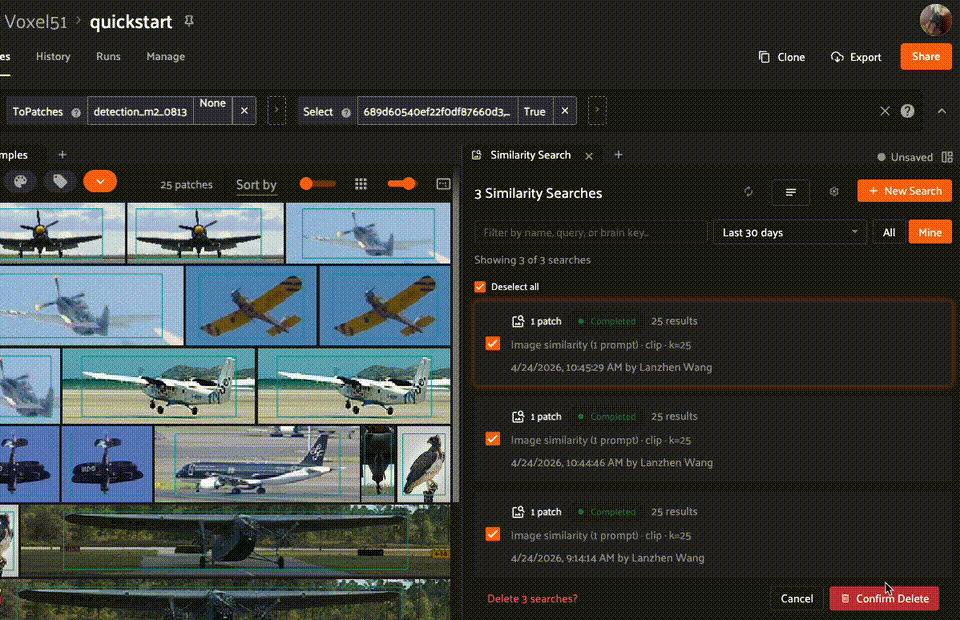
Managing runs#
From the home page, you can manage individual runs by cloning, renaming, or deleting them. You can also select multiple runs to delete in bulk — for example, filter by Older and bulk-delete stale runs.
Checking similarity indexes#
From the home page, you can also navigate to the Similarity Index page to view the similarity indexes available on your dataset, along with their configurations (e.g., similarity index name, model, metric, and whether the index supports text queries).
Creating a new search#
Click the New search button to open the search form. The form provides the following options:
Query type: choose between image similarity (using selected samples), text similarity (natural language query), or image upload
Similarity index (brain key): select which similarity index to use. The panel shows which indexes support text queries
Number of results: the maximum number of results to return
Reverse: toggle to find the least similar results instead of the most similar
Distance field: optionally specify a field name to store the computed distances on each result sample
Scope: search against the current view or the entire dataset
Note
In image mode, you can click samples in the grid to select them as positive examples (shown with a green check), and alt-click (option-click) to select them as negative examples (shown with a red mark). The search will return results similar to the positive samples but dissimilar to the negative ones. Using negative samples is not recommended when your similarity index uses the Euclidean distance metric.
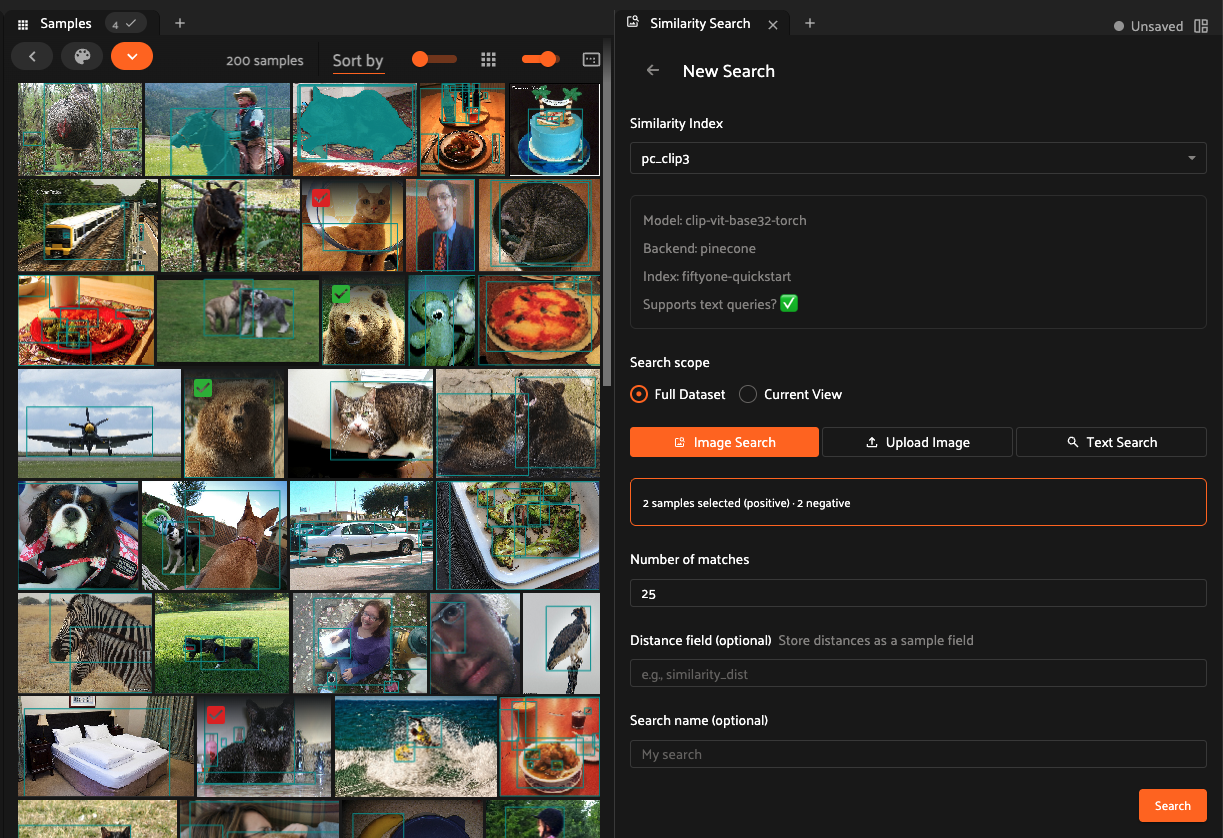
In upload mode, you can upload a local image (under 10MB) to use as the query. The uploaded image is used only for the search and will not be added to your dataset.
If the selected similarity index was built on object patches (e.g., Detections or Polylines), the search will return patch results; otherwise it returns sample results.
Delegated execution#
Triggered from the popover, similarity searches run immediately on the App server by default. If your deployment supports delegated operations, you can choose to run the search on a worker pod instead by selecting Delegate as the execution mode. This is useful for a large number of results or large datasets.
Triggering from the grid#
In addition to opening the panel from the panels menu, you can also trigger similarity searches directly from the sample grid via the similarity popover: a lightweight menu in the grid toolbar for quick searches. Select samples, patches, or labels and click the similarity icon to instantly sort by similarity or enter a text query.
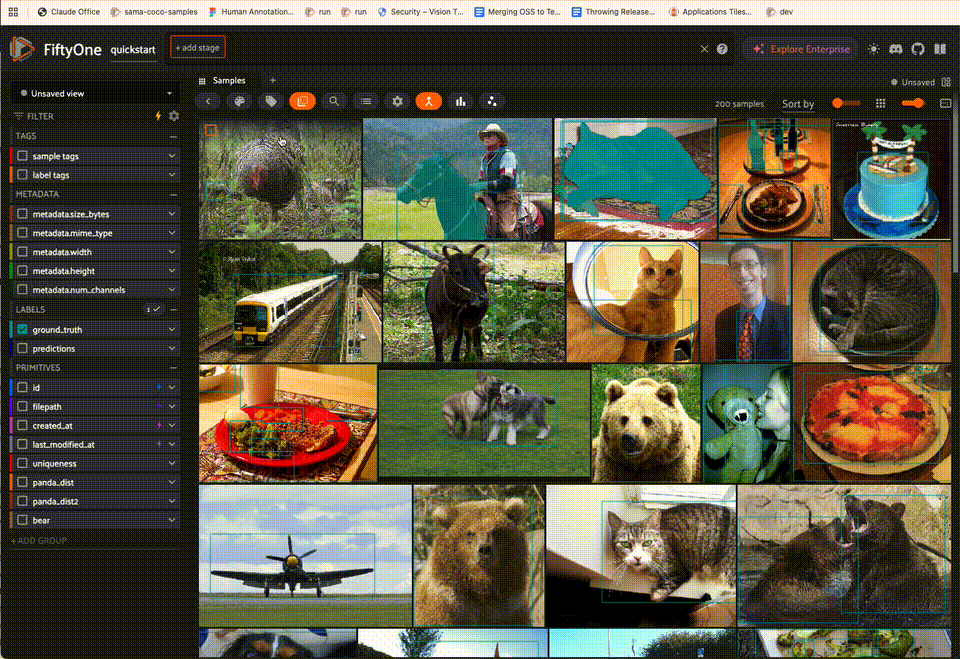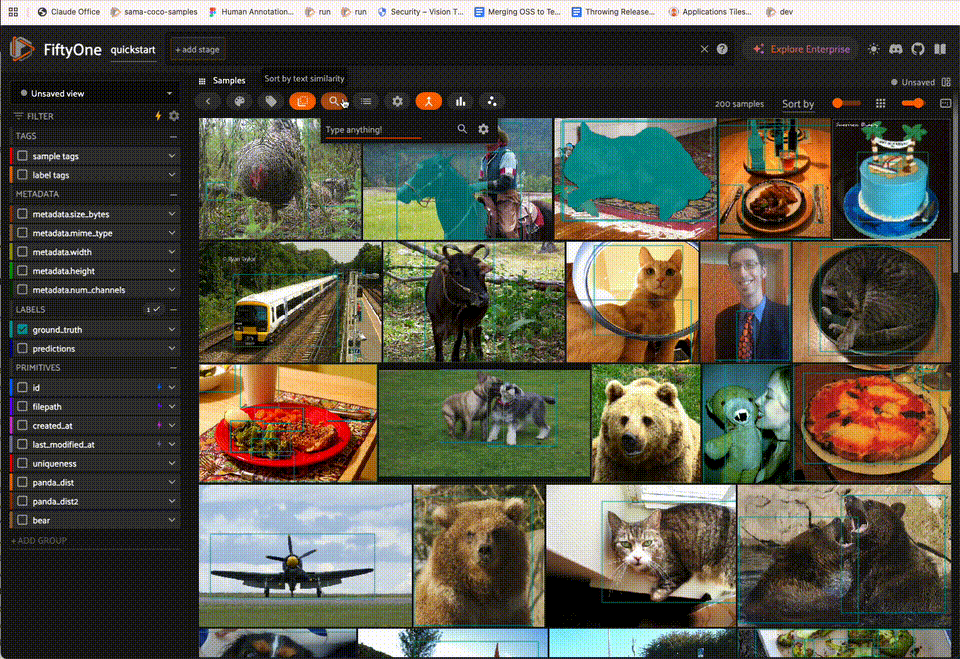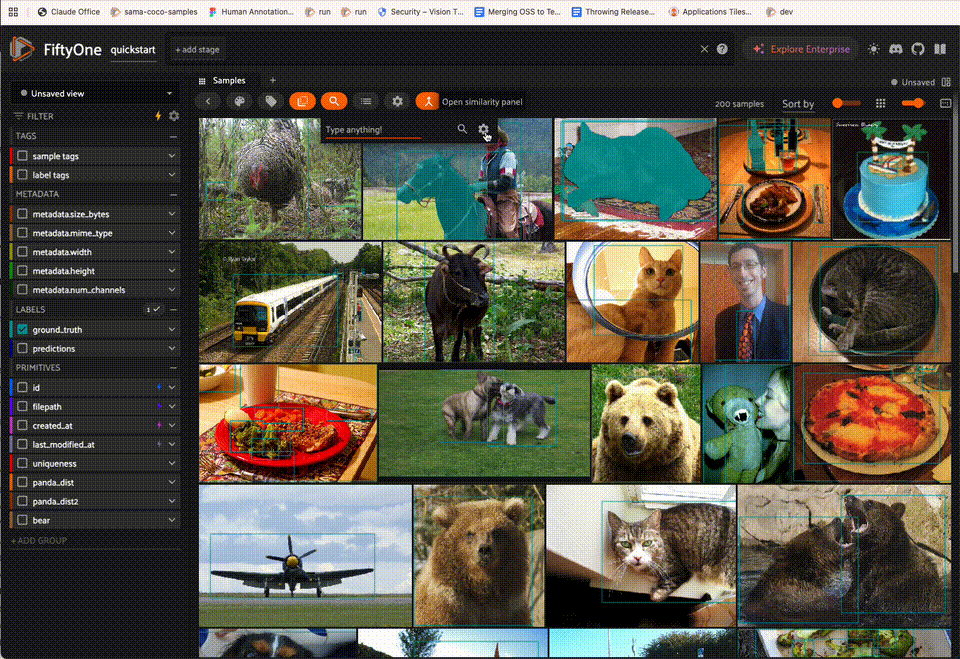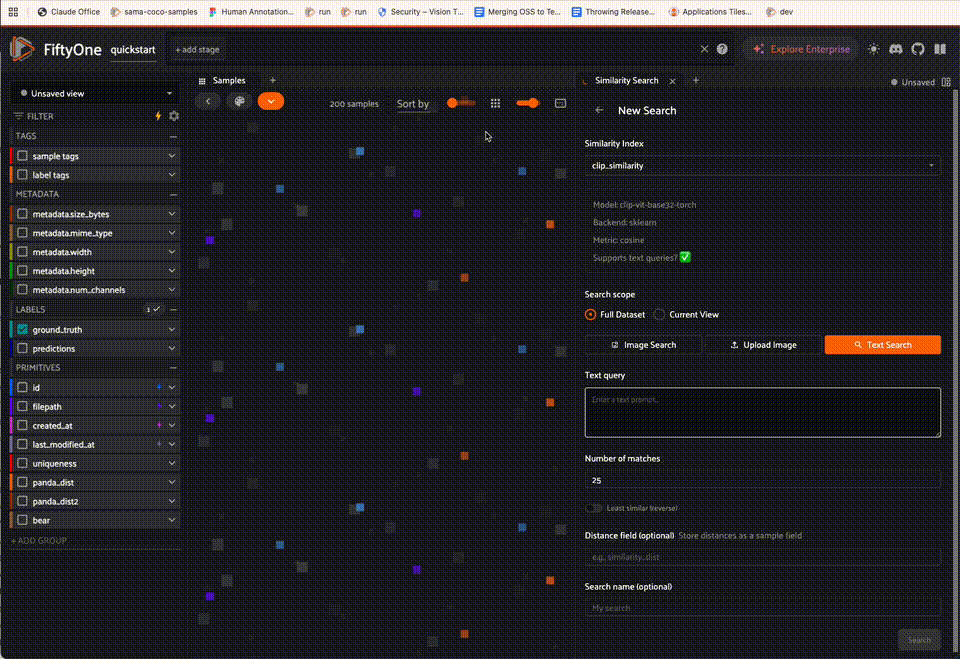
All popover workflows below share a settings icon that opens the full Similarity Search panel, where you can specify a larger number of results, query by greatest or least similarity (if supported), choose a different similarity index, or optionally save the computed distances as a new sample field.
Popover searches always run immediately. After you submit a search, you may
briefly see a loading indicator (...) while the search executes; once it
completes, the Similarity Search panel opens and displays the results.
Image similarity#
Whenever one or more images are selected in the App, the similarity icon appears above the grid. If you have indexed the dataset by image similarity, you can click the icon to sort by similarity to your current selection.
The popover lets you choose a similarity index and quickly run a search. After the search completes, the Similarity Search panel opens to display the results, where you can further refine your query or manage past searches.
Object similarity#
Whenever one or more labels or patches are selected in the App, the similarity icon appears above the sample grid. If you have indexed the dataset by object similarity, you can sort by similarity to your current selection.
The typical workflow for object similarity is to first switch to object patches view for the label field of interest. In this view, the similarity icon will appear whenever you have selected one or more patches from the grid, and the resulting view will sort the patches according to the similarity of their objects with respect to the objects in the query patches.
You can also sort by similarity to an object from the expanded sample view in
the App by selecting an object and then using the similarity menu that appears
in the upper-right corner of the modal:
Text similarity#
If you have indexed your dataset with a model that supports text queries, you can use the similarity popover to search for images (or object patches) of interest via arbitrary text queries. Simply type your query into the text input field and press search.
Model Evaluation panel NEW#
When you load a dataset in the App that contains one or more evaluations, you can open the Model Evaluation panel to visualize and interactively explore the evaluation results in the App:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5
6# Evaluate the objects in the `predictions` field with respect to the
7# objects in the `ground_truth` field
8results = dataset.evaluate_detections(
9 "predictions",
10 gt_field="ground_truth",
11 eval_key="eval",
12)
13
14session = fo.launch_app(dataset)
The panel’s home page shows a list of evaluation on the dataset, their current review status, and any evaluation notes that you’ve added. Click on an evaluation to open its expanded view, which provides a set of expandable cards that dives into various aspects of the model’s performance:
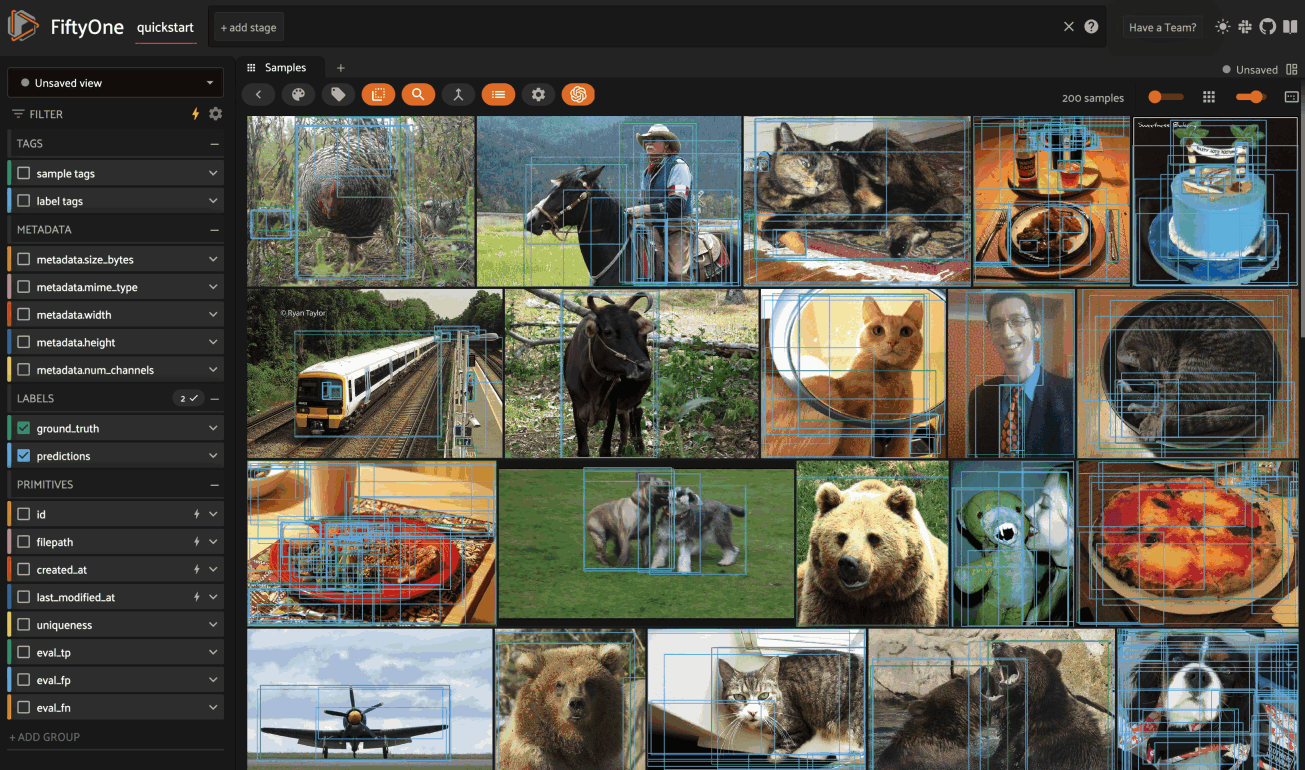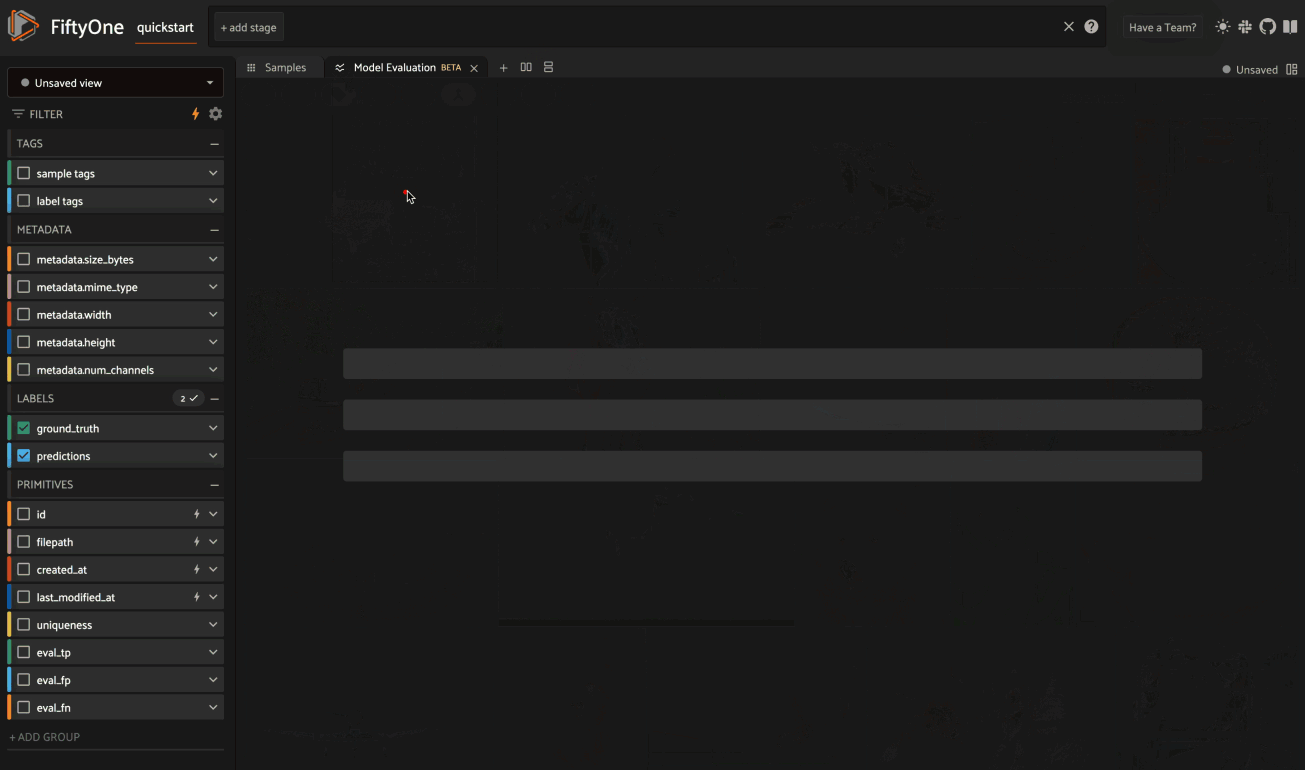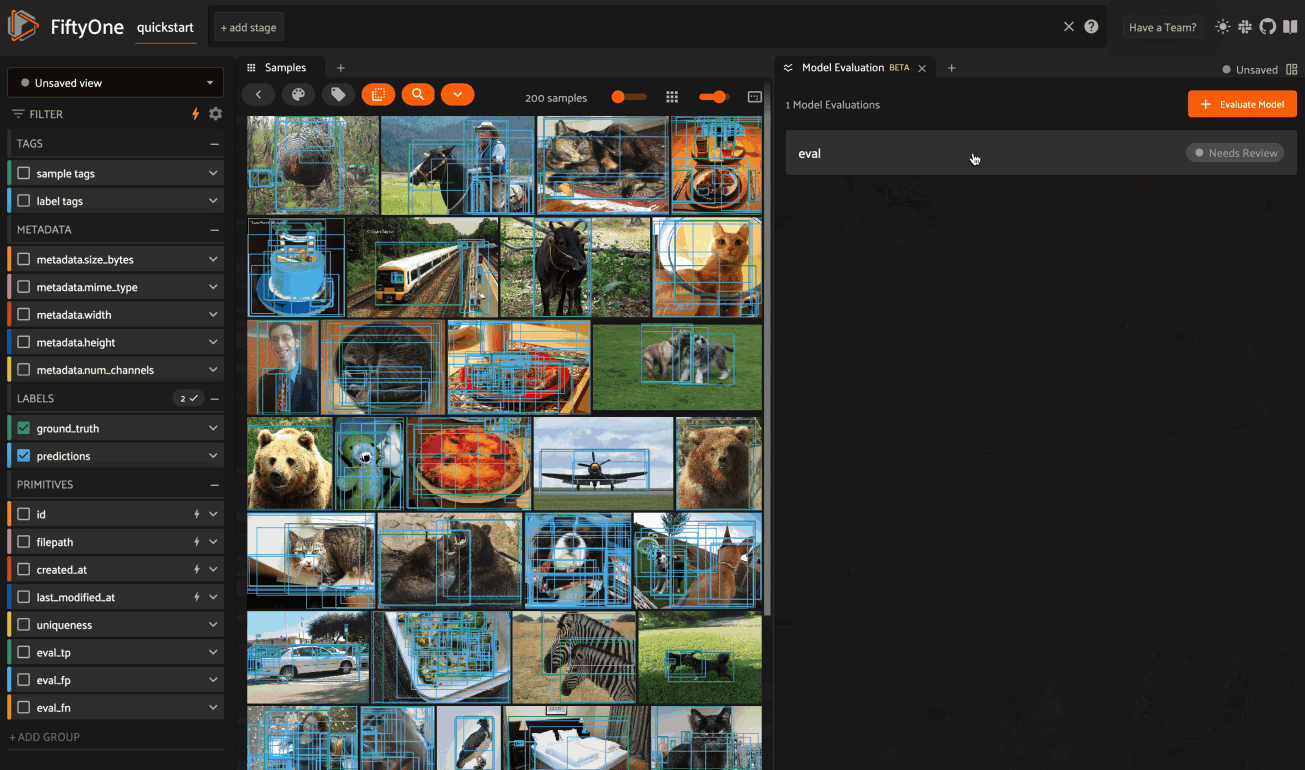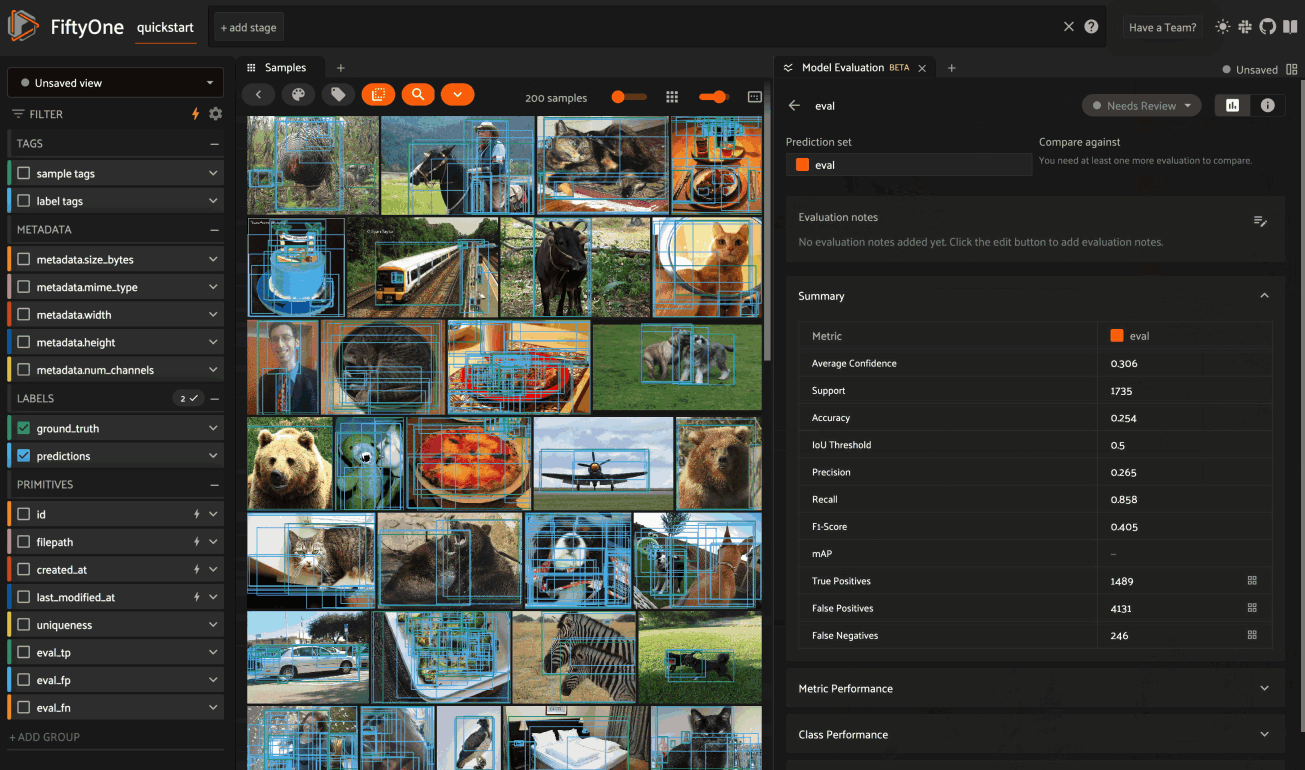
Note
Did you know? With FiftyOne Enterprise you can execute model evaluations natively from the App in the background while you work.
Review status#
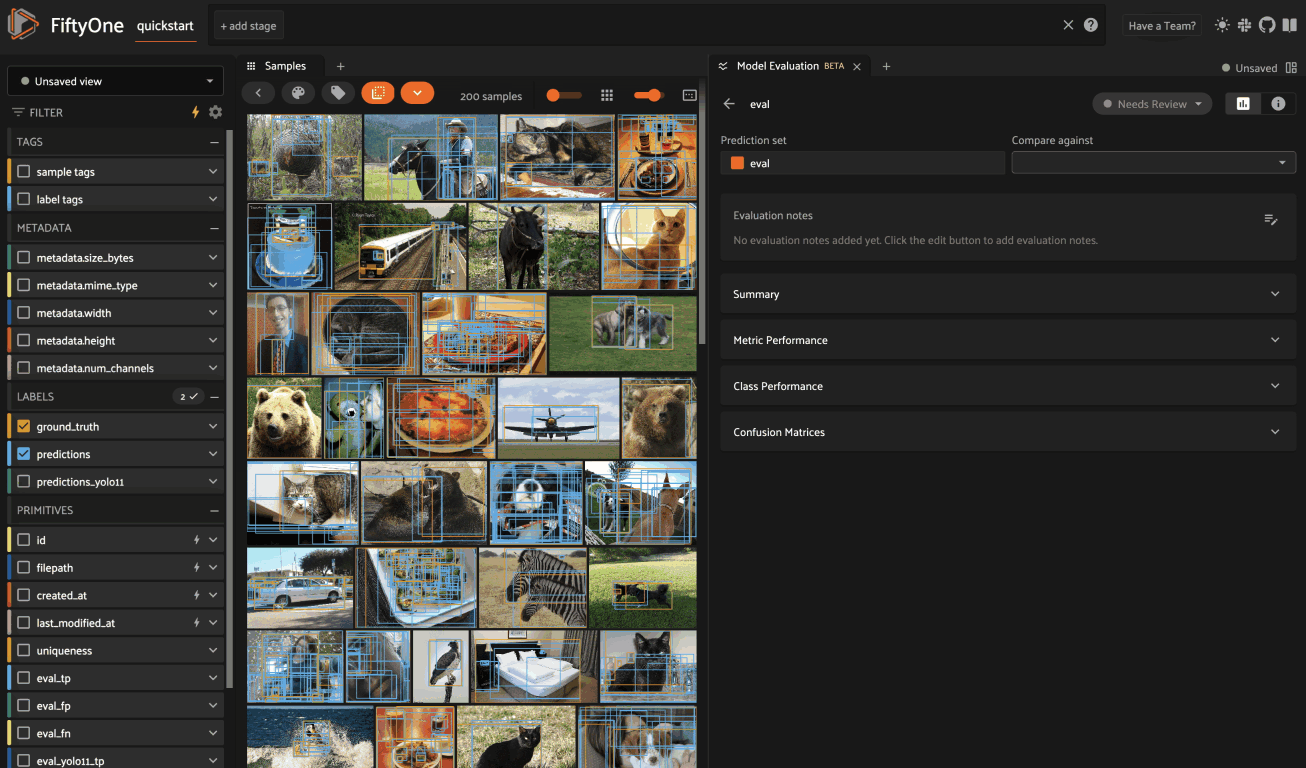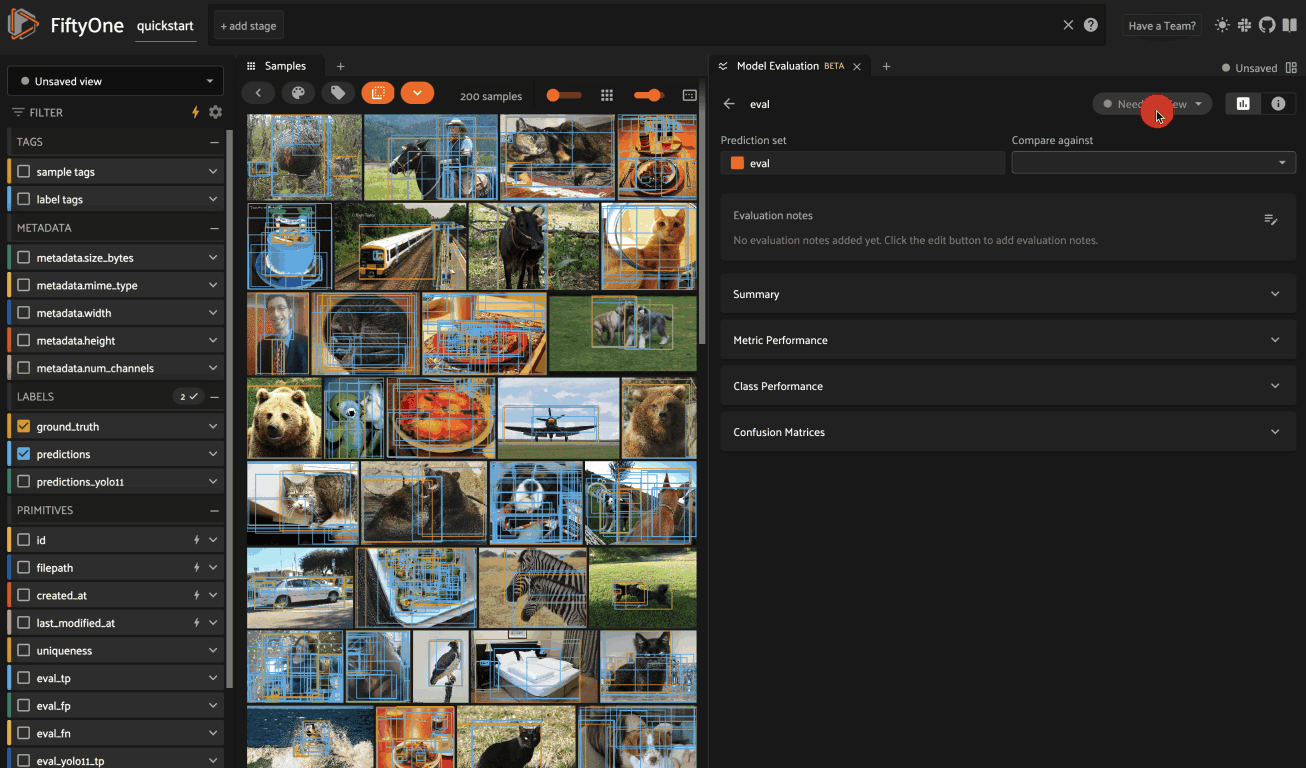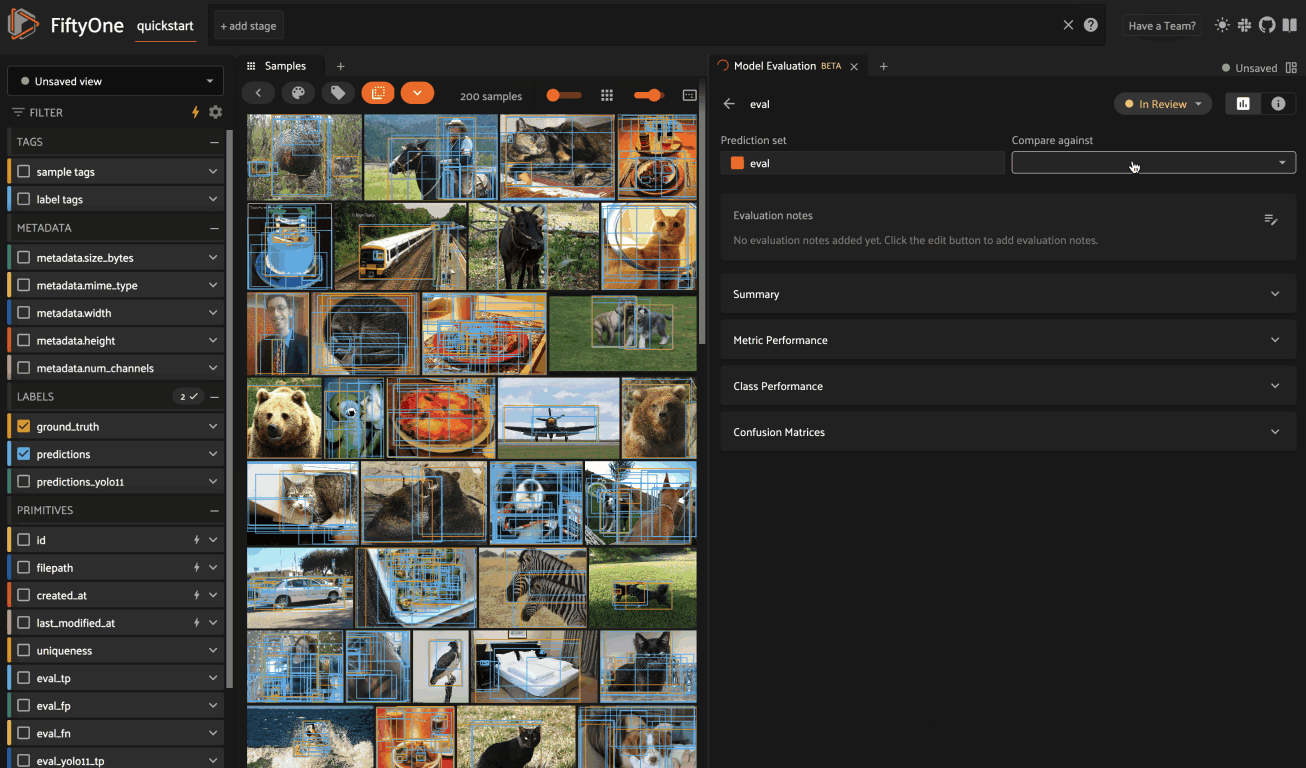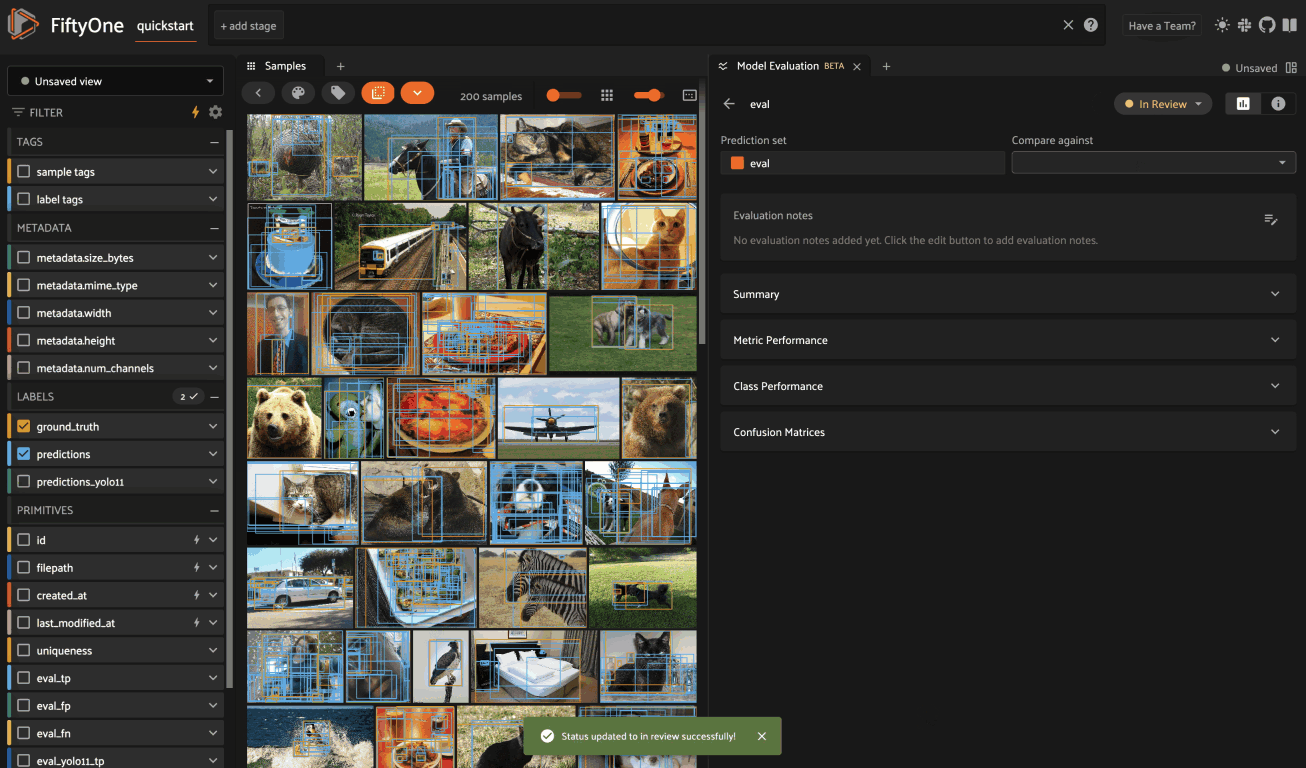
You can use the status pill in the upper right-hand corner of the panel to
toggle an evaluation between Needs Review, In Review, and Reviewed:
Evaluation notes#
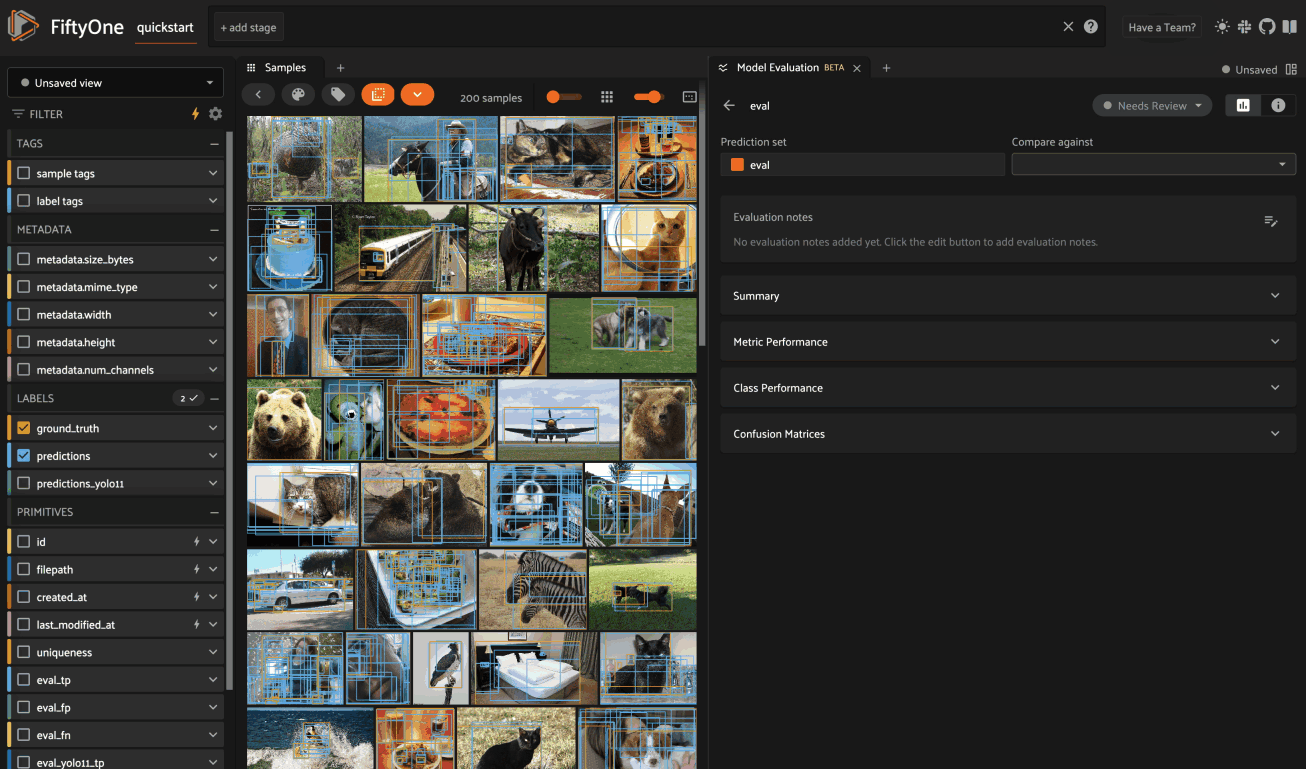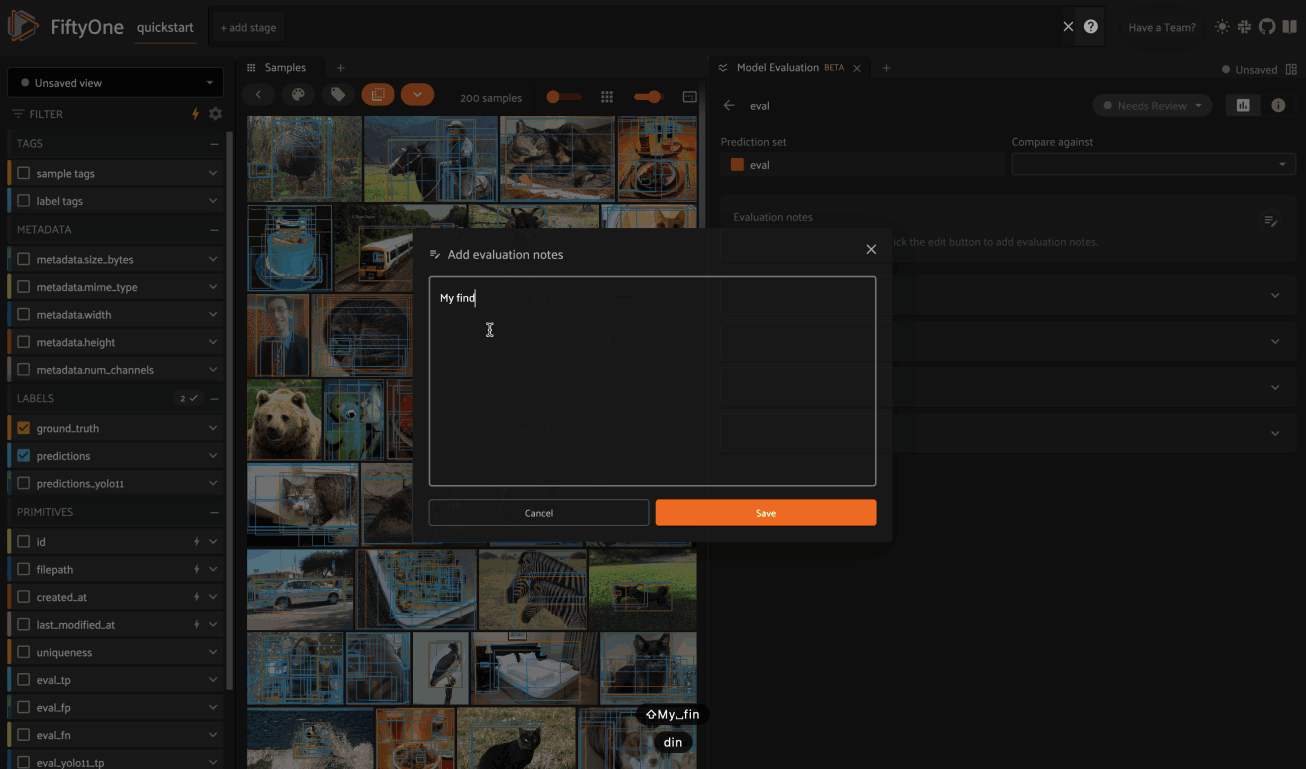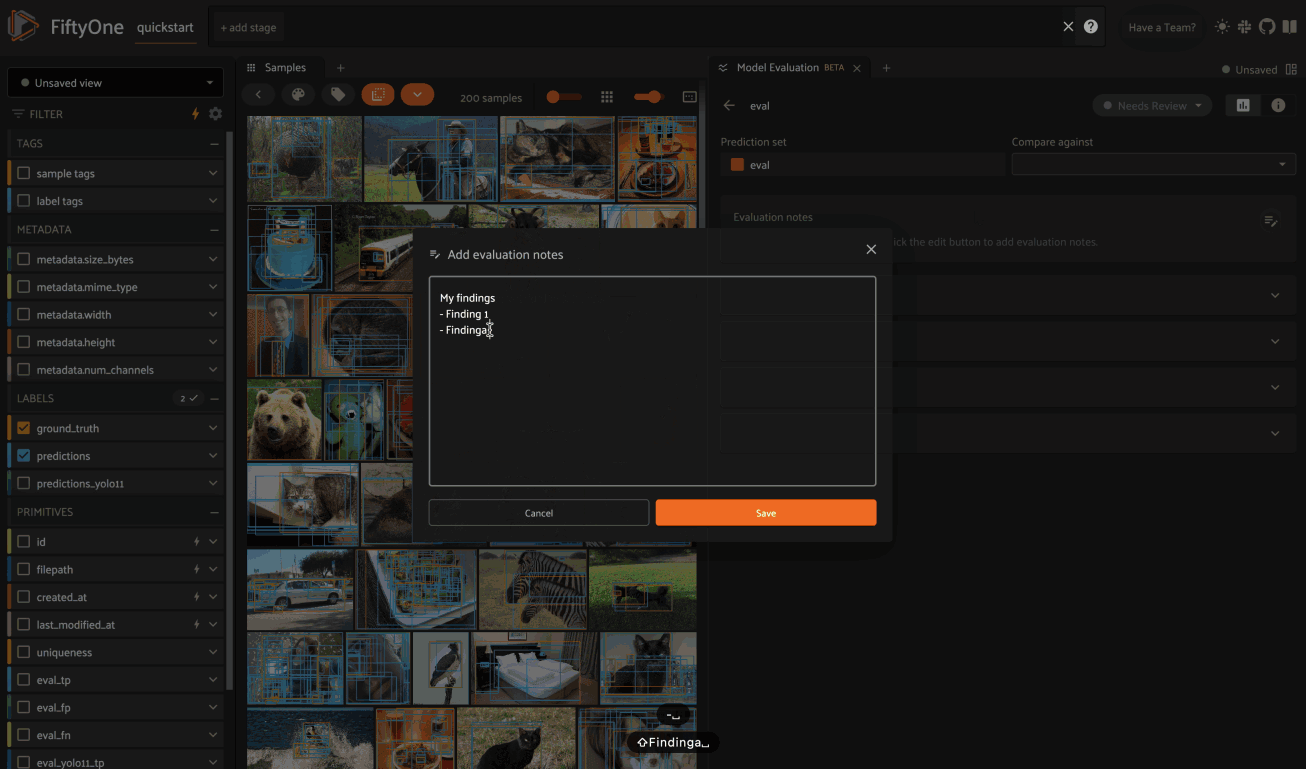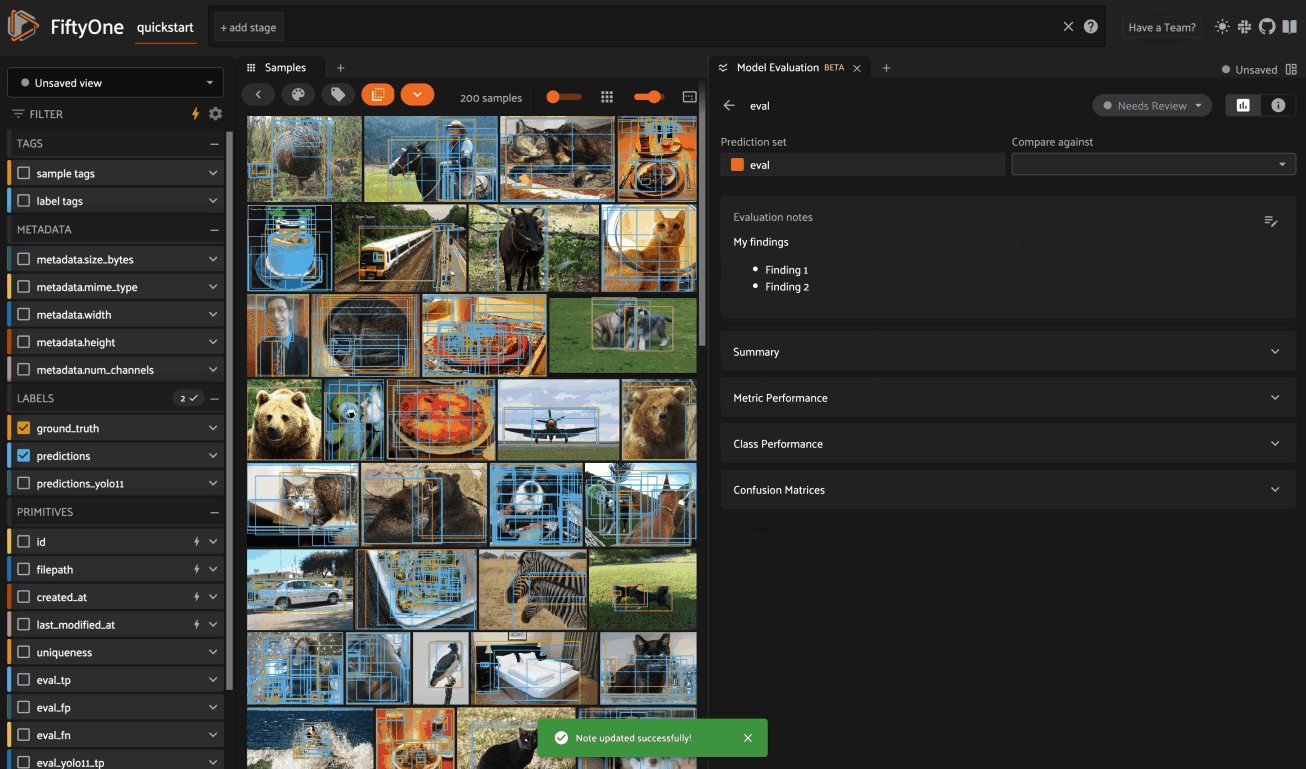
The Evaluation Notes card provides a place to add your own Markdown-formatted notes about the model’s performance:
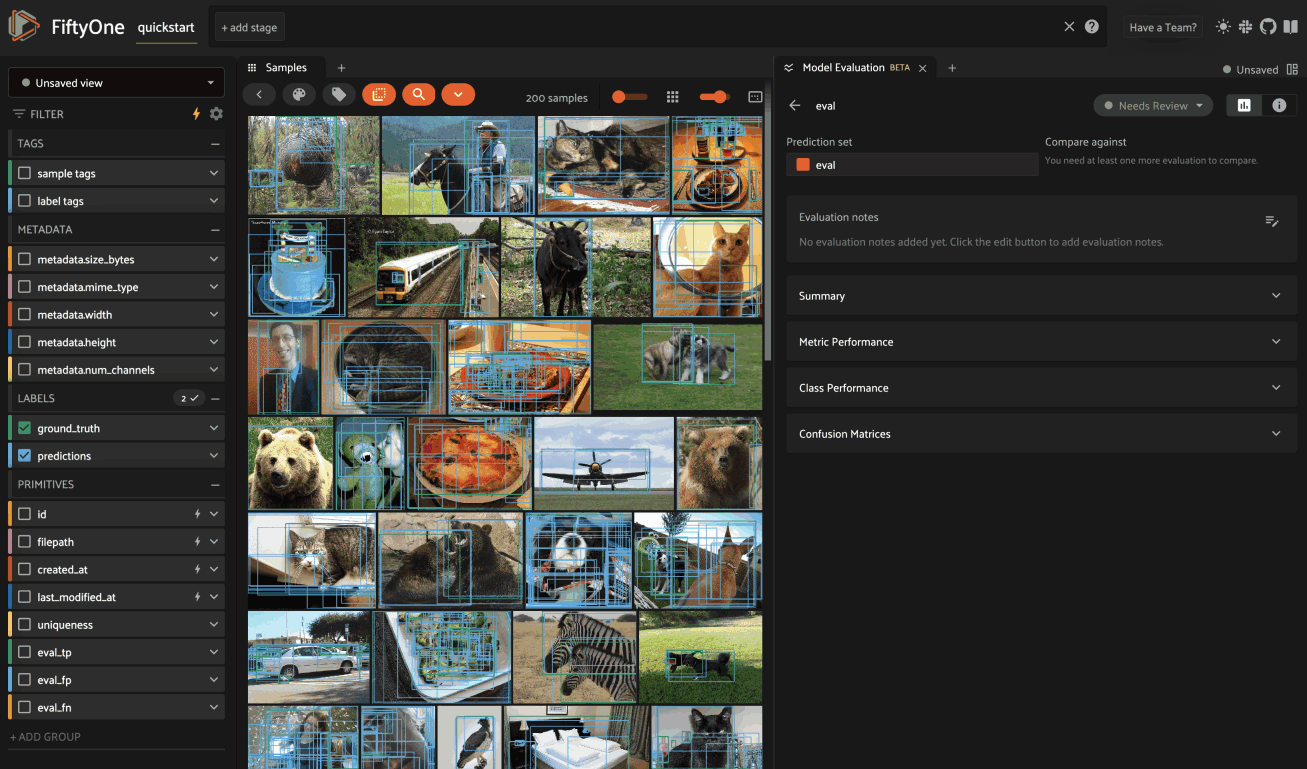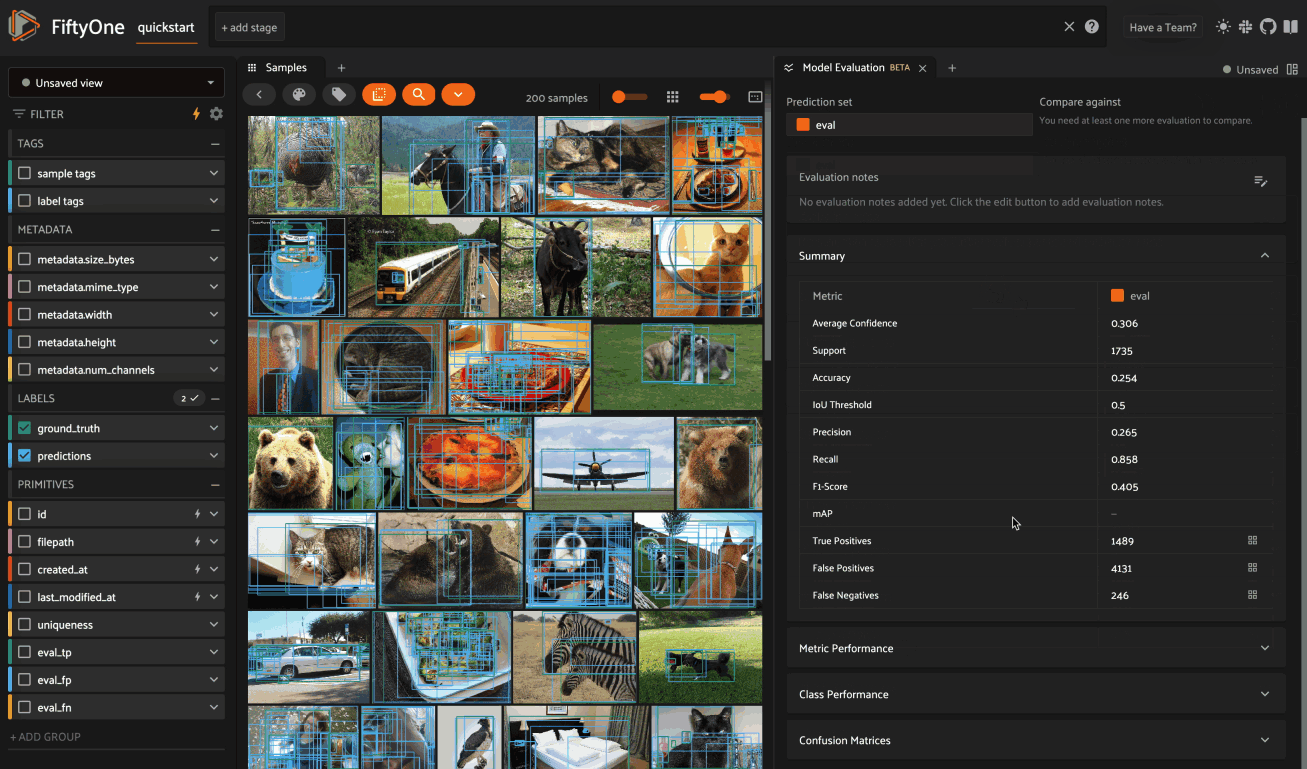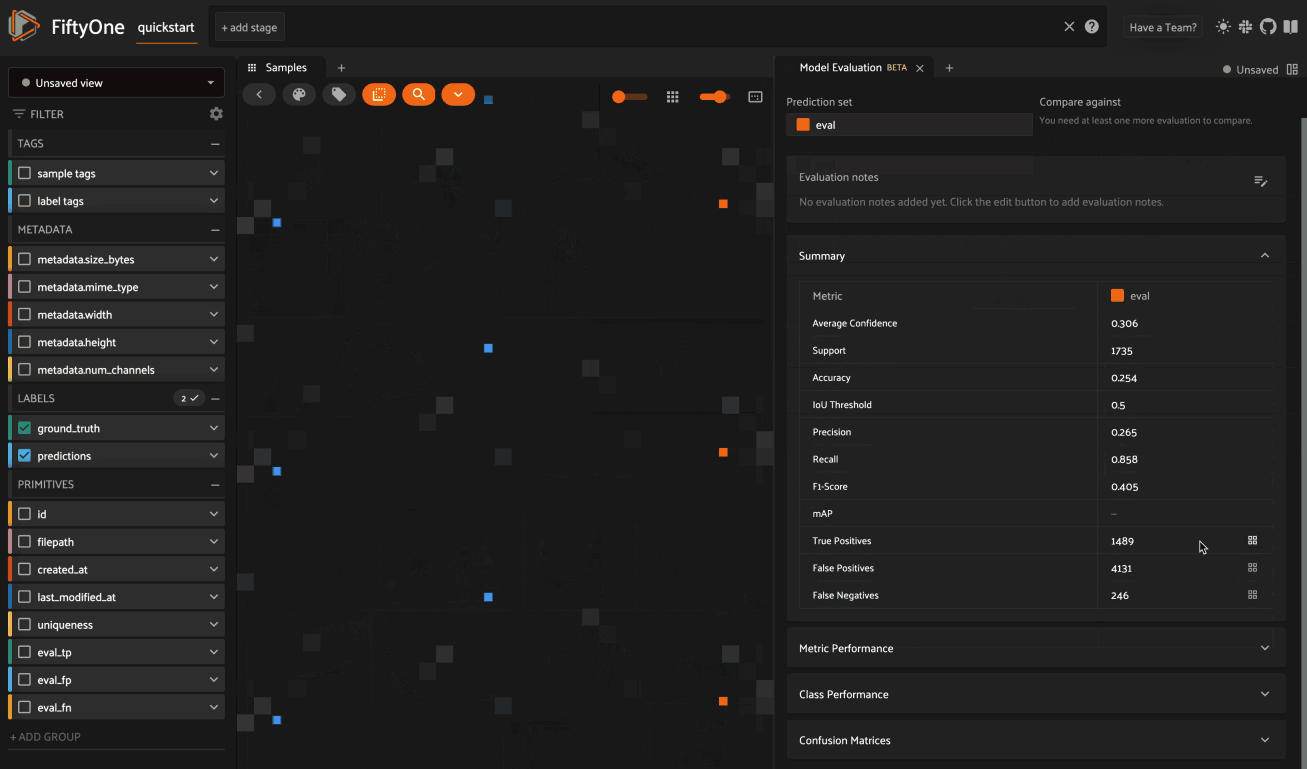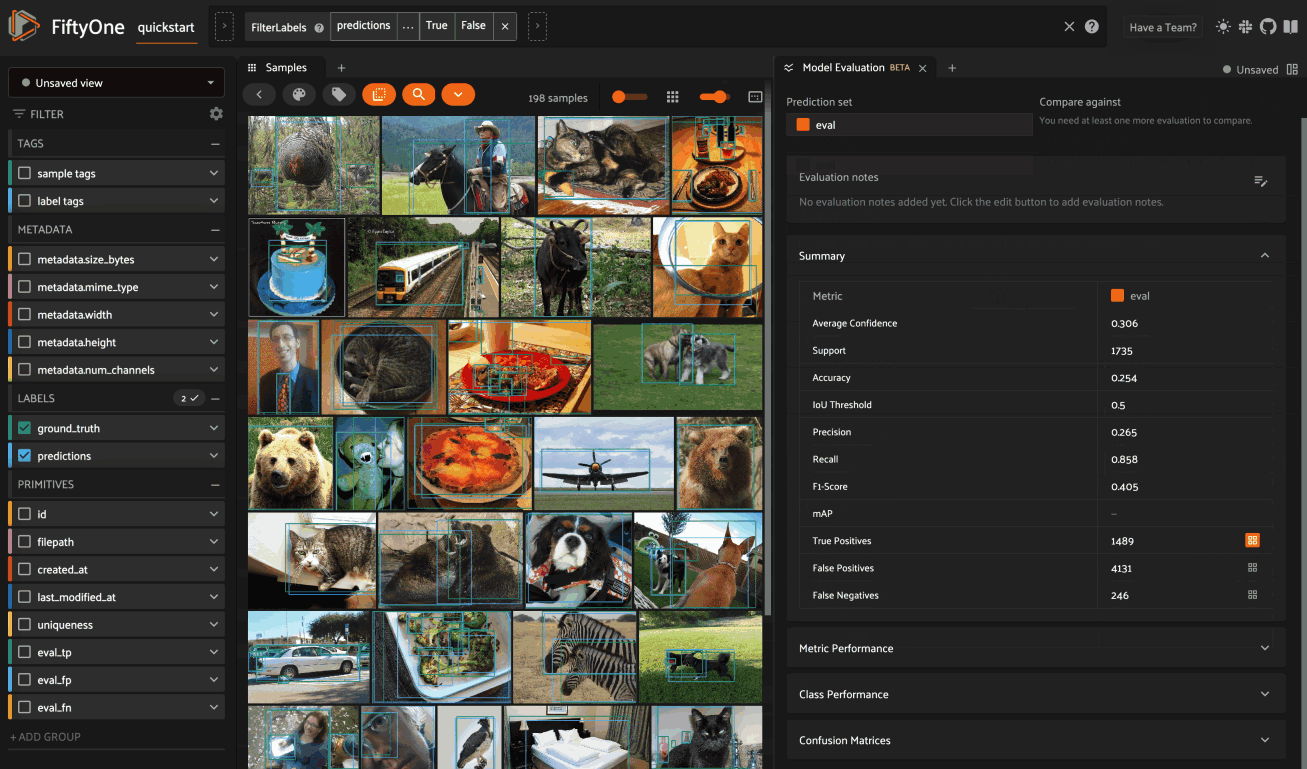
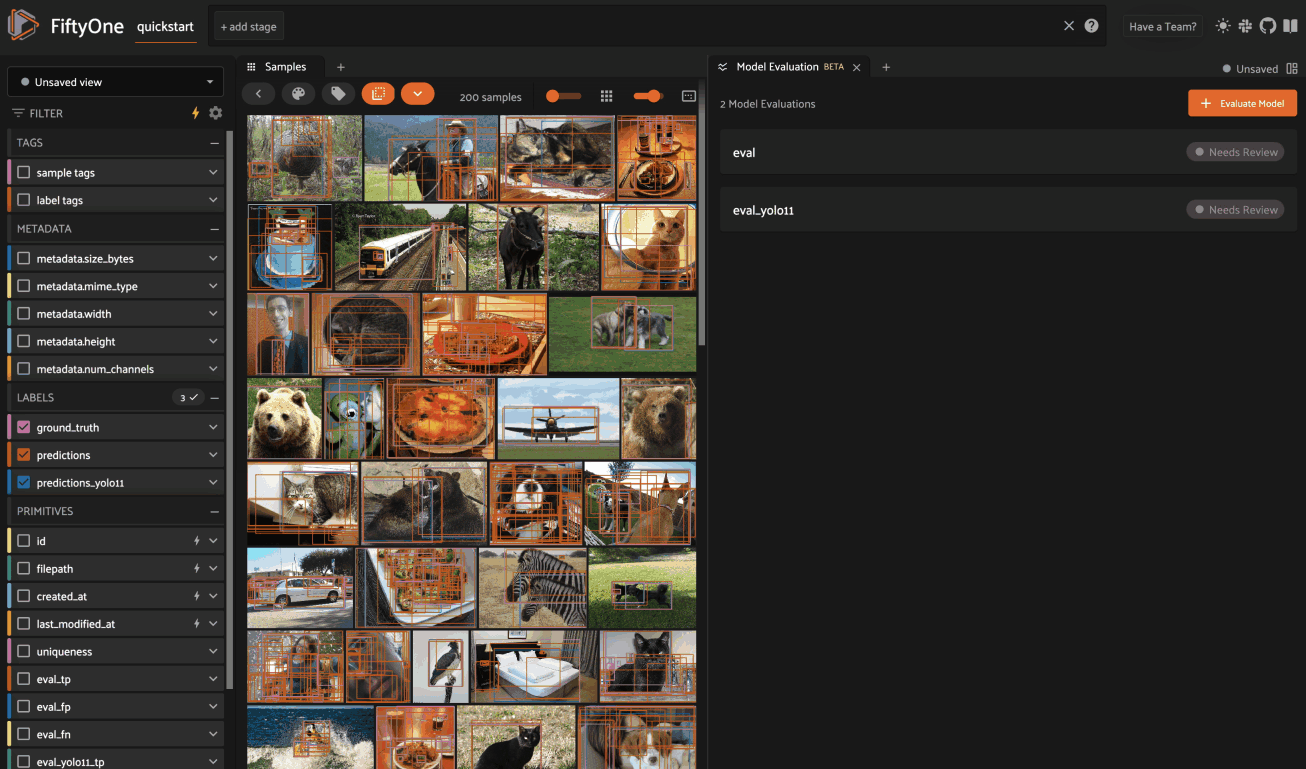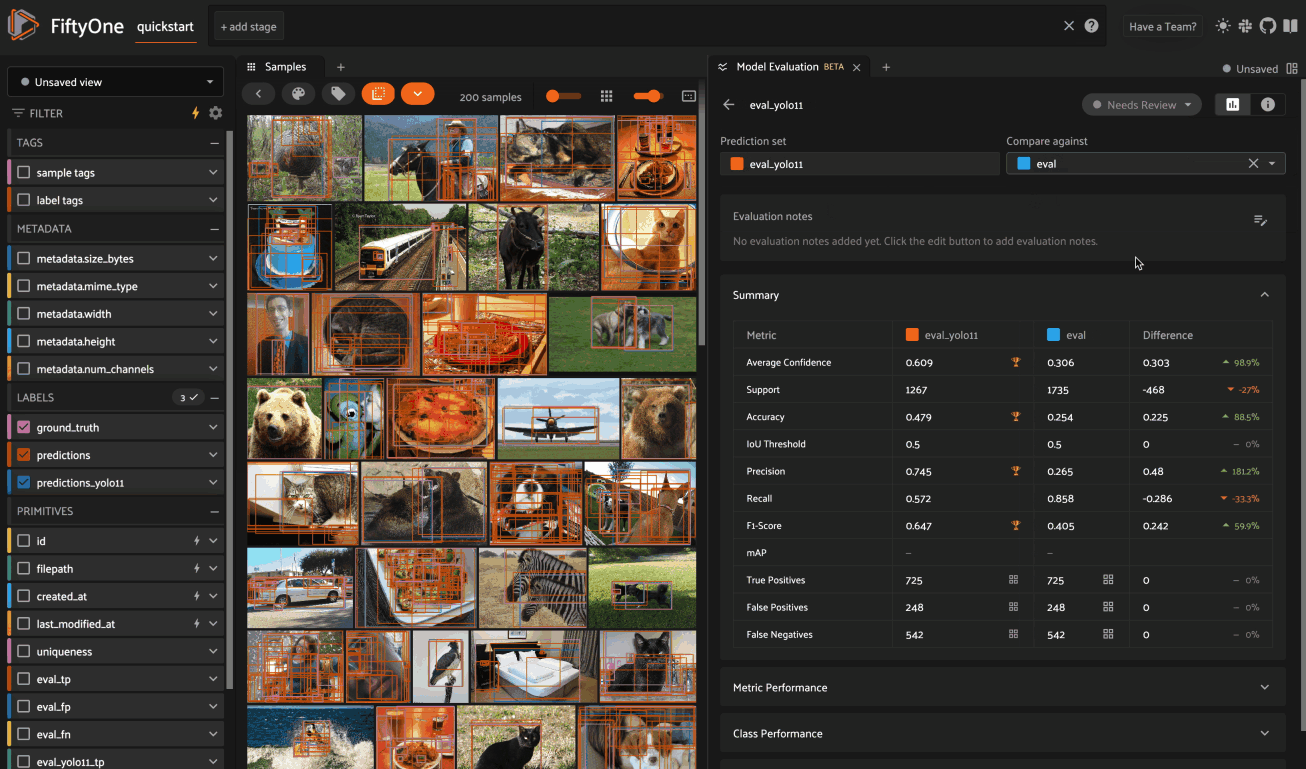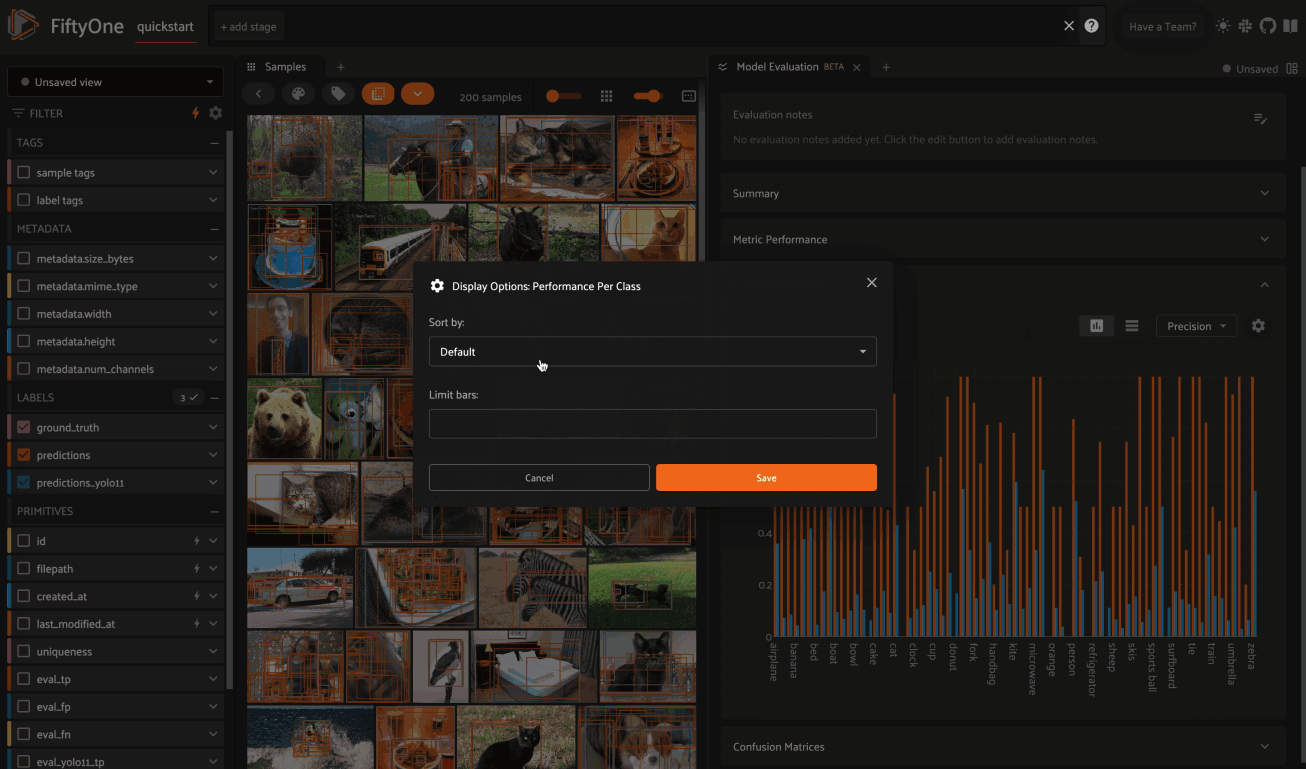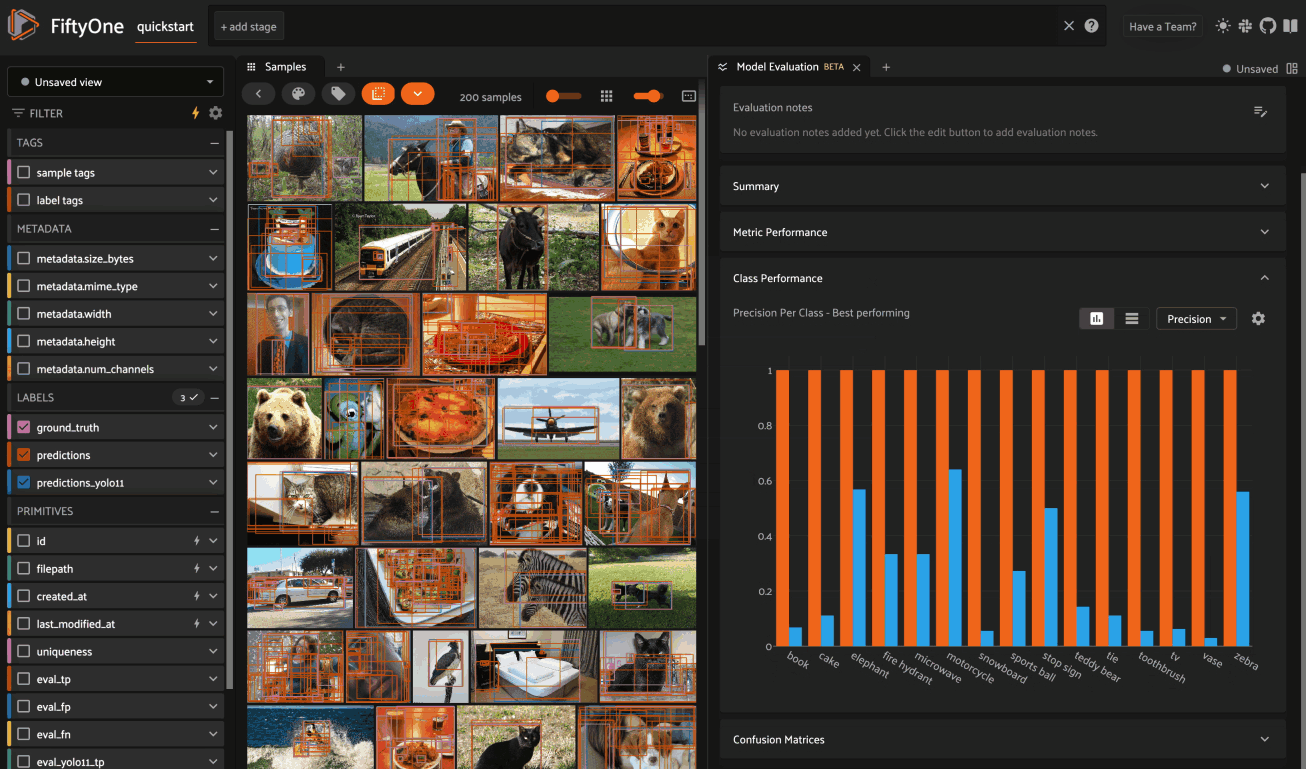
Summary#
The Summary card provides a table of common model performance metrics. You can click on the grid icons next to TP/FP/FN to load the corresponding labels in the Samples panel:
Metric performance#
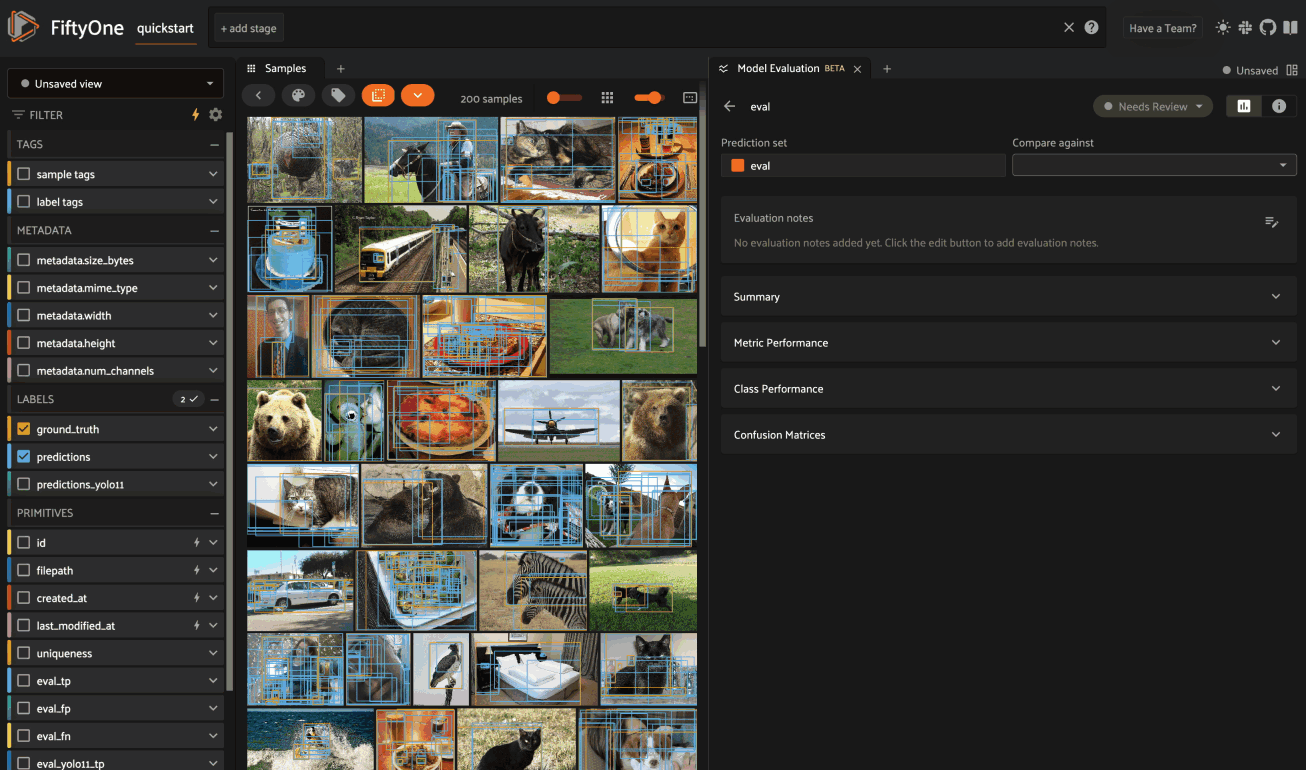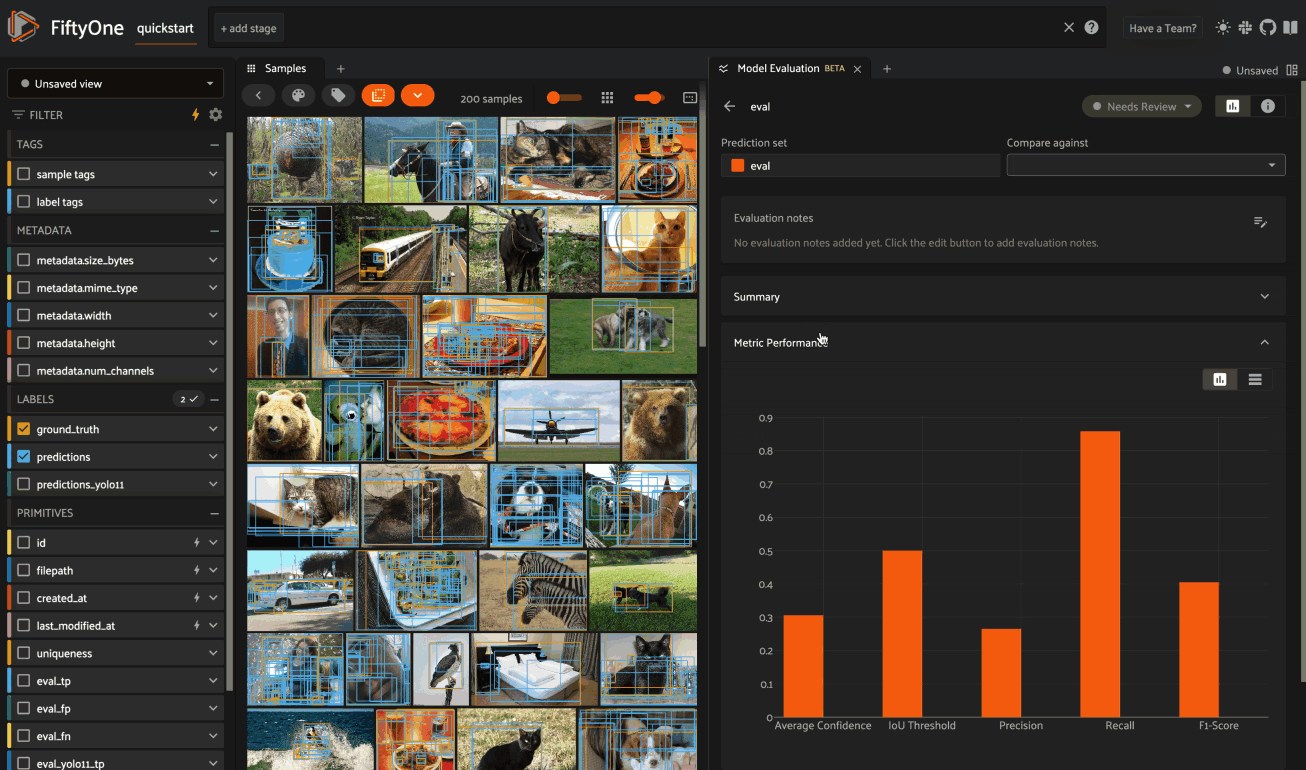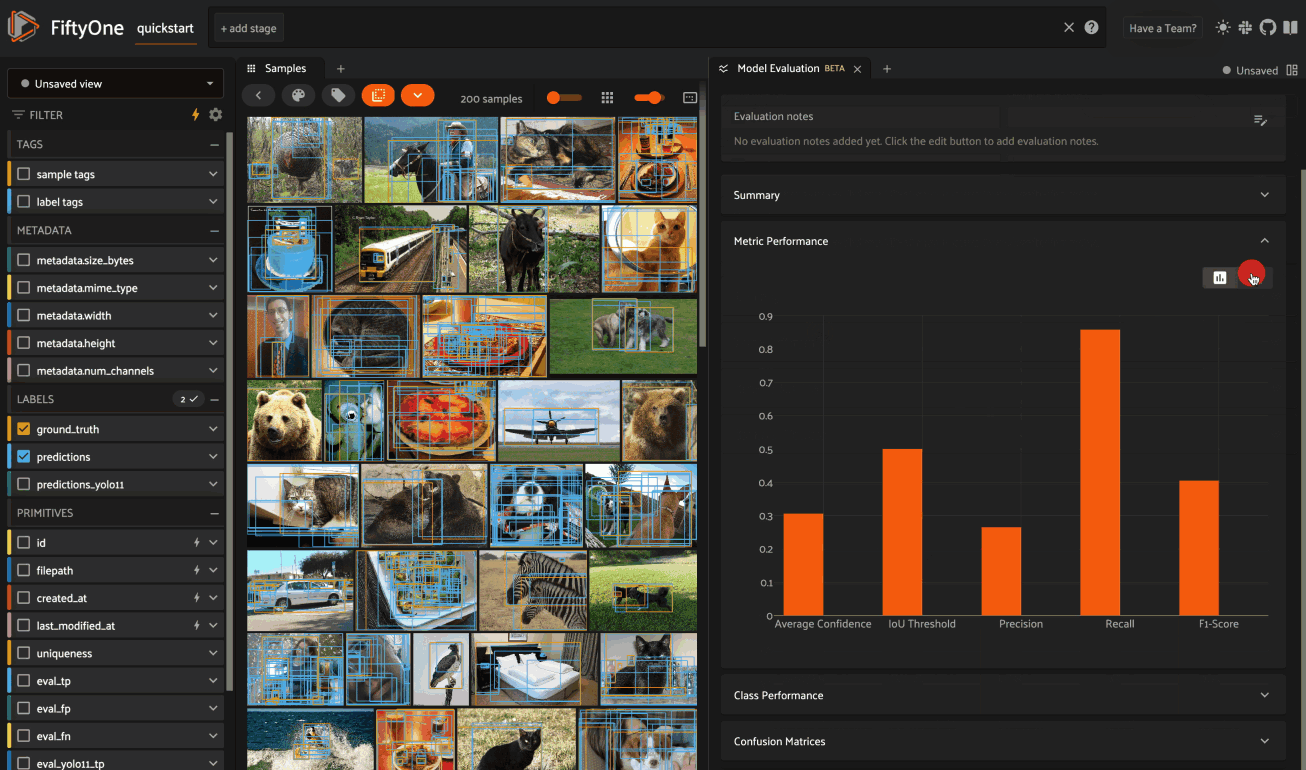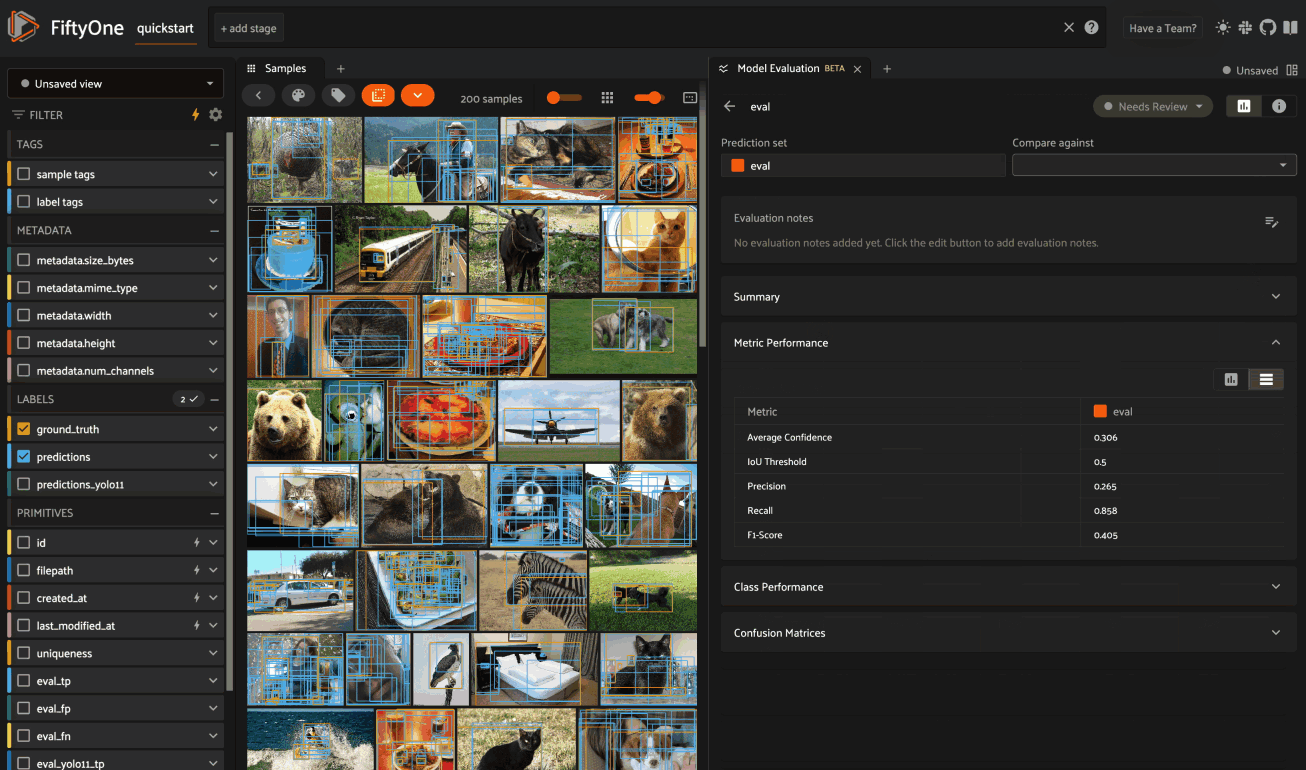
The Metric Performance card provides a graphical summary of key model performance metrics:
Class performance#
The Class Performance card provides a per-class breakdown of each model performance metric. If an evaluation contains many classes, you can use the settings menu to control which classes are shown. The histograms are also interactive: you can click on bars to show the corresponding labels in the Samples panel:
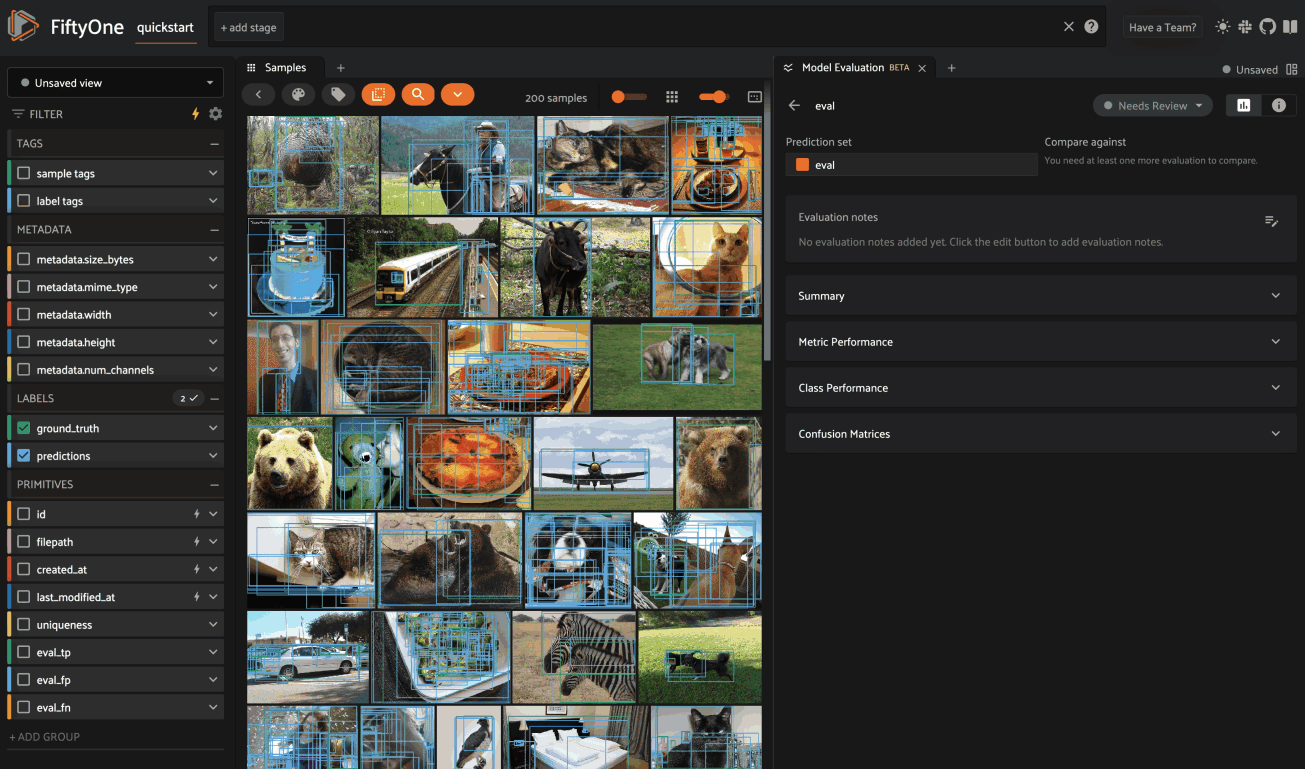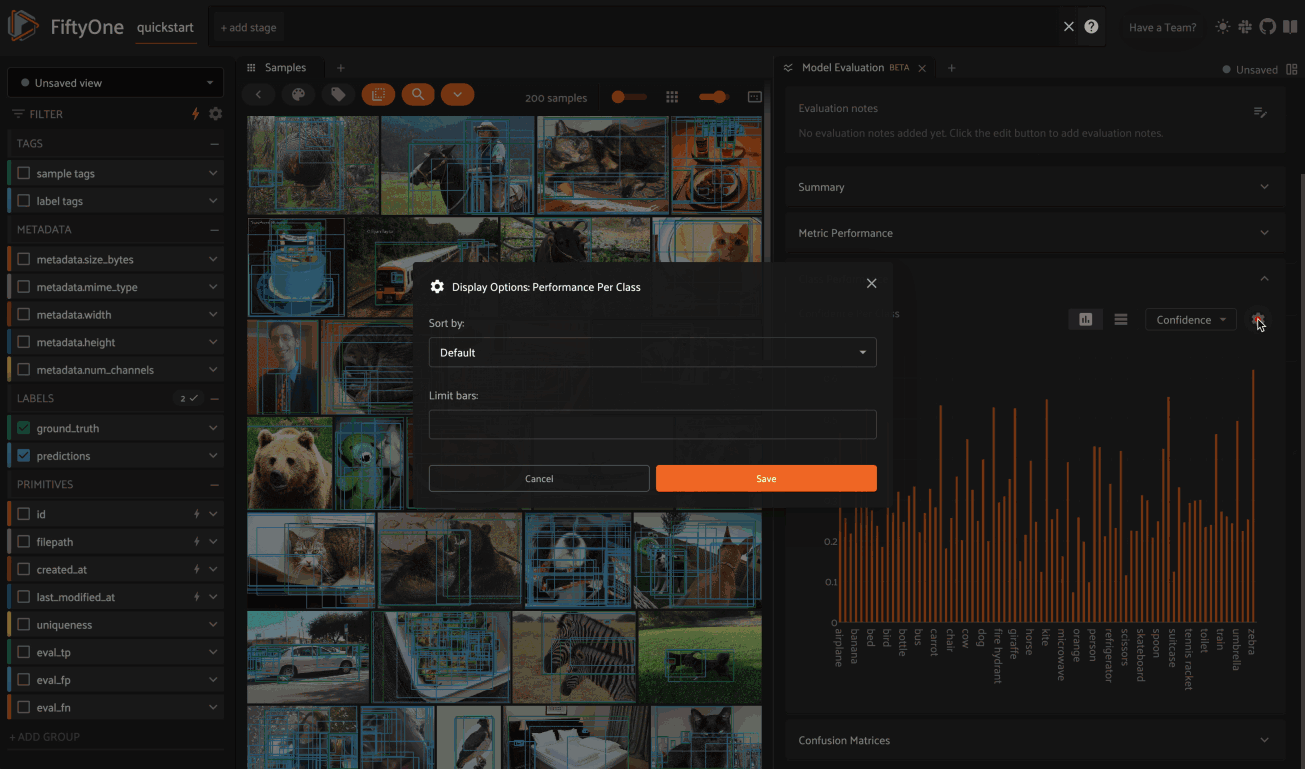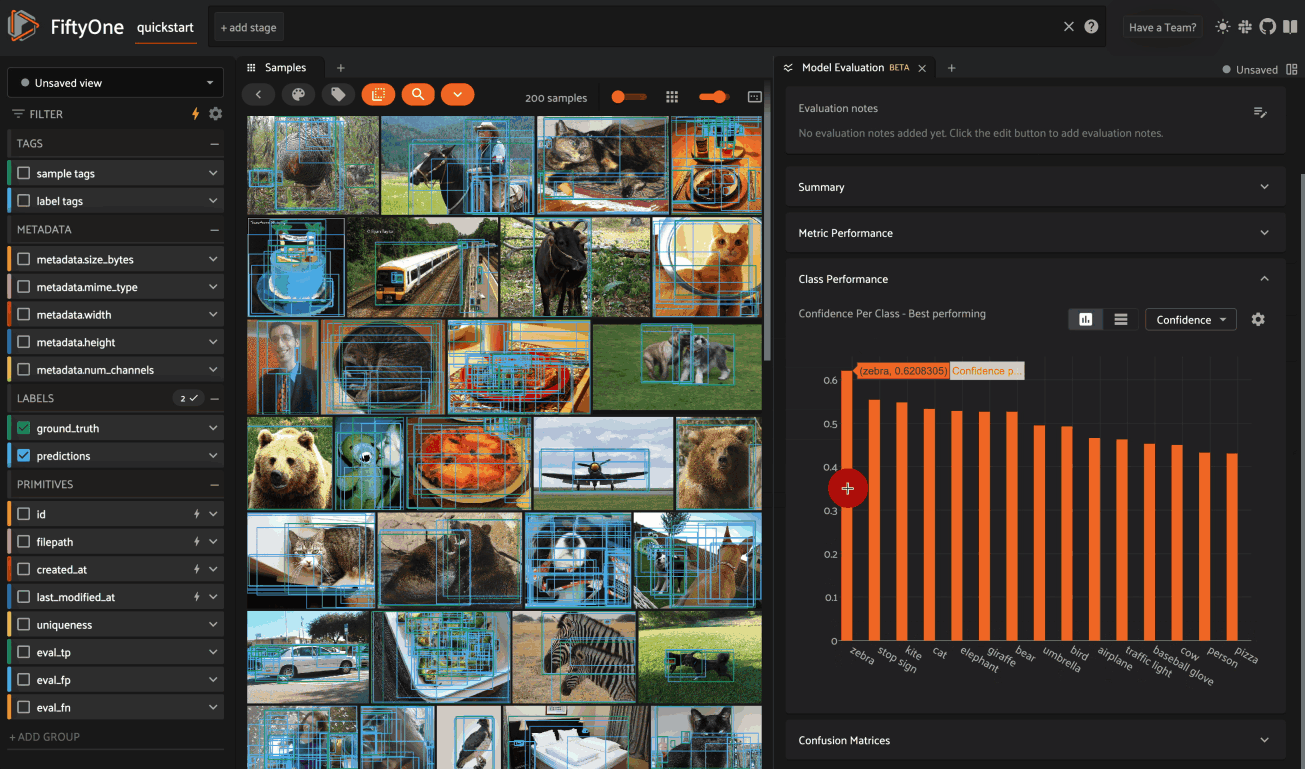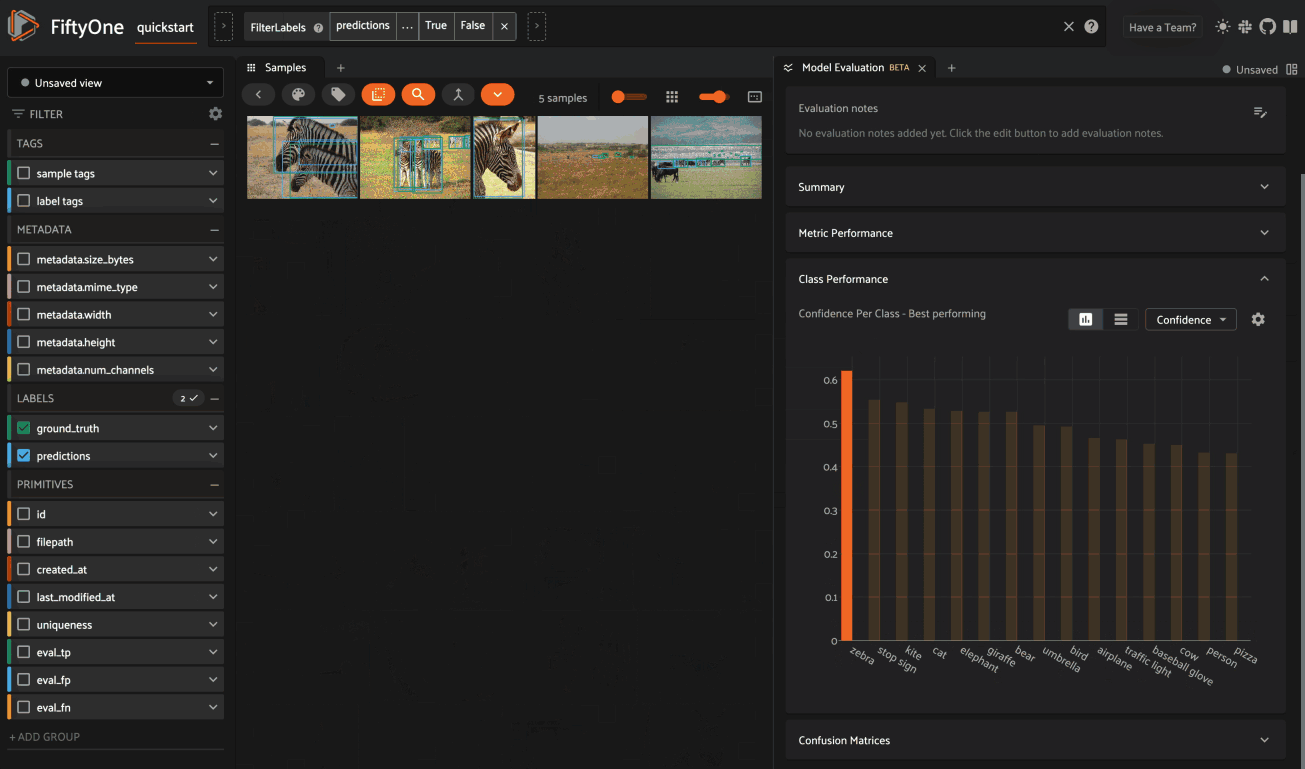
Confusion matrices#
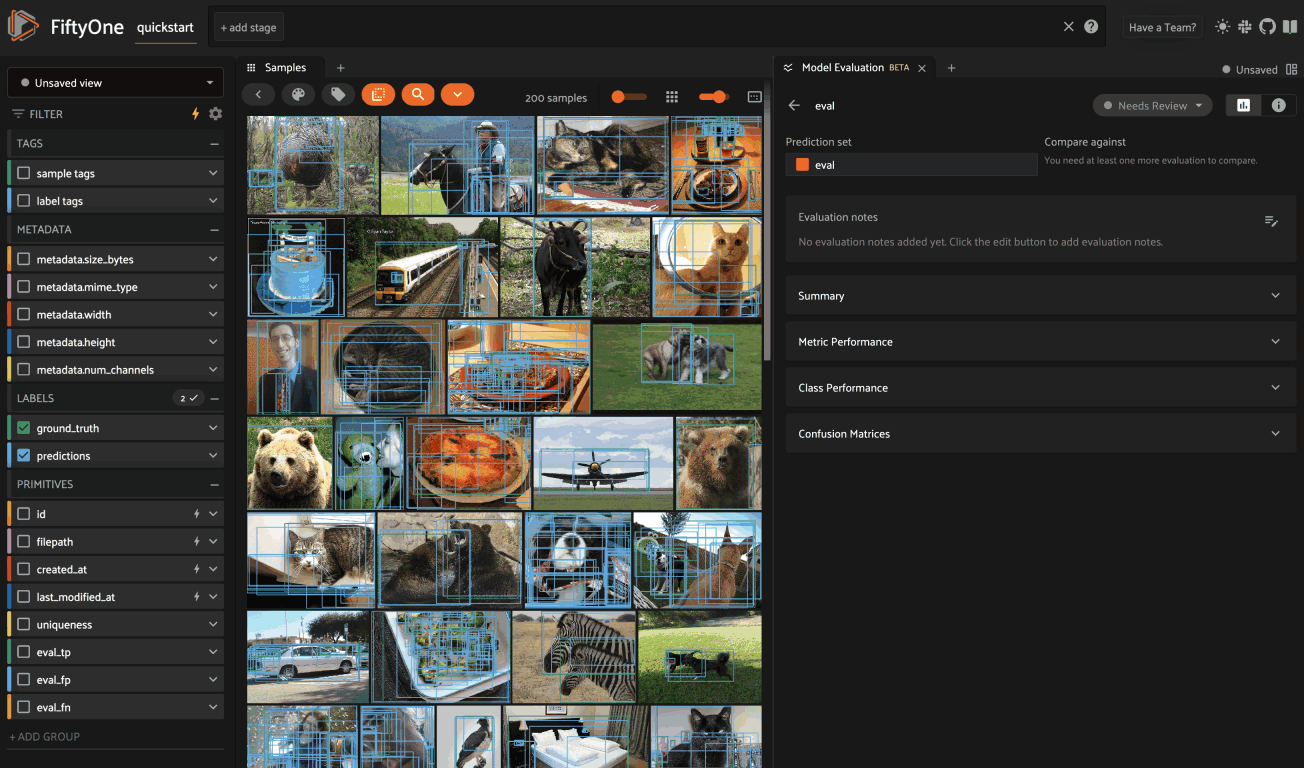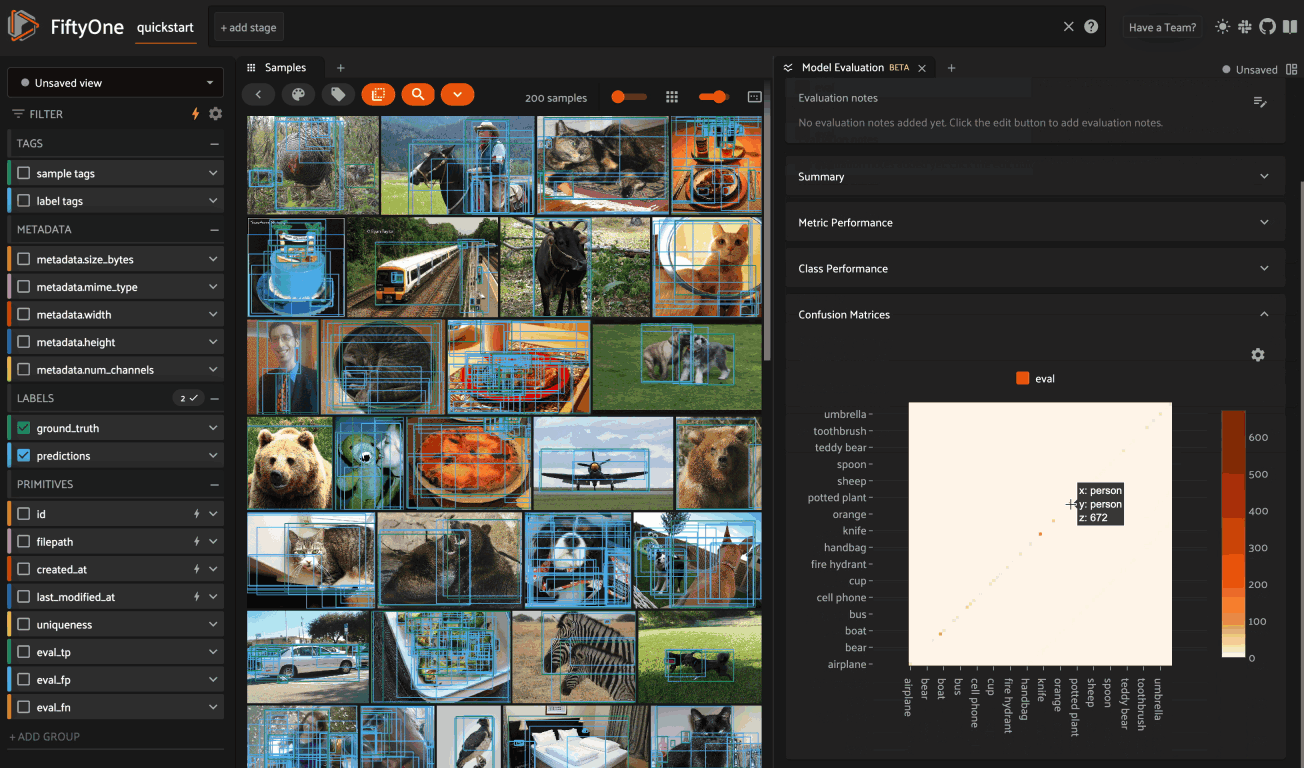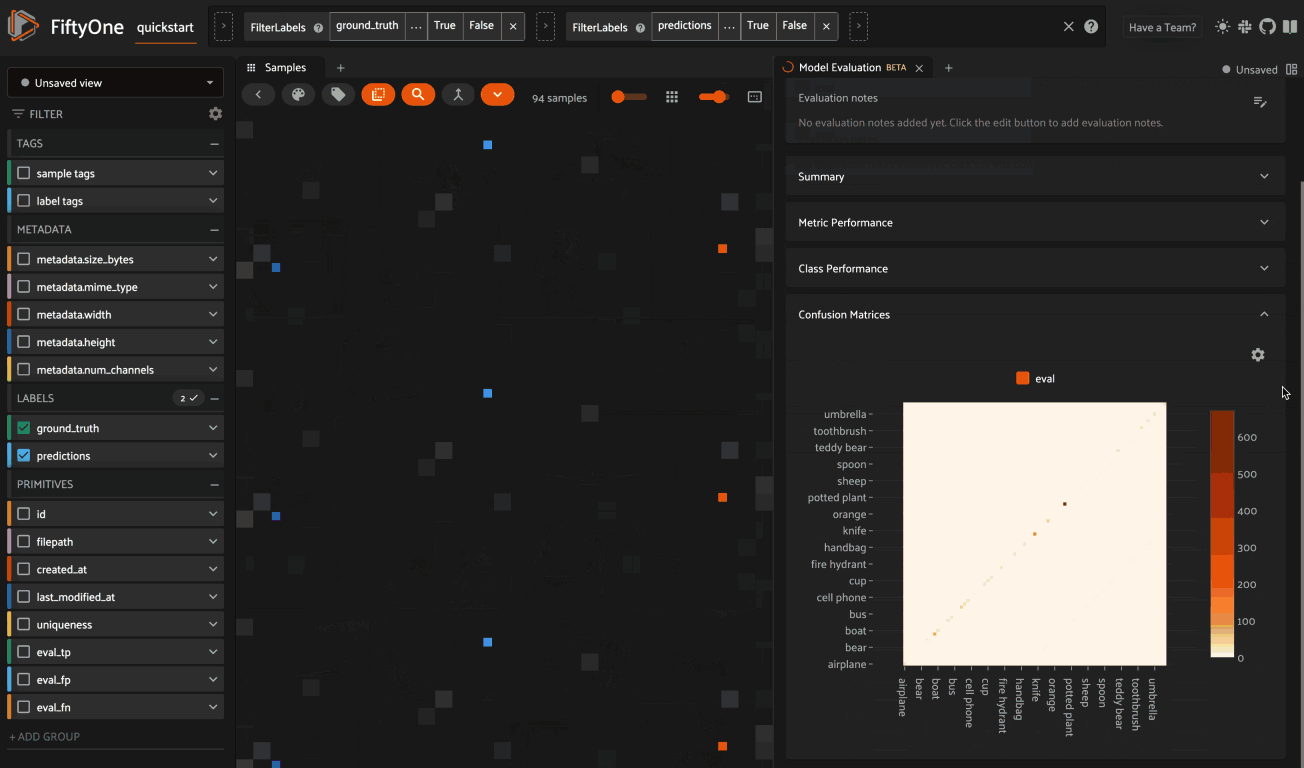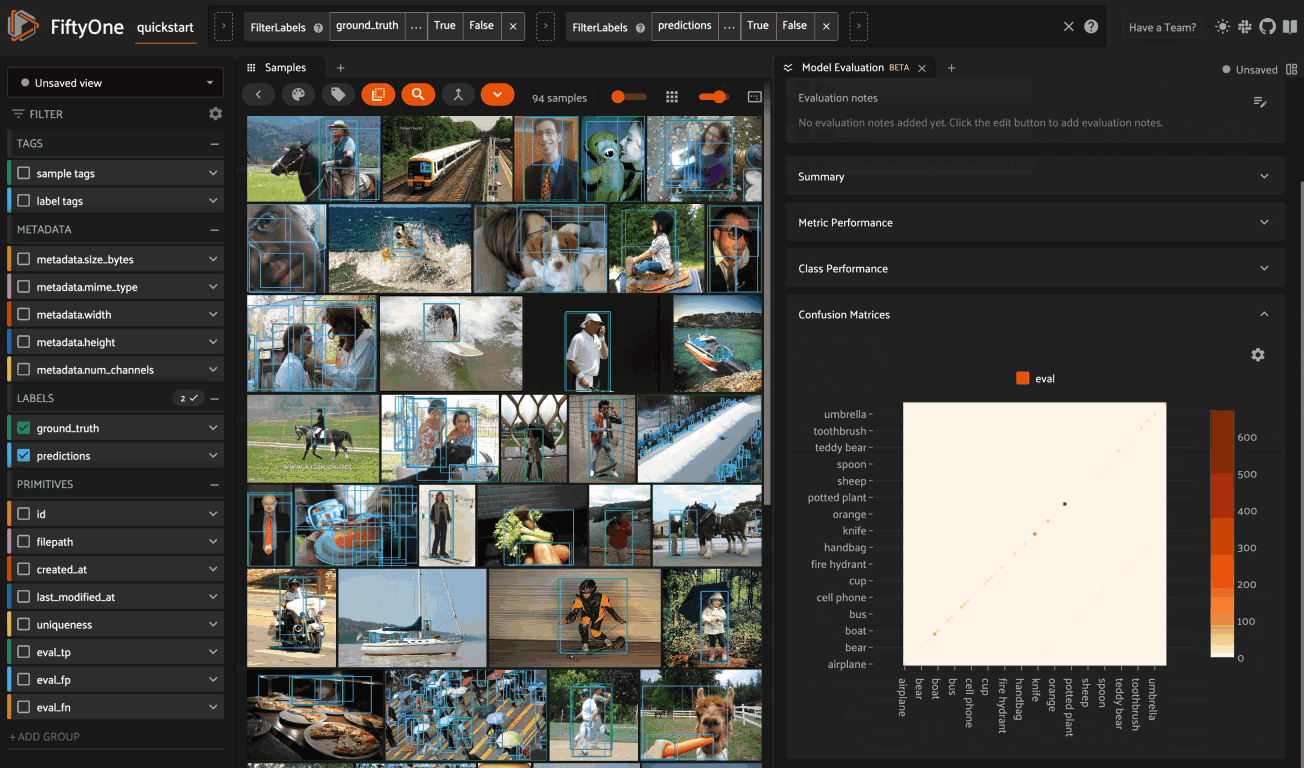
The Confusion Matrices card provides an interactive confusion matrix for the evaluation. If an evaluation contains many classes, you can use the settings menu to control which classes are shown. You can also click on cells to show the corresponding labels in the Samples panel:
Comparing models#
When a dataset contains multiple evaluations, you can compare two model’s performance by selecting a “Compare against” key:
1model = foz.load_zoo_model("yolo11s-coco-torch")
2
3dataset.apply_model(model, label_field="predictions_yolo11")
4
5dataset.evaluate_detections(
6 "predictions_yolo11",
7 gt_field="ground_truth",
8 eval_key="eval_yolo11",
9)
10
11session.refresh()
Scenario analysis NEW#
When evaluating models, it is often useful to deep dive into the behavior of your models in different scenarios. This technique can be extremely useful in a number of ways, including to:
Uncover edge cases that need more representation in your training data
Identify annotation mistakes that are confusing or misleading your model
Understand model performance in different contexts
Gain intuition about the strengths and weaknesses of your model based on properties of its predictions
Compare and contrast model performance under different input data and/or prediction characteristics
Scenario analysis is available for all evaluations by clicking on the Scenario Analysis tab of the Model Evaluation panel.
Example dataset#
The rest of the content in this section is applied to the following dataset:
1import fiftyone as fo
2import fiftyone.zoo as foz
3from fiftyone import ViewField as F
4
5# Load a dataset with `ground_truth` and `predictions` fields
6dataset = foz.load_zoo_dataset("quickstart")
7
8# Declare the `iscrowd` attribute on the "ground_truth" field
9dataset.add_dynamic_sample_fields()
10
11# Evaluate the `predictions` field
12results = dataset.evaluate_detections(
13 "predictions",
14 gt_field="ground_truth",
15 eval_key="eval",
16)
17
18# Add some additional model predictions in the `predictions_yolo11` field
19model = foz.load_zoo_model("yolo11s-coco-torch")
20dataset.apply_model(model, label_field="predictions_yolo11")
21
22# Evaluate the `predictions_yolo11` field
23dataset.evaluate_detections(
24 "predictions_yolo11",
25 gt_field="ground_truth",
26 eval_key="eval_yolo11",
27)
28
29# Classify each image as `indoor` or `outdoor`
30model = foz.load_zoo_model(
31 "clip-vit-base32-torch",
32 text_prompt="An image that is",
33 classes=["indoor", "outdoor"],
34)
35dataset.apply_model(model, label_field="scene")
36
37# Create some saved views
38dataset.save_view("indoor scenes", dataset.match(F("scene.label") == "indoor"))
39dataset.save_view("outdoor scenes", dataset.match(F("scene.label") == "outdoor"))
40
41session = fo.launch_app(dataset)
Defining scenarios#
When you first open the Scenario Analysis tab in the Model Evaluation panel, you’ll be prompted to create your first scenario:
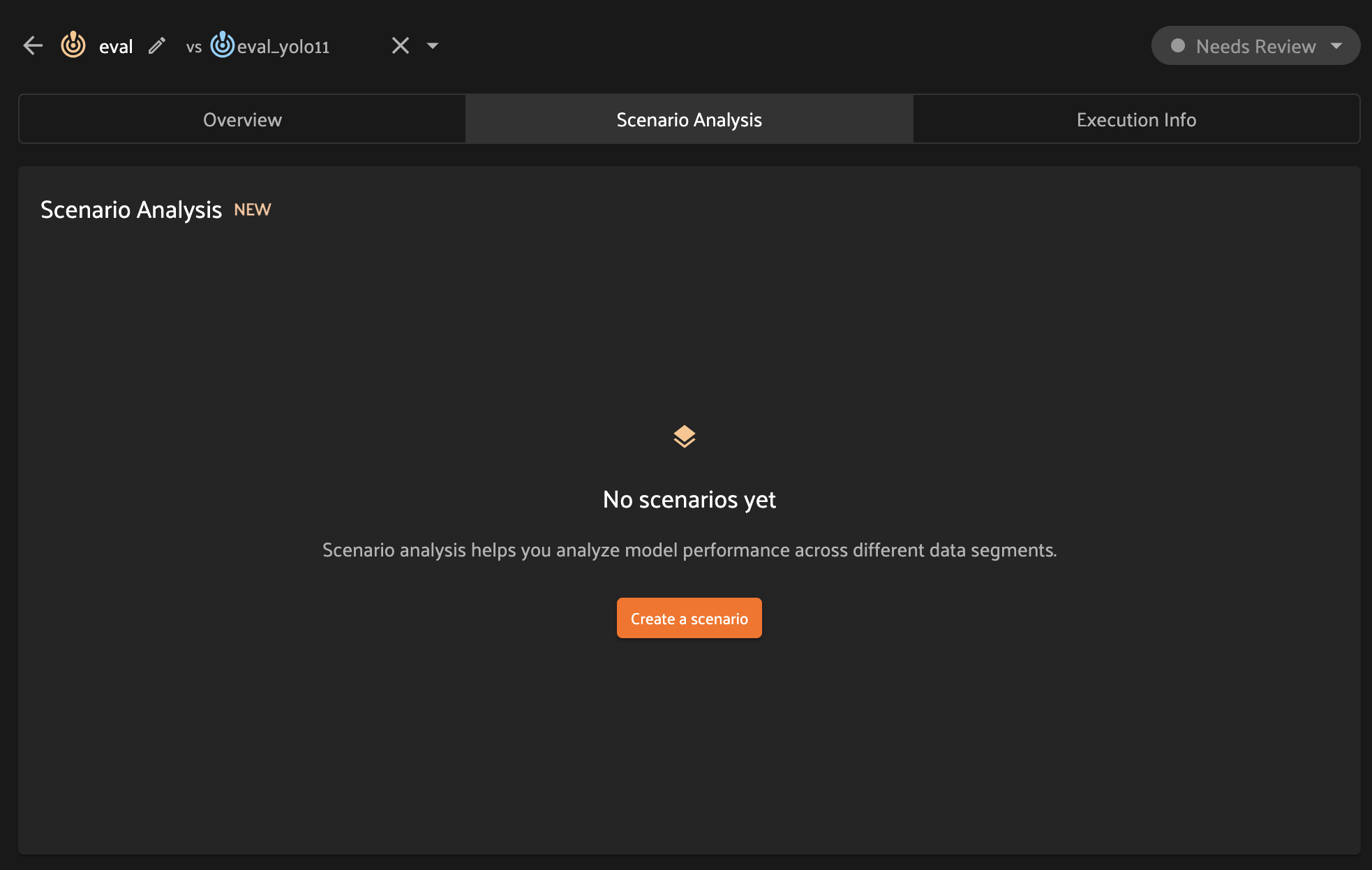
The scenario creation modal will prompt you to provide a name for the scenario, which will be used to identify the scenario subsequently in the panel, for example when switching between scenarios.
Each scenario is composed of multiple subsets that partition the ground truth labels involved in the evaluation into different semantically meaningful sets of interest. FiftyOne supports four methods to define subsets:
Sample field: partition at the sample-level by defining subsets based on the values that a particular sample field takes
Label attribute: partition at the label-level by defining subsets based on the values that a particular attribute of the ground truth labels takes
Saved views: define subsets based on the ground truth labels in a list of saved views
Custom code: use custom code to define subsets based on arbitrary Python expressions and/or combinations of the above methods
When distribution preview is enabled, you’ll see a histogram that represents the number of ground truth labels in each subset of the scenario you’re defining. This preview will automatically update as you continue adding/refining your subsets, which allows you to visually confirm that the subsets that you’re defining have the contents that you expect.
Once you’re happy with the scenario’s definition, click the Analyze scenario
button in the bottom-right of the modal to create it.
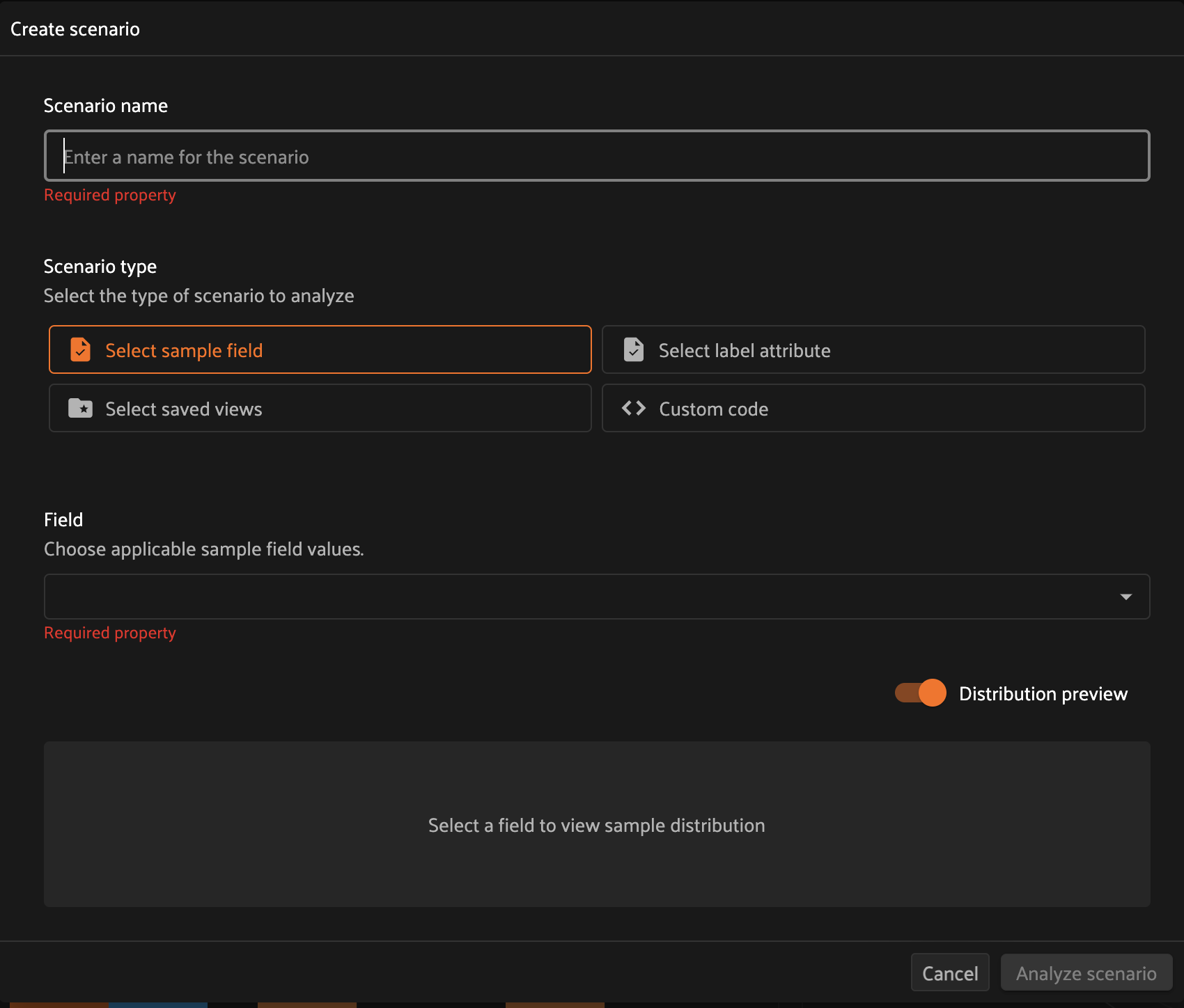
The following subsections describe how to use each of the four scenario definition types in detail.
Select sample field#
Selecting a sample field allows you to define a scenario whose subsets contain samples for which the specified field takes certain values.
For example, choosing the scene.label sample field allows us to define a
scenario that contains two subsets:
Samples whose
scene.labelfield isindoorSamples whose
scene.labelfield isoutdoor
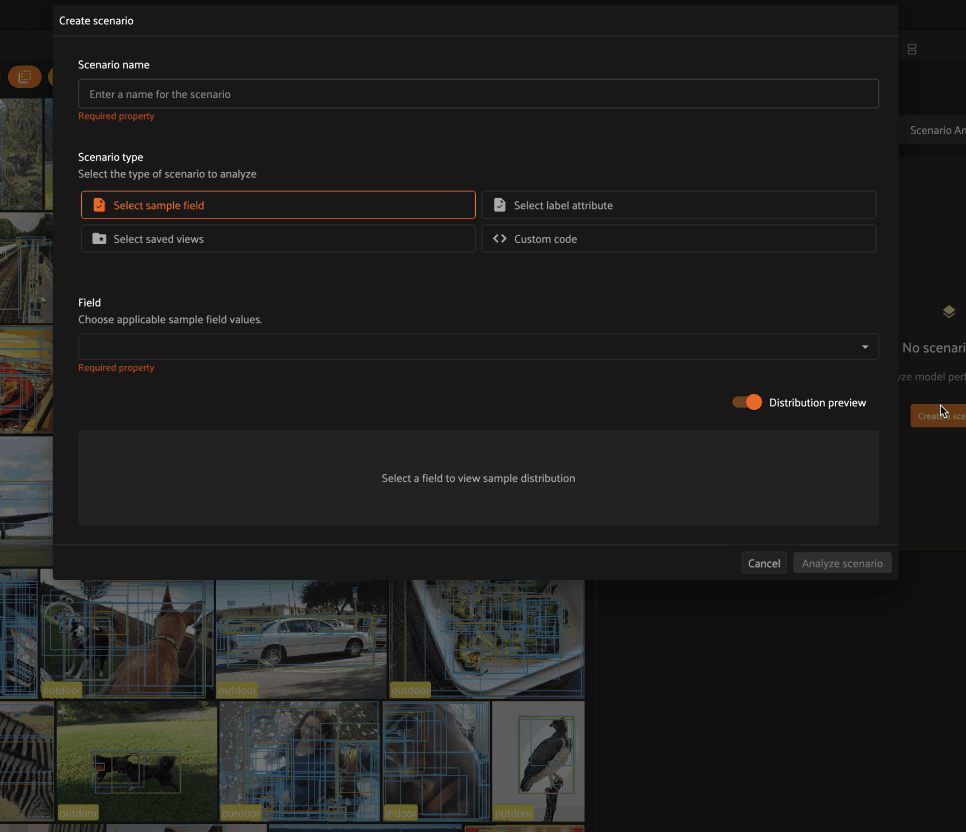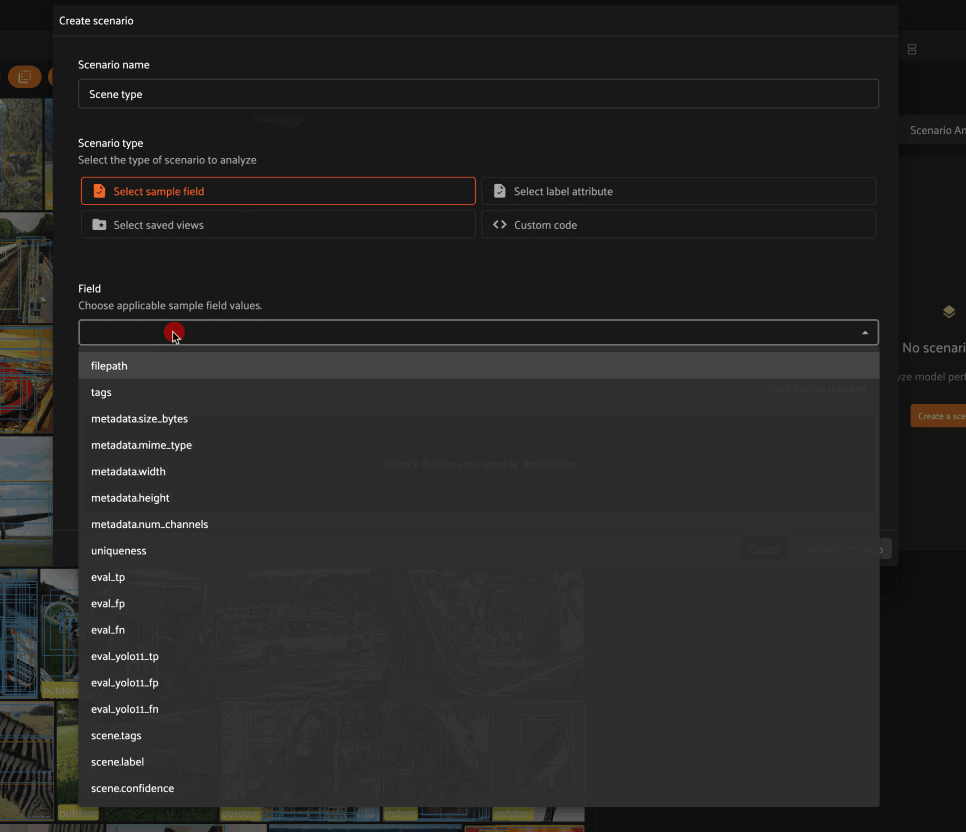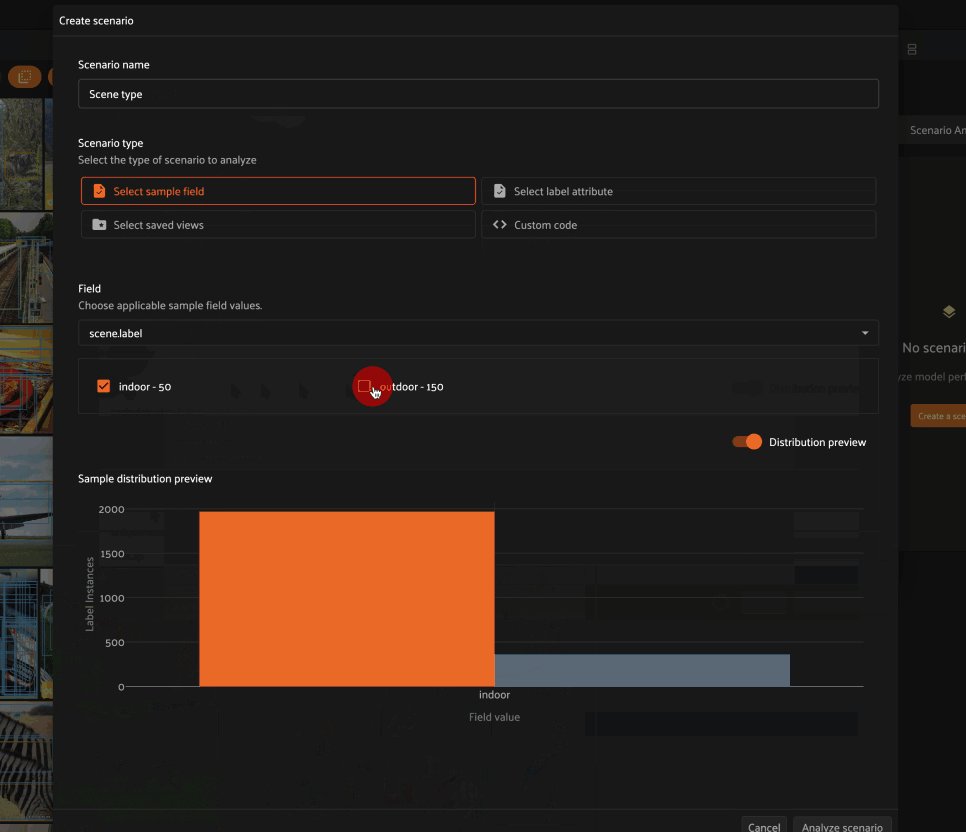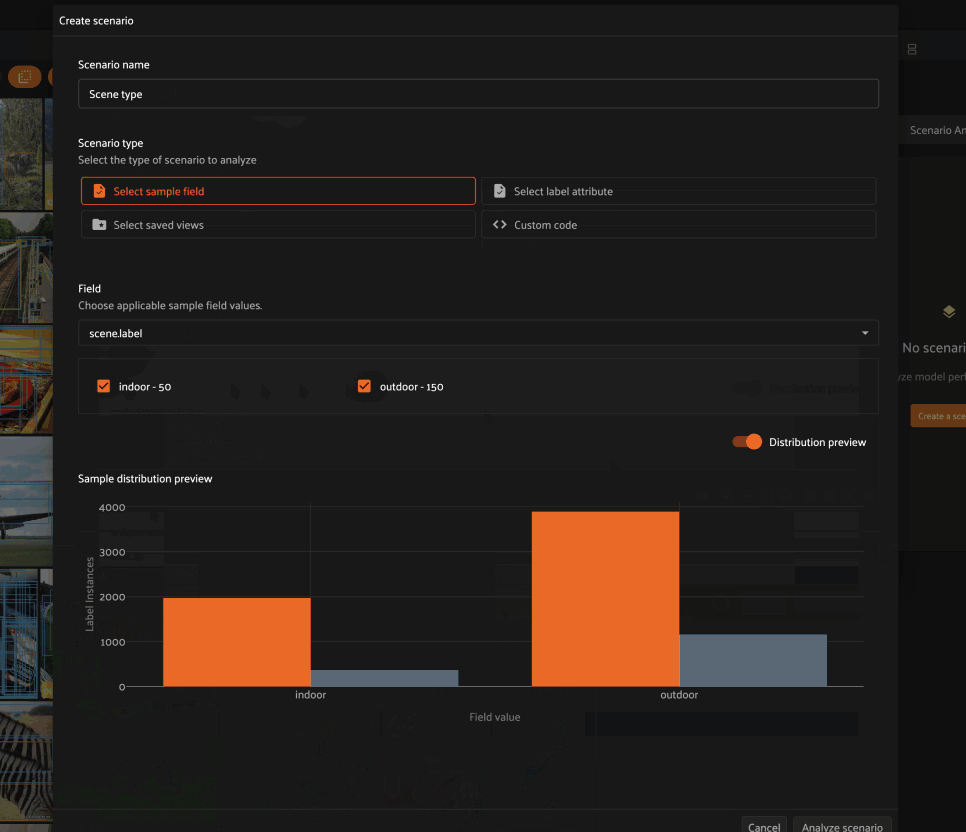
As you can see in the Distribution preview, each subset is assigned a name based on the field value that its member samples take.
Note
If you select a sample field that contains numeric values, or a categorical field that contains many distinct values, you will be prompted to define the subsets via custom code rather than by selecting values via checkboxes or a multiselect list.
Select label attribute#
Selecting a label attribute allows you to define a scenario whose subsets contain samples for which the specified attribute of the ground truth labels takes certain values.
For example, choosing the iscrowd attribute allows us to define a scenario
that contains two subsets:
Labels whose
iscrowdattribute is0Labels whose
iscrowdattribute is1
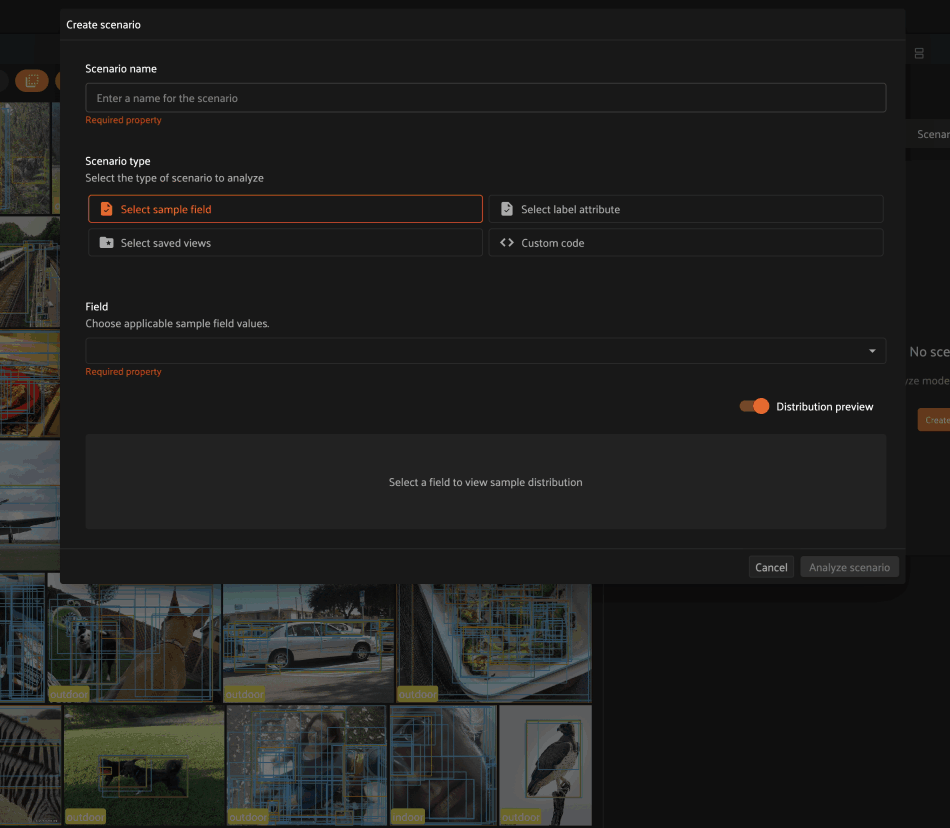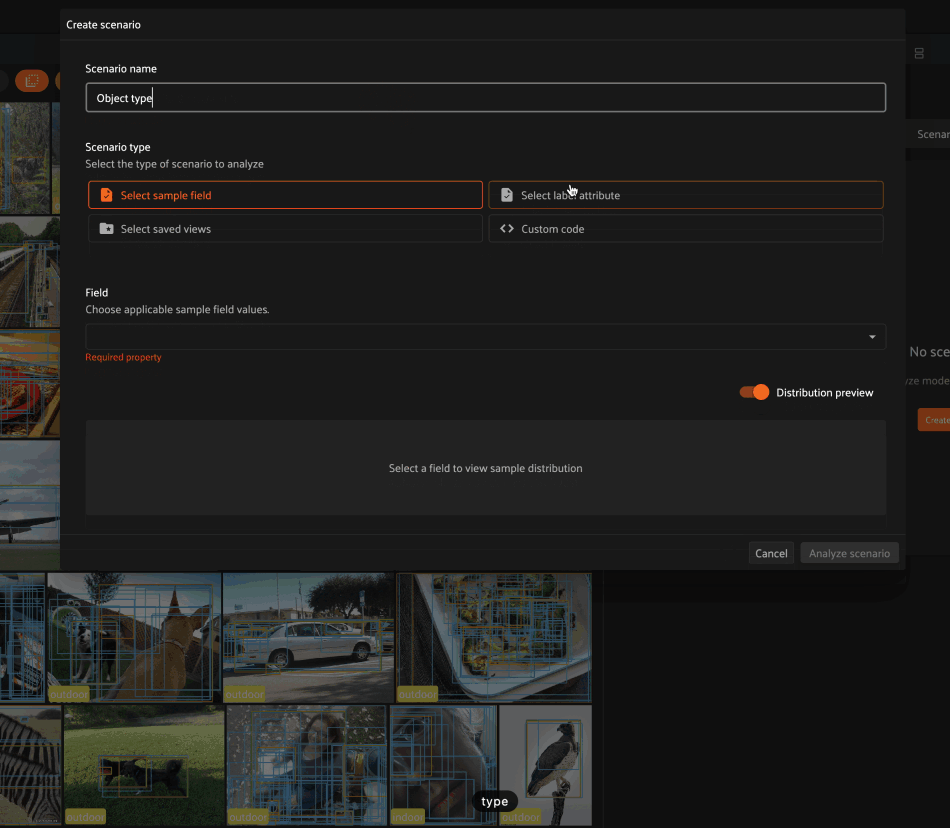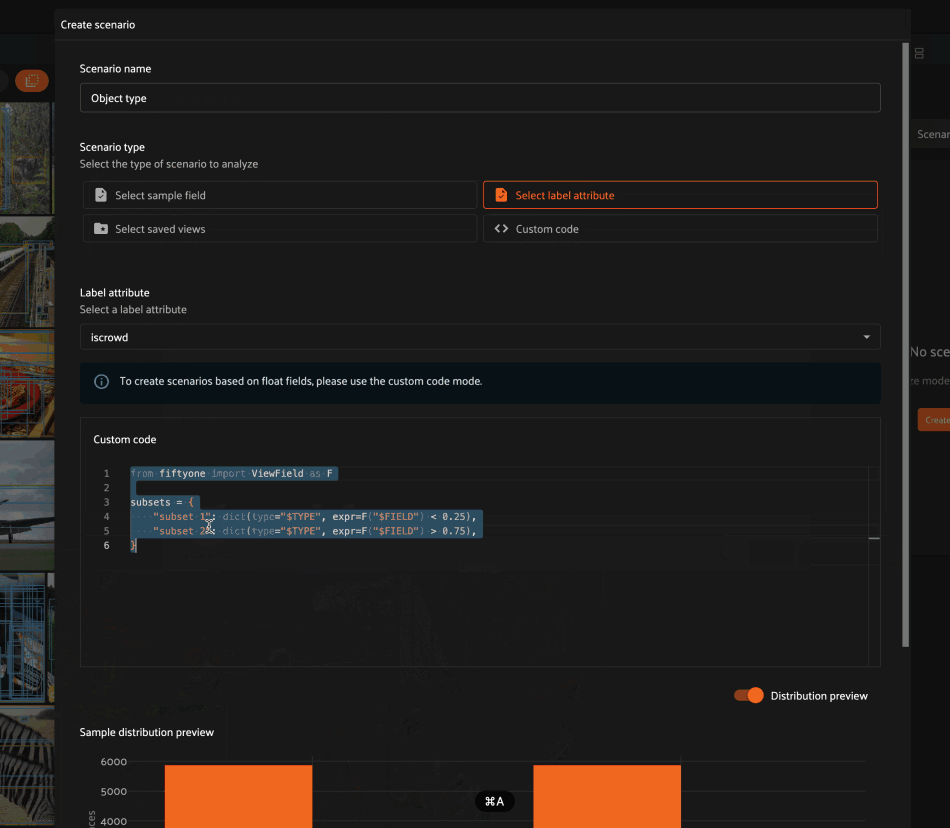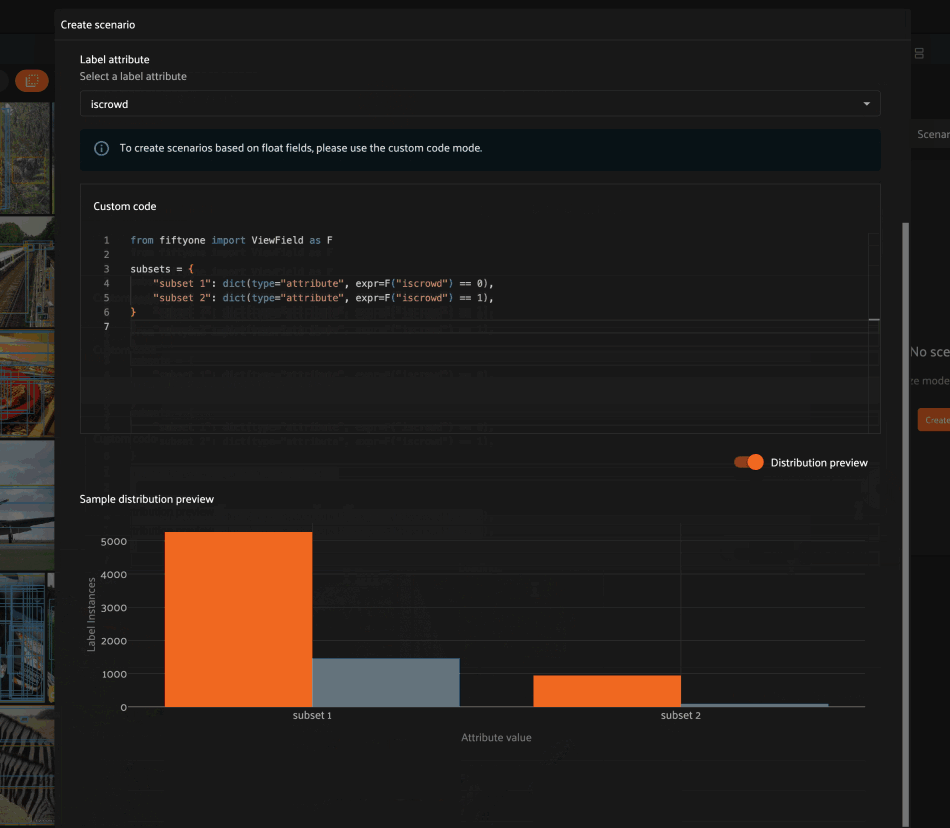
If you choose a categorical label attribute, each subset is assigned a name based on the field value that its member labels take.
Note
If you select a label attribute that contains numeric values, or a categorical attribute that contains many distinct values, you will be prompted to define the subsets via custom code rather than by selecting values via checkboxes or a multiselect list.
Select saved views#
Selecting saved views allows you to define a scenario where each subset contains the ground truth labels in a specified saved view.
For example, in the example below we define a scenario that contains two subsets:
Samples in the
indoor scenessaved viewSamples in the
outdoor scenessaved view
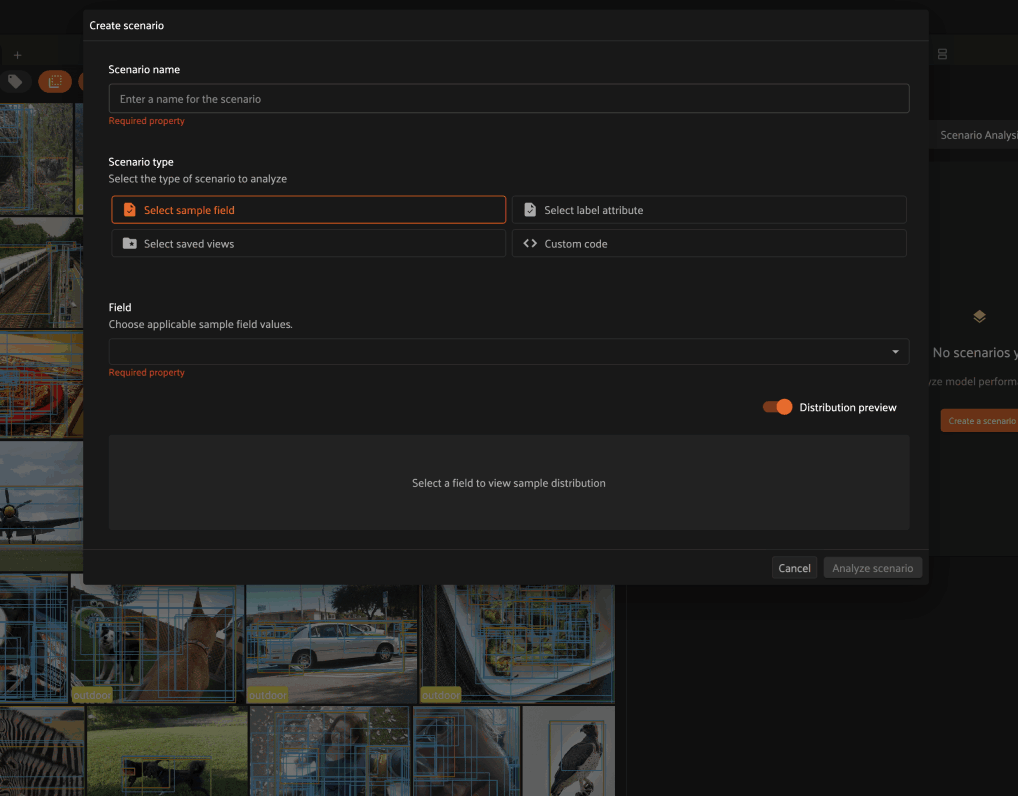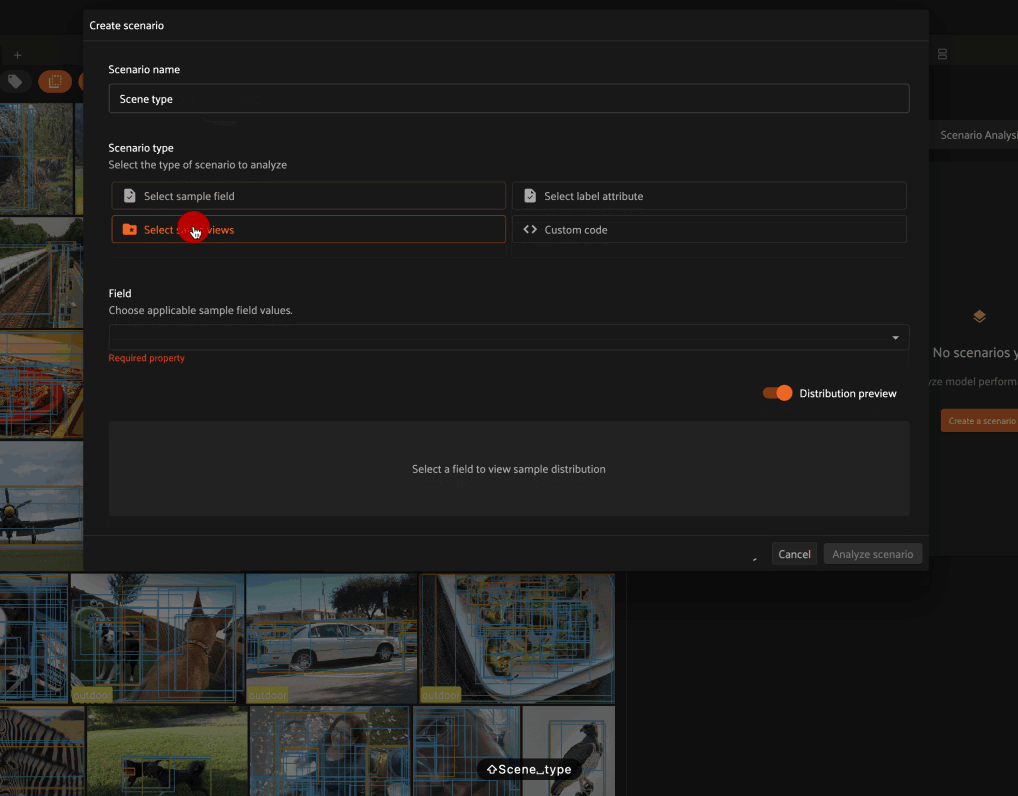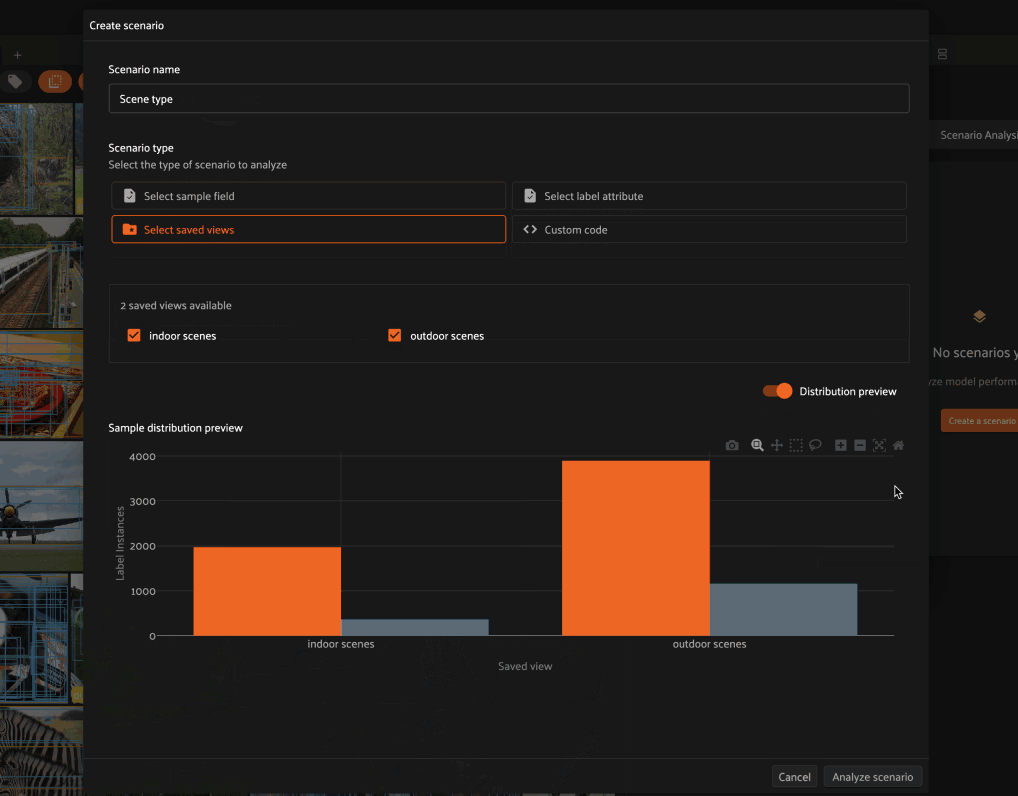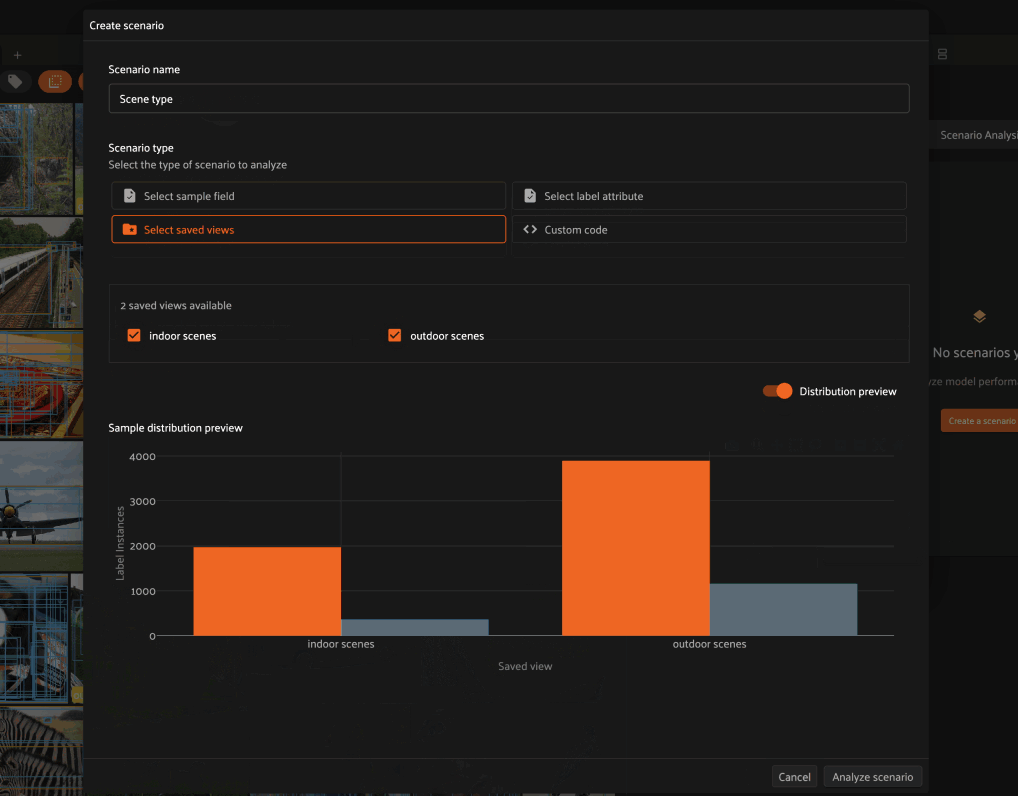
As you can see in the Distribution preview above, each subset is assigned the name of the saved view that defines it.
Custom code#
The most flexible option for constructing a scenario is to define its subsets via Python code.
By default, toggling to custom code mode for an object detection task inserts subset definitions that partition the ground truth labels based on their size relative to the image in which they reside:
Small objects: labels whose size is less than 5% of the image
Medium objects: labels whose size is between 5% and 50% of the image
Large objects: labels whose size is greater than 50% of the image
1from fiftyone import ViewField as F
2
3bbox_area = F("bounding_box")[2] * F("bounding_box")[3]
4subsets = {
5 "Small objects": dict(type="attribute", expr=bbox_area < 0.05),
6 "Medium objects": dict(type="attribute", expr=(0.05 <= bbox_area) & (bbox_area <= 0.5)),
7 "Large objects": dict(type="attribute", expr=bbox_area > 0.5),
8}
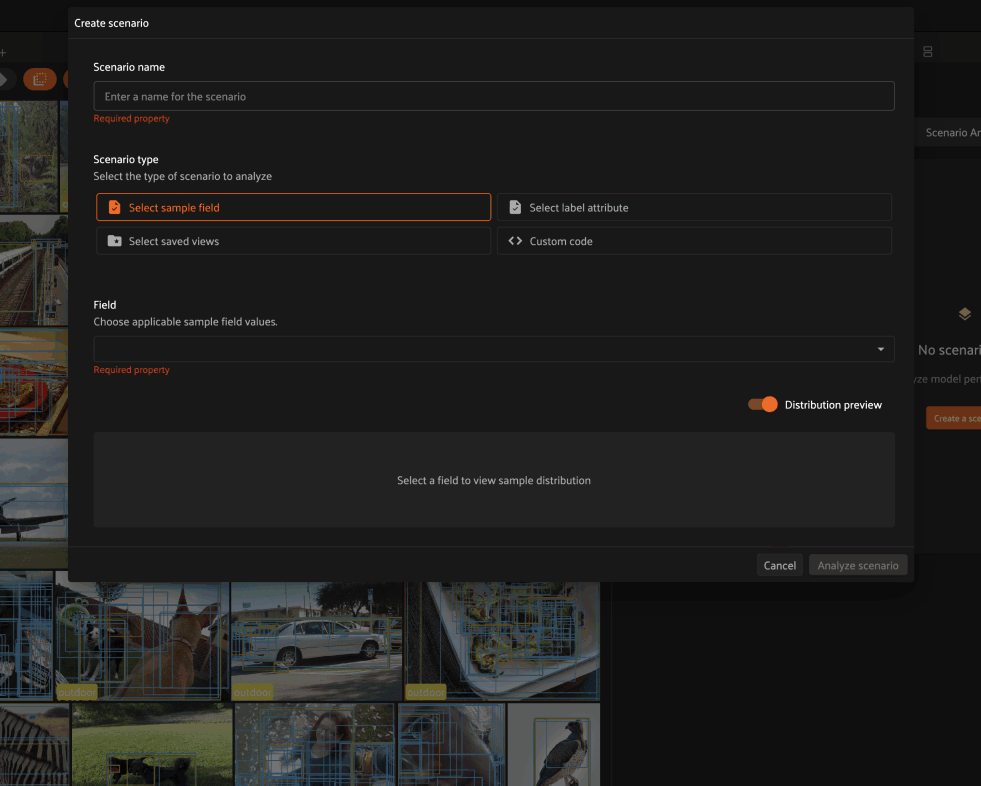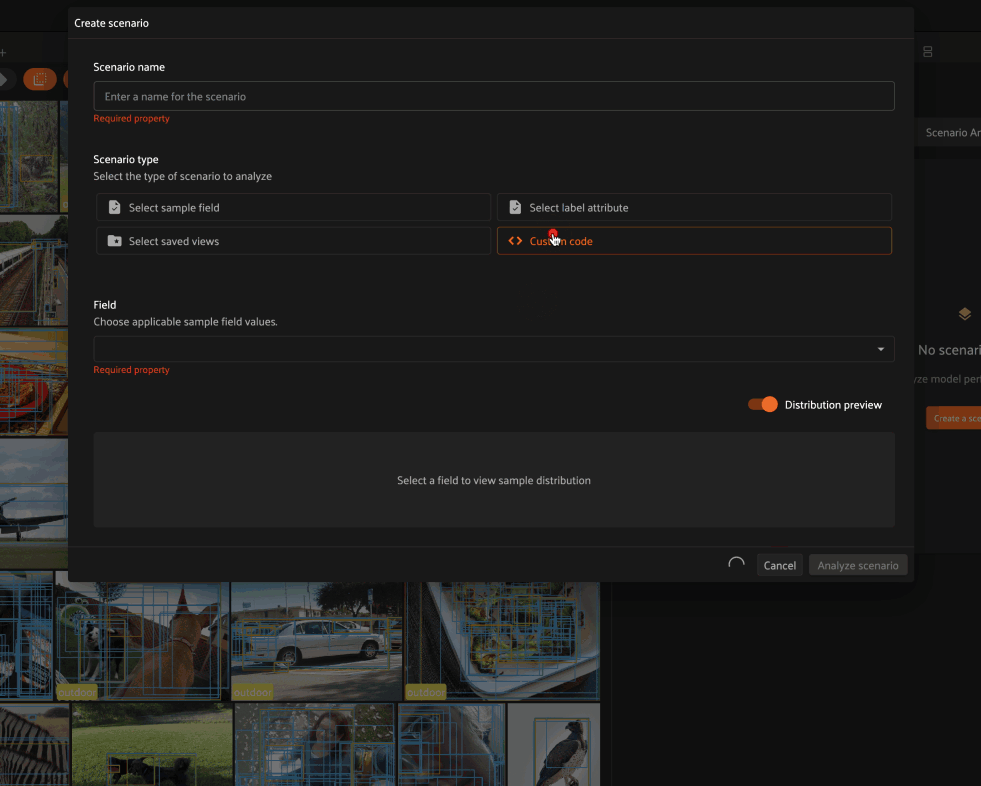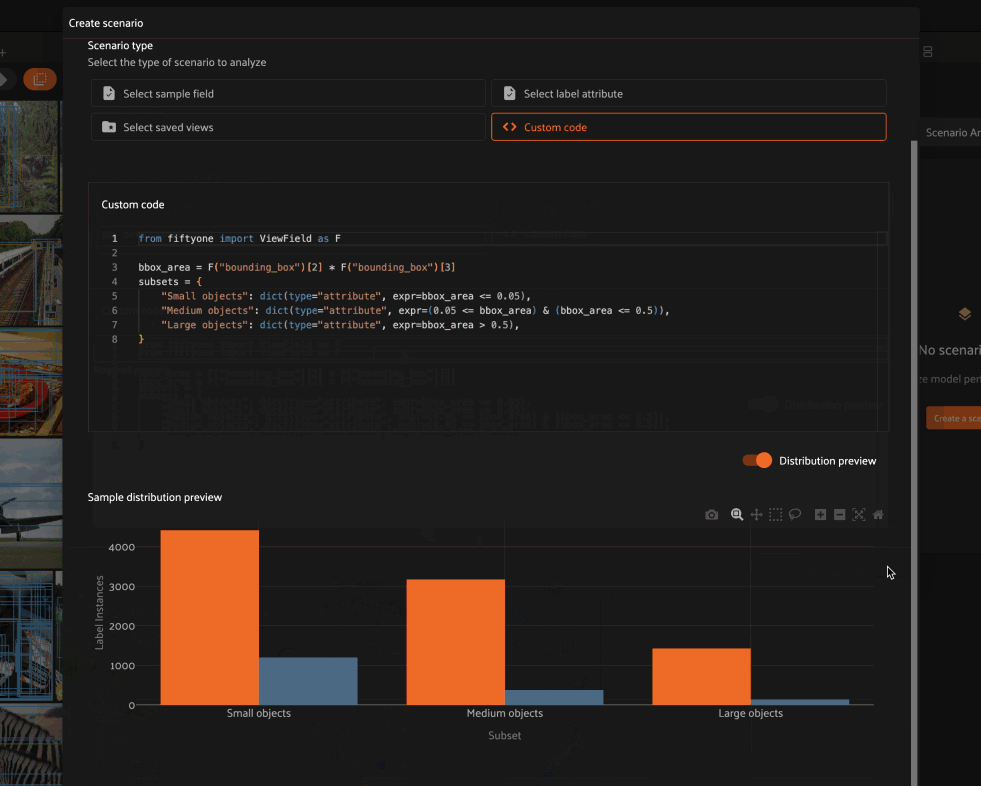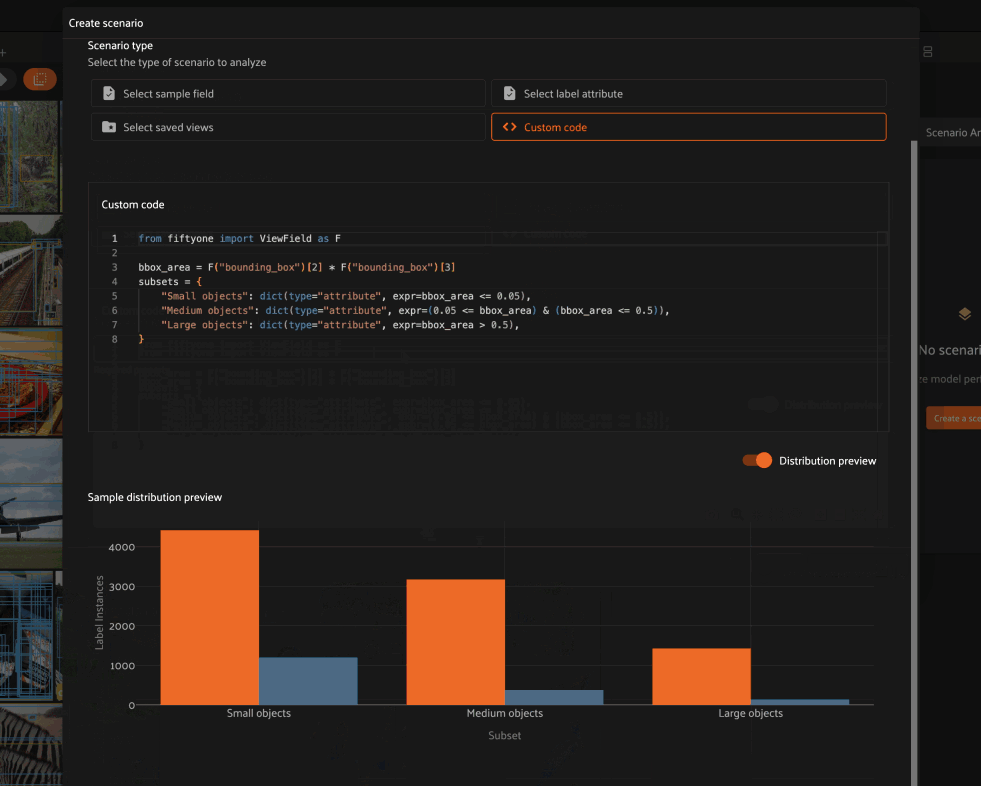
You could also define subsets based on the area of the object in pixels via the following subset definitions like so:
1from fiftyone import ViewField as F
2
3bbox_area = (
4 F("bounding_box")[2] * F("$metadata.frame_height")
5 * F("bounding_box")[3] * F("$metadata.frame_width")
6)
7
8subsets = {
9 "Small objects": dict(type="attribute", expr=bbox_area < 32**2),
10 "Medium objects": dict(type="attribute", expr=(32**2 <= bbox_area) & (bbox_area <= 96**2)),
11 "Large objects": dict(type="attribute", expr=bbox_area > 96**2),
12}
In general, the custom code option expects you to define the scenario by
providing a dict called subsets that maps scenario names to scenario
definitions:
1from fiftyone import ViewField as F
2
3subsets = {
4 "<subset_name>": subset_def,
5 ...
6}
where each subset_def can refer to sample fields, label attributes, saved
views, or a combination thereof to define the subset using the syntax described
below:
1# Subset defined by a sample field value
2subset_def = {
3 "type": "sample",
4 "field": "timeofday",
5 "value": "night",
6}
1# Subset defined by a sample field expression
2subset_def = {
3 "type": "field",
4 "expr": F("uniqueness") > 0.75,
5}
1# Subset defined by a label attribute value
2subset_def = {
3 "type": "attribute",
4 "field": "type",
5 "value": "sedan",
6}
1# Subset defined by a label expression
2bbox_area = F("bounding_box")[2] * F("bounding_box")[3]
3subset_def = {
4 "type": "attribute",
5 "expr": (0.05 <= bbox_area) & (bbox_area <= 0.5),
6}
1# Subset defined by a saved view
2subset_def = {
3 "type": "view",
4 "view": "night_view",
5}
1# Compound subset defined by a sample field value + sample expression
2subset_def = [
3 {
4 "type": "field",
5 "field": "timeofday",
6 "value": "night",
7 },
8 {
9 "type": "field",
10 "expr": F("uniqueness") > 0.75,
11 },
12]
1# Compound subset defined by a sample field value + label expression
2bbox_area = F("bounding_box")[2] * F("bounding_box")[3]
3subset_def = [
4 {
5 "type": "field",
6 "field": "timeofday",
7 "value": "night",
8 },
9 {
10 "type": "attribute",
11 "expr": (0.05 <= bbox_area) & (bbox_area <= 0.5),
12 },
13]
1# Compound subset defined by a saved view + label attribute value
2subset_def = [
3 {
4 "type": "view",
5 "view": "night_view",
6 },
7 {
8 "type": "attribute",
9 "field": "type",
10 "value": "sedan",
11 }
12]
Note
Refer to the ViewExpression docs for a full list of supported operations
when using expressions to define subsets.
Analyzing scenarios#
Once a scenario is created, you’ll see an array of graphs that describe various dimensions of the model(s) performance across each subset in the scenario.
As with the Overview tab, you can select one evaluation to analyze, or you
can select two evaluations to compare, in which case there will be two
series/columns in each graph/table as relevant.
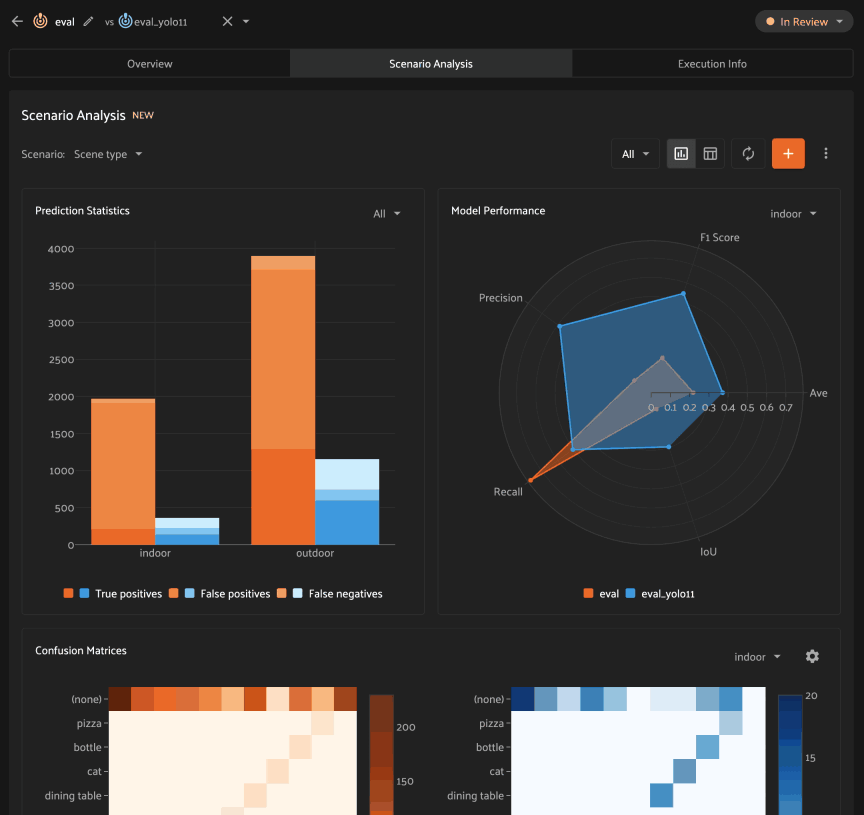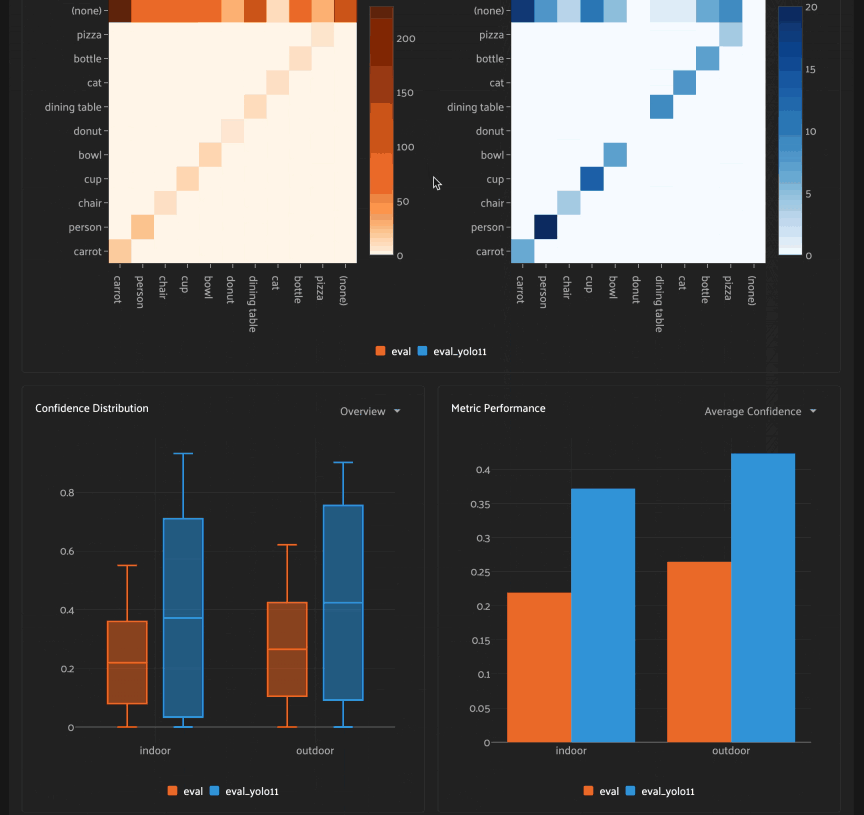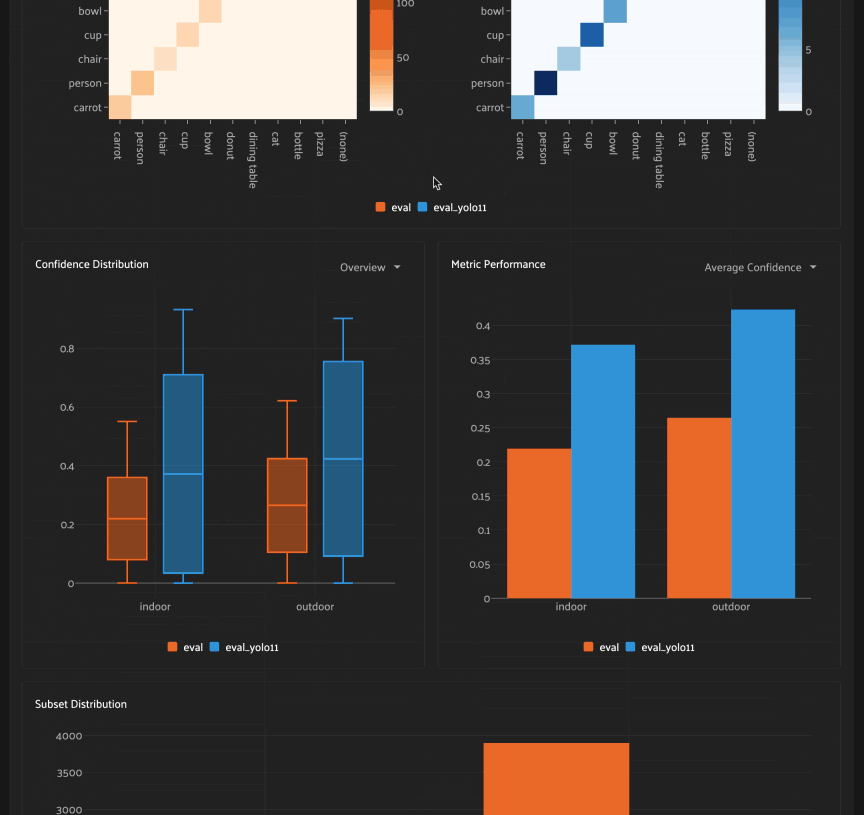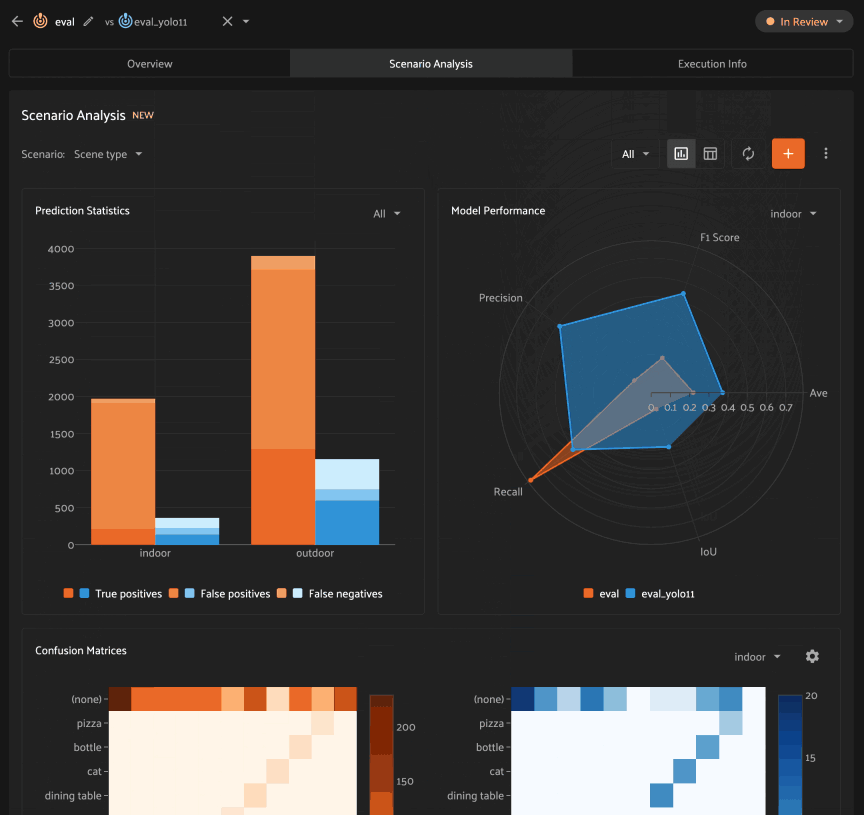
Each scenario analysis contains the following charts:
Prediction Statistics: this stacked bar chart shows the number of true positives, false positives, and false negatives for each model across each subset
Model Performance: this radar chart visually depicts each model(s) performance on a particular subset across standard metrics like precision, recall, F1 score, average confidence, and IoU (as relevant). Use the selector in the upper-right corner to toggle between subsets
Confusion Matrices: these heatmap(s) display standard confusion matrices for each model(s) on a particular subset. Use the selector in the upper-right corner to toggle between subsets
Confidence Distribution: this chart depicts the distribution of prediction confidences for each model across each subset
Metric Performance: a variation on the Model Performance chart that displays each model(s) performance across subsets for a particular metric. Use the selector in the upper-right corner to toggle between metrics of interest
Subset Distribution: this histogram shows the number of labels generated by each model in each subset
All applicable charts are interactive, meaning that you can click on specific bars or cells of interest to load the corresponding samples in the grid!
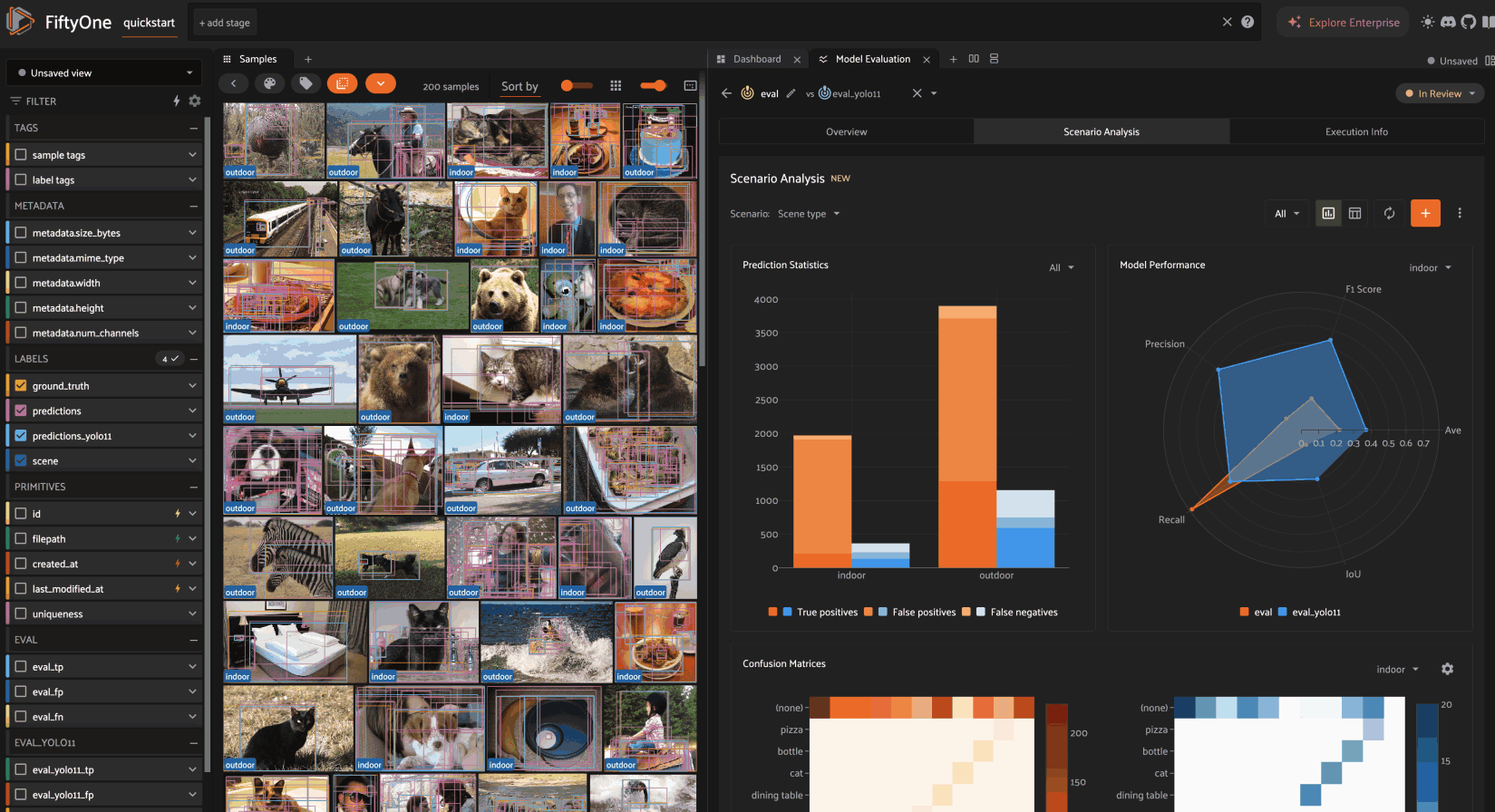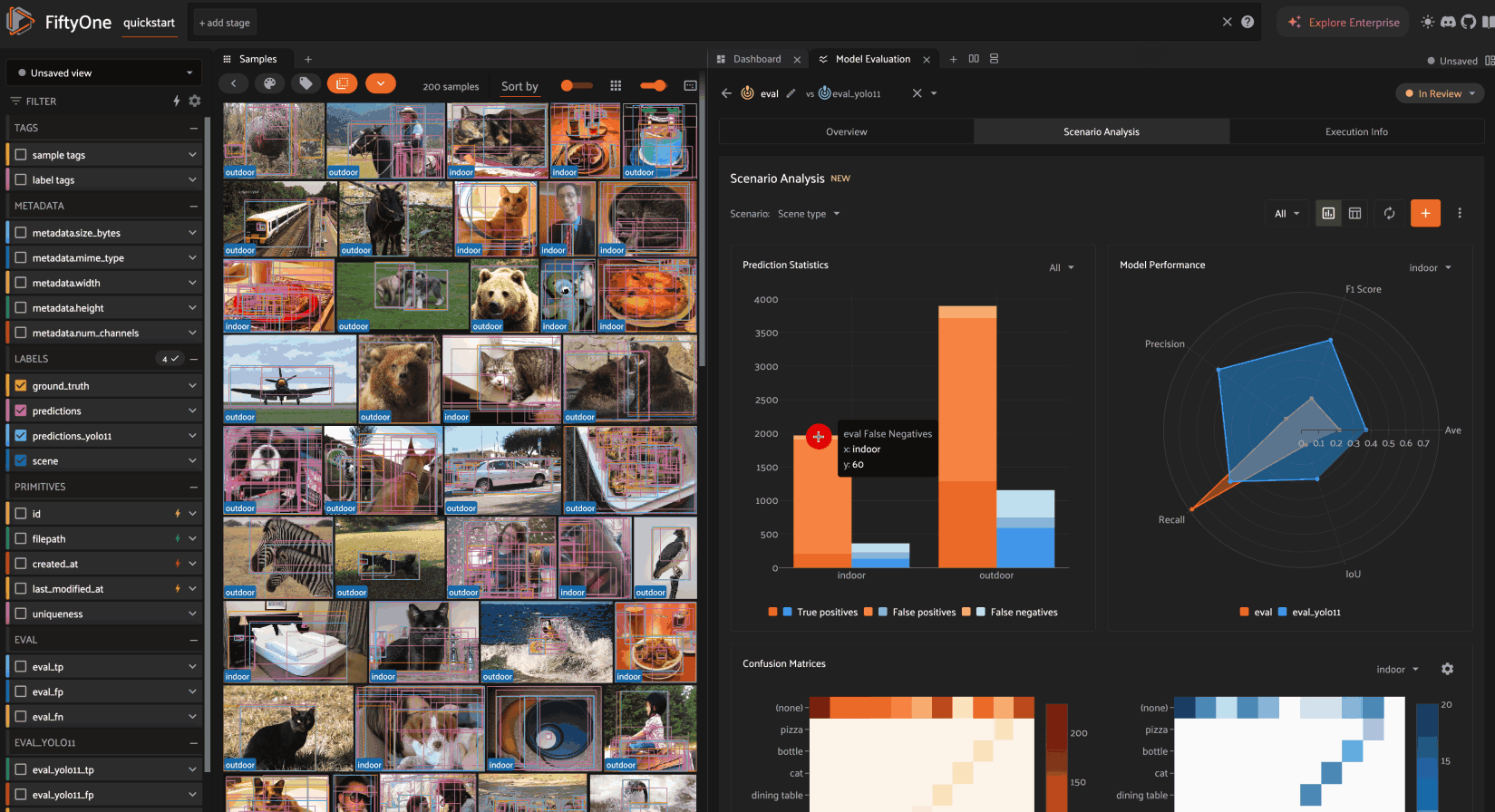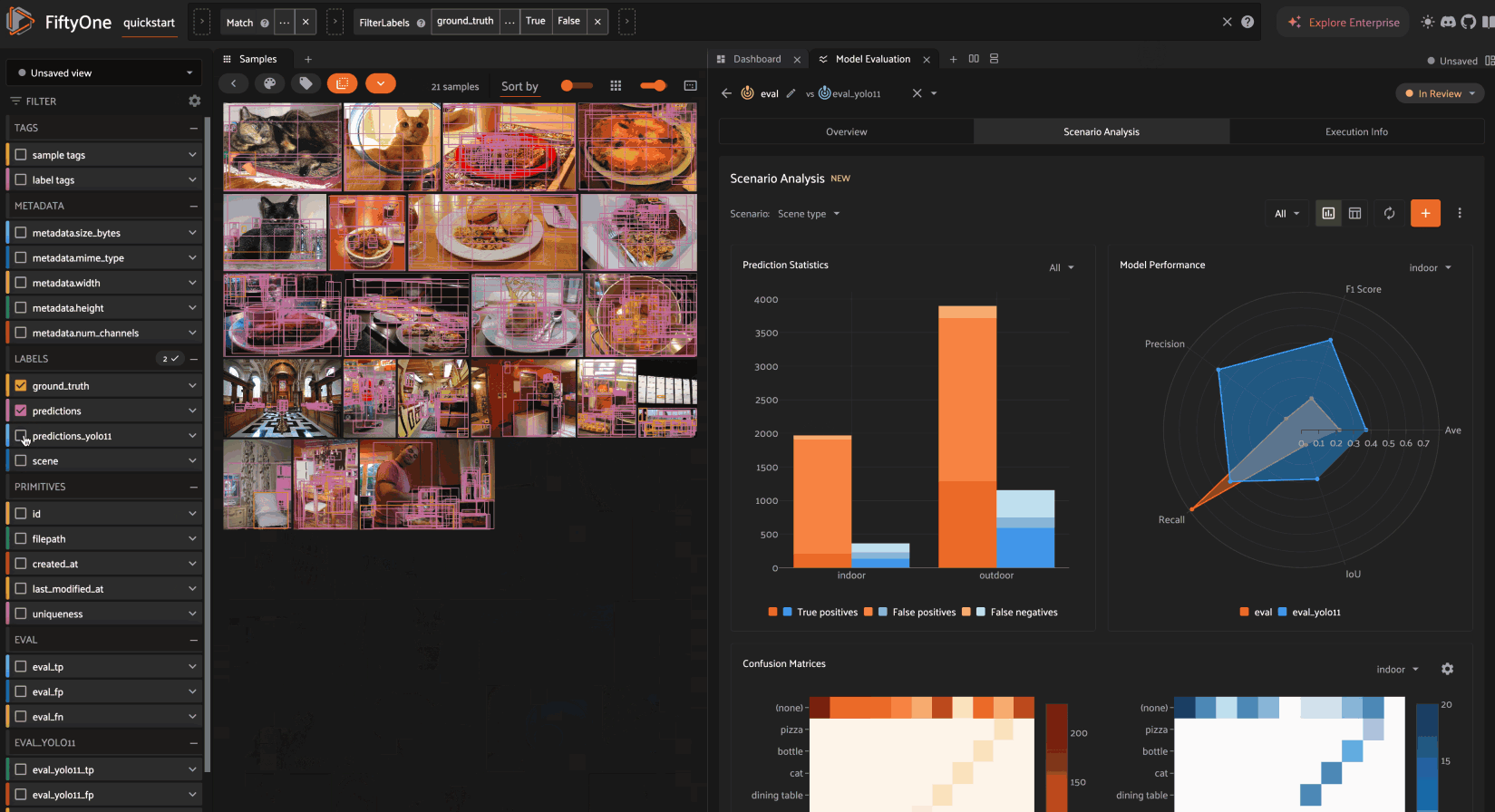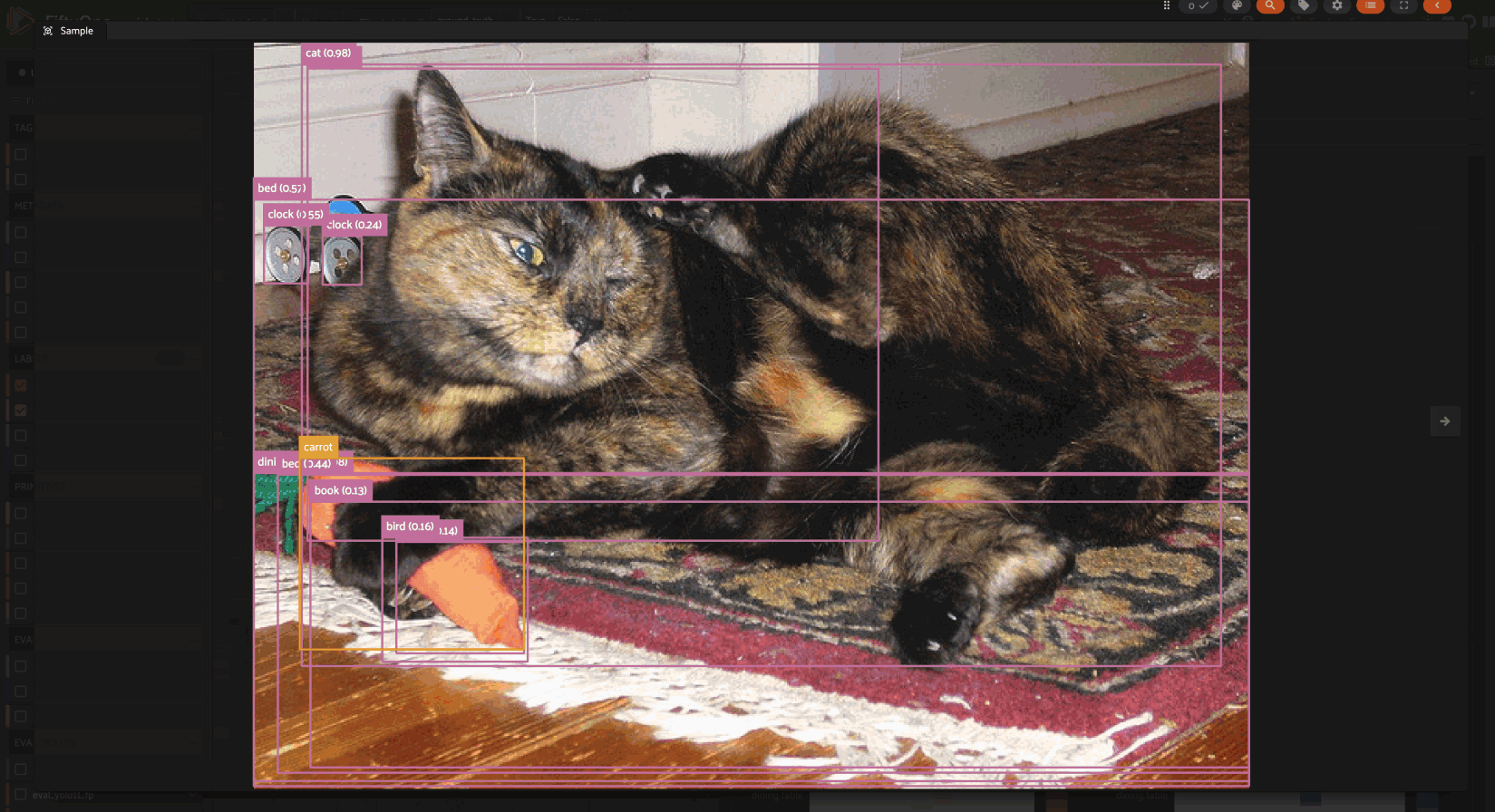
You can also view the results in tabular form by clicking the table icon in the upper right corner of the Scenario Analysis tab:
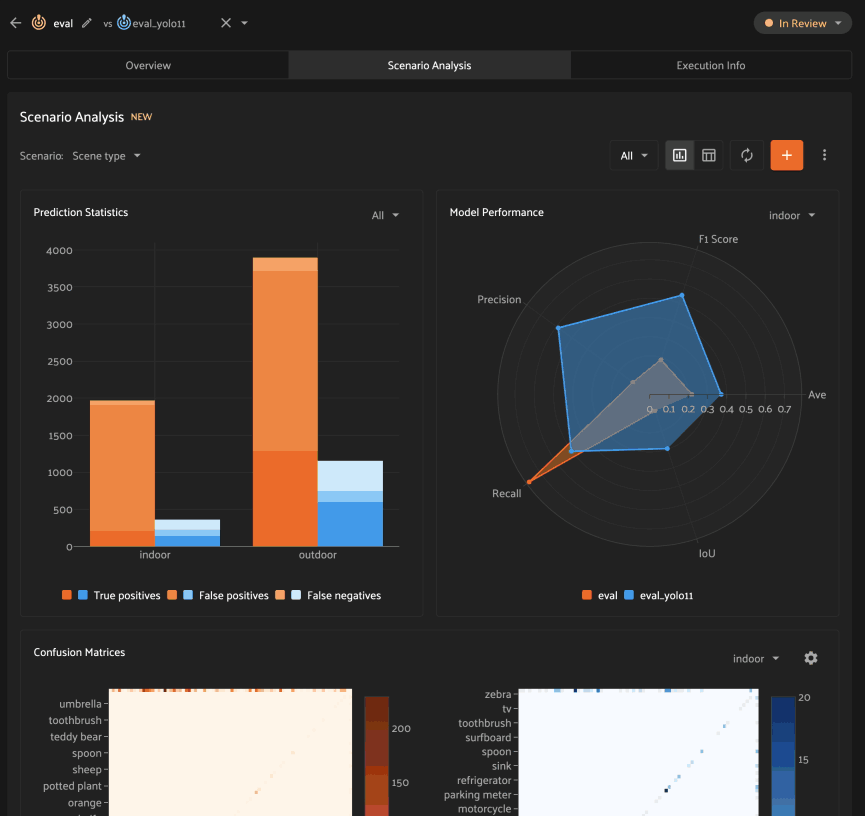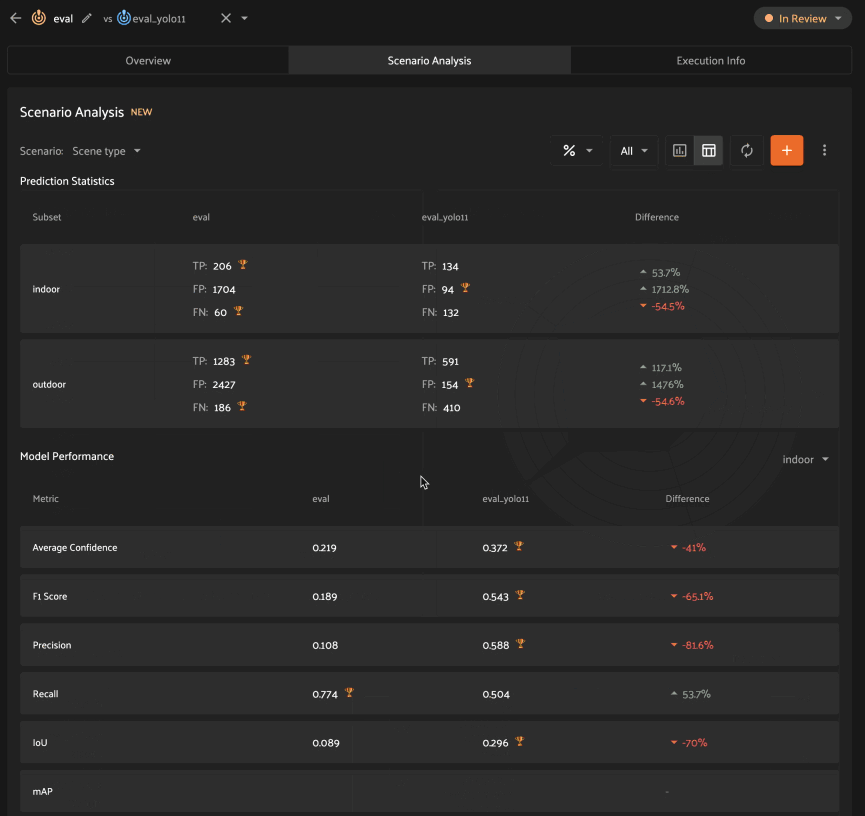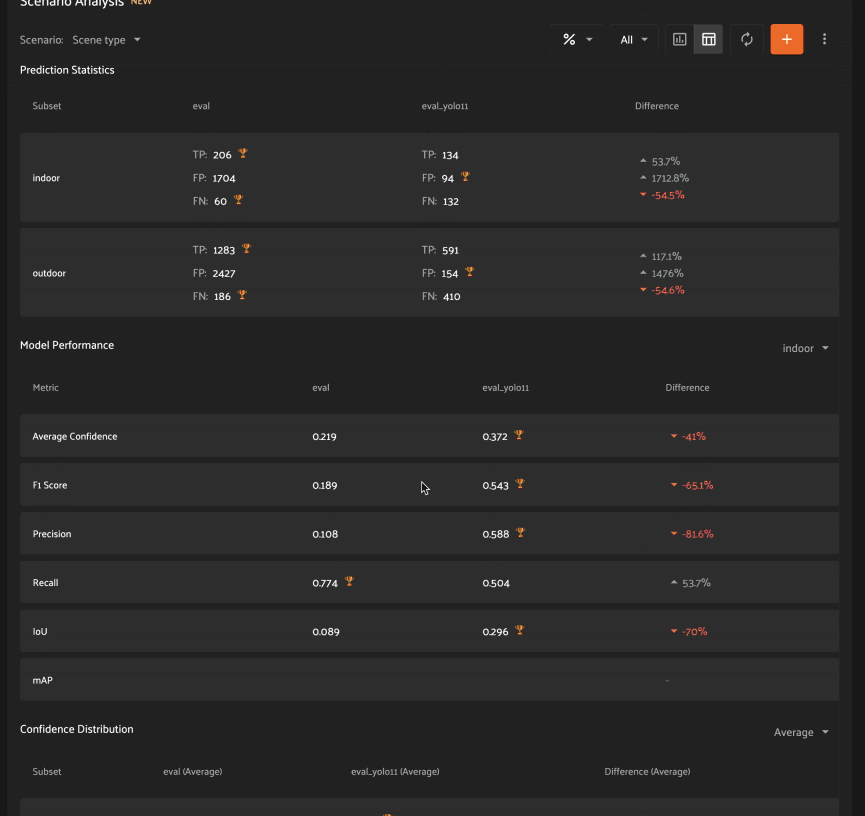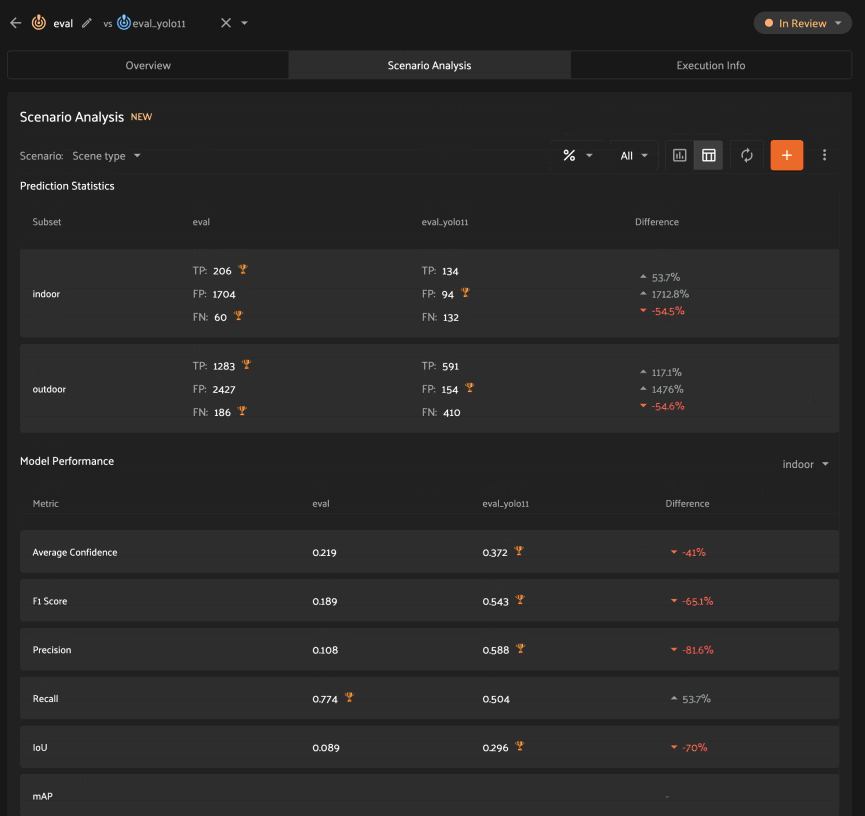
Updating scenarios#
Once generated, a scenario’s results are cached until the model evaluation is deleted or the scenario is edited. However, if the underlying dataset has changed in such a way that the samples/ground truth labels in a scenario has changed, you can click the refresh button at any time to regenerate the scenario’s results:
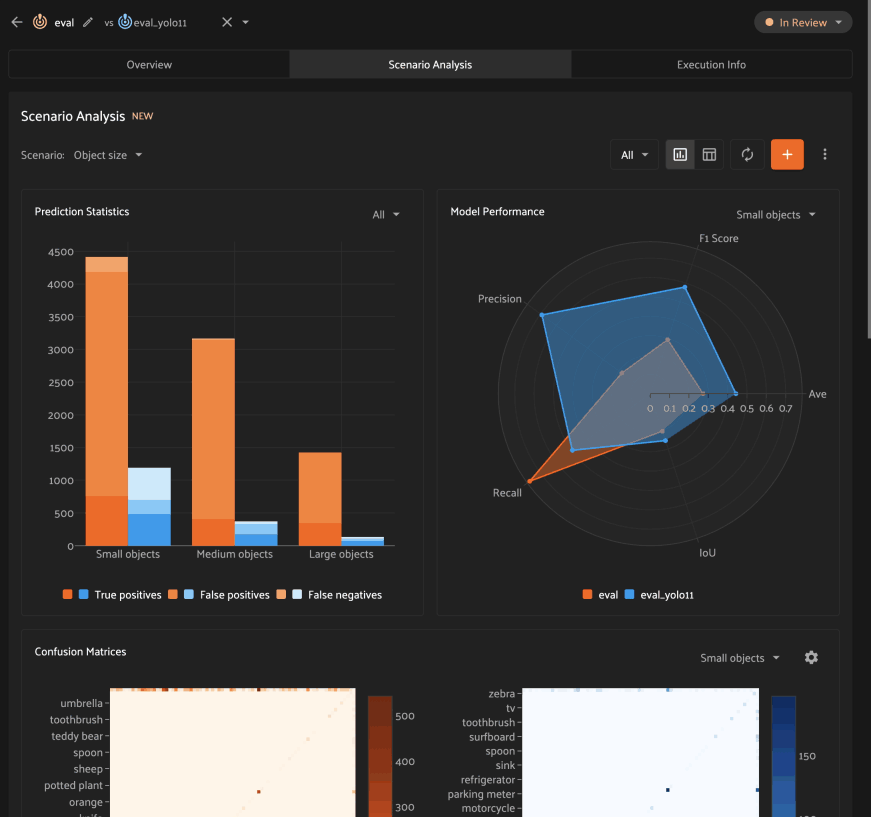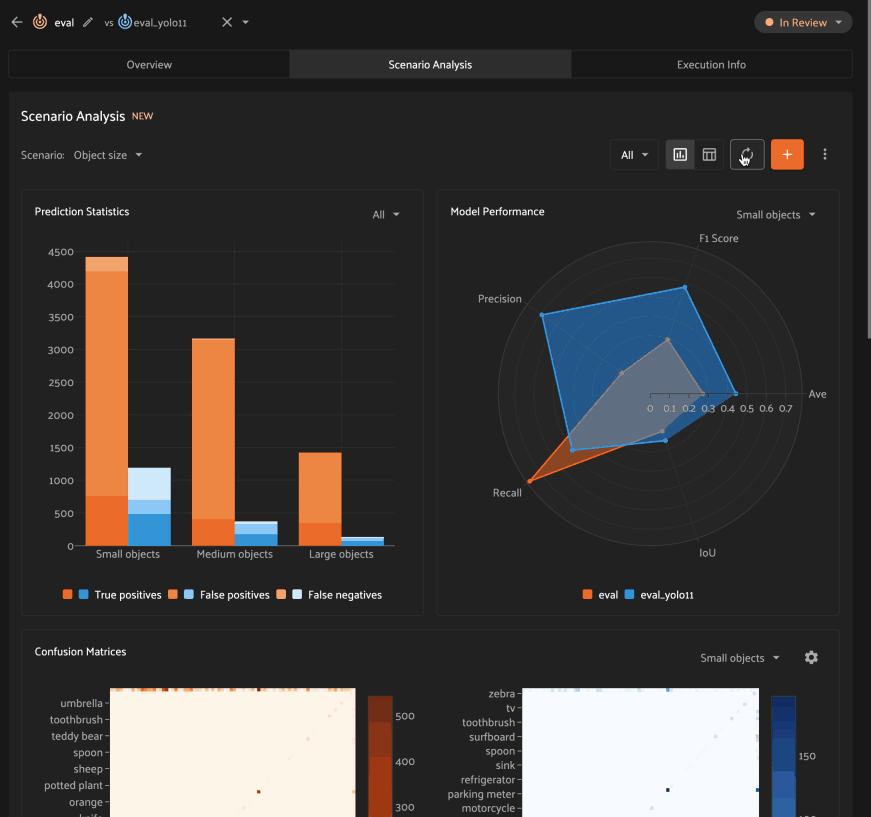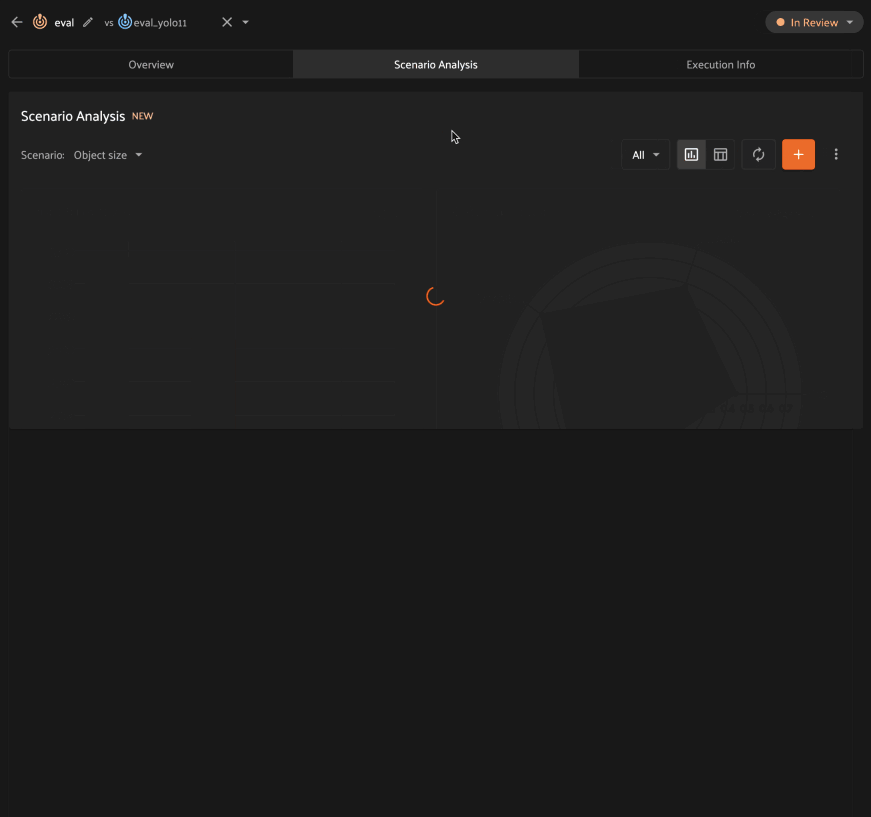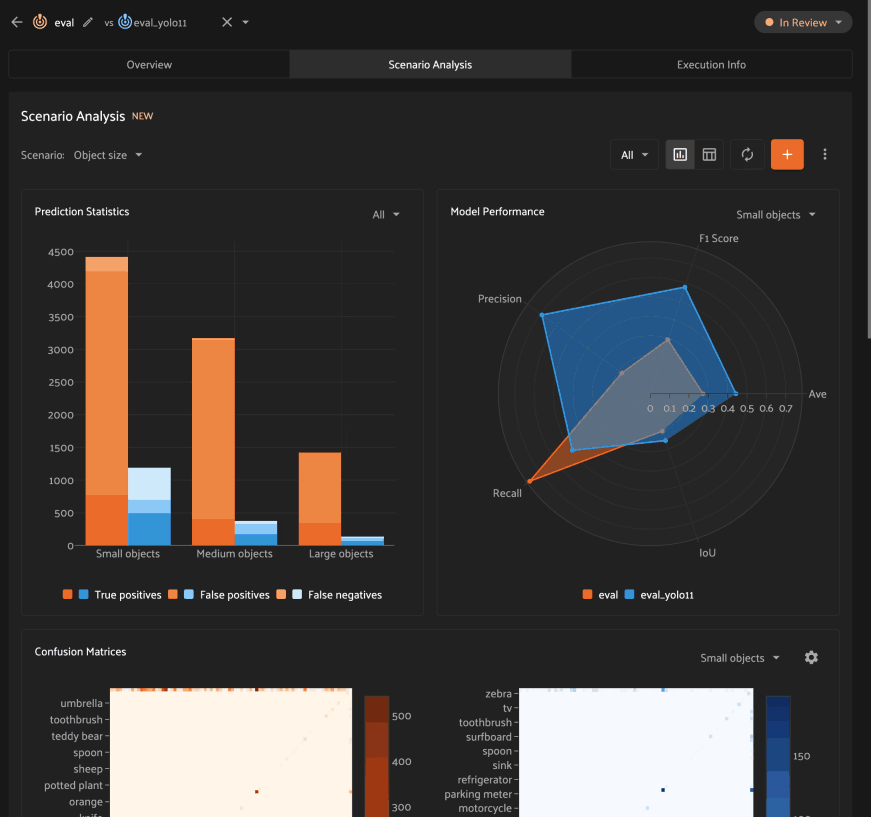
You can also create additional scenarios at any time by clicking the +
button:
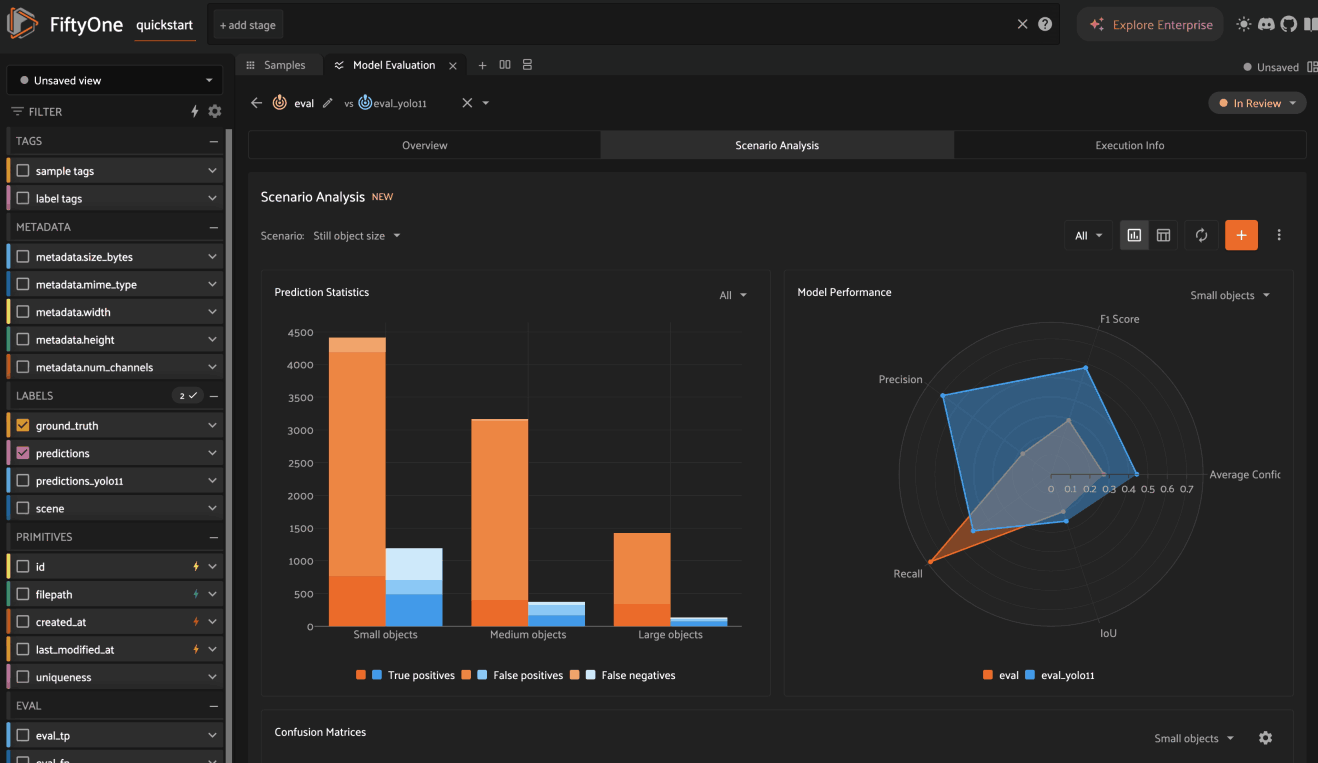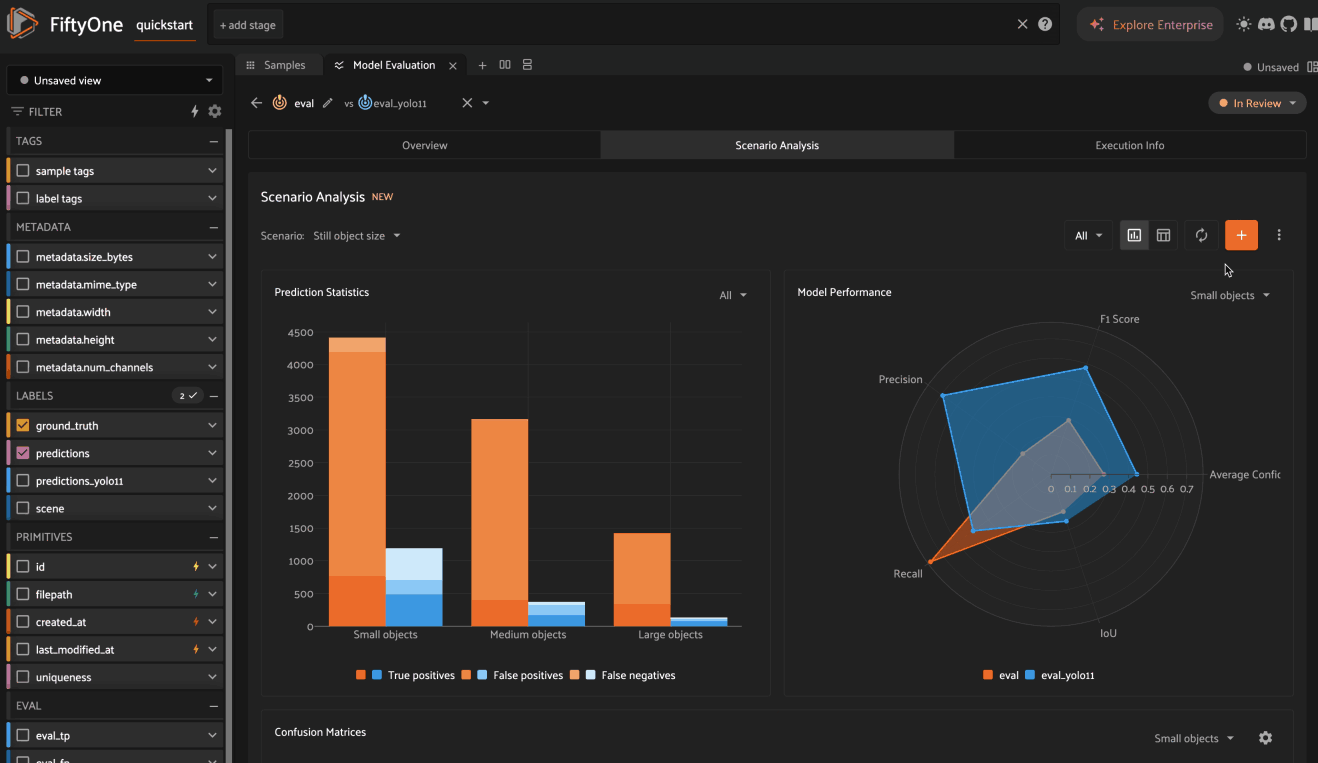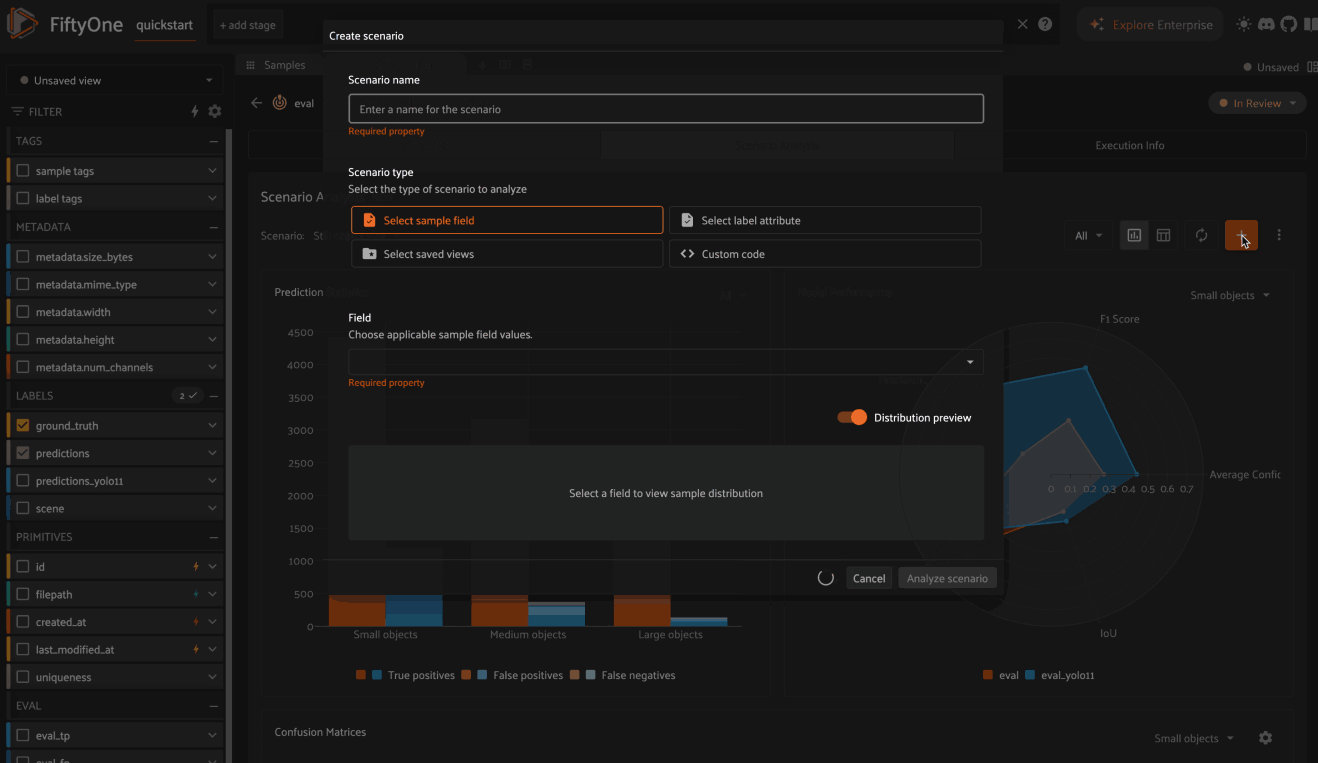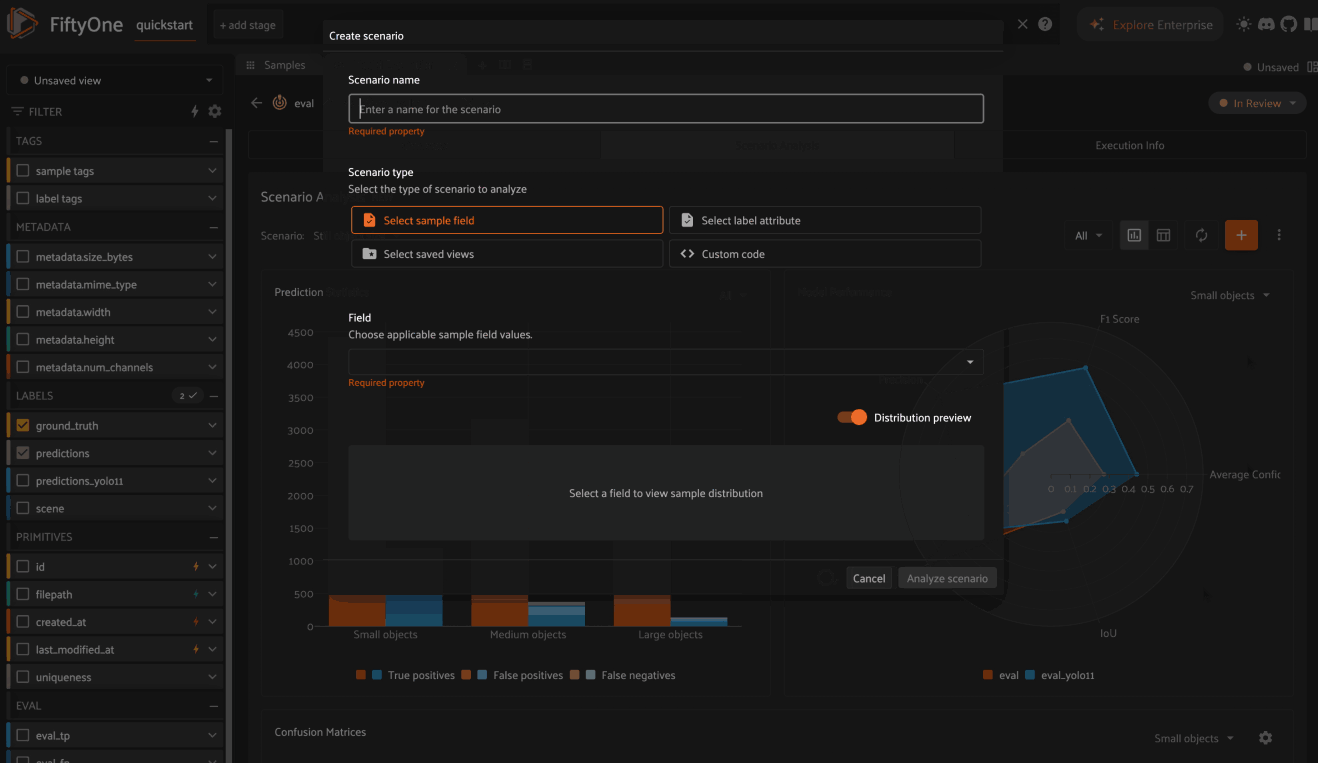
And you can edit or delete an existing scenario by selecting Edit or
Delete under the kebab menu:
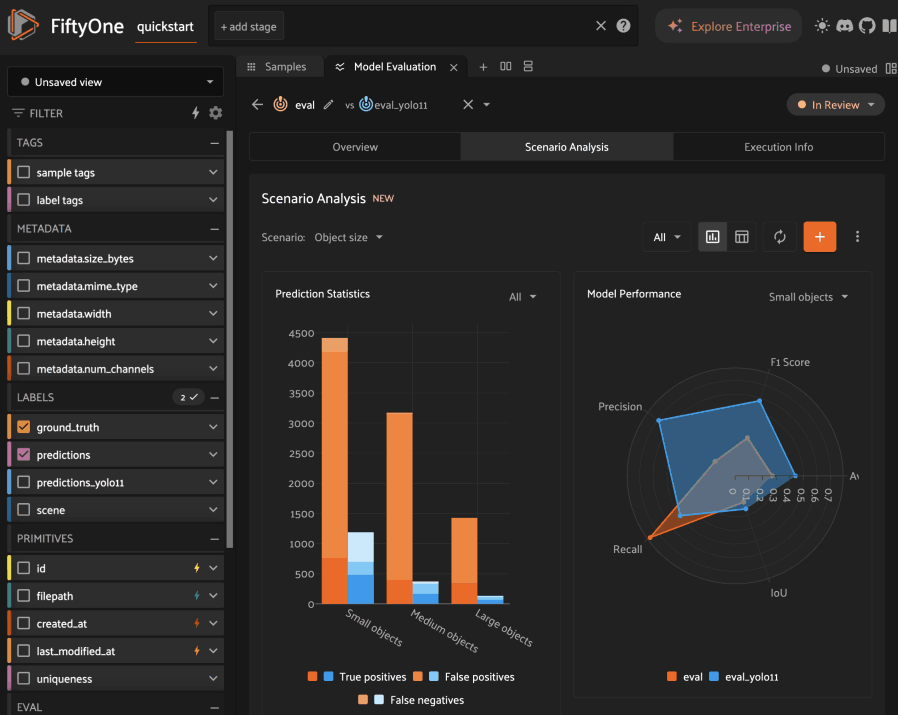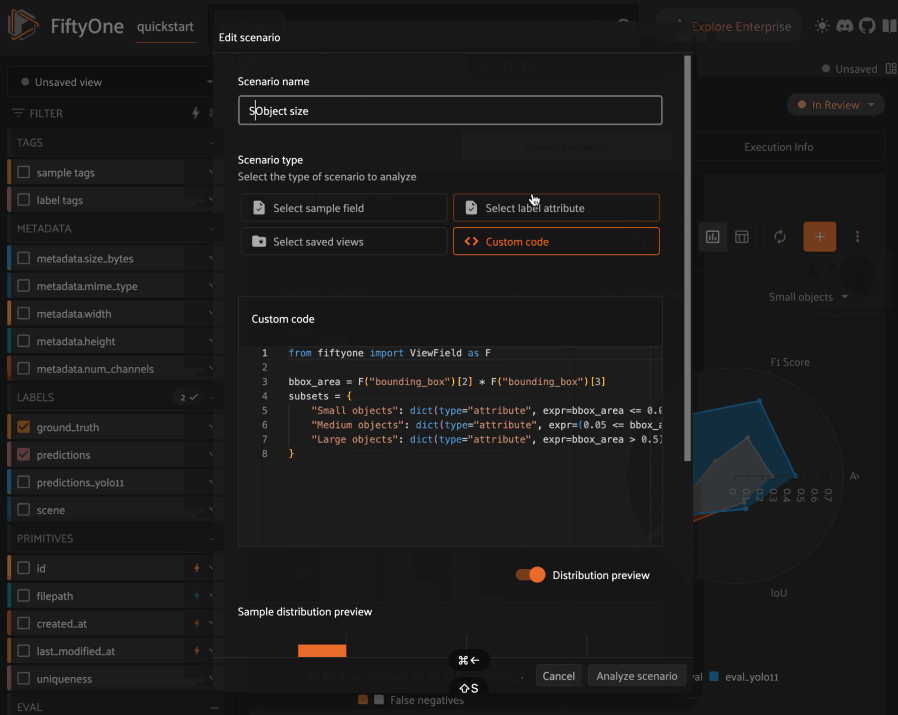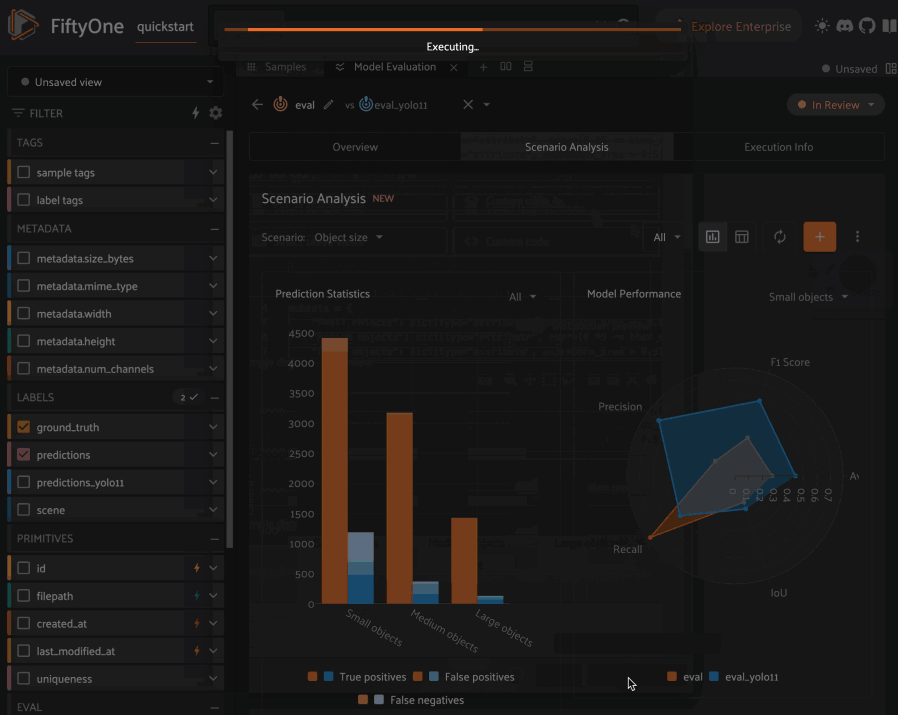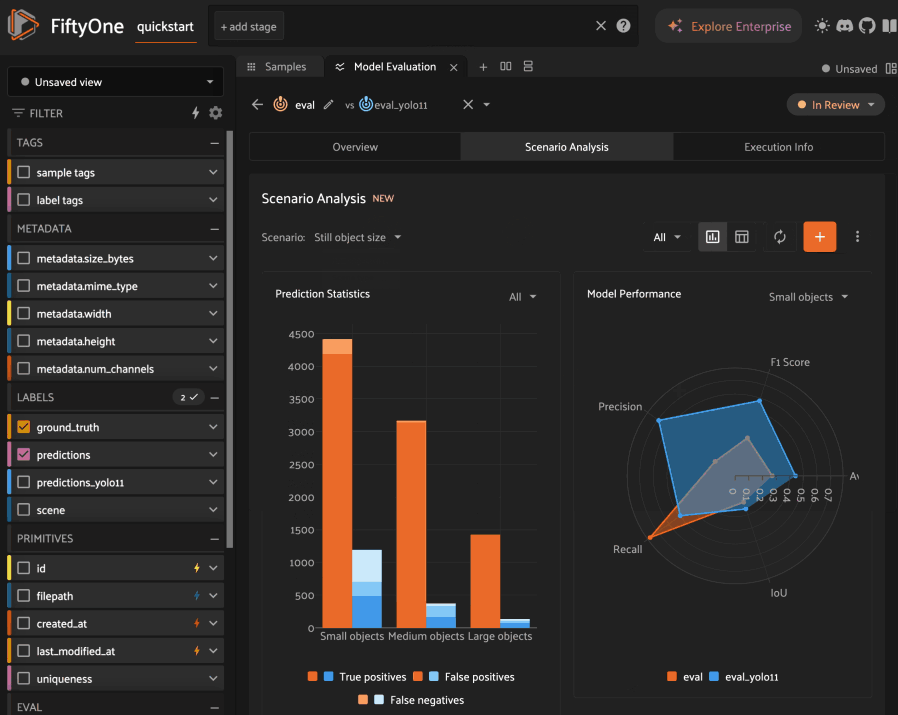
Map panel#
When you load a dataset in the App that contains a GeoLocation field with
point data populated, you can
open the Map panel to visualize and interactively explore a scatterplot of the
location data:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart-geo")
5
6session = fo.launch_app(dataset)
Note
You must configure a Mapbox access token in order to use the Map UI. See below for instructions.
FiftyOne uses the Mapbox GL JS API, which is free up to 50,000 map loads each month.
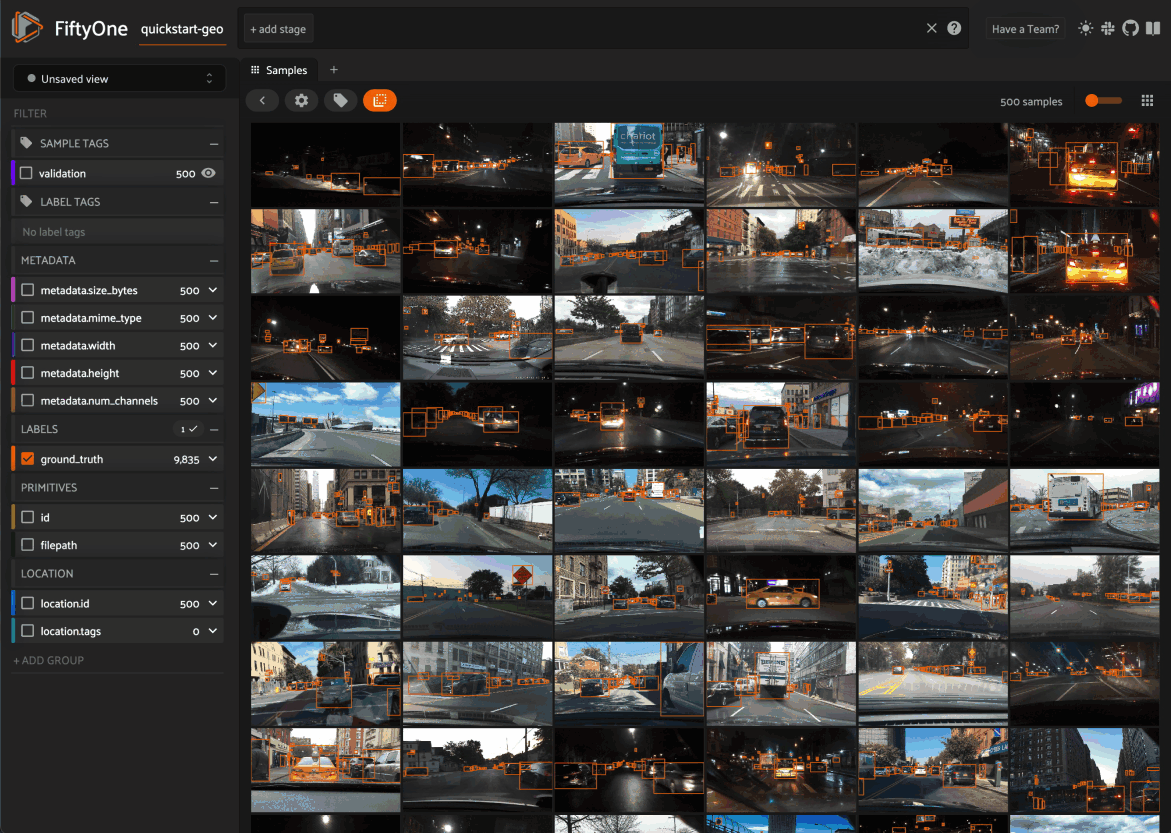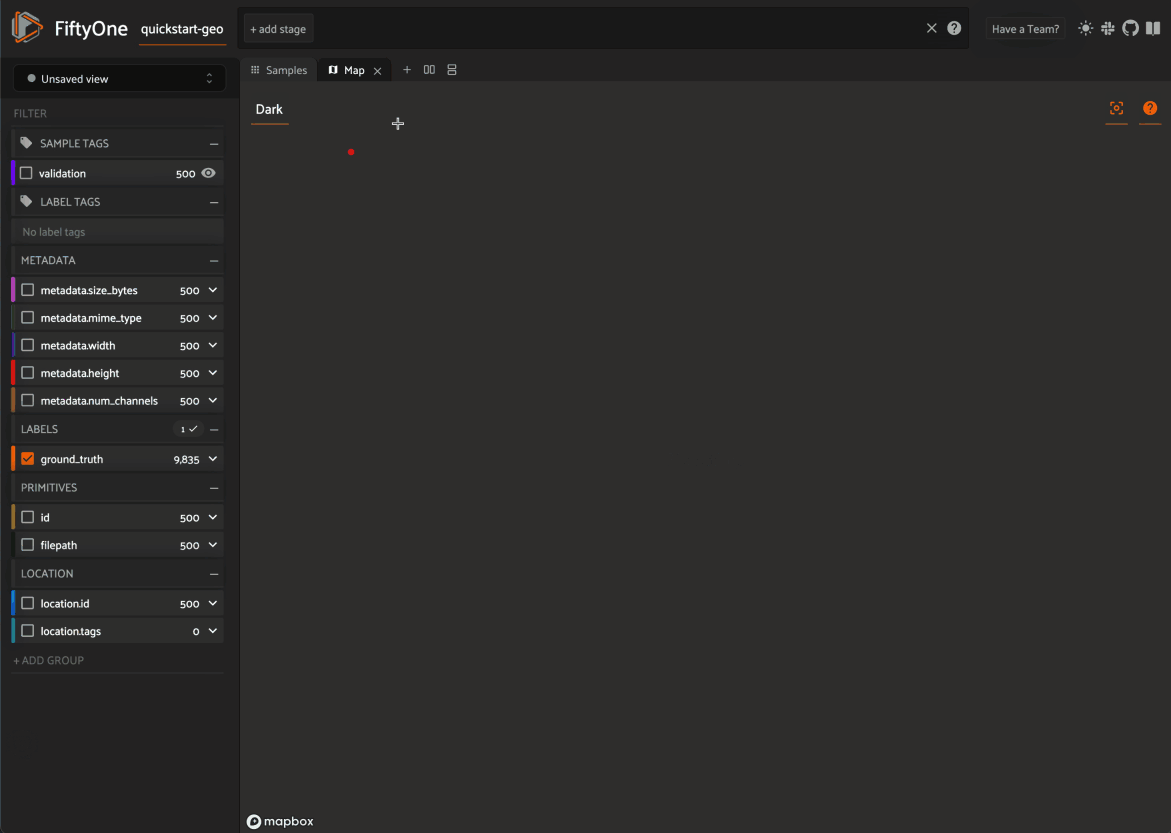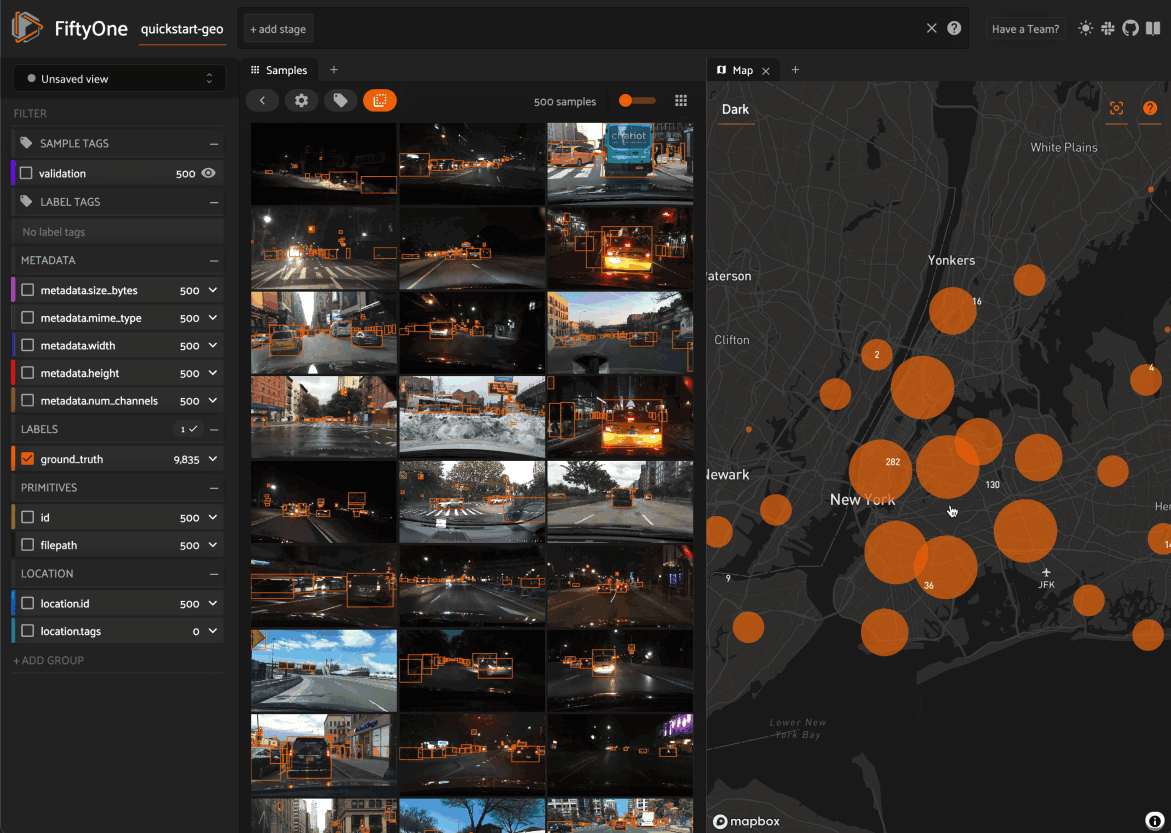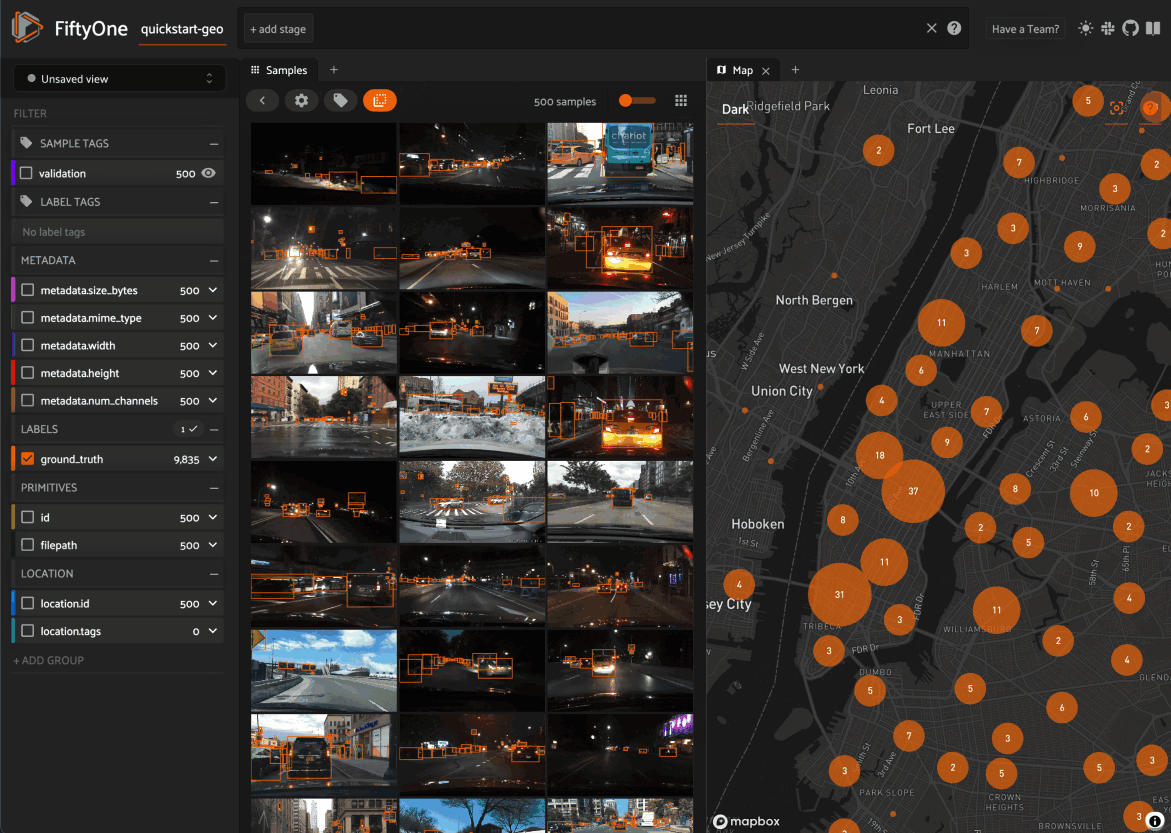
You can lasso points in the map to show only the corresponding data in the
Samples panel. Confirm the selection by either double-clicking the last
vertex or typing enter:
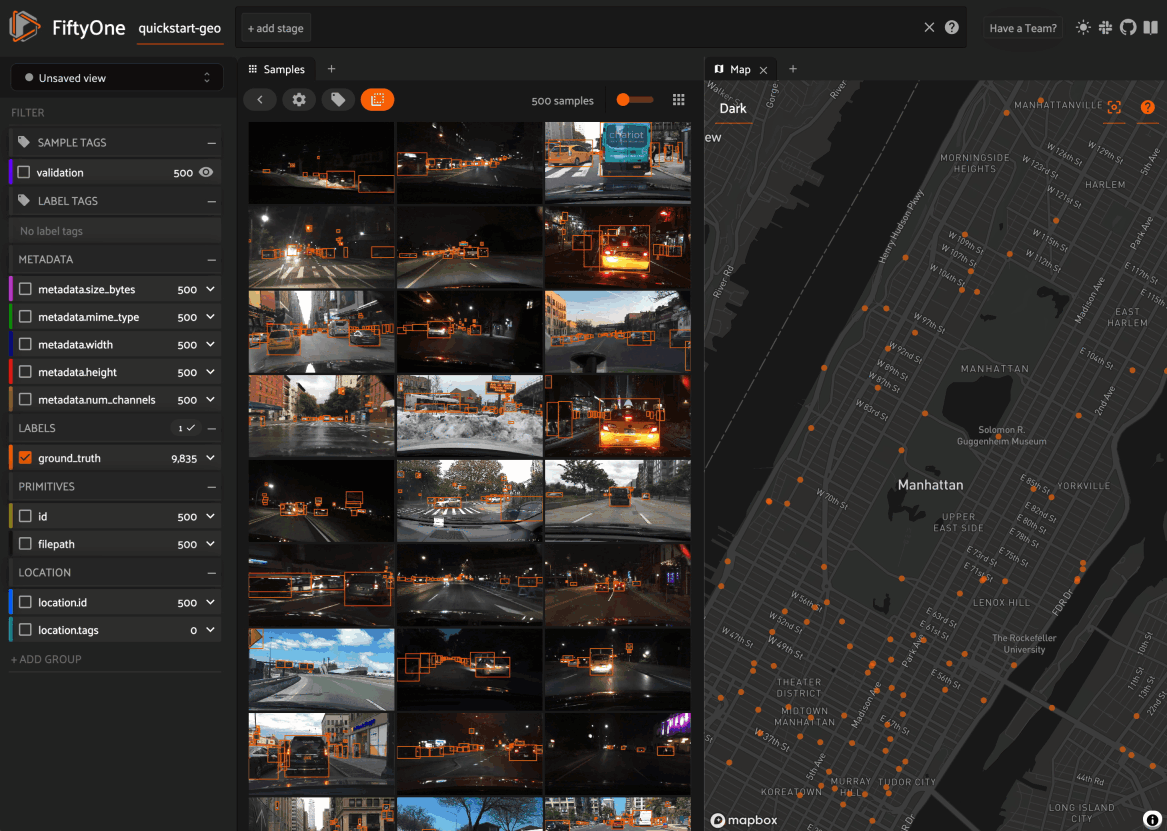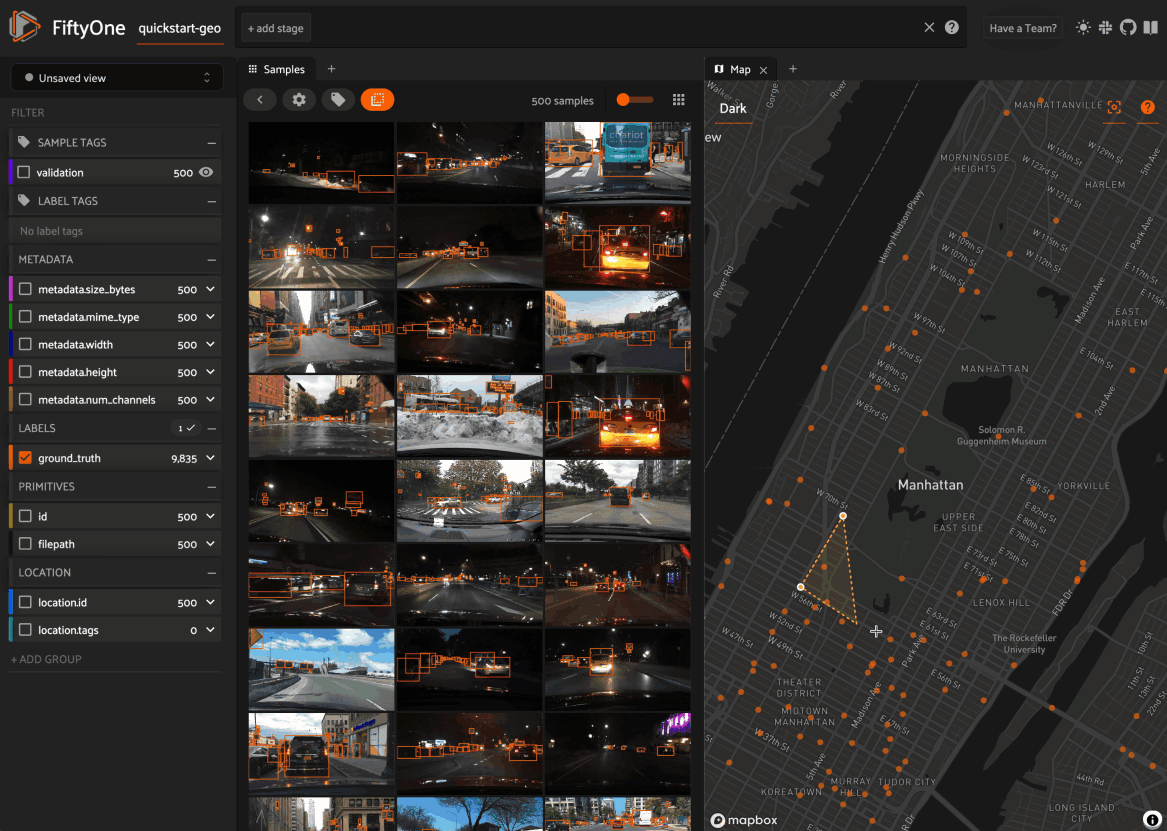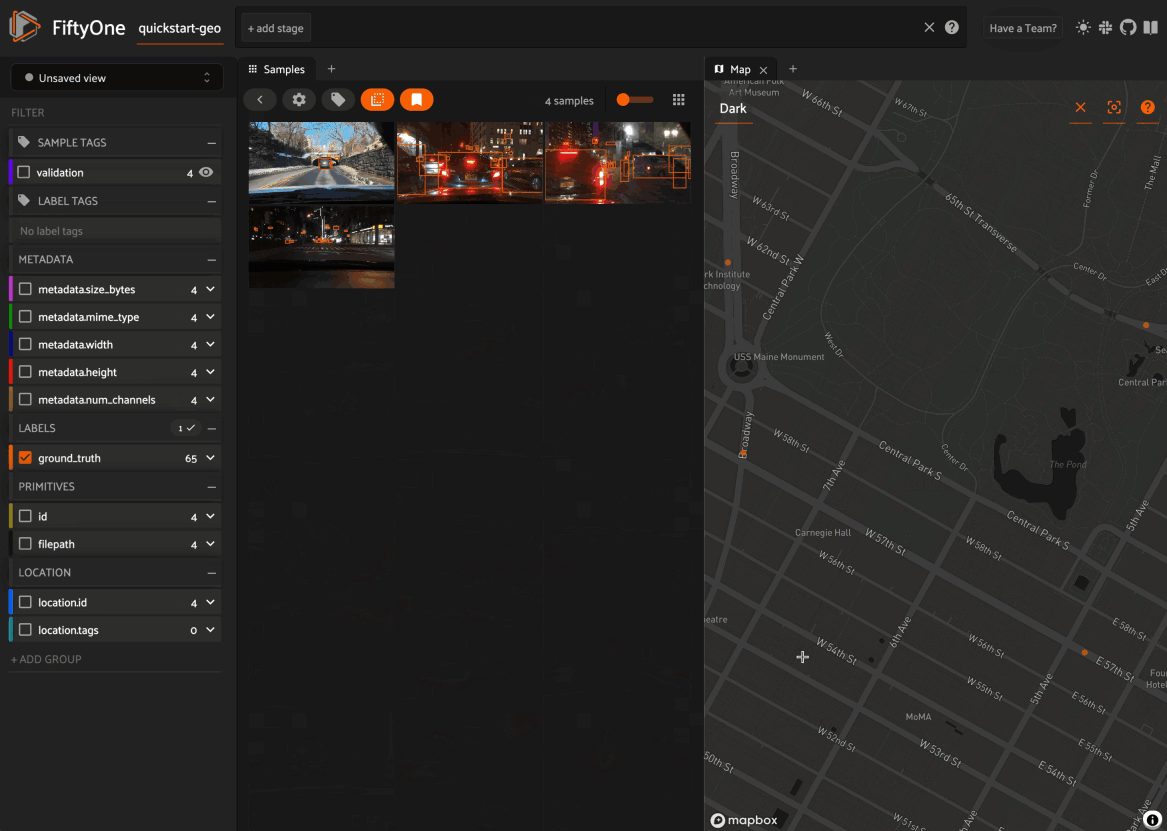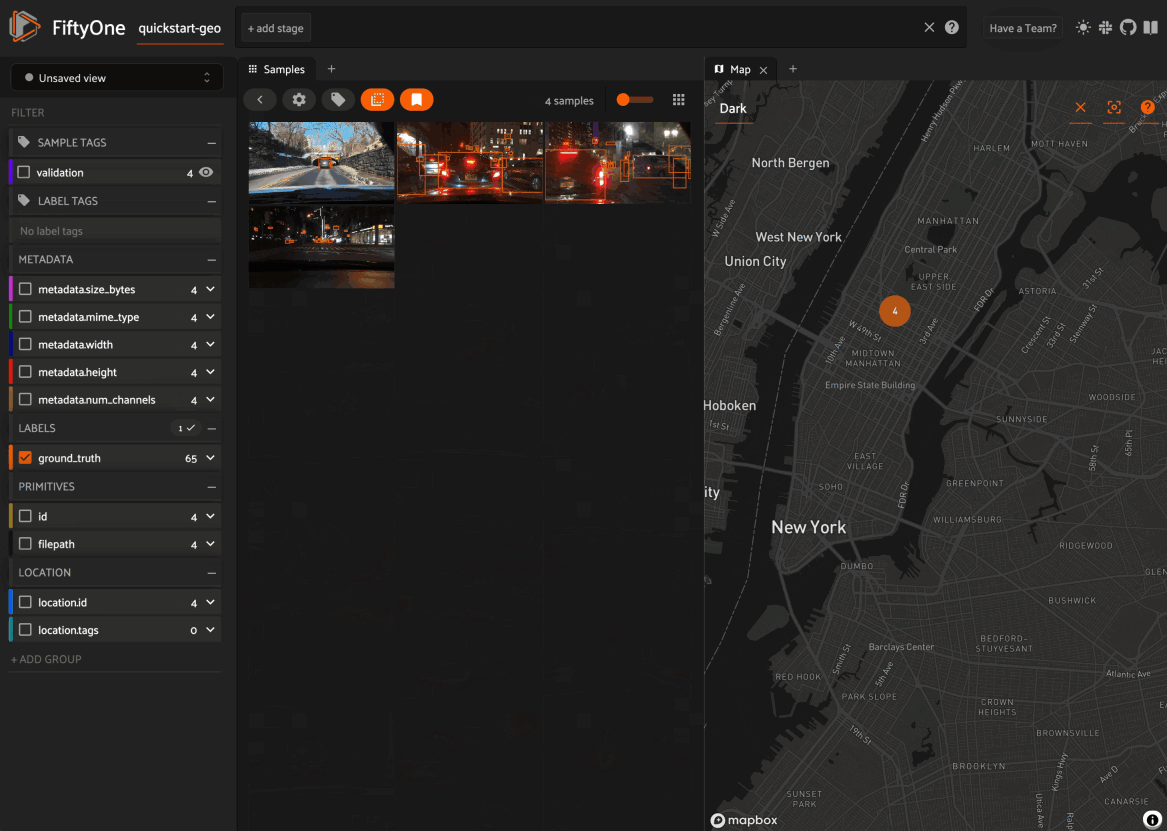
The map UI also provides a number of additional controls:
Use the menu in the upper-left corner to choose between the available map types
Press the
locateicon to reset the map’s viewport to a tight crop of the current view’s location dataPress the
xicon to clear the current selection
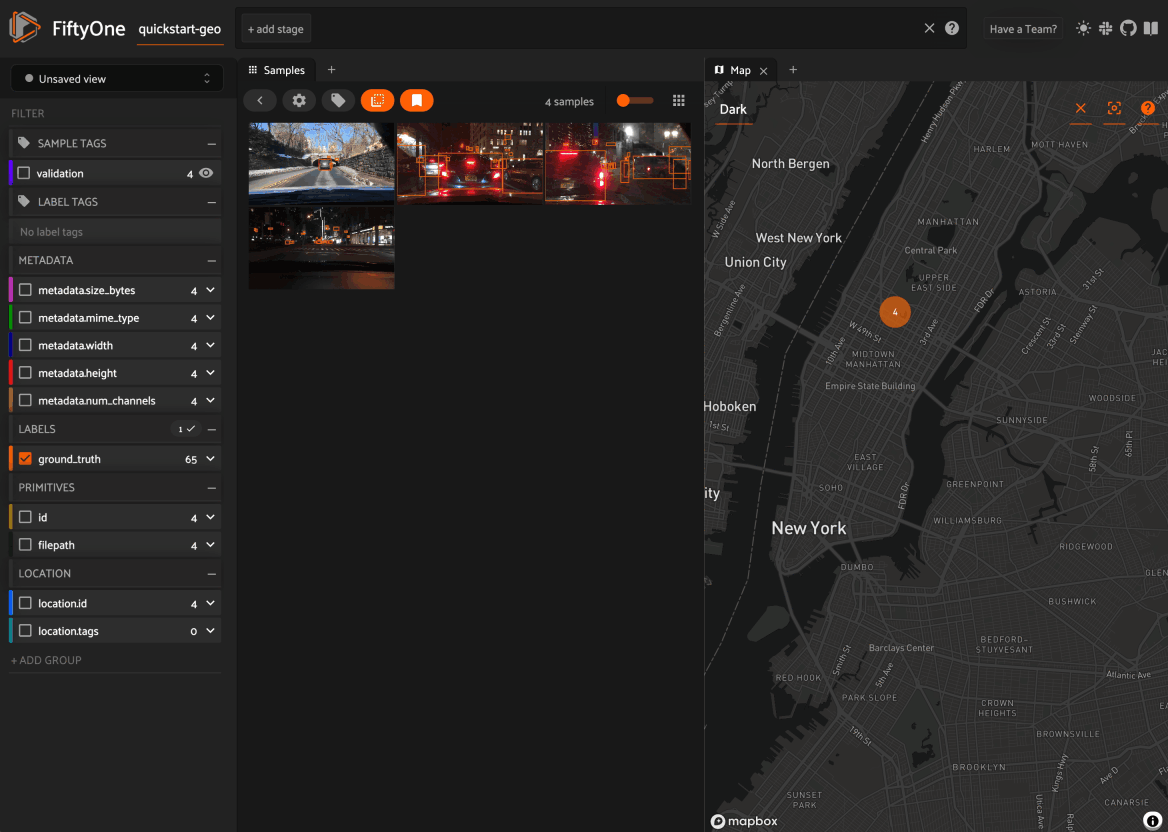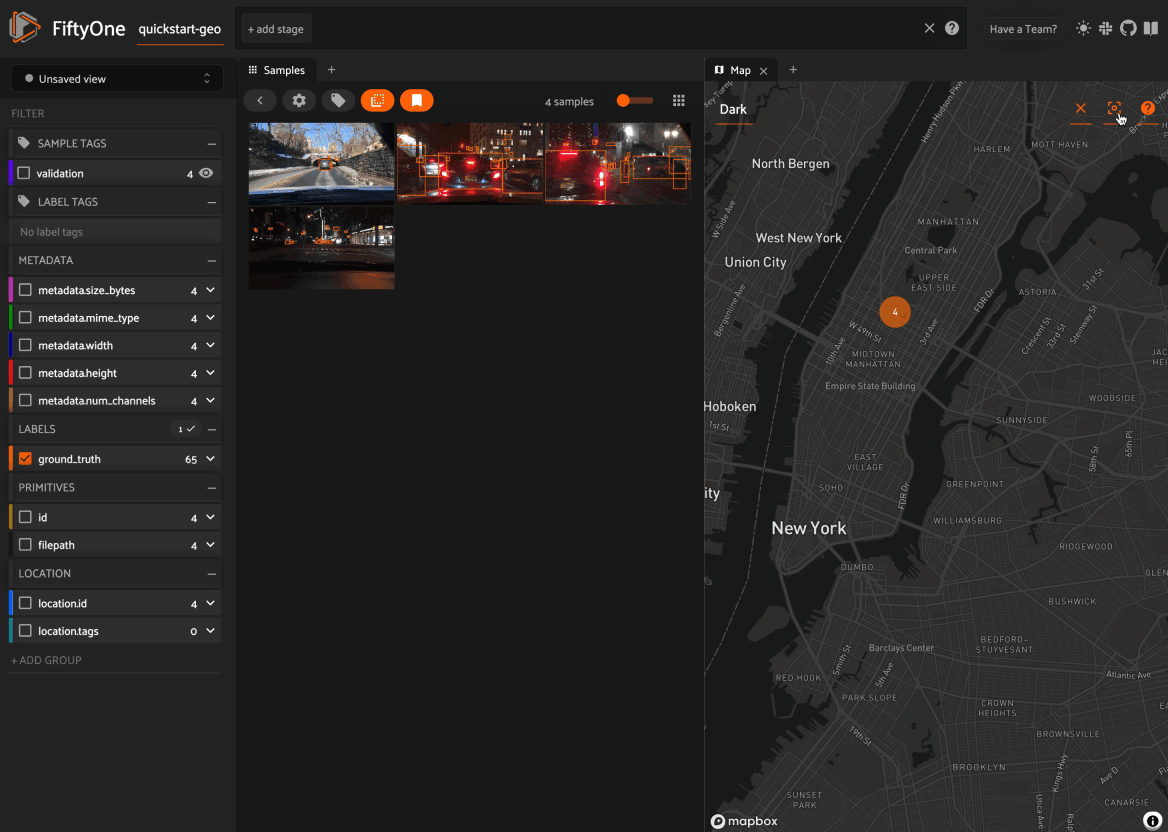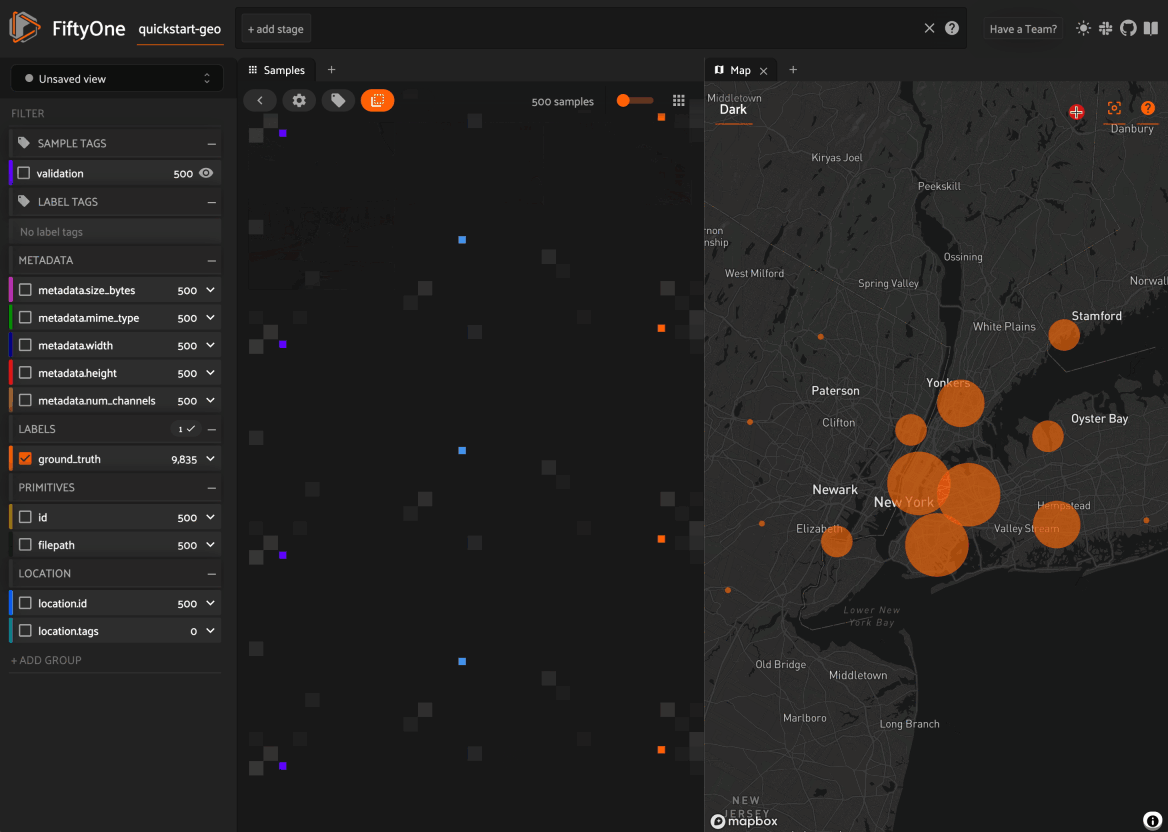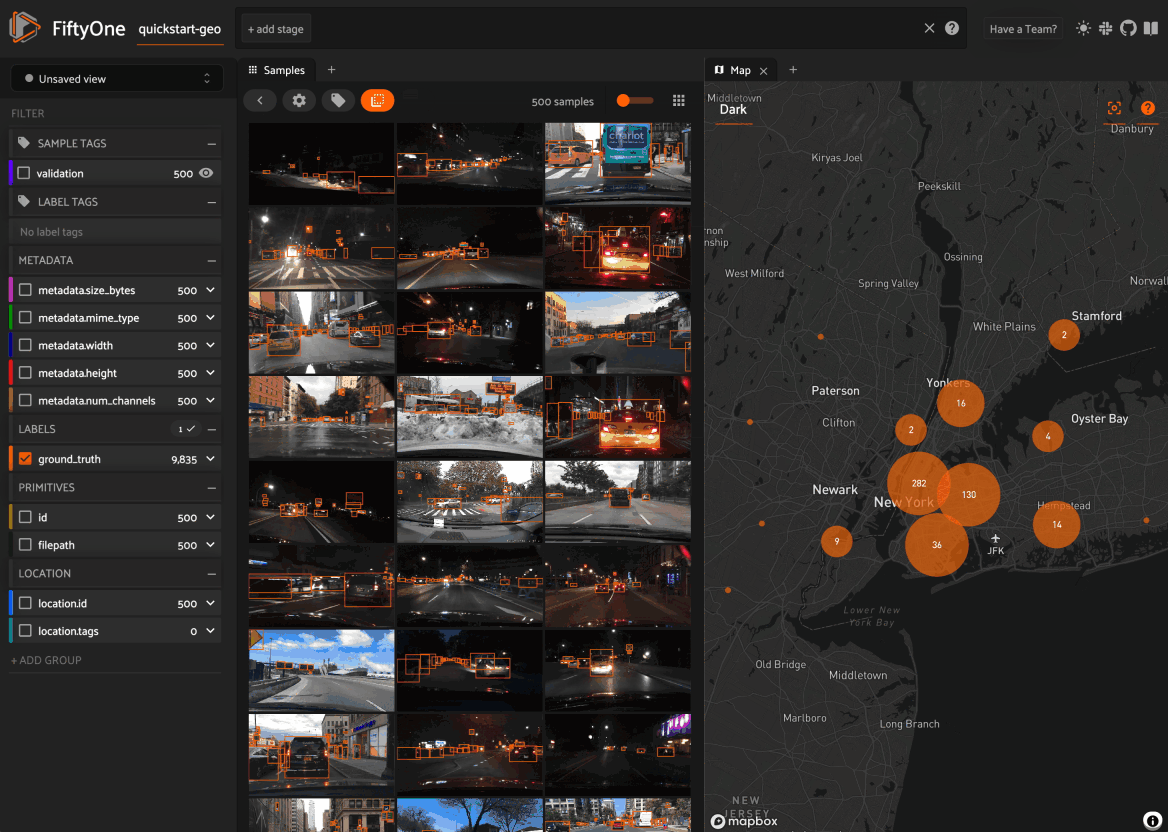
When configuring spaces in Python, you can define a Map panel as follows:
1map_panel = fo.Panel(type="Map")
Additionally, the map UI can be configured by including any subset of the
settings shown below under the plugins.map key of your
App config:
// The default values are shown below
{
"plugins": {
"map": {
// Your mapbox token. This is required
"mapboxAccessToken": "XXXXXXXX",
// Whether to enable clustering
"clustering": true,
// Never use clustering beyond this zoom level
// https://docs.mapbox.com/help/glossary/zoom-level
"clusterMaxZoom": 11,
// Controls the look and feel of clusters
"clusters": {
"paint": {
"circle-color": "rgb(244, 113, 6)",
"circle-opacity": 0.7,
// Step expressions can be used
// https://docs.mapbox.com/mapbox-gl-js/style-spec/#expressions-step
// 20px circles when point count is less than 10
// 30px circles when point count is between 10 and 25
// 40px circles when point count is greater than or equal to 25
"circle-radius": ["step", ["get", "point_count"], 20, 10, 30, 25, 40]
}
},
// Controls the look and feel of individual scatter points
"pointPaint": {
"circle-color": "rgb(244, 113, 6)",
"circle-opacity": 0.7,
"circle-radius": 4
}
}
}
}
If you prefer, you can provide your Mapbox token by setting the MAPBOX_TOKEN
environment variable:
export MAPBOX_TOKEN=XXXXXXXX
You can also store dataset-specific plugin settings by storing any subset of the above values on a dataset’s App config:
1# Disable clustering for this dataset
2dataset.app_config.plugins["map"] = {"clustering": False}
3dataset.save()
Note
Dataset-specific plugin settings will override any settings from your global App config.
Histograms panel#
The Histograms panel in the App lets you visualize different statistics about the fields of your dataset.
The
Sample tagsandLabel tagsmodes show the distribution of any tags that you’ve added to your datasetThe
Labelsmode shows the class distributions for each labels field that you’ve added to your dataset. For example, you may have histograms of ground truth labels and one more sets of model predictionsThe
Other fieldsmode shows distributions for numeric (integer or float) or categorical (e.g., string) primitive fields that you’ve added to your dataset. For example, if you computed uniqueness on your dataset, a histogram of uniqueness values will be available under this mode.
Note
The statistics in the plots automatically update to reflect the current view that you have loaded in the App!
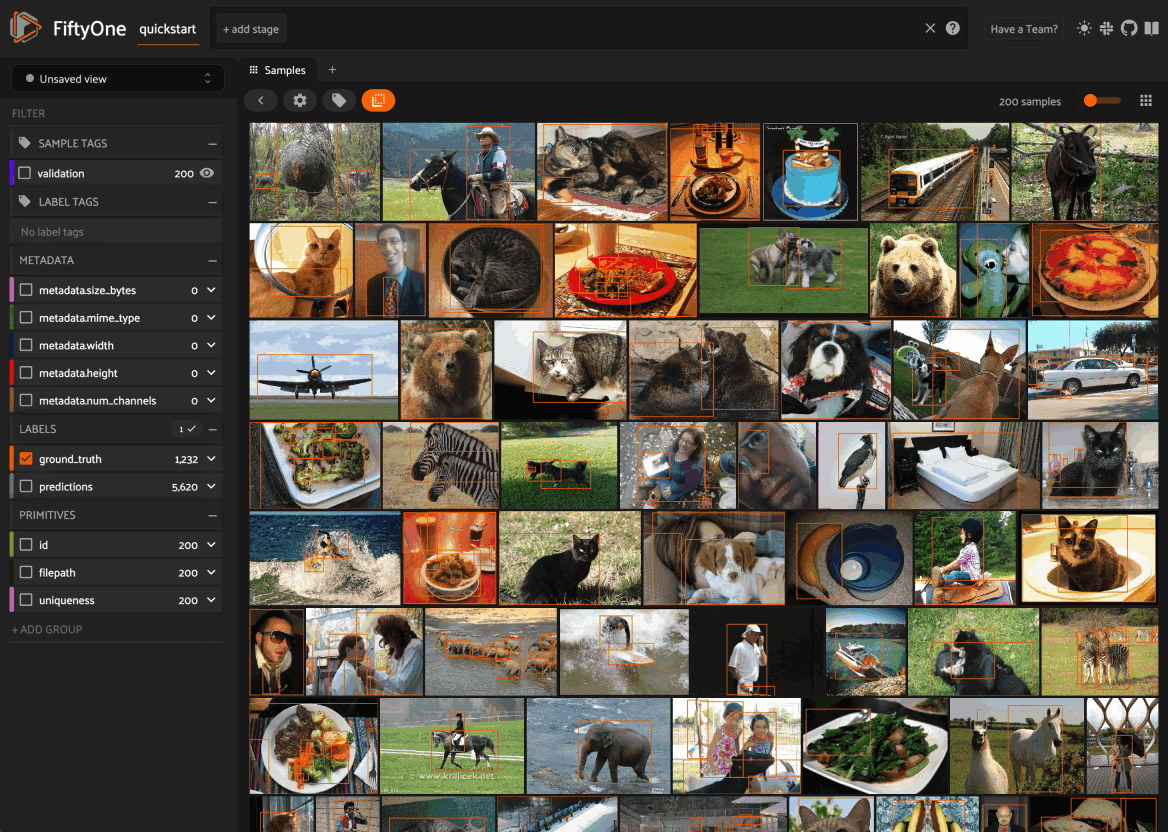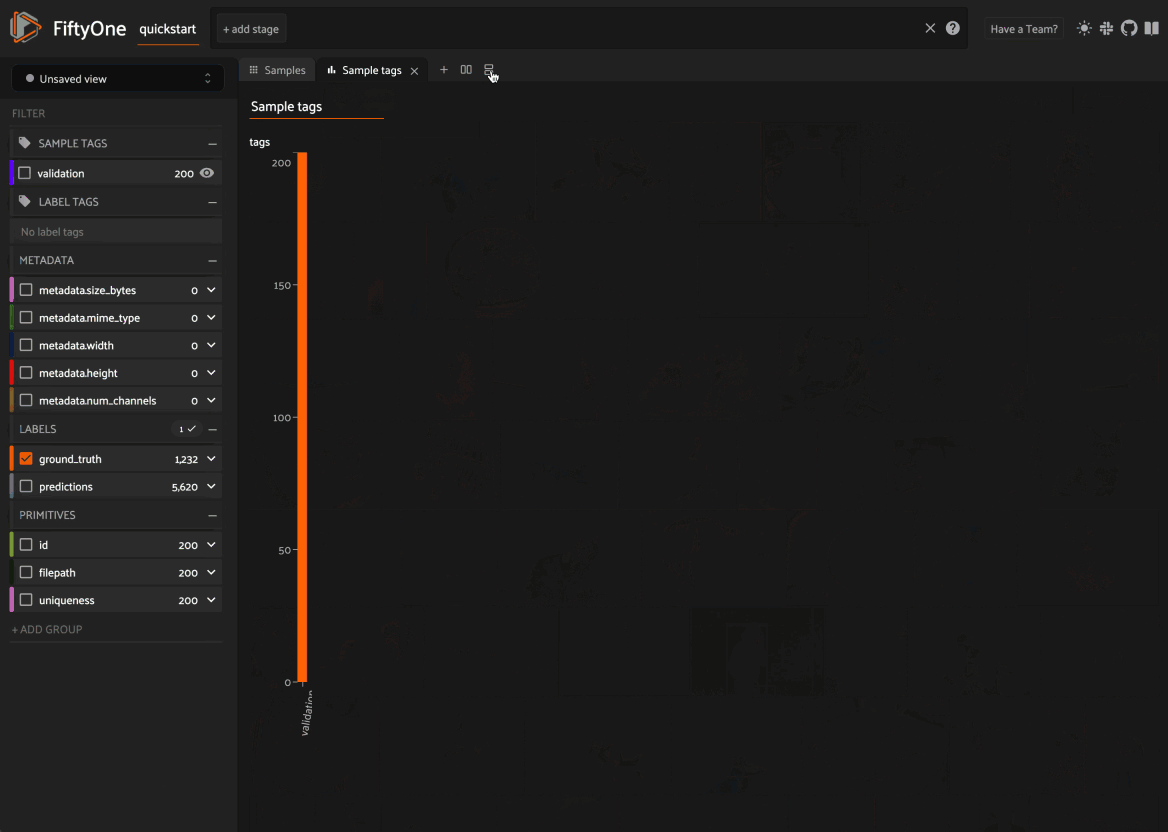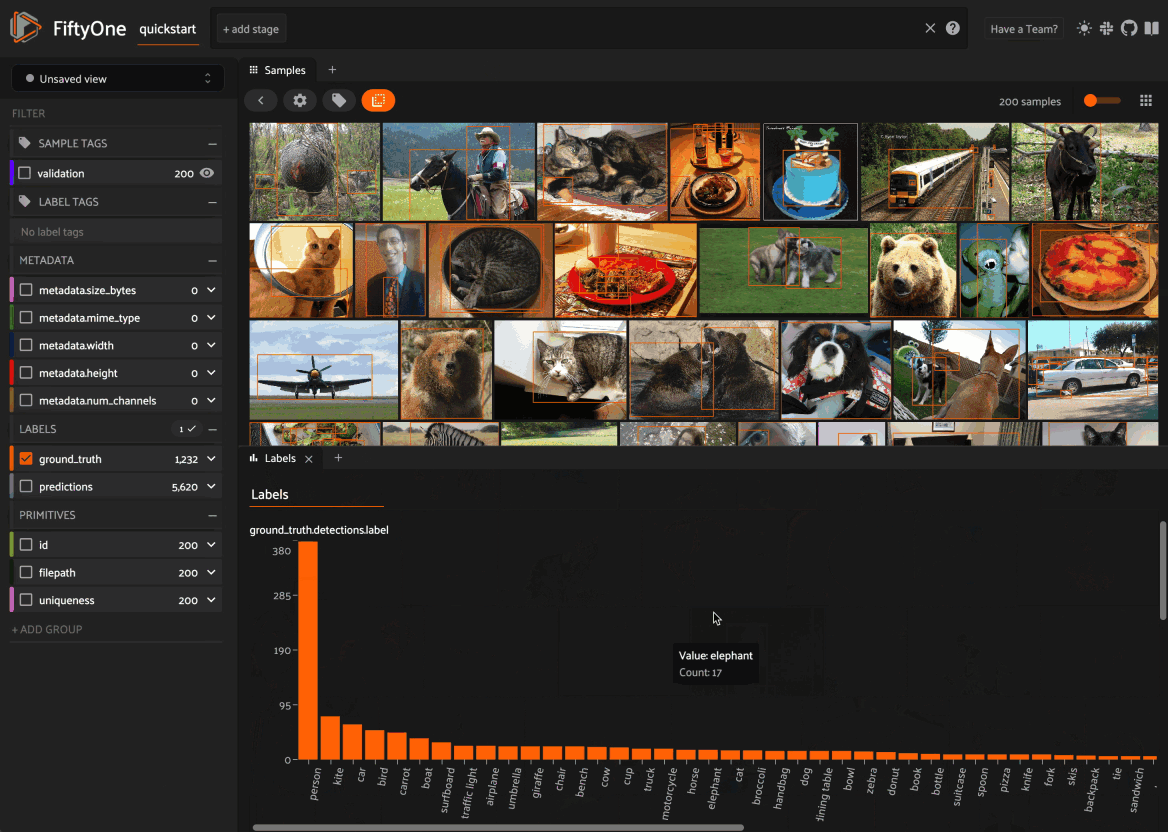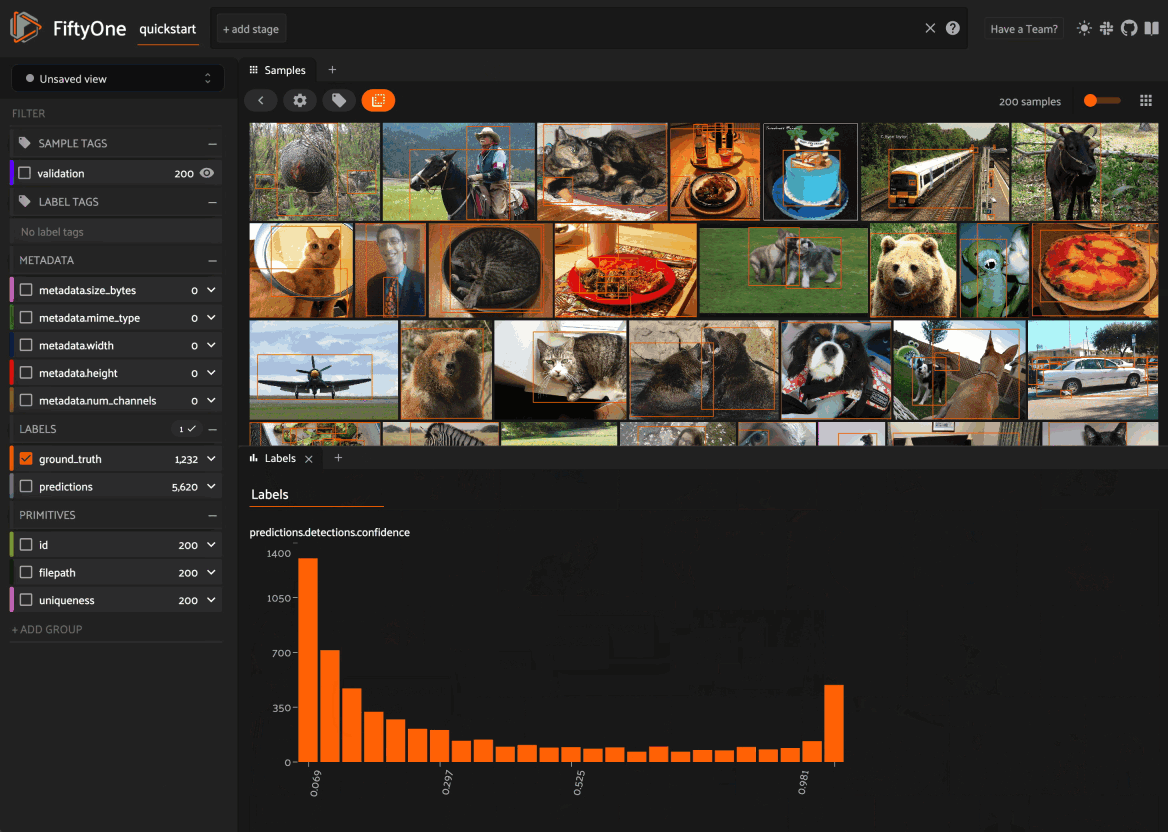
When configuring spaces in Python, you can define a Histograms panel as follows:
1histograms_panel = fo.Panel(type="Histograms", state=dict(plot="Labels"))
The Histograms panel supports the following state parameters:
plot: the histograms to plot. Supported values are
"Sample tags","Label tags","Labels", and"Other fields"
Selecting content#
The App supports selecting content such as samples or specific labels, which is useful to take contextual actions like tagging on only the selected content.
Selecting samples#
As previously explained, the Session object created when you launch the App
lets you interact with the App from your Python process.
One common workflow is to select samples visually in the App and then access the data for the selected samples in Python. To perform this workflow, first select some samples in the App:
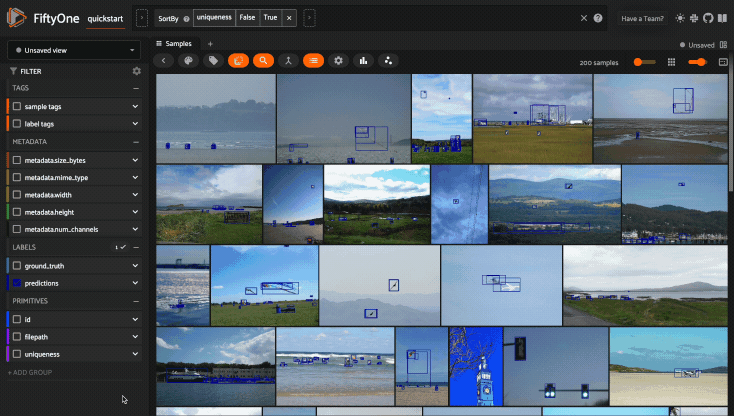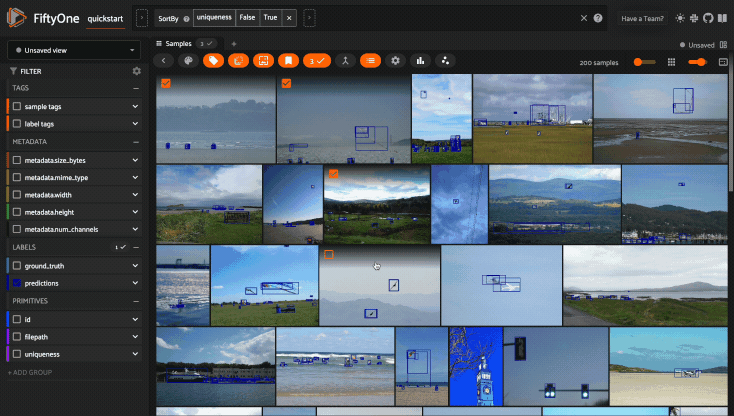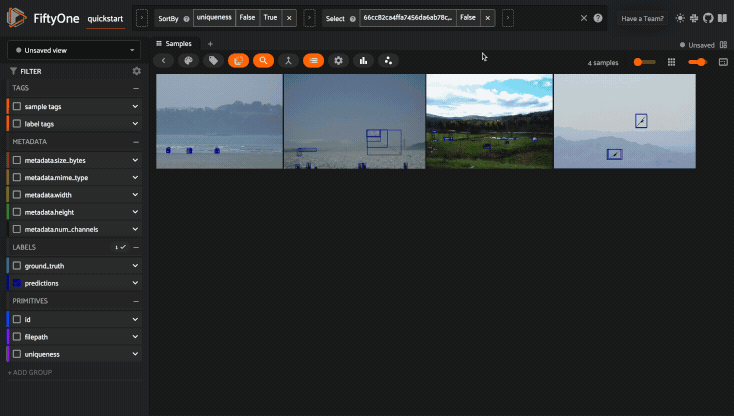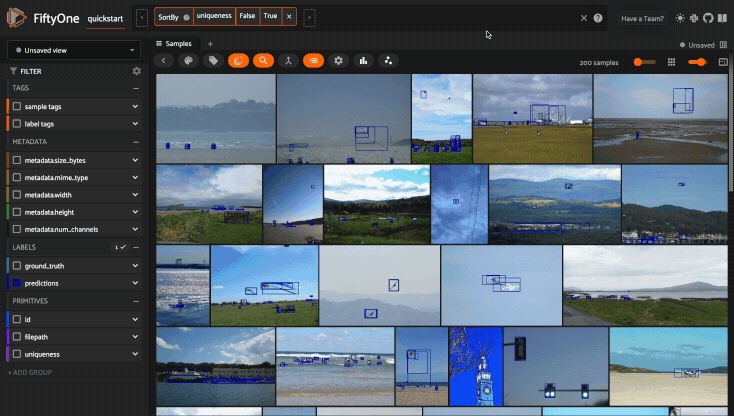
The selected samples checkmark in the options row in the upper-left corner of
the sample grid records the number of samples that you have currently selected.
You can also take actions such as updating the view to only show (or exclude)
the currently selected samples.
Tagging also automatically applies to selected samples or their labels when any samples are selected. See tagging for more details.
You can also access the
Session.selected property of
your session to retrieve the IDs of the currently selected samples in the App:
# Print the IDs of the currently selected samples
print(session.selected)
# Create a view containing only the selected samples
selected_view = dataset.select(session.selected)
['5ef0eef405059ebb0ddfa6cc',
'5ef0eef405059ebb0ddfa7c4',
'5ef0eef405059ebb0ddfa86e',
'5ef0eef405059ebb0ddfa93c']
Selecting labels#
You can also select individual labels within samples in the App, which is useful for a variety of reasons:
Visually show/hide labels of interest in the App
Take contextual actions such as tagging on only the selected labels
Access the data for selected labels from Python, for example by creating a
DatasetViewthat includes/excludes the selected labels
To perform this workflow, open the expanded sample view by clicking on a sample in the App. Then click on individual labels to select them:
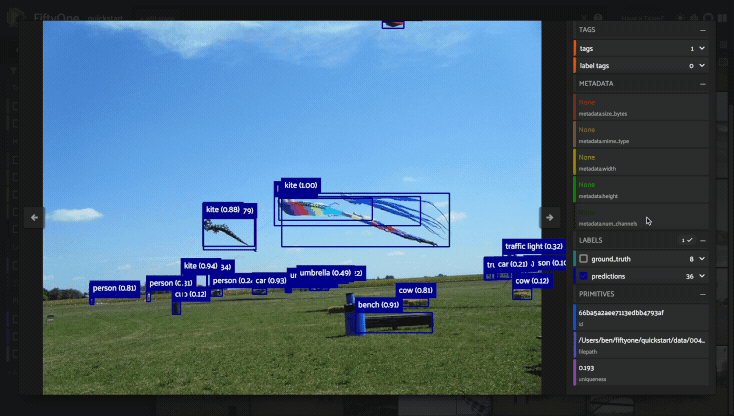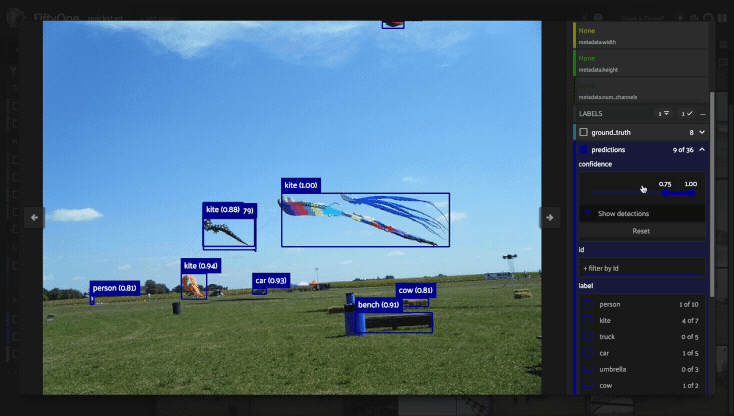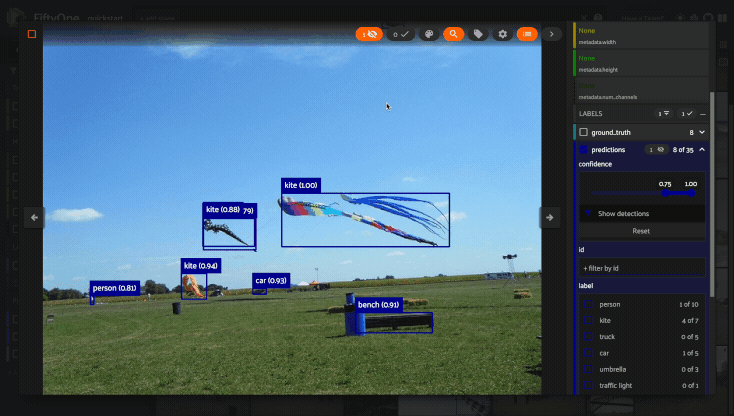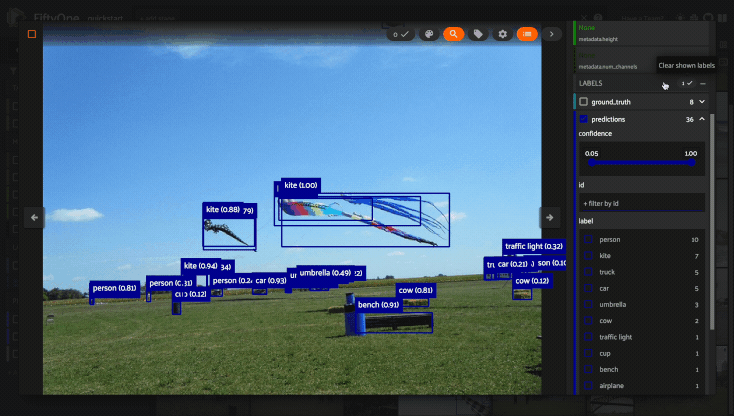
Selected labels will appear with dotted lines around them. The example above
shows selecting an object detection, but classifications, polygons, polylines,
segmentations, and keypoints can be selected as well.
When you have selected labels in the App, you can use the selected labels options in the upper-right (the orange checkmark button) to hide these labels from view or exclude all other labels.
You can also access the
Session.selected_labels
property of your session to retrieve information about the currently selected
labels in the App:
# Print information about the currently selected samples in the App
fo.pprint(session.selected_labels)
# Create a view containing only the selected labels
selected_view = dataset.select_labels(session.selected_labels)
# Create a view containing everything except the selected labels
excluded_view = dataset.exclude_labels(session.selected_labels)
[
{
'label_id': '5f99d2eb36208058abbfc02a',
'sample_id': '5f99d2eb36208058abbfc030',
'field': 'ground_truth',
},
{
'label_id': '5f99d2eb36208058abbfc02b',
'sample_id': '5f99d2eb36208058abbfc030',
'field': 'ground_truth',
},
...
]
If you are working with a dataset that leverages
linked labels, you can shift + click on a label
to select/deselect all instances of that object across video frames or group
slices of the dataset:
1import fiftyone as fo
2import fiftyone.zoo as foz
3import fiftyone.utils.labels as foul
4
5dataset = foz.load_zoo_dataset("quickstart-video")
6foul.index_to_instance(dataset, "frames.detections", clear_index=True)
7
8session = fo.launch_app(dataset)
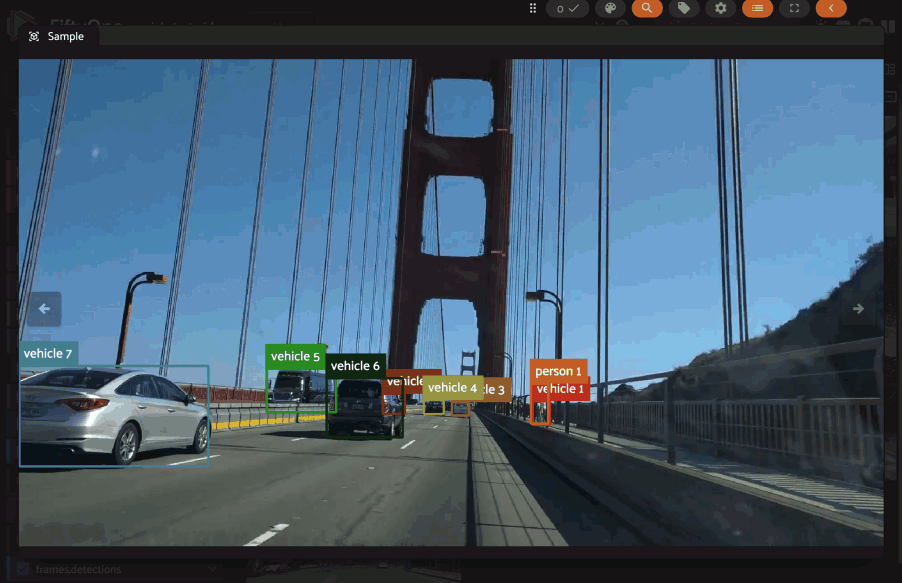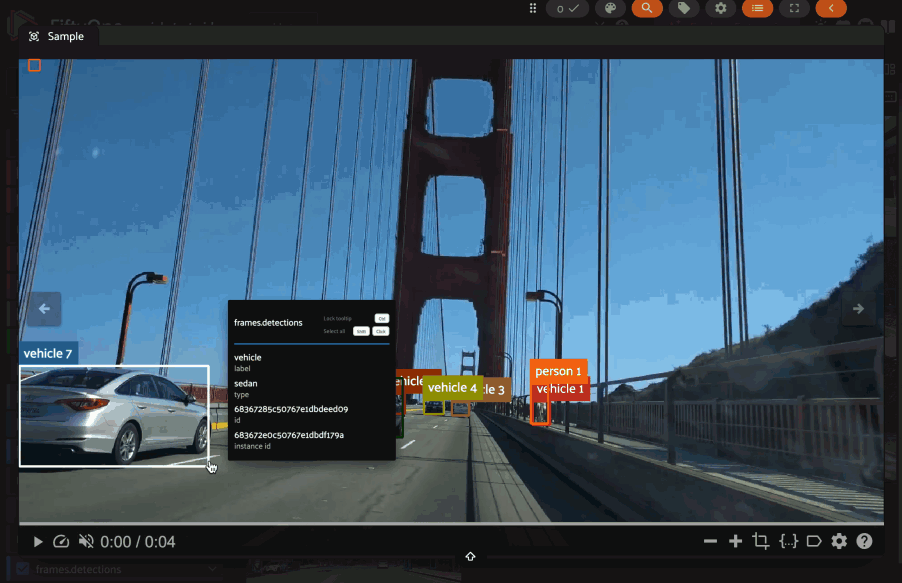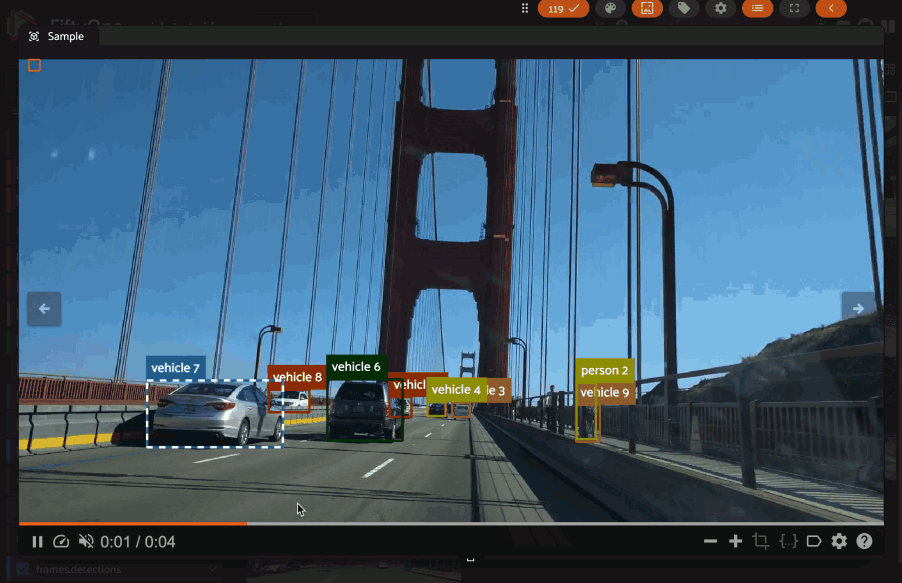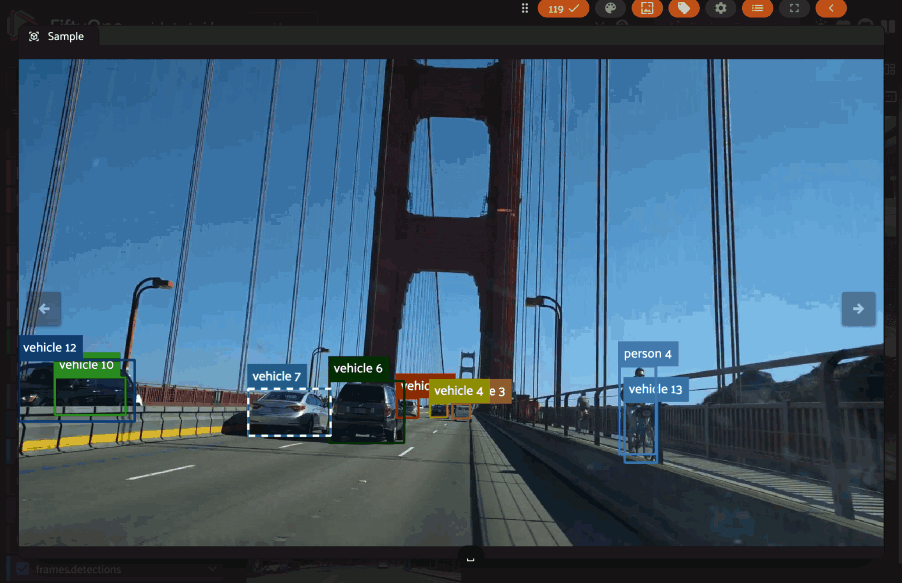
Note
Did you know? You can switch to “Color by instance” mode in the Color scheme editor to view each instance’s trajectory in a distinct color.
Persistent selections#
By default, selection of samples and/or labels in the App are persisted for the duration of the App session:
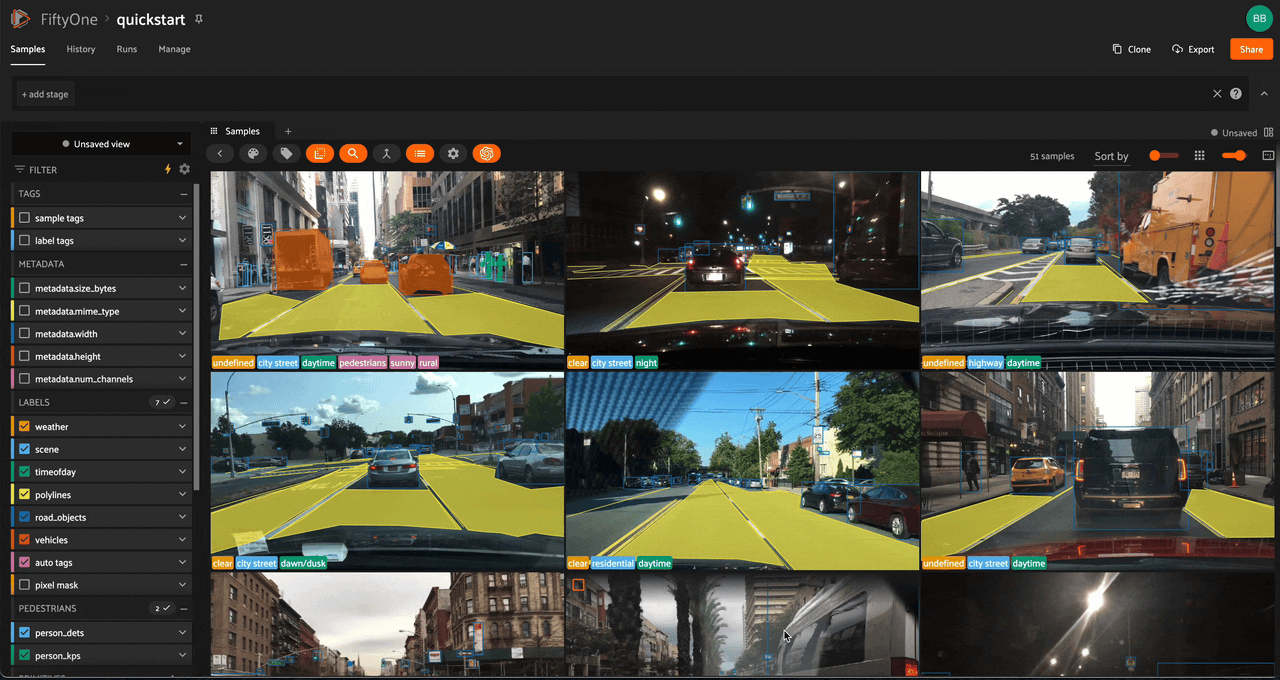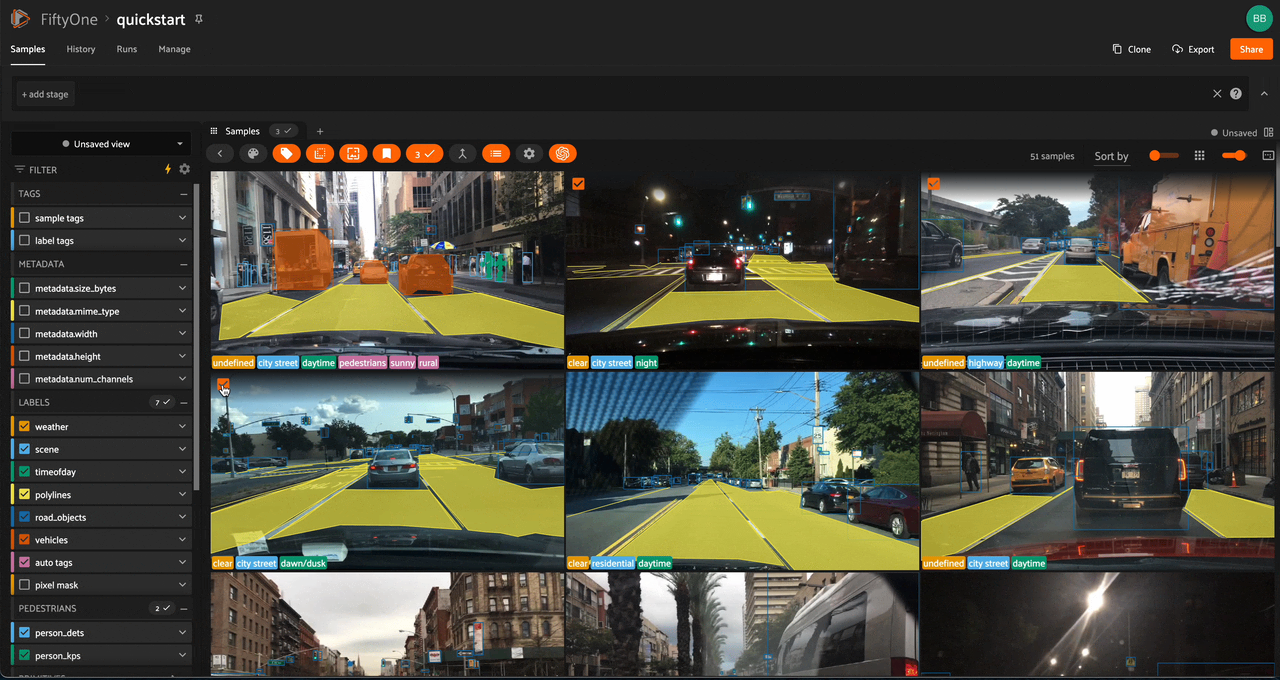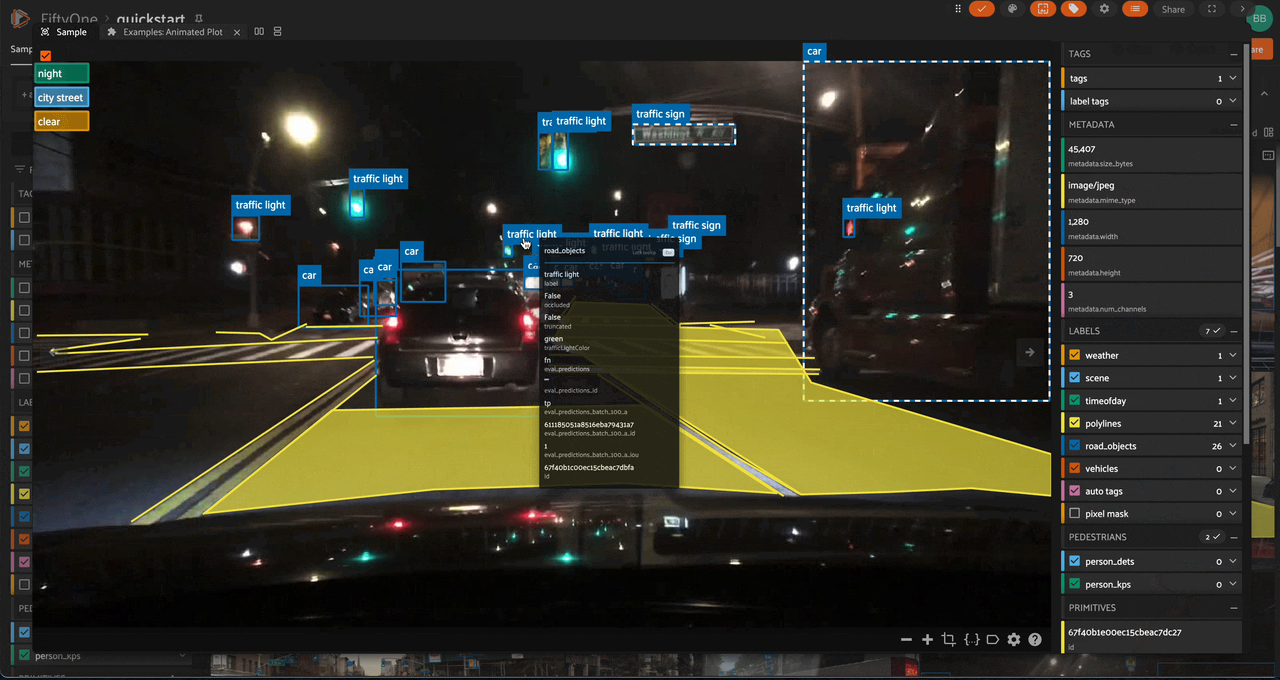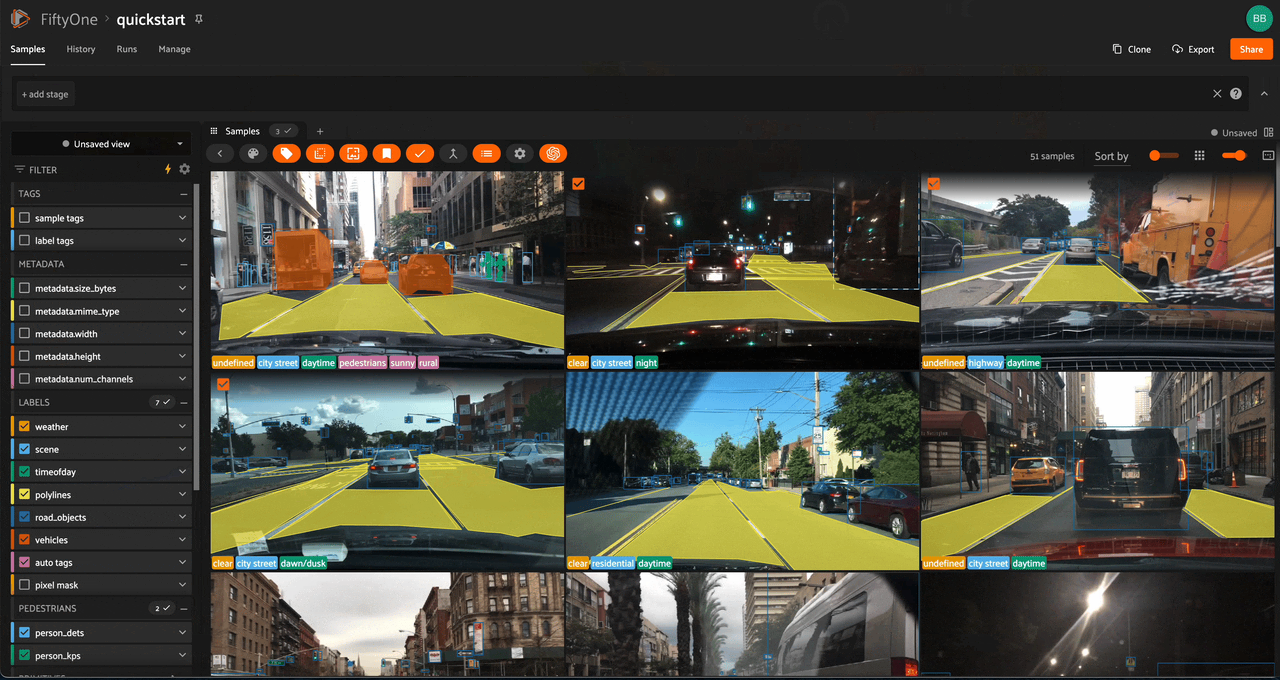
To clear selections, you can click the selection menu button and choose one of the following options.
When in grid view:
Clear selected sampleswill clear all sample selectionsClear selected labelswill clear all label selectionsOnly show selected sampleswill only show the selected samplesHide selected sampleswill hide the selected samples
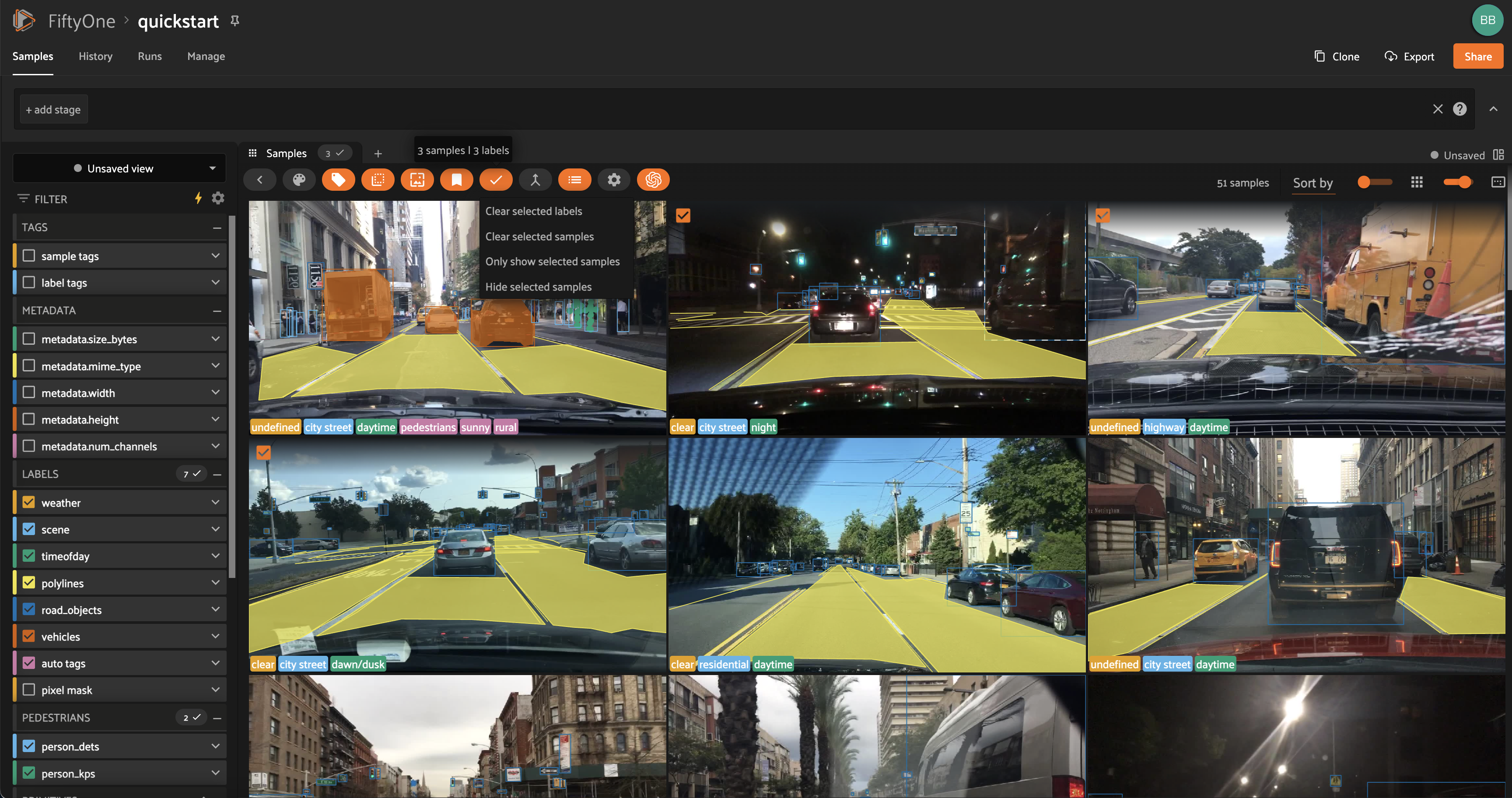
When in expanded sample mode:
Select visible (current sample)will select all visible labels in the current sampleUnselect visible (current sample)will unselect all visible labels in the current sampleClear selected labelswill clear all label selectionsHide selected labelswill hide the selected labelsHide unselected labels (current sample)will hide the unselected labels
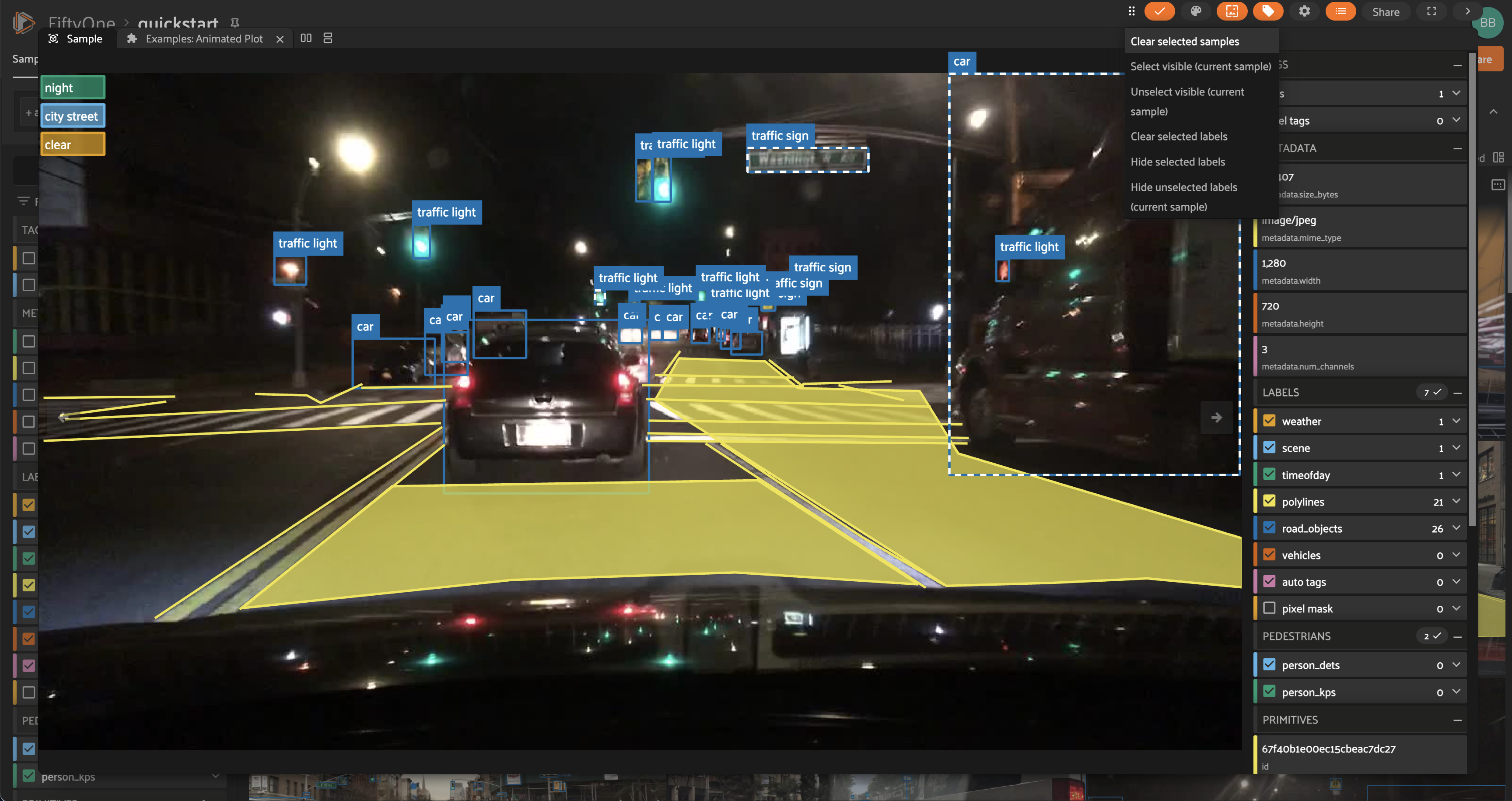
Tags and tagging#
Tagging is a first-class citizen in FiftyOne, as both Sample and Label
instances have a tags attribute that you can use to store arbitrary string
tags for your data.
The FiftyOne API provides methods like
tag_samples()
and
tag_labels()
that you can use to programmatically manage the tags on your dataset. However,
the App also provides a convenient UI for interactively adding, removing, and
filtering by Sample and Label tags.
You can tag or untag batches of samples/labels in the App by clicking on the tag icon above the sample grid.
For example, take the following steps to tag all labels in the predictions
field of a dataset:
Make sure that
predictionsis the onlyLabelfield checked in the filters sidebarClick the tag icon in the top-left corner of the grid
Select
Labels, type in the tag, and then clickApply
You can also use the tag menu to remove existing tags.
Note
Any tagging operations that you perform using the tagging UI above the sample grid will be applied to your current view, respecting any filters or show/hide checkboxes you have applied in the filters sidebar, unless you have selected individual samples, in which case the operation will only apply to the selected samples.
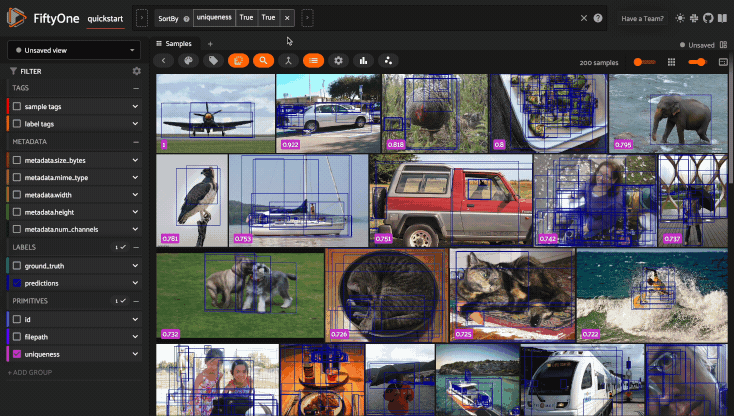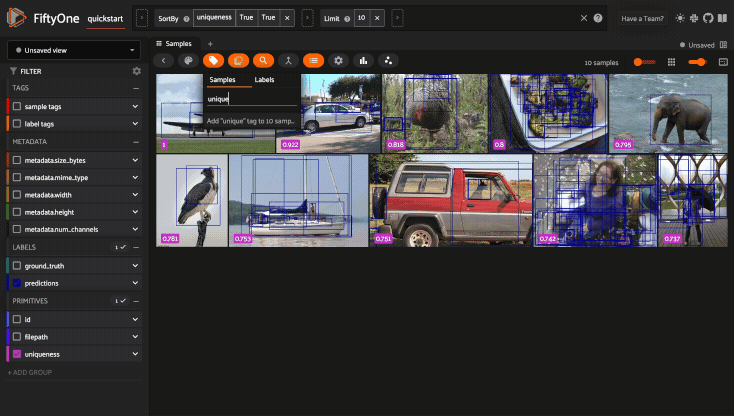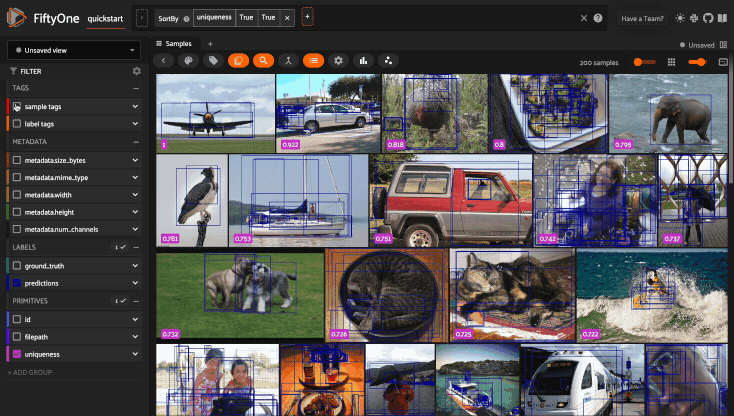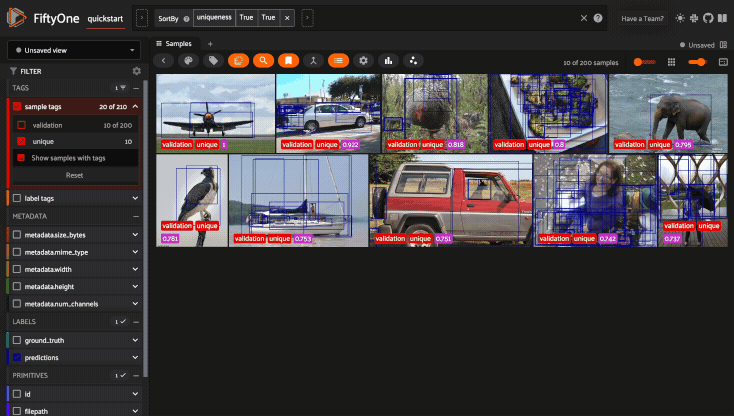
The App also supports tagging data in individual samples when you have opened
the expanded sample view by clicking on a sample. The tag icon is located in
the top-right corner of the modal.
Note
Any tagging operations that you perform using the tagging UI in expanded sample mode will be applied to the current sample, respecting any filters or show/hide checkboxes you have applied, unless you have selected individual labels, in which case the operation will only apply to the selected labels. The latter may span multiple samples.
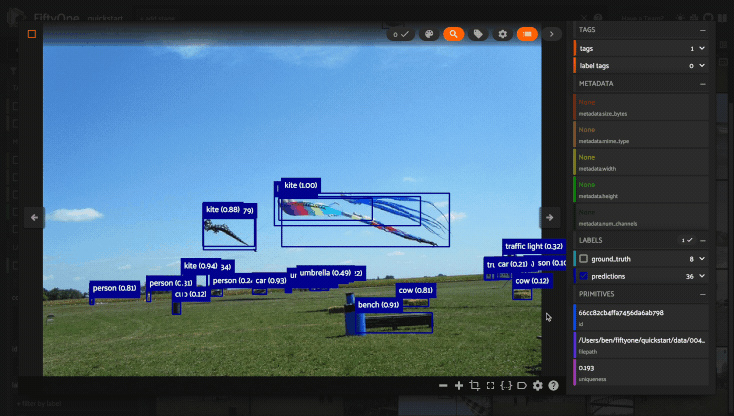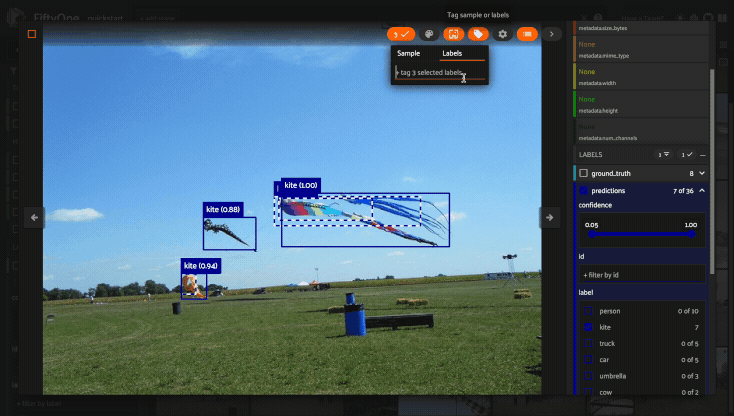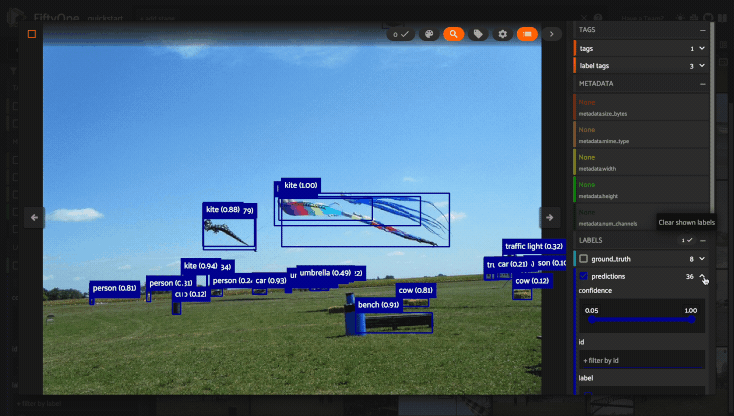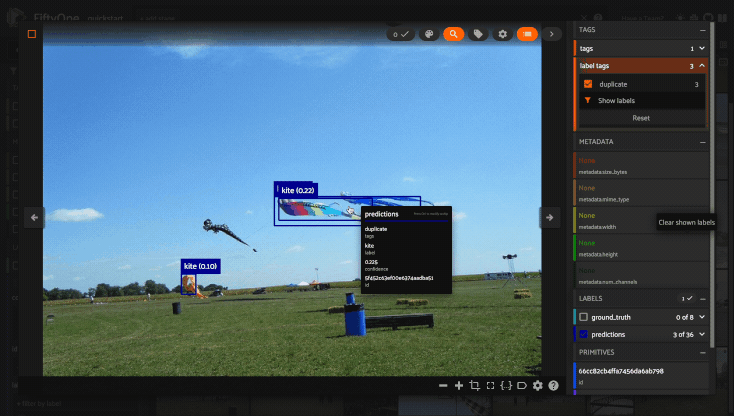
If your dataset has sample or label tags, you can use the SAMPLE TAGS and
LABEL TAGS sections of the filters sidebar to filter by your tags.
When you click the eye icon next to a sample tag, your view will update to only include samples with the tag(s) you have selected. When you click the eye icon next to a label tag, your view will update to only include labels with tag(s) you have selected, and any samples with no matches will be automatically excluded.
Note
Did you know? When you have applied filter(s) in the App, a save icon appears in the top-left corner of the sample grid. Clicking this button will convert your filters to an equivalent set of stage(s) in the view bar!
Viewing object patches#
Whenever you load a dataset in the App that contains label list fields in
Detections or Polylines format, you can use the patches menu to create a
view into your data that contains one sample per object patch in a specified
label field of your dataset.
To switch to patches view, simply click the patches icon above the sample grid
in the App, toggle to the Labels submenu, and then choose the field whose
object patches you want to view. After you make a selection, a new ToPatches
view stage will be appended to the view bar and your view will be updated to
show the patches.
By default, patches are cropped so only the label patch is visible, but you can
zoom in/out and pan as desired in the
image visualizer. If you would like to see the
entire image for each patch by default, click on the settings icon and uncheck
the Crop to patch setting. The setting is available in both the grid and
expanded sample view.
Note
Switching to patches view will create patches for only the contents of your current view, so you can use the view bar and the filters sidebar to select only the content of interest prior to extracting patches.
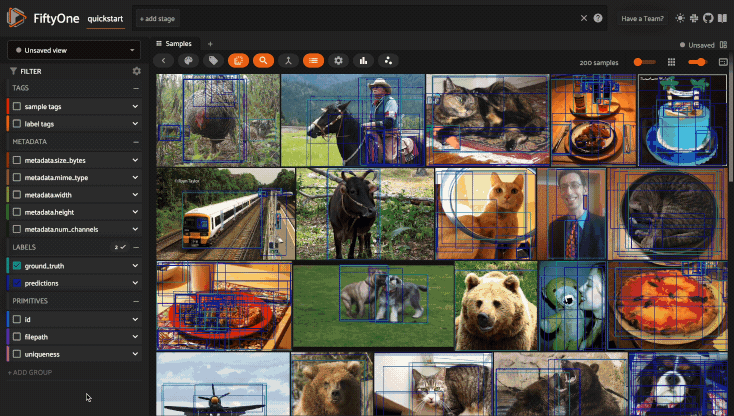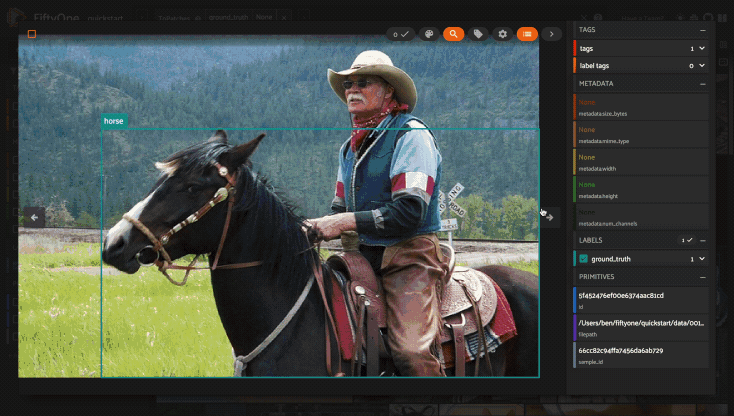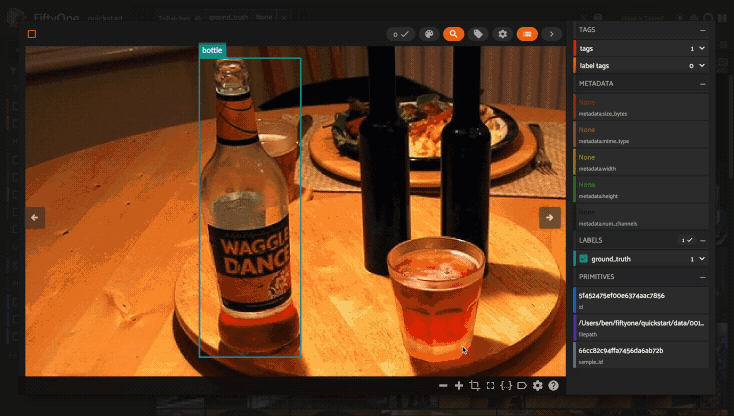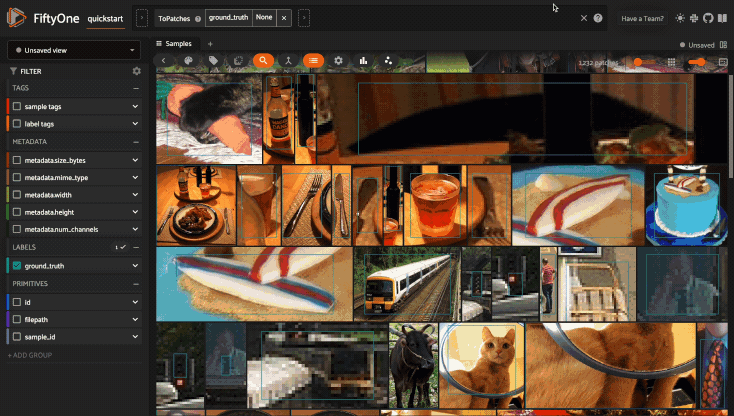
You can interact with object patches views in the App just like you would with
any other view, including:
You can filter and transform objects patches views using the filter sidebar or the view bar
Any modifications to patch label tags that you make via the tagging menu will be reflected on the source dataset
One notable exception is that tagging or untagging patches themselves (as
opposed to their labels) will not affect the sample tags of the underlying
Sample.
Note
Did you know? You can construct object patches views programmatically via dataset views!
Viewing evaluation patches#
Whenever you load a dataset in the App that contains object detections on which you have run evaluation, you can use the patches menu to create a view into your data that contains one sample for each true positive, false positive, and false negative example.
To switch to evaluation patches view, simply click the patches icon above the
sample grid in the App, toggle to the Evaluations submenu, and then choose
the eval_key under which you saved the evaluation results that you want
view. After you make a selection, a new ToEvaluationPatches view stage will
be appended to the view bar and your view will be updated to show the
evaluation patches!
By default, evaluation patches are cropped so only the label(s) that make up
the patch are visible, but you can zoom in/out and pan as desired in the
image visualizer. If you would like to see the
entire image for each patch by default, click on the settings icon and uncheck
the Crop to patch setting. The setting is available in both the grid and
expanded sample view.
Note
Refer to the evaluation guide guide for more information about running evaluations and using evaluation patches views to analyze object detection models.
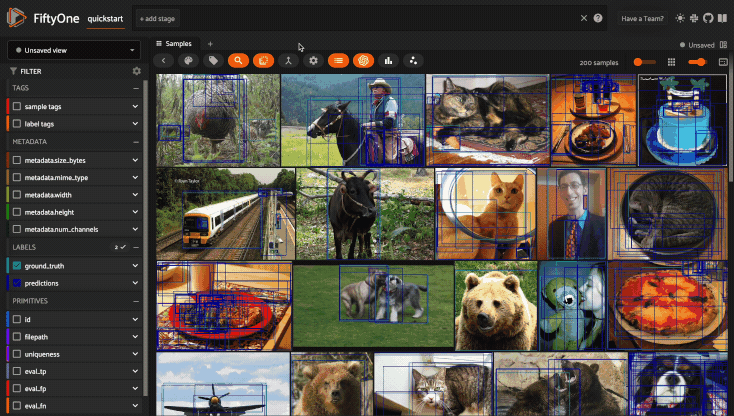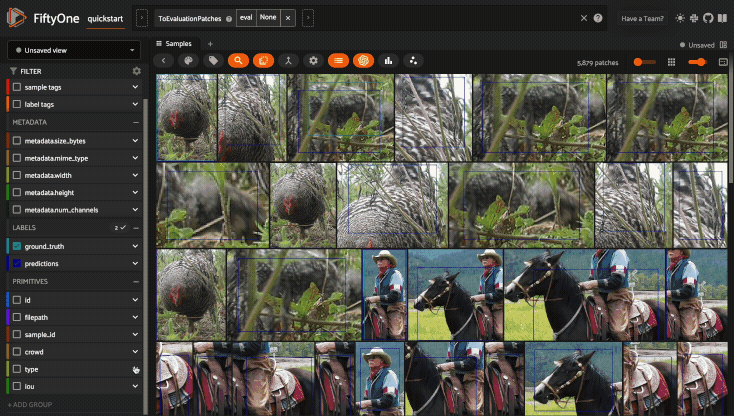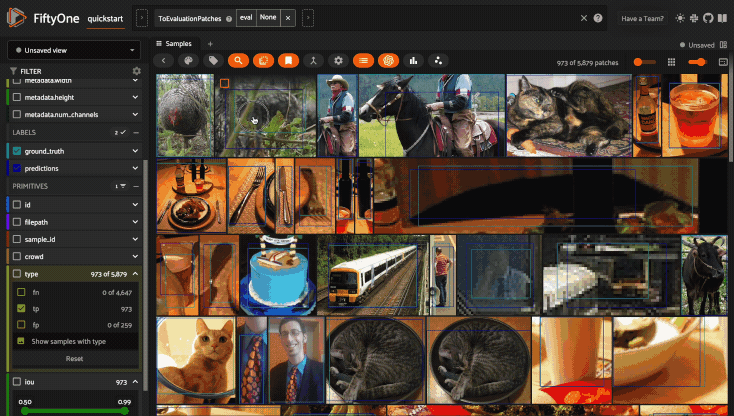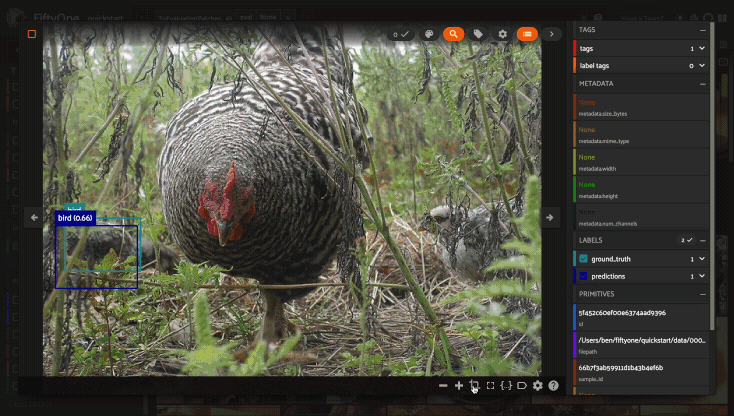
You can interact with evaluation patches views in the App just like you would
with any other view, including:
You can filter and transform evaluation patches views using the filter sidebar or the view bar
Any modifications to the tags of the ground truth or predicted labels that you make via the tagging menu will be reflected on the source dataset
One notable exception is that tagging or untagging patches themselves (as
opposed to their labels) will not affect the sample tags of the underlying
Sample.
Note
Switching to evaluation patches view will generate patches for only
the contents of the current view, which may differ from the view on which
the eval_key evaluation was performed. This may exclude some labels
that were evaluated and/or include labels that were not evaluated.
If you would like to see patches for the exact view on which an
evaluation was performed, first call
load_evaluation_view()
to load the view and then convert to patches.
Viewing video clips#
Whenever you load a video dataset in the App that contains TemporalDetection
labels or frame-level label lists such as Detections, you can use the patches
menu to create a view into your data that contains one sample per clip defined
by a specified label field of your dataset.
To switch to clips view, simply click the patches icon above the sample grid
in the App, toggle to the Labels submenu, and then choose the field whose
clips you want to view. After you make a selection, a new ToClips view stage
will be appended to the view bar and your view will be updated to show the
clips.
Creating a clips view for a TemporalDetection or TemporalDetections field
will create one sample per temporal detection defined by its [first, last]
frame support:
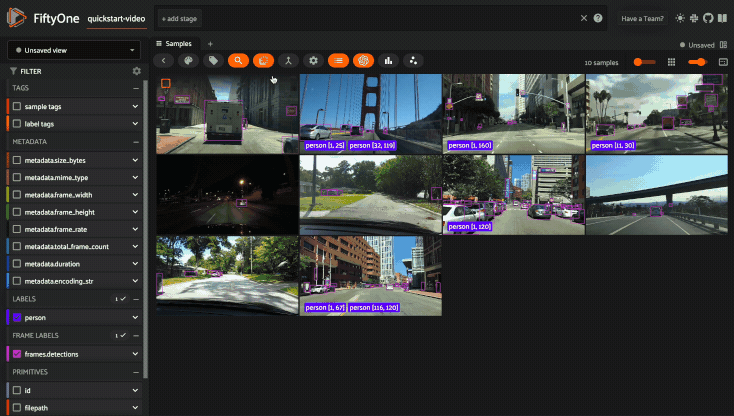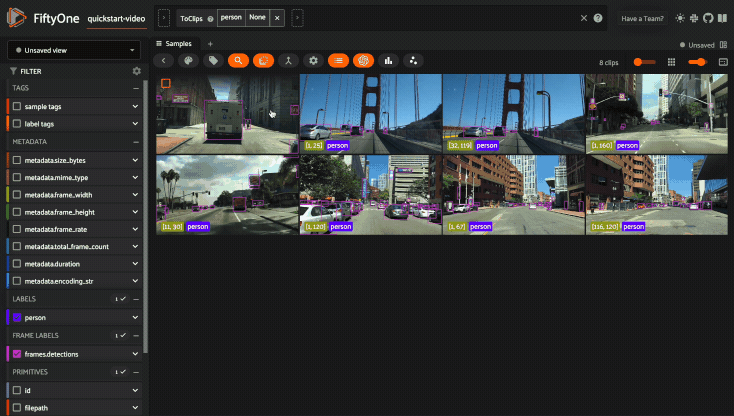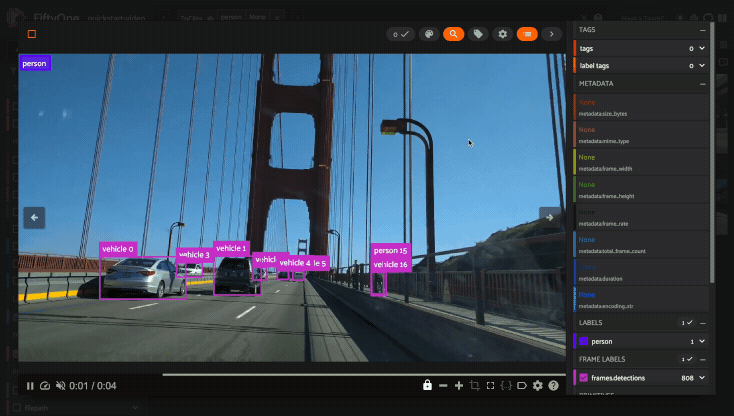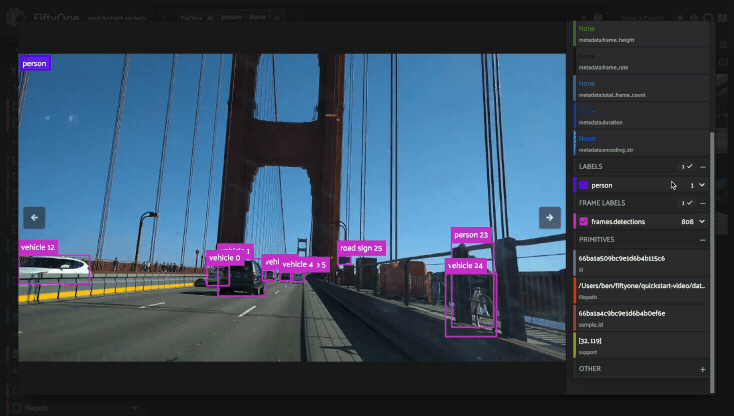
Creating a clips view for a frame-level label list field such as Detections
will contain one sample per contiguous range of frames that contains at least
one label in the specified field:
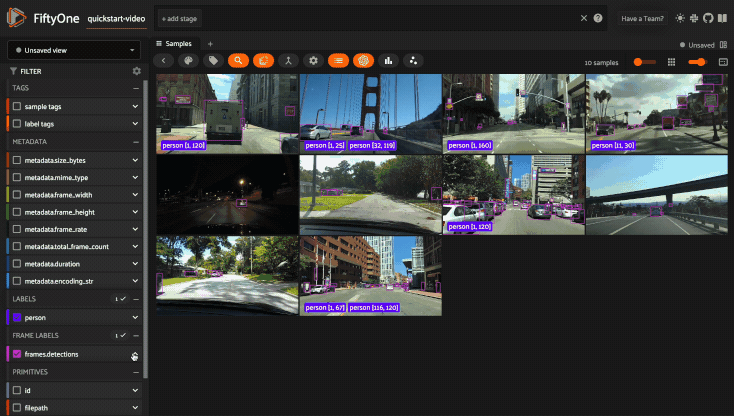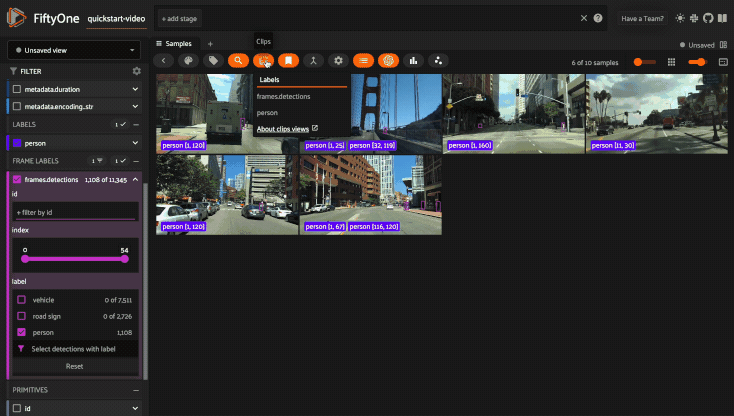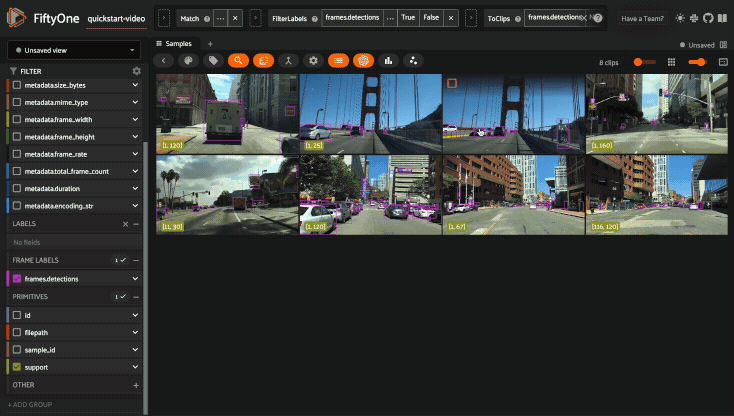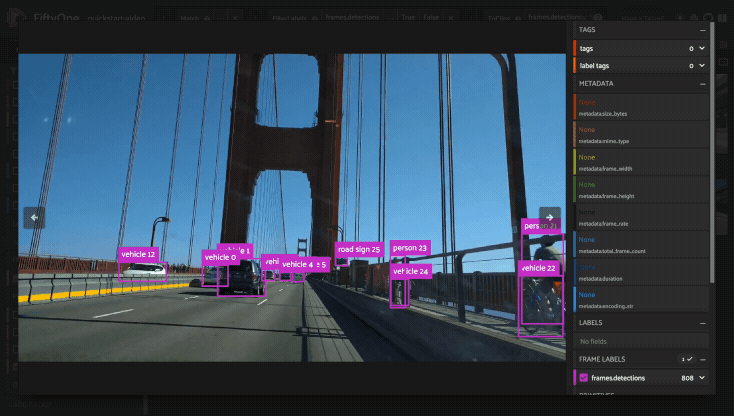
Note
Switching to clips view will create clips for only the contents of your current view, so you can use the view bar and the filters sidebar to select only the content of interest prior to extracting clips.
See this section for more information about defining clip views.
When you hover over a clip in the grid view, the clip and its labels will play on loop. Similarly, when you open a clip in the video visualizer, you will see only the clip when you play the video. If you would like to see other segments of the video from which a clip was extracted, simply drag the video scrubber outside the range of the clip.
You can interact with clip views in the App just like you would with any other view, including:
You can filter and transform clip views using the filter sidebar or the view bar
Any modifications to label tags that you make via the tagging menu will be reflected on the source dataset
One notable exception is that tagging or untagging clips themselves (as opposed
to their labels) will not affect the sample tags of the underlying Sample.
Note
Did you know? You can construct clip views programmatically via dataset views!
Multiple media fields#
There are use cases where you may want to associate multiple media versions with each sample in your dataset, such as:
Thumbnail images
Anonymized (e.g., blurred) versions of the images
You can work with multiple media sources in FiftyOne by simply adding extra field(s) to your dataset containing the paths to each media source and then configuring your dataset to expose these multiple media fields in the App.
For example, let’s create thumbnail images for use in the App’s grid view and
store their paths in a thumbnail_path field:
1import fiftyone as fo
2import fiftyone.utils.image as foui
3import fiftyone.zoo as foz
4
5dataset = foz.load_zoo_dataset("quickstart")
6
7# Generate some thumbnail images
8foui.transform_images(
9 dataset,
10 size=(-1, 32),
11 output_field="thumbnail_path",
12 output_dir="/tmp/thumbnails",
13)
14
15print(dataset)
Name: quickstart
Media type: image
Num samples: 200
Persistent: False
Tags: []
Sample fields:
id: fiftyone.core.fields.ObjectIdField
filepath: fiftyone.core.fields.StringField
tags: fiftyone.core.fields.ListField(fiftyone.core.fields.StringField)
metadata: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.metadata.ImageMetadata)
created_at: fiftyone.core.fields.DateTimeField
last_modified_at: fiftyone.core.fields.DateTimeField
ground_truth: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Detections)
uniqueness: fiftyone.core.fields.FloatField
predictions: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Detections)
thumbnail_path: fiftyone.core.fields.StringField
We can expose the thumbnail images to the App by modifying the dataset’s App config:
1# Modify the dataset's App config
2dataset.app_config.media_fields = ["filepath", "thumbnail_path"]
3dataset.app_config.grid_media_field = "thumbnail_path"
4dataset.save() # must save after edits
5
6session = fo.launch_app(dataset)
Adding thumbnail_path to the
media_fields property
adds it to the Media Field selector under the App’s settings menu, and
setting the
grid_media_field property
to thumbnail_path instructs the App to use the thumbnail images by default in
the grid view:
Warning
When populating multiple media fields on samples, keep in mind that all
media sources must have the same type (e.g., image) and
aspect ratio as the sample’s primary filepath, since the media must
be compatible with the dataset’s spatial labels (e.g., object detections).
Configuring the App#
The App’s behavior can be configured on a per-session, per-dataset, or global basis.
The order of precedence is:
Any changes that you make to the
session.configof a live sessionAny settings stored in a dataset’s
app_configSettings from your global App config
Any settings or changes made at higher levels of precedence will override any lower priority settings the next time you load/refresh the App.
Global App config#
FiftyOne provides a global App config that you can use to customize the default App behavior for all sessions and datasets on your machine.
You can also customize the global App config on a per-session basis:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5
6# Your default App config
7print(fo.app_config)
8
9# Create a custom App config
10app_config = fo.app_config.copy()
11app_config.show_confidence = False
12app_config.show_label = True
13print(app_config)
14
15# Launch App with custom config
16session = fo.launch_app(dataset, config=app_config)
17print(session.config)
Modifying your session#
You can configure a live Session by editing its
session.config property and
calling session.refresh() to
apply the changes:
1print(session.config)
2
3# Customize the config of a live session
4session.config.show_confidence = True
5session.config.show_label = True
6session.refresh() # must refresh after edits
Dataset App config#
Datasets also provide an app_config property that you can use to customize the behavior of the App for that particular dataset:
1import fiftyone as fo
2import fiftyone.utils.image as foui
3import fiftyone.zoo as foz
4
5dataset = foz.load_zoo_dataset("quickstart")
6
7# View the dataset's current App config
8print(dataset.app_config)
9
10# Generate some thumbnail images
11foui.transform_images(
12 dataset,
13 size=(-1, 32),
14 output_field="thumbnail_path",
15 output_dir="/tmp/thumbnails",
16)
17
18# Modify the dataset's App config
19dataset.app_config.media_fields = ["filepath", "thumbnail_path"]
20dataset.app_config.grid_media_field = "thumbnail_path"
21dataset.save() # must save after edits
22
23session = fo.launch_app(dataset)
Note
Any settings stored in a dataset’s
app_config will override
the corresponding settings from your
global App config.