|
|
|
|
Step 1: Loading a Detection Dataset in FiftyOne#
In our first step, we will be covering how you can load an object detection dataset into FiftyOne. Detection datasets usually come in a standard format that FiftyOne can load in one or two lines for you, making creating datasets fast and easy! However, not all datasets come in a known format and sometimes we have to add the detections on manually ourselves. With just a few more steps, FiftyOne still makes loading custom datasets easy.
Let’s take a look first at loading a common format.
Loading a Common Format Detection Dataset#
Detection datasets can come in many forms, but usually stick to a standard. For quick ingestion, FiftyOne is familiar with COCO, VOC, YOLO, KITTI, and FiftyOne formatted datasets. Check out each one to confirm the folder and file setup matches what your structure is. While uncommon, certain datasets tools will rename or move certain files, such as data.yaml in a YOLO dataset instead of dataset.yaml.
Once you have found the correct format of your dataset, we can follow the same pattern for each type:
[ ]:
!pip install fiftyone
[ ]:
import fiftyone as fo
name = "my-dataset"
dataset_dir = "/path/to/detection-dataset"
# Create the dataset
dataset = fo.Dataset.from_dir(
dataset_dir=dataset_dir,
dataset_type=fo.types.COCODetectionDataset, # Change with your type
name=name,
)
# View summary info about the dataset
print(dataset)
# Print the first few samples in the dataset
print(dataset.head())
Check out the docs for each format to find optional parameters you can pass for things like train/test split, subfolders, or labels paths.
Loading a Custom Format Detection Dataset#
Sometimes datasets don’t come in a common format or maybe you are just adding some additional labels to an existing dataset. Adding detections to these datasets is still easy with FiftyOne. We will learn how to do this by looping over our datasets and adding a new label field to each sample.
Let’s begin by first loading in a dataset. We will use a dice detection dataset from Kaggle. We start by downloading from kaggle_hub, and loading in just the images first.
[ ]:
!pip install kagglehub
[ ]:
import kagglehub
import fiftyone as fo
# Download dice dataset
path = kagglehub.dataset_download("nellbyler/d6-dice")
print("Path to dataset files:", path)
images_path = path + "/d6-dice/Images"
ann_path = path + "/d6-dice/Annotations"
name = "Dice Detection"
# Create the FiftyOne dataset
dataset = fo.Dataset.from_dir(
dataset_dir=images_path,
dataset_type=fo.types.ImageDirectory,
name=name,
)
# View summary info about the dataset
print(dataset)
# Print the first few samples in the dataset
print(dataset.head())
We can see our images have loaded in the app but no annotations yet:
[ ]:
session = fo.launch_app(dataset)
Now the annotations in the dataset are custom, with each image filepath having a corresponding label file in the Annotations folder like the following:
Images
- IMG_000.jpg
- IMG_001.jpg
...
Annotations
- IMG_000.txt
- IMG_001.txt
...
We can loop through our samples, grab the corresponding txt file for our sample, and load in the detections for each one. But first, we need to discuss how a FiftyOne Detection Label works!
The Detections class represents a list of object detections in an image. The detections are stored in the detections attribute of the Detections object.
Each individual object detection is represented by a Detection object. The string label of the object should be stored in the label attribute, and the bounding box for the object should be stored in the bounding_box attribute.
Lastly, bounding boxes in FiftyOne are always in the following format, normalized to be bounded by [0,1] relative to the image’s dimensions:
[<top-left-x>, <top-left-y>, <width>, <height>]
With that explained, let’s wrap up by adding detections to our dataset!
Our custom dice dataset has a custom annotation format that looks like:
class x_center y_center length width
On top of being in an incorrect bounding box format, the class is off by one for each dice since it starts at 0. So class 0 == side 1 on dice. Let’s look at how we can adjust our annotations and add to FiftyOne!
[ ]:
# Loop through for each sample in our dataset
for sample in dataset:
# Load our annotation file into a list of detections
sample_root = sample.filepath.split("/")[-1].split(".")[0]
sample_ann_path = ann_path + "/" + sample_root + ".txt"
with open(sample_ann_path, 'r') as file:
list_of_anns = [line.strip().split() for line in file]
# For each detection, adjust the format and add to our detections list
detections = []
for ann in list_of_anns:
# Make sure to make adjustments to custom formats!
# Move label up one
label = str(int(ann[0]) + 1)
# Adjust bounding box from x_center, y_center, length, width to top_left_x, top_left_y, width, height
bbox = [float(x) for x in ann[1:]] # x,y,l,w
bbox_adjusted = [bbox[0]-bbox[3]/2, bbox[1]-bbox[2]/2, bbox[3], bbox[2]] # x,y,w,h
# Add the object to the sample
det = fo.Detection(
label=label, bounding_box=bbox_adjusted
)
detections.append(det)
sample["ground_truth"] = fo.Detections(detections=detections)
sample.save()
Once it is all done, we can view our dataset to confirm that we were able to load our custom detections!
[ ]:
session.show()
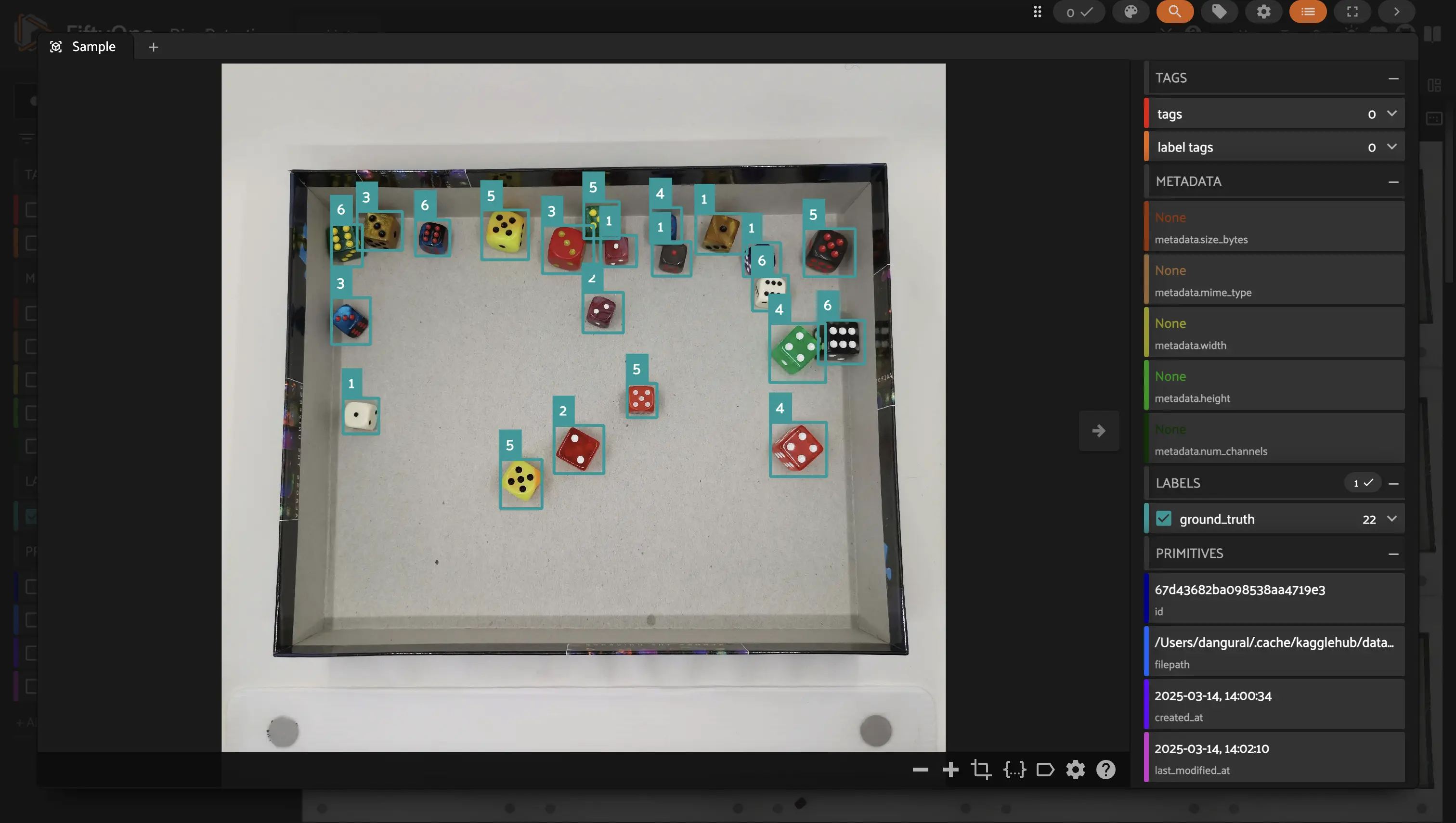
Summary#
Great work! You’ve learned how to load detection datasets into FiftyOne using both standard formats (COCO, VOC, YOLO) and custom formats by manually adding fo.Detection objects.
Next up: Step 2 - Visualizing and Analyzing Detection Data