CVAT Integration#
CVAT is one of the most popular open-source image and video annotation tools available, and we’ve made it easy to upload your data directly from FiftyOne to CVAT to add or edit labels.
You can use CVAT either through the hosted server at app.cvat.ai or through a self-hosted server. In either case, FiftyOne provides simple setup instructions that you can use to specify the necessary account credentials and server endpoint to use.
Note
Did you know? You can request, manage, and import annotations from within the FiftyOne App by installing the @voxel51/annotation plugin!
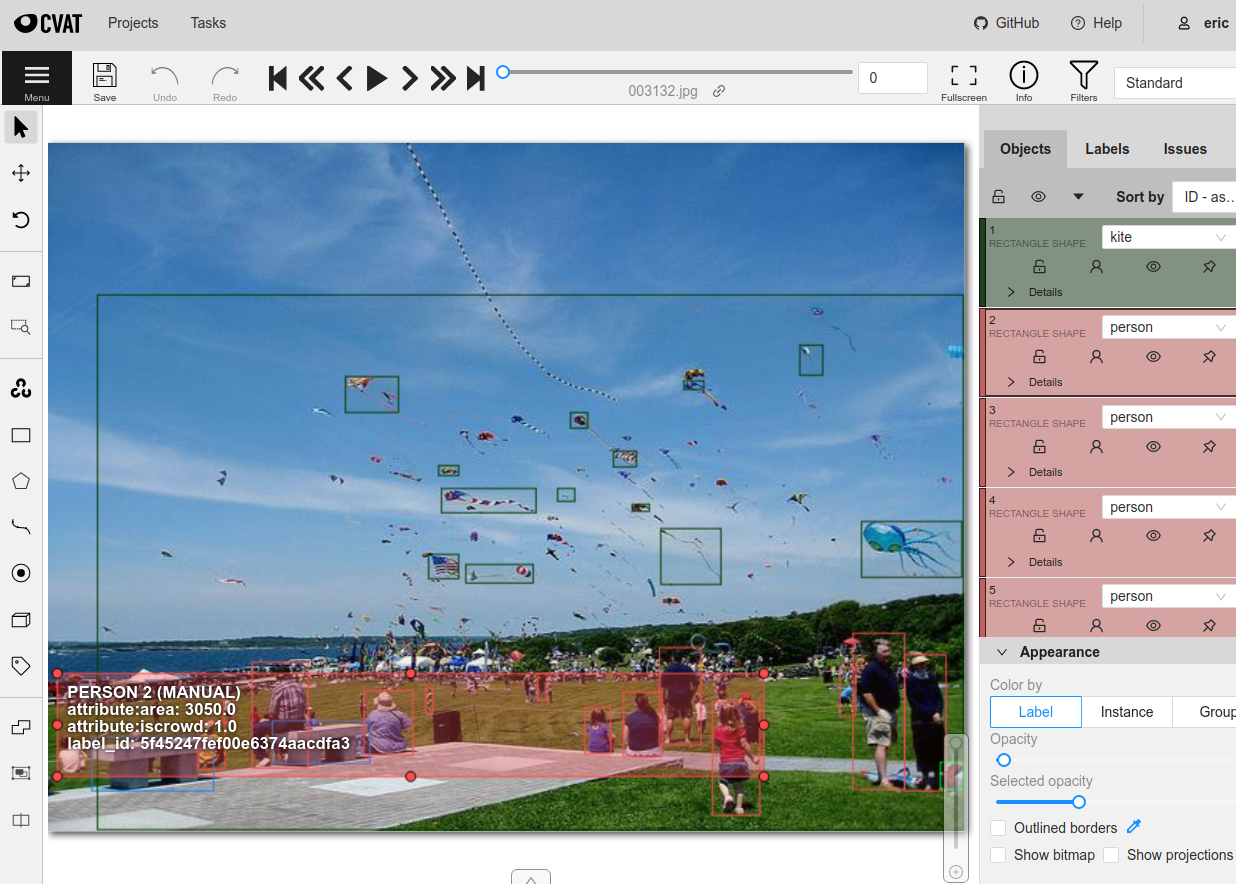
CVAT provides three levels of abstraction for annotation workflows: projects, tasks, and jobs. A job contains one or more images and can be assigned to a specific annotator or reviewer. A task defines the label schema to use for annotation and contains one or more jobs. A project can optionally be created to group multiple tasks together under a shared label schema.
FiftyOne provides an API to create tasks and jobs, upload data, define label schemas, and download annotations using CVAT, all programmatically in Python. All of the following label types are supported, for both image and video datasets:
Note
Check out this tutorial to see how you can use FiftyOne to upload your data to CVAT to create, delete, and fix annotations.
Basic recipe#
The basic workflow to use CVAT to add or edit labels on your FiftyOne datasets is as follows:
Load a dataset into FiftyOne
Explore the dataset using the App or dataset views to locate either unlabeled samples that you wish to annotate or labeled samples whose annotations you want to edit
Use the
annotate()method on your dataset or view to upload the samples and optionally their existing labels to CVATIn CVAT, perform the necessary annotation work
Back in FiftyOne, load your dataset and use the
load_annotations()method to merge the annotations back into your FiftyOne datasetIf desired, delete the CVAT tasks and the record of the annotation run from your FiftyOne dataset
The example below demonstrates this workflow.
Note
You must create an account at app.cvat.ai in order to run this example.
Note that you can store your credentials as described in this section to avoid entering them manually each time you interact with CVAT.
First, we create the annotation tasks in CVAT:
1import fiftyone as fo
2import fiftyone.zoo as foz
3from fiftyone import ViewField as F
4
5# Step 1: Load your data into FiftyOne
6
7dataset = foz.load_zoo_dataset(
8 "quickstart", dataset_name="cvat-annotation-example"
9)
10dataset.persistent = True
11
12dataset.evaluate_detections(
13 "predictions", gt_field="ground_truth", eval_key="eval"
14)
15
16# Step 2: Locate a subset of your data requiring annotation
17
18# Create a view that contains only high confidence false positive model
19# predictions, with samples containing the most false positives first
20most_fp_view = (
21 dataset
22 .filter_labels("predictions", (F("confidence") > 0.8) & (F("eval") == "fp"))
23 .sort_by(F("predictions.detections").length(), reverse=True)
24)
25
26# Let's edit the ground truth annotations for the sample with the most
27# high confidence false positives
28sample_id = most_fp_view.first().id
29view = dataset.select(sample_id)
30
31# Step 3: Send samples to CVAT
32
33# A unique identifier for this run
34anno_key = "cvat_basic_recipe"
35
36view.annotate(
37 anno_key,
38 label_field="ground_truth",
39 attributes=["iscrowd"],
40 launch_editor=True,
41)
42print(dataset.get_annotation_info(anno_key))
43
44# Step 4: Perform annotation in CVAT and save the tasks
Then, once the annotation work is complete, we merge the annotations back into FiftyOne:
1import fiftyone as fo
2
3anno_key = "cvat_basic_recipe"
4
5# Step 5: Merge annotations back into FiftyOne dataset
6
7dataset = fo.load_dataset("cvat-annotation-example")
8dataset.load_annotations(anno_key)
9
10# Load the view that was annotated in the App
11view = dataset.load_annotation_view(anno_key)
12session = fo.launch_app(view=view)
13
14# Step 6: Cleanup
15
16# Delete tasks from CVAT
17results = dataset.load_annotation_results(anno_key)
18results.cleanup()
19
20# Delete run record (not the labels) from FiftyOne
21dataset.delete_annotation_run(anno_key)
Note
Skip to this section to see a variety of common CVAT annotation patterns.
Setup#
FiftyOne supports both app.cvat.ai and self-hosted servers.
The easiest way to get started is to use the default server app.cvat.ai, which simply requires creating an account and then providing your authentication credentials as shown below.
Note
CVAT is the default annotation backend used by FiftyOne. However, if you
have changed your default backend, you can opt-in to using CVAT on a
one-off basis by passing the optional backend parameter to
annotate():
view.annotate(anno_key, backend="cvat", ...)
Refer to these instructions to see how to permanently change your default backend.
Authentication#
In order to connect to a CVAT server, you must provide your login credentials, which can be done in a variety of ways.
Environment variables (recommended)
The recommended way to configure your CVAT login credentials is to store them
in the FIFTYONE_CVAT_USERNAME and FIFTYONE_CVAT_PASSWORD environment
variables. These are automatically accessed by FiftyOne whenever a connection
to CVAT is made.
export FIFTYONE_CVAT_USERNAME=...
export FIFTYONE_CVAT_PASSWORD=...
export FIFTYONE_CVAT_EMAIL=... # if applicable
FiftyOne annotation config
You can also store your credentials in your
annotation config located at
~/.fiftyone/annotation_config.json:
{
"backends": {
"cvat": {
...
"username": ...,
"password": ...,
"email": ... # if applicable
}
}
}
Note that this file will not exist until you create it.
Warning
Storing your username and password in plain text on disk is generally not recommended. Consider using environment variables instead.
Keyword arguments
You can manually provide your login credentials as keyword arguments each time
you call methods like
annotate() and
load_annotations()
that require connections to CVAT:
1view.annotate(anno_key, ..., username=..., password=...)
Command line prompt
If you have not stored your login credentials via another method, you will be prompted to enter them interactively in your shell each time you call a method that requires a connection to CVAT:
1view.annotate(anno_key, label_field="ground_truth", launch_editor=True)
Please enter your login credentials.
You can avoid this in the future by setting your `FIFTYONE_CVAT_USERNAME` and `FIFTYONE_CVAT_PASSWORD` environment variables.
Username: ...
Password: ...
Self-hosted servers#
If you wish to use a self-hosted server, you can configure the URL of your server in any of the following ways:
Set the
FIFTYONE_CVAT_URLenvironment variable:
export FIFTYONE_CVAT_URL=http://localhost:8080
Store the
urlof your server in your annotation config at~/.fiftyone/annotation_config.json:
{
"backends": {
"cvat": {
"url": "http://localhost:8080",
...
}
}
}
Pass the
urlparameter manually each time you callannotate():
1view.annotate(anno_key, ..., url="http://localhost:8080")
If your self-hosted server requires additional headers in order to make HTTP requests, you can provide them in either of the following ways:
Store your custom headers in a
headerskey of your annotation config at~/.fiftyone/annotation_config.json:
{
"backends": {
"cvat": {
...
"headers": {
"<name>": "<value>",
...
}
}
}
}
Pass the
headersparameter manually each time you callannotate()andload_annotations():
1view.annotate(anno_key, ... headers=...)
2view.load_annotations(anno_key, ... headers=...)
Requesting annotations#
Use the
annotate() method
to send the samples and optionally existing labels in a Dataset or
DatasetView to CVAT for annotation.
The basic syntax is:
1anno_key = "..."
2view.annotate(anno_key, ...)
The anno_key argument defines a unique identifier for the annotation run, and
you will provide it to methods like
load_annotations(),
get_annotation_info(),
load_annotation_results(),
rename_annotation_run(), and
delete_annotation_run()
to manage the run in the future.
Warning
FiftyOne assumes that all labels in an annotation run can fit in memory.
If you are annotating very large scale video datasets with dense frame labels, you may violate this assumption. Instead, consider breaking the work into multiple smaller annotation runs that each contain limited subsets of the samples you wish to annotate.
You can use Dataset.stats()
to get a sense for the total size of the labels in a dataset as a rule of
thumb to estimate the size of a candidate annotation run.
In addition,
annotate()
provides various parameters that you can use to customize the annotation tasks
that you wish to be performed.
The following parameters are supported by all annotation backends:
backend (None): the annotation backend to use. Use
"cvat"for the CVAT backend. The supported values arefiftyone.annotation_config.backends.keys()and the default isfiftyone.annotation_config.default_backendmedia_field (“filepath”): the sample field containing the path to the source media to upload
launch_editor (False): whether to launch the annotation backend’s editor after uploading the samples
The following parameters allow you to configure the labeling schema to use for your annotation tasks. See this section for more details:
label_schema (None): a dictionary defining the label schema to use. If this argument is provided, it takes precedence over
label_fieldandlabel_typelabel_field (None): a string indicating a new or existing label field to annotate
label_type (None): a string indicating the type of labels to annotate. The possible label types are:
"classification": a single classification stored inClassificationfields"classifications": multilabel classifications stored inClassificationsfields"detections": object detections stored inDetectionsfields"instances": instance segmentations stored inDetectionsfields with theirmaskattributes populated"polylines": polylines stored inPolylinesfields with theirfilledattributes set toFalse"polygons": polygons stored inPolylinesfields with theirfilledattributes set toTrue"keypoints": keypoints stored inKeypointsfields"segmentation": semantic segmentations stored inSegmentationfields"scalar": scalar labels stored inIntField,FloatField,StringField, orBooleanFieldfields
All new label fields must have their type specified via this argument or in
label_schemaclasses (None): a list of strings indicating the class options for
label_fieldor all fields inlabel_schemawithout classes specified. All new label fields must have a class list provided via one of the supported methods. For existing label fields, if classes are not provided by this argument norlabel_schema, the observed labels on your dataset are usedattributes (True): specifies the label attributes of each label field to include (other than their
label, which is always included) in the annotation export. Can be any of the following:True: export all label attributesFalse: don’t export any custom label attributesa list of label attributes to export
a dict mapping attribute names to dicts specifying the
type,values, anddefaultfor each attribute
If a
label_schemais also provided, this parameter determines which attributes are included for all fields that do not explicitly define their per-field attributes (in addition to any per-class attributes)mask_targets (None): a dict mapping pixel values (2D masks) or RGB hex strings (3D masks) to semantic label strings. Only applicable when annotating semantic segmentations. All new label fields must have mask targets provided via one of the supported methods. For existing label fields, if mask targets are not provided by this argument nor
label_schema, any applicable mask targets stored on your dataset will be used, if availableallow_additions (True): whether to allow new labels to be added. Only applicable when editing existing label fields
allow_deletions (True): whether to allow labels to be deleted. Only applicable when editing existing label fields
allow_label_edits (True): whether to allow the
labelattribute of existing labels to be modified. Only applicable when editing existing fields withlabelattributesallow_index_edits (True): whether to allow the
indexattribute of existing video tracks to be modified. Only applicable when editing existing frame fields withindexattributesallow_spatial_edits (True): whether to allow edits to the spatial properties (bounding boxes, vertices, keypoints, masks, etc) of labels. Only applicable when editing existing spatial label fields
In addition, the following CVAT-specific parameters from
CVATBackendConfig can also be
provided:
task_size (None): an optional maximum number of images to upload per task. Videos are always uploaded one per task
segment_size (None): the maximum number of images to upload per job. Not applicable to videos
image_quality (75): an int in
[0, 100]determining the image quality to upload to CVATuse_cache (True): whether to use a cache when uploading data. Using a cache reduces task creation time as data will be processed on-the-fly and stored in the cache when requested
use_zip_chunks (True): when annotating videos, whether to upload video frames in smaller chunks. Setting this option to
Falsemay result in reduced video quality in CVAT due to size limitations on ZIP files that can be uploaded to CVATchunk_size (None): the number of frames to upload per ZIP chunk
task_assignee (None): the username to assign the generated tasks. This argument can be a list of usernames when annotating videos as each video is uploaded to a separate task
job_assignees (None): a list of usernames to assign jobs
job_reviewers (None): a list of usernames to assign job reviews. Only available in CVAT v1 servers
project_name (None): an optional project name to which to upload the created CVAT task. If a project with this name exists, it will be used, otherwise a new project is created. By default, no project is used
project_id (None): an optional ID of an existing CVAT project to which to upload the annotation tasks. By default, no project is used
task_name (None): an optional task name to use for the created CVAT task
occluded_attr (None): an optional attribute name containing existing occluded values and/or in which to store downloaded occluded values for all objects in the annotation run
group_id_attr (None): an optional attribute name containing existing group ids and/or in which to store downloaded group ids for all objects in the annotation run
issue_tracker (None): URL(s) of an issue tracker to link to the created task(s). This argument can be a list of URLs when annotating videos or when using
task_sizeand generating multiple tasksorganization (None): the name of the organization to use when sending requests to CVAT
frame_start (None): nonnegative integer(s) defining the first frame of videos to upload when creating video tasks. Supported values are:
integer: the first frame to upload for each videolist: a list of first frame integers corresponding to videos in the given samplesdict: a dictionary mapping sample filepaths to first frame integers to use for the corresponding videos
frame_stop (None): nonnegative integer(s) defining the last frame of videos to upload when creating video tasks. Supported values are:
integer: the last frame to upload for each videolist: a list of last frame integers corresponding to videos in the given samplesdict: a dictionary mapping sample filepaths to last frame integers to use for the corresponding videos
frame_step (None): positive integer(s) defining which frames to sample when creating video tasks. Supported values are:
integer: the frame step to apply to each video tasklist: a list of frame step integers corresponding to videos in the given samplesdict: a dictionary mapping sample filepaths to frame step integers to use for the corresponding videos
Note that this argument cannot be provided when uploading existing tracks
Label schema#
The label_schema, label_field, label_type, classes, attributes, and
mask_targets parameters to
annotate() allow
you to define the annotation schema that you wish to be used.
The label schema may define new label field(s) that you wish to populate, and it may also include existing label field(s), in which case you can add, delete, or edit the existing labels on your FiftyOne dataset.
The label_schema argument is the most flexible way to define how to construct
tasks in CVAT. In its most verbose form, it is a dictionary that defines the
label type, annotation type, possible classes, and possible attributes for each
label field:
1anno_key = "..."
2
3label_schema = {
4 "new_field": {
5 "type": "classifications",
6 "classes": ["class1", "class2"],
7 "attributes": {
8 "attr1": {
9 "type": "select",
10 "values": ["val1", "val2"],
11 "default": "val1",
12 },
13 "attr2": {
14 "type": "radio",
15 "values": [True, False],
16 "default": False,
17 }
18 },
19 },
20 "existing_field": {
21 "classes": ["class3", "class4"],
22 "attributes": {
23 "attr3": {
24 "type": "text",
25 }
26 }
27 },
28}
29
30dataset.annotate(anno_key, label_schema=label_schema)
You can also define class-specific attributes by setting elements of the
classes list to dicts that specify groups of classes and their
corresponding attributes. For example, in the configuration below, attr1
only applies to class1 and class2 while attr2 applies to all classes:
1anno_key = "..."
2
3label_schema = {
4 "new_field": {
5 "type": "detections",
6 "classes": [
7 {
8 "classes": ["class1", "class2"],
9 "attributes": {
10 "attr1": {
11 "type": "select",
12 "values": ["val1", "val2"],
13 "default": "val1",
14 }
15 }
16 },
17 "class3",
18 "class4",
19 ],
20 "attributes": {
21 "attr2": {
22 "type": "radio",
23 "values": [True, False],
24 "default": False,
25 }
26 },
27 },
28}
29
30dataset.annotate(anno_key, label_schema=label_schema)
Alternatively, if you are only editing or creating a single label field, you
can use the label_field, label_type, classes, attributes, and
mask_targets parameters to specify the components of the label schema
individually:
1anno_key = "..."
2
3label_field = "new_field",
4label_type = "classifications"
5classes = ["class1", "class2"]
6
7# These are optional
8attributes = {
9 "attr1": {
10 "type": "select",
11 "values": ["val1", "val2"],
12 "default": "val1",
13 },
14 "attr2": {
15 "type": "radio",
16 "values": [True, False],
17 "default": False,
18 }
19}
20
21dataset.annotate(
22 anno_key,
23 label_field=label_field,
24 label_type=label_type,
25 classes=classes,
26 attributes=attributes,
27)
When you are annotating existing label fields, you can omit some of these
parameters from
annotate(), as
FiftyOne can infer the appropriate values to use:
label_type: if omitted, the
Labeltype of the field will be used to infer the appropriate value for this parameterclasses: if omitted, the observed labels on your dataset will be used to construct a classes list
mask_targets: if omitted for a semantic segmentation field, the mask targets from the
mask_targetsordefault_mask_targetsproperties of your dataset will be used, if available
Label attributes#
The attributes parameter allows you to configure whether
custom attributes beyond the default label attribute
are included in the annotation tasks.
When adding new label fields for which you want to include attributes, you must use the dictionary syntax demonstrated below to define the schema of each attribute that you wish to label:
1anno_key = "..."
2
3attributes = {
4 "is_truncated": {
5 "type": "radio",
6 "values": [True, False],
7 "default": False,
8 },
9 "gender": {
10 "type": "select",
11 "values": ["male", "female"],
12 },
13 "caption": {
14 "type": "text",
15 }
16}
17
18view.annotate(
19 anno_key,
20 label_field="new_field",
21 label_type="detections",
22 classes=["dog", "cat", "person"],
23 attributes=attributes,
24)
You can always omit this parameter if you do not require attributes beyond the
default label.
For CVAT, the following type values are supported:
text: a free-form text box. In this case,defaultis optional andvaluesis unusedselect: a selection dropdown. In this case,valuesis required anddefaultis optionalradio: a radio button list UI. In this case,valuesis required anddefaultis optionalcheckbox: a boolean checkbox UI. In this case,defaultis optional andvaluesis unusedoccluded: CVAT’s builtin occlusion toggle icon. This widget type can only be specified for at most one attribute, which must be a booleangroup_id: CVAT’s grouping capabilities. This attribute type can only be specified for at most one attribute, which must be an integer
When you are annotating existing label fields, the attributes parameter can
take additional values:
True(default): export all custom attributes observed on the existing labels, using their observed values to determine the appropriate UI type and possible values, if applicableFalse: do not include any custom attributes in the exporta list of custom attributes to include in the export
a full dictionary syntax described above
Note that only scalar-valued label attributes are supported. Other attribute types like lists, dictionaries, and arrays will be omitted.
Restricting additions, deletions, and edits#
When you create annotation runs that involve editing existing label fields, you
can optionally specify that certain changes are not allowed by passing the
following flags to
annotate():
allow_additions (True): whether to allow new labels to be added
allow_deletions (True): whether to allow labels to be deleted
allow_label_edits (True): whether to allow the
labelattribute to be modifiedallow_index_edits (True): whether to allow the
indexattribute of video tracks to be modifiedallow_spatial_edits (True): whether to allow edits to the spatial properties (bounding boxes, vertices, keypoints, etc) of labels
If you are using the label_schema parameter to provide a full annotation
schema to
annotate(), you
can also directly include the above flags in the configuration dicts for any
existing label field(s) you wish.
For example, suppose you have an existing ground_truth field that contains
objects of various types and you would like to add new sex and age
attributes to all people in this field while also strictly enforcing that no
objects can be added, deleted, or have their labels or bounding boxes modified.
You can configure an annotation run for this as follows:
1anno_key = "..."
2
3attributes = {
4 "sex": {
5 "type": "select",
6 "values": ["male", "female"],
7 },
8 "age": {
9 "type": "text",
10 },
11}
12
13view.annotate(
14 anno_key,
15 label_field="ground_truth",
16 classes=["person"],
17 attributes=attributes,
18 allow_additions=False,
19 allow_deletions=False,
20 allow_label_edits=False,
21 allow_spatial_edits=False,
22)
You can also include a read_only=True parameter when uploading existing
label attributes to specify that the attribute’s value should be uploaded to
the annotation backend for informational purposes, but any edits to the
attribute’s value should not be imported back into FiftyOne.
For example, if you have vehicles with their make attribute populated and you
want to populate a new model attribute based on this information without
allowing changes to the vehicle’s make, you can configure an annotation run
for this as follows:
1anno_key = "..."
2
3attributes = {
4 "make": {
5 "type": "text",
6 "read_only": True,
7 },
8 "model": {
9 "type": "text",
10 },
11}
12
13view.annotate(
14 anno_key,
15 label_field="ground_truth",
16 classes=["vehicle"],
17 attributes=attributes,
18)
Note that, if you use CVAT projects to organize your annotation tasks, the
above restrictions must be manually re-specified in your call to
annotate() for
each annotation task that you add to an existing project, since CVAT does not
provide support for these settings natively.
Warning
The CVAT backend does not support restrictions to additions, deletions, spatial edits, and read-only attributes in its editing interface.
However, any restrictions that you specify via the above parameters will
still be enforced when you call
load_annotations()
to merge the annotations back into FiftyOne.
IMPORTANT: When uploading existing labels to CVAT, the id of the
labels in FiftyOne are stored in a label_id attribute of the CVAT shapes.
If a label_id is modified in CVAT, then FiftyOne may not be able to merge
the annotation with its existing Label instance; it must instead delete
the existing label and create a new Label with the shape’s contents. In
such cases, if allow_additions and/or allow_deletions were set to
False on the annotation schema, this can result in CVAT edits being
rejected. See this section for details.
Labeling videos#
When annotating spatiotemporal objects in videos, you have a few additional options at your fingertips.
First, each object attribute specification can include a mutable property
that controls whether the attribute’s value can change between frames for each
object:
1anno_key = "..."
2
3attributes = {
4 "type": {
5 "type": "select",
6 "values": ["sedan", "suv", "truck"],
7 "mutable": False,
8 },
9 "visible_license_plate": {
10 "type": "radio",
11 "values": [True, False],
12 "default": False,
13 "mutable": True,
14 },
15}
16
17view.annotate(
18 anno_key,
19 label_field="frames.new_field",
20 label_type="detections",
21 classes=["vehicle"],
22 attributes=attributes,
23)
The meaning of the mutable attribute is defined as follows:
True(default): the attribute is dynamic and can have a different value for every frame in which the object track appearsFalse: the attribute is static and is the same for every frame in which the object track appears
In addition, note that when you
download annotation runs that include track
annotations, the downloaded label corresponding to each keyframe of an object
track will have its keyframe=True attribute set to denote that it was a
keyframe.
Similarly, when you create an annotation run on a video dataset that involves
editing existing video tracks, if at least one existing label has its
keyframe=True attribute populated, then the available keyframe information
will be uploaded to CVAT.
Note
See this section for video annotation examples!
Warning
When uploading existing labels to CVAT, the id of the labels in FiftyOne
are stored in a label_id attribute of the CVAT shapes.
IMPORTANT: If a label_id is modified in CVAT, then FiftyOne may not
be able to merge the annotation with its existing Label instance; in such
cases, it must instead delete the existing label and create a new Label
with the shape’s contents. See this section for
details.
CVAT limitations#
When uploading existing labels to CVAT, FiftyOne uses two sources of provenance
to associate Label instances in FiftyOne with their corresponding CVAT
shapes:
The
idof eachLabelis stored in alabel_idattribute of the CVAT shape. When importing annotations from CVAT back into FiftyOne, if thelabel_idof a shape matches the ID of a label that was included in the annotation run, the shape will be merged into the existingLabelFiftyOne also maintains a mapping between
LabelIDs and the internal CVAT shape IDs that are created when the CVAT tasks are created. If, during download, a CVAT shape whoselabel_idhas been deleted or otherwise modified and doesn’t match an existing label ID but does have a recognized CVAT ID is encountered, this shape will be merged into the existingLabel
Unfortunately,
CVAT does not guarantee
that its internal IDs are immutable. Thus, if both the label_id attribute and
(unknown to the user) the internal CVAT ID of a shape are both modified,
merging the shape with its source Label is impossible.
CVAT automatically clears/edits all attributes of a shape, including the
label_id attribute, in the following cases:
When using a label schema with per-class attributes, all attributes of a shape are cleared whenever the class label of the shape is changed to a class whose attribute schema differs from the previous class. The recommended workaround in this case is to manually copy the
label_idbefore changing the class and then pasting it back to ensure that the ID doesn’t change.When splitting or merging video tracks, CVAT may clear or duplicate the shape’s attributes during the process. If this results in missing or duplicate
label_idvalues, then, although FiftyOne will gracefully proceed with the import, provenance has still been lost and thus existingLabelinstances whose IDs no longer exist must be deleted and replaced with newly createdLabelinstances.
The primary issues that can arise due to modified/deleted label_id attributes
are:
If the original
Labelin FiftyOne contained additional attributes that weren’t included in the CVAT annotation run, then those attributes will be lost whenever loading annotations requires deleting the existing label and creating a new one.When working with annotation schemas that specify edit restrictions, CVAT edits that cause
label_idchanges may need to be rejected. For example, ifallow_additionsandallow_deletionsare set toFalseand editing a CVAT shape’s class label causes its attributes to be cleared, then this change will be rejected by FiftyOne because it would require both deleting an existing label and creating a new one.
Note
Pro tip: If you are editing existing labels and only uploading a subset
of their attributes to CVAT,
restricting label deletions by setting
allow_deletions=False provides a helpful guarantee that no labels will be
deleted if label provenance snafus occur in CVAT.
Note
Pro tip: When working with annotation schemas that include
per-class attributes, be sure that any class
label changes that you would reasonably make all share the same attribute
schemas so that unwanted label_id changes are not caused by CVAT.
If a schema-altering class change must occur, remember to manually copy the
label_id before making the change and then paste it back to ensure that
the ID doesn’t change.
Loading annotations#
After your annotations tasks in the annotation backend are complete, you can
use the
load_annotations()
method to download them and merge them back into your FiftyOne dataset.
1view.load_annotations(anno_key)
The anno_key parameter is the unique identifier for the annotation run that
you provided when calling
annotate(). You
can use
list_annotation_runs()
to see the available keys on a dataset.
Note
By default, calling
load_annotations()
will not delete any information for the run from the annotation backend.
However, you can pass cleanup=True to delete all information associated
with the run from the backend after the annotations are downloaded.
You can use the optional dest_field parameter to override the task’s
label schema and instead load annotations into different field name(s) of your
dataset. This can be useful, for example, when editing existing annotations, if
you would like to do a before/after comparison of the edits that you import. If
the annotation run involves multiple fields, dest_field should be a
dictionary mapping label schema field names to destination field names.
Note that CVAT cannot explicitly prevent annotators from creating labels that
don’t obey the run’s label schema. However, you can pass the optional
unexpected parameter to
load_annotations()
to configure how to deal with any such unexpected labels that are found. The
supported values are:
"prompt"(default): present an interactive prompt to direct/discard unexpected labels"ignore": automatically ignore any unexpected labels"keep": automatically keep all unexpected labels in a field whose name matches the label type"return": return a dict containing all unexpected labels, if any
See this section for more details.
Managing annotation runs#
FiftyOne provides a variety of methods that you can use to manage in-progress or completed annotation runs.
For example, you can call
list_annotation_runs()
to see the available annotation keys on a dataset:
1dataset.list_annotation_runs()
Or, you can use
get_annotation_info()
to retrieve information about the configuration of an annotation run:
1info = dataset.get_annotation_info(anno_key)
2print(info)
Use load_annotation_results()
to load the AnnotationResults
instance for an annotation run.
All results objects provide a cleanup()
method that you can use to delete all information associated with a run from
the annotation backend.
1results = dataset.load_annotation_results(anno_key)
2results.cleanup()
In addition, the
AnnotationResults
subclasses for each backend may provide additional utilities such as support
for programmatically monitoring the status of the annotation tasks in the run.
You can use
rename_annotation_run()
to rename the annotation key associated with an existing annotation run:
1dataset.rename_annotation_run(anno_key, new_anno_key)
Finally, you can use
delete_annotation_run()
to delete the record of an annotation run from your FiftyOne dataset:
1dataset.delete_annotation_run(anno_key)
Note
Calling
delete_annotation_run()
only deletes the record of the annotation run from your FiftyOne
dataset; it will not delete any annotations loaded onto your dataset via
load_annotations(),
nor will it delete any associated information from the annotation backend.
Examples#
This section demonstrates how to perform some common annotation workflows on a FiftyOne dataset using the CVAT backend.
Note
All of the examples below assume you have configured your CVAT server and credentials as described in this section.
Adding new label fields#
In order to annotate a new label field, you can provide the label_field,
label_type, and classes parameters to
annotate() to
define the annotation schema for the field:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5view = dataset.take(1)
6
7anno_key = "cvat_new_field"
8
9view.annotate(
10 anno_key,
11 label_field="new_classifications",
12 label_type="classifications",
13 classes=["dog", "cat", "person"],
14 launch_editor=True,
15)
16print(dataset.get_annotation_info(anno_key))
17
18# Create annotations in CVAT
19
20dataset.load_annotations(anno_key, cleanup=True)
21dataset.delete_annotation_run(anno_key)
Alternatively, you can use the label_schema argument to define the same
labeling task:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5view = dataset.take(1)
6
7anno_key = "cvat_new_field"
8
9label_schema = {
10 "new_classifications": {
11 "type": "classifications",
12 "classes": ["dog", "cat", "person"],
13 }
14}
15
16view.annotate(anno_key, label_schema=label_schema, launch_editor=True)
17print(dataset.get_annotation_info(anno_key))
18
19# Create annotations in CVAT
20
21dataset.load_annotations(anno_key, cleanup=True)
22dataset.delete_annotation_run(anno_key)
Editing existing labels#
A common use case is to fix annotation mistakes that you discovered in your datasets through FiftyOne.
You can easily edit the labels in an existing field of your FiftyOne dataset
by simply passing the name of the field via the label_field parameter of
annotate():
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5view = dataset.take(1)
6
7anno_key = "cvat_existing_field"
8
9view.annotate(anno_key, label_field="ground_truth", launch_editor=True)
10print(dataset.get_annotation_info(anno_key))
11
12# Modify/add/delete bounding boxes and their attributes in CVAT
13
14dataset.load_annotations(anno_key, cleanup=True)
15dataset.delete_annotation_run(anno_key)
The above code snippet will infer the possible classes and label attributes
from your FiftyOne dataset. However, the classes and attributes parameters
can be used to annotate new classes and/or attributes:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5view = dataset.take(1)
6
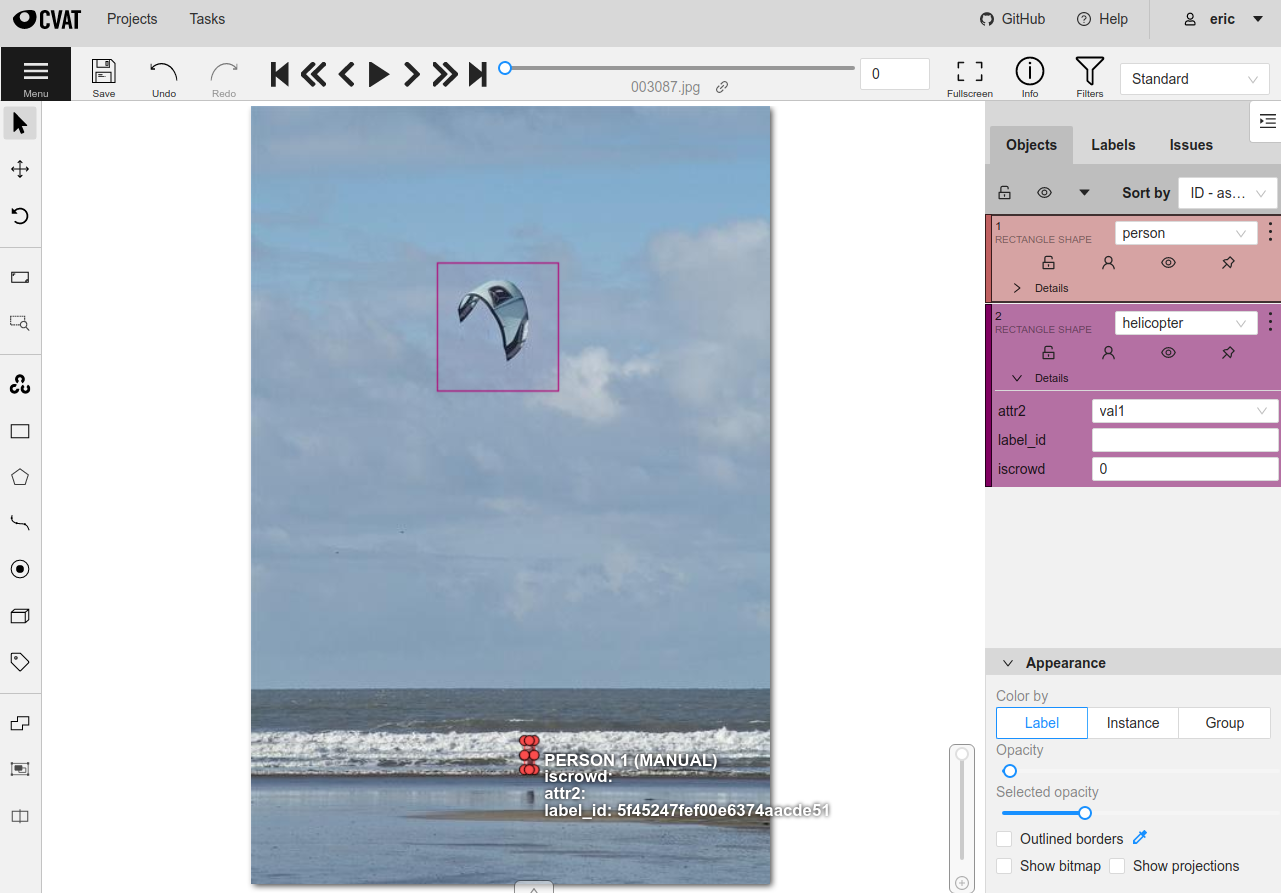
7anno_key = "cvat_existing_field"
8
9# The list of possible `label` values
10classes = ["person", "dog", "cat", "helicopter"]
11
12# Details for the existing `iscrowd` attribute are automatically inferred
13# A new `attr2` attribute is also added
14attributes = {
15 "iscrowd": {},
16 "attr2": {
17 "type": "select",
18 "values": ["val1", "val2"],
19 }
20}
21
22view.annotate(
23 anno_key,
24 label_field="ground_truth",
25 classes=classes,
26 attributes=attributes,
27 launch_editor=True,
28)
29print(dataset.get_annotation_info(anno_key))
30
31# Modify/add/delete bounding boxes and their attributes in CVAT
32
33dataset.load_annotations(anno_key, cleanup=True)
34dataset.delete_annotation_run(anno_key)
Warning
When uploading existing labels to CVAT, the id of the labels in FiftyOne
are stored in a label_id attribute of the CVAT shapes.
IMPORTANT: If a label_id is modified in CVAT, then FiftyOne may not
be able to merge the annotation with its existing Label instance; in such
cases, it must instead delete the existing label and create a new Label
with the shape’s contents. See this section for
details.
Restricting label edits#
You can use the allow_additions, allow_deletions, allow_label_edits,
allow_index_edits, and allow_spatial_edits parameters to configure whether
certain types of edits are allowed in your annotation run. See
this section for more information about the
available options.
For example, suppose you have an existing ground_truth field that contains
objects of various types and you would like to add new sex and age
attributes to all people in this field while also strictly enforcing that no
objects can be added, deleted, or have their labels or bounding boxes modified.
You can configure an annotation run for this as follows:
1import fiftyone as fo
2import fiftyone.zoo as foz
3from fiftyone import ViewField as F
4
5dataset = foz.load_zoo_dataset("quickstart")
6
7# Grab a sample that contains a person
8view = (
9 dataset
10 .match_labels(filter=F("label") == "person", fields="ground_truth")
11 .limit(1)
12)
13
14anno_key = "cvat_edit_restrictions"
15
16# The new attributes that we want to populate
17attributes = {
18 "sex": {
19 "type": "select",
20 "values": ["male", "female"],
21 },
22 "age": {
23 "type": "text",
24 },
25}
26
27view.annotate(
28 anno_key,
29 label_field="ground_truth",
30 classes=["person"],
31 attributes=attributes,
32 allow_additions=False,
33 allow_deletions=False,
34 allow_label_edits=False,
35 allow_spatial_edits=False,
36 launch_editor=True,
37)
38print(dataset.get_annotation_info(anno_key))
39
40# Populate attributes in CVAT
41
42dataset.load_annotations(anno_key, cleanup=True)
43dataset.delete_annotation_run(anno_key)
Similarly, you can include a read_only=True parameter when uploading existing
label attributes to specify that the attribute’s value should be uploaded to
the annotation backend for informational purposes, but any edits to the
attribute’s value should not be imported back into FiftyOne.
For example, the snippet below uploads the vehicle tracks in a video dataset
along with their existing type attributes and requests that a new make
attribute be populated without allowing edits to the vehicle’s type:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart-video")
5view = dataset.take(1)
6
7anno_key = "cvat_read_only_attrs"
8
9# Upload existing `type` attribute as read-only and add new `make` attribute
10attributes = {
11 "type": {
12 "type": "text",
13 "read_only": True,
14 },
15 "make": {
16 "type": "text",
17 "mutable": False,
18 },
19}
20
21view.annotate(
22 anno_key,
23 label_field="frames.detections",
24 classes=["vehicle"],
25 attributes=attributes,
26 launch_editor=True,
27)
28print(dataset.get_annotation_info(anno_key))
29
30# Populate make attributes in CVAT
31
32dataset.load_annotations(anno_key, cleanup=True)
33dataset.delete_annotation_run(anno_key)
Warning
The CVAT backend does not support restrictions to additions, deletions, spatial edits, and read-only attributes in its editing interface.
However, any restrictions that you specify via the above parameters will
still be enforced when you call
load_annotations()
to merge the annotations back into FiftyOne.
IMPORTANT: When uploading existing labels to CVAT, the id of the
labels in FiftyOne are stored in a label_id attribute of the CVAT shapes.
If a label_id is modified in CVAT, then FiftyOne may not be able to merge
the annotation with its existing Label instance; it must instead delete
the existing label and create a new Label with the shape’s contents. In
such cases, if allow_additions and/or allow_deletions were set to
False on the annotation schema, this can result in CVAT edits being
rejected. See this section for details.
Annotating multiple fields#
The label_schema argument allows you to define an annotation task that
involves multiple fields:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5view = dataset.take(1)
6
7anno_key = "cvat_multiple_fields"
8
9# The details for existing `ground_truth` field are inferred
10# A new field `new_keypoints` is also added
11label_schema = {
12 "ground_truth": {},
13 "new_keypoints": {
14 "type": "keypoints",
15 "classes": ["person", "cat", "dog", "food"],
16 "attributes": {
17 "is_truncated": {
18 "type": "select",
19 "values": [True, False],
20 }
21 }
22 }
23}
24
25view.annotate(anno_key, label_schema=label_schema, launch_editor=True)
26print(dataset.get_annotation_info(anno_key))
27
28# Add annotations in CVAT...
29
30dataset.load_annotations(anno_key, cleanup=True)
31dataset.delete_annotation_run(anno_key)
Note
CVAT annotation schemas do not have a notion of label fields. Therefore, if you define an annotation schema that involves the same class label in multiple fields, the name of the label field will be appended to the class in CVAT in order to distinguish the class labels.
Unexpected annotations#
The annotate()
method allows you to define the annotation schema that should be followed in
CVAT. However, CVAT does not explicitly allow for restricting the label types
that can be created, so it is possible that your annotators may accidentally
violate a task’s intended schema.
You can pass the optional unexpected parameter to
load_annotations()
to configure how to deal with any such unexpected labels that are found. The
supported values are:
"prompt"(default): present an interactive prompt to direct/discard unexpected labels"keep": automatically keep all unexpected labels in a field whose name matches the label type"ignore": automatically ignore any unexpected labels"return": return a dict containing all unexpected labels, if any
For example, suppose you upload a Detections field to CVAT for editing, but
then polyline annotations are added instead. When
load_annotations()
is called, the default behavior is to present a command prompt asking you what
field(s) (if any) to store these unexpected labels in:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5view = dataset.take(1)
6
7anno_key = "cvat_unexpected"
8
9view.annotate(anno_key, label_field="ground_truth", launch_editor=True)
10print(dataset.get_annotation_info(anno_key))
11
12# Add some polyline annotations in CVAT (wrong type!)
13
14# You will be prompted for a field in which to store the polylines
15dataset.load_annotations(anno_key, cleanup=True)
16dataset.delete_annotation_run(anno_key)
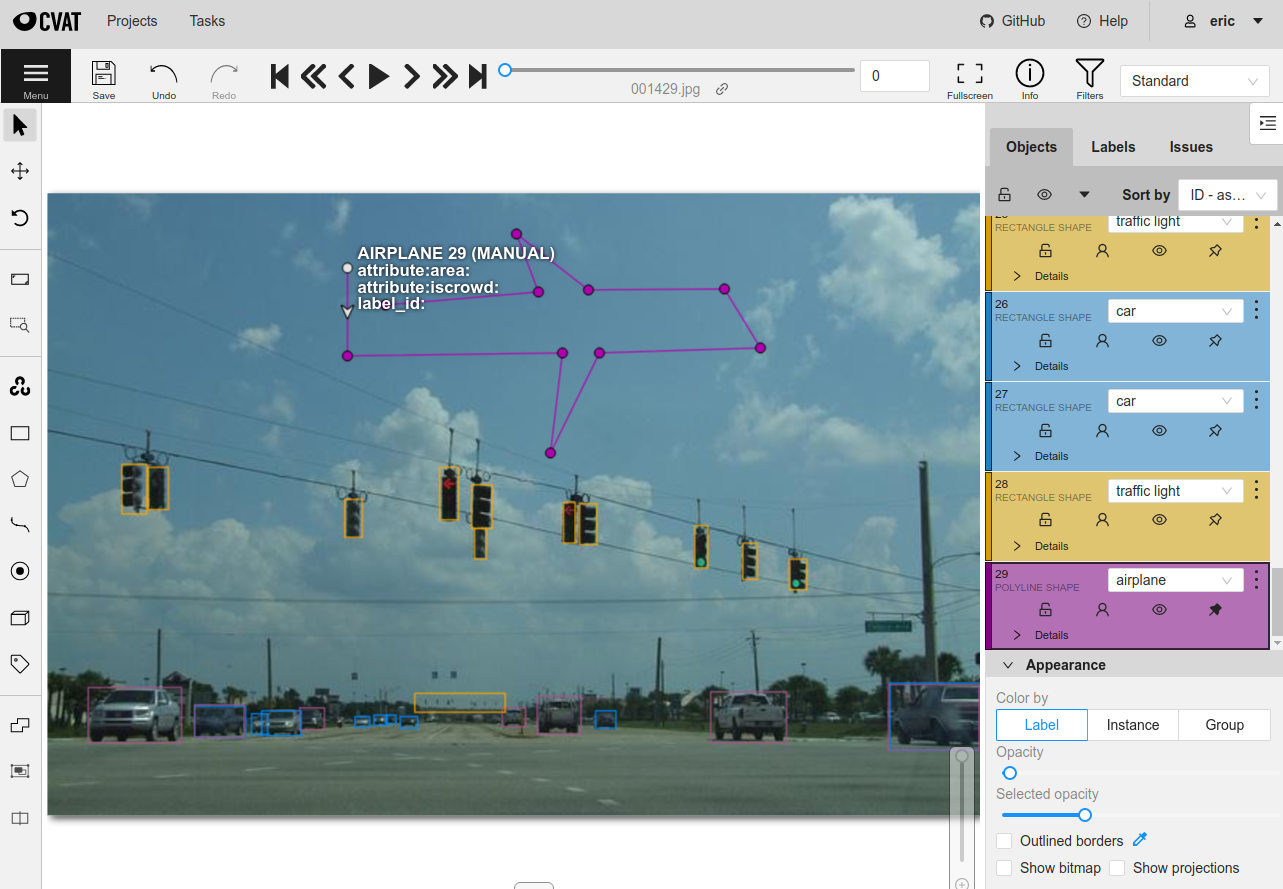
Creating projects#
You can use the optional project_name parameter to specify the name of a
CVAT project to which to upload the task(s) for an annotation run. If a project
with the given name already exists, the task will be uploaded to the existing
project and will automatically inherit its annotation schema. Otherwise, a new
project with the schema you define will be created.
A typical use case for this parameter is video annotation, since in CVAT every video must be annotated in a separate task. Creating a project allows all of the tasks to be organized together in one place.
As with tasks, you can delete the project associated with an annotation run by
passing the cleanup=True option to
load_annotations().
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart-video")
5view = dataset.take(3)
6
7anno_key = "cvat_create_project"
8
9view.annotate(
10 anno_key,
11 label_field="frames.detections",
12 project_name="fiftyone_project_example",
13 launch_editor=True,
14)
15print(dataset.get_annotation_info(anno_key))
16
17# Annotate videos in CVAT...
18
19dataset.load_annotations(anno_key, cleanup=True)
20dataset.delete_annotation_run(anno_key)
Uploading to existing projects#
The project_name and project_id parameters can both be used to specify an
existing CVAT project to which to upload the task(s) for an annotation run.
In this case, the schema of the project is automatically applied to your
annotation tasks.
A typical use case for this workflow is when you use the same annotation schema for multiple datasets, since this allows you to organize the tasks under one CVAT project and avoid the need to re-specify the label schema in FiftyOne.
Note
When uploading to existing projects, because the annotation schema is
inherited from the CVAT project definition, any class/attribute
specifications that you attempt to provide via arguments such as
label_schema, classes, and attributes to
annotate()
will be ignored.
You can, however, use the label_schema and label_field arguments for
the limited purpose of specifying the name of existing label field(s) to
upload or the name and type of new field(s) in which you want to store the
annotations that will be created. If no label fields are provided, then you
will receive command line prompt(s) at import time to provide label
field(s) in which to store the annotations.
Warning
Since the label_schema and attribute arguments are ignored, any occluded or
group id attributes defined there will also be ignored. In order to connect
occluded or group id attributes, use the occluded_attr and
group_id_attr arguments directly.
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart").clone()
5view = dataset.take(3)
6
7project_name = "fiftyone_project_example"
8
9#
10# Upload existing `ground_truth` labels to a new CVAT project
11# The label schema is automatically inferred from the existing labels
12#
13
14view.annotate(
15 "create_project",
16 label_field="ground_truth",
17 project_name=project_name,
18 launch_editor=True,
19)
20
21#
22# Now upload the `predictions` labels to the same CVAT project
23# Here the label schema of the existing CVAT project is automatically used
24#
25
26anno_key = "cvat_existing_project"
27view.annotate(
28 anno_key,
29 label_field="predictions",
30 project_name=project_name,
31 launch_editor=True,
32)
33print(dataset.get_annotation_info(anno_key))
34
35# Annotate in CVAT...
36
37dataset.load_annotations(anno_key, cleanup=True)
38dataset.delete_annotation_run(anno_key)
39
40#
41# Now add a task with unspecified label fields to the same CVAT project
42# In this case you will be prompted for field names at download time
43#
44
45anno_key = "cvat_new_fields"
46view.annotate(
47 anno_key,
48 project_name=project_name,
49 launch_editor=True,
50)
51print(dataset.get_annotation_info(anno_key))
52
53# Annotate in CVAT...
54
55dataset.load_annotations(anno_key, cleanup=True)
56dataset.delete_annotation_run(anno_key)
Assigning users#
When using the CVAT backend, you can provide the following optional parameters
to annotate() to
specify which users will be assigned to the created tasks:
segment_size: the maximum number of images to include in a single jobtask_assignee: a username to assign the generated tasks. This argument can be a list of usernames when annotating videos as each video is uploaded to a separate taskjob_assignees: a list of usernames to assign jobsjob_reviewers: a list of usernames to assign job reviews. Only available in CVAT v1 servers
If the number of jobs exceeds the number of assignees or reviewers, the jobs will be assigned using a round-robin strategy.
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5view = dataset.take(5)
6
7anno_key = "cvat_assign_users"
8
9task_assignee = "username1"
10job_assignees = ["username2", "username3"]
11
12# If using a CVAT v1 server
13# job_reviewers = ["username4", "username5", "username6", "username7"]
14
15# Load "ground_truth" field into one task
16# Create another task for "keypoints" field
17label_schema = {
18 "ground_truth": {},
19 "keypoints": {
20 "type": "keypoints",
21 "classes": ["person"],
22 }
23}
24
25view.annotate(
26 anno_key,
27 label_schema=label_schema,
28 segment_size=2,
29 task_assignee=task_assignee,
30 job_assignees=job_assignees,
31 launch_editor=True,
32)
33print(dataset.get_annotation_info(anno_key))
34
35# Cleanup
36results = dataset.load_annotation_results(anno_key)
37results.cleanup()
38dataset.delete_annotation_run(anno_key)
Large annotation runs#
The CVAT API imposes a limit on the size of all requests. By default, all images are uploaded to a single CVAT task, which can result in errors when uploading annotation runs for large sample collections.
Note
The CVAT maintainers made an update to resolve this issue natively, but if you still encounter issues, try the following workflow to circumvent the issue.
You can use the task_size parameter to break image annotation runs into
multiple CVAT tasks, each with a specified maximum number of images. Note that
we recommend providing a project_name whenever you use the task_size
parameter so that the created tasks will be grouped together.
The task_size parameter can also be used in conjunction with the
segment_size parameter to configure both the number of images per task as
well as the number of images per job within each task.
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart", max_samples=20).clone()
5
6anno_key = "batch_upload"
7
8results = dataset.annotate(
9 anno_key,
10 label_field="ground_truth",
11 task_size=6, # 6 images per task
12 segment_size=2, # 2 images per job
13 project_name="batch_example",
14 launch_editor=True,
15)
16
17# Annotate in CVAT...
18
19dataset.load_annotations(anno_key, cleanup=True)
Note
The task_size parameter only applies to image datasets, since videos are
always uploaded one per task.
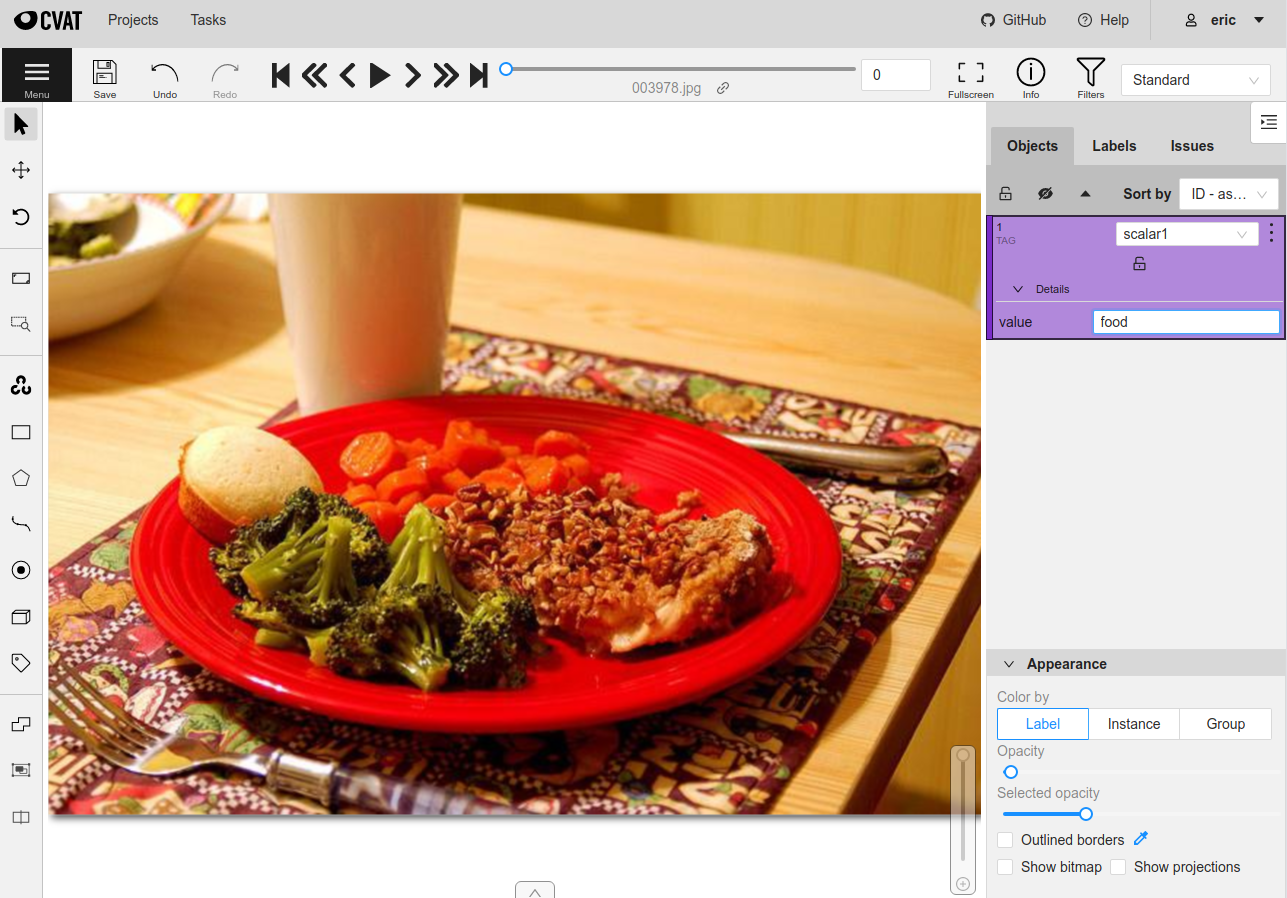
Scalar labels#
Label fields are the preferred way to store information for common tasks
such as classification and detection in your FiftyOne datasets. However, you
can also store CVAT annotations in scalar fields of type float, int, str,
or bool .
When storing annotations in scalar fields, the label_field parameter is still
used to define the name of the field, but the classes argument is now
optional and the attributes argument is unused.
If classes are provided, you will be able to select from these values in
CVAT; otherwise, the CVAT tag will show the label_field name and you must
enter the appropriate scalar in the value attribute of the tag.
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5view = dataset.take(1)
6
7anno_key = "cvat_scalar_fields"
8
9# Create two scalar fields, one with classes and one without
10label_schema = {
11 "scalar1": {
12 "type": "scalar",
13 },
14 "scalar2": {
15 "type": "scalar",
16 "classes": ["class1", "class2", "class3"],
17 }
18}
19
20view.annotate(anno_key, label_schema=label_schema, launch_editor=True)
21print(dataset.get_annotation_info(anno_key))
22
23# Cleanup (without downloading results)
24results = dataset.load_annotation_results(anno_key)
25results.cleanup()
26dataset.delete_annotation_run(anno_key)
Uploading alternate media#
In some cases, you may want to upload media files other than those stored in
the filepath field of your dataset’s samples for annotation. For example,
you may have a dataset with personal information like faces or license plates
that must be anonymized before uploading for annotation.
The recommended approach in this case is to store the alternative media files
for each sample on disk and record these paths in a new field of your FiftyOne
dataset. You can then specify this field via the media_field parameter of
annotate().
For example, let’s upload some blurred images to CVAT for annotation:
1import os
2import cv2
3
4import fiftyone as fo
5import fiftyone.zoo as foz
6
7dataset = foz.load_zoo_dataset("quickstart")
8view = dataset.take(1)
9
10alt_dir = "/tmp/blurred"
11if not os.path.exists(alt_dir):
12 os.makedirs(alt_dir)
13
14# Blur images
15for sample in view:
16 filepath = sample.filepath
17 alt_filepath = os.path.join(alt_dir, os.path.basename(filepath))
18
19 img = cv2.imread(filepath)
20 cv2.imwrite(alt_filepath, cv2.blur(img, (20, 20)))
21
22 sample["alt_filepath"] = alt_filepath
23 sample.save()
24
25anno_key = "cvat_alt_media"
26
27view.annotate(
28 anno_key,
29 label_field="ground_truth",
30 media_field="alt_filepath",
31 launch_editor=True,
32)
33print(dataset.get_annotation_info(anno_key))
34
35# Create annotations in CVAT
36
37dataset.load_annotations(anno_key, cleanup=True)
38dataset.delete_annotation_run(anno_key)
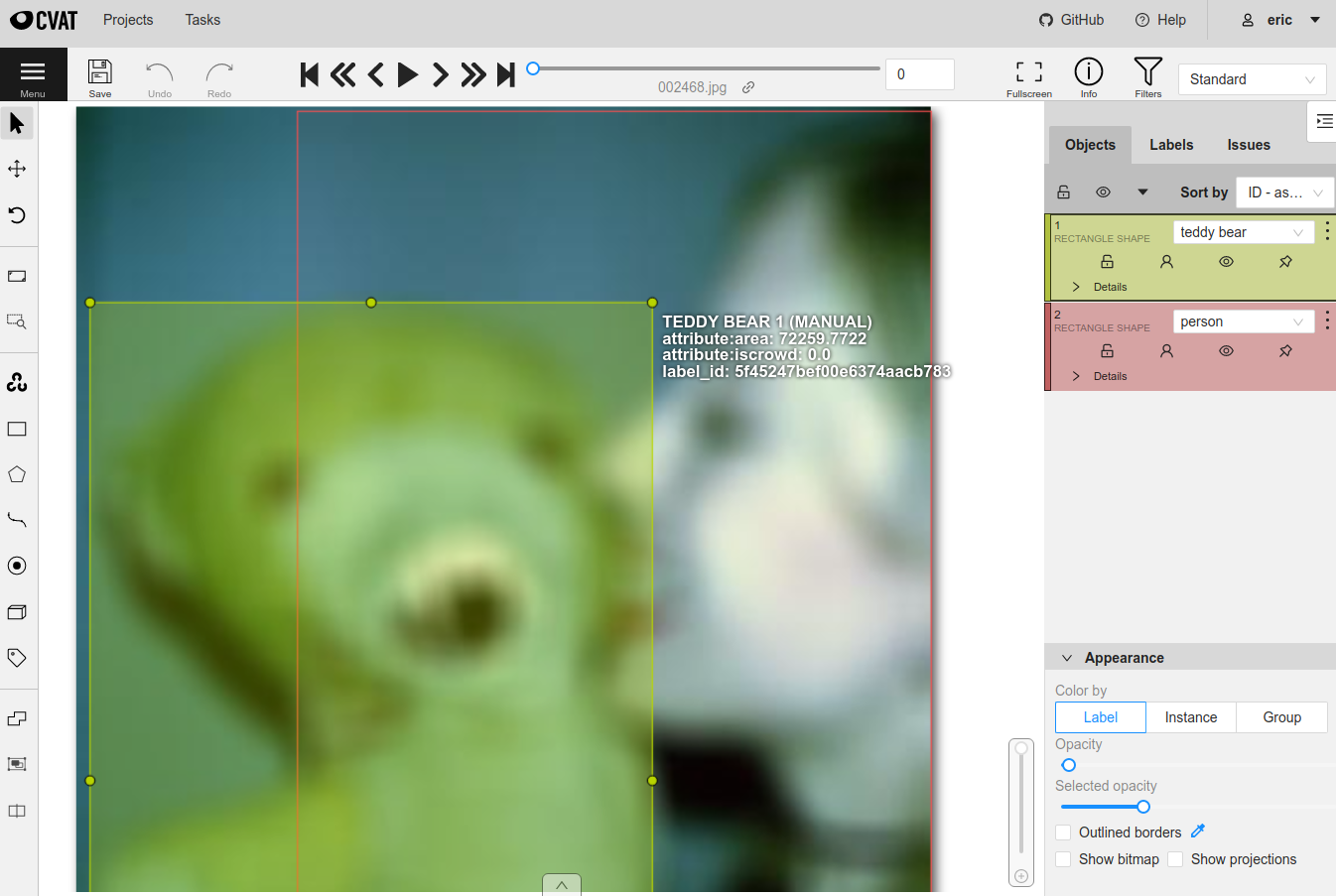
Using CVAT’s occlusion widget#
The CVAT UI provides a variety of builtin widgets on each label you create that control properties like occluded, hidden, locked, and pinned.
You can configure CVAT annotation runs so that the state of the occlusion
widget is read/written to a FiftyOne label attribute of your choice by
specifying the attribute’s type as occluded in your label schema.
In addition, if you are editing existing labels using the attributes=True
syntax (the default) to infer the label schema for an existing field, if a
boolean attribute with the name "occluded" is found, it will automatically be
linked to the occlusion widget.
Note
You can only specify the occluded type for at most one attribute of each
label field/class in your label schema, and, if you are editing existing
labels, the attribute that you choose must contain boolean values.
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart").clone()
5view = dataset.take(1)
6
7anno_key = "cvat_occluded_widget"
8
9# Populate a new `occluded` attribute on the existing `ground_truth` labels
10# using CVAT's occluded widget
11label_schema = {
12 "ground_truth": {
13 "attributes": {
14 "occluded": {
15 "type": "occluded",
16 }
17 }
18 }
19}
20
21view.annotate(anno_key, label_schema=label_schema, launch_editor=True)
22print(dataset.get_annotation_info(anno_key))
23
24# Mark occlusions in CVAT...
25
26dataset.load_annotations(anno_key, cleanup=True)
27dataset.delete_annotation_run(anno_key)
You can also use the occluded_attr parameter to sync the state of CVAT’s
occlusion widget with a specified attribute of all spatial fields that are being
annotated that did not explicitly have an occluded attribute defined in the
label schema.
This parameter is especially useful when working with existing CVAT projects, since CVAT project schemas are not able to retain information about occluded attributes between annotation runs.
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart").clone()
5view = dataset.take(1)
6
7anno_key = "cvat_occluded_widget_project"
8project_name = "example_occluded_widget"
9label_field = "ground_truth"
10
11# Create project
12view.annotate("new_proj", label_field=label_field, project_name=project_name)
13
14# Upload to existing project
15view.annotate(
16 anno_key,
17 label_field=label_field,
18 occluded_attr="is_occluded",
19 project_name=project_name,
20 launch_editor=True,
21)
22print(dataset.get_annotation_info(anno_key))
23
24# Mark occlusions in CVAT...
25
26dataset.load_annotations(anno_key, cleanup=True)
27dataset.delete_annotation_run(anno_key)
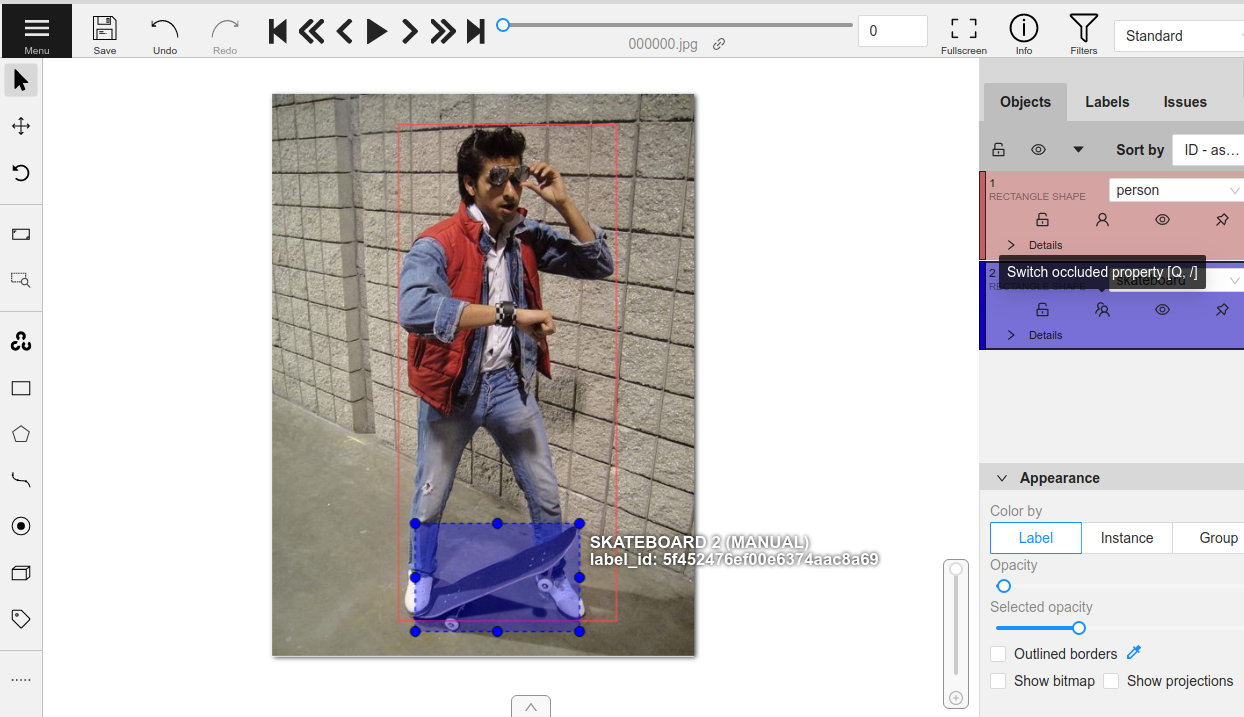
Using CVAT groups#
The CVAT UI provides a way to group objects together both visually and through a group id in the API.
You can configure CVAT annotation runs so that the state of the group id is
read/written to a FiftyOne label attribute of your choice by
specifying the attribute’s type as group_id in your label schema.
In addition, if you are editing existing labels using the attributes=True
syntax (the default) to infer the label schema for an existing field, if a
boolean attribute with the name "group_id" is found, it will automatically be
linked to CVAT groups.
Note
You can only specify the group_id type for at most one attribute of each
label field/class in your label schema, and, if you are editing existing
labels, the attribute that you choose must contain integer values.
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart").clone()
5view = dataset.take(1)
6
7anno_key = "cvat_group_id"
8
9# Populate a new `group_id` attribute on the existing `ground_truth` labels
10label_schema = {
11 "ground_truth": {
12 "attributes": {
13 "group_id": {
14 "type": "group_id",
15 }
16 }
17 }
18}
19
20view.annotate(anno_key, label_schema=label_schema, launch_editor=True)
21print(dataset.get_annotation_info(anno_key))
22
23# Mark groups in CVAT...
24
25dataset.load_annotations(anno_key, cleanup=True)
26dataset.delete_annotation_run(anno_key)
You can also use the group_id_attr parameter to sync the state of CVAT’s
group ids with a specified attribute of all spatial fields that are being
annotated that did not explicitly have a group id attribute defined in the
label schema.
This parameter is especially useful when working with existing CVAT projects, since CVAT project schemas are not able to retain information about group id attributes between annotation runs.
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart").clone()
5view = dataset.take(1)
6
7anno_key = "cvat_group_id_project"
8project_name = "example_group_id"
9label_field = "ground_truth"
10
11# Create project
12view.annotate("new_proj", label_field=label_field, project_name=project_name)
13
14# Upload to existing project
15view.annotate(
16 anno_key,
17 label_field=label_field,
18 group_id_attr="group_id_value",
19 project_name=project_name,
20 launch_editor=True,
21)
22print(dataset.get_annotation_info(anno_key))
23
24# Mark groups in CVAT...
25
26dataset.load_annotations(anno_key, cleanup=True)
27dataset.delete_annotation_run(anno_key)
Changing destination field#
When annotating an existing label field, it can be useful to load the
annotations into a different field than the one used to upload annotations. The
dest_field parameter can be used for this purpose when calling
load_annotations().
If your annotation run involves a single label field, set dest_field
to the name of the (new or existing) field you wish to load annotations into.
If your annotation run involves multiple fields, dest_field should be
a dictionary mapping existing field names in your run’s label schema to updated
destination fields.
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart").clone()
5view = dataset.take(1)
6
7anno_key = "dest_field"
8label_field = "ground_truth"
9
10# Upload from `ground_truth` field
11view.annotate(
12 anno_key,
13 label_field=label_field,
14)
15print(dataset.get_annotation_info(anno_key))
16
17# Load into `test_field`
18dest_field = "test_field"
19
20# If your run involves multiple fields, use this syntax instead
21# dest_field = {"ground_truth": "test_field", ...}
22
23dataset.load_annotations(
24 anno_key,
25 cleanup=True,
26 dest_field=dest_field,
27)
28dataset.delete_annotation_run(anno_key)
Using frame start, stop, step#
When annotating videos, you can use the arguments frame_start, frame_stop,
and frame_step to annotate subsampled clips of your videos rather than
loading every frame into CVAT. These arguments are only supported for video
tasks and accept either integer values to use for each video task that is
created, a list of values that will be applied to video tasks in a round-robin
strategy, or a dictionary of values mapping the video filepath to the
corresponding integer value.
Note: Uploading existing annotation tracks while using the frame_step
argument is not currently supported.
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart-video", max_samples=2).clone()
5sample_fps = dataset.values("filepath")
6
7# Start video 1 at frame 10 and video 2 at frame 5
8frame_start = {sample_fps[0]: 10, sample_fps[1]: 5}
9
10# For video 1, load every frame after the start
11# For video 2, load every 10th frame
12frame_step = [1, 10]
13
14# Stop all videos at frame 100
15frame_stop = 100
16
17anno_key = "frame_args"
18label_field = "frames.new_detections"
19label_type = "detections"
20classes = ["person", "vehicle"]
21
22# Annotate a new detections field
23dataset.annotate(
24 anno_key,
25 label_field=label_field,
26 label_type=label_type,
27 classes=classes,
28 frame_start=frame_start,
29 frame_stop=frame_stop,
30 frame_step=frame_step,
31)
32print(dataset.get_annotation_info(anno_key))
33
34# Annotate in CVAT
35
36dataset.load_annotations(
37 anno_key,
38 cleanup=True,
39)
40dataset.delete_annotation_run(anno_key)
Annotating videos#
You can add or edit annotations for video datasets using the CVAT backend
through the
annotate()
method.
All CVAT label types except tags provide an option to annotate tracks in
videos, which captures the identity of a single object as it moves through the
video. When you import video tracks into FiftyOne, the index attribute of
each label will contain the integer number of its track, and any labels that
are keyframes will have their keyframe=True attribute set.
Note that CVAT does not provide a straightforward way to annotate sample-level classification labels for videos. Instead, we recommend that you use frame-level fields to record classifications for your video datasets.
Note
CVAT only allows one video per task, so calling
annotate()
on a video dataset will result multiple tasks per label field.
Adding new frame labels#
The example below demonstrates how to configure a video annotation task that
populates a new frame-level field of a video dataset with vehicle detection
tracks with an immutable type attribute that denotes the type of each
vehicle:
Note
Prepend "frames." to reference frame-level fields when calling
annotate().
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart-video").clone()
5dataset.delete_frame_field("detections") # delete existing labels
6
7view = dataset.limit(1)
8
9anno_key = "video"
10
11# Create annotation task
12view.annotate(
13 anno_key,
14 label_field="frames.detections",
15 label_type="detections",
16 classes=["vehicle"],
17 attributes={
18 "type": {
19 "type": "select",
20 "values": ["sedan", "suv", "truck", "other"],
21 "mutable": False,
22 }
23 },
24 launch_editor=True,
25)
26
27# Add annotations in CVAT...
28
29# Download annotations
30dataset.load_annotations(anno_key)
31
32# Load the view that was annotated in the App
33view = dataset.load_annotation_view(anno_key)
34session = fo.launch_app(view=view)
35
36# Cleanup
37results = dataset.load_annotation_results(anno_key)
38results.cleanup()
39dataset.delete_annotation_run(anno_key)
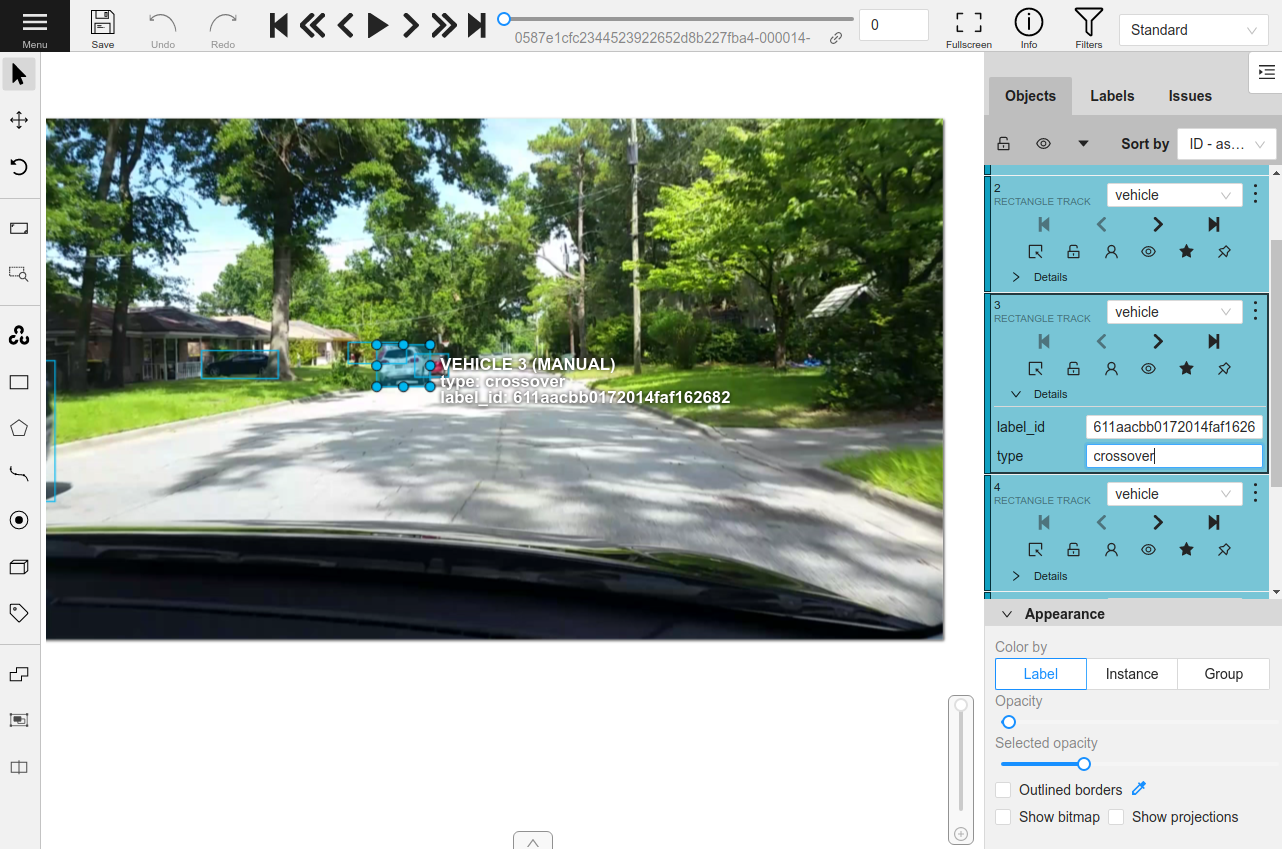
Editing frame-level label tracks#
You can also edit existing frame-level labels of video datasets in CVAT.
Note
If at least one existing label has its keyframe=True attribute set, only
the keyframe labels will be uploaded to CVAT, which provides a better
editing experience when performing spatial or time-varying attribute edits.
If no keyframe information is available, every existing label must be marked as a keyframe in CVAT.
The example below edits the existing detections of a video dataset. Note that, since the dataset’s labels do not have keyframe markings, we artificially tag every 10th frame as a keyframe to provide a better editing experience in CVAT:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart-video").clone()
5
6view = dataset.take(1)
7
8# Mark some keyframes
9sample = view.first()
10num_frames = len(sample.frames)
11keyframes = set(range(1, num_frames, 10)).union({1, num_frames})
12for frame_number in keyframes:
13 frame = sample.frames[frame_number]
14 for det in frame.detections.detections:
15 det.keyframe = True
16
17sample.save()
18
19anno_key = "cvat_video"
20
21# Send frame-level detections to CVAT
22view.annotate(
23 anno_key,
24 label_field="frames.detections",
25 launch_editor=True,
26)
27print(dataset.get_annotation_info(anno_key))
28
29# Edit annotations in CVAT...
30
31# Merge edits back in
32dataset.load_annotations(anno_key)
33
34# Load the view that was annotated in the App
35view = dataset.load_annotation_view(anno_key)
36session = fo.launch_app(view=view)
37
38# Cleanup
39results = dataset.load_annotation_results(anno_key)
40results.cleanup()
41dataset.delete_annotation_run(anno_key)
Warning
When uploading existing labels to CVAT, the id of the labels in FiftyOne
are stored in a label_id attribute of the CVAT shapes.
IMPORTANT: If a label_id is modified in CVAT, then FiftyOne may not
be able to merge the annotation with its existing Label instance; in such
cases, it must instead delete the existing label and create a new Label
with the shape’s contents. See this section for
details.
Annotating 3D data#
CVAT supports annotating 3D detections on point cloud data.
In order to perform 3D annotation with CVAT on 3D datasets in FiftyOne, you must populate a field on your FiftyOne dataset for each sample that you wish to annotate that contains the path to the 3D asset(s) to upload in one of CVAT’s supported formats, which includes:
the path to the
.pcdfile to uploadthe path to a structured zip archive including the PCD file and optional reference images
Then simply provide this field name via the media_field argument when you
call annotate():
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart-groups")
5view = dataset.select_group_slices("pcd")
6
7#
8# Populate a field on the dataset that points to the data to upload to CVAT
9#
10# This data can be as simple as a filepath to a .pcd file, or it could be a
11# structured zip archive including reference images along with the PCD
12#
13pcd_filepaths = [f.replace(".fo3d", ".pcd") for f in view.values("filepath")]
14view.set_values("pcd_filepath", pcd_filepaths)
15
16results = view[1:2].annotate(
17 "test",
18 label_field="ground_truth",
19 media_field="pcd_filepath",
20 launch_editor=True,
21)
22
23# Annotate the cuboids in CVAT...
24
25view.load_annotations("test")
26
27# View the newly created/edited cuboids in FiftyOne
28session = fo.launch_app(dataset)
Importing existing tasks#
FiftyOne’s CVAT integration is designed to manage the full annotation workflow, from task creation to annotation import.
However, if you have created CVAT tasks outside of FiftyOne, you can use the
import_annotations() utility
to import individual task(s) or an entire project into a FiftyOne dataset.
1import os
2
3import fiftyone as fo
4import fiftyone.utils.cvat as fouc
5import fiftyone.zoo as foz
6
7dataset = foz.load_zoo_dataset("quickstart", max_samples=3).clone()
8
9# Create a pre-existing CVAT project
10results = dataset.annotate(
11 "example_import",
12 label_field="ground_truth",
13 project_name="example_import",
14)
15
16#
17# In the simplest case, you can download both the annotations and the media
18# from CVAT
19#
20
21dataset = fo.Dataset()
22fouc.import_annotations(
23 dataset,
24 project_name=project_name,
25 data_path="/tmp/cvat_import",
26 download_media=True,
27)
28
29session = fo.launch_app(dataset)
30
31#
32# If you already have the media stored locally, you can instead provide a
33# mapping between filenames in the pre-existing CVAT project and the
34# locations of the media locally on disk for the FiftyOne dataset
35#
36# Since we're using a CVAT task uploaded via FiftyOne, the mapping is a bit
37# weird
38#
39
40data_map = {
41 "%06d_%s" % (idx, os.path.basename(p)): p
42 for idx, p in enumerate(dataset.values("filepath"))
43}
44
45dataset = fo.Dataset()
46fouc.import_annotations(
47 dataset,
48 project_name=project_name,
49 data_path=data_map,
50)
51
52session = fo.launch_app(dataset)
Note
Another strategy for importing existing CVAT annotations into FiftyOne is to simply export the annotations from the CVAT UI and then import them via the CVATImageDataset or CVATVideoDataset types.
Additional utilities#
You can perform additional CVAT-specific operations to monitor the progress
of an annotation task initiated by
annotate() via
the returned
CVATAnnotationResults
instance.
The sections below highlight some common actions that you may want to perform.
Using the CVAT API#
You can use the
connect_to_api()
to retrieve a
CVATAnnotationAPI instance,
which is a wrapper around the
CVAT REST API
that provides convenient methods for performing common actions on your CVAT
tasks:
1import fiftyone as fo
2import fiftyone.zoo as foz
3import fiftyone.utils.annotations as foua
4
5dataset = foz.load_zoo_dataset("quickstart")
6view = dataset.take(1)
7
8anno_key = "cvat_api"
9
10view.annotate(anno_key, label_field="ground_truth")
11
12api = foua.connect_to_api()
13
14# The context manager is optional and simply ensures that TCP connections
15# are always closed
16with api:
17 # Launch CVAT in your browser
18 api.launch_editor(api.base_url)
19
20 # Get info about all tasks currently on the CVAT server
21 response = api.get(api.tasks_url).json()
Viewing task statuses#
You can use the
get_status() and
print_status()
methods to get information about the current status of the task(s) and job(s)
for that annotation run:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5view = dataset.take(3)
6
7anno_key = "cvat_status"
8
9view.annotate(
10 anno_key,
11 label_field="ground_truth",
12 segment_size=2,
13 task_assignee="user1",
14 job_assignees=["user1"],
15 job_reviewers=["user2", "user3"],
16)
17
18results = dataset.load_annotation_results(anno_key)
19results.print_status()
20
21results.cleanup()
22dataset.delete_annotation_run(anno_key)
Status for label field 'ground_truth':
Task 331 (FiftyOne_quickstart_ground_truth):
Status: annotation
Assignee: user1
Last updated: 2021-08-11T15:09:02.680181Z
URL: http://localhost:8080/tasks/331
Job 369:
Status: annotation
Assignee: user1
Reviewer: user2
Job 370:
Status: annotation
Assignee: user1
Reviewer: user3
Note
Pro tip: If you are iterating over many annotation runs, you can use
connect_to_api() and
use_api() as
shown below to reuse a single
CVATAnnotationAPI instance
and avoid reauthenticating with CVAT for each run:
1import fiftyone.utils.annotations as foua
2
3api = foua.connect_to_api()
4
5for anno_key in dataset.list_annotation_runs():
6 results = dataset.load_annotation_results(anno_key)
7 results.use_api(api)
8 results.print_status()
Deleting tasks#
You can use the
delete_task()
method to delete specific CVAT tasks associated with an annotation run:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5view = dataset.take(1)
6
7anno_key = "cvat_delete_tasks"
8
9view.annotate(anno_key, label_field="ground_truth")
10
11results = dataset.load_annotation_results(anno_key)
12api = results.connect_to_api()
13
14print(results.task_ids)
15# [372]
16
17api.delete_task(372)