Using Aggregations#
Datasets are the core data structure in FiftyOne,
allowing you to represent your raw data, labels, and associated metadata. When
you query and manipulate a Dataset object using
dataset views, a DatasetView object is returned, which
represents a filtered view into a subset of the underlying dataset’s contents.
Complementary to this data model, one is often interested in computing
aggregate statistics about datasets, such as label counts, distributions, and
ranges, where each Sample is reduced to a single quantity in the aggregate
results.
The fiftyone.core.aggregations module offers a declarative and
highly-efficient approach to computing summary statistics about your datasets
and views.
Overview#
All builtin aggregations are subclasses of the Aggregation class, each
encapsulating the computation of a different statistic about your data.
Aggregations are conveniently exposed as methods on all Dataset and
DatasetView objects:
1import fiftyone.zoo as foz
2
3dataset = foz.load_zoo_dataset("quickstart")
4
5# List available aggregations
6print(dataset.list_aggregations())
7# ['bounds', 'count', 'count_values', 'distinct', ..., 'sum']
Think of aggregations as more efficient, concise alternatives to writing explicit loops over your dataset to compute a statistic:
1from collections import defaultdict
2
3# Compute label histogram manually
4manual_counts = defaultdict(int)
5for sample in dataset:
6 for detection in sample.ground_truth.detections:
7 manual_counts[detection.label] += 1
8
9# Compute via aggregation
10counts = dataset.count_values("ground_truth.detections.label")
11print(counts) # same as `manual_counts` above
You can even aggregate on expressions that transform the data in arbitrarily complex ways:
1from fiftyone import ViewField as F
2
3# Expression that computes the number of predicted objects
4num_objects = F("predictions.detections").length()
5
6# The `(min, max)` number of predictions per sample
7print(dataset.bounds(num_objects))
8
9# The average number of predictions per sample
10print(dataset.mean(num_objects))
The sections below discuss the available aggregations in more detail. You can
also refer to the fiftyone.core.aggregations module documentation for
detailed examples of using each aggregation.
Note
All aggregations can operate on embedded sample fields using the
embedded.field.name syntax.
Aggregation fields can also include array fields. Most array fields are
automatically unwound, but you can always manually unwind an array using
the embedded.array[].field syntax. See
this section for more details.
Compute bounds#
You can use the
bounds()
aggregation to compute the [min, max] range of a numeric field of a
dataset:
1import fiftyone.zoo as foz
2
3dataset = foz.load_zoo_dataset("quickstart")
4
5# Compute the bounds of the `uniqueness` field
6bounds = dataset.bounds("uniqueness")
7print(bounds)
8# (0.15001302256126986, 1.0)
9
10# Compute the bounds of the detection confidences in the `predictions` field
11bounds = dataset.bounds("predictions.detections.confidence")
12print(bounds)
13# (0.05003104358911514, 0.9999035596847534)
Count items#
You can use the
count() aggregation
to compute the number of non-None field values in a collection:
1import fiftyone.zoo as foz
2
3dataset = foz.load_zoo_dataset("quickstart")
4
5# Compute the number of samples in the dataset
6count = dataset.count()
7print(count)
8# 200
9
10# Compute the number of samples with `predictions`
11count = dataset.count("predictions")
12print(count)
13# 200
14
15# Compute the number of detections in the `ground_truth` field
16count = dataset.count("predictions.detections")
17print(count)
18# 5620
Count values#
You can use the
count_values()
aggregation to compute the occurrences of field values in a collection:
1import fiftyone.zoo as foz
2
3dataset = foz.load_zoo_dataset("quickstart")
4
5# Compute the number of samples in the dataset
6counts = dataset.count_values("tags")
7print(counts)
8# {'validation': 200}
9
10# Compute a histogram of the predicted labels in the `predictions` field
11counts = dataset.count_values("predictions.detections.label")
12print(counts)
13# {'bicycle': 13, 'hot dog': 8, ..., 'skis': 52}
Distinct values#
You can use the
distinct()
aggregation to compute the distinct values of a field in a collection:
1import fiftyone.zoo as foz
2
3dataset = foz.load_zoo_dataset("quickstart")
4
5# Get the distinct tags on the dataset
6values = dataset.distinct("tags")
7print(values)
8# ['validation']
9
10# Get the distinct labels in the `predictions` field
11values = dataset.distinct("predictions.detections.label")
12print(values)
13# ['airplane', 'apple', 'backpack', ..., 'wine glass', 'zebra']
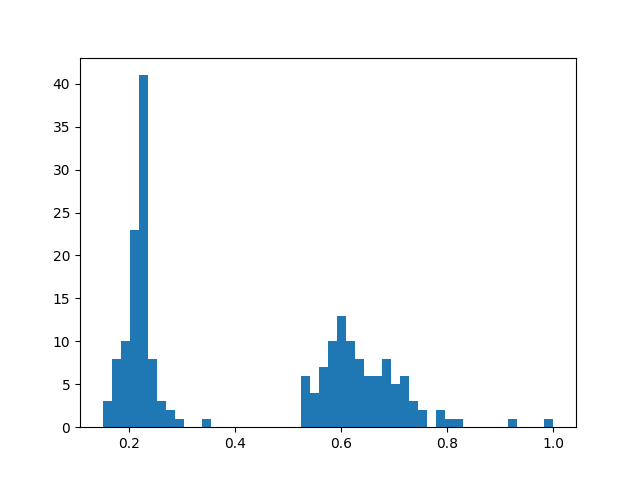
Histogram values#
You can use the
histogram_values()
aggregation to compute the histograms of numeric fields of a collection:
1import numpy as np
2import matplotlib.pyplot as plt
3
4import fiftyone.zoo as foz
5
6def plot_hist(counts, edges):
7 counts = np.asarray(counts)
8 edges = np.asarray(edges)
9 left_edges = edges[:-1]
10 widths = edges[1:] - edges[:-1]
11 plt.bar(left_edges, counts, width=widths, align="edge")
12
13dataset = foz.load_zoo_dataset("quickstart")
14
15#
16# Compute a histogram of the `uniqueness` field
17#
18
19counts, edges, other = dataset.histogram_values("uniqueness", bins=50)
20
21plot_hist(counts, edges)
22plt.show(block=False)
Schema#
You can use the
schema()
aggregation to extract the names and types of the attributes of a specified
embedded document field across all samples in a collection.
Schema aggregations are useful for detecting the presence and types of
dynamic attributes of Label fields across a
collection.
1import fiftyone.zoo as foz
2
3dataset = foz.load_zoo_dataset("quickstart")
4
5# Extract the names and types of all dynamic attributes on the
6# `ground_truth` detections
7print(dataset.schema("ground_truth.detections", dynamic_only=True))
{
'area': <fiftyone.core.fields.FloatField object at 0x7fc94015fb50>,
'iscrowd': <fiftyone.core.fields.FloatField object at 0x7fc964869fd0>,
}
You can also use the
list_schema()
aggregation to extract the value type(s) in a list field across all samples in
a collection:
1from datetime import datetime
2import fiftyone as fo
3
4dataset = fo.Dataset()
5
6sample1 = fo.Sample(
7 filepath="image1.png",
8 ground_truth=fo.Classification(
9 label="cat",
10 info=[
11 fo.DynamicEmbeddedDocument(
12 task="initial_annotation",
13 author="Alice",
14 timestamp=datetime(1970, 1, 1),
15 notes=["foo", "bar"],
16 ),
17 fo.DynamicEmbeddedDocument(
18 task="editing_pass",
19 author="Bob",
20 timestamp=datetime.utcnow(),
21 ),
22 ],
23 ),
24)
25
26sample2 = fo.Sample(
27 filepath="image2.png",
28 ground_truth=fo.Classification(
29 label="dog",
30 info=[
31 fo.DynamicEmbeddedDocument(
32 task="initial_annotation",
33 author="Bob",
34 timestamp=datetime(2018, 10, 18),
35 notes=["spam", "eggs"],
36 ),
37 ],
38 ),
39)
40
41dataset.add_samples([sample1, sample2])
42
43# Determine that `ground_truth.info` contains embedded documents
44print(dataset.list_schema("ground_truth.info"))
45# fo.EmbeddedDocumentField
46
47# Determine the fields of the embedded documents in the list
48print(dataset.schema("ground_truth.info[]"))
49# {'task': StringField, ..., 'notes': ListField}
50
51# Determine the type of the values in the nested `notes` list field
52# Since `ground_truth.info` is not yet declared on the dataset's schema, we
53# must manually include `[]` to unwind the info lists
54print(dataset.list_schema("ground_truth.info[].notes"))
55# fo.StringField
56
57# Declare the `ground_truth.info` field
58dataset.add_sample_field(
59 "ground_truth.info",
60 fo.ListField,
61 subfield=fo.EmbeddedDocumentField,
62 embedded_doc_type=fo.DynamicEmbeddedDocument,
63)
64
65# Now we can inspect the nested `notes` field without unwinding
66print(dataset.list_schema("ground_truth.info.notes"))
67# fo.StringField
Note
Schema aggregations are used internally by
get_dynamic_field_schema()
to impute the types of undeclared lists and embedded documents in a
dataset.
Sum values#
You can use the
sum() aggregation to
compute the sum of the (non-None) values of a field in a collection:
1import fiftyone.zoo as foz
2
3dataset = foz.load_zoo_dataset("quickstart")
4
5# Compute average confidence of detections in the `predictions` field
6print(
7 dataset.sum("predictions.detections.confidence") /
8 dataset.count("predictions.detections.confidence")
9)
10# 0.34994137249820706
Min values#
You can use the
min() aggregation to
compute the minimum of the (non-None) values of a field in a collection:
1import fiftyone.zoo as foz
2
3dataset = foz.load_zoo_dataset("quickstart")
4
5# Compute minimum confidence of detections in the `predictions` field
6print(dataset.min("predictions.detections.confidence"))
7# 0.05003104358911514
Max values#
You can use the
max() aggregation to
compute the maximum of the (non-None) values of a field in a collection:
1import fiftyone.zoo as foz
2
3dataset = foz.load_zoo_dataset("quickstart")
4
5# Compute maximum confidence of detections in the `predictions` field
6print(dataset.max("predictions.detections.confidence"))
7# 0.9999035596847534
Mean values#
You can use the
mean() aggregation to
compute the arithmetic mean of the (non-None) values of a field in a
collection:
1import fiftyone.zoo as foz
2
3dataset = foz.load_zoo_dataset("quickstart")
4
5# Compute average confidence of detections in the `predictions` field
6print(dataset.mean("predictions.detections.confidence"))
7# 0.34994137249820706
Quantiles#
You can use the
quantiles()
aggregation to compute the quantile(s) of the (non-None) values of a field
in a collection:
1import fiftyone.zoo as foz
2
3dataset = foz.load_zoo_dataset("quickstart")
4
5# Compute quantiles of the `uniqueness` field
6print(dataset.quantiles("uniqueness", [0.25, 0.5, 0.75, 0.9]))
7# [0.22027, 0.33771, 0.62554, 0.69488]
8
9# Compute quantiles of detection confidence in the `predictions` field
10quantiles = dataset.quantiles(
11 "predictions.detections.confidence",
12 [0.25, 0.5, 0.75, 0.9],
13)
14print(quantiles)
15# [0.09231, 0.20251, 0.56273, 0.94354]
Standard deviation#
You can use the
std() aggregation to
compute the standard deviation of the (non-None) values of a field in a
collection:
1import fiftyone.zoo as foz
2
3dataset = foz.load_zoo_dataset("quickstart")
4
5# Compute standard deviation of the confidence of detections in the
6# `predictions` field
7print(dataset.std("predictions.detections.confidence"))
8# 0.3184061813934825
Values#
You can use the
values()
aggregation to extract a list containing the values of a field across all
samples in a collection:
1import fiftyone.zoo as foz
2
3dataset = foz.load_zoo_dataset("quickstart")
4
5# Extract the `uniqueness` values for all samples
6uniqueness = dataset.values("uniqueness")
7print(len(uniqueness)) # 200
8
9# Extract the labels for all predictions
10labels = dataset.values("predictions.detections.label")
11print(len(labels)) # 200
12print(labels[0]) # ['bird', ..., 'bear', 'sheep']
Note
Unlike other aggregations,
values() does
not automatically unwind list fields, which ensures that the returned
values match the potentially-nested structure of the documents.
You can opt-in to unwinding specific list fields using the []
syntax, or you can pass the optional unwind=True parameter to unwind
all supported list fields. See Aggregating list fields for more
information.
Advanced usage#
Aggregating list fields#
Aggregations that operate on scalar fields can also be applied to the elements
of list fields by appending [] to the list component of the field path.
The example below demonstrates this capability:
1import fiftyone as fo
2
3dataset = fo.Dataset()
4dataset.add_samples(
5 [
6 fo.Sample(
7 filepath="/path/to/image1.png",
8 keypoints=fo.Keypoint(points=[(0, 0), (1, 1)]),
9 classes=fo.Classification(
10 label="cat", confidence=0.9, friends=["dog", "squirrel"]
11 ),
12 ),
13 fo.Sample(
14 filepath="/path/to/image2.png",
15 keypoints=fo.Keypoint(points=[(0, 0), (0.5, 0.5), (1, 1)]),
16 classes=fo.Classification(
17 label="dog", confidence=0.8, friends=["rabbit", "squirrel"],
18 ),
19 ),
20 ]
21)
22
23#
24# Count the number of keypoints in the dataset
25#
26# The `points` list attribute is declared on the `Keypoint` class, so it is
27# automatically unwound
28#
29count = dataset.count("keypoints.points")
30print(count)
31# 5
32
33#
34# Compute the values in the `friends` field of the predictions
35#
36# The `friends` list attribute is a dynamic custom attribute, so we must
37# explicitly request that it be unwound
38#
39counts = dataset.count_values("classes.friends[]")
40print(counts)
41# {'dog': 1, 'squirrel': 2, 'rabbit': 1}
Note
FiftyOne will automatically unwind all array fields that are defined in the
dataset’s schema without requiring you to explicitly specify this via the
[] syntax. This includes the following cases:
Top-level list fields: When you write an aggregation that refers to a
top-level list field of a dataset; i.e., list_field is automatically
coerced to list_field[], if necessary.
Frame fields: When you write an aggregation that refers to a
frame-level field of a video dataset; i.e.,
frames.classification.label is automatically coerced to
frames[].classification.label if necessary.
Embedded list fields: When you write an aggregation that refers to a
list attribute that is declared on a Sample, Frame, or Label class,
such as the
Classification.tags,
Detections.detections,
or Keypoint.points
attributes; i.e., ground_truth.detections.label is automatically
coerced to ground_truth.detections[].label, if necessary.
Aggregating expressions#
Aggregations also support performing more complex computations on fields via
the optional expr argument,
which is supported by all aggregations and allows you to specify a
ViewExpression defining an arbitrary transformation of the field you’re
operating on prior to aggregating.
The following examples demonstrate the power of aggregating with expressions:
The code sample below computes some statistics about the number of predicted objects in a dataset:
1import fiftyone as fo
2import fiftyone.zoo as foz
3from fiftyone import ViewField as F
4
5dataset = foz.load_zoo_dataset("quickstart")
6
7# Expression that computes the number of predicted objects
8num_objects = F("predictions.detections").length()
9
10# The `(min, max)` number of predictions per sample
11print(dataset.bounds(num_objects))
12
13# The average number of predictions per sample
14print(dataset.mean(num_objects))
15
16# Two equivalent ways of computing the total number of predictions
17print(dataset.sum(num_objects))
18print(dataset.count("predictions.detections"))
The code sample below computes some statistics about predicted object labels after doing some normalization:
1import fiftyone as fo
2import fiftyone.zoo as foz
3from fiftyone import ViewField as F
4
5dataset = foz.load_zoo_dataset("quickstart")
6
7ANIMALS = [
8 "bear", "bird", "cat", "cow", "dog", "elephant", "giraffe",
9 "horse", "sheep", "zebra"
10]
11
12# Expression that replaces all animal labels with "animal" and then
13# capitalizes all labels
14normed_labels = F("predictions.detections.label").map_values(
15 {a: "animal" for a in ANIMALS}
16).upper()
17
18# A histogram of normalized predicted labels
19print(dataset.count_values(normed_labels))
The code sample below computes some statistics about the sizes of ground truth and predicted bounding boxes in a dataset, in pixels:
1import fiftyone as fo
2import fiftyone.zoo as foz
3from fiftyone import ViewField as F
4
5dataset = foz.load_zoo_dataset("quickstart")
6dataset.compute_metadata()
7
8# Expression that computes the area of a bounding box, in pixels
9# Bboxes are in [top-left-x, top-left-y, width, height] format
10bbox_width = F("bounding_box")[2] * F("$metadata.width")
11bbox_height = F("bounding_box")[3] * F("$metadata.height")
12bbox_area = bbox_width * bbox_height
13
14# Expression that computes the area of ground truth bboxes
15gt_areas = F("ground_truth.detections[]").apply(bbox_area)
16
17# Compute (min, max, mean) of ground truth bounding boxes
18print(dataset.bounds(gt_areas))
19print(dataset.mean(gt_areas))
Note
When aggregating expressions, field names may contain list fields, and such field paths are handled as explained above.
However, there is one important exception when expressions are involved:
fields paths that end in array fields are not automatically unwound,
you must specify that they should be unwound by appending []. This
change in default behavior allows for the possibility that the
ViewExpression you provide is intended to operate on the array as a
whole.
import fiftyone as fo
import fiftyone.zoo as foz
from fiftyone import ViewField as F
dataset = foz.load_zoo_dataset("quickstart")
# Counts the number of predicted objects
# Here, `predictions.detections` is treated as `predictions.detections[]`
print(dataset.count("predictions.detections"))
# Counts the number of predicted objects with confidence > 0.9
# Here, `predictions.detections` is not automatically unwound
num_preds = F("predictions.detections").filter(F("confidence") > 0.9).length()
print(dataset.sum(num_preds))
# Computes the (min, max) bounding box area in normalized coordinates
# Here we must manually specify that we want to unwind terminal list field
# `predictions.detections` by appending `[]`
bbox_area = F("bounding_box")[2] * F("bounding_box")[3]
print(dataset.bounds(F("ground_truth.detections[]").apply(bbox_area)))
Batching aggregations#
Rather than computing a single aggregation by invoking methods on a Dataset
or DatasetView object, you can also instantiate an Aggregation object
directly. In this case, the aggregation is not tied to any dataset or view,
only to the parameters such as field name that define it.
1import fiftyone as fo
2
3# will count the number of samples in a dataset
4sample_count = fo.Count()
5
6# will count the labels in a `ground_truth` detections field
7count_values = fo.CountValues("ground_truth.detections.label")
8
9# will compute a histogram of the `uniqueness` field
10histogram_values = fo.HistogramValues("uniqueness", bins=50)
Instantiating aggregations in this way allows you to execute multiple
aggregations on a dataset or view efficiently in a batch via
aggregate():
1import fiftyone.zoo as foz
2
3dataset = foz.load_zoo_dataset("quickstart")
4
5results = dataset.aggregate([sample_count, count_values, histogram_values])
6
7print(results[0])
8# 200
9
10print(results[1])
11# {'bowl': 15, 'scissors': 1, 'cup': 21, ..., 'vase': 1, 'sports ball': 3}
12
13print(results[2][0]) # counts
14# [0, 0, 0, ..., 15, 12, ..., 0, 0]
15
16print(results[2][1]) # edges
17# [0.0, 0.02, 0.04, ..., 0.98, 1.0]
Transforming data before aggregating#
You can use view stages like
map_values()
and
map_labels()
in concert with aggregations to efficiently compute statistics on your
datasets.
For example, suppose you would like to compute the histogram of the labels in
a dataset with certain labels grouped into a single category. You can use
map_values() +
count_values()
to succinctly express this:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5
6# Map `cat` and `dog` to `pet`
7labels_map = {"cat": "pet", "dog": "pet"}
8
9counts = (
10 dataset
11 .map_values("ground_truth.detections.label", labels_map)
12 .count_values("ground_truth.detections.label")
13)
14
15print(counts)
16# {'toothbrush': 2, 'train': 5, ..., 'pet': 31, ..., 'cow': 22}
Or, suppose you would like to compute the average confidence of a model’s
predictions, ignoring any values less than 0.5. You can use
filter_labels() +
sum() +
count()
to succinctly express this:
1import fiftyone as fo
2import fiftyone.zoo as foz
3from fiftyone import ViewField as F
4
5dataset = foz.load_zoo_dataset("quickstart")
6
7avg_conf = (
8 dataset
9 .filter_labels("predictions", F("confidence") >= 0.5)
10 .mean("predictions.detections.confidence")
11)
12
13print(avg_conf)
14# 0.8170506501060617
Aggregating frame labels#
You can compute aggregations on the frame labels of a video dataset by adding
the frames prefix to the relevant frame field name:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart-video")
5
6# Count the number of video frames
7count = dataset.count("frames")
8print(count)
9# 1279
10
11# Compute a histogram of per-frame object labels
12counts = dataset.count_values("frames.detections.detections.label")
13print(counts)
14# {'person': 1108, 'vehicle': 7511, 'road sign': 2726}