Note
This is a community plugin, an external project maintained by its respective author. Community plugins are not part of FiftyOne core and may change independently. Please review each plugin’s documentation and license before use.
Nomic Embed Multimodal for FiftyOne#
Nomic Embed Multimodal is a family of vision-language models built on Qwen2.5-VL that generates high-dimensional embeddings for both images and text in a shared vector space. These models provide state-of-the-art performance for visual document understanding with efficient single-vector representations.
Available Models:
7B Model:
nomic-ai/nomic-embed-multimodal-7b(7 billion parameters)3B Model:
nomic-ai/nomic-embed-multimodal-3b(3 billion parameters)
Both models produce 3584-dimensional embeddings, offering a sweet spot between model size and embedding quality for document retrieval tasks.
Installation#
Note: This model requires
transformers<5.0. Install in this order to avoid version conflicts:
pip install fiftyone colpali-engine torch pillow peft "transformers<5.0"
Architecture#
Single-Vector Design#
Nomic Embed Multimodal uses a single-vector architecture where each input (image or text) is compressed into a single high-dimensional embedding:
# Image or Text → Processor → Model → (3584,) embedding
Benefits:
Fast retrieval: Single vector per item, efficient for large-scale search
High quality: 3584 dimensions capture rich semantic information
Simple: No multi-vector complexity or pooling strategies
Normalized: Ready for cosine similarity out of the box
Model Sizes#
Choose the model that fits your compute and quality requirements:
Model |
Parameters |
Speed |
Quality |
Best For |
|---|---|---|---|---|
7B |
7 billion |
Moderate |
Excellent |
Production, accuracy-critical |
3B |
3 billion |
Fast |
Very Good |
Development, real-time |
Both models use the same 3584-dimensional embedding space, so you can switch between them without recomputing your entire dataset.
How It Works#
Retrieval Pipeline:
dataset.compute_embeddings(model, embeddings_field="embeddings")
> embed_images()
> processor.process_images(imgs)
> model(**inputs)
> Returns (batch, 3584) normalized embeddings
> Stores in FiftyOne for cosine similarity search
Classification Pipeline:
dataset.apply_model(model, label_field="predictions")
> _predict_all()
> Get image embeddings (batch, 3584)
> Get text embeddings for classes (num_classes, 3584)
> processor.score() → Cosine similarity
> Returns classification logits
> Output processor → Classification labels
Note: This model requires the colpali-engine package which provides the BiQwen2_5 implementation.
Quick Start#
Load Dataset#
import fiftyone as fo
from fiftyone.utils.huggingface import load_from_hub
# Load document dataset from Hugging Face
dataset = load_from_hub(
"Voxel51/document-haystack-10pages",
overwrite=True,
max_samples=250 # Optional: subset for testing
)
Register the Zoo Model#
import fiftyone.zoo as foz
# Register this repository as a remote zoo model source
foz.register_zoo_model_source(
"https://github.com/harpreetsahota204/nomic-embed-multimodal",
overwrite=True
)
Basic Workflow#
import fiftyone.zoo as foz
import fiftyone.brain as fob
# Load Nomic Embed model (7B by default)
model = foz.load_zoo_model("nomic-ai/nomic-embed-multimodal-7b")
# Or use the 3B model for faster inference
# model = foz.load_zoo_model("nomic-ai/nomic-embed-multimodal-3b")
# Compute embeddings for all documents
dataset.compute_embeddings(
model=model,
embeddings_field="nomic_embeddings"
)
# Check embedding dimensions
print(dataset.first()['nomic_embeddings'].shape) # (3584,)
# Build similarity index
text_img_index = fob.compute_similarity(
dataset,
model="nomic-ai/nomic-embed-multimodal-7b",
embeddings_field="nomic_embeddings",
brain_key="nomic_sim"
)
# Query for specific content
results = text_img_index.sort_by_similarity(
"invoice from 2024",
k=10 # Top 10 results
)
# Launch FiftyOne App
session = fo.launch_app(results, auto=False)
Advanced Embedding Workflows#
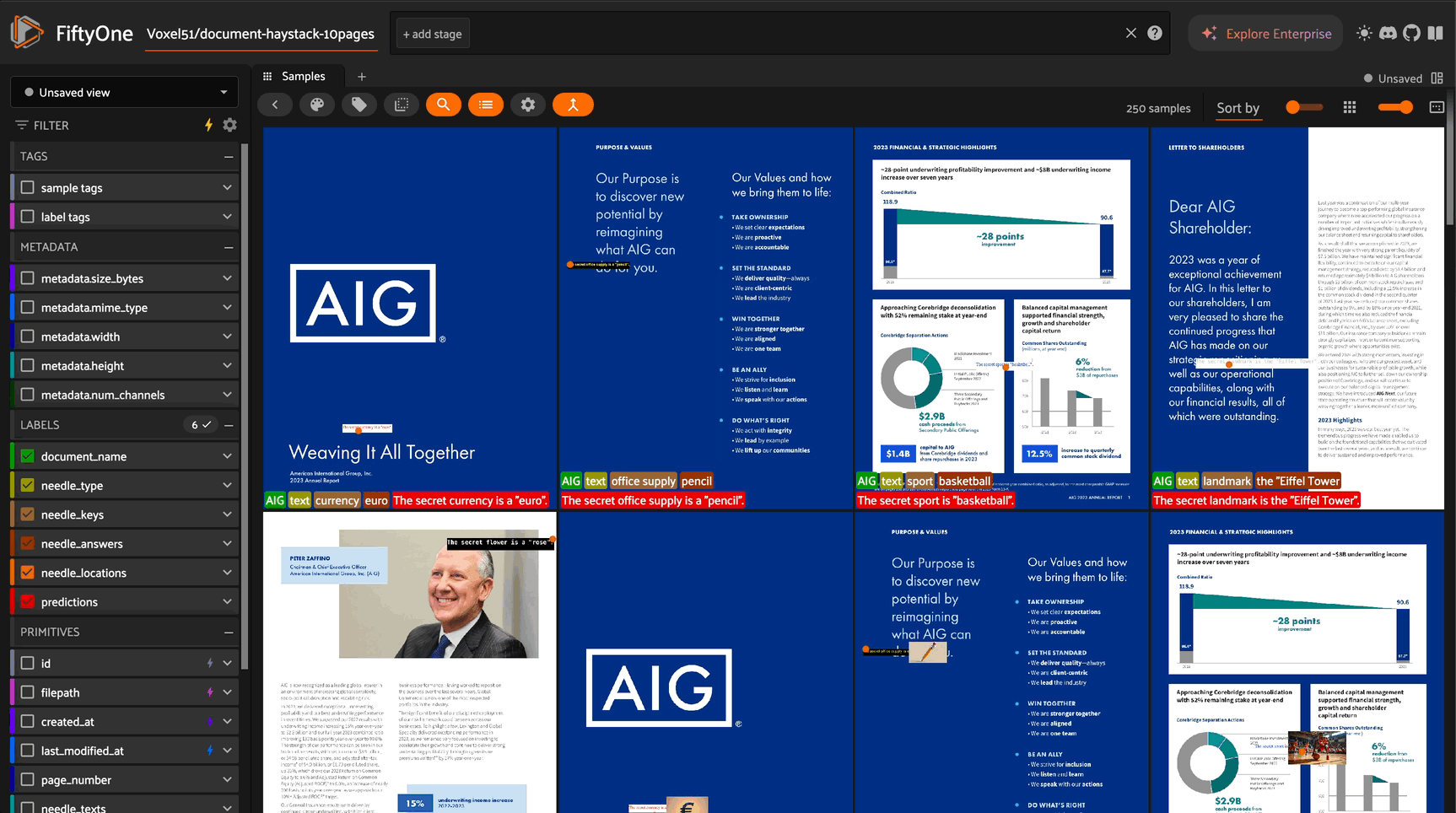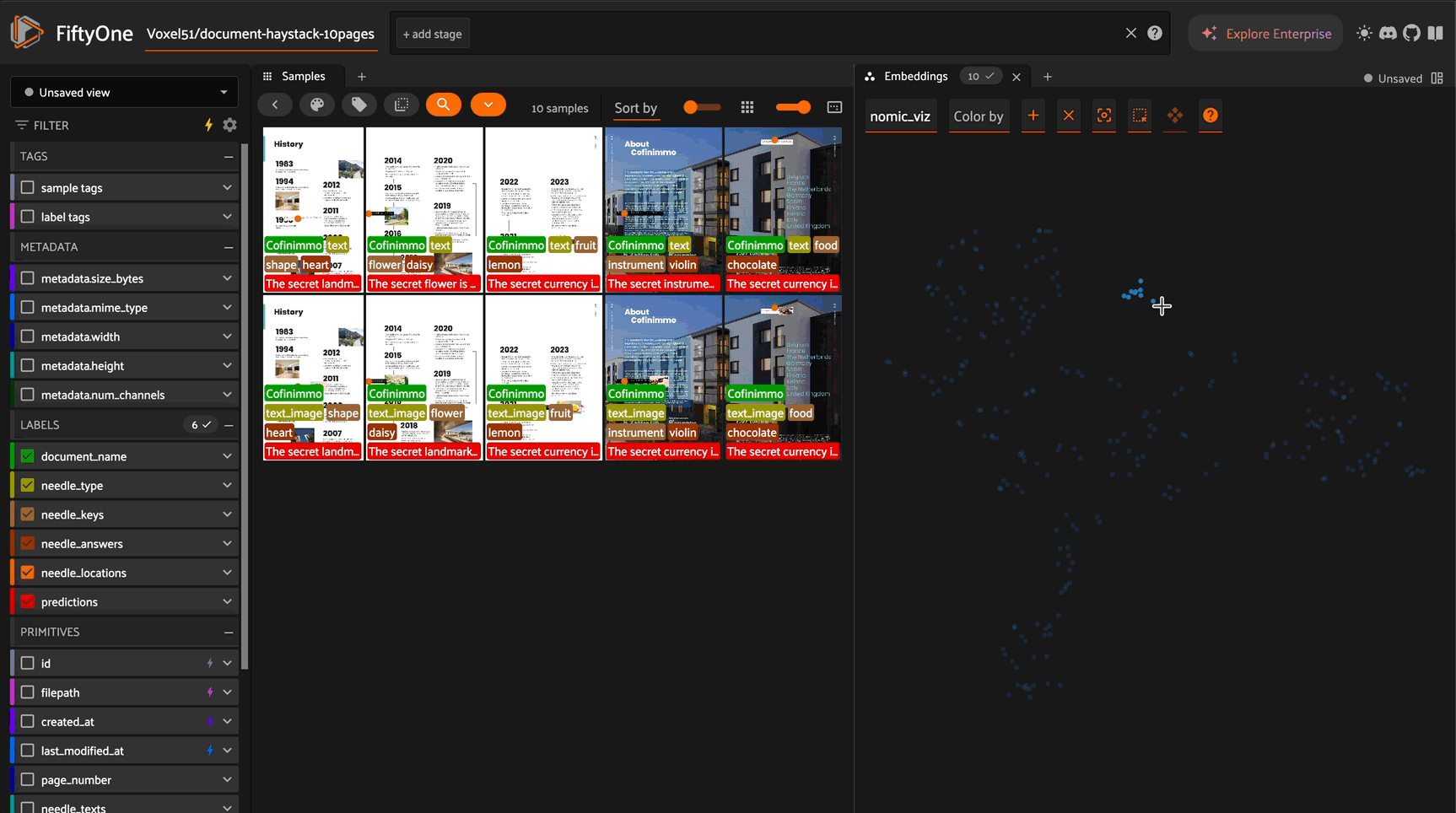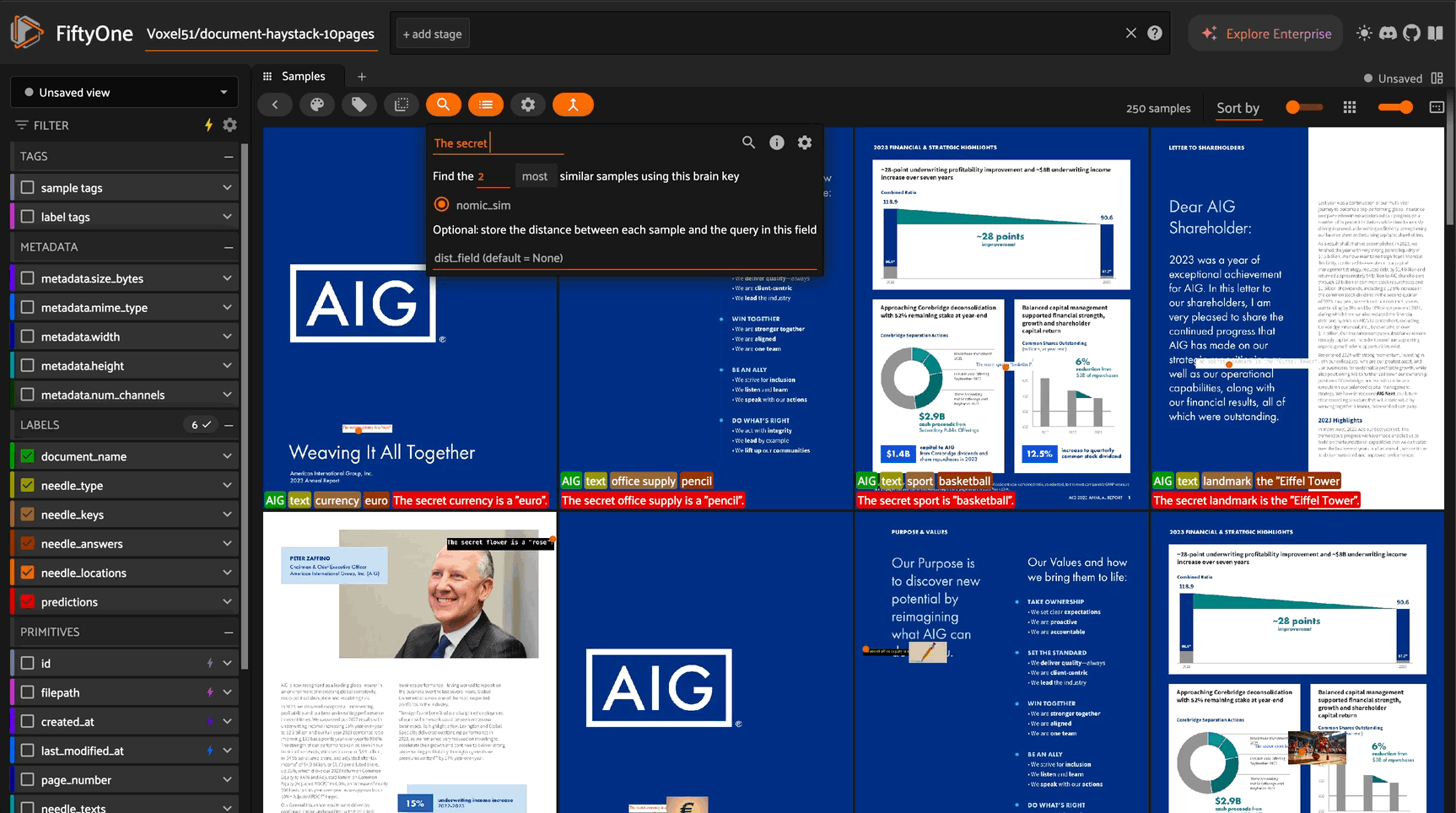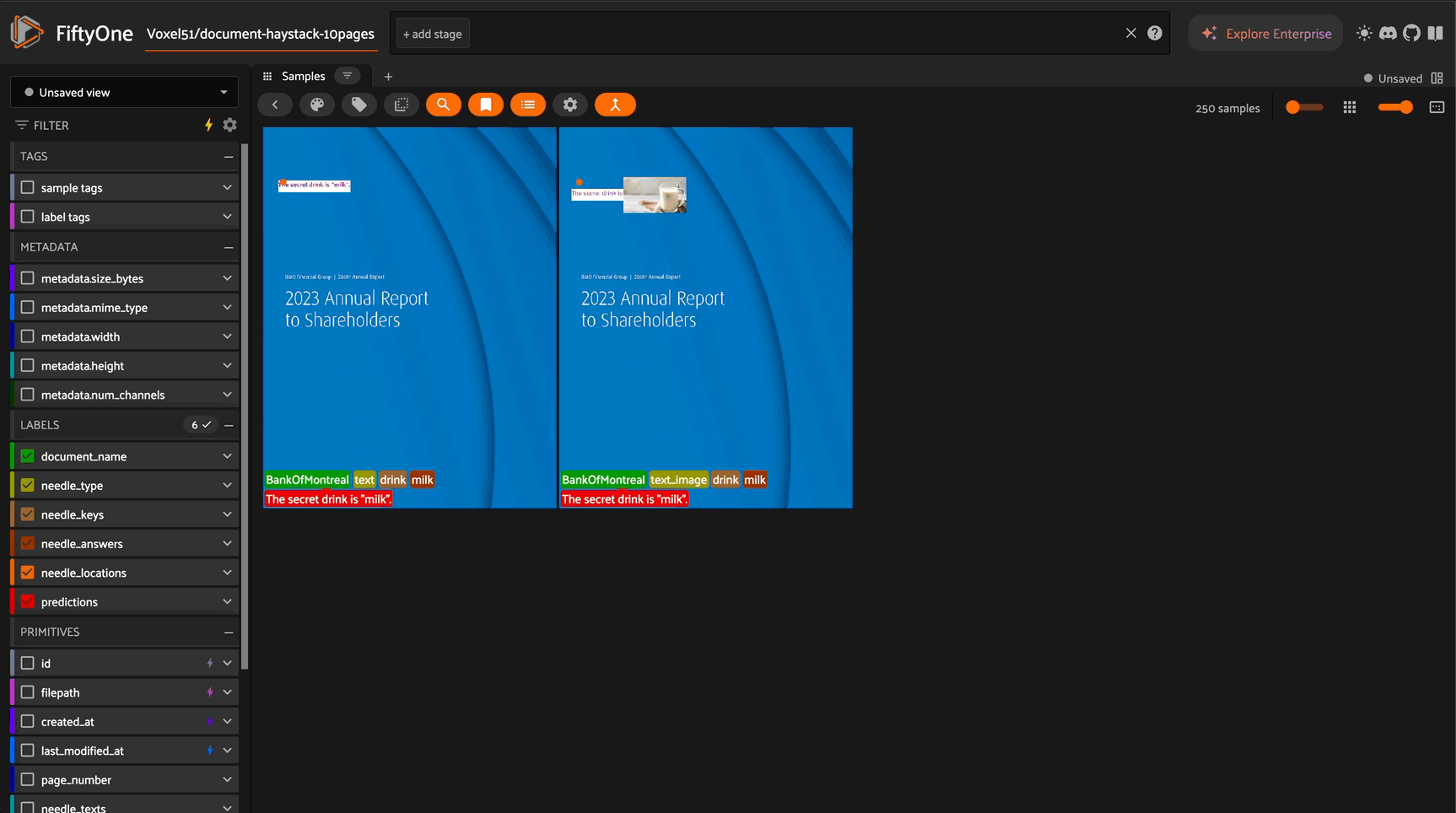
Embedding Visualization with UMAP#
Create 2D visualizations of your document embeddings:
import fiftyone.brain as fob
# First compute embeddings
dataset.compute_embeddings(
model=model,
embeddings_field="nomic_embeddings"
)
# Create UMAP visualization
results = fob.compute_visualization(
dataset,
method="umap", # Also supports "tsne", "pca"
brain_key="nomic_viz",
embeddings="nomic_embeddings",
num_dims=2
)
# Explore in the App
session = fo.launch_app(dataset)
Similarity Search#
Build powerful similarity search:
import fiftyone.brain as fob
results = fob.compute_similarity(
dataset,
backend="sklearn",
brain_key="nomic_sim",
embeddings="nomic_embeddings"
)
# Find similar images
sample_id = dataset.first().id
similar_samples = dataset.sort_by_similarity(
sample_id,
brain_key="nomic_sim",
k=10
)
# View results
session = fo.launch_app(similar_samples)
Dataset Representativeness#
Score how representative each sample is of your dataset:
import fiftyone.brain as fob
# Compute representativeness scores
fob.compute_representativeness(
dataset,
representativeness_field="nomic_represent",
method="cluster-center",
embeddings="nomic_embeddings"
)
# Find most representative samples
representative_view = dataset.sort_by("nomic_represent", reverse=True)
Duplicate Detection#
Find and remove near-duplicate documents:
import fiftyone.brain as fob
# Detect duplicates using embeddings
results = fob.compute_uniqueness(
dataset,
embeddings="nomic_embeddings"
)
# Filter to most unique samples
unique_view = dataset.sort_by("uniqueness", reverse=True)
Zero-Shot Classification#
Nomic Embed supports zero-shot classification using cosine similarity between image and text embeddings:
import fiftyone.zoo as foz
# Load model with classes for classification
model = foz.load_zoo_model(
"nomic-ai/nomic-embed-multimodal-7b",
classes=["invoice", "receipt", "form", "contract", "other"],
text_prompt="This document is a"
)
# Apply model for zero-shot classification
dataset.apply_model(
model,
label_field="document_type_predictions"
)
# View predictions
print(dataset.first()['document_type_predictions'])
session = fo.launch_app(dataset)
Dynamic Classification with Multiple Tasks#
Reuse the same model for different classification tasks:
import fiftyone.zoo as foz
# Load model once (7B for best accuracy)
model = foz.load_zoo_model("nomic-ai/nomic-embed-multimodal-7b")
# Task 1: Classify document types
model.classes = ["invoice", "receipt", "form", "contract"]
model.text_prompt = "This is a"
dataset.apply_model(model, label_field="doc_type")
# Task 2: Classify importance
model.classes = ["high_priority", "medium_priority", "low_priority"]
model.text_prompt = "The priority level is"
dataset.apply_model(model, label_field="priority")
# Task 3: Classify language
model.classes = ["english", "spanish", "french", "german", "chinese"]
model.text_prompt = "The document language is"
dataset.apply_model(model, label_field="language")
# Task 4: Classify completeness
model.classes = ["complete", "incomplete", "draft"]
model.text_prompt = "The document status is"
dataset.apply_model(model, label_field="status")
Combining Embeddings and Classification#
Use the same model for both workflows:
import fiftyone as fo
import fiftyone.zoo as foz
import fiftyone.brain as fob
# Load model once (choose size based on needs)
model = foz.load_zoo_model("nomic-ai/nomic-embed-multimodal-7b")
# Step 1: Compute embeddings for similarity search
dataset.compute_embeddings(
model=model,
embeddings_field="nomic_embeddings"
)
# Step 2: Build similarity index
index = fob.compute_similarity(
dataset,
model=model,
embeddings_field="nomic_embeddings",
brain_key="nomic_sim"
)
# Step 3: Add zero-shot classification
model.classes = ["technical", "financial", "legal", "personal"]
model.text_prompt = "This document category is"
dataset.apply_model(model, label_field="category")
# Step 4: Add more classifications
model.classes = ["urgent", "normal", "low_priority"]
model.text_prompt = "The urgency level is"
dataset.apply_model(model, label_field="urgency")
# Explore combined results
session = fo.launch_app(dataset)
Switching Between Model Sizes#
Both models use the same embedding dimension (3584), so you can compare them:
# Compute embeddings with 7B
model_7b = foz.load_zoo_model("nomic-ai/nomic-embed-multimodal-7b")
dataset.compute_embeddings(model_7b, embeddings_field="nomic_7b_embeddings")
# Compute embeddings with 3B
model_3b = foz.load_zoo_model("nomic-ai/nomic-embed-multimodal-3b")
dataset.compute_embeddings(model_3b, embeddings_field="nomic_3b_embeddings")
# Compare quality
# Both produce 3584-dim vectors, so they're directly comparable
# 7B will generally have slightly better semantic quality
Resources#
Model Hub (7B): nomic-ai/nomic-embed-multimodal-7b
Model Hub (3B): nomic-ai/nomic-embed-multimodal-3b
Nomic AI: nomic.ai
ColPali Engine: colpali-engine
FiftyOne Docs: docs.voxel51.com
Base Architecture: Qwen2.5-VL
Citation#
If you use Nomic Embed Multimodal in your research, please cite:
@misc{nomicembedmultimodal2025,
title={Nomic Embed Multimodal: Interleaved Text, Image, and Screenshots for Visual Document Retrieval},
author={Nomic Team},
year={2025},
publisher={Nomic AI},
url={https://nomic.ai/blog/posts/nomic-embed-multimodal},
}
License#
Model: Apache 2.0
Integration Code: Apache 2.0 (see LICENSE)