Evaluating Models#
FiftyOne provides a variety of builtin methods for evaluating your model predictions, including regressions, classifications, detections, polygons, instance and semantic segmentations, on both image and video datasets.
When you evaluate a model in FiftyOne, you get access to the standard aggregate metrics such as classification reports, confusion matrices, and PR curves for your model. In addition, FiftyOne can also record fine-grained statistics like accuracy and false positive counts at the sample-level, which you can interactively explore in the App to diagnose the strengths and weaknesses of your models on individual data samples.
Sample-level analysis often leads to critical insights that will help you improve your datasets and models. For example, viewing the samples with the most false positive predictions can reveal errors in your annotation schema. Or, viewing the cluster of samples with the lowest accuracy can reveal gaps in your training dataset that you need to address in order to improve your model’s performance. A key goal of FiftyOne is to help you uncover these insights on your data!
Note
Check out the tutorials page for in-depth walkthroughs of evaluating various types of models with FiftyOne.
Overview#
FiftyOne’s evaluation methods are conveniently exposed as methods on all
Dataset and DatasetView objects, which means that you can evaluate entire
datasets or specific views into them via the same syntax.
Let’s illustrate the basic workflow by loading the
quickstart dataset and analyzing the object
detections in its predictions field using the
evaluate_detections()
method:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5
6# Evaluate the objects in the `predictions` field with respect to the
7# objects in the `ground_truth` field
8results = dataset.evaluate_detections(
9 "predictions",
10 gt_field="ground_truth",
11 eval_key="eval",
12)
13
14session = fo.launch_app(dataset)
Per-class metrics#
You can also retrieve and interact with evaluation results via the SDK.
Running an evaluation returns an instance of a task-specific subclass of
EvaluationResults that provides a handful of methods for generating aggregate
statistics about your dataset.
1# Get the 10 most common classes in the dataset
2counts = dataset.count_values("ground_truth.detections.label")
3classes = sorted(counts, key=counts.get, reverse=True)[:10]
4
5# Print a classification report for the top-10 classes
6results.print_report(classes=classes)
precision recall f1-score support
person 0.45 0.74 0.56 783
kite 0.55 0.72 0.62 156
car 0.12 0.54 0.20 61
bird 0.63 0.67 0.65 126
carrot 0.06 0.49 0.11 47
boat 0.05 0.24 0.08 37
surfboard 0.10 0.43 0.17 30
traffic light 0.22 0.54 0.31 24
airplane 0.29 0.67 0.40 24
giraffe 0.26 0.65 0.37 23
micro avg 0.32 0.68 0.44 1311
macro avg 0.27 0.57 0.35 1311
weighted avg 0.42 0.68 0.51 1311
Note
For details on micro, macro, and weighted averaging, see the sklearn.metrics documentation.
Per-sample metrics#
In addition to standard aggregate metrics, when you pass an eval_key
parameter to the evaluation routine, FiftyOne will populate helpful
task-specific information about your model’s predictions on each sample, such
as false negative/positive counts and per-sample accuracies.
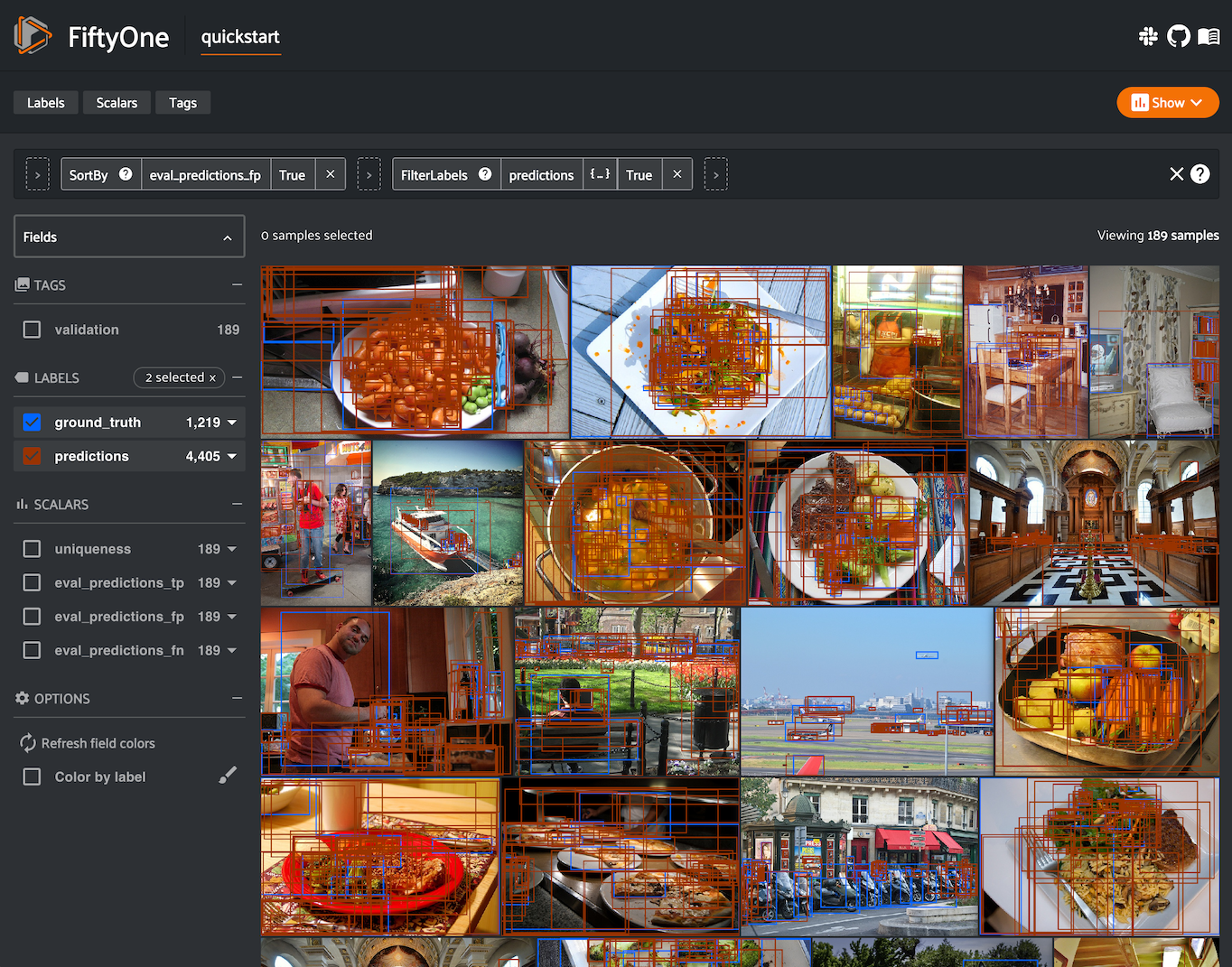
Continuing with our example, let’s use dataset views and the FiftyOne App to leverage these sample metrics to investigate the samples with the most false positive predictions in the dataset:
1import fiftyone as fo
2from fiftyone import ViewField as F
3
4# Create a view that has samples with the most false positives first, and
5# only includes false positive boxes in the `predictions` field
6view = (
7 dataset
8 .sort_by("eval_fp", reverse=True)
9 .filter_labels("predictions", F("eval") == "fp")
10)
11
12# Visualize results in the App
13session = fo.launch_app(view=view)
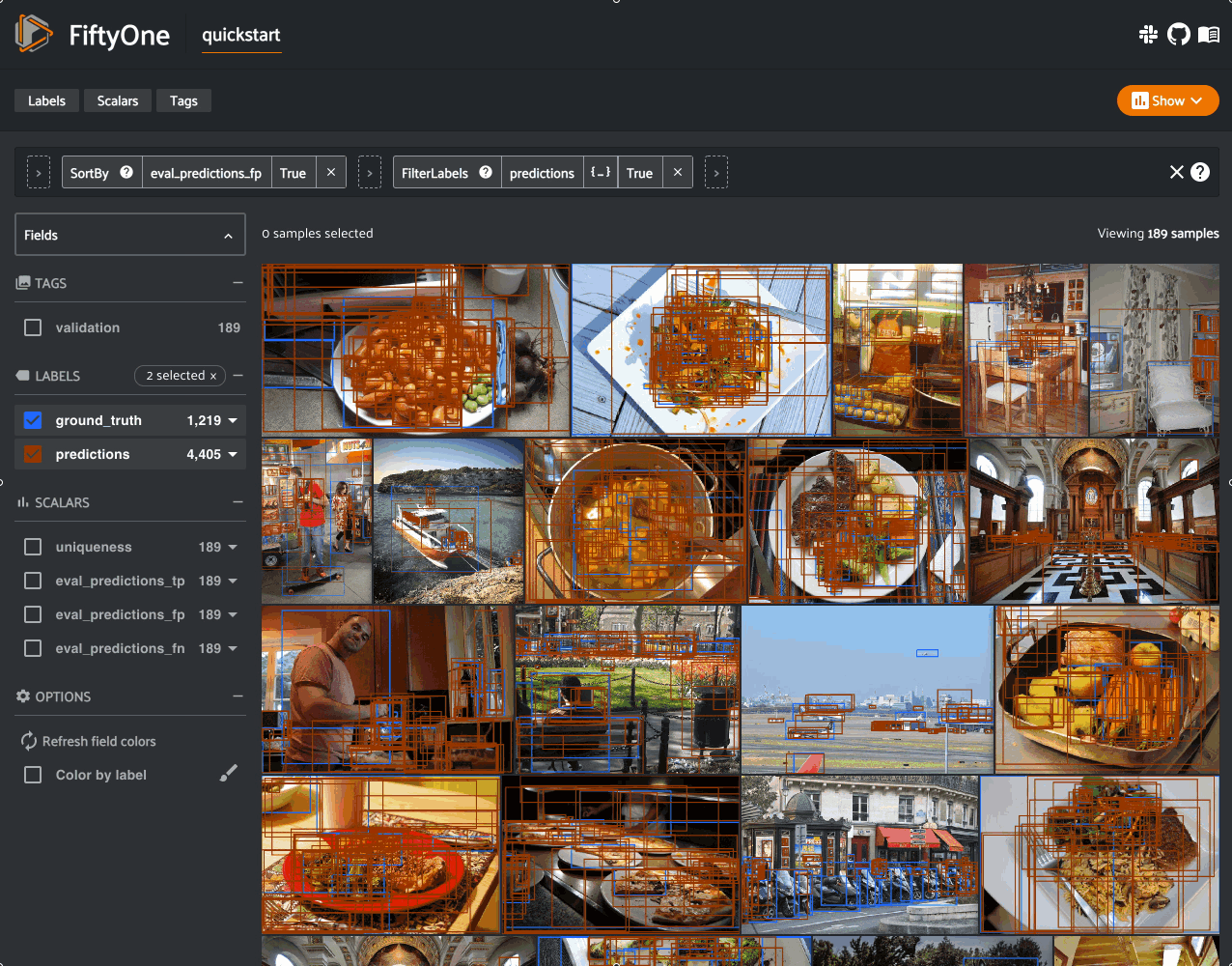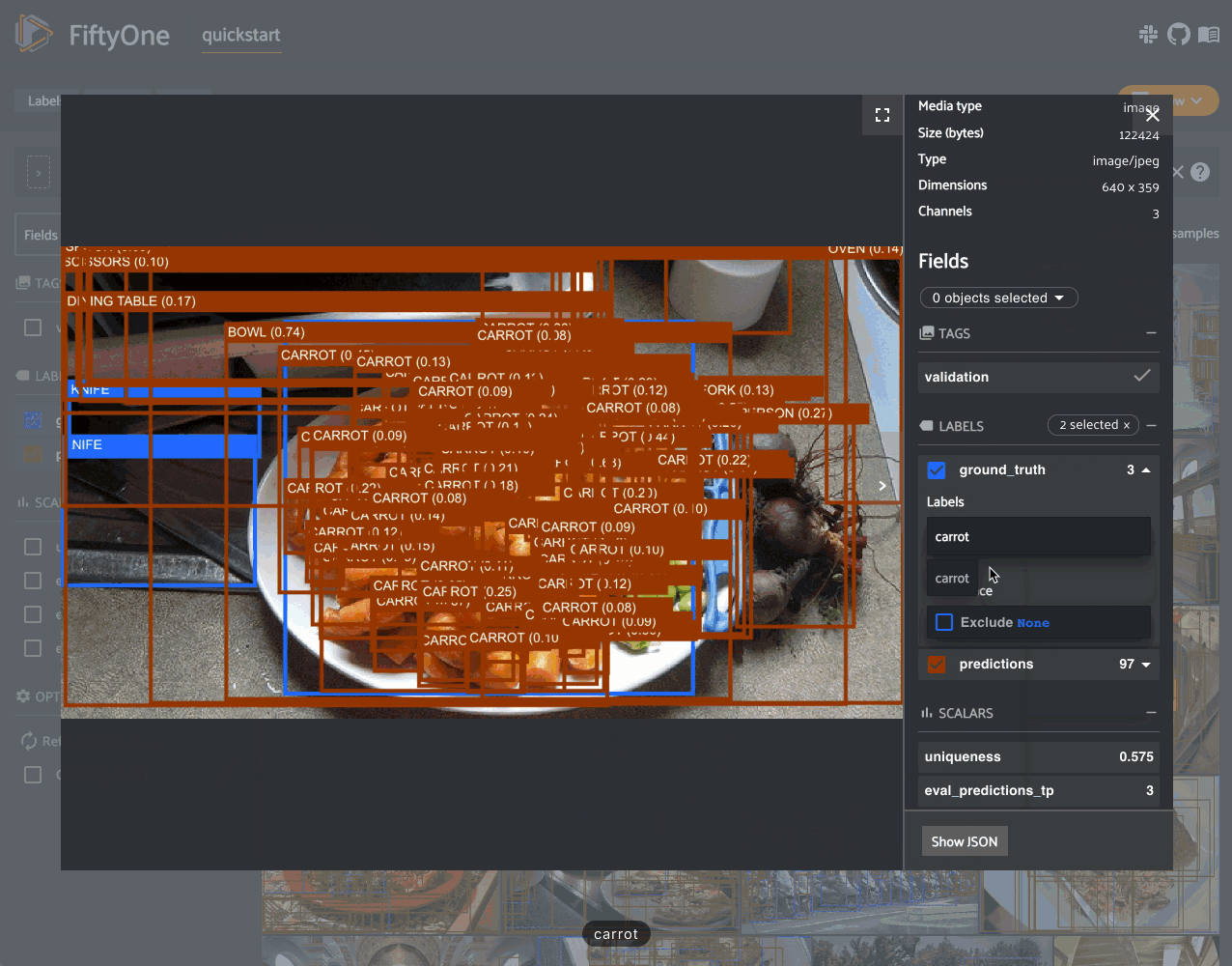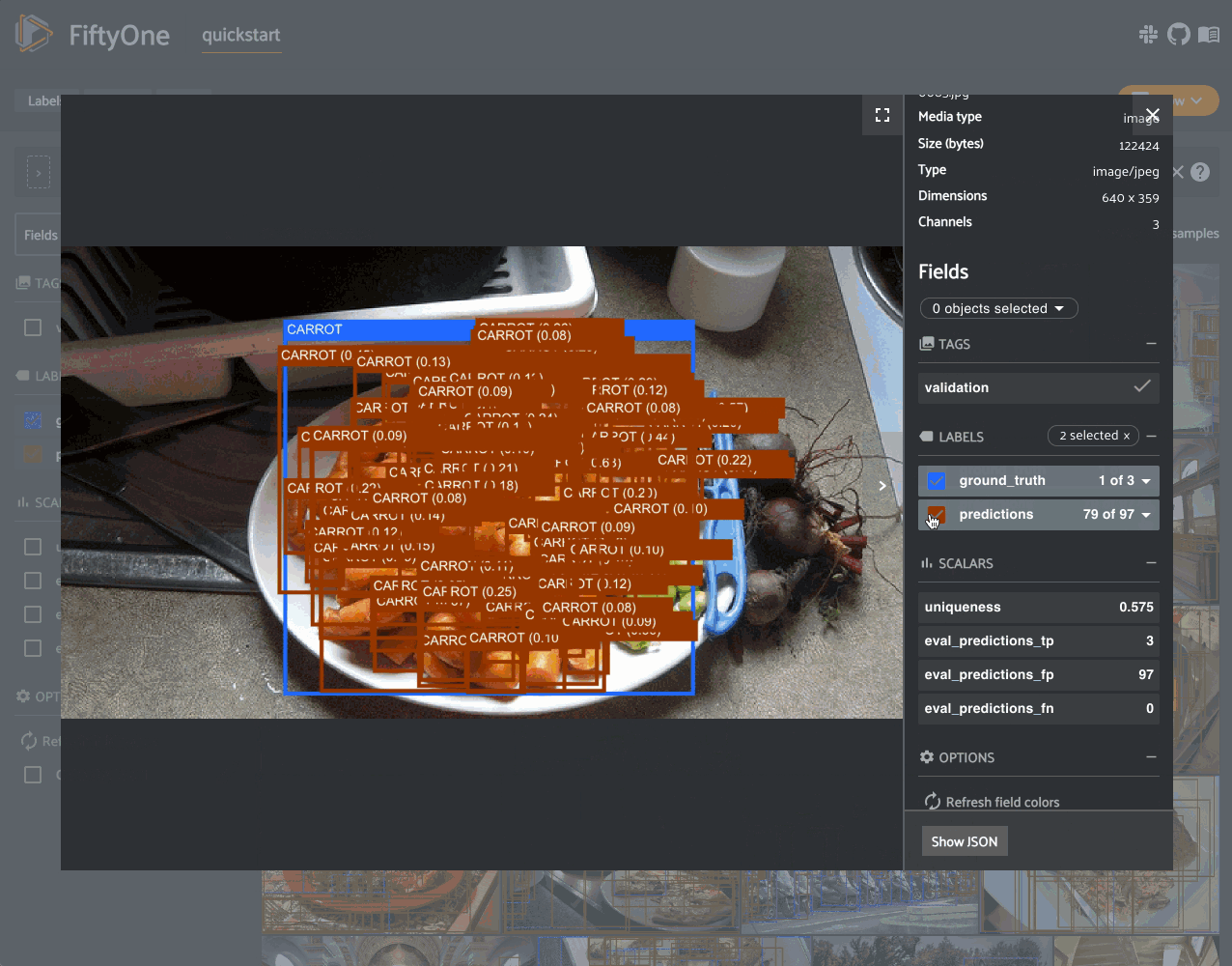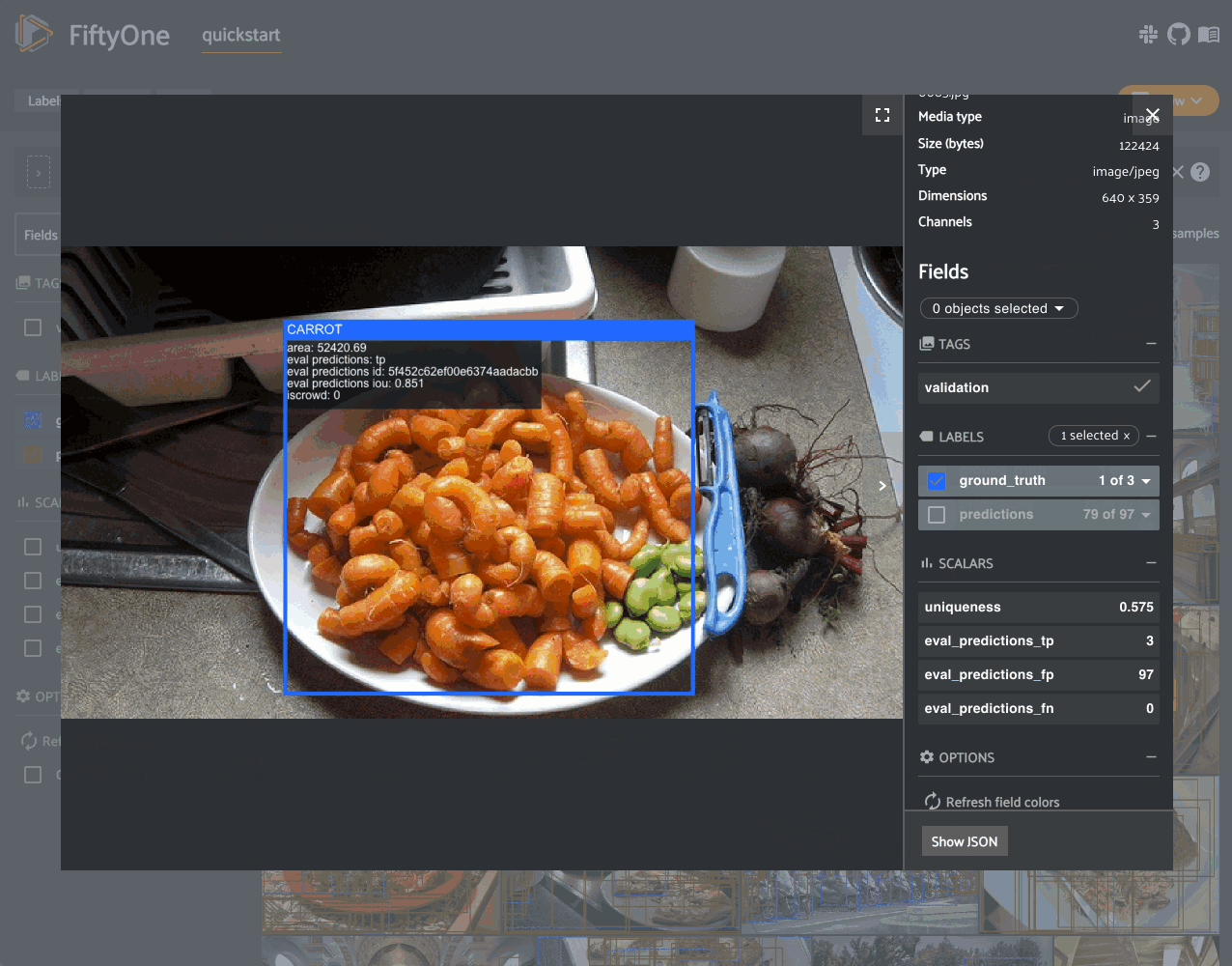
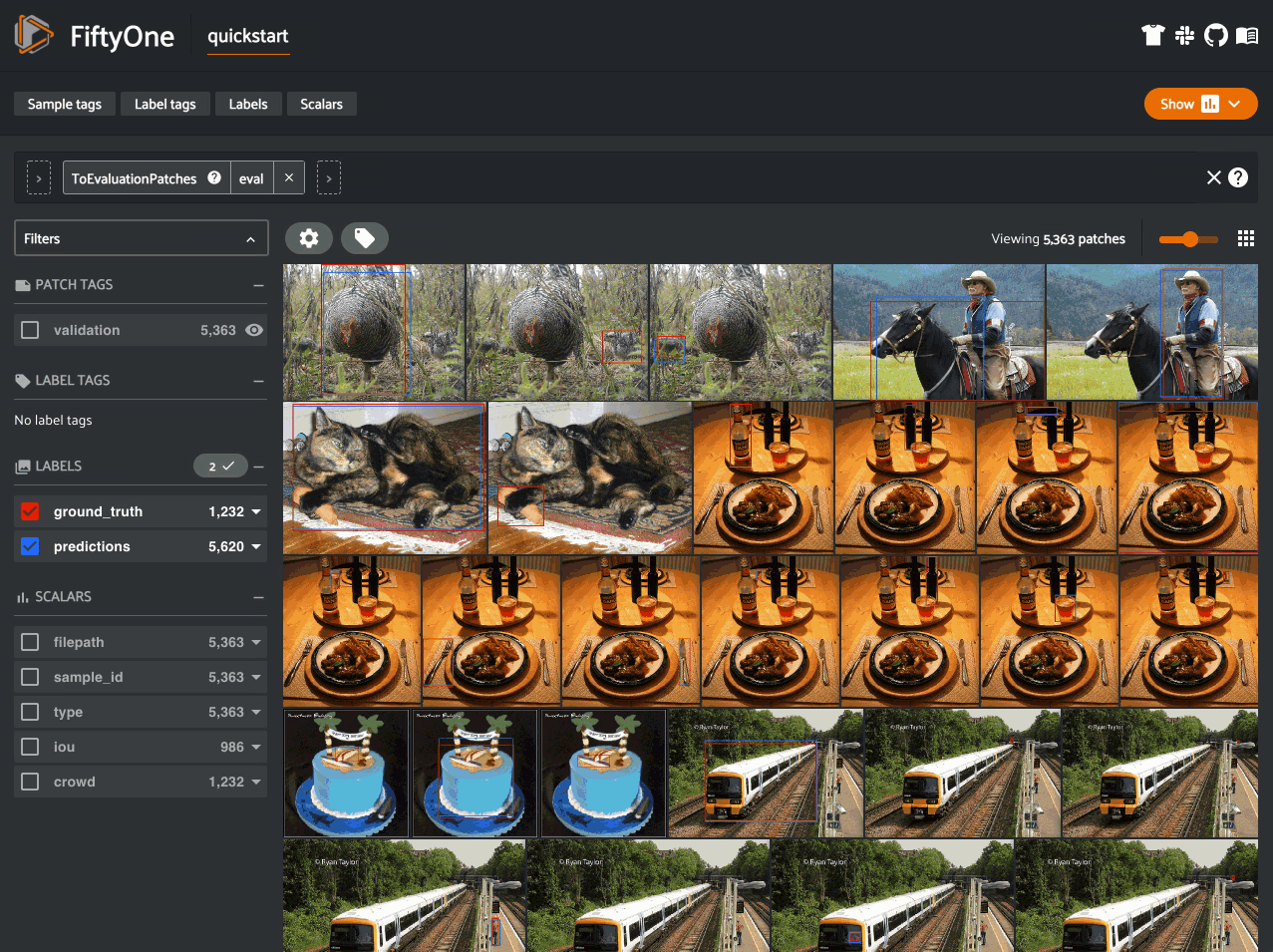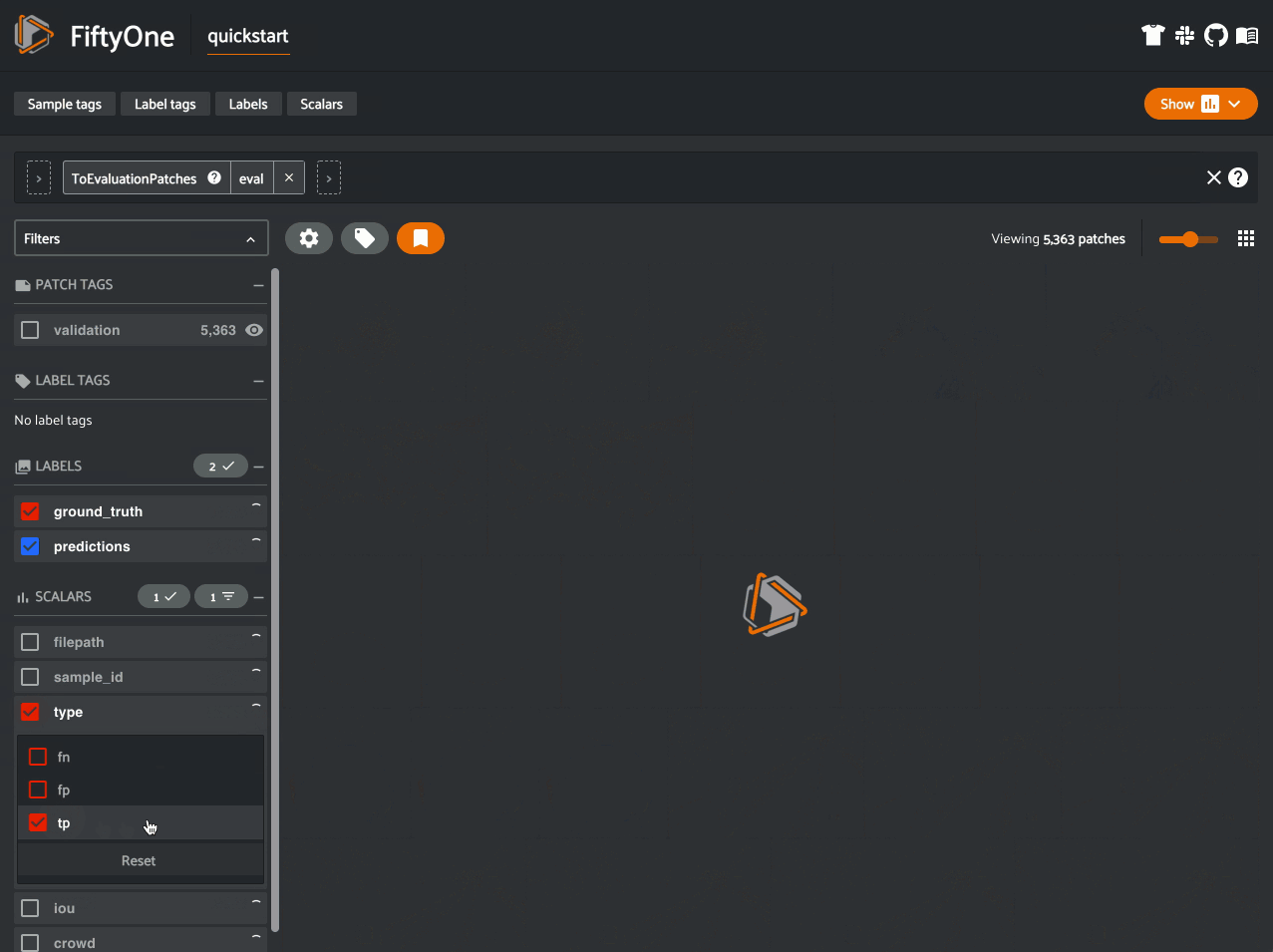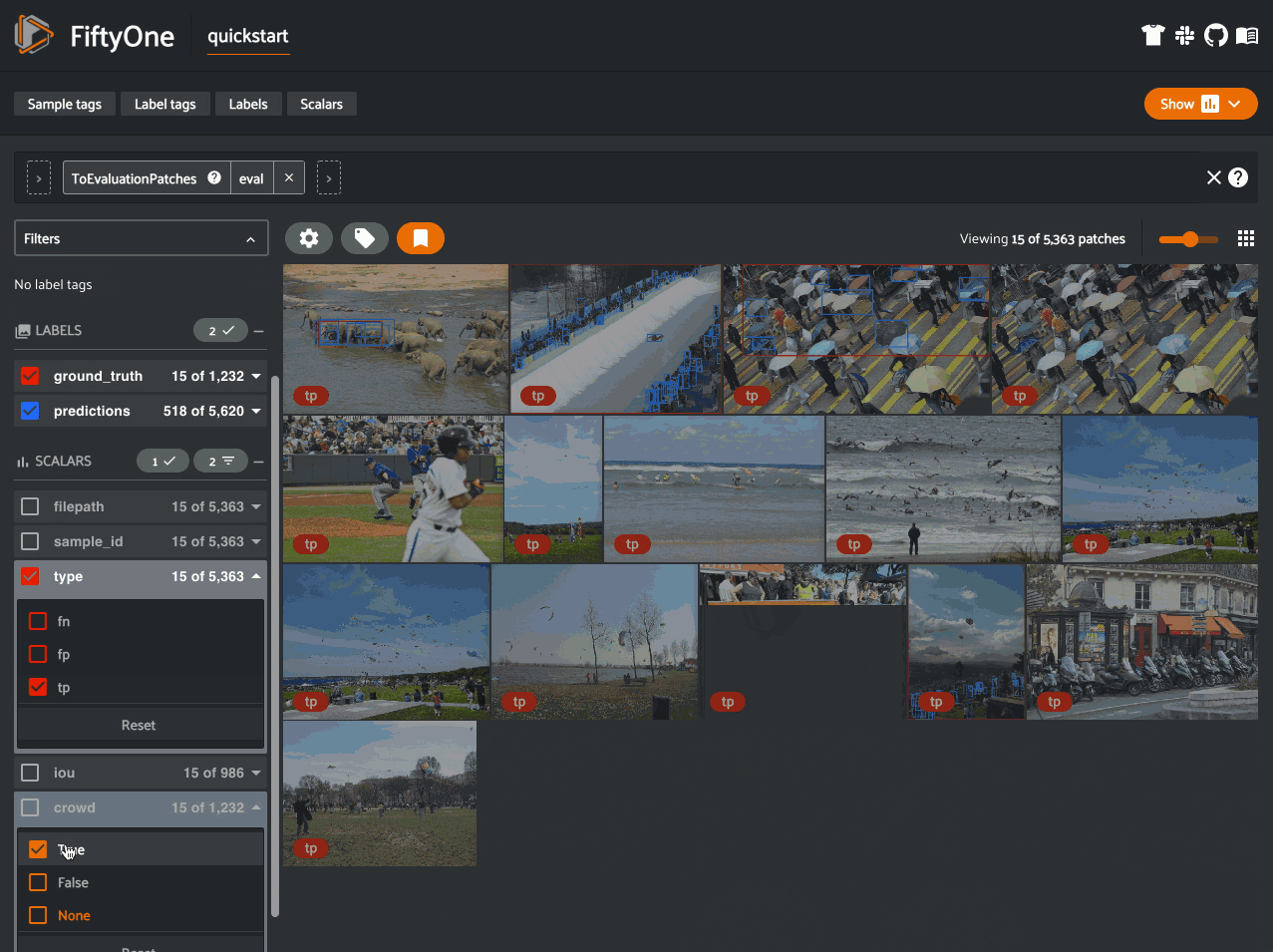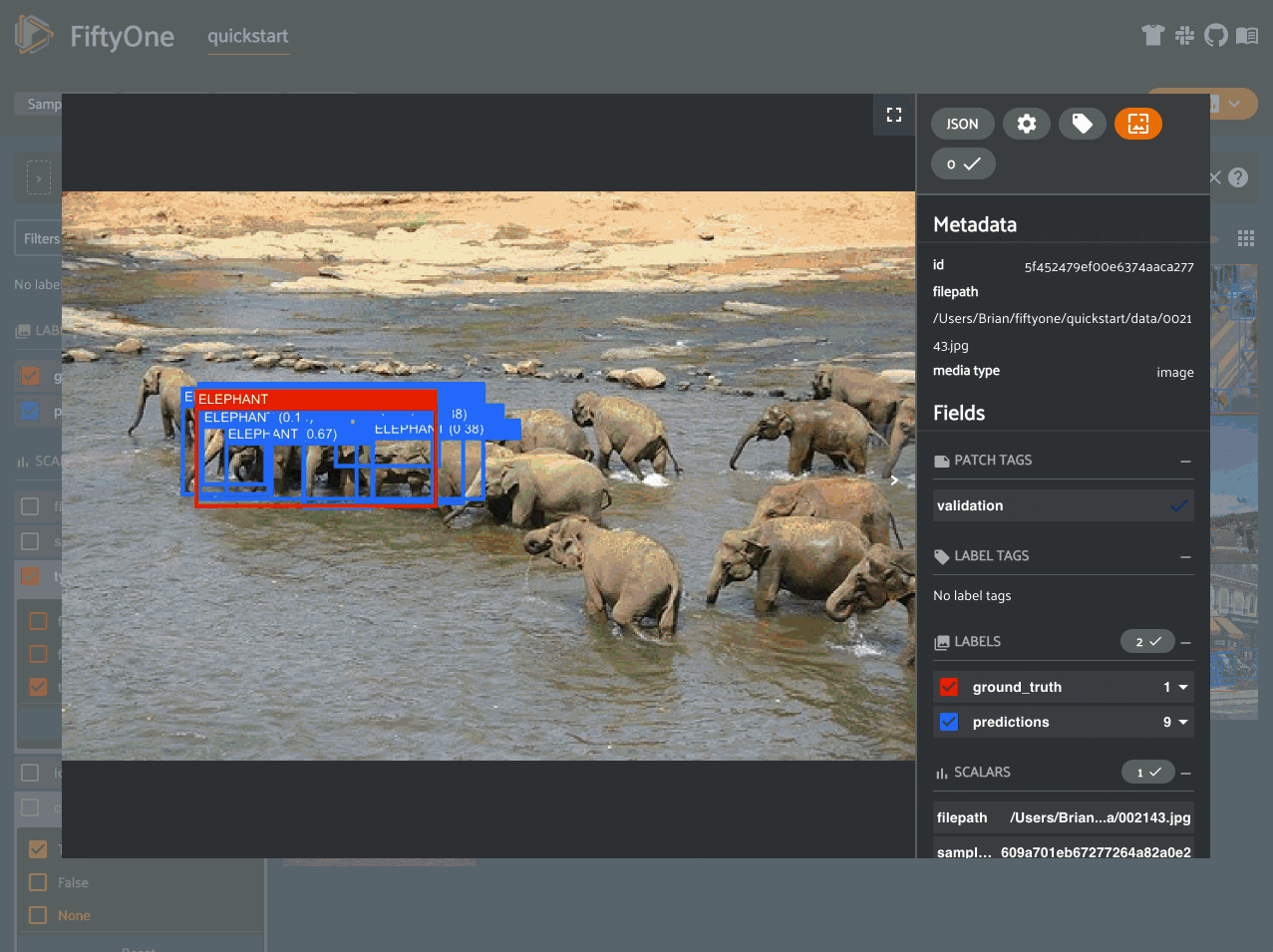
Notice anything wrong? The sample with the most false positives is a plate of
carrots where the entire plate has been boxed as a single example in the ground
truth while the model is generating predictions for individual carrots!
If you’re familiar with COCO format
(which is recognized by
evaluate_detections()
by default), you’ll notice that the issue here is that the iscrowd
attribute of this ground truth annotation has been incorrectly set to 0.
Resolving mistakes like these will provide a much more accurate picture of the
real performance of a model.
Confusion matrices#
Note
The easiest way to work with confusion matrices in FiftyOne is via the Model Evaluation panel!
When you use evaluation methods such as
evaluate_detections()
that support confusion matrices, you can use the
plot_confusion_matrix()
method to render responsive plots that can be attached to App instances to
interactively explore specific cases of your model’s performance:
1# Plot confusion matrix
2plot = results.plot_confusion_matrix(classes=classes)
3plot.show()
4
5# Connect to session
6session.plots.attach(plot)
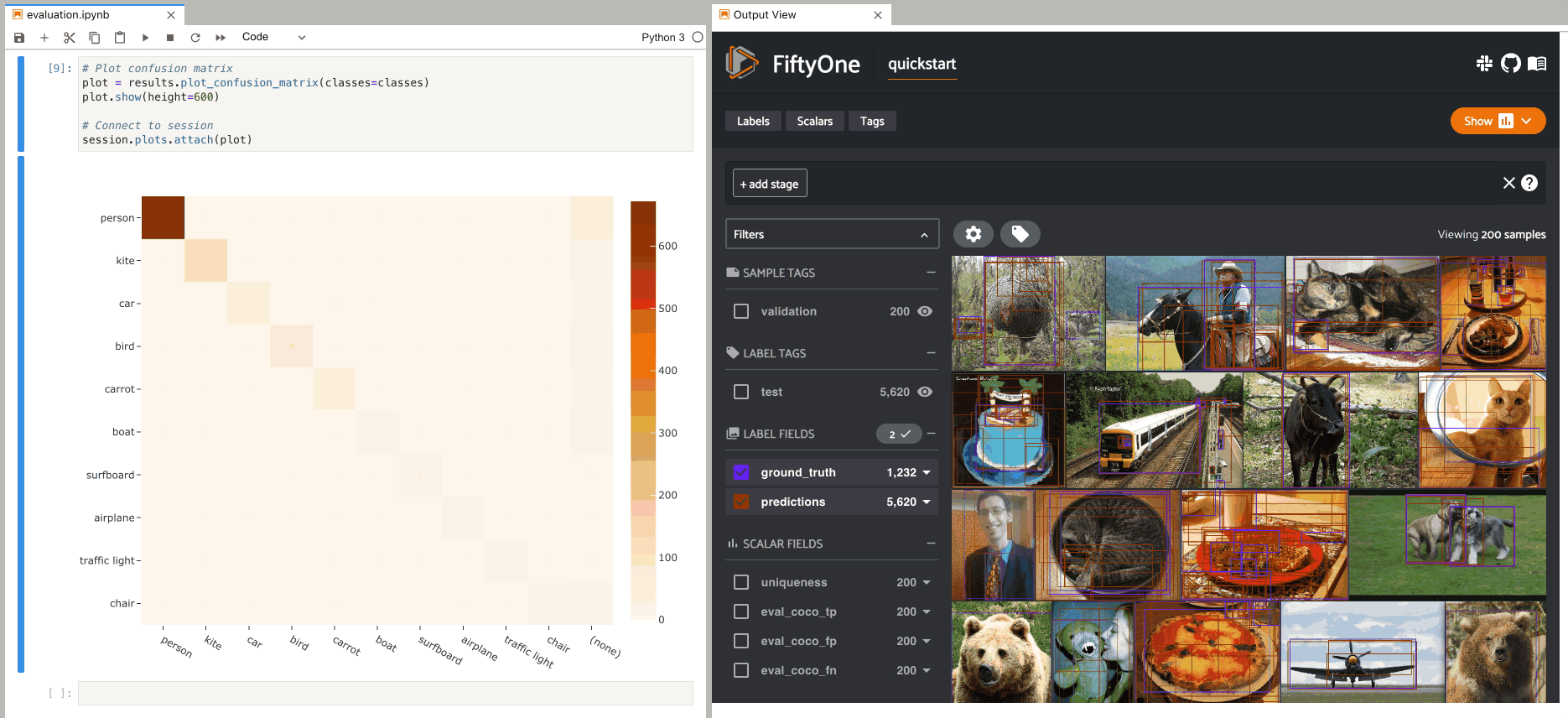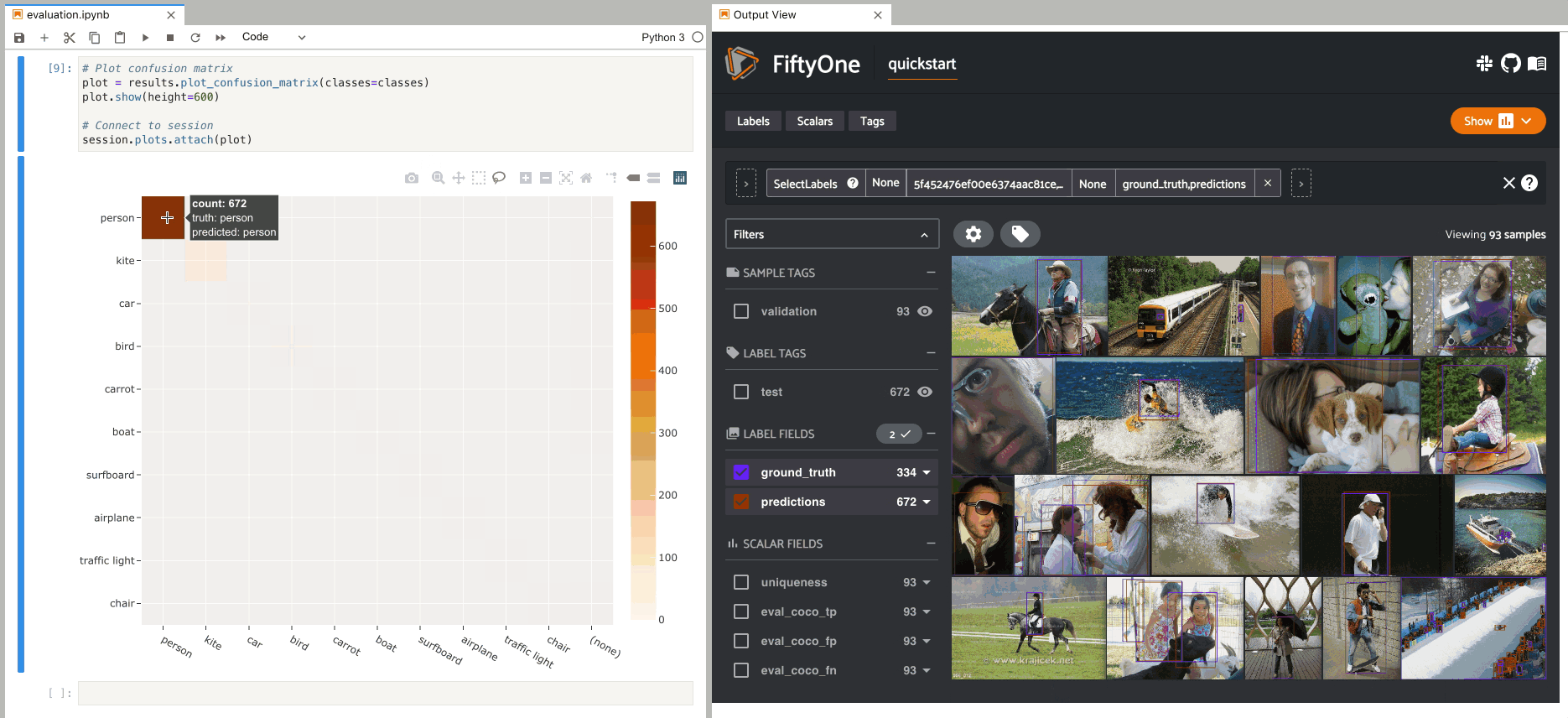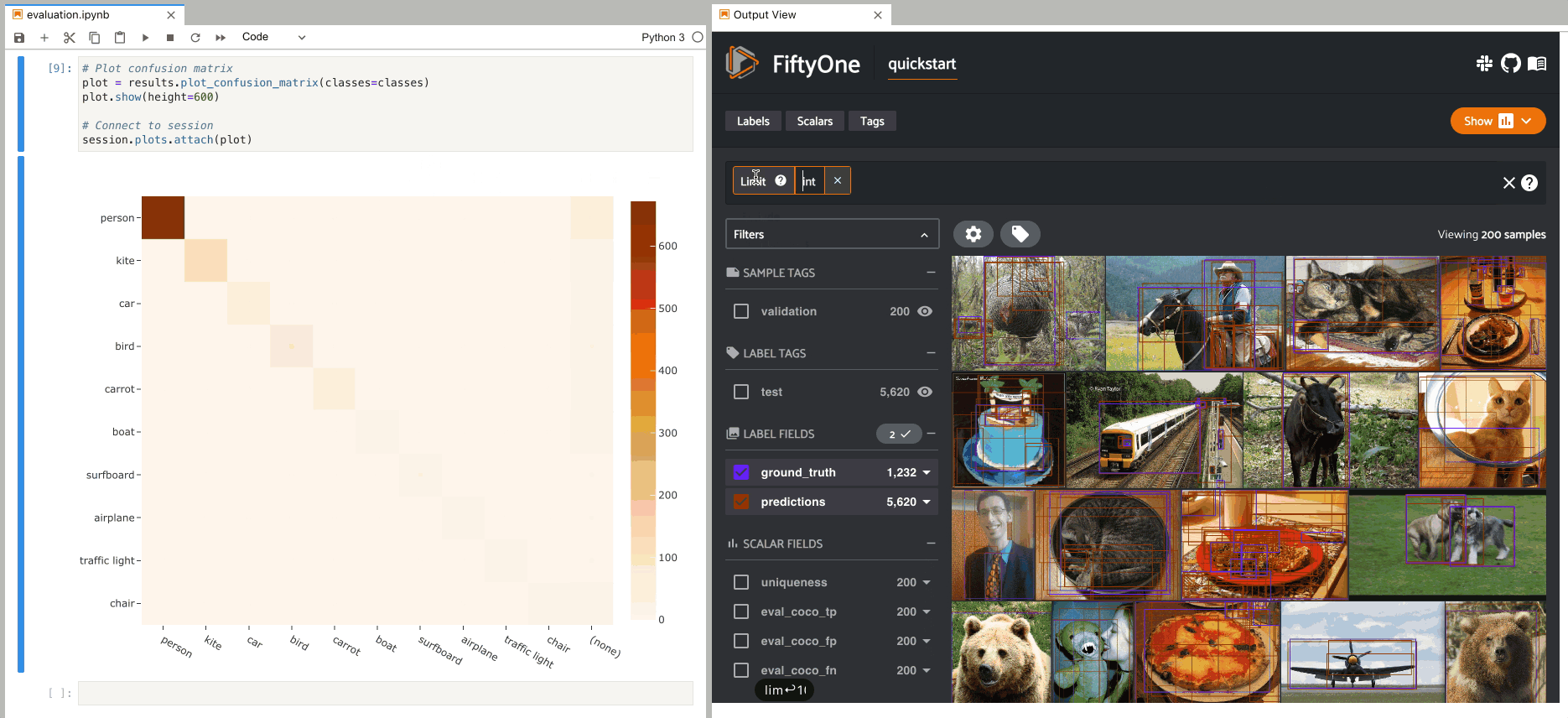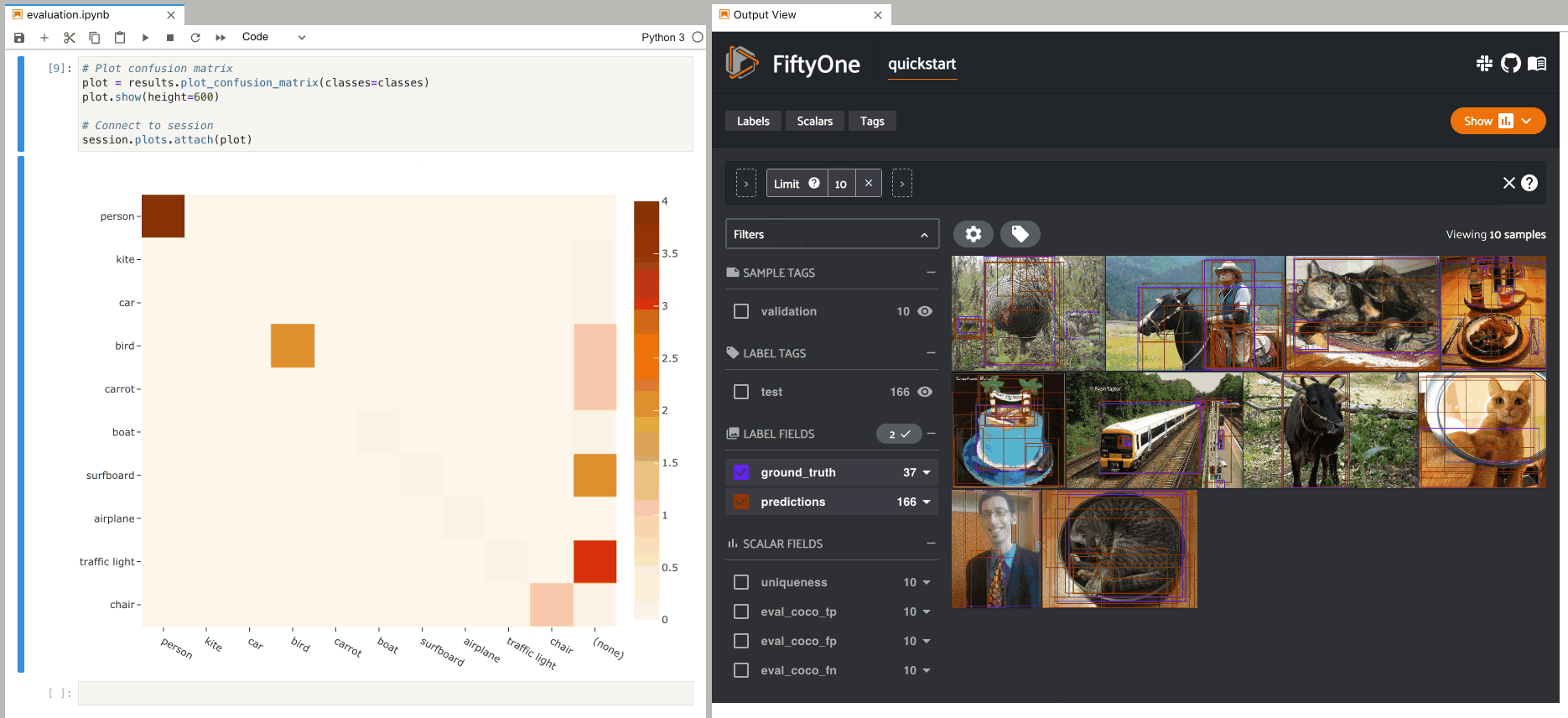
In this setup, you can click on individual cells of the confusion matrix to select the corresponding ground truth and/or predicted objects in the App. For example, if you click on a diagonal cell of the confusion matrix, you will see the true positive examples of that class in the App.
Likewise, whenever you modify the Session’s view, either in the App or by
programmatically setting
session.view, the confusion matrix
is automatically updated to show the cell counts for only those objects that
are included in the current view.
Analyzing scenarios NEW#
Note
Did you know? You can create and analyze model evaluation scenarios in the App via the Scenario Analysis tab.
The use_subset()
method allows you to evaluate the performance of your model under specific
scenarios, i.e., subsets of the overall dataset on which evaluation was
performed.
Consider the following example:
1import fiftyone as fo
2import fiftyone.zoo as foz
3import fiftyone.utils.random as four
4from fiftyone import ViewField as F
5
6dataset = foz.load_zoo_dataset("quickstart")
7
8four.random_split(dataset, {"sunny": 0.7, "cloudy": 0.2, "rainy": 0.1})
9
10counts = dataset.count_values("ground_truth.detections.label")
11classes = sorted(counts, key=counts.get, reverse=True)[:5]
12
13dataset.save_view("take100", dataset.take(100))
14
15results = dataset.evaluate_detections(
16 "predictions",
17 gt_field="ground_truth",
18 eval_key="eval",
19)
By default, invoking methods on an EvaluationResults instance reports
statistics across the entire evaluation:
1# Full results
2results.print_report(classes=classes)
precision recall f1-score support
person 0.52 0.94 0.67 716
kite 0.59 0.88 0.71 140
car 0.18 0.80 0.29 61
bird 0.65 0.78 0.71 110
carrot 0.09 0.74 0.16 47
micro avg 0.42 0.90 0.57 1074
macro avg 0.41 0.83 0.51 1074
weighted avg 0.51 0.90 0.64 1074
However, you can use
use_subset()
to analyze the performance of the model on specific subsets of interest:
1# Sunny samples
2subset_def = dict(type="field", field="tags", value="sunny")
3with results.use_subset(subset_def):
4 results.print_report(classes=classes)
precision recall f1-score support
person 1.00 0.93 0.96 495
kite 1.00 0.90 0.95 62
car 1.00 0.69 0.81 35
bird 1.00 0.78 0.88 104
carrot 1.00 0.69 0.82 36
micro avg 1.00 0.88 0.94 732
macro avg 1.00 0.80 0.88 732
weighted avg 1.00 0.88 0.94 732
1# Small objects
2bbox_area = F("bounding_box")[2] * F("bounding_box")[3]
3small_objects = bbox_area <= 0.05
4subset_def = dict(type="attribute", expr=small_objects)
5with results.use_subset(subset_def):
6 results.print_report(classes=classes)
precision recall f1-score support
person 1.00 0.87 0.93 324
kite 1.00 0.76 0.87 72
car 1.00 0.79 0.88 56
bird 1.00 0.52 0.69 46
carrot 1.00 0.75 0.86 40
micro avg 1.00 0.81 0.89 538
macro avg 1.00 0.74 0.84 538
weighted avg 1.00 0.81 0.89 538
1# Saved view
2subset_def = dict(type="view", view="take100")
3with results.use_subset(subset_def):
4 results.print_report(classes=classes)
precision recall f1-score support
person 1.00 0.94 0.97 292
kite 1.00 0.93 0.97 15
car 1.00 0.87 0.93 15
bird 1.00 0.35 0.52 23
carrot 1.00 0.67 0.80 9
micro avg 1.00 0.89 0.94 354
macro avg 1.00 0.75 0.84 354
weighted avg 1.00 0.89 0.93 354
1# Sunny samples + small objects
2subset_def = [
3 dict(type="field", field="tags", value="sunny"),
4 dict(type="attribute", expr=small_objects),
5]
6with results.use_subset(subset_def):
7 results.print_report(classes=classes)
precision recall f1-score support
person 1.00 0.85 0.92 227
kite 1.00 0.87 0.93 45
car 1.00 0.66 0.79 32
bird 1.00 0.48 0.65 42
carrot 1.00 0.71 0.83 31
micro avg 1.00 0.79 0.88 377
macro avg 1.00 0.71 0.82 377
weighted avg 1.00 0.79 0.87 377
Refer to
use_subset()
and
get_subset_view() for a
complete description of the supported syntax for defining subsets to analyze.
Managing evaluations#
When you run an evaluation with an eval_key argument, the evaluation is
recorded on the dataset and you can retrieve information about it later, rename
it, delete it (along with any modifications to your dataset that were performed
by it), and retrieve the view that you evaluated
on using the following methods on your dataset:
The example below demonstrates the basic interface:
1# List evaluations you've run on a dataset
2dataset.list_evaluations()
3# ['eval']
4
5# Print information about an evaluation
6print(dataset.get_evaluation_info("eval"))
7
8# Load existing evaluation results and use them
9results = dataset.load_evaluation_results("eval")
10results.print_report()
11
12# Rename the evaluation
13# This will automatically rename any evaluation fields on your dataset
14dataset.rename_evaluation("eval", "still_eval")
15
16# Delete the evaluation
17# This will remove any evaluation data that was populated on your dataset
18dataset.delete_evaluation("still_eval")
Model Evaluation panel NEW#
When you load a dataset in the App that contains one or more evaluations, you can open the Model Evaluation panel to visualize and interactively explore the evaluation results in the App:
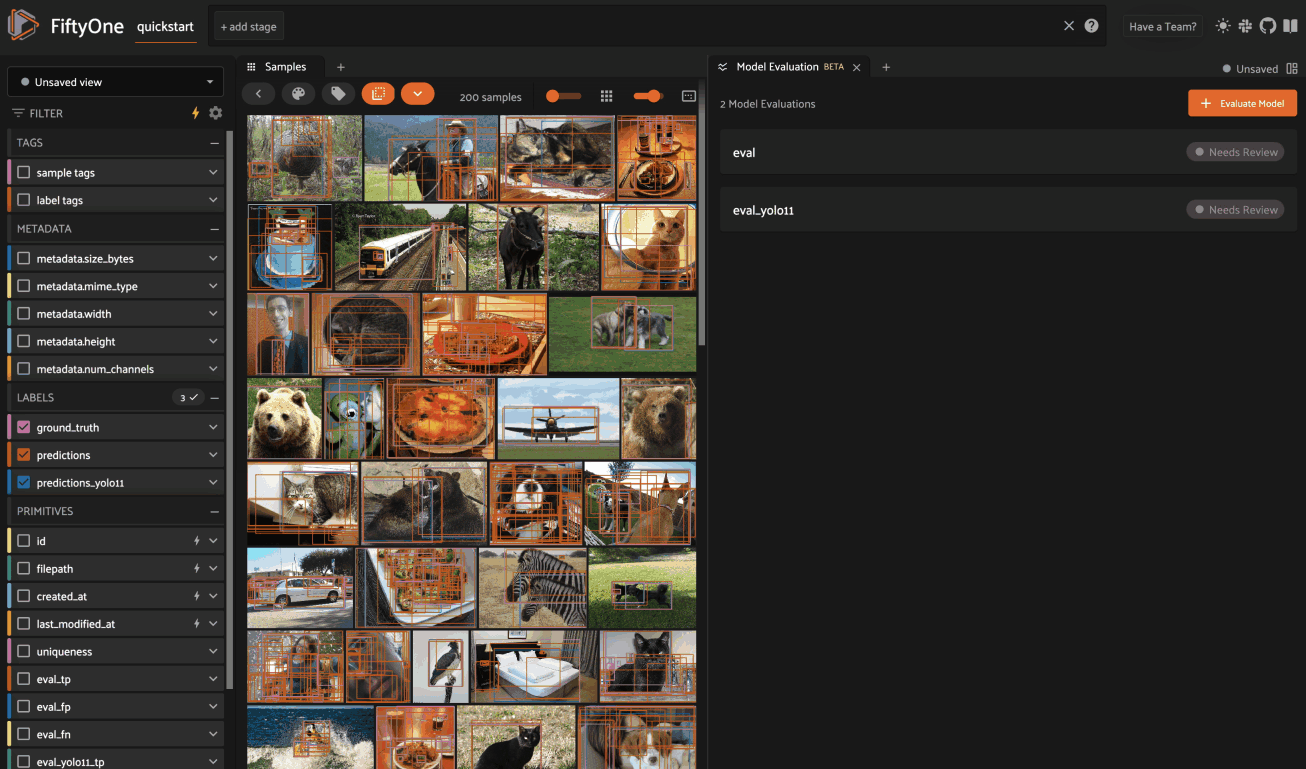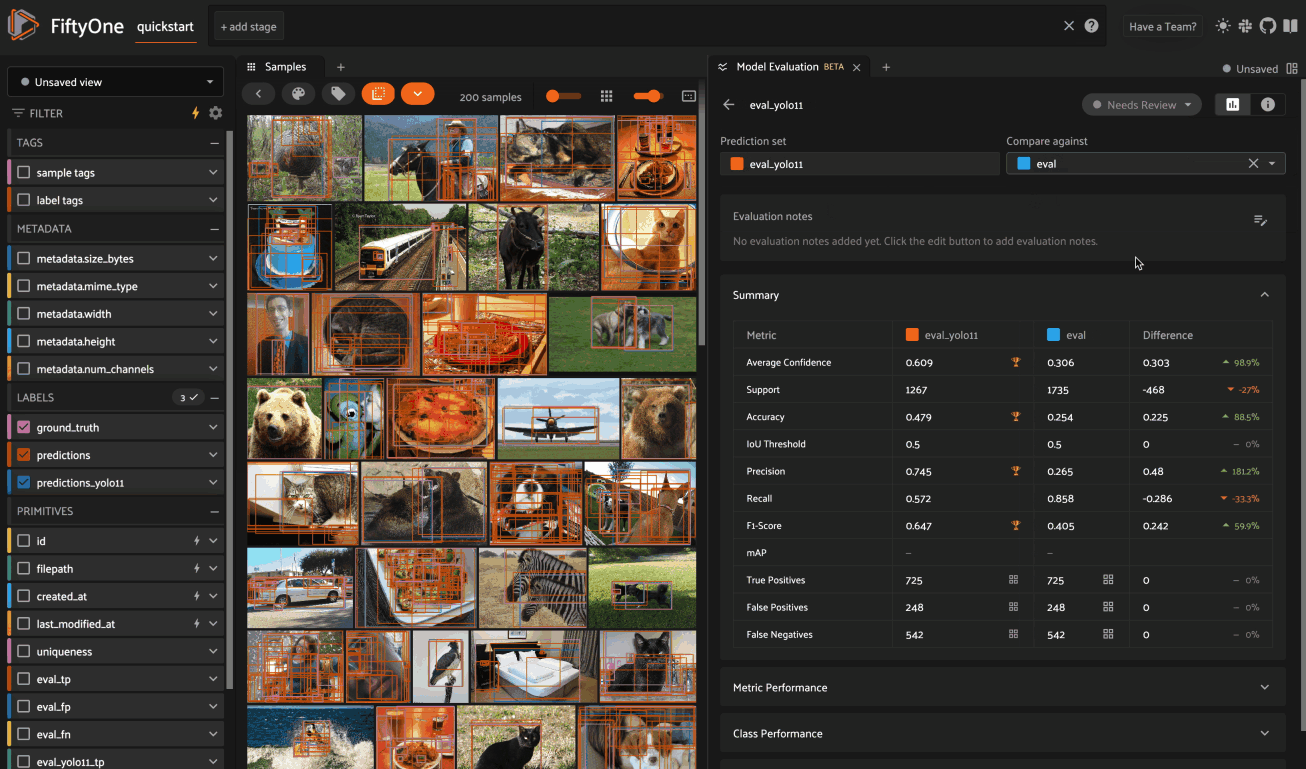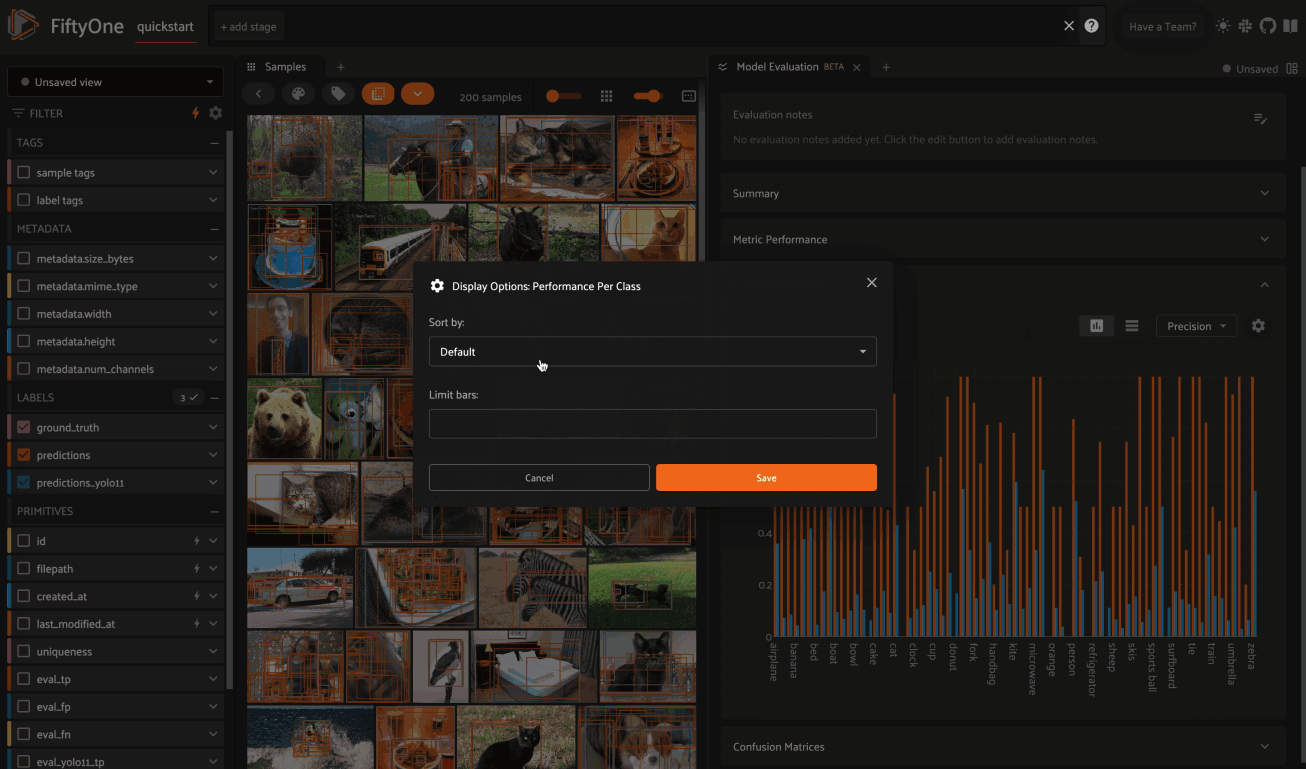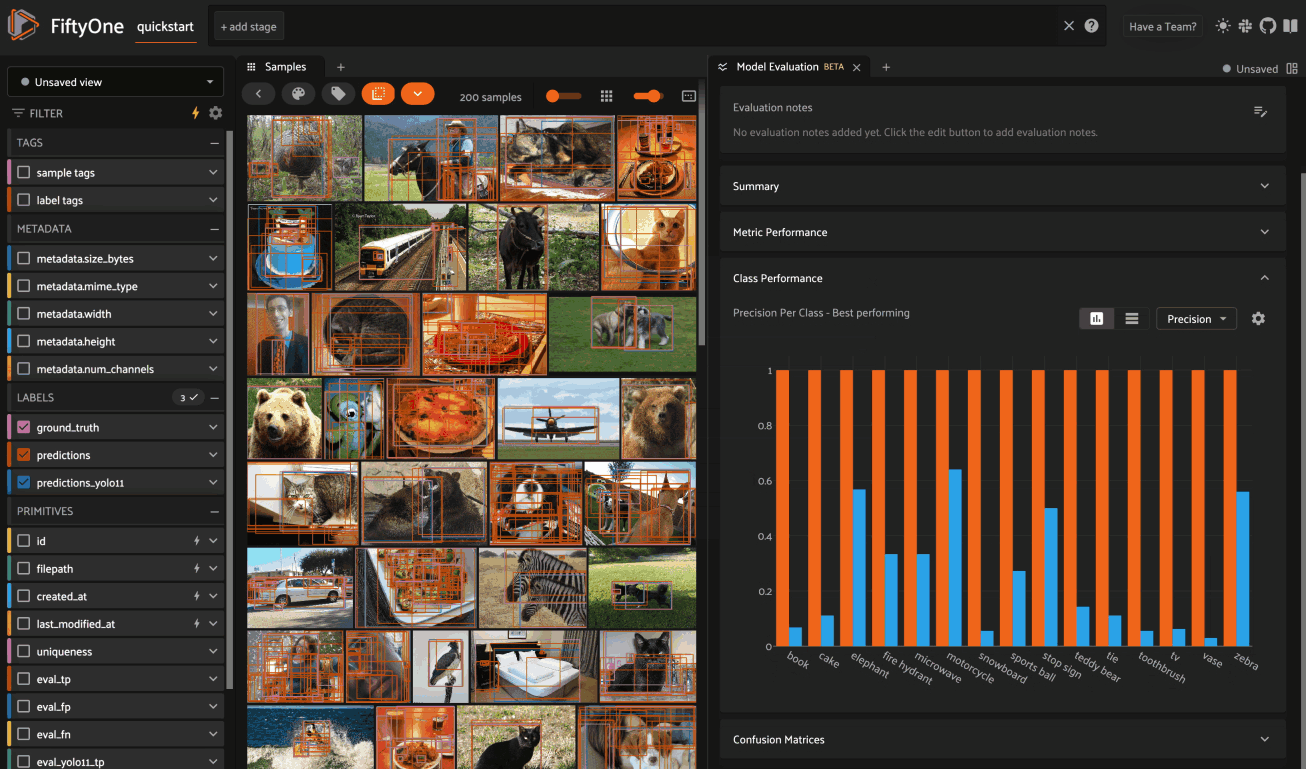
Note
Did you know? With FiftyOne Enterprise you can execute model evaluations natively from the App in the background while you work.
Regressions#
You can use the
evaluate_regressions()
method to evaluate the predictions of a regression model stored in a
Regression field of your dataset.
Invoking
evaluate_regressions()
returns a RegressionResults instance that provides a variety of methods for
evaluating your model.
In addition, when you specify an eval_key parameter, helpful fields will be
populated on each sample that you can leverage via the
FiftyOne App to interactively explore the strengths and
weaknesses of your model on individual samples.
Simple evaluation (default)#
By default,
evaluate_regressions()
will evaluate each prediction by directly comparing its value to the
associated ground truth value.
You can explicitly request that simple evaluation be used by setting the
method parameter to "simple".
When you specify an eval_key parameter, a float eval_key field will be
populated on each sample that records the error of that sample’s prediction
with respect to its ground truth value. By default, the squared error will be
computed, but you can customize this via the optional metric argument to
evaluate_regressions(),
which can take any value supported by
SimpleEvaluationConfig.
The example below demonstrates simple evaluation on the quickstart dataset with some fake regression data added to it to demonstrate the workflow:
1import random
2import numpy as np
3
4import fiftyone as fo
5import fiftyone.zoo as foz
6from fiftyone import ViewField as F
7
8dataset = foz.load_zoo_dataset("quickstart").select_fields().clone()
9
10# Populate some fake regression + weather data
11for idx, sample in enumerate(dataset, 1):
12 ytrue = random.random() * idx
13 ypred = ytrue + np.random.randn() * np.sqrt(ytrue)
14 confidence = random.random()
15 sample["ground_truth"] = fo.Regression(value=ytrue)
16 sample["predictions"] = fo.Regression(value=ypred, confidence=confidence)
17 sample["weather"] = random.choice(["sunny", "cloudy", "rainy"])
18 sample.save()
19
20print(dataset)
21
22# Evaluate the predictions in the `predictions` field with respect to the
23# values in the `ground_truth` field
24results = dataset.evaluate_regressions(
25 "predictions",
26 gt_field="ground_truth",
27 eval_key="eval",
28)
29
30# Print some standard regression evaluation metrics
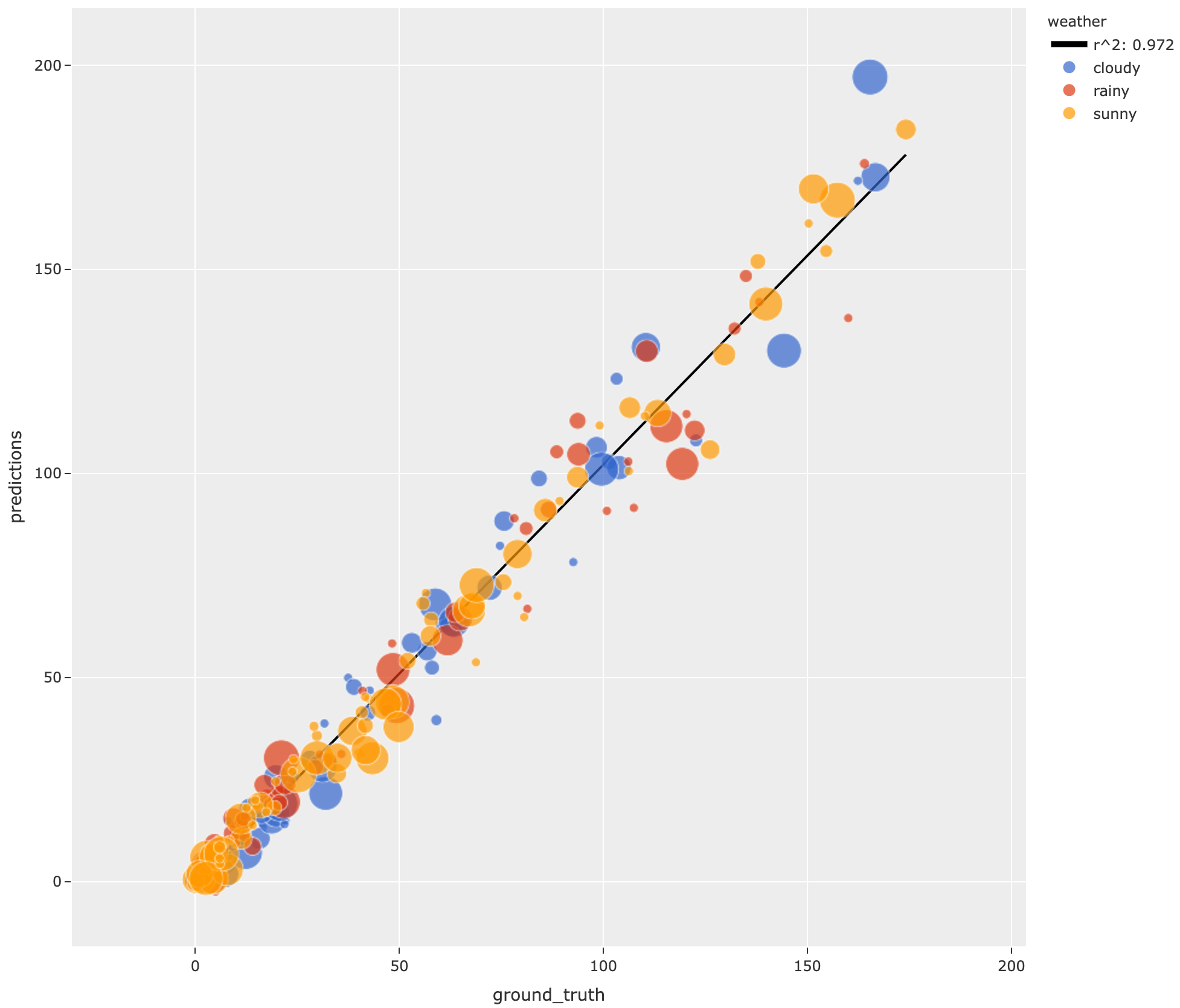
31results.print_metrics()
32
33# Plot a scatterplot of the results colored by `weather` and scaled by
34# `confidence`
35plot = results.plot_results(labels="weather", sizes="predictions.confidence")
36plot.show()
37
38# Launch the App to explore
39session = fo.launch_app(dataset)
40
41# Show the samples with the smallest regression error
42session.view = dataset.sort_by("eval")
43
44# Show the samples with the largest regression error
45session.view = dataset.sort_by("eval", reverse=True)
mean squared error 59.69
root mean squared error 7.73
mean absolute error 5.48
median absolute error 3.57
r2 score 0.97
explained variance score 0.97
max error 31.77
support 200
Note
Did you know? You can attach regression plots to the App and interactively explore them by selecting scatter points and/or modifying your view in the App.
Classifications#
You can use the
evaluate_classifications()
method to evaluate the predictions of a classifier stored in a
Classification field of your dataset.
By default, the classifications will be treated as a generic multiclass
classification task, but you can specify other evaluation strategies such as
top-k accuracy or binary evaluation via the method parameter.
Invoking
evaluate_classifications()
returns a ClassificationResults instance that provides a variety of methods
for generating various aggregate evaluation reports about your model.
In addition, when you specify an eval_key parameter, a number of helpful
fields will be populated on each sample that you can leverage via the
FiftyOne App to interactively explore the strengths and
weaknesses of your model on individual samples.
Simple evaluation (default)#
By default,
evaluate_classifications()
will treat your classifications as generic multiclass predictions, and it will
evaluate each prediction by directly comparing its label to the associated
ground truth prediction.
You can explicitly request that simple evaluation be used by setting the
method parameter to "simple".
When you specify an eval_key parameter, a boolean eval_key field will
be populated on each sample that records whether that sample’s prediction is
correct.
The example below demonstrates simple evaluation on the CIFAR-10 dataset with some fake predictions added to it to demonstrate the workflow:
1import random
2
3import fiftyone as fo
4import fiftyone.zoo as foz
5from fiftyone import ViewField as F
6
7dataset = foz.load_zoo_dataset(
8 "cifar10",
9 split="test",
10 max_samples=1000,
11 shuffle=True,
12)
13
14#
15# Create some test predictions by copying the ground truth labels into a
16# new `predictions` field with 10% of the labels perturbed at random
17#
18
19classes = dataset.distinct("ground_truth.label")
20
21def jitter(val):
22 if random.random() < 0.10:
23 return random.choice(classes)
24
25 return val
26
27predictions = [
28 fo.Classification(label=jitter(gt.label), confidence=random.random())
29 for gt in dataset.values("ground_truth")
30]
31
32dataset.set_values("predictions", predictions)
33
34print(dataset)
35
36# Evaluate the predictions in the `predictions` field with respect to the
37# labels in the `ground_truth` field
38results = dataset.evaluate_classifications(
39 "predictions",
40 gt_field="ground_truth",
41 eval_key="eval_simple",
42)
43
44# Print a classification report
45results.print_report()
46
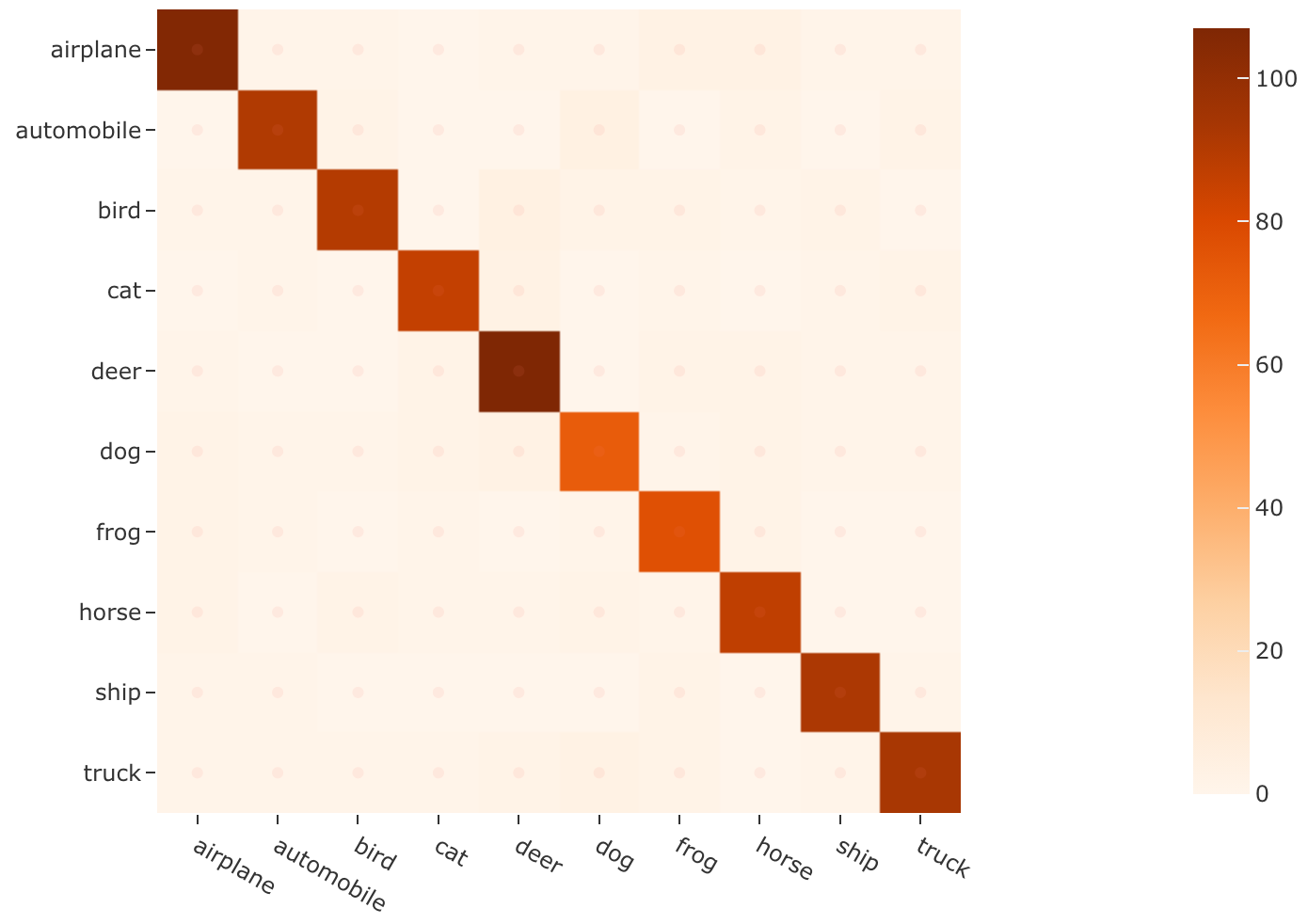
47# Plot a confusion matrix
48plot = results.plot_confusion_matrix()
49plot.show()
50
51# Launch the App to explore
52session = fo.launch_app(dataset)
53
54# View only the incorrect predictions in the App
55session.view = dataset.match(F("eval_simple") == False)
precision recall f1-score support
airplane 0.91 0.90 0.91 118
automobile 0.93 0.90 0.91 101
bird 0.93 0.87 0.90 103
cat 0.92 0.91 0.92 94
deer 0.88 0.92 0.90 116
dog 0.85 0.84 0.84 86
frog 0.85 0.92 0.88 84
horse 0.88 0.91 0.89 96
ship 0.93 0.95 0.94 97
truck 0.92 0.89 0.90 105
accuracy 0.90 1000
macro avg 0.90 0.90 0.90 1000
weighted avg 0.90 0.90 0.90 1000
Note
The easiest way to analyze models in FiftyOne is via the Model Evaluation panel!
Top-k evaluation#
Set the method parameter of
evaluate_classifications()
to top-k in order to use top-k matching to evaluate your classifications.
Under this strategy, predictions are deemed to be correct if the corresponding
ground truth label is within the top k predictions.
When you specify an eval_key parameter, a boolean eval_key field will
be populated on each sample that records whether that sample’s prediction is
correct.
Note
In order to use top-k evaluation, you must populate the logits field
of your predictions, and you must provide the list of corresponding class
labels via the classes parameter of
evaluate_classifications().
Did you know? Many models from the Model Zoo provide support for storing logits for their predictions!
The example below demonstrates top-k evaluation on a small ImageNet sample with predictions from a pre-trained model from the Model Zoo:
1import fiftyone as fo
2import fiftyone.zoo as foz
3from fiftyone import ViewField as F
4
5dataset = foz.load_zoo_dataset(
6 "imagenet-sample", dataset_name="top-k-eval-demo"
7)
8
9# We need the list of class labels corresponding to the logits
10logits_classes = dataset.default_classes
11
12# Add predictions (with logits) to 25 random samples
13predictions_view = dataset.take(25, seed=51)
14model = foz.load_zoo_model("resnet50-imagenet-torch")
15predictions_view.apply_model(model, "predictions", store_logits=True)
16
17print(predictions_view)
18
19# Evaluate the predictions in the `predictions` field with respect to the
20# labels in the `ground_truth` field using top-5 accuracy
21results = predictions_view.evaluate_classifications(
22 "predictions",
23 gt_field="ground_truth",
24 eval_key="eval_top_k",
25 method="top-k",
26 classes=logits_classes,
27 k=5,
28)
29
30# Get the 10 most common classes in the view
31counts = predictions_view.count_values("ground_truth.label")
32classes = sorted(counts, key=counts.get, reverse=True)[:10]
33
34# Print a classification report for the top-10 classes
35results.print_report(classes=classes)
36
37# Launch the App to explore
38session = fo.launch_app(dataset)
39
40# View only the incorrect predictions for the 10 most common classes
41session.view = (
42 predictions_view
43 .match(F("ground_truth.label").is_in(classes))
44 .match(F("eval_top_k") == False)
45)
Note
The easiest way to analyze models in FiftyOne is via the Model Evaluation panel!
Binary evaluation#
If your classifier is binary, set the method parameter of
evaluate_classifications()
to "binary" in order to access binary-specific evaluation information such
as precision-recall curves for your model.
When you specify an eval_key parameter, a string eval_key field will
be populated on each sample that records whether the sample is a true positive,
false positive, true negative, or false negative.
Note
In order to use binary evaluation, you must provide the
(neg_label, pos_label) for your model via the classes parameter of
evaluate_classifications().
The example below demonstrates binary evaluation on the CIFAR-10 dataset with some fake binary predictions added to it to demonstrate the workflow:
1import random
2
3import fiftyone as fo
4import fiftyone.zoo as foz
5
6# Load a small sample from the ImageNet dataset
7dataset = foz.load_zoo_dataset(
8 "cifar10",
9 split="test",
10 max_samples=1000,
11 shuffle=True,
12)
13
14#
15# Binarize the ground truth labels to `cat` and `other`, and add
16# predictions that are correct proportionally to their confidence
17#
18
19classes = ["other", "cat"]
20
21for sample in dataset:
22 gt_label = "cat" if sample.ground_truth.label == "cat" else "other"
23
24 confidence = random.random()
25 if random.random() > confidence:
26 pred_label = "cat" if gt_label == "other" else "other"
27 else:
28 pred_label = gt_label
29
30 sample.ground_truth.label = gt_label
31 sample["predictions"] = fo.Classification(
32 label=pred_label, confidence=confidence
33 )
34
35 sample.save()
36
37print(dataset)
38
39# Evaluate the predictions in the `predictions` field with respect to the
40# labels in the `ground_truth` field
41results = dataset.evaluate_classifications(
42 "predictions",
43 gt_field="ground_truth",
44 eval_key="eval_binary",
45 method="binary",
46 classes=classes,
47)
48
49# Print a classification report
50results.print_report()
51
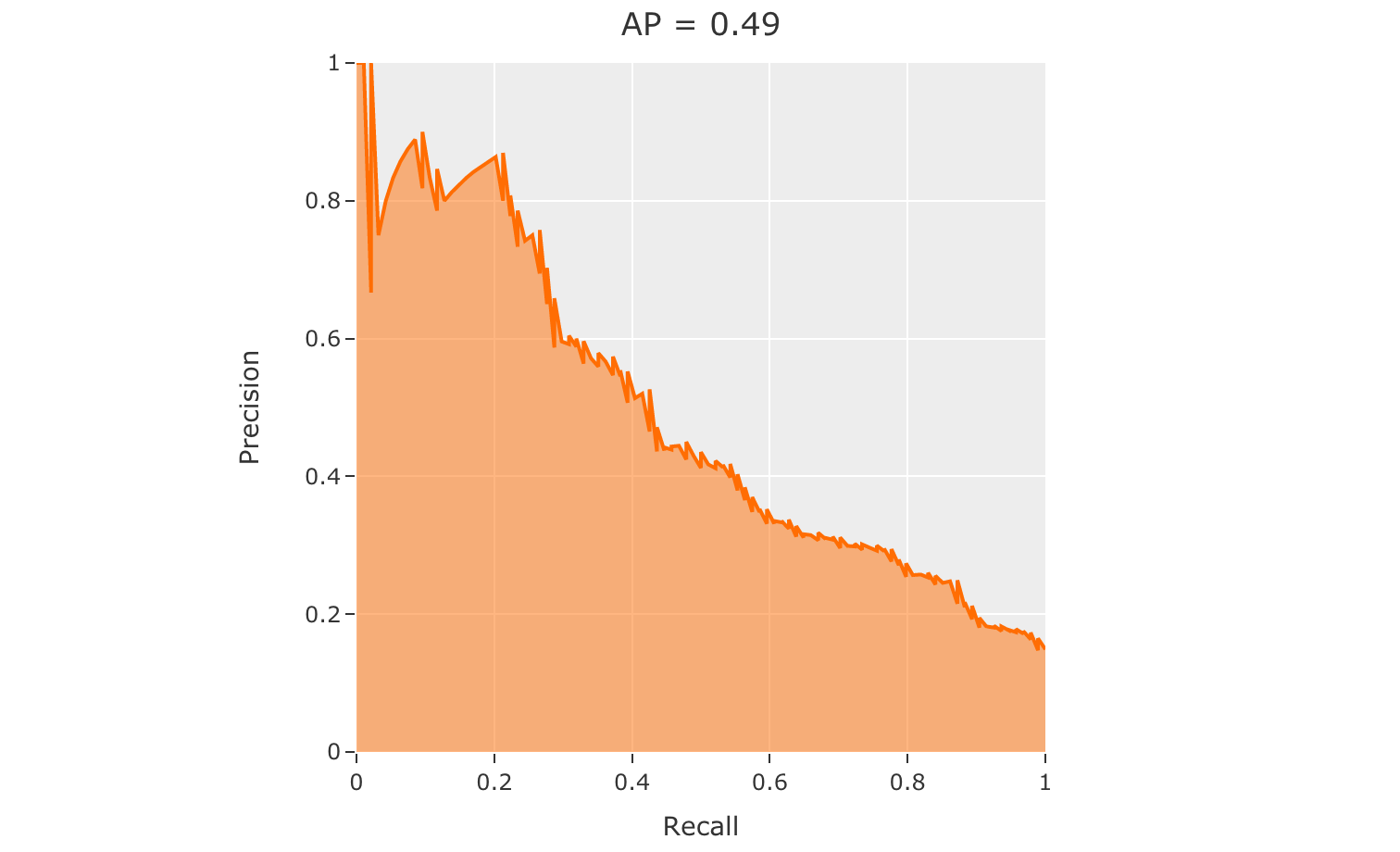
52# Plot a PR curve
53plot = results.plot_pr_curve()
54plot.show()
precision recall f1-score support
other 0.90 0.48 0.63 906
cat 0.09 0.50 0.15 94
accuracy 0.48 1000
macro avg 0.50 0.49 0.39 1000
weighted avg 0.83 0.48 0.59 1000
Note
The easiest way to analyze models in FiftyOne is via the Model Evaluation panel!
Detections#
You can use the
evaluate_detections()
method to evaluate the predictions of an object detection model stored in a
Detections, Polylines, or Keypoints field of your dataset or of a
temporal detection model stored in a TemporalDetections field of your
dataset.
Invoking
evaluate_detections()
returns a DetectionResults instance that provides a variety of methods for
generating various aggregate evaluation reports about your model.
In addition, when you specify an eval_key parameter, a number of helpful
fields will be populated on each sample and its predicted/ground truth
objects that you can leverage via the FiftyOne App to
interactively explore the strengths and weaknesses of your model on individual
samples.
Note
FiftyOne uses the COCO-style evaluation by default, but Open Images-style evaluation is also natively supported.
Supported types#
The evaluate_detections()
method supports all of the following task types:
The only difference between each task type is in how the IoU between objects is calculated:
For object detections, IoUs are computed between each pair of bounding boxes
For instance segmentations, when
use_masks=True, IoUs are computed between the dense pixel masks rather than their rectangular bounding boxesFor polygons, IoUs are computed between the polygonal shapes
For keypoint tasks, object keypoint similarity is computed for each pair of objects, using the extent of the ground truth keypoints as a proxy for the area of the object’s bounding box. By default, uniform falloff (\(\kappa\)) is assumed, but you can provide
keypoint_sigmasto customize the per-keypoint OKS falloffFor temporal detections, IoU is computed between the 1D support of two temporal segments
For object detection tasks, the ground truth and predicted objects should be
stored in Detections format.
For instance segmentation tasks, the ground truth and predicted objects should
be stored in Detections format, and each Detection instance should have its
mask populated to define the extent of the object within its bounding box.
Note
In order to use instance masks for IoU calculations, pass use_masks=True
to evaluate_detections().
For polygon detection tasks, the ground truth and predicted objects should be
stored in Polylines format with their
filled attribute set to
True to indicate that they represent closed polygons (as opposed to
polylines).
Note
If you are evaluating polygons but would rather use bounding boxes rather
than the actual polygonal geometries for IoU calculations, you can pass
use_boxes=True to
evaluate_detections().
For keypoint tasks, each Keypoint instance must contain point arrays of equal
length and semantic ordering.
Note
If a particular point is missing or not visible for a Keypoint instance,
use nan values for its coordinates. See here for more
information about structuring keypoints.
For temporal detection tasks, the ground truth and predicted objects should be
stored in TemporalDetections format.
Evaluation patches views#
Once you have run
evaluate_detections()
on a dataset, you can use
to_evaluation_patches()
to transform the dataset (or a view into it) into a new view that contains one
sample for each true positive, false positive, and false negative example.
True positive examples will result in samples with both their ground truth and predicted fields populated, while false positive/negative examples will only have one of their corresponding predicted/ground truth fields populated, respectively.
If multiple predictions are matched to a ground truth object (e.g., if the evaluation protocol includes a crowd attribute), then all matched predictions will be stored in the single sample along with the ground truth object.
Evaluation patches views also have top-level type and iou fields
populated based on the evaluation results for that example, as well as a
sample_id field recording the sample ID of the example, and a crowd
field if the evaluation protocol defines a crowd attribute.
Note
Evaluation patches views generate patches for only the contents of the
current view, which may differ from the view on which the eval_key
evaluation was performed. This may exclude some labels that were evaluated
and/or include labels that were not evaluated.
If you would like to see patches for the exact view on which an
evaluation was performed, first call
load_evaluation_view()
to load the view and then convert to patches.
The example below demonstrates loading an evaluation patches view for the results of an evaluation on the quickstart dataset:
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5
6# Evaluate `predictions` w.r.t. labels in `ground_truth` field
7dataset.evaluate_detections(
8 "predictions", gt_field="ground_truth", eval_key="eval"
9)
10
11session = fo.launch_app(dataset)
12
13# Convert to evaluation patches
14eval_patches = dataset.to_evaluation_patches("eval")
15print(eval_patches)
16
17print(eval_patches.count_values("type"))
18# {'fn': 246, 'fp': 4131, 'tp': 986}
19
20# View patches in the App
21session.view = eval_patches
Dataset: quickstart
Media type: image
Num patches: 5363
Patch fields:
filepath: fiftyone.core.fields.StringField
tags: fiftyone.core.fields.ListField(fiftyone.core.fields.StringField)
metadata: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.metadata.ImageMetadata)
predictions: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Detections)
ground_truth: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Detections)
sample_id: fiftyone.core.fields.StringField
type: fiftyone.core.fields.StringField
iou: fiftyone.core.fields.FloatField
crowd: fiftyone.core.fields.BooleanField
View stages:
1. ToEvaluationPatches(eval_key='eval', config=None)
Note
Did you know? You can convert to evaluation patches view directly from the App!
Evaluation patches views are just like any other
dataset view in the sense that:
You can append view stages via the App view bar or views API
Any modifications to ground truth or predicted label tags that you make via the App’s tagging menu or via API methods like
tag_labels()anduntag_labels()will be reflected on the source datasetAny modifications to the predicted or ground truth
Labelelements in the patches view that you make by iterating over the contents of the view or callingset_values()will be reflected on the source datasetCalling
save()on an evaluation patches view (typically one that contains additional view stages that filter or modify its contents) will sync anyLabeledits or deletions with the source dataset
However, because evaluation patches views only contain a subset of the contents
of a Sample from the source dataset, there are some differences in behavior
compared to non-patch views:
Tagging or untagging patches themselves (as opposed to their labels) will not affect the tags of the underlying
SampleAny new fields that you add to an evaluation patches view will not be added to the source dataset
COCO-style evaluation (default spatial)#
By default,
evaluate_detections()
will use COCO-style evaluation to
analyze predictions when the specified label fields are Detections or
Polylines.
You can also explicitly request that COCO-style evaluation be used by setting
the method parameter to "coco".
Note
FiftyOne’s implementation of COCO-style evaluation matches the reference implementation available via pycocotools.
Overview#
When running COCO-style evaluation using
evaluate_detections():
Predicted and ground truth objects are matched using a specified IoU threshold (default = 0.50). This threshold can be customized via the
iouparameterBy default, only objects with the same
labelwill be matched. Classwise matching can be disabled via theclasswiseparameterGround truth objects can have an
iscrowdattribute that indicates whether the annotation contains a crowd of objects. Multiple predictions can be matched to crowd ground truth objects. The name of this attribute can be customized by passing the optionaliscrowdattribute ofCOCOEvaluationConfigtoevaluate_detections()
When you specify an eval_key parameter, a number of helpful fields will be
populated on each sample and its predicted/ground truth objects:
True positive (TP), false positive (FP), and false negative (FN) counts for each sample are saved in top-level fields of each sample:
TP: sample.<eval_key>_tp FP: sample.<eval_key>_fp FN: sample.<eval_key>_fn
The fields listed below are populated on each individual object instance; these fields tabulate the TP/FP/FN status of the object, the ID of the matching object (if any), and the matching IoU:
TP/FP/FN: object.<eval_key> ID: object.<eval_key>_id IoU: object.<eval_key>_iou
Note
See COCOEvaluationConfig for complete descriptions of the optional
keyword arguments that you can pass to
evaluate_detections()
when running COCO-style evaluation.
Example evaluation#
The example below demonstrates COCO-style detection evaluation on the quickstart dataset:
1import fiftyone as fo
2import fiftyone.zoo as foz
3from fiftyone import ViewField as F
4
5dataset = foz.load_zoo_dataset("quickstart")
6print(dataset)
7
8# Evaluate the objects in the `predictions` field with respect to the
9# objects in the `ground_truth` field
10results = dataset.evaluate_detections(
11 "predictions",
12 gt_field="ground_truth",
13 eval_key="eval",
14)
15
16# Get the 10 most common classes in the dataset
17counts = dataset.count_values("ground_truth.detections.label")
18classes = sorted(counts, key=counts.get, reverse=True)[:10]
19
20# Print a classification report for the top-10 classes
21results.print_report(classes=classes)
22
23# Print some statistics about the total TP/FP/FN counts
24print("TP: %d" % dataset.sum("eval_tp"))
25print("FP: %d" % dataset.sum("eval_fp"))
26print("FN: %d" % dataset.sum("eval_fn"))
27
28# Create a view that has samples with the most false positives first, and
29# only includes false positive boxes in the `predictions` field
30view = (
31 dataset
32 .sort_by("eval_fp", reverse=True)
33 .filter_labels("predictions", F("eval") == "fp")
34)
35
36# Visualize results in the App
37session = fo.launch_app(view=view)
precision recall f1-score support
person 0.45 0.74 0.56 783
kite 0.55 0.72 0.62 156
car 0.12 0.54 0.20 61
bird 0.63 0.67 0.65 126
carrot 0.06 0.49 0.11 47
boat 0.05 0.24 0.08 37
surfboard 0.10 0.43 0.17 30
airplane 0.29 0.67 0.40 24
traffic light 0.22 0.54 0.31 24
bench 0.10 0.30 0.15 23
micro avg 0.32 0.68 0.43 1311
macro avg 0.26 0.54 0.32 1311
weighted avg 0.42 0.68 0.50 1311
Note
The easiest way to analyze models in FiftyOne is via the Model Evaluation panel!
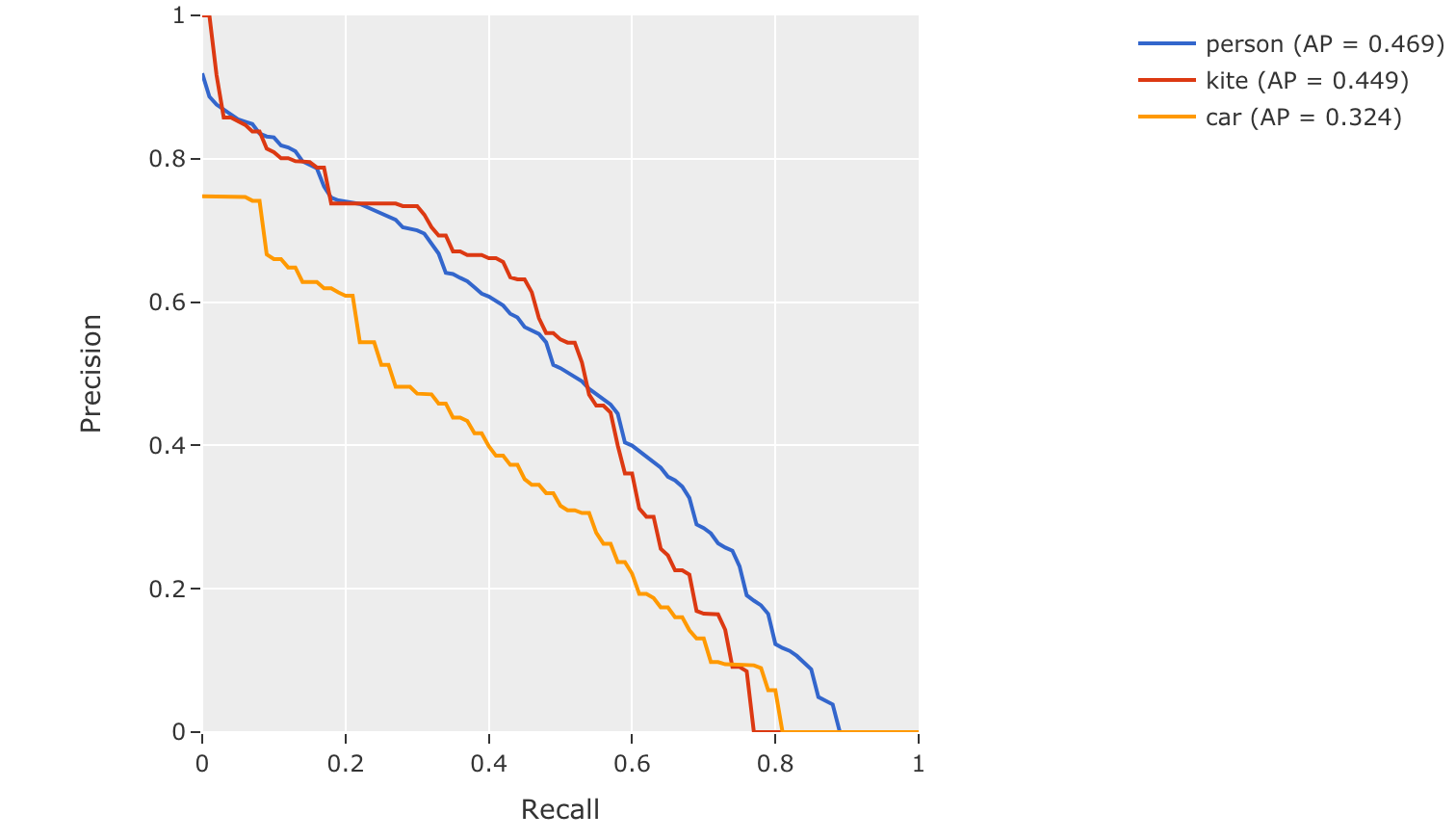
mAP, mAR and PR curves#
You can compute mean average precision (mAP), mean average recall (mAR), and
precision-recall (PR) curves for your predictions by passing the
compute_mAP=True flag to
evaluate_detections():
Note
All mAP and mAR calculations are performed according to the COCO evaluation protocol.
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5print(dataset)
6
7# Performs an IoU sweep so that mAP, mAR, and PR curves can be computed
8results = dataset.evaluate_detections(
9 "predictions",
10 gt_field="ground_truth",
11 compute_mAP=True,
12)
13
14print(results.mAP())
15# 0.3957
16
17print(results.mAR())
18# 0.5210
19
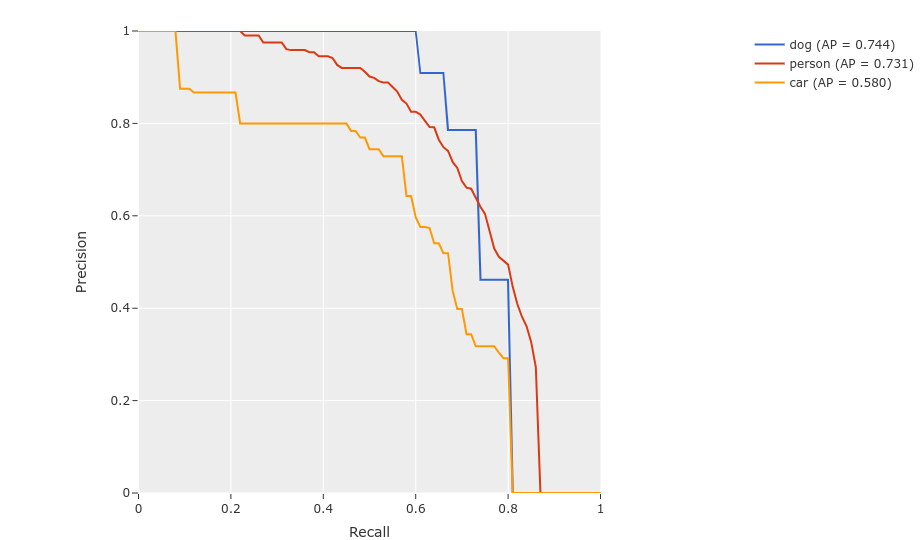
20plot = results.plot_pr_curves(classes=["person", "kite", "car"])
21plot.show()
Confusion matrices#
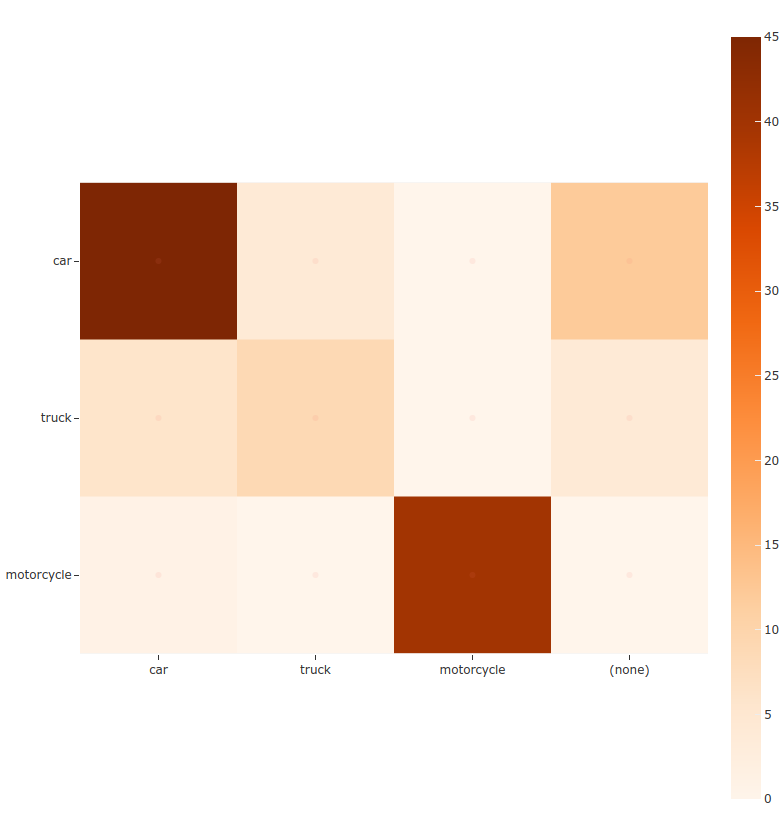
You can also easily generate confusion matrices for the results of COCO-style evaluations.
In order for the confusion matrix to capture anything other than false
positive/negative counts, you will likely want to set the
classwise parameter
to False during evaluation so that predicted objects can be matched with
ground truth objects of different classes.
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5
6# Perform evaluation, allowing objects to be matched between classes
7results = dataset.evaluate_detections(
8 "predictions", gt_field="ground_truth", classwise=False
9)
10
11# Generate a confusion matrix for the specified classes
12plot = results.plot_confusion_matrix(classes=["car", "truck", "motorcycle"])
13plot.show()
Open Images-style evaluation#
The evaluate_detections()
method also supports
Open Images-style evaluation.
In order to run Open Images-style evaluation, simply set the method
parameter to "open-images".
Note
FiftyOne’s implementation of Open Images-style evaluation matches the reference implementation available via the TF Object Detection API.
Overview#
Open Images-style evaluation provides additional features not found in COCO-style evaluation that you may find useful when evaluating your custom datasets.
The two primary differences are:
Non-exhaustive image labeling: positive and negative sample-level
Classificationsfields can be provided to indicate which object classes were considered when annotating the image. Predicted objects whose classes are not included in the sample-level labels for a sample are ignored. The names of these fields can be specified via thepos_label_fieldandneg_label_fieldparametersClass hierarchies: If your dataset includes a class hierarchy, you can configure this evaluation protocol to automatically expand ground truth and/or predicted leaf classes so that all levels of the hierarchy can be correctly evaluated. You can provide a label hierarchy via the
hierarchyparameter. By default, if you provide a hierarchy, then image-level label fields and ground truth detections will be expanded to incorporate parent classes (child classes for negative image-level labels). You can disable this feature by setting theexpand_gt_hierarchyparameter toFalse. Alternatively, you can expand predictions by setting theexpand_pred_hierarchyparameter toTrue
In addition, note that:
Like VOC-style evaluation, only one IoU (default = 0.5) is used to calculate mAP. You can customize this value via the
iouparameterWhen dealing with crowd objects, Open Images-style evaluation dictates that if a crowd is matched with multiple predictions, each counts as one true positive when computing mAP
When you specify an eval_key parameter, a number of helpful fields will be
populated on each sample and its predicted/ground truth objects:
True positive (TP), false positive (FP), and false negative (FN) counts for each sample are saved in top-level fields of each sample:
TP: sample.<eval_key>_tp FP: sample.<eval_key>_fp FN: sample.<eval_key>_fn
The fields listed below are populated on each individual
Detectioninstance; these fields tabulate the TP/FP/FN status of the object, the ID of the matching object (if any), and the matching IoU:TP/FP/FN: object.<eval_key> ID: object.<eval_key>_id IoU: object.<eval_key>_iou
Note
See OpenImagesEvaluationConfig for complete descriptions of the optional
keyword arguments that you can pass to
evaluate_detections()
when running Open Images-style evaluation.
Example evaluation#
The example below demonstrates Open Images-style detection evaluation on the quickstart dataset:
1import fiftyone as fo
2import fiftyone.zoo as foz
3from fiftyone import ViewField as F
4
5dataset = foz.load_zoo_dataset("quickstart")
6print(dataset)
7
8# Evaluate the objects in the `predictions` field with respect to the
9# objects in the `ground_truth` field
10results = dataset.evaluate_detections(
11 "predictions",
12 gt_field="ground_truth",
13 method="open-images",
14 eval_key="eval",
15)
16
17# Get the 10 most common classes in the dataset
18counts = dataset.count_values("ground_truth.detections.label")
19classes = sorted(counts, key=counts.get, reverse=True)[:10]
20
21# Print a classification report for the top-10 classes
22results.print_report(classes=classes)
23
24# Print some statistics about the total TP/FP/FN counts
25print("TP: %d" % dataset.sum("eval_tp"))
26print("FP: %d" % dataset.sum("eval_fp"))
27print("FN: %d" % dataset.sum("eval_fn"))
28
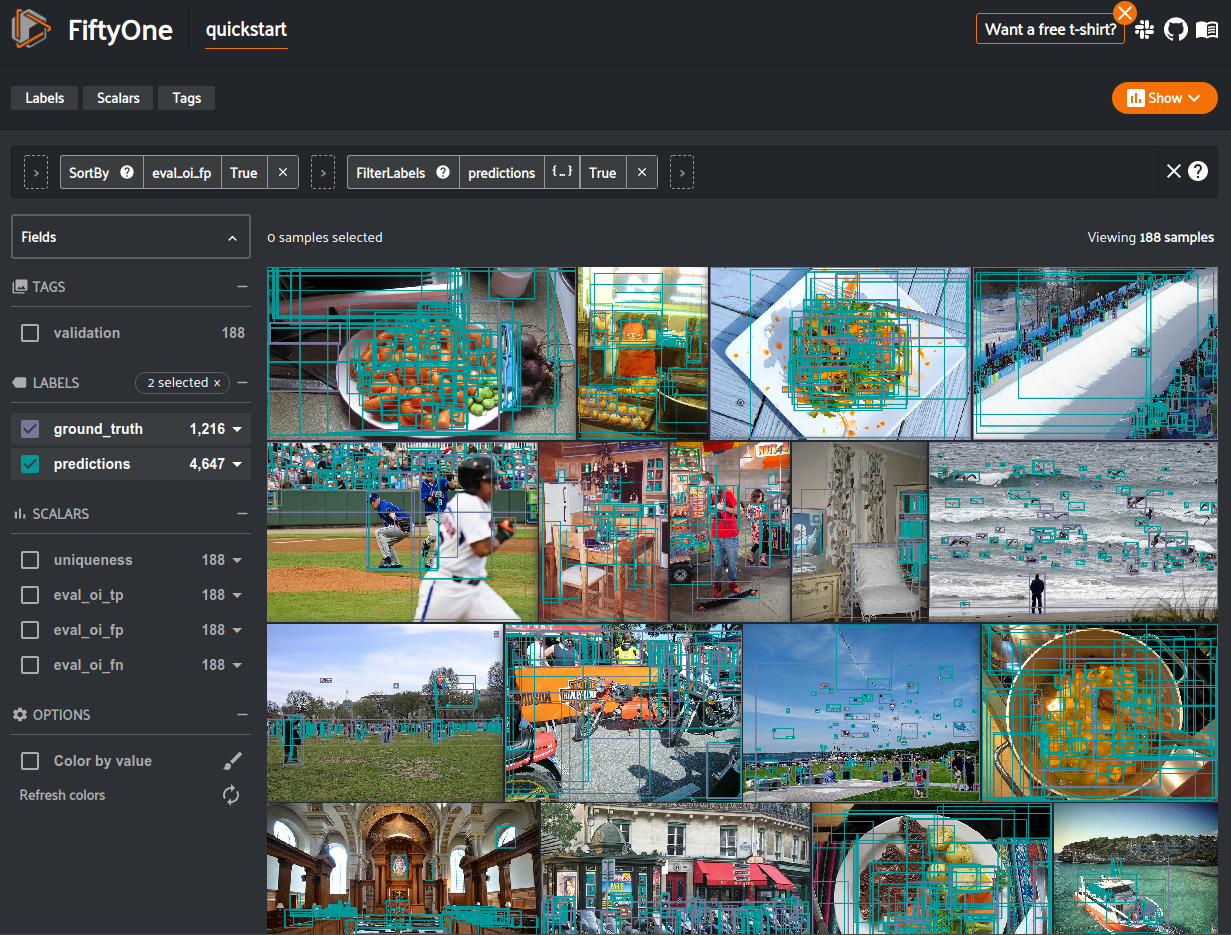
29# Create a view that has samples with the most false positives first, and
30# only includes false positive boxes in the `predictions` field
31view = (
32 dataset
33 .sort_by("eval_fp", reverse=True)
34 .filter_labels("predictions", F("eval") == "fp")
35)
36
37# Visualize results in the App
38session = fo.launch_app(view=view)
precision recall f1-score support
person 0.25 0.86 0.39 378
kite 0.27 0.75 0.40 75
car 0.18 0.80 0.29 61
bird 0.20 0.51 0.28 51
carrot 0.09 0.74 0.16 47
boat 0.09 0.46 0.16 37
surfboard 0.17 0.73 0.28 30
airplane 0.36 0.83 0.50 24
traffic light 0.32 0.79 0.45 24
giraffe 0.36 0.91 0.52 23
micro avg 0.21 0.79 0.34 750
macro avg 0.23 0.74 0.34 750
weighted avg 0.23 0.79 0.36 750
Note
The easiest way to analyze models in FiftyOne is via the Model Evaluation panel!
mAP and PR curves#
You can easily compute mean average precision (mAP) and precision-recall (PR)
curves using the results object returned by
evaluate_detections():
Note
FiftyOne’s implementation of Open Images-style evaluation matches the reference implementation available via the TF Object Detection API.
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5print(dataset)
6
7results = dataset.evaluate_detections(
8 "predictions",
9 gt_field="ground_truth",
10 method="open-images",
11)
12
13print(results.mAP())
14# 0.599
15
16plot = results.plot_pr_curves(classes=["person", "dog", "car"])
17plot.show()
Confusion matrices#
You can also easily generate confusion matrices for the results of Open Images-style evaluations.
In order for the confusion matrix to capture anything other than false
positive/negative counts, you will likely want to set the
classwise
parameter to False during evaluation so that predicted objects can be
matched with ground truth objects of different classes.
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5
6# Perform evaluation, allowing objects to be matched between classes
7results = dataset.evaluate_detections(
8 "predictions",
9 gt_field="ground_truth",
10 method="open-images",
11 classwise=False,
12)
13
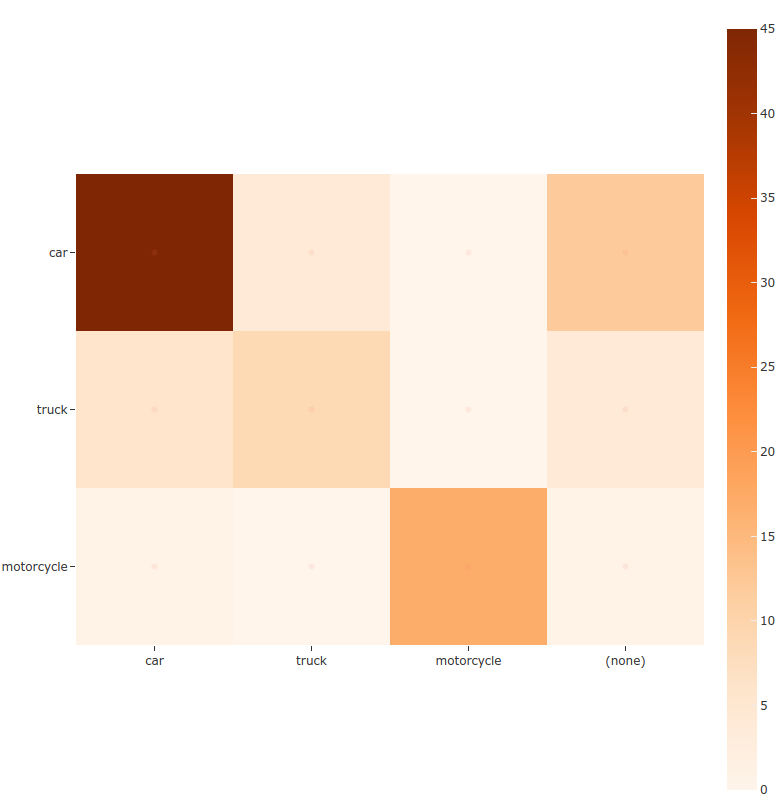
14# Generate a confusion matrix for the specified classes
15plot = results.plot_confusion_matrix(classes=["car", "truck", "motorcycle"])
16plot.show()
ActivityNet-style evaluation (default temporal)#
By default,
evaluate_detections()
will use
ActivityNet-style temporal detection evaluation.
to analyze predictions when the specified label fields are TemporalDetections.
You can also explicitly request that ActivityNet-style evaluation be used by setting
the method parameter to "activitynet".
Note
FiftyOne’s implementation of ActivityNet-style evaluation matches the reference implementation available via the ActivityNet API.
Overview#
When running ActivityNet-style evaluation using
evaluate_detections():
Predicted and ground truth segments are matched using a specified IoU threshold (default = 0.50). This threshold can be customized via the
iouparameterBy default, only segments with the same
labelwill be matched. Classwise matching can be disabled by passingclasswise=FalsemAP is computed by averaging over the same range of IoU values used by COCO
When you specify an eval_key parameter, a number of helpful fields will be
populated on each sample and its predicted/ground truth segments:
True positive (TP), false positive (FP), and false negative (FN) counts for each sample are saved in top-level fields of each sample:
TP: sample.<eval_key>_tp FP: sample.<eval_key>_fp FN: sample.<eval_key>_fn
The fields listed below are populated on each individual temporal detection segment; these fields tabulate the TP/FP/FN status of the segment, the ID of the matching segment (if any), and the matching IoU:
TP/FP/FN: segment.<eval_key> ID: segment.<eval_key>_id IoU: segment.<eval_key>_iou
Note
See ActivityNetEvaluationConfig for complete descriptions of the optional
keyword arguments that you can pass to
evaluate_detections()
when running ActivityNet-style evaluation.
Example evaluation#
The example below demonstrates ActivityNet-style temporal detection evaluation on the ActivityNet 200 dataset:
1import fiftyone as fo
2import fiftyone.zoo as foz
3from fiftyone import ViewField as F
4
5import random
6
7# Load subset of ActivityNet 200
8classes = ["Bathing dog", "Walking the dog"]
9dataset = foz.load_zoo_dataset(
10 "activitynet-200",
11 split="validation",
12 classes=classes,
13 max_samples=10,
14)
15print(dataset)
16
17# Generate some fake predictions for this example
18random.seed(51)
19dataset.clone_sample_field("ground_truth", "predictions")
20for sample in dataset:
21 for det in sample.predictions.detections:
22 det.support[0] += random.randint(-10,10)
23 det.support[1] += random.randint(-10,10)
24 det.support[0] = max(det.support[0], 1)
25 det.support[1] = max(det.support[1], det.support[0] + 1)
26 det.confidence = random.random()
27 det.label = random.choice(classes)
28
29 sample.save()
30
31# Evaluate the segments in the `predictions` field with respect to the
32# segments in the `ground_truth` field
33results = dataset.evaluate_detections(
34 "predictions",
35 gt_field="ground_truth",
36 eval_key="eval",
37)
38
39# Print a classification report for the classes
40results.print_report(classes=classes)
41
42# Print some statistics about the total TP/FP/FN counts
43print("TP: %d" % dataset.sum("eval_tp"))
44print("FP: %d" % dataset.sum("eval_fp"))
45print("FN: %d" % dataset.sum("eval_fn"))
46
47# Create a view that has samples with the most false positives first, and
48# only includes false positive segments in the `predictions` field
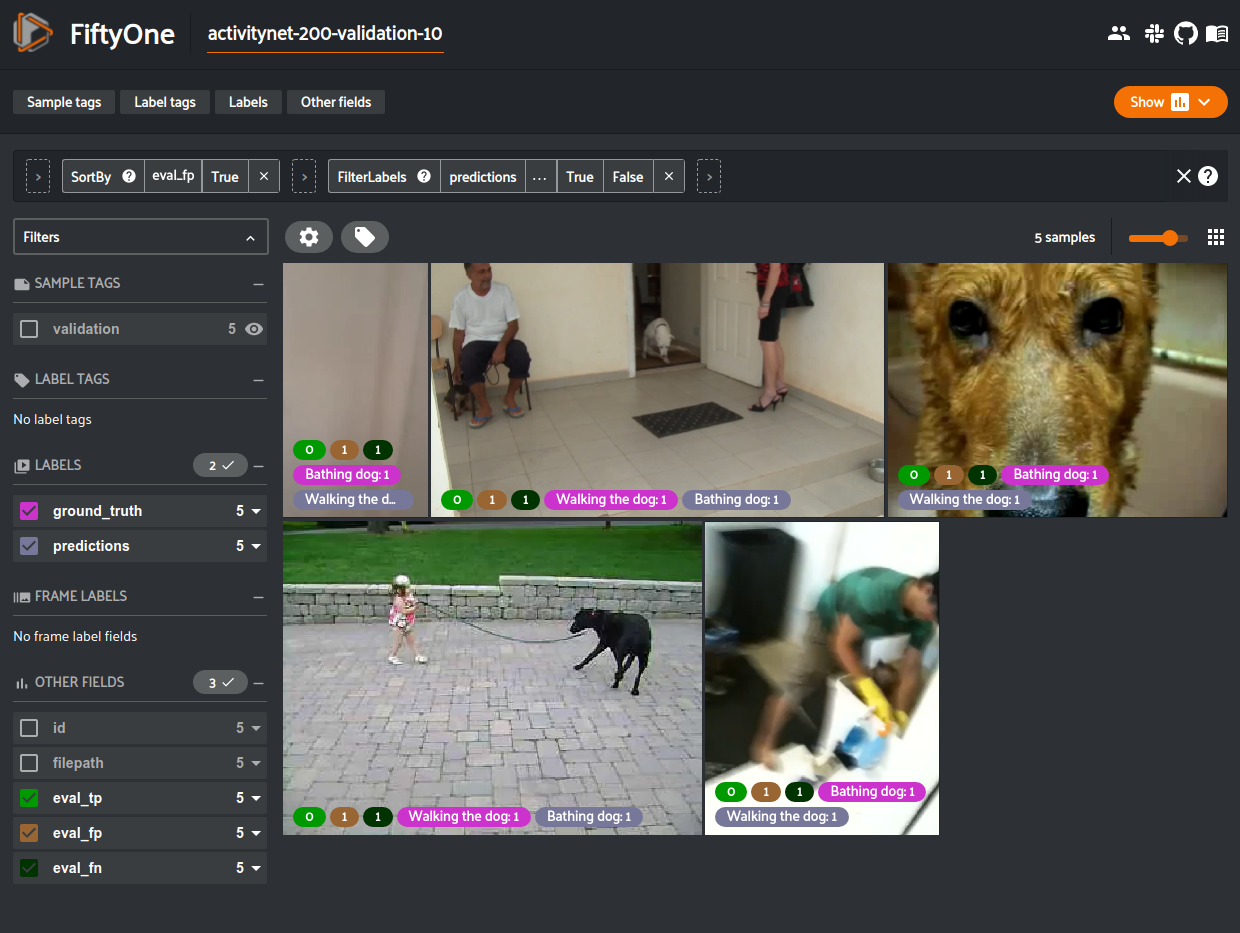
49view = (
50 dataset
51 .sort_by("eval_fp", reverse=True)
52 .filter_labels("predictions", F("eval") == "fp")
53)
54
55# Visualize results in the App
56session = fo.launch_app(view=view)
precision recall f1-score support
Bathing dog 0.50 0.40 0.44 5
Walking the dog 0.50 0.60 0.55 5
micro avg 0.50 0.50 0.50 10
macro avg 0.50 0.50 0.49 10
weighted avg 0.50 0.50 0.49 10
Note
The easiest way to analyze models in FiftyOne is via the Model Evaluation panel!
mAP and PR curves#
You can compute mean average precision (mAP) and precision-recall (PR) curves
for your segments by passing the compute_mAP=True flag to
evaluate_detections():
Note
All mAP calculations are performed according to the ActivityNet evaluation protocol.
1import random
2
3import fiftyone as fo
4import fiftyone.zoo as foz
5
6# Load subset of ActivityNet 200
7classes = ["Bathing dog", "Walking the dog"]
8dataset = foz.load_zoo_dataset(
9 "activitynet-200",
10 split="validation",
11 classes=classes,
12 max_samples=10,
13)
14print(dataset)
15
16# Generate some fake predictions for this example
17random.seed(51)
18dataset.clone_sample_field("ground_truth", "predictions")
19for sample in dataset:
20 for det in sample.predictions.detections:
21 det.support[0] += random.randint(-10,10)
22 det.support[1] += random.randint(-10,10)
23 det.support[0] = max(det.support[0], 1)
24 det.support[1] = max(det.support[1], det.support[0] + 1)
25 det.confidence = random.random()
26 det.label = random.choice(classes)
27
28 sample.save()
29
30# Performs an IoU sweep so that mAP and PR curves can be computed
31results = dataset.evaluate_detections(
32 "predictions",
33 gt_field="ground_truth",
34 eval_key="eval",
35 compute_mAP=True,
36)
37
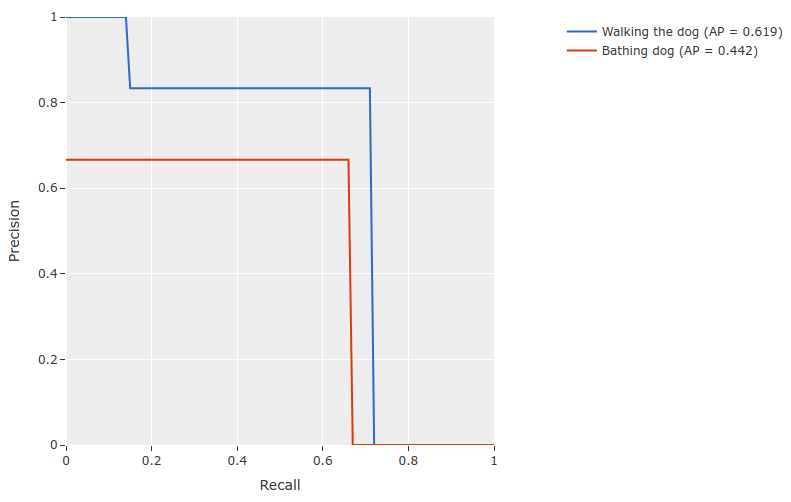
38print(results.mAP())
39# 0.367
40
41plot = results.plot_pr_curves(classes=classes)
42plot.show()
Confusion matrices#
You can also easily generate confusion matrices for the results of ActivityNet-style evaluations.
In order for the confusion matrix to capture anything other than false
positive/negative counts, you will likely want to set the
classwise
parameter to False during evaluation so that predicted segments can be
matched with ground truth segments of different classes.
1import random
2
3import fiftyone as fo
4import fiftyone.zoo as foz
5
6# Load subset of ActivityNet 200
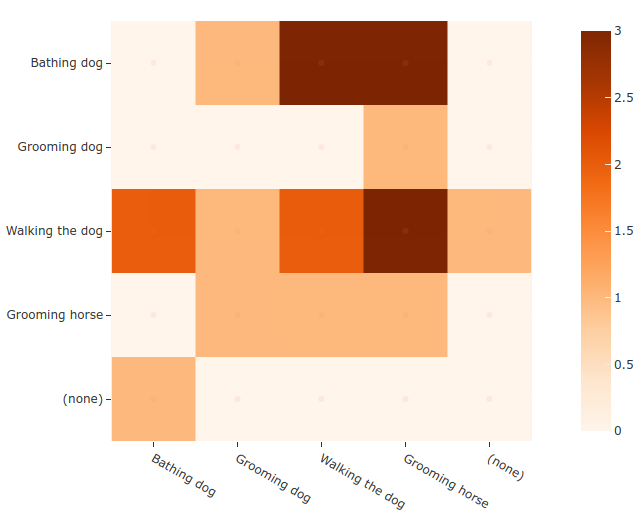
7classes = ["Bathing dog", "Grooming dog", "Grooming horse", "Walking the dog"]
8dataset = foz.load_zoo_dataset(
9 "activitynet-200",
10 split="validation",
11 classes=classes,
12 max_samples=20,
13)
14print(dataset)
15
16# Generate some fake predictions for this example
17random.seed(51)
18dataset.clone_sample_field("ground_truth", "predictions")
19for sample in dataset:
20 for det in sample.predictions.detections:
21 det.support[0] += random.randint(-10,10)
22 det.support[1] += random.randint(-10,10)
23 det.support[0] = max(det.support[0], 1)
24 det.support[1] = max(det.support[1], det.support[0] + 1)
25 det.confidence = random.random()
26 det.label = random.choice(classes)
27
28 sample.save()
29
30# Perform evaluation, allowing objects to be matched between classes
31results = dataset.evaluate_detections(
32 "predictions", gt_field="ground_truth", classwise=False
33)
34
35# Generate a confusion matrix for the specified classes
36plot = results.plot_confusion_matrix(classes=classes)
37plot.show()
Semantic segmentations#
You can use the
evaluate_segmentations()
method to evaluate the predictions of a semantic segmentation model stored in a
Segmentation field of your dataset.
By default, the full segmentation masks will be evaluated at a pixel level, but you can specify other evaluation strategies such as evaluating only boundary pixels (see below for details).
Invoking
evaluate_segmentations()
returns a SegmentationResults instance that provides a variety of methods for
generating various aggregate evaluation reports about your model.
In addition, when you specify an eval_key parameter, a number of helpful
fields will be populated on each sample that you can leverage via the
FiftyOne App to interactively explore the strengths and
weaknesses of your model on individual samples.
Note
You can store mask targets for your
Segmentation fields on your dataset so that you can view semantic labels
in the App and avoid having to manually specify the set of mask targets
each time you run
evaluate_segmentations()
on a dataset.
Simple evaluation (default)#
By default,
evaluate_segmentations()
will perform pixelwise evaluation of the segmentation masks, treating each
pixel as a multiclass classification.
Here are some things to keep in mind:
If the size of a predicted mask does not match the ground truth mask, it is resized to match the ground truth.
You can specify the optional
bandwidthparameter to evaluate only along the contours of the ground truth masks. By default, the entire masks are evaluated.
You can explicitly request that this strategy be used by setting the method
parameter to "simple".
When you specify an eval_key parameter, the accuracy, precision, and recall
of each sample is recorded in top-level fields of each sample:
Accuracy: sample.<eval_key>_accuracy
Precision: sample.<eval_key>_precision
Recall: sample.<eval_key>_recall
Note
The mask values 0 and #000000 are treated as a background class
for the purposes of computing evaluation metrics like precision and
recall.
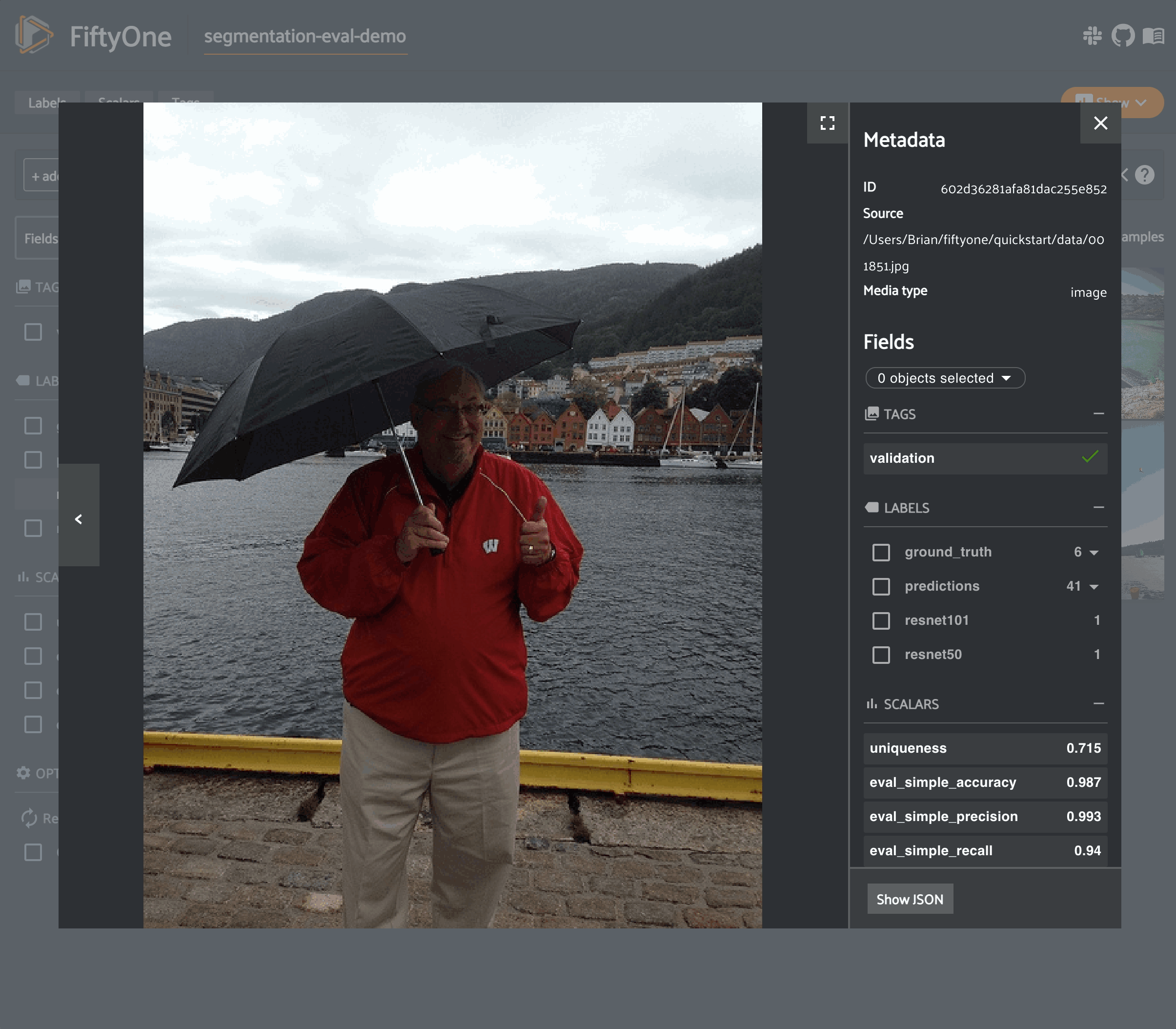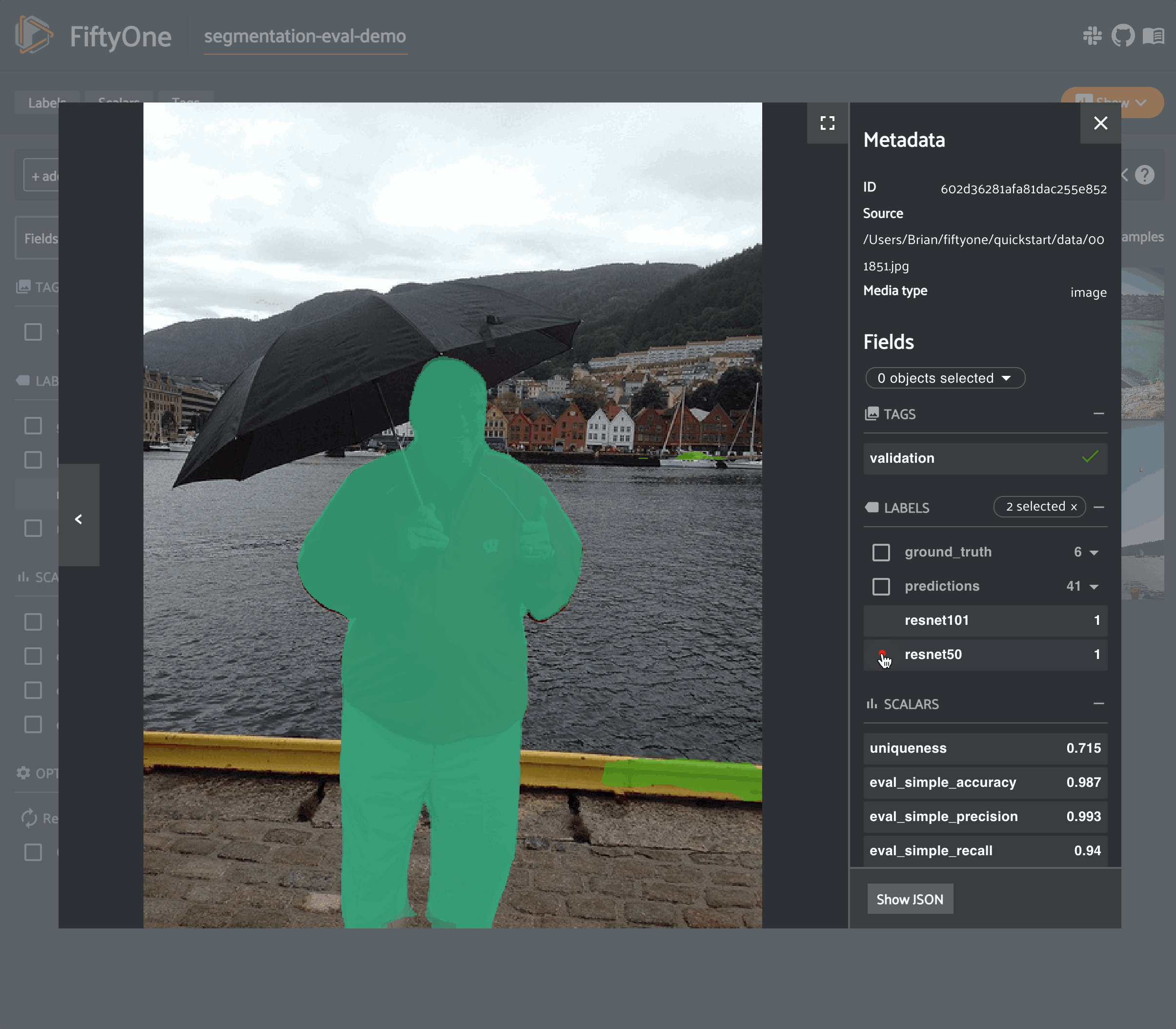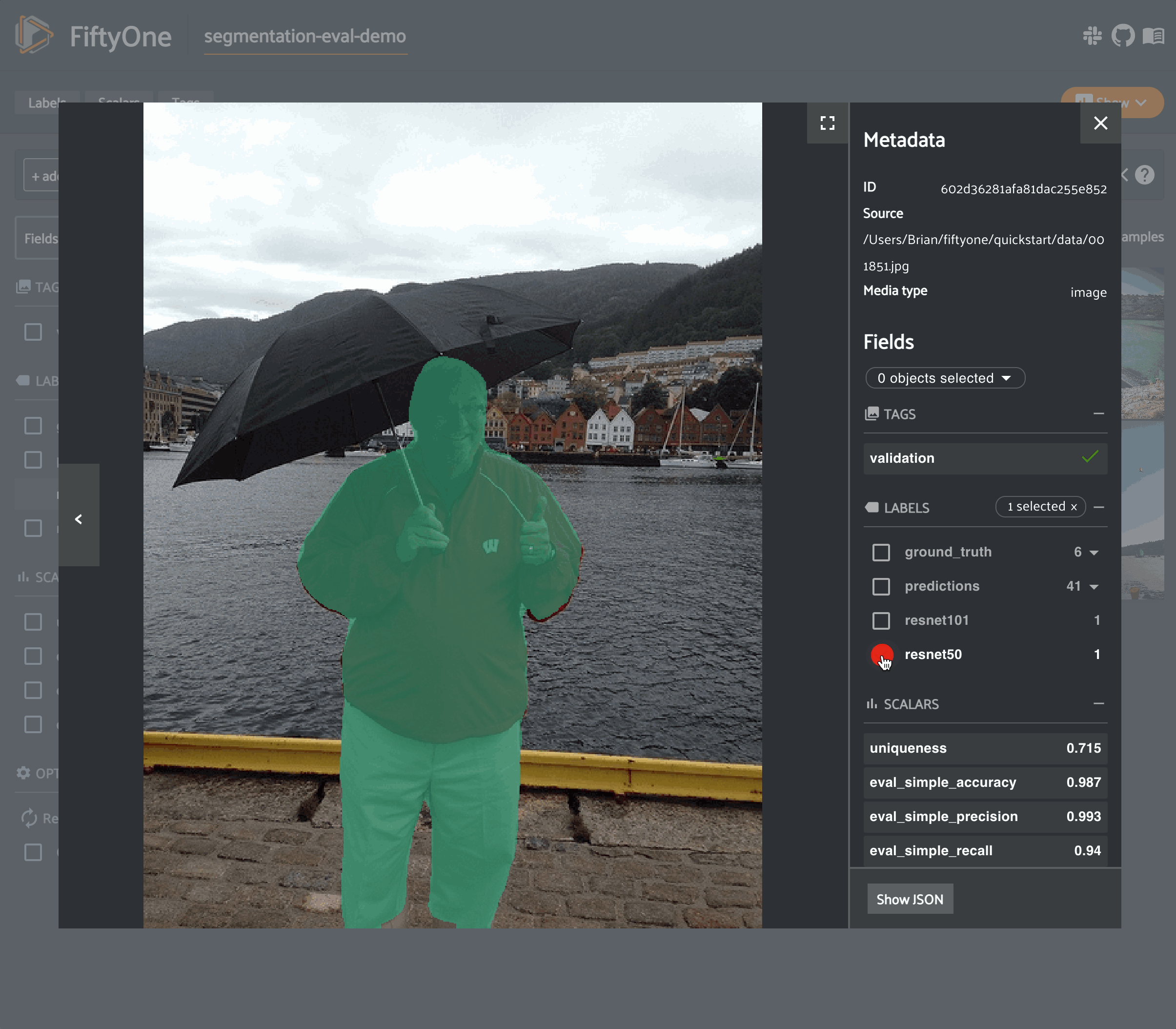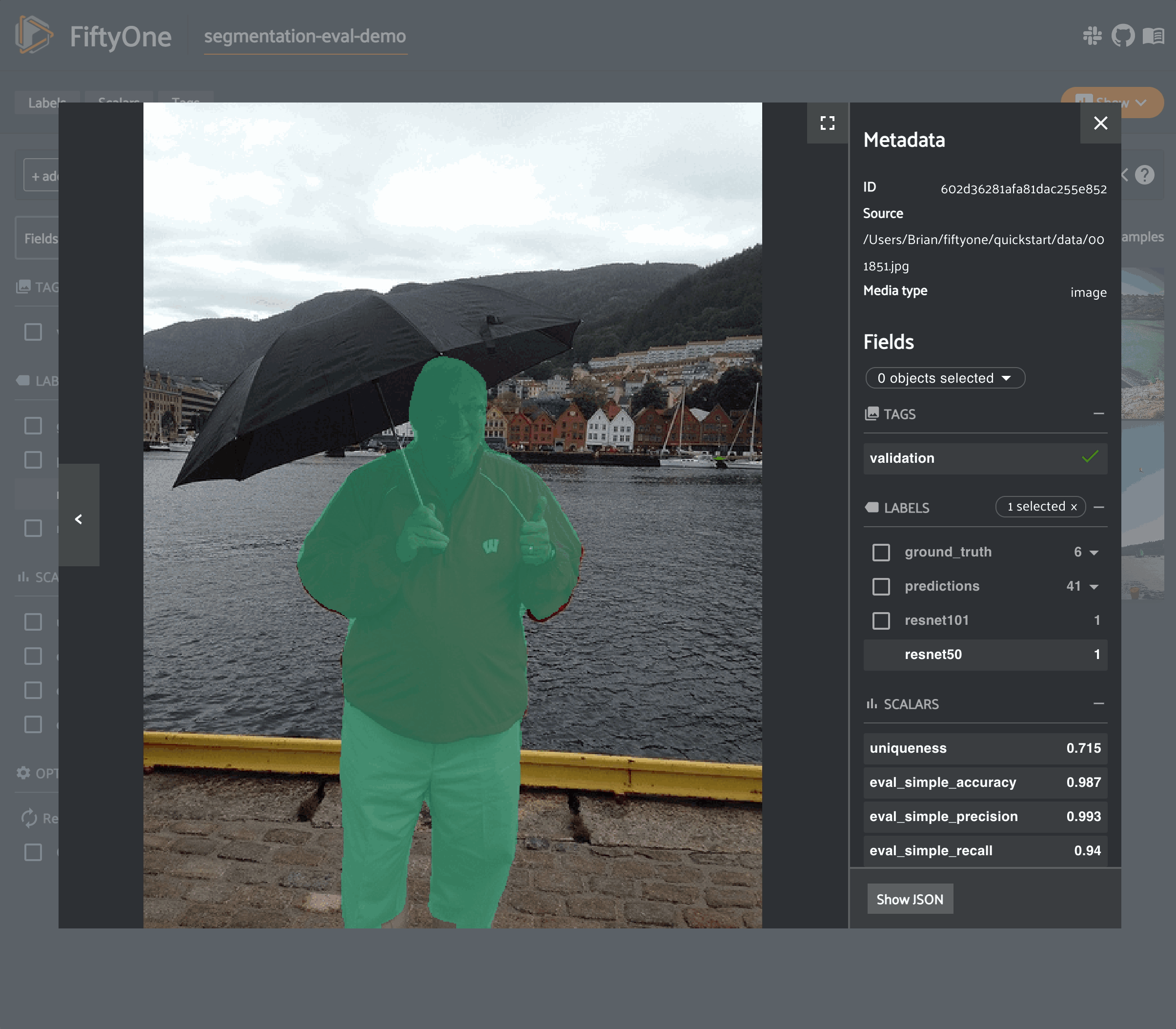
The example below demonstrates segmentation evaluation by comparing the masks generated by two DeepLabv3 models (with ResNet50 and ResNet101 backbones):
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4# Load a few samples from COCO-2017
5dataset = foz.load_zoo_dataset(
6 "quickstart",
7 dataset_name="segmentation-eval-demo",
8 max_samples=10,
9 shuffle=True,
10)
11
12# The models are trained on the VOC classes
13CLASSES = (
14 "background,aeroplane,bicycle,bird,boat,bottle,bus,car,cat,chair,cow," +
15 "diningtable,dog,horse,motorbike,person,pottedplant,sheep,sofa,train," +
16 "tvmonitor"
17)
18dataset.default_mask_targets = {
19 idx: label for idx, label in enumerate(CLASSES.split(","))
20}
21
22# Add DeepLabv3-ResNet101 predictions to dataset
23model = foz.load_zoo_model("deeplabv3-resnet101-coco-torch")
24dataset.apply_model(model, "resnet101")
25
26# Add DeepLabv3-ResNet50 predictions to dataset
27model = foz.load_zoo_model("deeplabv3-resnet50-coco-torch")
28dataset.apply_model(model, "resnet50")
29
30print(dataset)
31
32# Evaluate the masks w/ ResNet50 backbone, treating the masks w/ ResNet101
33# backbone as "ground truth"
34results = dataset.evaluate_segmentations(
35 "resnet50",
36 gt_field="resnet101",
37 eval_key="eval_simple",
38)
39
40# Get a sense for the per-sample variation in likeness
41print("Accuracy range: (%f, %f)" % dataset.bounds("eval_simple_accuracy"))
42print("Precision range: (%f, %f)" % dataset.bounds("eval_simple_precision"))
43print("Recall range: (%f, %f)" % dataset.bounds("eval_simple_recall"))
44
45# Print a classification report
46results.print_report()
47
48# Visualize results in the App
49session = fo.launch_app(dataset)
Note
The easiest way to analyze models in FiftyOne is via the Model Evaluation panel!
Advanced usage#
Evaluating views into your dataset#
All evaluation methods are exposed on DatasetView objects, which means that
you can define arbitrarily complex views into your datasets and run evaluation
on those.
For example, the snippet below evaluates only the medium-sized objects in a dataset:
1import fiftyone as fo
2import fiftyone.zoo as foz
3from fiftyone import ViewField as F
4
5dataset = foz.load_zoo_dataset("quickstart", dataset_name="eval-demo")
6dataset.compute_metadata()
7
8# Create an expression that will match objects whose bounding boxes have
9# areas between 32^2 and 96^2 pixels
10bbox_area = (
11 F("$metadata.width") * F("bounding_box")[2] *
12 F("$metadata.height") * F("bounding_box")[3]
13)
14medium_boxes = (32 ** 2 < bbox_area) & (bbox_area < 96 ** 2)
15
16# Create a view that contains only medium-sized objects
17medium_view = (
18 dataset
19 .filter_labels("ground_truth", medium_boxes)
20 .filter_labels("predictions", medium_boxes)
21)
22
23print(medium_view)
24
25# Evaluate the medium-sized objects
26results = medium_view.evaluate_detections(
27 "predictions",
28 gt_field="ground_truth",
29 eval_key="eval_medium",
30)
31
32# Print some aggregate metrics
33print(results.metrics())
34
35# View results in the App
36session = fo.launch_app(view=medium_view)
Note
If you run evaluation on a complex view, don’t worry, you can always load the view later!
Loading a previous evaluation result#
You can view a list of evaluation keys for evaluations that you have previously
run on a dataset via
list_evaluations().
Evaluation keys are stored at the dataset-level, but if a particular evaluation
was run on a view into your dataset, you can use
load_evaluation_view()
to retrieve the exact view on which you evaluated:
1import fiftyone as fo
2
3dataset = fo.load_dataset(...)
4
5# List available evaluations
6dataset.list_evaluations()
7# ["my_eval1", "my_eval2", ...]
8
9# Load the view into the dataset on which `my_eval1` was run
10eval1_view = dataset.load_evaluation_view("my_eval1")
Note
If you have run multiple evaluations on a dataset, you can use the
select_fields parameter of the
load_evaluation_view()
method to hide any fields that were populated by other evaluation runs,
allowing you to, for example, focus on a specific set of evaluation results
in the App:
import fiftyone as fo
dataset = fo.load_dataset(...)
# Load a view that contains the results of evaluation `my_eval1` and
# hides all other evaluation data
eval1_view = dataset.load_evaluation_view("my_eval1", select_fields=True)
session = fo.launch_app(view=eval1_view)
Evaluating videos#
All evaluation methods can be applied to frame-level labels in addition to sample-level labels.
You can evaluate frame-level labels of a video dataset by adding the frames
prefix to the relevant prediction and ground truth frame fields.
Note
When evaluating frame-level labels, helpful statistics are tabulated at both the sample- and frame-levels of your dataset. Refer to the documentation of the relevant evaluation method for more details.
The example below demonstrates evaluating (mocked) frame-level detections on the quickstart-video dataset from the Dataset Zoo:
1import random
2
3import fiftyone as fo
4import fiftyone.zoo as foz
5
6dataset = foz.load_zoo_dataset(
7 "quickstart-video", dataset_name="video-eval-demo"
8)
9
10#
11# Create some test predictions by copying the ground truth objects into a
12# new `predictions` field of the frames with 10% of the labels perturbed at
13# random
14#
15
16classes = dataset.distinct("frames.detections.detections.label")
17
18def jitter(val):
19 if random.random() < 0.10:
20 return random.choice(classes)
21
22 return val
23
24predictions = []
25for sample_gts in dataset.values("frames.detections"):
26 sample_predictions = []
27 for frame_gts in sample_gts:
28 sample_predictions.append(
29 fo.Detections(
30 detections=[
31 fo.Detection(
32 label=jitter(gt.label),
33 bounding_box=gt.bounding_box,
34 confidence=random.random(),
35 )
36 for gt in frame_gts.detections
37 ]
38 )
39 )
40
41 predictions.append(sample_predictions)
42
43dataset.set_values("frames.predictions", predictions)
44
45print(dataset)
46
47# Evaluate the frame-level `predictions` against the frame-level
48# `detections` objects
49results = dataset.evaluate_detections(
50 "frames.predictions",
51 gt_field="frames.detections",
52 eval_key="eval",
53)
54
55# Print a classification report
56results.print_report()
precision recall f1-score support
person 0.76 0.93 0.84 1108
road sign 0.90 0.94 0.92 2726
vehicle 0.98 0.94 0.96 7511
micro avg 0.94 0.94 0.94 11345
macro avg 0.88 0.94 0.91 11345
weighted avg 0.94 0.94 0.94 11345
You can also view frame-level evaluation results as evaluation patches by first converting to frames and then to patches!
1# Convert to frame evaluation patches
2frames = dataset.to_frames(sample_frames=True)
3frame_eval_patches = frames.to_evaluation_patches("eval")
4print(frame_eval_patches)
5
6print(frame_eval_patches.count_values("type"))
7# {'tp': 10578, 'fn': 767, 'fp': 767}
8
9session = fo.launch_app(view=frame_eval_patches)
Dataset: video-eval-demo
Media type: image
Num patches: 12112
Patch fields:
id: fiftyone.core.fields.ObjectIdField
sample_id: fiftyone.core.fields.ObjectIdField
frame_id: fiftyone.core.fields.ObjectIdField
filepath: fiftyone.core.fields.StringField
frame_number: fiftyone.core.fields.FrameNumberField
tags: fiftyone.core.fields.ListField(fiftyone.core.fields.StringField)
metadata: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.metadata.ImageMetadata)
created_at: fiftyone.core.fields.DateTimeField
last_modified_at: fiftyone.core.fields.DateTimeField
predictions: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Detections)
detections: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Detections)
type: fiftyone.core.fields.StringField
iou: fiftyone.core.fields.FloatField
crowd: fiftyone.core.fields.BooleanField
View stages:
1. ToFrames(config=None)
2. ToEvaluationPatches(eval_key='eval', config=None)
Custom evaluation metrics#
You can add custom metrics to your evaluation runs in FiftyOne.
Custom metrics are supported by all FiftyOne evaluation methods, and you can compute them via the SDK, or directly from the App if you’re running FiftyOne Enterprise.
Using custom metrics#
The example below shows how to compute a custom metric from the metric-examples plugin when evaluating object detections:
# Install the example metrics plugin
fiftyone plugins download \
https://github.com/voxel51/fiftyone-plugins \
--plugin-names @voxel51/metric-examples
1import fiftyone as fo
2import fiftyone.zoo as foz
3
4dataset = foz.load_zoo_dataset("quickstart")
5
6# Custom metrics are specified via their operator URI
7metric_uri = "@voxel51/metric-examples/example_metric"
8
9# Custom metrics can optionally accept kwargs that configure their behavior
10metric_kwargs = dict(value="spam")
11
12results = dataset.evaluate_detections(
13 "predictions",
14 gt_field="ground_truth",
15 eval_key="eval",
16 custom_metrics={metric_uri: metric_kwargs},
17)
18
19# Custom metrics may populate new fields on each sample
20dataset.count_values("eval_example_metric")
21# {'spam': 200}
22
23# Custom metrics may also compute an aggregate value, which is included in
24# the run's metrics report
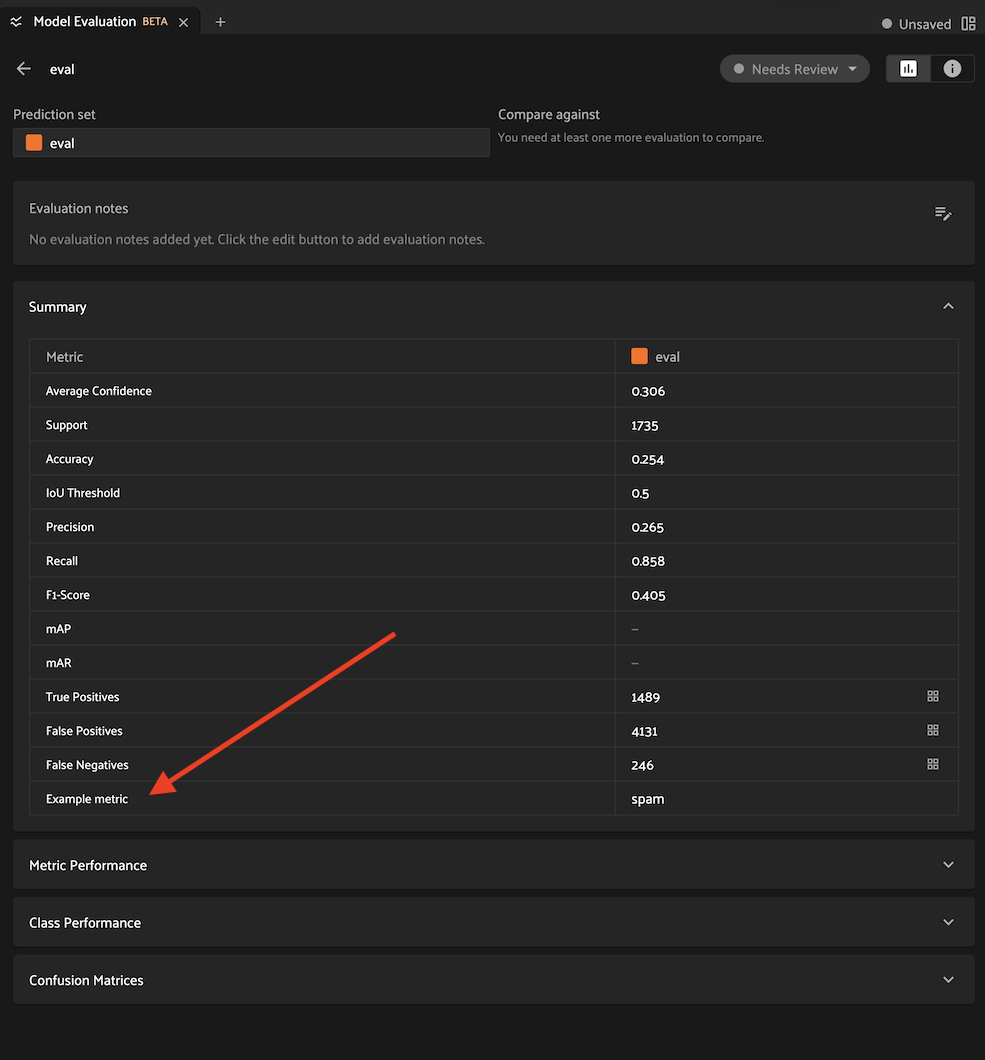
25results.print_metrics()
26"""
27accuracy 0.25
28precision 0.26
29recall 0.86
30fscore 0.40
31support 1735
32example spam # the custom metric
33"""
34
35#
36# Launch the app
37#
38# Open the Model Evaluation panel and you'll see the "Example metric" in
39# the Summary table
40#
41session = fo.launch_app(dataset)
42
43# Deleting an evaluation automatically deletes any custom metrics
44# associated with it
45dataset.delete_evaluation("eval")
46assert not dataset.has_field("eval_example_metric")
When using metric operators without custom parameters, you can also pass a list
of operator URI’s to the custom_metrics parameter:
1# Apply two custom metrics to a regression evaluation
2results = dataset.evaluate_regressions(
3 "predictions",
4 gt_field="ground_truth",
5 eval_key="eval",
6 custom_metrics=[
7 "@voxel51/metric-examples/absolute_error",
8 "@voxel51/metric-examples/squared_error",
9 ],
10)
You can also add custom metrics to an existing evaluation at any time via
add_custom_metrics():
1# Load an existing evaluation run
2results = dataset.load_evaluation_results("eval")
3
4# Add some custom metrics
5results.add_custom_metrics(
6 [
7 "@voxel51/metric-examples/absolute_error",
8 "@voxel51/metric-examples/squared_error",
9 ]
10)
Developing custom metrics#
Each custom metric is implemented as an operator
that implements the
EvaluationMetric
interface.
Let’s look at an example evaluation metric operator:
1import fiftyone.operators as foo
2from fiftyone.operators import types
3
4class ExampleMetric(foo.EvaluationMetric):
5 @property
6 def config(self):
7 return foo.EvaluationMetricConfig(
8 # The metric's URI: f"{plugin_name}/{name}"
9 name="example_metric", # required
10
11 # The display name of the metric in the Summary table of the
12 # Model Evaluation panel
13 label="Example metric", # required
14
15 # A description for the operator
16 description="An example evaluation metric", # optional
17
18 # List of evaluation types that the metrics supports
19 # EG: ["regression", "classification", "detection", ...]
20 # If omitted, the metric may be applied to any evaluation
21 eval_types=None, # optional
22
23 # An optional custom key under which the metric's aggregate
24 # value is stored and returned in methods like `metrics()`
25 # If omitted, the metric's `name` is used
26 aggregate_key="example", # optional
27
28 # Metrics are generally not designed to be directly invoked
29 # via the Operator browser, so they should be unlisted
30 unlisted=True, # required
31 )
32
33 def resolve_input(self, ctx, inputs):
34 """You can optionally implement this method to collect user input
35 for the metric's parameters in the App.
36
37 Returns:
38 a :class:`fiftyone.operators.types.Property`, or None
39 """
40 inputs = types.Object()
41 inputs.str(
42 "value",
43 label="Example value",
44 description="The example value to store/return",
45 default="foo",
46 required=True,
47 )
48 return types.Property(inputs)
49
50 def compute(self, samples, results, value="foo"):
51 """All metric operators must implement this method. It defines the
52 computation done by the metric and which per-frame and/or
53 per-sample fields store the computed value.
54
55 This method can return None or the aggregate metric value. The
56 aggregrate metric value is included in the result's `metrics()`
57 and displayed in the Summary table of the Model Evaluation panel.
58 """
59 dataset = samples._dataset
60 eval_key = results.key
61 metric_field = f"{eval_key}_{self.config.name}"
62 dataset.add_sample_field(metric_field, fo.StringField)
63 samples.set_field(metric_field, value).save()
64
65 return value
66
67 def get_fields(self, samples, config, eval_key):
68 """Lists the fields that were populated by the evaluation metric
69 with the given key, if any.
70 """
71 return [f"{eval_key}_{self.config.name}"]
Note
By convention, evaluation metrics should include f"{eval_key}" in any
sample fields that they populate. If your metric populates fields whose
names do not contain the evaluation key, then you must also implement
rename()
and
cleanup()
so that they are properly handled when renaming/deleting evaluation runs.
Custom evaluation backends#
If you would like to use an evaluation protocol that is not natively supported by FiftyOne, you can follow the instructions below to implement an interface for your protocol and then configure your environment so that FiftyOne’s evaluation methods will use it.
You can define custom regression evaluation backends that can be used by
passing the method parameter to
evaluate_regressions():
1view.evaluate_regressions(..., method="<backend>", ...)
Regression evaluation backends are defined by writing subclasses of the following two classes:
RegressionEvaluation: this class implements the evaluation protocol itself. Specifically you should implementevaluate_samples(), which accepts a sample collection to evaluate as input and returns aRegressionResultsinstance that contains the results of the evaluationRegressionEvaluationConfig: this class defines the available parameters that users can pass as keyword arguments toevaluate_regressions()to customize the behavior of the evaluation run
If desired, you can also implement and return a custom
RegressionResults
subclass. This is useful if you want to expose custom methods that users
can call to view and/or interact with the evaluation results
programmatically.
The recommended way to expose a custom regression evaluation method is to
add it to your evaluation config at
~/.fiftyone/evaluation_config.json as follows:
{
"default_regression_backend": "<backend>",
"regression_backends": {
"<backend>": {
"config_cls": "your.custom.RegressionEvaluationConfig"
}
},
...
}
In the above, <backend> defines the name of your custom backend, which
you can henceforward pass as the method parameter to
evaluate_regressions(),
and the config_cls parameter specifies the fully-qualified name of the
RegressionEvaluationConfig
subclass for your evaluation backend.
With the optional default_regression_backend parameter set to your custom
backend as shown above, calling
evaluate_regressions()
will automatically use your backend.
You can define custom classification evaluation backends that can be used
by passing the method parameter to
evaluate_classifications():
1view.evaluate_classifications(..., method="<backend>", ...)
Classification evaluation backends are defined by writing subclasses of the following two classes:
ClassificationEvaluation: this class implements the evaluation protocol itself. Specifically you should implementevaluate_samples(), which accepts a sample collection to evaluate as input and returns aClassificationResultsinstance that contains the results of the evaluationClassificationEvaluationConfig: this class defines the available parameters that users can pass as keyword arguments toevaluate_classifications()to customize the behavior of the evaluation run
If desired, you can also implement and return a custom
ClassificationResults
subclass. This is useful if you want to expose custom methods that users
can call to view and/or interact with the evaluation results
programmatically.
The recommended way to expose a custom classification evaluation method is
to add it to your evaluation config at
~/.fiftyone/evaluation_config.json as follows:
{
"default_classification_backend": "<backend>",
"classification_backends": {
"<backend>": {
"config_cls": "your.custom.ClassificationEvaluationConfig"
}
},
...
}
In the above, <backend> defines the name of your custom backend, which
you can henceforward pass as the method parameter to
evaluate_classifications(),
and the config_cls parameter specifies the fully-qualified name of the
ClassificationEvaluationConfig
subclass for your evaluation backend.
With the optional default_classification_backend parameter set to your
custom backend as shown above, calling
evaluate_classifications()
will automatically use your backend.
You can define custom detection evaluation backends that can be used by
passing the method parameter to
evaluate_detections():
1view.evaluate_detections(..., method="<backend>", ...)
Detection evaluation backends are defined by writing subclasses of the following two classes:
DetectionEvaluation: this class implements the evaluation protocol itself. Specifically you should implementevaluate(), which accepts a sample to evaluate as input and returns a list of matched ground truth/predicted object pairs, and you can optionally implementgenerate_results(), to compute aggregate evaluation results (e.g., mAP or PR curves) for the sample collection and return them in aDetectionResultsinstanceDetectionEvaluationConfig: this class defines the available parameters that users can pass as keyword arguments toevaluate_detections()to customize the behavior of the evaluation run
If desired, you can also implement and return a custom
DetectionResults
subclass. This is useful if you want to expose custom methods that users
can call to view and/or interact with the evaluation results
programmatically.
The recommended way to expose a custom detection evaluation method is to
add it to your evaluation config at
~/.fiftyone/evaluation_config.json as follows:
{
"default_detection_backend": "<backend>",
"detection_backends": {
"<backend>": {
"config_cls": "your.custom.DetectionEvaluationConfig"
}
},
...
}
In the above, <backend> defines the name of your custom backend, which
you can henceforward pass as the method parameter to
evaluate_detections(),
and the config_cls parameter specifies the fully-qualified name of the
DetectionEvaluationConfig
subclass for your evaluation backend.
With the optional default_detection_backend parameter set to your
custom backend as shown above, calling
evaluate_detections()
will automatically use your backend.
You can define custom segmentation evaluation backends that can be used by
passing the method parameter to
evaluate_segmentations():
1view.evaluate_segmentations(..., method="<backend>", ...)
Segmentation evaluation backends are defined by writing subclasses of the following two classes:
SegmentationEvaluation: this class implements the evaluation protocol itself. Specifically you should implementevaluate_samples(), which accepts a sample collection to evaluate as input and returns aSegmentationResultsinstance that contains the results of the evaluationSegmentationEvaluationConfig: this class defines the available parameters that users can pass as keyword arguments toevaluate_segmentations()to customize the behavior of the evaluation run
If desired, you can also implement and return a custom
SegmentationResults
subclass. This is useful if you want to expose custom methods that users
can call to view and/or interact with the evaluation results
programmatically.
The recommended way to expose a custom segmentation evaluation method is to
add it to your evaluation config at
~/.fiftyone/evaluation_config.json as follows:
{
"default_segmentation_backend": "<backend>",
"segmentation_backends": {
"<backend>": {
"config_cls": "your.custom.SegmentationEvaluationConfig"
}
},
...
}
In the above, <backend> defines the name of your custom backend, which
you can henceforward pass as the method parameter to
evaluate_segmentations(),
and the config_cls parameter specifies the fully-qualified name of the
SegmentationEvaluationConfig
subclass for your evaluation backend.
With the optional default_segmentation_backend parameter set to your
custom backend as shown above, calling
evaluate_segmentations()
will automatically use your backend.
Evaluation config#
FiftyOne provides an evaluation config that you can use to either temporarily or permanently configure the behavior of the evaluation API.
Viewing your config#
You can print your current evaluation config at any time via the Python library and the CLI:
import fiftyone as fo
# Print your current evaluation config
print(fo.evaluation_config)
{
"default_regresion_backend": "simple",
"default_classification_backend": "simple",
"default_detection_backend": "coco",
"default_segmentation_backend": "simple",
"regression_backends": {
"simple": {
"config_cls": "fiftyone.utils.eval.regression.SimpleEvaluationConfig"
}
},
"classification_backends": {
"binary": {
"config_cls": "fiftyone.utils.eval.classification.BinaryEvaluationConfig"
},
"simple": {
"config_cls": "fiftyone.utils.eval.classification.SimpleEvaluationConfig"
},
"top-k": {
"config_cls": "fiftyone.utils.eval.classification.TopKEvaluationConfig"
}
},
"detection_backends": {
"activitynet": {
"config_cls": "fiftyone.utils.eval.activitynet.ActivityNetEvaluationConfig"
},
"coco": {
"config_cls": "fiftyone.utils.eval.coco.COCOEvaluationConfig"
},
"open-images": {
"config_cls": "fiftyone.utils.eval.openimages.OpenImagesEvaluationConfig"
}
},
"segmentation_backends": {
"simple": {
"config_cls": "fiftyone.utils.eval.segmentation.SimpleEvaluationConfig"
}
}
}
# Print your current evaluation config
fiftyone evaluation config
{
"default_regresion_backend": "simple",
"default_classification_backend": "simple",
"default_detection_backend": "coco",
"default_segmentation_backend": "simple",
"regression_backends": {
"simple": {
"config_cls": "fiftyone.utils.eval.regression.SimpleEvaluationConfig"
}
},
"classification_backends": {
"binary": {
"config_cls": "fiftyone.utils.eval.classification.BinaryEvaluationConfig"
},
"simple": {
"config_cls": "fiftyone.utils.eval.classification.SimpleEvaluationConfig"
},
"top-k": {
"config_cls": "fiftyone.utils.eval.classification.TopKEvaluationConfig"
}
},
"detection_backends": {
"activitynet": {
"config_cls": "fiftyone.utils.eval.activitynet.ActivityNetEvaluationConfig"
},
"coco": {
"config_cls": "fiftyone.utils.eval.coco.COCOEvaluationConfig"
},
"open-images": {
"config_cls": "fiftyone.utils.eval.openimages.OpenImagesEvaluationConfig"
}
},
"segmentation_backends": {
"simple": {
"config_cls": "fiftyone.utils.eval.segmentation.SimpleEvaluationConfig"
}
}
}
Note
If you have customized your evaluation config via any of the methods described below, printing your config is a convenient way to ensure that the changes you made have taken effect as you expected.
Modifying your config#
You can modify your evaluation config in a variety of ways. The following sections describe these options in detail.
Order of precedence#
The following order of precedence is used to assign values to your evaluation config settings as runtime:
Config settings applied at runtime by directly editing
fiftyone.evaluation_configFIFTYONE_XXXenvironment variablesSettings in your JSON config (
~/.fiftyone/evaluation_config.json)The default config values
Editing your JSON config#
You can permanently customize your evaluation config by creating a
~/.fiftyone/evaluation_config.json file on your machine. The JSON file may
contain any desired subset of config fields that you wish to customize.
For example, the following config JSON file declares a new custom detection
evaluation backend without changing any other default config settings:
{
"default_detection_backend": "custom",
"detection_backends": {
"custom": {
"config_cls": "path.to.your.CustomDetectionEvaluationConfig"
}
}
}
When fiftyone is imported, any options from your JSON config are merged into
the default config, as per the order of precedence described above.
Note
You can customize the location from which your JSON config is read by
setting the FIFTYONE_EVALUATION_CONFIG_PATH environment variable.
Setting environment variables#
Evaluation config settings may be customized on a per-session basis by setting
the FIFTYONE_<TYPE>_XXX environment variable(s) for the desired config
settings, where <TYPE> can be REGRESSION, CLASSIFICATION, DETECTION, or
SEGMENTATION.
The FIFTYONE_DEFAULT_<TYPE>_BACKEND environment variables allows you to
configure your default backend:
export FIFTYONE_DEFAULT_DETECTION_BACKEND=coco
You can declare parameters for specific evaluation backends by setting
environment variables of the form FIFTYONE_<TYPE>_<BACKEND>_<PARAMETER>. Any
settings that you declare in this way will be passed as keyword arguments to
methods like
evaluate_detections()
whenever the corresponding backend is in use:
export FIFTYONE_DETECTION_COCO_ISCROWD=is_crowd
The FIFTYONE_<TYPE>_BACKENDS environment variables can be set to a
list,of,backends that you want to expose in your session, which may exclude
native backends and/or declare additional custom backends whose parameters are
defined via additional config modifications of any kind:
export FIFTYONE_DETECTION_BACKENDS=custom,coco,open-images
When declaring new backends, you can include * to append new backend(s)
without omitting or explicitly enumerating the builtin backends. For example,
you can add a custom detection evaluation backend as follows:
export FIFTYONE_DETECTION_BACKENDS=*,custom
export FIFTYONE_DETECTION_CUSTOM_CONFIG_CLS=your.custom.DetectionEvaluationConfig
Modifying your config in code#
You can dynamically modify your evaluation config at runtime by directly
editing the fiftyone.evaluation_config object.
Any changes to your evaluation config applied via this manner will immediately
take effect in all subsequent calls to fiftyone.evaluation_config during your
current session.
1import fiftyone as fo
2
3fo.evaluation_config.default_detection_backend = "custom"