Note
This is a community plugin, an external project maintained by its respective author. Community plugins are not part of FiftyOne core and may change independently. Please review each plugin’s documentation and license before use.
Jina Embeddings v4 for FiftyOne#
Integration of Jina Embeddings v4 as a FiftyOne Zoo Model for multimodal document retrieval, text matching, and code understanding.
Overview#
Jina Embeddings v4 is a state-of-the-art Vision Language Model that generates embeddings for both images and text in a shared vector space. Built on a parameter-efficient architecture using PEFT (Parameter-Efficient Fine-Tuning), it supports multiple tasks including document retrieval, multilingual text matching, and code understanding. This integration adapts Jina v4 for use with FiftyOne’s embedding and similarity infrastructure.
Key Features#
Multimodal Embeddings: Embed both images and text in the same vector space
Multiple Tasks: Optimized for retrieval, text-matching, and code understanding
Multilingual Support: Cross-lingual text matching across 89+ languages
High-Dimensional Embeddings: 2048-dim single vectors or variable-length multi-vectors (128 dim each)
PIL Image Support: Direct PIL Image input without preprocessing
Zero-Shot Classification: Use text prompts to classify images without training
Deviations from Native Implementation#
The Challenge#
Jina v4 natively produces two types of embeddings:
Single-vector mode: Fixed 2048-dimensional vectors (standard retrieval)
Multi-vector mode: Variable-length multi-vector embeddings with 128 dimensions per vector
FiftyOne’s similarity infrastructure requires fixed-dimension vectors for storage and search.
Our Solution: Dual-Mode Support#
For Retrieval/Similarity Search (Single-Vector Mode)#
We use Jina’s native single-vector embeddings:
Dimension: 2048 (no pooling needed!)
Performance: Full native accuracy
Use case: Standard similarity search, embeddings visualization
For Zero-Shot Classification (Multi-Vector Mode)#
We use Jina’s multi-vector embeddings with final pooling:
Classification: Uses full multi-vectors with MaxSim scoring for accuracy
Storage: Applies final pooling (mean/max) to produce 128-dim vectors for FiftyOne compatibility
Strategy |
Output |
Best For |
|---|---|---|
|
|
Holistic document matching, semantic similarity |
|
|
Specific content/keyword matching, exact phrase detection |
Trade-off: When using multi-vector mode for embeddings storage, you lose the high dimensionality (2048 → 128) but gain consistency with classification.
Installation#
Note: This model requires transformers<5.0, torch, and peft.
# Install FiftyOne and Jina v4 dependencies
pip install fiftyone transformer torch torchvision pillow peft
Quick Start#
Register the Zoo Model#
import fiftyone.zoo as foz
# Register this repository as a remote zoo model source
foz.register_zoo_model_source(
"https://github.com/harpreetsahota204/jina_embeddings_v4",
overwrite=True
)
Load Dataset#
import fiftyone as fo
from fiftyone.utils.huggingface import load_from_hub
# Load document dataset from Hugging Face
dataset = load_from_hub(
"Voxel51/document-haystack-10pages",
overwrite=True,
max_samples=250 # Optional: subset for testing
)
Basic Workflow#
import fiftyone.zoo as foz
import fiftyone.brain as fob
# Load Jina v4 model with desired configuration
model = foz.load_zoo_model(
"jinaai/jina-embeddings-v4",
task="retrieval", # or "text-matching", "code", but for visualzing embeddings this is best
)
# Compute embeddings for all documents
dataset.compute_embeddings(
model=model,
embeddings_field="jina_embeddings",
)
# Check embedding dimensions
print(dataset.first()['jina_embeddings'].shape) # Should be (2048,) for single-vector
# Build similarity index
text_img_index = fob.compute_similarity(
dataset,
model="jinaai/jina-embeddings-v4",
embeddings_field="jina_embeddings",
brain_key="jina_sim",
)
# Query for specific content
sims = text_img_index.sort_by_similarity(
"invoice from 2024",
k=10 # Top 10 results
)
# Launch FiftyOne App
session = fo.launch_app(sims, auto=False)
Advanced Embedding Workflows#
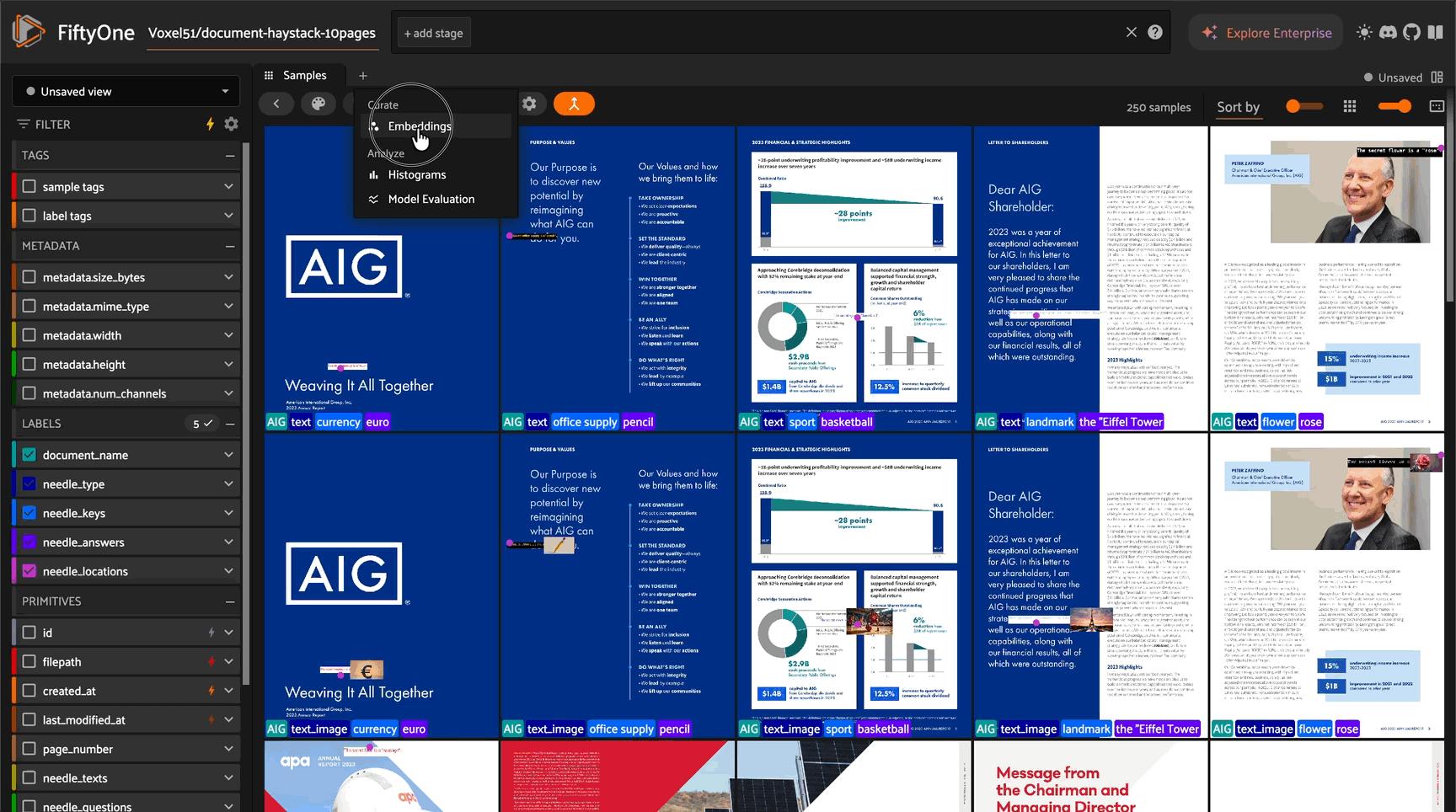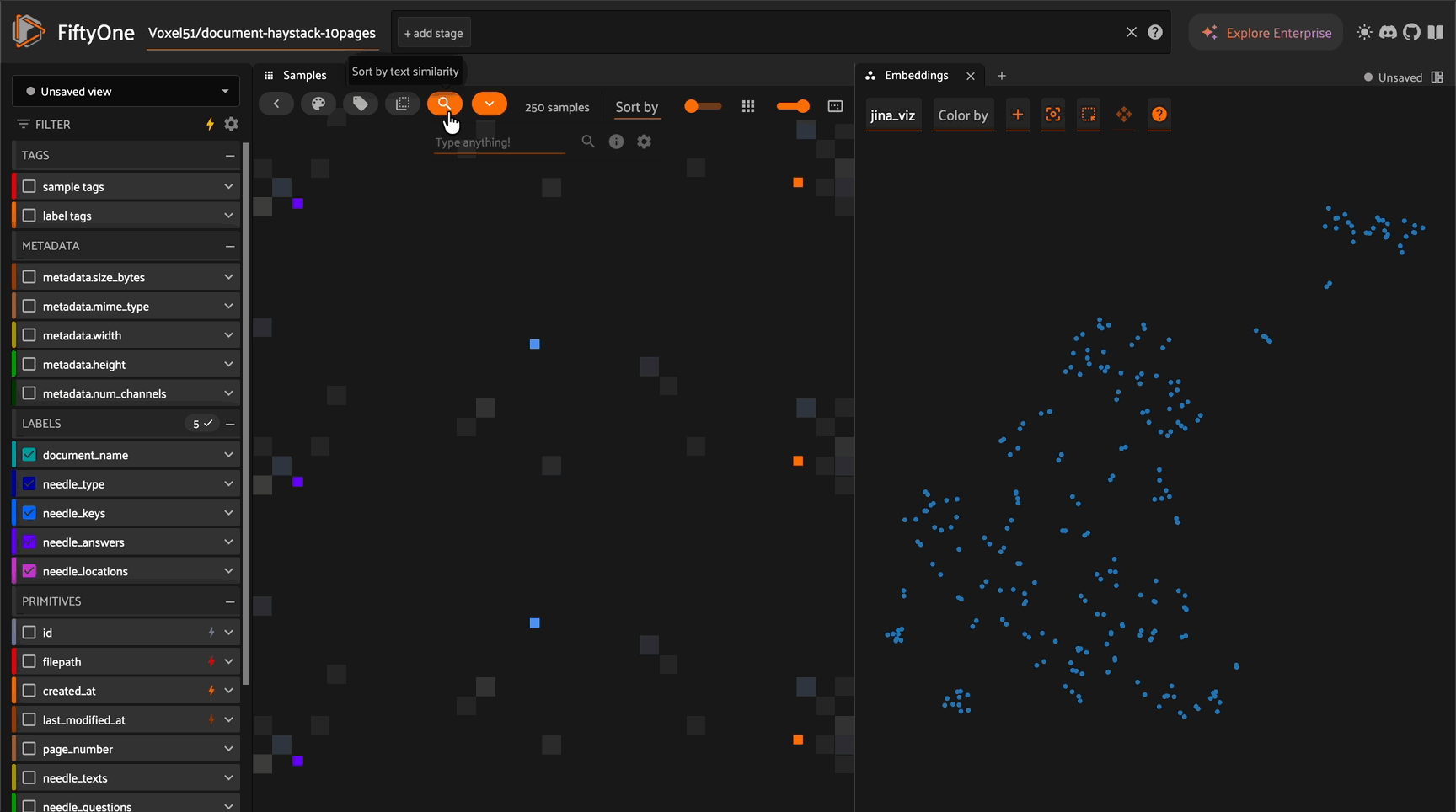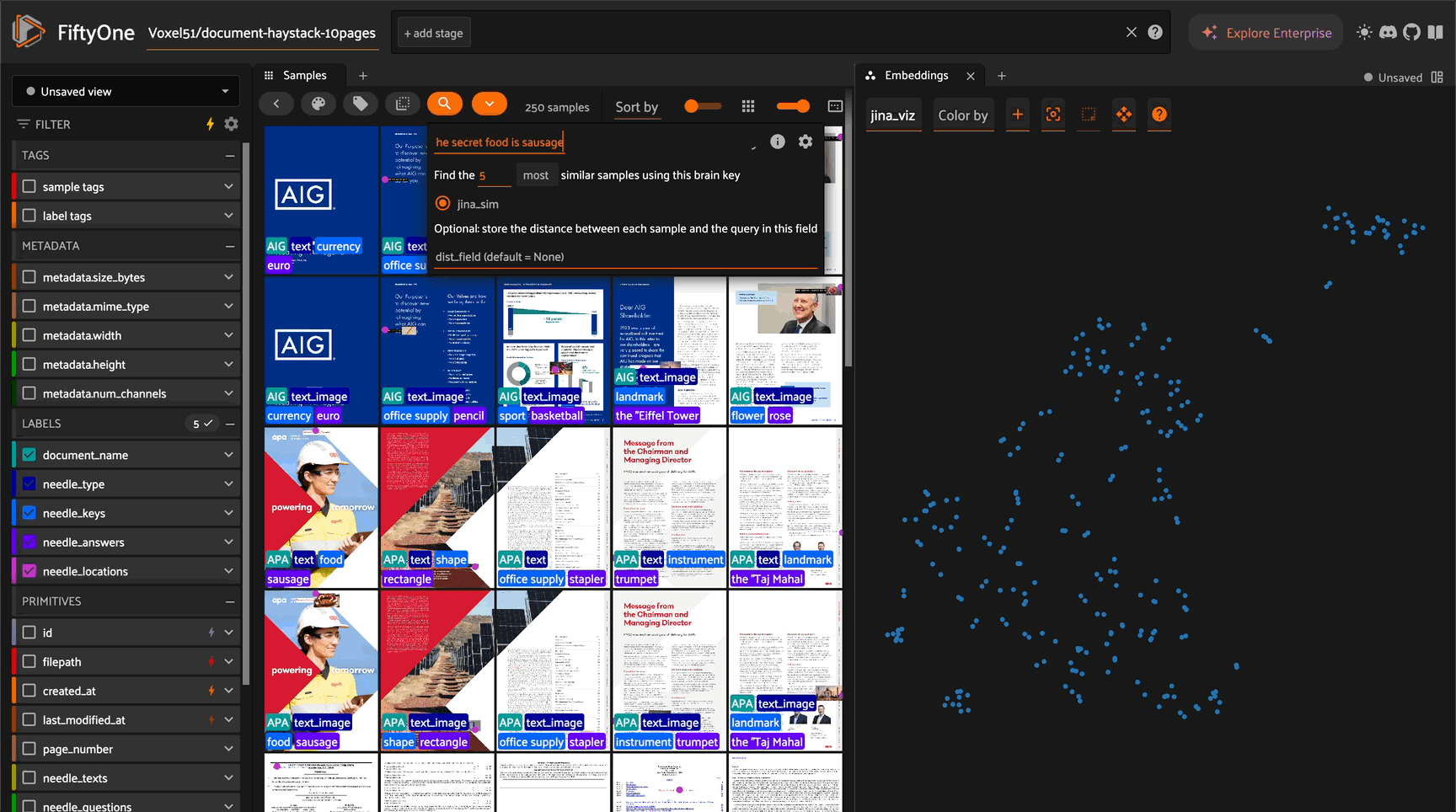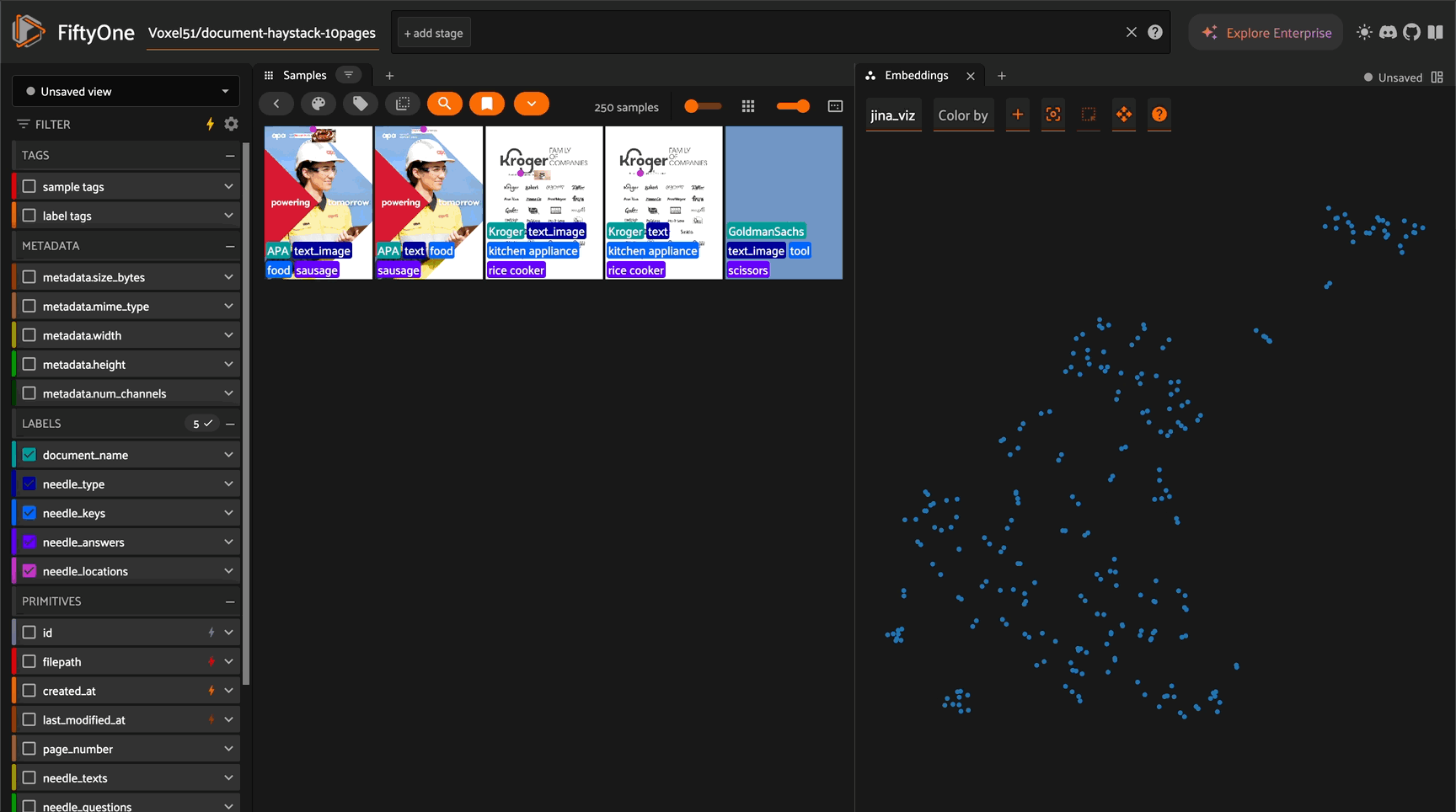
Embedding Visualization with UMAP#
Create 2D visualizations of your document embeddings:
import fiftyone.brain as fob
# First compute embeddings
dataset.compute_embeddings(
model=model,
embeddings_field="jina_embeddings"
)
# Create UMAP visualization
results = fob.compute_visualization(
dataset,
method="umap", # Also supports "tsne", "pca"
brain_key="jina_viz",
embeddings="jina_embeddings",
num_dims=2
)
# Explore in the App
session = fo.launch_app(dataset)
Similarity Search with Different Backends#
Build powerful similarity search with various backends:
import fiftyone.brain as fob
results = fob.compute_similarity(
dataset,
backend="sklearn", #default backend
brain_key="jina_sim_sklearn",
embeddings="jina_embeddings"
)
# Find similar images
sample_id = dataset.first().id
similar_samples = dataset.sort_by_similarity(
sample_id,
brain_key="jina_sim_sklearn",
k=10
)
# View results
session = fo.launch_app(similar_samples)
Dataset Representativeness#
Score how representative each sample is of your dataset:
import fiftyone.brain as fob
# Compute representativeness scores
fob.compute_representativeness(
dataset,
representativeness_field="jina_represent",
method="cluster-center",
embeddings="jina_embeddings"
)
# Find most representative samples
representative_view = dataset.sort_by("jina_represent", reverse=True)
Duplicate Detection#
Find and remove near-duplicate documents:
import fiftyone.brain as fob
# Detect duplicates using embeddings
results = fob.compute_uniqueness(
dataset,
embeddings="jina_embeddings"
)
# Filter to most unique samples
unique_view = dataset.sort_by("uniqueness", reverse=True)
Zero-Shot Classification#
Jina v4 supports zero-shot classification using multi-vector similarity:
import fiftyone.zoo as foz
classes = dataset.distinct("needle_texts")
# Load model if you haven't already
model = foz.load_zoo_model(
"jinaai/jina-embeddings-v4",
classes = classes,
# text_prompt = "An optional text prompt prepended to the classes",
task="text-matching", #seems to work best for zero shot classification
)
# If you've already loaded the model, ie for embeddings, then you can set the following
model.classes = classes
model.text_prompt = "An optional text prompt prepended to the classes"
# Apply model for zero-shot classification
dataset.apply_model(
model,
label_field="needle_text_predictions"
)
# View predictions
print(dataset.first()['needle_text_predictions'])
session = fo.launch_app(dataset)
Dynamic Classification with Multiple Tasks#
import fiftyone.zoo as foz
# Load model once
model = foz.load_zoo_model("jinaai/jina-embeddings-v4", task="retrieval")
# Task 1: Classify document types
model.classes = ["invoice", "receipt", "form", "contract"]
model.text_prompt = "This is a"
dataset.apply_model(model, label_field="doc_type")
# Task 2: Classify importance (reuse same model!)
model.classes = ["high_priority", "medium_priority", "low_priority"]
model.text_prompt = "The priority level is"
dataset.apply_model(model, label_field="priority")
# Task 3: Classify language
model.classes = ["english", "spanish", "french", "german", "chinese"]
model.text_prompt = "The document language is"
dataset.apply_model(model, label_field="language")
Technical Details#
FiftyOne Integration Architecture#
Single-Vector Mode (Retrieval/Embeddings):
Raw multi-vector → Native single-vector compression → Fixed (2048,)
Multi-Vector Mode (Classification):
Raw multi-vector → Final pooling (mean/max) → Fixed (128,)
Retrieval Pipeline:
dataset.compute_embeddings(model, embeddings_field="embeddings")
> embed_images(): Uses single-vector mode
> Returns (2048,) vectors
> Stores in FiftyOne for similarity search
Classification Pipeline:
dataset.apply_model(model, label_field="predictions")
> _predict_all(): Uses multi-vector mode
> Multi-vector MaxSim scoring for accuracy
> Returns Classification labels
Key Implementation Notes#
raw_inputs=True: Jina’sencode_image()handles all preprocessing internallyImage Format Conversion: FiftyOne may pass images as PIL, numpy arrays, or tensors; we convert all to PIL for compatibility
No Token Pooling Needed: Unlike ColPali, Jina v4 handles compression internally
Variable-Length Multi-Vectors: Images produce 258-341 vectors each, text produces 9-12 vectors
Dual Output Modes:
Single-vector: 2048 dim (retrieval)
Multi-vector pooled: 128 dim (classification storage)
MaxSim Scoring: Implements ColBERT-style late interaction for zero-shot classification
Configuration Options#
Task Selection#
# Document/image retrieval (default)
model = foz.load_zoo_model(
"jinaai/jina-embeddings-v4",
task="retrieval"
)
# Multilingual text matching
model = foz.load_zoo_model(
"jinaai/jina-embeddings-v4",
task="text-matching" #probably best for zero-shot classification
)
# Code understanding
model = foz.load_zoo_model(
"jinaai/jina-embeddings-v4",
task="code" #for code heavy document images
)
Performance Characteristics#
Embedding Dimensions#
Single-vector retrieval: 2048 dimensions
Multi-vector: Variable length (9-12 for text, 258-341 for images)
Multi-vector dimension: 128 per vector
After pooling (classification): 128 dimensions
Inference Speed#
GPU (recommended): 0.1-0.5s per query
CPU: 2-5s per query
Model size: ~3B parameters (PEFT)
Typical Use Cases#
Use Case |
Recommended Task |
Pooling Strategy |
|---|---|---|
Document retrieval |
|
N/A (use 2048-dim) |
Invoice/receipt search |
|
|
Multilingual matching |
|
|
Code snippet search |
|
|
Zero-shot classification |
|
|
Resources#
Model Hub: jinaai/jina-embeddings-v4
Jina AI: jina.ai
Documentation: Jina Embeddings Docs
Base Architecture: PEFT (Parameter-Efficient Fine-Tuning)
Citation#
If you use Jina Embeddings v4 in your research, please cite:
@misc{günther2025jinaembeddingsv4universalembeddingsmultimodal,
title={jina-embeddings-v4: Universal Embeddings for Multimodal Multilingual Retrieval},
author={Michael Günther and Saba Sturua and Mohammad Kalim Akram and Isabelle Mohr and Andrei Ungureanu and Sedigheh Eslami and Scott Martens and Bo Wang and Nan Wang and Han Xiao},
year={2025},
eprint={2506.18902},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2506.18902},
}
License#
Model: Apache 2.0 (same as Qwen2.5-VL license)
Integration Code: Apache 2.0 (see LICENSE)
Contributing#
Found a bug or have a feature request? Please open an issue!
Acknowledgments#
Jina AI for the excellent Jina Embeddings v4 model
Voxel51 for the FiftyOne framework and brain module architecture
HuggingFace for model hosting and transformers library