|
|
|
|
Step 4: Evaluating Detections#
This step demonstrates how to use FiftyOne to perform hands-on evaluation of your detection model.
It covers the following concepts:
Evaluating your model using FiftyOne’s evaluation API
Viewing the best and worst performing samples in your dataset
Load a Detection Dataset#
In this example, we’ll load the quickstart dataset again from the FiftyOne Dataset Zoo, which has ground truth annotations and predictions from a PyTorch Faster-RCNN model for a few samples from the COCO dataset.
[ ]:
import fiftyone as fo
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset("quickstart")
session = fo.launch_app(dataset)
Evaluate Detections#
Now that we have samples with ground truth and predicted objects, let’s use FiftyOne to evaluate the quality of the detections.
FiftyOne provides a powerful evaluation API that contains a collection of methods for performing evaluation of model predictions. Since we’re working with object detections here, we’ll use detection evaluation.
We can run evaluation on our samples via evaluate_detections(). Note that this method is available on both the Dataset and DatasetView classes, which means that we can run evaluation on our high_conf_view to assess the quality of only the high confidence predictions in our dataset.
By default, this method will use the COCO evaluation protocol, plus some extra goodies that we will use later.
[ ]:
# Evaluate the predictions in the `predictions` field of our dataset
# with respect to the objects in the `ground_truth` field
results = dataset.evaluate_detections(
"predictions",
gt_field="ground_truth",
eval_key="eval",
compute_mAP=True,
)
The results object returned by the evaluation routine provides a number of convenient methods for analyzing our predictions.
For example, let’s print a classification report for the top-10 most common classes in the dataset, as well as the mAP score:
[ ]:
# Get the 10 most common classes in the dataset
counts = dataset.count_values("ground_truth.detections.label")
classes_top10 = sorted(counts, key=counts.get, reverse=True)[:10]
# Print a classification report for the top-10 classes
results.print_report(classes=classes_top10)
# Print out the mAP score
print(f"mAP score: {results.mAP()}")
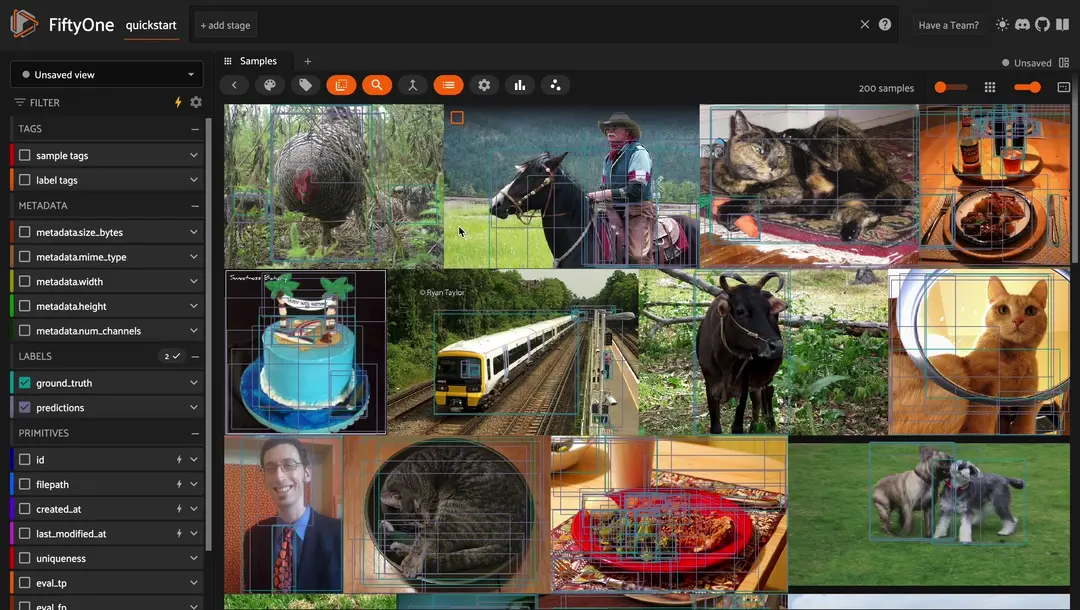
Model Evaluation Panel#
You can observe all of your model evaluation results in the FiftyOne app with the Model Evaluation Panel!
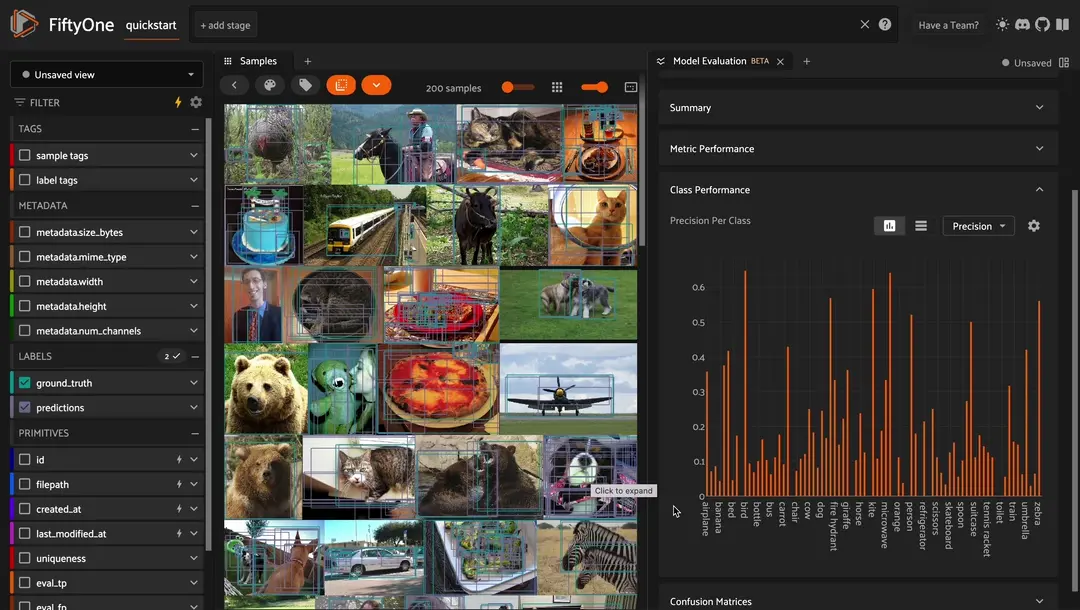
When you load a dataset in the App that contains one or more evaluations, you can open the Model Evaluation panel to visualize and interactively explore the evaluation results in the App:
You can even click into individual classes to see model performance on filtered samples as well!
Follow to Model Evaluation Doc Page to learn more about how you can perform model eval, compare multiple models, and more!